7.1 并行流
Stream 接口能非常方便地并行处理其元素:对收集源调用 parallelStream 方法就能将集合转换为并行流。并行流就是一个把内容拆分成多个数据块,用不同线程分别处理每个数据块的流。
public long sequentialSum(long n) {
return Stream.iterate(1L, i -> i + 1) // 生成自然数无限流
.limit(n) // 限制到前n 个数
.reduce(0L, Long::sum); // 对所有数字求和来归约流
}
传统的写法
public long iterativeSum(long n) {
long result = 0;
for (long i = 1L; i <= n; i++) {
result += i;
}
return result;
}
7.1.1 将顺序流转换为并行流
调用 parallel 方法,就成了并行流,
public long parallelSum(long n) {
return Stream.iterate(1L, i -> i + 1)
.limit(n)
.parallel() // 将流转换为并行流
.reduce(0L, Long::sum);
}
现在 Stream 由内部被分成了几块。因此能对不同的块执行独立并行的归约操作.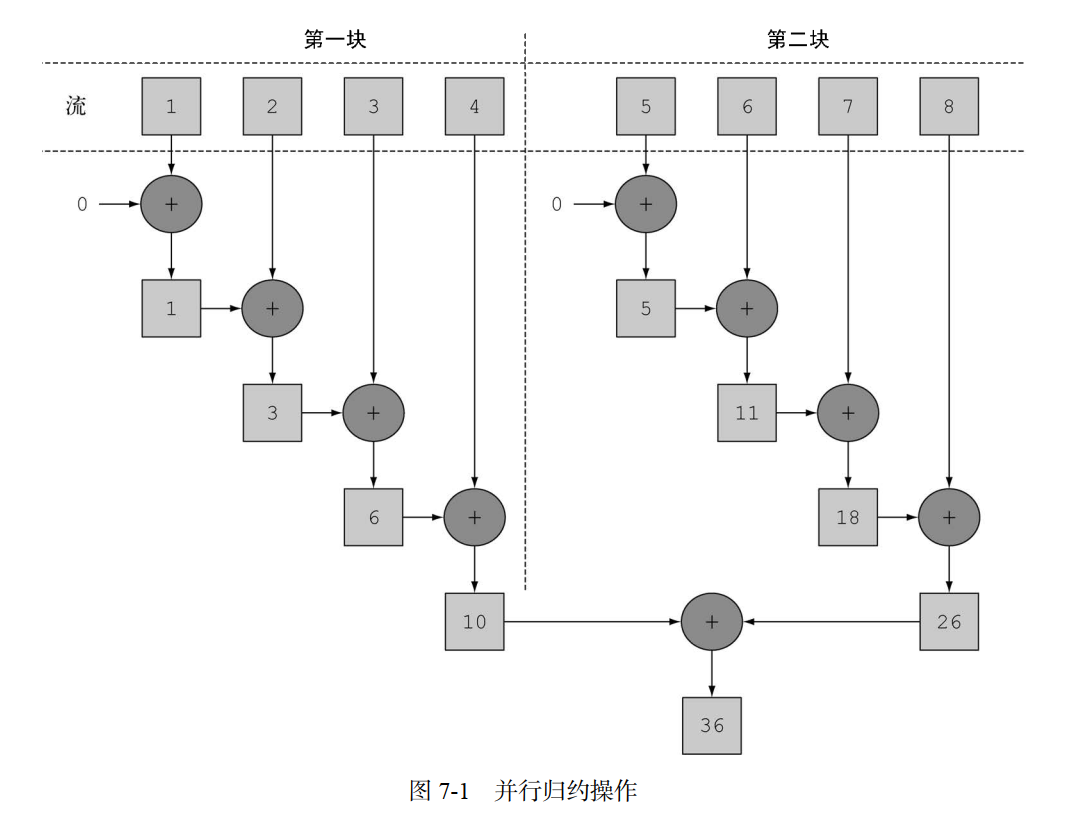
配置并行流使用的线程池
看看流的 parallel 方法,你可能会想,并行流用的线程是从哪儿来的?有多少个?怎么自定义这个过程呢?
并行流内部使用了默认的 ForkJoinPool(7.2节会进一步讲到分支/合并框架),它默认的线程数量就是你的处理器数量,这个值是由 Runtime.getRuntime().availableProcessors()得到的。
但是这并非一成不变,你可以通过系统属性 java.util.concurrent.ForkJoinPool. common.parallelism 来修改线程池大小,如下所示:
System.setProperty(“java.util.concurrent.ForkJoinPool.common.parallelism”,“12”);
这是一个全局设置,因此它会对代码中所有的并行流产生影响。反过来说,目前我们还无法专为某个并行流指定这个值。一般而言,让 ForkJoinPool 的大小等于处理器数量是个不错的默认值,除非你有很充足的理由,否则强烈建议你不要修改它。
7.1.2 测量流性能
并行求和法和顺序、迭代法比较性能。
需要使用名为 Java 微基准套件(Java microbenchmark harness,JMH)的库实现了一个微基准测试。
加入maven依赖
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.17.4</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.17.4</version>
</dependency>
<build>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<executions>
<execution>
<phase>package</phase>
<goals><goal>shade</goal></goals>
<configuration>
<finalName>benchmarks</finalName>
<transformers>
<transformer implementation="org.apache.maven.plugins.shade.
resource.ManifestResourceTransformer">
<mainClass>org.openjdk.jmh.Main</mainClass>
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
测量对前 n 个自然数求和的函数的性能
// 测量用于执行基准测试目标方法所花费的平均时间
@BenchmarkMode(Mode.AverageTime)
// 以毫秒为单位,打印输出基准测试的结果
@OutputTimeUnit(TimeUnit.MILLISECONDS)
// 采用 4Gb 的堆,执行基准测试两次以获得更可靠的结果
@Fork(2, jvmArgs={"-Xms4G", "-Xmx4G"})
public class ParallelStreamBenchmark {
private static final long N= 10_000_000L;
// 基准测试的目标方法
@Benchmark
public long sequentialSum() {
return Stream.iterate(1L, i -> i + 1).limit(N)
.reduce( 0L, Long::sum);
}
// 尽量在每次基准测试迭代结束后都进行一次垃圾回收
@TearDown(Level.Invocation)
public void tearDown() {
System.gc();
}
}
编译这个类时,你之前配置的 Maven 插件会生成一个名为 benchmarks.jar 的 JAR 文件,你可以像下面这样执行它:
java -jar ./target/benchmarks.jar ParallelStreamBenchmark
但是因为出现自动装箱拆箱,所以性能还没有普通的快,而且因为是一个无线流的原因,修改:
@Benchmark
public long parallelRangedSum() {
return LongStream.rangeClosed(1, N)
.parallel()
.reduce(0L, Long::sum);
}
7.1.3 正确使用并行流
错用并行流而产生错误的首要原因,就是使用的算法改变了某些共享状态。
public long sideEffectSum(long n) {
Accumulator accumulator = new Accumulator();
LongStream.rangeClosed(1, n).forEach(accumulator::add);
return accumulator.total;
}
public class Accumulator {
public long total = 0;
public void add(long value) { total += value; }
}
上面的代码 每次访问 total 都会出现数据竞争。
7.1.4 高效使用并行流
- 如果有疑问,测量。把顺序流转成并行流轻而易举,却不一定是好事。
- 留意装箱。自动装箱和拆箱操作会大大降低性能。Java 8 中有原始类型流(IntStream、LongStream 和 DoubleStream)来避免这种操作,但凡有可能都应该用这些流。
- 有些操作本身在并行流上的性能就比顺序流差。特别是 limit 和 findFirst 等依赖于元素顺序的操作
- 还要考虑流的操作流水线的总计算成本。设 N 是要处理的元素的总数, Q 是一个元素通过流水线的大致处理成本,则 N*Q 就是这个对成本的一个粗略的定性估计。
- 对于较小的数据量,选择并行流几乎从来都不是一个好的决定。
- 要考虑流背后的数据结构是否易于分解。例如,ArrayList 的拆分效率比 LinkedList高得多
- 流自身的特点以及流水线中的中间操作修改流的方式,都可能会改变分解过程的性能。
- 还要考虑终端操作中合并步骤的代价是大是小(例如 Collector 中的 combiner 方法)。

7.2 分支/合并框架
分支/合并框架的目的是以递归方式将可以并行的任务拆分成更小的任务,然后将每个子任务的结果合并起来生成整体结果。
7.2.1 使用 RecursiveTask
要把任务提交到这个池,必须创建 RecursiveTask的一个子类,其中 R 是并行化任务(以及所有子任务)产生的结果类型,或者如果任务不返回结果,则是 RecursiveAction类型(当然它可能会更新其他非局部机构)
要定义 RecursiveTask,只需实现它唯一的抽象方法 compute:protected abstract R compute();
if (任务足够小或不可分) {
顺序计算该任务
} else {
将任务分成两个子任务
递归调用本方法,拆分每个子任务,等待所有子任务完成
合并每个子任务的结果
}

现在编写一个方法来并行对前 n 个自然数求和就很简单了。你只需把想要的数字数组传给ForkJoinSumCalculator 的构造函数:
public static long forkJoinSum(long n) {
long[] numbers = LongStream.rangeClosed(1, n).toArray();
ForkJoinTask<Long> task = new ForkJoinSumCalculator(numbers);
return new ForkJoinPool().invoke(task);
}
这里用了一个 LongStream 来生成包含前 n 个自然数的数组,然后创建一个 ForkJoinTask(RecursiveTask 的父类)
使用多个 ForkJoinPool 是没有什么意义的。正是出于这个原因,一般来说把它实例化一次,然后把实例保存在静态字段中,使之成为单例,这样就可以在软件中任何部分方便地重用了
运行 ForkJoinSumCalculator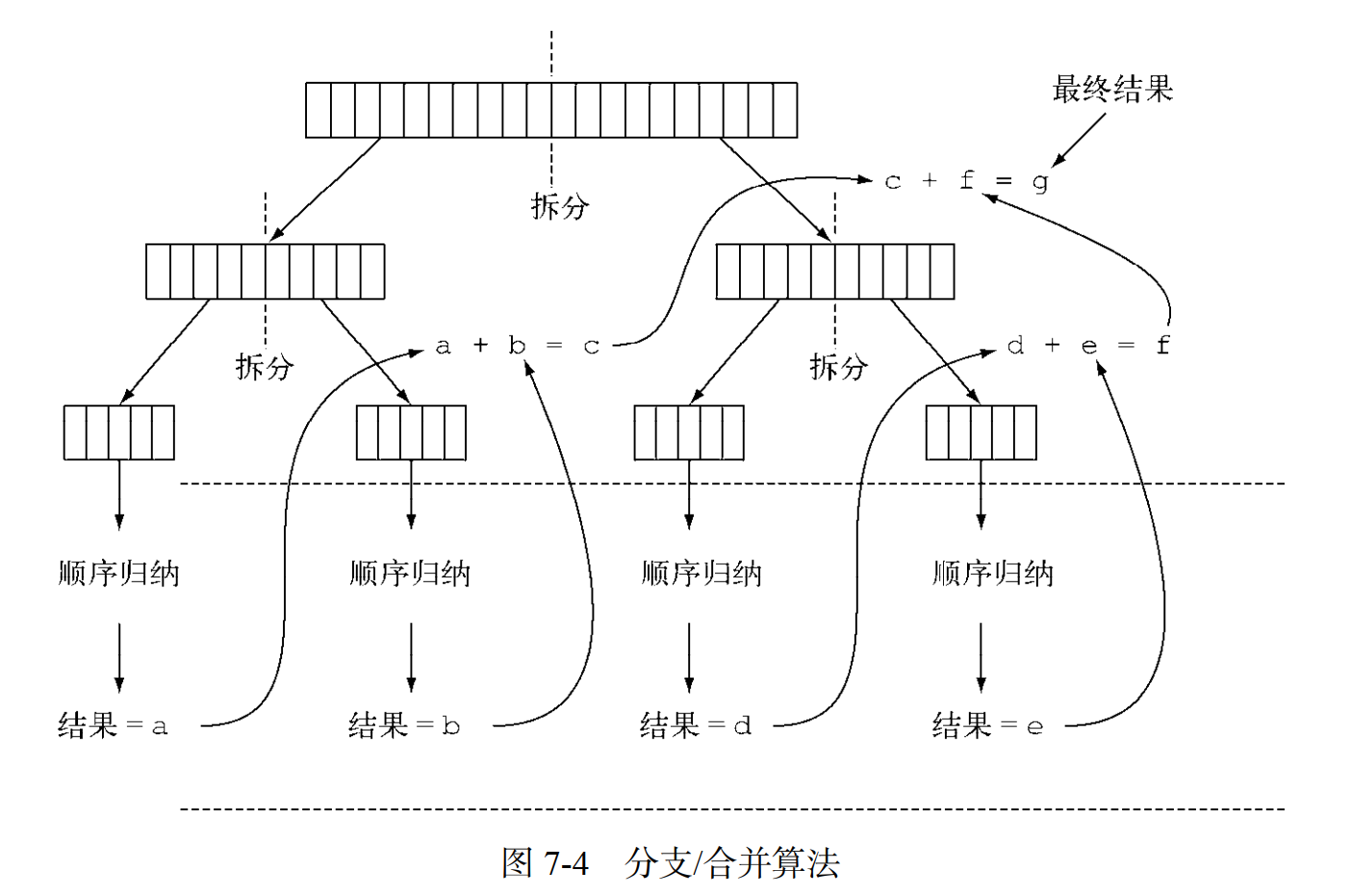
7.2.2 使用分支/合并框架的最佳做法
对一个任务调用 join 方法会阻塞调用方,直到该任务做出结果。因此,有必要在两个子任务的计算都开始之后再调用它。
不应该在 RecursiveTask 内部使用 ForkJoinPool 的 invoke 方法。
对子任务调用 fork 方法可以把它排进 ForkJoinPool。同时对左边和右边的子任务调用它似乎很自然,但这样做的效率要比直接对其中一个调用 compute 低。
和并行流一样,你不应理所当然地认为在多核处理器上使用分支/合并框架就比顺序计算快。
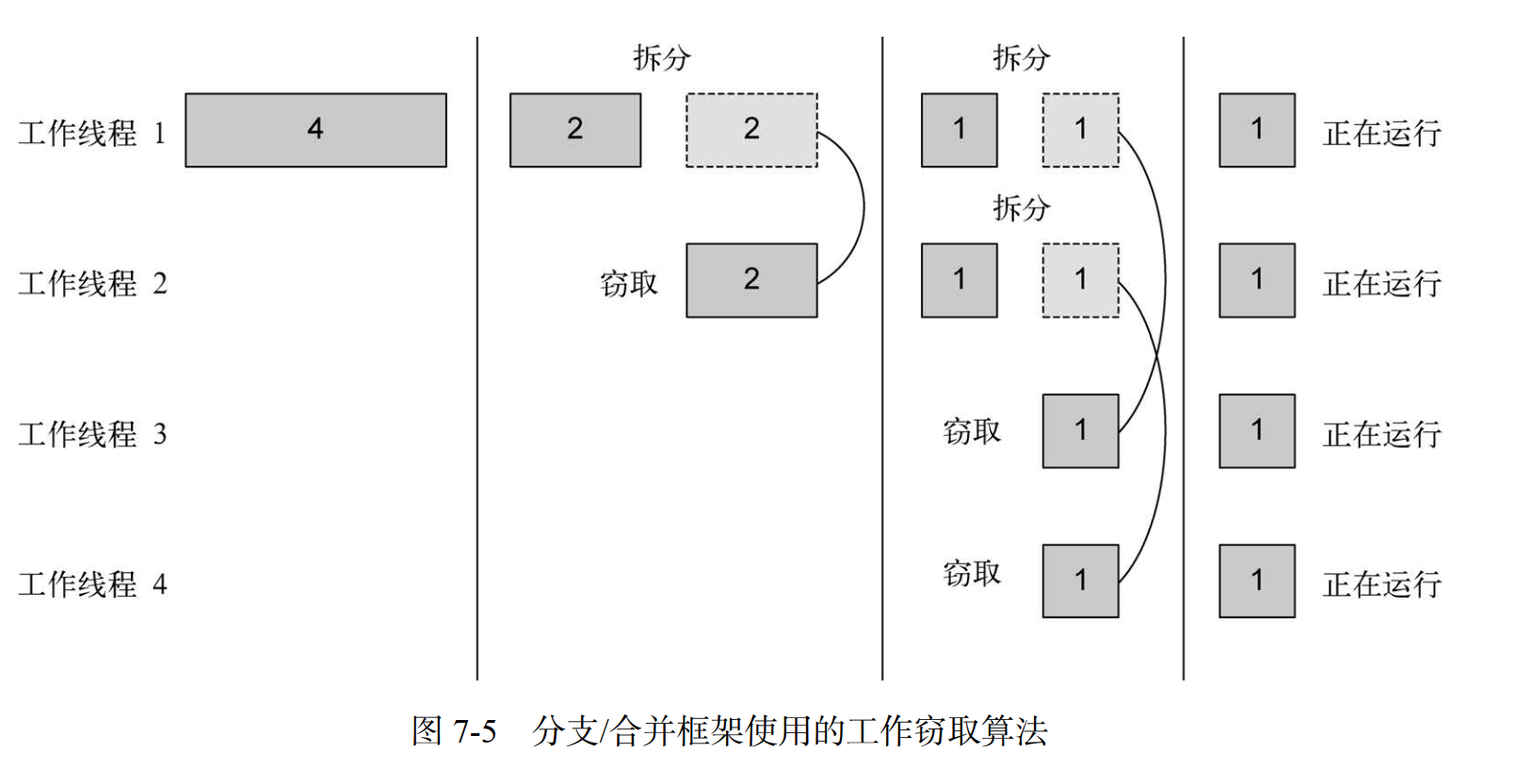
7.2.3 工作窃取
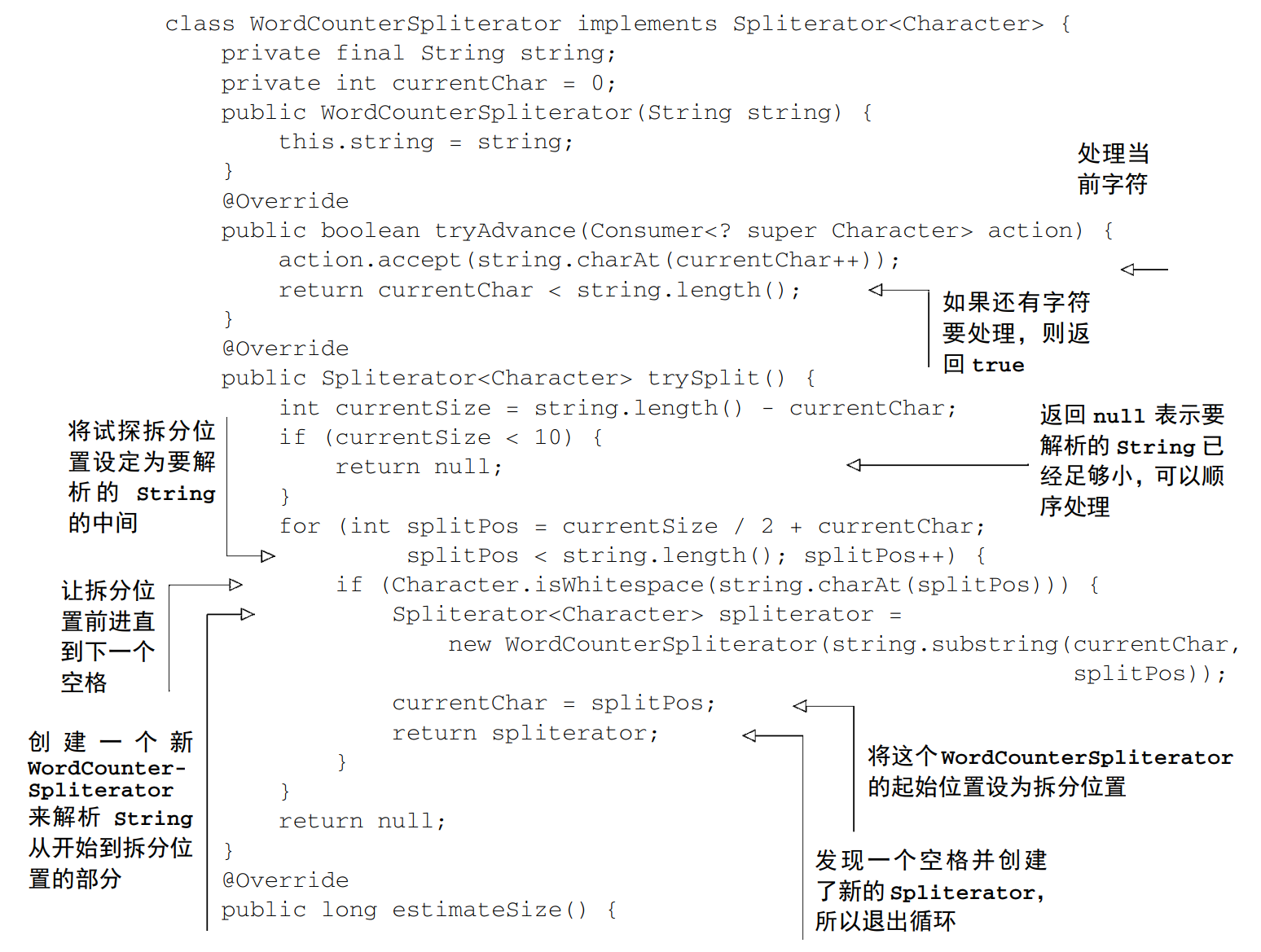
7.3 Spliterator
Spliterator 是 Java 8中加入的另一个新接口,这个名字代表“可分迭代器”(splitable iterator)。和 Iterator 一样,Spliterator 也用于遍历数据源中的元素,但它是为了并行执行而设计的。
public interface Spliterator<T> {
boolean tryAdvance(Consumer<? super T> action);
Spliterator<T> trySplit();
long estimateSize();
int characteristics();
}
7.3.1 拆分过程
将 Stream 拆分成多个部分的算法是一个递归过程,如图 7-6 所示。第一步是对第一个Spliterator 调用 trySplit,生成第二个 Spliterator。第二步是对这两个 Spliterator 调用trysplit,这样总共就有了四个Spliterator。这个框架不断对Spliterator调用trySplit直到它返回 null,表明它处理的数据结构不能再分割,如第三步所示。最后,这个递归拆分过程到第四步就终止了,这时所有的 Spliterator 在调用 trySplit 时都返回了 null。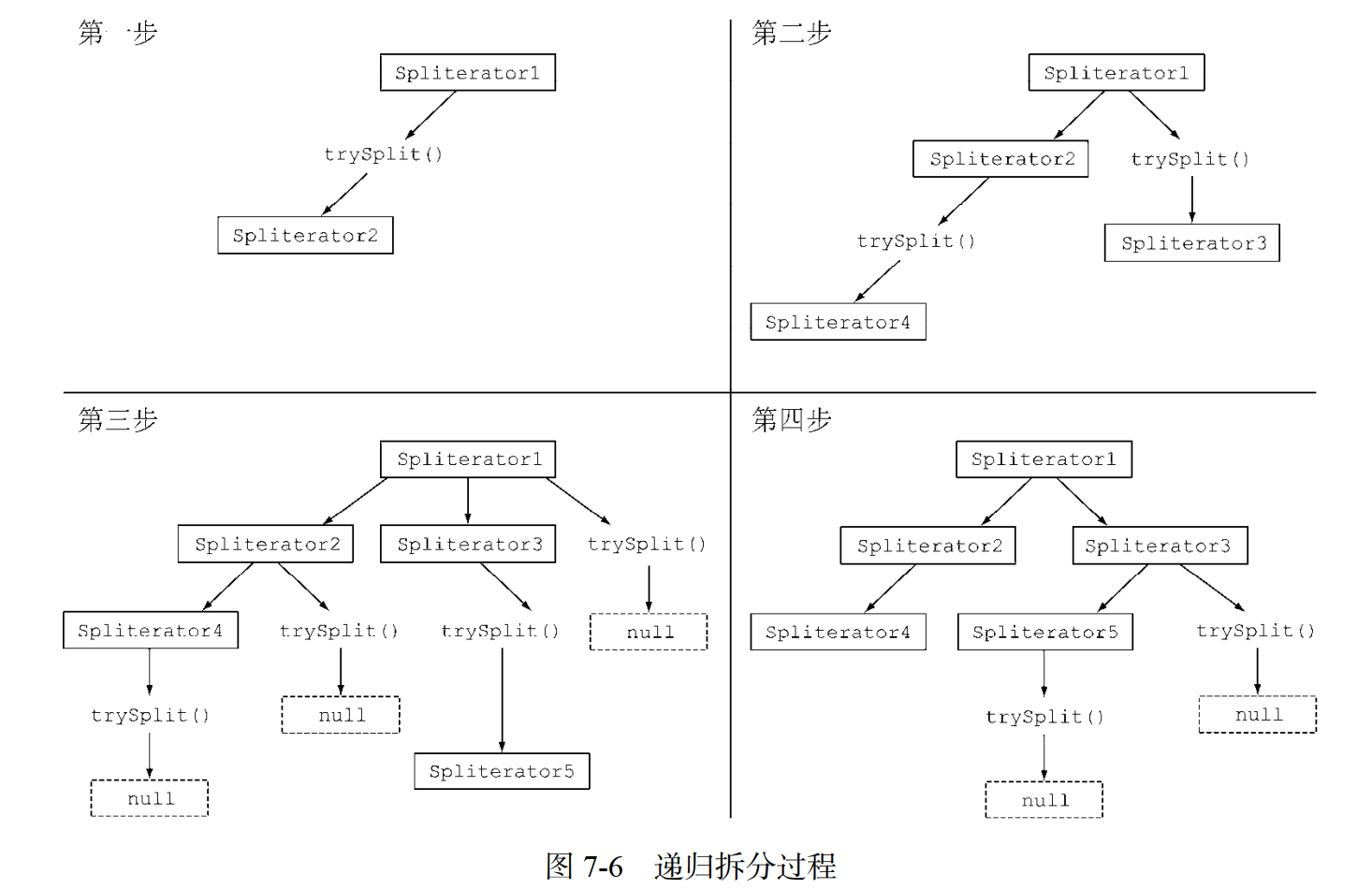
7.3.2 实现你自己的 Spliterator
一个迭代式词数统计方法
public int countWordsIteratively(String s) {
int counter = 0;
boolean lastSpace = true;
// 逐个遍历 String中的所有字符
for (char c : s.toCharArray()) {
if (Character.isWhitespace(c)) {
lastSpace = true;
} else {
// 上一个字符是空格,而当前遍历的字符不是空格时,将单词计数器加一
if (lastSpace) counter++;
lastSpace = false;
}
}
return counter;
}
- 以函数式风格重写单词计数器
Stream<Character> stream = IntStream.range(0, SENTENCE.length()).mapToObj(SENTENCE::charAt); 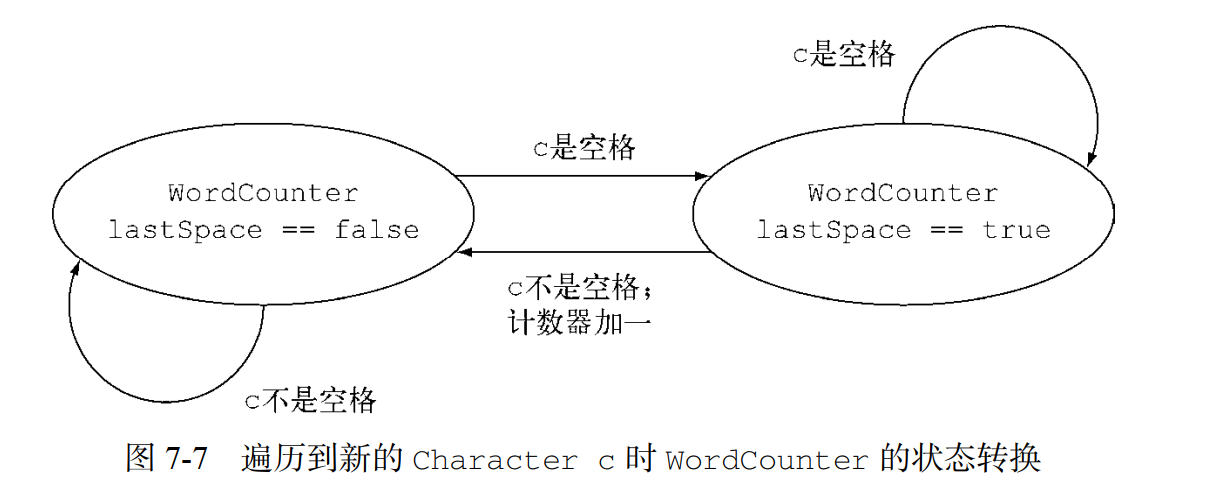
private int countWords(Stream<Character> stream) {
WordCounter wordCounter = stream.reduce(new WordCounter(0, true),
WordCounter::accumulate,
WordCounter::combine);
return wordCounter.getCounter();
}
- 让 WordCounter 并行工作
7.4 小结
- 内部迭代让你可以并行处理一个流,而无须在代码中显式使用和协调不同的线程。
- 虽然并行处理一个流很容易,但是不能保证程序在所有情况下都运行得更快。并行软件的行为和性能有时是违反直觉的,因此一定要测量,确保你并没有把程序拖得更慢。
- 像并行流那样对一个数据集并行执行操作可以提升性能,特别是要处理的元素数量庞大,或处理单个元素特别耗时的时候。
- 从性能角度来看,使用正确的数据结构,如尽可能利用原始流而不是一般化的流,几乎总是比尝试并行化某些操作更为重要。
- 分支/合并框架让你得以用递归方式将可以并行的任务拆分成更小的任务,在不同的线程上执行,然后将各个子任务的结果合并起来生成整体结果。
- Spliterator 定义了并行流如何拆分它要遍历的数据。