前言
本文分为两部分。
第一部分是基础章节。可以帮助我们了解线程池的概念,用法,以及他们之间的的关系和实际应用。
第二部分是实现机制篇。通过源码解析,更深刻理解线程池的工作原理,以及各个概念的准确含义。
原本是一篇文章,因为篇幅太长,所以拆成的两篇,所以建议都看。
一、概念
创建线程,启动/销毁线程,是一件很消耗性能的事情:
创建线程:和创建普通对象相比,还增加了分配栈空间。
启动/销毁线程:涉及到线程的调度导致线程上下文切换。
所以:看似简单的创建并使用一个线程,其实很消耗资源。
如果只执行一个任务就创建一个线程。
这就相当于:某一天,你为了出趟远门而去买了辆车。
多浪费呀,租车不香吗。
租车公司就相当于一个线程池,负责车辆(线程)的创建启动和销毁,还有公司的日常运维。
继续思考:
上面的场景是临时用车的场景。
假如不是临时用车,而是打算开10年甚至更长时间,你还会租车吗。此时肯定是去买车了对吧。
所以:
- 引入线程池不仅仅是写起来方便的问题,更本质的原因是对系统资源的合理利用。
- 使用线程池的场景是短时间的任务,如果是非常耗时的任务,不宜使用线程池(比如你要写一个类似web容器的http接口,那么这个线程就需要一直处于运行监听的状态,此时最好的办法就是自己单独new一个Thread)
有些文章说,使用线程池还有一个考量因素:任务量比较大。我是不太认同的。
任务量大不大,那是一个整体视角。租车公司管你租几辆车。一辆也是租,十辆车也是租。只要这个地区的整体租车需求足够大就行。
站在用户角度,只需要考虑自己的单个任务时长问题。时长太短,自己单独创建线程不值得,就可以考虑使用线程池。
平时我们说:CPU四核心八线程。指的就是最多同时处理八个线程(实际上并不一定,多出来的四条线程处理能力,其实是CPU虚拟出来的。但同时能处理四个线程是肯定的)。
二、Demo
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
public class TestThreadPool {
public static void main(String[] args) {
TestThreadPool t = new TestThreadPool();
t.m1();
}
public void m1() {
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 3; i++) {
executorService.execute(() -> {
System.out.println(Thread.currentThread().getName() + "----------start----");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println(Thread.currentThread().getName() + "----------end----");
});
}
executorService.shutdown();
System.out.println("-----over");
}
输出
pool-1-thread-1----------start----
pool-1-thread-3----------start----
pool-1-thread-2----------start----
-----over
pool-1-thread-1----------end----
pool-1-thread-2----------end----
pool-1-thread-3----------end----
在这个demo里
- 我们先创建了一个线程池executorService。
- 依次往线程池中添加了三个任务(也就是三个Runable,这里用的是lambda写法)
三个线程由线程池executorService管理并运行。
注意:shutdown()的意思是不再接收新的线程,但会把未执行完的线程跑完。
三、相关概念关系
在学线程池过程中,也许我们会接触很多类,时间长就晕了。
我来一句话概况线程池的所有相关概念:线程池吃进任务,吐出返回值。
如下图所示
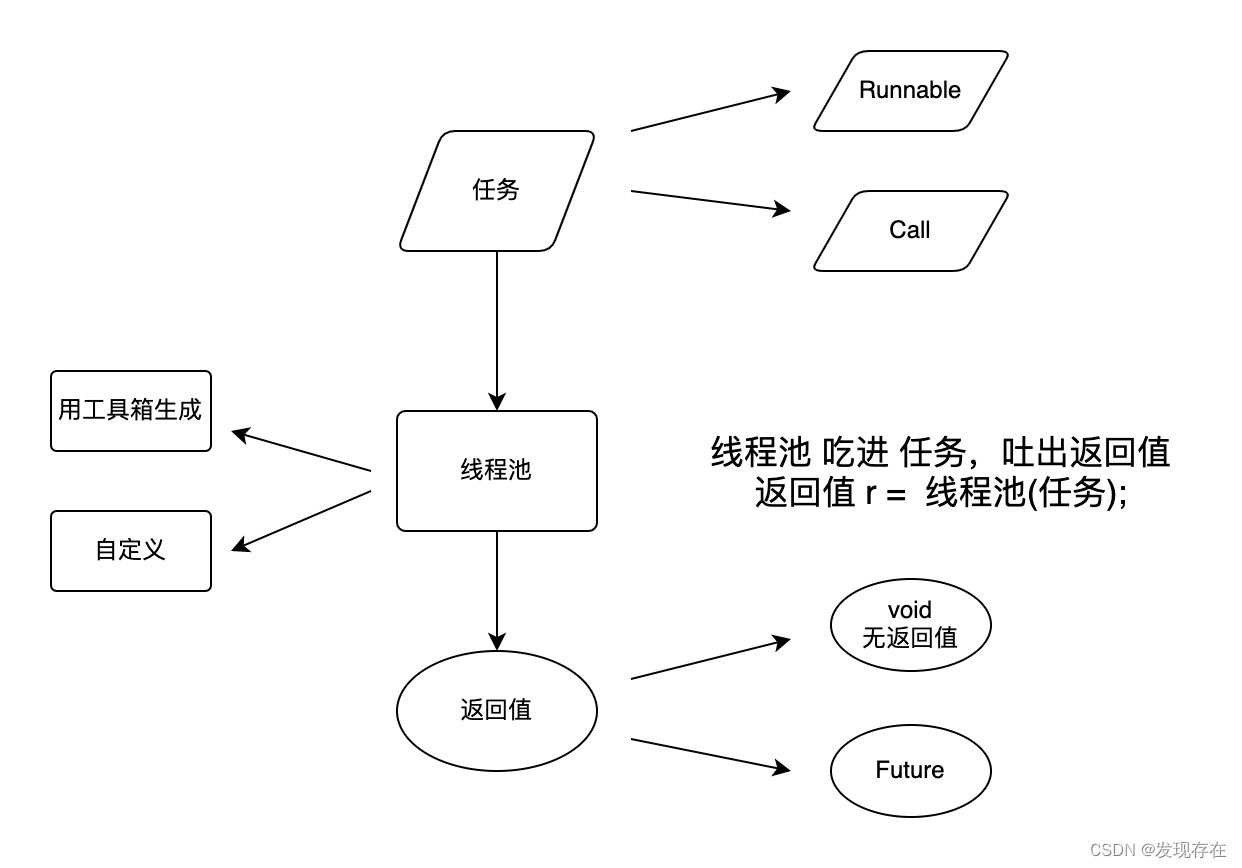
从图中就可以发现,线程池相关的就是三个概念:任务(入参),线程池(核心),返回值。
问:为什么前面第一个demo中,把任务塞给线程池后,好像也没有返回值。
答:是的。所以上图中的返回值有两种。其中一种就是void,也就是:无返回值。第一个demo中就是这种情况。
四、线程池
概述
先看一个线程池相关类图
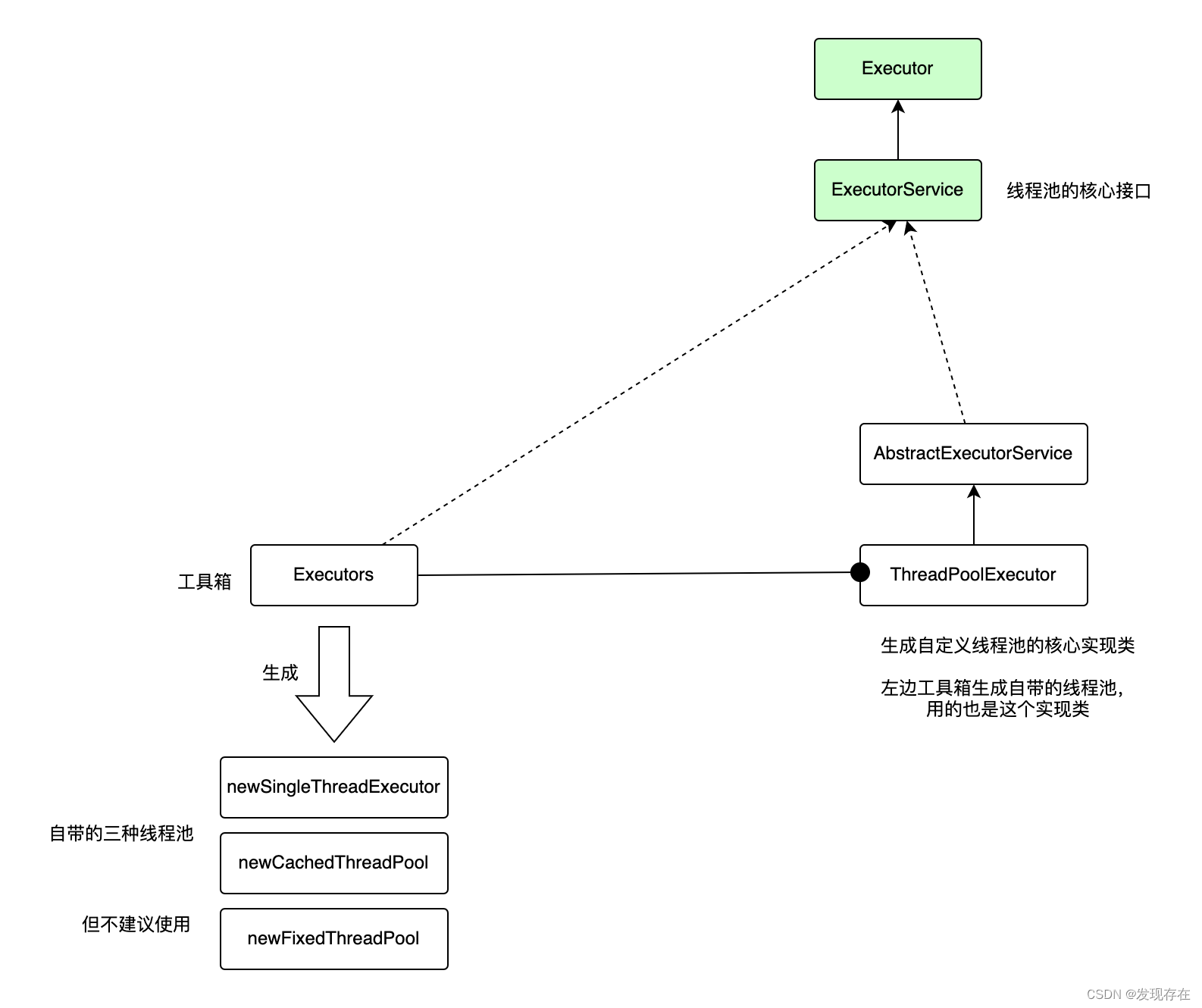
这个图解释了两个问题:
-
什么是线程池
- 线程池就是图中的上面的两个绿色方块,这是两个接口。所以可以简单认为Executor或ExecutorService就是线程池(的接口)。
- 但这两个都是接口。要实现功能,还需要接口的具体实现类。其中最典型最常用的实现类就是右下角的ThreadPoolExecutor(它上面继承的是个抽象类,没法直接用)。
-
线程池怎么生成
- 前面说了线程池的一个实现类就是ThreadPoolExecutor,所以第一种最朴素的方式就是new ThreadPoolExecutor。我们称之为自定义线程池。
- 左下角画的就是第二种方式:通过一个叫Executors的工具类,直接生成。所谓直接生成的意思,还是利用了new ThreadPoolExecutor。只不过这个工具类给用户提供了一个静态方法,直接调用。不用用户自己new了。可以生成三种不同类型的线程池。
小结
- 真正的线程池类图,其实只是上图的右半部分。因为左边只是一个工具类,以及工具类生成的东西。
- 右半部分。上面是接口,下面是实现类。我们一般直接使用的是实现类ThreadPoolExecutor。(这个实现类也只是其中一个最常用的)
三种内置线程池及问题
下面先从简单的内置线程池说起(上图中的左下角部分)。
newCachedThreadPool
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
- 名称: 可缓存线程池。
- 使用方式:
ExecutorService executorService = Executors.newCachedThreadPool() - 特点: 一直添加,一直new新线程。
- 问题:使用newCachedThreadPool生成的线程池,不会让任务等待。最忙的时候相当于添加一个任务,就new一个Thread。然后耗尽资源,导致OOM。
- 适用场景:任务量小,小任务(能快速运行完)
newFixedThreadPool
public static ExecutorService newFixedThreadPool(int nThreads) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>());
}
- 名称: 定长线程池。
- 使用方式:
ExecutorService executorService = Executors.newFixedThreadPool(5) - 特点: 核心线程和最大线程一样,而且是固定的。
- 问题:虽然这个线程池有最大线程数,但是它的等待队列是不设置长度的。理论上可以一直往等待队列里塞任务,队列过长,最终导致OOM。
- 适用场景:已知线程大致数量的任务。
newSingleThreadExecutor
public static ExecutorService newSingleThreadExecutor() {
return new FinalizableDelegatedExecutorService
(new ThreadPoolExecutor(1, 1,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>()));
}
- 名称: 单线程线程池。
- 使用方式:
ExecutorService executorService = Executors.newSingleThreadExecutor() - 特点: 线程池只有一个线程。
- 问题:和定长线程池问题的一样。理论上可以一直往等待队列里塞任务,最终导致OOM。
- 适用场景:希望任务一个一个的顺序执行。
小结
实际生产中,严格来说,这三种线程池都不建议使用。
当然,如果项目中基本没有其他线程。要使用线程池的任务量也不大。也可以使用。
自定义线程池
ThreadPoolExecutor入门
这是线程池的很重要的一个实现类。在定义线程池时,需要我们自己new。通过学习这个类的使用,我们可以大体了解线程池的概念。
在此之前,我们先看看Executors工具类是怎么创建的,先学习一下。后面我们再根据我们自己的业务需求自定义。
就以第一个demo中的线程池为例:ExecutorService executorService = Executors.newCachedThreadPool()
看一下Executors.newCachedThreadPool这个静态方法
public static ExecutorService newCachedThreadPool() {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>());
}
首先第一点,就像我们前面说的。Executors是一个工具类,它创建线程池,也是通过new的ThreadPoolExecutor类。
第二点,这个ThreadPoolExecutor入参有点多,看起来有点复杂。我们依次看一下各个参数的概念。
主要参数解析
- 核心线程数(corePoolSize)
即便线程池没有任何任务可执行了,线程池里也会保留的线程数量,叫做核心线程数。这里是0,表示没有任务,就不保留线程。 - 最大线程数(maximumPoolSize)
为了应对偶尔的高并发,线程池允许线程池数量向上浮动,但会规定一个上限。这里Integer.MAX_VALUE表示$ 2^{31} -1$,几乎等于没有上限。 - 最长存活时间(keepAliveTime)
如果超出核心线程数的线程运行结束,需要等多久才把这个线程关闭掉。这里是60。 - 存活时间的时间单位(unit) 时间单位
这里是TimeUnit.SECONDS。加上前面的数量,就表示等待60秒。 - 任务队列(workQueue)
当当前活跃的任务数超过核心线程数。再添加任务时,就需要往任务队列里添加了。这里用的是一个叫SynchronousQueue的队列。
ThreadPoolExecutor构造方法
下面是ThreadPoolExecutor完整的的构造方法
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.acc = System.getSecurityManager() == null ?
null :
AccessController.getContext();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
}
比我们前面看到的参数还要多两个:
- 线程工厂(threadFactory)
前面我们只是很简单的手动一个一个的添加Runnable。这里就是为了应对更复杂的情况,直接从一个线程工厂里获取线程任务。 - 拒绝策略(RejectedExecutionHandler)
当当前任务数量超过线程池的承载能力,就会把新添加进来的任务简单处理掉。处理方式就是这个拒绝策略。
阻塞队列(BlockingQueue)
只要是实现了BlockingQueue接口的实现类基本都可以,不需要我们自己实现,用JDK已有一些实现类就行,如下图所示
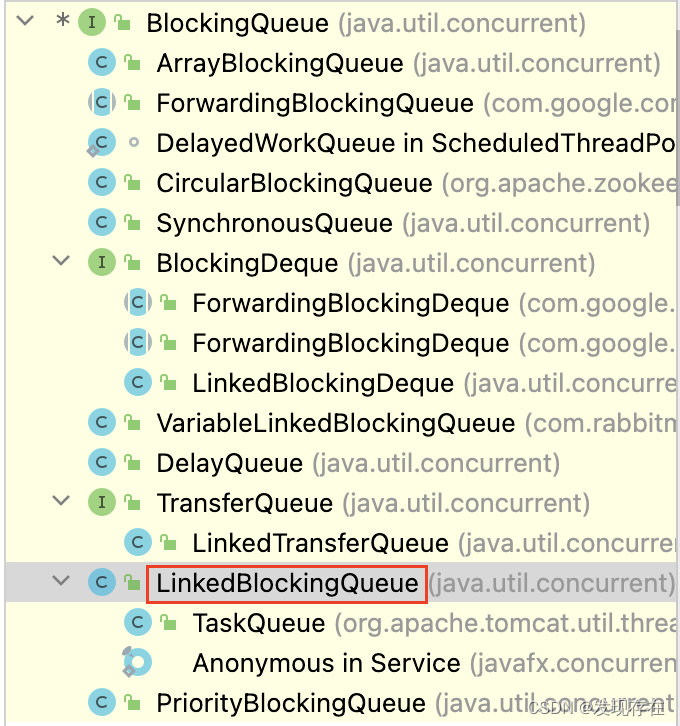
实现类很多,但一般像newFixedThreadPool那样,用LinkedBlockingQueue就可以,关键在于把队列定多大。
像newFixedThreadPool那样不设置new LinkedBlockingQueue<Runnable>()不设置,就是无限大的队列
而我们建议new LinkedBlockingQueue<Runnable>(100),这样给阻塞队列设置一个大小。
线程工厂(ThreadFactory)
ThreadFactory是一个需要我们实现的接口,接口内容很简单,只有一个方法
public interface ThreadFactory {
Thread newThread(Runnable r);
}
还是参考一下newFixedThreadPool。它用的是Executors.defaultThreadFactory()这样一个默认线程工厂,它的内部实现如下图所示
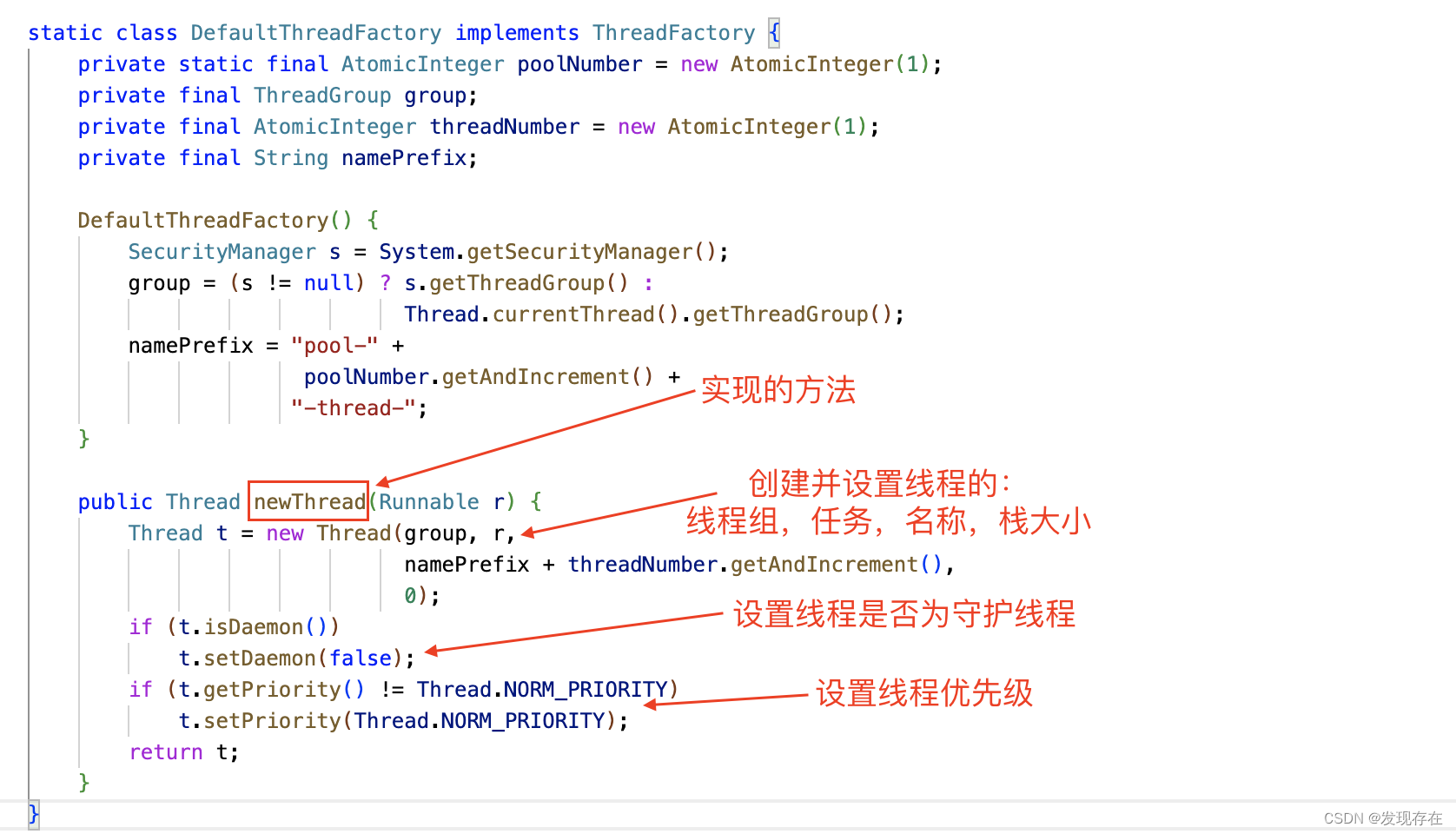
我们自己创建,并不需要像上面这样设置如此繁琐。主要就是线程名称控制好就可以了(线程出了问题,马上知道是哪里的问题)。
拒绝策略(RejectStrategy)
什么叫拒绝策略:是入线程池前的筛选条件?是线程池不够用的时候的处理方案?还是报错的时候的处理方案?
答:是第二种理解方式:如果线程池已经满了,队列也满了。我们要怎么处理。所以本质上这是一种为保护线程池的服务降级策略(为保证核心线程正常执行,把一部分任务简单处理掉)。
和前面一样,同样看一下需要实现的接口:
public interface RejectedExecutionHandler {
void rejectedExecution(Runnable r, ThreadPoolExecutor executor);
}
看起来也很简单,只需要实现一个方法。需要传两个参数:一个任务,一个线程池。
还是看一下newFixedThreadPool默认使用的拒绝策略,结果发现Executors根本没管这个参数。默认拒绝策略是线程池ThreadPoolExecutor内实现的。
public static class AbortPolicy implements RejectedExecutionHandler {
public AbortPolicy() { }
public void rejectedExecution(Runnable r, ThreadPoolExecutor e) {
throw new RejectedExecutionException("Task " + r.toString() +
" rejected from " +
e.toString());
}
}
这个拒绝策略正如它的名字Abort(终止),简单粗暴,啥也没干,直接报错。
除了这个拒绝策略,ThreadPoolExecutor还为我们实现另外三种。实现类都写在ThreadPoolExecutor内部,作为内部类。
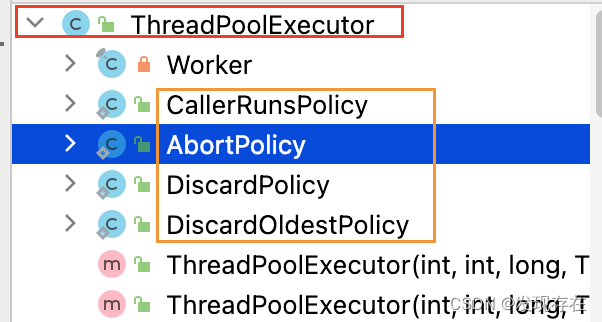
特点如下:
- 终止策略(AbortPolicy):直接报错RejectedExecutionException
- 丢弃策略(DiscardPolicy):啥也不干(空方法),相当于被默默丢弃了(也不入队列,也不报错)
- 丢弃老任务策略(DiscardOldestPolicy):把线程里的头结点移除掉(.pull())
- 独立运行策略(CallerRunsPolicy):线程池满了,就原地直接运行(在主线程里直接运行)。
当然,一旦我们需要考虑拒绝策略,那么以上这些可能都无法满足实际生产需要(过于简单粗暴)。
我们需要自己实现拒绝策略接口,比如记录日志或Redis缓存,等过了高峰期再执行等。
概念之间的逻辑关系
相信通过上面的介绍,你已经对线程池有了自己的一个理解。下面我们来总结一下核心线程数,最大线程数,任务队列之间的关系。
关系图:
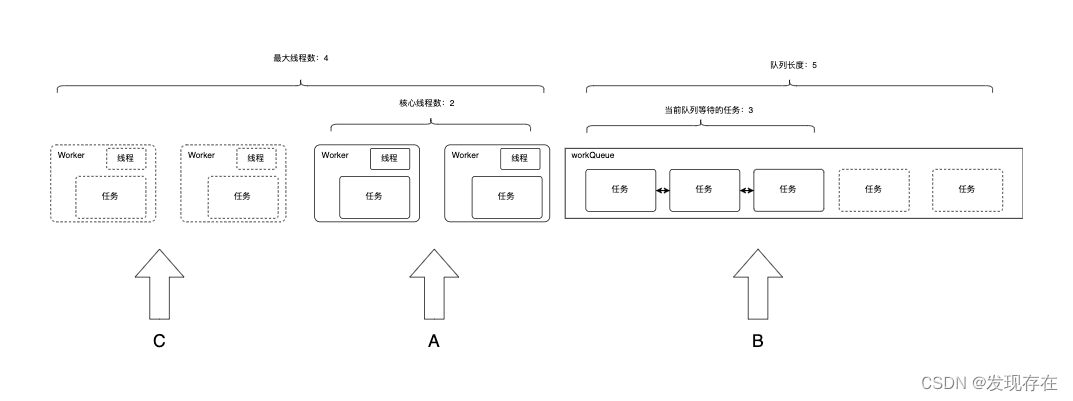
如果用taskCount表示当前线程池内所有任务量(正在执行的+队列等待的)。 queueSize表示队列最大长度。
- 其中A,B是正常运行中最常见的两种任务状态。
- A:taskCount <= corePoolSize
- B:corePoolSize < taskCount <= corePoolSize + queueSize
- C:corePoolSize + queueSize < taskCount <= maximumPoolSize + queueSize
源码中并没有taskCount这样一个统计数据。但我发现,如果不加这个概念去讲,很容易越讲让人越糊涂。原本是正确理解,讲完反而把人带沟里了(本质是因为线程池的设计思想其实很容易想明白,但源码写的有点反直觉)
流程图
下面我们看看,当我们执行executorService.execute的流程图,下图展示的就是在正常执行状态下的流程(没有执行shutDown等操作)
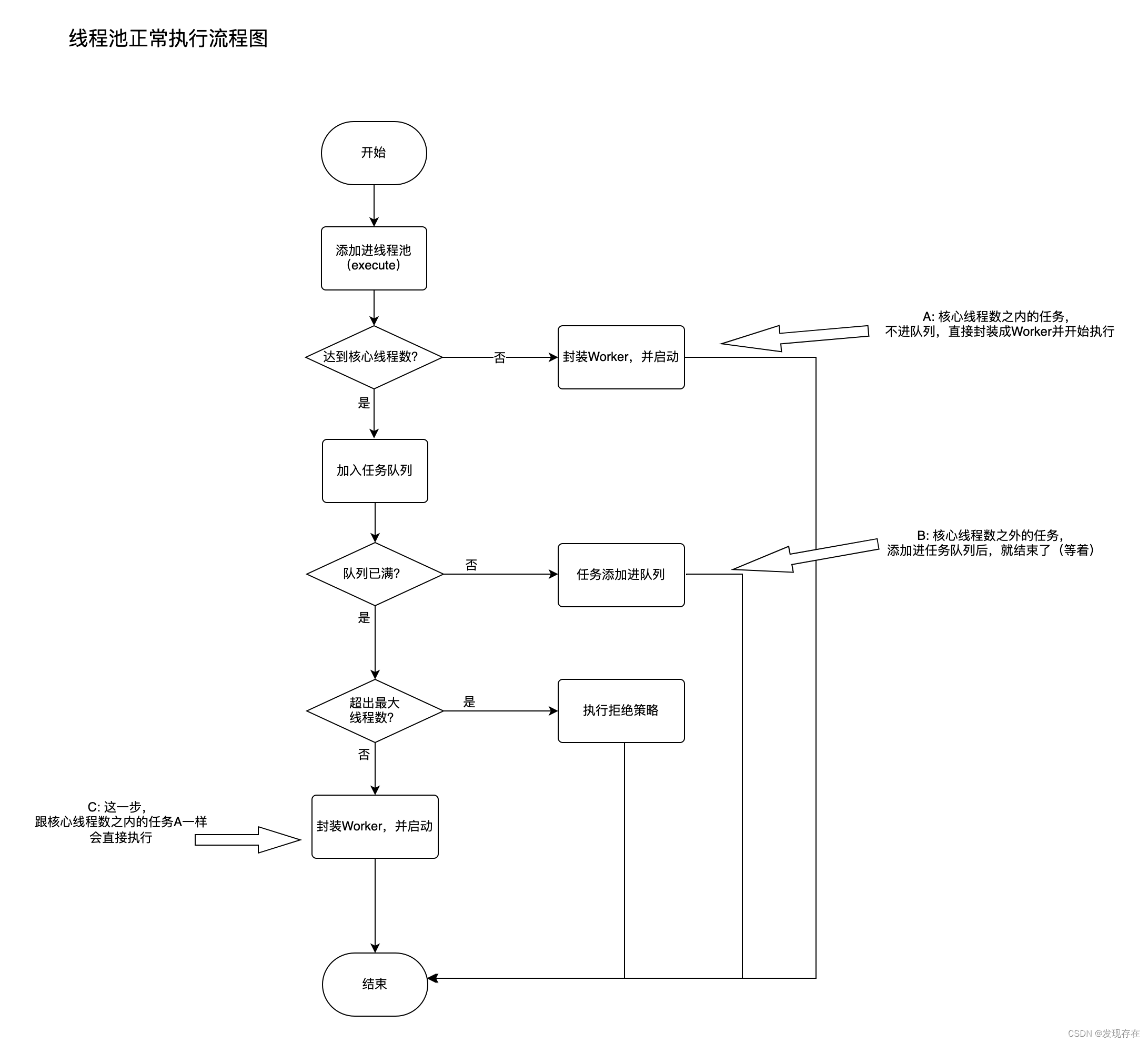
步骤如下:
- 判断是否达到最大核心线程数。
- 如果还没,那就把Runnable任务封装成Worker,分配线程,然后启动(A)
- 如果已经达到,就尝试让任务入队列,并判断队列是否已满
- 如果队列没满,就把任务添加进队列,然后就在队列中等待(B)
- 如果队列也满了,就判断是否超出最大线程数
- 如果超了,就执行拒绝策略(D)
- 如果没超,和核心线程一样封装Worker,分配线程,然后启动(C)
一个比喻
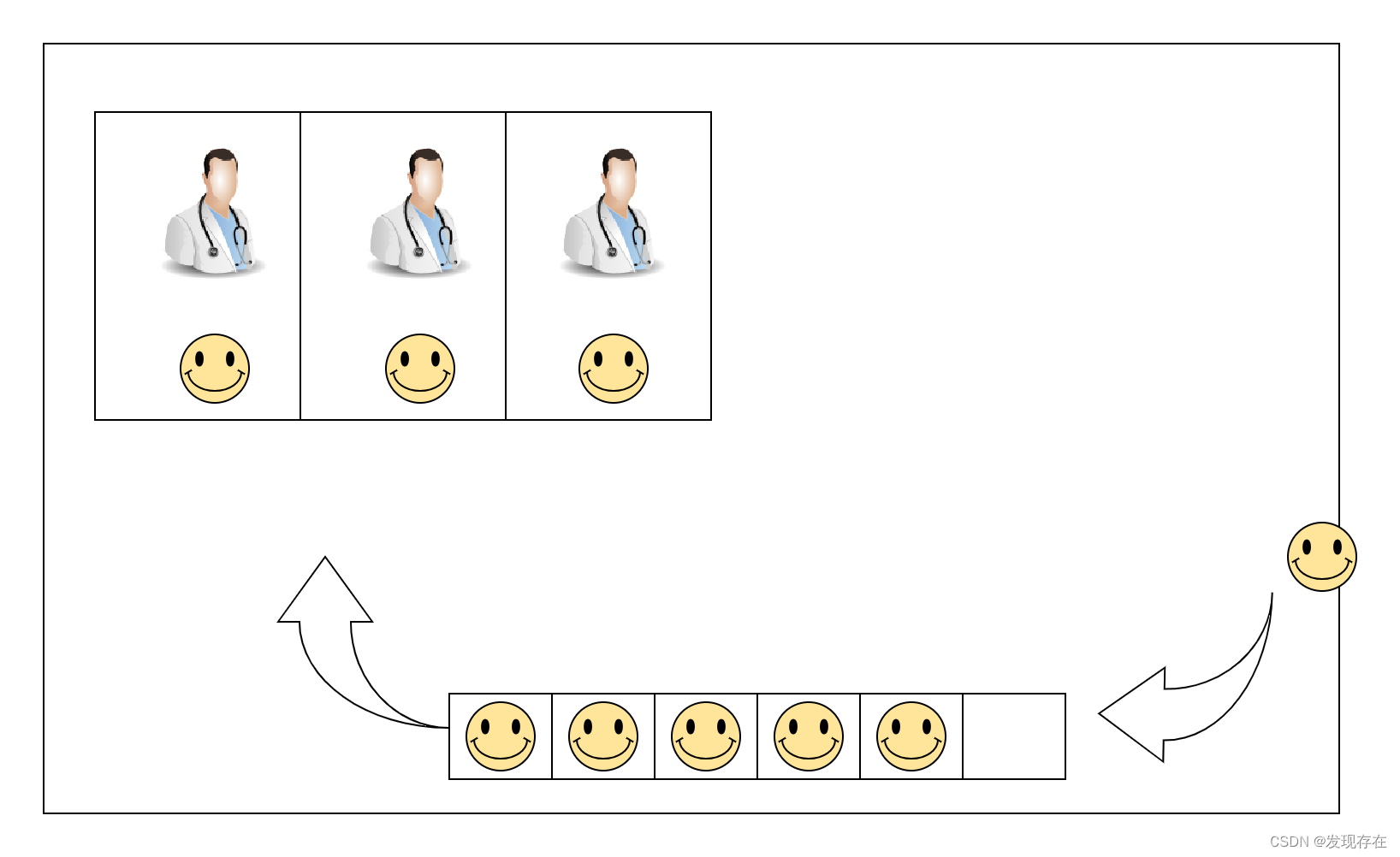
线程池(ThreadPoolExecutor)就像一个医院。线程(Thread)就是医生。医院只有固定数量的医生(核心线程数)。任务(Runnable)就是病人。
Worker就像是门诊(把医生和病人封装在一起空间里工作),门诊和医生一样都是不会随意增加的,创建出来,就和医生一起“重复使用”。(除非有新的医生被创建)
一个医生一个门诊,等待队列就是门诊外的椅子。如果门诊里有人看病,其他人就可以坐在椅子上排队(有人从门诊里出来,等待的病人就往前挪一挪)。
医院规定了一个最多医生上限(医院也要考虑用人成本。这里指的就是最大线程数)。如果某个前来看病的人发现当前医生数量已经达到最多医生上限,而且门外没座位可坐,此时他就会被拒绝。
如果医院比较贪心,虽然定了最多医生上限,却在门外放了好多椅子。病人来了就可以排队,导致病人需要排好长的队。
如果医院比较吝啬,门外只放置了少量椅子。病人来了一看,医生人数并没有超出最多医生上限,但自己也没有位置可排队。怎么办呢(任务不是人,人有没有椅子也可以自觉排队,但任务不行)。医院此时就得向其他医院临时借调医生来处理。然后这个新来的医生就会和其他医生一起把等待的线程处理完,这个临时医生发现处理完了,就可以回去了。
当然,比喻终归是比喻,能帮助我们简化理解,但也可能会引起误解。如果要看线程池具体实现逻辑,请看后面的实现机制。
线程池状态
线程池的状态变化本来是打算写在这一小节的。但是细想了一下,按照我的学习过程。一开始我并没有怎么关心状态变化以及怎么变化的。
基础篇是以让人知道是什么,怎么用以及大体逻辑关系。
所以这部分就放在实现机制篇里讲。
如果想现在就了解的,请看实现机制篇的最后[线程池状态变化]。
深度定制化线程池
前面的自定义线程池其实已经非常灵活了,所以才有那么多的参数需要我们自己创建。
但有些场景下可能觉得这些参数还不够。这就需要自己写个线程池实现类,继承ThreadPoolExecutor,并对ThreadPoolExecutor这个类中的一些方法进行重写。ThreadPoolExecutor为我们提供了一些模板方法(钩子函数),如下所示
- protected void beforeExecute(Thread t, Runnable r) { }: 任务执行之前的钩子方法
- protected void afterExecute(Runnable r, Throwable t) { }: 任务执行之后的钩子方法
- protected void terminated() { }: 线程池终止时的钩子方法
这些钩子方法可以在执行任务之前、之后,关闭线程池的时候被触发(AOP思想)。
当然,如果这些定制化接口还不够。那就干脆抛弃JDK给我们的实现类ThreadPoolExecutor,直接自己去实现ExecutorService接口(实际生产中应该很少有人这么干)。
小结
创建线程池的方式:
- 一种是工具类Executors内置的三种线程池。应对简单的应用场景。但在复杂的使用场景会有OOM的风险,所以不建议使用。
- 第二种是自定义线程池。通过自己new ThreadPoolExecutor,并创建并添加各种参数来精细控制线程池。
- 为了更复杂的场景,我们还可以通过继承ThreadPoolExecutor,写自己的线程池类,并重写其中的模板方法进一步扩展ThreadPoolExecutor。
- 甚至可以直接抛弃ThreadPoolExecutor,自己直接实现ExecutorService接口。
五、任务(task)
有两种任务类型:
- Runnable:这个比较常见,前面的demo里我们往线程池里添加就是Runnable。
- Callable:和Runnable类似,但执行这个任务可以有返回值,并且可以捕获异常。
看一下这两个接口
@FunctionalInterface
public interface Runnable {
public abstract void run();//无返回值,也没有抛异常
}
@FunctionalInterface
public interface Callable<V> {
V call() throws Exception;//有返回值V,并且可以抛出异常Exception
}
可以看到Runnable接口中的run方法,既没有返回值,也不抛异常。
@FunctionalInterface是什么意思?
加上这个注解之后,这两个接口都称为:函数式接口。是java8增加的“函数式编程”里的内容。
所以前面我们添加的任务可以写成:() -> {xxxx} 这种lambda表达式的形式。
如果对这一块不太清楚,可以看另一篇博客Lamdba表达式应用及总结
六、返回值
两种返回值,其中一种是void,没有返回值
还有一种是Future,字面意思是“将来”。的意思。表示在将来可以获得值,因为是异步获取的任务返回值。
具体实现机制可以看实现机制篇的[submit + Future + Callable实现异步返回值]
七、添加任务
前面已经介绍了:线程池、任务、返回值。
现在把他们组装在一起。根据一开始说的线程池吃下任务,吐出返回值,看看实际有哪些组合方式。
前面我们看到把任务添加进线程池,用的是execute。其实还有另一种添加进程的方法:submit。总共有如下一些组合方式:
- void execute(Runnable command)
- <T><T> Future<T> submit(Callable<T> task)
- <T> Future<T> submit(Runnable task, T result)
- Future<?> submit(Runnable task)
其中execute方法没有返回值,而submit都有返回值。
八、有返回值的线程池Demo
public void m4() {
ExecutorService executorService = Executors.newCachedThreadPool();
Future<String> future = executorService.submit(() -> {
System.out.println("----------start----");
try {
Thread.sleep(5000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("----------end----");
return "ok";
});
System.out.println("------------------");
try {
System.out.println(future.get());//在这里阻塞,等待着线程池返回结果
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
} finally {
executorService.shutdown();
}
System.out.println("-----over");
}
输出
------------------
----------start----
----------end----
ok
-----over
future.get()会阻塞住,等待线程池返回结果。
在上面的demo里,往submit方法里传入的其实是Callable类的lambda写法(和Runnable一样)。而Callable的call方法除了有返回值,还可以抛异常。那这个异常怎么捕获呢?
对Future<String> future = executorService.submit...这句话捕获异常吗?
不,其实代码里已经写了。看future.get()被莫名其妙的包裹了一堆异常捕获。就是用来捕获方法里的异常的。
所以:如果方法里抛异常了,就会在future.get()被捕获到。
上面demo中只添加了一个任务。但线程池一般不止一个任务,那多个返回值怎么接收呢。
很简单:创建一个List<Future>,把结果都塞进去,最后去遍历这个List。
如果觉得这个不够优雅,可以把submit替换成invokeAll,直接传入任务集合,然后返回结果集合。
九、关闭线程池
关闭线程池有两种操作:
- shutdown():不再接收新的线程,但会把未执行完的任务跑完。这是比较推荐的优雅的停止线程池的方式。
- shutdownNow():直接中断所有正在执行的线程,清空等待队列,关闭线程池。
- shutdown的demo:
/**
* 多线程运行,shutdown()
* 其他正在运行的线程会执行完,但不再接收新的任务(报错)
*/
public void m6() {
ExecutorService executorService = Executors.newCachedThreadPool();
for (int i = 0; i < 5; i++) {
executorService.execute(() -> {
String threadName = Thread.currentThread().getName();
System.out.println(threadName + ": ok");
});
}
System.out.println("------------------");
executorService.shutdown();
//再次尝试添加任务
executorService.execute(() -> {
String threadName = Thread.currentThread().getName();
System.out.println(threadName + ": ok");
});
System.out.println("-----over");
}
结果:
pool-1-thread-1: ok
pool-1-thread-3: ok
------------------
pool-1-thread-2: ok
pool-1-thread-5: ok
pool-1-thread-4: ok
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task com.yc.testThread.TestThreadPool$$Lambda$2/359023572@123a439b rejected from java.util.concurrent.ThreadPoolExecutor@7de26db8[Terminated, pool size = 0, active threads = 0, queued tasks = 0, completed tasks = 5]
at java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2063)
at java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:830)
at java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1379)
at com.yc.testThread.TestThreadPool.m6(TestThreadPool.java:177)
at com.yc.testThread.TestThreadPool.main(TestThreadPool.java:16)
可见shutdown(),并没影响其他正在运行的线程,但会通过报错的方式拒绝新添加线程。
- shutdownNow的demo
/**
* 多线程运行,shutdownNow()
* 正在运行的线程都会停止
*/
public void m7() {
ExecutorService executorService = Executors.newFixedThreadPool(2);
for (int i = 0; i < 5; i++) {
executorService.execute(() -> {
System.out.println(Thread.currentThread().getName() + ": ok");
});
}
List<Runnable> res = executorService.shutdownNow();
System.out.println("-----over: " + res.size());
}
输出:
pool-1-thread-1: ok
pool-1-thread-2: ok
-----over: 3
虽然还是输出了两条,但这是因为任务比较简单,执行的特别快,在执行到shutdownNow()时,有两个任务就已经执行完了。而哪些还没来得及执行的,就被中断了。
虽然shutdownNow()看起来比较粗暴,但也做到了尽量”优雅“:把没执行的任务返回来。可以看到输出3,表示还有三个任务没执行。
十、应用中的注意事项
防止死锁
如下图所示
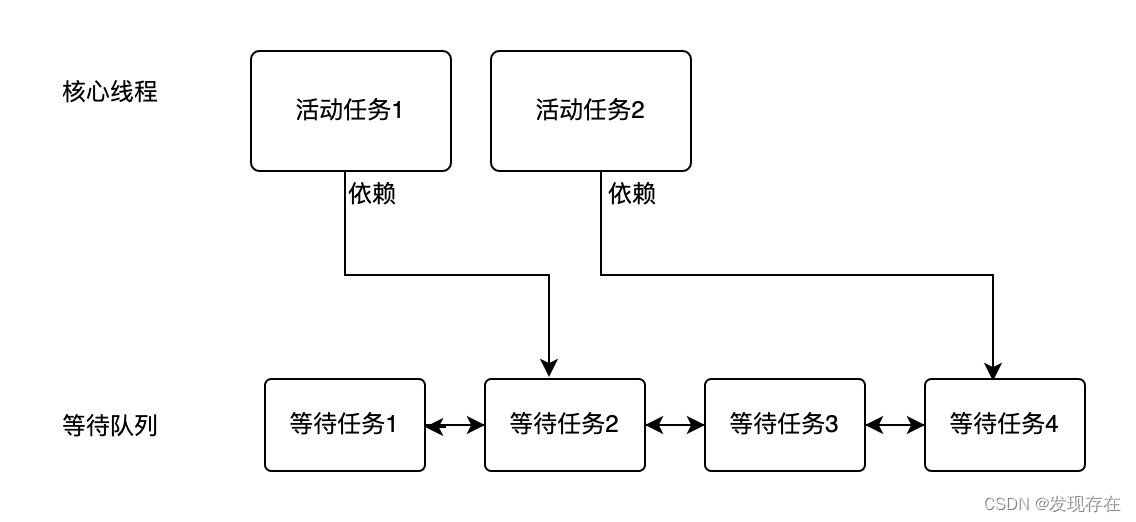
- 这个线程池有两个核心线程,其中执行的任务都依赖于另外的任务结果。
- 但另外两个任务都还在等待队列里排队
- 这样就形成了,核心线程和任务队列互等的死锁状态。
所以提交给线程池的任务,一定要是独立的任务,不可相互依赖。如果有依赖,可以分别提交给不同的线程池去执行。
当然,如果用newCachedThreadPool,就不会有这个问题。因为没有任务会进队列等待。
核心线程数太少,队列太长:超时
当核心线程数设置的太少,最大线程数和队列太长,那么就会出现大量任务等在队列里的情况。使得任务从提交到执行完成,经历时间过长。如果此时有其他程序等任务结果,那么极有可能出现等待超时,使得系统不可用。
核心线程数和最大线程数太少:拒绝
如果线程池配置的过于保守,而业务量太大,则会出现大量任务被执行拒绝策略的情况。
如何配置线程池
根据前面所说的情况,我们可知,线程池的配置其实很不容易。所以就有人提出了动态线程池的方案。
简单来说就是通过监控线程池状况,设置阈值。然后通过配置环境直接动态修改线程池的参数(核心线程数,最大线程数,等待时间等)。
线程池中的监控和动态修改参数的方法:
// 监控
getRejectedExecutionHandler()
getCorePoolSize()
getMaximumPoolSize()
getKeepAliveTime(TimeUnit unit)
getQueue()
getPoolSize()
getLargestPoolSize()
getTaskCount()
// 动态配置
setRejectedExecutionHandler(RejectedExecutionHandler handler)
setCorePoolSize(int corePoolSize)
setMaximumPoolSize(int maximumPoolSize)
setKeepAliveTime(long time, TimeUnit unit)
我们可以给系统增加一个线程池监控、配置的页面。从而根据实际情况,随时调整线程池的各项配置(动态配置完,线程池会马上生效)。
至此,基础部分就结束了,后半部分是深入解析。主要是通过源码,更进一步理解线程池。
建议继续看一下,因为尽管我已经尽量通俗详细的解释,其实还是有可能会让人产生误解的地方。而且有很多细节是看了源码后才能更深刻的理解它的准确含义。