一、ProxySQL基本介绍
1.1 前言
ProxySQL是 MySQL 的高性能、高可用性、协议感知代理。以下为结合主从复制对ProxySQL读写分离、黑白名单、路由规则等做些基本测试。
1.2 基本介绍
先简单介绍下ProxySQL及其功能和配置,主要包括:
最基本的读/写分离,且方式有多种;
可定制基于用户、基于schema、基于语句的规则对SQL语句进行路由,规则很灵活;
动态加载配置,即绝大部分的配置可以在线修改,但有少部分参数还是需要重启来生效;
可缓存查询结果。虽然缓存策略比较简陋,但实现了基本的缓存功能;
过滤危险的SQL,增加防火墙等功能;
提供连接池、日志记录、审计日志等功能;
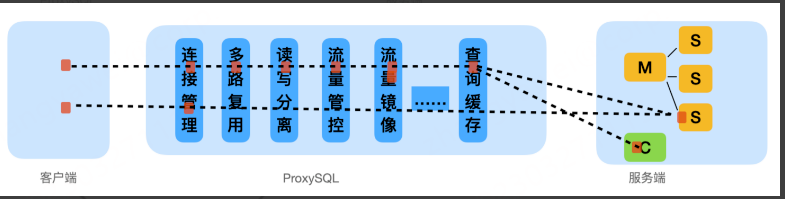
1.2.1 请求流程
流量从客户端发出 → ProxySQL进行处理转发 → 后端处理 → ProxySQL的前端连接 → 返回客户端的基本流程
1.2.2 核心功能
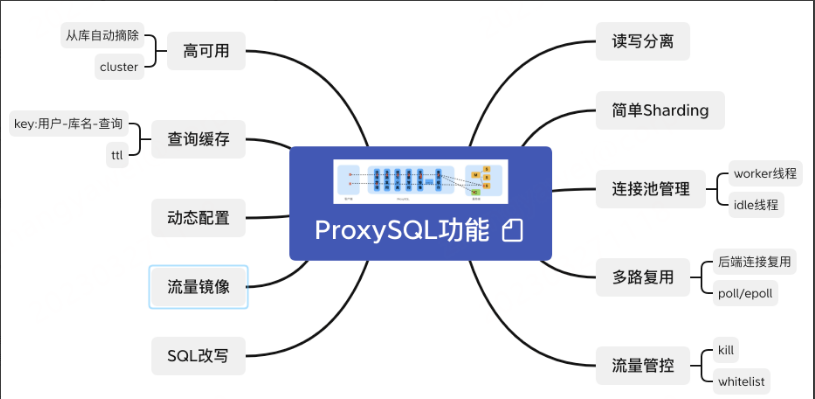
读写分离:可查询走从库,写入走主库
简单Sharding:ProxySQL的sharding是通过正则匹配来实现的,对于需要拆分SQL以及合并SQL执行结果的不能支持,所以写了简单sharding
连接池管理:常规功能,为了提高SQL执行效率。
多路复用:主要优化点在后端mysql连接的复用,对比smart client,中间层不仅对前端建连也会对后端建连,可自行控制后端连接的复用逻辑。
流量管控:kill连接和kill query;whitelist配置。
高可用:底层mysql,如果从库挂了,自动摘除流量;主库挂了暂不处理。proxysql自身高可用,提供cluster的功能,cluster内部会自行同步元数据以及配置变更信息。
查询缓存:对username+schema+query的key进行缓存,设置ttl过期,不适合写完就查的场景,因为在数据在未过期之前可能是脏数据。
动态配置:大部分的配置可动态变更,先load到runtime,在save到disk,通过cluster的功能同步到其他的节点。
流量镜像:同一份流量可以多出写入,但是并不保证mirror的流量一定成功。
SQL改写:在query rules中配置replace规则,可以对指定的SQL进行改写。
1.2.3 多层的配置系统
ProxySQL的配置有三层,且绝大部分参数均可以通过动态配置并热加载到运行层,并通过save命令保存到持久层。
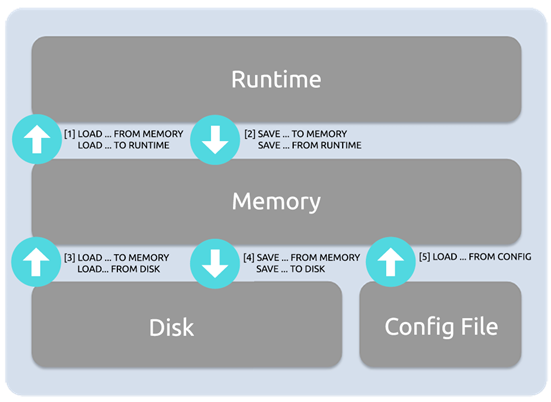
RUNTIME层
runtime层是即时生效的;表示当前生效的配置,该层的配置无法直接修改,必须要从下一层即MEMORY层load进来;
MEMORY层
memory层是保存在内存中,但不立即生效的;该层通常通过admin端口进来后,直接修改。
DISK层|CONFIG FILE层
disk层表示持久化层,config file表示从配置文件中加载的;
不同层的加载和保存
# 以修改mysql servers为例,以下为不同层之间的同步关系
## 将修改层的配置加载到运行层
load mysql servers to runtime;
## 将运行层的配置同步到修改层
save mysql servers to memroy;
## 将持久层的配置加载到memory层
load mysql servers to memory;
## 将修改层的配置保存到持久层
save mysql servers to disk;
## 从配置文件中将配置信息加载到修改层
load mysql servers from config;1.2.4 第一次启动
配置文件
第一次启动时,会从proxysql.cnf配置文件中加载相关配置项来初始化memory和runtime层,并最终持久化到sqlite数据库中;如果想重新初始化proxysql,可以在启动时使用--initial选项来强制初始化proxysql,这会将sqlite数据库重置为最原始的状态,并在必须要时重命名sqlite的数据文件
持久层disk的配置
再次启动时,如果配置文件指定的datadir目录下sqlite数据文件存在,则会将sqlite中的配置项读取到内存,最终会加载到runtime层。此时不再读取proxysql.cnf配置文件的相关配置。
1.2.5 ProxySQL相关表配置
ProxySQL后端采用sqlite对配置进行存储,有以下几个库:
下列库中:main表示runtime运行层,disk表示持久化库,stats表示统计数据库,monitor存储监控相关表,stats_history表示统计历史库。
3306-Admin > show databases;
+-----+---------------+--------------------------------------------------+
| seq | name | file |
+-----+---------------+--------------------------------------------------+
| 0 | main | |
| 2 | disk | /var/lib/data/3306/proxysql.db |
| 3 | stats | |
| 4 | monitor | |
| 5 | stats_history | /var/lib/data/3306/proxysql_stats.db |
+-----+---------------+--------------------------------------------------+
5 rows in set (0.00 sec)global_variables表
全局配置表,用于存储admin接口、mysql接口、监控等相关参数的配置,其相关配置可以通过以下两种方式进行修改:
## 直接通过SQL修改表
3306-Admin > update global_variables set variable_value='xxx' where variable_name='xxx';
## 通过set方式
3306-Admin > set variable_name='xxx';mysql_servers表
定义后端backends,如MySQL Server或者使用MySQL协议的其他实例,同一个hostgroup组中的backends具有相同的逻辑功能;
主要字段
hostgroup_id:指定后端MySQL所在的hostgroup_id组,同一个后端MySQL可以分属不同的组;
hostname,port: 指定后端MySQL的主机和端口;
status: 后端MySQL的状态,online表示在线提供服务,即正常状态;offline_soft表示非强制下线,即不再接受新的请求,但可以处理当前已建立的会话请求;offline_hard表示强制下线,即强制关闭当前的所有会话且不再接受新请求;shunned表示后端MySQL临时不可用,如因为连接数过多或者主从延迟超过设置的阈值等;
weight:backend的权重,权重越大,则同hostgroup中被选择的概率越大;
max_connections:设置ProxySQL能连接后端MySQL的最大连接;
max_replication_lag:设置后端MySQL允许的最大延迟时间;
mysql_users表
用于存储访问ProxySQL的相关用户,并最终连接到后端的MySQL上;
主要字段
username, password:连接ProxySQL来访问后端MySQL的用户名和密码。
需注意:
用户需要在后端MySQL实例中创建且能确保ProxySQL所在的机器IP已加白;
在mysql_users表中配置的用户不能再被用到mysql-monitor_username监控配置用户上;
active:指定用户是否是激活有效的,如果设置为0,则该用户不会被加载到runtime层;
default_hostgroup:指定用户默认访问的主机组,如果没有配置查询规则,则SQL统一会分流到默认主机组;
推荐默认组设置为写组;
transaction_persistent:表示是否持久化事务,设置为1表示开启一个事务后,该事务的所有操作均在同一个hostgroup中操作完成,其会忽略设置的任何查询规则;
frontend,backend:指定用户是属于前端和后端;前端表示用户通过ProxySQL进行连接,后端表示ProxySQL连接后端MySQL;通常添加一个用户后,在runtime层,ProxySQL默认会将该用户同时设定为前端和后端;
max_connections:设定该用户的最大连接;
mysql_replication_hostgroups表
定义使用异步同步 /半同步的传统主从复制中各个hostgroup的对应关系。
主要字段
writer_hostgroup:指定写组id,如设置10表示所有主机组为10的后端MySQL将会处理写请求;
reader_hostgroup: 指定读组id,如设置20表示所有主机组为20的后端MySQL将会处理读请求;
check_type: 判断MySQL只读的类型,ProxySQL也是通过该只读属性来自动判断添加的后端MySQL是属于读组还是写组;
检查类型支持单一参数值的检查,也支持一些参数值逻辑运算后检查,支持的类型如下:
read_only 默认值,通过read_only参数判断
innodb_read_only
super_read_only
read_only|innodb_read_only 通过
read_only&innodb_read_only
mysql_query_rules表
定义路由策略和属性;
主要字段
rule_id:全局唯一的规则id,规则是按照rule_id的顺序进行处理的;
active:表示该规则是否生效。只有该字段值为1的规则才会加载到runtime数据结构;
username:用户名筛选,当设置为非NULL值时,只有匹配的用户建立的连接发出的查询才会被匹配;
schemaname:schema筛选,当设置为非NULL值时,只有当连接使用schemaname作为默认schema时,该连接发出的查询才会被匹配;
flagIN, flagOUT:这两个字段允许我们创建"链式规则"(chains of rules),即一个规则接一个规则的链式处理;
apply:表示是否apply该规则;
client_addr:通过源地址进行匹配;从1.4.7开始,支持按网段进行匹配,如192.168.56.% 匹配C网段;
match_digest:通过正则表达式匹配digest;
match_pattern:通过正则表达式匹配查询语句的文本内容;
destination_hostgroup:将匹配到的查询路由到该主机组。当然设置transaction_persistent=1的事务除外;cache_ttl:设置查询结果缓存的ttl失效时间;
error_msg:当查询被阻塞时,则该列设置的值将会返回给客户端。通常用于黑名单功能,即如果匹配该规则后,如果其error_msg不为空,则客户端的操作将会接受到error_msg设置的错误信息;
二、ProxySQL相关功能介绍
2.1 读写分离
ProxySQL官方demo演示了三种读写分离的方式:使用不同的端口进行读写分离、使用正则表达式进行通用的读写分离、使用正则和摘要进行更智能的读写分离。
最后一种是针对特定业务进行的优化调整,也可将其归结为第二种方式,下边分别进行测试。
2.1.1 使用不同端口的读写分离
基础环境准备
写端口通过6401端口,读端口通过6402端口,从而通过不同端口来实现读写分离功能。
## 在mysql servers表中插入一主一从两个server的信息
## 其中master的hostgroup为10,其余两个slave的hostgroup为20
INSERT INTO mysql_servers(hostgroup id,hostname, port)VALUES(10,'db.test.master',3306);
INSERT INTO mysql_servers(hostgroup id,hostname, port)VALUES(20,'db.test.slave1',3306);
## 插入连接proxysq1的用户
INSERT INTO mysql_users(username,password,default_hostgroup)
VALUES('proxysql_test','proxysql',10);
## 基于入口端添加路由
INSERT INTO mysql_query_rules (rule_id,active,proxy_port,destination_hostgroup,apply)
VALUES (1,1,6401,10,1), (2,1,6402,20,1);
## 设置读写分离的端口
3306-Admin > SET mysql-interfaces='0.0.0.0:6401;0.0.0.0:6402';
## 持久化配置
3306-Admin > SAVE MYSQL SERVERS TO DISK;
3306-Admin > SAVE MYSQL QUERY RULES TO DISK;
3306-Admin > SAVE MYSQL VARIABLES TO DISK;
## 因端口的修改不能动态加载,需重启ProxySQL实例
$ sudo sysetmctl restart proxysql测试验证
所有来自于6401端口连接的查询都将被发送到hostgroup为10的组中;
所有来自于6402端口连接的查询都将被发送到hostgroup为20的组中;
配置缺点
该配置需要应用有内置的读写分离功能,以便区分读和写;
通常应用只配置一个单独的入口来连接ProxySQL,这对很多业务来说是不可接受的。
2.1.2 基于通用正则规则的读写分离
开启eventlog
eventslog可以记录用户在通过ProxySQL访问时的所有SQL语句,可以用其观察具体的路由规则,以下为开启方法:
## 设置eventslog的文件名称
3306-Admin > SET mysql-eventslog_filename='queries.log';
## 设置eventslog的格式为json
3306-Admin > SET mysql-eventslog_format=2;
## 加载到runtime层并保存到持久层
load mysql variables to runtime;
save mysql variables to disk;## 清空查询规则表
delete from mysql_query_rules;
## 延续上面配置,添加查询规则记录eventslog,如下表示对所有的操作都记录
INSERT INTO mysql_query_rules(active, match_digest, log,apply)
VALUES(1,'.',1,0);
## 添加基于正则的路由规则
INSERT INTO mysql_query_rules(active,match_digest,destination_hostgroup,apply)
VALUES(1,'^SELECT.*FOR UPDATE$',10,1),(1,'^SELECT',20,1);
## 加载配置到运行层并保存配置到持久层
LOAD MYSQL QUERY RULES TO RUNTIME;
SAVE MYSQL QUERY RULES TO DISK;测试预测
所有的SELECT FOR UPDATE语句将被路由到hostgroup为10的组中;
其他的SELECT语句将被路由到hostgroup为 20的组中;
除以上外的其他语句,将被路由到连接用户默认的hostgroup组中;
测试验证
## 小写查询(select请求忽略大小写,查看eventslog,该SQL路由到读组20)
mysql> select * from sbtest1 limit 1;
## 大写查询(select请求忽略大小写,查看eventslog,该SQL路由到读组20)
mysql> SELECT * from sbtest1 limit 1;
## 大小写混合查询(select请求忽略大小写,查看eventslog,该SQL路由到读组20)
mysql> SelECT * from sbtest1 limit 1;
## 有多余字符查询(select请求需以select作为开头,查看eventslog,该SQL路由到默认组10)
mysql> /* hints*/SelECT * from sbtest1 limit 1;
## 包含空格的查询(ProxySQL会对包含空格的SQL进行处理,查看eventslog,该SQL路由到读组20)
mysql> SelECT * from sbtest1 limit 1;2.2 hostgroup组相关
2.2.1 组故障场景
测试当ProxySQL中某个hostgroup组中所有的servers均故障后,ProxySQL的表现;
测试步骤
## 1. 查看runtime下的servers的各个状态(各个hostgroup组的server均为ONLINE)
3306-Admin > select hostgroup_id,hostname,port,status,max_replication_lag from runtime_mysql_servers;
+--------------+-----------------+-------+--------+---------------------+
| hostgroup_id | hostname | port | status | max_replication_lag |
+--------------+-----------------+-------+--------+---------------------+
| 10 | db.test.master | 3306 | ONLINE | 100 |
| 20 | db.test.slave1 | 3306 | ONLINE | 100 |
+--------------+-----------------+-------+--------+---------------------+
## 2. 手动将hostgroup_id=20的读组所有servers进行关闭
## 3. 查看runtime下的servers的各个状态(hostgroup_id的server状态已变为SHUNNED)
3306-Admin > select hostgroup_id,hostname,port,status,max_replication_lag from runtime_mysql_servers;
+--------------+-----------------+-------+---------+---------------------+
| hostgroup_id | hostname | port | status | max_replication_lag |
+--------------+-----------------+-------+---------+---------------------+
| 10 | db.test.master | 3306 | ONLINE | 100 |
| 20 | db.test.slave1 | 3306 | SHUNNED | 100 |
+--------------+-----------------+-------+---------+---------------------+
## 4. 发起查询语句(已配置了读写分离规则)
## 因为根据读写分离路由规则,select查询会路由到hostgroup_id为20的读组中,但因该组的所有servers均处于SHUNNED,故查询报错
mysql> select * from sbtest1 where id=1;
ERROR 9001 (HY000): Max connect timeout reached while reaching hostgroup 20 after 10001ms测试结论
如果ProxySQL根据路由规则路由到的hostgroup组中所有的servers都不可用,则操作将会失败;
对于读写分离一主一从架构来说,如果从库有故障,则仍然会影响线上故障,这是不可接受的;
解决方式之一:对于一主一从架构来说,可以将主从server均配置到读组中,并调整主库的优先级为最低,当从库不可用时,依然能保证读的请求不受影响;
2.2.2 同组server不同权重值影响
测试目的
测试在同hostgroup组下的servers的weight权重有差异情况下的路由情况;
测试步骤
## 1.更新mysql_servers的信息(读组中包含一主一从两个servers)
3306-Admin > select hostgroup_id,hostname,port,status,weight,max_replication_lag from mysql_servers;
+--------------+-----------------+-------+--------+--------+---------------------+
| hostgroup_id | hostname | port | status | weight | max_replication_lag |
+--------------+-----------------+-------+--------+--------+---------------------+
| 10 | db.test.master | 3306 | ONLINE | 1 | 100 |
| 20 | db.test.slave1 | 3306 | ONLINE | 2 | 100 |
| 20 | db.test.master | 3306 | ONLINE | 1 | 100 |
+--------------+-----------------+-------+--------+--------+---------------------+
## 2. 使用sysbench发起oltp_read_only的只读请求,使读的请求全部落到hostgoup_id=20的读组中
## 3. 分别对读组中db.test.slave1 的Server进行权重的更新
## 4. 对查询日志进行统计分析测试结果
不断修改20组下的db.test.slave1读库权重weight值:
权重为2时,该读库的请求占比为66.828%;
权重为100时,该读库的请求占比为98.997%;
权重为10000时,该读库的请求占比为99.989%;
权重为10000000最大值时,该读库的请求占比为99.99991%;
测试结论
同组内servers的询选择与servers的weight值正向相关:同组内servers的weight权重值越大,则其被轮询访问的概率越大
对于一主一从架构,从读写分离角度来看,如果想要实现绝大多数的读路由到从库上,则需要增大从库的weight权重,使其跟主库的权重差值越大越好;生产建议直接配置最大值10000000;
ProxySQL默认的负载轮询算法为random-weighted,通过该轮询算法可知,轮询与权重值的设置正向相关,但也并不能完全避免一些低权重的servers不被路由到;
2.2.3 组server延迟场景
测试目的
测试在hostgroup组下的servers的延迟配置情况;
影响因素
mysql_servers.max_replication_lag
server的延迟最大允许值,当判定延迟超过设置的该值后,则从库会处于SHUNNED状态。
monitor_replication_lag_use_percona_heartbeat
动态配置,可以使用pt-heartbeat作为延迟的判断,默认为空表示使用show slave status来判断。如配置成percona.heartbeat表示在percona库下的heartbeat表
monitor_slave_lag_when_null
当复制延迟检查发现Seconds_Behind_Master=NULL时,使用该参数设置一个值用来假设当前延迟的时间,默认为60秒;
测试步骤
monitor_replication_lag_use_percona_heartbeat为空
为空表示使用show slave status来判断主从延迟
## 1.设置max_replication_lag为100秒,monitor_slave_lag_when_null默认值60
## 2. 停掉主从相关线程或者子线程
mysql> stop slave;
## 3. 观察服务状态(从库server始终处于ONLINE状态)
## 4. 设置max_replication_lag为59秒,monitor_slave_lag_when_null默认值60
## 5. 停掉主从相关线程或者子线程
mysql> stop slave;
## 6. 观察服务状态(从库server立刻变为SHUNNED状态)
## 结论:
因主从复制被中断,当通过show slave status获取Seconds_Behind_Master时为空,则设置延迟值为60,如果小于max_replication_lag设置的值则不延迟,反之则延迟。monitor_replication_lag_use_percona_heartbeat不为空
## 1.设置max_replication_lag为100秒,monitor_slave_lag_when_null默认值60,配置参数值为percona.heartbeat
## 2. 使用pt-heartbeat做心跳
pt-heartbeat -D percona --user dba_user --password xxx -h master_ip -P 3306 --update --daemonize --create-table --check-read-only
## 3. 停掉主从相关线程或者子线程
mysql> stop slave;
## 4. 观察服务状态(从库server超100秒后处于SHUNNED状态)
## 5. 将主从恢复,且等延迟追上,设置配置参数为一个不存在的心跳表
3306-Admin > set mysql-monitor_replication_lag_use_percona_heartbeat='percona.heartbeat1';
3306-Admin > load mysql variables to runtime;
## 6. 停掉主从相关线程或者子线程
mysql> stop slave;
## 7. 等待100秒后,发现从库仍处于ONLINE状态(查询mysql_server_replication_lag_log表提示如下错误)
Table 'percona.heartbeat1' doesn't exist
## 8. 将主从恢复,且等延迟追上,并配置正确的心跳表,但取消monitor_username用户对心跳表的查询权限
mysql> revoke select on percona.heartbeat from monitor@'192.168.56.101';
## 9. 停掉主从相关线程或者子线程
mysql> stop slave;
## 10. 等待100秒后发现从库仍处于ONLINE状态,延迟日志表中出现如下错误:
SELECT command denied to user 'monitor'@'192.168.56.101' for table 'heartbeat'
## 结论:
主从复制被中断,当ProxySQL通过pt-heartbeat表作为延迟判断时,因心跳值持续增长,当达到设置的最大延迟时则从库处于SHUNNED状态不可用;
如果参数设置为一个不存在的心跳表,则无法判断延迟情况(repl_lag为NULL),此时即使主从复制中断从库依然可用;
如果监控后端MySQL的用户没有心跳表的查询权限,则仍然无法判断延迟情况,表现同上;测试总结
ProxySQL可以通过show slave status、也提供通过pt-heartbeat工具来判断主从的延迟情况;可以根据不同的故障场景进行不同的配置:在MySQL无高可用、主库宕机业务仍然能追求读时,可以设置mysql-monitor_slave_lag_when_null的值小于max_replication_lag,且不依赖pt-heartbeat心跳表;
2.3 黑白名单介绍
ProxySQL 可以通过路由规则来支持IP或网段的黑名单和白名单功能,从ProxySQL2.0.9开始还启用了防火墙来简化类似功能。
2.3.1 黑名单实现
对黑名单的支持很简单,如果想禁用某个IP或网段的访问,则可以通过如下方式进行禁用
测试步骤
## 1. 延续之前的配置,对mysql_query_rules进行清空
delete from mysql_query_rules;
## 2. 插入一条黑名单
insert into mysql_query_rules (rule_id,active,client_addr,error_msg,apply)values(3,1,'192.168.216.146','this ip is banned!',1);
## 3. 加载配置
load mysql query rules to run;测试结果
通过192.168.216.146机器连接到ProxySQL,在执行SQL时,返回this ip is banned! 错误。
测试结论
ProxySQL的黑名单功能是通过mysql_query_rules.error_msg来设置的,如果mysql_query_rules.error_msg不为空,则当匹配该规则后,操作就会出现error_msg,从而实现黑名单功能。
2.3.2 白名单实现
链式规则的介绍
在mysql_query_rules表中,有两个特殊字段"flagIN"和"flagOUT",它们分别用来定义规则的入口和出口,从而实现链式规则(chains of rules)。
链式规则的路由
当入口值flagIN设置为0时,表示开始进入链式规则;
当语句匹配完当前规则后,则记下当前规则的flagOUT值,如果flagOUT值非空(NOT NULL),则为该语句打上flagOUT标记。如果该规则的apply字段值不是1,则继续向下匹配;如果apply字段值为1,则进行apply并结束匹配;
如果语句的flagOUT标记和下一条规则的flagIN值不同,则跳过该规则,继续向下匹配。直到匹配到flagOUT=flagIN的规则,则匹配该规则,该规则是链式规则中的另一条规则;
直到某规则的apply字段设置为1,或者已经匹配完所有规则,则最后一次被评估的规则将直接生效;
测试步骤
# 1. 清理mysql_query_rules表
delete from mysql_query_rules;
## 插入白名单及相关链式规则
## 2. 插入eventslog记录的所有日志路由规则(rule_id为1表示记录所有操作语句)
insert into mysql_query_rules (rule_id,active, match_digest, log,apply) VALUES (1,1,'.',1,0);
## 3. 插入由client_addr指定ip的白名单路由规则(设置apply为0)
insert into mysql_query_rules(rule_id,active,client_addr,flagOUT,apply) values(2,1,'192.168.56.%',10,0);
insert into mysql_query_rules(rule_id,active,client_addr,flagOUT,apply) values(3,1,'192.168.58.100',10,0);
## 4. 插入链式规则中的SQL查询路由规则(其flagIN要与白名单规则的flagOUT匹配,并设置apply为1)
insert into mysql_query_rules (rule_id,active,flagIN,match_digest,destination_hostgroup,apply)values(4,1,10,'^SELECT.*FOR UPDATE$',10,1);
insert into mysql_query_rules (rule_id,active,flagIN,match_digest,destination_hostgroup,apply)values(5,1,10,'^SELECT',20,1);
## 5. 插入非白名单拒绝的路由规则(对于非白的IP走到该规则时,返回拒绝连接)
INSERT INTO mysql_query_rules (rule_id,active, match_digest, error_msg, apply) VALUES (6,1,'.','not allow to connect db',1);
## 6. 加载新的路由规则到runtime
load mysql query rules to runtime;
## 7. 查询规则
+---------+--------+----------+----------------+-------------------------+--------+---------+--------+--------------+------------------------+-----------------------+-----+-------+
| rule_id | active | username | client_addr | error_msg | flagIN | flagOUT | digest | match_digest | match_pattern | destination_hostgroup | log | apply |
+---------+--------+----------+----------------+-------------------------+--------+---------+--------+--------------+------------------------+-----------------------+-----+-------+
| 1 | 1 | NULL | NULL | NULL | 0 | NULL | NULL | . | NULL | NULL | 1 | 0 |
| 2 | 1 | NULL | 192.168.56.% | NULL | 0 | 10 | NULL | NULL | NULL | NULL | NULL | 0 |
| 3 | 1 | NULL | db01.test.net | NULL | 0 | 10 | NULL | NULL | NULL | NULL | NULL | 0 |
| 4 | 1 | NULL | NULL | NULL | 10 | NULL | NULL | NULL | ^SELECT .* FOR UPDATE$ | 10 | NULL | 1 |
| 5 | 1 | NULL | NULL | NULL | 10 | NULL | NULL | NULL | ^SELECT | 20 | NULL | 1 |
| 6 | 1 | NULL | NULL | not allow to connect db | 0 | NULL | NULL | . | NULL | NULL | NULL | 1 |
+---------+--------+----------+----------------+-------------------------+--------+---------+--------+--------------+------------------------+-----------------------+-----+-------+
6 rows in set (0.00 sec)测试验证
## 在192.168.56.1加白的机器上执行select查询语句(执行成功并返回查询结果)
$ /usr/bin/mysql -uuser_test -pxxxx -hxxx.xxx.xxx.xx -P6032 -e "select * from sbtest.sbtest1 limit 1"
# 查看命中规则(命中rule_id为1、2、5的规则,符合预期)
3306-Admin > select * from stats_mysql_query_rules;
+---------+------+
| rule_id | hits |
+---------+------+
| 1 | 1 |
| 2 | 1 |
| 3 | 0 |
| 4 | 0 |
| 5 | 1 |
| 6 | 0 |
+---------+------+
6 rows in set (0.00 sec)
## 在192.168.100.100非加白的机器上执行select查询语句(执行失败,提示错误)
$ /usr/bin/mysql -uuser_test -pxxxx -hxxx.xxx.xxx.xx -P6032 -e "select * from sbtest.sbtest1 limit 1"
ERROR 1148 (42000) at line 1: not allow to connect db
# 查看命中规则(命中rule_id为1、6的规则,符合预期)
3306-Admin > select * from stats_mysql_query_rules;
+---------+------+
| rule_id | hits |
+---------+------+
| 1 | 2 |
| 2 | 1 |
| 3 | 0 |
| 4 | 0 |
| 5 | 1 |
| 6 | 1 |
+---------+------+
6 rows in set (0.00 sec)
## 在域名为db01.test.net的机器上执行select查询语句(执行失败,提示错误)
$ /usr/bin/mysql -uuser_test -pxxxx -hxxx.xxx.xxx.xx -P6032 -e "select * from sbtest.sbtest1 limit 1"
ERROR 1148 (42000) at line 1: not allow to connect db测试结论
通过mysql_query_rules可以通过client_addr结合读写分离规则做相关黑白名单的路由;
client_addr支持IP和标准网段的授权,但不支持域名;
说明:
查询规则是根据rule_id由小到大进行匹配,如果想继续添加白名单,则其rule_id需要小于读写分离的规则rule_id;建议将本测试用例中rule_id为4、5、6的三条更新为更大的值,如同时加100,则新添加的白名单rule_id可以在[4,103]之间选择。
2.3.3 防火墙功能
如果查询限制ip、定向的根据指纹进行路由,则通过mysql_query_rules可能需要定义很多复杂的规则,从ProxySQL2.0.9开始,启用了防火墙功能。其简化了这类的需求配置。
防火墙的两张表
mysql_firewall_whitelist_users
设置防火墙用户的表,一个用户由username和client_address作为唯一主键;
主要字段
active:表示是否是否生效;
username:指定ProxySQL中mysql_users表定义的用户名;
client_address:表示连接ProxySQL的客户端IP,为空表示匹配任意ip;需注意其只支持ip,暂不支持子网段;
mode:OFF模式表示允许定义的username@client_address用户执行任意的查询,完全忽略mysql_firewall_whitelist_rules中定义的规则;DETECTING模式下,允许用户查询,但当执行的SQL指纹不在mysql_firewall_whitelist_rules中时,则会在错误日志中输出一条告警;PROTECTING模式下,只允许用户执行在mysql_firewall_whitelist_rules中定义的SQL指纹语句,如果不在该表里,则将会报错;
mysql_firewall_whitelist_rules
定义防火墙SQL指纹规则,一条规则由username、client_address、schemaname、flagIN、digest共同组成;如果mysql_firewall_whitelist_users中有用户匹配执行的SQL,且其mode为DETECTING或者PROTECTING模式,则将会在该表中查找SQL指纹规则,以决定执行的SQL是否会被执行;
说明:通常建议对已经运行一段时间的业务SQL进行收集整理,挑选出受信SQL后存放到该表中。
INSERT INTO mysql_firewall_whitelist_rules(active, username, client_address, schemaname, flagIN, digest, comment)SELECT DISTINCT 1, username, client_address, schemaname, 0, digest, '' FROM stats_history.history_mysql_query_digest;
如果该表为空,则在PROTECTING模式下,将拒绝任何SQL的执行。
防火墙相关参数
mysql-firewall_whitelist_enabled
是否开启防火墙。
mysql-firewall_whitelist_errormsg
用来返回给执行被阻止SQL的客户端信息。
测试防火墙白名单功能
测试DETECTING模式
## 1. 开启防火墙功能
3306-Admin > set mysql-firewall_whitelist_enabled=1;
3306-Admin > load mysql variables to runtime;
## 2. 添加用户和ip白名单到mysql_firewall_whitelist_users表中(使用DETECTING模式),同时不设置mysql_firewall_whitelist_rules
3306-Admin > INSERT INTO mysql_firewall_whitelist_users(active, username, client_address, mode,comment) values(1,'user_test', '192.168.56.100', 'DETECTING', '');
## 添加一条包含网段的白名单
3306-Admin > INSERT INTO mysql_firewall_whitelist_users(active, username, client_address, mode,comment) values(1,'user_test', '192.168.58.%', 'DETECTING', '');
## 3. 加载防火墙配置到运行层
3306-Admin > load mysql firewall to runtime;
## 4. 在192.168.56.100上执行查询语句(能正常查询,但在proxysql的日志上出现告警)
$ /usr/bin/mysql -uuser_test -pxxxx -hxxx.xxx.xxx.xx -P6032 -e "select * from sbtest.sbtest1 limit 1"
## 告警log
Query_Processor.cpp:1814:process_mysql_query(): [WARNING] Firewall detected unknown query with digest 0x02033E45904D3DF0 from user user_test@192.168.56.100
## 5. 在192.168.56.101上执行查询语句(无法正常查询,未加白出现如下错误)
$ /usr/bin/mysql -uuser_test -pxxxx -hxxx.xxx.xxx.xx -P6032 -e "select * from sbtest.sbtest1 limit 1"
ERROR 1148 (42000) at line 1: Firewall blocked this query
## 6. 在192.168.58.100上执行查询语句(无法正常查询,虽然按网段加白但不生效)
$ /usr/bin/mysql -uuser_test -pxxxx -hxxx.xxx.xxx.xx -P6032 -e "select * from sbtest.sbtest1 limit 1"
ERROR 1148 (42000) at line 1: Firewall blocked this query测试PROTECTING模式
## 1. 将模式更改为PROTECTING模式
3306-Admin > update mysql_firewall_whitelist_users set mode='PROTECTING';
## 2. 加载防火墙配置到运行层
3306-Admin > load mysql firewall to runtime;
## 3. 在192.168.56.100上执行查询语句(无法正常查询,出现错误。因为只有匹配mysql_firewall_whitelist_rules表中设置的SQL指纹SQL才能被执行)
$ /usr/bin/mysql -uuser_test -pxxxx -hxxx.xxx.xxx.xx -P6032 -e "select * from sbtest.sbtest1 limit 1"
ERROR 1148 (42000) at line 1: Firewall blocked this query
## 4. 在192.168.56.101上执行查询语句(无法正常查询,因未加白)
$ /usr/bin/mysql -uuser_test -pxxxx -hxxx.xxx.xxx.xx -P6032 -e "select * from sbtest.sbtest1 limit 1"
ERROR 1148 (42000) at line 1: Firewall blocked this query
## 5. 在192.168.58.100上执行查询语句(无法正常查询,虽然按网段加白但不生效)
$ /usr/bin/mysql -uuser_test -pxxxx -hxxx.xxx.xxx.xx -P6032 -e "select * from sbtest.sbtest1 limit 1"
ERROR 1148 (42000) at line 1: Firewall blocked this query测试结论
防火墙功能比直接在mysql_query_rules中设置查询规则要简单一些,其能很方便的实现白名单功能,但因为暂不支持网段的设置,目前还有些缺陷。
三 总结
本文通过ProxySQL主要功能介绍以及应用案例演示,包括:读写分离、黑白名单、路由规则、主从延迟等,使读者更了解ProxySQL。总体来说,ProxySQL是一款功能强大、易于配置和管理的MySQL代理,可以帮助我们提高MySQL服务的性能和可用性。
四 参考连接
https://proxysql.com/documentation/
https://www.cnblogs.com/hahaha111122222/p/16305988.html
https://www.cnblogs.com/Alpes/p/15217774.html
https://www.cnblogs.com/gered/p/15868767.html