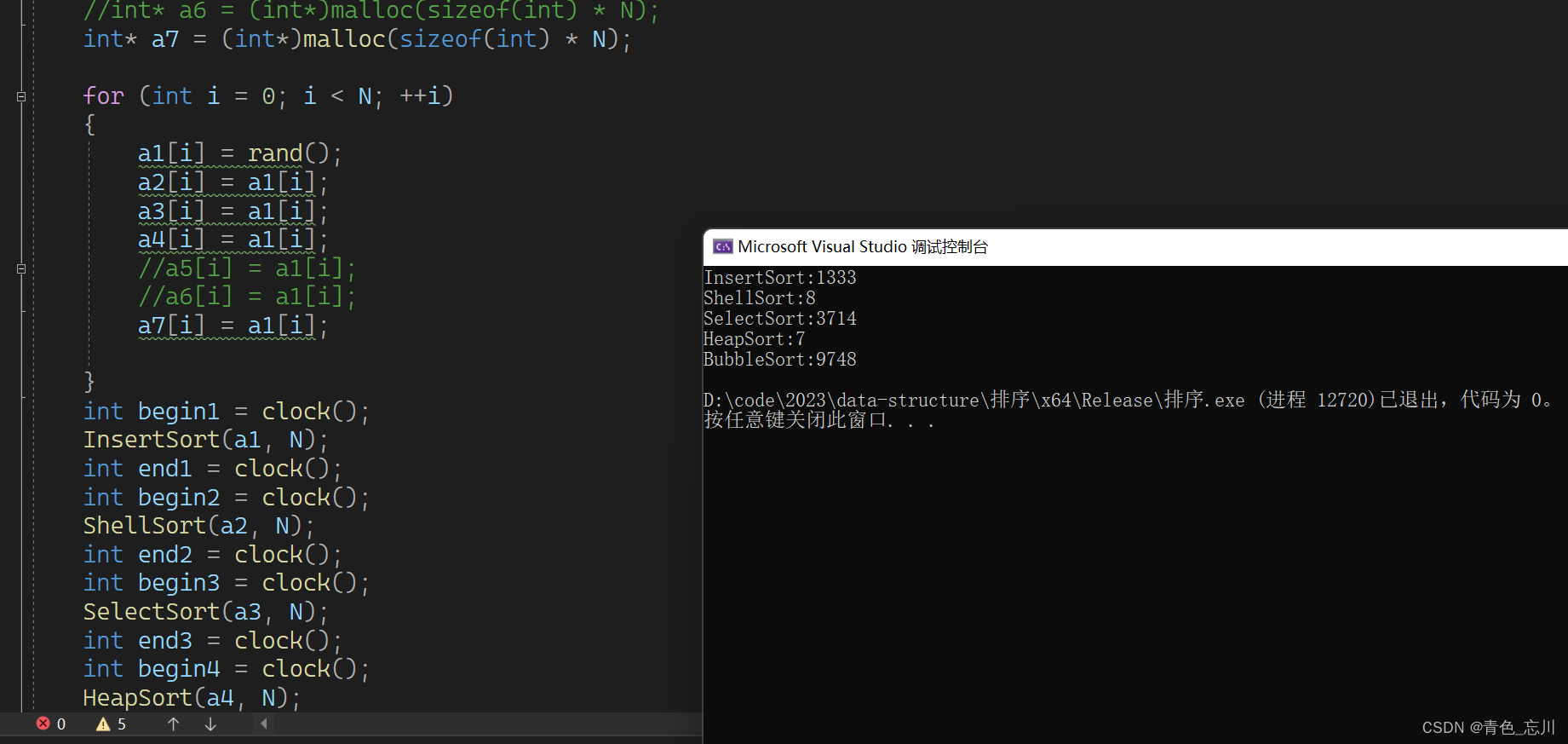
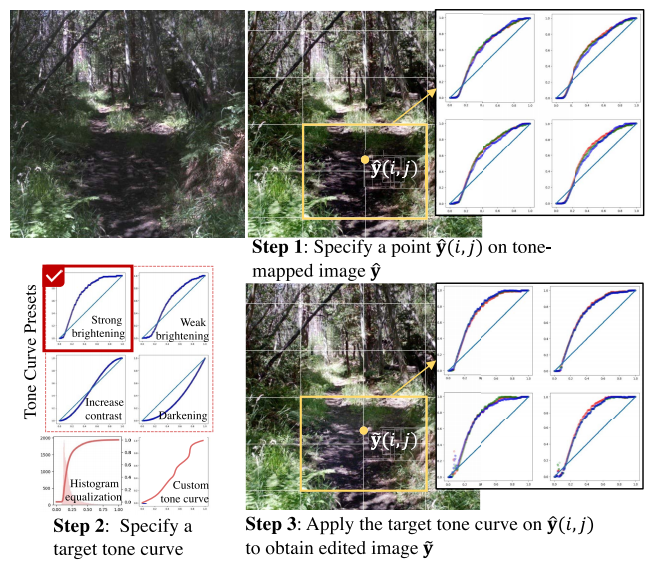
XLA IR:HLO、LHLO、MHLO和LMHLO
- HLO
- LHLO
- MHLO
- LMHLO
- XLA IR 总结
- HLO->LMHLO
xla基本编译流程如下:

- HLO Optimization: 硬件无关优化和硬件相关优化
- LHLO Codegen: 算子向量化和llvmir的生成
- HLO&LHLO是XLA-HLO;MHLO&LMHLO是MLIR-HLO,也即MLIR HLO的dialect
HLO
HLO(High Level Optimizer),是XLA IR。XLA支持一组正交的基础operators(原子算子),其他的operators都可以由这组基础算子组合而成。HLO IR是分层的嵌套结构,由以下三个层次组成:
-
HloModule:HLO IR最高层的表示,可以理解成整个程序。一个HloModule可以包含很多个HloComputation。
-
HloComputation:HLO IR中间层的表示,相当于程序中的一个函数。一个HloModule只能有一个entry_conputation,其他的computation是被entry_computation调用的。我们可以把entry_computation类比作main函数。每个HloComputation可以包含多个HloInstruction。
-
HloInstruction:HLO IR最底层的表示,相当于程序中的一条指令。每个HloComputation只能有一个root_instruction。root_instruction的output就是该computation的output。computation的input用parameter表示。HloInstruction也可以调用HloComputation,HloInstruction中有一个called_computations_来表示该instruction调用的computation。不同HloInstruction参数和属性可能存在区别,HloInstruction只是一个base class,特殊的Instruction可以由HloInstruction派生得到,例如HloSliceInstruction。

HloInstruction通过call_computations_调用另一个comoutation,实现IR的嵌套。例如XLA的融合优化,会将被融合的指令替换成一条HloFusionInstruction,被融合被组装到一个HloComputation,并被HloFusionInstruction调用。
1 HloModule m, is_scheduled=true, entry_computation_layout={(f32[8]{0},f32[8]{0})->f32[8]{0}}
2
3 fused_computation {
4 p0 = f32[8]{0} parameter(0)
5 p1 = f32[8]{0} parameter(1)
6 multiply0 = f32[8]{0} multiply(p0, p1)
7 ROOT add0 = f32[8]{0} add(multiply0, p1)
8 }
9
10 ENTRY PredFloatMOF {
11 p0.1 = f32[8]{0} parameter(0)
12 p1.1 = f32[8]{0} parameter(1)
13 ROOT fusion = f32[8]{0} fusion(p0.1, p1.1), kind=kLoop, calls=fused_computation
14 }
XLA HLO的op操作的是immutable、静态shape和显示广播的tensor。
HLO的入口:
- TF、PT和JAX转换成HLO。
- 经过mlir_bridge,先转成mlir(tf_executor dialect and mhlo),在mlir上做一些优化,再转为HLO。此路线在XLA中还是experimental,还在开发中。
出口:
- LHLO、MHLO或LMHLO。XLA的pipeline是将HLO转成MHLO和LMHLO,然后用于codegen。
LHLO
LHLO:“late”-HLO,经过buffer assignment后的HLO。HLO和LHLO的区别在于HLO注重的是tensor的表达,不考虑到内存的分配,比如tensor<8x32x16xfp32>,仅仅表示为tensor,没有具体的内存信息,没有side-effect的。LHLO会为tensor开辟内存空间,也即经过buffer assign,buffer assign相当于传统编译器中的内存分配,LHLO的op具有side-effect。
入口:
- HLO
出口:
- 用于codegen。
MHLO
MHLO:“meta”-HLO dialect,是HLO风格的MLIR dialect, 并且在IR上扩展支持了dynamic shape。XLA HLO 的shape是静态不可变的,不同shape需要重新编译;MHLO支持动态shape,IR本身有能力表达shape计算和动态shape信息的传递。
MLIR-HLO使得HLO可以从XLA中独立出来,可以结合MLIR构建端到端的编译器。
入口:
- TF Graph
- XLA HLO
出口:
- Linalg IREE、LMHLO,直接用于codegen。使用mlir构建编译器可以选择使用hlo为输入,转换为mlir的MHLO,做相关的分析、变换和优化,再转成LMHLO或者Linalg等做codegen。
- XLA HLO
LMHLO
LMHLO:“late”-“meta”-HLO dialect。是LHLO风格的MLIR dialect。
入口:
- MHLO或者XLA HLO经过shedule 和 buffer assign 后再转换的到。
出口:
- 用于codegen到llvm ir。
XLA IR 总结
-
(M)HLO的op是tensor类型,是不可变的 (immutable)、并且不具有 side effect,tensor的数据流分析(例如ssa def-use chain )和转换会比较容易。而L(M)HLO是经过buffer assign的,buffer 是可变的 (mutable)和有别名的 (alias),buffer上分析和转换需要比较复杂的依赖分析 (dependency analysis) 和别名分析 (alias analysis)。XLA会在HLO上做优化相对比较容易,包括传统的图优化(代数化简、死代码删除等)、融合相关优化等等。在完成HLO层的优化后转为LMHLO,利用mlir LMHO dialect做codegen生成llvm ir。
-
XLA pipeline中是直接将XLA HLO转换为LMHLO,然后在LMHLO上codegen。
-
按照xla的技术路线,lmhlo将合并到mhlo中,将不再区分mhlo和lmhlo,mhlo可以同时操作tensor和memref。
HLO->LMHLO
主要的处理过程如下:
1、buffer assignment。
- hlo instruction schedule,确定buffer liveness(减少内存使用)等。
- buffer assignment。
2、HLO转换为LMHLO。
- 创建mlir module、funcOp及其参数。
- 以SequentialHloOrdering顺序(可以先简单理解成指令执行顺序,这里会考虑到节省内存)处理entry computation中的每条指令,不同的指令类型进入不同的处理函数。例如:为hlo的instruction创建lmhlo的op;有call_computation时,以root节点后序遍历(post order)顺序处理computation中每条指令。
参考:
- https://github.com/tensorflow/tensorflow/tree/master/tensorflow/compile r/xla/mlir_hlo
- https://mlir.llvm.org/docs/LangRef/#high-level-structure