C语言函数大全
本篇介绍C语言函数大全-- n 开头的函数
1. nan
1.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
double nan(const char *tagp); | 用于返回一个表示 NaN(非数值)的 double 类型数字 |
参数:
- tagp : 指向字符串的指针;用于指定 NaN 数字的类型。如果不需要指定类型,则可以将该参数设置为 NULL。
1.2 演示示例
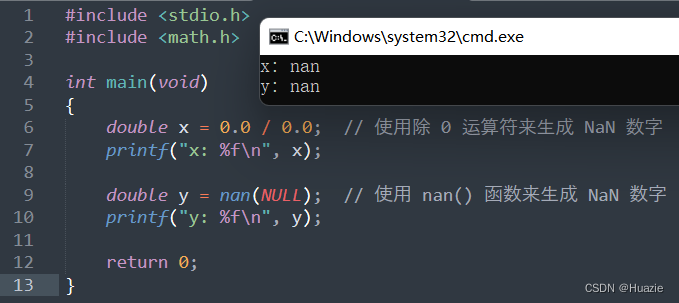
#include <stdio.h>
#include <math.h>
int main(void)
{
double x = 0.0 / 0.0; // 使用除 0 运算符来生成 NaN 数字
printf("x: %f\n", x);
double y = nan(NULL); // 使用 nan() 函数来生成 NaN 数字
printf("y: %f\n", y);
return 0;
}
注意:
NaN数字具有一些特殊的属性,例如与任何数字进行比较都会返回false,因此在实际编程中需要特别小心处理NaN的情况,避免出现异常结果
1.3 运行结果
2. nanosleep
2.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
int nanosleep(const struct timespec *req, struct timespec *rem); | 用于暂停当前进程的执行一段指定的时间。相比于 sleep() 函数,nanosleep() 函数可以精确地指定等待时间,以纳秒为单位。 |
参数:
- req : 指向 timespec 结构体的指针,用于指定要等待的时间。
timespec结构体包含两个成员变量:tv_sec表示等待时间的整数部分(秒),tv_nsec表示等待时间的小数部分(纳秒)。如果rem参数不为NULL,则在函数返回时,未完成的等待时间将被存储在rem指向的timespec结构体中。- rem : 未完成的等待时间
2.2 演示示例
#include <stdio.h>
#include <time.h>
int main(void)
{
struct timespec req = { 0 };
req.tv_sec = 2; // 等待时间为 2 秒
req.tv_nsec = 5000000; // 加上 5 毫秒
int ret = nanosleep(&req, NULL);
if (ret == 0) {
printf("nanosleep completed\n");
} else {
printf("nanosleep interrupted by signal\n");
}
return 0;
}
在上述的程序中,
- 我们首先创建一个
timespec结构体变量req,用于指定等待时间。在本例中,我们将等待时间设置为2秒加上5毫秒。 - 接着,我们调用
nanosleep()函数,并传递req变量的地址作为第一个参数。如果函数执行成功(即完成了预定的等待时间),则返回值为0,否则返回-1。 - 最后,我们检查函数的返回值,以确定
nanosleep()是否成功完成。如果返回值为0,则表示函数已经完成了预定的等待时间;如果返回值为-1,则说明函数被信号中断。在实际编程中,我们还可以通过检查errno变量来获取更具体的错误信息。
3. nearbyint,nearbyintf,nearbyintl
3.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
double nearbyint(double x); | 用于将一个浮点数四舍五入到最接近的整数值(double) |
float nearbyintf(float x); | 用于将一个浮点数四舍五入到最接近的整数值(float) |
long double nearbyintl(long double x); | 用于将一个浮点数四舍五入到最接近的整数值(long double) |
3.2 演示示例
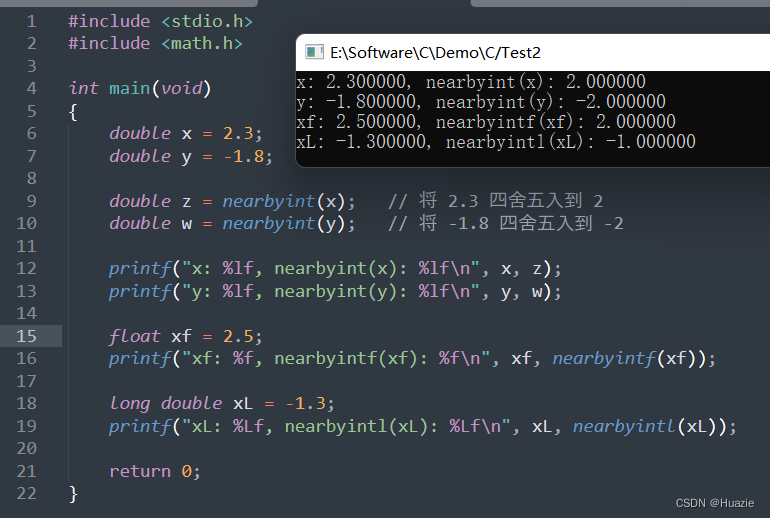
#include <stdio.h>
#include <math.h>
int main(void)
{
double x = 2.3;
double y = -1.8;
double z = nearbyint(x); // 将 2.3 四舍五入到 2
double w = nearbyint(y); // 将 -1.8 四舍五入到 -2
printf("x: %lf, nearbyint(x): %lf\n", x, z);
printf("y: %lf, nearbyint(y): %lf\n", y, w);
float xf = 2.5;
printf("xf: %f, nearbyintf(xf): %f\n", xf, nearbyintf(xf));
long double xL = -1.3;
printf("xL: %Lf, nearbyintl(xL): %Lf\n", xL, nearbyintl(xL));
return 0;
}
注意:
nearbyint()函数对于0.5的情况具有特殊处理:如果要转换的数恰好与两个整数的距离相等,则按照偶数方向进行舍入(即选择更接近偶数的整数)。例如,如果要将2.5转换为整数,那么将近似到最接近的偶数2,而不是3。这种舍入方式称为 “银行家舍入法” 或 “四舍六入五成双”。
3.3 运行结果
4. nextafter,nextafterf,nextafterl
4.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
double nextafter(double x, double y); | 用于找出与给定的浮点数最接近的下一个浮点数(double) |
float nextafterf(float x, float y); | 用于找出与给定的浮点数最接近的下一个浮点数(float) |
long double nextafterl(long double x, long double y); | 用于找出与给定的浮点数最接近的下一个浮点数(long double) |
参数:
- x : 要查找其下一个浮点数的浮点数
- y : 给定浮点数的目标值,表示前进方向。
返回值:
- 如果
y大于x,则向正无穷方向查找;- 如果
y小于x,则向负无穷方向查找;如果y等于x,则返回y。
4.2 演示示例
#include <stdio.h>
#include <math.h>
int main(void)
{
double x = 1.0;
double y = 2.0;
printf("nextafter(%lf, %lf): %.20lf\n", x, y, nextafter(x, y));
printf("nextafter(%lf, %lf): %.20lf\n", y, x, nextafter(y, x));
float xf = 2.0;
float yf = 1.0;
printf("nextafterf(%f, %f): %.20f\n", xf, yf, nextafterf(xf, yf));
long double xL = -1.2;
long double yL = - 1.5;
printf("nextafterl(%Lf, %Lf): %.20Lf\n", xL, yL, nextafterl(xL, yL));
return 0;
}
注意: 由于计算机内部存储浮点数的方式是有限制的,因此在进行浮点数计算时可能会存在误差。在实际编程中,我们应该特别小心处理这些情况,避免出现异常结果。
4.3 运行结果
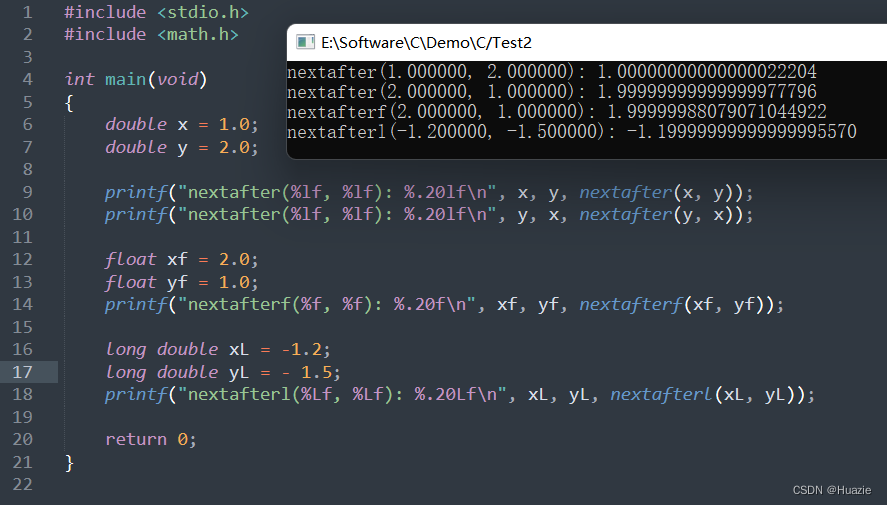
5. nexttoward,nexttowardf,nexttowardl
5.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
double nexttoward(double x, long double y); | 用于找出与给定的浮点数最接近、并朝着指定方向的下一个浮点数(double) |
float nexttowardf(float x, long double y); | 用于找出与给定的浮点数最接近、并朝着指定方向的下一个浮点数(float) |
long double nexttowardl(long double x, long double y); | 用于找出与给定的浮点数最接近、并朝着指定方向的下一个浮点数(long double) |
参数:
- x : 要查找其下一个浮点数的浮点数
- y : 给定浮点数的目标值,表示前进方向。
返回值:
- 如果
y大于x,则向正无穷方向查找;- 如果
y小于x,则向负无穷方向查找;如果y等于x,则返回y。
5.2 演示示例
#include <stdio.h>
#include <math.h>
int main(void)
{
double x = 1.0;
long double y = 2.0;
printf("nexttoward(%lf, %Lf): %.20lf\n", x, y, nexttoward(x, y));
float xf = 3.2;
printf("nexttowardf(%f, %Lf): %.20f\n", xf, y, nexttowardf(xf, y));
long double xL = 1.9;
printf("nexttowardl(%Lf, %Lf): %.20Lf\n", xL, y, nexttowardl(xL, y));
return 0;
}
5.3 运行结果
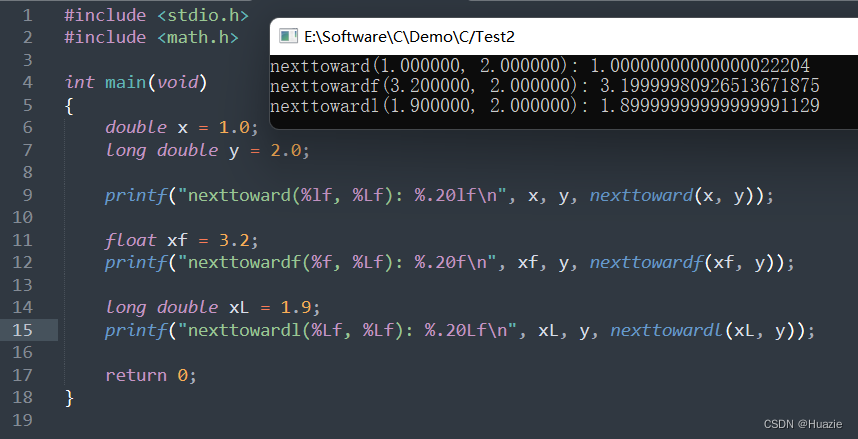
6. newlocale
6.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
locale_t newlocale(int category_mask, const char *locale, locale_t base); | 用于创建并返回一个新的本地化环境变量,以便在不同的本地化设置之间进行切换。 |
参数:
- category_mask : 指定了要创建的本地化环境变量包含哪些类别。可以使用下列常量按位或来指定:
LC_ALL_MASK:表示所有类别。LC_COLLATE_MASK:表示字符串比较和排序规则。LC_CTYPE_MASK:表示字符分类和转换规则。LC_MESSAGES_MASK:表示本地化消息文本。LC_MONETARY_MASK:表示货币格式。LC_NUMERIC_MASK:表示数字格式。LC_TIME_MASK:表示时间和日期格式。- locale : 指定了要使用的区域设置名称。如果为
NULL或空字符串,则使用当前系统默认的本地化设置。- base : 指定了要基于的基础本地化环境变量。如果为
NULL,则使用LC_GLOBAL_LOCALE。
6.2 演示示例
#include <stdio.h>
#include <locale.h>
int main()
{
// 创建一个新的本地化环境变量,用于解析德语字符串比较和排序规则。
locale_t loc = newlocale(LC_COLLATE_MASK, "de_DE.UTF-8", LC_GLOBAL_LOCALE);
// 在新的本地化环境变量下比较两个字符串,并输出比较结果。
const char *str1 = "äbc";
const char *str2 = "abc";
int result = strcoll_l(str1, str2, loc);
printf("%s %s %s\n", str1, (result < 0 ? "<" : (result > 0 ? ">" : "==")), str2);
// 释放本地化环境变量
freelocale(loc);
return 0;
}
在上述程序中,
- 我们首先使用
newlocale()函数创建一个新的本地化环境变量loc,以便比较和排序德语字符串。 - 接着,我们使用
strcoll_l()函数来在新的本地化环境变量下比较两个字符串str1和str2。 - 最后,我们输出比较结果,并使用
freelocale()函数释放loc变量。
注意: 在实际编程中应该特别注意本地化设置对字符处理、货币格式、时间格式等方面的影响,避免出现不必要的错误。
7. nftw
7.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
int nftw(const char *dirpath, int (*fn)(const char *fpath, const struct stat *sb, int typeflag, struct FTW *ftwbuf), int nopenfd, int flags); | 用于递归遍历指定目录下的所有文件和子目录,并对每个文件或目录执行指定操作。 |
参数:
- dirpath : 要遍历的目录路径
- fn : 一个回调函数,用于在遍历过程中对每个文件或目录执行指定操作。该函数的参数如下:
- fpath : 当前文件的完整路径。
- sb : 当前文件的
struct stat结构体指针,包含了当前文件的各种属性信息。- typeflag : 表示当前文件的类型,可能为以下值之一:
FTW_F:普通文件。FTW_D:目录。FTW_DNR:无法读取的目录。FTW_NS:无法访问的文件(可能是因为权限问题)。FTW_SL:符号链接。FTW_DP:与 FTW_D 相同,但目录本身还未被访问。FTW_SLN:符号链接,指向不存在的文件。- ftwbuf : 一个
struct FTW结构体指针,包含了一些关于遍历状态的信息。- nopenfd : 最大打开文件描述符数
- flags : 控制遍历行为的标志位,可以使用下列常量按位或来指定:
FTW_CHDIR:进入目录后更改工作目录。FTW_DEPTH:深度优先遍历。FTW_MOUNT:不跨越文件系统边界。FTW_PHYS:不跟随符号链接。
7.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <ftw.h>
static int count = 0;
int print_file_info(const char *fpath, const struct stat *sb, int typeflag, struct FTW *ftwbuf)
{
// 打印文件路径和类型
printf("%s ", fpath);
if (typeflag == FTW_F) {
printf("(file)\n");
} else if (typeflag == FTW_D) {
printf("(dir)\n");
} else {
printf("(other)\n");
}
// 计数器加一
count++;
return 0;
}
int main(void)
{
int result = nftw(".", print_file_info, 10, FTW_PHYS);
if (result == -1) {
perror("nftw");
exit(EXIT_FAILURE);
}
printf("Total files and directories: %d\n", count);
return 0;
}
在上述的程序中,
- 我们首先定义了一个回调函数
print_file_info(),用于打印每个文件或目录的路径和类型,并将计数器加一。 - 接着,我们调用
nftw()函数来递归遍历当前目录下的所有文件和子目录,并对每个文件或目录执行print_file_info()函数。 - 最后,我们输出遍历总数。
注意: 在实际编程中应该特别注意文件访问权限等问题,以避免出现不必要的错误。
7.3 运行结果
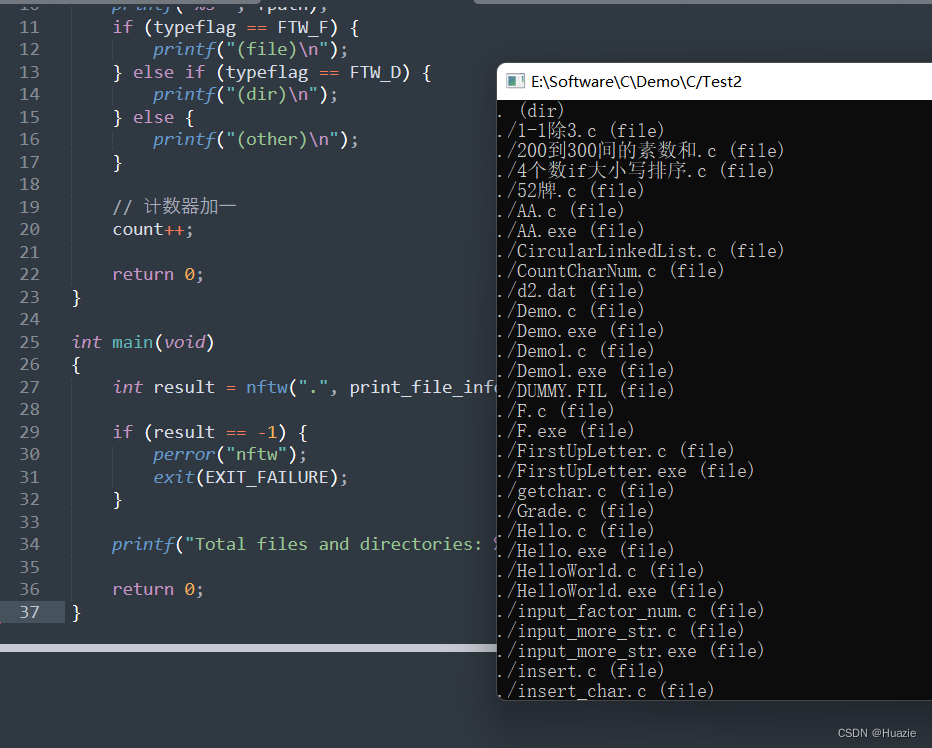
8. nice
8.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
int nice(int inc); | 它是一个系统调用,可将进程截止到当前用户的最大优先级减少指定的优先级,以更改进程的调度优先级。较高的 niceness 值意味着较低的优先级。 |
参数:
- inc : 要增加或减少的优先级值。如果
inc的值为正数,则表示将进程的优先级降低;如果inc的值为负数,则表示将进程的优先级提高。通常情况下,只有具有root权限的进程才能将自己的优先级升高。
8.2 演示示例
#include <stdio.h>
#include <unistd.h>
int main(void)
{
// 输出当前进程的初始优先级
printf("Initial nice value: %d\n", nice(0));
// 将进程的优先级减少 10
int result = nice(10);
if (result == -1) {
perror("nice");
} else {
printf("New nice value: %d\n", result);
}
return 0;
}
在上述程序中,
- 我们首先使用
nice(0)函数输出当前进程的初始优先级; - 接着,我们使用
nice(10)函数将进程的调度优先级降低10; - 最后将新的优先级值输出到终端。
注意: 由于
nice()函数并不是标准C库中的函数,因此在编译时需要传递-posix参数或其他类似参数以启用POSIX标准。在实际编程中应该特别注意优先级修改对进程正常运行的影响,以避免出现不必要的错误。
9. nl_langinfo
9.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
char *nl_langinfo(nl_item item); | 它是一个 POSIX 标准函数,用于获取当前本地化环境下的语言环境信息。它可以返回一些与语言、货币、日期和时间格式等相关的信息。 |
参数:
- item : 指定要获取的本地化信息。可以使用下列常量之一来指定:
ABDAY_*:星期缩写名称(0 ~ 6 表示周日到周六)。DAY_*:星期全称(0 ~ 6 表示周日到周六)。ABMON_*:月份缩写名称(0 ~ 11 表示一月到十二月)。MON_*:月份全称(0 ~ 11 表示一月到十二月)。AM_STR:上午字符串。PM_STR:下午字符串。D_FMT:日期格式字符串。T_FMT:时间格式字符串。ERA:纪元字符串。ERA_D_T_FMT:带日期和时间的纪元字符串。ERA_D_FMT:仅带日期的纪元字符串。ERA_T_FMT:仅带时间的纪元字符串。ALT_DIGITS:非十进制数字字符。
9.2 演示示例
#include <stdio.h>
#include <langinfo.h>
int main(void)
{
char *time_fmt = nl_langinfo(T_FMT);
char *date_fmt = nl_langinfo(D_FMT);
printf("Time format: %s\n", time_fmt);
printf("Date format: %s\n", date_fmt);
return 0;
}
在上述的程序中,
- 我们使用
nl_langinfo(T_FMT)函数获取当前本地化环境下的时间格式字符串,并将其输出到终端。 - 接着,我们使用
nl_langinfo(D_FMT)函数获取当前本地化环境下的日期格式字符串,并将其输出到终端。
注意: 在实际编程中应该特别注意处理不同本地化环境下信息的差异,以避免出现不必要的错误。
10. nrand48
10.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
long nrand48(unsigned short xsubi[3]); | 用于生成带有指定状态的随机数。它使用 48 位整数来表示随机数的状态,可以方便地切换不同的随机数生成器状态。 |
参数:
- xsubi : 一个包含
3个16位无符号整数的数组,表示了当前随机数生成器的状态。如果想更改随机数生成器的状态,只需修改xsubi数组即可。
10.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
int main(void)
{
unsigned short seed[3];
seed[0] = (unsigned short) time(NULL);
seed[1] = (unsigned short) getpid();
seed[2] = 12345;
srand48(seed);
printf("Random number: %ld\n", nrand48(seed));
return 0;
}
在上述的程序中,
- 我们首先创建了一个包含
3个16位无符号整数的数组seed,并将其用作随机数生成器的种子。 - 接着,我们使用
srand48()函数初始化随机数生成器,并使用nrand48()函数生成一个随机数,并将其输出到终端。
注意: 由于
nrand48()函数生成的是伪随机数,因此在实际使用时需要注意选择足够复杂的种子,并采取适当的加密措施以避免出现不必要的安全问题。
11. ntohl,ntohs
11.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
uint32_t ntohl(uint32_t netlong); | 用于将网络字节序(大端序)转换为主机字节序(小端序)。 |
uint16_t ntohs(uint16_t netshort); | 用于将网络字节序(大端序)转换为主机字节序(小端序)。 |
参数:
- netlong : 表示要转换的
32位整数。- netshort : 表示要转换的
16位整数。
11.2 演示示例
#include <stdio.h>
#include <stdint.h>
#include <netinet/in.h>
int main(void)
{
uint32_t num1 = 0x12345678;
uint16_t num2 = 0x5678;
printf("Original value (hex):\n");
printf("num1: %08X\n", num1);
printf("num2: %04X\n", num2);
num1 = ntohl(num1);
num2 = ntohs(num2);
printf("Converted value (hex):\n");
printf("num1: %08X\n", num1);
printf("num2: %04X\n", num2);
return 0;
}
注意: 在实际编程中应该特别注意不同平台之间的字节序差异,以避免出现不必要的错误。