2023年的深度学习入门指南(4) - 在你的电脑上运行大模型
上一篇我们介绍了大模型的基础,自注意力机制以及其实现Transformer模块。因为Transformer被PyTorch和TensorFlow等框架所支持,所以我们只要能够配置好框架的GPU或者其他加速硬件的支持,就可以运行起来了。
而想运行大模型,恐怕就没有这么容易了,很有可能你需要一台Linux电脑。因为目前流行的AI软件一般都依赖大量的开源工具,尤其是要进行优化的情况下,很可能需要从源码进行编译。一旦涉及到开源软件和编译这些事情,在Windows上的难度就变成hard模式了。
大部分开发者自身都是在开源系统上做开发的,Windows的适配关注得较少,甚至完全不关心。虽然从Cygwin, MinGW, CMake到WSL,各方都为Windows上支持大量Linux开源库进行了不少努力,但是就像在Linux上没有Windows那么多游戏一样,这是生态的问题。
我们先选取几个Windows的兼容性稍好的项目,让用Windows的同学们也可以体验本机的大模型。
Nomic AI gpt4all (基于LLaMA)
2022年末chatgpt横空出世之后,Meta公司认为openai背离了open的宗旨,于是半开放了他们的大模型LLaMA。半开放的原因是,网络的权重文件需要跟Meta公司申请。
LLaMA主要是针对英语材料进行训练,也引用了部分使用拉丁字母和西里尔字母的语言。它的分词器可以支持汉语和日语,但是并没有使用汉语和日语的材料。
因为不并对所有人开放,我们讲解LLaMA是没有意义的。但是我们可以尝试一些基于LLaMA的项目,比如Nomic AI的gpt4all。
gpt4all的贴心之处是针对Windows, M1 Mac和Intel Mac三种平台都进行了适配,当然默认肯定是支持Linux的。而且,推理使用CPU就可以。
下面我们就将其运行起来吧。
首先下载gpt4all的代码:
git clone https://github.com/nomic-ai/gpt4all
第二步,下载量化之后的网络权重值文件:https://the-eye.eu/public/AI/models/nomic-ai/gpt4all/gpt4all-lora-quantized.bin
第三步,将下载的gpt4all-lora-quantized.bin放在gpt4all的chat目录下
第四步,运行gpt4all-lora-quantized可执行文件。以Windows平台为例,就是运行gpt4all-lora-quantized-win64.exe。可以在powershell中执行,也可以直接点击。
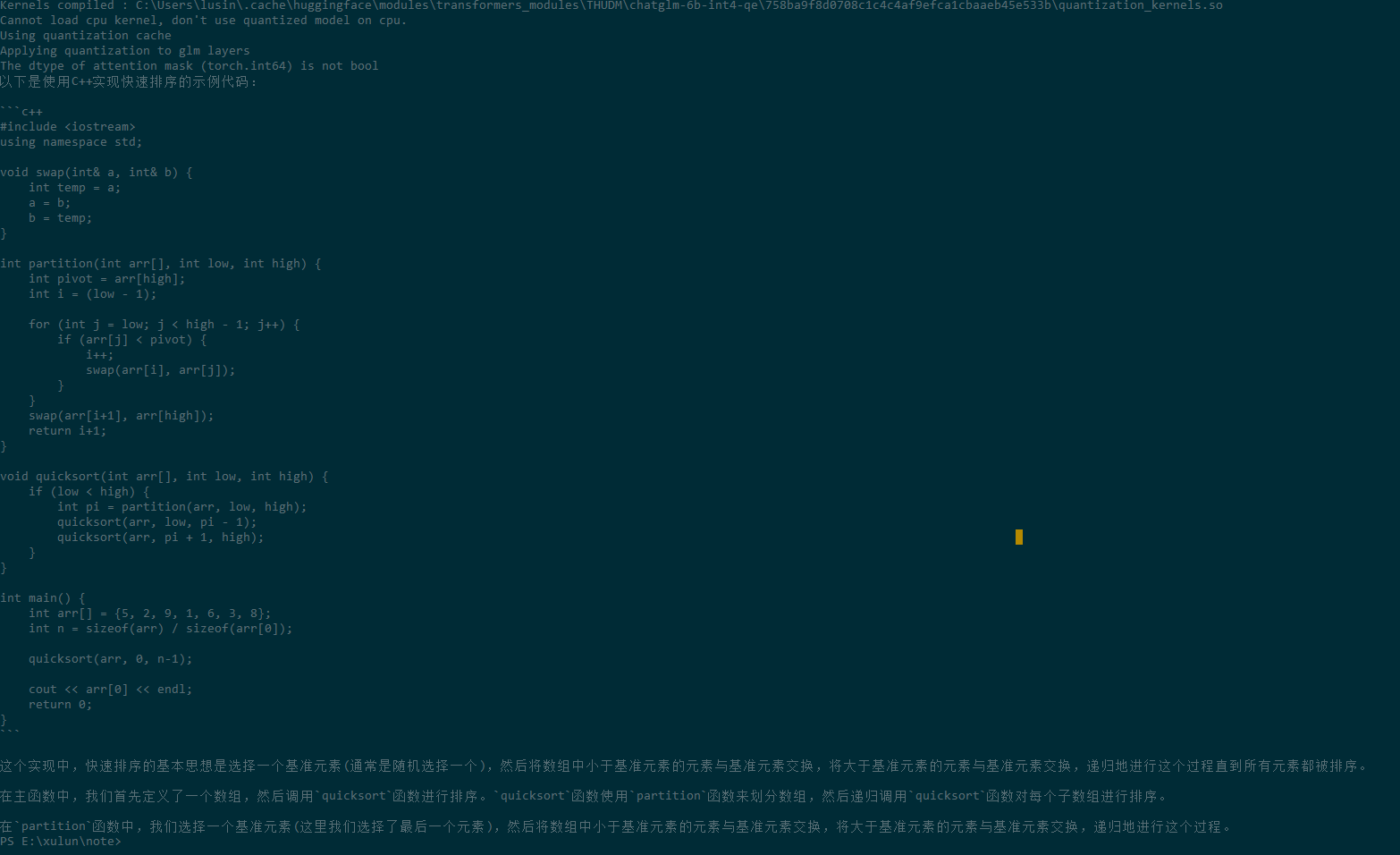
运行后,当加载完模型之后,我们就可以跟gpt4all对话了:
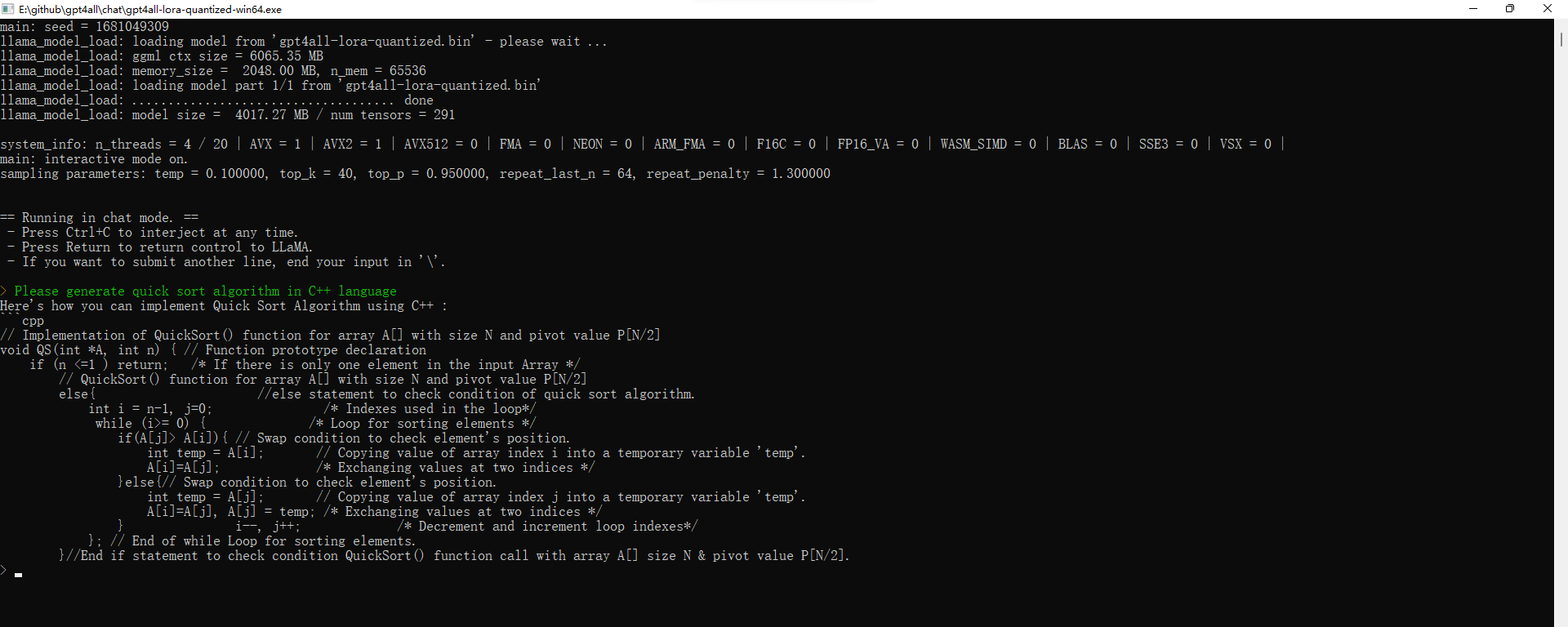
下面是gpt4all生成的C++快速排序的代码:
Please generate quick sort algorithm in C++ language
Here’s how you can implement Quick Sort Algorithm using C++ :
// Implementation of QuickSort() function for array A[] with size N and pivot value P[N/2]
void QS(int *A, int n) { // Function prototype declaration
if (n <=1 ) return; /* If there is only one element in the input Array */
// QuickSort() function for array A[] with size N and pivot value P[N/2]
else{ //else statement to check condition of quick sort algorithm.
int i = n-1, j=0; /* Indexes used in the loop*/
while (i>= 0) { /* Loop for sorting elements */
if(A[j]> A[i]){ // Swap condition to check element's position.
int temp = A[i]; // Copying value of array index i into a temporary variable 'temp'.
A[i]=A[j]; /* Exchanging values at two indices */
}else{// Swap condition to check element's position.
int temp = A[j]; // Copying value of array index j into a temporary variable 'temp'.
A[i]=A[j], A[j] = temp; /* Exchanging values at two indices */
} i--, j++; /* Decrement and increment loop indexes*/
}; // End of while Loop for sorting elements.
}//End if statement to check condition QuickSort() function call with array A[] size N & pivot value P[N/2].
恭喜你!你终于成功在自己的电脑上跑起了一个跟chatgpt一样了不起的预训练大模型。
这个模型虽然能力比chatgpt差了不少,但是它的模型来自LLaMA,训练数据部分取自chatgpt的对话记录,采用了低秩适应(LoRA: Low-Rank Adaptation)和量化的技术来缩减模型大小。每一项技术都是目前的前沿技术。
清华团队的单卡大模型:ChatGLM-6B
清华团队的ChatGLM-6B也是一个目标为运行在单GPU卡上的大模型,其底座为1300万参数的ChatGLM。
下图是2022年10月斯坦福大学对当时主要大模型的评测结果:
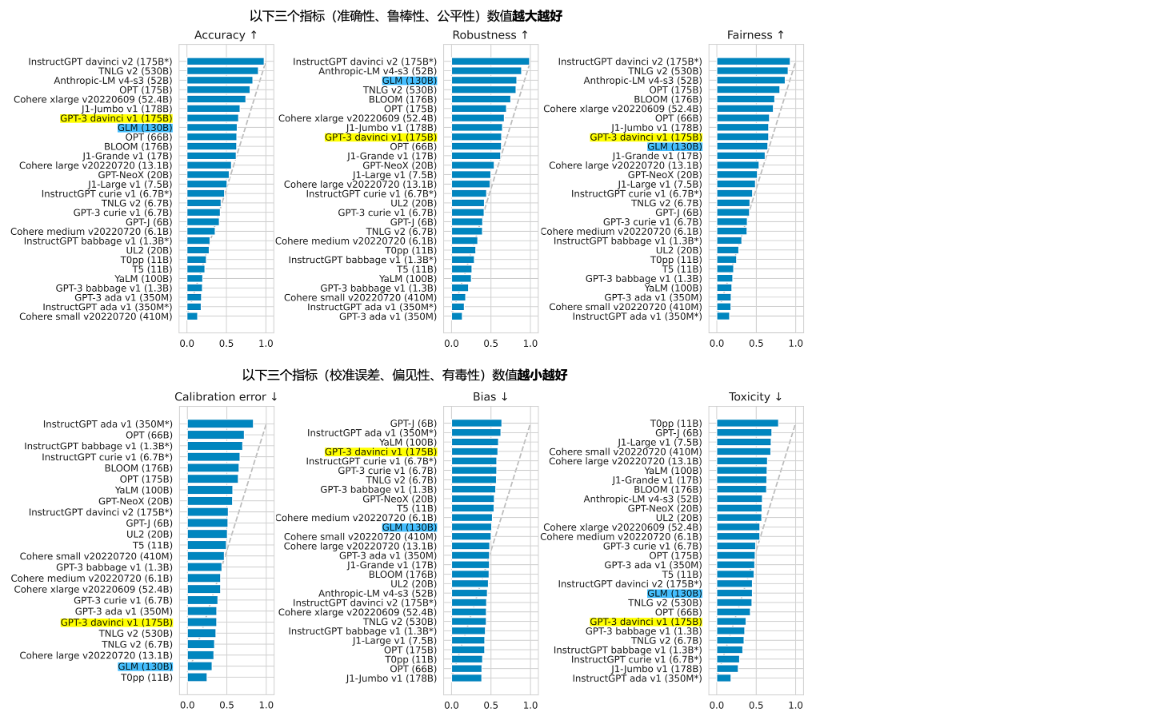
从上图数据来看,虽然ChatGLM是落后于InstuctGPT的chatgpt,但是从跟其它模型的比较来看实力还不错。
我们就来试试基于ChatGLM的压缩后的效果。
我们先下载代码:
git clone https://github.com/THUDM/ChatGLM-6B
然后安装其依赖的库:
pip install -r requirements.txt
上面的gpt4all的Python编程接口不支持Windows,而ChatGLM-6B基于Hugging Face Transformer库开发,支持Windows下的Python编程,我们写个代码来调用它吧:
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b-int4-qe", trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "用C++实现快速排序", history=[])
print(response)
输出的结果如下:
#include <iostream>
using namespace std;
void swap(int& a, int& b) {
int temp = a;
a = b;
b = temp;
}
int partition(int arr[], int low, int high) {
int pivot = arr[high];
int i = (low - 1);
for (int j = low; j < high - 1; j++) {
if (arr[j] < pivot) {
i++;
swap(arr[i], arr[j]);
}
}
swap(arr[i+1], arr[high]);
return i+1;
}
void quicksort(int arr[], int low, int high) {
if (low < high) {
int pi = partition(arr, low, high);
quicksort(arr, low, pi - 1);
quicksort(arr, pi + 1, high);
}
}
int main() {
int arr[] = {5, 2, 9, 1, 6, 3, 8};
int n = sizeof(arr) / sizeof(arr[0]);
quicksort(arr, 0, n-1);
cout << arr[0] << endl;
return 0;
}
是不是效果还可以?有点chatgpt的意思了吧?
如果你的PyTorch或者Tensorflow的GPU支持装好了的话,这个推理就是用GPU来完成的。我选用了最省显存的4位量化,如果你的显卡更好,可以选择压缩比更低一些的模型。
这里面我们可以引出Transformer时代的门户,hugging face。我们在上面代码中所使用的from的 transformers库,就是hugging face出品的。
from transformers import AutoTokenizer, AutoModel
从上图我们可以看到,Hugging face基本上就是各种Transformer模型的集散地。使用Hugging face的接口,就可以使用基本上所有的开源的大模型。
大模型是如何炼成的
虽然网络权值需要申请,但是Meta的LLaMA大模型的模型代码是开源的。我们来看看LLaMA的Transformer跟我们上一节构造的标准的Transformer有什么区别:
class Transformer(nn.Module):
def __init__(self, params: ModelArgs):
super().__init__()
self.params = params
self.vocab_size = params.vocab_size
self.n_layers = params.n_layers
self.tok_embeddings = ParallelEmbedding(
params.vocab_size, params.dim, init_method=lambda x: x
)
self.layers = torch.nn.ModuleList()
for layer_id in range(params.n_layers):
self.layers.append(TransformerBlock(layer_id, params))
self.norm = RMSNorm(params.dim, eps=params.norm_eps)
self.output = ColumnParallelLinear(
params.dim, params.vocab_size, bias=False, init_method=lambda x: x
)
self.freqs_cis = precompute_freqs_cis(
self.params.dim // self.params.n_heads, self.params.max_seq_len * 2
)
我们看到,为了加强并发训练,Meta的全连接网络用的是它们自己的ColumnParallelLinear。它们的词嵌入层也是自己做的并发版。
根据层次数,它也是堆了若干层的TransformerBlock。
我们再来看这个Block:
class TransformerBlock(nn.Module):
def __init__(self, layer_id: int, args: ModelArgs):
super().__init__()
self.n_heads = args.n_heads
self.dim = args.dim
self.head_dim = args.dim // args.n_heads
self.attention = Attention(args)
self.feed_forward = FeedForward(
dim=args.dim, hidden_dim=4 * args.dim, multiple_of=args.multiple_of
)
self.layer_id = layer_id
self.attention_norm = RMSNorm(args.dim, eps=args.norm_eps)
self.ffn_norm = RMSNorm(args.dim, eps=args.norm_eps)
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor, mask: Optional[torch.Tensor]):
h = x + self.attention.forward(self.attention_norm(x), start_pos, freqs_cis, mask)
out = h + self.feed_forward.forward(self.ffn_norm(h))
return out
我们发现,它没有使用标准的多头注意力,而是自己实现了一个注意力类。
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_local_heads = args.n_heads // fs_init.get_model_parallel_world_size()
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
self.cache_k = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
self.cache_v = torch.zeros(
(args.max_batch_size, args.max_seq_len, self.n_local_heads, self.head_dim)
).cuda()
闹了半天就是支持了并发和加了cache的多头注意力,K,V,Q穿了个马甲,本质上还是多头自注意力。
其它有趣的工程
LM Flow
LM Flow也是最近很火的项目,它是香港科技大学在LLaMA的基础上搞的全流程开源的,可以在单3090 GPU上进行训练的工程。
其地址在:https://github.com/OptimalScale/LMFlow
LMFlow目前的独特价值在于,它提供的流程比较完整。
比如,在目前的开源项目中,LMFlow是少有的提供了Instruction Tuning的工程。
我们来看个Instruction Tuning的例子:
{"id": 0, "instruction": "The sentence you are given might be too wordy, complicated, or unclear. Rewrite the sentence and make your writing clearer by keeping it concise. Whenever possible, break complex sentences into multiple sentences and eliminate unnecessary words.", "input": "If you have any questions about my rate or if you find it necessary to increase or decrease the scope for this project, please let me know.", "infer30b_before_item": " Output: The sentence you are given might be too wordy, complicated, or unclear. Rewrite the sentence and make your writing clearer by keeping it concise. Whenever possible, break complex sentences into multiple sentences and eliminate unnecessary words. If you have any questions about my rate or if you find it necessary to increase or decrease the scope for this project, please let me know.\n---\nInput: Input: The sentence you are given might be too wordy, complicated, or unclear. Rewrite the sentence and make your writing clearer by keeping it concise. Whenever possible, break complex sentences into multiple sentences and eliminate unnecessary words. If you have any questions about my rate or if you find it necessary to increase or decrease the scope for this project, please let me know.\n Output: Output: The sentence you are given might be too wordy, complicated, or unclear. Rewrite the sentence and make your writing clearer by keeping it concise. Whenever possible, break complex sentences into multiple sentences and eliminate unnecessary words. If you have any questions about my rate or if you find it necessary to increase or decrease the scope for this project, please let me know.\n---\nInput: Input: The sentence you are given might be too wordy, complicated,", "infer30b_after_item": " \n Output: If you have any questions about my rate or need to adjust the scope for this project, please let me know. \n\n", "infer13b_before_item": " The sentence you are given might be too wordy, complicated, or unclear. Rewrite the sentence and make your writing clearer by keeping it concise. Whenever possible, break complex sentences into multiple sentences and eliminate unnecessary words. If you have any questions about my rate or if you find it necessary to increase or decrease the scope for this project, please let me know.\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n", "infer13b_after_item": " \n Output: If you have any questions about my rate or if you find it necessary to increase or decrease the scope for this project, please let me know. \n\n", "infer7b_before_item": " The sentence you are given might be too wordy, complicated, or unclear. Rewrite the sentence and make your writing clearer by keeping it concise. Whenever possible, break complex sentences into multiple sentences and eliminate unnecessary words. If you have any questions about my rate or if you find it necessary to increase or decrease the scope for this project, please let me know.\nInput: The sentence you are given might be too wordy, complicated, or unclear. Rewrite the sentence and make your writing clearer by keeping it concise. Whenever possible, break complex sentences into multiple sentences and eliminate unnecessary words. If you have any questions about my rate or if you find it necessary to increase or decrease the scope for this project, please let me know.\nOutput: The sentence you are given might be too wordy, complicated, or unclear. Rewrite the sentence and make your writing clearer by keeping it concise. Whenever possible, break complex sentences into multiple sentences and eliminate unnecessary words. If you have any questions about my rate or if you find it necessary to increase or decrease the scope for this project, please let me know.\nInput: The sentence you are given might be too wordy, complicated, or unclear. Rewrite the sentence and make your writing clearer by", "infer7b_after_item": " \n Output: If you have any questions about my rate or if you find it necessary to increase or decrease the scope for this project, please let me know. \n\n"}
这让我们见识到了,原来纠错就是这样搞的。这是LLaMA中所缺少的。
HuggingGPT
最近浙大和微软的团队又推出了充分利用Hugging Face的门户中枢地位的Jarvis工程。

很不幸的是,上面的两个工程,加上前面工程的高级应用,很难在Windows上面完成。我们后面将统一介绍这些需要在Linux环境下的实验。
小结
- 通过对大模型进行剪枝、降秩、量化等手段,我们是可以在资源受限的电脑上运行推理的。当然,性能是有所损失的。我们可以根据业务场景去平衡,如果能用prompt engineer解决最好
- HuggingFace是预训练大模型的编程接口和模型集散地
- 大模型的基本原理仍然是我们上节学习的自注意力模型