4.5 创建透视表与交叉表
- 4.5.1利用pivot_table函数可以实现透视表
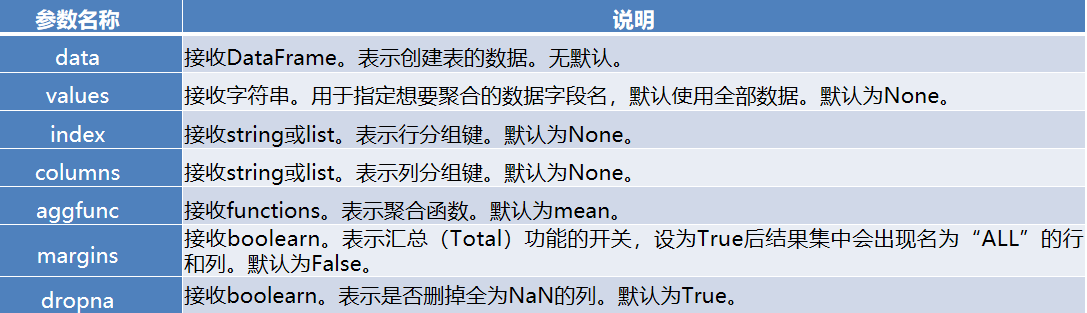
- pivot_table函数的常用参数及其说明
- 4.5.2 使用crosstab函数创建交叉表
- crosstab函数的常用参数及其说明
- 4.5.3 任务实现
- 数据
- 完整代码
数据透视表(Pivot Table)是数据分析中一种常用的工具之一,根据一个或多个键值对数据进行聚合,根据行或列的分组键将数据划分到各个区域。在pandas中,除了可以使用groupby对数据分组聚合实现透视功能外,还提供了更为简单的方法。这里以菜单订单数据为例制作透视表与交叉表,分析不同菜品的销量和金额之间的关系。
(1)使用pivot_table函数制作菜品日销量透视表。
(2)使用crosstab函数制作菜品销量交叉表。
4.5.1利用pivot_table函数可以实现透视表
pandas.pivot_table(data, values=None, index=None, columns=None, aggfunc=‘mean’, fill_value=None, margins=False, dropna=True, margins_name=‘All’)
pivot_table函数的常用参数及其说明
import pandas as pd
import numpy as np
detail = pd.read_csv('E:/Input/ptest.csv', encoding='ANSI')
## 1、使用订单号作为透视表索引制作透视表
# 以id作为分组键创建的订单透视表
detailPivot = pd.pivot_table(detail[['id', 'counts', 'amounts']], index='id')
print(detailPivot)
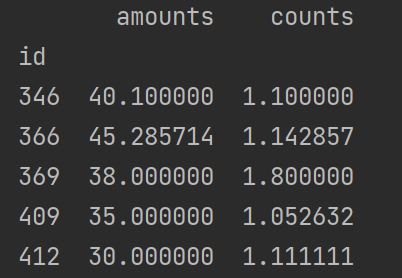
由上面结果可以看出,在不特殊指定聚合函数aggfunc时,会默认使用numpy.mean进行聚合运算,numpy.mean会自动过滤掉非数值类型数据。可以通过指定aggfunc参数修改聚合函数。
## 2、修改聚合函数后的透视表
# 以id作为分组键创建的订单销量与售价总和透视表
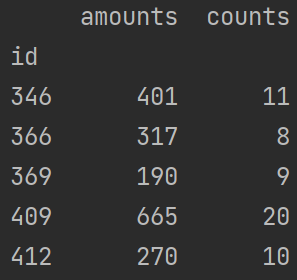
detailPivot2 =pd.pivot_table(detail[['id', 'counts', 'amounts']], index='id', aggfunc=np.sum)
print(detailPivot2)
和groupby方法分组的时候相同,pivot_table函数在创建透视表的时候分组键index可以有多个。
## 3、使用id和name作为索引的透视表
detailPivot3 = pd.pivot_table(detail[['id', 'name', 'counts', 'amounts']],
index=['id', 'name'], aggfunc=np.sum)
print(detailPivot3)
通过设置columns参数可以指定列分组。
## 4、指定name为列分组键的透视表
detailPivot4 = pd.pivot_table(detail[['id', 'name', 'counts', 'amounts']],
index='id', columns='name', aggfunc=np.sum)
print(detailPivot4)
当全部数据列数很多时,若只想要显示某列,可以通过指定values参数来实现。
## 5、指定某些列制作透视表
detailPivot5 = pd.pivot_table(detail[['id', 'name', 'counts', 'amounts']],
index='id', values='counts', aggfunc=np.sum)
print(detailPivot5)
当某些数据不存在时,会自动填充NaN,因此可以指定fill_value参数,表示当存在缺失值时,以指定数值进行填充。
## 6、对透视表中的缺失值进行填充
detailPivot6 = pd.pivot_table(detail[['id', 'name', 'counts', 'amounts']],
index='id', columns='name', aggfunc=np.sum, fill_value=0)
print(detailPivot6)
可以更改margins参数,查看汇总数据。
## 7、在透视表中添加汇总数据,结果集中会出现名为All的行和列
detailPivot7 = pd.pivot_table(detail[['id', 'name', 'counts', 'amounts']],
index='id', columns='name', aggfunc=np.sum,
fill_value=0, margins=True)
print(detailPivot7)
4.5.2 使用crosstab函数创建交叉表
交叉表是一种特殊的透视表,主要用于计算分组频率。
由于交叉表是透视表的一种,其参数基本保持一致,不同之处在于crosstab函数中的index,columns,values填入的都是对应的从Dataframe中取出的某一列。
pandas.crosstab(index, columns, values=None, rownames=None, colnames=None, aggfunc=None, margins=False, dropna=True, normalize=False)
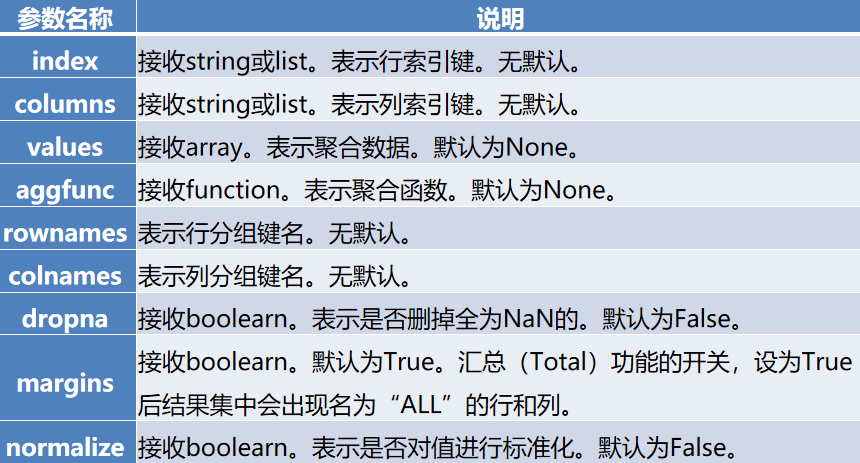
crosstab函数的常用参数及其说明
# 4.5.2 使用crosstab函数创建交叉表
# 4.5.2 使用crosstab函数创建交叉表
detailCross = pd.crosstab(index = detail['id'], columns=detail['name'],
values=detail['counts'], aggfunc=np.sum)
print(detailCross)
4.5.3 任务实现
# 4.5.3 任务实现
## 1、创建单日菜品成交总额与总数均价透视表
import pandas as pd
import numpy as np
detail = pd.read_csv('E:/Input/ptest.csv', encoding='ANSI')
# print(detail)
detail['time'] = pd.to_datetime(detail['time'])
detail['date'] = [i.date() for i in detail['time']]
# print(detail['date'])
PivotDetail = pd.pivot_table(detail[['date', 'name', 'counts', 'amounts']],
index='date', aggfunc=np.sum, margins=True)
print(PivotDetail)
# 2、创建单个菜品单日成交总额透视表
## 方法1
PivotDetail2 = pd.pivot_table(detail[['date', 'name', 'amounts']],
index='date',columns='name', aggfunc=np.sum, margins=True)
print(PivotDetail2)
## 方法2
CrossDetail2 = pd.crosstab(index=detail['date'], columns=detail['name'],
values=detail['amounts'], aggfunc=np.sum, margins=True)
print(CrossDetail2)
数据
完整代码
import pandas as pd
import numpy as np
detail = pd.read_csv('E:/Input/ptest.csv', encoding='ANSI')
print(detail)
## 1、使用订单号作为透视表索引制作透视表
# 以id作为分组键创建的订单透视表
detailPivot = pd.pivot_table(detail[['id', 'counts', 'amounts']], index='id')
print(detailPivot)
## 2、修改聚合函数后的透视表
# 以id作为分组键创建的订单销量与售价总和透视表
detailPivot2 =pd.pivot_table(detail[['id', 'counts', 'amounts']], index='id', aggfunc=np.sum)
print(detailPivot2)
## 3、使用id和name作为索引的透视表
detailPivot3 = pd.pivot_table(detail[['id', 'name', 'counts', 'amounts']],
index=['id', 'name'], aggfunc=np.sum)
print(detailPivot3)
## 4、指定name为列分组键的透视表
detailPivot4 = pd.pivot_table(detail[['id', 'name', 'counts', 'amounts']],
index='id', columns='name', aggfunc=np.sum)
print(detailPivot4)
## 5、指定某些列制作透视表
detailPivot5 = pd.pivot_table(detail[['id', 'name', 'counts', 'amounts']],
index='id', values='counts', aggfunc=np.sum)
print(detailPivot5)
## 6、对透视表中的缺失值进行填充
detailPivot6 = pd.pivot_table(detail[['id', 'name', 'counts', 'amounts']],
index='id', columns='name', aggfunc=np.sum, fill_value=0)
print(detailPivot6)
## 7、在透视表中添加汇总数据,结果集中会出现名为All的行和列
detailPivot7 = pd.pivot_table(detail[['id', 'name', 'counts', 'amounts']],
index='id', columns='name', aggfunc=np.sum,
fill_value=0, margins=True)
print(detailPivot7)
# 4.5.2 使用crosstab函数创建交叉表
detailCross = pd.crosstab(index=detail['id'], columns=detail['name'],
values=detail['counts'], aggfunc=np.sum)
print(detailCross)
# 4.5.3 任务实现
## 1、创建单日菜品成交总额与总数均价透视表
import pandas as pd
import numpy as np
detail = pd.read_csv('E:/Input/ptest.csv', encoding='ANSI')
# print(detail)
detail['time'] = pd.to_datetime(detail['time'])
detail['date'] = [i.date() for i in detail['time']]
# print(detail['date'])
PivotDetail = pd.pivot_table(detail[['date', 'name', 'counts', 'amounts']],
index='date', aggfunc=np.sum, margins=True)
print(PivotDetail)
# 2、创建单个菜品单日成交总额透视表
## 方法1
PivotDetail2 = pd.pivot_table(detail[['date', 'name', 'amounts']],
index='date',columns='name', aggfunc=np.sum, margins=True)
print(PivotDetail2)
## 方法2
CrossDetail2 = pd.crosstab(index=detail['date'], columns=detail['name'],
values=detail['amounts'], aggfunc=np.sum, margins=True)
print(CrossDetail2)





![[5 种有效方法] 适用于 Android 的通用解锁图案/密码](https://img-blog.csdnimg.cn/img_convert/0f923c47f83491bbb36cbf0891e49194.png)