文章目录
- 文章目的
- 注意事项
- 1.什么是跳表-skiplist
- 2.skiplist的效率如何保证?
- 2.1 一个节点的平均层数
- 3. skiplist的实现
文章目的
- 让你知道什么是跳表,梳理跳表
- 跳表的设计思路及实现
注意事项
- 下面有数学公式,需要数学功底,只要弄清楚用来干嘛就行
- 有兴趣的人可以了解详细的推导过程
1.什么是跳表-skiplist
skiplist本质上也是一种查找结构,用于解决算法中的查找问题,跟平衡搜索树和哈希表的价值是
一样的,可以作为key或者key/value的查找模型。那么相比而言它的优势是什么的呢?这么等我
们学习完它的细节实现,我们再来对比。
skiplist是由William Pugh发明的,最早出现于他在1990年发表的论文**《Skip Lists: A
Probabilistic Alternative to Balanced Trees》**。对细节感兴趣的同学可以下载论文原文来阅读。
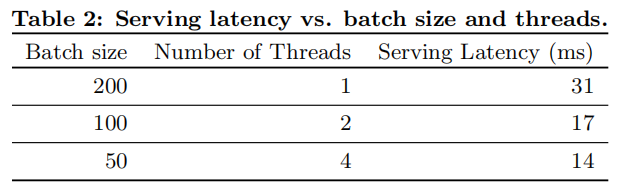
skiplist,顾名思义,首先它是一个list。实际上,它是在有序链表的基础上发展起来的。如果是一
个有序的链表,查找数据的时间复杂度是O(N)。
William Pugh开始的优化思路:
- 1.假如我们每相邻两个节点升高一层,增加一个指针,让指针指向下下个节点,如下图b所
示。这样所有新增加的指针连成了一个新的链表,但它包含的节点个数只有原来的一半。由
于新增加的指针,我们不再需要与链表中每个节点逐个进行比较了,需要比较的节点数大概
只有原来的一半。
- 以此类推,我们可以在第二层新产生的链表上,继续为每相邻的两个节点升高一层,增加一
个指针,从而产生第三层链表。如下图c,这样搜索效率就进一步提高了。 - skiplist正是受这种多层链表的想法的启发而设计出来的。实际上,按照上面生成链表的方
式,上面每一层链表的节点个数,是下面一层的节点个数的一半,这样查找过程就非常类似
二分查找,使得查找的时间复杂度可以降低到O(log n)。
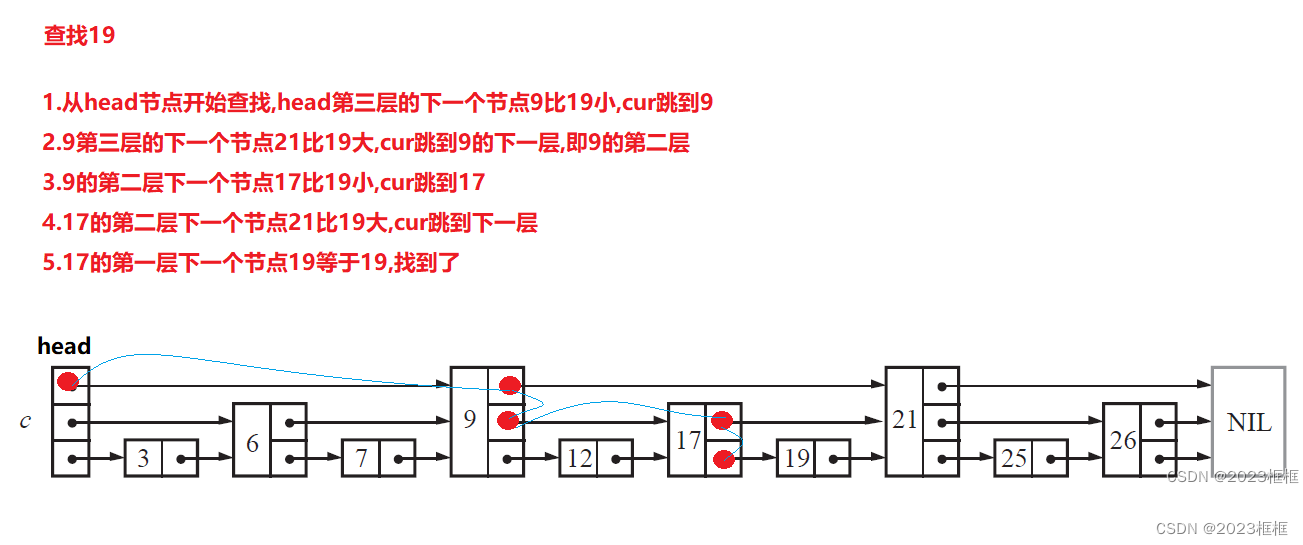
 模拟查找过程:
模拟查找过程:
存在的问题:
- 但是这个结构在插入删除数据的时
- 候有很大的问题,插入或者删除一个节点之后,就会打乱上下相邻两层链表上节点个数严格
的2:1的对应关系。 - 如果要维持这种对应关系,就必须把新插入的节点后面的所有节点(也包括新插入的节点)重新进行调整,这会让时间复杂度重新蜕化成O(n).
解决方法:
skiplist的设计为了避免这种问题,做了一个大胆的处理,不再严格要求对应比例关系,而是插入一个节点的时候随机出一个层数。这样每次插入和删除都不需要考虑其他节点的层数,这样就好处理多了。细节过程入下图:
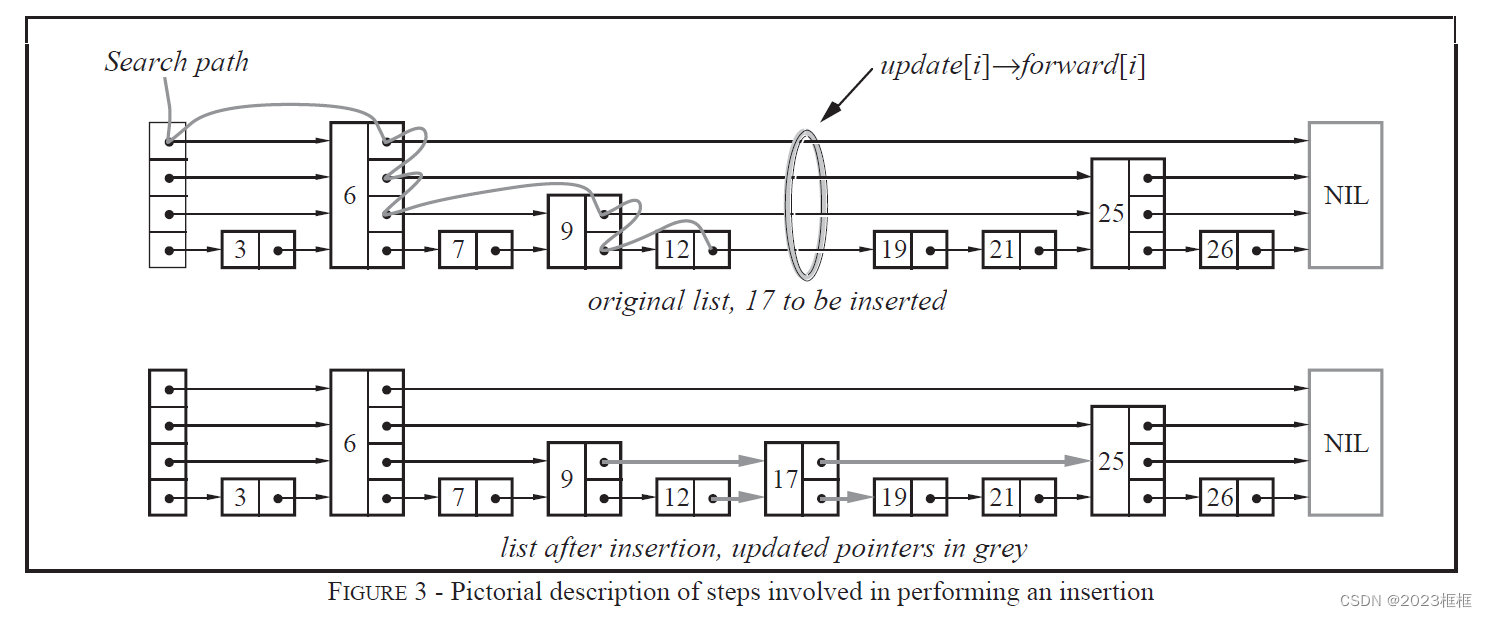
2.skiplist的效率如何保证?
上面我们说到,skiplist插入一个节点时随机出一个层数,听起来怎么这么随意,如何保证搜索时的效率呢?
这里首先要细节分析的是这个随机层数是怎么来的。一般跳表会设计一个最大层数maxLevel的限制,其次会设置一个多增加一层的概率p。
那么计算这个随机层数的伪代码如下图:
|V|是一个变量

2.1 一个节点的平均层数
根据前面randomLevel()的伪码,我们很容易看出,产生越高的节点层数,概率越低。
定量的分析如下:
- 节点层数至少为1。而大于1的节点层数,满足一个概率分布。
- 节点层数恰好等于1的概率为1-p。
- 节点层数大于等于2的概率为p,而节点层数恰好等于2的概率为p(1-p)。
- 节点层数大于等于3的概率为p^2 ,而节点层数恰好等于3的概率为p^2*(1-p)。
- 节点层数大于等于4的概率为p^3, 而节点层数恰好等于4的概率为p^3*(1-p)。
- …
因此,一个节点的平均层数(也即包含的平均指针数目),计算如下:
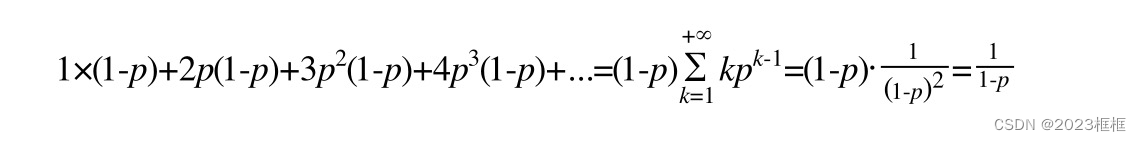 通过该公式可以算法实际的值:
通过该公式可以算法实际的值:
- 当p=1/2时,每个节点所包含的平均指针数目为2;
- 当p=1/4时,每个节点所包含的平均指针数目为1.33
公式的用途:
- 当层数越大那么搜索的效率也就越好,但是空间复杂度增大
- 节点出现的层数是均衡的,例如平均数为2,randomLevel函数计算出1,2,…,n,MaxLevel的层数.
- 节点会较为平均的出现1,2. 但是n往后的层数会出现的很少.
- 该公式可以计算出空间复杂度,例如平均每个结点的层数是2,那么每一层就需要一个指针来指向下一个结点, 层数越高指针越多,所以空间占用就越多了.
- 所以该公式是用来均衡时间复杂度和空间复杂度的.
在Redis的skiplist实现中,这两个参数的取值为:
p = 1/4
maxLevel = 32
跳表的平均时间复杂度为O(logN),这个推导的过程较为复杂,需要有一定的数据功底,有兴趣的
老铁,可以参考以下文章中的讲解
铁蕾大佬的博客:http://zhangtielei.com/posts/blog-redis-skiplist.html
William_Pugh大佬的论文:ftp://ftp.cs.umd.edu/pub/skipLists/skiplists.pdf
3. skiplist的实现
leetcode1206. 设计跳表
- 设计结构体
a. SkiplistNode,使用vector可以很好的缩放大小
b. vecotr存放每一层指向下一个结点的指针
struct SkiplistNode
{
int _val;
vector<SkiplistNode*> _nextV;
SkiplistNode(int val, int level)
:_val(val)
, _nextV(level, nullptr)
{}
};
a. 根链表一样,先设计节点,然后才能实现链表
b._maxLevel 为最大层数,默认为32
c. _p 为概率值
class Skiplist {
typedef SkiplistNode Node;
private:
Node* _head;
size_t _maxLevel = 32;
double _p = 0.5;
public:
Skiplist() {
srand(time(0));
// 头节点,层数是1
_head = new SkiplistNode(-1, 1);
}
};
- 查找函数
a. bool search(int target) : 返回target是否存在于跳表中.
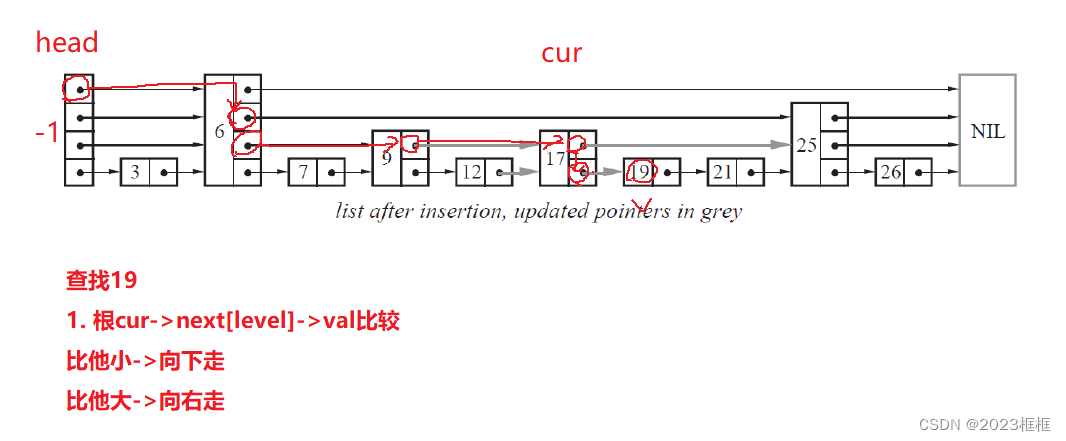
bool search(int target) {
Node* cur = _head;
int level = _head->_nextV.size() - 1;
while (level >= 0)
{
// 目标值比下一个节点值要大,向右走
// 下一个节点是空(尾),目标值比下一个节点值要小,向下走
if (cur->_nextV[level] && cur->_nextV[level]->_val < target)
{
// 向右走
cur = cur->_nextV[level];
}
else if (cur->_nextV[level] == nullptr || cur->_nextV[level]->_val > target)
{
// 向下走
--level;
}
else
{
return true;
}
}
return false;
}
- 随机层数
c库实现:
int RandomLevel()
{
size_t level = 1;
// rand() ->[0, RAND_MAX]之间
while (rand() <= RAND_MAX*_p && level < _maxLevel)
{
++level;
}
return level;
}
c++库实现:
int RandomLevel()
{
static std::default_random_engine generator(std::chrono::system_clock::now().time_since_epoch().count());
static std::uniform_real_distribution<double> distribution(0.0, 1.0);
size_t level = 1;
while (distribution(generator) <= _p && level < _maxLevel)
{
++level;
}
return level;
}
4.插入节点
a. 首先找到一个合适的地方.
b. 找到插入节点这个位置的每一层前一个节点,使用有一个数组存储
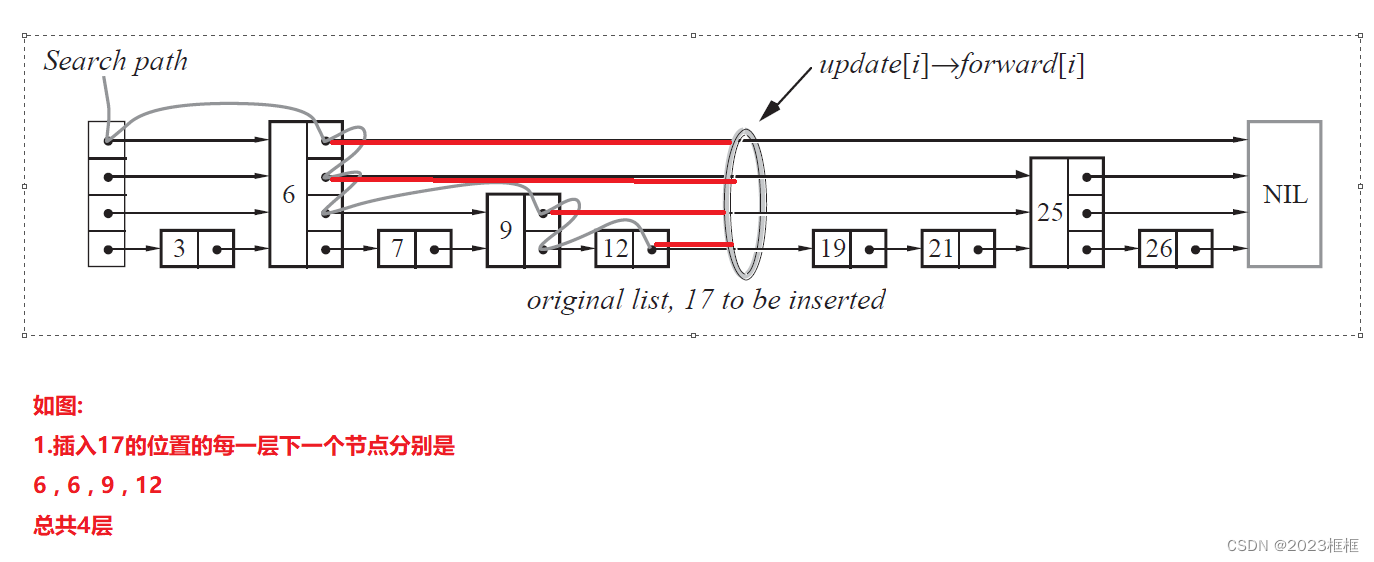
c. 求出一个随机层数, 用它new一个插入节点
d. 链接前后节点
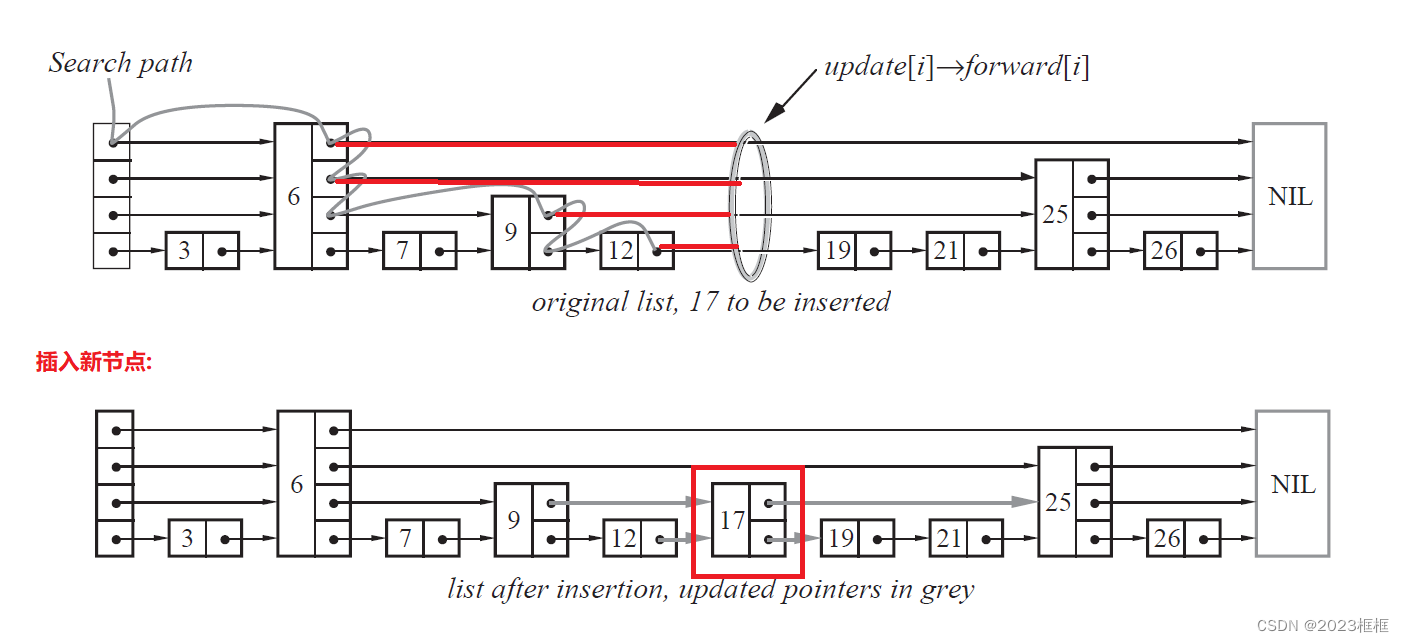
vector<Node*> FindPrevNode(int num)
{
Node* cur = _head;
int level = _head->_nextV.size() - 1;
// 插入位置每一层前一个节点指针
vector<Node*> prevV(_head->_nextV.size(), _head);
while (level >= 0)
{
// 目标值比下一个节点值要大,向右走
// 下一个节点是空(尾),目标值比下一个节点值要小,向下走
if (cur->_nextV[level] && cur->_nextV[level]->_val < num)
{
// 向右走
cur = cur->_nextV[level];
}
else if (cur->_nextV[level] == nullptr
|| cur->_nextV[level]->_val >= num)
{
// 更新level层前一个
prevV[level] = cur;
// 向下走
--level;
}
}
return prevV;
}
void add(int num) {
vector<Node*> prevV = FindPrevNode(num);
int n = RandomLevel();
Node* newnode = new Node(num, n);
// 如果n超过当前最大的层数,那就升高一下_head的层数
if (n > _head->_nextV.size())
{
_head->_nextV.resize(n, nullptr);
prevV.resize(n, _head);
}
// 链接前后节点
for (size_t i = 0; i < n; ++i)
{
newnode->_nextV[i] = prevV[i]->_nextV[i];
prevV[i]->_nextV[i] = newnode;
}
}
- 删除节点
a. 根插入类似
b. 找到插入节点这个位置的每一层前一个节点,使用有一个数组存储.
c. 删除节点每一层前一个节点 链接 删除节点的下一个节点.
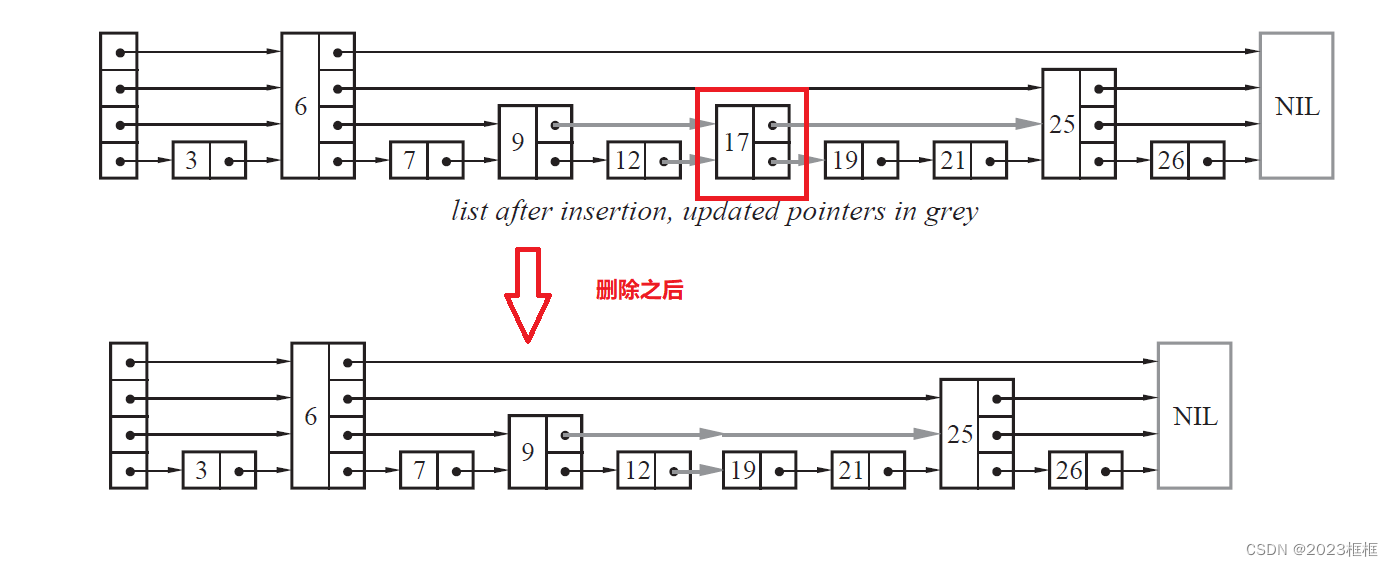
bool erase(int num) {
vector<Node*> prevV = FindPrevNode(num);
// 第一层下一个不是val,val不在表中
if (prevV[0]->_nextV[0] == nullptr || prevV[0]->_nextV[0]->_val != num)
{
return false;
}
else
{
Node* del = prevV[0]->_nextV[0];
// del节点每一层的前后指针链接起来
for (size_t i = 0; i < del->_nextV.size(); i++)
{
prevV[i]->_nextV[i] = del->_nextV[i];
}
delete del;
// 如果删除最高层节点,把头节点的层数也降一下(优化步骤,减少头节点的高度)
int i = _head->_nextV.size() - 1;
while (i >= 0)
{
if (_head->_nextV[i] == nullptr)
--i;
else
break;
}
_head->_nextV.resize(i + 1);
return true;
}
}
- 完整代码和测试用例
#include <iostream>
#include <vector>
#include <time.h>
#include <random>
#include <chrono>
using namespace std;
struct SkiplistNode
{
int _val;
vector<SkiplistNode*> _nextV;
SkiplistNode(int val, int level)
:_val(val)
, _nextV(level, nullptr)
{}
};
class Skiplist {
typedef SkiplistNode Node;
public:
Skiplist() {
srand(time(0));
// 头节点,层数是1
_head = new SkiplistNode(-1, 1);
}
bool search(int target) {
Node* cur = _head;
int level = _head->_nextV.size() - 1;
while (level >= 0)
{
// 目标值比下一个节点值要大,向右走
// 下一个节点是空(尾),目标值比下一个节点值要小,向下走
if (cur->_nextV[level] && cur->_nextV[level]->_val < target)
{
// 向右走
cur = cur->_nextV[level];
}
else if (cur->_nextV[level] == nullptr || cur->_nextV[level]->_val > target)
{
// 向下走
--level;
}
else
{
return true;
}
}
return false;
}
vector<Node*> FindPrevNode(int num)
{
Node* cur = _head;
int level = _head->_nextV.size() - 1;
// 插入位置每一层前一个节点指针
vector<Node*> prevV(level + 1, _head);
while (level >= 0)
{
// 目标值比下一个节点值要大,向右走
// 下一个节点是空(尾),目标值比下一个节点值要小,向下走
if (cur->_nextV[level] && cur->_nextV[level]->_val < num)
{
// 向右走
cur = cur->_nextV[level];
}
else if (cur->_nextV[level] == nullptr
|| cur->_nextV[level]->_val >= num)
{
// 更新level层前一个
prevV[level] = cur;
// 向下走
--level;
}
}
return prevV;
}
void add(int num) {
vector<Node*> prevV = FindPrevNode(num);
int n = RandomLevel();
Node* newnode = new Node(num, n);
// 如果n超过当前最大的层数,那就升高一下_head的层数
if (n > _head->_nextV.size())
{
_head->_nextV.resize(n, nullptr);
prevV.resize(n, _head);
}
// 链接前后节点
for (size_t i = 0; i < n; ++i)
{
newnode->_nextV[i] = prevV[i]->_nextV[i];
prevV[i]->_nextV[i] = newnode;
}
}
bool erase(int num) {
vector<Node*> prevV = FindPrevNode(num);
// 第一层下一个不是val,val不在表中
if (prevV[0]->_nextV[0] == nullptr || prevV[0]->_nextV[0]->_val != num)
{
return false;
}
else
{
Node* del = prevV[0]->_nextV[0];
// del节点每一层的前后指针链接起来
for (size_t i = 0; i < del->_nextV.size(); i++)
{
prevV[i]->_nextV[i] = del->_nextV[i];
}
delete del;
// 如果删除最高层节点,把头节点的层数也降一下
int i = _head->_nextV.size() - 1;
while (i >= 0)
{
if (_head->_nextV[i] == nullptr)
--i;
else
break;
}
_head->_nextV.resize(i + 1);
return true;
}
}
//int RandomLevel()
//{
// size_t level = 1;
// // rand() ->[0, RAND_MAX]之间
// while (rand() <= RAND_MAX*_p && level < _maxLevel)
// {
// ++level;
// }
// return level;
//}
int RandomLevel()
{
static std::default_random_engine generator(std::chrono::system_clock::now().time_since_epoch().count());
static std::uniform_real_distribution<double> distribution(0.0, 1.0);
size_t level = 1;
while (distribution(generator) <= _p && level < _maxLevel)
{
++level;
}
return level;
}
void Print()
{
/*int level = _head->_nextV.size();
for (int i = level - 1; i >= 0; --i)
{
Node* cur = _head;
while (cur)
{
printf("%d->", cur->_val);
cur = cur->_nextV[i];
}
printf("\n");
}*/
Node* cur = _head;
while (cur)
{
printf("%2d\n", cur->_val);
// 打印每个每个cur节点
for (auto e : cur->_nextV)
{
printf("%2s", "↓");
}
printf("\n");
cur = cur->_nextV[0];
}
}
private:
Node* _head;
size_t _maxLevel = 32;
double _p = 0.5;
};
/**
* Your Skiplist object will be instantiated and called as such:
* Skiplist* obj = new Skiplist();
* bool param_1 = obj->search(target);
* obj->add(num);
* bool param_3 = obj->erase(num);
*/
//int main()
//{
// Skiplist sl;
// int max = 0;
// for (size_t i = 0; i < 1000000000; ++i)
// {
// //cout << sl.RandomLevel() <<" ";
// int r = sl.RandomLevel();
// if (r > max)
// max = r;
// }
// cout <<max<< endl;
//
// return 0;
//}
int main()
{
Skiplist sl;
//int a[] = { 5, 2, 3, 8, 9, 6, 5, 2, 3, 8, 9, 6, 5, 2, 3, 8, 9, 6 };
int a[] = { 5, 2, 3, 8, 9, 6 };
for (auto e : a)
{
//sl.Print();
//printf("--------------------------------------\n");
sl.add(e);
}
sl.Print();
int x;
cin >> x;
sl.erase(x);
return 0;
}
//int main()
//{
// unsigned seed = std::chrono::system_clock::now().time_since_epoch().count();
// std::default_random_engine generator(seed);
//
// std::uniform_real_distribution<double> distribution(0.0, 1.0);
// size_t count = 0;
// for (int i = 0; i < 100; ++i)
// {
// if (distribution(generator) <= 0.25)
// ++count;
// }
// cout << count << endl;
//
// return 0;
//}