前言✈
上回说到,我们学习了一些与指针相关的数据类型,如指针数组,数组指针,函数指针等等,我们还学习了转移表的基本概念,学会了如何利用转移表来实现一个简易计算器。详情请点击传送门:【C语言】深度理解指针(上)
本期我们将继续指针的话题,学习有关回调函数的相关内容,以及分析一些与指针相关的常见笔试题。
事不宜迟,让我们进入今天的第一个主题----回调函数。
2. 回调函数💫
2.1 定义
首先,回调函数是什么意思呢?👇
回调函数就是一个 通过函数指针调用的函数。如果你把函数的指针(地址)作为参数传递给另一个函数,当这个指针被用来调用其所指向的函数时,我们就说这是回调函数。 回调函数不是由该函数的实现方直接调用,而是在特定的事件或条件发生时由另外的一方调用的,用于对该事件或条件进行响应。
2.2 qsort函数
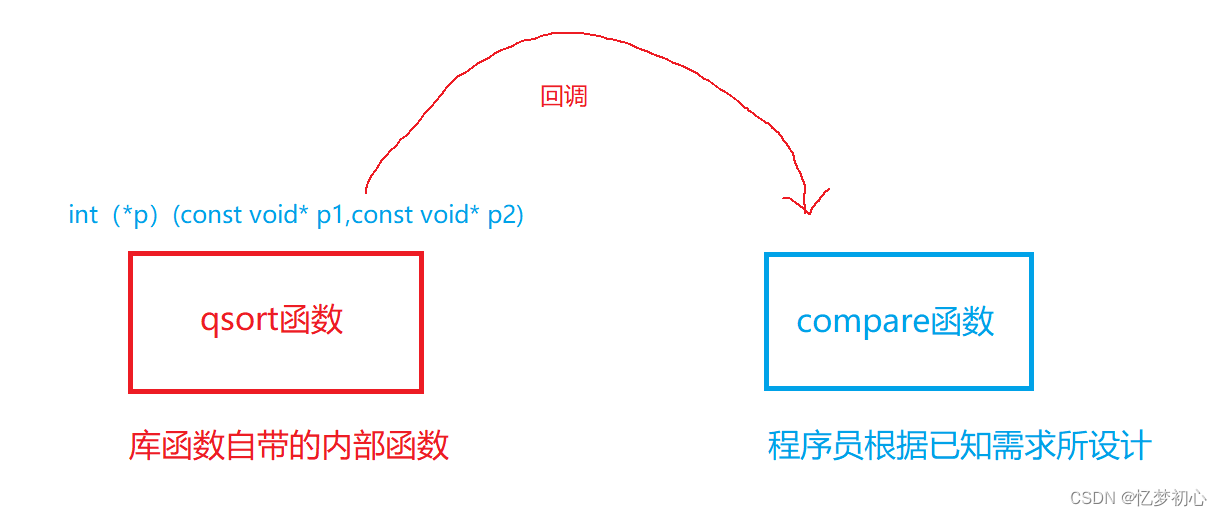
在stdlib.h头文件中有个函数叫qsort,它的用途是用来进行快速排序。它有个特点,就是我们通过它可以排序任何类型的数据,这便是使用了回调函数的思想,我们来看看它的函数原型:

参数 | 作用 |
base | 用于接收需要排序数组的首元素地址,由于不知道传入类型,类型为void* |
num | 表示数组共有几个元素,用于确定循环的次数 |
width | 表示数组每个元素所占的字节数,用于确定指针移动的步长,指向相应元素进行比较 |
compare | 函数指针,即回调函数。指向用户外部设计的比较函数,调用函数对数组元素进行比较,然后排序。 |
在使用qsort时, 我们用户只需要设计compare指向的回调函数即可。由于用户知道要排序什么类型的数据,因此可以设计对应的比较函数以供qsort函数内部进行回调。这就是为什么qsort可以排序任意类型数据的原因。其关系如下:
例如,我们可以使用它排序整形数据:
#include<stdlib.h>
#include<stdio.h>
//递增
int cmp_int1(const void* p1, const void* p2) //比较函数,参数要与qsort中的函数指针指向函数类型一致
{
return *((int*)p1) - *((int*)p2); //p1大于p2,返回正数,小于返回负数,等于返回0
}
int main()
{
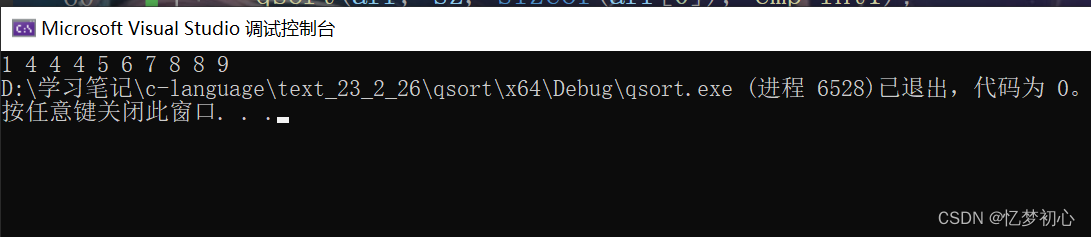
int arr[10] = { 8,5,4,6,4,7,8,1,9,4 };
int sz = sizeof(arr) / sizeof(arr[0]);
qsort(arr, sz, sizeof(arr[0]), cmp_int1);
//打印
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
这是升序排列,那么如果我们需要进行降序排序呢?很简单,将p1与p2对调即可(这是因为qsort当回调函数返回正数时会进行操作):
//递减
int cmp_int2(const void* p1, const void* p2) //比较函数,参数要与qsort中的函数指针指向函数类型一致
{
return *((int*)p2) - *((int*)p1); //p1小于p2,返回正数,小于返回负数,等于返回0
}
我们还可以使用qsort来排序一个结构体(按照姓名升序排列):
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
struct student
{
char name[20];
int age;
};
int cmp_name(const void* p1, const void* p2)//对结构体中的姓名进行排序
{
//字符串的比较用strcmp,strcmp相等返回0,大于返回1,小于返回-1,与设定的返回值相对应
return strcmp(((struct student*)p1)->name, ((struct student*)p2)->name);
}
int main()
{
struct student arr[3] = { {"zhangsan",16},{"lisi",14},{"lihau",18} };
int sz = sizeof(arr) / sizeof(arr[0]);
qsort(arr, sz, sizeof(arr[0]), cmp_name);
//打印
for (int i = 0; i < sz; i++)
{
printf("%s %d\n", arr[i].name, arr[i].age);
}
return 0;
}
2.3 回调函数的应用
学习了qsort是如何借助回调函数来实现排序任意类型的数据,我们是不是可以模拟qsort来实现我们曾经写过的冒泡排序函数,使得这个冒泡排序函数可以排序任意类型的数据。下面,我们逐步分析如何实现这样的一个代码:
由于排序的数组类型不固定,因此我们第一个参数采用void*类型的指针接收(void*类型的指针被称为万能指针,可以接收任意类型的指针)第二个参数与第三个参数分别是数组元素个数和每个元素的大小,最后一个参数即为函数指针,指向回调函数。
//冒泡排序,模拟qsort的思想
void my_bubble_sort(void* arr, size_t sz, size_t k, int (*cmp)(const void*, const void*))
{
//实现
}接下来我们来实现冒泡排序算法,由于我们不知道数组元素的类型,因此不能直接通过下标来定位某个元素,那要怎么办呢?这里最巧妙的点来了,我们知道char*类型的指针的步长为1个字节,并且数组每个元素的所占的字节数我们又是已知的(参数k),那么我们是不是就可以将arr强制类型转换为char*,然后加上k的整数倍即可得到相应元素所在地址。怎么样,是不是太巧妙了,下面来看代码:
void my_bubble_sort(void* arr, size_t sz, size_t k, int (*cmp)(const void*, const void*))
{
for (int i = 0; i < sz - 1; i++)
{
for (int j = 0; j < sz - i - 1; j++)
{
//对相邻两个元素进行比较
if (cmp((char*)arr + j * k, (char*)arr + (j + 1) * k)>0)
{
//swap交换两个元素
}
}
}
}由于cmp()为回调函数,是用户根据需求所设计的,因此我们的冒泡排序函数只剩下最后一个函数swap()了,用于交换两个元素。那么swap()函数的参数要如何设计呢,用int*?还是用flost*?都不是,这里我们采用char*来接收操作数的地址,并且再用一个参数来接收元素的大小(原因下面解释)函数原型如下:
void swap(char* p1, char* p2, int k) //p1,p2指向操作数首地址,k为每个元素的字节数最后,我们来实现这个函数。因为我们不知道元素的类型,所以我们交换只能一个字节一个字节交换。而对char*指针解引用即向后访问一个字节,又已知元素的大小为k个字节,我们通过循环k次即可将k个字节全部交换完毕。这也是为什么参数要以char*类型接收以及要接收元素的大小的原因。实现如下:
void swap(char* p1, char* p2, int k)
{
//循环k次,k个字节依次交换
for (int i = 1; i <= k; i++)
{
//交换
char temp = *p1;
*p1 = *p2;
*p2 = temp;
//指向下一字节
p1++;
p2++;
}
}至此,我们完成的整个冒泡函数的实现, 总代码如下:
void swap(char* p1, char* p2, int k)
{
for (int i = 1; i <= k; i++)
{
char temp = *p1;
*p1 = *p2;
*p2 = temp;
p1++;
p2++;
}
}
void my_bubble_sort(void* arr, size_t sz, size_t k, int (*cmp)(const void*, const void*))
{
for (int i = 0; i < sz - 1; i++)
{
for (int j = 0; j < sz - i - 1; j++)
{
if (cmp((char*)arr + j * k, (char*)arr + (j + 1) * k)>0)
{
swap((char*)arr + j * k, (char*)arr + (j + 1) * k, k);
}
}
}
}我们可以用来排序整形:
#include<stdlib.h>
#include<stdio.h>
//递增
int cmp_int1(const void* p1, const void* p2) //回调函数,用于比较整形
{
return *((int*)p1) - *((int*)p2);
}
int main()
{
int arr[10] = { 8,5,4,6,4,7,8,1,9,4 };
int sz = sizeof(arr) / sizeof(arr[0]);
my_bubble_sort(arr, sz, sizeof(arr[0]), cmp_name);
//打印
for (int i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}
也可以用来排序结构体等等:
#include<stdlib.h>
#include<stdio.h>
#include<string.h>
struct student
{
char name[20];
int age;
};
int cmp_name(const void* p1, const void* p2) 回调函数,用于比较结构体中的姓名
{
return strcmp(((struct student*)p1)->name, ((struct student*)p2)->name);
}
int main()
{
struct student arr[3] = { {"zhangsan",16},{"lisi",14},{"lihau",18} };
int sz = sizeof(arr) / sizeof(arr[0]);
my_bubble_sort(arr, sz, sizeof(arr[0]), cmp_name);
//打印
for (int i = 0; i < sz; i++)
{
printf("%s %d\n", arr[i].name, arr[i].age);
}
return 0;
}3. 指针和数组笔试题🍜
学习了那么多关于指针的知识点,我们也要学会如何运用。下面给各位带来了一些有关指针与数组的笔试题作为饭后甜点。事不宜迟,让我们马上开始品尝吧!
3.1 一维整形数组
首先是一维整形数组,求下列十条语句输出的结果:
//一维数组
int a[] = {1,2,3,4};
printf("%d\n",sizeof(a));//1
printf("%d\n",sizeof(a+0));//2
printf("%d\n",sizeof(*a));//3
printf("%d\n",sizeof(a+1));//4
printf("%d\n",sizeof(a[1]));//5
printf("%d\n",sizeof(&a));//6
printf("%d\n",sizeof(*&a));//7
printf("%d\n",sizeof(&a+1));//8
printf("%d\n",sizeof(&a[0]));//9
printf("%d\n",sizeof(&a[0]+1));//10答案及解释如下表:
语句编号 | 答案 | 解释 |
1 | 16 | 数组名单独放在sizeof内部代表整个数组,即求整个数组所占空间 |
2 | 4/8 | 由于数组名并非单独在sizeof内部,其代表首元素地址,求的就是指针的大小 |
3 | 4 | 同理,a为首元素地址,对其解引用得到首元素,即求首元素所占空间 |
4 | 4/8 | 首元素地址加1,向后移动4个字节,还是指针,求的为指针的大小 |
5 | 4 | 求下标为1的元素,即第二个整形元素所占空间 |
6 | 4/8 | &数组名取出的是整个数组的地址,因此求的为指针的大小 |
7 | 16 | 取出整个数组的地址然后解引用,最后得到整个数组,因此求整个数组所占空间 |
8 | 4/8 | 取出整个数组的地址,然后加1,还是指针,求的为指针的大小 |
9 | 4/8 | 取出数组第一个元素的地址,因此求的为指针的大小 |
10 | 4/8 | 取出数组第一个元素的地址,然后加1指向下一个元素,还是指针,求的为指针的大小 |
怎么样,你都做对了吗?
3.2 二维整形数组
同样,求下列几条语句输出的结果:
//二维数组
int a[3][4] = {0};
printf("%d\n",sizeof(a));//1
printf("%d\n",sizeof(a[0][0]));//2
printf("%d\n",sizeof(a[0]));//3
printf("%d\n",sizeof(a[0]+1));//4
printf("%d\n",sizeof(*(a[0]+1)));//5
printf("%d\n",sizeof(a+1));//6
printf("%d\n",sizeof(*(a+1)));//7
printf("%d\n",sizeof(&a[0]+1));//8
printf("%d\n",sizeof(*(&a[0]+1)));//9
printf("%d\n",sizeof(*a));//10
printf("%d\n",sizeof(a[3]));//11答案及解释如下表:
语句编号 | 答案 | 解释 |
1 | 48 | 数组名单独放在sizeof内部代表整个数组,即求整个数组所占空间 |
2 | 4 | a[0][0]代表第一行第一列元素,即求第一行第一列元素所占空间 |
3 | 16 | a[0]代表第一行数组,即第一行数组的数组名,数组名单独放在sizeof内部,求的为整个数组的大小,即第一行一维数组的大小。 |
4 | 4/8 | a[0]为第一行数组的数组名,但没有单独放在sizeof内部,因此为第一行一维数组首元素地址,加一后为第二个元素地址,因此求的是整形指针的大小 |
5 | 4 | 上面说到a[0]+1为第一行数组第二个元素地址,解引用后即为第一行数组的第二个元素,求的为整形元素的大小 |
6 | 4/8 | a数组名没有单独在sizeof内部,因此为首元素地址,即第一行数组的地址,加一后为第二行数组的地址,为指针,求的为数组指针的大小 |
7 | 16 | 由6可得a+1为第二行数组的地址,解引用后为第二行数组,求的即为第二行一维数组的大小 |
8 | 4/8 | a[0]为第一行数组名,取地址后取出的是第一行数组的地址,加1后为第二行数组的地址,为指针,求的数组指针的大小 |
9 | 16 | 由8得a[0]+1为第二行数组的地址,解引用后为第二行数组,求的是第二行一维数组的大小 |
10 | 16 | 数组名没有单独放在sizeof内部,代表首元素地址,即第一行数组的地址,解引用后得到第一行数组,求的是第一行一维数组的大小 |
11 | 16 | 1.sizeof()并不会对括号内部的表达式进行运算操作,即sizeof(arr[3])并不会去访问arr[3],因此不构成越界访问。 2.sizeof()是通过变量的类型属性来确定变量所占空间的大小,arr[3]的类型是一个一维数组,因此sizeof(arr[3])求的即为一维数组的大小 |
3.3 字符数组
根据初始化方式的不同我们分为三组题,我们先来看第一组:
//用字符初始化数组,数组存放的内容为a,b,c,d,e,f
char arr[] = {'a','b','c','d','e','f'};
printf("%d\n", sizeof(arr)); //1
printf("%d\n", sizeof(arr+0));//2
printf("%d\n", sizeof(*arr));//3
printf("%d\n", sizeof(arr[1]));//4
printf("%d\n", sizeof(&arr));//5
printf("%d\n", sizeof(&arr+1));//6
printf("%d\n", sizeof(&arr[0]+1));//7
printf("%d\n", strlen(arr));//8
printf("%d\n", strlen(arr+0));//9
printf("%d\n", strlen(*arr));//10
printf("%d\n", strlen(arr[1]));//11
printf("%d\n", strlen(&arr));//12
printf("%d\n", strlen(&arr+1));//13
printf("%d\n", strlen(&arr[0]+1));//14语句编号 | 答案 | 解释 |
1 | 6 | 数组名单独放在sizeof()内部,代表整个数组,求的为整个数组的大小 |
2 | 4/8 | 数组名没有单独放于内部,代表首元素地址,最终求的为指针的大小 |
3 | 1 | arr代表首元素地址,解引用后得到首元素,求的为第一个字符的大小 |
4 | 1 | arr[1]为数组第2个元素,求的为第二个字符的大小 |
5 | 4/8 | &数组名取出整个数组的地址,因此求的是字符数组指针的大小 |
6 | 4/8 | &arr为字符数组的地址,加1后越过一个字符数组,类型属性还是指针,求的是字符数组指针的大小 |
7 | 4/8 | 取出第一个元素的地址,然后加1,指向第二个元素,还是指针,因此求的是字符指针的大小 |
8 | 随机值 | 由于strlen()遇到'\0'停止计数,但是我们的字符数组中不存在'\0',所以会继续向后统计直到遇到'\0'。何时遇到'\0'是我们不可预知的,为随机值 |
9 | 随机值 | 在strlen()中,arr与arr+0都表示首元素地址,由于不知道何时遇到'\0',因此为随机值 |
10 | 非法访问 | arr为首元素地址,解引用后为首元素。本条语句实际上是将首元素的字面值作为地址传入函数向后进行统计,显然造成了非法访问 |
11 | 非法访问 | arr[1]代表数组第二个元素,同理会造成非法访问 |
12 | 随机值 | &arr为字符数组的地址,指向数组开头。由于不知道'\0'的位置,因此为随机值 |
13 | 随机值 | &arr为数组的地址,加1后越过一个数组,指向后续元素。但是我们任然不知道'\0'的位置,因此为随机值(这里的随机值比第12的随机值小6) |
14 | 随机值 | &arr[0]为数组首元素地址,加1后为第2个元素地址。因此不用多说,这里还是随机值,只不过这个随机值比第12小1 |
紧接着我们来看第二组:
char arr[] = "abcdef"; //用字符串初始化数组,相当于将字符串拷贝到数组中
printf("%d\n", sizeof(arr));//1
printf("%d\n", sizeof(arr+0));//2
printf("%d\n", sizeof(*arr));//3
printf("%d\n", sizeof(arr[1]));//4
printf("%d\n", sizeof(&arr));//5
printf("%d\n", sizeof(&arr+1));//6
printf("%d\n", sizeof(&arr[0]+1));//7
printf("%d\n", strlen(arr));//8
printf("%d\n", strlen(arr+0));//9
printf("%d\n", strlen(*arr));//10
printf("%d\n", strlen(arr[1]));//11
printf("%d\n", strlen(&arr));//12
printf("%d\n", strlen(&arr+1));//13
printf("%d\n", strlen(&arr[0]+1));//14语句编号 | 答案 | 解释 |
1 | 7 | 数组名单独放在sizeof()内部,代表整个数组,求的为整个数组的所占空间(包括字符串末尾隐藏的'\0') |
2 | 4/8 | 数组名没有单独放于内部,代表首元素地址,最终求的为指针的大小 |
3 | 1 | arr代表首元素地址,解引用后得到首元素,求的为第一个字符的大小 |
4 | 1 | arr[1]为数组第2个元素,求的为第二个字符的大小 |
5 | 4/8 | &数组名取出整个数组的地址,因此求的是字符数组指针的大小 |
6 | 4/8 | &arr为字符数组的地址,加1后越过一个字符数组,类型属性还是指针,求的是字符数组指针的大小 |
7 | 4/8 | 取出第一个元素的地址,然后加1,指向第二个元素,还是指针,因此求的是字符指针的大小 |
8 | 6 | 由于字符串以'\0'结尾,末尾隐藏了'\0',因此strlen计算的结果即为字符串的长度(不包括末尾隐藏的'\0') |
9 | 6 | 在strlen()中,arr与arr+0都表示首元素地址,因此结果为字符串长度 |
10 | 非法访问 | arr为首元素地址,解引用后为首元素。本条语句实际上是将首元素的字面值作为地址传入函数向后进行统计,显然造成了非法访问 |
11 | 非法访问 | arr[1]代表数组第二个元素,同理会造成非法访问 |
12 | 6 | &arr为字符数组的地址,指向数组开头。于是从数组开头向后统计字符串个数直到遇到'\0'停止,因此结果为字符串的长度 |
13 | 随机值 | &arr为数组的地址,加1后越过一个数组,即越过了字符串末尾的'\0'指向下一元素。由于不知道后续的'\0'处于何处,因此为随机值 |
14 | 5 | &arr[0]为数组首元素地址,加1后为第2个元素地址,即从第二个元素开始向后统计字符的个数。结果为字符串个数-1 |
最后一组是将字符串赋给一个字符指针,如下:
char* p = "abcdef";//字符串初始化字符指针,指针指向字符串首元素地址
printf("%d\n", sizeof(p));//1
printf("%d\n", sizeof(p + 1));//2
printf("%d\n", sizeof(*p));//3
printf("%d\n", sizeof(p[0]));//4
printf("%d\n", sizeof(&p));//5
printf("%d\n", sizeof(&p + 1));//6
printf("%d\n", sizeof(&p[0] + 1));//7
printf("%d\n", strlen(p));//8
printf("%d\n", strlen(p + 1));//9
printf("%d\n", strlen(*p));//10
printf("%d\n", strlen(p[0]));//11
printf("%d\n", strlen(&p));//12
printf("%d\n", strlen(&p + 1));//13
printf("%d\n", strlen(&p[0] + 1));//14语句编号 | 答案 | 解释 |
1 | 4/8 | p是个指针,存放字符串首元素地址,因此结果为一个指针的大小 |
2 | 4/8 | p加1指向字符串常量中第2个字符的地址,还是指针,因此结果为指针的大小 |
3 | 1 | 对p指针解引用后得到a,求的就为字符a的大小 |
4 | 1 | p[0]与*(p+0)等价,因此最终得到字符a,求的为字符a的大小 |
5 | 4/8 | 对一级指针变量取地址即为二级指针,二级指针也是指针,因此结果为指针的大小 |
6 | 4/8 | &p为二级指针,加1越过4个字节空间,还是个指针,结果为指针的大小 |
7 | 4/8 | p[0]为字符串首元素,&p[0]即为字符串首元素地址,加1后为第二个元素地址,是个指针,因此结果为指针的大小 |
8 | 6 | p存放着字符串首元素的地址,strlen(p)求得的即为字符串长度 |
9 | 5 | p+1指向字符串第二个元素,因此结果为字符串长度-1 |
10 | 非法访问 | *p得到首元素a,strlen(*p)即把a的ASCII码值当作地址传入strlen()函数向后进行计数,显然会形成非法访问 |
11 | 非法访问 | p[0]等价于*(p+0),因此结果与10相同,形成非法访问 |
12 | 随机值 | 传入p的地址,函数从p的低地址处开始向后统计有几个字符。由于我们不知道'\0'的位置,因此最终结果为随机值 |
13 | 随机值 | &p取出p的地址,加1后相当于越过指针变量p指向下一地址,但我们还是不知道'\0'的位置,因此最终结果为随机值 |
14 | 5 | p[0]相当于*(p+0),由于*和&可以互相抵消,因此&p[0]相当于p。所以本语句结果和第9条语句一样,都为字符串长度-1 |
3.4 总结
数组名的意义:
1. sizeof(数组名),这里的数组名代表整个数组,计算的是整个数组的大小
2. &数组名,这里的数组名表示整个数组,取出的是整个数组的地址。
3. 除了以上两种情况其他所有的数组名都代表首元素地址。
以上,就是本期的全部内容啦🌸
制作不易,能否点个赞再走呢🙏









![[NOIP1999 普及组] Cantor 表](https://img-blog.csdnimg.cn/2b6f01e012f2409ea18a7505f214950c.png)