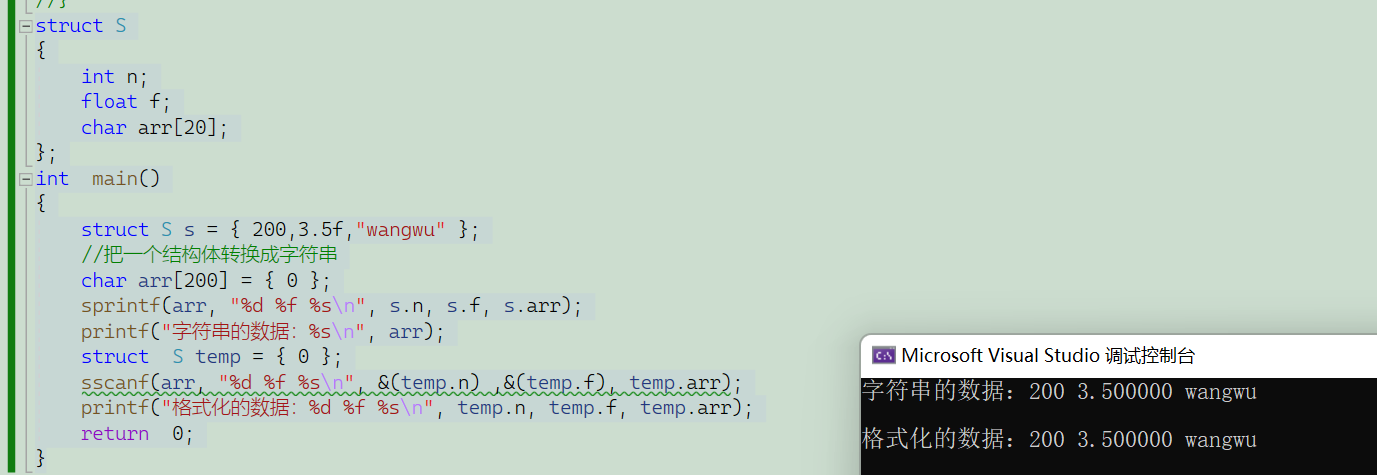
深度学习中经常要对概率密度建模。对于多维度随机变量来说,这有些困难。概率化结构(既图模型)是处理这个问题的手段之一。这引出了两个问题。为什么建模困难?图模型怎样解决了这个困难?
关于这个问题,花书给出了回答。关于图模型解释主要是围绕展开可以降低参数量展开。很多博客也对此进行了回答,但我对那些回答并不满意。这些博客多是摘取了书中的几句话,也不说清楚参数多在哪里。在我看来,发这样的笔记,不如保存本地不要发布。
结构化数据
很多随机变量之间是有相互关系的,比如图片生成。相邻的两个像素之间关联很大。对于一张3232的黑白图片,我们想要表示概率密度函数,就需要表示3232*2种情况,也就是 32 ∗ 32 ∗ 2 个 32*32*2个 32∗32∗2个参数。也就是每一个情况的概率值,都用一个参数表示。我们知道,所有情况概率和为1,所以知道 32 ∗ 32 ∗ 2 − 1 个 32*32*2-1个 32∗32∗2−1个参数即可。这时候如果考虑了随机变量之间的关联性是怎样的,便可以减少表示所用的参数,简化问题。
贝叶斯网络如何减少参数?
拿我自己博客的例子:
- 谈到毕业生的薪水时,我们很感兴趣的两个随机变量是 X 1 X_{1} X1为哪个学校毕业, X 2 X_{2} X2为薪水多少。在这个随机试验里, P ( X 2 = 高薪 ∣ X 1 = 清华大学 ) > P ( X 2 = 高薪 ∣ X 1 = 10422 ) P(X_{2}=高薪|X_{1}=清华大学)>P(X_{2}=高薪|X_{1}=10422) P(X2=高薪∣X1=清华大学)>P(X2=高薪∣X1=10422)。
- 对于身高,以父母身高为 X 1 和 X 2 X_{1}和X_{2} X1和X2,孩子身高为 X 3 X_{3} X3,成长省份为 X 4 X_{4} X4,苹果手机今年的发布价格为 X 5 X_{5} X5,苹果手机的销量为 X 6 X_{6} X6。在这个随机试验里, P ( X 1 = 1.7 , X 2 = 1.7 , X 3 = 1.7 , X 4 = 湖南 , X 5 = 9 k ) = P ( X 1 = 1.7 , X 2 = 1.7 , X 3 = 1.7 , X 4 = 湖南 ) P(X_{1}=1.7,X_{2}=1.7,X_{3}=1.7,X_{4}=湖南,X_{5}=9k)=P(X_{1}=1.7,X_{2}=1.7,X_{3}=1.7,X_{4}=湖南) P(X1=1.7,X2=1.7,X3=1.7,X4=湖南,X5=9k)=P(X1=1.7,X2=1.7,X3=1.7,X4=湖南)。很明显苹果手机的价格和身高这几个随机变量无关。
随机变量之间存在着复杂的关系。从上面的例子看出,我们研究的部分随机变量存在关联,有些不存在关联。直接求解联合概率分布显然是非常复杂的。当我们知道各个随机变量之间的依赖关系时,便可以通过概率图模型降低求解联合分布的难度。随机变量间是有向、无环关系的时候,这种概率图结构就是贝叶斯网络。(无向时为马尔可夫随机场,另一种概率图)
对一个学生能否拿到的薪水进行建模。假设相关的随机变量有5个
X
1
X_{1}
X1~
X
5
X_{5}
X5分别是
高考成绩、学校招生人数、就读大学、大学成绩、薪水。
我们关心的是随机变量间的关系,直接用一张图表示出来
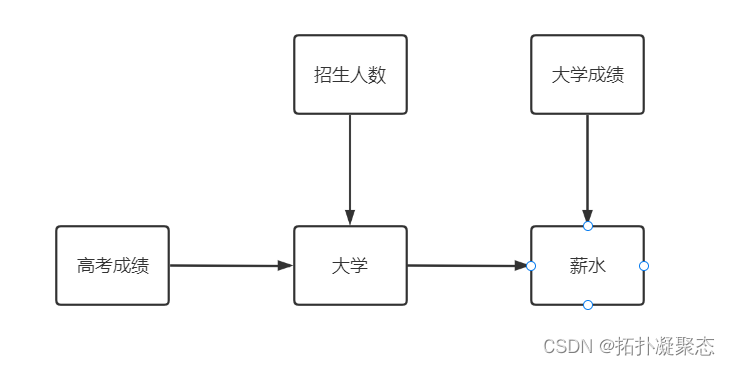
显然从图中可以看出各个变量的依赖关系。这张图体现了2个要素:有向、无环。距离一个完整的贝叶斯网络只差一部,那便是求出多维随机变量的分布。
要求分别,那先明确各个变量的取值(或者说给图的节点定义):
- 高考成绩 X 1 X_{1} X1:高分、低分
- 招生人数 X 2 X_{2} X2:多、中、少
- 入读大学 X 3 X_{3} X3:清华大学、北京城市学院
- 大学成绩 X 4 X_{4} X4:高分、普通、低分
- 薪水 X 5 X_{5} X5:高薪、低薪
问题介绍完了。如果直接建模需要多少参数?
2
∗
3
∗
2
∗
3
∗
2
=
72
2*3*2*3*2=72
2∗3∗2∗3∗2=72
也就是说我们需要表示出:
P
(
X
1
=
高分
,
X
2
=
多
,
X
3
=
清华大学
,
X
4
=
高分
,
X
5
=
高薪
)
=
θ
1
P(X_{1}=高分,X_{2}=多,X_{3}=清华大学,X_{4}=高分,X_{5}=高薪)=\theta_{1}
P(X1=高分,X2=多,X3=清华大学,X4=高分,X5=高薪)=θ1
P
(
X
1
=
低分
,
X
2
=
多
,
X
3
=
清华大学
,
X
4
=
高分
,
X
5
=
高薪
)
=
θ
2
P(X_{1}=低分,X_{2}=多,X_{3}=清华大学,X_{4}=高分,X_{5}=高薪)=\theta_{2}
P(X1=低分,X2=多,X3=清华大学,X4=高分,X5=高薪)=θ2
P
(
X
1
=
高分
,
X
2
=
中
,
X
3
=
清华大学
,
X
4
=
高分
,
X
5
=
高薪
)
=
θ
3
P(X_{1}=高分,X_{2}=中,X_{3}=清华大学,X_{4}=高分,X_{5}=高薪)=\theta_{3}
P(X1=高分,X2=中,X3=清华大学,X4=高分,X5=高薪)=θ3
.
.
.
...
...
一直遍历所有情况。右边的
θ
\theta
θ便是这种模型表示下的参数。
如果用了贝叶斯网络,那么概率密度可以表示成如下的形式:
P ( X 1 , X 2 , X 3 , X 4 , X 5 ) = P ( X 1 ) P ( X 2 ) P ( X 3 ∣ X 1 , X 2 ) P ( X 4 ) P ( X 5 ∣ X 3 , X 4 ) P(X_{1},X_{2},X_{3},X_{4},X_{5})=P(X_{1})P(X_{2})P(X_{3}|X_{1},X_{2})P(X_{4})P(X_{5}|X_{3},X_{4}) P(X1,X2,X3,X4,X5)=P(X1)P(X2)P(X3∣X1,X2)P(X4)P(X5∣X3,X4)
这意味着:1.我们只需要分别表示出各项,再通过计算,得出联合概率密度。
2.每个单独的一项,又可以用概率合为1的规定。
这两条极大的减少了我们需要表示的情况。
P
(
X
1
=
高分
)
=
θ
1
P(X_{1}=高分)=\theta_{1}
P(X1=高分)=θ1
P
(
X
1
=
低分
)
=
1
−
θ
1
P(X_{1}=低分)=1-\theta_{1}
P(X1=低分)=1−θ1
P
(
X
2
=
多
)
=
θ
2
P(X_{2}=多)=\theta_{2}
P(X2=多)=θ2
P
(
X
2
=
中
)
=
θ
3
P(X_{2}=中)=\theta_{3}
P(X2=中)=θ3
P
(
X
3
=
少
)
=
1
−
θ
2
−
θ
3
P(X_{3}=少)=1-\theta_{2}-\theta_{3}
P(X3=少)=1−θ2−θ3
X
1
需要
1
个,
X
2
需要
1
个,
X
3
需要
4
个
,
X
4
需要
3
个
,
X
5
需要
6
个。总共是
15
个
X_{1}需要1个,X_{2}需要1个,X_{3}需要4个,X_{4}需要3个,X_{5}需要6个。总共是15个
X1需要1个,X2需要1个,X3需要4个,X4需要3个,X5需要6个。总共是15个
可以看出,这样的做法确实降低了模型的参数量。通过这样的方式,我们依然可以得到所有情况,也就是72种情况各自对应的概率。先计算出各个分项的参数,随后通过乘积的方式计算出那个想要表示的联合概率。
![成功解决:OSError: [E050] Can’t find model ‘en_core_web_sm’.](https://img-blog.csdnimg.cn/fb161a0e7da14a2fa7480a1986d82087.png)