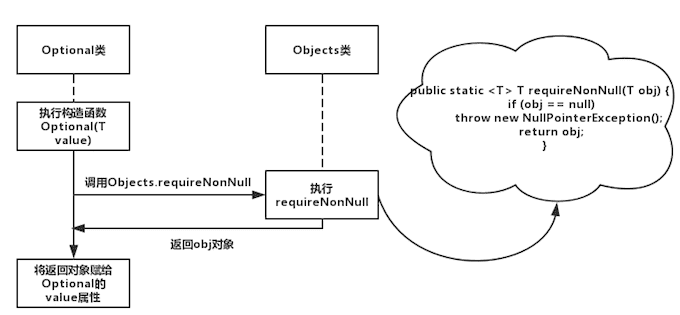
上一篇文章介绍了线程的基本概念
而本篇文章我们来深入理解一下, CPU再调度我们以往理解的进程和如今的线程都会涉及到的一个内容: 页表
文章目录
- 深入理解页表 *
- 页表的实际组成*
- 什么是page?
深入理解页表 *
在介绍进程时, 博主没有深入介绍过页表.
只是简单说了 页表是进程地址空间和物理内存之间的相互映射. 而且, 画图也对页表做了简单化处理:
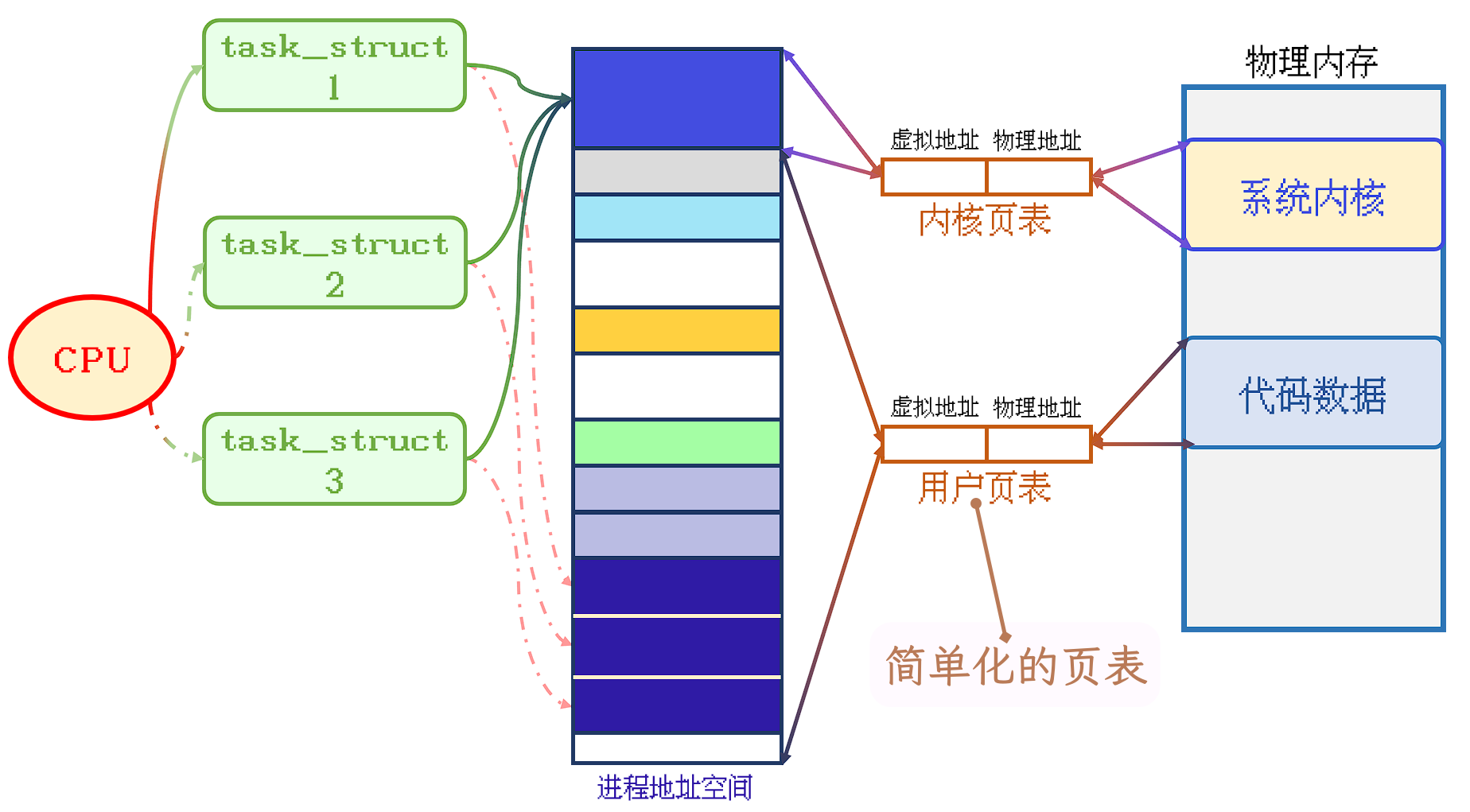
但是实际上, 页表并不是只有简单的两栏, 页表的实现是有些复杂的, 不是一张表可以描述的.
不过 整个结构抽象一下暂时还是可以以一级页表来表示:

页表可以看作, 除了有虚拟地址或物理地址两栏之外, 其实还有其他栏:名中、RWX权限、U/K权限
这三个栏中, 最简单理解的是两个权限:
- RWX权限, 即为
读、写、执行三权限, 表示进程对物理内存的访问权限
我们知道C/C++中, 常量数据是不能做修改的. 其实, 原因就是页表对进程做出了限制.
实际上物理内存(硬件)是不具备访问控制的, 谁都可以读写.
而实际情况是我们并不能随意读写, 这是由于软件的限制.
以我们的视角来看, 程序的代码和部分数据是无法被修改的. 但是这些代码和数据又可以被加载到内存中.
其实就是因为 物理内存本身是不具备访问控制的, 我们看到的不可被修改是通过软件来限制的.
- U/K权限, 其实是User/Kernel权限, 即表示用户和内核. 这里就可以区分访问内存的用户权限和内核权限
除了这两个权限之外, 还有一栏 是 是否命中
是否命中这一栏是什么意思呢?
当CPU需要访问指定内存的数据的时候, 会用虚拟地址通过页表向物理内存中查询数据.
但是, 程序的数据并不是一下子全部加载到物理内存中的, 即 页表中可能不存在指定的物理内存. 所以CPU需要访问数据的时候, 可能存在第一次找不到的情况. 这种情况我们称为 没有命中.
当CPU访问数据没有命中时, 整个进程会从CPU上拉下来先不运行, 然后操作系统会将未命中的数据从磁盘程序中加载到指定的物理内存中, 然后CPU才会再运行此进程.
所以, 是否命中这一栏其实是 表示此次CPU访问数据是否在物理内存中找到了.
这种进程数据不一次性加载到物理内存的机制, 是因为进程地址空间的存在才存在的.
可以允许进程在使用指定数据或代码的时候才将代码和数据真正加载到物理内存中. 这样可以更有效地利用内存资源
先以一级页表介绍了CPU从虚拟地址到物理内存查询数据的机制.
下面来介绍一下, 操作系统中 页表究竟是以什么形式存在的.
页表的实际组成*
我们以32位环境(进程地址空间和物理内存最大都为4GB)为例:
如果使用一级页表(即只使用一张页表), 想要将虚拟地址和物理地址意义对应, 那么页表需要多少行条目?
如果 页表的一行只表示一个地址, 那么32位 就是 2^32 个地址. 页表中的一行并不只存储一个地址(32位环境, 地址的大小为4字节). 至少有两个, 那么我们按最少来假设一行条目大小是8字节.
那么要存储着 2^32 个地址, 页表至少需要多大?
2^32 * 8 = 34,359,738,368, 单位是字节. 一共是32GB. 而我们32位环境下的物理内存最大才4GB.
很明显, 以一级页表来将虚拟内存对应的物理内存全部映射到, 是不切合实际的.
那么, 页表实际在操作系统中是以什么形式存在的呢?
其实 操作系统中的页表是多级页表. 在 32位系统中, 采用两级页表的形式.
在正式分析介绍页表的实际构成之前, 还需要补充一部分内容.
在32位环境下, 物理内存最大为4GB. 虚拟地址空间也是4GB.
那么CPU在访问数据时, 提供的虚拟地址也就是32位的.
因为CPU 需要有能力提供 能覆盖所有物理内存的地址, 32位环境下, 就是32位二进制
CPU给页表提供的虚拟地址是32位的, 但是 却并不是直接将32位作为一个整体在页表中查找物理地址的.
而是 将 32位二进制 分为了 10 + 10 + 12 的形式.
// CPU提供的32位二进制地址
// 会分为10、10、12位的三部分来进行查找
0000 0000 00 0000 0000 00 0000 0000 0000
xxxx xxxx xx yyyy yyyy yy zzzz zzzz zzzz
CPU会分别用这三部分查找到物理内存.
为什么CPU会以这样的形式查找物理内存呢?
其实主要是因为页表是这样设计的.
32位环境下, 页表映射的实现使用的是二级页表, 情况如下:
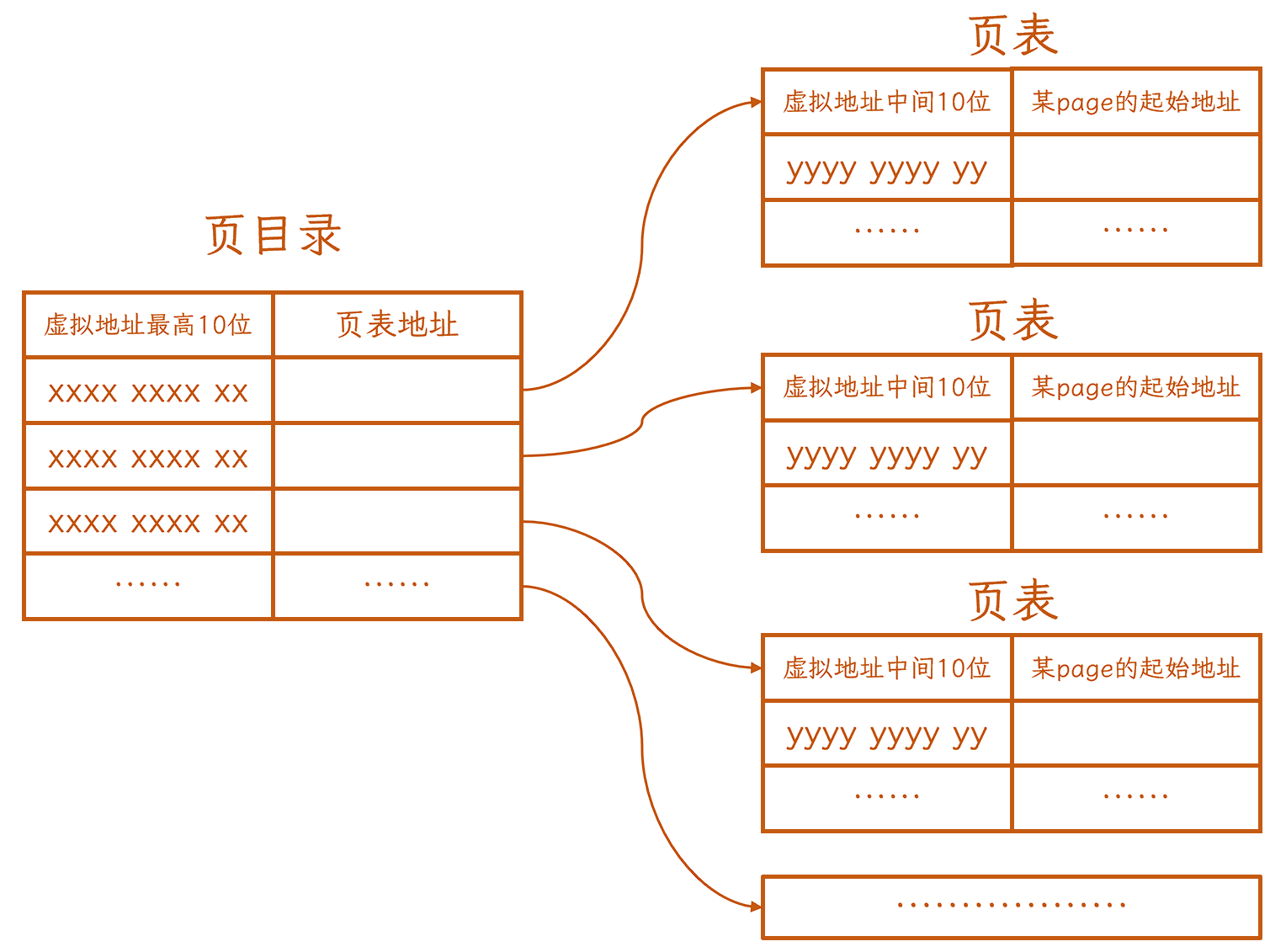
首先使用虚拟地址的最高10位, 在页目录中找到一个相应的页表
然后再在找到的页表中, 找到page的起始地址.
什么是page?
在介绍Linux文件系统时, 提到过一个概念:
操作系统的I/O操作的基本单位通常是4KB.这是因为通常磁盘的物理块大小一般是4KB. 操作系统将I/O操作的基本单位通常设置为 与磁盘的物理块大小一致
既然操作系统将I/O操作的基本单位设置为了4KB, 那么其实操作系统也会将内存以4KB为基本单位来进行管理.
操作系统会将物理内存以4KB为基本单位, 并将其称为页或页框(page)来进行管理.即, 在操作系统中 物理内存被划分为了若干个4KB的单位, 被称为页框.
除了物理内存之外, 磁盘中的程序在编译的时候, 也是按照4KB为单位划分好的.
程序中的4KB单位被称为页帧那么操作系统通过程序中的地址区域进一步生成的进程地址空间, 其实也会按照4KB为单位划分.
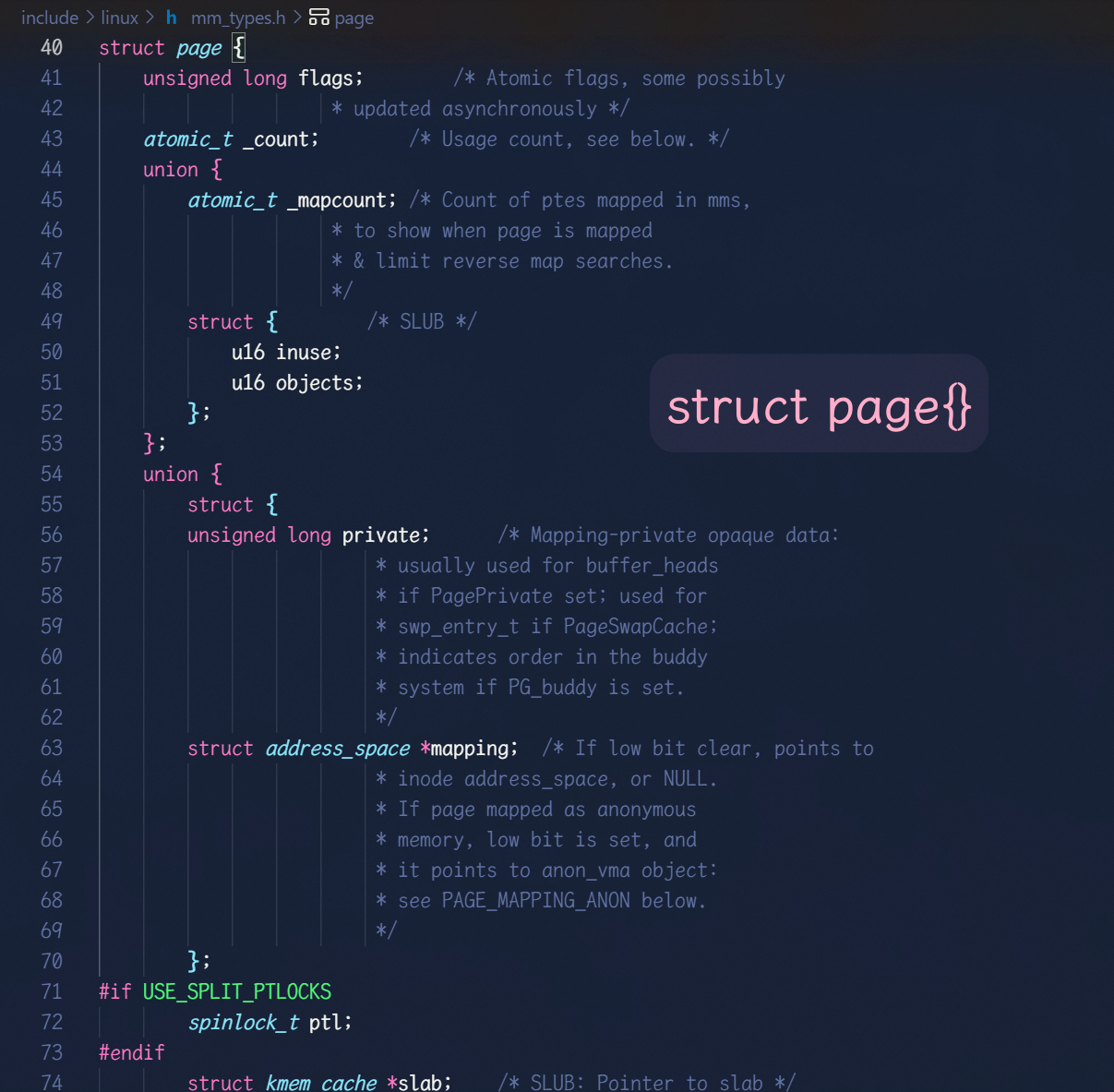
page在Linux内核源代码中是以一个结构体维护的:
那么, 4GB的内存可以划分为多少page呢?
4GB的内存是
4 * 1024 * 1024 * 1024字节, 4KB 则是4 * 1024字节.即, 最终操作系统中会存在
1024*1024 个page.操作系统会**
将这些page统一以一个数据结构维护起来**, 最终对内存的管理 其实就可以看作对此数据结构的管理
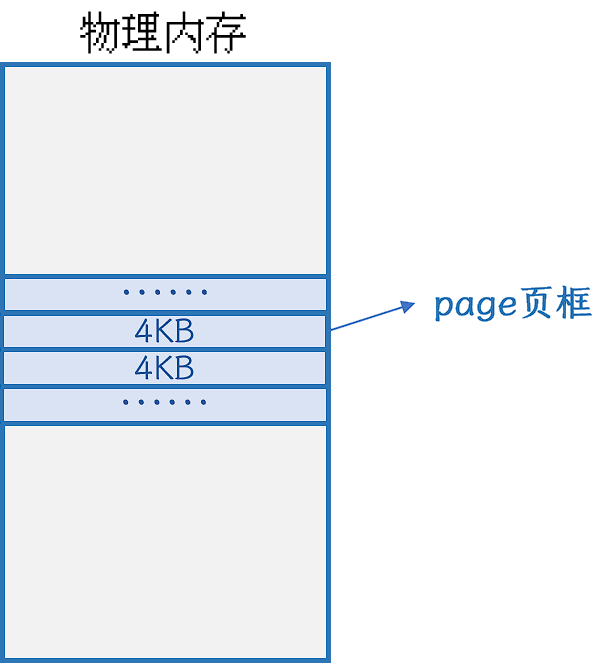
这里通过二级页表找到的page的起始地址, 其实是一个真实的物理内存, 找到的就是物理内存中的一页page
但是, 找到page做什么用呢?我们虚拟地址中的最低12位也没有用到, 怎么能够找到指定的物理地址呢?
其实, 虚拟地址的最低12位起到了一个偏移量的作用, 我们称虚拟地址的最后12位为 页内偏移量
我们可以**找到 page的起始地址, 在将虚拟地址的最低12位作为偏移量, 就能够找到一个准确的物理地址**.
不过, 这个条件是 虚拟地址的12位可以全覆盖一个page的大小. 这个条件成立吗?
成立.
page的大小是4KB, 即 4 * 1024 = 4 * 2^10 = 2^2 * 2^10 = 2^12
而 虚拟地址的最低12位刚好可以覆盖到page的全部地址.
这样 先后通过虚拟地址的最高10位, 虚拟地址的中间10位 和 虚拟地址的最低12位, 就可以找到指定的物理地址
然后就可以读取物理内存中的数据.
用一张图表示整个流程就是:
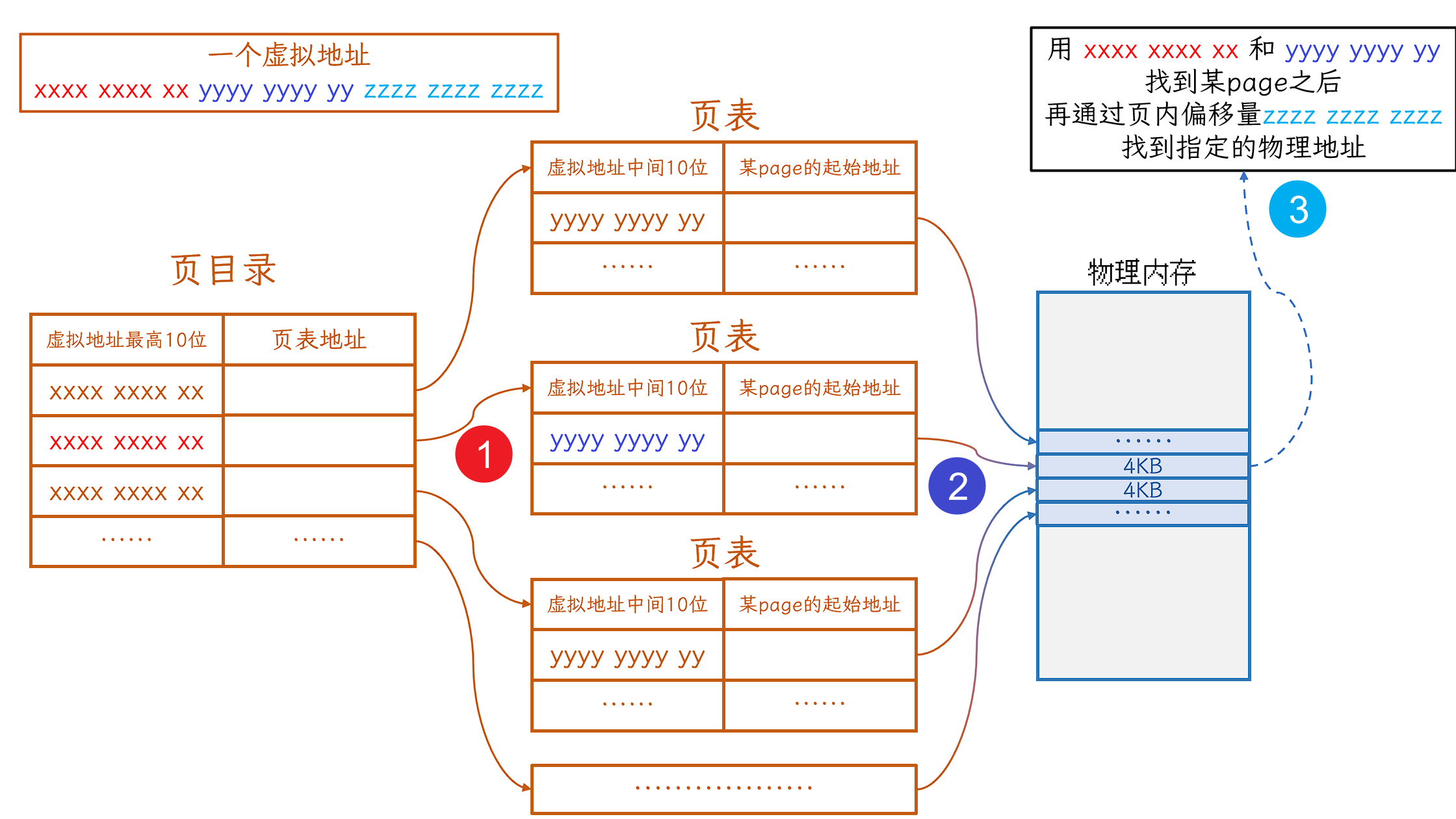
那么介绍到这里, 其实针对页表中是否名中这一栏目, 就可以有一个更加具体的理解了.
即, 二级页表中 应该记录指定page的位置, 存储的是null. 出现此情况时, 也就说明了程序的数据并没有加载到某page中, CPU此次查找也就无法找到指定的物理地址, 此时就是未命中. 也就是说, CPU查找物理内存, 其实只关心page是否存在, 不关心内容. 并且, 资源也是以page为单位加载到内存中的.
这也是 页表设计的第一个优点: 进程虚拟地址管理与物理内存管理之间, 通过页表和page做了解耦. 即, 进程虚拟地址与物理内存之间不存在实际具体数据的关联, 从虚拟地址找物理地址只能做到判断物理地址、数据是否存在, 而不会有数值耦合的情况.
第二个优点就是, 更加节省内存. 如果只使用一张一级页表, 这张页表要在一开始就创建好, 并且4GB的内存需要一一对应, 那么占用内存太大 不合实际.
而如果是像这样的多级页表, 页目录的大小最大也就KB量级. 并且 由于使用二级页表, 第一级和第二级是可以分离的, 那么第二级页表的分配其实也可以按需创建、按需分配. 需要第二级页表的时候再创建, 不需要的时候不用创建. 这样就可以大大的节省内存, 最多最多也就是MB量级了.
第三个优点就是, 方便管理. 从页目录这张第一级页表, 去找指定的第二级页表, 这个结构其实就像是一颗多叉树. 第二级页表就可以像树的节点一样, 按需创建、删除、管理等.