选择与训练模型
使用线性回归
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared, housing_labels)
housing_predictions = lin_reg.predict(housing_prepared)
lin_mse = mean_squared_error(housing_labels, housing_predictions)
lin_rmse = np.sqrt(lin_mse)
# 太高的表示Underfit
print(lin_rmse) # 68627.87390018745
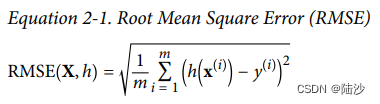
使用决策树
from sklearn.metrics import mean_squared_error
from sklearn.tree import DecisionTreeRegressor
tree_reg = DecisionTreeRegressor()
tree_reg.fit(housing_prepared, housing_labels)
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
# 太低的表示overfit
print(tree_rmse) # 0.0
k-fold cross-validation
fold指不同的数据子集。k-fold cross-validation就是随机产生k个fold,每次选一个fold来评估效果,其他k-1个fold用来训练。这样会得到k个评估分数。
由于scikit-learn的cross-validation用的是utility function(越大越好)而非cost function(越小越好),所以这里选用了负数的mse。
def display_scores(scores):
print("Scores: ", scores)
print("Mean: ", scores.mean())
print("Standard deviation: ", scores.std())
...
from sklearn.tree import DecisionTreeRegressor
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score
tree_reg = DecisionTreeRegressor()
scores = cross_val_score(tree_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
tree_rmse_scores = np.sqrt(-scores)
print(display_scores(tree_rmse_scores))
scores2 = cross_val_score(LinearRegression(), housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
lin_rmse_scores = np.sqrt(-scores2)
print(display_scores(lin_rmse_scores))
from sklearn.ensemble import RandomForestRegressor
forest_reg = RandomForestRegressor()
scores3 = cross_val_score(forest_reg, housing_prepared, housing_labels,
scoring="neg_mean_squared_error", cv=10)
forest_rmse_scores = np.sqrt(-scores3)
print(display_scores(forest_rmse_scores))
Scores: [72747.0548719 69975.38915452 68277.88913022 71825.88436612
69330.68736727 76568.19953125 72764.63740705 72219.04604848
69031.97373315 70374.45146712]
Mean: 71311.52130770871
Standard deviation: 2321.1947983407713
Scores: [71762.76364394 64114.99166359 67771.17124356 68635.19072082
66846.14089488 72528.03725385 73997.08050233 68802.33629334
66443.28836884 70139.79923956]
Mean: 69104.07998247063
Standard deviation: 2880.3282098180657
Scores: [51627.53671267 49369.27783646 46517.4011464 51846.1271283
47431.17962375 51357.65695338 52565.55993554 49896.31387898
48580.76091798 53639.76973388]
Mean: 50283.15838673507
Standard deviation: 2192.6847023341056
可以看到,随机森林的效果好一点点。
保存模型可以用joblib包:
import joblib
joblib.dump(forest_reg, "forest_regression.pkl")
使用时:
import joblib
my_model_loaded = joblib.load("forest_regression.pkl")
y_pred = my_model_loaded.predict(X_test)
Fine-tune(微调)
Grid Search
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
forest_reg = RandomForestRegressor()
param_grid = [
{'n_estimators': [3, 10, 30, 50], 'max_features': [2, 4, 6, 8, None]},
{'bootstrap': [False], 'n_estimators': [3, 10, 30], 'max_features': [2, 3, 4, 8]}
]
grid_search = GridSearchCV(forest_reg, param_grid, cv=5,
scoring="neg_mean_squared_error",
return_train_score=True)
grid_search.fit(housing_prepared, housing_labels)
print(grid_search.best_params_)
print(grid_search.best_estimator_)
print(np.sqrt(-grid_search.best_score_))
# 输出训练结果
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"], cvres["params"]):
print(np.sqrt(-mean_score), params)
{'bootstrap': False, 'max_features': 4, 'n_estimators': 30}
RandomForestRegressor(bootstrap=False, max_features=4, n_estimators=30)
49184.012820612865
63296.60697816219 {'max_features': 2, 'n_estimators': 3}
55506.98954834032 {'max_features': 2, 'n_estimators': 10}
52588.29130799578 {'max_features': 2, 'n_estimators': 30}
52209.351970524105 {'max_features': 2, 'n_estimators': 50}
61124.66160352609 {'max_features': 4, 'n_estimators': 3}
52392.16874785449 {'max_features': 4, 'n_estimators': 10}
50273.44009993824 {'max_features': 4, 'n_estimators': 30}
50073.39902683726 {'max_features': 4, 'n_estimators': 50}
58727.56972424551 {'max_features': 6, 'n_estimators': 3}
51782.31672170441 {'max_features': 6, 'n_estimators': 10}
49980.86986567165 {'max_features': 6, 'n_estimators': 30}
49621.90325596429 {'max_features': 6, 'n_estimators': 50}
59108.772714035185 {'max_features': 8, 'n_estimators': 3}
52103.26690162754 {'max_features': 8, 'n_estimators': 10}
50132.82702279907 {'max_features': 8, 'n_estimators': 30}
49781.109586154096 {'max_features': 8, 'n_estimators': 50}
59531.39144640905 {'max_features': None, 'n_estimators': 3}
53194.75190489223 {'max_features': None, 'n_estimators': 10}
51329.73377108047 {'max_features': None, 'n_estimators': 30}
50826.59885373242 {'max_features': None, 'n_estimators': 50}
61849.029391012125 {'bootstrap': False, 'max_features': 2, 'n_estimators': 3}
54126.80686429009 {'bootstrap': False, 'max_features': 2, 'n_estimators': 10}
51848.68218742629 {'bootstrap': False, 'max_features': 2, 'n_estimators': 30}
60098.910109841345 {'bootstrap': False, 'max_features': 3, 'n_estimators': 3}
52334.13150446245 {'bootstrap': False, 'max_features': 3, 'n_estimators': 10}
50341.87869180483 {'bootstrap': False, 'max_features': 3, 'n_estimators': 30}
57650.86470796738 {'bootstrap': False, 'max_features': 4, 'n_estimators': 3}
51682.89592908345 {'bootstrap': False, 'max_features': 4, 'n_estimators': 10}
49184.012820612865 {'bootstrap': False, 'max_features': 4, 'n_estimators': 30}
57308.84929909555 {'bootstrap': False, 'max_features': 8, 'n_estimators': 3}
51285.68101404841 {'bootstrap': False, 'max_features': 8, 'n_estimators': 10}
49469.879650849194 {'bootstrap': False, 'max_features': 8, 'n_estimators': 30}
解释:param_grid表示要测试两组参数,第一组是n_estimators和max_features的组合,所以共有4 x 5 = 20种;第二组是 3 x 4 = 12种,所以一共测试了20 + 12 = 32种参数设置方式。每一种训练5次。训练结束后可以通过best_params_获取参数组合。
- n_estimators:随机森林中树的数量,默认为 100
- max_features:选择特征的方式,可以是整数、浮点数、字符串或 None。默认为 “auto”,即使用所有特征。如果是整数,则表示每次分裂只考虑部分特征;如果是浮点数,则表示每次分裂只考虑部分特征的比例;如果是字符串 “sqrt” 或 “log2”,则表示每次分裂只考虑特征数的平方根或对数;如果是 None,则表示每次分裂都使用所有特征
- bootstrap 参数是指是否使用自助法(bootstrap)从原始样本中进行有放回的抽样来生成新的训练集。默认值为 True,即使用自助法。如果将其设为 False,则表示不使用自助法,即不进行有放回的抽样。
gs也可以用自定义的参数。
from sklearn.pipeline import Pipeline
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import GridSearchCV
# 定义自定义的 Transformer
class MyTransformer(BaseEstimator, TransformerMixin):
def __init__(self, param1=1, param2=1):
self.param1 = param1
self.param2 = param2
def fit(self, X, y=None):
# ...
return self
def transform(self, X, y=None):
# ...
return X_transformed
# 定义 Pipeline 和 param_grid
pipeline = Pipeline([
('my_transformer', MyTransformer()),
('rf', RandomForestRegressor())
])
param_grid = {
'my_transformer__param1': [1, 2, 3],
'my_transformer__param2': [0.1, 0.2, 0.3],
'rf__n_estimators': [10, 50, 100],
'rf__max_depth': [None, 5, 10],
}
# 进行网格搜索
grid_search = GridSearchCV(pipeline, param_grid=param_grid, cv=5, n_jobs=-1)
grid_search.fit(X, y)