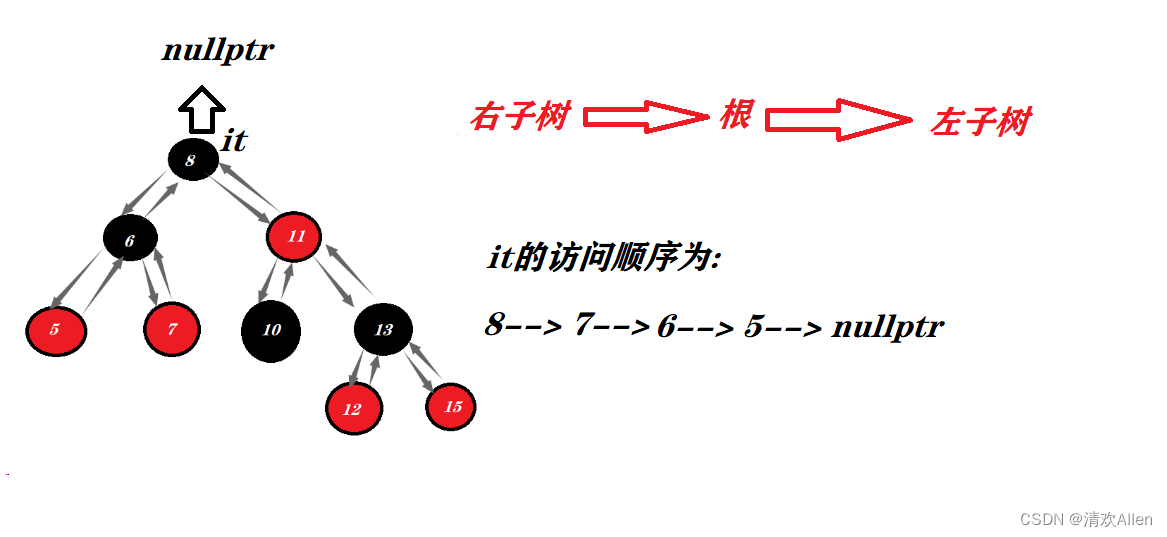
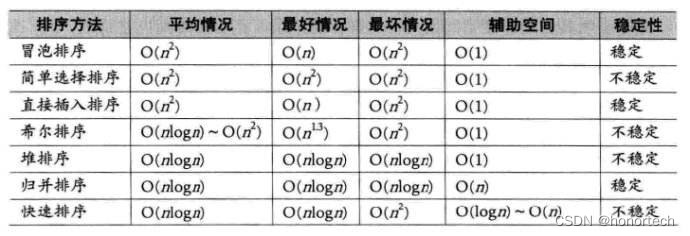
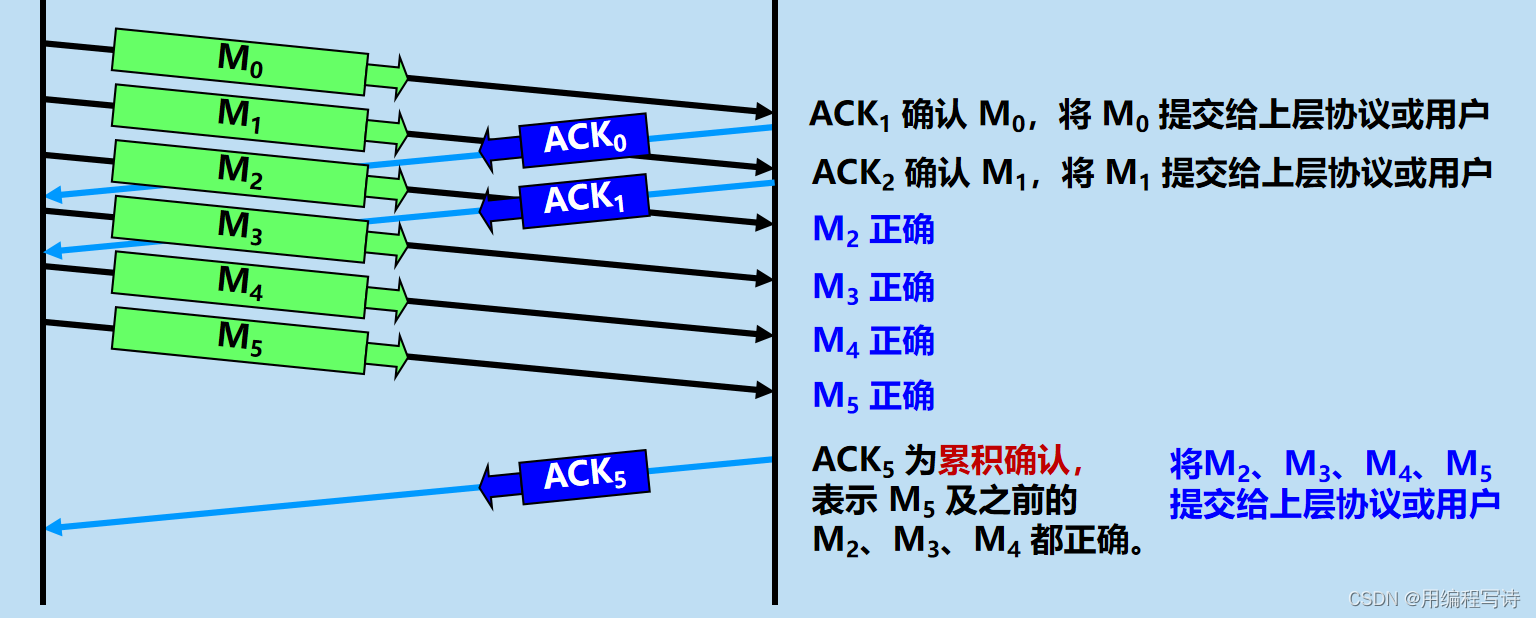
事务特性
A(Atomic):原子性,构成事务的所有操作,要么都执行完成,要么全部不执行,不可能出现部分成功部分失败的情况。
C(Consistency):一致性,在事务执行前后,数据库的一致性约束没有被破坏。比如:张三向李四转100元, 转账前和转账后的数据是正确状态这叫一致性,如果出现张三转出100元,李四账户没有增加100元这就出现了数 据错误,就没有达到一致性。
I(Isolation):隔离性,数据库中的事务一般都是并发的,隔离性是指并发的两个事务的执行互不干扰,一个事 务不能看到其他事务运行过程的中间状态。通过配置事务隔离级别可以避脏读、重复读等问题。
D(Durability):持久性,事务完成之后,该事务对数据的更改会被持久化到数据库,且不会被回滚。
分类
单机事务:通过关系型数据库来控制事务,这是利用数据库本身的事务特性来实现
分布式事务:事务的参与者、支持事务的服务器、资源服务器以及事务管理器分别位于不同的分布式系统的不同节点之上,且属于不同的应用,分布式事务需要保证这些操作要么全部成功,要么全部失败。本质上来说,分布式事务就是为了保证不同数据库的数据一致性。
分布式事务理论
CAP
这个定理的内容是指的是在一个分布式系统中、Consistency(一致性)、 Availability(可用性)、Partition tolerance(分区容错性),三者不可兼得。
一致性(C)
在分布式系统中的所有数据备份,在同一时刻是否同样的值。(等同于所有节点访问同一份最新的数据副本)
可用性(A)
在集群中一部分节点故障后,集群整体是否还能响应客户端的读写请求。(对数据更新具备高可用性)
分区容错性(P)
以实际效果而言,分区相当于对通信的时限要求。系统如果不能在时限内达成数据一致性,就意味着发生了分区的情况,必须就当前操作在C和A之间做出选择
BASE理论
BASE是Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent(最终一致性)三个短语的缩写。BASE理论是对CAP中一致性和可用性权衡的结果,其来源于对大规模互联网系统分布式实践的总结, 是基于CAP定理逐步演化而来的。BASE理论的核心思想是:即使无法做到强一致性,但每个应用都可以根据自身业务特点,采用适当的方式来使系统达到最终一致性。
基本可用
基本可用是指分布式系统在出现不可预知故障的时候,允许损失部分可用性—-注意,这绝不等价于系统不可用。比如:
(1)响应时间上的损失。正常情况下,一个在线搜索引擎需要在0.5秒之内返回给用户相应的查询结果,但由于出现故障,查询结果的响应时间增加了1~2秒
(2)系统功能上的损失:正常情况下,在一个电子商务网站上进行购物的时候,消费者几乎能够顺利完成每一笔订单,但是在一些节日大促购物高峰的时候,由于消费者的购物行为激增,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面
软状态
软状态指允许系统中的数据存在中间状态,并认为该中间状态的存在不会影响系统的整体可用性,即允许系统在不同节点的数据副本之间进行数据同步的过程存在延时
最终一致性
最终一致性强调的是所有的数据副本,在经过一段时间的同步之后,最终都能够达到一个一致的状态。因此,最终一致性的本质是需要系统保证最终数据能够达到一致,而不需要实时保证系统数据的强一致性。
SEATA简介
官网: https://seata.io/zh-cn/docs/overview/what-is-seata.html
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。

TC (Transaction Coordinator) - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
TM (Transaction Manager) - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
RM (Resource Manager) - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
SEATA下载
官方下载地址: https://seata.io/zh-cn/blog/download.html
seata-server配置
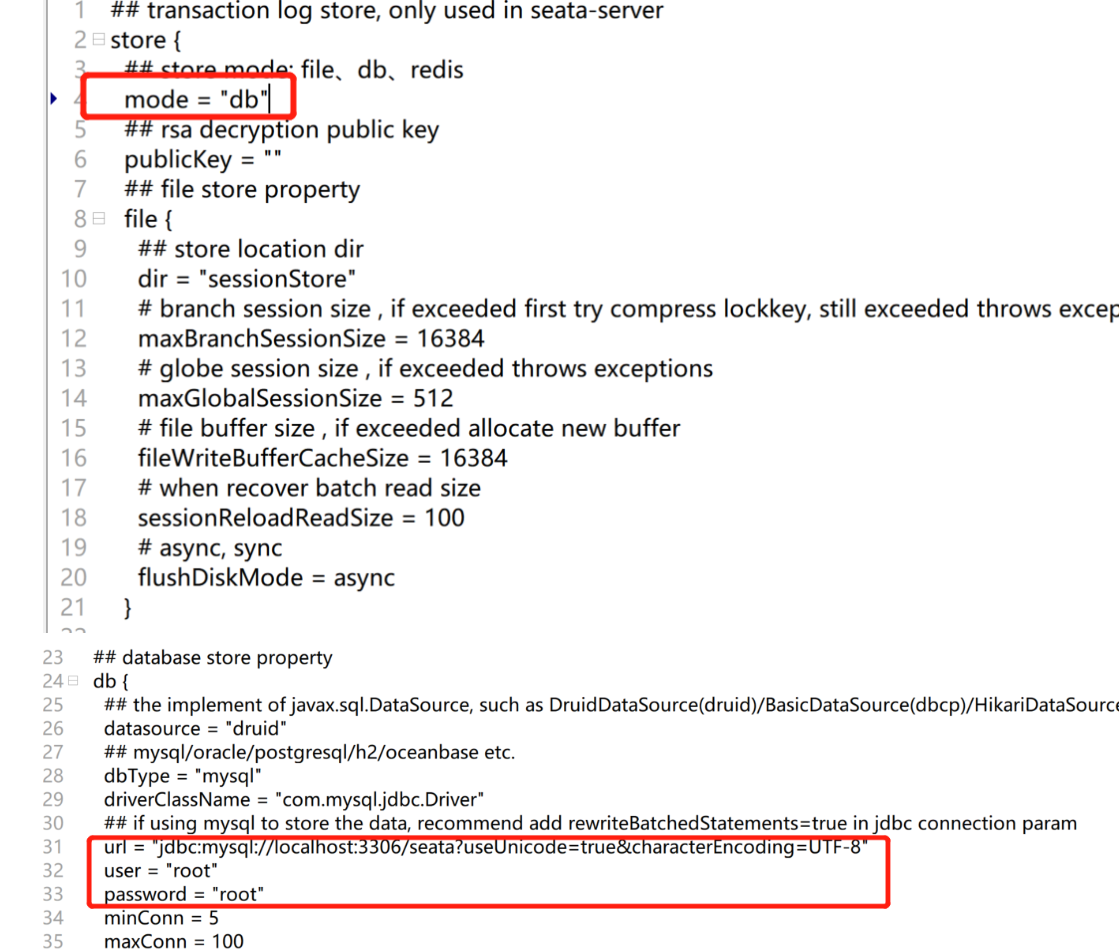
打开conf目录的registry.conf文件
修改Seata的注册中心和配置中心为Nacos

修改Seata的存储模式,修改file.conf文件,把Seata的默认存储模式修改为数据库"DB",同时需要配置JDBC
启动
先启动nacos,然后再启动Seata-Server
启动Seata-Server的方式非常简单,直接双击seata-server.bat
然后在nacos控制台上就可以看到Seata-Server
seata的默认端口是8091
Server端存储模式(store.mode)支持三种
file:单机模式,全局事务会话信息内存中读写并持久化本地文件root.data,性能较高(默认)
DB:高可用模式,全局事务会话信息通过DB共享,相对性能差一些
redis:Seata-Server1.3及以上版本支持,性能较高,存在事务信息丢失风险,需要配合实际场景使用。
file.conf中配置的seata数据库,以及对应的global_table、branch_table、lock_table都需要自己建

建表语句地址: https://github.com/seata/seata/blob/develop/script/server/db/mysql.sql
完成以后需要重启seata
配置nacos
Seata支持注册服务到Nacos,以及支持Seata所有配置放到Nacos配置中心,在Nacos中统一维护;
高可用模式下就需要配合Nacos来完成

注册中心
Seata-server端配置注册中心,在registry.conf中加入配置注册中心nacos
注意:确保client与server的注册处于同一个namespace和group,不然会找不到服务。
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "nacos"
nacos {
application = "seata-server"
serverAddr = "127.0.0.1:8848"
group = "SEATA_GROUP" # 这里的配置要和客户端保持一致
namespace = "" # 这里的配置要和客户端保持一致
cluster = "default"
username = "nacos"
password = "nacos"
}配置中心
Seata-Server配置配置中心,在registry.conf中加入配置使用nacos作为配置中心
config {
# file、nacos 、apollo、zk、consul、etcd3
type = "nacos"
nacos {
serverAddr = "127.0.0.1:8848"
namespace = ""
group = "SEATA_GROUP"
username = ""
password = ""
dataId = "seataServer.properties"
}我们需要把Seata的一些配置上传到Nacos中,配置比较多,所以官方给我们提供了一个config.txt,我们下载并且修改其中参数,上传到Nacos中
下载地址:https://github.com/seata/seata/tree/develop/script/config-center
具体修改:
注意:事务分组:用于防护机房停电,来启用备用机房,或者异地机房,容错机制,当然如果Seata-Server配置了对应的事务分组,Client也需要配置相同的事务分组
service.vgroupMapping.可以自定义=default
default这里必须等于 registry.config 中的cluster="default"(当然可以更改 )
修改好这个文件以后,我们就需要把这个文件放到seata目录下
此时我们需要把这些配置一个个的加入到Nacos配置中,所以我们需要一个脚本来进行执行,官方已经提供好了
地址为:https://github.com/seata/seata/blob/develop/script/config-center/nacos/nacos-config.sh
我们需要在seata-server-1.4.2文件夹中新建一个脚本文件nacos-config.sh,然后把脚本内容复制进去
利用git来进行执行命令:
sh nacos-config.sh -h localhost -p 8848 -g SEATA_GROUP -t 命名空间 -u nacos -w nacos
参数说明:
-h:host,默认值localhost
-p:port,默认值8848
-g:配置分组,默认为SEATA_GROUP
-t:租户信息,对应Nacos的命名空间ID,默认为空
在执行naocs-config文件的时候要注意,它默认寻找config.txt的路径和我们的路径不同,所以要打开naocs-config文件进行修改,否则无法执行。

当以上的这些配置完成以后,我们就可以启动nacos和seata-server了,此时我们查看Nacos的配置中心,就会看到我们传入的所有配置信息
AT模式(常用)
AT模式是一种无侵入的分布式事务解决方案,在 AT 模式下,用户只需关注自己的“业务 SQL”,用户的 “业务 SQL” 作为一阶段,Seata 框架会自动生成事务的二阶段提交和回滚操作。
通过Seata的AT模式解决分布式事务
首先增加对应的Seata依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
</dependency>在对应的微服务数据库上加上undo_log表,此表用于数据的回滚
具体的建表语句
https://github.com/seata/seata/blob/master/script/client/at/db/mysql.sql
配置yml(8801和8802Seata的配置保持一致)
server:
port: 8801
spring:
application:
name: seata-order
cloud:
nacos:
discovery:
server-addr: localhost:8848
alibaba:
seata:
tx-service-group: mygroup # 事务组, 随便写
datasource:
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://localhost:3306/test_at?characterEncoding=utf8&useSSL=false&serverTimezone=Asia/Shanghai&rewriteBatchedStatements=true
username: root
password: root
type: com.alibaba.druid.pool.DruidDataSource
seata:
tx-service-group: mygroup # 事务组名称,要和服务端对应
service:
vgroup-mapping:
mygroup: default # key是事务组名称 value要和服务端的机房名称保持一致在order8801(TM)的Controller上添加注解
@GlobalTransactional,加在TM上
@RestController
public class OrderController {
@Autowired
private OrderService orderService;
@GetMapping("/order/create")
@GlobalTransactional// 开启分布式事务
public String create(){
orderService.create();
return "生成订单";
}
}把8801和8802都跑起来,当然Nacos和Seata都要进行启动
这个时候我们进行访问Order的REST接口:http://localhost:8801/order/create,我们就会发现此时已经解决了分布式事务问题
XA模式
在 Seata 定义的分布式事务框架内,利用事务资源(数据库、消息服务等)对 XA 协议的支持,以 XA 协议的机制来管理分支事务的一种 事务模式。
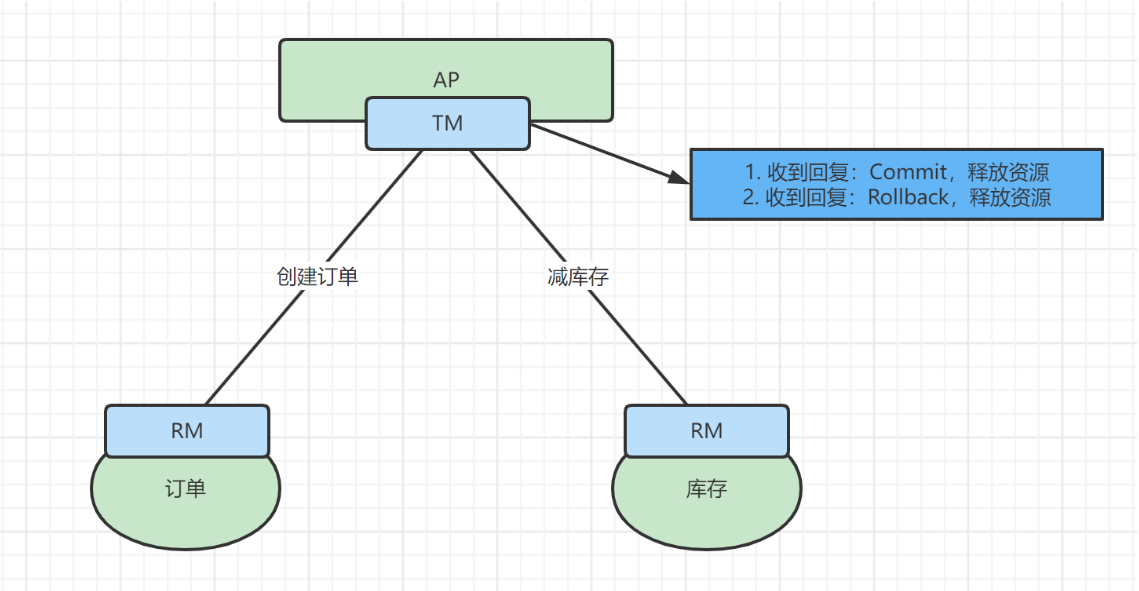
应用程序(AP)持有订单库和商品库两个数据源。
应用程序(AP)通过TM通知订单库(RM)和商品库(RM),来创建订单和减库存,RM此时未提交事务,此时商品和订单资源锁定。
TM收到执行回复,只要有一方失败则分别向其他RM发送回滚事务,回滚完毕,资源锁释放。
TM收到执行回复,全部成功,此时向所有的RM发起提交事务,提交完毕,资源锁释放。
XA协议的痛点
如果一个参与全局事务的资源 “失联” 了(收不到分支事务结束的命令),那么它锁定的数据,将一直被锁定。进而,甚至可能因此产生死锁。
这是 XA 协议的核心痛点,也是 Seata 引入 XA 模式要重点解决的问题。

与AT不同的是,XA没有undo_log表;
AT利用undo log实现了最终一致性,会有中间状态(可能会导致脏读);
XA实现了强一致性,没有中间状态,利用数据库自带的事务进行回滚
XA模式优点:
业务无侵入:和 AT 一样,XA 模式将是业务无侵入的,不给应用设计和开发带来额外负担。
数据库的支持广泛:XA 协议被主流关系型数据库广泛支持,不需要额外的适配即可使用。
多语言支持容易:因为不涉及 SQL 解析,XA 模式对 Seata 的 RM 的要求比较少。
传统基于 XA 应用的迁移:传统的,基于 XA 协议的应用,迁移到 Seata 平台,使用 XA 模式将更平滑。

从编程模型上,XA 模式与 AT 模式保持完全一致。
在样例中,上层编程模型与 AT 模式完全相同。只需要修改数据源代理,即可实现 XA 模式与 AT 模式之间的切换。
@Bean("dataSource")
public DataSource dataSource(DruidDataSource druidDataSource) {
// DataSourceProxy for AT mode
// return new DataSourceProxy(druidDataSource);
// DataSourceProxyXA for XA mode
return new DataSourceProxyXA(druidDataSource);
}TCC模式
TCC 是分布式事务中的二阶段提交协议,它的全称为 Try-Confirm-Cancel,即资源预留(Try)、确认操作(Confirm)、取消操作(Cancel),他们的具体含义如下:
1. Try:对业务资源的检查并预留;
2. Confirm:对业务处理进行提交,即 commit 操作,只要 Try 成功,那么该步骤一定成功;
3. Cancel:对业务处理进行取消,即回滚操作,该步骤回对 Try 预留的资源进行释放。
TCC和AT的区别是TCC不依赖数据库本身的ACID,都是调用自定义的方法;
侵入性比较强,并且需要自己实现相关事务控制逻辑
在整个过程基本没有锁,性能较强
SAGA模式
Saga模式是SEATA提供的长事务解决方案,在Saga模式中,业务流程中每个参与者都提交本地事务,当出现某一个参与者失败则补偿前面已经成功的参与者,一阶段正向服务和二阶段补偿服务都由业务开发实现。

适用场景:
业务流程长、业务流程多
参与者包含其它公司或遗留系统服务,无法提供 TCC 模式要求的三个接口
优势:
一阶段提交本地事务,无锁,高性能
事件驱动架构,参与者可异步执行,高吞吐
补偿服务易于实现
缺点:
不保证隔离性(应对方案见后面文档)
Saga的实现:
基于状态机引擎的 Saga 实现:
目前SEATA提供的Saga模式是基于状态机引擎来实现的,机制是:
通过状态图来定义服务调用的流程并生成 json 状态语言定义文件
状态图中一个节点可以是调用一个服务,节点可以配置它的补偿节点
状态图 json 由状态机引擎驱动执行,当出现异常时状态引擎反向执行已成功节点对应的补偿节点将事务回滚
注意: 异常发生时是否进行补偿也可由用户自定义决定
可以实现服务编排需求,支持单项选择、并发、子流程、参数转换、参数映射、服务执行状态判断、异常捕获等功能