文章目录
- 预定义符号
- #define
- #define定义标识符
- #define定义宏
- #define替换规则
- #和##
- 带副作用的宏参数
- 宏和函数对比
- #undef
- 命令行定义
- 条件编译
- 文件包含
- 头文件被包含的方式
- 嵌套文件包含
- 其他预处理指令
- 总结

预定义符号
__FILE__ //进行编译的源文件
__LINE__ //文件当前的行号
__DATE__ //文件被编译的日期
__TIME__ //文件被编译的时间
__STDC__ //如果编译器遵循ANSI C,其值为1,否则未定义
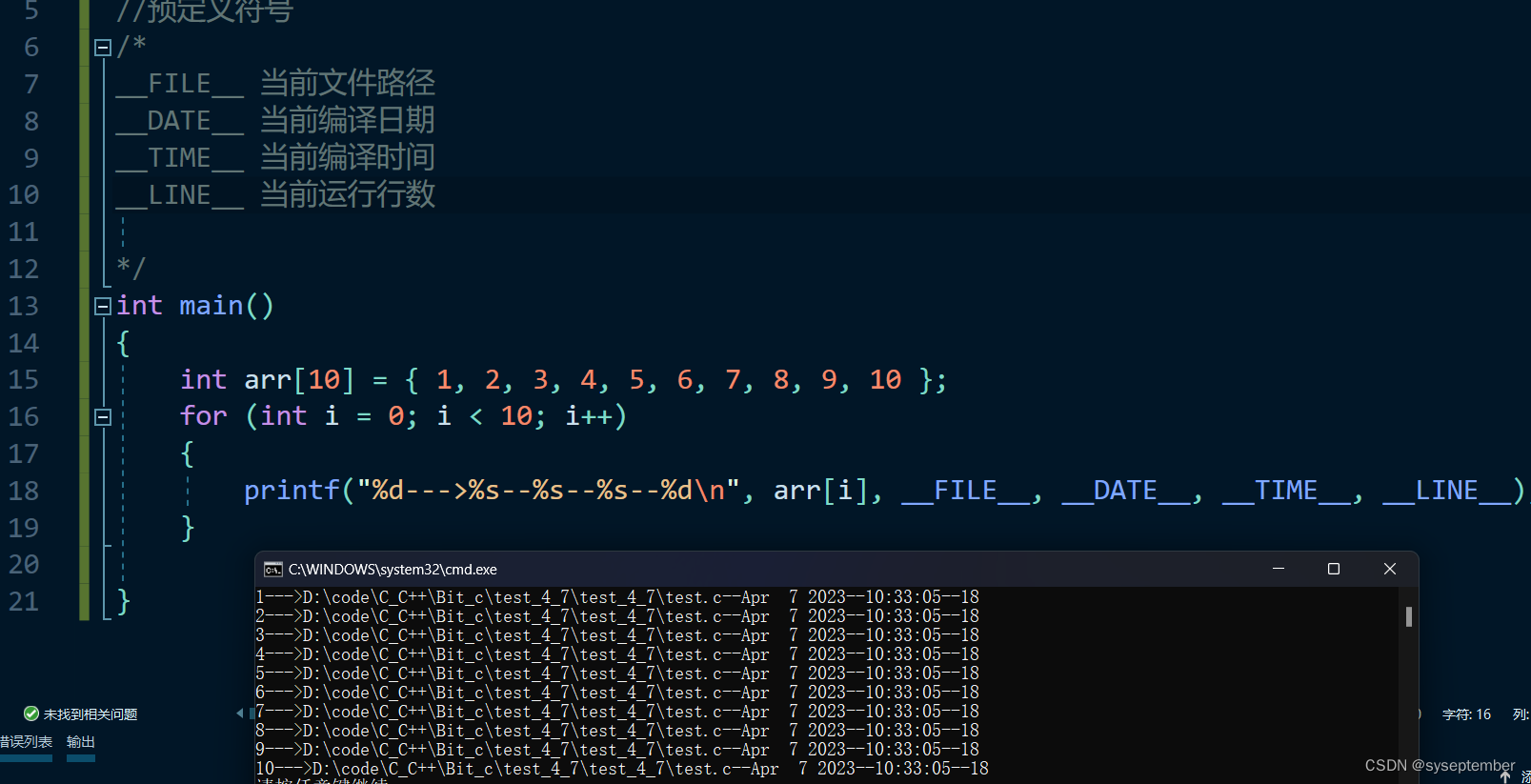
MSVC编译器不是完全遵循ANSIC标准

gcc编译器严格遵循ANSIC标准
#define
#define定义标识符
语法:#define name stuff
#define MAX 1000
#define reg register //为 register这个关键字,创建一个简短的名字
#define do_forever for(;;) //用更形象的符号来替换一种实现
#define CASE break;case //在写case语句的时候自动把 break写上。
// 如果定义的 stuff过长,可以分成几行写,除了最后一行外,每行的后面都加一个反斜杠(续行符)。
#define DEBUG_PRINT printf("file:%s\tline:%d\t \
date:%s\ttime:%s\n" ,\
__FILE__,__LINE__ , \
__DATE__,__TIME__ )
注意:转义字符是让计算机识别的,计算机看见
\Enter不会认为这是分开的两行,因此不存在语法问题
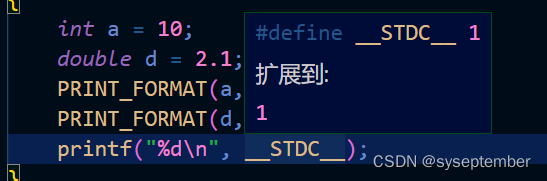
在#define定义标识符时,不要加上;否则可能出问题,看下面这个例子
#define定义宏
#define 机制包括了一个规定,允许把参数替换到文本中,这种实现通常称为宏(macro)或定义宏(define macro)。
定义宏的语法:
#define macro_name(pramaent-list) stuff
pramament-list是一个由逗号隔开的参数列表,它们可能出现在stuff中
tips:参数列表和宏名字中间必须紧邻,不能有任何空白,否则宏会被解释为表示符
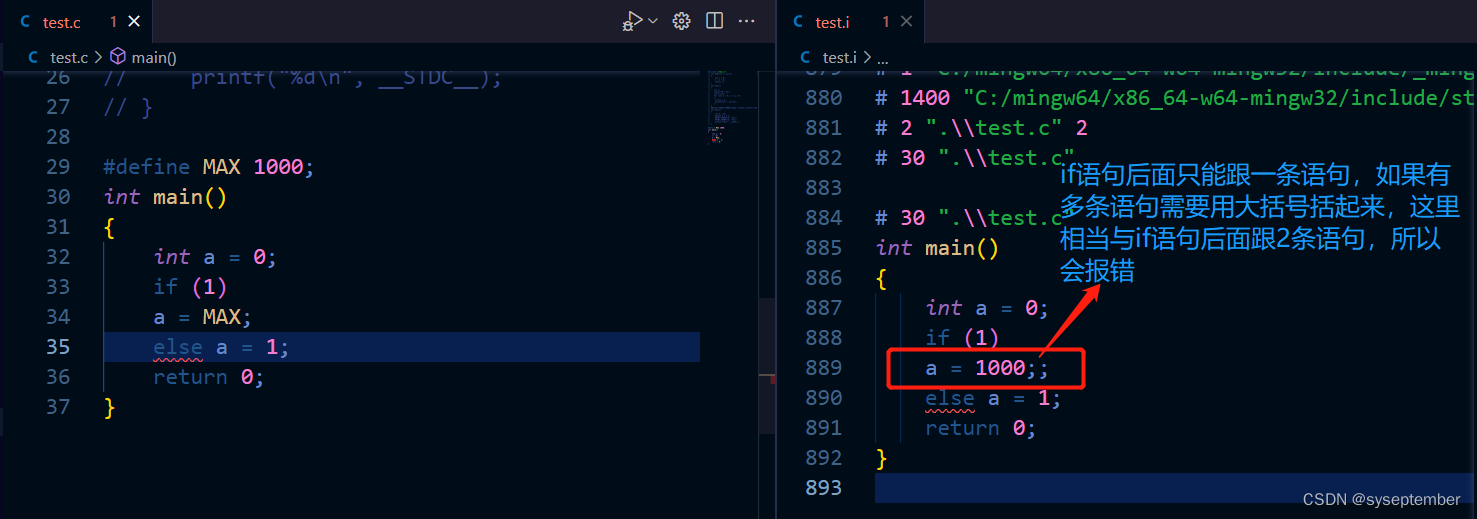
由于宏是先替换在进行运算,所以定义宏时stuff的每一部分最好用()括起来,防止因为优先级而产生问题请看下面示例
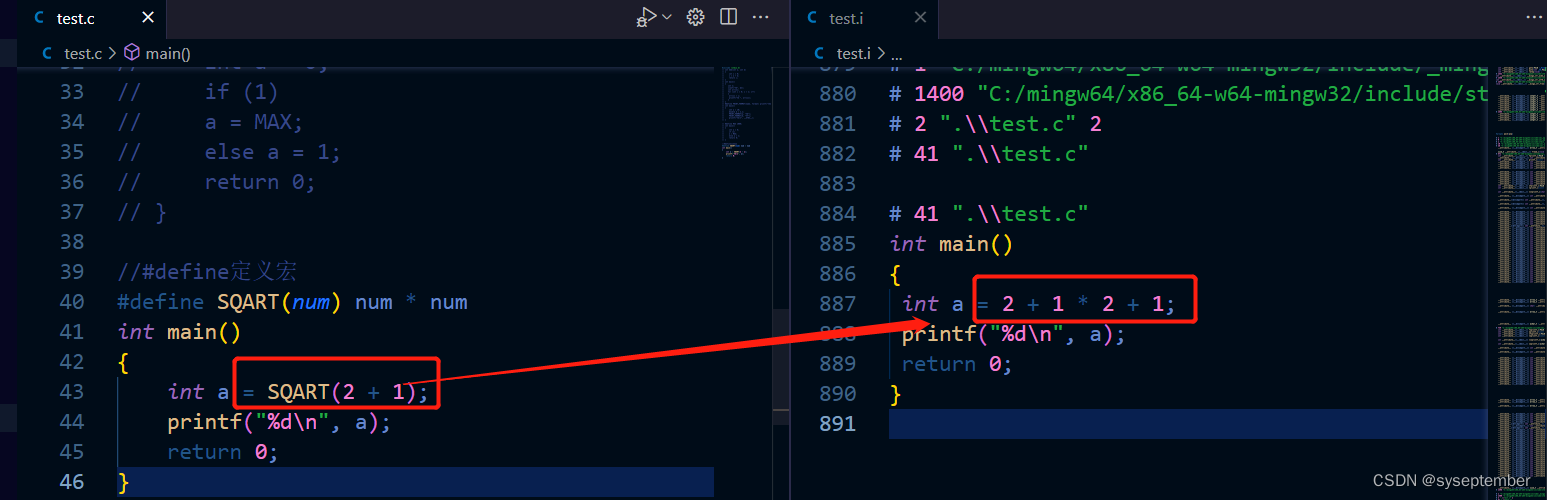
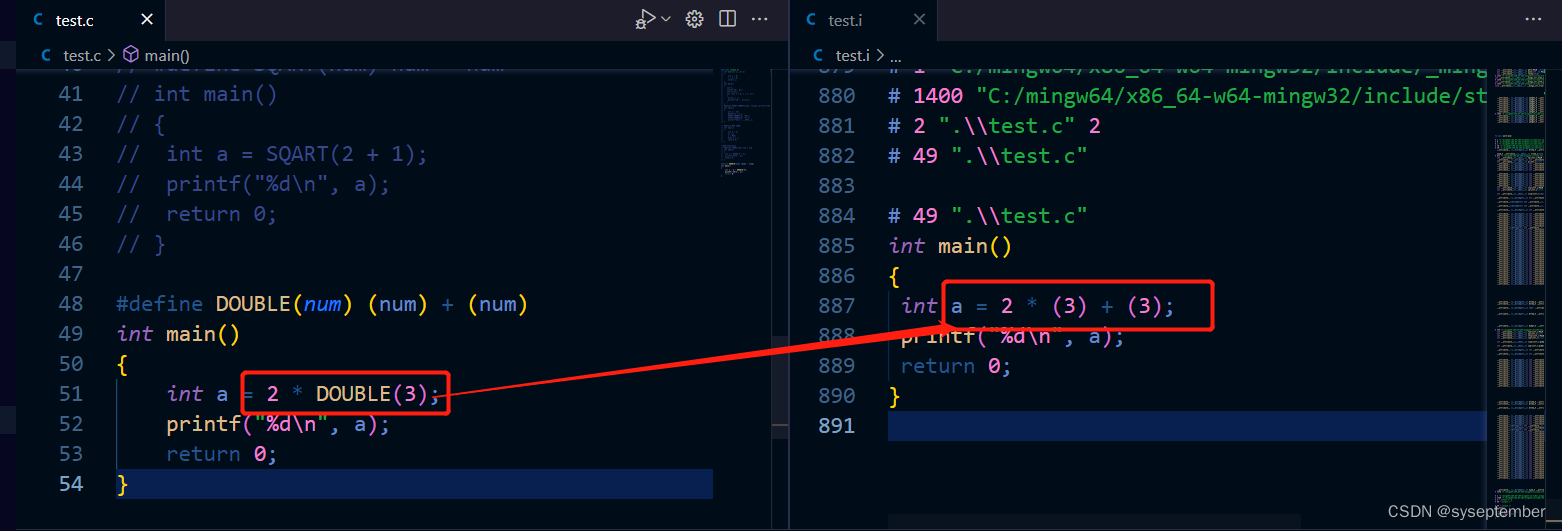
将上述num+num改成((num) + (num)),num * num 改成((num) * (num))即可
#define替换规则
在程序中扩展#define定义符号和宏时,需要涉及几个步骤。
- 在调用宏时,首先对参数进行检查,看看是否包含任何由#define定义的符号。如果是,它们首先被替换。
- 替换文本随后被插入到程序中原来文本的位置。对于宏,参数名被他们的值所替换。
- 最后,再次对结果文件进行扫描,看看它是否包含任何由#define定义的符号。如果是,就重复上述处理过程
#和##
C语言的字符串具有自动连接的特点
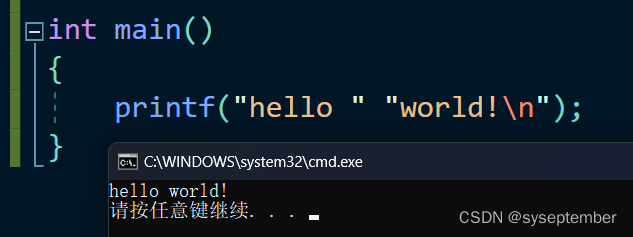
所以我们可以利用这个特点来实现一些特定的功能,比如将宏的参数插入到字符串中
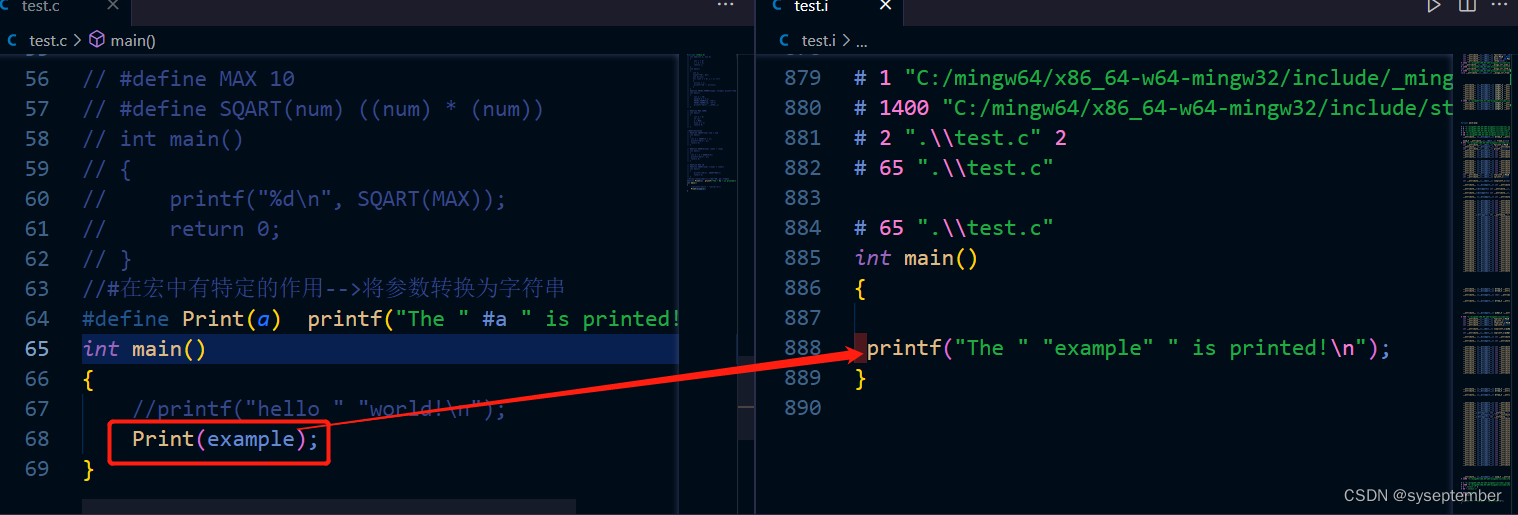
总结:#操作符可以在宏中将宏参数转换为字符串
##操作符可以在宏体中完成拼接操作(拼接后的字符一定要是被定义过的)
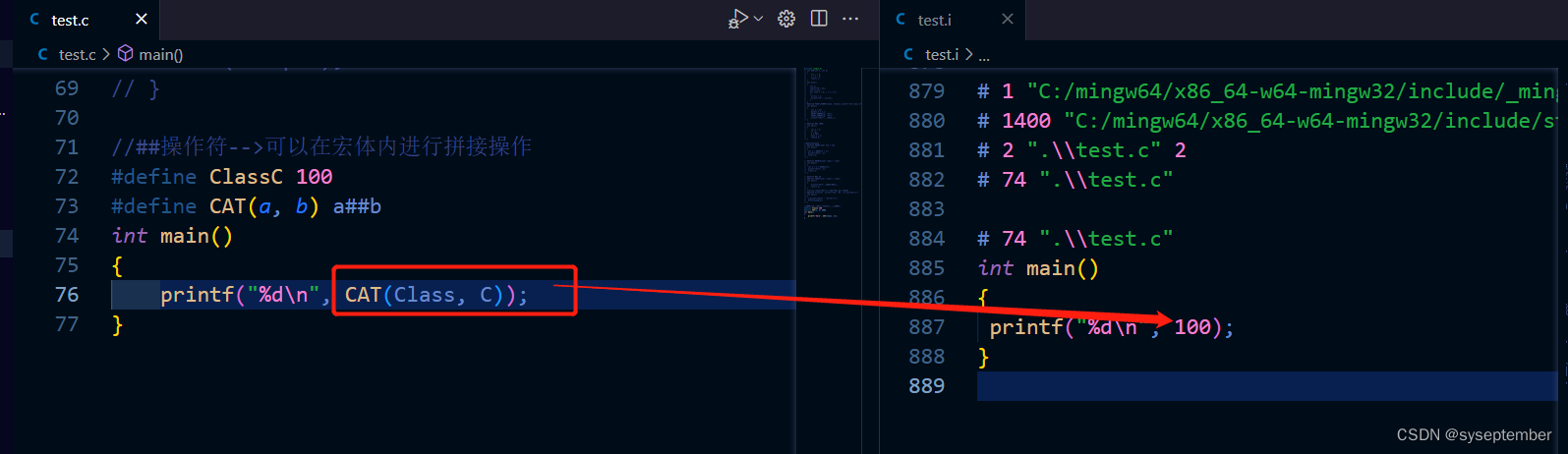
将Class和C拼接在一起ClassC,ClassC是已经被定义过的标识符
注意:使用##拼接后的结果一定要是已定义的
带副作用的宏参数
当宏参数在宏的定义中出现超过一次的时候,如果参数带有副作用,那么你在使用这个宏的时候就可能
出现危险,导致不可预测的后果。副作用就是表达式求值的时候出现的永久性效果。
x+1;//不带副作用
x++;//带有副作用
MAX宏可以证明具有副作用的参数所引起的问题。
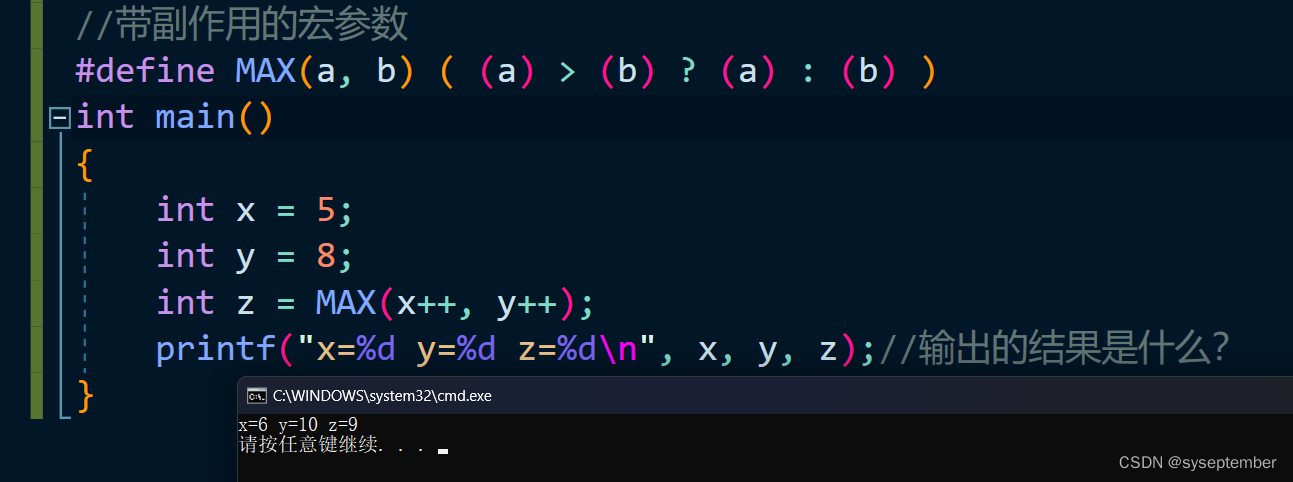
我们只看这个代码会认为x和y分别++了一次,但是由于这是宏,所以x和y其中有一个++了两次,所以这会导致意外的结果
tips:宏的命名往往是全字母大写,这是为了方便区分宏和函数
宏和函数对比
宏和函数的用法是一样的,都是名字紧跟参数列表,我们下面来看看它们的区别
用宏和函数实现求最大值
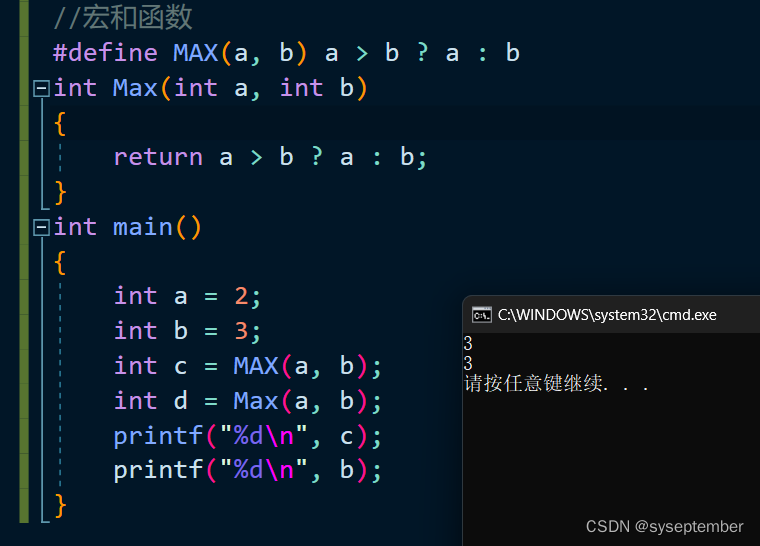
可以看见,两者都可以完成求最大值的功能,但是在这串代码中使用宏比函数要合适,原因有下:
- 宏是直接替换的,不需要开辟额外的空间,而函数调用需要开辟栈帧
- 宏比函数执行速度要快,函数调用时需要
为形参压栈、为函数体开辟栈帧、执行函数体、销毁栈帧,执行速度小于宏 - 函数的定义必须要指名参数类型,而宏不用,所以宏和以比所有类型的数据大小,而函数不行
那是不是所有情况下都应该用宏而不是函数呢?
答案是否定的,宏的缺点有如下几点:
- 每次使用宏时,宏的代码会插入到当前代码块中,除非宏的代码块很短,否则会增加代码的长度
- 使用宏是不会做类型检查,这有可能是不安全的
- 使用宏可能存在优先级的问题
- 宏没有办法调试的
宏和函数对比👇

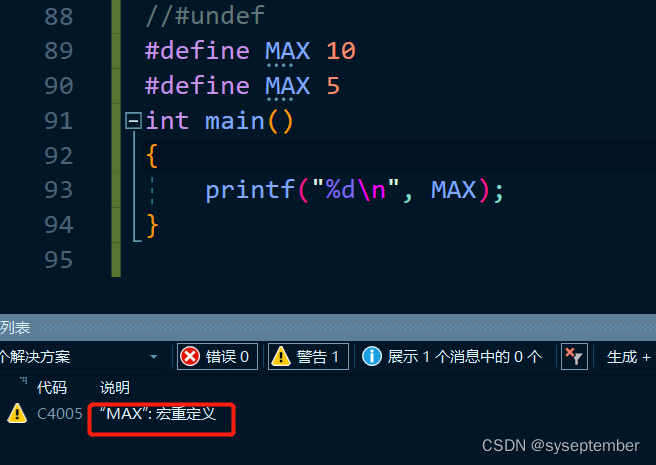
#undef
这条指令用于移除一个宏定义
#undef NAME
//如果存在一个名字需要重新被定义,那么它应该先移除之前的定义
这是没有移除之前的定义
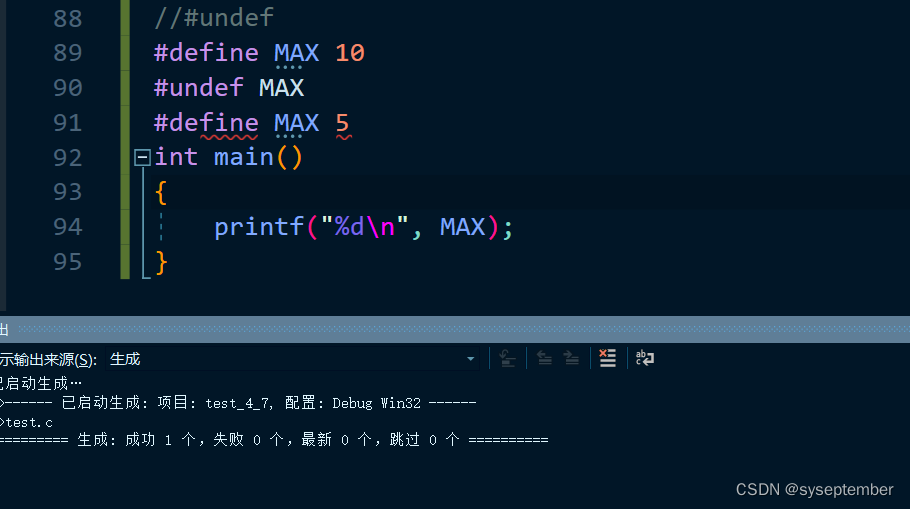
这是移除之前的定义
命令行定义
许多C 的编译器提供了一种能力,允许在命令行中定义符号。用于启动编译过程。
例如:当我们根据同一个源文件要编译出一个程序的不同版本的时候,这个特性有点用处。(假定某个程序中声明了一个某个长度的数组,如果机器内存有限,我们需要一个很小的数组,但是另外一个机器内存大些,我们需要一个数组能够大些。)
下面演示Linux环境下的命令行编译👇
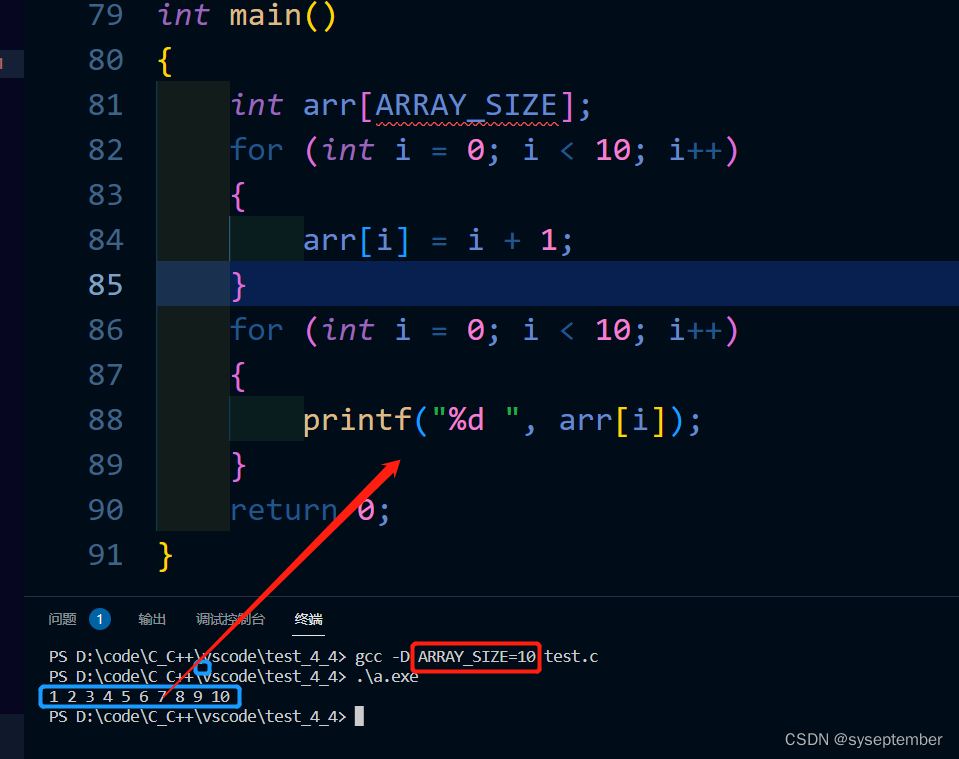
命令行
gcc -D ARRAY_SIZE=10 test.c表示在test.c文件中将ARRAY_SIZE定义为10
条件编译
在编译一个程序时,如果我们可以选择某条语句或某组语句进行翻译或者被忽略,常常会显得很方便。只用于调试程序的语句就是一个明显的例子。它们不应该出现在程序的产品版本中,但是你可能并不想把这些语句从源代码中物理删除,因为如果需要一些维护性修改时,你可能需要重新调试这个程序,还需要这些语句。
条件编译(conditionalcompilation)就是用于实现这个目的。使用条件编译,你可以选择代码的-部分是被正常编译还是完全忽略。用于支持条件编译的基本结构是#if指令和与其匹配的#endif指令。下面显示了它最简单的语法形式。
#if constant-expression
statements
#endif
constant-expression(常量表达式)由预处理器进行求值,如果它的值是非0,an那么statements会被编译,如果它的值是0,那么statements不会被编译
条件编译都是预处理指令,是在程序运行前进行的操作,如果此时出现了预处理时无法得知的数据(比如变量),那么程序会报错
注意:枚举常量和全局变量都是预处理之后、运行之前才知道的值
👇常见的条件编译指令👇
1.
#if 常量表达式
//...
#endif
//常量表达式由预处理器求值。
如:
#define __DEBUG__ 1
#if __DEBUG__
//..
#endif
2.多个分支的条件编译
#if 常量表达式
//...
#elif 常量表达式
//...
#else
//...
#endif
3.判断是否被定义
#if defined(symbol)
#ifdef symbol
#if !defined(symbol)
#ifndef symbol
4.嵌套指令
#if defined(OS_UNIX)
#ifdef OPTION1
unix_version_option1();
#endif
#ifdef OPTION2
unix_version_option2();
#endif
#elif defined(OS_MSDOS)
#ifdef OPTION2
msdos_version_option2();
#endif
注意:每一条
#if语句一定要有对应的#endif
演示预处理指令#if #elif #else
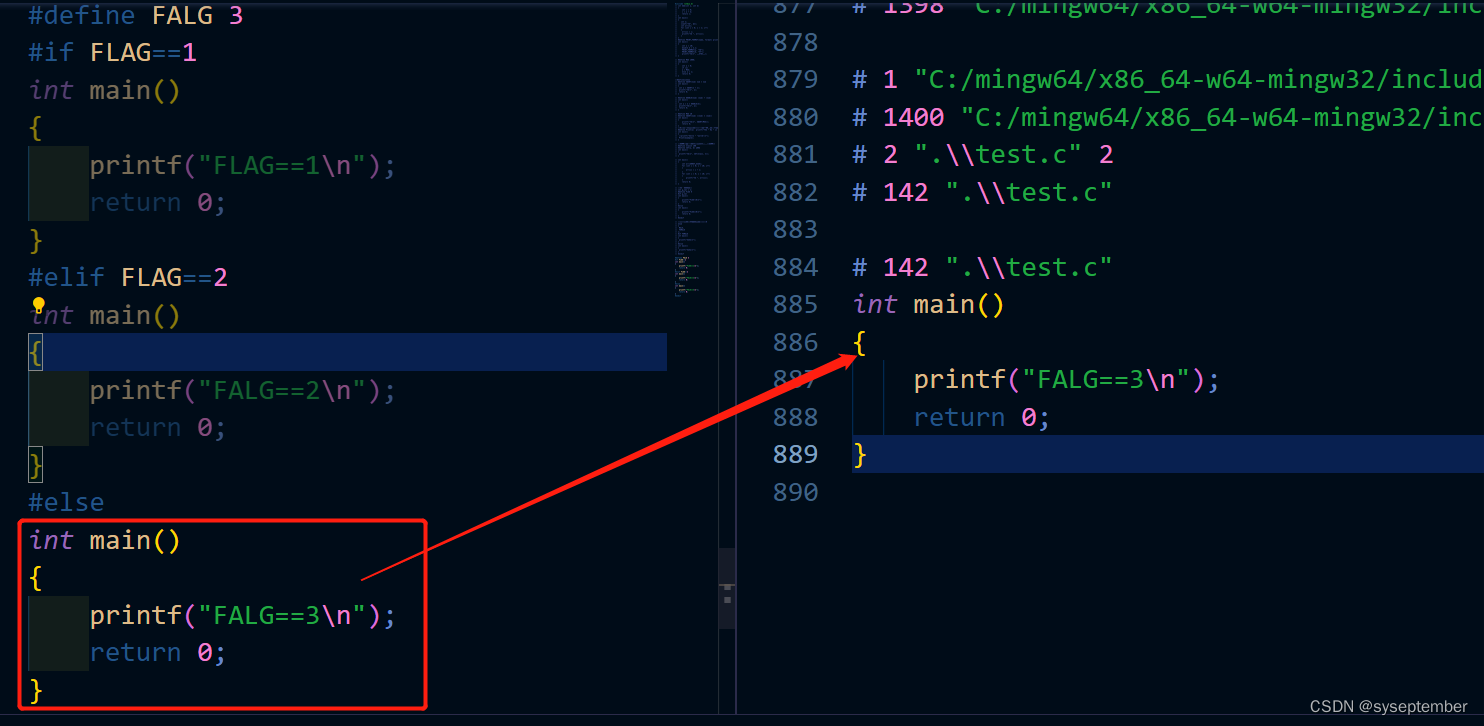
演示嵌套指令
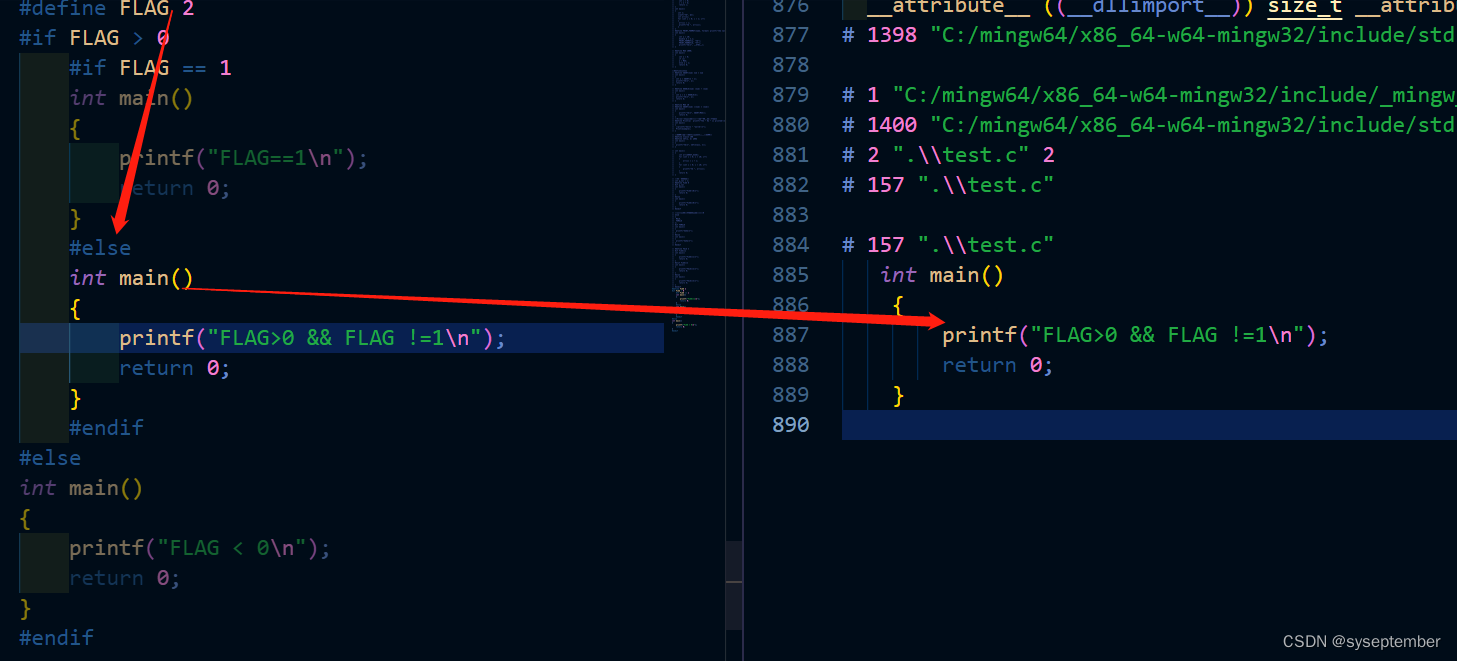
文件包含
我们已经知道, #include 指令可以使另外一个文件被编译。就像它实际出现于 #include 指令的地方一样
这种替换的方式很简单:
预处理器先删除这条指令,并用包含文件的内容替换。
这样一个源文件被包含10次,那就实际被编译10次。
头文件被包含的方式
- 本地文件包含
#include "filename"
查找策略:先在源文件目录底下找,如果该头文件未找到,编译器就像查找库函数头文件一样在标准位置查找头文件(标准位置是由编译器所决定的)如果找不到就会显示编译错误。
- 库文件包含
#include <filename>
查找策略:只在标准位置查找该文件,找不到就会显示编译错误.
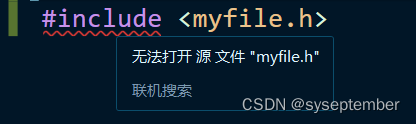
所以理论上来说使用本地文件包含既可以引入自定义文件,又可以引入包含库函数的头文件,只是在引入库函数头文件时速度会慢一点
嵌套文件包含
在编写多文件时可能会出现重复包含一个文件的情况,虽说这样的问题不是很大,但我们还是需要尽量避免嵌套文件包含
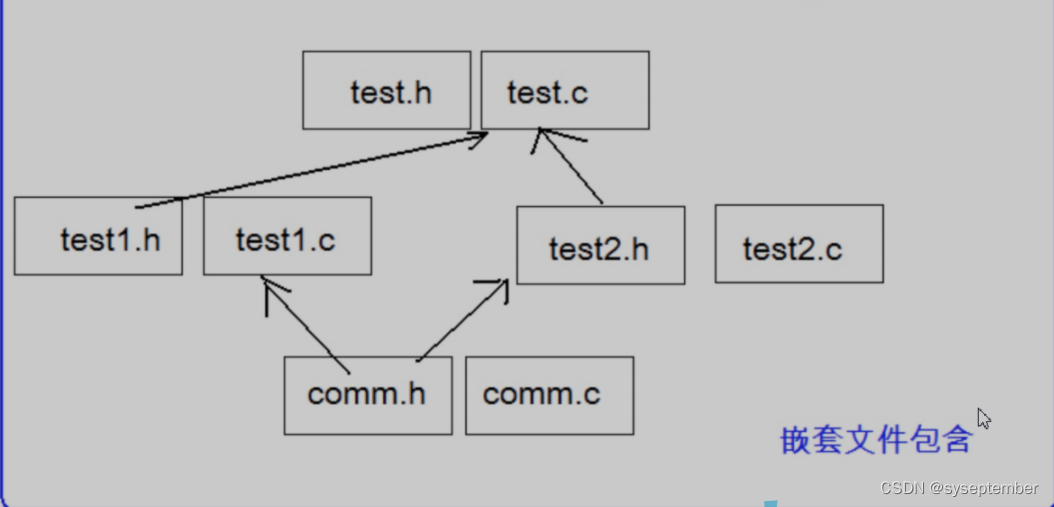
comm.h和comm.c是公共模块。
test1.h和test1.c使用了公共模块。
test2.h和test2.c使用了公共模块。
test.h和test.c使用了test1模块和test2模块。
演示重复包含头文件
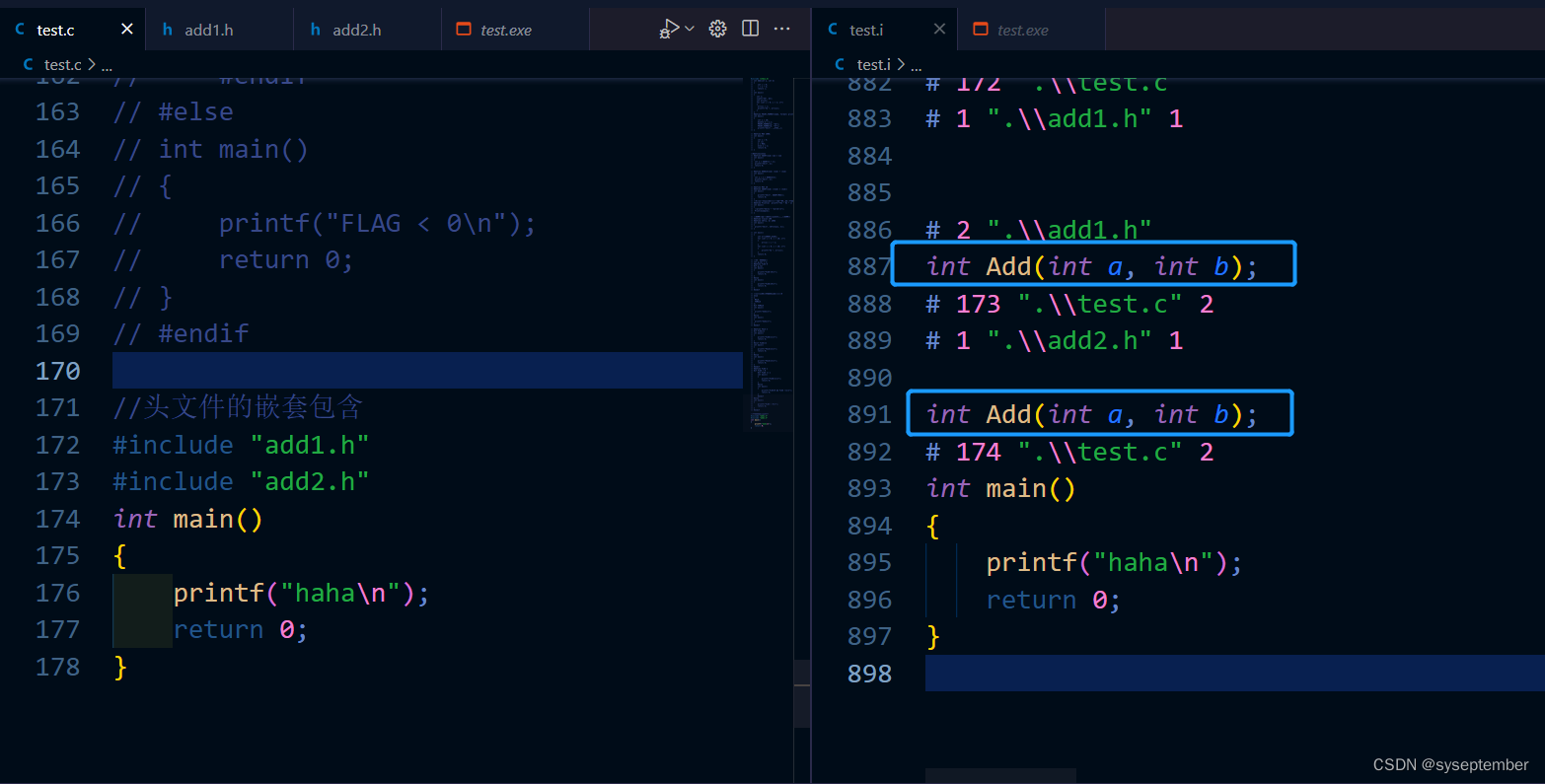
我们需要条件编译来避免这个问题
头文件中加上这句话
#ifndef __TEST_H__
#defince __TEST_H__
//头文件内容
...
#endif //__TEST_H__
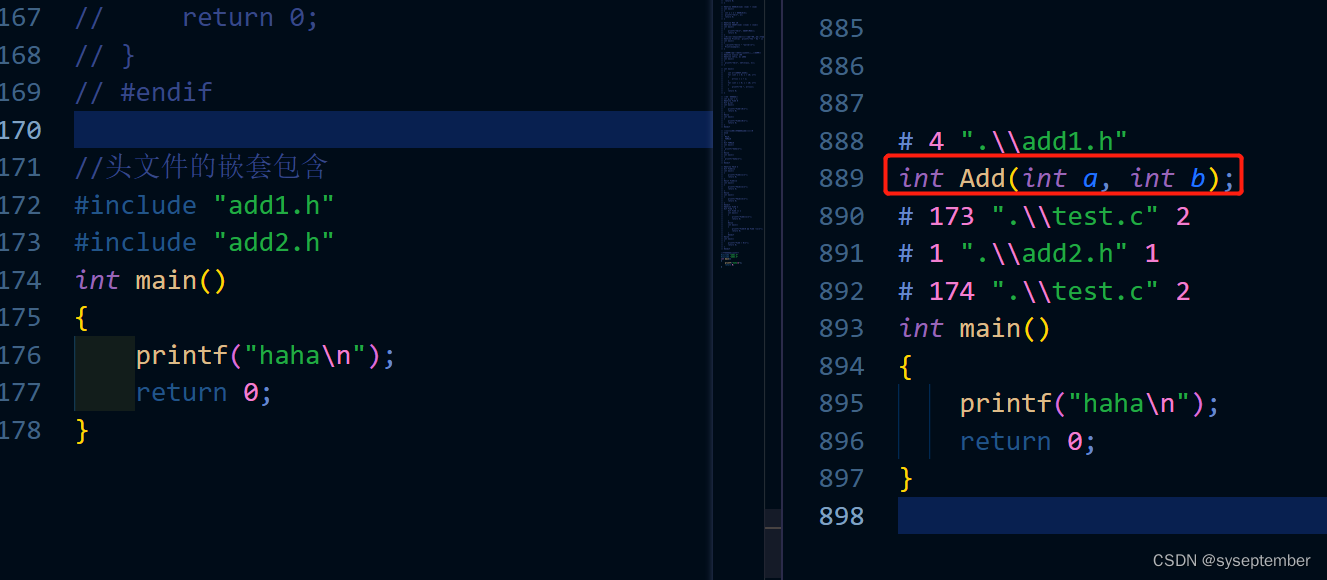
演示结果
也可以使用预处理指令#pragma once避免头文件的重复引用
演示结果
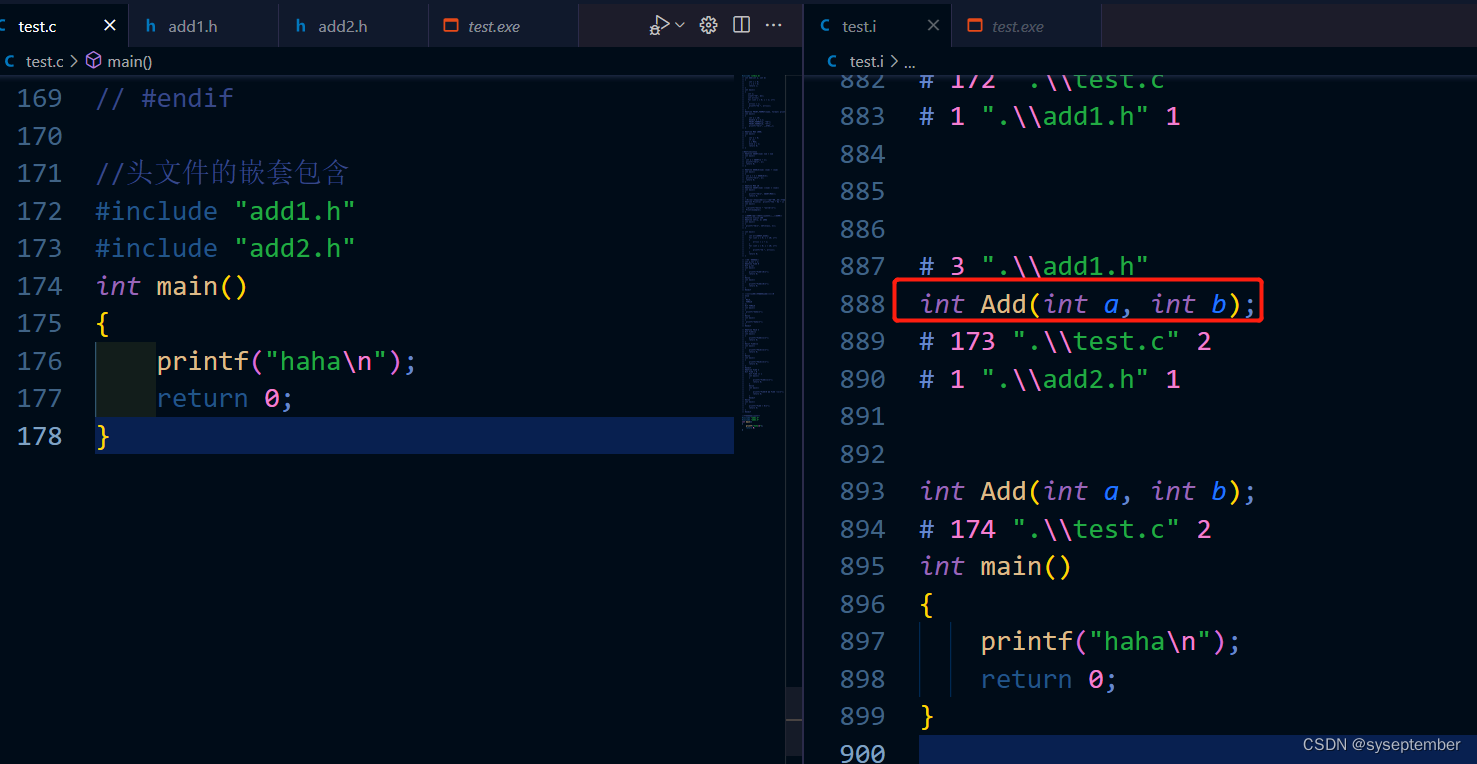
可以看见预处理指令和条件编译的结果是一样的
其他预处理指令
#error text of error message用于编译时生成错误信息
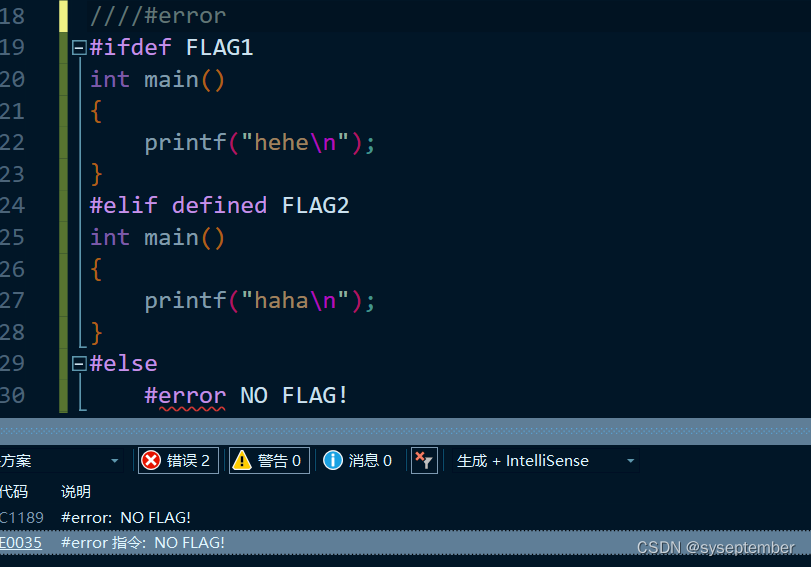
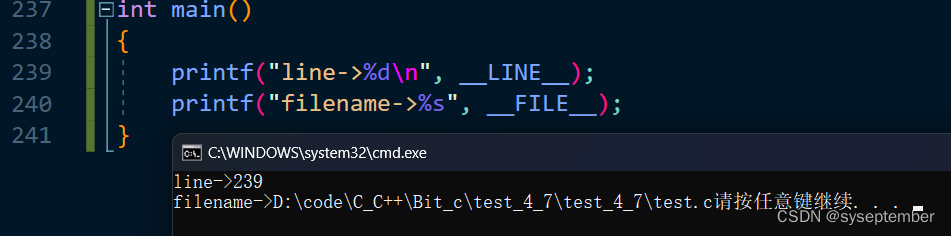
#line number "string""string"部分是可选的,将#line这一行的行数更改为number,该源文件名称更改为string
没有使用#line指令
使用#line指令
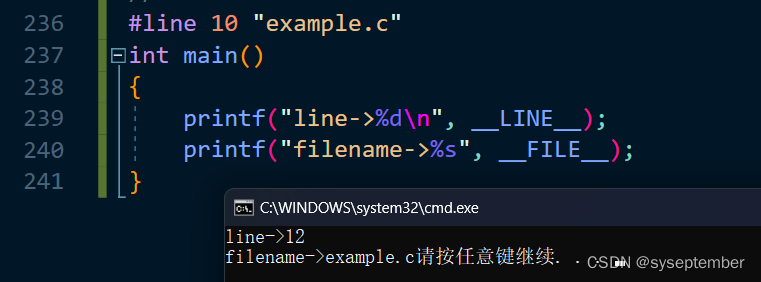
这条指令最常用于把其他语言的代码转换为 C代码的程序。C 编译器产生的错误信息可以引用源文件而不是翻译程序产生的 C 中间源文件的文件名和行号。
#pragma
#progma 指令是另一种机制,用于支持因编译器而异的特性。它的语法也是因编译器而异。有些环境可能提供一些#pragma 指令,允许一些编译选项或其他任何方式无法实现的一些处理方式。例如,有些编译器使用#pragma 指令在编译过程中打开或关闭清单显示,或者把汇编代码插入到C程序中。从本质上说,#pragma 是不可移植的。预处理器将忽略它不认识的#pragma 指令,两个不同的编译器可能以两种不同的方式解释同一条#pragma 指令。
总结
- 程序编译时第一步就是预处理,预处理器支持5个预处理符号
#define指令将一个符号和任意的字符序列联系在一起,这个字符序列可以是字面量、也可以是一段程序,如果字符序列太长需换行,则需要在除开最一行的每一行加上\- 宏就是一个被定义的序列,它的参数将被替换。当一个宏被调用时,它的每个参数都会被具体的值替换,宏完整表达式的两边应该加上
{} #argument会被预处理器看作"argument",argumen1t##argument2会被预处理器会将argument1和argument2粘贴为一个文本- 宏的命名习惯是全字母大写
- 宏与函数相比不会做类型检查,运行速度比函数快,带副作用的宏参数可能会产生意料之外的结果
- 可以使用
#undef name来取消对name的定义 - 使用条件编译可以从单一的源文件创建不同程序的版本
#include指令可以实现头文件的包含。如果文件名位于尖括号之中,那么只会在编译器定义的标准路径下查找;如果文件名位于双引号之中,那么编译器优先到当前文件路径下查找,如果没找到再去标准路径下查找- 编写头文件时,记得加上防止重复包含的预处理指令
#pragma once或者条件编译指令 #error在编译时产生一条错误信息,错误信息是#error后面的文本,#line告诉编译器当前行号,如果加上可选分"string"会告诉编译器源文件名字。#pragma允许编译器提供不标准的处理过程