视觉SLAM14讲ch1和ch2的学习
- 视觉SLAM14讲ch1和ch2的学习
- 前言:
- 一、SLAM是什么
- 二、视觉SLAM14讲学习前的基础
- 三、初步了解
- 1. 小萝卜的例子
- 2. 了解一些视觉SLAM的框架
- 3. 一些数学问题的表述
视觉SLAM14讲ch1和ch2的学习
前言:
开始学习视觉SLAM,全过程以高翔老师的视觉SLAM十四讲的学习为主,逐步了解并熟练掌握视觉SLAM的理论与实践,并且不停记录学习过程与心得。
一、SLAM是什么
SLAM(同时定位与地图构建),是指搭载特定传感器的主体,在没有环境先验信息的情况下,在运动过程中建立环境的模型,同时估计自己的运动。如果这里的传感器是相机,那就称为视觉SLAM。
二、视觉SLAM14讲学习前的基础
此书的所有源代码可以在GitHub上下载,网址为:https://github.com/gaoxiang12/slambook2
最好有一些以下基础:
- 数学方面:高数、线代、概率论
- C++基础
- Linux基础
三、初步了解
1. 小萝卜的例子

图中的小萝卜是比较建议的小机器人,可以进行信号收发、移动、对外界的感知。
想要让小萝卜自主运动,必须要考虑的两个基本问题就是:我在哪? 我周围是啥?
想要回答这两个问题,就需要对自身进行定位并建立地图。
也就是:我在哪——定位;我周围是啥——建图。
定位主要是小萝卜自身
建图主要是小萝卜对外界的感知
其中定位和建图是密不可分、相辅相成的,精准的定位需要准确的地图、准确的地图是来自精准的定位。
机器人对外界环境的感知主要是通过传感器进行的。
传感器主要分为两种:
-
携带与机器人上的传感器有 :相机、激光传感器、 IMU等
-
安装于环境中的传感器有 :导轨、二维码等
环境中的传感器要比携带的传感器限制多一些,比如:GPS必须在能接受到卫星信号的情况下才能使用、二维码并不是任何地方都能够张贴的。而携带在本体上的传感器是通过一些间接的物理量来获取位置的信息。
因为,即将学习的是视觉SLAM,所以主要了解小萝卜的眼睛也就是现实中的相机。
相机的分类以及优缺点:
| 相机种类 | 简介 | 优点 | 缺点 |
|---|---|---|---|
| 单目相机 | 利用视差 测量相对深度 | 结构简单、成本低、便于标定和识别 | 单张图片无法确定物体真是大小 具有尺度不确定性 |
| 双目相机 | 利用基线估计像素的空间位置 类似于人眼 | 基线距离越大,测量距离越远 可以运用到室内和室外 | 配置复杂、量程和精度收到基线和分辨率的限制、计算消耗资源 需要GPU(图形处理器)和FPA设备(现场可编程门阵列)加速用两部相机来定位 |
| 深度相机(RGB_D) | 利用 红外结构光 或 ToF 测量深度信息 主要用来三维成像和测量距离 | 节约大量的计算资源 | 范围窄、噪声大、事业小、容易受日光干扰、无法测量透射材质、在室外很难应用 |
2. 了解一些视觉SLAM的框架

整个视觉 SLAM 流程分为以下几步:
- 传感器信息读取,在视觉 SLAM 中主要为相机图像信息的读取和预处理。如果在机
器人中,还可能有码盘、惯性传感器等信息的读取和同步。 - 视觉里程计 (Visual Odometry, VO),视觉里程计任务是估算相邻图像间相机的运动,
以及局部地图的样子。VO 又称为前端(Front End)。 - 后端优化(Optimization),后端接受不同时刻视觉里程计测量的相机位姿,以及回
环检测的信息,对它们进行优化,得到全局一致的轨迹和地图。由于接在 VO 之后,
又称为后端(Back End)。 - 回环检测(Loop Closing),回环检测判断机器人是否曾经到达过先前的位置。如果
检测到回环,它会把信息提供给后端进行处理。 - 建图(Mapping),它根据估计的轨迹,建立与任务要求对应的地图
视觉里程计:
视觉里程计通过相邻帧之间的图像估计相机运动,并恢复场景的空间结构,但是计算相邻时刻的运动,不关心再往前的信息。但前端过程中必然存在误差,误差会不断的积累,形成累积漂移。为了解决漂移的问题,所以进行回环检测和后端优化。
后端优化:
后端优化主要就是处理SLAM过程中的噪声问题;
后端优化需要考虑的问题就是:如何从带有噪声的数据中估计整个系统的状态,以及这个状态估计有多大的不确定性——这称为最大后验概率估计。
在视觉SLAM中,前端和计算机视觉研究领域更为相关,比如图像的特征提取与匹配等,后端主要时滤波与非线性优化算法。
SLAM问题的本质:对运动主体和周围环境空间不确定性的估计。(状态估计理论——估计状态的均值和不确定性)
回环检测:
作用: 解决位置估计随时间飘逸的问题。(当机器人再次经过之前已经经过的位置时,机器人却没有认出来)
目标: 通过某种手段,让机器人知道“回到原点”这件事情,让机器人具有识别到已经经过的场景的能力。再把位置估计值“拉回去”。
手段: 判断位置间差异,计算图像之间的相似性。
结果: 可以将得到的信息告诉后端优化算法,把轨迹和地图调整到符合回环检测结果的样子。

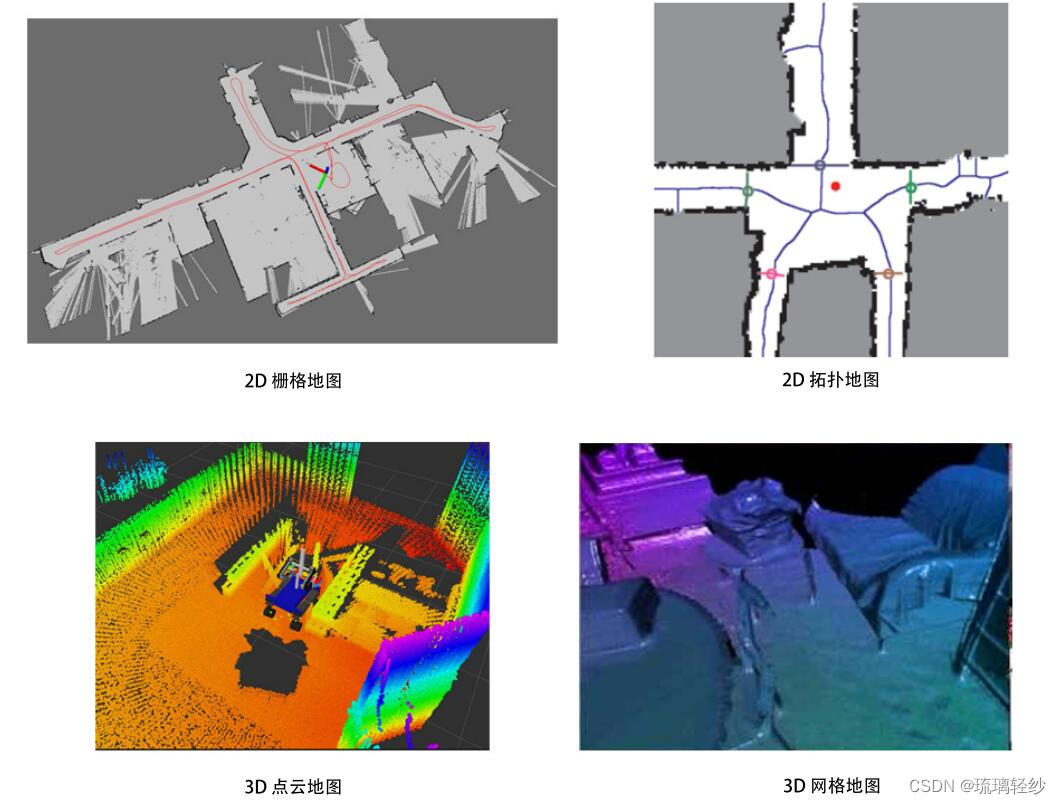
建图:
-
度量地图(强调精确的表示地图中的位置关系)
- 稀疏地图:由路标组成的地图
- 稠密地图:着重于建模所有看到的东西(可用于导航)(储存空间耗费较大)
-
拓扑地图(更加强盗元素之间的关系)
是一个图:由点和边组成 只考虑节点间的连通性,例如 A,B 点是连通的,而不考虑如何从 A 点到达 B 点的过程
它是一种更为紧凑的表达方式。但,拓扑地图不擅长表达具有复杂结构的地图
3. 一些数学问题的表述
对于视觉SLAM,本身就是定位和建图,所以只需要关心运动和观测。因为确定运动情况,才能对机器人进行实时的定位,准确的观测才嫩建立起精确的地图。因此在数学表达中,可以抽象出两个描述即运动模型和观测模型。
运动方程:
从k-1时刻到k时刻,小萝卜x的变化
x
⃗
=
f
(
x
k
−
1
⃗
,
u
k
⃗
,
w
k
⃗
)
,
k
=
1
,
…
…
,
K
\vec x_ = f(\vec {x_{k-1}} ,\vec {u_k},\vec {w_k}), k = 1,……,K
x=f(xk−1,uk,wk),k=1,……,K
u
k
⃗
\vec {u_k}
uk是运动传感器的读数,
w
k
⃗
\vec {w_k}
wk是运动过程中加入的噪声。
观测方程:
小萝卜在
x
k
x_k
xk处位置上看到了某个路标点
y
k
y_k
yk,产生了一个观测数据
z
k
,
j
z_{k,j}
zk,j
z
k
,
j
⃗
=
h
(
y
j
⃗
,
x
k
⃗
,
v
k
,
j
⃗
)
,
k
,
j
∈
O
\vec {z_{k,j}} = h(\vec {y_j} ,\vec {x_k},\vec {v_{k,j}}), k ,j \in O
zk,j=h(yj,xk,vk,j),k,j∈O
v
k
,
j
⃗
\vec {v_{k,j}}
vk,j是观测的噪声,O是一个集合。