已解决,使用关键词进行百度搜索,然后爬取搜索结果,请求数据后,返回的是百度安全验证,网络不给力,请稍后重试。无法请求到正确数据。且尝试在header中增加Accept参数还是不行。
一、问题产生的现象
在学习过程中,写了一小段练习用的爬取程序,获取百度关键词搜索后的结果,代码如下:
import requests
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36',
}
url = 'https://www.baidu.com/s?wd=python'
reponse = requests.get(url, headers=headers, timeout=10)
reponse.encoding = reponse.apparent_encoding
content = reponse.text
print(content) 运行后,打印出来的结果显示: 

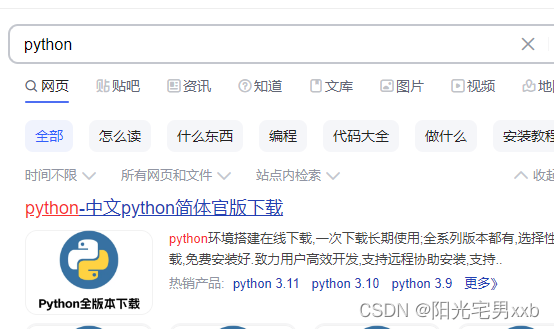
但是,我把这个url网址复制到浏览器打开时可以看到搜索结果的:
二、问题解决过程
1、看到网上有人说要在header中,增加一个accept参数,于是加了下:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.5359.95 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'
}然后运行,哦哦,还是打印出来的是百度安全验证。
2、从这个错误来看,像是百度有反爬虫措施,需要验证才能获取它的数据。但我记得之前是可以的,难道现在不可以了么。
于是看了之前的代码,发现我之前写的是http而不是https 于是修改下url:
url = 'http://www.baidu.com/s?wd=python'运行,哦,终于成功,不再是百度安全验证的信息了:

3、试着将一开始加的accept参数删除,依然能够成功,说明还是这个url要使用http的问题。
三、最终解决方案
将url中的https修改为http