文章目录
- 文件操作介绍
- 文件的打开操作open()
- 文件的关闭操作
- os模块
- 关于操作系统
- 关于路径
- json模块
- 将python对象编码成json字符串
- 序列化和反序列化常用参数
- 将json字符串解码为python对象
- 存储为excel文件
文件操作介绍
文件的作用:数据的持久化存储
一个程序在运行过程中用了九牛二虎之力终于计算出了结果,试想一下如果不把这些数据存放起来,那么重启电脑之后,这些数据就都丢失了。这是因为默认数据是加载到内存中,结果也是保存到内存中,程序执行结束,所有的数据都将释放。
新建文件:
文件的打开操作open()
编写python文件(文件操作.py)
#打开文件,相对路径
f = open('doc/test.txt') #文件打开之后,将其存储为一个文件对象
#文件的读写操作
print(f.read())
#关闭文件
f.close()

open()默认 mode=r,只有读权限
open()函数设置 mode=w,具有写权限,但是会先将文件原内容清空,然后再写进去
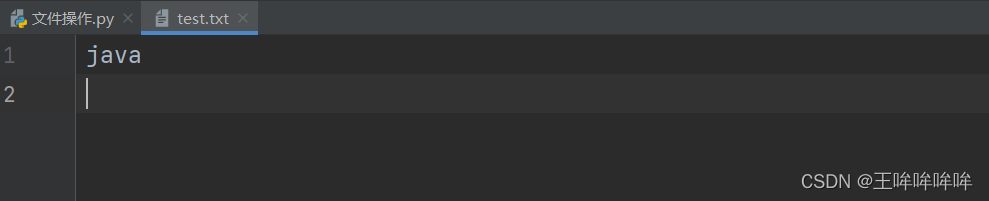
#打开文件,相对路径
f = open('doc/test.txt',mode='w') #文件打开之后,将其存储为一个文件对象
#文件的读写操作
f.write('java\n')
#关闭文件
f.close()
但是如果不想清空文件原内容,可以使用open()函数的追加模式,mode='a'
#打开文件,相对路径
f = open('doc/test.txt',mode='a') #文件打开之后,将其存储为一个文件对象
#文件的读写操作
f.write('linux\nlinux')
#关闭文件
f.close()

open函数的模式,看下图:

文件的关闭操作
- 调用 close() 方法关闭文件。文件使用之后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的
- python中引入了with语句,能自动调用 close() 方法
python中的with语句适用于对资源进行访问的场合,保证不管处理过程中是否发生错误或异常都会自动执行规定的 “清理” 操作,释放被访问的资源,比如文件读写后自动关闭,线程中锁的自动获取或释放等。
#doc/hello.txt是不存在的文件,对其写入
with open('doc/hello.txt','w+') as f: #将打开的文件对象赋值给f
f.write('hello world\n')
print(f.read())

上述程序语句 print(f.read()) 不会输出,因为在doc/hello.txt文件写入内容之后,指针是指向内容末尾,没东西能读。如果要读取文件内容,需要将指针移向文件最开始的位置。
seek(offset ,from) :offset表示偏移量,from表示方向
0:表示文件开头
1:表示当前位置
2:表示文件末尾
把位置设置成文件最开始:seek(0,0)
把位置设置成文件最末尾:seek(0,2)
# doc/hello.txt是不存在的文件,对其写入
with open('doc/hello.txt', 'w+') as f: # 将打开的文件对象赋值给f
f.write('hello world\n')
f.seek(0, 0) #将指针移动到开头位置
print('当前指针位置:', f.tell()) #打印指针位置
print(f.read())
f.seek(0, 2) #将指针移动到末尾位置
print('当前指针位置:', f.tell()) #打印指针位置

os模块
是管理操作系统的一些方法
os,语义为操作系统,处理操作系统相关的功能,可跨平台。
关于操作系统
import os
import platform
print(os.name) # 1、获取操作系统类型,nt是指Windows操作系统
# 2、获取主机信息,
#Linux系统使用os模块,Windows使用platform模块
# 不能的平台需要使用不同的代码,如何实现代码的跨平台?
try: # 可能报错的代码
uname = os.uname()
except Exception: # 出现异常执行的代码
uname = platform.uname()
finally: # 不管是否有异常,都会执行的代码
print(uname)
# 3、获取系统的环境变量
envs = os.environ
print(envs)
# 4、通过key值,获取系统变量对应的value值
print(os.environ.get('PATH'))
print(os.getenv('PATH'))
关于路径
import os
# 判断是否为绝对路径
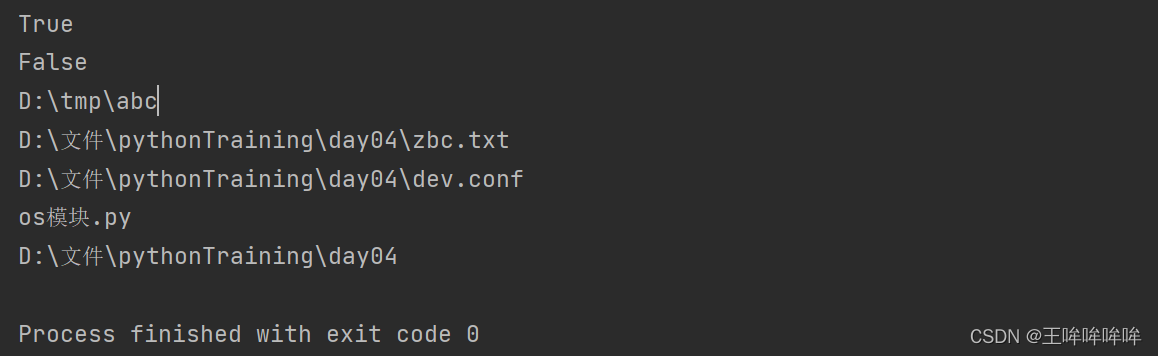
print(os.path.isabs('/tmp/abc')) #True
print(os.path.isabs('abc')) # false
# 生成绝对路径
print(os.path.abspath('/tmp/abc'))
print(os.path.abspath('zbc.txt'))
#文件名和目录名的拼接,join拼接
#os.path.dirname()获取某个文件对应的目录名
# _ _file_ _ 表示当前文件
base_dir=os.path.dirname(_ _file_ _) #获取当前目录名
#setting_file1=base_dir + '/' + 'abc.txt' #拼接方法一,不建议
#print(setting_file1)
setting_file2=os.path.join(base_dir,'dev.conf') #拼接方法二,建议
print(setting_file2)
#获取当前文件名、目录名
print(os.path.basename(_ _file_ _))
print(os.path.dirname(_ _file_ _))
另外,还有rename()可以完成对文件的重命名操作。os模块中的remove()可以完成对文件的删除操作
-
rename(需要修改的文件名,新的文件名)
-
remove(待删除的文件名)
-
os.mknod(‘abc.txt’) ,Linux下创建文件,Windows下创建文件可以按照如下方式
with open(‘doc/hello.txt’,‘w+’) as f:
pass -
os.exists(‘abc.txt’) 判断文件或目录是否存在
-
os.path.splitext(‘hello.txt’) 将文件名和后缀名分隔开
-
os.path.split(‘hello.txt’) 将文件名和后缀名分隔开
-
os.path.split(‘/tmp/hello/hello.txt’) 将文件名和目录名分隔开
json模块
json(javascript object notation) 是一种轻量级的数据交换格式。
可能一个项目是由多种语言编写的,比如 c 、python、Java等等,那么怎么把C语言得到的结果传递给python呢?然后python对得到的数据进一步操作呢?
json采用完全独立于语言的文本格式,是一种理想的数据交换语言。易于人们阅读和编写,同时也易于机器解析和生成。(一般用于提升网络传输效率)
python中的集合不能转换成json格式
具体实现:

dump() 表示存储到某一个文件中去,如果不需要存储到文件就使用 dumps()
将python对象编码成json字符串
- json.dumps()将python中字典类型的数据转成json字符串
- json.dump()将python中的字典数据类型转换为json字符串,并写入文件中
# 将python对象编码成json字符串
import json
users = {"name": "lee", "age": 18, "city": "上海"}
json_str = json.dumps(users) #不存储到文件中
print(json_str,type(json_str)) #字符串类型
#将python对象编码成json字符串,并保存到文件中
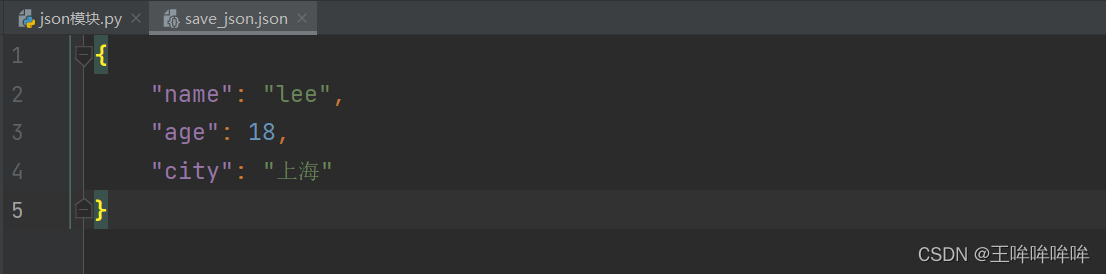
with open('doc/save_json.json','w') as f:
json.dump(users,f)
print("存储成功")


但是保存到文件中之后,中文看不懂,
序列化和反序列化常用参数
json.dumps()函数有一些常用参数:
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True,
allow_nan=True, cls=None, indent=None, separators=None,
encoding=“utf-8”, default=None, sort_keys=False, **kw)
- ensure_ascii=false , 则设定了中文存储
- indent=4 , 设定缩进为4个空格,增强可读性,但是缩进空格会使数据变大
- separators(‘,’,‘:’) , 自定义分隔符,元素间分隔符为逗号,字典key和value的分隔符为冒号
- sort_keys=True , 字典排序
# 将python对象编码成json字符串
import json
users = {"name": "lee", "age": 18, "city": "上海"}
json_str = json.dumps(users) #不存储到文件中
print(json_str,type(json_str))
#将python对象编码成json字符串,并保存到文件中
with open('doc/save_json.json','w') as f:
json.dump(users,f,ensure_ascii=False,indent=4)
print("存储成功")
将json字符串解码为python对象
- json.load()操作的是文件流,把json格式字符串转化为python中的字典,读取的是文件
- json.loads()操作的是字符串,把json格式字符串转换为python中的字典
json文件:
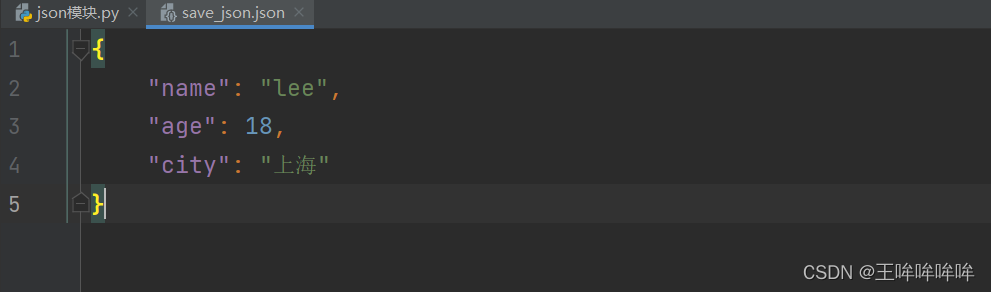
import json
with open('doc/save_json.json') as f: #只读方式打开json文件
py_obj=json.load(f)
print(py_obj,type(py_obj))
运行结果:

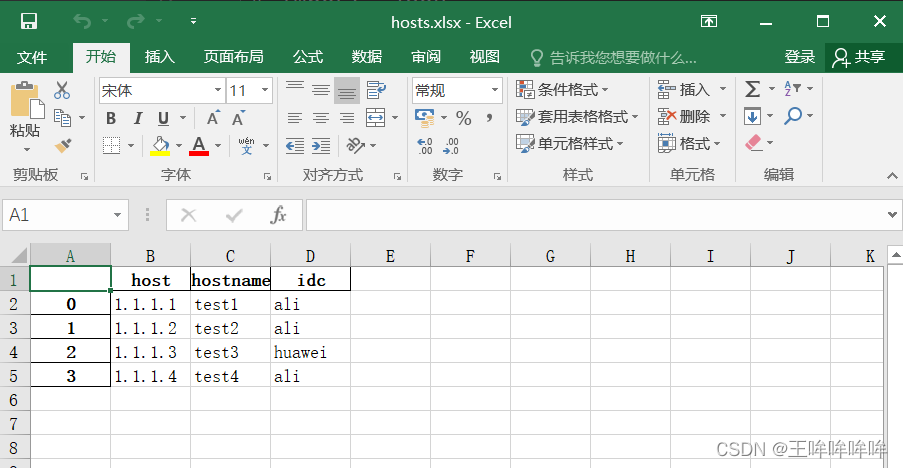
存储为excel文件
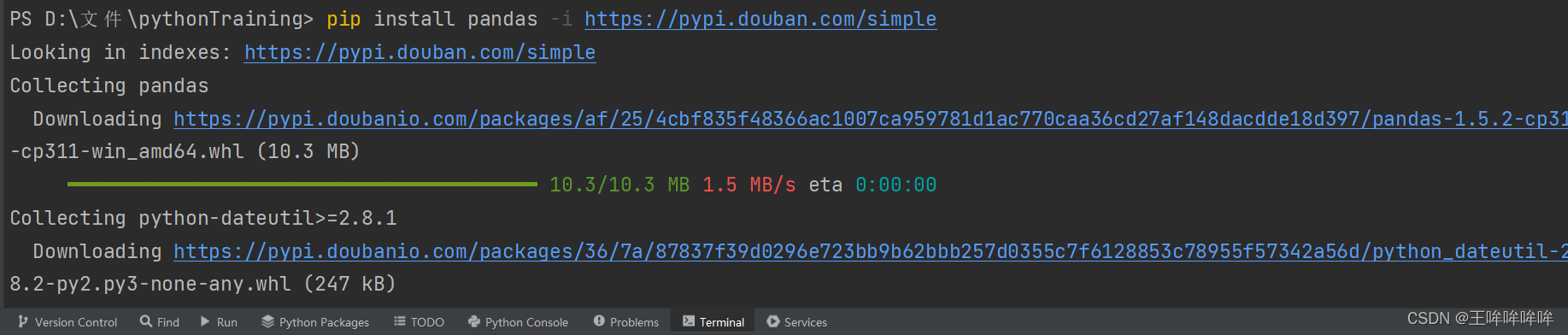
import pandas 出现错误,未安装pandas,
打开terminal,pip install pandas -i https://pypi.douban.com/simple
安装对excel操作的模块: pip install openpyxl -i https://pypi.douban.com/simple
 安装openpyxl成功之后还是会显示“no module named openpyxl”,是因为还没有把这个库加入到Pycharm中,按照文章 https://blog.csdn.net/Mr_kanger/article/details/111879098,程序运行成功
安装openpyxl成功之后还是会显示“no module named openpyxl”,是因为还没有把这个库加入到Pycharm中,按照文章 https://blog.csdn.net/Mr_kanger/article/details/111879098,程序运行成功
import pandas
hosts=[
{'host':'1.1.1.1','hostname':'test1','idc':'ali'},
{'host':'1.1.1.2','hostname':'test2','idc':'ali'},
{'host':'1.1.1.3','hostname':'test3','idc':'huawei'},
{'host':'1.1.1.4','hostname':'test4','idc':'ali'}
]
#转换数据类型
df = pandas.DataFrame(hosts) #将hosts转换成二维DataFrame对象
#存储成excel
df.to_excel('doc/hosts.xlsx')
print('success')