【Java-Java集合】Java集合详解与区别
- 1)概述
- 2)集合框架图
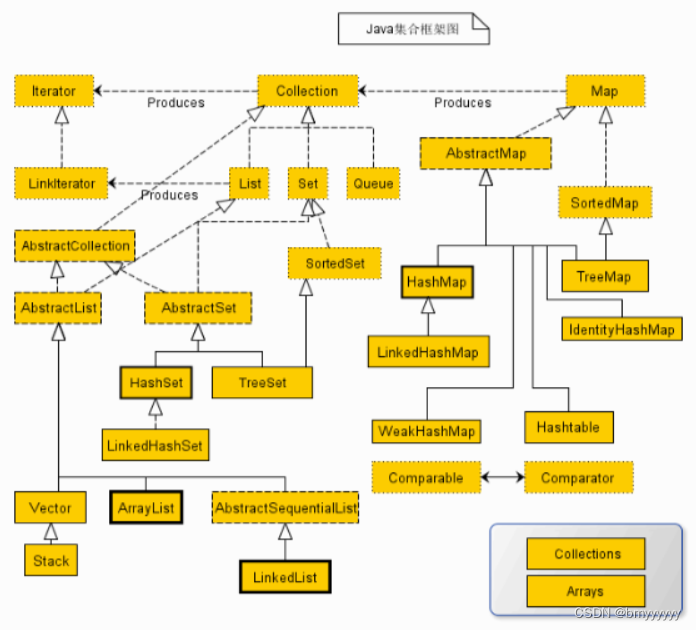
- 2.1.总框架图
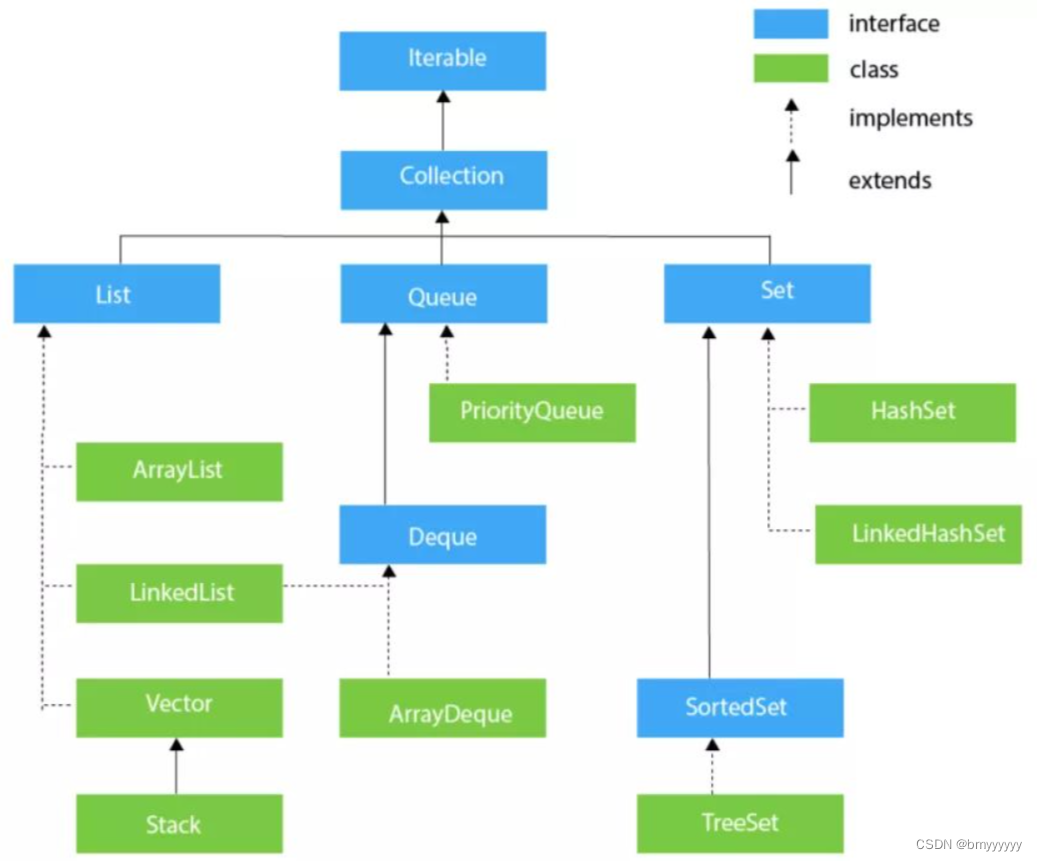
- 2.2.Iterable 框架图
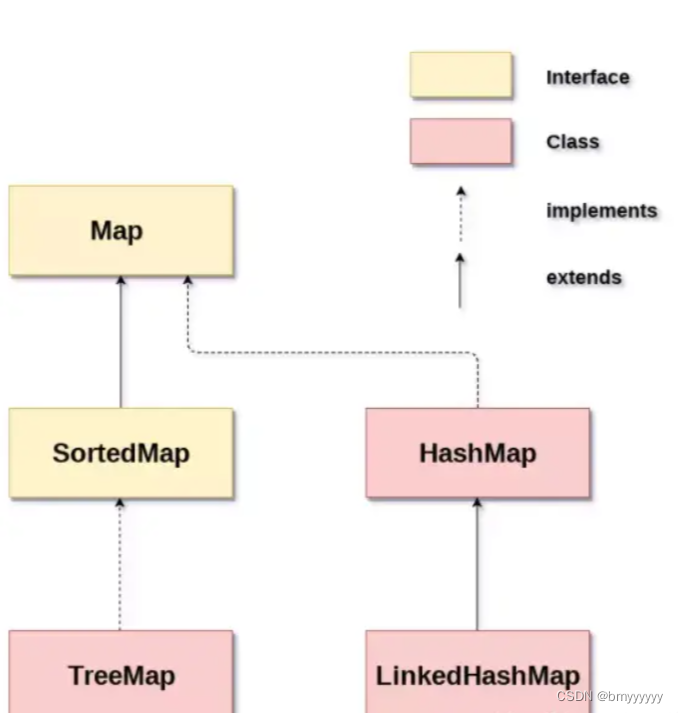
- 2.3.Map 框架图
- 3)List
- 3.1.ArrayList 类继承图
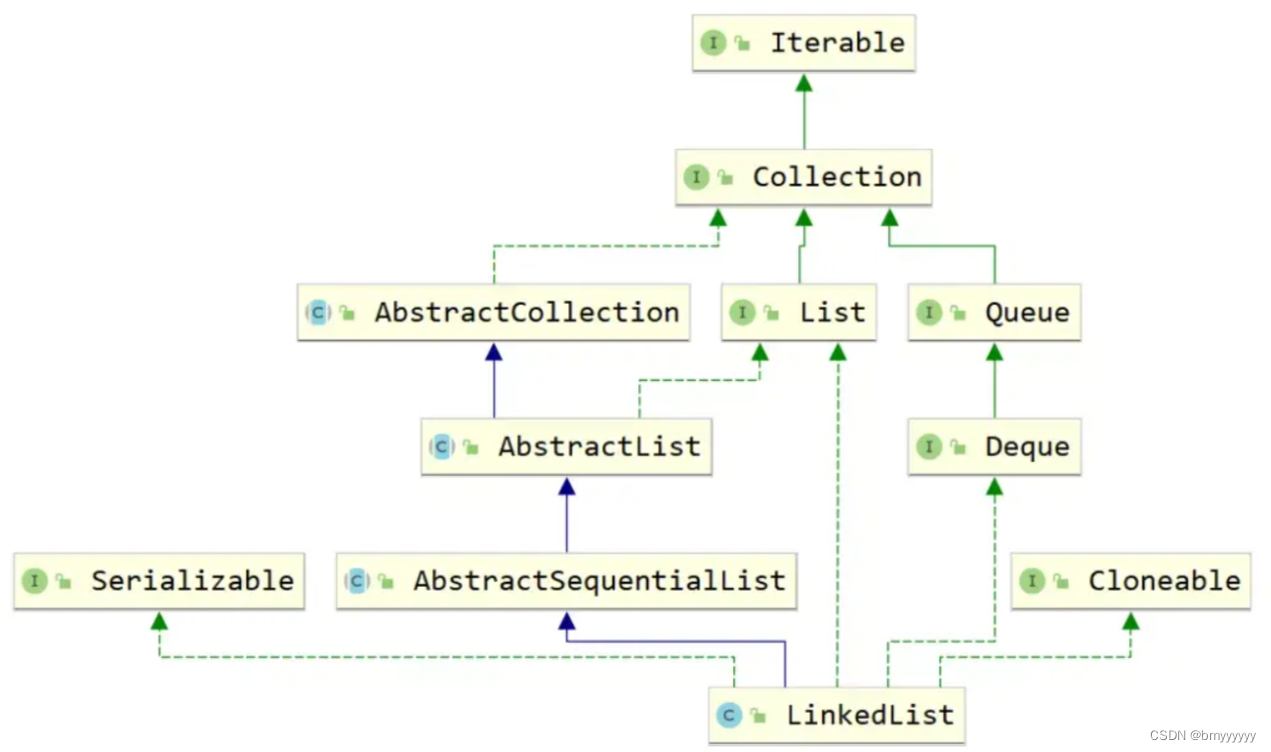
- 3.2.LinkedList 类继承图
- 4)Set
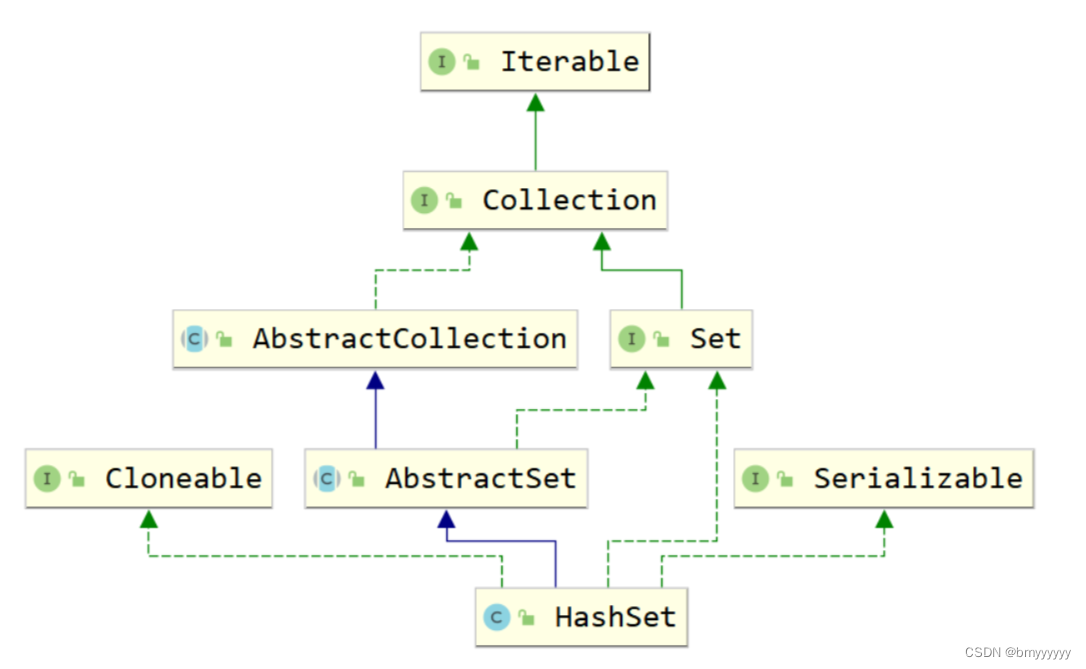
- 4.1.HashSet 类继承图
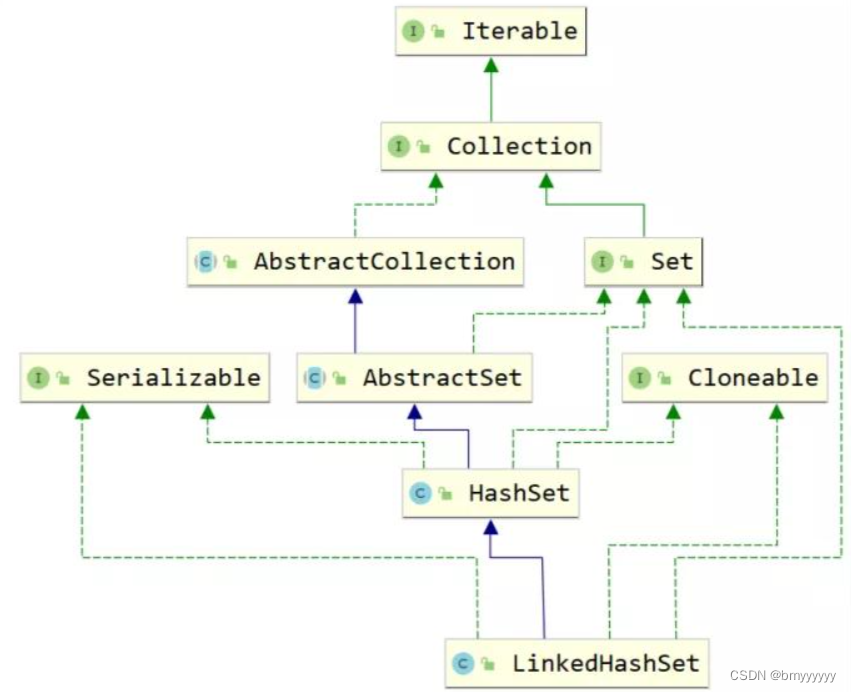
- 4.2.LinkedHashSet 类继承图
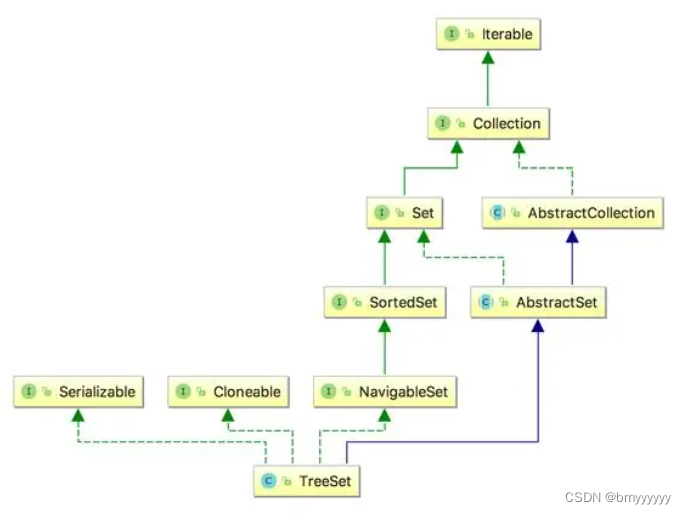
- 4.3.TreeSet 类继承图
- 5)Map
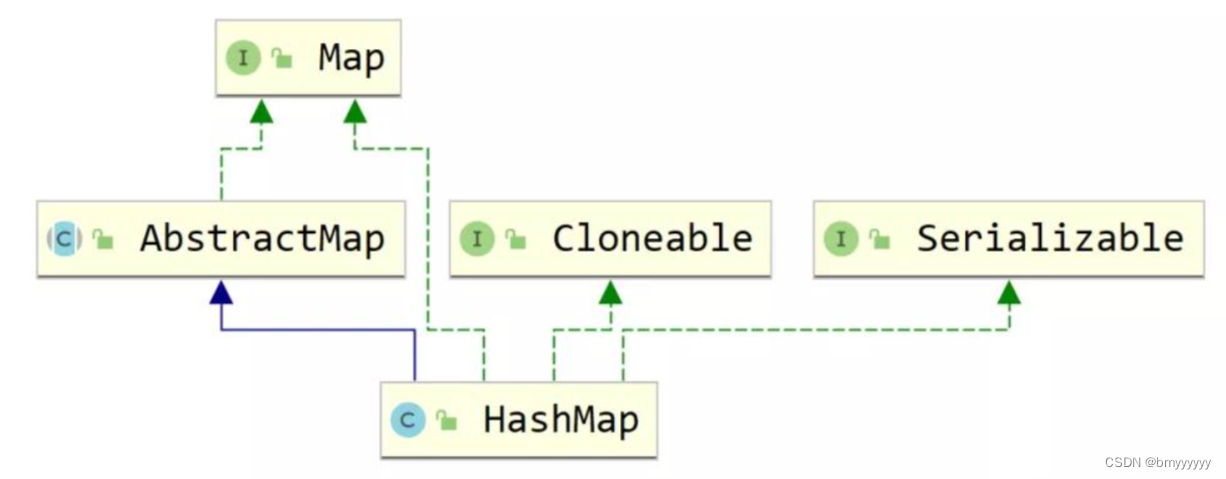
- 5.1.HashMap 类继承图
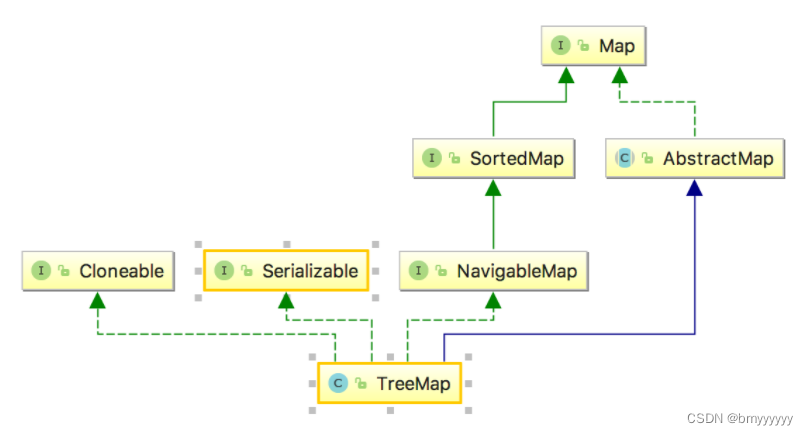
- 5.2.TreeMap 类继承图
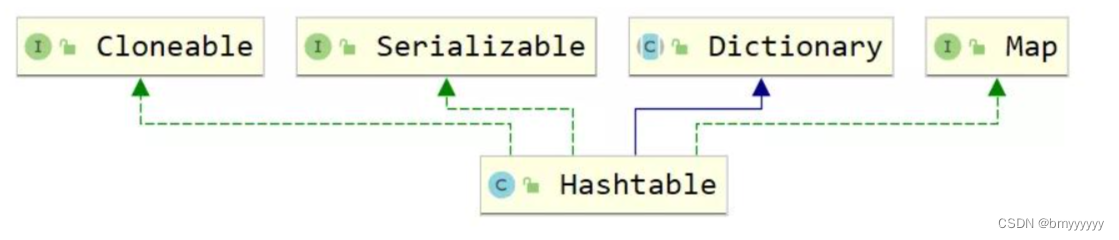
- 5.3.HashTable 类继承图
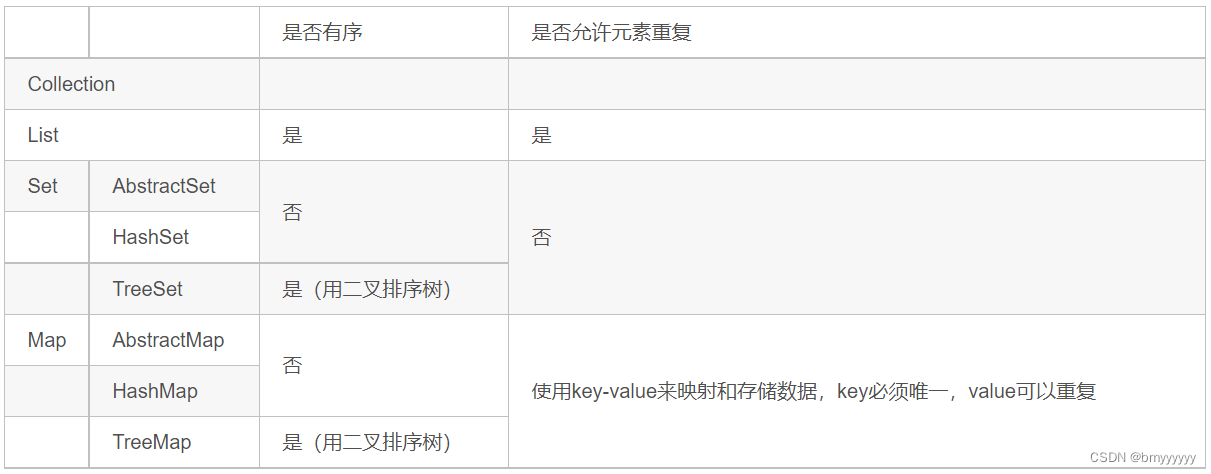
- 6)集合对比
1)概述
1、所有的集合类和集合接口都在 java.util 包下。
2、在内存中申请一块空间用来存储数据,在Java中集合就是替换掉定长的数组的一种引用数据类型。
3、集合类型主要有3种:Set(集)、List(列表)和 Map(映射)。当然还有一些底层的集合如:Vector,Stack,Queue等,但是在日常使用中用的并不多,这里我们只介绍开发中常用的集合。
4、集合接口分为:Collection 和 Map(List、Set 实现了Collection接口)
2)集合框架图
2.1.总框架图
2.2.Iterable 框架图
2.3.Map 框架图
3)List
1、可以重复,有序,通过索引取出加入数据,顺序与插入顺序一致,可以含有 null 元素。
2、List 集合分为两类,ArrayList、LinkedList,还有 Vector(不常用)。
-
ArrayList:底层数据结构使数组结构 array,查询速度快,增删改慢,因为是一种类似数组的形式进行存储,因此它的随机访问速度极快,线程不安全。 -
LinkedList:底层使用链表结构,增删速度快,查询稍慢。LinkedList的每个元素是互相连接的,一旦查询数据,每次都要重头开始查询,费时间,但是增删改查就可以准确的找到对应的位置了,线程不安全。 -
Vector:底层是数组结构array,与ArrayList相同,查询速度快,增删改慢,线程安全。
3、ArrayList 与 Vector 的区别:
-
如果集合中的元素数量大于当前集合数组的长度时,Vector的增长率是目前数组长度的100%,而ArryaList增长率为目前数组长度的50%。所以,如果集合中使用数据量比较大的数据,用Vector有一定优势。
-
线程同步ArrayList是线程不同步,所以Vector线程安全,但是因为每个方法都加上了synchronized,所以在效率上小于ArrayList。
4、集合的常用遍历方式:
-
普通for循环
-
增强for循环
-
迭代器遍历
3.1.ArrayList 类继承图

3.2.LinkedList 类继承图
4)Set
1、数据不可以重复(唯一),无序,实现类都不是线程安全的类,解决方案:Set set = Collections.sysnchronizedSet(Set对象)
2、Set 集合大致分为两类:HashSet、LinkedHashSet、TreeSet。
-
HashSet:是 Set 接口(Set 接口是继承了 Collection 接口的)最常用的实现类,顾名思义,底层是用了哈希表(散列/hash)算法。其底层其实也是一个数组,存在的意义是提供查询速度,插入的速度也是比较快,但是适用于少量数据的插入操作,线程不安全。
-
LinkedHashSet:继承了 HashSet 类,所以它的底层用的也是哈希表的数据结构,但因为保持数据的先后添加顺序,所以又加了链表结构,但因为多加了一种数据结构,所以效率较低,不建议使用,如果要求一个集合急要保证元素不重复,也需要记录元素的先后添加顺序,才选择使用 LinkedHashSet,线程不安全。
-
TreeSet:Set 接口的实现类,也拥有 Set 接口的一般特性,但是不同的是他也实现了 SortSet 接口,它底层采用的是红黑树算法(红黑树就是满足一下红黑性质的二叉搜索树),要注意的是在 TreeSet 集合中只能存储相同类型对象的引用,线程不安全。
3、Tree最重要的就是它的两种排序方式:自然排序、客户端排序。
-
自然排序:实现了 Comparable 接口,所以 TreeSet 可以调用对象的 ComparableTo() 方法来比较集合的大小,然后进行升序排序,这种排序方式叫做自然排序。其中实现了 Comparable 接口的还有 BigDecimal、BigInteger、Byte、Double、Float、Integer、Long、Short(按照数字大小排序)、Character(按照 Unicode 值的数字大小进行排序)String(按照字符串中字符的Unicode值进行排序)类等。 -
客户化排序:其实就是实现 java.util.Comparator 接口提供的具体的排序方式, 是具体要比较对象的类型,他有个 compare 的方法,如 compare(x,y) 返回值大于 0 表示 x 大于 y,以此类推,当我们希望按照自己的想法排序的时候可以重写 compare 方法。
4、集合的常用遍历方式:
-
普通for循环
-
增强for循环
-
迭代器遍历
4.1.HashSet 类继承图
4.2.LinkedHashSet 类继承图
4.3.TreeSet 类继承图
5)Map
1、Map 是一种把键对象和值对象进行映射的集合,其中每一个元素都包含了键对象和值对象,其中值对象也可以是 Map 类型的数据,因此,Map 支持多级映射,Map 中的键是唯一的,但值可以不唯一。
2、Map 大致分为三类:HashMap、TreeMap、HashTable (不常用)。
-
HashMap:(无序)它和 HashSet 都是利用哈希表来完成的,区别其实就是在哈希表的每个桶中,HashSet 只有 key,而 HashMap 在每个 key 上挂了一个 value,线程不安全。
-
TreeMap:(有序)它实现了 SortMap 接口,也就是使用了红黑树的数据结构,和 TreeSet 一样也能实现自然排序和客户化排序两种排序方式,而哈希表不提供排序,线程不安全。
-
HashTable:Hashtable 继承 Map 接口,实现一个 key-value 映射的哈希表。任何非空(non-null)的对象都可作为 key 或者 value,线程安全。
3、集合的常用遍历方式:
-
KeySet():是将 Map 中所有的 Key 放在一起,然后通过 get(key),获取对应的 Value。 -
EntrySet():将 Key-Value 当做一个整体放到一个 Set 中,通过 getKey() 和 getValue() 的方法获取对应的 Key 和 Value。
5.1.HashMap 类继承图
5.2.TreeMap 类继承图
5.3.HashTable 类继承图
6)集合对比
详细 :https://blog.csdn.net/u010775025/article/details/79315361