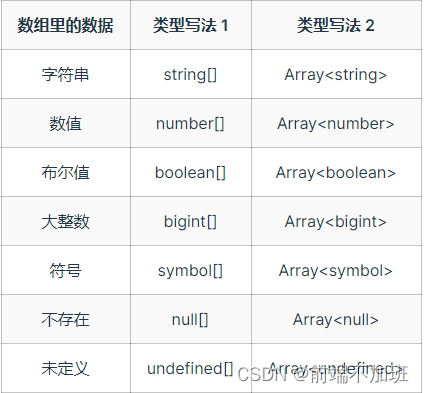
目录
五:用户域用户注册各窗口汇总表
5.1 主要任务
5.2 思路分析
5.3 图解
5.4 ClickHouse建表语句
六:交易域加购各窗口汇总表
6.1 主要任务
6.2 思路分析
6.3 图解
6.4 ClickHouse建表语句
七:交易域支付各窗口汇总表
7.1 主要任务
7.2 思路分析
7.3 图解
7.4 ClickHouse建表语句
八:交易域下单各窗口汇总表
8.1 主要任务
8.2 思路分析
8.3 图解
8.4 ClickHouse建表语句
五:用户域用户注册各窗口汇总表
5.1 主要任务
从 DWD 层用户注册表中读取数据,统计各窗口注册用户数,写入 ClickHouse。
5.2 思路分析
1)读取 Kafka 用户注册主题数据
2)转换数据结构
String 转换为 JSONObject。
3)设置水位线
4)开窗、聚合
5)写入 ClickHouse
5.3 图解
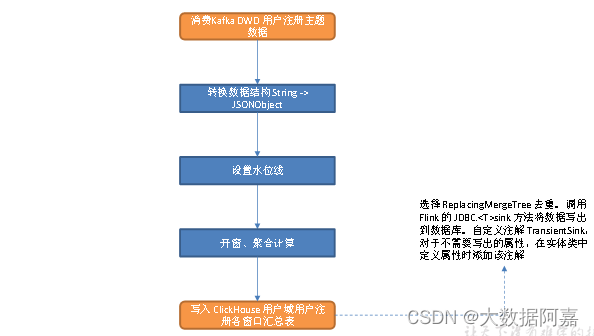
5.4 ClickHouse建表语句
drop table if exists dws_user_user_register_window;
create table if not exists dws_user_user_register_window
(
stt DateTime,
edt DateTime,
register_ct UInt64,
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt);六:交易域加购各窗口汇总表
6.1 主要任务
从 Kafka 读取用户加购明细数据,统计每日各窗口加购独立用户数,写入 ClickHouse。
6.2 思路分析
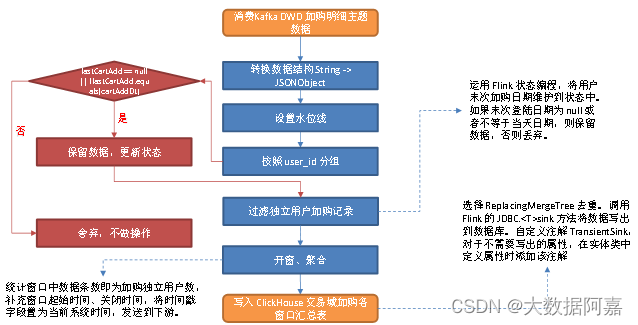
1)从 Kafka 加购明细主题读取数据
2)转换数据结构
将流中数据由 String 转换为 JSONObject。
3)设置水位线
4)按照用户 id 分组
5)过滤独立用户加购记录
运用 Flink 状态编程,将用户末次加购日期维护到状态中。
如果末次登陆日期为 null 或者不等于当天日期,则保留数据并更新状态,否则丢弃,不做操作。
6)开窗、聚合
统计窗口中数据条数即为加购独立用户数,补充窗口起始时间、关闭时间,将时间戳字段置为当前系统时间,发送到下游。
7)将数据写入 ClickHouse。
6.3 图解
6.4 ClickHouse建表语句
drop table if exists dws_trade_cart_add_uu_window;
create table if not exists dws_trade_cart_add_uu_window
(
stt DateTime,
edt DateTime,
cart_add_uu_ct UInt64,
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt);七:交易域支付各窗口汇总表
7.1 主要任务
从 Kafka 读取交易域支付成功主题数据,统计支付成功独立用户数和首次支付成功用户数。
7.2 思路分析
我们在 DWD 层提到,订单明细表数据生成过程中会形成回撤流。left join 生成的数据集中,相同唯一键的数据可能会有多条。上文已有讲解,不再赘述。回撤数据在 Kafka 中以 null 值的形式存在,只需要简单判断即可过滤。我们需要考虑的是如何对其余数据去重。
对回撤流数据生成过程进行分析,可以发现,字段内容完整数据的生成一定晚于不完整数据的生成,要确保统计结果的正确性,我们应保留字段内容最全的数据,基于以上论述,内容最全的数据生成时间最晚。要想通过时间筛选这部分数据,首先要获取数据生成时间。
1)知识储备
FlinkSQL 提供了几个可以获取当前时间戳的函数
-
- localtimestamp:返回本地时区的当前时间戳,返回类型为 TIMESTAMP(3)。在流处理模式下会对每条记录计算一次时间。而在批处理模式下,仅在查询开始时计算一次时间,所有数据使用相同的时间。
- current_timestamp:返回本地时区的当前时间戳,返回类型为 TIMESTAMP_LTZ(3)。在流处理模式下会对每条记录计算一次时间。而在批处理模式下,仅在查询开始时计算一次时间,所有数据使用相同的时间。
- now():与 current_timestamp 相同。
- current_row_timestamp():返回本地时区的当前时间戳,返回类型为 TIMESTAMP_LTZ(3)。无论在流处理模式还是批处理模式下,都会对每行数据计算一次时间。
函数测试。查询语句如下。
tableEnv.sqlQuery("select localtimestamp," +
"current_timestamp," +
"now()," +
"current_row_timestamp()")
.execute()
.print();查询结果如下。
+----+-------------------------+-------------------------+-------------------------+-------------------------+
| op | localtimestamp | current_timestamp | EXPR$2 | EXPR$3 |
+----+-------------------------+-------------------------+-------------------------+-------------------------+
| +I | 2022-04-13 20:42:28.529 | 2022-04-13 20:42:28.529 | 2022-04-13 20:42:28.529 | 2022-04-13 20:42:28.529Z |
+----+-------------------------+-------------------------+-------------------------+-------------------------+动态表属于流处理模式,所以四种函数任选其一即可。此处选择 current_row_timestamp()。
2)时间比较工具类
动态表中获取的数据生成时间精确到毫秒,前文提供的日期格式化工具类无法实现此类日期字符串向时间戳的转化,也就不能通过直接转化为时间戳的方式比较两条数据的生成时间。因此,单独封装工具类用于比较 TIME_STAMP(3) 类型的时间。比较逻辑是将时间拆分成两部分:小数点之前和小数点之后的。小数点之前的日期格式为 yyyy-MM-dd HH:mm:ss,这部分可以直接转化为时间戳比较,如果这部分时间相同,再比较小数点后面的部分,将小数点后面的部分转换为整型比较,从而实现 TIME_STAMP(3) 类型时间的比较。
3)去重思路
获取了数据生成时间,接下来要考虑的问题就是如何获取生成时间最晚的数据。此处提供两种思路。
(1)按照唯一键分组,开窗,在窗口闭合前比较窗口中所有数据的时间,将生成时间最晚的数据发送到下游,其它数据舍弃。
(2)按照唯一键分组,对于每一个唯一键,维护状态和定时器,当状态中数据为 null 时注册定时器,把数据维护到状态中。此后每来一条数据都比较它与状态中数据的生成时间,状态中只保留生成最晚的数据。如果两条数据生成时间相同(系统时间精度不足),则保留后进入算子的数据。因为我们的 Flink 程序并行度和 Kafka 分区数相同,可以保证数据有序,后来的数据就是最新的数据。
两种方案都可行,此处选择方案二。
本节的数据来源于 Kafka dwd_trade_pay_detail_suc 主题,后者的数据由 payment_info、dwd_trade_order_detail、base_dic 三张表通过内连接关联获得,这一过程不会产生重复数据,因此,该表的重复数据由订单明细表决定。而 dwd_trade_order_detail 表的数据来源于 dwd_trade_order_pre_process,后者数据生成过程中使用了 left join,因此包含 null 数据和重复数据。订单明细表读取数据使用的 Kafka Connector 会过滤掉 null 数据,程序内只做了过滤没有去重,因此该表不存在 null 数据,但对于相同唯一键 order_detail_id 存在重复数据。综上,支付成功明细表存在唯一键 order_detail_id 相同的数据,但不存在 null 数据,因此仅须去重。
4)实现步骤
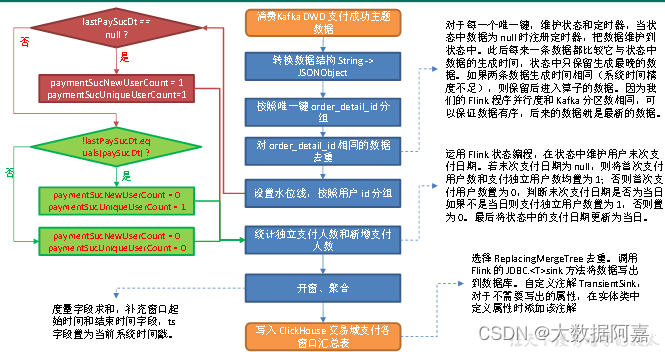
(1)从 Kafka 支付成功明细主题读取数据
(2)转换数据结构
String 转换为 JSONObject。
(3)按照唯一键分组
(4)去重
与前文同理。
(5)设置水位线,按照 user_id 分组
(6)统计独立支付人数和新增支付人数
运用 Flink 状态编程,在状态中维护用户末次支付日期。
若末次支付日期为 null,则将首次支付用户数和支付独立用户数均置为 1;否则首次支付用户数置为 0,判断末次支付日期是否为当日,如果不是当日则支付独立用户数置为 1,否则置为 0。最后将状态中的支付日期更新为当日。
(7)开窗、聚合
度量字段求和,补充窗口起始时间和结束时间字段,ts 字段置为当前系统时间戳。
(8)写出到 ClickHouse
7.3 图解
7.4 ClickHouse建表语句
drop table if exists dws_trade_payment_suc_window;
create table if not exists dws_trade_payment_suc_window
(
stt DateTime,
edt DateTime,
payment_suc_unique_user_count UInt64,
payment_new_user_count UInt64,
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt);八:交易域下单各窗口汇总表
8.1 主要任务
从 Kafka 订单明细主题读取数据,对数据去重,统计当日下单独立用户数和新增下单用户数,封装为实体类,写入 ClickHouse。
8.2 思路分析
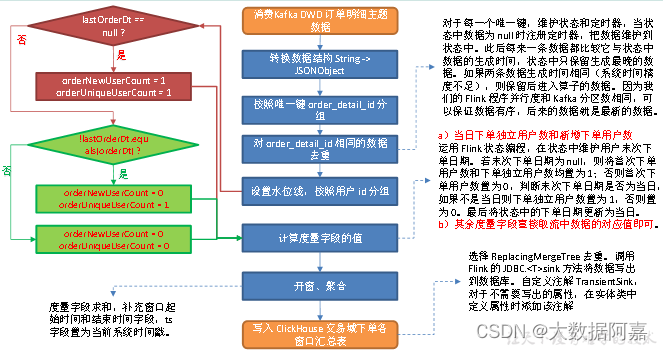
1)从 Kafka订单明细主题读取数据
2)转换数据结构
Kafka 订单明细主题的数据是通过 Kafka-Connector 从订单预处理主题读取后进行过滤获取的,Kafka-Connector 会过滤掉主题中的 null 数据,因此订单明细主题不存在为 null 的数据,直接转换数据结构即可。
3)按照 order_detail_id 分组
order_detail_id 为数据唯一键。
4)对 order_detail_id 相同的数据去重
按照上文提到的方案对数据去重。
5)设置水位线
6)按照用户 id 分组
7)计算度量字段的值
(1)当日下单独立用户数和新增下单用户数
运用 Flink 状态编程,在状态中维护用户末次下单日期。
若末次下单日期为 null,则将首次下单用户数和下单独立用户数均置为 1;否则首次下单用户数置为 0,判断末次下单日期是否为当日,如果不是当日则下单独立用户数置为 1,否则置为 0。最后将状态中的下单日期更新为当日。
(2)其余度量字段直接取流中数据的对应值即可。
8)开窗、聚合
度量字段求和,补充窗口起始时间和结束时间字段,ts 字段置为当前系统时间戳。
9)写出到 ClickHouse。
8.3 图解
8.4 ClickHouse建表语句
drop table if exists dws_trade_order_window;
create table if not exists dws_trade_order_window
(
stt DateTime,
edt DateTime,
order_unique_user_count UInt64,
order_new_user_count UInt64,
order_activity_reduce_amount Decimal(38, 20),
order_coupon_reduce_amount Decimal(38, 20),
order_origin_total_amount Decimal(38, 20),
ts UInt64
) engine = ReplacingMergeTree(ts)
partition by toYYYYMMDD(stt)
order by (stt, edt);







![[附源码]Python计算机毕业设计Django财务管理系统](https://img-blog.csdnimg.cn/d6298cada9f44b29815667df310709e4.png)