Stacking算法预测银行客户流失率
描述
为了防止银行的客户流失,通过数据分析,识别并可视化哪些因素导致了客户流失,并通过建立一个预测模型,识别客户是否会流失,流失的概率有多大。以便银行的客户服务部门更加有针对性的去挽留这些流失的客户。
本任务的实践内容包括:
1、学习并熟悉Stacking/Blending算法原理。
2、使用Stacking算法预测银行客户流失率。
源码下载
环境
-
操作系统:Windows 10、Ubuntu18.04
-
工具软件:Anaconda3 2019、Python3.7
-
硬件环境:无特殊要求
-
依赖库列表
scikit-learn 1.0.2 numpy 1.19.3 pandas 1.3.5
分析
本任务涉及以下环节:
A)熟悉Stacking/Blending算法原理
B)加载并观察银行客户
C)使用决策树分类器和KNN分类器模型,分别生成预测结果
D)把上面的预测结果连接成一个新的特征集,标签则保持不变,用回原始的标签集
E)最后使用逻辑回归算法对新的特征集进行分类预测
实施
1、Stacking/Blending算法原理
1.1 Stacking算法
Stacking算法的思路是使用初始训练集学习若干个基模型之后,用这几个基模型的预测结果作为新的训练集的特征来训练新模型。Stacking算法的流程如下图所示:
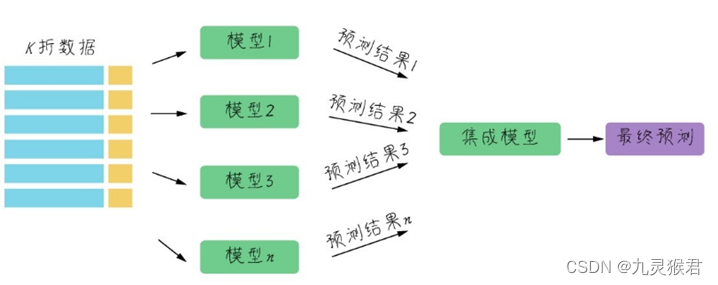
这些基模型在异质类型中进行选择,比如决策树、KNN、SVM或神经网络等,都可以组合在一起。
Stacking具体步骤如图:

Stacking具体步骤如下:
(1)通常把训练集拆成K折(请大家回忆第1课中介绍过的K折验证)
(2)利用K折验证的方法在K-1折上训练模型,在第K折上进行验证
(3)这样训练K次之后,用训练好的模型对训练集整体进行最终训练,得到一个基模型
(4)使用基模型预测训练集,得到对训练集的预测结果
(5)使用基模型预测测试集,得到对测试集的预测结果
(6)重复步骤(2)~(5),生成全部基模型和预测结果(比如CART、KNN、SVM以及神经网络,4组预测结果)
(7)只需要用训练集预测结果作为新训练集的特征,测试集预测结果作为新测试集的特征去训练新模型。新模型的类型不必与基模型有关联
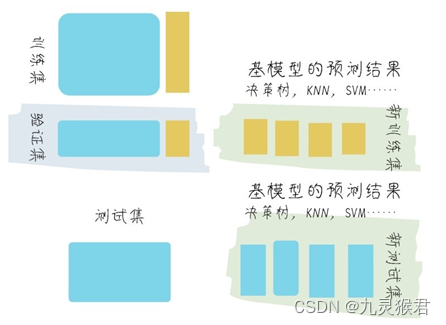
1.2 Blending算法
Blending的思路和Stacking几乎是完全一样的,唯一的不同之处在于Blending的过程中不进行k折验证,而是只将原始样本训练集分为训练集和验证集,然后只针对验证集进行预测,生成的新训练集就只是对于验证集的预测结果,而不是对全部训练集生成的预测结果。Blending集成的流程如图所示:
2、加载分析银行客户数据集
import numpy as np # 基础线性代数扩展包
import pandas as pd # 数据处理工具箱
df_bank = pd.read_csv("../dataset/BankCustomer.csv") # 读取文件
df_bank.head() # 显示文件前5行
结果如下:
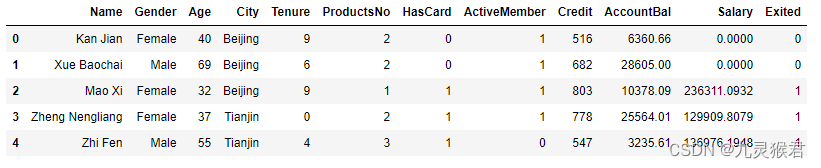
数据集特征说明:
-
name:客户姓名
-
Gender:客户性别
-
Age:客户年龄
-
City:城市
-
Tenure:用户时长
-
ProductsNo:使用产品数量
-
HasCard:是否拥有信用卡
-
ActiveMember:是否为活跃会员
-
Credit:信用评分
-
AccountBal:账户余额
-
Salary:薪资
-
Exited(标签):是否流失,1代表流失,0代表没有流失
3、数据处理
将二元数据文本化,创建数据集。
# 把二元类别文本数字化
df_bank['Gender'].replace("Female",0,inplace = True)
df_bank['Gender'].replace("Male",1,inplace=True)
# 显示数字类别
print("Gender unique values",df_bank['Gender'].unique())
# 把多元类别转换成多个二元哑变量,然后贴回原始数据集
d_city = pd.get_dummies(df_bank['City'], prefix = "City")
df_bank = [df_bank, d_city]
df_bank = pd.concat(df_bank, axis = 1)
# 构建特征和标签集合
y = df_bank['Exited']
X = df_bank.drop(['Name', 'Exited', 'City'], axis=1)
X.head() #显示新的特征集
结果如下:

4、拆分数据集
使用sklearn.model_selection.train_test_split()方法将数据集划分为训练集和测试集。
from sklearn.model_selection import train_test_split # 拆分数据集
X_train, X_test, y_train, y_test = train_test_split(X, y,
test_size=0.2, random_state=0)
5、Stacking算法实现
定义函数,实现Stacking算法流程。
from sklearn.model_selection import StratifiedKFold
'''
train:训练集特征
y:训练集标签
test:测试集
'''
def Stacking(model, train, y, test, n_fold):
folds = StratifiedKFold(n_splits=n_fold, random_state=None)
test_pred = np.empty((0, 1), float)
train_pred = np.empty((0, 1), float)
for train_indices, val_indices in folds.split(train, y.values): # 将测试集特征和标签划分为n个子集
X_train, x_val = train.iloc[train_indices], train.iloc[val_indices] # X_train:训练集特征, x_val:验证集特征
y_train, y_val = y.iloc[train_indices], y.iloc[val_indices] # y_train:训练集标签, y_val:验证集标签
model.fit(X=X_train, y=y_train)
train_pred = np.append(train_pred, model.predict(x_val)) # 验证集预测
test_pred = np.append(test_pred, model.predict(test)) # 传入的测试集预测
return test_pred, train_pred
6、训练基模型
创建决策树分类器模型和KNN分类器模型,用刚才定义的Stacking函数训练两个模型:
from sklearn.tree import DecisionTreeClassifier
from sklearn.neighbors import KNeighborsClassifier
model1 = DecisionTreeClassifier(random_state=1)
test_pred1, train_pred1 = Stacking(model=model1, n_fold=10,
train=X_train, test=X_test, y=y_train)
train_pred1 = pd.DataFrame(train_pred1)
test_pred1 = pd.DataFrame(test_pred1)
model2 = KNeighborsClassifier()
test_pred2, train_pred2 = Stacking(model=model2, n_fold=10,
train=X_train, test=X_test, y=y_train)
train_pred2 = pd.DataFrame(train_pred2)
test_pred2 = pd.DataFrame(test_pred2)
7、分类预测
把上面的预测结果连接成一个新的特征集,标签则保持不变,用回原始的标签集。最后使用逻辑回归算法对新的特征集进行分类预测:
from sklearn.linear_model import LogisticRegression
df = pd.concat([train_pred1, train_pred2], axis=1) # (8000,2)
df_test = pd.concat([test_pred1, test_pred2], axis=1) # (20000,2)
a = y_test
for i in range(9):
y_test = pd.concat([y_test, a], axis=0)
model = LogisticRegression(random_state=1)
model.fit(df, y_train)
print(model.score(df_test, y_test))
结果如下:
0.7915