C语言函数大全
本篇介绍C语言函数大全-- m 开头的函数
1. malloc
1.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
void *malloc(size_t size); | 用于动态分配内存 |
参数:
- size : 需要分配的内存大小(以字节为单位)
返回值:
- 如果分配成功,返回分配的内存块的指针;
- 如果分配失败,则返回 NULL。
1.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main()
{
char *str = NULL;
// 分配内存
str = (char *)malloc(20 * sizeof(char));
if (str == NULL)
{
printf("Failed to allocate memory.\n");
return 1;
}
// 将字符串复制到内存中
strcpy(str, "Hello, world!");
// 输出字符串
printf("%s\n", str);
// 释放内存
free(str);
return 0;
}
在上面的示例程序中,
- 我们首先声明一个指向字符型的指针
str,并将其初始化为NULL; - 然后使用
malloc()函数动态分配了 20 字节的内存空间,并将其赋值给str指针; - 接下来,我们使用
strcpy()函数将字符串"Hello, world!"复制到内存中,并使用printf()函数输出字符串; - 最后,我们使用
free()函数释放了分配的内存空间。
1.3 运行结果

2. mblen
2.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
int mblen(const char *s, size_t n); | 检查多字节字符的长度 |
参数:
- s : 指向待检查的多字节字符或多字节字符序列的指针
- n : 要检查的最大字节数
注意:如果
s是空指针,则返回 0,表示不是多字节字符;否则,如果n不足以包含完整的多字节字符,则返回 -1,表示需要更多的输入;否则,返回多字节字符所需的字节数。
2.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
int main()
{
// 设置本地化环境
setlocale(LC_ALL, "");
char str[] = u8"你好,世界!";
int len;
// 检查第一个字符的长度
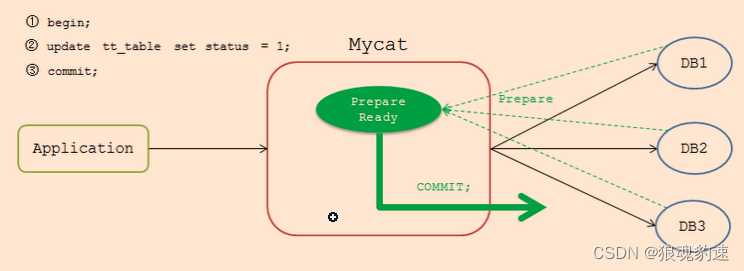
len = mblen(str, MB_CUR_MAX);
if (len == -1)
{
printf("Failed to determine the length of the multibyte character.\n");
return 1;
}
printf("The length of the first multibyte character is %d bytes.\n", len);
return 0;
}
在上面的示例程序中,
- 我们首先使用
setlocale()函数设置本地化环境,以便正确处理多字节字符。 - 然后我们定义了一个包含中文字符的字符串
str; - 接着使用
mblen()函数检查第一个字符的长度,并将其保存到变量len中。 - 最后,我们输出该字符的长度。
2.3 运行结果
3. mbrlen
3.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
size_t mbrlen(const char *s, size_t n, mbstate_t *ps); | 检查多字节字符的长度 |
参数:
- s : 指向待检查的多字节字符或多字节字符序列的指针
- n : 要检查的最大字节数
- ps : 描述转换状态的
mbstate_t结构体的指针
注意: 如果
s是空指针,则返回 0,表示不是多字节字符;否则,如果n不足以包含完整的多字节字符,则返回(size_t)-2,表示需要更多的输入;否则,如果ps是NULL,则使用默认转换状态;否则,将ps的值更新为已经转换的字符数,并返回多字节字符所需的字节数。
3.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <wchar.h>
#include <locale.h>
int main()
{
// 设置本地化环境
setlocale(LC_ALL, "");
char str[] = u8"你好,世界!";
int len;
// 检查第一个字符的长度
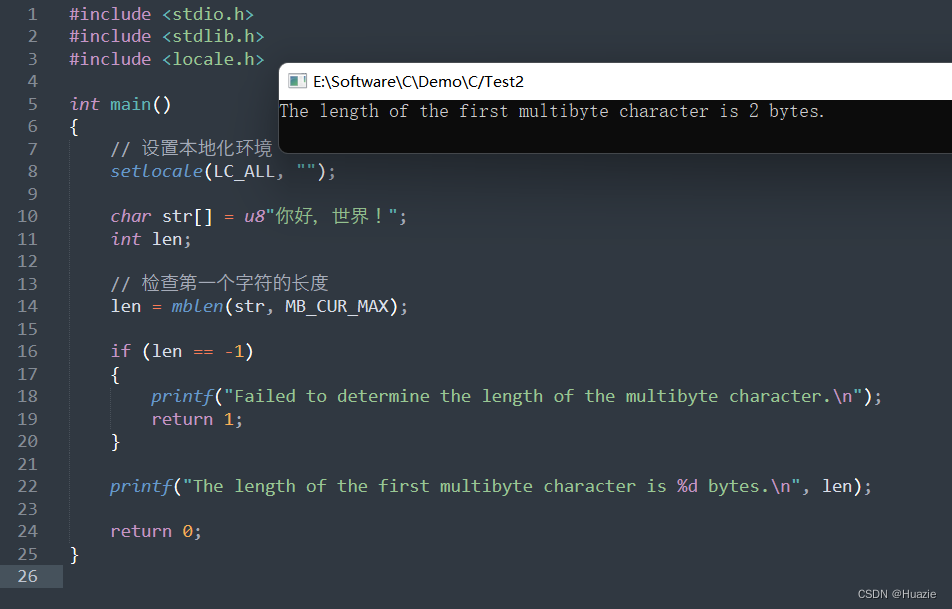
len = mbrlen(str, MB_CUR_MAX, NULL);
if (len == (size_t)-2) // 特殊的返回值,表示发生了错误
{
printf("Failed to determine the length of the multibyte character.\n");
return 1;
}
printf("The length of the first multibyte character is %d bytes.\n", len);
return 0;
}
在上面的示例程序中,
- 我们首先使用
setlocale()函数设置本地化环境,以便正确处理多字节字符。 - 然后我们定义了一个包含中文字符的字符串
str; - 接着使用
mbrlen()函数检查第一个字符的长度,并将其保存到变量len中。 - 最后,我们输出该字符的长度。
3.3 运行结果
4. mbrtowc
4.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
size_t mbrtowc(wchar_t *pwc, const char *s, size_t n, mbstate_t *ps); | 将多字节字符转换为宽字符 |
参数:
- pwc : 一个指向宽字符的指针,表示将要存入转换后的宽字符;
- s : 一个指向多字节字符或字符序列的指针;
- n : 一个表示最多转换的字节数的整数;
- ps : 一个指向转换状态的指针,如果为 NULL,则使用默认转换状态。
返回值:
- 如果能转换,返回转换的字符数;
- 如果不能转换,则返回
(size_t)-1。
4.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
#include <wchar.h>
int main()
{
// 设置本地化环境
setlocale(LC_ALL, "");
char str[] = u8"你好,世界!";
wchar_t wc;
mbstate_t state = {0};
// 将第一个字符转换为宽字符
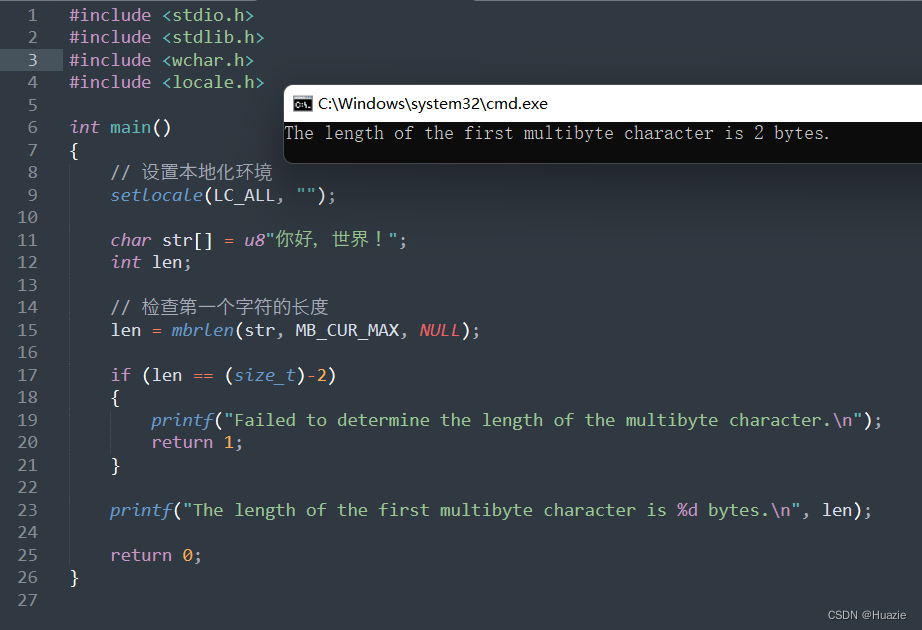
size_t len = mbrtowc(&wc, str, MB_CUR_MAX, &state);
if (len == (size_t)-1)
{
printf("Failed to convert multibyte character.\n");
return 1;
}
// 输出宽字符
wprintf(L"The first wide character is: %lc\n", wc);
return 0;
}
在上面的示例程序中,
- 我们首先使用
setlocale()函数设置本地化环境,以便正确处理多字节字符。 - 然后我们定义了一个包含中文字符的字符串
str; - 接着使用
mbrtowc()函数将第一个字符转换为宽字符,并将其保存到变量wc中。 - 最后,我们使用
wprintf()函数输出宽字符。
注意: 在调用
mbrtowc()函数之前,必须将mbstate_t结构体的值初始化为0。在 C99 标准中,可以使用大括号对结构体进行初始化,这会把结构体或数组的每个元素都初始化为默认值(0或NULL)。
4.3 运行结果
5. mbsinit
5.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
int mbsinit(const mbstate_t *ps); | 检查转换状态是否为起始状态 |
参数:
- ps : 指向
mbstate_t结构体的指针,表示要检查的转换状态。
注意: 如果
ps是空指针,则返回非零值(真),表示默认转换状态已经初始化;否则,如果ps描述的转换状态是起始状态,则返回非零值(真);否则,返回0(假)。
5.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
#include <wchar.h>
int main()
{
// 设置本地化环境
setlocale(LC_ALL, "");
char str[] = u8"你好,世界!";
mbstate_t state = {0};
// 检查转换状态是否为起始状态
if (!mbsinit(&state))
{
printf("The conversion state is not initial.\n");
return 1;
}
// 打印转换状态
printf("The conversion state is %s.\n", (mbsinit(&state) ? "initial" : "not initial"));
return 0;
}
在上面的示例程序中,
- 我们首先定义了一个包含中文字符的字符串
str和一个转换状态结构体state; - 然后我们使用
mbsinit()函数检查转换状态是否为起始状态; - 最后在控制台输出
"The conversion state is initial."。
5.3 运行结果

6. mbstowcs
6.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
size_t mbstowcs(wchar_t *pwcs, const char *s, size_t n); | 用于将多字节字符序列转换为宽字符序列。 |
参数:
- pwcs : 指向存储结果宽字符序列的缓冲区的指针
- s : 待转换的多字节字符序列
- n : 缓冲区的最大长度(以宽字符数计)
返回值:
- 如果成功地将多字节字符序列转换为宽字符序列,则该函数返回实际写入缓冲区中的宽字符数,不包括空字符
\0;- 如果遇到了无效的多字节字符或编码,或者宽字符缓冲区不足,导致转换失败,则该函数返回
(size_t)-1。
6.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
#include <wchar.h>
int main()
{
// 设置本地化环境
setlocale(LC_ALL, "");
char str[] = u8"你好,世界!";
wchar_t wcbuf[20];
// 将多字节字符序列转换为宽字符序列
size_t ret = mbstowcs(wcbuf, str, sizeof(wcbuf)/sizeof(wchar_t));
if (ret == (size_t)-1)
{
printf("Failed to convert multibyte character sequence.\n");
return 1;
}
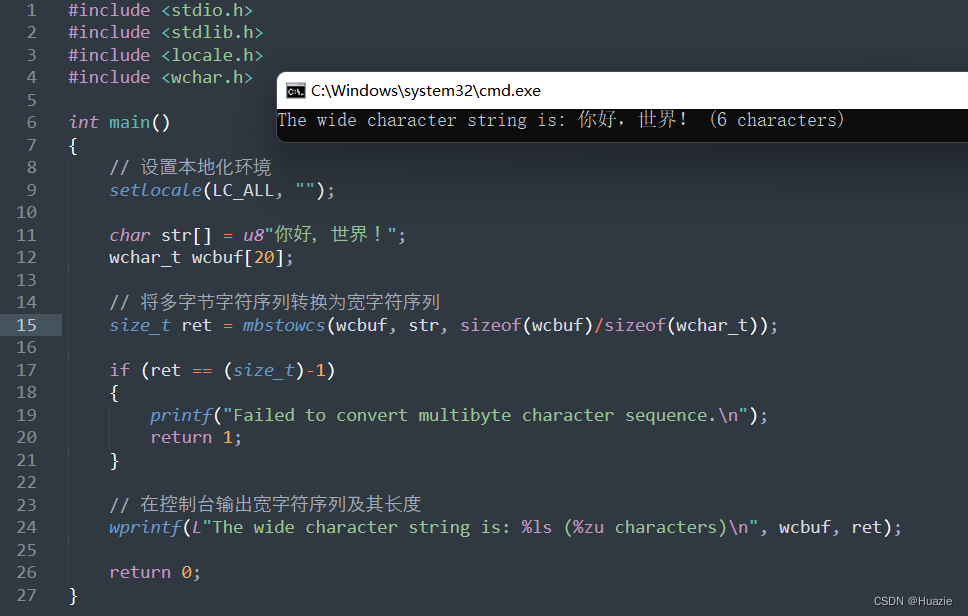
// 在控制台输出宽字符序列及其长度
wprintf(L"The wide character string is: %ls (%zu characters)\n", wcbuf, ret);
return 0;
}
在上面的示例程序中,我们首先定义了一个包含中文字符的字符串 str 和一个用于存储结果宽字符序列的缓冲区 wcbuf。然后我们使用 mbstowcs() 函数将多字节字符序列转换为宽字符序列,并在控制台输出相应的信息。
注意: 在计算缓冲区大小时,必须将其指定为宽字符数(即
sizeof(wcbuf)/sizeof(wchar_t)),而不是字节数或字符数。这是因为在Windows等一些操作系统中,wchar_t类型并不总是占用固定的字节数,而可能会根据编译器和平台而变化。
6.3 运行结果
7. mbstowcs
7.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
size_t mbsrtowcs(wchar_t *dst, const char **src, size_t len, mbstate_t *ps); | 用于将多字节字符序列转换为宽字符序列,并在转换过程中自动更新 mbstate_t 转换状态结构体。 |
参数:
- dst: 指向存储结果宽字符序列的缓冲区的指针
- src : 指向待转换的多字节字符序列的指针的指针
- len : 缓冲区的最大长度(以宽字符数计)
- ps : 指向包含转换状态信息的结构体 mbstate_t 的指针
返回值:
- 如果成功地将多字节字符序列转换为宽字符序列,则该函数返回实际写入缓冲区中的宽字符数,不包括空字符
\0;- 如果遇到了无效的多字节字符或编码,或者宽字符缓冲区不足,导致转换失败,则该函数返回
(size_t)-1。
注意:
mbsrtowcs()函数会自动更新转换状态结构体mbstate_t,以记录上一次调用的状态并在下一次调用时继续使用。这使得mbsrtowcs()函数适用于处理长的、包含部分多字节字符的字符串。它会自动识别和处理多字节字符序列中的部分字符,并等待更多的字节,直到可以完成转换为止。
7.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
#include <wchar.h>
int main()
{
// 设置本地化环境
setlocale(LC_ALL, "");
char str[] = u8"你好,世界!";
wchar_t wcbuf[20];
mbstate_t state = {0};
// 将多字节字符序列转换为宽字符序列
size_t ret = mbsrtowcs(wcbuf, (const char**)&str, sizeof(wcbuf)/sizeof(wchar_t), &state);
if (ret == (size_t)-1)
{
printf("Failed to convert multibyte character sequence.\n");
return 1;
}
// 在控制台输出宽字符序列及其长度
wprintf(L"The wide character string is: %ls (%zu characters)\n", wcbuf, ret);
return 0;
}
8. mbtowc
8.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
int mbtowc(wchar_t *restrict pwc, const char *restrict s, size_t n); | 用于将一个多字节字符 (Multibyte Character) 转换成一个宽字符 (Wide Character)。 |
参数:
- pwc : 指向存储宽字符的指针。
- s : 指向要转换的多字节字符的指针。
- n : 要转换的最大字节数。
返回值:
- 如果转换成功,则返回转换后的宽字符数;
- 如果遇到无效的多字节字符,则返回
-1;- 如果传递了空指针,则返回
0。
8.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <locale.h>
#include <wchar.h>
int main(void)
{
setlocale(LC_ALL, "");
char mbstr[] = "Hello, world!";
wchar_t wc;
int len = mbtowc(&wc, mbstr, sizeof(mbstr));
if (len > 0) {
wprintf(L"%lc\n", wc);
} else if (len == 0) {
wprintf(L"Empty string.\n");
} else if (len == -1) {
wprintf(L"Invalid multibyte character.\n");
}
return EXIT_SUCCESS;
}
8.3 运行结果

9. memccpy
9.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
void *memccpy(void *restrict dst, const void *restrict src, int c, size_t n); | 用于将内存块的内容复制到另一个内存块中,并在指定字符出现时停止复制。 |
参数:
- dst : 要复制到的目标内存块的指针
- src : 要从中复制数据的源内存块的指针
- c : 指定的字符值
- n : 要复制的字节数
返回值:
- 如果源内存块的前
n个字节中包含字符c,则返回指向字符c后面一个字节的指针;- 否则返回
NULL。
9.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
char src[] = "Hello, world!";
char dst[20];
memset(dst, 0, sizeof(dst));
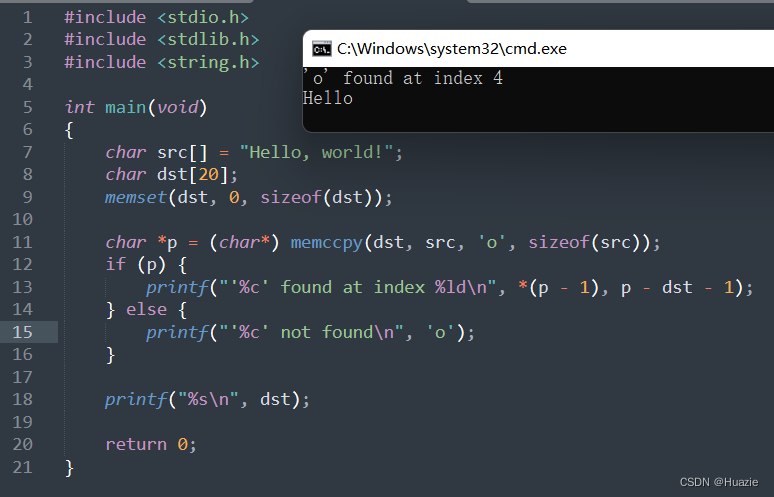
char *p = (char*) memccpy(dst, src, 'o', sizeof(src));
if (p) {
printf("'%c' found at index %ld\n", *(p - 1), p - dst - 1);
} else {
printf("'%c' not found\n", 'o');
}
printf("%s\n", dst);
return 0;
}
9.3 运行结果
10. memchr
10.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
void *memchr(const void *s, int c, size_t n); | 用于在某一内存块中查找指定字符的位置。 |
参数:
- s : 要进行查找的内存块的起始地址
- c : 要查找的指定字符,以整数形式表示
- n : 要查找的字节数,即在前
n个字节中查找指定字符
10.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
char str[] = "Hello, world!";
char ch = 'w';
char *p;
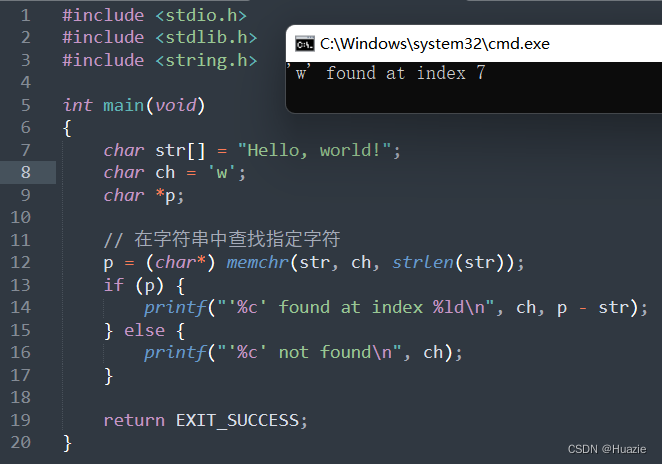
// 在字符串中查找指定字符
p = (char*) memchr(str, ch, strlen(str));
if (p) {
printf("'%c' found at index %ld\n", ch, p - str);
} else {
printf("'%c' not found\n", ch);
}
return EXIT_SUCCESS;
}
在上述程序中,
- 我们首先定义了一个字符串
str和要查找的指定字符ch; - 然后使用
memchr()函数查找字符串str中是否包含指定字符ch; - 最后如果找到了该字符,则输出它的索引位置;否则,输出未找到的提示信息。
10.3 运行结果
11. memcpy
11.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
void *memcpy(void *dest, const void *src, size_t n); | 用于将源内存块中的 n 个字节复制到目标内存块中。 |
参数:
- dest : 目标内存块的起始地址
- src : 源内存块的起始地址
- n : 要复制的字节数
11.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
char src[] = "Hello, world!";
char dst[20];
memset(dst, 0, sizeof(dst));
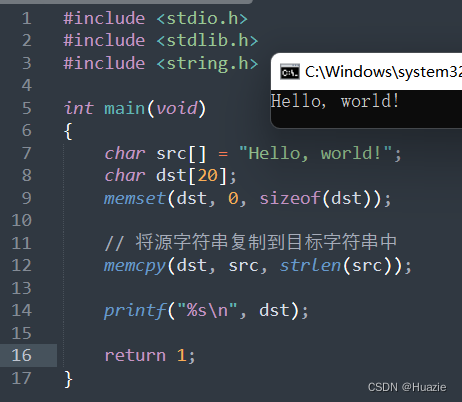
// 将源字符串复制到目标字符串中
memcpy(dst, src, strlen(src));
printf("%s\n", dst);
return 1;
}
注意: 在使用
memcpy()函数进行内存复制时,目标内存块必须足够大,以容纳源内存块中的全部内容。否则,复制过程可能会导致访问非法内存空间,从而导致代码异常或崩溃。因此,在进行内存复制时,应该尽量避免超出目标内存块大小的范围。
11.3 运行结果
12. memcmp
12.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
int memcmp(const void *s1, const void *s2, size_t n); | 用于比较两个内存块的内容是否相同。 |
参数:
- s1 : 要进行比较的第一个内存块的起始地址
- s2 : 要进行比较的第二个内存块的起始地址
- n : 要比较的字节数。
注意:
memcmp()函数会逐一比较两个内存块中对应位置上的字节大小,直到找到差异或者比较完全部字节。
- 如果两个内存块完全相同,则返回值为
0;- 如果两个内存块不同,则返回值是两个内存块中第一个不同字节处的差值(
s1中该字节的值减去s2中该字节的值)。
12.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
char str1[] = "Hello, world!";
char str2[] = "Hello, everyone!";
// 比较两个字符串
int result = memcmp(str1, str2, strlen(str1));
printf("result = %d\n", result);
if (result == 0) {
printf("Strings are equal\n");
} else if (result < 0) {
printf("String '%s' is smaller than string '%s'\n", str1, str2);
} else {
printf("String '%s' is larger than string '%s'\n", str1, str2);
}
return 1;
}
注意: 在比较两个内存块时,应该确保被比较的内存块中包含足够的字节,并且待比较的字节数不超过内存块大小,否则函数可能会出现异常行为。另外,由于返回值是有符号整数类型,因此在比较时应该将其强制转换为无符号整数类型,以避免出现不必要的错误。
12.3 运行结果

13. memmove
13.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
void *memmove(void *dest, const void *src, size_t n); | 用于将源内存块中的 n 个字节复制到目标内存块中。与 memcpy() 函数不同的是,memmove() 函数在复制过程中会处理内存块重叠的情况。 |
参数:
- dest : 目标内存块的起始地址
- src : 源内存块的起始地址
- n : 要复制的字节数。
注意:
memmove()函数会将源内存块中的前n个字节复制到目标内存块中,并返回指向目标内存块起始地址的指针。
13.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
int main(void)
{
char str[] = "Hello, world!";
char tmp[20];
memset(tmp, 0, sizeof(tmp));
// 将源字符串复制到目标字符串中(处理重叠的情况)
memmove(tmp, str + 6, strlen(str) - 6);
printf("%s\n", tmp);
return 0;
}
注意: 在使用
memmove()函数进行内存复制时,目标内存块必须足够大,以容纳源内存块中的全部内容。否则,复制过程可能会导致访问非法内存空间,从而导致代码异常或崩溃。此外,由于memmove()函数的处理开销较大,因此在不涉及内存块重叠时,应该尽量使用memcpy()函数以提高效率。
13.3 运行结果

14. memset,memset_s
14.1 函数说明
| 函数声明 | 函数功能 |
|---|---|
void *memset(void *s, int c, size_t n); | 用于将一个内存块中的所有字节都设置为指定的值。 |
errno_t memset_s(void *s, rsize_t smax, int c, rsize_t n); | C11 标准新增了一个名为 memset_s() 的安全版本函数。与 memset() 函数不同的是,memset_s() 函数会在设置内存块值时检查目标内存块大小,并防止缓冲区溢出、重叠等安全问题。 |
memset 参数:
- s : 要进行设置的内存块的起始地址
- c : 要设置的值,以整数形式表示
- n : 要设置的字节数
memset_s 参数:
- s : 要进行设置的内存块的起始地址
- smax : 目标内存块的大小
- c : 要设置的值,以整数形式表示
- n : 要设置的字节数
14.2 演示示例
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
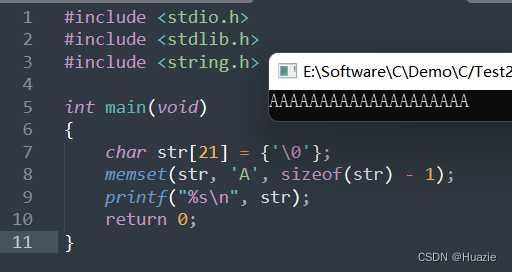
int main(void)
{
char str[21] = {'\0'};
memset(str, 'A', sizeof(str) - 1);
printf("%s\n", str);
return 0;
}
14.3 运行结果
参考
- [API Reference Document]



![[RoarCTF 2019]Easy Calc、攻防世界 ics07、[极客大挑战 2019]EasySQL](https://img-blog.csdnimg.cn/19b985e34bab40f59d2e89eaa21ffc99.png)