make_shared的使用:
shared_ptr<string> p1 = make_shared<string>(10, '9');
shared_ptr<string> p2 = make_shared<string>("hello");
shared_ptr<string> p3 = make_shared<string>();
好处:减少分配次数
std::shared_ptr<Widget> spw(new Widget); 分配2次内存
auto spw = std::make_shared<Widget>(); 只分配1次内存
尽量使用make_shared初始化
C++11 中引入了智能指针, 同时还有一个模板函数 std::make_shared 可以返回一个指定类型的 std::shared_ptr, 那与 std::shared_ptr 的构造函数相比它能给我们带来什么好处呢 ?
make_shared初始化的优点
1、提高性能
shared_ptr 需要维护引用计数的信息:
强引用, 用来记录当前有多少个存活的 shared_ptrs 正持有该对象. 共享的对象会在最后一个强引用离开的时候销毁( 也可能释放).
弱引用, 用来记录当前有多少个正在观察该对象的 weak_ptrs. 当最后一个弱引用离开的时候, 共享的内部信息控制块会被销毁和释放 (共享的对象也会被释放, 如果还没有释放的话).
如果你通过使用原始的 new 表达式分配对象, 然后传递给 shared_ptr (也就是使用 shared_ptr 的构造函数) 的话, shared_ptr 的实现没有办法选择, 而只能单独的分配控制块:
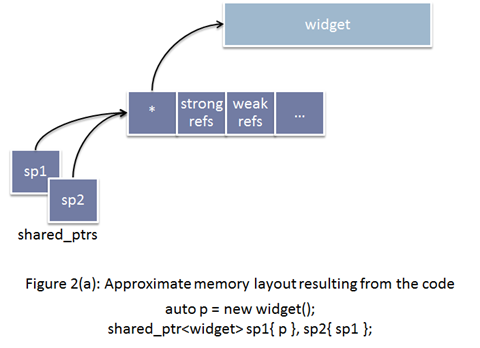
如果选择使用 make_shared 的话, 情况就会变成下面这样:

std::make_shared(比起直接使用new)的一个特性是能提升效率。使用std::make_shared允许编译器产生更小,更快的代码,产生的代码使用更简洁的数据结构。考虑下面直接使用new的代码:
std::shared_ptr<Widget> spw(new Widget);
很明显这段代码需要分配内存,但是它实际上要分配两次。每个std::shared_ptr都指向一个控制块,控制块包含被指向对象的引用计数以及其他东西。这个控制块的内存是在std::shared_ptr的构造函数中分配的。因此直接使用new,需要一块内存分配给Widget,还要一块内存分配给控制块。
如果使用std::make_shared来替换
auto spw = std::make_shared<Widget>();
一次分配就足够了。这是因为std::make_shared申请一个单独的内存块来同时存放Widget对象和控制块。这个优化减少了程序的静态大小,因为代码只包含一次内存分配的调用,并且这会加快代码的执行速度,因为内存只分配了一次。另外,使用std::make_shared消除了一些控制块需要记录的信息,这样潜在地减少了程序的总内存占用。
对std::make_shared的效率分析可以同样地应用在std::allocate_shared上,所以std::make_shared的性能优点也可以扩展到这个函数上。
对std::make_shared的性能分析同样适用于std::allocated_shared,因此std::make_shared的性能优势也同样存在于std::allocated_shared。
2、 异常安全
我们在调用processWidget的时候使用computePriority(),并且用new而不是std::make_shared:
processWidget(std::shared_ptr<Widget>(new Widget), //潜在的资源泄露
computePriority());
就像注释指示的那样,上面的代码会导致new创造出来的Widget发生泄露。那么到底是怎么泄露的呢?调用代码和被调用函数都用到了std::shared_ptr,并且std::shared_ptr就是被设计来阻止资源泄露的。当最后一个指向这儿的std::shared_ptr消失时,它们会自动销毁它们指向的资源。如果每个人在每个地方都使用std::shared_ptr,那么这段代码是怎么导致资源泄露的呢?
答案和编译器的翻译有关,编译器把源代码翻译到目标代码,在运行期,函数的参数必须在函数被调用前被估值,所以在调用processWidget时,下面的事情肯定发生在processWidget能开始执行之前:
表达式“new Widget”必须被估值,也就是,一个Widget必须被创建在堆上。
std::shared_ptr(负责管理由new创建的指针)的构造函数必须被执行。
computePriority必须跑完。
编译器不需要必须产生这样顺序的代码。但“new Widget”必须在std::shared_ptr的构造函数被调用前执行,因为new的结构被用为构造函数的参数,但是computePriority可能在这两个调用前(后,或很奇怪地,中间)被执行。也就是,编译器可能产生出这样顺序的代码:
执行“new Widget”。
执行computePriority。
执行std::shared_ptr的构造函数。
如果这样的代码被产生出来,并且在运行期,computePriority产生了一个异常,则在第一步动态分配的Widget就会泄露了,因为它永远不会被存放到在第三步才开始管理它的std::shared_ptr中。
使用std::make_shared可以避免这样的问题。调用代码将看起来像这样:
processWidget(std::make_shared<Widget>(), //没有资源泄露
computePriority());
在运行期,不管std::make_shared或computePriority哪一个先被调用。如果std::make_shared先被调用,则在computePriority调用前,指向动态分配出来的Widget的原始指针能安全地被存放到被返回的std::shared_ptr中。如果computePriority之后产生一个异常,std::shared_ptr的析构函数将发现它持有的Widget需要被销毁。并且如果computePriority先被调用并产生一个异常,std::make_shared就不会被调用,因此这里就不需要考虑动态分配的Widget了。
如果使用std::unique_ptr和std::make_unique来替换std::shared_ptr和std::make_shared,事实上,会用到同样的理由。因此,使用std::make_unique代替new就和“使用std::make_shared来写出异常安全的代码”一样重要。
缺点
构造函数是保护或私有时,无法使用 make_shared
make_shared 虽好, 但也存在一些问题, 比如, 当我想要创建的对象没有公有的构造函数时, make_shared 就无法使用了, 当然我们可以使用一些小技巧来解决这个问题, 比如这里 How do I call ::std::make_shared on a class with only protected or private constructors?
对象的内存可能无法及时回收
make_shared 只分配一次内存, 这看起来很好. 减少了内存分配的开销. 问题来了, weak_ptr 会保持控制块(强引用, 以及弱引用的信息)的生命周期, 而因此连带着保持了对象分配的内存, 只有最后一个 weak_ptr 离开作用域时, 内存才会被释放. 原本强引用减为 0 时就可以释放的内存, 现在变为了强引用, 若引用都减为 0 时才能释放, 意外的延迟了内存释放的时间. 这对于内存要求高的场景来说, 是一个需要注意的问题.
std::make_unique 和 std::make_shared是三个make函数中的两个,make函数用来把一个任意参数的集合完美转移给一个构造函数从而生成动态分配内存的对象,并返回一个指向那个对象的灵巧指针。第三个make是std::allocate_shared。它像std::make_shared一样,除了第一个参数是一个分配器对象,用来进行动态内存分配。
优先使用make函数的第一个原因即使用最简单的构造灵巧指针也能看出来。考虑如下代码:
auto upw1(std::make_unique<Widget>()); // with make func
std::unique_ptr<Widget> upw2(new Widget); // without make func
auto spw1(std::make_shared<Widget>()); // with make func
std::shared_ptr<Widget> spw2(new Widget); // without make func
我标注了基本的区别:
使用new的版本重复了被创建对象的键入,但是make函数则没有。重复类型违背了软件工程的一个重要原则:应该避免代码重复,代码中的重复会引起编译次数增加,导致目标代码膨胀,最终产生更难以维护的代码,通常会引起代码不一致,而不一致经常导致bug产生。另外,输入两次比输入一次要费力些,谁都想减少敲键盘的负担。
优先使用make函数的第二个原因是和异常安全有关。假设我们有个函数来根据一些优先级处理一个Widget对象:
void processWidget(std::shared_ptr spw, int priority);
……
见前面的 《2、 异常安全》
假如我们把std::shared_ptr和std::make_shared替换成std::unique_ptr 和std::make_unique,会发生相同的事情。使用std::make_unique来代替new在写异常安全的代码里是和使用std::make_shared一样重要。
make函数的参数相对直接使用new来说也更健壮。尽管有如此多的工程特性、异常安全以及效率优势,我们这个条款是“尽量”使用make函数,而没有说排除其他情况。那是因为还有情况不能或者不应该使用make函数。
比如,make函数都不允许使用定制删除器(见条款18,条款19),但是std::unique_ptr和std::shared_ptr的构造函数都可以给Widget对象一个定制删除器。
auto widgetDeleter = [](Widget* pw) { … };
直接使用new来构造一个有定制删除器的灵巧指针:
std::unique_ptr<Widget, decltype(widgetDeleter)>
upw(new Widget, widgetDeleter);
std::shared_ptr<Widget> spw(new Widget, widgetDeleter);
用make函数没法做到这一点。
make函数的第二个限制是无法从实现中获得句法细节。条款7解释了当创建一个对象时,如果其类型通过std::initializer_list参数列表来重载构造函数的,尽量用大括号来创建对象而不是std::initializer_list构造函数。相反,用圆括号创建对象时,会调用non-std::initializer_list构造函数。make函数完美传递了参数列表到对象的构造函数,但它们在使用圆括号或大括号时,也是如此吗?对某些类型来说,这个问题的答案有很大不同。比如:
auto upv = std::make_unique<std::vector<int>>(10, 20);
auto spv = std::make_shared<std::vector<int>>(10, 20);
结果指针是指向一个10个元素的数组每个元素值是20,还是指向2个元素的数组其值分别是10和20 ?或者无限制?
好消息是并非无限制的 :两个调用都是构造了10元素的数组,每个元素值都是20。说明在make函数里,转移参数的代码使用了圆括号,而不是大括号。坏消息是,假如你想使用大括号初始化器( braced initializer)来创建自己的指向对象的指针,你必须直接使用new。使用make函数需要能够完美传递一个大括号初始化器的能力,但是,如条款30中所说的,大括号初始化器不能够完美传递。但条款30也给出了一个补救方案:从大括号初始化器根据auto类型推导来创建一个 std::initializer_list对象,然后把auto对象传递给make函数:
// create std::initializer_list
auto initList = { 10, 20 };
// create std::vector using std::initializer_list ctor
auto spv = std::make_shared<std::vector<int>>(initList);
对于std::unique_ptr来说,其make函数就只在这两种场景(定制删除器和大括号初始化器)有问题。对于std::shared_pr来说,其make函数的问题会更多一些。这两种都是边缘情况,但是一些开发者就喜欢处理边缘情况,你也许也是其中之一。
一些类会定义自己的opeator new和operator delete。这表示全局的内存分配和释放函数对该对象不合适。通常情况下,类特定的这两个函数被设计成精确的分配或释放类大小的内存块,比如,类Widget的operator new和operator delete仅仅处理sizeof(Widget)大小的内存块。这两个函数作为定制的分配器(通过std::allocate_shared)和解析器(通过定制解析器),对std::shared_ptr的支持并不是很好的选择。因为std::allocate_shared需要的内存数量并不是动态分配的对象的大小,而是对象的大小加上控制块的大小。因此,对于某些对象,其类有特定的operate new和operator delete,使用make函数去创建并不是很好的选择。
std::make_shared在尺寸和速度上的优点同直接使用new相比,阻止了std::shared_ptr的控制块作为管理对象在同样的内存块上分配。当对象的引用计数变为0,对象被销毁(析构函数被调)。然而,直到控制块同样也被销毁,它所拥有的内存才被释放,因为两者都在同一块动态分配的内存上。
我前面提到过,控制块除了引用计数本身还包含了其他一些信息。引用计数记录了有多少std::shared_ptr指针指向控制块。另外控制块中还包含了第二个引用计数,记录了有多少个std::weak_ptr指针指向控制块。这第二个引用计数被称作weak count。当一个std::weak_ptr检查是否过期时(见条款19),它会检查控制块里的引用计数(并不是weak count)。假如引用计数为0(假如被指对象没有std::shared_ptr指向了从而已经被销毁),则过期,否则就没过期。
只要有std::weak_ptr指向一个控制块(weak count大于0),那控制块就一定存在。只要控制块存在,包含它的内存必定存在。这样通过std::shared_ptr的make函数分配的函数则在最后一个std::shared_ptr和最后一个std::weak_ptr被销毁前不能被释放。
假如对象类型很大,以至于最后一个std::shared_ptr和最后一个std::weak_ptr的销毁之间的时间不能忽略时,对象的销毁和内存的释放间会有个延迟发生。
class ReallyBigType { … };
auto pBigObj = // create very large
std::make_shared<ReallyBigType>(); // object via
// std::make_shared
… // create std::shared_ptrs and std::weak_ptrs to
// large object, use them to work with it
… // final std::shared_ptr to object destroyed here,
// but std::weak_ptrs to it remain
… // during this period, memory formerly occupied
// by large object remains allocated
… // final std::weak_ptr to object destroyed here;
// memory for control block and object is released
当直接使用new时,ReallyBigType对象的内存可以在最后一个std::shared_ptr销毁时被释放:
class ReallyBigType { … }; // as before
std::shared_ptr<ReallyBigType> pBigObj(new ReallyBigType);
// create very large
// object via new
… // as before, create std::shared_ptrs and
// std::weak_ptrs to object, use them with it
… // final std::shared_ptr to object destroyed here,
// but std::weak_ptrs to it remain;
// memory for object is deallocated
… // during this period, only memory for the
// control block remains allocated
… // final std::weak_ptr to object destroyed here;
// memory for control block is released
你有没有发现,你处在一个不可能或者不适合用std::make_shared的情况下,你会确保避免之前我们见到的这类异常安全问题。最好的办法是确保你直接用new的时候,立即把new的结果传递给一个灵巧指针的构造函数,别的什么先不做。这样会阻止编译器生成代码,避免在new和灵巧指针的构造函数(会接管new出来的对象)直接产生异常。
举个例子,考虑一个对processWidget函数(我们之前测试过)的非异常安全的调用,这次我们定义一个定制删除器:
void processWidget(std::shared_ptr<Widget> spw, // as before
int priority);
void cusDel(Widget *ptr); // custom
// deleter
这里有个非异常安全的调用:
processWidget( // as before,
std::shared_ptr<Widget>(new Widget, cusDel), // potential
computePriority() // resource
); // leak!
回忆下:假如computePriority函数在new Widget之后,但是在std::shared_ptr的构造函数之前被调用,如果computePriority抛了异常,那么动态分配的Widget会被泄露。
这里因为使用了定制删除器,所以不能使用std::make_shared,这里避免问题的方法是把Widget分配内存和构造std::shared_ptr放置到自己的语句中,然后再用std::shared_ptr去调用processWidget。这是这个技巧的本质,当然我们后面会看到我们可以提升其性能:
std::shared_ptr<Widget> spw(new Widget, cusDel);
processWidget(spw, computePriority()); // correct, but not
// optimal; see below
因为std::shared_ptr拥有从构造函数传递给它的原始指针,即使在构造函数产生异常时,所以上述代码运行正常。在这个例子中,如果spw的构造函数抛异常(比如因为不能够为控制块分配到动态内存),它仍然会保证调用cusDel去析构new Widget返回的结果。
不同之处在于,我们在非异常安全的代码里给processWidget传递了一个右值。
processWidget(
std::shared_ptr<Widget>(new Widget, cusDel), // arg is rvalue
computePriority()
);
而在异常安全的调用中,我们传递了一个左值
processWidget(spw, computePriority()); // arg is lvalue
因为processWidget的std::shared_ptr参数是通过传值的,从一个右值去构造仅仅需要一个move,而从左值去构造需要一个拷贝。对std::shared_ptr来说,这个区别很重要,因为拷贝一个std::shared_ptr需要对其引用计数进行加1的原子操作,而移动一个std::shared_ptr根本不需要对引用计数进行操作。对于这段异常安全的代码如果要达到非异常安全的代码的性能,我们在spw上应用std::move,而把它转化成一个右值(见条款23):
processWidget(std::move(spw), // both efficient and
computePriority()); // exception safe
这个很有趣,也应该知道。但是同时也无关紧要。因为你应该很少有理由不直接使用make函数。除非你有特别的理由不去用它,否则你应该使用make函数来完成你要做的。
需要记住的事情:
1.同直接使用new相比,make函数减小了代码重复,提高了异常安全,并且对于std::make_shared和std::allcoated_shared,生成的代码会更小更快。
2.不能使用make函数的情况包括我们需要定制删除器和期望直接传递大括号初始化器。
3.对于std::shared_ptr,额外的不建议使用make函数的情况包括:
(1)定制内存管理的类,
(2)关注内存的系统,非常大的对象,以及生存期比 std::shared_ptr长的std::weak_ptr。