在这里总结一下所有组件:
springcloud是分布式微服务的一站式解决方案,可以说微服务是一个概念,而springcloud就是这个的实现
springcloud有五大核心组件:
注册中心
引言
由于微服务处于不同的进程,也就是说,涉及到了不同进程之间的通信,于是我们就需要在计算机网络体系的“运输层”中将进程定位,即ip+端口号。那么如果让程序员去记忆这些ip-端口数据,是非常麻烦的,我们有“服务”的概念,就是说,微服务之间,只需要知道自己要调用外部的什么服务就行了,因此我们可以考虑做一个服务与(ip:port)的映射关系,这样程序员只需要知道自己调用什么服务就可以了,不需要去记忆对应服务的(ip:port)了。
而且,既然说到了分布式,那一个服务在应对并发高的场景时基本都会搭建集群,那么集群就需要负载均衡,注册中心能很好的实现负载均衡,我们只需要在向注册中心获取对应服务的所有(ip:port),再插入一个负载均衡算法即可。
既然是注册中心,也就是说要面对所有的微服务,因此这个注册中心也应该是一个服务,可以让所有的微服务去拉取数据(拉取所有服务的ip-port信息)以及注册数据(将对应服务的ip-port存储到注册中心中)
Eureka
Eureka注册中心是springcloud最初的注册中心组件,但是现在停止更新了
Eureka 分为服务端(Eureka server)和客户端(Eureka client)
其中Eureka server就是我们上面说的面向所有微服务的注册服务,而Eureka client端,将运行在所有微服务上,Eureka client又分为两个模块,一个是生产者模块(专门向Eureka server发送注册信息,以及心跳信号等),另一个是消费者模块(向Eureka server拉取注册信息,并存储在本地,其实就是服务发现)。
Eureka的注册表是一个双字典结构的数据,服务发现的目的是标识服务和服务状态的管理,所以注册表中有服务标识、服务基本信息、服务状态信息等
为什么是双字典结构呢?我们知道,1个服务可以对应多个ip,每个服务器又需要存储多个值,即(服务标识,服务基本信息,服务状态信息)等,这就需要考虑了。
这个双字典结构用java来描述就是这样的
ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry = new ConcurrentHashMap();
zookeeper
zookeeper是Eureka的替代,它也可以成为注册中心。我们知道zookeeper的一段介绍是“zookeeper是一个分布式系统的协调工具”,我们得到了关键词,分布式、协调,这就是我们想要的。我们可以利用zookeeper的路径节点特性去存储对应服务下的ip-port信息,如在父节点定义服务名称,而子节点存储该服务下的所有ip-port信息以及服务器信息,可以说,zookeeper非常适合作为注册中心来使用。而springcloud也整合了zookeeper作为注册中心的各种逻辑,可以完美取代Eureka。
Eureka 和zookeeper的对比:
对比就不得不说到分布式系统的cap理论了,c是一致性(Consistency),a是可用性(Availability),p是分区容错性(Partition tolerance)。
可用性和一致性注定是冲突的,因为高可用意味着有其他主机宕机了,也一样可以继续提供服务,但是宕机的服务器也就无法实现数据的一致性了。
因此Eureka决定实现的是高可用和分区容错性
也就是说,当Eureka 集群中有主机宕机了,也一样接收并保存服务的注册请求,仅仅是数据不一致,实际上并不影响使用
而zookeeper实现的是数据一致性以及分区容错性
就是说,zookeeper集群中有一台宕机了,这时候zookeeper无法再处理新的注册请求,因为无法同步到所有的zookeeper主机上
Feign
其实使用注册中心以后我们微服务已经可以使用了,我们通过注册中心拉取注册表信息,得到了对应服务的ip-port,于是就可以封装http请求,然后通过RestTemplate客户端发送请求过去了,获取响应值,然后再解析并封装成为对象。
这样子其实还是挺繁琐的,因为每次请求一个服务,都要自己封装请求,自己去解析响应的信息,封装成为对应。如果是在业务代码中呢?一般也是会在service中进行调用的,这样一些与业务无关的代码就掺杂在业务代码中,使得观感不好,而且违背了单一职责的原则,封装请求头,解析响应信息这些工作不应该在业务代码中去做。
我们希望,在service层中调用服务,不需要关注怎么封装请求头,只关注解析后的结果对象。这时候,Feign就出现了,它采用了jdk动态代理,我们只管在服务消费者中定义Feign的接口,在请求进来时,动态生成该接口实例,然后通过Feign定义的invocationHandler对象进行具体的封装请求逻辑,invocationHandler对象中又涉及到获取对应服务的ip-port,封装请求头,解析响应数据。
既然是动态代理,那么代理的对象就是对应微服务,invocationHandler中保存着Feign接口方法-methodHandler的映射,这个methodHandler,也称为方法处理器。
MethodHandler 的invoke(…)方法,主要职责是完成实际远程URL请求,然后返回解码后的远程URL的响应结果。
它们需要完成以下事情:
- 获取@RequestMapping的路径,处理路径变量,拼接服务名称,生成requestTemplate
- [负载均衡]拉取注册表,获取对应服务的ip-port,拼接url信息
- 封装请求头,发送请求
- 解析响应值
请注意,它们的后三个是由feign.client去完成的
Ribbon负载均衡
微服务是运行在不同进程上的,因此它们调用其他服务时,就称为服务消费者(也就是客户端),我们实现的是客户端负载均衡,而不是服务端负载均衡。
为什么选择客户端负载均衡,而不是服务端负载均衡?
有以下原因:
- 实现简单:客户端负载均衡只需要在客户端进行配置即可,相对于服务端负载均衡需要在服务端进行配置,客户端实现简单,适用于大规模的微服务架构。
- 无单点故障:客户端负载均衡可以从多个服务提供者中选择响应时间最快的服务,不存在单点故障的问题,提高了系统的可用性。(单点故障,即访问代理服务器,然后负载均衡给我们转发到合适的服务器上,如果代理服务器宕机,将无法访问该服务)
- 按需调整:客户端负载均衡可以根据不同的实际情况动态调整负载均衡策略,对网关和服务提供者具有更好的掌控能力。
ribbon需要配合服务发现一起使用,即discoveryClient,其实就是拉取注册中心的注册表缓存到本地,然后进行通过负载均衡算法去选出对应服务集群中合适的服务器(ip:port)。
在springcloud中,Feign会和ribbon一起搭配使用,具体的使用就在于feign.Client对象中。
ribbon采用了Template的模式,规范了负载均衡的三个步骤:
1、负载均衡
2、执行HttpClient
3、记录请求信息
ribbon只需要将第2步开放给请求客户端对象去做即可
Hystrix
Hystrix采用了命令模式,可以将使用了@HystrixCommand反射出来成为一个命令类,为该命令分配一个线程池,将方法的请求与执行分离开来,当我们请求执行一个command时,Hystrix,就会分出一个Hystrix线程执行该命令。由于请求和执行是分离的,因此如果外部服务出现宕机,我们就可以快速失败,而不是一直让线程等待,导致服务器线程资源来不及释放。我们还可以在失败的时候,调用一些降级策略,如记录到日志中等,然后快速返回。
当请求失败到达一定阈值(次数)的时候,Hystrix会采用信号量对这个服务进行熔断,当其他请求再次请求该外部服务时,实际的执行都不会访问外部服务(因为检测到信号量熔断了),于是快速返回失败以及调用fallback方法。这里熔断时Hystrix还会间隔一段时间让一部分请求通过,访问外部服务,去检测外部服务是否已经恢复,这个状态称熔断半开
网关
既然有了多个微服务,尽管我们可以通过微服务名称来访问这个微服务,但是对于前端来说,与它们打交道的不过是uri,映射路径罢了,于是我们采用了网关的概念,网关处理外部所有的用户请求,将匹配的路径的请求,ip:port替换成对应的服务或者对应的服务器ip:port,这个过程称之为”路由“。
网关有以下几个作用:
- 统一入口:为全部为服务提供一个唯一的入口,网关起到外部和内部隔离的作用,保障了后台服务的安全性。
- 鉴权校验:识别每个请求的权限,拒绝不符合要求的请求。(判断权限)
- 动态路由:动态的将请求路由到不同的后端集群中。(通过记录的路由表)
- 减少客户端与服务端的耦合:服务可以独立发展,通过网关层来做映射。(即客户端,也就是浏览器端无需记住要访问的微服务名称,只需要去访问zuul网关即可)
zuul
zuul网关依然采用的是springmvc,这个称之为同步阻塞,承担不了太大的并发量,因为每进来一个请求,都分出了一个线程去处理。
gateway
gateway采用了Netty通信框架,Netty底层采用了reactor模式进行响应式编程,即对数据流进行处理,是非阻塞的。比zuul效率要高得多,不会每进来一个请求,都分出一个线程去处理,而是固定线程数量,去不断的对进来的数据流进行处理。
响应式编程:就是以数据为主体,对外界的动作做出响应,这些“动作”就是一系列的“逻辑”。而平常我们开发,是以逻辑为主体,等待外界传入数据进行处理
(左边是响应式编程,右边是我们日常开发的编程逻辑)
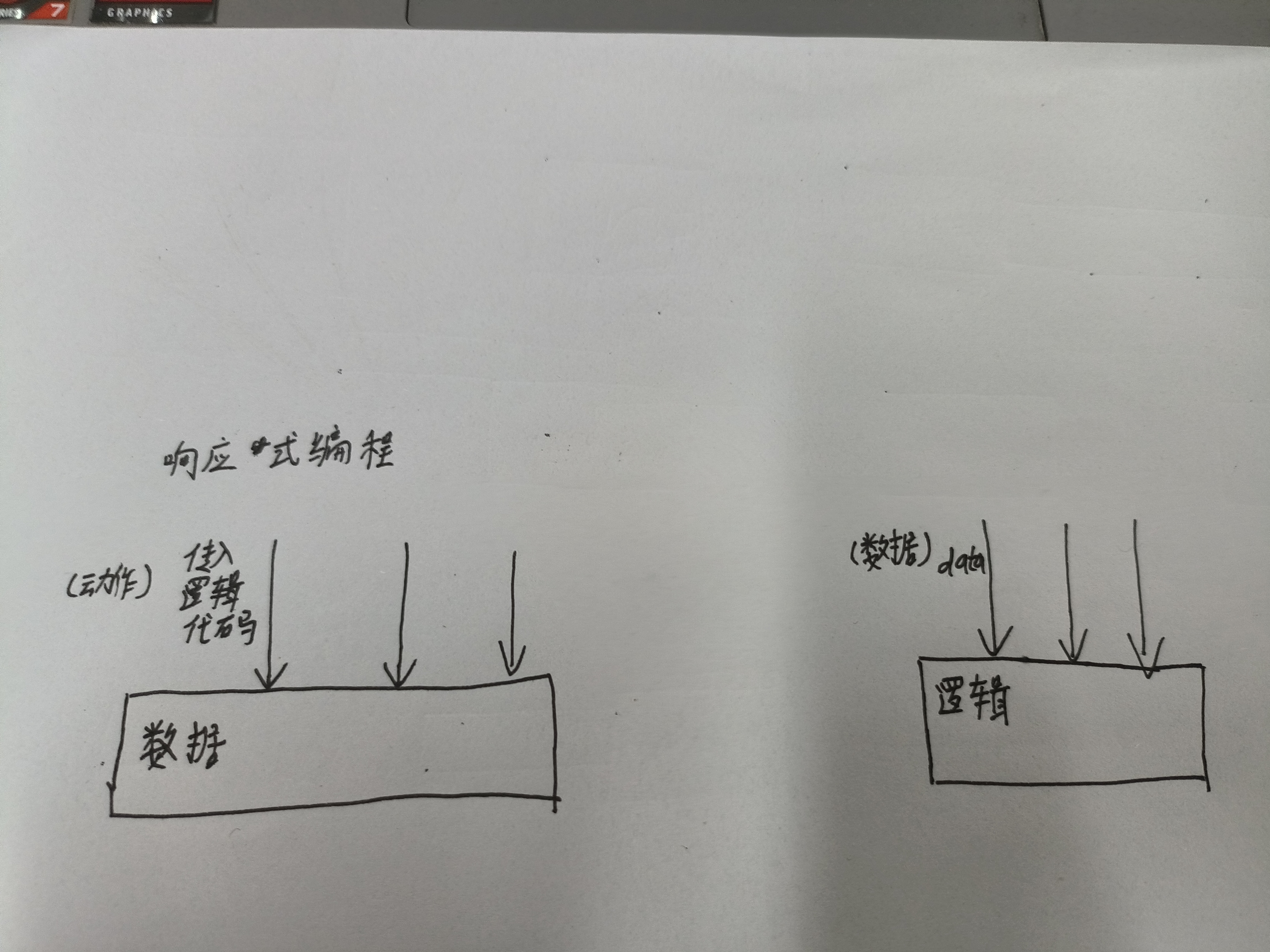
现在请大家和我一起扭转思维。原来以逻辑代码执行作为主线,数据作为参与者。现在以数据作为主线,逻辑代码执行作为参与者。说的再白一些,原来是数据传递到逻辑代码里,现在是逻辑代码传递到数据里。
有人也许会问,逻辑代码怎么传递?哈哈,通过传递Lambda表达式呀,函数式编程来实现逻辑的传入。
其他组件
config分布式配置中心
由于将系统拆分成多个微服务,因此也会导致有很多配置文件,如application.yaml等,会导致我们如果要修改配置文件,就需要进入对应微服务的项目下去修改,非常不便于操作,而且,运维人员应该直接对所有的配置信息进行集中化管理,如管理服务运行的端口等。
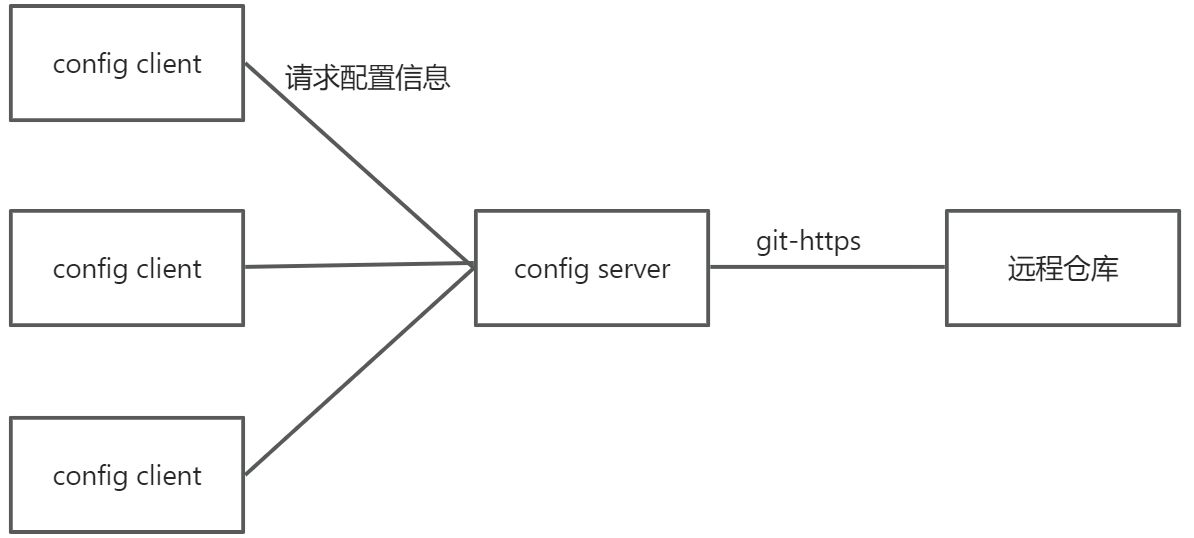
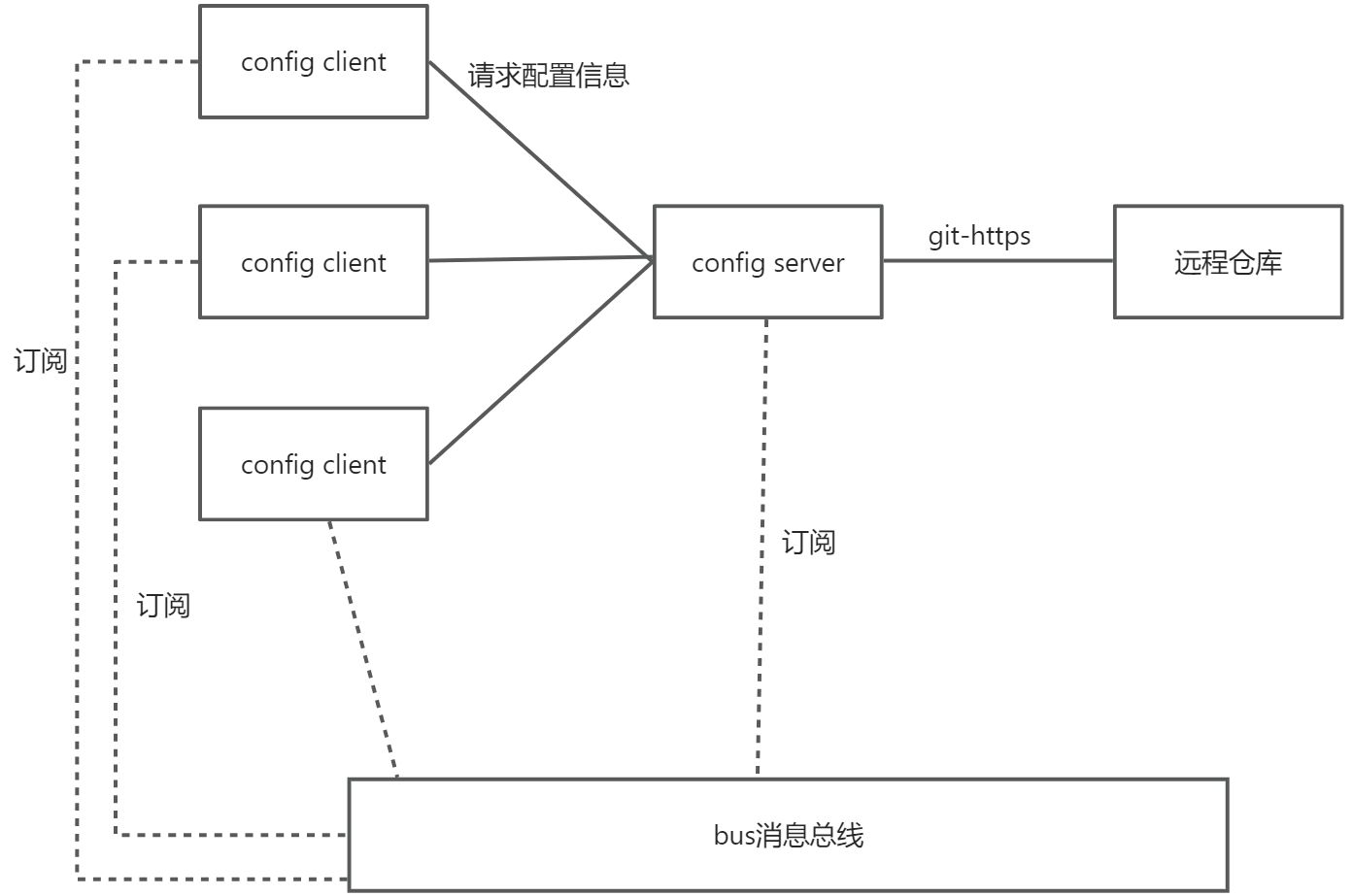
于是,为了集中化管理配置文件,我们使用了config配置中心,config内部采用了git对配置文件进行集中化管理。config server端,本质上也是一个微服务,需要注册到注册中心中。然后在所有服务上运行对应的config client模块,config client向config server请求获取配置信息,将响应的最新配置信息应用于当前服务。
具体架构如下:
bus消息总线
由于系统是分布式微服务的,因此不同服务之间的通信,报文广播等,就需要使用消息总线。而bus消息总线本质上是整合了消息队列来实现的,即依靠了消息队列的发布-订阅功能。这需要所有的微服务都导入对应的bus依赖,并且于消息队列进行连接。
bus消息总线的一个典型应用就是于config配合使用,进行所有配置的动态刷新。具体架构如下

![[计算机图形学]几何:网格处理(前瞻预习/复习回顾)](https://img-blog.csdnimg.cn/d6a5f9c260034cd2a5b8c9c39821107f.png)