数仓(十八)数仓建模以及分层总结(ODS、DIM、DWD、DWS、DWT、ADS层) - 墨天轮
一、维度模型分类:星型模型,雪花模型,星座模型
1、星型模型
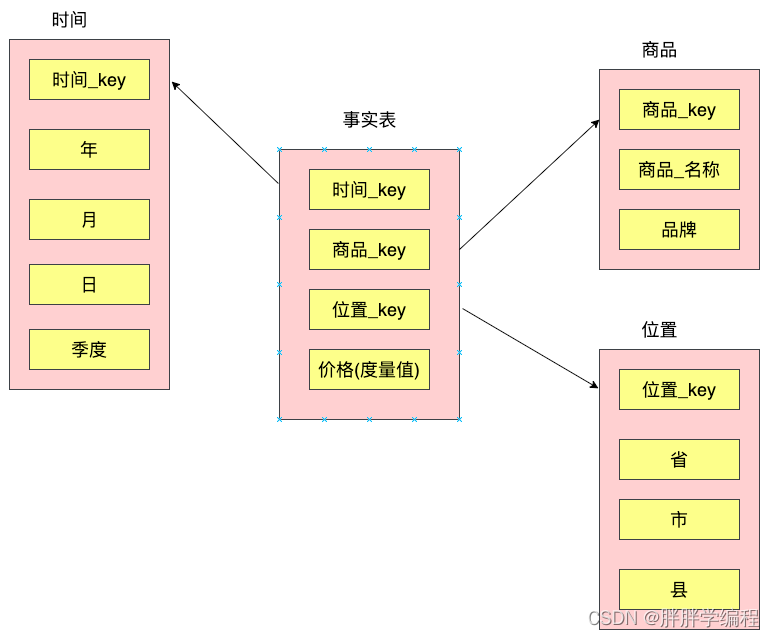
星型模型中只有一张事实表,以及0张或多张维度表,事实与纬度表通过主键外键相关联,维度之间不存在关联关系,当所有纬度都关联到事实表时,整个图形非常像一种星型的结构,所以称之为“星型模型”。
注:事实表中只存外键和度量值。
2、雪花模型
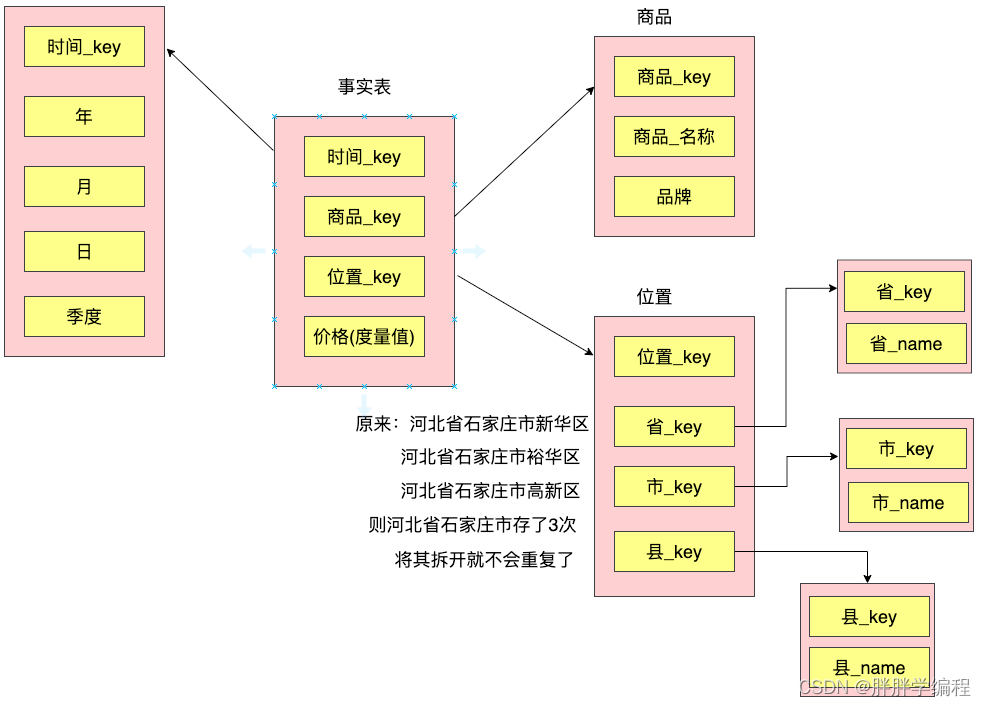
当一个或多个纬度表没有直接连接到事实表,而是通过其他维度表连接到事实表时,其图解就像多个雪花连接在一起,故称雪花模型。雪花模型是对星型模型的扩展,它对星型模型的维度进一步层次化。
优点是避免了数据冗余。
缺点是增加了join,导致效率低。
3、星座模型
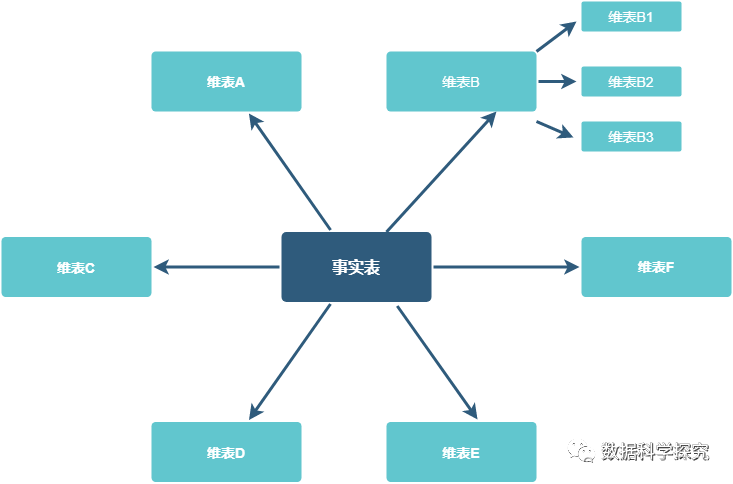
星座模型也是星型模型的扩展,区别是星座模型中存在多张事实表,不同的事实表之间共享维度表信息。日常开发用的就是星座模型。
二、范式
范式:在进行关系建模时,需要遵循的规则。
范式的作用:降低数据的冗余性,减少存储空间,保持数据一致性。
1、函数依赖:
完全函数依赖,部分函数依赖,传递函数依赖。
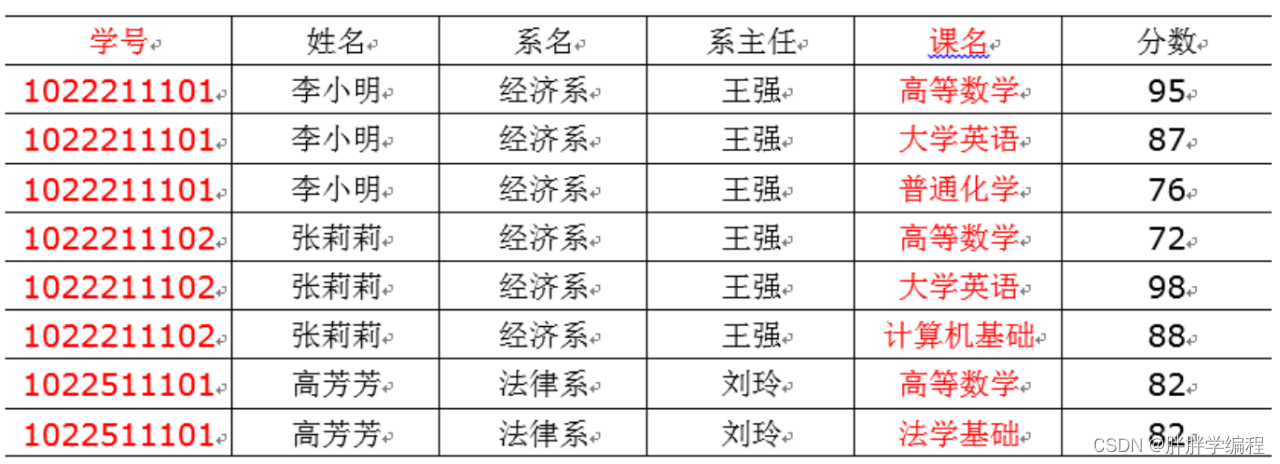
1)完全函数依赖
z=f(x,y)有了x,y才能计算出z,所以z完全函数依赖于x,y。比如通过(学号,课程)推出分数,但是单纯用学号推断不出来分数,那么就可以说分数全完依赖于(学号,课程)。
2)部分函数依赖
z=f(x,y)当给定x,y则能计算出z,当给x,y,n时,也能计算出z,此时z部分函数依赖于z,y,n。比如通过(学号,课程)推出姓名,因为可以直接通过学号退出姓名,所以:姓名部分依赖于(学号,课程)。
3)传递函数依赖
y=f(x),z=g(y),依赖x可以得到y,从而得到z,z传递依赖于x。比如:学号推出系名,系名退出系主任,系主任传递依赖于学号。
2、第一范式
字段不可分割。

商品字段中"5台电脑"可以切割成"5台"+"电脑",改为

3、第二范式
满足第一范式,且不能存在非主键字段部分函数依赖于主键字段。
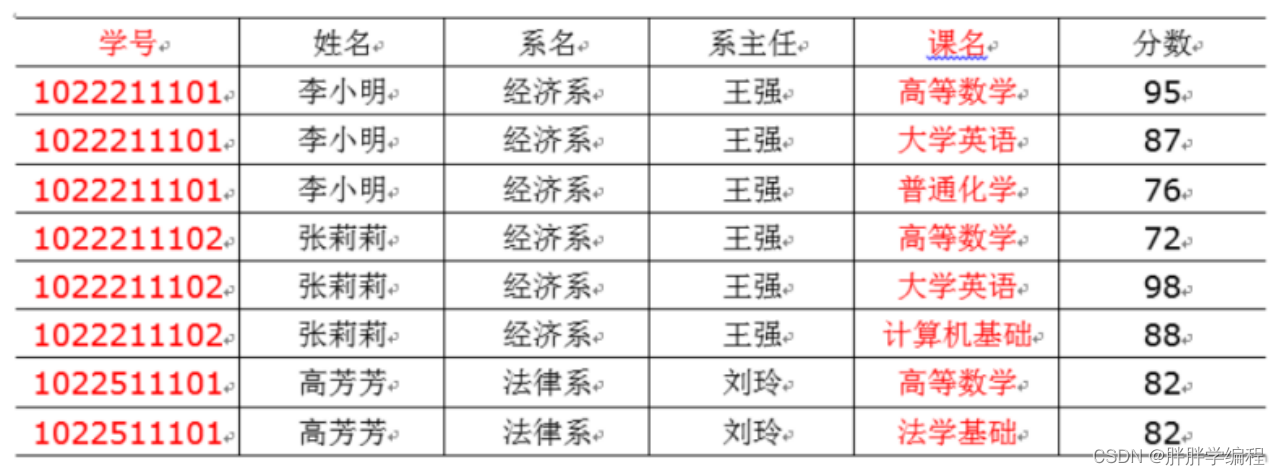
主键为:"学号"+"课名"。"分数”完全依赖于(学号,课名),但是姓名并不完全依赖于(学号,课名),姓名只依赖于学号。

4、第三范式
满足第一二范式,且不能存在非主键字段传递函数依赖于主键字段。
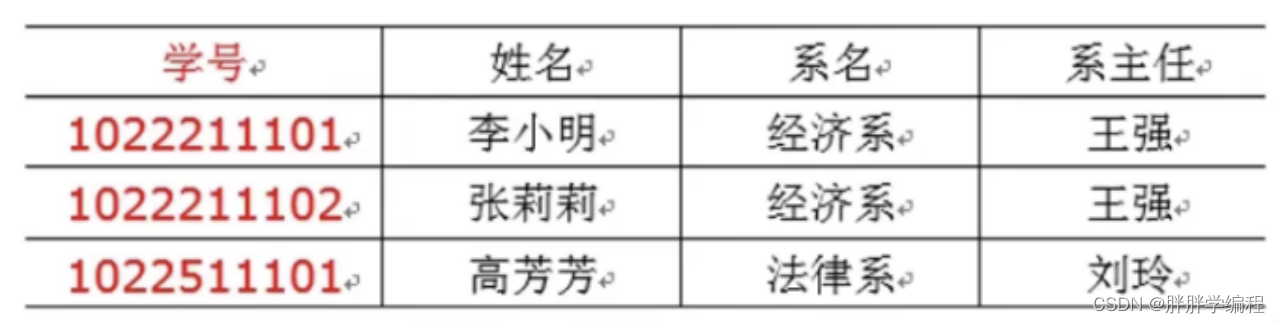
主键:学号。学号->系名->系主任
上面表需要再次拆解:

三、纬度建模
纬度建模步骤:选择业务过程声明粒度、确认纬度、确认事实

1、选择业务过程
整个业务流程中选取我们需要建模的业务,根据公司业务提供的需求及日后的易扩展性等进行选择业务。
这里我们选择了几个业务过程是:支付、订单、加购物车、优惠券领用、收藏、评论、退款等。
2、声明粒度
总体采用最小粒度规则,不做任何聚合操作。而在实际公司应用中,对于有明确需求的数据,我们建立针对需求上卷汇总粒度,对需求不明朗的数据我们建立原子粒度。
对于支付业务,声明粒度:支付业务中(事实表)中一行数据表示的是一条支付记录。
对于订单业务,声明粒度:订单业务中一行数据表示的是一个订单中的一个商品项。
3、确认纬度
这里我们确认维度的原则是:
1)根据目前业务需求的相关描述性标识
2)描述业务相关的维度指标
3)后续需要相关维度指标
4、确认事实
确认业务中的度量值(如次数、个数、件数、金额等其他可以进行累加的值)例如订单金额、下单次数。简单理解为:我们站在事实表的角度上,分别对每个事实表进行维度关联操作,建立关联关系。
四、数仓分层
1、ODS层:原始数据层
ODS(O=original D=data S=store)
1)设计要点
存储来自多个业务系统、前端埋点、爬虫获取的一系列数据源的数据。
我们要做三件事:
【1】保持数据原貌不做任何修改,保留历史数据,起到数据备份的作用。
【2】使用lzo压缩。
【3】创建分区表,防止后续的全表扫描,一般按天存储。
2)ODS层数据组成
【1】前端埋点日志:由kafka或者sqoop采集到HDFS上
【2】由前端业务数据库采集到HDFS上
3)前端埋点日志的处理
前端埋点日志以JSON格式形式存在
建表语句
create external table ods_log
(
line string
)
partitioned by (dt string)
Stored as
inputformat 'com.hadoop.mapred.DeprecatedLzoTextInputFormat'
outputformat 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
;将kafka落盘的数据建立lzo索引,否则无法分片
hadoop jar /opt/module/hadoop-3.1.4/share/hadoop/common/hadoop-lzo-0.4.20.jar \
com.hadoop.compression.lzo.DistributedLzoIndexer \
-Dmapreduce.job.queuename=hive \
/warehouse/gmail/ods/ods_log/dt=2021-05-01加载建立好所以的数据
load data inpath '/origin_data/gmall/log/topic_log/2021-05-01'
into table ods_log partition (dt='2021-05-01');4)MySQL数据库的处理
mysql数据库的表通过sqoop采集到HDFS,用的是\t作为分割,那数仓里面ODS层也需要\t作为分割;
5)同步策略
【1】增量同步:订单表
【2】全量同步:商品表
【3】特殊:一次性拉取,不建分区表(DIM层的父数据)
3、DIM
dim=dimension
存储为Parquet格式
1)同步策略
全量同步:商品维度,优惠券维度。首日和每日都是全量先导入到ODS再导入到DIM层
特殊:日期,地区(自己处理)
拉链表:用户维度表
4、DWD层
dwd=data warehouse detail
5、dws、
dws= data warehouse service
6、dwt、
dwt=data warehosue topic
7、ads
ads=application data store
四、DIM层用户维度拉链表
1、什么是拉链表
用于存储变化,但变化的频率较慢的数据。这样的数据用全量存存储大量重复数据,因此用拉链表。
2、每条数据的意义
该条数据的有效时间
3、制造拉链表
1)建表语句
create table dim_user_info(
id string,
user_name string --用户名称,
name string --真实姓名,
phone_num string,
gerder string --性别,
email string,
create_time string --创建时间,
operate_time string --操作时间,
start_date string --开始日期(拉链表特有),
end_date string --结束日期(拉链表特有)
)
partitioned by(dt string)
stored as parquet
table properties("parquet.compression"="lzo")
;
2) 分区规划:

3)首日装载
要进行初始化,ods层该表第一天从MySQL拉取的所有数据放到9999-99-99分区
insert overwrite table dim.dim_user_info partition(dt='9999-99-99')
select
id,
user_name,
name,
phone_num,
gerder,
email,
create_time,
operate_time,
'2022-19-01' start_date,
'9999-99-99' end_date
from
ods.ods_user_info
where dt='2022-10-01'4)每日装载
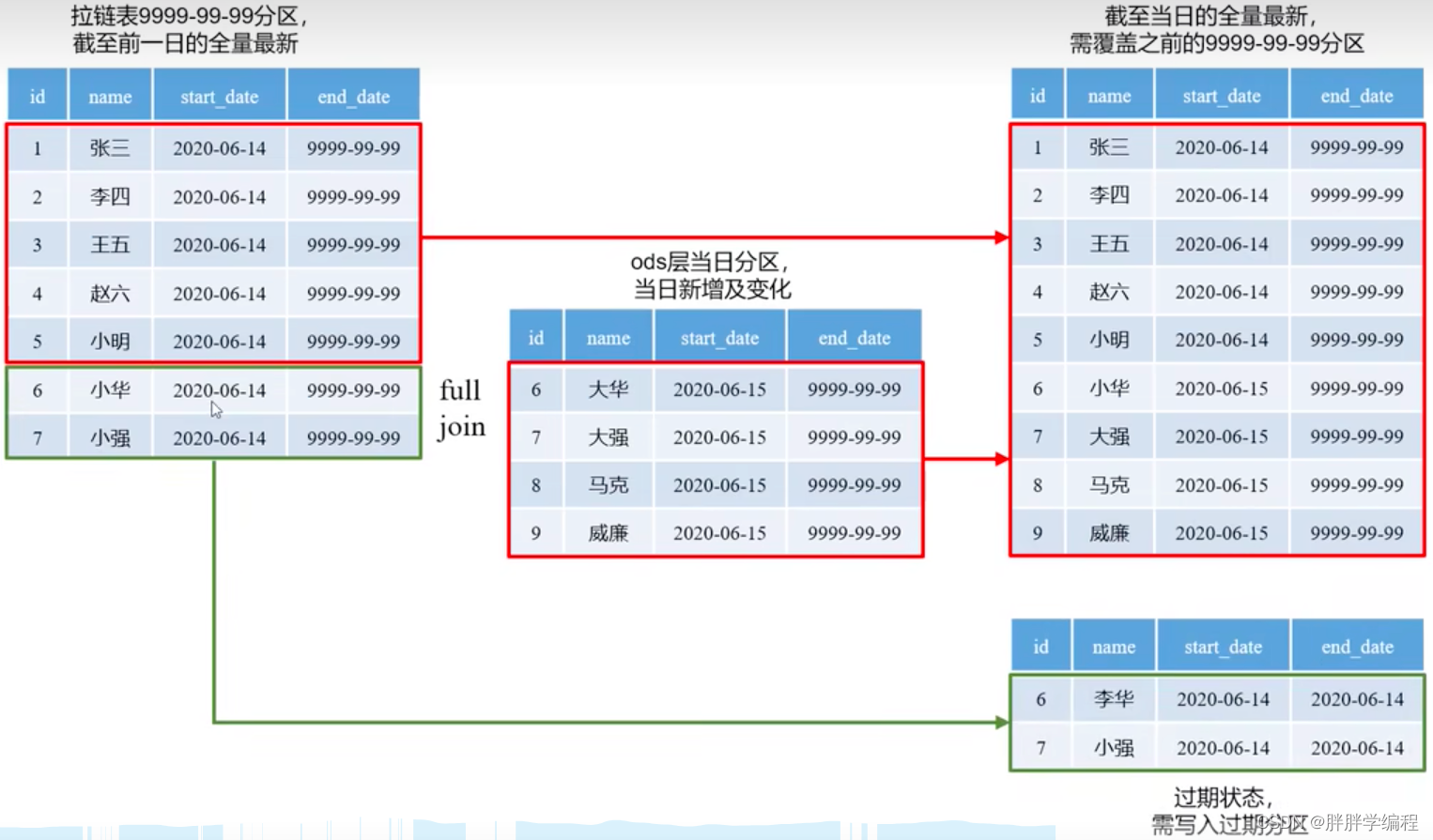
【1】将最新的数据装载到9999-99-99分区
如果new为null(没有变化),则取old,
如果new不为null(今日发生了新增及变化),则取new
select
if(new.id is not null,new.id,old.id) id,
if(new.user_name is not null,new.user_name,old.user_name) user_name,
if(new.name is not null,new.name,old.name) name,
if(new.phone_num is not null,new.phone_num,old.phone_num) num,
if(new.gerder is not null,new.gerder,old.gerder) gerder,
if(new.email is not null,new.email,old.email) nemail,
if(new.create_time is not null,new.create_time,old.create_time) create_time ,
if(new.operate_time is not null,new.operate_time,old.operate_time) operate_time,
if(new.start_date is not null,new.start_date,old.start_date) start_date,
if(new.end_date is not null,new.end_date,old.end_date) end_date
(
select
id,
user_name,
name,
phone_num,
gerder,
email,
create_time,
operate_time,
'2022-19-01' start_date,
'9999-99-99' end_date
from
dim.dim_user_info
where dt='9999-99-99'
)ods
full join
(
select
id,
user_name,
name,
phone_num,
gerder,
email,
create_time,
operate_time,
'2022-10-01' start_date,
'9999-99-99' end_date --新增及变化的数据都是最新数据
from
ods.ods_user_info --ods_user_info表是每日增量导入的
where dt='2022-10-01' --新增及变化的数据
)new
on ods.id=new.id【2】将过期数据装载到前一天的分区(注意日期之间没有重合)
new和old都有的数据取old的
select
old.id id,
old.user_name user_name,
old.name name,
old.phone_num num,
old.gerder gerder,
old.email nemail,
old.create_time create_time ,
old.operate_time operate_time,
old.start_date start_date,
old.end_date end_date
(
select
id,
user_name,
name,
phone_num,
gerder,
email,
create_time,
operate_time,
'2022-19-01' start_date,
'9999-99-99' end_date
from
dim.dim_user_info
where dt='9999-99-99'
)ods
full join
(
select
id,
user_name,
name,
phone_num,
gerder,
email,
create_time,
operate_time,
'2022-10-01' start_date,
'9999-99-99' end_date --新增及变化的数据都是最新数据
from
ods.ods_user_info --ods_user_info表是每日增量导入的
where dt='2022-10-01' --新增及变化的数据
)new
on ods.id=new.id
where new.id is not null and old.id is not null
;4.对拉链表进行查询
1)获取在某天有效的的所有用户的数据
--获取2019-01-01有效的所有历史数据
select * from user_info where start_date<='2019-01-01' and end_date>='2019-01-01';2)获取目前所有用户的最新的数据
select * from user_info where end_date>='9999-99-99';






![[Android移动安全渗透基础教程] 如何为Android Studio 模拟器(AVD)设置Frida?](https://img-blog.csdnimg.cn/0b5221ebfa6b4b3584d0067b8fba521d.png)