theme: orange
本文正在参加「金石计划」
接上文OpenAI Embedding:快速实现聊天机器人(三)如何使用Python实现embedding相似度搜索,这篇文章继续讲如何将搜索到的相似文本进行提炼,并最终得出问题的答案。
提炼文本
通过调用azure openai服务使用模型 text-davinci-003完成对文本的提炼,以得到最终的答案。
python def do_chat(text): url = f"{ENDPOINT}/openai/deployments/{MODEL_NAME2}/completions?api-version=2022-12-01" headers = {"api-key": SUBSCRIPTION_KEY} data = { 'prompt': text, 'temperature': 0.05, 'max_tokens': 250 } response = requests.post(url, headers=headers, json=data) response_json = response.json() return response_json['choices'][0]['text']
在data变量存储的json中,其中有temperature,max_tokens参数要设置,这关系到最终答案的输出。
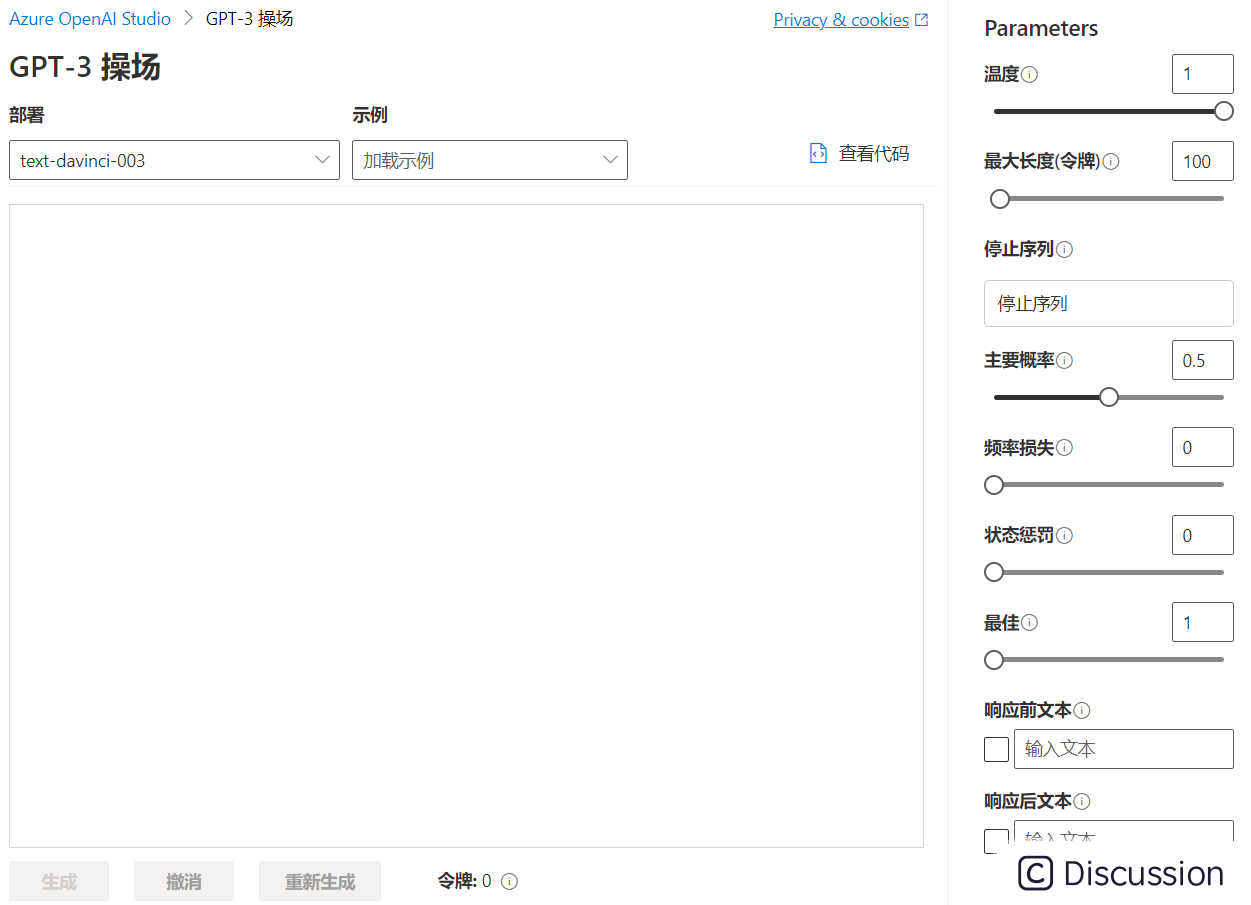
解释下上图右侧调用OpenAI的参数:
| 参数 | 参数(英文) | 介绍 | 详情 | | -------- | ------------------ | -------------------- | ------------------------------------------------------------------------------------------------------------ | | 温度 | Temperature | 控制模型的创造力 | 控制随机性。降低温度意味着模型将产生更多重复和确定性的响应。增加温度会导致更多意外或创造性的响应。尝试调整温度或 Top P,但不要同时调整两者。 | | 最大长度(令牌) | Max Length(tokens) | 限制返回响应文本长度 | 设置每个模型响应的令牌数量限制。API 支持最多 4000 个令牌,这些令牌在提示(包括系统消息、示例、消息历史记录和用户查询)和模型响应之间共享。一个令牌大约是典型英文文本的 4 个字符。 | | 停止序列 | Stop sequences | 限定响应在指定返回词后停止继续生成语句 | 使响应在所需的点停止,例如句子或列表的结尾。指定最多四个序列,其中模型将停止在响应中生成进一步的令牌。返回的文本将不包含停止序列。 | | 主要概率 | Top probabilities | 决定模型返回的随机性 | 与温度类似,这控制随机性但使用不同的方法。降低 Top P 将缩小模型的令牌选择范围,使其更有可能选择令牌。增加 Top P 将让模型从高概率和低概率的令牌中进行选择。尝试调整温度或 Top P,但不要同时调整两者。 | | 频率损失 | Frequency penalty | 调整返回词的新颖程度 | 根据令牌到目前为止在文本中出现的频率,按比例减少重复令牌的几率。这降低了在响应中重复完全相同的文本的可能性。 | | 状态惩罚 | presence penalty | 调整返回词的新颖程度 | 减少到目前为止文本中出现的任何标记重复的可能性。这增加了在响应中引入新主题的可能性。 | | 最佳 | Best of | 选择生成多个响应,并返回最佳的响应 | 生成多个响应,并仅显示其所有令牌中总概率最大的响应。未使用的候选项仍会产生使用成本,因此请谨慎使用此参数,并确保同时设置最大响应长度和结束触发器的参数。请注意,仅当设置为 1 时,流式处理才有效。 | | 响应前文本 | Pre-response text | 勾选后可以指定在响应之前输出固定文字 | 在用户输入后和模型响应之前插入文本。这有助于为响应准备模型。 | | 响应后文本 | Post-response text | 勾选后可以指定在返回响应之后输出固定文字 | 在模型生成的响应后插入文本以鼓励进一步的用户输入,就像对话建模一样。 |
封装Prompt并执行提炼文本
在原来search_docs函数的基础上,增加Prompt封装和调用do_chat函数逻辑。记得控制相似度的评分,过滤评分较低的相似文本。
```python def searchdocs(df, userquery, topn=3, toprint=True):
embedding = getnativeembeddings(userquery)
df["similarities"] = df.searchembeddings.apply(lambda x: cosinesimilarity(x, embedding))
results = (
df.sortvalues("similarities", ascending=False)
.head(top_n)
)
prompt = ''
for row in results.itertuples():
text = getattr(row, 'text')
similarities = getattr(row, 'similarities')
score = float(similarities)
# 防御,防止不相干的问题,可动态调节分数
if score < 0.8:
continue
prompt += text
print(f"\t{text} (Score: {round(score, 3)})")
# 特殊处理过滤
if len(prompt) == 0:
return "No results found"
prompt += ' 通过上面的内容回答:' + user_query
return do_chat(prompt)```
执行结果
Q:破镜效应有哪些应用实践?
过程:找到相似度最高的四条文本

A:建立良好的社会环境:社会环境是破窗效应的重要因素,因此,要想有效地抑制破窗效应,就必须建立良好的社会环境,营造一种文明、和谐、安全的社会氛围,让人们能够在良好的社会环境中自由地行使自己的权利,从而减少破窗效应的发生。
注意:这儿回复的文档长度被最大长度(令牌) 参数限制住了,通过调节这个参数可获得更多的返回内容。
下篇文章用 Redis Search 来实现相似度搜索。