Deploy Ceph(v17.2.5 Quincy) cluster to use Cephadm - DevOps - dbaselife
Install cephadm
Cephadm creates a new Ceph cluster by “bootstrapping” on a single host, expanding the cluster to encompass any additional hosts, and then deploying the needed services.
Cephadm通过SSH连接manager daemon到主机,从而部署和管理Ceph群集。manager daemon能够添加,删除或更新Ceph containers。Cephadm首先在单节点上引导一个微小的Ceph集群(one monitor and one manager),然后自动将集群扩展到多个节点,并提供所有Ceph守护程序和服务。
Requirements
- Python 3
- Systemd
- Podman or Docker for running containers
- Time synchronization (such as chrony or NTP)
- LVM2 for provisioning storage devices
install Ceph-pacific-15.2.13 using cephadm - DevOps - dbaselife
Podman与 Ceph兼容的版本的表
Compatibility and Stability — Ceph Documentation
There are two ways to install cephadm:
- a curl-based installation method
- distribution-specific installation methods
Deploying a new Ceph cluster — Ceph Documentation
2.部署准备
| Host_Name | public_ip | admin_ip | cluster | OS | role |
|---|---|---|---|---|---|
| Ceph-stroage01 | 193.169.100.58 | 10.10.15.225 | 172.150.0.58 | Centos_steam_9 | admin,mon,mgr,osd,httpd for yum server |
| Ceph-stroage02 | 193.169.100.59 | 10.10.15.226 | 172.150.0.59 | Centos_steam_9 | mon,mgr,osd |
| Ceph-stroage03 | 193.169.100.60 | 10.10.15.227 | 172.150.0.60 | Centos_steam_9 | mon,osd |
网络的配置:
- admin网络: 用来运行yum install从外网下载和安装
- public网络: 是client和Ceph cluster之间通信与数据传输的网络
- cluster网络: 是Ceph节点之间通信和传输数据的网络
rpm 下载:
Index of /
Ceph-pacific-17.2.5 版:
Index of /rpm-17.2.5/el9/
https://download.ceph.com/tarballs/ceph_17.2.5.orig.tar.gz
2.1.配置防火墙和selinux(所有节点)
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
sed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config
2.2.配置 hosts(所有节点)
修改主机名
nmcli g hostname ceph-stroage01
配置主机名解析
cat >> /etc/hosts << EOF
# Ceph public network
193.169.100.58 ceph-stroage01
193.169.100.59 ceph-stroage02
193.169.100.60 ceph-stroage03
# Ceph admin network
10.10.15.225 ceph-node01
10.10.15.226 ceph-node02
10.10.15.227 ceph-node03
# Ceph cluster network
172.150.0.58 ceph-priv01
172.150.0.59 ceph-priv02
172.150.0.60 ceph-priv03
EOF
2.3.配置SSH互信(所有节点)
管理节点创建ssh密钥
# ssh-keygen
分发密钥,认证
# ssh-copy-id ceph-stroage01
2.4.配置时间同步(所有节点)
step 1.所有节点安装 chrony
dnf install chrony -y
step 2.配置时间服务器
[root@localhost yum.repos.d]# cat /etc/chrony.conf
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server 193.169.100.58 iburst
# Record the rate at which the system clock gains/losses time.
driftfile /var/lib/chrony/drift
# Allow the system clock to be stepped in the first three updates
# if its offset is larger than 1 second.
makestep 1.0 3
# Enable kernel synchronization of the real-time clock (RTC).
rtcsync
# Enable hardware timestamping on all interfaces that support it.
#hwtimestamp *
# Increase the minimum number of selectable sources required to adjust
# the system clock.
#minsources 2
# Allow NTP client access from local network.
#allow 192.168.0.0/16
allow 193.169.100.0/24
# Serve time even if not synchronized to a time source.
#local stratum 10
local stratum 3
# Specify file containing keys for NTP authentication.
#keyfile /etc/chrony.keys
# Specify directory for log files.
logdir /var/log/chrony
# Select which information is logged.
#log measurements statistics tracking
[root@localhost yum.repos.d]#
step 3.配置客户端
[root@localhost ~]# cat /etc/chrony.conf
# Use public servers from the pool.ntp.org project.
# Please consider joining the pool (http://www.pool.ntp.org/join.html).
server 193.169.100.58 iburst
# Record the rate at which the system clock gains/losses time.
driftfile /var/lib/chrony/drift
# Allow the system clock to be stepped in the first three updates
# if its offset is larger than 1 second.
makestep 1.0 3
# Enable kernel synchronization of the real-time clock (RTC).
rtcsync
# Enable hardware timestamping on all interfaces that support it.
#hwtimestamp *
# Increase the minimum number of selectable sources required to adjust
# the system clock.
#minsources 2
# Allow NTP client access from local network.
#allow 192.168.0.0/16
# Serve time even if not synchronized to a time source.
#local stratum 10
# Specify file containing keys for NTP authentication.
#keyfile /etc/chrony.keys
# Specify directory for log files.
logdir /var/log/chrony
# Select which information is logged.
#log measurements statistics tracking
[root@localhost ~]#
2.5.配置 yum 源
dnf install yum-utils createrepo httpd wget -y
step 1.备份yum 配置
rm -rf /etc/yum.repo.d/ *.repo
step 2.创建 yum 配置
docker-ce 源
wget -O /etc/yum.repos.d/docker-ce.repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
Ceph quincy 源:
cat > /etc/yum.repos.d/ceph.repo<<EOF
[Ceph]
name=Ceph packages for $basearch
baseurl=https://mirrors.aliyun.com/ceph/rpm-quincy/el9/x86_64/
enabled=1
gpgcheck=0
[Ceph-noarch]
name=Ceph noarch packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-quincy/el9/noarch/
enabled=1
gpgcheck=0
[ceph-SRPMS]
name=Ceph source packages
baseurl=https://mirrors.aliyun.com/ceph/rpm-quincy/el9/SRPMS/
enabled=1
gpgcheck=0
EOF
step 3.同步相关rpm包
查看 repo name
[root@ceph-node01 ~]# dnf repolist
repo id repo name
Ceph Ceph packages for
Ceph-noarch Ceph noarch packages
appstream CentOS Stream 9 - AppStream
baseos CentOS Stream 9 - BaseOS
ceph-SRPMS Ceph source packages
docker-ce-stable Docker CE Stable - x86_64
[root@ceph-node01 ~]#
同步rpm
# docker-ce
mkdir -p /root/docker-ce/x86_64
reposync --repo docker-ce-stable -p /root/docker-ce/x86_64
mkdir -p /root/ceph/x86_64
reposync --repo Ceph -p /root/ceph/x86_64
mkdir -p /root/ceph/SRPMS/
reposync --repo ceph-SRPMS -p /root/ceph/SRPMS
mkdir -p /root/ceph/noarch/
reposync --repo ceph-noarch -p /root/ceph/noarch/
step 4.生成用于离线安装的仓库元数据
createrepo -v /root/docker-ce/x86_64
createrepo -v /root/ceph-quincy
将目录打包到目标机器用于搭建ceph安装的本地或者私有 yum源。
tar -zcf docker-ce-stable.tar.gz docker-ce-stable
step 5.创建本地私有yum源
在本地网络中安装HTTP服务器,将打包的rpm源文件部署到本地HTTP服务中。
2.6.导出ceph 相关的images(外部节点)
docker save quay.io/ceph/ceph:v17 -o quay.io_ceph_ceph_v17.tar.gz
docker save quay.io/ceph/ceph-grafana:8.3.5 -o quay.io_ceph_ceph-grafana_8.3.5.tar.gz
docker save quay.io/prometheus/prometheus:v2.33.4 -o quay.io_prometheus_prometheus_v2.33.4.tar.gz
docker save quay.io/prometheus/node-exporter:v1.3.1 -o quay.io_prometheus_node-exporter_v1.3.1.tar.gz
docker save quay.io/prometheus/alertmanager:v0.23.0 -o quay.io_prometheus_alertmanager_v0.23.0.tar.gz
2.7.安装Python3(所有节点)
3.部署CEPH
3.1.安装docker(所有节点)
cephadm基于容器运行所有ceph组件,所有节点需要安装docker或podman,这里以安装docker为例。
step 1.配置本地yum源
step 2.安装docker-ce
dnf install -y docker-ce
step 3.启动docker服务
systemctl enable --now docker
3.2.安装Cephadm
curl-based installation
使用curl获取独立脚本的最新版本
# curl --silent --remote-name --location https://github.com/ceph/ceph/raw/quincy/src/cephadm/cephadm
Make the cephadm script executable:
# chmod +x cephadm
此脚本可以直接从当前目录运行:
# ./cephadm <arguments...>
尽管独立脚本足以启动集群,但在主机上安装cephadm命令是很方便的。要安装提供cephadm命令的软件包,请运行以下命令:
# ./cephadm add-repo --release quincy
# ./cephadm install
通过运行以下命令确认cephadm现在位于PATH中:
# which cephadm
成功的cephadm命令将返回以下内容:
/usr/sbin/cephadm
distribution-specific installations
step 1.安装 cephadm (管理节点)
# dnf search release-ceph
# dnf install --assumeyes centos-release-ceph-quincy
# dnf install --assumeyes cephadm
step 2.使用以下命令确认cephadm已经加入PATH环境变量,可能需要退出命令行界面重新登录:
[root@localhost ~]# which cephadm
/usr/sbin/cephadm
3.3.Bootstrap a new cluster
创建新 Ceph 集群的第一步是在 Ceph 集群的第一台主机上运行 cephadm bootstrap 命令。 在 Ceph 集群的第一台主机上运行 cephadm bootstrap 命令的行为会创建 Ceph 集群的第一个“监视器守护进程”,并且该监视器守护进程需要一个 IP 地址。 您必须将 Ceph 集群的第一台主机的 IP 地址传递给 ceph bootstrap 命令,因此您需要知道该主机的 IP 地址。
如果有多个网络和接口,请确保选择一个可供访问 Ceph 集群的任何主机访问的网络和接口。
step 1.导入镜像
docker load -i /root/ceph_for_docker/ceph_v15.tar.gz
docker load -i /root/ceph_for_docker/ceph-grafana_6.7.4.tar.gz
docker load -i /root/ceph_for_docker/prometheus_v2.18.1.tar.gz
docker load -i /root/ceph_for_docker/alertmanager_v0.20.0.tar.gz
docker load -i /root/ceph_for_docker/node-exporter_v0.18.1.tar.gz
step 2.引导集群
您可以运行 “cephadm bootstrap-h” 来查看cephadm的所有可用选项
# mkdir -p /etc/ceph
# cephadm bootstrap --mon-ip 193.169.100.58 --skip-pull
使用docker而不是podman(默认值:False)
此命令将:
- 在本地主机上为新集群创建监视器和管理器守护程序。
- 为Ceph集群生成一个新的SSH密钥,并将其添加到root用户的/root/.SSH/authorized_keys文件中
- 将公钥副本写入/etc/ceph/ceph.pub,这是cephadm(ceph orch命令)用来连接其他节点的公钥
- 将最小配置文件写入/etc/ceph/ceph.conf ,此文件是与新集群通信所必需的
- 将client.admin管理(特权!)密钥的副本写入/etc/ceph/ceph.client.admin.keyring
- 将_admin标签添加到引导主机,默认情况下,具有此标签的任何主机都将(同时)获得/etc/ceph/ceph.conf和/etc/ceph/ceph.client.admin.keyring的副本
-
默认情况下,Ceph守护进程将其日志输出发送到stdout/stderr,由容器运行时(docker或podman)获取并(在大多数系统上)发送到journal。如果希望Ceph将传统日志文件写入/var/log/Ceph/$fsid,请在引导过程中使用–log-to-file选项。
-
当(Ceph集群外部)公共网络流量与(Ceph群集内部)集群流量分离时,较大的Ceph集群性能更好。内部集群流量处理OSD后台进程之间的复制、恢复和心跳。您可以通过向bootstrap子命令提供–clusternetwork选项来定义集群网络。此参数必须以CIDR表示法定义子网(例如10.90.900/24或fe80::/64)。
-
cephadm引导程序将访问新集群所需的文件写入/etc/ceph。这个中心位置使得安装在主机上的Ceph包(例如,可以访问cephadm命令行界面的包)可以找到这些文件。
-
然而,使用cephadm部署的Daemon容器根本不需要/etc/ceph。使用–output-dir*<directory>*选项将它们放在不同的目录中(例如.)。这可能有助于避免与同一主机上的现有Ceph配置(cephadm或其他)发生冲突。
-
您可以将任何初始Ceph配置选项传递给新集群,方法是将它们放在标准的ini样式配置文件中,并使用–config *<configfile>*选项。例如:
# cat <<EOF > initial-ceph.conf
[global]
osd crush chooseleaf type = 0
EOF
# ./cephadm bootstrap --config initial-ceph.conf ...
指定自定义引导,以添加专用集群网络(如果您确实需要,列表中已对其进行了广泛讨论):
cat <<EOF > /root/ceph.conf
[global]
public network = 193.169.0.0/24
cluster network = 172.150.0.0/24
EOF
# cephadm bootstrap -c /root/ceph.conf --mon-ip 193.169.100.58
部署过程:
[root@ceph-node01 ceph]# cephadm bootstrap --mon-ip 193.169.100.58 --cluster-network 172.150.0.0/24 --docker
Verifying podman|docker is present...
Verifying lvm2 is present...
Verifying time synchronization is in place...
Unit chronyd.service is enabled and running
Repeating the final host check...
podman (/usr/bin/podman) version 4.4.0 is present
systemctl is present
lvcreate is present
Unit chronyd.service is enabled and running
Host looks OK
Cluster fsid: c4729d68-aed9-11ed-9ef4-4a1e3146f08c
Verifying IP 193.169.100.58 port 3300 ...
Verifying IP 193.169.100.58 port 6789 ...
Mon IP `193.169.100.58` is in CIDR network `193.169.100.0/24`
Mon IP `193.169.100.58` is in CIDR network `193.169.100.0/24`
Pulling container image quay.io/ceph/ceph:v17...
Ceph version: ceph version 17.2.5 (98318ae89f1a893a6ded3a640405cdbb33e08757) quincy (stable)
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start...
Waiting for mon...
mon is available
Assimilating anything we can from ceph.conf...
Generating new minimal ceph.conf...
Restarting the monitor...
Setting mon public_network to 193.169.100.0/24
Setting cluster_network to 172.150.0.0/24
Wrote config to /etc/ceph/ceph.conf
Wrote keyring to /etc/ceph/ceph.client.admin.keyring
Creating mgr...
Verifying port 9283 ...
Cannot bind to IP 0.0.0.0 port 9283: [Errno 98] Address already in use
ceph-mgr TCP port(s) 9283 already in use
Waiting for mgr to start...
Waiting for mgr...
mgr not available, waiting (1/15)...
mgr not available, waiting (2/15)...
mgr not available, waiting (3/15)...
mgr is available
Enabling cephadm module...
Waiting for the mgr to restart...
Waiting for mgr epoch 5...
mgr epoch 5 is available
Setting orchestrator backend to cephadm...
Generating ssh key...
Wrote public SSH key to /etc/ceph/ceph.pub
Adding key to root@localhost authorized_keys...
Adding host ceph-node01...
Deploying mon service with default placement...
Deploying mgr service with default placement...
Deploying crash service with default placement...
Deploying prometheus service with default placement...
Deploying grafana service with default placement...
Deploying node-exporter service with default placement...
Deploying alertmanager service with default placement...
Enabling the dashboard module...
Waiting for the mgr to restart...
Waiting for mgr epoch 9...
mgr epoch 9 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at:
URL: https://ceph-node01:8443/
User: admin
Password: 987kcgzp0c
Enabling client.admin keyring and conf on hosts with "admin" label
Saving cluster configuration to /var/lib/ceph/c4729d68-aed9-11ed-9ef4-4a1e3146f08c/config directory
Enabling autotune for osd_memory_target
You can access the Ceph CLI as following in case of multi-cluster or non-default config:
sudo /usr/sbin/cephadm shell --fsid c4729d68-aed9-11ed-9ef4-4a1e3146f08c -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Or, if you are only running a single cluster on this host:
sudo /usr/sbin/cephadm shell
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
Bootstrap complete.
[root@ceph-node01 ceph]#
部署后,它们应该连接到群集网络,您应该会看到相应接口上的复制流量。
-
–ssh-user*<user>*选项可以选择cephadm将使用哪个ssh用户连接到主机。关联的SSH密钥将添加到/home/<user>/.SSH/authorized_keys。使用此选项指定的用户必须具有无密码sudo访问权限。
-
使用 “–skip-pull” 参数来跳过 pull 镜像,实现离线安装
-
如果要使用私有的仓库,则可以添加三个参数:
- –registry-url <注册表的url>
- –registry-username <注册表中帐户的用户名>
- –registry-password <注册表中帐户的密码>
- –registry-json <带有登录信息的json文件>
如果在需要登录的经过身份验证的注册表上使用容器,则可以添加参数:
--registry-json <path to json file>
example contents of JSON file with login info:
{"url":"REGISTRY_URL", "username":"REGISTRY_USERNAME", "password":"REGISTRY_PASSWORD"}
Cephadm将尝试登录到此注册表,以便它可以提取您的容器,然后将登录信息存储在其配置数据库中。然后,添加到集群的其他主机也可以使用经过身份验证的注册表。
[root@ceph-stroage01 ceph_for_docker]# cephadm bootstrap --mon-ip 193.169.100.58 --skip-pull
Verifying podman|docker is present...
Verifying lvm2 is present...
Verifying time synchronization is in place...
Unit chronyd.service is enabled and running
Repeating the final host check...
podman|docker (/usr/bin/docker) is present
systemctl is present
lvcreate is present
Unit chronyd.service is enabled and running
Host looks OK
Cluster fsid: 152735aa-d4f4-11eb-b108-e6f1aaf957fd
Verifying IP 193.169.100.58 port 3300 ...
Verifying IP 193.169.100.58 port 6789 ...
Mon IP 193.169.100.58 is in CIDR network 193.169.100.0/24
Extracting ceph user uid/gid from container image...
Creating initial keys...
Creating initial monmap...
Creating mon...
Waiting for mon to start...
Waiting for mon...
mon is available
Assimilating anything we can from ceph.conf...
Generating new minimal ceph.conf...
Restarting the monitor...
Setting mon public_network...
Creating mgr...
Verifying port 9283 ...
Wrote keyring to /etc/ceph/ceph.client.admin.keyring
Wrote config to /etc/ceph/ceph.conf
Waiting for mgr to start...
Waiting for mgr...
mgr not available, waiting (1/10)...
mgr not available, waiting (2/10)...
mgr is available
Enabling cephadm module...
Waiting for the mgr to restart...
Waiting for Mgr epoch 5...
Mgr epoch 5 is available
Setting orchestrator backend to cephadm...
Generating ssh key...
Wrote public SSH key to to /etc/ceph/ceph.pub
Adding key to root@localhost's authorized_keys...
Adding host ceph-stroage01...
Deploying mon service with default placement...
Deploying mgr service with default placement...
Deploying crash service with default placement...
Enabling mgr prometheus module...
Deploying prometheus service with default placement...
Deploying grafana service with default placement...
Deploying node-exporter service with default placement...
Deploying alertmanager service with default placement...
Enabling the dashboard module...
Waiting for the mgr to restart...
Waiting for Mgr epoch 13...
Mgr epoch 13 is available
Generating a dashboard self-signed certificate...
Creating initial admin user...
Fetching dashboard port number...
Ceph Dashboard is now available at:
URL: https://ceph-stroage01:8443/
User: admin
Password: lb83cil354
You can access the Ceph CLI with:
sudo /usr/sbin/cephadm shell --fsid 152735aa-d4f4-11eb-b108-e6f1aaf957fd -c /etc/ceph/ceph.conf -k /etc/ceph/ceph.client.admin.keyring
Please consider enabling telemetry to help improve Ceph:
ceph telemetry on
For more information see:
https://docs.ceph.com/docs/master/mgr/telemetry/
Bootstrap complete.
[root@ceph-stroage01 ceph_for_docker]#
URL: https://ceph-stroage01:8443/
User: admin
Password: lb83cil354
输出信息中,包括 Dashboard 的地址,用户名和密码
首次登陆,需要修改密码
step 3.安装完成,发现已经启动了几个容器:
[root@localhost ceph_for_docker]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
8aa0bb78930f ceph/ceph-grafana:6.7.4 "/bin/sh -c 'grafana…" 23 seconds ago Up 21 seconds ceph-d864c568-d4e1-11eb-8bcf-e6f1aaf957fd-grafana.ceph-stroage01
7887d685d59c prom/alertmanager:v0.20.0 "/bin/alertmanager -…" 40 seconds ago Up 38 seconds ceph-d864c568-d4e1-11eb-8bcf-e6f1aaf957fd-alertmanager.ceph-stroage01
7224ff18b199 prom/prometheus:v2.18.1 "/bin/prometheus --c…" 59 seconds ago Up 56 seconds ceph-d864c568-d4e1-11eb-8bcf-e6f1aaf957fd-prometheus.ceph-stroage01
e1cd3ba2221e prom/node-exporter:v0.18.1 "/bin/node_exporter …" About a minute ago Up About a minute ceph-d864c568-d4e1-11eb-8bcf-e6f1aaf957fd-node-exporter.ceph-stroage01
e2421fb4dbd3 ceph/ceph:v15 "/usr/bin/ceph-crash…" About a minute ago Up About a minute ceph-d864c568-d4e1-11eb-8bcf-e6f1aaf957fd-crash.ceph-stroage01
93dba4172741 ceph/ceph:v15 "/usr/bin/ceph-mgr -…" 3 minutes ago Up 3 minutes ceph-d864c568-d4e1-11eb-8bcf-e6f1aaf957fd-mgr.ceph-stroage01.pyaevp
298dfcbce078 ceph/ceph:v15 "/usr/bin/ceph-mon -…" 3 minutes ago Up 3 minutes ceph-d864c568-d4e1-11eb-8bcf-e6f1aaf957fd-mon.ceph-stroage01
[root@localhost ceph_for_docker]#
Copy
step 4.查看当前配置文件变化:
[root@localhost ceph]# ll
total 12
-rw-------. 1 root root 63 Jun 24 18:57 ceph.client.admin.keyring
-rw-r--r--. 1 root root 179 Jun 24 18:57 ceph.conf
-rw-r--r--. 1 root root 595 Jun 24 18:57 ceph.pub
[root@localhost ceph]#
Copy
查看集群配置文件
[root@localhost ceph]# cat ceph.conf
# minimal ceph.conf for d864c568-d4e1-11eb-8bcf-e6f1aaf957fd
[global]
fsid = d864c568-d4e1-11eb-8bcf-e6f1aaf957fd
mon_host = [v2:193.169.100.58:3300/0,v1:193.169.100.58:6789/0]
[root@localhost ceph]#
此时已经运行了以下组件:
- ceph-mgr ceph管理程序
- ceph-monitor ceph监视器
- ceph-crash 崩溃数据收集模块
- prometheus prometheus监控组件
- grafana 监控数据展示dashboard
- alertmanager prometheus告警组件
- node_exporter prometheus节点数据收集组件
3.4.启用CEPH命令(主节点执行)
Cephadm不需要在主机上安装任何Ceph软件包。但是,我们建议允许轻松访问ceph命令。有几种方法可以做到这一点:
- cephadm shell 命令在安装了所有Ceph包的容器中启动bash shell。默认情况下,如果在主机上的/etc/ceph中找到配置和keyring文件,则会将它们传递到容器环境中,以便shell完全正常工作。注意,在MON主机上执行时,cephadm shell将从MON容器推断配置,而不是使用默认配置。如果给定 –mount <path>,则主机 (文件或目录)将显示在容器中的 /mnt下:
cephadm shell:
需执行命令 “cephadm shell” 进入容器中使用ceph cil
[root@localhost ceph]# cephadm shell
Inferring fsid db51539c-d566-11eb-a3e9-e6f1aaf957fd
Inferring config /var/lib/ceph/db51539c-d566-11eb-a3e9-e6f1aaf957fd/mon.ceph-stroage01/config
Using recent ceph image ceph/ceph@<none>
Non-zero exit code 125 from /usr/bin/docker run --rm --ipc=host --net=host --entrypoint stat -e CONTAINER_IMAGE=ceph/ceph@<none> -e NODE_NAME=ceph-stroage01 ceph/ceph@<none> -c %u %g /var/lib/ceph
stat: stderr docker: invalid reference format.
stat: stderr See 'docker run --help'.
Traceback (most recent call last):
File "/usr/sbin/cephadm", line 6223, in <module>
r = args.func()
File "/usr/sbin/cephadm", line 1363, in _infer_fsid
return func()
File "/usr/sbin/cephadm", line 1394, in _infer_config
return func()
File "/usr/sbin/cephadm", line 1422, in _infer_image
return func()
File "/usr/sbin/cephadm", line 3546, in command_shell
make_log_dir(args.fsid)
File "/usr/sbin/cephadm", line 1520, in make_log_dir
uid, gid = extract_uid_gid()
File "/usr/sbin/cephadm", line 2133, in extract_uid_gid
raise RuntimeError('uid/gid not found')
RuntimeError: uid/gid not found
[root@localhost ceph]#
执行命令报错,查看日志:
2021-06-25 11:59:47,786 DEBUG --------------------------------------------------------------------------------
cephadm ['shell']
2021-06-25 11:59:47,809 DEBUG Could not locate podman: podman not found
2021-06-25 11:59:47,809 DEBUG container_init=False
2021-06-25 11:59:47,809 INFO Inferring fsid db51539c-d566-11eb-a3e9-e6f1aaf957fd
2021-06-25 11:59:47,810 INFO Inferring config /var/lib/ceph/db51539c-d566-11eb-a3e9-e6f1aaf957fd/mon.ceph-stroage01/config
2021-06-25 11:59:47,810 DEBUG Running command: /usr/bin/docker images --filter label=ceph=True --filter dangling=false --format {{.Repository}}@{{.Digest}}
2021-06-25 11:59:47,910 DEBUG /usr/bin/docker: stdout ceph/ceph@<none>
2021-06-25 11:59:47,914 INFO Using recent ceph image ceph/ceph@<none>
2021-06-25 11:59:47,914 DEBUG Running command: /usr/bin/docker run --rm --ipc=host --net=host --entrypoint stat -e CONTAINER_IMAGE=ceph/ceph@<none> -e NODE_NAME=ceph-stroage01 ceph/ceph@<none> -c %u %g /var/lib/ceph
2021-06-25 11:59:47,999 DEBUG stat: stderr docker: invalid reference format.
2021-06-25 11:59:47,999 DEBUG stat: stderr See 'docker run --help'.
2021-06-25 11:59:48,001 INFO Non-zero exit code 125 from /usr/bin/docker run --rm --ipc=host --net=host --entrypoint stat -e CONTAINER_IMAGE=ceph/ceph@<none> -e NODE_NAME=ceph-stroage01 ceph/ceph@<none> -c %u %g /var/lib/ceph
2021-06-25 11:59:48,002 INFO stat: stderr docker: invalid reference format.
2021-06-25 11:59:48,002 INFO stat: stderr See 'docker run --help'.
Copy
经过分析,确认 “cephadmin shell” 命令会启动一个 ceph容器;因安装在离线环境中,通过docker load的镜像,丢失了 “RepoDigest” 信息,所有无法启动容器。
参考文档:
请输入访问码 - dbaselife
使用docker registry 创建本地仓库,然后推送镜像到仓库,再拉取该镜像来完善 “RepoDigest” 信息。(所有主机)
docker run -d -v /opt/registry:/var/lib/registry -p 5000:5000 --restart=always --name registry registry:latest
docker tag ceph/ceph:v15 193.169.100.58:5000/ceph/ceph:v15
docker push 193.169.100.58:5000/ceph/ceph:v15
docker pull 193.169.100.58:5000/ceph/ceph:v15
启用CEPH命令
[root@ceph-stroage01 yum.repos.d]# cephadm shell
Inferring fsid db51539c-d566-11eb-a3e9-e6f1aaf957fd
Inferring config /var/lib/ceph/db51539c-d566-11eb-a3e9-e6f1aaf957fd/mon.ceph-stroage01/config
Using recent ceph image 193.169.100.58:5000/ceph@sha256:0368cf225b3a13b7bdeb3d81ecf370a62931ffa5ff87af880d66aebae74f910a
[ceph: root@ceph-stroage01 /]#
[ceph: root@ceph-stroage01 /]# ceph status
cluster:
id: db51539c-d566-11eb-a3e9-e6f1aaf957fd
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum ceph-stroage01 (age 41m)
mgr: ceph-stroage01.cdthyk(active, since 40m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
[ceph: root@ceph-stroage01 /]#
创建别名可能会有所帮助(省略):
# alias ceph='cephadm shell -- ceph'
要执行ceph命令,还可以运行以下命令
# cephadm shell -- ceph -s
ceph-common
可以安装ceph-common包,里面包含了所有的ceph命令,其中包括ceph,rbd,mount.ceph(用于安装CephFS文件系统)等:
step 1.安装ceph-common包使本地主机支持ceph基本命令
[root@localhost docker]# cephadm add-repo --release ceph
[root@localhost docker]# cephadm install ceph-common
step 2.使用 ceph cli
[root@ceph-stroage01 html]# ceph -s
cluster:
id: 152735aa-d4f4-11eb-b108-e6f1aaf957fd
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum ceph-stroage01 (age 58m)
mgr: ceph-stroage01.zgfhtm(active, since 55m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
[root@ceph-stroage01 html]#
使用以下ceph命令确认该命令是否可访问:
[root@ceph-stroage01 html]# ceph -v
ceph version 15.2.13 (c44bc49e7a57a87d84dfff2a077a2058aa2172e2) octopus (stable)
[root@ceph-stroage01 html]#
Copy
通过以下ceph命令确认命令可以连接到集群及显示状态:
[root@ceph-stroage01 html]# ceph -s
cluster:
id: 152735aa-d4f4-11eb-b108-e6f1aaf957fd
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum ceph-stroage01 (age 58m)
mgr: ceph-stroage01.zgfhtm(active, since 55m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
[root@ceph-stroage01 html]# ceph -v
ceph version 15.2.13 (c44bc49e7a57a87d84dfff2a077a2058aa2172e2) octopus (stable)
[root@ceph-stroage01 html]# ceph status
cluster:
id: 152735aa-d4f4-11eb-b108-e6f1aaf957fd
health: HEALTH_WARN
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum ceph-stroage01 (age 59m)
mgr: ceph-stroage01.zgfhtm(active, since 56m)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
[root@ceph-stroage01 html]#
Copy
查看所有组件运行状态
[root@ceph-stroage01 html]# ceph orch ps
NAME HOST STATUS REFRESHED AGE VERSION IMAGE NAME IMAGE ID CONTAINER ID
alertmanager.ceph-stroage01 ceph-stroage01 running (72m) 71s ago 73m 0.20.0 docker.io/prom/alertmanager:v0.20.0 0881eb8f169f 75db978f9d87
crash.ceph-stroage01 ceph-stroage01 running (73m) 71s ago 73m 15.2.13 docker.io/ceph/ceph:v15 2cf504fded39 ebfb81e2cb06
grafana.ceph-stroage01 ceph-stroage01 running (72m) 71s ago 73m 6.7.4 docker.io/ceph/ceph-grafana:6.7.4 ae5c36c3d3cd 3451b55e01ec
mgr.ceph-stroage01.zgfhtm ceph-stroage01 running (77m) 71s ago 77m 15.2.13 docker.io/ceph/ceph:v15 2cf504fded39 f8bd6d46adc8
mon.ceph-stroage01 ceph-stroage01 running (77m) 71s ago 77m 15.2.13 docker.io/ceph/ceph:v15 2cf504fded39 9ab90483082a
node-exporter.ceph-stroage01 ceph-stroage01 running (73m) 71s ago 73m 0.18.1 docker.io/prom/node-exporter:v0.18.1 e5a616e4b9cf ffa579959351
prometheus.ceph-stroage01 ceph-stroage01 running (72m) 71s ago 72m 2.18.1 docker.io/prom/prometheus:v2.18.1 de242295e225 bde09adb8c3a
Copy
查看某个组件运行状态
[root@ceph-stroage01 html]# ceph orch ps --daemon-type mds
No daemons reported
[root@ceph-stroage01 html]#
Copy
4.添加/删除主机到集群中
默认情况下,ceph.conf文件和client.admin密钥环的副本在/etc/ceph中维护在所有带有_admin标签的主机上,该标签最初仅应用于引导主机。我们通常建议为一个或多个其他主机提供_admin标签,以便在多个主机上轻松访问Ceph CLI(例如,通过cephadm shell)。要将_admin标签添加到其他主机,请执行以下操作:
4.1.查看可用主机
step 1.运行以下形式的命令以列出与群集关联的主机:
ceph orch host ls [--format yaml] [--host-pattern <name>] [--label <label>] [--host-status <status>]
在这种形式的命令中,参数“主机模式”、“标签”和“主机状态”是可选的,用于过滤。
- “host-pattern”是一个正则表达式,它与主机名匹配,并且只返回匹配的主机。
- “label”仅返回具有指定标签的主机。
- “host-status”仅返回具有指定状态(当前为“脱机”或“维护”)的主机。
- 这些筛选标志的任何组合都是有效的。可以同时根据名称、标签和状态进行筛选,也可以根据名称、标记和状态的任何适当子集进行筛选。
执行结果如下:
[root@ceph-stroage01 yum.repos.d]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph-stroage01 ceph-stroage01
[root@ceph-stroage01 yum.repos.d]#
Copy
4.2.Adding Hosts
主机必须安装这些要求。 没有所有必要要求的主机将无法添加到集群中。
要将每个新主机添加到集群,请执行两个步骤:
step 1.在新主机的 root 用户的 authorized_keys 文件中安装集群的公共 SSH 密钥:
ssh-copy-id -f -i /etc/ceph/ceph.pub root@*<new-host>*
Copy
执行结果如下:
[root@ceph-stroage01 yum.repos.d]# ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph-stroage02
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/etc/ceph/ceph.pub"
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@ceph-stroage02'"
and check to make sure that only the key(s) you wanted were added.
[root@ceph-stroage01 yum.repos.d]# ssh-copy-id -f -i /etc/ceph/ceph.pub root@ceph-stroage03
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/etc/ceph/ceph.pub"
Number of key(s) added: 1
Now try logging into the machine, with: "ssh 'root@ceph-stroage03'"
and check to make sure that only the key(s) you wanted were added.
[root@ceph-stroage01 yum.repos.d]#
Copy
step 2.添加指定新节点加入Ceph集群中
ceph orch host add *<newhost>* [*<ip>*] [*<label1> ...*]
Copy
执行结果如下:
[root@ceph-stroage01 yum.repos.d]# ceph orch host add ceph-stroage02 193.169.100.59
Added host 'ceph-stroage02'
[root@ceph-stroage01 yum.repos.d]#
[root@ceph-stroage01 yum.repos.d]# ceph orch host add ceph-stroage03 193.169.100.60
Added host 'ceph-stroage03'
[root@ceph-stroage01 yum.repos.d]#
Copy
验证查看ceph纳管的所有节点
[root@ceph-stroage01 yum.repos.d]# ceph orch host ls
HOST ADDR LABELS STATUS
ceph-stroage01 ceph-stroage01
ceph-stroage02 193.169.100.59
ceph-stroage03 193.169.100.60
[root@ceph-stroage01 yum.repos.d]#
Copy
最好明确提供主机IP地址。如果未提供IP,则将立即通过DNS解析主机名,并使用该IP。
还可以包括一个或多个标签,以立即为新主机添加标签。例如,默认情况下,_admin标签将使cephadm在/etc/ceph中维护ceph.conf文件和client.admin keyring文件的副本:
ceph orch host add host4 10.10.0.104 --labels _admin
Copy
添加完成后ceph会自动扩展monitor和manager到另外节点(此过程时间可能会稍久,耐心等待),另外可用命令(ceph -s)或Ceph的Ceph Dashboard页面查看添加情况
[root@ceph-stroage01 ~]# ceph -s
cluster:
id: db51539c-d566-11eb-a3e9-e6f1aaf957fd
health: HEALTH_WARN
2 failed cephadm daemon(s)
failed to probe daemons or devices
OSD count 0 < osd_pool_default_size 3
services:
mon: 1 daemons, quorum ceph-stroage01 (age 3h)
mgr: ceph-stroage01.cdthyk(active, since 2h)
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:
[root@ceph-stroage01 ~]#
Copy
4.3.删除主机
如果要删除的节点正在运行 OSD,请确保从节点中删除 OSD。
从群集中删除所有守护程序后,可以安全地从群集中移除主机。
要从主机中排出所有守护程序,请运行以下形式的命令
ceph orch host drain *<host>*
_no_schedule标签将应用于主机。请参见特殊主机标签。
将计划删除主机上的所有OSD。您可以使用以下命令检查OSD删除操作的进度:
# ceph orch osd rm status
使用以下命令确定主机上是否仍有任何守护程序:
# ceph orch ps <host>
对于除 node-exporter 和 crash 之外的所有 Ceph 服务类型,从放置规范文件(例如 cluster.yml)中删除主机。 例如,如果您要删除名为 host2 的主机,请从所有 place: 部分删除所有出现的 -host2。
Update:
service_type: rgw
placement:
hosts:
- host1
- host2
Copy
To:
service_type: rgw
placement:
hosts:
- host1
Copy
从 cephadm 的环境中删除主机:
ceph orch host rm host2
Copy
如果主机正在运行 node-exporter 和 crash 服务,请通过在主机上运行以下命令来删除它们:
cephadm rm-daemon --fsid CLUSTER_ID --name SERVICE_NAME
Copy
脱机主机删除
即使主机处于脱机状态且无法恢复,也可以通过运行以下形式的命令将其从群集中删除:
# ceph orch host rm <host> --offline --force
警告
这可能会导致数据丢失。该命令通过为每个osd调用osd-purge actual,从集群中强制清除osd。应手动更新仍然包含此主机的任何服务规范。
4.4.Host labels
Orchestrator 支持为主机分配标签。 标签是自由形式的,本身没有特别的意义,每个主机可以有多个标签。 它们可用于指定守护进程的位置。 请参阅按标签放置
添加带有 –labels 标志的主机时可以添加标签:
ceph orch host add my_hostname --labels=my_label1
ceph orch host add my_hostname --labels=my_label1,my_label2
Copy
要为现有主机添加标签
ceph orch host label add my_hostname my_label
Copy
要删除标签
ceph orch host label rm my_hostname my_label
Copy
特殊主机标签
以下主机标签对 cephadm 具有特殊意义。都以_开头。
- _no_schedule:
不要在此主机上安排或部署守护进程。
此标签可防止 cephadm 在此主机上部署守护程序。如果它被添加到已经包含 Ceph 守护进程的现有主机,它会导致 cephadm 将这些守护进程移动到其他地方(OSD 除外,它们不会被自动删除)。 - _no_autotune_memory:
不要在此主机上自动调整内存。
即使为该主机上的一个或多个守护程序启用了 osd_memory_target_autotune 或类似选项,该标签也将阻止对守护程序内存进行调整。 - _admin:
将client.admin 和ceph.conf 分发到该主机。
默认情况下,_admin 标签应用于集群中的第一台主机(引导程序最初运行的地方),并且 client.admin 密钥设置为通过 ceph orch client-keyring … 功能分发到该主机。将此标签添加到其他主机通常会导致 cephadm 在 /etc/ceph 中部署配置和密钥环文件。
4.4.维护模式
使主机进入和退出维护模式(停止主机上的所有 Ceph 守护进程):
ceph orch host maintenance enter <hostname> [--force]
ceph orch host maintenace exit <hostname>
Copy
进入维护时的强制标志允许用户绕过警告(但不是警报)
4.5.Rescanning Host Devices
某些服务器和外部机柜可能不会向内核注册设备移除或插入。在这些情况下,您需要执行主机重新扫描。重新扫描通常无中断,可以使用以下CLI命令执行:
# ceph orch host rescan <hostname> [--with-summary]
带有摘要标志提供了找到和扫描的HBA数量的细目,以及任何失败的HBA:
# ceph orch host rescan rh9-ceph1 --with-summary
Ok. 2 adapters detected: 2 rescanned, 0 skipped, 0 failed (0.32s)
4.6.Creating many hosts at once
可以使用 ceph orch apply -i 通过提交多文档 YAML 文件一次添加多个主机:
---
service_type: host
hostname: node-00
addr: 192.168.0.10
labels:
- example1
- example2
---
service_type: host
hostname: node-01
addr: 192.168.0.11
labels:
- grafana
---
service_type: host
hostname: node-02
addr: 192.168.0.12
Copy
这可以与服务规范(如下)相结合,创建一个集群规范文件,以在一个命令中部署整个集群。 参见 cephadm bootstrap –apply-spec 也可以在引导期间执行此操作。 在添加之前,必须将集群 SSH 密钥复制到主机。
4.7.Setting the initial CRUSH location of host
主机可以包含位置标识符,该标识符将指示cephadm创建位于指定层次结构中的新CRUSH主机。
service_type: host
hostname: node-00
addr: 192.168.0.10
location:
rack: rack1
location属性将仅影响初始CRUSH位置。将忽略位置属性的后续更改。此外,删除主机不会删除任何CRUSH存储桶。
4.8.OS Tuning Profiles
Cephadm可用于管理将sysctl设置集应用于主机集的操作系统调优配置文件。
以以下格式创建YAML规范文件:
profile_name: 23-mon-host-profile
placement:
hosts:
- mon-host-01
- mon-host-02
settings:
fs.file-max: 1000000
vm.swappiness: '13'
Apply the tuning profile with the following command:
# ceph orch tuned-profile apply -i <tuned-profile-file-name>
该概要文件被写入与yaml放置块中指定的主机匹配的每个主机上的/etc/sysctl.d/,sysctl–system在该主机上运行。
Note: 配置文件在/etc/sysctl.d/中写入的确切文件名是<profile name>-cephadm-tuned-profile.conf,其中<profile name>是您在YAML规范中指定的profile_name设置。因为sysctl设置是按字典顺序应用的(按指定设置的文件名排序),您可能希望在规范中设置profilename,以便在其他conf文件之前或之后应用它。
Note: 这些设置仅在主机级别应用,不特定于任何特定的守护程序或容器。
Note: 当传递–no覆盖选项时,应用调优的概要文件是幂等的。此外,如果传递–no覆盖选项,则不会覆盖同名的现有配置文件。
查看配置文件
运行以下命令以查看cephadm当前管理的所有配置文件:
# ceph orch tuned-profile ls
要进行修改并重新应用概要文件,请将–format yaml传递给调优的概要文件ls命令。调优后的概要文件ls–format yaml命令以易于复制和重新应用的格式显示概要文件。
删除配置文件
要删除以前应用的配置文件,请运行以下命令:
# ceph orch tuned-profile rm <profile-name>
删除配置文件后,cephadm会清理之前写入/etc/sysctl.d的文件。
修改配置文件
可以通过重新应用与要修改的配置文件同名的YAML规范来修改配置文件,但可以使用以下命令调整现有配置文件中的设置。
要在现有配置文件中添加或修改设置,请执行以下操作:
# ceph orch tuned-profile add-setting <profile-name> <setting-name> <value>
要从现有配置文件中删除设置,请执行以下操作:
# ceph orch tuned-profile rm-setting <profile-name> <setting-name>
修改放置需要重新应用同名的轮廓。请记住,概要文件是按其名称跟踪的,因此当应用与现有概要文件同名的概要文件时,它将覆盖旧概要文件,除非传递–no覆盖标志。
4.9.SSH 配置
Cephadm 使用 SSH 连接到远程主机。 SSH 使用密钥以安全的方式向这些主机进行身份验证。
默认SSH配置
Cephadm 在监视器中存储一个 SSH 密钥,用于连接到远程主机。 集群启动后,此 SSH 密钥会自动生成,无需额外配置。
可以使用以下命令生成新的 SSH 密钥:
ceph cephadm generate-key
Copy
可以通过以下方式检索 SSH 密钥的公共部分:
ceph cephadm get-pub-key
Copy
可以使用以下命令删除当前存储的 SSH 密钥:
ceph cephadm clear-key
Copy
您可以通过直接导入现有密钥来使用它:
ceph config-key set mgr/cephadm/ssh_identity_key -i <key>
ceph config-key set mgr/cephadm/ssh_identity_pub -i <pub>
Copy
然后,您需要重新启动 mgr 守护程序以重新加载配置:
ceph mgr fail
Copy
配置不同的 SSH 用户
Cephadm 必须能够以具有足够权限的用户身份登录所有 Ceph 集群节点,无需提示输入密码即可下载容器镜像、启动容器和执行命令。 如果不想使用“root”用户(cephadm 中的默认选项),则必须向 cephadm 提供将用于执行所有 cephadm 操作的用户名。 使用命令:
ceph cephadm set-user <user>
Copy
在运行之前,需要将集群 ssh 密钥添加到此用户的 authorized_keys 文件中,并且非 root 用户必须具有无密码的 sudo 访问权限。
自定义 SSH 配置
Cephadm 生成一个适当的 ssh_config 文件,用于连接到远程主机
Host *
User root
StrictHostKeyChecking no
UserKnownHostsFile /dev/null
Copy
有两种方法可以为您的环境自定义此配置:
1.导入将由监视器存储的自定义配置文件:
ceph cephadm set-ssh-config -i <ssh_config_file>
Copy
要删除自定义 SSH 配置并恢复为默认行为:
ceph cephadm clear-ssh-config
Copy
2.您可以使用以下命令为 SSH 配置文件配置文件位置:
ceph config set mgr mgr/cephadm/ssh_config_file <path>
Copy
我们不推荐这种方法。 路径名必须对任何 mgr 守护进程可见,并且 cephadm 将所有守护进程作为容器运行。 这意味着该文件要么需要放置在自定义容器映像中以进行部署,要么手动分发到 mgr 数据目录(主机上的 /var/lib/ceph/<cluster-fsid>/mgr.<id>, 从容器内部的 /var/lib/ceph/mgr/ceph-<id> 可见)。
4.10.Fully qualified domain names vs bare host names
cephadm 要求通过 ceph orch host add 给出的主机名等于远程主机上 hostname 的输出。
否则 cephadm 无法确保 ceph * 元数据返回的名称与 cephadm 已知的主机匹配。 这可能会导致 CEPHADM_STRAY_HOST 警告。
配置新主机时,有两种有效的方法可以设置主机的主机名:
1.使用裸主机名。 在这种情况下:
- hostname returns the bare host name.
- hostname -f returns the FQDN.
2.使用完全限定的域名作为主机名。 在这种情况下:
- hostname returns the FQDN
- hostname -s return the bare host name
系统的FQDN(完全限定域名)是解析器(3)为主机名返回的名称,例如ursula.example.com。通常是主机名后跟DNS域名(第一个点之后的部分)。可以使用hostname–FQDN检查FQDN,也可以使用dnsdomainname检查域名。
You cannot change the FQDN with hostname or dnsdomainname.
The recommended method of setting the FQDN is to make the hostname
be an alias for the fully qualified name using /etc/hosts, DNS, or
NIS. For example, if the hostname was "ursula", one might have
a line in /etc/hosts which reads
127.0.1.1 ursula.example.com ursula
这反过来意味着Ceph将在执行Ceph*metadata 时返回裸机名。这反过来意味着cephadm在向集群添加主机时也需要裸机名:ceph-orch-host-add<bare-name>。
5.部署 MONs
为监视器指定特定子网
ceph config set mon public_network *<mon-cidr-network>*
For example:
ceph config set mon public_network 10.1.2.0/24
Cephadm 仅在指定子网中具有 IP 地址的主机上部署新的监视器守护程序。
更改默认监视器的数量
如果要调整 5 个监视器的默认值,请运行以下命令:
ceph orch apply mon *<number-of-monitors>*
仅将监视器部署到特定主机
要在一组特定的主机上部署监视器,请运行以下命令:
ceph orch apply mon *<host1,host2,host3,...>*
确保在此列表中包含第一个(引导)主机。
Using Host Labels
您可以通过使用主机标签来控制监视器在哪些主机上运行。 要将 mon 标签设置为适当的主机,请运行以下命令:
ceph orch host label add *<hostname>* mon
要查看当前主机和标签,请运行以下命令:
ceph orch host ls
添加主机标签
ceph orch host label add host1 mon
ceph orch host label add host2 mon
ceph orch host label add host3 mon
ceph orch host ls
查看标签
HOST ADDR LABELS STATUS
host1 mon
host2 mon
host3 mon
host4
host5
通过运行以下命令,告诉 cephadm 根据标签部署监视器:
ceph orch apply mon label:mon
在特定网络上部署监视器
您可以为每个监视器明确指定 IP 地址或 CIDR 网络,并控制放置每个监视器的位置。 要禁用自动监视器部署,请运行以下命令:
ceph orch apply mon --unmanaged
要部署每个额外的监视器:
ceph orch daemon add mon *<host1:ip-or-network1> [<host1:ip-or-network-2>...]*
例如,要使用 IP 地址 10.1.2.123 在 newhost1 上部署第二个监视器并在网络 10.1.2.0/24 中的 newhost2 上部署第三个监视器,请运行以下命令:
[root@ceph-stroage01 ~]# ceph orch apply mon --unmanaged
Scheduled mon update...
[root@ceph-stroage01 ~]#
[root@ceph-stroage01 ~]# ceph orch daemon add mon ceph-stroage02:193.169.100.59
Deployed mon.ceph-stroage02 on host 'ceph-stroage02'
[root@ceph-stroage01 ~]#
[root@ceph-stroage01 ~]# ceph orch daemon add mon ceph-stroage03:193.169.100.60
Deployed mon.ceph-stroage03 on host 'ceph-stroage03'
[root@ceph-stroage01 ~]#
Copy
6.Adding Storage
6.1.List Devices
ceph-volume 会不时扫描主机中的每个集群,以确定存在哪些设备以及它们是否适合用作 OSD。
ceph orch device ls [--hostname=...] [--wide] [--refresh]
Copy
使用 –wide 选项提供与设备相关的所有详细信息,包括设备可能不适合用作 OSD 的任何原因。
在上面的示例中,您可以看到名为“Health”、“Ident”和“Fault”的字段。 此信息是通过与 libstoragemgmt 集成提供的。 默认情况下,此集成被禁用(因为 libstoragemgmt 可能与您的硬件不 100% 兼容)。 要使 cephadm 包含这些字段,请启用 cephadm 的“增强设备扫描”选项
ceph config set mgr mgr/cephadm/device_enhanced_scan true
Copy
建议您在启用此功能之前,先测试您的硬件与 libstoragemgmt 的兼容性,以避免计划外的服务中断。
测试兼容性的方法有很多种,但最简单的可能是使用cephadm shell直接调用libstoragemgmt——cephadm shell lsmcli ldl。
[root@ceph-stroage01 ~]# cephadm shell lsmcli ldl
Inferring fsid db51539c-d566-11eb-a3e9-e6f1aaf957fd
Inferring config /var/lib/ceph/db51539c-d566-11eb-a3e9-e6f1aaf957fd/mon.ceph-stroage01/config
Using recent ceph image 193.169.100.58:5000/ceph@sha256:0368cf225b3a13b7bdeb3d81ecf370a62931ffa5ff87af880d66aebae74f910a
Path | SCSI VPD 0x83 | Link Type | Serial Number | Health Status
---------------------------------------------------------------------
/dev/sda | | No Support | | Unknown
/dev/sdc | | No Support | | Unknown
/dev/sdb | | No Support | | Unknown
[root@ceph-stroage01 ~]#
Copy
启用 libstoragemgmt 支持后,输出所有群集主机上的存储设备清单可以显示为:
[root@ceph-stroage01 ~]# ceph orch device ls
Hostname Path Type Serial Size Health Ident Fault Available
ceph-stroage01 /dev/sdb hdd drive-scsi2 107G Unknown N/A N/A No
ceph-stroage01 /dev/sdc hdd drive-scsi1 107G Unknown N/A N/A No
ceph-stroage02 /dev/sdb hdd drive-scsi2 107G Unknown N/A N/A No
ceph-stroage02 /dev/sdc hdd drive-scsi1 107G Unknown N/A N/A No
ceph-stroage03 /dev/sdb hdd drive-scsi2 107G Unknown N/A N/A No
ceph-stroage03 /dev/sdc hdd drive-scsi1 107G Unknown N/A N/A No
[root@ceph-stroage01 ~]#
Copy
如果满足以下所有条件,则认为存储设备可用:
- 设备必须没有分区。
- 设备不得具有任何LVM状态。
- 不得安装设备。
- 该设备不得包含文件系统。
- 该设备不得包含Ceph BlueStore OSD。
- 设备必须大于5 GB。
Ceph拒绝在不可用的设备上配置OSD。
当前版本的 libstoragemgmt (1.8.8) 仅支持基于 SCSI、SAS 和 SATA 的本地磁盘。 没有对 NVMe 设备 (PCIe) 的官方支持
6.2.Creating New OSDs
添加所有未使用的设备
要向集群添加存储,请告诉 Ceph 使用任何可用和未使用的设备:
ceph orch apply osd --all-available-devices
Copy
运行上述命令后:
- 如果您向集群添加新磁盘,它们将自动用于创建新的 OSD。
- 如果您移除 OSD 并清理 LVM 物理卷,则会自动创建一个新的 OSD。
要禁用在可用设备上自动创建 OSD,请使用 unmanaged 参数:
ceph orch apply osd --all-available-devices --unmanaged=true
Copy
从特定主机上的特定设备创建 OSD:
ceph orch daemon add osd *<host>*:*<device-path>*
Copy
执行结果如下:
ceph orch daemon add osd ceph-stroage01:/dev/sdb
Copy
高级 OSD 服务
您可以使用高级 OSD 服务规范根据设备的属性对设备进行分类。 这可能有助于更清晰地了解哪些设备可供消费。 属性包括设备类型(SSD 或 HDD)、设备型号名称、大小以及设备所在的主机:
ceph orch apply -i spec.yml
Copy
6.3.Dry Run
–dry-run 标志使协调器在不实际创建 OSD 的情况下呈现将发生的情况的预览。
[root@ceph-stroage01 ~]# ceph orch apply osd --all-available-devices --dry-run
WARNING! Dry-Runs are snapshots of a certain point in time and are bound
to the current inventory setup. If any on these conditions changes, the
preview will be invalid. Please make sure to have a minimal
timeframe between planning and applying the specs.
################
OSDSPEC PREVIEWS
################
Preview data is being generated.. Please re-run this command in a bit.
[root@ceph-stroage01 ~]# ceph orch apply osd --all-available-devices --dry-run
WARNING! Dry-Runs are snapshots of a certain point in time and are bound
to the current inventory setup. If any on these conditions changes, the
preview will be invalid. Please make sure to have a minimal
timeframe between planning and applying the specs.
################
OSDSPEC PREVIEWS
################
+---------+------+------+------+----+-----+
|SERVICE |NAME |HOST |DATA |DB |WAL |
+---------+------+------+------+----+-----+
+---------+------+------+------+----+-----+
[root@ceph-stroage01 ~]#
Copy
6.4.Remove an OSD
从集群中移除 OSD 包括两个步骤:
- 从集群中撤出所有归置组 (PG)
- 从集群中删除 PG-free OSD
以下命令执行这两个步骤:
ceph orch osd rm <osd_id(s)> [--replace] [--force]
Copy
执行结果如下:
ceph orch osd rm 0
Scheduled OSD(s) for removal
Copy
不能安全销毁的 OSD 将被拒绝。
6.5.监控 OSD 状态
您可以使用以下命令查询 OSD 运行的状态:
ceph orch osd rm status
OSD_ID HOST STATE PG_COUNT REPLACE FORCE STARTED_AT
2 cephadm-dev done, waiting for purge 0 True False 2020-07-17 13:01:43.147684
3 cephadm-dev draining 17 False True 2020-07-17 13:01:45.162158
4 cephadm-dev started 42 False True 2020-07-17 13:01:45.162158
Copy
当 OSD 上没有剩余 PG 时,它将退役并从集群中删除。
移除一个 OSD 后,如果您擦除被移除的 OSD 使用的设备中的 LVM 物理卷,则会创建一个新的 OSD。
6.6.停止 OSD 移除
可以使用以下命令停止排队的 OSD 移除:
ceph orch osd rm stop <osd_id(s)>
Copy
执行结果如下:
ceph orch osd rm stop 4
Stopped OSD(s) removal
Copy
这会重置 OSD 的初始状态并将其从移除队列中移除
6.7.更换 OSD
orch osd rm <osd_id(s)> --replace [--force]
Copy
执行结果如下:
ceph orch osd rm 4 --replace
Scheduled OSD(s) for replacement
Copy
保留 OSD ID
‘destroyed’ 标志用于确定哪些 OSD id 将在下一次 OSD 部署中重用。
如果您使用 OSDSpecs 进行 OSD 部署,您新添加的磁盘将被分配其替换对应项的 OSD id。 这假设新磁盘仍然与 OSDSpecs 匹配。
使用 –dry-run 标志确保 ceph orch apply osd 命令执行您想要的操作。 –dry-run 标志向您显示命令的结果,而无需进行您指定的更改。 当您对命令可以执行您想要的操作感到满意时,请在不带 –dry-run 标志的情况下运行该命令。
6.8.擦除设备(Zapping Devices)
擦除 (zap) 设备以便可以重复使用。 zap 在远程主机上调用 ceph-volume zap。
orch device zap <hostname> <path>
执行结果如下:
ceph orch device zap my_hostname /dev/sdx
Copy
如果未设置 unmanaged 标志,cephadm 会自动部署与 OSDSpec 中的 DriveGroup 匹配的驱动器。 例如,如果您在创建 OSD 时使用 all-available-devices 选项,则当您 zap 设备时,cephadm Orchestrator 会自动在该设备中创建一个新的 OSD。 要禁用此行为,请参阅声明性状态。
6.9.自动调整 OSD 内存
OSD 守护进程将根据 osd_memory_target 配置选项(默认为几 GB)调整它们的内存消耗。 如果 Ceph 部署在不与其他服务共享内存的专用节点上,cephadm 可以根据 RAM 总量和部署的 OSD 数量自动调整每个 OSD 的内存消耗。
默认情况下,cephadm在引导时启用osd_memory_target_autotune,mgr/cephadm/autotune_memory_target_ratio设置为主机总内存的 70%。
要使用TripleO部署超融合Ceph,请参阅TripleO文档:场景:部署超融合的Ceph.
在其他情况下,如果Ceph不专门使用集群硬件(超转换),请减少Ceph的内存消耗,如下所示:
# hyperconverged only:
ceph config set mgr mgr/cephadm/autotune_memory_target_ratio 0.2
此选项通过以下方式全局启用:
ceph config set osd osd_memory_target_autotune true
Copy
Cephadm 将从系统总 RAM 的一小部分(mgr/cephadm/autotune_memory_target_ratio,默认为 .7)开始,减去非自动调优守护进程(非 OSD,对于 osd_memory_target_autotune 为 false 的 OSD)消耗的任何内存 ,然后除以剩余的 OSD。
最终目标反映在配置数据库中,其中包含以下选项:
WHO MASK LEVEL OPTION VALUE
osd host:foo basic osd_memory_target 126092301926
osd host:bar basic osd_memory_target 6442450944
Copy
每个守护进程消耗的限制和当前内存都可以从 ceph orch ps 输出的 MEM LIMIT 列中看到:
NAME HOST PORTS STATUS REFRESHED AGE MEM USED MEM LIMIT VERSION IMAGE ID CONTAINER ID
osd.1 dael running (3h) 10s ago 3h 72857k 117.4G 17.0.0-3781-gafaed750 7015fda3cd67 9e183363d39c
osd.2 dael running (81m) 10s ago 81m 63989k 117.4G 17.0.0-3781-gafaed750 7015fda3cd67 1f0cc479b051
osd.3 dael running (62m) 10s ago 62m 64071k 117.4G 17.0.0-3781-gafaed750 7015fda3cd67 ac5537492f27
Copy
要从内存自动调整中排除某个 OSD,请禁用该 OSD 的自动调整选项并设置特定的内存目标。 例如,
ceph config set osd.123 osd_memory_target_autotune false
ceph config set osd.123 osd_memory_target 16G
Copy
6.10.激活现有 OSD
如果重新安装主机的操作系统,则需要再次激活现有的 OSD。 对于这个用例,cephadm 提供了一个用于激活主机上所有现有 OSD 的 activate 包装器。
ceph cephadm osd activate <host>...
Copy
这将扫描所有现有磁盘的 OSD 并部署相应的守护程序。
7.Deploy CephFS
使用 CephFS 文件系统需要一个或多个 MDS 守护进程。 如果使用较新的 ceph fs volume 接口来创建新文件系统,则会自动创建这些文件系统。
ceph fs volume create <fs_name> --placement="<placement spec>"
Copy
其中 fs_name 是 CephFS 的名称,placement 是放置规范。
step 1.创建两个 Pool,如果不创建的话,会默认创建的
[root@node1 ~]# ceph osd pool create cephfs_data 64 64
pool 'cephfs_data' created
[root@node1 ~]# ceph osd pool create cephfs_metadata 64 64
pool 'cephfs_metadata' created
Copy
step 2.创建一个文件系统卷cephfs
[root@node1 ~]# ceph fs new cephfs cephfs_metadata cephfs_data
new fs with metadata pool 3 and data pool 2
step 3.查看一下当前的文件系统卷有哪些
[root@ceph-stroage01 ~]# ceph fs volume ls
[
{
"name": "cephfs"
}
]
[root@ceph-stroage01 ~]#
或
[root@node1 ~]# ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
step 4.添加 mds (元数据)服务,设置副本数量
[root@ceph-stroage01 ~]# ceph orch apply mds cephfs --placement="3 ceph-stroage01 ceph-stroage02 ceph-stroage03"
Scheduled mds.cephfs update...
[root@ceph-stroage01 ~]#
step 5.查看节点各启动了一个mds容器
[root@ceph-stroage01 ~]# docker ps | grep mds
e990482e87bc ceph/ceph:v15 "/usr/bin/ceph-mds -…" About a minute ago Up About a minute ceph-db51539c-d566-11eb-a3e9-e6f1aaf957fd-mds.cephfs.ceph-stroage01.coufjx
[root@ceph-stroage01 ~]#
step 6.查看集群状态
[root@ceph-stroage01 ~]# ceph -s
cluster:
id: db51539c-d566-11eb-a3e9-e6f1aaf957fd
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph-stroage01,ceph-stroage02,ceph-stroage03 (age 9m)
mgr: ceph-stroage01.cdthyk(active, since 9m), standbys: ceph-stroage03.dtasrq
mds: cephfs:1 {0=cephfs.ceph-stroage01.coufjx=up:active} 2 up:standby
osd: 6 osds: 6 up (since 9m), 6 in (since 2w)
data:
pools: 9 pools, 233 pgs
objects: 95 objects, 87 MiB
usage: 6.7 GiB used, 593 GiB / 600 GiB avail
pgs: 233 active+clean
io:
client: 1.1 KiB/s wr, 0 op/s rd, 3 op/s wr
[root@ceph-stroage01 ~]#
查看一下文件系统状态
[root@ceph-stroage01 ~]# ceph fs status cephfs
cephfs - 0 clients
======
RANK STATE MDS ACTIVITY DNS INOS
0 active cephfs.ceph-stroage01.coufjx Reqs: 0 /s 10 13
POOL TYPE USED AVAIL
cephfs_metadata metadata 1536k 187G
cephfs_data data 0 187G
STANDBY MDS
cephfs.ceph-stroage03.pfzpwl
cephfs.ceph-stroage02.cuokts
MDS version: ceph version 15.2.13 (c44bc49e7a57a87d84dfff2a077a2058aa2172e2) octopus (stable)
[root@ceph-stroage01 ~]#
使用命令 ceph mds stat 查看下 mds 服务状态
[root@ceph-stroage01 ~]# ceph mds stat
cephfs:1 {0=cephfs.ceph-stroage01.coufjx=up:active} 2 up:standby
[root@ceph-stroage01 ~]#
在节点 ceph-mon1 上添加 mds 服务
ceph orch daemon add mds cepfs ceph-mon1
8.Deploy RGWs
Cephadm将radosgw部署为守护进程的集合,这些守护进程管理单个集群部署或多站点部署中的特定领域和区域。(有关领域和区域的更多信息,请参阅多站点。)
对于cephadm,radosgw守护进程是通过监视器配置数据库而不是通过ceph.conf或命令行配置的。如果该配置尚未到位(通常在client.rgw.<something> section),那么radosgw守护程序将以默认设置(例如,绑定到端口80)启动。
要使用任意服务名称部署一组 radosgw 守护进程,请运行以下命令:
ceph orch apply rgw *<name>* [--realm=*<realm-name>*] [--zone=*<zone-name>*] --placement="*<num-daemons>* [*<host1>* ...]"
Copy
8.1.Trivial setup
例如,要在任意服务id foo下为单个集群RGW部署部署2个RGW守护进程(默认):
ceph orch apply rgw foo
8.2.指定网关
一个常见的场景是有一组标记的主机作为网关,在连续的端口 8000 和 8001 上运行多个 radosgw 实例:
# 为主机添加标签'rgw'
ceph orch host label add gwhost1 rgw
ceph orch host label add gwhost2 rgw
ceph orch apply rgw foo '--placement=label:rgw count-per-host:2' --port=80
8.3.指定网络
RGW服务可以使用yaml服务规范配置它们绑定到的网络。
example spec file:
service_type: rgw
service_id: foo
placement:
label: rgw
count_per_host: 2
networks:
- 192.169.142.0/24
spec:
rgw_frontend_port: 8080
8.4.多站点区域
要在myhost1和myhost2上部署服务于多站点myorg领域和us-east-1区域的RGW,请执行以下操作:
ceph orch apply rgw east --realm=myorg --zone=us-east-1 --placement="2 myhost1 myhost2"
注意,在多站点情况下,cephadm只部署守护进程。它不会创建或更新领域或区域配置。要创建新的领域和区域,您需要执行以下操作:
如果尚未创建领域,请首先创建一个领域:
radosgw-admin realm create --rgw-realm=<realm-name> --default
接下来创建一个新的区域组:
radosgw-admin zonegroup create --rgw-zonegroup=<zonegroup-name> --master --default
接下来创建一个区域:
radosgw-admin zone create --rgw-zonegroup=<zonegroup-name> --rgw-zone=<zone-name> --master --default
为特定领域和区域部署一组radosgw守护程序:
radosgw-admin period update --rgw-realm=<realm-name> --commit
查看服务状态
[root@node1 ~]# docker ps | grep rgw
78f9a9dfc46c ceph/ceph:v15 "/usr/bin/radosgw -n…" 2 hours ago Up 2 hours ceph-55e5485a-b292-11ea-8087-000c2993d00b-rgw.myorg.cn-east-1.node1.yjurkc
[root@node1 ~]# ceph orch ls | grep rgw
rgw.myorg.cn-east-1 3/3 6m ago 2h count:3 node1,node2,node3 docker.io/ceph/ceph:v15 d72755c420bc
8.5.Setting up HTTPS
为了为RGW服务启用HTTPS,请按照以下方案应用规范文件:
service_type: rgw
service_id: myrgw
spec:
rgw_frontend_ssl_certificate: |
-----BEGIN PRIVATE KEY-----
V2VyIGRhcyBsaWVzdCBpc3QgZG9vZi4gTG9yZW0gaXBzdW0gZG9sb3Igc2l0IGFt
ZXQsIGNvbnNldGV0dXIgc2FkaXBzY2luZyBlbGl0ciwgc2VkIGRpYW0gbm9udW15
IGVpcm1vZCB0ZW1wb3IgaW52aWR1bnQgdXQgbGFib3JlIGV0IGRvbG9yZSBtYWdu
YSBhbGlxdXlhbSBlcmF0LCBzZWQgZGlhbSB2b2x1cHR1YS4gQXQgdmVybyBlb3Mg
ZXQgYWNjdXNhbSBldCBqdXN0byBkdW8=
-----END PRIVATE KEY-----
-----BEGIN CERTIFICATE-----
V2VyIGRhcyBsaWVzdCBpc3QgZG9vZi4gTG9yZW0gaXBzdW0gZG9sb3Igc2l0IGFt
ZXQsIGNvbnNldGV0dXIgc2FkaXBzY2luZyBlbGl0ciwgc2VkIGRpYW0gbm9udW15
IGVpcm1vZCB0ZW1wb3IgaW52aWR1bnQgdXQgbGFib3JlIGV0IGRvbG9yZSBtYWdu
YSBhbGlxdXlhbSBlcmF0LCBzZWQgZGlhbSB2b2x1cHR1YS4gQXQgdmVybyBlb3Mg
ZXQgYWNjdXNhbSBldCBqdXN0byBkdW8=
-----END CERTIFICATE-----
ssl: true
应用此yaml文档:
# ceph orch apply -i myrgw.yaml
请注意,rgw_frontend_ssl_certificate的值是一个文字字符串,由保留换行符的|字符表示。
8.6.Service specification
class ceph.deployment.service_spec.RGWSpec(service_type='rgw', service_id=None, placement=None, rgw_realm=None, rgw_zone=None, rgw_frontend_port=None, rgw_frontend_ssl_certificate=None, rgw_frontend_type=None, unmanaged=False, ssl=False, preview_only=False, config=None, networks=None, subcluster=None, extra_container_args=None, custom_configs=None)
Settings to configure a (multisite) Ceph RGW
service_type: rgw
service_id: myrealm.myzone
spec:
rgw_realm: myrealm
rgw_zone: myzone
ssl: true
rgw_frontend_port: 1234
rgw_frontend_type: beast
rgw_frontend_ssl_certificate: ...
-
rgw_frontend_port: Optional[int]
Port of the RGW daemons -
rgw_frontend_ssl_certificate: Optional[List[str]]
List of SSL certificates -
rgw_frontend_type: Optional[str]
civetweb or beast (default: beast). See HTTP Frontends -
rgw_realm: Optional[str]
The RGW realm associated with this service. Needs to be manually created -
rgw_zone: Optional[str]
The RGW zone associated with this service. Needs to be manually created -
ssl
enable SSL
8.7.High availability service for RGW
ingress服务允许您使用最少的一组配置选项为RGW创建高可用性端点。协调器将部署和管理haproxy和keepalive的组合,以在浮动虚拟IP上提供负载平衡。
如果使用SSL,则必须由入口服务而不是RGW本身配置和终止SSL。
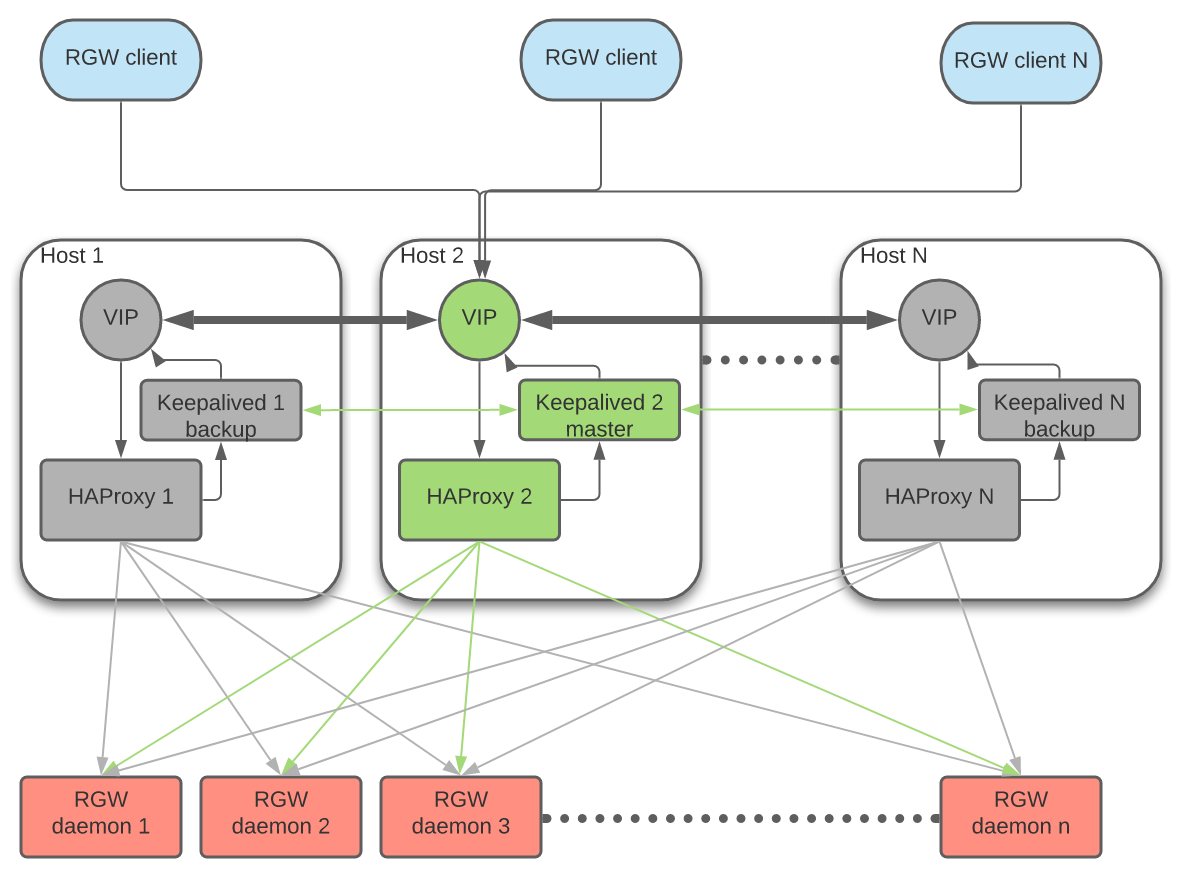
有N个主机部署了入口服务。每个主机都有一个haproxy守护程序和一个keepalive守护程序。一次只能在其中一台主机上自动配置虚拟IP。
每个keepalive守护程序每隔几秒钟检查同一主机上的haproxy守护程序是否正在响应。Keepalived还将检查主Keepalived守护进程是否运行正常。如果“主”keepalive守护程序或活动haproxy没有响应,则在备份模式下运行的其余keepalive后台程序之一将被选为主节点,虚拟IP将被移动到该节点。
活动haproxy充当负载平衡器,在所有可用的RGW守护进程之间分发所有RGW请求。
先决条件,没有SSL的现有RGW服务。(如果您需要SSL服务,则应在入口服务而不是RGW服务上配置证书。)
step 1.Use the command:
ceph orch apply -i <ingress_spec_file>
step 2.服务规范
它是一个具有以下yaml格式文件:
service_type: ingress
service_id: rgw.something # adjust to match your existing RGW service
placement:
hosts:
- host1
- host2
- host3
spec:
backend_service: rgw.something # adjust to match your existing RGW service
virtual_ip: <string>/<string> # ex: 192.168.20.1/24
frontend_port: <integer> # ex: 8080
monitor_port: <integer> # ex: 1967, used by haproxy for load balancer status
virtual_interface_networks: [ ... ] # optional: list of CIDR networks
ssl_cert: | # optional: SSL certificate and key
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
-----BEGIN PRIVATE KEY-----
...
-----END PRIVATE KEY---
service_type: ingress
service_id: rgw.something # adjust to match your existing RGW service
placement:
hosts:
- host1
- host2
- host3
spec:
backend_service: rgw.something # adjust to match your existing RGW service
virtual_ips_list:
- <string>/<string> # ex: 192.168.20.1/24
- <string>/<string> # ex: 192.168.20.2/24
- <string>/<string> # ex: 192.168.20.3/24
frontend_port: <integer> # ex: 8080
monitor_port: <integer> # ex: 1967, used by haproxy for load balancer status
virtual_interface_networks: [ ... ] # optional: list of CIDR networks
ssl_cert: | # optional: SSL certificate and key
-----BEGIN CERTIFICATE-----
...
-----END CERTIFICATE-----
-----BEGIN PRIVATE KEY-----
...
-----END PRIVATE KEY-----
step 4.为虚拟IP选择以太网接口
您不能简单地提供要在其上配置虚拟IP的网络接口的名称,因为接口名称往往会因主机而异(和/或重新启动)。相反,cephadm将根据已配置的其他现有IP地址选择接口。
通常,虚拟IP将配置在同一子网中具有现有IP的第一个网络接口上。例如,如果虚拟IP为192.168.0.80/24,eth2的静态IP为192.168.0.40/24,则cephadm将使用eth2。
在某些情况下,虚拟IP可能与现有静态IP不属于同一子网。在这种情况下,您可以提供与现有IP匹配的子网列表,cephadm会将虚拟IP放在第一个要匹配的网络接口上。例如,如果虚拟IP为192.168.0.80/24,并且我们希望它与10.10.0.0/16中的机器静态IP位于同一个接口上,则可以使用如下规范:
service_type: ingress
service_id: rgw.something
spec:
virtual_ip: 192.168.0.80/24
virtual_interface_networks:
- 10.10.0.0/16
...
此策略的结果是,当前无法在没有现有IP地址的接口上配置虚拟IP。在这种情况下,我们建议将“虚拟”IP地址配置为正确接口上的不可路由网络,并在网络列表中引用该虚拟网络(见上文)。
最好至少有3个RGW守护进程。我们建议至少3台主机用于入口服务。
9.Deploying NFS ganesha
Cephadm使用预定义的RADOS池和可选的namespace部署NFS Ganesha 。
仅支持 NFSv4 协议。
Cephadm部署NFS Ganesha守护程序(或一组守护程序)。NFS的配置存储在NFS ganesha池中,并通过ceph-NFS导出管理导出。。。命令和通过仪表板。
要部署NFS Ganesha网关,请执行以下操作:
# ceph orch apply nfs *<svc_id>* [--port *<port>*] [--placement ...]
例如,要在默认端口2049上部署服务id为foo的NFS,并默认放置单个守护程序:
ceph orch apply nfs foo
例如,同一个服务ID部署NFSFOO,将使用RADOS池NFS的象头和命名空间NFS-NS,:
ceph osd pool create nfs-ganesha 64 64
ceph orch apply nfs foo nfs-ganesha nfs-ns --placement="3 node1 node2 node3"
ceph osd pool application enable nfs-ganesha cephfs
查看容器和服务
[root@node1 ~]# docker ps | grep nfs
b89fe9bb981d ceph/ceph:v15 "/usr/bin/ganesha.nf…" About a minute ago Up About a minute ceph-55e5485a-b292-11ea-8087-000c2993d00b-nfs.foo.node1
[root@node1 ~]# ceph orch ls | grep nfs
nfs.foo 3/3 2m ago 2m count:3 node1,node2,node3 docker.io/ceph/ceph:v15 d72755c420bc
Service Specification
或者,可以使用YAML规范应用NFS服务。
service_type: nfs
service_id: mynfs
placement:
hosts:
- host1
- host2
spec:
port: 12345
在主机1和主机2上的非默认端口12345(而不是默认端口2049)上运行服务器。
然后可以通过运行以下命令应用该规范:
# ceph orch apply -i nfs.yaml
High-availability NFS
为现有nfs服务部署入口服务将提供:
- 可用于访问NFS服务器的稳定虚拟IP
- 如果主机发生故障,则在主机之间进行故障切换
- 跨多个NFS网关的负载分布(尽管这很少需要)
可以使用以下规范为现有NFS服务(本例中为NFS.mynfs)部署NFS入口:
service_type: ingress
service_id: nfs.mynfs
placement:
count: 2
spec:
backend_service: nfs.mynfs
frontend_port: 2049
monitor_port: 9000
virtual_ip: 10.0.0.123/24
注意事项
- virtual_ip必须包含CIDR前缀长度,如上面的示例所示。虚拟IP通常将配置在第一个标识的网络接口上,该接口在同一子网中具有现有IP。您还可以指定virtual_interface_networks属性以与其他网络中的IP相匹配;有关更多信息,请参阅为虚拟IP选择以太网接口。
- monitor_port用于访问haproxy加载状态页面。默认情况下,用户是管理员,但可以通过规范中的管理员属性进行修改。如果未通过规范中密码属性指定密码,则可以通过以下方式找到自动生成的密码:
For example:# ceph config-key get mgr/cephadm/ingress.*{svc_id}*/monitor_password# ceph config-key get mgr/cephadm/ingress.nfs.myfoo/monitor_password - 后端服务(在本例中为nfs.mynfs)应包含非2049的端口属性,以避免与入口服务发生冲突,入口服务可能位于同一主机上。
10.iSCSI Service
要部署 iSCSI 网关,请创建一个包含 iSCSI 服务规范的 yaml 文件:
service_type: iscsi
service_id: iscsi
placement:
hosts:
- host1
- host2
spec:
pool: mypool # RADOS pool where ceph-iscsi config data is stored.
trusted_ip_list: "IP_ADDRESS_1,IP_ADDRESS_2"
api_port: ... # optional
api_user: ... # optional
api_password: ... # optional
api_secure: true/false # optional
ssl_cert: | # optional
...
ssl_key: | # optional
...
参考示例:
service_type: iscsi
service_id: iscsi
placement:
hosts:
- [...]
spec:
pool: iscsi_pool
trusted_ip_list: "IP_ADDRESS_1,IP_ADDRESS_2,IP_ADDRESS_3,..."
api_user: API_USERNAME
api_password: API_PASSWORD
api_secure: true
ssl_cert: |
-----BEGIN CERTIFICATE-----
MIIDtTCCAp2gAwIBAgIYMC4xNzc1NDQxNjEzMzc2MjMyXzxvQ7EcMA0GCSqGSIb3
DQEBCwUAMG0xCzAJBgNVBAYTAlVTMQ0wCwYDVQQIDARVdGFoMRcwFQYDVQQHDA5T
[...]
-----END CERTIFICATE-----
ssl_key: |
-----BEGIN PRIVATE KEY-----
MIIEvQIBADANBgkqhkiG9w0BAQEFAASCBKcwggSjAgEAAoIBAQC5jdYbjtNTAKW4
/CwQr/7wOiLGzVxChn3mmCIF3DwbL/qvTFTX2d8bDf6LjGwLYloXHscRfxszX/4h
[...]
-----END PRIVATE KEY-----
可以使用以下方法应用规范:
ceph orch apply -i iscsi.yaml
配置iSCSI客户端
通过配置iscsi启动器,可以从任何主机使用容器化的iscsi服务,iscsi启动器将使用TCP/IP向iscsi目标(网关)发送SCSI命令。
11.监控 ceph 集群
11.1.使用ceph dashboard
URL: https://ceph-stroage01:8443/
User: admin
Password: lb83cil354
输出信息中,包括 Dashboard 的地址,用户名和密码
11.2.查看prometheus监控信息
step 1.查看grafana监听端口为3000
[root@ceph-stroage01 yum.repos.d]# ss -ntlp | grep grafana
LISTEN 0 128 :::3000 :::* users:(("grafana-server",pid=9290,fd=7))
[root@ceph-stroage01 yum.repos.d]#
step 2.altermanager告警模块监听端口
[root@ceph-stroage01 yum.repos.d]# ss -ntlp | grep alert
LISTEN 0 128 :::9093 :::* users:(("alertmanager",pid=29624,fd=6))
LISTEN 0 128 :::9094 :::* users:(("alertmanager",pid=29624,fd=3))
[root@ceph-stroage01 yum.repos.d]#
step 3.node_exporter监听端口
[root@ceph-stroage01 yum.repos.d]# ss -ntlp | grep node
LISTEN 0 128 :::9100 :::* users:(("node_exporter",pid=8112,fd=3))
[root@ceph-stroage01 yum.repos.d]#
step 4.prometheus监听端口
[root@ceph-stroage01 yum.repos.d]# ss -ntlp | grep prometh
LISTEN 0 128 :::9095 :::* users:(("prometheus",pid=29949,fd=9))
[root@ceph-stroage01 yum.repos.d]#
step 5.访问grafana
访问grafana:https://193.169.100.58:3000
点击左上角选择某个dashboard,默认支持以下模块监控数据展示
包括以下监控信息:
- 查看ceph集群监控信息
- 查看存储池监控
- 存储池详情
- 主机监控
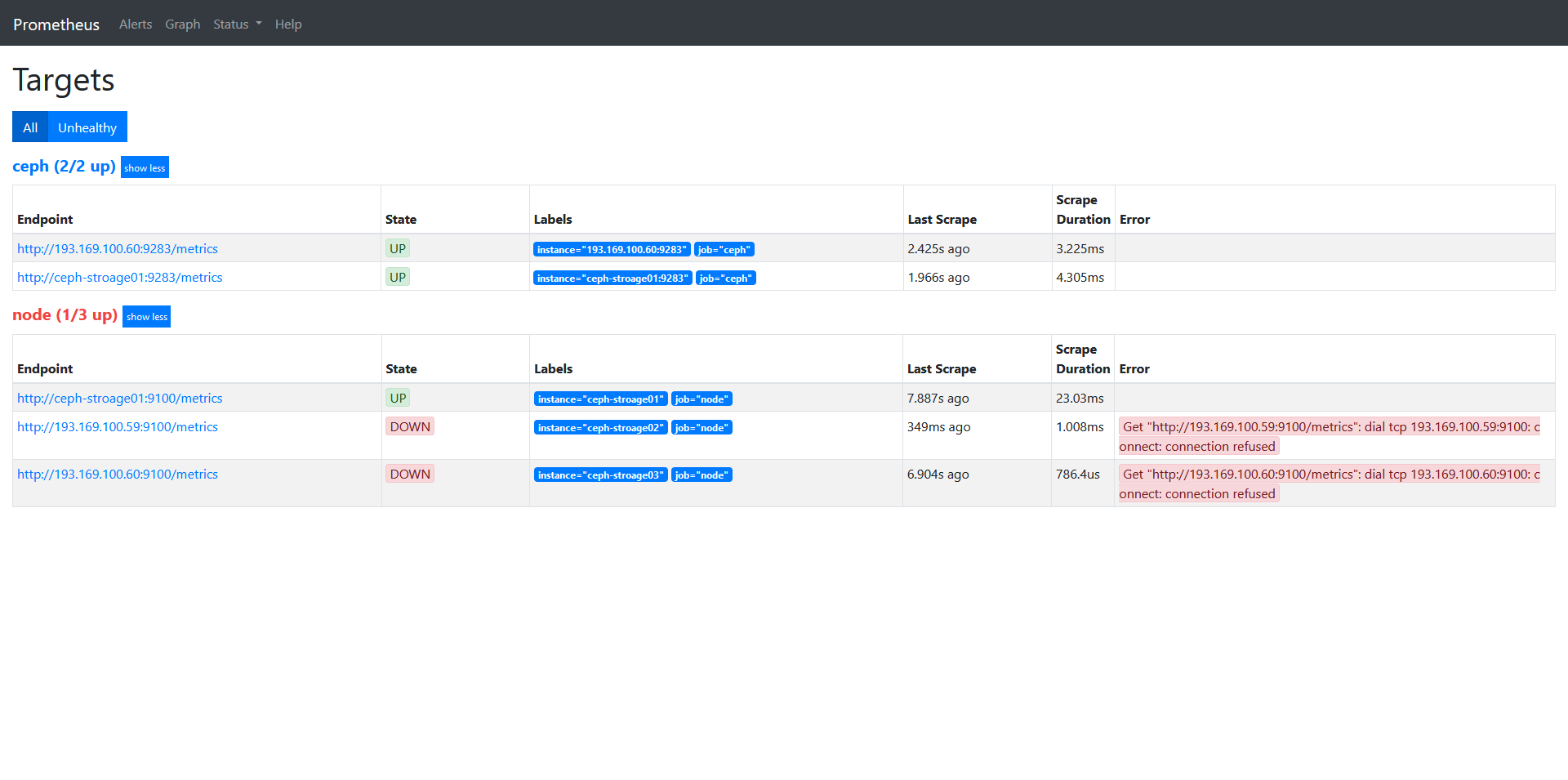
step 6.prometheus配置的targets
访问prometheus: http://193.169.100.58:9095/targets
12.Service Management
Service Management — Ceph Documentation
13.Cephadm Operations
Cephadm Operations — Ceph Documentation
14.Basic Ceph Client Setup
Basic Ceph Client Setup — Ceph Documentation
15.Troubleshooting
Troubleshooting — Ceph Documentation
16.Installation (Manual)
Installation (Manual) — Ceph Documentation
![【洛谷 P1003】[NOIP2011 提高组] 铺地毯 题解(数组+贪心算法)](https://img-blog.csdnimg.cn/img_convert/823ec298bd31c29535b292affc8edf1f.png)