模型训练
- 卷积神经网络分类算法的模型训练
- 模型创建与编译
- 模型训练及保存
- 模型保存
- 模型生成
- 图像预处理
卷积神经网络分类算法的模型训练
启动Web服务器、应用使用说明和测试结果示例。
模型创建与编译
原VGG-16模型要求输入224×224×3的图片,限于GPU的计算能力,选择将28×28×1的数据集图片大小重置为56×56×1,由此计算出进入第一个全连接层的图像尺寸为7×7×256;最后一个全连接层输出值设为类别数量10。按设计好的参数定义模型结构,代码如下:

为了评估实际情况和预测情况的差距,引入相对熵来描述这一差距。本模型是多类别的分类问题,因此选用经典的交叉熵作为损失函数,代码如下:
#损失函数
loss=nn.CrossEntropyLoss()
为了进行参数的调整和更新,以达到损失函数的最小化或最大化,使模型产生更好更快的效果,需要选择训练策略。本模型选择Adam优化算法,它具有能计算每个参数的自适应学习率的特点。因此,可以设置学习率为默认值0.001。
#优化算法
optimizer=optim.Adam(net.parameters(),lr=0.001)
模型训练及保存
定义模型结构及损失函数后,需要对模型进行训练,使其具有服装图像分类的能力。经过训练的模型需要测试,以评估模型的训练效果。根据训练和测试的效果进行参数的调整后,保存模型。设定训练集batch_size=50,则每训练50张图片后进行一次迭代,根据损失函数前向传播,完成参数更新。
为使训练效果更加直观,可以借助画图工具对训练过程可视化,模型将在每一个训练周期结束后保存损失值和准确度。
模型保存
在模型训练过程中,同时保存模型当前已训练周期数、权重、损失函数、优化算法,便于在训练终止后从当前进度恢复训练,并同时保存每个周期的损失值和正确率,以方便数据可视化。
模型生成
该应用分两部分:一是网页端交互功能,用户可以上传需要分类的图片并查看分类结果;二是图片预处理,将图片转换为PyTorch能够处理的格式并输入模型中,获取图片分类结果。
获得用户上传的图片并输入至模型获得对应的分类,将标签和图片写入数据库中。为了提高数据库的稳定性,采用bulk_create()方法批量写入数据,避免每写入一条数据就需要调用和关闭数据库的烦琐操作。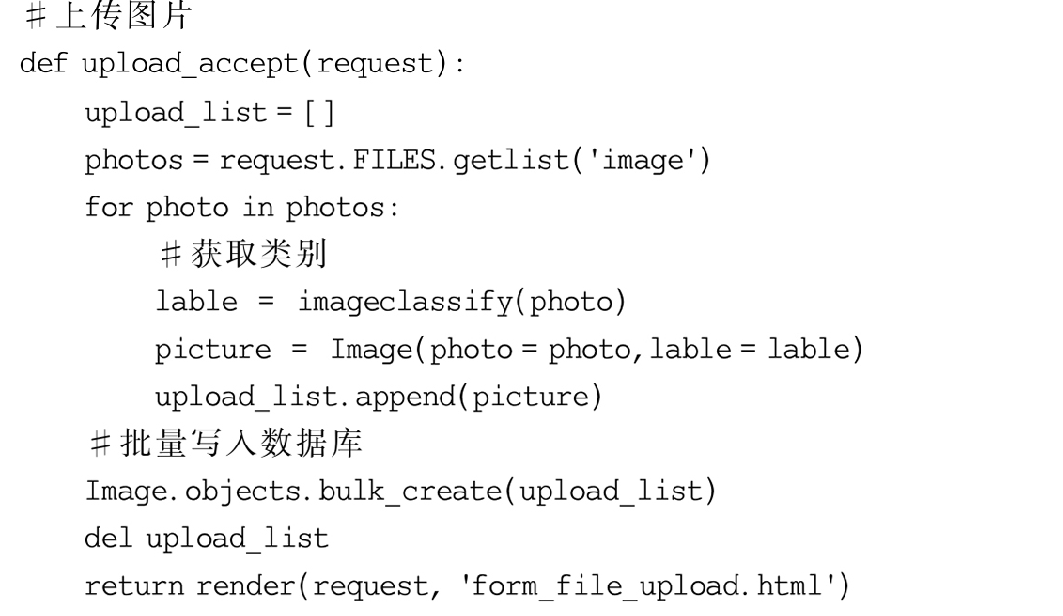
图像预处理
使用PIL库作为打开图片的方式,类型为Image,并将图片转为灰度图像。

为使图片符合输入模型的数据格式,对图像进行预处理。模型输入图像大小要求为56×56,因此,修改用户输入的图像分辨率为56×56;为了对图像进行数据化处理,将PIL Image对象转换为numpy类型;原始数据集图片为黑底色白图案,将输入图片进行黑白色反转;PyTorch要求的数据输入格式为[b,c,h,w],需要扩展numpy的维数,再转换成Tensor张量。
模型调用与导入
首先,进行实例化;其次,使用load()方法加载模型的权重;最后,使用load_state_dict()方法将参数加载到网络上。