LRU(Least Recently Used)最近最少使用,淘汰最近最少使用的数据,
LFU(Least Frequently Used)最近最不频繁用,淘汰最不常用的数据。
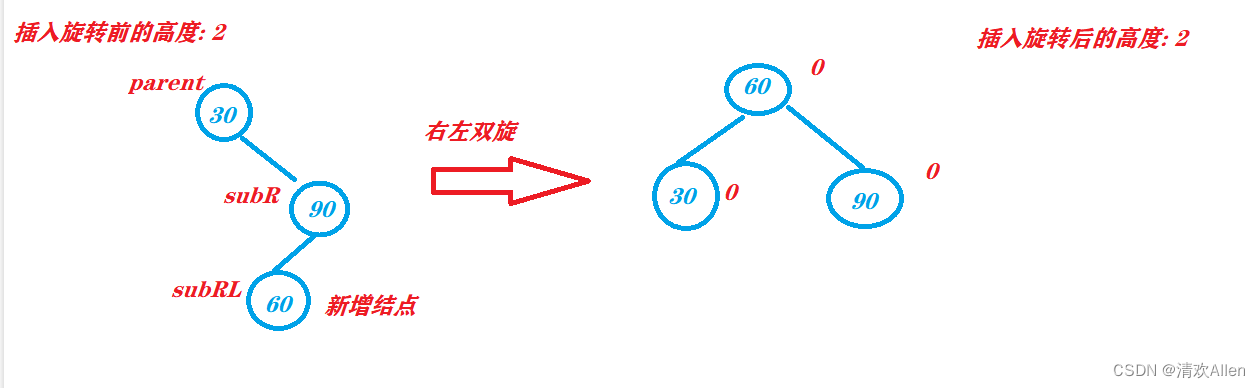
LRU算法
传统的LRU基于链表实现。基本的一个LRU算法实现就是【Hash表+双向链表】。
算法执行:
按最近使用顺序排序,被操作的数据元素,会拆链表,把该数据元素移到最前面,合链表。
链表尾部代表最久未使用的数据元素。
操作两个问题:
① 链表存储所有数据带来开销;
② 大量数据访问时,过多的解链表、合链表会严重影响性能。
LFU算法
核心思想是:默认访问多的数据越重要。
解决偶尔访问一次数据就会存留较长时间的情况,会比较符合应用场景。但实现起来较复杂,基本的一个LFU算法实现需要【两个Hash表+多个双向链表】。不过两者的Hash表都是用来存储key-节点的关系。不同在于LFU需要多一个Hash去记录在哪一个双向链表。
执行:
-
key不存在返回null;
-
key存在,返回对应节点的value值。同时,需将节点的访问次数+1,然后将该节点从原双向链表中移除,添加到新的访问次数对应的双向链表中。若hash表不存在对应的双向链表则需要先创建链表。(访问次数与双向链表数对应)
Redis实现
Redis的内存淘汰策略中,就有LRU和LFU算法的实现,不完全相同但类似。Redis3.0之前使用的内存淘汰策略为:volatile-lru(基于设置过期时间数据进行淘汰的LRU算法)
Redis实现LRU算法:
是在Redis的对象结构体中添加一额外字段,记录最新一次的访问时间。
当Redis进行内存淘汰时, 会使用随机采样的方式来淘汰数据,淘汰访问时间距离最近的数据。
优点:
相比传统LRU算法,省内存空间,不必去维护一个较大占空间的链表。
相比传统LRU算法,省去链表数据移到操作,提高性能。
缺点:
缓存污染问题:一次读取大量数据后,这些数据会留在数据库较长时间。这也是引入LFU算法
的目的之一。
Redis实现LFU算法:
是在Redis对象头中存放 ldt (占16bit)和 logc (占8bit)分别记录key的最新访问时间戳和key的访问频次。 当为什么这里需要时间呢,不是论次数吗?因为这里的 logc 不是记录单纯的访问次数,而是频次,会随时间衰减,随访问次数增加而增长,因此有 ldt 存在的必要性。
ps:Redis中是有两个参数lfu-decay-time和lfu-log-factor分别用于设置logc的衰减和增长速度。
回想起Leetcode上一道经典的算法题LRU(纯思路题,并不涉及复杂算法):
力扣![]() https://leetcode.cn/problems/lru-cache/附上题解:
https://leetcode.cn/problems/lru-cache/附上题解:
class LRUCache {
class LinkList {
int key;
int value;
LinkList prev;
LinkList next;
public LinkList() {}
public LinkList(int key, int value) {
this.key = key;
this.value = value;
}
}
private int size;
private int capacity;
private HashMap<Integer, LinkList> map = new HashMap<>();
private LinkList head; // 头指针
private LinkList tail; // 尾指针
public LRUCache(int capacity) {
this.capacity = capacity;
size = 0;
head = new LinkList();
tail = new LinkList();
head.next = tail;
tail.prev = head; // 头尾互指易漏
}
public int get(int key) {
LinkList node = map.get(key);
if (node == null) {
return -1;
}
moveToHead(node);
return node.value;
}
public void put(int key, int value) {
LinkList node = map.get(key);
if (node == null) {
if (size++ == capacity) {
LinkList tailNode = removeTail();
map.remove(tailNode.key);
size--; // 必须有size--,不然其实一直在size++
}
node = new LinkList(key, value); // 因为下面同一个了,所以这里必须更新node
addHead(node);
map.put(key, node);
} else {
node.value = value; // 更新value值
}
moveToHead(node);
}
void moveToHead(LinkList node) {
removeNode(node);
addHead(node);
}
void removeNode(LinkList node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
void addHead(LinkList node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
LinkList removeTail() {
LinkList tailNode = tail.prev;
removeNode(tailNode);
return tailNode;
}
}







![[java基础]面向对象(五)](https://img-blog.csdnimg.cn/1f22341aa7614927a4aaa4a7794ea8c2.png)

![[oeasy]python0135_命名惯用法_name_convention](https://img-blog.csdnimg.cn/img_convert/7f5348309a2643a5d0efffff92cd9943.png)