1. 存储系统的层次结构
为了解决容量、速度和价格之间的矛盾,把各种不同存储容量,不同存取速度,不同价格的存储器,按照一定的体系结构组织起来,使所存放的程序和数据按层次分布在各存储器中,形成---多层次的存储系统。
常见的就是三级存储系统,即:Cache、主存、辅存。如果希望长久的保存程序或者数据,那么可以将其放在辅存中,譬如磁盘。如果要执行这个程序或者处理这个数据,就需要把它调进主存中。通常情况下,为了弥补主存容量不足的问题,主存和辅存之间会附加一些硬件及存储管理软件。而数据访问最为活跃的部分,就将其存在Cache中。
就存储速度而言,Cache>主存>辅存。
就存储容量而言,辅存>主存>Cache。
2. 高速缓存的工作原理
Cache又叫高速缓冲存储器,用来存储数据当中最活跃的部分,那么怎么判断哪些数据活跃呢?这里涉及程序访问的两个概念:时间局部性和空间局部性。
时间局部性反映了数据在一定时间内被访问的频率,比如有一个阶乘程序:for(i=0;i<100;i=i+1) a = a * i; 在这里变量a就被频繁的访问到了;空间局部性指的是数据在空间上有很大的关系,例如数组变量,数组a[100]有100个元素,数组元素之间在空间上就有一定的关系。
高速缓存的工作原理主要有以下三点:
①:Cache采用SRAM器件,构成小容量高速存储器。
②:把程序中经常使用的部分存放在Cache中。
③:使CPU的访存操作大多数在Cache中命中,从而使程序的执行速度大大提高。
CPU访存Cache时能不能命中就取决于当时Cache的状态,Cache中的数据是从主存中选择出来的,具体放在什么位置和Cache的映射方式有关。
3. Cache的读写操作
3.1. Cache读
当CPU发出读请求时,如果Cache命中,就直接对Cache进行读操作,与主存无关;如果Cache不命中,则仍需访问主存,并把该块信息一次从主存调入Cache内。
3.2. Cache写
3.2.1. Cache写命中
当CPU发出写请求时,如果Cache命中,有可能会遇到Cache与主存中内容不一致的问题。例如,由于CPU写Cache,把Cache某单元的内容从x修改为y,而主存对应单元中的内容仍然是x。所以如果Cache命中,则需要进行一定的写处理,处理方法有:写直达法和写回法。
写直达法是指一旦CPU修改Cache,就同步的将主存中对应位置的内容一起修改,这样就能保持Cache和主存的实时一致性。
写回法是指当CPU修改Cache时,记一下修改的地方为修改位,也叫脏位,指这个Cache块的内容发生变化了。如果这个Cache块要被替换时,这时再将整个Cache块写回主存。
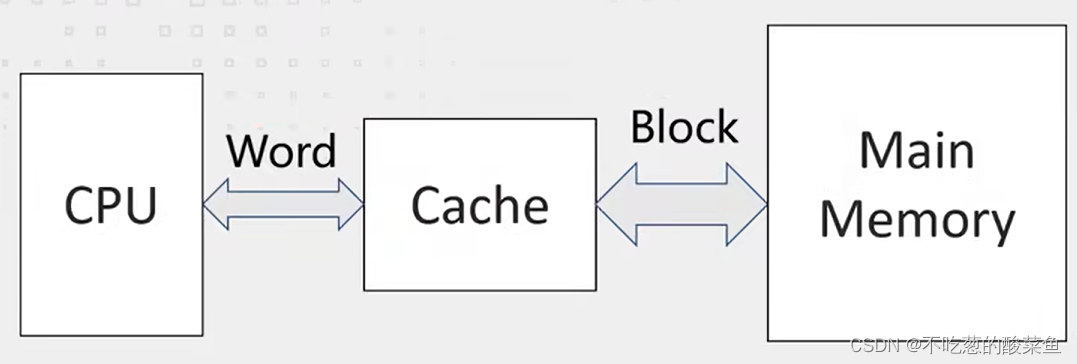
主存和Cache之间交换的是块(block),块里面可以有若干字(word),块有时候也被称做行。CPU读或者写,则是某一个字(word),这个字是属于某个块的。CPU把内存地址发给Cache,Cache就找自己里面有没有这个地址,如果有,则命中(hit),如果没有,则Miss。命中的是Cache中的一个块,而这个块是Cache从主存中取出来的,命中后Cache再将这个块中的某个字给到CPU完成一个高速存储访问。
3.2.2. Cache写Miss
当Cache写不命中时,有两种处理办法。1.按写分配法:把信息写入主存,同时将该块信息装入Cache。2.不按写分配法:直接更新物理内存中的值,而不把值装入Cache。
4. 高速缓存的地址映射方法
假设Cache大小为:4*32Byte,即Cache有4个block,每个block大小为32Byte,空间4*32Byte以字节为单位编码地址,需要地址位宽为7位。
假设主存momery大小为16*32Byte,即memory有16个block,每个block大小和Cache的block大小一致都是32Byte,那么memory按字节为单位编码地址,需要地址位宽为9位。
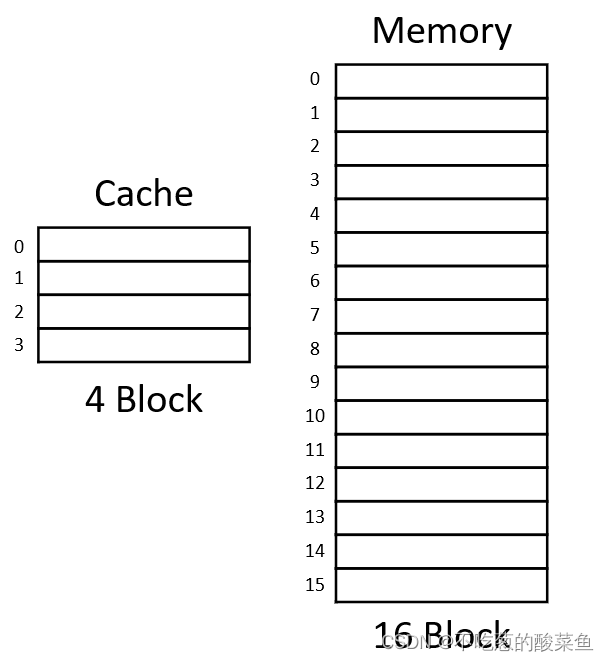
4.1. 全相联映射
全相联映射是指:主存中任何一块均可定位于Cache中的任意一块,可提高命中率,但是硬件开销增加。因为主存中的Block存到Cache中的Block是任意的,所以具体主存的Block会存到Cache中的哪一块Block是不确定的。
CPU在访问Cache中的某一字节时,会给出一个9位的地址,其中低5位用来表示该字节是Block中32个字节的哪一字节。高4位用来表示该字节属于主存16个Block中的哪一Block。
前面说过Block在Cache中的位置是不确定的,因此CPU在Cache中找数据的时候,首先会用9位地址表示块序号的高4bit去和Cache中块的序号进行比对。所以在Cache中存储数据除了Block数据以外,还需要额外的空间来存储Block的序号,记为Tag位。有的时候在Cache中还会有一些空间用来表示Cache的有效位,因为有些时候Cache的内容是随机的无效的,所以可以用一些有效位来表示,初始化的时候直接将这些有效位全置为0。
这种存储方式的缺点很明显,也是因为Block在Cache中位置的任意性,所以在Cache中寻找比对Block序号时,需要寻遍Cache中所有的Block,若全都比对失败则Miss,这种全局比较方式是很费时的。并且增加了硬件开销(Tag),具体Tag有多少位,取决于主存块号的位数。具体比较方式如下图所示:
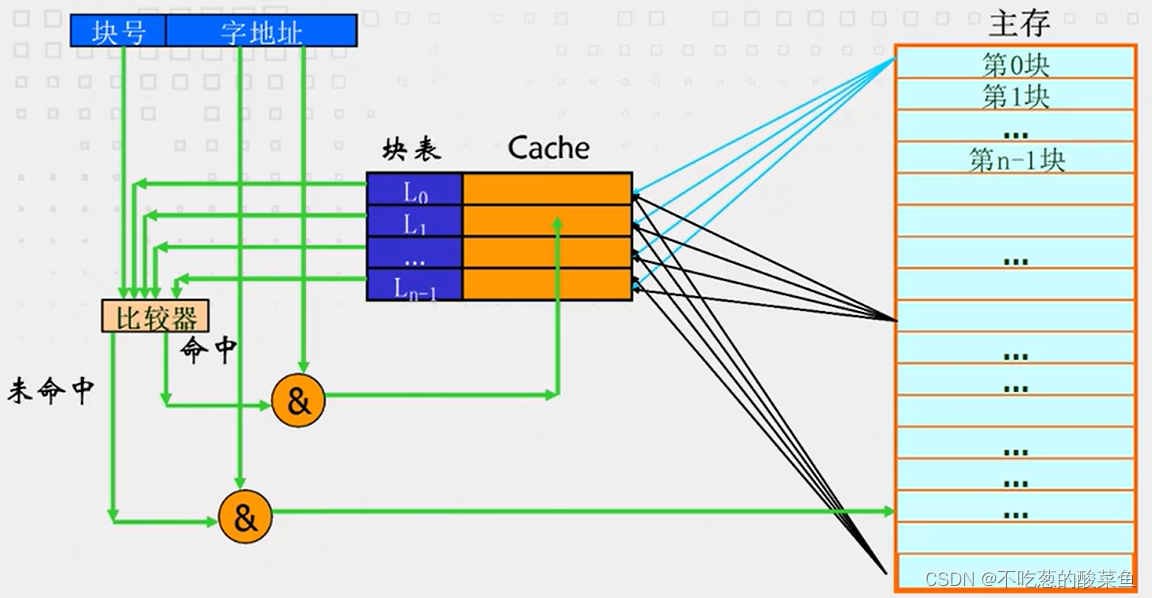
综上,全相联映射Cache,主存中的任意一块可能存在Cache中的任意位置,因此该存储方式需要Cache内额外有一个Tag部分,用来存放映射关系。Tag部分字长等于Cache的标记+Cache块号+有效位部分。主存的Block放进Cache中,只要Cache内有空Block,就可以存储主存内容,因此这种映射方式的Cache利用率是很高的,也很容易命中。
4.2. 直接映射
直接映射的存储是有规律的,不再随机放块数据了,是分区的。按我们举的例子来说,Cache的大小是4*32Byte,也就是4块Block,以4块Block为一个区,对主存进行划区,如下图所示:
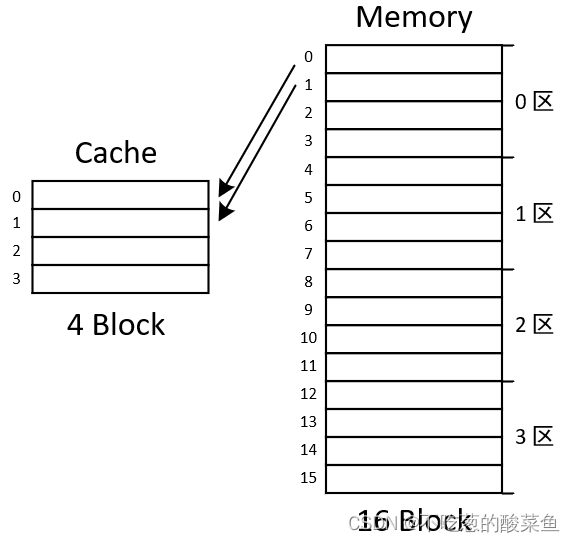
0区的0号块,只能放在Cache的0号位置,0区的1号块,只能放在Cache的1号位置;同样的1区的第0块,只能放在Cace的0号位置,1区的第1块,只能方才Cache的1号位置。所以直接映射的存储是有规律的,比如判断1区的第1个块是否在Cache中时,若在,则一定存放在Cache的1号位置。
因此分析容易发现,Cache的0号位置,只能存放主存的0号、4号、8号、12号Block;Cache的1号位置,只能存放主存的1号、5号、9号、13号Block...
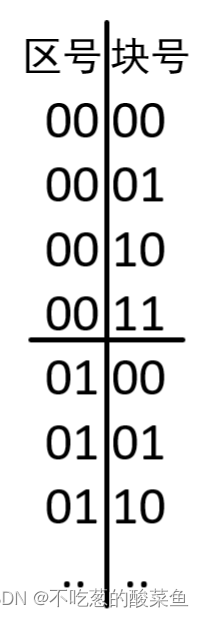
把主存中的Block号用二进制表示出来,可以发现高2bit表示区号,低2bit表示块号。所以CPU去检索某一字节时,会给出一个9位的地址索引,其中低5位用来表示该字节是Block中32个字节的哪一字节。剩下的4bit表示区号和块号。Cache拿到CPU给出的地址后,会优先判断该地址属于区中的第几块,进而可以判断存放在Cache中的哪一行。具体比较方式如下图所示: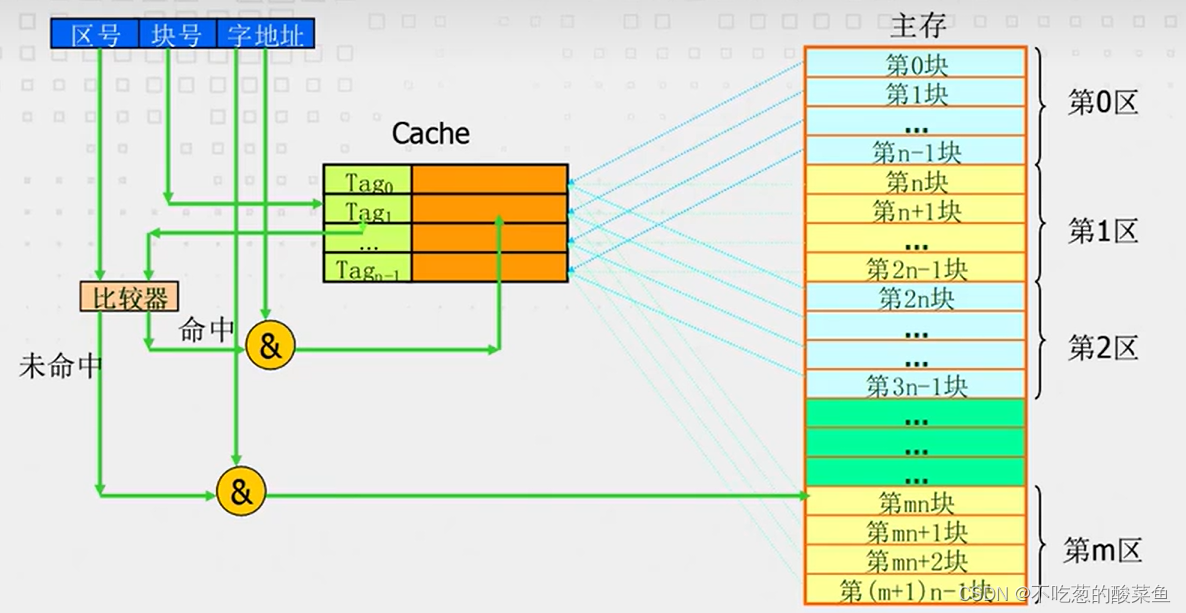
而在Cache中,需要有一个2位的Tag位,来表示该位置的块属于主存中的哪个区,以及一个有效位。所以Cache组成应该如下所示:
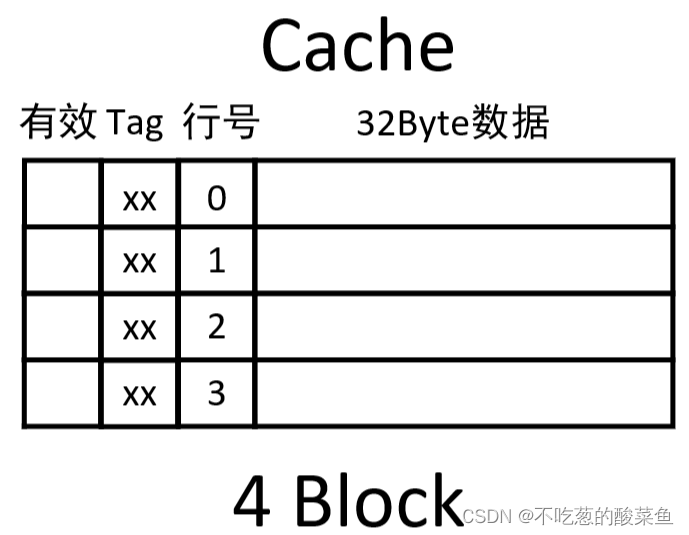
地址转换过程:
用CPU给出的主存地址中的块号找到Cache中对应的块,读出块的Tag标记,与主存地址给出的区号进行比较,按照一下几种情况进行判断:
① 如果与主存地址给出的区号相等,且有效位为1,命中。
② 如果区号相等,有效位为0,则失效(作废)。
③ 如果区号不相等,有效位为0,Cache块为空,可以直接装入。
④ 如果区号不相等,有效位为1,则该块内容有用,将此时Cache中的内容写回到内存后,再用新的数据替换。
有效位为0就意味着Cache该位置的块数据是没有意义的,有时候还可以进行一些Cache冲刷操作,直接将Cache中的所有有效位都置成0。
综上。直接映射的硬件实现非常简单,查找方便,成本低。不需要对所有Cache进行比较,拿到地址直接查找Cache对应行,区号对且有效就命中,不对就Miss。缺点就是Cache对应行只能放主存区中对应位置的块。比如Cache的第0行有数据,其它行空闲,主存的第0行数据要写入Cache时,即便Cache其它行是空闲的,也不会利用起来,而是覆盖掉Cache的第0行不管其它的空闲行,因此Cache的利用率是低的。这种Cache映射方式,有时候还会进入到一个极端的情况,就是Cache中某一行被频繁的替换,这种情况叫“颠簸”。
4.3. 组相联映射
组相联映射是全相联映射和直接映射的折衷方法。比如将Cache分成两组,并且主存中的Block也被两两分区,主存中每一区的第0块只能放在Cache的第0组,具体是第0组的第几行,是任意的;同样的,主存中每一区的第1块只能放在Cache的第1组,具体是第1组的第几行,也是任意的,即:
Cache0组存放:0、2、4、6、8、10、12、14号块;
Cache1组存放:1、3、5、7、9、11、13、15号块。

所以组相联映射可以说是:内存块“直接映射”进Cache组、Cache组内“全相联映射”。在CPU给出9位地址索引,低5位用来表示该字节是Block中32个字节的哪一字节,剩下的看主存块的序号是奇数还是偶数(看最低位),若最低位为0,则去Cache第0组找;若最低位为1,则去Cache第1组找。具体是第0组的第几行,需要一 一比较剩下的三位(主存中的第几区),如果Cache的组内Tag都不匹配,那就Miss。

5. 地址映射实例分析
1.某计算机采用主存--Cache存储层次结构,主存容量有8个块,Cache容量有4个块,采用直接映射方式。若主存块地址流为0,1,2,5,4,6,4,7,1,2,4,1,3,7,2,一开始Cache为空,此期间Cache的命中率为多少?
解:直接映射,Cache有4个块,所以主存地址模4存储。一开始Cache全空,0存在Cache0,1存在Cache1,2存在Cache2;5存在Cache1替换掉1,4存在Cache0替换掉0,6存在Cache2替换掉2,4存在Cache0命中!7存在Cache3,1存在Cache1替换掉5,2存在Cache2替换掉6,4存在Cache0命中!1存在Cache1命中!3存在Cache3替换掉7,7存在Cache3替换掉3,2存在Cache2命中!共15笔数据,命中4次,命中率为4/15=26.7%

2.某计算机的Cache共有16块,采用二路组相联映射方式(即每组2块)。每个主存块大小为32Byte,按字节编址。主存129号单元所在主存块应装入到的Cache组号是什么?
解:两路组相联,每组两块,所以Cache可以分出来8组。所以主存中每8Block分一个区,129号单元即第129Byte,位于4号Block 32Byte数据的第1Byte(从0开始计数,4号Block即第5个Block),所以应该被分到Cache中的第4组,但具体第4组的第几条是不确定的(“全相联”)。
6. Cache的替换策略与算法
CPU访存Cache时,如果访问的数据在Cache中存在则命中。若不存在Miss,则需要对Cache中的数据进行替换,需要从主存中将数据搬运到Cache进行替换,Cache的数据替换也有很多的策略。
6.1. 先进先出(FIFO)算法
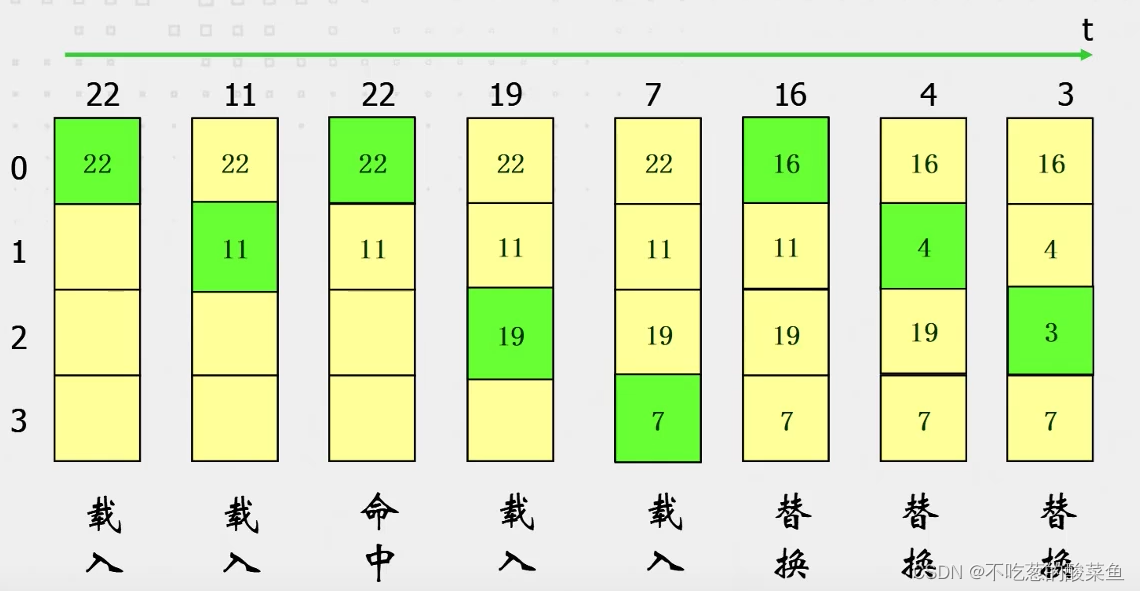
暂不考虑Cache的映射规则,仅考虑Cache内数据的话,FIFO算法可以如下描述:随着时间的推移,当Cache被完全填满时,如果再次载入了新的数(未命中)则将该数替换掉最老的数,若命中,则不变。
这种算法实现简单,但是存在一个问题,就是先进来的数,未必后续就用不到,因此这种算法命中率不会很高。
6.2. 近期最少使用(LRU)算法
每个Cache单元需要一个计数器跟踪最近访问的数据,每次访问的数据相应的计数器置为0;其余的计数器依次加1。这个计数器又叫“年龄计数器”,可以反应出某个Cache单元多久没被访问过了,然后可以替换最久未被访问的数据。如下图所示,其中右上角标为计数器:
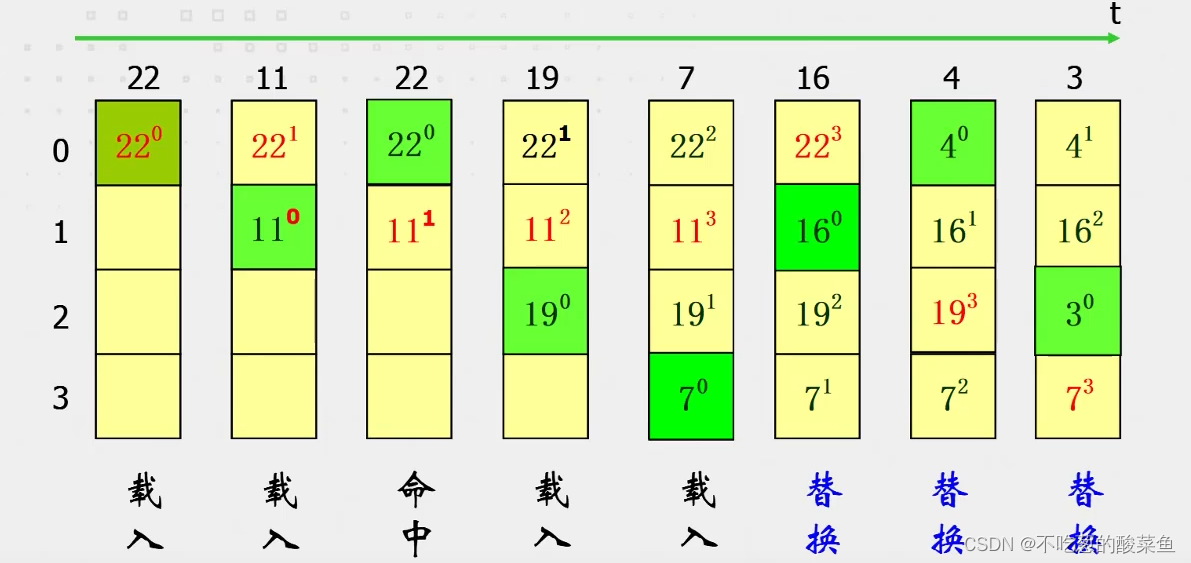
替换时,谁的年龄计数器最大,代表它长时间未被访问,就替换谁。这种替换策略比先进先出的替换策略更合理一些,但是它的硬件开销会更大,需要给每个Cache单元配一个计数器模块。
7. 地址映射&&替换策略实例分析
1. 假设某计算机按字编址,Cache 有4个行,Cache和主存之间交换的块大小为1个字。若Cache的内容初始为空,采用二路组相联映射方式和LRU替换算法,当访问的主存地址依次为0,4,8,2,0,6,8,6,4,8时,命中Cache的次数是多少?
解:Cache有4行,采用二路组相联,所以Cache被分为了两组,且每组有2行。由于计算机按字编址,因此主存地址就是Block块号。访问的主存地址都是偶数,因此都会访问Cache中的第0组。所以关注点可以转移到Cache一组当中两行的LRU替换情况了。
初始状态Cache为空,进来0,4,0最老。进来8替换0,4最老。进来2替换4,8最老。进来0替换8,2最老。进来6替换2,0最老。进来8替换0,6最老。进来6,命中6,8最老。进来4替换8,6最老。进来8替换6,4最老。总共访问10次,命中Cache 1次。
8. Cache性能评价指标
8.1. 命中率
在一个程序执行期间,设Nc表示Cache完成存取的总次数,Nm表示主存完成存取的总次数,h定义为命中率。则有:
命中率跟程序、Cache容量、组织方式、块的大小有关。
8.2. 存储系统平均存取时间
Cache存取时间为tc,命中率为h,主存的存取时间为tm,则系统平均存取时间为:
8.3. 存储系统的访问效率
8.4. 性能评价实例
某计算机系统的内存存储系统是由Cache和主存构成,Cache的存取周期是45ns,主存的存取周期是200ns,已知在一段给定的时间内,CPU共访问存储系统2000次,其中访问主存100次,问:
1)Cache的命中率为多少?
2)CPU访问该内存存储系统的平均时间是多少?
3)Cache--主存的效率是多少?
解:命中率h=1900/2000=95%。CPU访问的平均时间t_a=45*95%+200*5%=52.75ns。Cache--主存的效率为:45ns/52.75ns=85.3%。