winograd卷积基本原理参考
Winograd算法实现卷积原理_Luchang-Li的博客-CSDN博客_optimizing batched winograd convolution on gpus
winograd卷积图示:
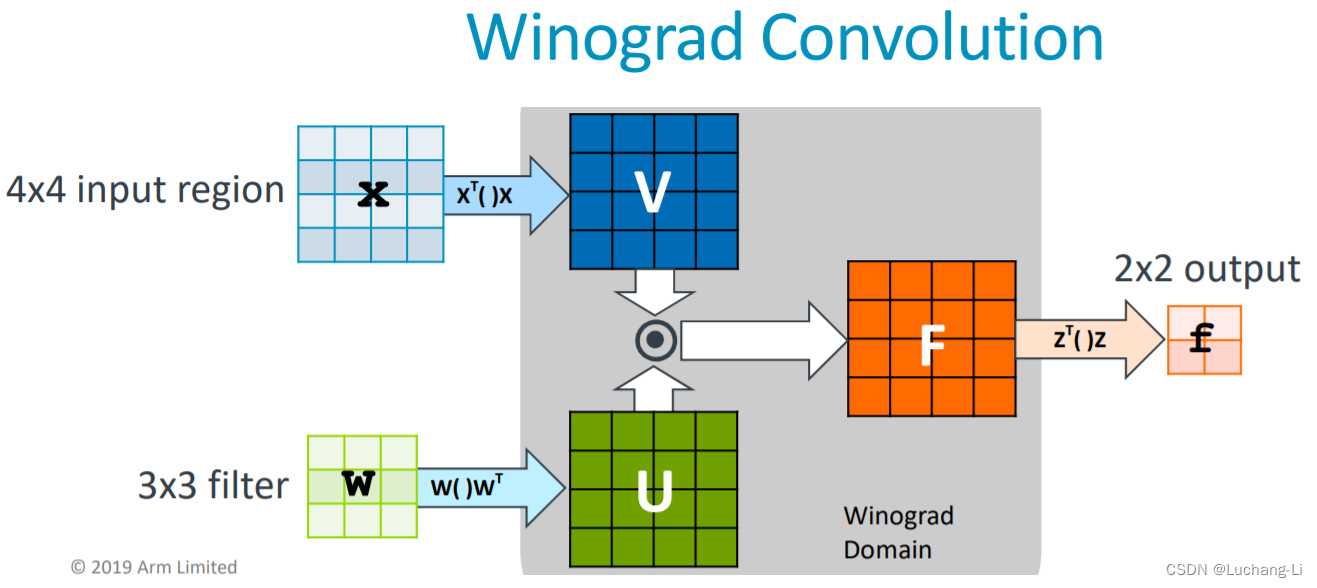
注意这张图里面隐藏了input和output channel。实际上每个空间维度里面还包含了batch和in/out channel维度。
输入数据格式为[n, h, w, c],input transform后格式原始的论文[Fast Algorithms for Convolutional Neural Networks]的格式是[ho/2*w0/2, 16, n, ci],实际也常用[n, ho/2*w0/2, 16, 1, ci]。ho, wo是输出height和width尺寸,除以2是因为两个相邻元素共享一个4x4矩阵。
输入变换是空间维乘以变换矩阵,由于每个空间维元素实际上对应于一个2维向量,实际上相当于每个空间维元素对应的的向量之间做各种乘加运算。
weight原始格式为[c0, ci, h, w],这里h = w = 3, 先处理为[h, w, ci, co], 然后weight transform转换后为[4*4, ci, co]。
转换后的输入和weight做batch矩阵乘得到数据格式为[n, ho/2*w0/2, 4*4, 1, co]。
[1, ci]与[ci, co]的矩阵乘可以考虑通过每个线程计算1x1*1x4大小矩阵乘(常用的方法是每个线程计算4x1*1x4或者8x1*1x4矩阵乘并沿着k方向循环,这里行数只有1,因此缩减到1x1*1x4,可参考[施工中] CUDA GEMM 理论性能分析与 kernel 优化 - 知乎)。
最后做输出transform得到格式为[n, ho/2*w0/2, 2*2, co],也就是[n, ho, wo, co]
端侧推理引擎如mnn由于通常没有或只有很少的shared mem,线程之间数据交换能力比较弱,通常按照这个流程把整个计算流程拆分为了三个步骤而不是写在一个完整的kernel:input transform, matmul, output transform。而权重在推理时是常量,可以通过常量折叠提前做好weight transform。
对于NHWC的数据,通常采用每个thread读取4x4,并且channel深度为4的输入数据做input transform。
卷积通过im2row+matmul的实现问题,其一是相邻的卷积框有重复的数据,对于3x3 stride=1,每个位置数据读取一次,写出9次,因此im2row写回和matmul读取数据量增大了9倍。
winograd input transform相当于4x4 kernel, stride = 2,input transform写回和matmul读取数据数据量相比输入增大4倍。

![[附源码]Python计算机毕业设计SSM基于Java的音乐网站(程序+LW)](https://img-blog.csdnimg.cn/1420367c9d9f44db9ef0b907f2a03436.png)