List 队列:
生产者存入消息:
LPUSH queue2 msg1
LPUSH queue2 msg2
LPUSH queue2 msg3
消费者消费消息:
RPOP queue2
RPOP queue2
RPOP queue2
写个死循环消费:
while true:
//没消息阻塞等待,3秒超时返回null,设置0时没消息一直浪费cpu;
msg = redis.brpop("queue2",3);
if(msg==null): continue
//处理消息
handleMsg(msg)
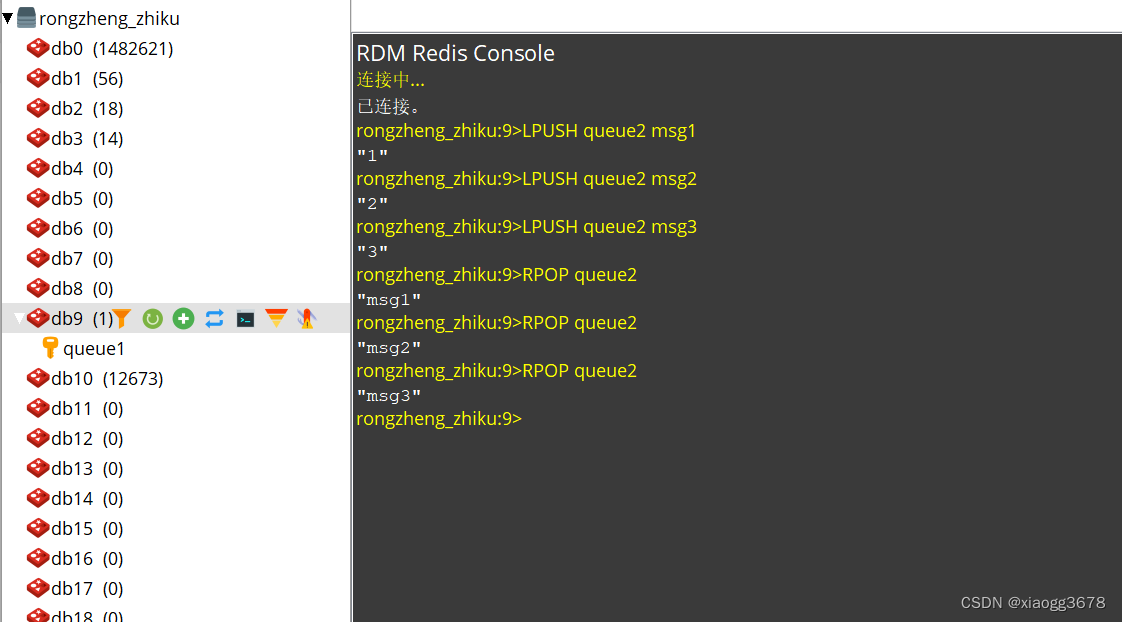
不支持重复消费 :消费者拉取消息后,这条消息就从 List 中删除了,无法被其它消费者再次消费,即不支持多个消费者消费同一批数据
消息丢失:消费者拉取到消息后,如果发生异常宕机,那这条消息就丢失了
-
发布/订阅模型:Pub/Sub
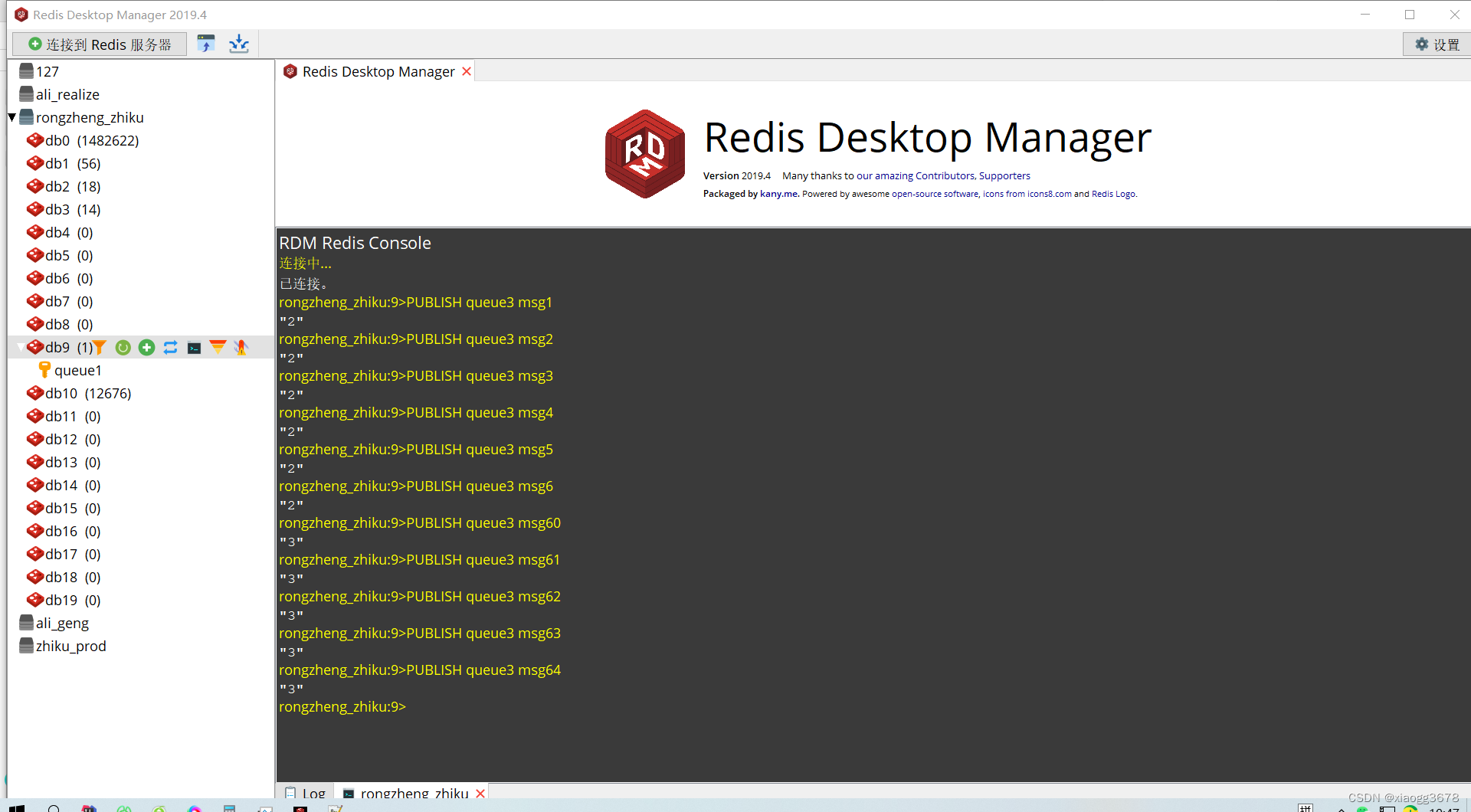
发送消息:
2个监听消费者消息
生产者生产消息:
PUBLISH queue3 msg1
PUBLISH queue3 msg2
PUBLISH queue3 msg3
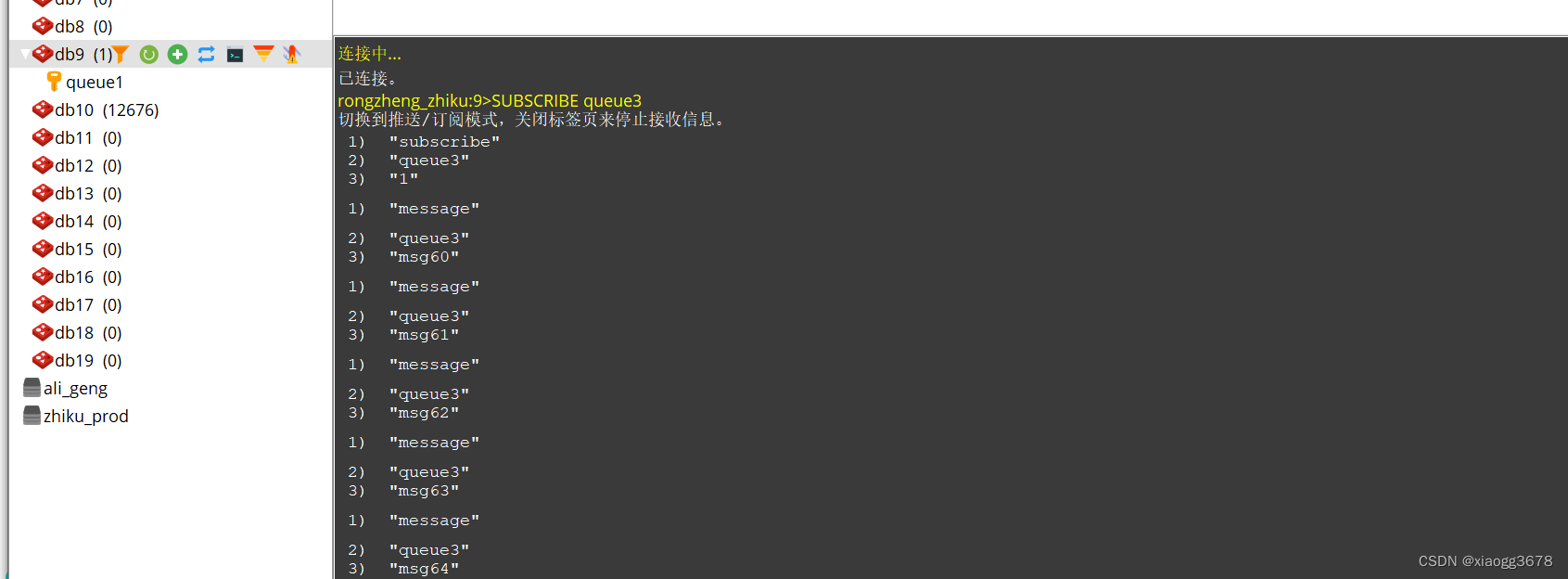
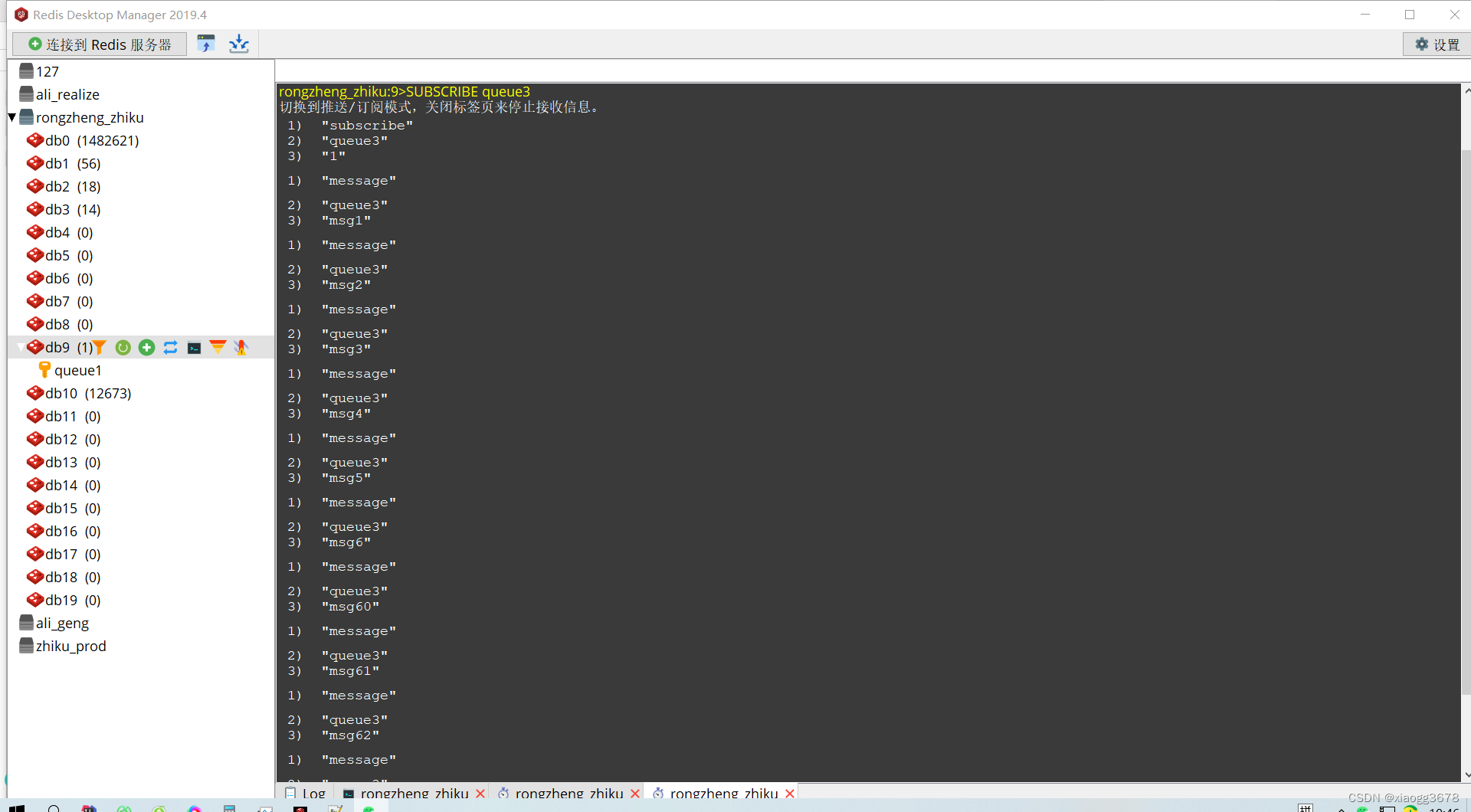
消费者消费消息:
SUBSCRIBE queue3
Pub/Sub 还提供了「匹配订阅」模式,允许消费者根据一定规则,订阅「多个」自己感兴趣的队列。
PSUBSCRIBE queue.*生产者分别向 queue.p1 和 queue.p2 发布消息
PUBLISH queue.p1 msg1PUBLISH queue.p2 msg2这时再看消费者,它就可以接收到这 2 个生产者的消息了。
我们可以看到,Pub/Sub 最大的优势就是,支持多组生产者、消费者处理消息
除了第一个是优点之外,剩下的都是缺点
支持发布 / 订阅,支持多组生产者、消费者处理消息
- 消费者下线,数据会丢失
- 不支持数据持久化,Redis 宕机,数据也会丢失
- 消息堆积,缓冲区溢出,消费者会被强制踢下线,数据也会丢失
- Pub/Sub 在实际的应用场景中用得并不多
Stream队列