原文:OpenCV with Python Blueprints
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 计算机视觉 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
当别人说你没有底线的时候,你最好真的没有;当别人说你做过某些事的时候,你也最好真的做过。
一、过滤器的乐趣
本章的目的是开发许多图像处理过滤器,并将其实时应用于网络摄像头的视频流。 这些过滤器将依靠各种 OpenCV 函数来通过拆分,合并,算术运算以及为复杂函数应用查找表来操纵矩阵。
这三种效果如下:
- 黑白铅笔素描:要使产生此效果,我们将使用两种图像融合技术,即,淡化和加深
- 加热/冷却过滤器:为创建这些效果,我们将使用查找表实现我们自己的曲线过滤器
- 卡通化器:要创建这种效果,我们将结合使用双边过滤器,中值过滤器和自适应阈值
OpenCV 是这样的高级工具链,通常的问题不是如何从头开始实现某些东西,而是要选择哪种预定义的实现来满足您的需求。 如果您有很多可用的计算资源,则生成复杂的效果并不难。 挑战通常在于寻找一种不仅可以完成工作而且还要及时完成的方法。
与其通过理论课程教授图像处理的基本概念,我们将采用一种实用的方法,并开发一个集成了多种图像过滤技术的端到端应用。 我们将运用我们的理论知识来寻求一个不仅可以工作而且可以加快看似复杂的效果的解决方案,以便笔记本电脑可以实时生产它们。
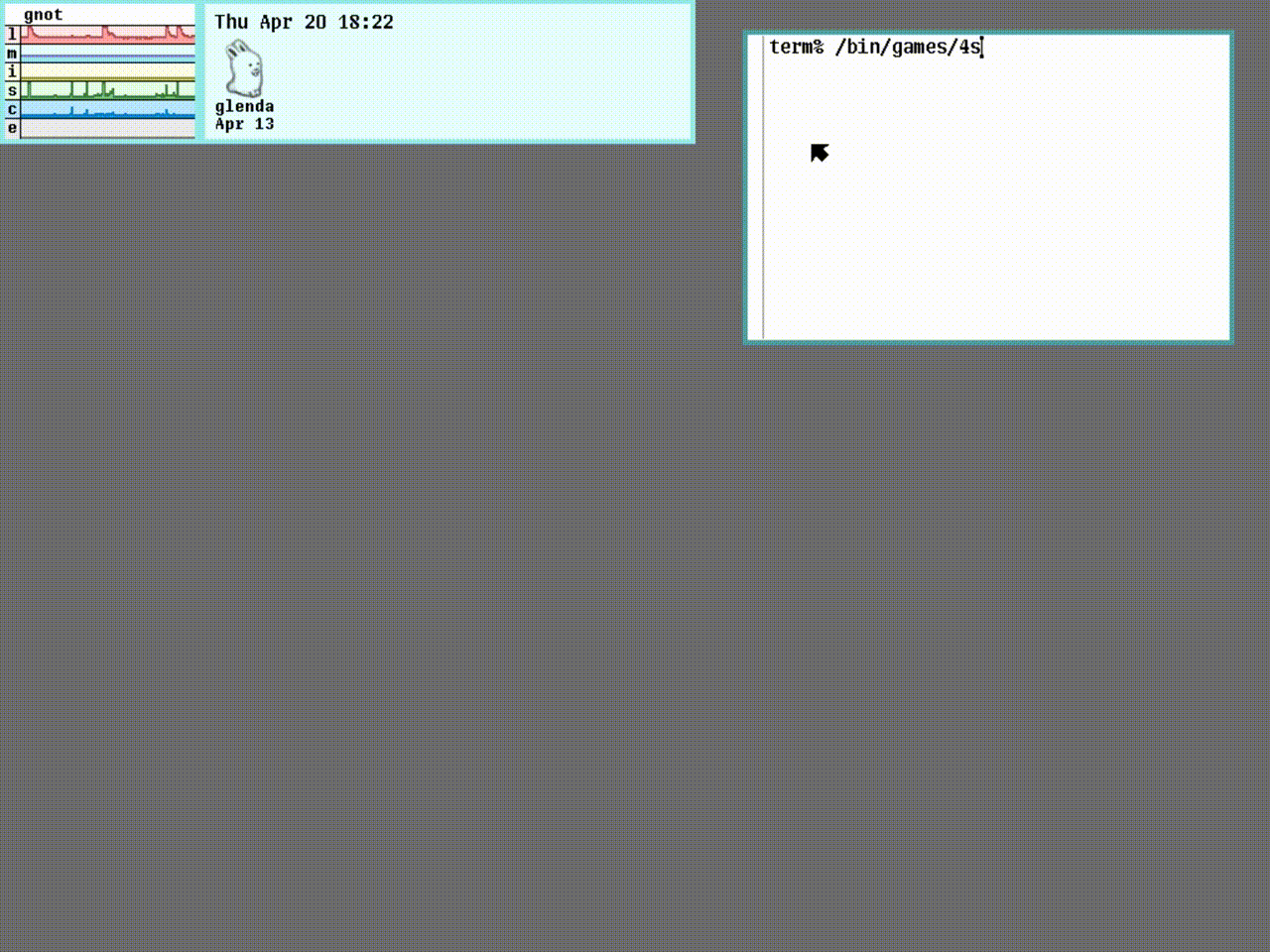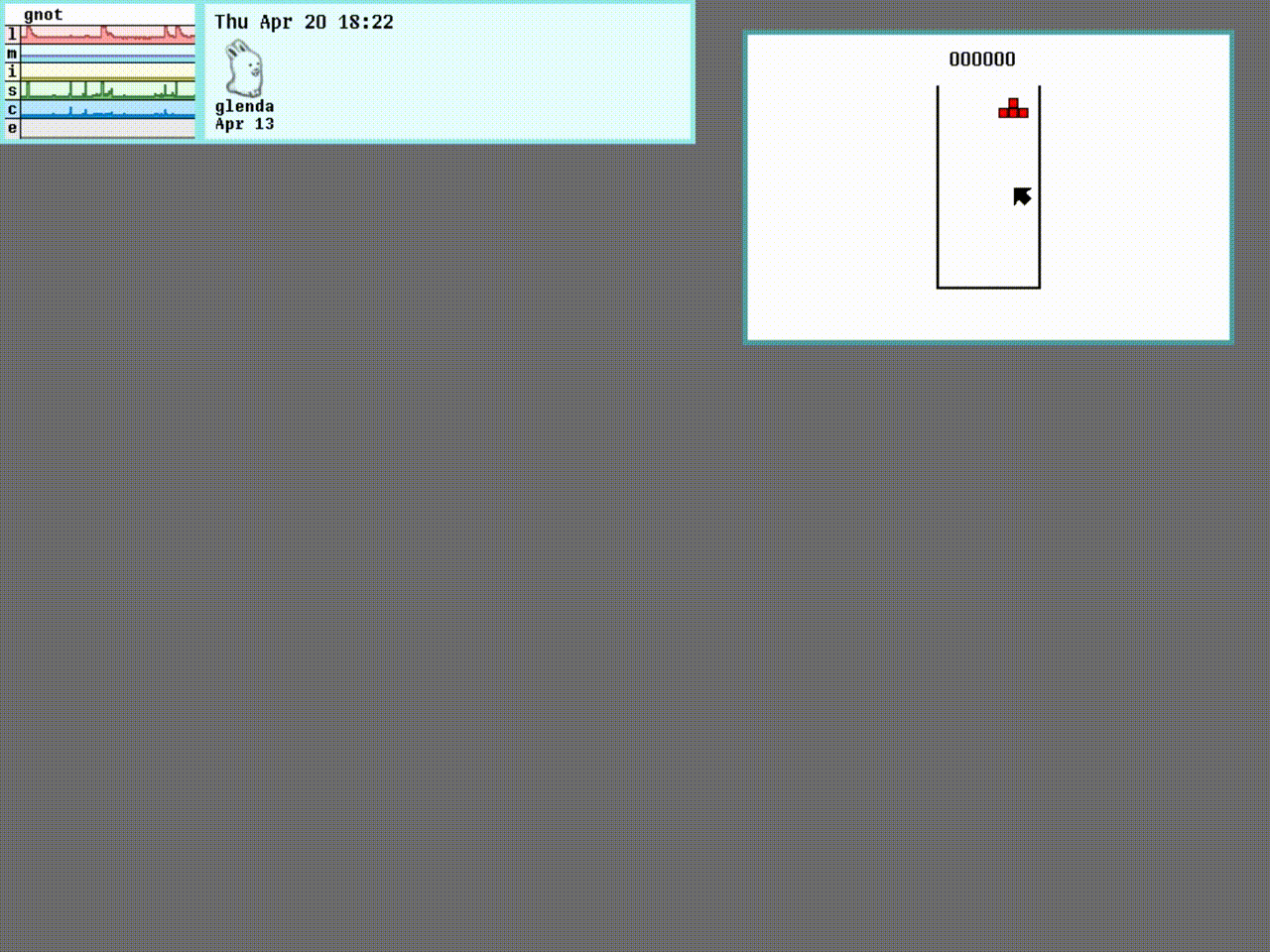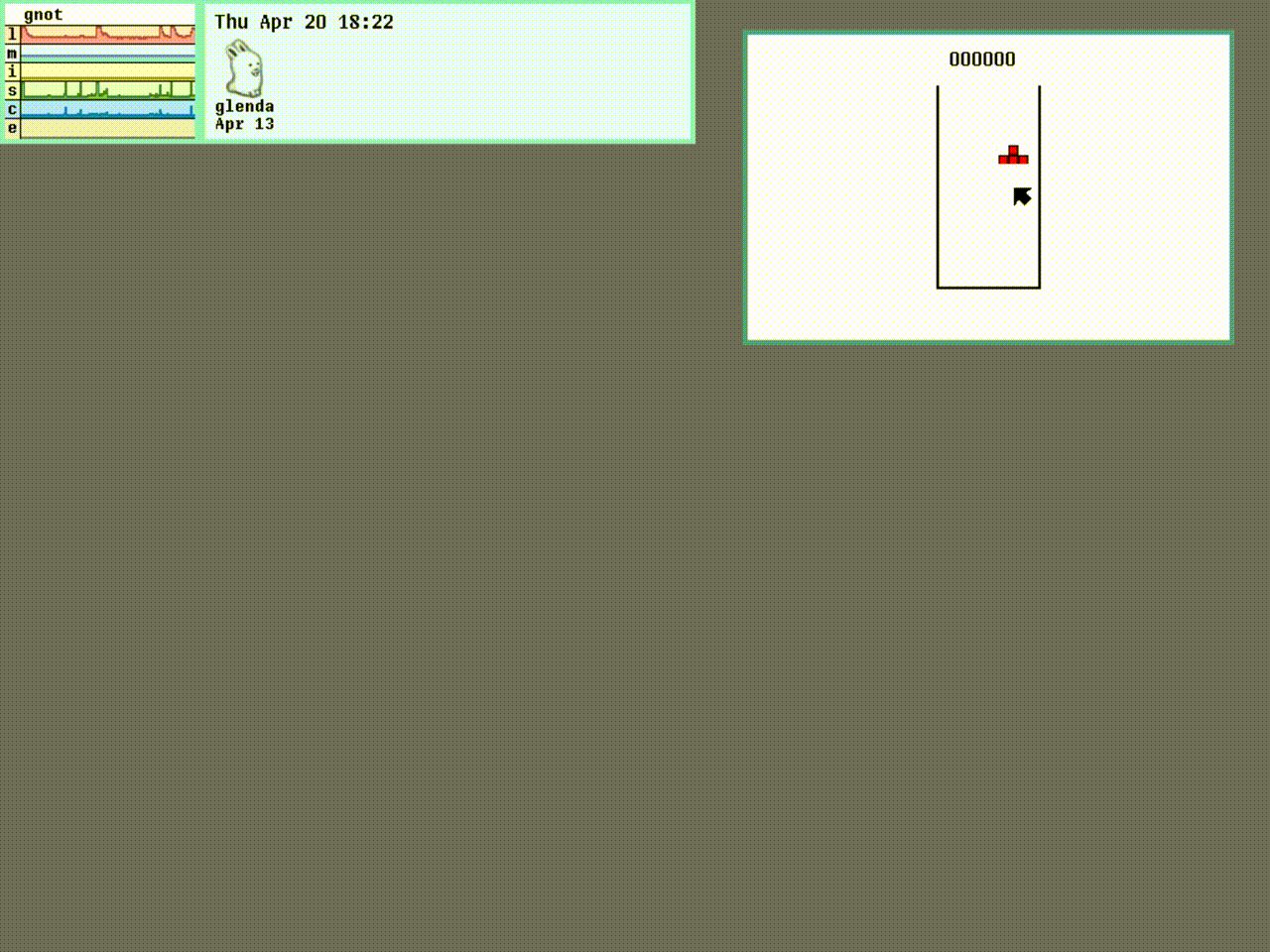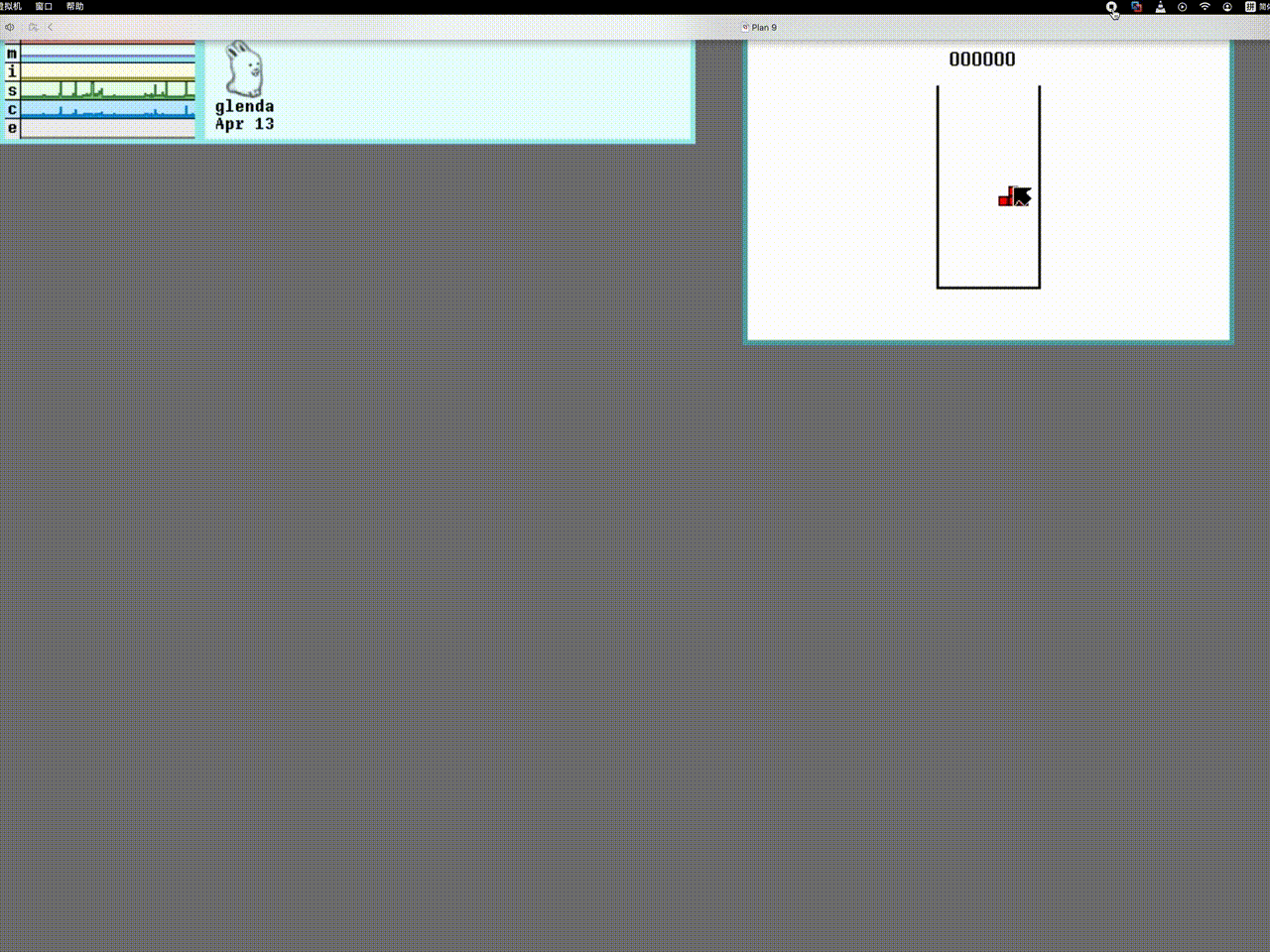
以下屏幕截图显示了在笔记本电脑上运行的三种效果的最终结果:

注意
本书中的所有代码均针对 OpenCV 2.4.9,并已在 Ubuntu 14.04 上进行了测试。 在本书中,我们将广泛使用 NumPy 包。 此外,本章还需要 SciPy 包的UnivariateSpline模块以及 wxPython 2.8 图形化用户界面,用于跨平台的 GUI 应用。 我们将尽可能地避免进一步的依赖。
规划应用
最终的应用将包含以下模块和脚本:
filters:模块包含针对三种不同图像效果的不同类别。 模块化方法将使我们能够独立使用任何图形用户界面(GUI)的过滤器。filters.PencilSketch:用于将铅笔素描效果应用于 RGB 彩色图像的类。filters.WarmingFilter:类别,用于将预热过滤器应用于 RGB 彩色图像。filters.CoolingFilter:类别,用于将冷却过滤器应用于 RGB 彩色图像。filters.Cartoonizer:一种用于将卡通化效果应用于 RGB 彩色图像的方法。gui:提供 wxPython GUI 应用以访问网络摄像头并显示摄像头提要的模块,我们将在本书中广泛使用该模块。gui.BaseLayout:可以从中构建更复杂布局的通用布局。chapter1:本章的主要脚本。chapter1.FilterLayout:基于gui.BaseLayout的自定义布局,用于显示摄像机源和一行单选按钮,允许用户从可用的图像过滤器中进行选择,以将其应用于摄像机源的每一帧。chapter1.main:用于启动 GUI 应用和访问网络摄像头的main函数例程。
创建黑白铅笔素描
为了获得相机帧的铅笔素描(即黑白图),我们将使用两种图像融合技术,分别是,淡化和加深。 这些术语是指在传统摄影的打印过程中使用的技术; 摄影师可以控制暗室打印物中某个区域的曝光时间,以使其变暗或变暗。 淡化使图像变亮,而加深使图像变暗。
不应该进行更改的区域由遮罩保护。 如今,现代的图像编辑程序,例如 Photoshop 和 Gimp,提供了在数字图像中模拟这些效果的方法。 例如,掩模仍然被用来模仿改变图像曝光时间的效果,其中具有相对强的值的掩模区域将更多地暴露图像,从而使图像变亮。 OpenCV 没有提供实现这些技术的本机功能,但是有了一点见识和一些技巧,我们将得出我们自己的有效实现,可以用来产生漂亮的铅笔素描效果。
如果在互联网上进行搜索,则可能会发现以下常见过程无法从 RGB 彩色图像中获得铅笔素描:
- 将彩色图像转换为灰度。
- 反转灰度图像得到负片。
- 将高斯模糊应用于步骤 2 中的负片。
- 使用彩色减淡功能将步骤 1 的灰度图像与步骤 3 的模糊负片混合。
第 1 步到第 3 步很简单,而第 4 步可能有些棘手。 让我们先解决这个问题。
注意
OpenCV 3 附带了铅笔素描效果。 cv2.pencilSketch函数使用由 Eduardo Gastal 和 Manuel Oliveira 在 2011 年论文《域变换中引入的域过滤器进行边缘感知的图像和视频处理》。 但是,出于本书的目的,我们将开发自己的过滤器。
在 OpenCV 中实现淡化和加深
在现代图像编辑工具(例如 Photoshop)中,对带有掩膜B的图像A的颜色减淡实现为以下三元语句,作用于称为idx的每个像素索引:
((B[idx] == 255) ? B[idx] : min(255, ((A[idx] << 8) / (255-B[idx]))))
本质上,将A[idx]图像像素的值除以B[idx]遮罩像素值的倒数,同时确保所得的像素值在[0, 255]的范围内,并且不被零除。
我们可以将其转换为以下朴素的 Python 函数,该函数接受两个 OpenCV 矩阵(image和mask)并返回混合图像:
def dodgeNaive(image, mask):
# determine the shape of the input image
width,height = image.shape[:2]
# prepare output argument with same size as image
blend = np.zeros((width,height), np.uint8)
for col in xrange(width):
for row in xrange(height):
# shift image pixel value by 8 bits
# divide by the inverse of the mask
tmp = (image[c,r] << 8) / (255.-mask)
# make sure resulting value stays within bounds
if tmp > 255:
tmp = 255
blend[c,r] = tmp
return blend
您可能已经猜到了,尽管这段代码在功能上可能是正确的,但无疑会非常慢。 首先,该函数使用for循环,这在 Python 中几乎总是一个坏主意。 其次,NumPy 数组(Python 中 OpenCV 图像的基本格式)已针对数组计算进行了优化,因此分别访问和修改每个image[c,r]像素将非常慢。
相反,我们应该认识到<<8操作与将像素值乘以2 ^ 8 = 256相同,并且可以通过cv2.divide函数实现按像素划分。 因此,我们的淡化函数的改进版本可能如下所示:
import cv2
def dodgeV2(image, mask):
return cv2.divide(image, 255-mask, scale=256)
我们将淡化函数减少到了一行! dodgeV2函数产生的结果与dodgeNaive相同,但是速度要快几个数量级。 此外,cv2.divide自动处理零除,使255-mask为零的结果0。
现在,的实现很简单,可以实现类似的加深函数,该函数将反转的图像除以反转的遮罩并反转结果:
import cv2
def burnV2(image, mask):
return 255 – cv2.divide(255-image, 255-mask, scale=256)
铅笔素描变换
有了这些技巧,我们现在就可以看看整个过程了。 最终代码将在filters模块中位于其自己的类中。 将彩色图像转换为灰度后,我们的目标是将该图像与其模糊的负片混合:
-
我们导入 OpenCV 和
numpy模块:import cv2 import numpy as np -
实例化
PencilSketch类:class PencilSketch: def __init__(self, (width, height), bg_gray='pencilsketch_bg.jpg'):此类的构造器将接受图像尺寸以及可选的背景图像,我们将在稍后使用它。 如果文件存在,我们将打开它并缩放到合适的大小:
self.width = width self.height = height # try to open background canvas (if it exists) self.canvas = cv2.imread(bg_gray, cv2.CV_8UC1) if self.canvas is not None: self.canvas = cv2.resize(self.canvas, (self.width, self.height)) -
添加将执行铅笔素描的渲染方法:
def renderV2(self, img_rgb): -
将 RGB 图像(
imgRGB)转换为灰度很简单:img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_RGB2GRAY)请注意,输入图像是 RGB 还是 BGR 都没有关系。
-
然后,我们反转图像并使用大小为
(21,21)的高斯高斯核模糊它:img_gray_inv = 255 – img_gray img_blur = cv2.GaussianBlur(img_gray_inv, (21,21), 0, 0) -
我们使用上述代码中的
dodgeV2淡化函数将原始灰度图像与模糊逆混合:img_blend = dodgeV2(mg_gray, img_blur) return cv2.cvtColor(img_blend, cv2.COLOR_GRAY2RGB)
生成的图像如下所示:

您是否注意到我们的代码可以进一步优化?
高斯模糊本质上是具有高斯函数的卷积。 卷积的优点之一是它们的关联属性。 这意味着我们先反转图像然后对其进行模糊处理,还是先模糊图像然后对其进行反转都没有关系。
“那有什么关系呢?” 你可能会问。 好吧,如果我们从模糊的图像开始并将其逆数传递给dodgeV2函数,则在该函数内,图像将再次反转(255-mask部分),实质上产生了原始图像。 如果我们摆脱了这些多余的操作,经过优化的render方法将如下所示:
def render(img_rgb):
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
img_blur = cv2.GaussianBlur(img_gray, (21,21), 0, 0)
img_blend = cv2.divide(img_gray, img_blur, scale=256)
return img_blend
对于踢脚和傻笑,我们想将转换后的图像(img_blend)与背景图像(self.canvas)轻轻混合,使其看起来就像在画布上绘制了图像一样:
if self.canvas is not None:
img_blend = cv2.multiply(img_blend, self.canvas, scale=1./256)
return cv2.cvtColor(img_blend, cv2.COLOR_GRAY2BGR)
我们完成了! 最终输出如下所示:

生成加热/冷却过滤器
当我们感知图像时,我们的大脑会从许多微妙的线索中推断出有关场景的重要细节。 例如,在明亮的日光下,高光可能会因为在阳光直射下而具有淡黄色的色彩,而阴影可能由于蓝天的环境光而显得略带蓝色。 当我们查看具有这种颜色属性的图像时,我们可能会立即想到晴天。
对于有时会故意操纵图像的白平衡以传达某种情绪的摄影师而言,这种效果并不神秘。 暖色通常被认为更令人愉悦,而冷色则与夜晚和昏暗有关。
为了操纵图像的感知到的色温,我们将实现和曲线过滤器。 这些过滤器控制颜色过渡如何在图像的不同区域之间出现,从而使我们可以巧妙地改变色谱图,而不会给图像增加看起来不自然的整体色调。
通过曲线移动的色彩操作
曲线过滤器本质上是一个函数,y = f(x),其将输入像素值x映射到输出像素值y。 通过一组n + 1锚点对曲线进行参数化,如下所示: {(x[0], y[0]), ..., (x[n], y[n])}。
每个锚点都是一对数字,分别代表输入和输出像素值。 例如,对(30, 90)表示将输入像素值 30 增加到输出值 90。沿着平滑曲线对锚点之间的值进行插值(因此,名称曲线过滤器) 。
这种过滤器可以应用于任何图像通道,无论是单个灰度通道还是 RGB 彩色图像的 R,G 和 B 通道。 因此,出于我们的目的,x和y的所有值必须保持在 0 到 255 之间。
例如,如果我们想使灰度图像稍微亮一些,可以使用带有以下控制点集的曲线过滤器: {(0, 0), (128, 192), (255, 255)}。 这意味着除 0 和 255 以外的所有输入像素值都会略微增加,从而导致图像的整体增亮效果。
如果我们希望这样的过滤器产生看起来自然的图像,则必须遵守以下两个规则:
- 每组锚点都应包括
(0, 0)和(255, 255)。 这对于防止图像看起来好像具有整体色调非常重要,因为黑色保持黑色,白色保持白色。 - 函数
f(x)应该单调增加。 换句话说,随着x的增加,f(x)保持不变或增加(即,从不减少)。 这对于确保阴影仍然是阴影而高光仍然是高光非常重要。
使用查找表实现曲线过滤器
曲线过滤器在计算上是昂贵,因为每当x与预定锚点之一不一致时,都必须插值f(x)的值 。 对我们遇到的每个图像帧的每个像素执行此计算将对性能产生巨大影响。
相反,我们使用查找表。 由于出于我们的目的,只有 256 个可能的像素值,因此我们只需要为x的所有 256 个可能值计算f(x)。 插值由scipy.interpolate模块的UnivariateSpline函数处理,如以下代码片段所示:
from scipy.interpolate import UnivariateSpline
def _create_LUT_8UC1(self, x, y):
spl = UnivariateSpline(x, y)
return spl(xrange(256))
函数的return自变量是一个 256 个元素的列表,其中包含x的每个可能值的内插的f(x)值。
现在,我们需要做的所有事情都带有一组锚点(x[i], y[i]),我们准备将过滤器应用于灰度输入图像(img_gray):
import cv2
import numpy as np
x = [0, 128, 255]
y = [0, 192, 255]
myLUT = _create_LUT_8UC1(x, y)
img_curved = cv2.LUT(img_gray, myLUT).astype(np.uint8)
结果看起来像这样(原始图像在左侧,转换后的图像在右侧):

设计加热/冷却效果
通过机制,可以将通用曲线过滤器快速应用于适当的任何图像通道,现在我们来探讨如何操纵图像的感知色温的问题。 同样,最终代码将在filters模块中具有其自己的类。
如果您有空余时间,建议您暂时尝试一下不同的曲线设置。 您可以选择任意数量的锚点,并将曲线过滤器应用于您可以想到的任何图像通道(红色,绿色,蓝色,色相,饱和度,亮度,亮度等)。 您甚至可以合并多个通道,或者减少一个通道,然后将另一个通道转移到所需区域。 结果会是什么样?
但是,如果各种可能性使您眼花缭乱,请采取更为保守的方法。 首先,通过使用前面步骤中开发的_create_LUT_8UC1函数,我们定义两个通用曲线过滤器,一个(按趋势)增加通道的所有像素值,而一个通常降低它们:
class WarmingFilter:
def __init__(self):
self.incr_ch_lut = _create_LUT_8UC1([0, 64, 128, 192, 256],
[0, 70, 140, 210, 256])
self.decr_ch_lut = _create_LUT_8UC1([0, 64, 128, 192, 256],
[0, 30, 80, 120, 192])
使图像看起来像是在炎热的晴天(可能接近日落)拍摄时,最简单的方法是增加图像中的红色并通过增加色彩饱和度使颜色显得鲜艳。 我们将分两步实现:
-
使用
incr_ch_lut和decr_ch_lut分别增加 RGB 彩色图像的 R 通道中的像素值和 B 通道中的像素值:def render(self, img_rgb): c_r, c_g, c_b = cv2.split(img_rgb) c_r = cv2.LUT(c_r, self.incr_ch_lut).astype(np.uint8) c_b = cv2.LUT(c_b, self.decr_ch_lut).astype(np.uint8) img_rgb = cv2.merge((c_r, c_g, c_b)) -
将图像转换为和 HSV 色彩空间(H 表示色相,S 表示饱和度,V 表示值), 并使用
incr_ch_lut增加 S 通道。 这可以通过以下功能来实现,需要 RGB 彩色图像作为输入:c_b = cv2.LUT(c_b, decrChLUT).astype(np.uint8) # increase color saturation c_h, c_s, c_v = cv2.split(cv2.cvtColor(img_rgb, cv2.COLOR_RGB2HSV)) c_s = cv2.LUT(c_s, self.incr_ch_lut).astype(np.uint8) return cv2.cvtColor(cv2.merge((c_h, c_s, c_v)), cv2.COLOR_HSV2RGB)
结果如下所示:

类似地,我们可以定义一个冷却过滤器,该过滤器可以增加 RGB 图像的 B 通道中的像素值,减小 R 通道中的像素值,将图像转换为 HSV 色彩空间,并通过 S 降低色彩饱和度通道:
class CoolingFilter:
def render(self, img_rgb):
c_r, c_g, c_b = cv2.split(img_rgb)
c_r = cv2.LUT(c_r, self.decr_ch_lut).astype(np.uint8)
c_b = cv2.LUT(c_b, self.incr_ch_lut).astype(np.uint8)
img_rgb = cv2.merge((c_r, c_g, c_b))
# decrease color saturation
c_h, c_s, c_v = cv2.split(cv2.cvtColor(img_rgb, cv2.COLOR_RGB2HSV))
c_s = cv2.LUT(c_s, self.decr_ch_lut).astype(np.uint8)
return cv2.cvtColor(cv2.merge((c_h, c_s, c_v)), cv2.COLOR_HSV2RGB)
现在,结果看起来像这样:

将图像卡通化
在过去的几年中,专业的卡通化软件迅速出现。 为了实现基本的卡通效果,我们需要的是双边过滤器和一些边缘检测。 双边过滤器将减少调色板或图像中使用的颜色数。 这模仿了卡通图画,其中漫画家通常只有很少的颜色可以使用。 然后,我们可以对生成的图像进行边缘检测,以生成粗体轮廓。 然而,真正的挑战在于双边过滤器的计算成本。 因此,我们将使用一些技巧来实时产生可接受的卡通效果。
我们将遵循以下过程将 RGB 彩色图像转换为卡通图像:
- 应用双边过滤器来减少图像的调色板。
- 将原始彩色图像转换为灰度。
- 应用中值模糊来减少图像噪声。
- 使用自适应阈值检测并强调边缘遮罩中的边缘。
- 将步骤 1 中的彩色图像与步骤 4 中的边缘遮罩合并。
使用双边过滤器进行边缘感知的平滑
强大的双边过滤器非常适合将 RGB 图像转换为彩色绘画或卡通,因为它可以平滑平坦区域,同时保持边缘清晰。 过滤器的唯一缺点似乎是其计算成本,因为它比其他平滑操作(例如高斯模糊)要慢几个数量级。
当我们需要减少计算成本时,要采取的第一个措施是对低分辨率的图像执行操作。 为了将 RGB 图像(imgRGB)缩小到其尺寸的四分之一(将宽度和高度减小到一半),我们可以使用cv2.resize:
import cv2
img_small = cv2.resize(img_rgb, (0,0), fx=0.5, fy=0.5)
调整大小后的图像中的像素值将对应于原始图像中小邻域的像素平均值。 但是,此过程可能会产生图像伪影,这也称为混叠。 尽管这本身就够糟糕的,但可以通过后续处理(例如边缘检测)来增强效果。
更好的替代方法可能是使用高斯金字塔进行缩放(缩小至原始大小的四分之一)。 高斯金字塔由模糊操作组成,该操作在对图像重新采样之前执行,从而减少了混叠效果:
img_small = cv2.pyrDown(img_rgb)
但是,即使在这种规模下,双边过滤器仍然可能太慢而无法实时运行。 另一个技巧是重复(例如五次)对图像应用一个小的双边过滤器,而不是一次应用一个大的双边过滤器:
num_iter = 5
for _ in xrange(num_iter):
img_small = cv2.bilateralFilter(img_small, d=9, sigmaColor=9, sigmaSpace=7)
cv2.bilateralFilter中的三个参数控制像素邻域(d)的直径以及过滤器在色彩空间(sigmaColor)和坐标空间(sigmaSpace)中的标准差。
不要忘记将图像恢复为原始大小:
img_rgb = cv2.pyrUp(img_small)
结果看起来像是一个令人毛骨悚然的程序员的彩色绘画,如下所示:

检测并突出边缘
同样,当用于边缘检测时,挑战通常不在于底层算法如何工作,而在于为手头任务选择哪种特定算法。 您可能已经熟悉各种边缘检测器。 例如,Canny 边缘检测(cv2.Canny)提供了一种相对简单有效的方法来检测图像中的边缘,但是它容易受到噪声的影响。
Sobel 运算符(cv2.Sobel)可以减少此类伪像,但它不是旋转对称的。 Scharr 运算符(cv2.Scharr)的目标是对此进行校正,但仅查看第一个图像导数。 如果您感兴趣,还有更多运算符,例如拉普拉斯算子或山脊运算符(包括二阶导数),但它们却更加复杂。 最后,出于我们的特定目的,它们可能看起来并不好,也许是因为它们像其他任何算法一样容易受到光照条件的影响。
出于本项目的目的,我们将选择甚至与常规边缘检测都不相关的函数-cv2.adaptiveThreshold。 像cv2.threshold一样,此函数使用阈值像素值将灰度图像转换为二进制图像。 也就是说,如果原始图像中的像素值大于阈值,则最终图像中的像素值将为 255。否则,它将为 0。但是,自适应阈值的优点在于它不会查看图像的整体属性。 取而代之的是,它独立于每个小邻域中检测最显着的特征,而不考虑全局图像的最优性。 这使算法在光照条件下具有极强的鲁棒性,这正是我们试图在卡通物体和人物周围绘制粗体黑色轮廓时所需要的。
但是,这也使算法易受噪声影响。 为了解决这个问题,我们将使用中值过滤器对图像进行预处理。 中值过滤器按照其名称的含义执行; 它将每个像素值替换为小像素邻域中所有像素的中值。 我们首先将 RGB 图像(img_rgb)转换为灰度(img_gray),然后应用具有七个像素局部邻域的中值模糊:
# convert to grayscale and apply median blur
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_RGB2GRAY)
img_blur = cv2.medianBlur(img_gray, 7)
降低噪声后,现在可以使用自适应阈值检测和增强边缘。 即使剩下一些图像噪声,带blockSize=9的cv2.ADAPTIVE_THRESH_MEAN_C算法也可以确保将阈值应用于9 x 9邻域平均值C=2的平均值:
img_edge = cv2.adaptiveThreshold(img_blur, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 9, 2)
注意
下载示例代码
您可以从这个页面上的帐户下载示例代码文件,以获取已购买的所有 Packt Publishing 图书。 如果您在其他地方购买了此书,则可以访问这个页面并注册以将文件直接通过电子邮件发送给您。
自适应阈值的结果如下所示:

组合颜色和轮廓来制作卡通
最后一步是将两者合并。 只需使用cv2.bitwise_and将两种效果融合在一起成为一张图像。 完整的函数如下:
def render(self, img_rgb):
numDownSamples = 2 # number of downscaling steps
numBilateralFilters = 7 # number of bilateral filtering steps
# -- STEP 1 --
# downsample image using Gaussian pyramid
img_color = img_rgb
for _ in xrange(numDownSamples):
img_color = cv2.pyrDown(img_color)
# repeatedly apply small bilateral filter instead of applying
# one large filter
for _ in xrange(numBilateralFilters):
img_color = cv2.bilateralFilter(img_color, 9, 9, 7)
# upsample image to original size
for _ in xrange(numDownSamples):
img_color = cv2.pyrUp(img_color)
# -- STEPS 2 and 3 --
# convert to grayscale and apply median blur
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_RGB2GRAY)
img_blur = cv2.medianBlur(img_gray, 7)
# -- STEP 4 --
# detect and enhance edges
img_edge = cv2.adaptiveThreshold(img_blur, 255,
cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY, 9, 2)
# -- STEP 5 --
# convert back to color so that it can be bit-ANDed
# with color image
img_edge = cv2.cvtColor(img_edge, cv2.COLOR_GRAY2RGB)
return cv2.bitwise_and(img_color, img_edge)
结果如下所示:

全部放在一起
在以交互方式使用设计的图像过滤器效果之前,我们需要设置主脚本并设计 GUI 应用。
运行应用
要运行应用,我们将转到chapter1.py.脚本,我们将从导入所有必需的模块开始:
import numpy as np
import wx
import cv2
我们还必须导入通用的 GUI 布局(从gui)和所有设计的图像效果(从filters):
from gui import BaseLayout
from filters import PencilSketch, WarmingFilter, CoolingFilter, Cartoonizer
OpenCV 提供了一种直接的方法来访问计算机的网络摄像头或摄像头设备。 以下代码段使用cv2.VideoCapture打开计算机的默认摄像机 ID(0):
def main():
capture = cv2.VideoCapture(0)
在某些平台上,对cv2.VideoCapture的首次调用无法打开通道。 在这种情况下,我们可以通过自己打开渠道来提供解决方法:
if not(capture.isOpened()):
capture.open()
为了给我们的应用一个实时运行的机会,我们将视频流的大小限制为640 x 480像素:
capture.set(cv2.cv.CV_CAP_PROP_FRAME_WIDTH, 640)
capture.set(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT, 480)
注意
如果使用的是 OpenCV 3,则所要查找的常量可能称为cv3.CAP_PROP_FRAME_WIDTH和cv3.CAP_PROP_FRAME_HEIGHT。
然后,可以将capture流传递到我们的 GUI 应用,该应用是FilterLayout类的实例:
# start graphical user interface
app = wx.App()
layout = FilterLayout(None, -1, 'Fun with Filters', capture)
layout.Show(True)
app.MainLoop()
现在唯一要做的就是设计上述 GUI。
GUI 基类
FilterLayout GUI 将基于称为BaseLayout的通用平面布局类,我们也将在以后的章节中使用它。
BaseLayout类被设计为抽象基类。 您可以将此类视为可以应用于我们尚未设计的所有布局的蓝图或秘籍-如果您愿意,可以将其作为骨架类,用作将来所有 GUI 代码的基础。 为了使用抽象类,我们需要以下import语句:
from abc import ABCMeta, abstractmethod
我们还包括其他一些有用的模块,特别是wx Python 模块和 OpenCV(当然):
import time
import wx
import cv2
该类被设计为从蓝图或框架派生,即wx.Frame类。 我们还通过添加__metaclass__属性将类标记为抽象类:
class BaseLayout(wx.Frame):
__metaclass__ = ABCMeta
稍后,当我们编写自己的自定义布局(FilterLayout)时,将使用相同的符号来指定该类基于BaseLayout蓝图(或骨架)类,例如,在class FilterLayout(BaseLayout):中。 现在,让我们集中讨论BaseLayout类。
抽象类至少具有一个抽象方法。 抽象方法类似于指定某种方法必须存在,但是我们不确定当时的外观。 例如,假设BaseLayout包含如下指定的方法:
@abstractmethod
def _init_custom_layout(self):pass
然后,派生自该类的任何类,例如FilterLayout,都必须指定具有该确切签名的方法的完全充实的实现。 稍后您将看到,这将使我们能够创建自定义布局。
但是首先,让我们进入 GUI 构造器。
GUI 构造器
BaseLayout构造器接受一个 ID(-1),一个标题字符串(‘Fun with Filters’),一个视频捕获对象以及一个可选参数,该参数指定每秒的帧数。 然后,在构造器中要做的第一件事是尝试从捕获的对象中读取一个帧以确定图像大小:
def __init__(self, parent, id, title, capture, fps=10):
self.capture = capture
# determine window size and init wx.Frame
_, frame = self.capture.read()
self.imgHeight,self.imgWidth = frame.shape[:2]
我们将使用图像大小准备一个缓冲区,该缓冲区将每个视频帧存储为位图,并设置 GUI 的大小。 因为我们想在当前视频帧下方显示一堆控制按钮,所以我们将 GUI 的高度设置为self.imgHeight+20:
self.bmp = wx.BitmapFromBuffer(self.imgWidth,
self.imgHeight, frame)
wx.Frame.__init__(self, parent, id, title,size=(self.imgWidth, self.imgHeight+20))
然后,我们提供了两种方法来初始化更多参数并创建 GUI 的实际布局:
self._init_base_layout()
self._create_base_layout()
处理视频流
网络摄像头的视频流由_init_base_layout方法开始的一系列步骤处理。 这些步骤起初看起来可能过于复杂,但是它们是使视频即使在更高的帧速率下也能平稳运行的必要条件(也就是说,可以防止闪烁)。
wxPython模块可用于事件和回调方法。 当某个事件被触发时,它可以导致某个类方法被执行(换句话说,一种方法可以将绑定到事件)。 我们将利用这种机制来发挥优势,并经常通过以下步骤来显示新的框架:
-
我们创建了一个计时器,只要经过 1000./fps 毫秒,它就会生成
wx.EVT_TIMER事件:def _init_base_layout(self): self.timer = wx.Timer(self) self.timer.Start(1000./self.fps) -
每当计时器启动时,我们都希望调用
_on_next_frame方法。 它将尝试获取新的视频帧:self.Bind(wx.EVT_TIMER, self._on_next_frame) -
_on_next_frame方法将处理新的视频帧并将处理后的帧存储在位图中。 这将触发另一个事件wx.EVT_PAINT。 我们想将此事件绑定到_on_paint方法,该方法将在显示器上绘制新的帧:self.Bind(wx.EVT_PAINT, self._on_paint)
_on_next_frame方法抓取一个新帧,完成后,将该帧发送到另一种方法__process_frame进行进一步处理:
def _on_next_frame(self, event):
ret, frame = self.capture.read()
if ret:
frame = self._process_frame(cv2.cvtColor(frame,cv2.COLOR_BGR2RGB))
然后将已处理的帧(frame)存储在位图缓冲区(self.bmp)中:
self.bmp.CopyFromBuffer(frame)
调用Refresh会触发上述wx.EVT_PAINT事件,该事件绑定到_on_paint:
self.Refresh(eraseBackground=False)
然后paint方法从缓冲区中抓取帧并将其显示:
def _on_paint(self, event):
deviceContext = wx.BufferedPaintDC(self.pnl)
deviceContext.DrawBitmap(self.bmp, 0, 0)
基本的 GUI 布局
通用布局的创建通过称为_create_base_layout的方法完成。 最基本的布局仅由一个大的黑色面板组成,该面板提供了足够的空间来显示视频供稿:
def _create_base_layout(self):
self.pnl = wx.Panel(self, -1,
size=(self.imgWidth, self.imgHeight))
self.pnl.SetBackgroundColour(wx.BLACK)
为了使布局可扩展,我们将其添加到垂直排列的wx.BoxSizer对象中:
self.panels_vertical = wx.BoxSizer(wx.VERTICAL)
self.panels_vertical.Add(self.pnl, 1, flag=wx.EXPAND)
接下来,我们指定一个抽象方法_create_custom_layout,我们将不填写任何代码。 相反,我们基类的任何用户都可以对基本布局进行自己的自定义修改:
self._create_custom_layout()
然后,我们只需要设置结果布局的最小尺寸并将其居中即可:
self.SetMinSize((self.imgWidth, self.imgHeight))
self.SetSizer(self.panels_vertical)
self.Centre()
自定义过滤器布局
现在我们即将完成! 如果要使用BaseLayout类,则需要为以前留空的三种方法提供代码:
_init_custom_layout:这是我们可以初始化特定于任务的参数的_create_custom_layout:这是,我们可以在其中对 GUI 布局进行特定于任务的修改_process_frame:这是,我们在其中对摄像机供稿的每个捕获帧执行特定于任务的处理
在这一点上,初始化图像过滤器是不言自明的,因为它只需要我们实例化相应的类:
def _init_custom_layout(self):
self.pencil_sketch = PencilSketch((self.imgWidth,
self.imgHeight))
self.warm_filter = WarmingFilter()
self.cool_filter = CoolingFilter()
self.cartoonizer = Cartoonizer()
为了自定义布局,我们水平排列了多个单选按钮,每个图像效果模式一个按钮:
def _create_custom_layout(self):
# create a horizontal layout with all filter modes
pnl = wx.Panel(self, -1 )
self.mode_warm = wx.RadioButton(pnl, -1, 'Warming Filter',
(10, 10), style=wx.RB_GROUP)
self.mode_cool = wx.RadioButton(pnl, -1, 'Cooling Filter',
(10, 10))
self.mode_sketch = wx.RadioButton(pnl, -1, 'Pencil Sketch',
(10, 10))
self.mode_cartoon = wx.RadioButton(pnl, -1, 'Cartoon',
(10, 10))
hbox = wx.BoxSizer(wx.HORIZONTAL)
hbox.Add(self.mode_warm, 1)
hbox.Add(self.mode_cool, 1)
hbox.Add(self.mode_sketch, 1)
hbox.Add(self.mode_cartoon, 1)
pnl.SetSizer(hbox)
在此,style=wx.RB_GROUP选项可确保一次只能选择这些单选按钮之一。
为了使这些更改生效,需要将pnl添加到现有面板列表中:
self.panels_vertical.Add(pnl, flag=wx.EXPAND | wx.BOTTOM | wx.TOP, border=1)
最后要指定的方法是_process_frame。 回想一下,只要接收到新的相机帧,就会触发此方法。 我们需要做的就是选择要应用的正确图像效果,这取决于单选按钮的配置。 我们只需检查当前选择了哪个按钮,然后调用相应的render方法:
def _process_frame(self, frame_rgb):
if self.mode_warm.GetValue():
frame = self.warm_filter.render(frame_rgb)
elif self.mode_cool.GetValue():
frame = self.cool_filter.render(frame_rgb)
elif self.mode_sketch.GetValue():
frame = self.pencil_sketch.render(frame_rgb)
elif self.mode_cartoon.GetValue():
frame = self.cartoonizer.render(frame_rgb)
不要忘记返回已处理的帧:
return frame
我们完成了!
这是结果:

总结
在本章中,我们探讨了许多有趣的图像处理效果。 我们使用淡化和刻录来创建黑白铅笔素描效果,探索了查找表以实现曲线过滤器的有效实现,并具有创造卡通效果的创造力。
在下一章中,我们将稍作调整,并探索使用深度传感器(例如 Microsoft Kinect 3D)来实时识别手势。
二、使用 Kinect 深度传感器的手势识别
本章的目的是开发一个应用,该应用使用深度传感器(例如 Microsoft Kinect 3D 传感器或 Asus Xtion)的输出实时检测和跟踪简单手势。 该应用将分析每个捕获的帧以执行以下任务:
- 手部区域分割:将通过分析 Kinect 传感器的深度图输出在每帧中提取用户的手部区域,此操作由完成阈值化,应用一些形态学操作,然后发现连通组件
- 手形分析:将通过确定轮廓,凸性和凸度缺陷来分析分段的手部区域的形状
- 手势识别:将根据手轮廓的凸度缺陷确定伸出手指的数量,然后将手势分类(没有伸出手指) 对应于拳头,五个伸出的手指对应于张开的手)
手势识别是计算机科学中一个非常受欢迎的话题。 这是因为它不仅使人类能够与机器进行通信(人机交互或 HMI),而且还构成了机器开始理解人类语言的第一步。 借助价格实惠的传感器(例如 Microsoft Kinect 或 Asus Xtion)以及开源软件(例如 OpenKinect 和 OpenNI),您自己在该领域就很难开始。 那么,我们将如何使用所有这些技术?
我们将在本章中实现的算法的优点在于,它适用于许多手势,但是足够简单,可以在通用笔记本电脑上实时运行。 同样,如果需要,我们可以轻松地将其扩展为合并更复杂的手势估计。 最终产品如下所示:
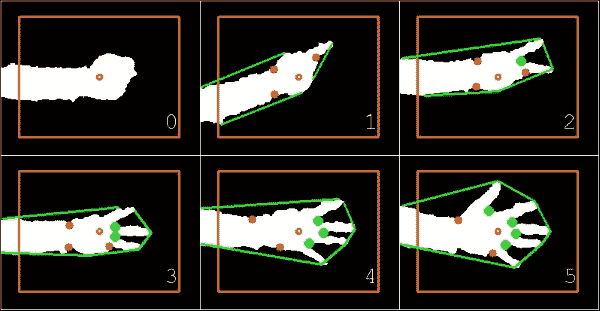
无论我伸出左手的手指多少,该算法都会正确分割手部区域(白色),绘制相应的凸包(围绕手的绿线),找到所有属于手指之间的空间的凸度缺陷(绿色的大点),而忽略其他手指(红色的小点),即使是拳头,也可以推断出正确的伸出手指数(右下角的数字)。
注意
本章假定您已安装 Microsoft Kinect 3D 传感器。 或者,您可以安装 Asus Xtion 或 OpenCV 内置支持的任何其他深度传感器。 首先,从这个页面安装 OpenKinect 和 libfreenect。 然后,您需要使用 OpenNI 支持来构建(或重建)OpenCV。 将再次使用 wxPython 设计本章中使用的 GUI,可以从这个页面获得。
规划应用
最终的应用将包含以下模块和脚本:
gestures:包含一个用于识别手势的算法的模块。 我们将该算法与应用的其余部分分开,以便无需 GUI 即可将其用作独立模块。gestures.HandGestureRecognition:一个类,用于实现手势识别的整个过程。 它接受单通道深度图像(从 Kinect 深度传感器获取),并返回带有估计数量的扩展手指的带标注的 RGB 彩色图像。gui:提供 wxPython GUI 应用以访问捕获设备并显示视频提要的模块。 这与我们在上一章中使用的模块相同。 为了使它能够访问 Kinect 深度传感器而不是通用相机,我们将不得不扩展一些基类功能。gui.BaseLayout:可从中构建更复杂布局的通用布局。chapter2:本章的主要脚本。chapter2.KinectLayout:基于gui.BaseLayout的自定义布局,显示 Kinect 深度传感器供稿。 每个捕获的帧都使用前面描述的HandGestureRecognition类进行处理。chapter2.main:main函数例程,用于启动 GUI 应用和访问深度传感器。
设置应用
在深入了解手势识别算法之前,我们需要确保可以访问 Kinect 传感器并在简单的 GUI 中显示深度帧流。
访问 Kinect 3D 传感器
从 OpenCV 中访问 Microsoft Kinect 与访问计算机的网络摄像头或摄像头设备没有太大区别。 将 Kinect 传感器与 OpenCV 集成的最简单方法是使用称为freenect的OpenKinect模块。 有关安装说明,请查看前面的信息框。 以下代码段使用cv2.VideoCapture授予对传感器的访问权限:
import cv2
import freenect
device = cv2.cv.CV_CAP_OPENNI
capture = cv2.VideoCapture(device)
在某些平台上,对cv2.VideoCapture的首次调用无法打开捕获通道。 在这种情况下,我们通过自己打开渠道来提供一种解决方法:
if not(capture.isOpened(device)):
capture.open(device)
如果要连接到 Asus Xtion,则应为device变量分配cv2.cv.CV_CAP_OPENNI_ASUS值。
为了给我们的应用一个实时运行的机会,我们将帧大小限制为640 x 480像素:
capture.set(cv2.cv.CV_CAP_PROP_FRAME_WIDTH, 640)
capture.set(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT, 480)
注意
如果使用的是 OpenCV 3,则所要查找的常量可能称为cv3.CAP_PROP_FRAME_WIDTH和cv3.CAP_PROP_FRAME_HEIGHT。
当我们需要同步一组摄像机或多头摄像机(例如 Kinect)时,cv2.VideoCapture的read()方法是不合适的。 在这种情况下,我们应该改用grab()和retrieve()方法。 使用OpenKinect时,一个更简单的方法是使用sync_get_depth()和sync_get_video()方法。
就本章而言,我们仅需要 Kinect 的深度图,它是单通道(灰度)图像,其中每个像素值是从摄像机到视觉场景中特定表面的估计距离。 可以通过以下代码获取最新的帧:
depth, timestamp = freenect.sync_get_depth()
前面的代码返回深度图和时间戳。 我们现在将忽略后者。 默认情况下,图为 11 位格式,不足以立即使用cv2.imshow进行可视化。 因此,最好先将图像转换为 8 位精度。
为了减小帧中深度值的范围,我们将将最大距离限制为 1,023(或2**10-1)。 这将消除与噪声或距离过大而令我们不感兴趣的值相对应的值:
np.clip(depth, 0, 2**10-1, depth)
depth >>= 2
然后,我们将图像转换为 8 位格式并显示:
depth = depth.astype(np.uint8)
cv2.imshow("depth", depth)
运行应用
为了运行我们的应用,我们将需要执行一个访问 Kinect,生成 GUI 并执行该应用主循环的主函数例程。 这是通过chapter2.py的main函数完成的:
import numpy as np
import wx
import cv2
import freenect
from gui import BaseLayout
from gestures import HandGestureRecognition
def main():
device = cv2.cv.CV_CAP_OPENNI
capture = cv2.VideoCapture()
if not(capture.isOpened()):
capture.open(device)
capture.set(cv2.cv.CV_CAP_PROP_FRAME_WIDTH, 640)
capture.set(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT, 480)
与上一章一样,我们将为当前项目设计合适的布局(KinectLayout):
# start graphical user interface
app = wx.App()
layout = KinectLayout(None, -1, 'Kinect Hand Gesture Recognition', capture)
layout.Show(True)
app.MainLoop()
Kinect GUI
为当前项目(KinectLayout)选择的布局尽可能简单。 它应该仅以每秒 10 帧的舒适帧速率显示 Kinect 深度传感器的实时流。 因此,无需进一步自定义BaseLayout:
class KinectLayout(BaseLayout):
def _create_custom_layout(self):
pass
这次需要初始化的唯一参数是识别类。 这将在短时间内有用:
def _init_custom_layout(self):
self.hand_gestures = HandGestureRecognition()
代替读取常规摄像机帧,我们需要通过freenect方法sync_get_depth()获取深度帧。 这可以通过重写以下方法来实现:
def _acquire_frame(self):
如前所述,默认情况下,此函数返回具有 11 位精度和时间戳的单通道深度图像。 但是,我们对时间戳不感兴趣,只要获取成功,我们就简单地传递帧:
frame, _ = freenect.sync_get_depth()
# return success if frame size is valid
if frame is not None:
return (True, frame)
else:
return (False, frame)
可视化管道的其余部分由BaseLayout类处理。 我们只需要确保提供_process_frame方法即可。 此方法接受 11 位精度的深度图像,对其进行处理,然后返回带标注的 8 位 RGB 彩色图像。 转换为常规灰度图像与上一小节中提到的相同:
def _process_frame(self, frame):
# clip max depth to 1023, convert to 8-bit grayscale
np.clip(frame, 0, 2**10 – 1, frame)
frame >>= 2
frame = frame.astype(np.uint8)
然后可以将生成的灰度图像传递到手势识别器,该手势识别器将返回估计的扩展手指数(num_fingers)和前面提到的带标注的 RGB 彩色图像(img_draw):
num_fingers, img_draw = self.hand_gestures.recognize(frame)
为了简化HandGestureRecognition类的细分任务,我们将指示用户将手放在屏幕中央。 为了对此提供视觉帮助,让我们在图像中心周围绘制一个矩形,并以橙色突出显示图像的中心像素:
height, width = frame.shape[:2]
cv2.circle(img_draw, (width/2, height/2), 3, [255, 102, 0], 2)
cv2.rectangle(img_draw, (width/3, height/3), (width*2/3, height*2/3), [255, 102, 0], 2)
另外,我们将在屏幕上打印num_fingers:
cv2.putText(img_draw, str(num_fingers), (30, 30), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255))
return img_draw
实时跟踪手势
手势由HandGestureRecognition类分析,尤其是通过recognize方法进行分析。 此类从一些参数初始化开始,稍后将对其进行说明和使用:
class HandGestureRecognition:
def __init__(self):
# maximum depth deviation for a pixel to be considered # within range
self.abs_depth_dev = 14
# cut-off angle (deg): everything below this is a convexity
# point that belongs to two extended fingers
self.thresh_deg = 80.0
recognize方法是真正的魔术发生的地方。 该方法处理从原始灰度图像一直到识别手势的整个处理流程。 它执行以下过程:
-
它通过分析深度图(
img_gray)并返回手部区域遮罩(segment)来提取用户的手部区域:def recognize(self, img_gray): segment = self._segment_arm(img_gray) -
它在手部区域遮罩(
segment)上执行轮廓分析。 然后,它返回图像中发现的最大轮廓区域(contours)和任何凸度缺陷(defects):[contours, defects] = self._find_hull_defects(segment) -
基于找到的轮廓和凸度缺陷,它可以检测图像中伸出的手指数(
num_fingers)。 然后,它用轮廓,缺陷点和伸出的手指数标注输出图像(img_draw):img_draw = cv2.cvtColor(img_gray, cv2.COLOR_GRAY2RGB) [num_fingers, img_draw] = self._detect_num_fingers(contours, defects, img_draw) -
它返回扩展手指的估计数量(
num_fingers)以及带标注的输出图像(img_draw):return (num_fingers, img_draw)
手部区域分割
手臂和手部区域的自动自动检测可以设计为任意复杂,可能是通过组合有关手臂或手的形状和颜色的信息来实现的。 但是,使用皮肤颜色作为确定特征以在视觉场景中找到手可能会在光线不足的情况下或用户戴着手套时严重失败。 相反,我们选择通过深度图中的形状来识别用户的手。 允许在图像的任何区域出现各种手都不必要地使本章的任务复杂化,因此我们做出两个简化的假设:
- 我们将指示我们应用的用户将手放在屏幕中心之前,使其手掌大致平行于 Kinect 传感器的方向,以便于识别手的相应深度层。
- 我们还将指示用户坐在距 Kinect 大约一到两米的位置,并在自己的身体前稍稍伸出手臂,以使手最终伸入的深度与手臂略有不同。 但是,即使整个手臂可见,该算法仍将起作用。
以此方式,仅基于深度层来分割图像将相对直接。 否则,我们将不得不首先提出手检测算法,这将不必要地使我们的任务复杂化。 如果您喜欢冒险,可以随时自己做。
查找图像中心区域最突出的深度
一旦将手大致放置在屏幕中央,我们就可以开始查找与手位于同一深度平面上的所有图像像素。
为此,我们只需要确定图像中心区域的最突出深度值即可。 最简单的方法如下:仅查看中心像素的深度值:
width, height = depth.shape
center_pixel_depth = depth[width/2, height/2]
然后,创建一个遮罩,其中center_pixel_depth深度处的所有像素均为白色,而所有其他像素均为黑色:
import numpy as np
depth_mask = np.where(depth == center_pixel_depth, 255, 0).astype(np.uint8)
但是,此方法并不是很可靠,因为以下情况可能会损害它:
- 您的手不会与 Kinect 传感器完全平行放置
- 您的手不会完全平坦
- Kinect 传感器的值会很嘈杂
因此,手的不同区域的深度值会略有不同。
_segment_arm方法采用更好的方法; 也就是说,请查看图像中心的一个小邻域,然后确定中值(即最突出的)深度值。 首先,我们找到图像帧的中心区域(例如21 x 21像素):
def _segment_arm(self, frame):
""" segments the arm region based on depth """
center_half = 10 # half-width of 21 is 21/2-1
lowerHeight = self.height/2 – center_half
upperHeight = self.height/2 + center_half
lowerWidth = self.width/2 – center_half
upperWidth = self.width/2 + center_half
center = frame[lowerHeight:upperHeight, lowerWidth:upperWidth]
然后,我们可以将此中心区域的深度值整形为一维向量,并确定中值深度值med_val:
med_val = np.median(center)
现在,我们可以将med_val与图像中所有像素的深度值进行比较,并创建一个掩码,其中深度值在特定范围[med_val-self.abs_depth_dev, med_val+self.abs_depth_dev]内的所有像素均为白色,而所有其他像素均为黑色。 但是,由于稍后会阐明的原因,让我们将像素绘制为灰色,而不是白色的:
frame = np.where(abs(frame – med_val) <= self.abs_depth_dev,128, 0).astype(np.uint8)
结果将如下所示:

应用形态学闭合来平滑分割遮罩
分割常见的问题是,硬阈值通常会在分割区域中导致较小的瑕疵(即,如前一个图像中的孔)。 这些孔可以通过使用形态学的开闭来缓解。 打开将删除前景中的小对象(假设对象在黑暗的前景中很亮),而关闭将删除小孔(黑暗的区域)。
这意味着我们可以通过使用3 x 3像素小核进行形态学封闭(先扩张后腐蚀)来消除遮罩中小的黑色区域:
kernel = np.ones((3, 3), np.uint8)
frame = cv2.morphologyEx(frame, cv2.MORPH_CLOSE, kernel)
结果看起来更加平滑,如下所示:

但是请注意,该遮罩仍然包含不属于手或手臂的区域,例如左侧似乎是我的膝盖之一,右侧是一些家具。 这些物体恰好与我的手臂和手位于同一深度层。 如果可能的话,我们现在可以将深度信息与另一个描述符(可能是基于纹理或基于骨骼的手分类器)结合使用,以清除所有非皮肤区域。
在分段掩码中查找连通组件
一种更简单的方法是认识到大多数时候手没有与膝盖或家具相连。 我们已经知道中心区域属于手,因此我们只需应用cv2.floodfill即可找到所有连接的图像区域。
在执行此操作之前,我们要绝对确定洪水填充的种子点属于正确的遮罩区域。 这可以通过将128的灰度值分配给种子点来实现。 但是,我们也要确保中心像素不会由于巧合而位于形态操作无法关闭的空腔内。 因此,我们将其灰度值设置为128设置一个7 x 7的小像素区域:
small_kernel = 3
frame[self.height/2-small_kernel :
self.height/2+small_kernel, self.width/2-small_kernel : self.width/2+small_kernel] = 128
由于洪水填充(以及形态学操作)具有潜在的危险,因此以后的 OpenCV 版本需要指定一个遮罩,以避免淹没整个图像。 此遮罩必须比原始图像宽 2 像素高,并且必须与cv2.FLOODFILL_MASK_ONLY标志结合使用。 在将洪水填充限制到图像的一小部分或特定轮廓方面非常有帮助,这样我们就不需要连接两个本来就不会连接的相邻区域。 安全胜于后悔,对吧?
啊,拧! 今天,我们感到勇敢! 让我们把面具变成黑色:
mask = np.zeros((self.height+2, self.width+2), np.uint8)
然后,我们可以将泛洪填充应用于中心像素(种子点),并将所有连接的区域涂成白色:
flood = frame.copy()
cv2.floodFill(flood, mask, (self.width/2, self.height/2), 255, flags=4 | (255 << 8))
在这一点上,很清楚为什么我们决定更早地使用灰色遮罩。 现在,我们有了一个遮罩,其中包含白色区域(手臂和手),灰色区域(手臂和手都不是,但在同一深度平面上的其他物体)和黑色区域(所有其他)。 通过此设置,很容易应用简单的二进制阈值以仅突出显示预先分割的深度平面的相关区域:
ret, flooded = cv2.threshold(flood, 129, 255, cv2.THRESH_BINARY)
这是结果遮罩的样子:

现在可以将生成的分割遮罩返回到recognize方法,在该方法中它将用作作为_find_hull_defects的输入,以及用作绘制最终输出图像(img_draw)的画布。
手形分析
现在我们大致了解了手的位置,我们旨在学习有关其形状的信息。
确定分割的手部区域的轮廓
第一步涉及确定分割的手部区域的轮廓。 幸运的是,OpenCV 附带了这种算法的预装版本-cv2.findContours。 该函数作用在二进制图像上,并返回被认为是轮廓一部分的一组点。 由于图像中可能存在多个轮廓,因此可以检索轮廓的整个层次结构:
def _find_hull_defects(self, segment):
contours, hierarchy = cv2.findContours(segment, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
此外,由于我们不知道要寻找哪个轮廓,因此必须做出假设以清理轮廓结果。 由于即使在形态闭合后,仍有可能留下一些小空腔,但是我们可以肯定我们的面罩仅包含感兴趣的分割区域,因此我们假设找到的最大轮廓就是我们要找的。 因此,我们只需遍历轮廓列表,计算轮廓区域(cv2.contourArea),并仅存储最大的轮廓(max_contour):
max_contour = max(contours, key=cv2.contourArea)
查找轮廓区域的凸包
一旦我们在遮罩中识别出最大轮廓,就可以很容易地计算轮廓区域的凸包。 凸包基本上是轮廓区域的包络。 如果将属于轮廓区域的所有像素视为钉子从板上伸出来,则凸包的形状是由围绕所有钉子的紧密橡皮筋形成的。
我们可以直接从最大轮廓线(max_contour)获得凸包:
hull = cv2.convexHull(max_contour, returnPoints=False)
现在,我们要查看该壳体中的凸度缺陷,因此 OpenCV 文档指示我们将returnPoints可选标志设置为False。
在分段的手部区域周围以黄色绘制的凸包看起来像这样:

查找凸包的凸度缺陷
从前面的屏幕快照中可以明显看出,凸包上的所有点均不是属于分割的手部区域。 实际上,所有的手指和手腕都会造成严重的凸度缺陷,即轮廓线远离船体的点。
通过查看最大轮廓(max_contour)和相应的凸包(hull),我们可以找到这些缺陷:
defects = cv2.convexityDefects(max_contour, hull)
此函数的输出(defects)是一个四元组,其中包含start_index(缺陷开始的轮廓点),end_index(缺陷结束的轮廓点),farthest_pt_index (距离缺陷内凸包点最远)和fixpt_depth(最远点到凸包之间的距离)。 当我们尝试提取伸出手指的数量时,我们将在短时间内使用此信息。
目前,我们的工作已经完成。 提取的轮廓(max_contour)和凸度缺陷(defects)可以传递到recognize,它们将用作_detect_num_fingers的输入:
return (cnt,defects)
手势识别
剩下要做的是基于伸出手指的数量对手势进行分类。 例如,如果我们找到五个伸出的手指,则假定手是张开的,而没有伸出的手指则表示是拳头。 我们要做的只是从零到五计数,并使应用识别相应的手指数。
实际上,比起初看起来要棘手。 例如,欧洲的人可能会通过伸出拇指,食指和中指来计数到三。 如果您在美国这样做,那里的人们可能会感到非常困惑,因为他们在发信号表示第二时往往不会用拇指。 这可能会导致沮丧,尤其是在餐馆(请相信我)。 如果我们可以找到一种方法来概括这两种情况(也许通过适当地计算伸出的手指的数量),我们将拥有一种算法,该算法不仅可以将简单的手势识别教给机器,而且还可以教给普通的女服务员。
您可能已经猜到了,答案与凸度缺陷有关。 如前所述,伸出的手指会导致凸包的缺陷。 但是,反之则不成立。 也就是说,并非所有的凸度缺陷都是由手指造成的! 腕部以及手或手臂的整体方向可能会导致其他缺陷。 我们如何区分这些不同的缺陷原因?
区分凸度缺陷的不同原因
技巧是查看缺陷中距凸包点最远的点(farthest_pt_index)与缺陷的起点和终点(分别为start_index和end_index)之间的角度,在以下屏幕截图中说明:
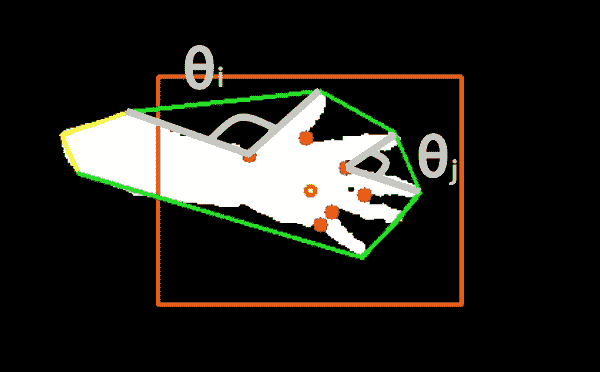
在此屏幕截图中,橙色标记用作视觉辅助,将手放在屏幕中间,而凸包以绿色勾勒。 对于每个检测到的凸度缺陷,每个红点距凸包*(farthest_pt_index)最远。 如果我们将属于两个伸出手指的典型角度(例如θ[j])与由一般手部几何形状引起的角度(例如θ[i])进行比较,则会注意到前者比后者小得多。 显然,这是因为人类只能张开一点手指,从而由最远的缺陷点和相邻的指尖形成一个狭窄的角度。
因此,我们可以遍历所有凸度缺陷并计算所述点之间的角度。 为此,我们将需要一个实用函数来计算两个任意类似列表的向量v1和v2之间的角度(以弧度为单位):
def angle_rad(v1, v2):
return np.arctan2(np.linalg.norm(np.cross(v1, v2)), np.dot(v1, v2))
此方法使用叉积来计算角度,而不是以标准方式进行计算。 计算两个向量v1和v2之间的角度的标准方法是计算它们的点积,然后将其除以v1的norm和v2的norm。 但是,此方法有两个缺点:
- 如果
v1的norm或v2的norm为零,则必须手动避免被零除 - 对于小角度,该方法返回相对不准确的结果
类似地,我们提供了一个简单的函数来将角度从度转换为弧度:
def deg2rad(angle_deg):
return angle_deg/180.0*np.pi
根据伸出的手指数对手势分类
要做的实际上是根据伸出的手指数对手势进行分类。 _detect_num_fingers方法将检测到的轮廓(contours),凸度缺陷(defects)和要绘制的画布(img_draw)作为输入:
def _detect_num_fingers(self, contours, defects, img_draw):
基于这些参数,它将确定伸出的手指数。
但是,我们首先需要定义一个截止角,该截止角可以用作阈值,以将凸出缺陷归类为是否由伸出的手指引起。 除了拇指和食指之间的夹角之外,很难使任何东西接近 90 度,因此任何接近该数字的东西都应该起作用。 我们不希望截止角太大,因为这可能导致错误分类:
self.thresh_deg = 80.0
为简单起见,让我们先关注特殊情况。 如果我们没有发现任何凸度缺陷,则意味着我们可能在凸度船体计算过程中犯了一个错误,或者帧中根本没有延伸的手指,因此我们将返回0作为检测到的手指的数量:
if defects is None:
return [0, img_draw]
但是,我们可以进一步扩大这个想法。 由于手臂通常比手或拳头更苗条,因此我们可以假设手的几何形状总是会产生至少两个凸度缺陷(通常属于腕部)。 因此,如果没有其他缺陷,则意味着没有延伸的手指:
if len(defects) <= 2:
return [0, img_draw]
既然我们已经排除了所有特殊情况,我们就可以开始计算真手指了。 如果有足够数量的缺陷,我们将在每对手指之间发现缺陷。 因此,为了得到正确的数字(num_fingers),我们应该从1开始计数:
num_fingers = 1
然后,我们可以开始遍历所有凸度缺陷。 对于每个缺陷,我们将提取四个元素并绘制其外壳以用于可视化目的:
for i in range(defects.shape[0]):
# each defect point is a 4-tuplestart_idx, end_idx, farthest_idx, _ == defects[i, 0]
start = tuple(contours[start_idx][0])
end = tuple(contours[end_idx][0])
far = tuple(contours[farthest_idx][0])
# draw the hull
cv2.line(img_draw, start, end [0, 255, 0], 2)
然后,我们将计算从far到start以及从far到end的两个边缘之间的角度。 如果角度小于self.thresh_deg度,则意味着我们正在处理的缺陷很可能是由两个伸出的手指引起的。 在这种情况下,我们要增加检测到的手指的数量(num_fingers),并用绿色绘制该点。 否则,我们用红色画点:
# if angle is below a threshold, defect point belongs
# to two extended fingers
if angle_rad(np.subtract(start, far), np.subtract(end, far))
< deg2rad(self.thresh_deg):
# increment number of fingers
num_fingers = num_fingers + 1
# draw point as green
cv2.circle(img_draw, far, 5, [0, 255, 0], -1)
else:
# draw point as red
cv2.circle(img_draw, far, 5, [255, 0, 0], -1)
遍历所有凸度缺陷后,我们将检测到的手指的数量和组合的输出图像传递给recognize方法:
return (min(5, num_fingers), img_draw)
这将确保我们不会超过每只手的普通手指数。
结果可以在以下屏幕截图中看到:
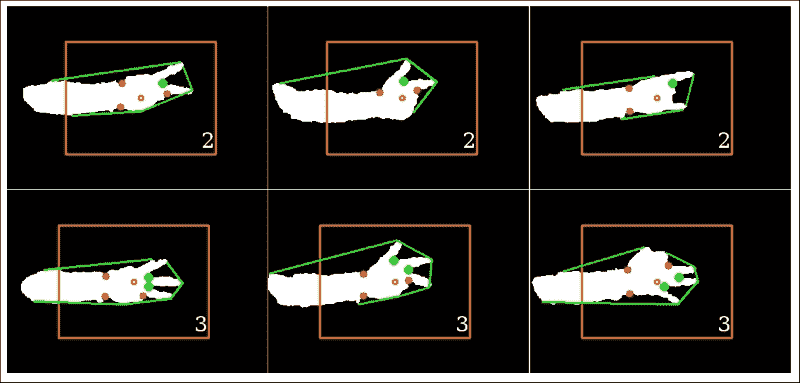
有趣的是,我们的应用能够在各种手配置中检测到正确数量的伸出手指。 扩展手指之间的缺陷点可以通过算法轻松地进行分类,而其他缺陷点则可以成功忽略。
总结
本章介绍了一种通过计数伸出的手指数来识别各种手势的相对简单但令人惊讶的鲁棒方法。
该算法首先显示如何使用从 Microsoft Kinect 3D Sensor 获取的深度信息对图像的任务相关区域进行分割,以及如何使用形态学操作来清理分割结果。 通过分析分割的手部区域的形状,该算法提出了一种基于图像中凸出效果的类型对手势进行分类的方法。 再一次,掌握我们对 OpenCV 的使用来执行所需的任务并不需要我们产生大量的代码。 取而代之的是,我们面临着获得重要见解的挑战,这些见解使我们能够以最有效的方式使用 OpenCV 的内置功能。
手势识别是计算机科学中一个受欢迎但充满挑战的领域,它在许多领域中都有应用,例如人机交互,视频监控,甚至是视频游戏行业。 现在,您可以使用对分段和结构分析的高级理解来构建自己的最新手势识别系统。
在下一章中,我们将继续专注于检测视觉场景中感兴趣的对象,但是我们将假设一个更复杂的情况-从任意角度和距离查看对象。 为此,我们将透视变换与比例尺不变的特征描述符相结合,以开发出可靠的特征匹配算法。
三、通过特征匹配和透视变换查找对象
本章的目的是开发一种应用,即使从不同角度或距离或在部分遮挡的情况下查看该对象,该应用也可以检测并跟踪网络摄像头的视频流中的对象。
在本章中,我们将介绍以下主题:
- 特征提取
- 特征匹配
- 特征追踪
在上一章中,您学习了如何在受控的环境中检测和跟踪简单的对象(手的轮廓)。 更具体地说,我们指示应用的用户将手放在屏幕的中央区域,并假设了对象(手)的大小和形状。 但是,如果我们想检测和跟踪任意大小的物体(可能是从多个角度或部分遮挡的角度观察)怎么办?
为此,我们将使用特征描述符,这是捕获感兴趣对象的重要属性的一种方式。 我们这样做是为了即使将对象嵌入繁忙的视觉场景中也可以对其进行定位。 我们将再次将算法应用于网络摄像头的实时流,并尽最大努力使算法鲁棒而又足够简单,可以实时运行。
应用执行的任务
该应用将分析每个捕获的帧以执行以下任务:
- 特征提取:我们将使用加速鲁棒特征(SURF)描述一个感兴趣的对象,这是一种用于查找与众不同的[ 图像中的关键点既是比例不变的,也是旋转不变的。 这些关键点将帮助我们确保在多个帧上跟踪正确的对象。 由于对象的外观可能会不时发生变化,因此重要的是要找到关键点,即不取决于对象的观看距离或视角(因此,缩放比例和旋转不变性)。
- 特征匹配:我们将尝试使用近似最近邻居的快速库(FLANN)在关键点之间建立对应关系,以查看帧是否包含类似于我们感兴趣的对象的关键点。 如果找到合适的匹配项,则将在每个帧中标记对象。
- 特征跟踪:我们将使用各种形式的早期离群值检测和离群值剔除以加快算法的速度。
- 透视变换:然后,我们将通过扭曲透视图来使对象经受过的所有平移和旋转,以使对象在屏幕中央竖直显示。 这样会产生一种很酷的效果,其中对象看起来像冻结在一个位置上,而整个周围的场景都围绕着它旋转。
下图显示了前三个步骤的示例,左图为我们感兴趣的对象的模板图像,右图为我的模板图像的打印输出。 两个框架中的匹配特征用蓝线连接,并且找到的对象在右侧以绿色勾勒出轮廓:

最后一步是变换定位的对象,以便将其投影到正面(应该看起来像原始模板图像,看起来像是特写镜头,并且大致垂直),而整个场景似乎都在扭曲, 如下图所示:

注意
同样, GUI 将使用 wxPython 2.8 设计,可以从这个页面获得。 本章已经过 OpenCV 2.4.9 的测试。 请注意,如果您使用的是 OpenCV 3,则可能必须从这个页面获得所谓的额外的模块 3 设置OPENCV_EXTRA_MODULES_PATH变量以安装 SURF 和 FLANN。 另外,请注意,您可能必须获得许可才能在商业应用中使用 SURF。
规划应用
最终的应用将包括一个用于检测,匹配和跟踪图像特征的 Python 类,以及一个访问网络摄像头并显示每个处理过的帧的 wxPython GUI 应用。
该项目将包含以下模块和脚本:
feature_matching:模块包含用于特征提取,特征匹配和特征跟踪的算法。 我们将该算法与应用的其余部分分开,以便无需 GUI 即可将其用作独立模块。feature_matching.FeatureMatching:一个类,用于实现整个特征匹配的处理流程。 它接受 RGB 相机帧并尝试在其中找到感兴趣的对象。gui:提供 wxPython GUI 应用以访问捕获设备并显示视频提要的模块。 这与我们在前面各章中使用的模块相同。gui.BaseLayout:一种通用布局,可以从中构建更复杂的布局。 本章不需要对基本布局进行任何修改。chapter3:本章的主要脚本。chapter3.FeatureMatchingLayout:基于gui.BaseLayout的自定义布局,显示网络摄像头视频供稿。 每个捕获的帧将使用前面描述的FeatureMatching类进行处理。chapter3.main:main函数例程,用于启动 GUI 应用和访问深度传感器。
设置应用
在深入研究特征匹配算法之前,我们需要确保可以访问网络摄像头并在简单的 GUI 中显示视频流。 幸运的是,我们已经在第 1 章“过滤器的乐趣”中找到了解决方法。
运行应用
为了运行我们的应用,我们将需要执行访问网络摄像头,生成 GUI 并执行应用主循环的主函数例程:
import cv2
import wx
from gui import BaseLayout
from feature_matching import FeatureMatching
def main():
capture = cv2.VideoCapture(0)
if not(capture.isOpened()):
capture.open()
capture.set(cv2.cv.CV_CAP_PROP_FRAME_WIDTH, 640)
capture.set(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT, 480)
# start graphical user interface
app = wx.App()
layout = FeatureMatchingLayout(None, -1, 'Feature Matching', capture)
layout.Show(True)
app.MainLoop()
注意
如果使用的是 OpenCV 3,则所要查找的常量可能称为cv3.CAP_PROP_FRAME_WIDTH和cv3.CAP_PROP_FRAME_HEIGHT。
FeatureMatching GUI
与上一章相似,为当前项目(FeatureMatchingLayout)选择的布局尽可能简单。 它应该仅以每秒 10 帧的舒适帧速率显示网络摄像头的视频提要。 因此,无需进一步自定义BaseLayout:
class FeatureMatchingLayout(BaseLayout):
def _create_custom_layout(self):
pass
这次需要初始化的唯一参数是特征匹配类。 我们将描述感兴趣对象的模板(或训练)文件的路径传递给它:
def _init_custom_layout(self):
self.matching = FeatureMatching(train_image='salinger.jpg')
可视化管道的其余部分由BaseLayout类处理。 我们只需要确保我们为提供了_process_frame方法。 此方法接受 RGB 彩色图像,通过FeatureMatching方法match的对其进行处理,然后将处理后的图像进行可视化。 如果在当前帧中检测到对象,则match方法将报告success=True,我们will返回已处理的帧。 如果match方法不成功,我们将简单地返回输入帧:
def _process_frame(self, frame):
self.matching = FeatureMatching(train_image='salinger.jpg')
# if object detected, display new frame, else old one
success, new_frame = self.matching.match(frame)
if success:
return new_frame
else:
return frame
处理流程
通过FeatureMatching类,尤其是通过其公共match方法来提取,匹配和跟踪特征。 但是,在开始分析传入的视频流之前,我们需要做一些功课。 可能尚不清楚其中的某些含义(特别是对于 SURF 和 FLANN),但我们将在以下各节中详细讨论这些步骤。 现在,我们只需要担心初始化:
class FeatureMatching:
def __init__(self, train_image='salinger.jpg'):
-
这将设置 SURF 检测器(有关详细信息,请参见下一部分),其 Hessian 阈值在 300 到 500 之间:
self.min_hessian = 400 self.SURF = cv2.SURF(self.min_hessian) -
我们加载了我们感兴趣的对象(
self.img_obj)的模板,或者在找不到该模板时显示错误:self.img_obj = cv2.imread(train_image, cv2.CV_8UC1) if self.img_obj is None: print "Could not find train image " + train_imageraise SystemExit -
另外,为方便起见,存储图像的形状(
self.sh_train):self.sh_train = self.img_train.shape[:2] # rows, cols由于的原因很快就会清楚,我们将模板图像称为训练图像,并将每个传入帧称为查询图像。 训练图像的尺寸为
480 x 270像素,如下所示:
-
将 SURF 应用于感兴趣的对象。 这可以通过方便的函数调用来完成,该函数返回键点列表和描述符(请参阅下一节以获取详细信息):
self.key_train, self.desc_train = self.SURF.detectAndCompute(self.img_obj, None)我们将对每个传入的帧执行相同的操作,并比较图像中的特征列表。
-
设置一个 FLANN 对象(有关详细信息,请参阅下一节)。 这要求通过字典指定一些其他参数,例如使用哪种算法以及并行运行多少棵树:
FLANN_INDEX_KDTREE = 0 index_params = dict(algorithm = FLANN_INDEX_KDTREE,trees = 5) search_params = dict(checks=50) self.flann = cv2.FlannBasedMatcher(index_params, search_params) -
最后,初始化一些其他簿记变量。 当我们想使特征跟踪更快,更准确时,这些工具将很方便。 例如,我们将跟踪最新的计算单应性矩阵以及已花费的帧数,而不会找到感兴趣的对象(有关详细信息,请参阅下一节):
self.last_hinv = np.zeros((3,3)) self.num_frames_no_success = 0 self.max_frames_no_success = 5 self.max_error_hinv = 50.
然后,大部分工作通过FeatureMatching方法match完成。 此方法遵循此处阐述的过程:
- 它从每个传入的视频帧中提取有趣的图像特征。 这是在
FeatureMatching._extract_features中完成的。 - 它与模板图像和视频帧之间的特征匹配。 这是在
FeatureMatching._match_features中完成的。 如果找不到这样的匹配项,它将跳到下一帧。 - 它找到视频帧中模板图像的角点。 这是在
FeatureMatching._detect_corner_points中完成的。 如果任何一个角位于(显着)框架外,则跳至下一帧。 - 它计算四个角点跨越的四边形的面积。 如果该区域太小或太大,则跳至下一帧。
- 它概述了当前帧中模板图像的角点。
- 它找到将定位对象从当前帧移到
frontoparallel平面所必需的透视变换。 这是在FeatureMatching._warp_keypoints中完成的。 如果结果与我们先前在较早的帧中得到的结果明显不同,则跳至下一帧。 - 它扭曲当前帧的透视图,以使感兴趣的对象显得居中且直立。
在以下各节中,我们将详细讨论这些步骤。
特征提取
一般来说,特征是图像的兴趣区域。 它是图像的可测量属性,对于图像所代表的内容非常有用。 通常,单个像素的灰度值(原始数据)不会告诉我们很多有关图像的整体信息。 相反,我们需要派生一个更具信息量的属性。
例如,知道图像中有看起来像眼睛,鼻子和嘴巴的斑点,将使我们能够推断出图像代表面部的可能性。 在这种情况下,描述数据所需的资源数量(我们看到的是人脸图像?)被大大减少了(图像中是否包含两只眼睛,鼻子或嘴巴?)。
通常,更底层的特征(例如,边缘,角点,斑点或山脊的存在)可能会提供更多信息。 根据应用的不同,某些特征可能会比其他特征更好。 一旦确定了如何描述我们喜欢的特征,就需要想出一种方法来检查图像是否包含此类特征以及在何处包含这些特征。
特征检测
在图像中查找兴趣区域的过程称为特征检测。 OpenCV 提供了一系列特征检测算法,例如:
- 哈里斯角点检测:知道边缘是在所有方向上都有高强度变化的区域,因此哈里斯和 Stephens 提出了一种快速找到此类区域的方法。 该算法在 OpenCV 中实现为
cv2.cornerHarris。 - Shi-Tomasi 角点检测:Shi 和 Tomasi 对要跟踪的好特征有自己的想法,通常通过找到最强的
N来比哈里斯角点检测做得更好。 角落。 该算法在 OpenCV 中实现为cv2.goodFeaturesToTrack。 - 尺度不变特征变换(SIFT):当图像的尺度改变时,角落检测不足。 为此,Lowe 开发了一种方法来描述图像中与方向和大小无关的关键点(因此,名称为缩放不变式)。该算法在 OpenCV2 中实现为
cv2.SIFT,但是由于其代码是专有的,因此已被移至 OpenCV3 中的额外的模块。 - 加速鲁棒特征(SURF):SIFT 已被证明是非常好的,但是对于大多数应用而言,它的速度还不够快。 这就是 SURF 的用武之地,它用盒式过滤器代替了 SIFT 中昂贵的高斯拉普拉斯算子。 算法在 OpenCV2 中实现为
cv2.SURF,但与 SIFT 一样,由于其代码是专有的,因此已移至 OpenCV3 中的额外的模块。
OpenCV 支持更多的特征描述符,例如,(来自加速段测试的特征(FAST),二进制鲁棒独立基本特征(BRIEF)和定向的 FAST 和旋转 BRIEF(ORB),后者是 SIFT 或 SURF 的替代品。
使用 SURF 检测图像中的特征
在本章的其余部分中,我们将使用 SURF 检测器。
SURF 算法可以粗略地分为两个不同的步骤:检测兴趣点和制定描述符。 SURF 依赖于 Hessian 角点检测器进行兴趣点检测,这需要设置min_hessian阈值。 该阈值确定了将点用作兴趣点必须使用的 Hessian 过滤器的输出大小。 值越大,则理论上的兴趣点就越少,但(理论上)就越多,而值越小,结果点的数量就越多但就越少。 随意尝试不同的值。 在本章中,我们将选择400的值,如先前在FeatureMatching.__init__中所见,我们在其中创建了具有以下代码段的 SURF 描述符:
self.min_hessian = 400
self.SURF = cv2.SURF(self.min_hessian)
然后可以在一个步骤中,例如在输入图像img_query上不使用遮罩(None)即可获得特征和描述符:
key_query, desc_query = self.SURF.detectAndCompute(img_query, None)
在 OpenCV 2.4.8 或更高版本中,我们现在可以使用以下函数轻松绘制关键点:
imgOut = cv2.drawKeypoints(img_query, key_query, None, (255, 0, 0), 4)
cv2.imshow(imgOut)
注意
确保先检查len(keyQuery),因为 SURF 可能会返回大量特征。 如果只关心绘制关键点,请尝试将min_hessian设置为较大的值,直到返回的关键点数量可控。
如果我们的 OpenCV 发行版本早于该版本,则可能必须编写我们自己的函数。 注意 SURF 受专利法保护。 因此,如果您希望在商业应用中使用 SURF,则将需要获得许可证。
特征匹配
一旦从两个(或多个)图像中提取了特征及其描述符,就可以开始询问这些特征中的某些特征是否同时出现在两个(或所有)图像中。 例如,如果我们同时拥有我们感兴趣的对象(self.desc_train)和当前视频帧(desc_query)的描述符,则可以尝试查找当前帧中看起来像我们感兴趣的对象的区域。 这是通过以下方法完成的,其中利用获取近似最近的邻居的快速库(FLANN):
good_matches = self._match_features(desc_query)
查找帧到帧对应关系的过程可以公式化为:从一组描述符中为另一组的每个元素搜索最近的邻居。
第一组描述符通常称为训练集,因为在机器学习中,这些描述符用于训练某些模型,例如我们要检测的对象的模型。 在我们的例子中,训练集对应于模板图像(我们感兴趣的对象)的描述符。 因此,我们将模板图像称为训练图像(self.img_train)。
第二个集合通常称为查询集,因为我们不断询问它是否包含训练图像。 在我们的情况下,查询集对应于每个传入帧的描述符。 因此,我们将帧称为查询图像(img_query)。
可以通过多种方式对特征进行匹配,例如,借助蛮力匹配器(cv2.BFMatcher),通过尝试每一个来查找第一组中的每个描述符,然后查找第二组中的最接近描述符。 一(详尽搜索)。
使用 FLANN 在图像之间匹配特征
替代方法是使用近似 K 最近邻(kNN)算法来查找对应关系,该算法基于快速第三方库 FLANN。 使用以下代码段执行 FLANN 匹配,其中我们将 kNN 与k=2结合使用:
def _match_features(self, desc_frame):
matches = self.flann.knnMatch(self.desc_train, desc_frame, k=2)
flann.knnMatch的结果是两个描述符集之间的对应关系列表,两个描述符都包含在matches变量中。 这些是训练集,因为它对应于我们感兴趣的对象的模式图像,而查询集是因为它对应于我们正在搜索我们的感兴趣对象的图像。
用于离群值去除的比率测试
找到的正确匹配越多(这意味着存在更多的图案与图像对应关系),则图案出现在图像中的机会就越大。 但是,某些匹配可能是误报。
消除异常值的一种众所周知的技术称为比率测试。 由于我们执行了k = 2的 kNN 匹配,因此每次匹配都会返回两个最近的描述符。 第一个匹配是最接近的邻居,第二个匹配是第二个最接近的邻居。 直观地,正确的匹配将使第一个邻居比第二个邻居更近。 另一方面,两个最近的邻居与不正确匹配的距离相近。 因此,我们可以通过查看距离之间的差异来找出匹配的良好程度。 比率测试说,只有当第一个匹配项和第二个匹配项之间的距离比小于给定的数字(通常为 0.5 左右)时,该匹配项才是好的。 在我们的案例中,该数字选择为 0.7。 要删除所有不满足此要求的匹配项,我们过滤匹配项列表并将好的匹配项存储在good_matches变量中:
# discard bad matches, ratio test as per Lowe's paper
good_matches = filter(lambda x: x[0].distance<0.7*x[1].distance,matches)
然后,将找到的匹配项传递给FeatureMatching.match,以便可以对其进行进一步处理:
return good_matches
可视化特征匹配
在 OpenCV 的较新版本中,我们可以轻松地使用cv2.drawMatches或cv3.drawMatchesKnn进行匹配。
在旧版本的 OpenCV 中,我们可能需要编写我们自己的函数。 目的是将感兴趣的对象和当前视频帧(我们希望将对象嵌入其中)彼此相邻绘制:
def draw_good_matches(img1, kp1, img2, kp2, matches):
# Create a new output image that concatenates the
# two images together (a.k.a) a montage
rows1, cols1 = img1.shape[:2]
rows2, cols2 = img2.shape[:2]
out = np.zeros((max([rows1, rows2]), cols1+cols2, 3), dtype='uint8')
为了在图像上绘制彩色线条,我们创建了一个三通道 RGB 图像:
# Place the first image to the left, copy 3x for RGB
out[:rows1, :cols1, :] = np.dstack([img1, img1, img1])
# Place the next image to the right of it, copy 3x for RGB
out[:rows2, cols1:cols1 + cols2, :] = np.dstack([img2, img2,img2])
然后,对于两个图像之间的每对点,我们绘制一个小的蓝色圆圈,并用一条线连接两个圆圈。 为此,我们必须遍历匹配的关键点列表。 关键点在 Python 中以元组存储,其中x和y坐标有两个条目。 每个匹配项m将索引存储在关键点列表中,其中m.trainIdx指向第一个关键点列表(kp1)中的索引,而m.queryIdx指向第二个关键点列表(kp2中的索引) ):
for m in matches:
# Get the matching keypoints for each of the images
c1, r1 = kp1[m.trainIdx].pt
c2, r2 = kp2[m.queryIdx].pt
使用正确的索引,我们现在可以在正确的位置绘制一个圆(半径为 4,颜色为蓝色,厚度为 1),然后用一条线连接这些圆:
radius = 4
BLUE = (255, 0, 0)
thickness = 1
# Draw a small circle at both co-ordinates
cv2.circle(out, (int(c1), int(r1)), radius, BLUE, thickness)
cv2.circle(out, (int(c2) + cols1, int(r2)), radius, BLUE, thickness
# Draw a line in between the two points
cv2.line(out, (int(c1), int(r1)), (int(c2) + cols1, int(r2)), BLUE, thickness)
return out
然后,可以使用以下代码绘制返回的图像:
cv2.imshow('imgFlann', draw_good_matches(self.img_train, self.key_train, img_query, key_query, good_matches))
蓝线将对象(左)的特征连接到风景(右)的特征,如下所示:

在像这样的简单示例中,这可以很好地工作,但是当场景中还有其他对象时会发生什么呢? 由于我们的对象包含一些看起来很突出的字母,所以当出现其他单词时会发生什么?
事实证明,该算法即使在这样的条件下也可以工作,如您在此屏幕快照中所见:

有趣的是,该算法并未将作者的姓名与场景中该书旁边的黑白字母字母混淆,即使他们拼出了相同的名字。 这是,因为该算法找到了不完全依赖灰度表示的对象描述。 另一方面,进行逐像素比较的算法可能很容易混淆。
单应性估计
由于我们假设感兴趣的对象是平面(图像)且是刚性的,因此我们可以找到两个图像的特征点之间的单应性变换。 全息术将计算将物体图像(self.key_train)中的所有特征点与当前图像帧(self.key_query)中的所有特征点置于同一平面所需的透视变换。 但是首先,我们需要找到所有匹配良好的关键点的图像坐标:
def _detect_corner_points(self, key_frame, good_matches):
src_points = [self.key_train[good_matches[i].trainIdx].pt
for i in xrange(len(good_matches))]
dst_points = [keyQuery[good_matches[i].queryIdx].pt
for i in xrange(len(good_matches))]
为了找到正确的透视图变换(单应矩阵H),cv2.findHomography函数将使用随机样本共识(RANSAC)方法来探测输入点的不同子集:
H, _ = cv2.findHomography(np.array(src_points), np.array(dst_points), cv2.RANSAC)
单应矩阵H然后可以帮助我们将模式中的任何点转换为风景,例如将训练图像中的角点转换为查询图像中的角点。 换句话说,这意味着我们可以通过变换训练图像的角点在查询图像中绘制书籍封面的轮廓! 为此,我们获取训练图像(src_corners)的角点列表,并通过执行透视变换来查看它们在查询图像中的投影位置:
self.sh_train = self.img_train.shape[:2] # rows, cols
src_corners = np.array([(0,0), (self.sh_train[1],0), (self.sh_train[1],self.sh_train[0]), (0,self.sh_train[0])], dtype=np.float32)
dst_corners = cv2.perspectiveTransform(src_corners[None, :, :], H)
dst_corners返回参数是图像点的列表。 我们要做的就是在dst_corners中的每个点和下一个点之间画一条线,然后在风景中勾画出轮廓。 但是首先,为了在正确的图像坐标处画线,我们需要将x坐标偏移图案图像的宽度(因为我们将两个图像彼此相邻显示):
dst_corners = map(tuple,dst_corners[0])
dst_corners = [(np.int(dst_corners[i][0]+self.sh_train[1]),np.int(dst_corners[i][1]))
然后,我们可以从列表中的第i点到第i + 1点画线(环绕到 0):
for i in xrange(0,len(dst_corners)):
cv2.line(img_flann, dst_corners[i], dst_corners[(i+1) % 4],(0, 255, 0), 3)
最后,我们绘制书籍封面的轮廓,如下所示:

即使对象仅部分可见,此方法也适用,如下所示:

扭曲图像
我们也可以做相反的工作-从探查的风景到训练模式的坐标。 使书的封面可以放在正面,就像我们直接从上方看一样。 为此,我们可以简单地采用单应矩阵的逆来获得逆变换:
Hinv = cv2.linalg.inverse(H)
但是,这会将书皮的左上角映射到我们新图像的原点,这将切断书皮左侧和上方的所有内容。 取而代之的是,我们希望将书的封面大致居中。 因此,我们需要计算一个新的单应矩阵。 作为输入,我们将有我们的pts_scene风景点。 作为输出,我们需要具有与图案图像相同形状的图像:
dst_size = img_in.shape[:2] # cols, rows
书的封面应该大约是书本大小的一半。 我们可以提出一个比例因子和一个偏差项,以便将风景图像中的每个关键点映射到新图像中的正确坐标:
scale_row = 1./src_size[0]*dst_size[0]/2.
bias_row = dst_size[0]/4.
scale_col = 1./src_size[1]*dst_size[1]/2.
bias_col = dst_size[1]/4.
接下来,我们只需要将此线性缩放应用于列表中的每个关键点即可。 最简单的方法是使用列表推导:
src_points = [key_frame[good_matches[i].trainIdx].pt
for i in xrange(len(good_matches))]
dst_points = [self.key_train[good_matches[i].queryIdx].pt
for i in xrange(len(good_matches))]
dst_points = [[x*scale_row+bias_row, y*scale_col+bias_col]
for x, y in dst_points]
然后,我们可以找到这些点之间的单应性矩阵(确保将列表转换为 NumPy 数组):
Hinv, _ = cv2.findHomography(np.array(src_points), np.array(dst_points), cv2.RANSAC)
之后,我们可以使用单应性矩阵来变换图像中的每个像素(也称为使图像变形):
img_warp = cv2.warpPerspective(img_query, Hinv, dst_size)
结果看起来像这样(左侧匹配,右侧图像变形):

透视变换产生的图像可能无法与frontoparallel平面完全对齐,因为毕竟单应性矩阵只是近似的。 但是,在大多数情况下,我们的方法很好用,例如下图所示的示例:

特征跟踪
现在我们的算法适用于单帧,我们如何确保在一帧中找到的图像也会在下一帧中找到?
在FeatureMatching.__init__中,我们创建了一些簿记变量,我们说过这些变量将用于特征跟踪。 主要思想是在从一帧到下一帧的同时增强一些一致性。 由于我们每秒捕获大约 10 帧,因此可以合理地假设从一帧到下一帧的变化不会太大。 因此,我们可以确保在任何给定帧中获得的结果都必须与在前一帧中获得的结果相似。 否则,我们将丢弃结果并继续进行下一帧。
但是,我们必须注意不要卡在我们认为合理但实际上是异常值的结果上。 为了解决此问题,我们一直在跟踪找到的帧数,但找不到合适的结果。 我们使用self.num_frames_no_success; 如果此数字小于某个阈值,例如self.max_frames_no_success,我们将在帧之间进行比较。 如果它大于阈值,则我们认为自从获得最后一个结果以来已经过去了太多的时间,在这种情况下,比较帧之间的结果将是不合理的。
早期异常值检测和拒绝
我们可以将异常排除的概念扩展到计算的每个步骤。 然后目标就变成了,从而最大程度地减少了工作量,同时最大程度地提高了我们获得的结果是好的结果的可能性。
用于早期异常值检测和拒绝的结果过程嵌入在FeatureMatching.match中,其外观如下:
def match(self, frame):
# create a working copy (grayscale) of the frame
# and store its shape for convenience
img_query = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
sh_query = img_query.shape[:2] # rows,cols
-
在模式的特征描述符和查询图像之间找到良好的匹配:
key_query, desc_query = self._extract_features(img_query) good_matches = self._match_features(descQuery)为了使 RANSAC 能够在下一步工作,我们至少需要进行四次匹配。 如果发现较少的比赛,我们承认失败并立即返回
False:if len(good_matches) < 4: self.num_frames_no_success=self.num_frames_no_success + 1 return False, frame -
在查询图像(
dst_corners)中找到图案的角点:dst_corners = self._detect_corner_points(key_query, good_matches)如果这些点中的任何一个位于图像的外面(在本例中为 20 像素),则意味着我们不是在关注感兴趣的对象,或者感兴趣的对象并不完全在图像中。 在这两种情况下,我们都不会继续进行,因此我们返回
False:if np.any(filter(lambda x: x[0] < -20 or x[1] < -20 or x[0] > sh_query[1] + 20 or x[1] > sh_query[0] + 20, dst_corners)): self.num_frames_no_success = self.num_frames_no_success + 1 return False, frame -
如果四个恢复的角点未跨越合理的四边形(具有四个边的多边形),则意味着我们可能没有在看我们感兴趣的对象。 可以使用以下代码计算四边形的面积:
area = 0 for i in xrange(0, 4): next_i = (i + 1) % 4 area = area + (dst_corners[i][0]*dst_corners[next_i][1]- dst_corners[i][1]*dst_corners[next_i][0])/2.如果区域不合理地小或不合理地大,我们将丢弃该帧并返回
False:if area < np.prod(sh_query)/16\. or area > np.prod(sh_query)/2.: self.num_frames_no_success=self.num_frames_no_success + 1 return False, frame -
如果恢复的单应性矩阵与上一次恢复的单应性矩阵(
self.last_hinv)太不同,则意味着我们可能正在寻找其他对象,在这种情况下,我们将丢弃该帧并返回False。 通过计算两个矩阵之间的距离,我们将当前的单应性矩阵与最后一个单应性矩阵进行比较:np.linalg.norm(Hinv – self.last_hinv)但是,我们只想考虑
self.last_hinv是否是最近的,例如,从上一个self.max_frames_no_success开始。 这就是为什么我们跟踪self.num_frames_no_success的原因:recent = self.num_frames_no_success < self.max_frames_no_success similar = np.linalg.norm(Hinv - self.last_hinv) < self.max_error_hinv if recent and not similar: self.num_frames_no_success = self.num_frames_no_success + 1 return False, frame
随着时间的流逝,这将有助于我们跟踪一个相同的关注对象。 如果由于某种原因,我们失去了超过self.max_frames_no_success帧的图案图像跟踪,则跳过此条件,并接受到那时为止恢复的所有单应矩阵。 这确保了我们不会陷入某些实际上是异常值的self.last_hinv矩阵。
否则,我们可以肯定地说我们已经在当前帧中成功定位了感兴趣的对象。 在这种情况下,我们存储单应性矩阵并重置计数器:
self.num_frames_no_success = 0
self.last_hinv = Hinv
剩下要做的就是使图像变形,并(第一次)将True与变形的图像一起返回,以便可以绘制图像:
img_out = cv2.warpPerspective(img_query, Hinv, dst_size)
img_out = cv2.cvtColor(img_out, cv2.COLOR_GRAY2RGB)
return True, imgOut
查看实际的算法
便携式计算机的网络摄像头实时流中匹配过程的结果如下所示:

如您所见,模式图像中的大多数关键点都与右侧查询图像中的关键点正确匹配。 现在可以缓慢地移动,倾斜和旋转图案的打印输出。 只要所有角点都停留在当前帧中,就可以相应地更新单应性矩阵并正确绘制图案图像的轮廓。
即使打印输出上下颠倒,此功能也适用,如下所示:

在所有情况下,翘曲图像都会使图案图像到达frontoparallel平面上的直立居中位置。 这会产生一种很酷的效果,即将图案图像冻结在屏幕中央,而周围的环境会扭曲并围绕它旋转,如下所示:

在大多数情况下,翘曲的图像看起来相当准确,如前面的图像所示。 如果由于某种原因该算法接受了错误的单应性矩阵而导致了不合理的扭曲图像,则该算法将丢弃异常值并在半秒内恢复(即在self.max_frames_no_success帧内),从而确保准确高效全程跟踪。
总结
本章介绍了一种强大的特征跟踪方法,当将其应用于网络摄像头的实时流时,该方法足够快以实时运行。
首先,该算法将向您展示如何独立于透视图和大小来提取和检测图像中的重要特征,无论是在我们感兴趣的对象(训练图像)的模板中,还是在更复杂的场景中,我们期望感兴趣的对象嵌入(查询图像)。 然后,通过使用最近邻居算法的快速版本对关键点进行聚类,从而找到两个图像中的特征点之间的匹配。 从那里开始,可以计算将一组特征点映射到另一组特征点的透视变换。 有了这些信息,我们可以勾勒出在查询图像中找到的训练图像,并扭曲查询图像,以使感兴趣的对象在屏幕中央垂直显示。
有了这个,我们现在就可以设计出先进的特征跟踪,图像拼接或增强现实应用。
在下一章中,我们将继续研究场景的几何特征,但是这次,我们将专注于运动。 具体来说,我们将研究如何通过从摄像机运动中推断场景的几何特征来重建 3D 场景。 为此,我们必须将我们的特征匹配知识与光流和运动结构技术结合起来。
四、使用运动结构重建 3D 场景
本章的目的是研究如何通过从摄像机运动推断场景的几何特征来重建 3D 场景。 有时将该技术称为运动结构。 通过从不同角度查看同一场景,我们将能够推断场景中不同特征的真实 3D 坐标。 此过程称为三角剖分,它使我们可以将重建场景作为 3D 点云。
在上一章中,您学习了如何在网络摄像机的视频流中检测和跟踪感兴趣的对象,即使从不同角度或距离或部分遮挡观看该对象也是如此。 在这里,我们将进一步跟踪有趣的特征,并考虑通过研究图像帧之间的相似性,我们可以了解整个视觉场景。 如果我们从不同角度拍摄同一场景的两张图片,则可以使用特征匹配或光流来估计在拍摄两张照片之间,相机经过的任何平移和旋转运动。 但是,为了使其正常工作,我们首先必须校准摄像机。
完整的过程包括以下步骤:
-
摄像机校准:我们将使用棋盘图案提取固有的摄像机矩阵以及失真系数,这对于执行场景重建非常重要。
-
特征匹配:我们将通过加速鲁棒特征(SURF)或通过光流,如下图所示:

-
图像校正:通过从一对图像中估计摄像机的运动,我们将提取基本矩阵并校正图像。

-
三角剖分:我们将利用对极几何形状的约束来重建图像点的 3D 现实世界坐标。
-
3D 点云可视化:最后,我们将使用 Matplotlib 中的散点图可视化场景的恢复 3D 结构,这在使用
pyplot的 Pan 轴按钮进行研究时最为引人注目。 使用此按钮可以在所有三个维度上旋转和缩放点云。 如下图所示,在静止帧中的可视化要困难一些(左图:在喷泉的左侧稍稍向前站立,中面板:在喷泉上向下看,右面板:在喷泉中略微站立) 喷泉右前方):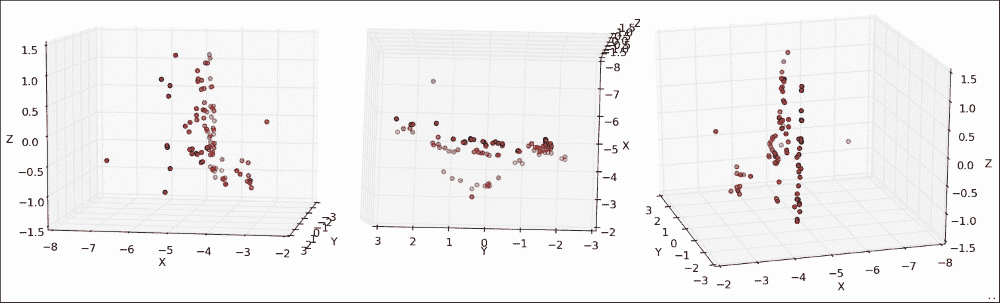
注意
本章已经过 OpenCV 2.4.9 和 wxPython 2.8的测试。 它还需要 NumPy和 matplotlib。 请注意,如果您使用的是 OpenCV3,则可能必须从这个页面获得所谓的额外的模块并使用以下命令安装 OpenCV3 设置OPENCV_EXTRA_MODULES_PATH变量以安装 SURF。 另请注意,您可能必须获得许可才能在商业应用中使用 SURF。
规划应用
最终的应用将提取,并在一对图像上显示运动的结构。 我们将假定这两个图像是使用同一相机拍摄的,我们知道其内部相机参数。 如果这些参数未知,则需要在相机校准过程中首先对其进行估计。
然后,最终的应用将包含以下模块和脚本:
chapter4.main:这是启动应用的main函数例程。scene3D.SceneReconstruction3D:这是一个类,包含用于计算和可视化运动结构的一系列功能。 它包括以下公共方法:__init__:此构造器将接受固有的相机矩阵和失真系数load_image_pair:一种用于从文件中加载之前描述的相机拍摄的两个图像的方法plot_optic_flow:一种用于可视化两个图像帧之间的光流的方法draw_epipolar_lines:一种用于绘制两个图像的对极线的方法plot_rectified_images:一种用于绘制两个图像的校正版本的方法
plot_point_cloud:这是一种用于将场景的恢复的现实世界坐标可视化为 3D 点云的方法。 为了到达 3D 点云,我们将需要利用极线几何。 但是,对极几何结构假设使用针丨孔摄像机模型,因此没有真正的摄像机可以使用。 我们需要校正图像以使其看起来好像来自针孔相机。 为此,我们需要估计摄像机的参数,这将我们引向摄像机校准领域。
相机校准
到目前为止,我们已经处理了网络摄像头中直接输出的图像,而没有质疑其拍摄方式。 但是,每个摄像机镜头都有独特的参数,例如焦距,主点和镜头失真。 当照相机拍照时,封面后面会发生什么? 光线先落入镜头,然后再穿过光圈,然后再落入光传感器的表面。 这个过程可以用针孔相机模型来近似。 估计实际镜头参数以适合针孔相机模型的过程称为相机校准(或相机切除,并且不应与光度学混淆) 相机校准)。
针孔相机模型
针孔照相机模型是没有镜头且照相机光圈通过单个点(针孔)近似的真实照相机的简化。 在查看真实的 3D 场景(例如树)时,光线穿过点大小的光圈并落在相机内部的 2D 图像平面上,如下图所示:
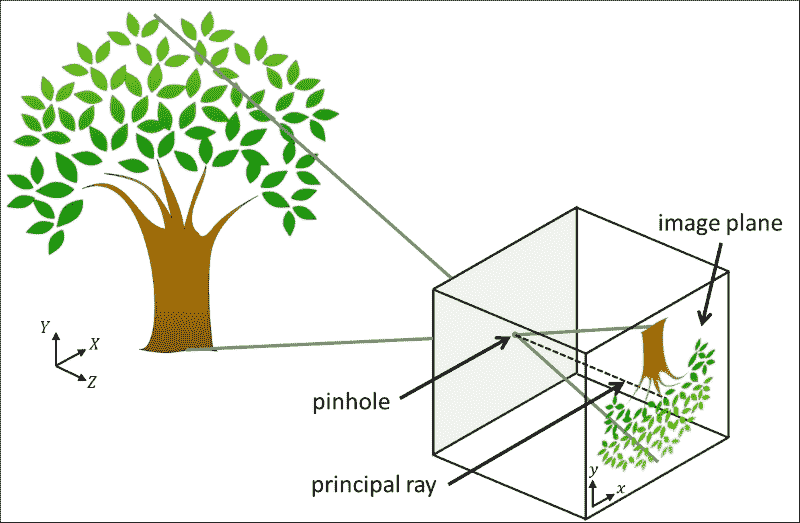
在此模型中,将坐标为(X, Y, Z)的 3D 点映射到坐标为(x, y)的 2D 点,该点位于图像平面。 请注意,这会导致树在图像平面上倒置出现。 垂直于像平面并穿过针孔的线称为主光线,其长度称为焦距。 焦距是内部相机参数的一部分,因为焦距可能会因所使用的相机而异。
Hartley 和 Zisserman 发现了一个数学公式来描述如何从坐标(X, Y, Z)的 3D 点和相机的固有参数推断出具有坐标(x, y)的 2D 点,如下所示:*
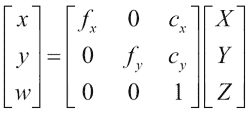
现在,让我们集中讨论上一个公式中的3 x 3矩阵,即固有摄像机矩阵,该矩阵紧凑地描述了所有内部摄像机参数。 矩阵包括以像素坐标表示的焦距(fx和fy)和光学中心(cx和cy)。 如前所述,焦距是针孔与像平面之间的距离。 真正的针孔相机只有一个焦距,在这种情况下fx = fy = f。 但是,实际上,这两个值可能有所不同,这可能是由于数码相机传感器中的缺陷所致。 主光线与像平面相交的点称为主点,其在像平面上的相对位置由光学中心捕获(或主点偏移)。
此外,照相机可能会受到径向或切向失真的影响,从而导致鱼眼效果。 这是由于硬件缺陷和镜头未对准造成的。 可以用失真系数的列表来描述这些失真。 有时,径向变形实际上是一种理想的艺术效果。 在其他时间,需要对其进行更正。
注意
有关针孔相机模型的更多信息,网络上有很多不错的教程,例如这个页面。
由于这些参数是特定于相机硬件的(因此称为“固有”),因此我们只需在相机的使用寿命内计算一次即可。 这称为摄像机校准。
估计相机的固有参数
在 OpenCV 中,相机校准非常简单。 正式的文档在这个页面上提供了有关该主题的良好概述以及一些示例 C++ 脚本。
出于教育目的,我们将使用 Python 开发我们自己的校准脚本。 我们将需要向我们要校准的相机展示具有已知几何形状(棋盘或白色背景上的黑色圆圈)的特殊图案图像。 因为我们知道图案图像的几何形状,所以我们可以使用特征检测来研究内部相机矩阵的属性。 例如,如果照相机遭受不希望的径向变形,则棋盘图案的不同角将在图像中显得变形并且不位于矩形网格上。 通过从不同的角度拍摄棋盘图案的大约 10 到 20 张快照,我们可以收集足够的信息来正确推断相机矩阵和失真系数。
为此,我们将使用calibrate.py脚本。 与前面的章节类似,我们将使用基于BaseLayout的简单布局(CameraCalibration)嵌入网络摄像头视频流。 脚本的main函数将生成 GUI 并执行应用的主循环:
import cv2
import numpy as np
import wx
from gui import BaseLayout
def main():
capture = cv2.VideoCapture(0)
if not(capture.isOpened()):
capture.open()
capture.set(cv2.cv.CV_CAP_PROP_FRAME_WIDTH, 640)
capture.set(cv2.cv.CV_CAP_PROP_FRAME_HEIGHT, 480)
# start graphical user interface
app = wx.App()
layout = CameraCalibration(None, -1, 'Camera Calibration', capture)
layout.Show(True)
app.MainLoop()
注意
如果使用的是 OpenCV 3,则要查找的常量可能称为cv3.CAP_PROP_FRAME_WIDTH和cv3.CAP_PROP_FRAME_HEIGHT。
相机校准 GUI
GUI 是通用BaseLayout的定制版本:
class CameraCalibration(BaseLayout):
布局仅由当前相机帧和下方的单个按钮组成。 此按钮使我们可以开始校准过程:
def _create_custom_layout(self):
"""Creates a horizontal layout with a single button"""
pnl = wx.Panel(self, -1)
self.button_calibrate = wx.Button(pnl,label='Calibrate Camera')
self.Bind(wx.EVT_BUTTON, self._on_button_calibrate)
hbox = wx.BoxSizer(wx.HORIZONTAL)
hbox.Add(self.button_calibrate)
pnl.SetSizer(hbox)
为了使这些更改生效,需要将pnl添加到现有面板列表中:
self.panels_vertical.Add(pnl, flag=wx.EXPAND | wx.BOTTOM | wx.TOP, border=1)
可视化管道的其余部分由BaseLayout类处理。 我们只需要确保提供_init_custom_layout和_process_frame方法即可。
初始化算法
为了执行校准过程,我们需要做一些簿记。 现在,让我们集中讨论一个10 x 7的棋盘。 该算法将检测棋盘的所有10 x 7个内角(称为目标点)并将检测到的这些角点的图像存储在列表中。 因此,让我们首先将棋盘大小初始化为内角数:
def _init_custom_layout(self):
"""Initializes camera calibration"""
# setting chessboard size
self.chessboard_size = (9, 6)
接下来,我们需要枚举所有对象点并为其分配对象点坐标,以便第一个点的坐标为(0, 0),第二个点的顶部坐标为(1, 0),最后一个坐标为(8, 5):
# prepare object points
self.objp = np.zeros((np.prod(self.chessboard_size), 3), dtype=np.float32)
self.objp[:, :2] = np.mgrid[0:self.chessboard_size[0],0:self.chessboard_size[1]].T.reshape(-1, 2)
我们还需要跟踪当前是否正在记录对象和图像点。 用户单击self.button_calibrate按钮后,我们将启动此过程。 之后,算法将尝试在所有后续帧中检测棋盘,直到检测到许多self.record_min_num_frames棋盘为止:
# prepare recording
self.recording = False
self.record_min_num_frames = 20
self._reset_recording()
每当单击self.button_calibrate按钮时,我们都会重置所有簿记变量,禁用该按钮,然后开始记录:
def _on_button_calibrate(self, event):
self.button_calibrate.Disable()
self.recording = True
self._reset_recording()
重置簿记变量包括清除记录的对象和图像点(self.obj_points和self.img_points)列表以及将检测到的棋盘(self.recordCnt)的数量重置为0:
def _reset_recording(self):
self.record_cnt = 0
self.obj_points = []
self.img_points = []
收集图像和对象点
_process_frame方法由负责完成校准技术的艰苦工作。 单击self.button_calibrate按钮后,此方法开始收集数据,直到检测到总共self.record_min_num_frames个棋盘为止:
def _process_frame(self, frame):
"""Processes each frame"""
# if we are not recording, just display the frame
if not self.recording:
return frame
# else we're recording
img_gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY).astype(np.uint8)
if self.record_cnt < self.record_min_num_frames:
ret, corners = cv2.findChessboardCorners(img_gray, self.chessboard_size, None)
cv2.findChessboardCorners函数将解析灰度图像(img_gray)以找到大小为self.chessboard_size的棋盘。 如果图像确实包含棋盘,则该函数将返回true(ret)以及棋盘角的列表(corners)。
然后,绘制棋盘很简单:
if ret:
cv2.drawChessboardCorners(frame, self.chessboard_size, corners, ret)
结果如下所示(为效果绘制彩色的棋盘角):

现在,我们可以简单地存储检测到的角的列表,然后移至下一帧。 但是,为了使校准尽可能准确,OpenCV 提供了完善角点测量的功能:
criteria = (cv2.TERM_CRITERIA_EPS +
cv2.TERM_CRITERIA_MAX_ITER, 30, 0.01)
cv2.cornerSubPix(img_gray, corners, (9, 9), (-1, -1),
criteria)
这会将检测到的角的坐标细化为子像素精度。 现在我们准备将对象和图像点添加到列表中,并前进帧计数器:
self.obj_points.append(self.objp)
self.img_points.append(corners)
self.record_cnt += 1
查找相机矩阵
一旦我们收集了足够的数据(即self.record_cnt达到self.record_min_num_frames的值),该算法就可以执行校准了。 只需调用cv2.calibrateCamera即可执行此过程:
else:
print "Calibrating..."
ret, K, dist, rvecs, tvecs = cv2.calibrateCamera(self.obj_points, self.img_points, (self.imgHeight, self.imgWidth), None, None)
函数成功返回true(ret),固有摄像机矩阵(K),畸变系数(dist)以及两个旋转和平移矩阵(rvecs和tvecs)。 目前,我们主要对摄像机矩阵和失真系数感兴趣,因为它们将使我们能够补偿内部摄像机硬件的任何缺陷。 我们将它们简单地打印在控制台上以便于检查:
print "K=", K
print "dist=", dist
例如,笔记本电脑网络摄像头的校准恢复了以下值:
K= [[ 3.36696445e+03 0.00000000e+00 2.99109943e+02]
[ 0.00000000e+00 3.29683922e+03 2.69436829e+02]
[ 0.00000000e+00 0.00000000e+00 1.00000000e+00]]
dist= [[ 9.87991355e-01 -3.18446968e+02 9.56790602e-02 -3.42530800e-02 4.87489304e+03]]
这告诉我们网络摄像头的焦距为fx=3366.9644像素和fy=3296.8392像素,光学中心为cx=299.1099像素和cy=269.4368像素。
一个好主意可能是仔细检查校准过程的准确率。 这可以通过使用恢复的相机参数将对象点投影到图像上来完成,以便我们可以将它们与通过cv2.findChessboardCorners函数收集的图像点列表进行比较。 如果两点大致相同,则表明校准成功。 更好的是,我们可以通过投影列表中的每个对象点来计算重建的平均误差:
mean_error = 0
for i in xrange(len(self.obj_points)):
img_points2, _ = cv2.projectPoints(self.obj_points[i], rvecs[i], tvecs[i], K, dist)
error = cv2.norm(self.img_points[i], img_points2, cv2.NORM_L2)/len(img_points2)
mean_error += error
print "mean error=", {} pixels".format(mean_error)
在笔记本电脑的网络摄像头上执行此检查会导致 0.95 像素的平均误差,该误差几乎接近零。
恢复内部摄像机参数后,我们现在可以着手拍摄世界的美丽,不失真的照片,可能是从不同的角度出发,以便可以从运动中提取某些结构。
设置应用
展望未来,我们将使用著名的开源数据集fountain-P11。 它描绘了从各个角度观看的瑞士喷泉。 下图显示了一个示例:

该数据集包含 11 张高分辨率图像,可以从这个页面下载。 如果我们自己拍摄照片,我们将必须经历整个相机校准过程才能恢复相机的固有矩阵和失真系数。 幸运的是,这些参数对于拍摄喷泉数据集的相机是已知的,因此我们可以继续在代码中对这些值进行硬编码。
main函数例程
我们的main函数例程将包括创建并与SceneReconstruction3D类的实例进行交互。 可以在chapter4.py文件中找到此代码,该文件导入所有必需的模块并实例化该类:
import numpy as np
from scene3D import SceneReconstruction3D
def main():
# camera matrix and distortion coefficients
# can be recovered with calibrate.py
# but the examples used here are already undistorted, taken
# with a camera of known K
K = np.array([[2759.48/4, 0, 1520.69/4, 0, 2764.16/4,1006.81/4, 0, 0, 1]]).reshape(3, 3)
d = np.array([0.0, 0.0, 0.0, 0.0, 0.0]).reshape(1, 5)
在此,K矩阵是拍摄喷泉数据集的摄像机的固有摄像机矩阵。 根据摄影师的说法,这些图像已经没有失真,因此我们将所有失真系数(d)设置为零。
注意
请注意,如果要在fountain-P11以外的数据集上运行本章介绍的代码,则必须调整固有摄像机矩阵和失真系数。
接下来,我们加载一对图像,我们希望将其应用从运动构造技术。 我将数据集下载到名为fountain_dense的子目录中:
# load a pair of images for which to perform SfM
scene = SceneReconstruction3D(K, d)
scene.load_image_pair("fountain_dense/0004.png", "fountain_dense/0005.png")
现在我们准备执行各种计算,例如:
scene.plot_optic_flow()
scene.draw_epipolar_lines()
scene.plot_rectified_images()
# draw 3D point cloud of fountain
# use "pan axes" button in pyplot to inspect the cloud (rotate
# and zoom to convince you of the result)
scene.plot_point_cloud()
下一节将详细解释这些函数。
SceneReconstruction3D类
本章的所有相关 3D 场景重构代码都可以在scene3D模块中的SceneReconstruction3D类中找到。 实例化后,该类存储要在所有后续计算中使用的固有摄像机参数:
import cv2
import numpy as np
import sys
from mpl_toolkits.mplot3d import Axes3D
import matplotlib.pyplot as plt
class SceneReconstruction3D:
def __init__(self, K, dist):
self.K = K
self.K_inv = np.linalg.inv(K)
self.d = dist
然后,第一步是加载要对其进行操作的一对图像:
def load_image_pair(self, img_path1, img_path2,downscale=True):
self.img1 = cv2.imread(img_path1, cv2.CV_8UC3)
self.img2 = cv2.imread(img_path2, cv2.CV_8UC3)
# make sure images are valid
if self.img1 is None:
sys.exit("Image " + img_path1 + " could not be loaded.")
if self.img2 is None:
sys.exit("Image " + img_path2 + " could not be loaded.")
如果加载的图像是灰度图像,则该方法会将其转换为 BGR 格式,因为其他方法期望使用三通道图像:
if len(self.img1.shape)==2:
self.img1 = cv2.cvtColor(self.img1, cv2.COLOR_GRAY2BGR)
self.img2 = cv2.cvtColor(self.img2, cv2.COLOR_GRAY2BGR)
在喷泉序列的情况下,所有图像均具有相对较高的分辨率。 如果设置了可选的downscale标志,则该方法会将图像缩小到大约 600 像素的宽度:
# scale down image if necessary
# to something close to 600px wide
target_width = 600
if downscale and self.img1.shape[1]>target_width:
while self.img1.shape[1] > 2*target_width:
self.img1 = cv2.pyrDown(self.img1)
self.img2 = cv2.pyrDown(self.img2)
另外,我们需要使用先前指定的失真系数(如果有)来补偿径向和切向透镜的失真:
self.img1 = cv2.undistort(self.img1, self.K, self.d)
self.img2 = cv2.undistort(self.img2, self.K, self.d)
最后,我们准备继续进行项目的工作-估计摄像机的运动并重建场景!
从一对图像估计相机运动
现在我们已经加载了相同场景的两个图像(self.img1和self.img2),例如来自源数据集的两个示例,我们发现自己处于与上一章类似的情况。 我们给出了两个图像,它们应该显示相同的刚性对象或静态场景,但视角不同。 但是,这次我们想更进一步。 如果在拍摄两张照片之间唯一改变的是相机的位置,我们是否可以通过查看匹配特征来推断相机的相对运动?
好吧,我们当然可以。 否则,这一章就没有多大意义了? 我们将把相机在第一张图像中的位置和方向作为给定,然后找出要重新定位和重新定位相机以使其视点与第二张图像相匹配的位置。
换句话说,我们需要在第二张图像中恢复摄像机的基本矩阵。 基本矩阵是4 x 3矩阵,它是4 x 3旋转矩阵和4 x 3平移矩阵的连接。 它通常表示为[R | t]。 您可以将其视为捕获第二张图像中相机相对于第一张图像中相机的位置和方向。
恢复基本矩阵(以及本章中的所有其他转换)的关键步骤是特征匹配。 我们可以重用上一章中的代码,然后对两个图像应用加速的鲁棒特征(SURF)检测器,或者计算两个图像之间的光通量。 用户可以通过指定特征提取模式来选择自己喜欢的方法,这将通过以下私有方法来实现:
def ___extract_keypoints(self, feat_mode):
if featMode == "SURF":
# feature matching via SURF and BFMatcher
self._extract_keypoints_surf()
else:
if feat_mode == "flow":
# feature matching via optic flow
self._extract_keypoints_flow()
else:
sys.exit("Unknown mode " + feat_mode+ ". Use 'SURF' or 'FLOW'")
使用丰富特征描述符的点匹配
正如我们在上一章中所看到的,快速可靠的提取图像重要特征的方法是使用 SURF 检测器。 在本章中,我们想将其用于两个图像self.img1和self.img2:
def _extract_keypoints_surf(self):
detector = cv2.SURF(250)
first_key_points, first_des = detector.detectAndCompute(self.img1, None)
second_key_points, second_desc = detector.detectAndCompute(self.img2, None)
对于特征匹配,我们将使用BruteForce匹配器,但其他匹配器(例如 FLANN)也可以使用:
matcher = cv2.BFMatcher(cv2.NORM_L1, True)
matches = matcher.match(first_desc, second_desc)
对于每个匹配项,我们需要恢复相应的图像坐标。 这些都保存在self.match_pts1和self.match_pts2列表中:
first_match_points = np.zeros((len(matches), 2), dtype=np.float32)
second_match_points = np.zeros_like(first_match_points)
for i in range(len(matches)):
first_match_points[i] =
first_key_points[matches[i].queryIdx].pt
second_match_points[i] =
second_key_points[matches[i].trainIdx].pt
self.match_pts1 = first_match_points
self.match_pts2 = second_match_points
以下屏幕截图显示了特征匹配器应用于喷泉序列的两个任意帧的示例:

使用光流的点匹配
丰富特征的替代品是使用光流。 光学流是通过计算位移向量来估计两个连续图像帧之间运动的过程。 可以为图像中的每个像素(密集)或仅针对选定点(稀疏)计算位移向量。
Lukas-Kanade 方法是计算密集光通量最常用的技术之一。 通过使用cv2.calcOpticalFlowPyrLK函数,可以用一行代码在 OpenCV 中实现。
但是在此之前,我们需要选择图像中值得跟踪的一些点。 同样,这是特征选择的问题。 如果我们只想对几个高度突出的图像点获得准确的结果,则可以使用 Shi-Tomasi 的cv2.goodFeaturesToTrack函数。 此函数可能会恢复以下特征:

但是,为了从运动推断结构,我们可能需要更多的特征,而不仅仅是最显着的哈里斯角。 一种替代方法是检测 FAST 特征:
def _extract_keypoints_flow(self):
fast = cv2.FastFeatureDetector()
first_key_points = fast.detect(self.img1, None)
然后我们可以计算这些特征的光通量。 换句话说,我们要在第二张图像中找到最有可能与第一张图像中的first_key_points相对应的点。 为此,我们需要将关键点列表转换为(x,y)坐标的 NumPy 数组:
first_key_list = [i.pt for i in first_key_points]
first_key_arr = np.array(first_key_list).astype(np.float32)
然后,光流将在第二张图像(second_key_arr)中返回相应特征的列表:
second_key_arr, status, err = cv2.calcOpticalFlowPyrLK(self.img1, self.img2, first_key_arr)
该函数还向返回状态位的向量(status),该状态位的向量指示是否已找到关键点的流,以及估计错误值的向量(err)。 如果我们忽略这两个附加向量,则恢复的流场可能看起来像这样:

在此图像中,从每个关键点的图像位置开始绘制一个箭头,该箭头从第一个图像中关键点的图像位置开始,指向第二个图像中相同关键点的图像位置。 通过检查流动图像,我们可以看到摄像机大部分向右移动,但是似乎还有一个旋转分量。 但是,其中一些箭头的确很大,而其中的一些则没有意义。 例如,右下角的像素实际上不可能一直一直移动到图像的顶部。 该特定关键点的流量计算很可能是错误的。 因此,我们要排除状态位为零或估计的误差大于某个值的所有关键点:
condition = (status == 1) * (err < 5.)
concat = np.concatenate((condition, condition), axis=1)
first_match_points = first_key_arr[concat].reshape(-1, 2)
second_match_points = second_key_arr[concat].reshape(-1, 2)
self.match_pts1 = first_match_points
self.match_pts2 = second_match_points
如果我们使用一组有限的关键点再次绘制流场,则图像将如下所示:
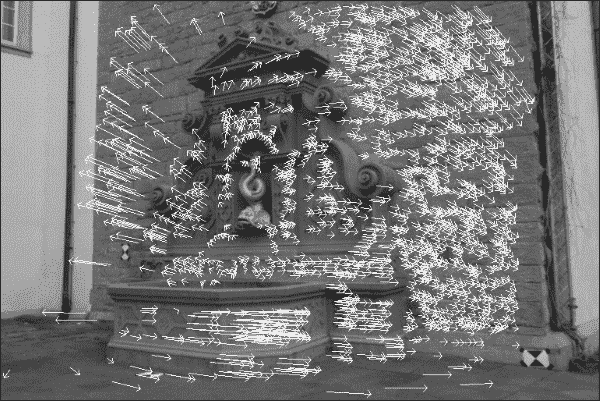
可以使用以下公共方法绘制流场,该方法首先使用前面的代码提取关键点,然后在图像上绘制实际线条:
def plot_optic_flow(self):
self._extract_key_points("flow")
img = self.img1
for i in xrange(len(self.match_pts1)):
cv2.line(img, tuple(self.match_pts1[i]), tuple(self.match_pts2[i]), color=(255, 0, 0))
theta = np.arctan2(self.match_pts2[i][1] – self.match_pts1[i][1], self.match_pts2[i][0] – self.match_pts1[i][0])
cv2.line(img, tuple(self.match_pts2[i]),
(np.int(self.match_pts2[i][0] – 6*np.cos(theta+np.pi/4)),
np.int(self.match_pts2[i][1] –
6*np.sin(theta+np.pi/4))), color=(255, 0, 0))
cv2.line(img, tuple(self.match_pts2[i]), (np.int(self.match_pts2[i][0] –6*np.cos(theta-np.pi/4)),np.int(self.match_pts2[i][1] –
6*np.sin(theta-np.pi/4))), color=(255, 0, 0))
for i in xrange(len(self.match_pts1)):
cv2.line(img, tuple(self.match_pts1[i]), tuple(self.match_pts2[i]), color=(255, 0, 0))
theta = np.arctan2(self.match_pts2[i][1] -self.match_pts1[i][1],self.match_pts2[i][0] - self.match_pts1[i][0])
cv2.imshow("imgFlow",img)
cv2.waitKey()
使用光流代替丰富特征的优点通常是过程更快,并且可以容纳更多点的匹配,从而使重建更加密集。
使用光流的警告是,它最适用于相同硬件连续拍摄的图像,而丰富特征对此几乎一无所知。
查找相机矩阵
现在我们已经获得了关键点之间的匹配,我们可以计算出两个重要的相机矩阵:基本矩阵和基本矩阵。 这些矩阵将根据旋转和平移分量指定摄像机的运动。 获得基本矩阵(self.F)是另一种 OpenCV 单行代码:
def _find_fundamental_matrix(self):
self.F, self.Fmask = cv2.findFundamentalMat(self.match_pts1, self.match_pts2, cv2.FM_RANSAC, 0.1, 0.99)
基本矩阵和基本矩阵之间的唯一区别是,后者在校正图像上运行:
def _find_essential_matrix(self):
self.E = self.K.T.dot(self.F).dot(self.K)
然后可以将基本矩阵(self.E)分解为旋转分量和平移分量,表示为[R | t],使用奇异值分解(SVD):
def _find_camera_matrices(self):
U, S, Vt = np.linalg.svd(self.E)
W = np.array([0.0, -1.0, 0.0, 1.0, 0.0, 0.0, 0.0, 0.0, 1.0]).reshape(3, 3)
使用单一的矩阵U和V结合其他矩阵W,我们现在可以重建[R | t]。 但是,可以证明该分解具有四个可能的解,而其中只有一个是有效的第二摄像机矩阵。 我们唯一能做的就是检查所有四个可能的解决方案,并找到一个可以预测所有成像关键点都位于两个摄像机前面的解决方案。
但在此之前,我们需要将关键点从 2D 图像坐标转换为同构坐标。 我们通过添加z坐标(将其设置为 1)来实现此目标:
first_inliers = []
second_inliers = []
for i in range(len(self.Fmask)):
if self.Fmask[i]:
first_inliers.append(self.K_inv.dot([self.match_pts1[i][0], self.match_pts1[i][1], 1.0]))
second_inliers.append(self.K_inv.dot([self.match_pts2[i][0], self.match_pts2[i][1], 1.0]))
然后,我们遍历四种可能的解决方案,并选择一种使_in_front_of_both_cameras返回True的解决方案:
# First choice: R = U * Wt * Vt, T = +u_3 (See Hartley
# & Zisserman 9.19)
R = U.dot(W).dot(Vt)
T = U[:, 2]
if not self._in_front_of_both_cameras(first_inliers,second_inliers, R, T):
# Second choice: R = U * W * Vt, T = -u_3
T = - U[:, 2]
if not self._in_front_of_both_cameras(first_inliers, second_inliers, R, T):
# Third choice: R = U * Wt * Vt, T = u_3
R = U.dot(W.T).dot(Vt)
T = U[:, 2]
if not self._in_front_of_both_cameras(first_inliers, second_inliers, R, T):
# Fourth choice: R = U * Wt * Vt, T = -u_3
T = - U[:, 2]
现在,我们终于可以构造[R | [t]这两个相机的矩阵。 第一个摄像机只是一个标准摄像机(不平移,也不旋转):
self.Rt1 = np.hstack((np.eye(3), np.zeros((3, 1))))
第二个摄影机矩阵由[R | t]较早恢复:
self.Rt2 = np.hstack((R, T.reshape(3, 1)))
__InFrontOfBothCameras私有方法是一个辅助函数,可确保每对关键点都映射到 3D 坐标,使它们位于两个摄像机的前面:
def _in_front_of_both_cameras(self, first_points, second_points, rot, trans):
rot_inv = rot
for first, second in zip(first_points, second_points):
first_z = np.dot(rot[0, :] - second[0]*rot[2, :], trans) / np.dot(rot[0, :] - second[0]*rot[2, :], second)
first_3d_point = np.array([first[0] * first_z, second[0] * first_z, first_z])
second_3d_point = np.dot(rot.T, first_3d_point) – np.dot(rot.T, trans)
如果函数找到不在两个摄像机前面的关键点,它将返回False:
if first_3d_point[2] < 0 or second_3d_point[2] < 0:
return False
return True
图像校正
也许,确保我们已恢复正确的相机矩阵的最简单方法是校正图像。 如果纠正正确,则; 第一张图片中的一个点和第二张图片中与同一 3D 世界点对应的点将位于相同的垂直坐标上。 在一个更具体的示例中,例如在我们的示例中,由于我们知道相机是直立的,因此我们可以验证校正后的图像中的水平线与 3D 场景中的水平线相对应。
首先,我们执行前面小节中描述的所有步骤来获得[R | [t]第二个相机的矩阵:
def plot_rectified_images(self, feat_mode="SURF"):
self._extract_keypoints(feat_mode)
self._find_fundamental_matrix()
self._find_essential_matrix()
self._find_camera_matrices_rt()
R = self.Rt2[:, :3]
T = self.Rt2[:, 3]
然后,可以使用两个 OpenCV 单线进行校正,该两个线性基于相机矩阵(self.K),失真系数(self.d),基本矩阵的旋转分量(R),以及基本矩阵(T)的平移成分:
R1, R2, P1, P2, Q, roi1, roi2 = cv2.stereoRectify(self.K, self.d, self.K, self.d, self.img1.shape[:2], R, T,
alpha=1.0)
mapx1, mapy1 = cv2.initUndistortRectifyMap(self.K, self.d, R1, self.K, self.img1.shape[:2], cv2.CV_32F)
mapx2, mapy2 = cv2.initUndistortRectifyMap(self.K, self.d, R2, self.K, self.img2.shape[:2], cv2.CV_32F)
img_rect1 = cv2.remap(self.img1, mapx1, mapy1, cv2.INTER_LINEAR)
img_rect2 = cv2.remap(self.img2, mapx2, mapy2, cv2.INTER_LINEAR)
为了确保校正正确,我们将两个校正后的图像(img_rect1和img_rect2)彼此相邻绘制:
total_size = (max(img_rect1.shape[0], img_rect2.shape[0]), img_rect1.shape[1] + img_rect2.shape[1], 3)
img = np.zeros(total_size, dtype=np.uint8)
img[:img_rect1.shape[0], :img_rect1.shape[1]] = img_rect1
img[:img_rect2.shape[0], img_rect1.shape[1]:] = img_rect2
我们还会在并排图像中每隔 25 个像素绘制一条蓝色的水平线,以进一步帮助我们直观地观察校正过程:
for i in range(20, img.shape[0], 25):
cv2.line(img, (0, i), (img.shape[1], i), (255, 0, 0))
cv2.imshow('imgRectified', img)
现在,我们可以轻松地使我们自己确信整改成功,如下所示:

重建场景
最后,我们可以利用称为三角剖分的过程来重建 3D 场景。 由于对极几何的工作方式,我们能够推断出点的 3D 坐标。 通过计算基本矩阵,我们可以比想象的更多地了解视觉场景的几何形状。 由于两台摄像机描绘的是同一真实世界场景,因此我们知道在这两个图像中都可以找到大多数 3D 真实世界点。 此外,我们知道从 2D 图像点到对应的 3D 现实世界点的映射将遵循几何规则。 如果我们研究足够多的图像点,则可以构造和求解(大型)线性方程组,以获得真实世界坐标的真实情况。
让我们回到瑞士喷泉数据集。 如果我们要求两位摄影师同时从不同的角度拍摄喷泉的照片,不难发现第一位摄影师可能会出现在第二位摄影师的照片中,反之亦然。 图像平面上其他拍摄者可见的点称为极点或对极点。 用更专业的术语来说,子极是一台相机的图像平面上另一台相机的投影中心投影到的点。 有趣的是,它们各自像面上的两个极点和两个投影中心都位于一条 3D 线上。 通过查看子极和图像点之间的线,我们可以限制图像点可能的 3D 坐标数。 实际上,如果投影点已知,那么对极线(即像点与子极之间的线)就已知,并且投影到第二张图像上的同一点也必须位于该特定对极线上。 令人困惑? 我是这么想的。 让我们看一下这些图像:

这里的每条线都是图像中特定点的对极线。 理想情况下,左侧图像中绘制的所有对极线都应在一个点处相交,并且该点通常位于图像外部。 如果计算准确,则该点应与从第一个摄像机看到的第二个摄像机的位置重合。 换句话说,左侧图像中的对极线告诉我们拍摄右侧图像的相机位于我们(即第一个相机的)右侧。 类似地,右侧图像中的对极线告诉我们,在左侧拍摄图像的相机位于我们(即第二相机的)左侧。
此外,对于在一个图像中观察到的每个点,必须在已知对极线上的另一个图像中观察到相同的点。 这被称为对极约束。 我们可以利用这一事实来表明,如果两个图像点对应于同一 3D 点,则这两个图像点的投影线必须在 3D 点处精确相交。 这意味着可以从两个图像点计算出 3D 点,这是我们接下来要做的。
幸运的是,OpenCV 再次提供了一个包装器来求解大量线性方程组。 首先,我们必须将匹配的特征点列表转换为 NumPy 数组:
first_inliers = np.array(self.match_inliers1).reshape(-1, 3)[:, :2]
second_inliers = np.array(self.match_inliers2).reshape(-1, 3)[:, :2]
接下来,使用前两个矩阵[R | Rt]进行三角剖分(第一个摄像机为self.Rt1,第二个摄像机为self.Rt2):
pts4D = cv2.triangulatePoints(self.Rt1, self.Rt2, first_inliers.T,second_inliers.T).T
这将使用 4D 齐次坐标返回真实的三角剖分点。 要将它们转换为 3D 坐标,我们需要将(X, Y, Z)坐标除以第四坐标,通常称为W:
pts3D = pts4D[:, :3]/np.repeat(pts4D[:, 3], 3).reshape(-1, 3)
3D 点云可视化
最后一步是可视化三角剖分的 3D 现实世界点。 创建 3D 散点图的一种简单方法是使用 Matplotlib。 但是,如果您正在寻找更专业的可视化工具,则可能对 Mayavi,VisPy 或点云库。 尽管后者还不支持 Python 对点云的可视化,但是它是用于点云分割,过滤和样本一致性模型拟合的出色工具。 有关更多信息,请访问这个页面上的 strawlab 的 GitHub 存储库。
在绘制 3D 点云之前,我们显然必须提取[R | Rt]矩阵并执行三角剖分,如前所述:
def plot_point_cloud(self, feat_mode="SURF"):
self._extract_keypoints(feat_mode)
self._find_fundamental_matrix()
self._find_essential_matrix()
self._find_camera_matrices_rt()
# triangulate points
first_inliers = np.array(self.match_inliers1).reshape(-1, 3)[:, :2]
second_inliers = np.array(self.match_inliers2).reshape(-1, 3)[:, :2]
pts4D = cv2.triangulatePoints(self.Rt1, self.Rt2,first_inliers.T, second_inliers.T).T
# convert from homogeneous coordinates to 3D
pts3D = pts4D[:, :3]/np.repeat(pts4D[:, 3], 3).reshape(-1, 3)
然后,我们要做的就是打开一个matplotlib图形,并在 3D 散点图中绘制pts3D的每个条目:
Ys = pts3D[:,0]
Zs = pts3D[:,1]
Xs = pts3D[:,2]
fig = plt.figure()
ax = fig.add_subplot(111, projection='3d')
ax.scatter(Xs, Ys, Zs, c='r', marker='o')
ax.set_xlabel('Y')
ax.set_ylabel('Z')
ax.set_zlabel('X')
plt.show()
使用pyplot的平移轴按钮进行研究时,其结果是最引人注目,它使您可以在所有三个维度上旋转和缩放点云。 这将立即清楚地表明,您看到的大多数点都位于同一平面上,即喷泉后面的墙,并且喷泉本身从该墙以负z坐标延伸。 令人信服地画出这个要困难一点,但是我们开始:
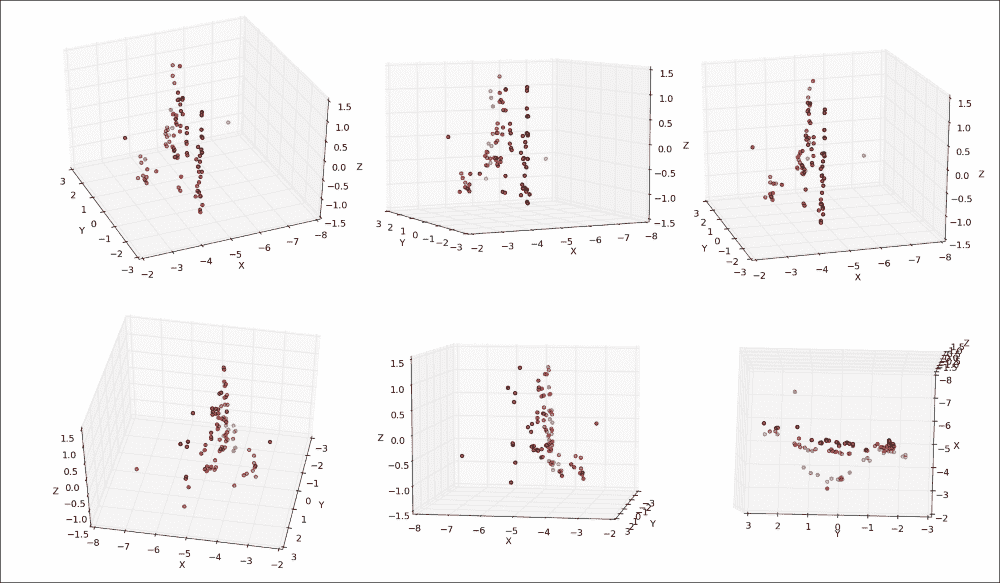
每个子图显示从不同角度观察到的喷泉的 3D 坐标。 在最上面一行中,我们从与上一个图像中的第二个摄像头相似的角度看喷泉,也就是说,是站在喷泉的右侧并稍微向前。 您可以看到大多数点如何映射到相似的x坐标,该坐标对应于喷泉后面的墙。 对于集中在z坐标-0.5和-1.0之间的点子集,x坐标有显着差异,显示了属于喷泉的表面的不同关键点。 下排的前两个面板从另一侧看喷泉。 最后一个面板显示了喷泉的鸟瞰图,在图像的下半部分突出了喷泉的轮廓为半圆。
总结
在本章中,我们通过推断同一相机拍摄的 2D 图像的几何特征,探索了一种 3D 场景重建方法。 我们编写了一个脚本来校准相机,您了解了基本矩阵和基本矩阵。 我们使用此知识执行三角剖分。 然后,我们继续在 3D 点云中可视化场景的真实几何形状。 通过在 Matplotlib 中使用简单的 3D 散点图,我们找到了一种使自己相信我们的计算准确且实用的方法。
从这里继续,可以将三角 3D 点存储在可以由点云库解析的文件中,或者对不同的图像对重复该过程,以便我们可以生成更密集,更准确的重建。 尽管本章已经介绍了很多内容,但还有很多工作要做。 通常,在谈论“从运动开始的结构”管道时,我们包括到目前为止还没有讨论的两个附加步骤:束调整和几何拟合。 在这种流水线中最重要的步骤之一是优化 3D 估计,以最大程度地减少重建误差。 通常,我们还希望从云中获取所有不属于我们感兴趣的对象的点。 但是,有了基本代码,您现在就可以继续编写自己的高级动感结构管道!
在下一章中,我们将远离刚性场景,而将重点放在跟踪场景中视觉上显着和移动的对象上。 这将使您了解如何处理非静态场景。 我们还将探索如何使算法快速专注于场景中的重要对象,这是一种已知的技术,可以加快对象检测,对象识别,对象跟踪和内容感知图像编辑的速度。
五、跟踪视觉上显着的对象
本章的目的是一次跟踪视频序列中的多个视觉上显着的对象。 与其自己在视频中标记感兴趣的对象,不如让算法确定视频帧的哪些区域值得跟踪。
以前,我们已经学习了如何在严格控制的场景中检测感兴趣的简单对象(例如人的手),或者如何从摄像机运动中推断出视觉场景的几何特征。 在本章中,我们将询问通过查看大量帧的图像统计数据,我们可以了解视觉场景。 通过分析自然图像的傅里叶光谱,我们将构建一个显着性图,这使我们可以将图像的某些统计上有意义的斑块标记为(潜在或) 原型对象。 然后,我们将所有原型对象的位置提供给均值漂移跟踪器,这将使我们能够跟踪对象从一帧移动到下一帧的位置。
要构建应用,我们需要结合以下两个主要功能:
- 显着性图:我们将使用傅立叶分析对自然图像统计数据有一个总体了解,这将有助于我们建立一个一般图像背景外观的模型。 通过将背景模型与特定的图像帧进行比较和对比,我们可以找到弹出其周围的图像子区域。 理想情况下,这些子区域与图像块相对应,这些块在观看图像时会立即引起我们的注意。
- 对象跟踪:找到图像的所有潜在有趣的块之后,我们将使用一种称为均值漂移跟踪的简单而有效的方法跟踪它们在许多帧上的运动。 由于场景中可能有多个原型对象,这些对象可能会随着时间的流逝而改变外观,因此我们需要能够区分它们并跟踪所有它们。
视觉显着性是认知心理学的技术术语,旨在描述某些物体或物品的视觉质量,以使它们立即引起我们的注意。 我们的大脑不断将视线移向视觉场景的重要区域,并随着时间的推移对其进行跟踪,从而使我们能够快速扫描周围的环境以找到有趣的物体和事件,而忽略了次要的部分。
下图显示了一个常规 RGB 图像及其转换为显着性图的示例,其中统计上有趣的弹出区域显得明亮而其他区域则较暗:

传统模型可能会尝试将特定特征与每个目标相关联(非常类似于第 3 章,“通过特征匹配和透视变换查找对象”的特征匹秘籍法),这会将问题转换为特定类别或对象的检测。 但是,这些模型需要人工标记和训练。 但是,如果不知道要跟踪的特征或对象数量怎么办?
取而代之的是,我们将尝试模仿大脑的行为,也就是说,将算法调整为自然图像的统计数据,以便我们可以立即在视觉场景中找到“吸引我们注意力”的模式或子区域(即偏离这些统计规律的模式),并标记它们以进行进一步检查。 结果是一种适用于场景中任意数量的原型对象的算法,例如跟踪足球场上的所有运动员。 请参考下图:
注意
本章使用 OpenCV 2.4.9,以及其他包 NumPy,wxPython 2.8 和 matplotlib。 尽管本章介绍的部分算法已添加到 OpenCV 3.0.0 发行版的可选Saliency模块中,但目前尚无 Python API,因此我们将编写自己的代码。
规划应用
最终的应用将将视频序列的每个 RGB 帧转换为显着图,提取所有有趣的原型对象,并将其提供给均值漂移跟踪算法。 为此,我们需要以下组件:
main:启动应用的main函数例程(在chapter5.py中)。Saliency:类从 RGB 彩色图像生成显着性图。 它包括以下公共方法:Saliency.get_saliency_map:将 RGB 彩色图像转换为显着图的主要方法Saliency.get_proto_objects_map:将显着性图转换为包含所有原型对象的二进制掩码的方法Saliency.plot_power_density:一种用于显示 RGB 彩色图像的 2D 功率密度的方法,有助于理解傅立叶变换Saliency.plot_power_spectrum:一种显示 RGB 彩色图像的径向平均功率谱的方法,有助于理解自然图像统计信息
MultiObjectTracker:一个类,使用均值漂移跟踪来跟踪视频中的多个对象。 它包含以下公共方法,该方法本身包含许多私有帮助器方法:MultiObjectTracker.advance_frame:结合从显着图和均值漂移跟踪获得的边界框,为新帧更新跟踪信息的方法
在以下各节中,我们将详细讨论这些步骤。
设置应用
为了运行我们的应用,我们将需要执行一个主函数例程,该例程读取视频流的帧,生成显着图,提取原型对象的位置,并将这些位置从一帧跟踪到下一帧。
main函数例程
主要处理流程由chapter5.py中的main函数处理,该函数实例化两个类(Saliency和MultipleObjectTracker)并打开一个视频文件,该文件显示了场上足球运动员的人数:
import cv2
import numpy as np
from os import path
from saliency import Saliency
from tracking import MultipleObjectsTracker
def main(video_file='soccer.avi', roi=((140, 100), (500, 600))):
if path.isfile(video_file):
video = cv2.VideoCapture(video_file)
else:
print 'File "' + video_file + '" does not exist.'
raise SystemExit
# initialize tracker
mot = MultipleObjectsTracker()
然后,该函数将逐帧读取视频,提取一些有意义的兴趣区域(出于说明目的),并将其提供给Saliency模块:
while True:
success, img = video.read()
if success:
if roi:
# grab some meaningful ROI
img = img[roi[0][0]:roi[1][0], roi[0][1]:roi[1][1]]
# generate saliency map
sal = Saliency(img, use_numpy_fft=False, gauss_kernel=(3, 3))
显着性将生成所有有趣的原型对象的映射,并将其馈入跟踪器模块。 跟踪器模块的输出是输入框,该输入框带有边框,如上图所示。
cv2.imshow("tracker", mot.advance_frame(img, sal.get_proto_objects_map(use_otsu=False)))
该应用将在视频的所有帧中运行,直到到达文件末尾或用户按下q键:
if cv2.waitKey(100) & 0xFF == ord('q'):
break
Saliency类
Saliency类的构造器接受视频帧,该视频帧可以是灰度或 RGB,还可以使用某些选项,例如使用 NumPy 还是 OpenCV 的傅里叶包:
def __init__(self, img, use_numpy_fft=True, gauss_kernel=(5, 5)):
self.use_numpy_fft = use_numpy_fft
self.gauss_kernel = gauss_kernel
self.frame_orig = img
显着图将从图像的向下采样版本生成,并且由于计算是相对耗时的,因此我们将维护一个标志need_saliency_map,以确保仅进行一次计算:
self.small_shape = (64, 64)
self.frame_small = cv2.resize(img, self.small_shape[1::-1])
# whether we need to do the math (True) or it has already
# been done (False)
self.need_saliency_map = True
从那时起,用户可以调用该类的任何公共方法,这些方法都将在同一图像上传递。
MultiObjectTracker类
跟踪器类的构造器很简单。 它所做的全部工作就是设置均值漂移跟踪的终止标准,并存储在随后的计算步骤中要考虑的最小轮廓区域(min_area)和最小逐帧漂移(min_shift2)的条件:
def __init__(self, min_area=400, min_shift2=5):
self.object_roi = []
self.object_box = []
self.min_cnt_area = min_area
self.min_shift2 = min_shift2
# Setup the termination criteria, either 100 iteration or move
# by at least 1 pt
self.term_crit = (cv2.TERM_CRITERIA_EPS | cv2.TERM_CRITERIA_COUNT, 100, 1)
从那时起,用户可以调用advance_frame方法将新的帧提供给跟踪器。
但是,在我们使用所有这些功能之前,我们需要了解图像统计信息以及如何生成显着性图。
视觉显着性
正如引言中已经提到的,视觉显着性试图描述某些物体或物品的视觉质量,从而使它们立即引起我们的注意。 我们的大脑不断将视线移向视觉场景的重要区域,就好像是将手电筒照在视觉世界的不同子区域上一样,从而使我们能够快速扫描周围的环境来寻找有趣的物体和事件,而忽略次要部分。
人们认为,这是一种进化策略,用于应对在视觉上丰富的环境中不断出现的信息溢出。 例如,如果您在丛林中漫步,您希望能够在欣赏您前方蝴蝶翅膀上复杂的色彩图案之前注意到左侧灌木丛中的猛虎。 结果,视觉上显着的对象具有突显其周围环境的卓越品质,非常类似于下图中的目标条:
弹出这些目标的视觉质量可能并不总是那么琐碎。 如果您正在查看左侧的图像,则可能会立即注意到图像中唯一的红色条。 但是,如果您以灰度查看同一图像,则目标条将很难找到(它是顶部的第四条,左边的第五条)。 与颜色显着性相似,右侧图像中有一个视觉上显着的条。 尽管目标栏在左侧图像中具有唯一的颜色,在右侧图像中具有独特的方向,但是将这两个特征放在一起,突然间,唯一的目标栏不再弹出:

在前面的显示中,再次有一个唯一且与其他所有酒吧都不相同的酒吧。 但是,由于分散注意力项目的设计方式,引导您走向目标栏的引人注目之处很少。 相反,您发现自己似乎随机地扫描图像,寻找有趣的东西。 (提示:目标是图像中唯一的红色且几乎垂直的条形,顶部为第二行,左侧为第三列。)
您问,这与计算机视觉有什么关系? 实际上,很多。 人工视觉系统像您和我一样遭受信息超载的困扰,除了它们对世界的了解比我们少。 如果我们可以从生物学中汲取一些见识并将其用于教导我们的算法有关世界的知识该怎么办? 想象一下您的汽车中的仪表板摄像头会自动聚焦在最相关的交通标志上。 想象一下一个监视摄像头,它是野生动植物观测站的一部分,它将自动检测并跟踪臭名昭著的害羞鸭嘴兽的踪迹,但会忽略其他一切。 我们如何教导算法什么是重要的而不是什么? 我们如何使鸭嘴兽“弹出”?
傅立叶分析
为了找到图像的视觉显着子区域,我们需要查看其频谱。 到目前为止,我们已经处理了空间域中的所有图像和视频帧; 也就是说,通过分析像素或研究图像强度在图像的不同子区域中如何变化。 但是,图像也可以在频域中表示; 也就是说,通过分析像素频率或研究像素在图像中出现的频率和频率。
通过应用傅里叶变换,可以将图像从空间域转换到频域。 在频域中,我们不再考虑图像坐标(x, y)。 相反,我们旨在找到图像的光谱。 傅立叶的激进思想基本上可以归结为以下问题:如果将任何信号或图像转换成一系列圆形路径(也称为谐波)怎么办?
例如,想想彩虹。 美丽,不是吗? 在彩虹中,白色的阳光(由许多不同的颜色或光谱的一部分组成)散布在其光谱中。 当光线穿过雨滴时(类似于穿过玻璃棱镜的白光),这里的阳光光谱就会暴露出来。 傅立叶变换的目的是做同样的事情:恢复阳光中包含的光谱的所有不同部分。
对于任意图像,可以实现类似的效果。 与彩虹相反,在彩虹中,频率对应于电磁频率,对于图像,我们将其视为空间频率; 即,像素值的空间周期性。 在监狱牢房的图像中,您可以将空间频率视为两个相邻监狱钢筋之间的距离(的倒数)。
从这种观点转变中可以获得的见解非常有力。 在不赘述的情况下,让我们仅说明一下,傅立叶频谱同时具有幅度和相位。 幅度描述了图像中不同频率的数量,而相位则讨论了这些频率的空间位置。 下图在左侧显示了自然图像,在右侧显示了相应的傅立叶幅度谱(灰度版本):

右边的幅度谱告诉我们,在左边图像的灰度版本中,哪些频率分量最突出(明亮)。 调整频谱,使图像的中心对应于 x 和 y 中的零频率。 移到图像的边界越远,频率越高。 这个特殊的频谱告诉我们,左侧图像中有很多低频分量(聚集在图像中心附近)。
在 OpenCV 中,可以使用Saliency类的plot_magnitude方法,通过离散傅里叶变换(DFT)实现此变换。 步骤如下:
-
如有必要,将图像转换为灰度:因为该方法同时接受灰度和 RGB 彩色图像,所以我们需要确保对单通道图像进行操作:
def plot_magnitude(self): if len(self.frame_orig.shape)>2: frame = cv2.cvtColor(self.frame_orig, cv2.COLOR_BGR2GRAY) else: frame = self.frame_orig -
扩展图像至最佳尺寸:事实证明 DFT 的性能取决于图像尺寸。 对于第二个倍数的图像,它往往最快。 因此,通常最好用零填充图像:
rows, cols = self.frame_orig.shape[:2] nrows = cv2.getOptimalDFTSize(rows) ncols = cv2.getOptimalDFTSize(cols) frame = cv2.copyMakeBorder(frame, 0, ncols-cols, 0, nrows-rows, cv2.BORDER_CONSTANT, value = 0) -
应用 DFT:这是 NumPy 中的单个函数调用。 结果是复数的 2D 矩阵:
img_dft = np.fft.fft2(frame) -
将实数和复数值转换为幅度:复数具有实数(Re)和复数(虚数,Im)。 要提取幅度,我们取绝对值:
magn = np.abs(img_dft) -
切换到对数刻度:结果表明,傅立叶系数的动态范围通常太大而无法在屏幕上显示。 我们有一些小的和一些高变化的值,我们无法像这样观察到。 因此,高值将全部显示为白点,小值将全部显示为黑点。 要使用灰度值进行可视化,我们可以将线性比例转换为对数比例:
log_magn = np.log10(magn) -
平移象限:使光谱在图像上居中。 这样可以更容易地目视检查幅度谱:
spectrum = np.fft.fftshift(log_magn) -
返回绘制的结果:
return spectrum/np.max(spectrum)*255
自然场景统计
人的大脑很久以前就想出了如何聚焦于视觉上显着的物体。 我们所生活的自然世界具有一些统计规律,使其与棋盘图案或随机的公司徽标相反,具有独特的自然。 最常见的统计规律可能是1 / f定律。 它指出自然图像的整体幅度遵循1 / f分布,如下图所示。这有时也称为比例不变。
可以使用Saliency类的plot_power_spectrum方法可视化 2D 图像的 1D 功率谱(作为频率的函数)。 我们可以使用与以前使用的幅值谱类似的方法,但是必须确保将 2D 谱正确折叠到一个轴上。
-
如有必要,将图像转换为灰度(与之前相同):
def plot_power_spectrum(self): if len(self.frame_orig.shape)>2: frame = cv2.cvtColor(self.frame_orig, cv2.COLOR_BGR2GRAY) else: frame = self.frame_orig -
将图像扩展到最佳尺寸(与之前相同):
rows, cols = self.frame_orig.shape[:2] nrows = cv2.getOptimalDFTSize(rows) ncols = cv2.getOptimalDFTSize(cols) frame = cv2.copyMakeBorder(frame, 0, ncols-cols, 0, nrows-rows, cv2.BORDER_CONSTANT, value = 0) -
应用 DFT 并获取对数谱:在这里,我们为用户提供了一个选项(通过标志
use_numpy_fft),以使用 NumPy 或 OpenCV 的傅里叶工具:if self.use_numpy_fft: img_dft = np.fft.fft2(frame) spectrum = np.log10(np.real(np.abs(img_dft))**2) else: img_dft = cv2.dft(np.float32(frame), flags=cv2.DFT_COMPLEX_OUTPUT) spectrum = np.log10(img_dft[:,:,0]**2 + img_dft[:,:,1]**2) -
进行径向平均:这是棘手的部分。 仅在 x 或 y 方向上对 2D 光谱求平均是错误的。 我们感兴趣的是频谱与频率的关系,与确切的方向无关。 有时也称为径向平均功率谱(RAPS),可以通过对所有频率幅值求和来实现,从图像的中心开始, 从某个频率
r到r+dr进入所有可能的(径向)方向。 我们使用 NumPy 直方图的合并功能对数字求和,并将它们累加在变量histo中:L = max(frame.shape) freqs = np.fft.fftfreq(L)[:L/2] dists = np.sqrt(np.fft.fftfreq(frame.shape[0])[:,np.newaxis]**2 + np.fft.fftfreq(frame.shape[1])**2) dcount = np.histogram(dists.ravel(), bins=freqs)[0] histo, bins = np.histogram(dists.ravel(), bins=freqs,weights=spectrum.ravel()) -
绘制结果:最后,我们可以绘制历史数据中的累积数,但一定不要忘记通过箱子大小(
dcount)将其标准化:centers = (bins[:-1] + bins[1:]) / 2 plt.plot(centers, histo/dcount) plt.xlabel('frequency') plt.ylabel('log-spectrum') plt.show()
结果是与频率成反比的函数。 如果要绝对确定1 / f属性,则可以取所有x值的np.log10并确保曲线大致呈线性减小。 在线性x轴和对数y轴上,曲线如下所示:
此属性非常。 它指出,如果我们对自然场景拍摄的所有图像的所有光谱求平均(当然,忽略了使用奇特图像过滤器拍摄的所有光谱),我们将得到一条曲线,看起来与前一个图像相似。
但是回到利马特河上一艘宁静的小船的图像,那单个图像呢? 我们刚刚查看了此图像的功率谱,并见证了1 / f属性。 我们如何利用自然图像统计知识告诉算法,不要盯着左边的树,而是专注于在水里的船?

这就是我们意识到显着性真正含义的地方。
使用光谱残差法生成显着图
在图像中值得我们关注的事物不是遵循1 / f定律的图像斑块,而是从平滑曲线中伸出的斑块。 换句话说,统计异常。 这些异常称为图像的光谱残差,并对应于图像(或原型物体)的潜在有趣的色块。 将这些统计异常显示为亮点的图称为显着图。
注意
此处描述的频谱残留方法基于 Hou Xiaodi 和 Zhang Liqing (2007)的原始科学出版物,《显着性检测:频谱残留方法》。
为了基于光谱残差法生成显着图,我们需要分别处理输入图像的每个通道(在灰度输入图像的情况下为单个通道,在 RGB 输入图像的情况下为三个独立通道) 。
可以使用以下方法通过专用方法Saliency._get_channel_sal_magn生成单个通道的显着图:
-
再次使用 NumPy 的
fft模块或 OpenCV 功能,计算图像的(幅度和相位)傅里叶光谱:def _get_channel_sal_magn(self, channel): if self.use_numpy_fft: img_dft = np.fft.fft2(channel) magnitude, angle = cv2.cartToPolar(np.real(img_dft), np.imag(img_dft)) else: img_dft = cv2.dft(np.float32(channel), flags=cv2.DFT_COMPLEX_OUTPUT) magnitude, angle = cv2.cartToPolar(img_dft[:, :, 0], img_dft[:, :, 1]) -
计算傅立叶光谱的对数幅度。 我们将幅度的下限裁剪为
1e-9,以便在计算对数时防止被零除:log_ampl = np.log10(magnitude.clip(min=1e-9)) -
通过使用局部平均过滤器对图像进行卷积来近似估计自然图像的平均光谱:
log_ampl_blur = cv2.blur(log_amlp, (3, 3)) -
计算光谱残差。 光谱残差主要包含场景的非平凡(或意外)部分。
magn = np.exp(log_amlp – log_ampl_blur) -
再次通过 NumPy 中的
fft模块或使用 OpenCV 使用傅立叶逆变换来计算显着性图:if self.use_numpy_fft: real_part, imag_part = cv2.polarToCart(residual, angle) img_combined = np.fft.ifft2(real_part + 1j*imag_part) magnitude, _ = cv2.cartToPolar( np.real(img_combined), np.imag(img_combined)) else: img_dft[:, :, 0], img_dft[:, :, 1] = cv2.polarToCart( residual, angle) img_combined = cv2.idft(img_dft) magnitude, _ = cv2.cartToPolar(img_combined[:, :, 0], img_combined[:, :, 1]) return magnitude
然后将生成的单通道显着性映射(magnitude)返回到Saliency.get_saliency_map,在此对输入图像的所有通道重复此过程。 如果输入图像是灰度图像,那么我们就完成了:
def get_saliency_map(self):
if self.need_saliency_map:
# haven't calculated saliency map for this frame yet
num_channels = 1
if len(self.frame_orig.shape)==2:
# single channel
sal = self._get_channel_sal_magn(self.frame_small)
但是,如果输入图像具有多个通道(例如 RGB 彩色图像),我们需要分别考虑每个通道:
else:
# consider each channel independently
sal = np.zeros_like(self.frame_small).astype(np.float32)
for c in xrange(self.frame_small.shape[2]):
sal[:, :, c] = self._get_channel_sal_magn(self.frame_small[:, :, c])
然后,由所有通道的平均值确定多通道图像的整体显着性:
sal = np.mean(sal, 2)
最后,我们需要进行一些后期处理,例如可选的模糊处理,以使结果看起来更平滑:
if self.gauss_kernel is not None:
sal = cv2.GaussianBlur(sal, self.gauss_kernel,
sigmaX=8, sigmaY=0)
同样,我们需要对sal中的值求平方,以突出显示高显着性的区域,如原始论文的作者所概述的那样。 为了显示图像,我们将其缩放回其原始分辨率并对其值进行归一化,以使最大值为 1:
sal = sal**2
sal = np.float32(sal)/np.max(sal)
sal = cv2.resize(sal, self.frame_orig.shape[1::-1])
为了避免重做所有这些繁琐的计算,我们存储了显着性图的本地副本以供进一步参考,并确保降低标志:
self.saliency_map = sal
self.need_saliency_map = False
return self.saliency_map
然后,当用户对依赖于引擎盖下显着图的计算的类方法进行后续的调用时,我们可以简单地引用本地副本,而不必再次进行计算。
然后,所得的显着性贴图如下图所示:
现在我们可以清楚地看到船在水中(左下角),该船似乎是图像中最突出的子区域之一。 还有其他显着区域,例如右侧的 Grossmünster(您猜猜这座城市吗?)。
注意
顺便说一句,图像中这两个区域是最显着的区域的原因似乎是清楚无可争辩的证据,表明该算法意识到苏黎世市中心可笑的教堂塔楼数量之多,有效地阻止了它们被标记为“突出”的可能性。
在场景中检测原型对象
从某种意义上说,显着性图已经是原型对象的明确表示形式,因为它仅包含图像的有趣的部分。 因此,既然我们已经完成了所有艰苦的工作,为了获得原型图,剩下要做的就是对显着图进行阈值处理。
此处要考虑的唯一开放参数是阈值。 将阈值设置得太低将导致将很多区域标记为原型对象,包括一些可能不包含任何感兴趣内容的区域(错误警报)。 另一方面,将阈值设置得太高将忽略图像中的大多数显着区域,并可能使我们根本没有原型对象。 原始光谱残留论文的作者选择仅将图像的那些区域标记为原始对象,其显着性大于图像平均显着性的三倍。 通过将输入标志use_otsu设置为true,我们为用户提供了实现此阈值或采用大津阈值的选择:
def get_proto_objects_map(self, use_otsu=True):
然后,我们检索当前帧的显着性图,并确保将其转换为uint8精度,以便可以将其传递给cv2.threshold:
saliency = self.get_saliency_map()
if use_otsu:
_, img_objects = cv2.threshold(np.uint8(saliency*255), 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
否则,我们将使用阈值thresh:
else:
thresh = np.mean(saliency)*255
_, img_objects = cv2.threshold(np.uint8(saliency*255), thresh, 255, cv2.THRESH_BINARY)
return img_objects
生成的原始对象遮罩如下图所示:

然后,原始对象遮罩用作跟踪算法的输入。
均值漂移跟踪
事实证明,前面讨论的显着性检测器本身已经是对原型物体的出色跟踪器。 只需将算法应用于视频序列的每一帧,就可以很好地了解对象的位置。 但是,丢失的是对应信息。 想象一下从市中心或体育馆等繁忙场景的视频片段。 尽管显着性图可以突出显示已录制视频的每个帧中的所有原始对象,但是该算法无法知道前一帧中的哪些原始对象在当前帧中仍然可见。 另外,原始对象映射可能包含一些假正例,例如以下示例:

请注意,从原始对象映射中提取的边界框在上一个示例中犯了(至少)三个错误:错过了突出显示玩家(左上),将两个玩家合并到同一个边界框中,以及突出显示了一些其他对象,它们可以说是无趣的(尽管在视觉上很显眼)。 为了改善这些结果,我们想利用跟踪算法。
为了解决对应问题,我们可以使用以前学习的方法,例如特征匹配和光流。 或者,我们可以使用另一种称为均值漂移跟踪的技术。
均值平移是一种用于跟踪任意对象的简单但非常有效的技术。 均值平移背后的直觉是考虑从最能描述一个目标的潜在概率密度函数中采样的一个较小的兴趣区域(例如,我们要跟踪的对象的边界框)中的像素。
例如,考虑以下图像:
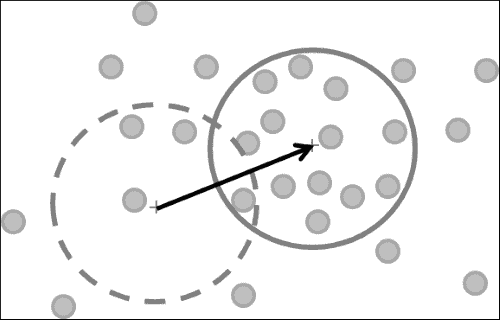
在这里,小的灰色点表示来自概率分布的样本。 假设点越近,它们彼此之间越相似。 直观地讲,均值偏移试图做的是在该景观中找到最密集的区域并在其周围绘制一个圆圈。 该算法可能首先将圆心定在风景完全不密集的区域上(虚线圆)。 随着时间的流逝,它将缓慢地移向最密集的区域(实心圆)并锚定在其上。 如果我们将景观设计为比点更有意义(例如,通过使点对应于图像小邻域中的颜色直方图),则可以使用均值平移跟踪,通过查找最接近目标对象直方图的直方图,来找到场景中感兴趣的对象。
均值平移具有许多应用(例如聚类或寻找概率密度函数的模式),但它也特别适合于目标跟踪。 在 OpenCV 中,该算法在cv2.meanShift中实现,但需要进行一些预处理才能正确运行。 我们可以将过程概述如下:
- 在每个数据点周围固定一个窗口:例如,围绕对象或兴趣区域的边界框。
- 计算窗口内的数据平均值:在跟踪的情况下,通常将其实现为兴趣区域中像素值的直方图。 为了在彩色图像上获得最佳性能,我们将转换为 HSV 色彩空间。
- 将窗口移至均值并重复直到收敛:
cv2.meanShift透明地处理了此问题。 通过指定终止条件,我们可以控制迭代方法的长度和准确率。
自动跟踪足球场上的所有球员
在本章的其余部分,我们的目标是将显着性检测器与均值漂移跟踪相结合,以自动跟踪足球场上的所有球员。 由显着性检测器识别的原始对象将用作均值漂移跟踪器的输入。 具体而言,我们将重点关注 Alfheim 数据集的视频序列,该视频序列可从这个页面中免费获取。
结合两种算法(显着性图和均值漂移跟踪)的原因是为了消除误报并提高整体跟踪的准确率。 这将分两步完成:
- 显着性检测器和均值漂移跟踪都可以为框架中的所有原始对象装配边界框列表。 显着性检测器将在当前帧上运行,而均值漂移跟踪器将尝试从当前帧中的前一帧查找原型对象。
- 仅保留两种算法在位置和大小上都一致的边界框。 这将消除被两种算法之一误标记为原型对象的离群值。
辛苦的工作是由先前引入的MultiObjectTracker类及其advance_frame方法完成的。 该方法依赖于一些私有工作者方法,下面将对其进行详细说明。 每当有新帧到达时,都会调用advance_frame方法,并接受原型对象图作为输入:
def advance_frame(self, frame, proto_objects_map):
self.tracker = copy.deepcopy(frame)
然后,该方法构建所有候选边界框的列表,将当前帧的显着性图中的边界框以及从前一帧到当前帧的均值漂移跟踪结果进行组合:
# build a list of all bounding boxes
box_all = []
# append to the list all bounding boxes found from the
# current proto-objects map
box_all = self._append_boxes_from_saliency(proto_objects_map,box_all)
# find all bounding boxes extrapolated from last frame
# via mean-shift tracking
box_all = self._append_boxes_from_meanshift(frame, box_all)
然后,该方法尝试合并候选边界框以删除重复项。 这可以通过cv2.groupRectangles实现,如果group_thresh+1或更多边界框在图像中重叠,它将返回一个边界框:
# only keep those that are both salient and in mean shift
if len(self.object_roi)==0:
group_thresh = 0 # no previous frame: keep all form
# saliency
else:
group_thresh = 1 # previous frame + saliency
box_grouped,_ = cv2.groupRectangles(box_all, group_thresh, 0.1)
为了进行平均移动,我们将不得不做一些簿记工作,以下各小节将对此进行详细说明:
# update mean-shift bookkeeping for remaining boxes
self._update_mean_shift_bookkeeping(frame, box_grouped)
然后,我们可以在输入图像上绘制唯一边界框的列表,并返回该图像以进行绘制:
for (x, y, w, h) in box_grouped:
cv2.rectangle(self.tracker, (x, y), (x + w, y + h),(0, 255, 0), 2)
return self.tracker
提取原型对象的边界框
第一个私有工作者方法相对简单。 它以原型对象图和边界框(以前聚合的)列表作为输入。 在此列表中,它将添加从原型对象的轮廓中找到的所有边界框:
def _append_boxes_from_saliency(self, proto_objects_map, box_all):
box_sal = []
cnt_sal, _ = cv2.findContours(proto_objects_map, 1, 2)
但是,它将丢弃小于某个阈值self.min_cnt_area的边界框,该阈值是在构造器中设置的:
for cnt in cnt_sal:
# discard small contours
if cv2.contourArea(cnt) < self.min_cnt_area:
continue
结果将附加到box_all列表中,并传递进行进一步处理:
# otherwise add to list of boxes found from saliency map
box = cv2.boundingRect(cnt)
box_all.append(box)
return box_all
为均值漂移跟踪设置必要的簿记
第二种私有工作者方法与有关,它设置了执行均值平移跟踪所需的所有簿记。 该方法接受输入图像和边界框列表,为其生成簿记信息:
def _update_mean_shift_bookkeeping(self, frame, box_grouped):
簿记主要包括计算每个原型对象边界框的 HSV 颜色值的直方图。 因此,输入的 RGB 图像立即转换为 HSV:
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
然后,解析box_grouped中的每个边界框。 我们需要存储边界框的位置和大小(self.object_box),以及 HSV 颜色值的直方图(self.object_roi):
self.object_roi = []
self.object_box = []
从列表中提取边界框的位置和大小,并从 HSV 图像中切出兴趣区域:
for box in box_grouped:
(x, y, w, h) = box
hsv_roi = hsv[y:y + h, x:x + w]
然后,我们计算兴趣区域中所有色相(H)值的直方图。 我们还通过使用遮罩忽略边界框的暗淡或微弱的区域,并最终对直方图进行归一化:
mask = cv2.inRange(hsv_roi, np.array((0., 60., 32.)), np.array((180., 255., 255.)))
roi_hist = cv2.calcHist([hsv_roi], [0], mask, [180], [0, 180])
cv2.normalize(roi_hist, roi_hist, 0, 255, cv2.NORM_MINMAX)
然后,我们将此信息存储在相应的私有成员变量中,以便在过程循环的下一帧中可用,我们将使用均值漂移算法来定位兴趣区域 :
self.object_roi.append(roi_hist)
self.object_box.append(box)
使用均值漂移算法跟踪对象
最后,第三种私有工作者方法通过使用先前帧中存储的簿记信息来跟踪原型对象。 与_append_boxes_from_meanshift相似,我们建立了一个从均值偏移聚合的所有边界框的列表,并将其传递给进一步处理。 该方法接受输入图像和以前聚合的边界框列表:
def _append_boxes_from_meanshift(self, frame, box_all):
hsv = cv2.cvtColor(frame, cv2.COLOR_BGR2HSV)
然后,该方法解析所有先前存储的原型对象(来自self.object_roi和self.object_box):
for i in xrange(len(self.object_roi)):
roi_hist = copy.deepcopy(self.object_roi[i])
box_old = copy.deepcopy(self.object_box[i])
为了找到记录在先前图像帧中的兴趣区域的新的,已移位的位置,我们将反向投影的兴趣区域馈送到均值漂移算法。 终止条件(self.term_crit)将确保尝试足够的迭代次数(100),并寻找至少一些像素(1)的均值偏移:
dst = cv2.calcBackProject([hsv], [0], roi_hist, [0, 180], 1)
ret, box_new = cv2.meanShift(dst, tuple(box_old), self.term_crit)
但是,在将新检测到的,已移动的边界框添加到列表之前,我们要确保我们实际上正在跟踪移动的对象。 不移动的对象很可能是假正例,例如与当前任务无关的线条标记或其他视觉上显着的斑点。
为了舍弃无关的跟踪结果,我们比较了前一帧(box_old)和当前帧(box_new)对应的边界框的位置:
(xo, yo, wo, ho) = box_old
(xn, yn, wn, hn) = box_new
如果它们的重心至少没有偏移sqrt(self.min_shift2)像素,则我们不在列表中包括边界框:
co = [xo + wo/2, yo + ho/2]
cn = [xn + wn/2, yn + hn/2]
if (co[0] - cn[0])**2 + (co[1] - cn[1])**2 >= self.min_shift2:
box_all.append(box_new)
生成的边界框列表再次传递给进一步处理:
return box_all
全部放在一起
下图显示了我们应用的结果:
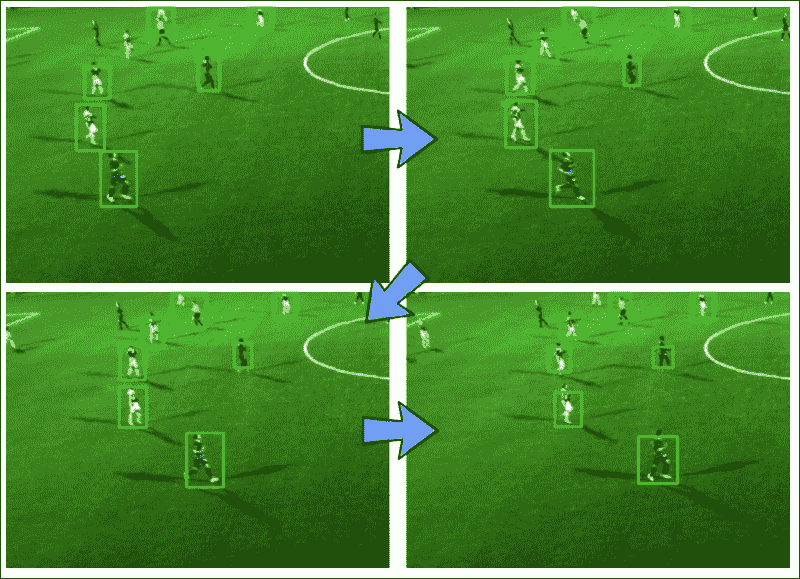
在整个视频序列中,该算法能够拾取玩家的位置,通过使用均值漂移跟踪成功逐帧跟踪他们,并将所得边界框与显着性探测器返回的边界框进行组合。
只有通过显着性图和跟踪的巧妙组合,我们才能排除假正例,例如显着性图的线标记和伪影。 不可思议的事情发生在cv2.groupRectangles中,它需要一个类似的边界框在box_all列表中至少出现两次,否则将被丢弃。 这意味着,只有均值漂移跟踪和显着图(大致)都同意边界框的位置和大小时,才将边界框保留在列表中。
总结
在本章中,我们探索了一种在视觉场景中标记潜在有趣对象的方法,即使它们的形状和数量未知。 我们使用傅里叶分析探索了自然图像统计数据,并实现了一种用于提取自然场景中视觉显着区域的最新方法。 此外,我们将显着性检测器的输出与跟踪算法结合在一起,可以跟踪足球比赛视频序列中形状和数量未知的多个对象。
现在将有可能扩展我们的算法,使其具有原型对象的更复杂的特征描述。 实际上,当对象快速改变大小时,均值漂移跟踪可能会失败,例如,如果感兴趣的对象要直接对准相机,就会出现这种情况。 在 OpenCV 中免费提供的更强大的跟踪器是cv2.CamShift。 CAMShift 代表连续自适应均值偏移,并在均值偏移后赋予功率以自适应地更改窗口大小。 当然,也可以用先前研究的技术(例如特征匹配或光流)简单地替换均值漂移跟踪器。
在下一章中,我们将进入机器学习的迷人领域,这将使我们能够构建功能更强大的对象描述符。 具体而言,我们将集中于检测图像中的路标(在哪里?)和识别(什么?)。 这将使我们能够训练可在您的汽车仪表盘相机中使用的分类器,并使我们熟悉机器学习和对象识别的重要概念。