基础 XGBoost 实战以 iris 数据集为例
- 1、导入数据
- 2、数据预处理
- 3、分训练集和测试集
- 4、训练模型构建
- 5、测试集预测准确度
- 6、构建混淆矩阵
- 7、特征重要性
对于很多只是小小使用机器学习,而不是深入了解的人来说,了解各种原理可能是十分痛苦的,所以这里就以 XGBoost 为例,从导入数据到最后预测都用简单代码求解。 注意:以下图表是在 Jupyter 上运行得到的。
1、导入数据
不管怎么样,先导入数据,然后观察数据是否需要进行预处理
import pandas as pd
df = pd.read_csv('iris.csv')
df.head()
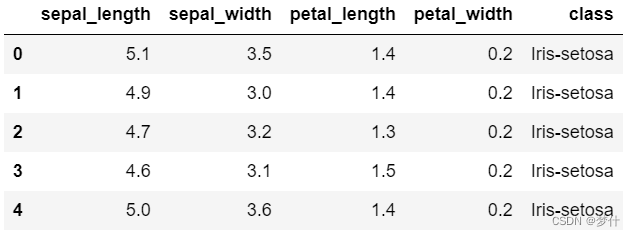
2、数据预处理
从上表可以发现,数据集的最后一列是字符型,需要转化为数值型(也就是 0 , 1 , 2 0,1,2 0,1,2)才能进行后续操作。
from sklearn.preprocessing import LabelEncoder
df['class'] = LabelEncoder().fit_transform(df.iloc[:,-1])
3、分训练集和测试集
把特征和标签分开,得到 X X X 和 y . y. y.
X = df.drop(columns='class')
y = df['class']
提取完特征变量后,通过如下代码将数据分为 80 % 80\% 80% 的训练集和 20 % 20\% 20% 的测试集。
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=123)
4、训练模型构建
划分为训练集和测试集之后,就可以引入 X G B o o s t XGBoost XGBoost 分类器进行模型训练了,参数的选择可以根据自己的实际情况设置,这里随便设置,代码如下:
from xgboost import XGBClassifier
clf = XGBClassifier(n_estimators=100, learning_rate=0.05)
clf.fit(X_train, y_train)

5、测试集预测准确度
模型训练完毕后,通过如下代码预测测试集数据,并将预测值和实际值进行对比
y_pred = clf.predict(X_test)
a = pd.DataFrame() # 创建一个空DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
a.head()
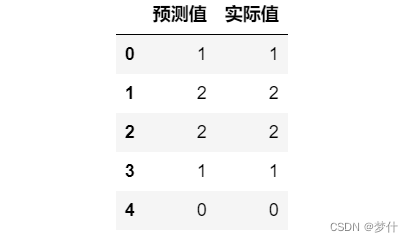
计算测试值的预测准确度,可以使用如下两个代码中的一个,第一个是
s
k
l
e
a
r
n
sklearn
sklearn 的,第二个是模型自带的。准确度为
93.33
%
93.33\%
93.33%
# 第一种
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred, y_test)
score
# 第二种
clf.score(X_test, y_test)
XGBClassifier 分类器本质预测的并不是准确的 0 0 0 或 1 1 1 的分类,而是预测其属于某一分类的概率,查看预测属于各个分类的概率
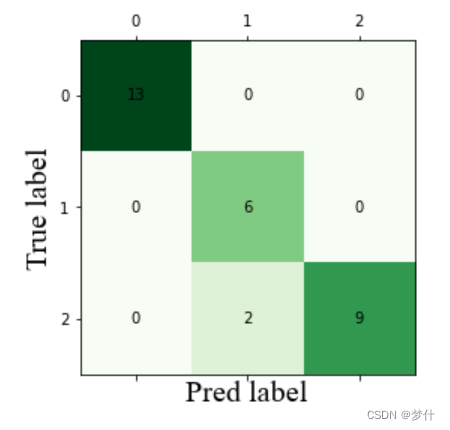
6、构建混淆矩阵
y_pred_proba = clf.predict_proba(X_test)
r o c roc roc 曲线通常用于二分类,多分类选择用混淆矩阵
# 多分类用混淆矩阵
from sklearn.metrics import confusion_matrix
C = confusion_matrix(y_test,y_pred)
# 画图
import matplotlib.pyplot as plt
plt.matshow(C,cmap=plt.cm.Greens)
for i in range(len(C)):
for j in range(len(C)):
plt.annotate(C[j, i], xy=(i, j), horizontalalignment='center', verticalalignment='center')
# 加标签
plt.ylabel('True label')
plt.xlabel('Pred label')
# 设置字体大小。
plt.ylabel('True label', fontdict={'family': 'Times New Roman', 'size': 20})
plt.xlabel('Pred label', fontdict={'family': 'Times New Roman', 'size': 20})
plt.show()
7、特征重要性
展示各个特征的重要性
# 获取特征名称
features = X.columns
# 获取特征重要性
importances = clf.feature_importances_
# 通过二维表格形式显示
importances_df = pd.DataFrame()
importances_df['特征名称'] = features
importances_df['特征重要性'] = importances
importances_df.sort_values('特征重要性', ascending=False)
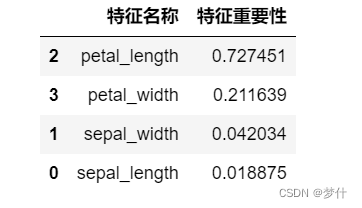
可以发现第三个特征
p
e
t
a
l
_
l
e
n
g
t
h
petal\_length
petal_length 的重要性高达
72
%
72\%
72%,第二个特征
p
e
t
a
l
_
w
i
d
t
h
petal\_width
petal_width 的重要性高达
21
%
21\%
21%,这两个特征加起来高达
93
%
93\%
93%.