目录
一、基本概念和排序方法概述
1.1 - 排序的基本概念
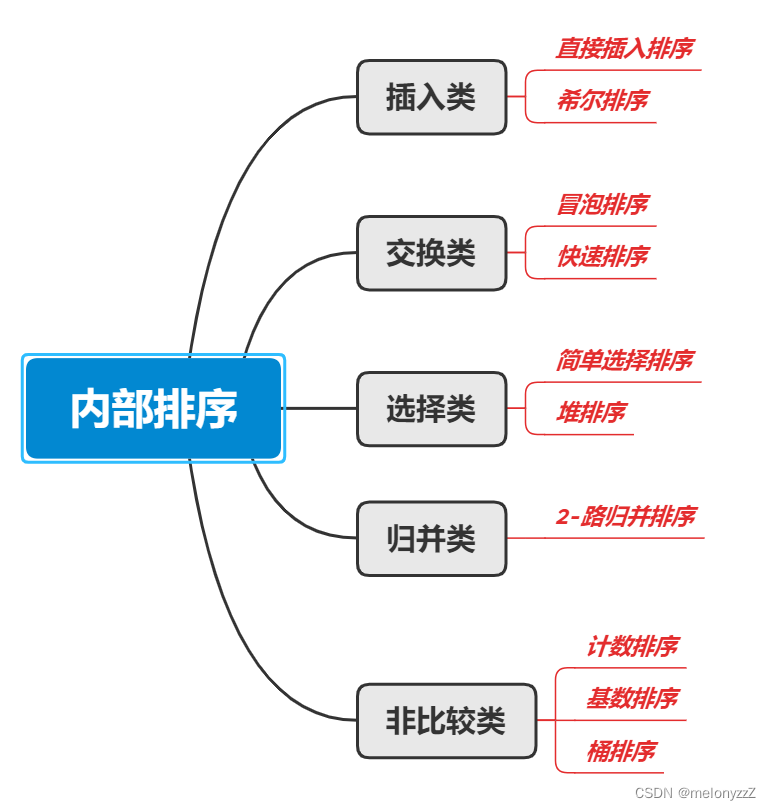
1.2 - 内部排序的分类
二、插入排序
2.1 - 直接插入排序
2.2 - 希尔排序
三、交换排序
3.1 - 冒泡排序
3.2 - 快速排序
3.2.1 - 递归算法
3.2.2 - 优化
3.2.3 - 非递归算法
四、选择排序
4.1 - 简单选择排序
4.2 - 堆排序
五、归并排序
5.1 - 递归
5.2 - 迭代
六、排序算法复杂度及稳定性分析
一、基本概念和排序方法概述
1.1 - 排序的基本概念
-
排序(Sorting)是按照关键字(例如:销量、价格等)的非递减或非递增顺序对一组记录重新进行排列的操作。
-
关键字相等的两个或两个以上的记录,若在排序后的序列中,它们的前后位置不发生改变,则称所用的排序方法是稳定的;反之,则称所用的排序方法是不稳定的。
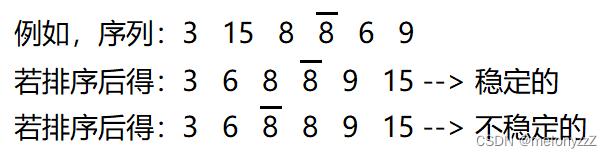
-
根据在排序过程中记录所占用的存储设备,可将排序方法分为两大类:一类是内部排序,指的是待排序记录全部存放在计算机内存中进行排序的过程;另一类是外部排序,指的是待排序记录的数量很大,以致内存一次不能容纳全部记录,在排序过程中尚需对外存进行访问的排序过程。
1.2 - 内部排序的分类
二、插入排序
插入排序的基本思想是:每一趟将一个待排序的记录,按其关键字的大小插入到已经排好序的一组记录的适当位置上,直到所有待排序记录全部插入为止。
例如,打扑克牌在抓牌时要保证抓过的牌有序排列,则每抓一张牌,就插入到合适的位置,直到抓完牌为止,即可得到一个有序序列。

2.1 - 直接插入排序
直接插入排序(Straight Insertion Sort)的基本操作是将一条记录插入到已排好序的有序表中,从而得到一个新的、记录数量增 1 的有序表。
算法步骤:
-
设待排序的记录存放在数组
arr[0...n-1]中,arr[0]是一个有序序列。 -
循环 n - 1 次,每次使用顺序查找法,查找
arr[i](i = 1, ..., n - 1)在已排好序的序列arr[0...i-1]中的插入位置,然后将arr[i]插入。具体操作则是将
arr[i]与arr[i - 1],arr[i - 2],...,arr[0]从后向前顺序比较,并在自arr[i - 1]起往前查找插入位置的过程中,同时后移记录。
void InsertSort(int* arr, int n)
{
for (int i = 1; i < n; ++i)
{
// 一趟直接排序:将 arr[i] 插入到已排好序的序列 arr[0...i-1] 中
int tmp = arr[i];
int end = i - 1;
while (end >= 0) // 从后向前寻找插入位置
{
if (tmp < arr[end]) // 后移
{
arr[end + 1] = arr[end];
--end;
}
else
{
break;
}
}
arr[end + 1] = tmp;
}
}注意:需要提前将
arr[i]保存到临时变量tmp中,因为如果arr[i - 1] < arr[i],在后移的过程中会覆盖arr[i]。
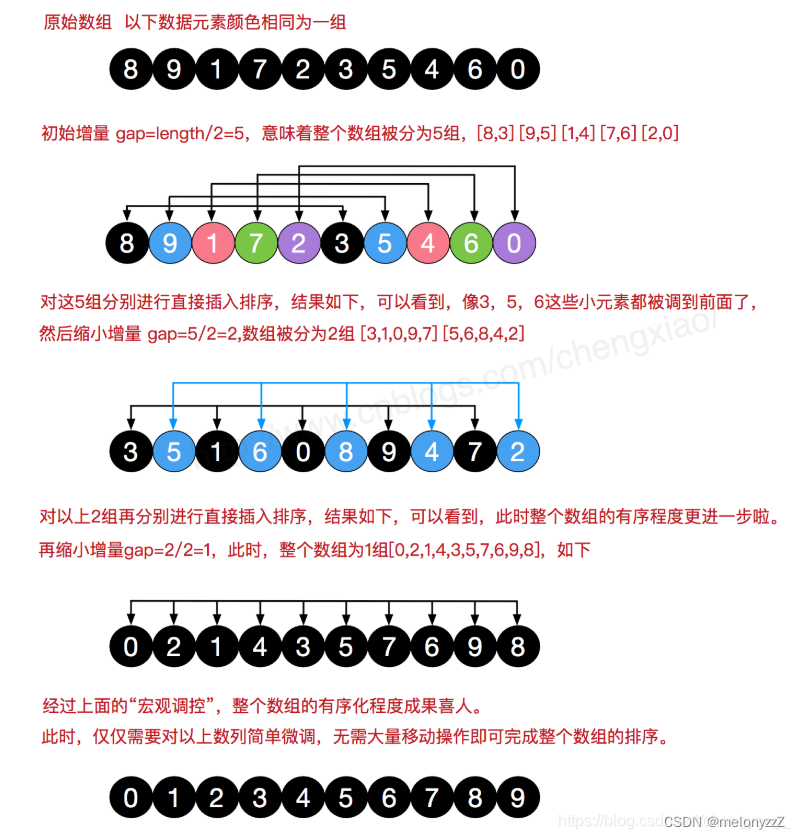
2.2 - 希尔排序
希尔排序(Shell's Sort)又称 "缩小增量排序"(Diminishing Increment Sort),是插入排序的一种,因为 D.L.Shell 于 1959 年提出而得名。
直接插入排序,当待排序的记录个数较少且待排序序列的关键字基本有序时,效率较高。希尔排序基于以上两点,从 "减少记录个数" 和 "序列基本有序" 这两个方面对直接插入排序进行了改进。
希尔排序实质上是采用分组插入的方法。先将整个待排序记录分割成几组,从而减少参与直接插入排序的数据量,对每组分别进行直接插入排序,然后增加每组的数据量,重新分组。这样经过几次分组排序后,整个序列中的记录 "基本有序" 时,再对全体记录进行一次直接插入排序。
算法步骤:
-
第一趟取增量
把全部记录分成 组,所有间隔为
的记录分在同一组,在各个组中进行直接插入排序。
-
第二趟取增量
,重复上述的分组和排序。
-
依次类推,直到所取得增量
,所有记录在同一组中进行直接插入排序为止。
gap 的取法有多种。最初 Shell 提出取 gap = ⌊n / 2⌋,gap = ⌊gap / 2⌋,直到 gap = 1,后来 Knuth 提出取 gap = ⌊gap / 3⌋ + 1。还有人提出都取奇数为好,也有人提出各 gap 互质为好。无论哪一种主张都没有得到证明。
例如:
void ShellSort(int* arr, int n)
{
int gap = n;
while (gap > 1)
{
gap /= 2; // 缩小增量
for (int i = 0; i < gap; ++i) // 将整个数组分为 gap 组
{
for (int j = gap + i; j < n; j += gap) // 对每组分别进行直接插入排序
{
int tmp = arr[j];
int end = j - gap;
while (end >= 0)
{
if (tmp < arr[end])
{
arr[end + gap] = arr[end];
end -= gap;
}
else
{
break;
}
}
arr[end + gap] = tmp;
}
}
}
}写法二:
void ShellSort(int* arr, int n)
{
int gap = n;
while (gap > 1)
{
gap /= 2;
for (int i = gap; i < n; ++i) // 对所有组同时进行直接插入排序
{
int tmp = arr[i];
int end = i - gap;
while (end >= 0)
{
if (tmp < arr[end])
{
arr[end + gap] = arr[end];
end -= gap;
}
else
{
break;
}
}
arr[end + gap] = tmp;
}
}
}三、交换排序
交换排序的基本思想是:两两比较待排序记录的关键字,一旦发现两个记录不满足次序要求时则进行交换,直到整个序列全部满足要求为止。
3.1 - 冒泡排序
冒泡排序(Bubble Sort)是一种最简单的交换排序方法,它通过两两比较相邻记录的关键字,如果发生逆序,则进行交换,从而使关键字小的记录如气泡一般逐渐往上 "漂浮"(左移),或者使关键字大的记录如石块一样逐渐向下 "坠落"(右移)。
算法步骤:
-
设待排序的记录存放在数组
arr[0...n-1]中。首先将第一个记录的关键字和第二个记录的关键字进行比较,若为逆序(即arr[0] > arr[1]),则交换两个记录。然后比较第二个记录和第三个记录的关键字。依次类推,直至arr[n - 2]和arr[n - 1]进行比较过为止。上述过程称作第一趟起泡排序,其结果使得关键字最大的记录被安置到最后一个记录的位置上。 -
然后进行第二趟起泡排序,对前 n - 1 个记录进行同样的操作,其结果是使关键字次大的记录被安置到第 n - 1 个记录的位置上。
-
重复上述比较和交换的过程,直到某一趟排序过程中没有进行过交换记录的操作,说明序列已全部达到排序要求,则完全排序。
void Swap(int* e1, int* e2)
{
int tmp = *e1;
*e1 = *e2;
*e2 = tmp;
}
void BubbleSort(int* arr, int n)
{
for (int i = 0; i < n - 1; ++i)
{
int flag = 0; // flag 用来标记某一趟排序是否发生交换
for (int j = 0; j < n - 1 - i; ++j)
{
if (arr[j] > arr[j + 1])
{
Swap(&arr[j], &arr[j + 1]);
flag = 1;
}
}
if (flag == 0)
{
break;
}
}
}3.2 - 快速排序
快速排序(Quick Sort)是对冒泡排序的一种改进,由 C.A.R.Hoare(霍尔)于 1962 年提出。在冒泡排序过程中,只对相邻的两个记录进行比较,因此每次交换两个相邻的记录时只能消除一个逆序。如果能通过两个(不相邻)记录的一次交换,消除多个逆序,则会大大加快排序的速度。快速排序方法中的一次交换可能消除多个逆序。
快速排序的基本思想是:在待排序的 n 个记录中任取一个记录作为枢轴(或支点),设其关键字为 pivotkey。经过一趟快速排序后,把所有关键字小于 pivotkey 的记录交换到前面,把所有关键字大于 pivotkey 的记录交换到后面,结果将待排序记录分成两个子表,最后将枢轴放置在分界处的位置。然后,分别对左、右子表重复上述过程,直至每一子表只有一个记录时,排序完成。
3.2.1 - 递归算法
Hoare 版本:
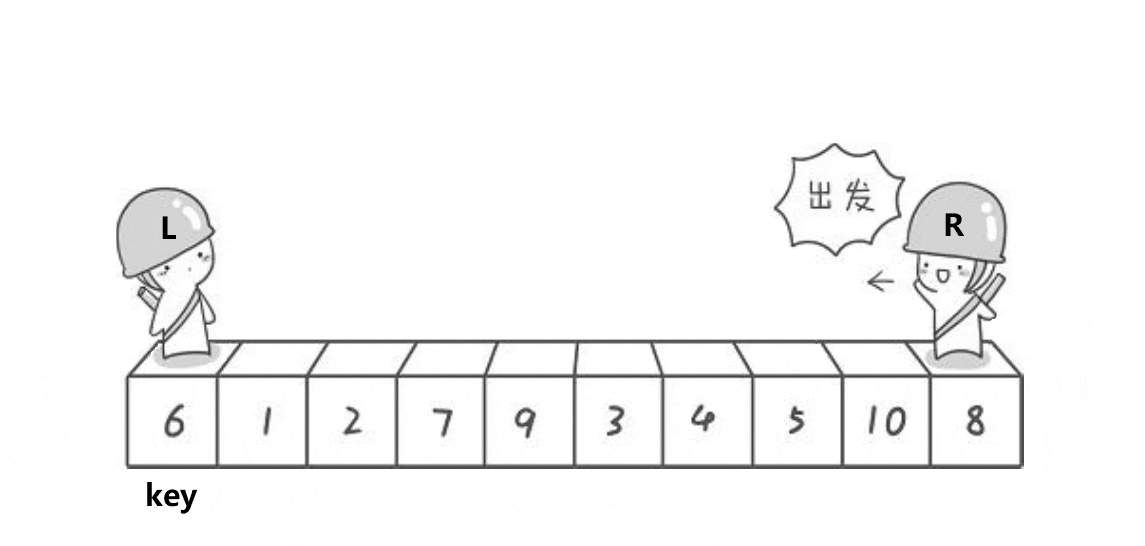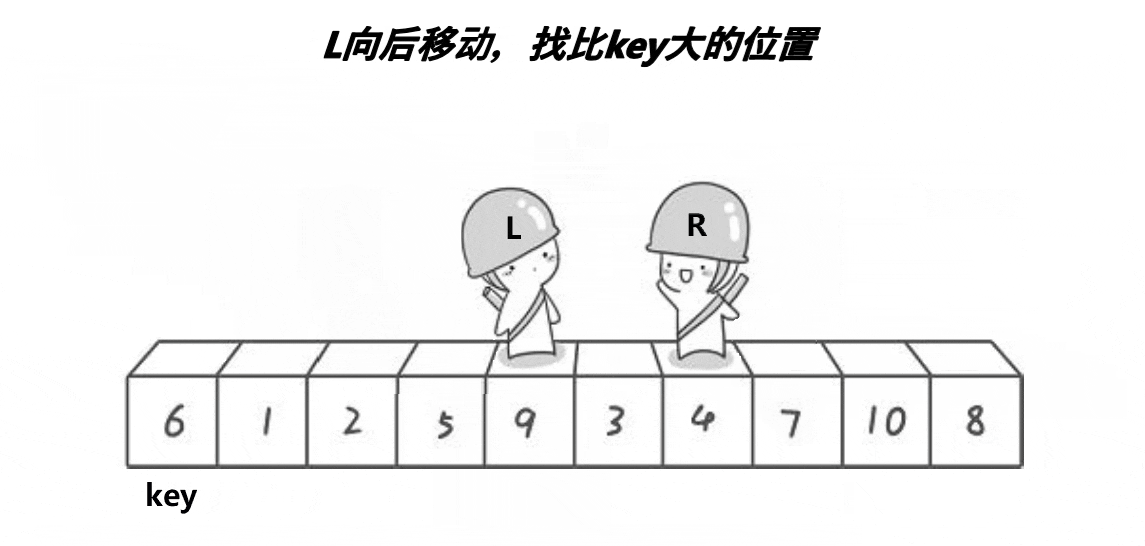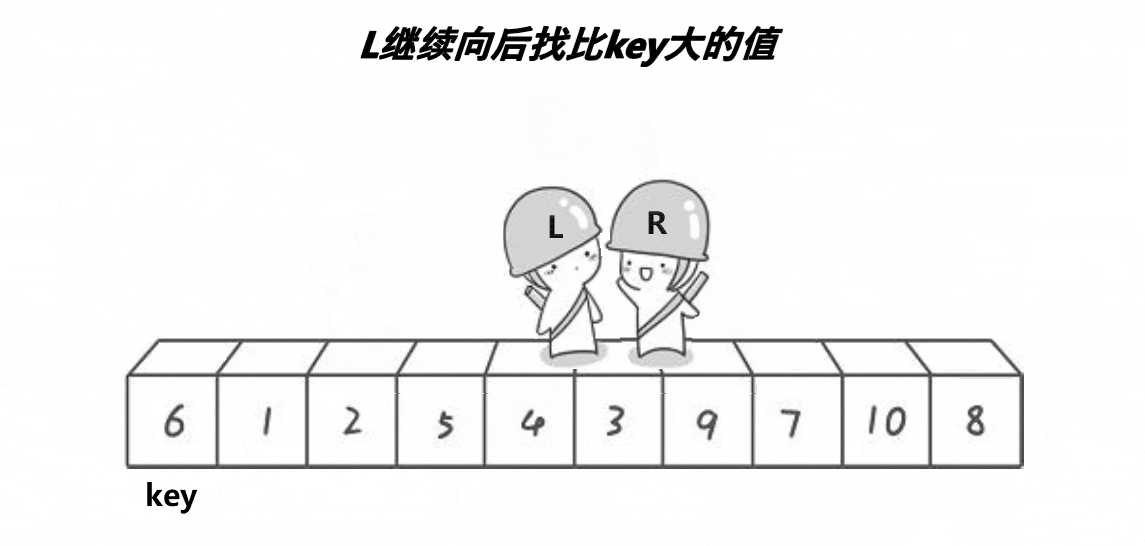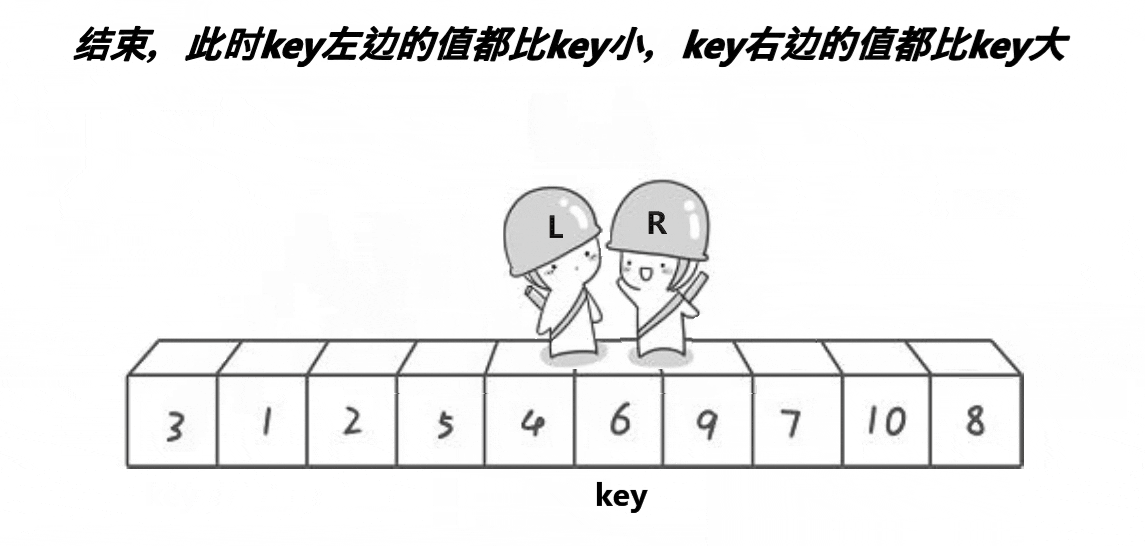
int Partion(int* arr, int left, int right)
{
int pivotloc = left; // 取第一个元素作为枢轴
int pivotkey = arr[pivotloc];
while (left < right)
{
// 从右往左搜索,找到第一个小于 pivotkey 的元素
while (left < right && arr[right] >= pivotkey)
{
--right;
}
// 从左往右搜索,找到第一个大于 pivotkey 的元素
while (left < right && arr[left] <= pivotkey)
{
++left;
}
// 交换
Swap(&arr[left], &arr[right]);
}
// left 和 right 相遇,即 left == right
Swap(&arr[pivotloc], &arr[left]);
pivotloc = left;
return pivotloc;
}
void QSort(int* arr, int left, int right)
{
if (left < right) // 长度大于 1
{
// 将 arr[left...right] 一分为二,pivotloc 是枢轴位置
int pivotloc = Partion(arr, left, right);
// 对左子表递归排序
QSort(arr, left, pivotloc - 1);
// 对右子表递归排序
QSort(arr, pivotloc + 1, right);
}
}
void QuickSort(int* arr, int n)
{
QSort(arr, 0, n - 1);
}当 left == right,可以分以下两种情况讨论:
从左往右搜索时,left 遇到了 right,此时 arr[left] == arr[right] < pivotkey。
从右往左搜索时,right 遇到了 left,若 left 已经移动过了,那么经过交换
Swap(&arr[left], &arr[right]),arr[left] < pivotkey;若 left 没有移动过,则 arr[left] == pivotkey。
挖坑法:
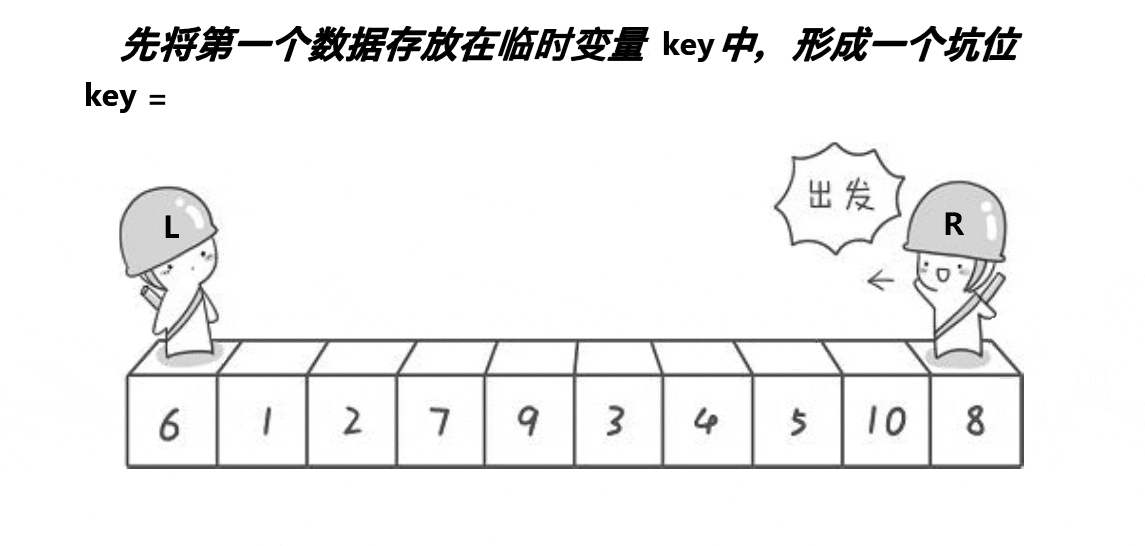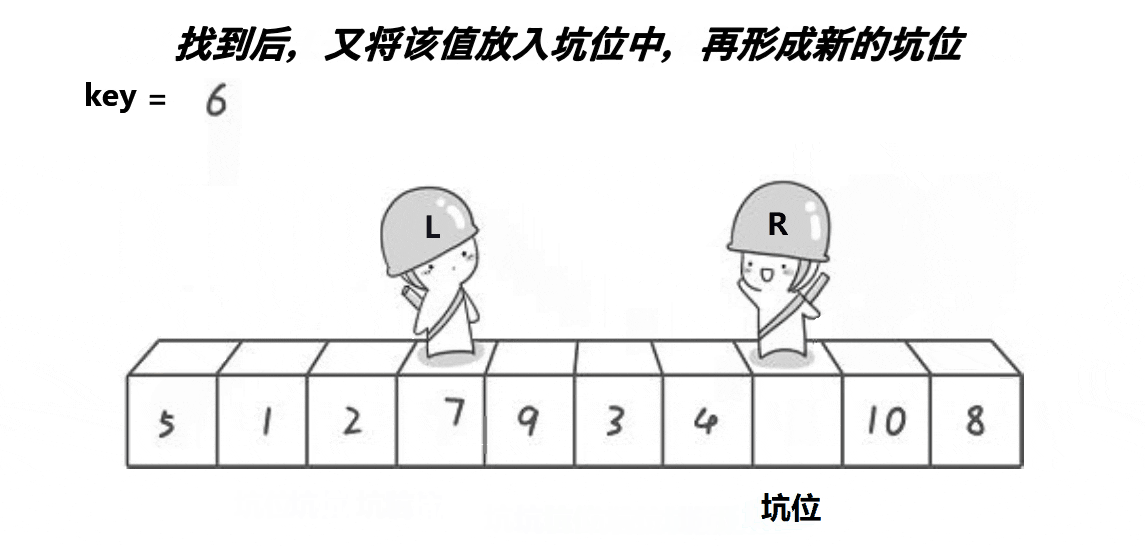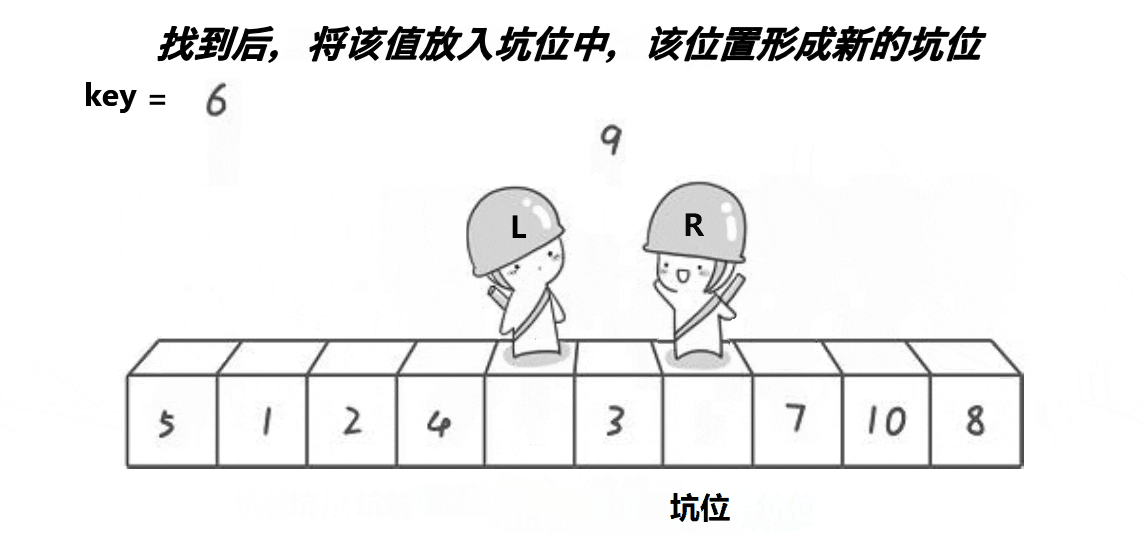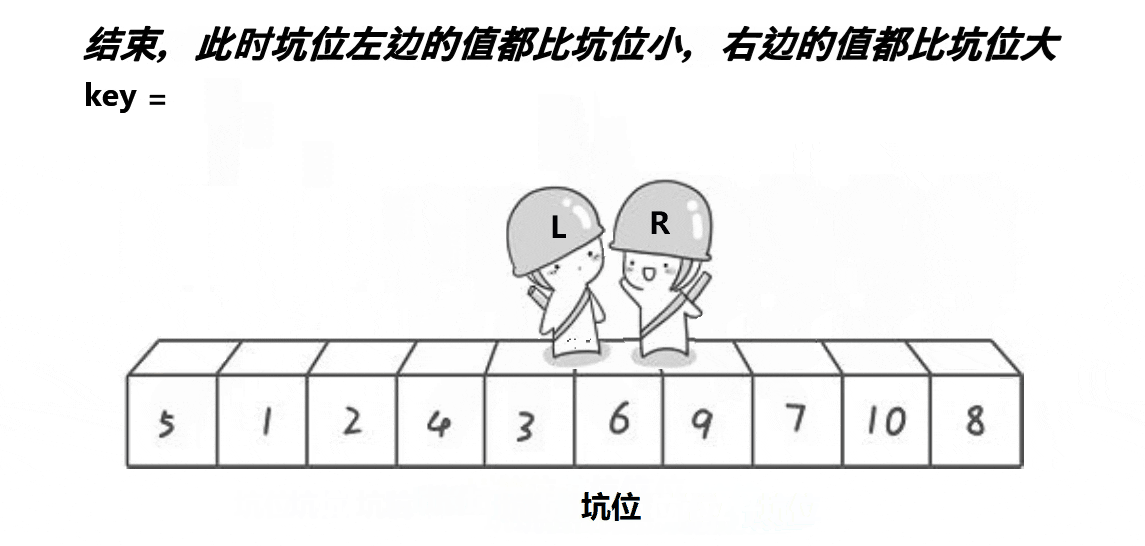
int Partion(int* arr, int left, int right)
{
int pivotloc = left; // 取第一个元素作为枢轴
int pivotkey = arr[pivotloc];
int pit = left; // 坑位
while (left < right)
{
// 从右往左搜索,找到第一个小于 pivotkey 的元素
while (left < right && arr[right] >= pivotkey)
{
--right;
}
arr[pit] = arr[right];
pit = right;
// 从左往右搜索,找到第一个大于 pivotkey 的元素
while (left < right && arr[left] <= pivotkey)
{
++left;
}
arr[pit] = arr[left];
pit = left;
}
// left 和 right 相遇,即 left == right
arr[pit] = pivotkey;
pivotloc = pit;
return pivotloc;
}前后指针法:
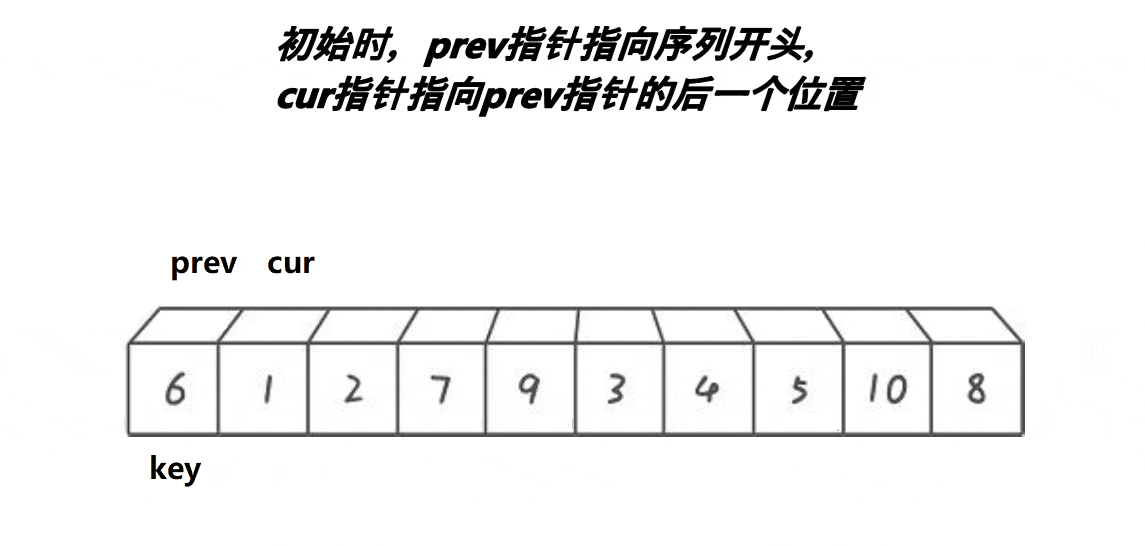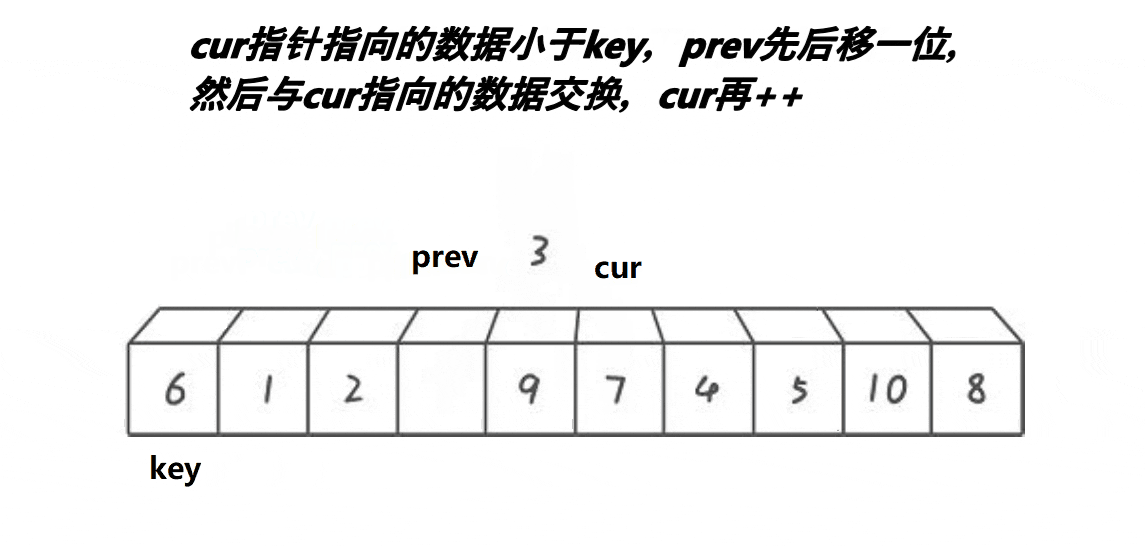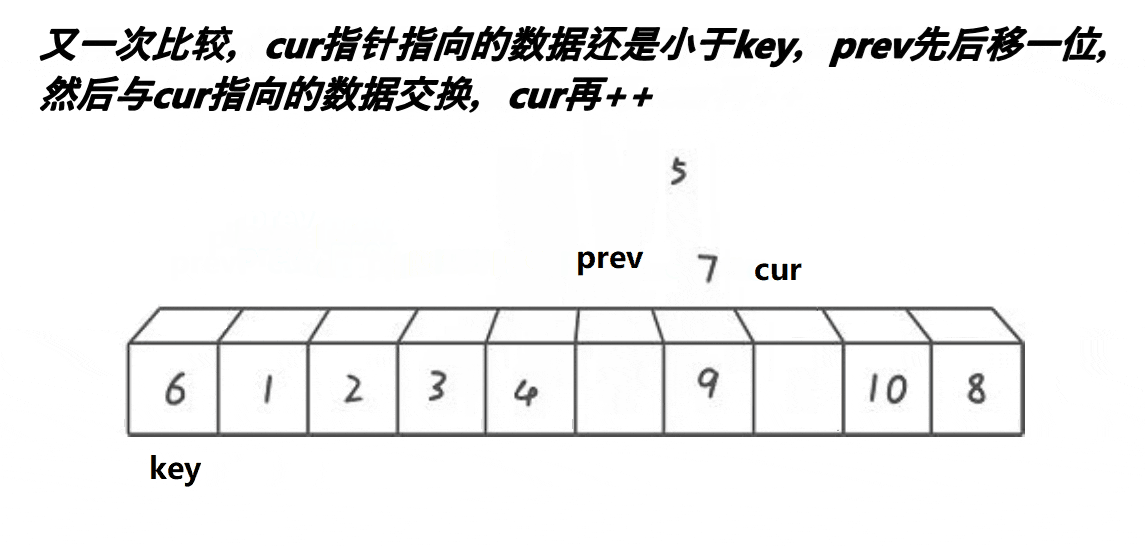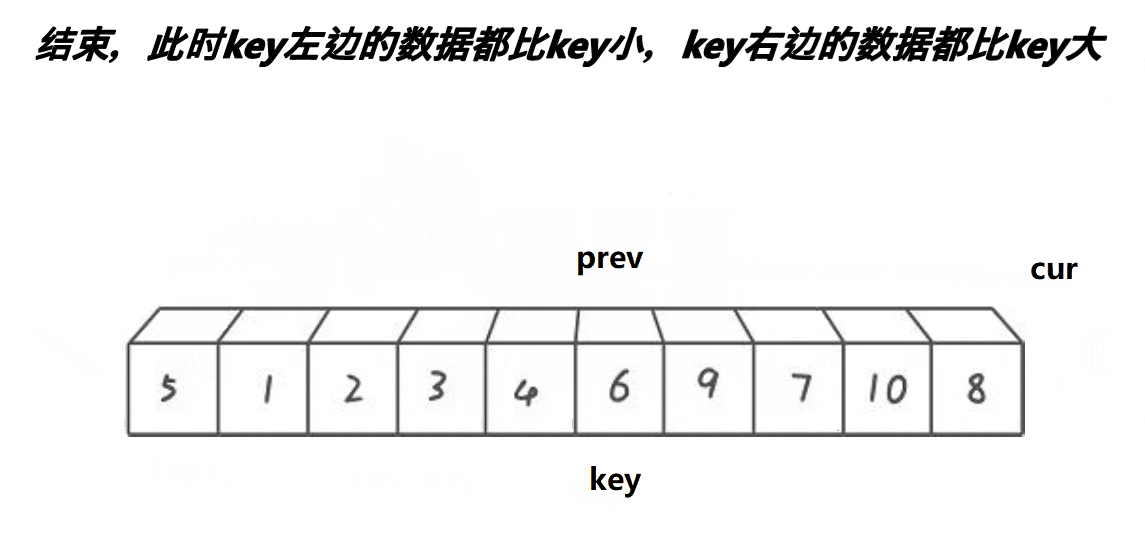
int Partion(int* arr, int left, int right)
{
int pivotloc = left; // 取第一个元素作为枢轴
int pivotkey = arr[pivotloc];
int prev = left;
int cur = prev + 1;
while (cur <= right)
{
if (arr[cur] < pivotkey && ++prev != cur)
{
Swap(&arr[prev], &arr[cur]);
}
++cur;
}
Swap(&arr[prev], &arr[pivotloc]);
pivotloc = prev;
return pivotloc;
}3.2.2 - 优化
以 Hoare 版本为例,假设 int arr[10] = { 6, 1, 2, 7, 9, 3, 4, 5, 10, 8 },整个快速排序的递归过程如下图所示:
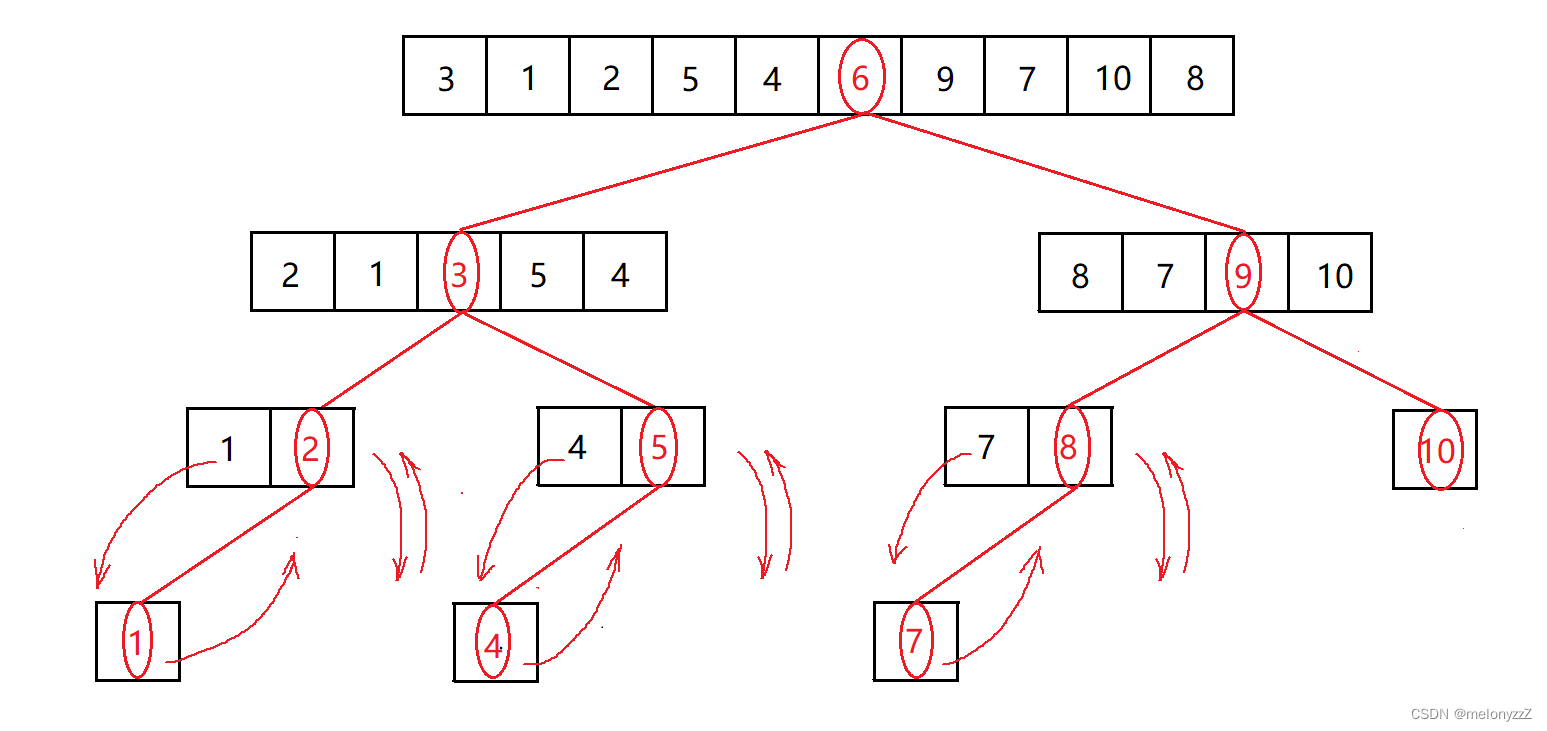
从快速排序递归算法的递归树可知,快速排序的趟数取决于递归树的深度。
最好情况:每一趟排序后都能将记录均匀地分割成两个大致相等的子表,类似于二分查找,时间复杂度为 O(nlogn)。
最坏情况:在待排序序列已经排好序的情况下,其递归树成为单支数,每次划分只得到一个比上一次少一个记录的子序列,时间复杂度为 O(n^2)。
枢轴的合理选择可以避免最坏情况的出现,如利用 "三者取中" 的规则:比较当前表中第一个记录、最后一个记录和中间一个记录的关键字,取关键字居中的记录作为枢轴记录,事先调换到第一个记录的位置。
int GetMidIndex(int* arr, int left, int right)
{
int mid = left + (right - left) / 2;
if (arr[left] < arr[mid])
{
if (arr[right] > arr[mid])
return mid;
else if (arr[right] > arr[left])
return right;
else
return left;
}
else
{
if (arr[right] > arr[left])
return left;
else if (arr[right] > arr[mid])
return right;
else
return mid;
}
}
// 以 Hoare 版本为例
int Partion(int* arr, int left, int right)
{
int ret = GetMidIndex(arr, left, right);
if (ret != left)
{
Swap(&arr[ret], &arr[left]); // 将居中的元素交换到第一个元素的位置
}
int pivotloc = left;
int pivotkey = arr[pivotloc];
// ... ....
}除此之外,还可以进一步优化,即小区间优化:
#define MAX_LENGTH_INSERT_SORT 7 // 数组长度阈值
void QSort(int* arr, int left, int right)
{
if (right - left + 1 > MAX_LENGTH_INSERT_SORT)
{
// 将 arr[left...right] 一分为二,pivotloc 是枢轴位置
int pivotloc = Partion(arr, left, right);
// 对左子表递归排序
QSort(arr, left, pivotloc - 1);
// 对右子表递归排序
QSort(arr, pivotloc + 1, right);
}
else
{
InsertSort(arr + left, right - left + 1);
}
}3.2.3 - 非递归算法
可以借助栈将递归算法改写成非递归算法。
void QuickSortNonRecursion(int* arr, int n)
{
Stack st;
StackInit(&st);
range r = { 0, n - 1 }; // 区间
StackPush(&st, r);
while (!StackEmpty(&st))
{
range top = StackTop(&st);
StackPop(&st);
if (top.left < top.right)
{
int pivotloc = Partion(arr, top.left, top.right);
range rr = { pivotloc + 1, top.right }; // 右区间
StackPush(&st, rr);
range lr = { top.left, pivotloc - 1 }; // 左区间
StackPush(&st, lr);
}
}
StackDestroy(&st);
}四、选择排序
选择排序的基本思想是:每一趟从待排序的记录中选出关键字最小的记录,按顺序放在已排序的记录序列的最后,直到全部排完为止。
4.1 - 简单选择排序
简单选择排序(Simple Selection Sort)也称作直接选择排序。
算法步骤:
-
设待排序的记录存放在数组
arr[0...n-1]中。第一趟从arr[0]开始,通过 n - 1 次比较,从 n 个记录中选出关键字最小的记录,记为arr[k],交换arr[0]和arr[k]。 -
第二趟从
arr[1]开始,通过 n - 2 次比较,从 n - 1 个记录中选出关键字最小的记录,记为arr[k],交换arr[1]和arr[k]。 -
重复上述过程,经过 n - 1 趟,排序完成。
void SelectSort(int* arr, int n)
{
for (int i = 0; i < n - 1; ++i)
{
int k = i;
for (int j = i + 1; j < n; ++j)
{
if (arr[j] < arr[k])
{
k = j;
}
}
if (k != i) // 交换 arr[i] 和 arr[k]
{
Swap(&arr[i], &arr[k]);
}
}
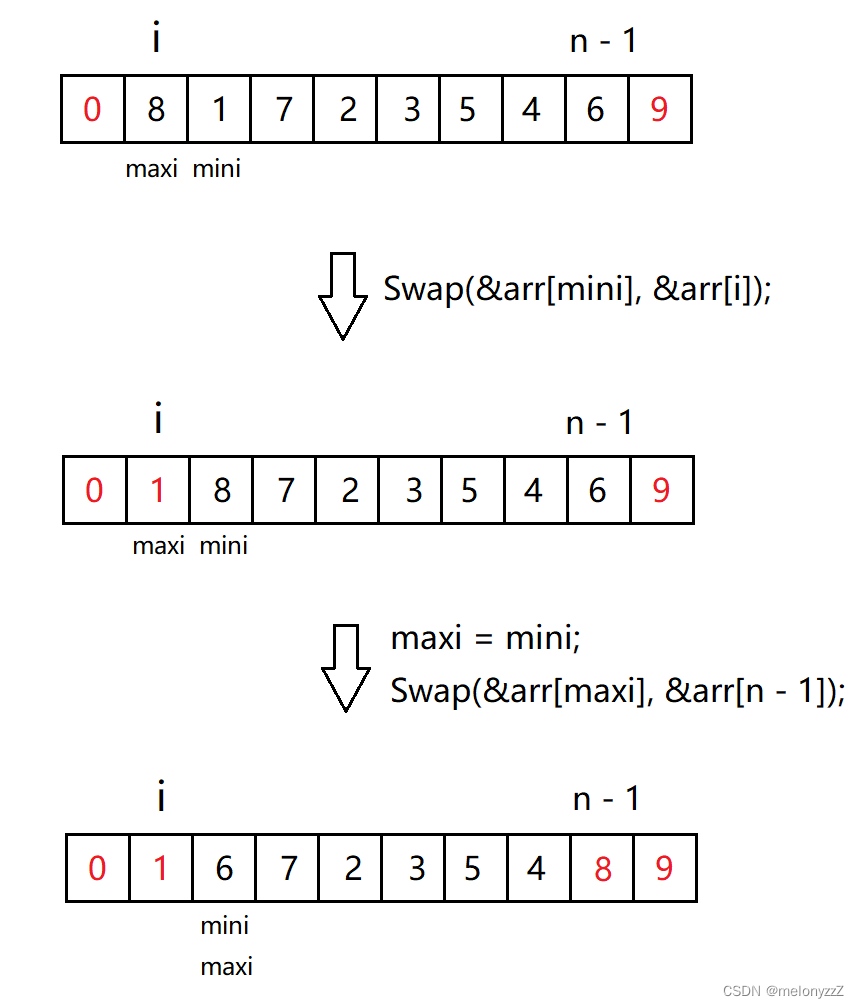
}改进:
void SelectSort(int* arr, int n)
{
for (int i = 0; i < n - 1; ++i, --n)
{
int mini = i; // 最小的元素下标
int maxi = i; // 最大的元素下标
for (int j = i + 1; j < n; ++j)
{
if (arr[j] < arr[mini])
{
mini = j;
}
if (arr[j] > arr[maxi])
{
maxi = j;
}
}
if (mini != i)
{
Swap(&arr[mini], &arr[i]);
}
if (maxi == i)
{
maxi = mini;
}
if (maxi != n - 1)
{
Swap(&arr[maxi], &arr[n - 1]);
}
}
}最开始
arr[i]可能就是关键字最大的记录,但经过交换后,即Swap(&arr[mini], &arr[i]),arr[i]就变成了关键字最小的记录,因此,如果不修改maxi,就会错误。
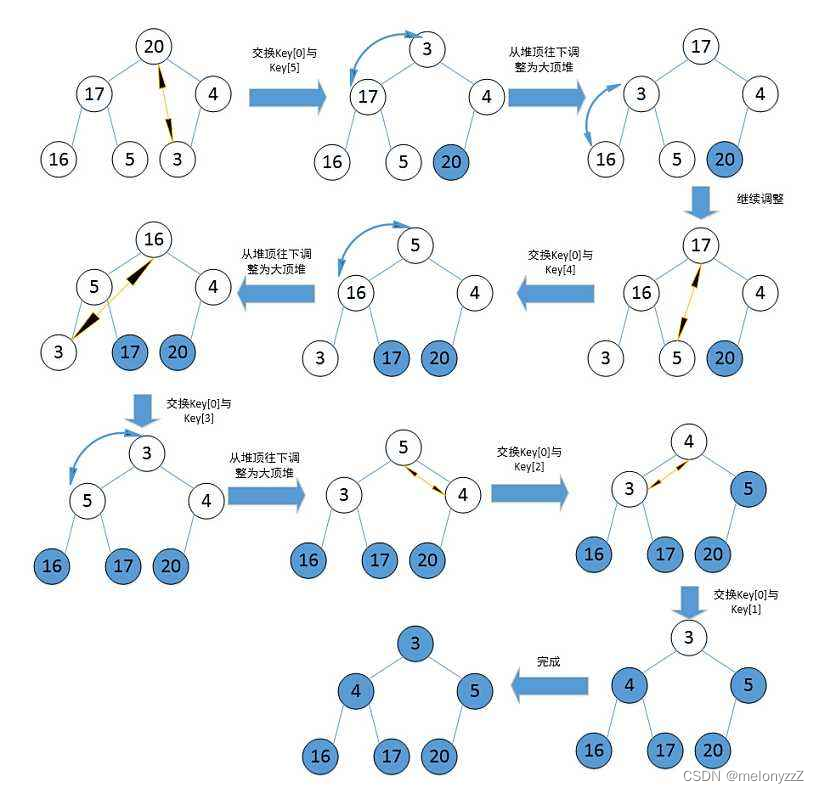
4.2 - 堆排序
算法步骤:
-
按堆的定义将待排序记录
arr[0...n-1]调整为大根堆(这个过程称为建初堆),交换arr[0]和arr[n - 1],则arr[n - 1]为关键字最大的记录。 -
将
arr[0...n-2]重新调整为堆,交换arr[0]和arr[n - 2],则arr[n - 2]为关键字次大的记录。 -
循环 n - 1 次,直到交换了
arr[0]和arr[1],得到了一个非递减的有序序列arr[0...n-1]。
同样,可以通过构造小根堆得到一个非递增的有序序列。
// 向下调整堆
void HeapAdjustDown(int* arr, int n, int parent)
{
int child = 2 * parent + 1; // 假设左孩子较大
while (child < n)
{
if (child + 1 < n && arr[child + 1] > arr[child])
{
++child;
}
if (arr[parent] < arr[child])
{
Swap(&arr[parent], &arr[child]);
parent = child;
child = 2 * parent + 1;
}
else
{
break;
}
}
}
// 建初堆
void HeapCreate(int* arr, int n)
{
for (int i = (n - 2) / 2; i >= 0; --i)
{
HeapAdjustDown(arr, n, i);
}
}
// 堆排序
void HeapSort(int* arr, int n)
{
HeapCreate(arr, n);
for (int i = n - 1; i > 0; --i)
{
Swap(&arr[0], &arr[i]);
HeapAdjustDown(arr, i, 0);
}
}五、归并排序
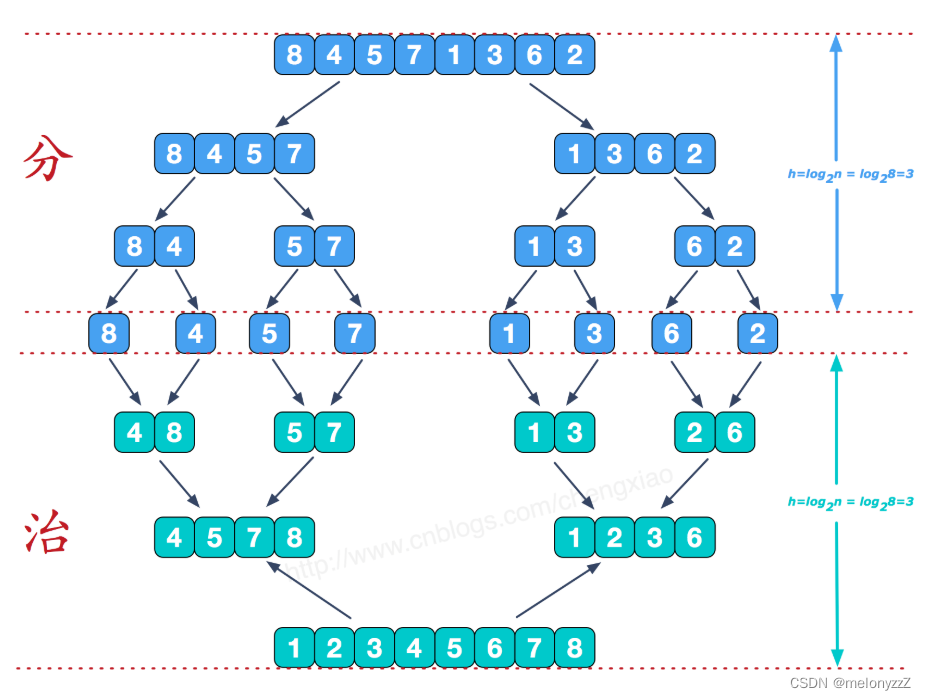
归并排序(Merging Sort)就是将两个或两个以上的有序表合并成一个有序表的过程。将两个有序表合并成一个有序表的过程称为 2-路归并。
归并排序算法的思想是:假设初始序列含有 n 个记录,则可看成是 n 个有序的子序列,每个子序列的长度为 1,然后两两归并,得到 个长度为 2 或 1 的有序子序列;再两两归并,... ...,如此重复,直至得到一个长度为 n 的有序序列为止。
5.1 - 递归
void Merge(int* arr, int* tmp, int left, int mid, int right)
{
int i = left;
int j = mid + 1;
int k = left;
while (i <= mid && j <= right)
{
if (arr[i] <= arr[j])
{
tmp[k++] = arr[i++];
}
else
{
tmp[k++] = arr[j++];
}
}
while (i <= mid)
{
tmp[k++] = arr[i++];
}
while (j <= right)
{
tmp[k++] = arr[j++];
}
// 最后将 tmp 中的内容拷贝到原数组 arr 中
memmove(arr + left, tmp + left, sizeof(int) * (right - left + 1));
}
void MSort(int* arr, int* tmp, int left, int right)
{
if (left < right)
{
int mid = (left + right) / 2;
// 对子序列 arr[left...mid] 递归归并排序
MSort(arr, tmp, left, mid);
// 对子序列 arr[mid+1...right] 递归归并排序
MSort(arr, tmp, mid + 1, right);
// 将相邻的两个有序表 arr[left...mid] 和 arr[mid+1...right]
// 归并为有序表 arr[left...right]
Merge(arr, tmp, left, mid, right);
}
}
void MergeSort(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (NULL == tmp)
{
perror("malloc failed!");
return;
}
MSort(arr, tmp, 0, n - 1);
free(tmp);
tmp = NULL;
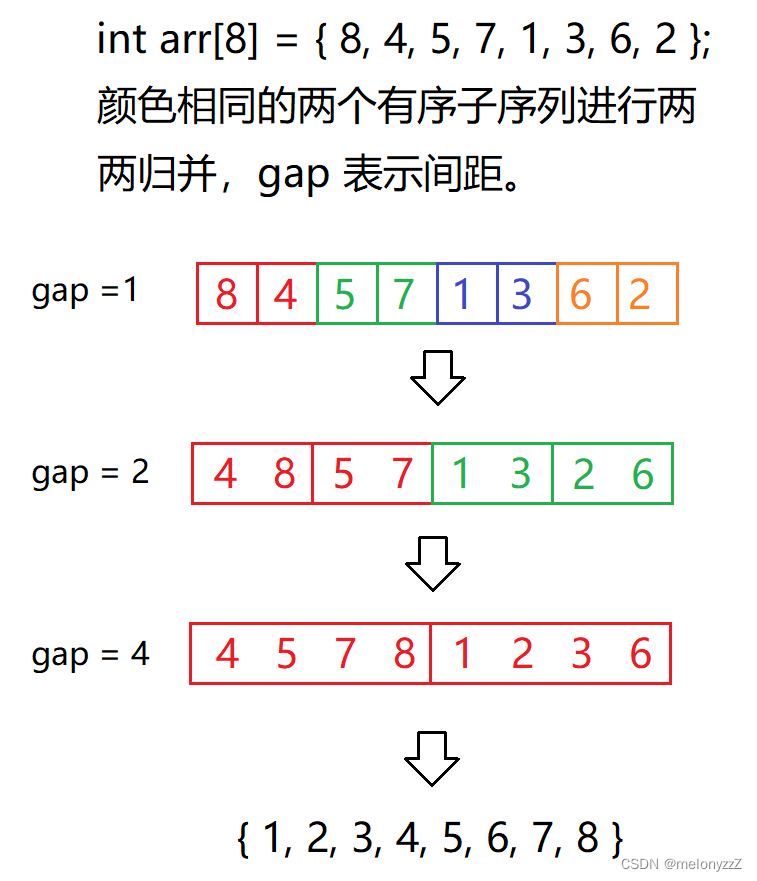
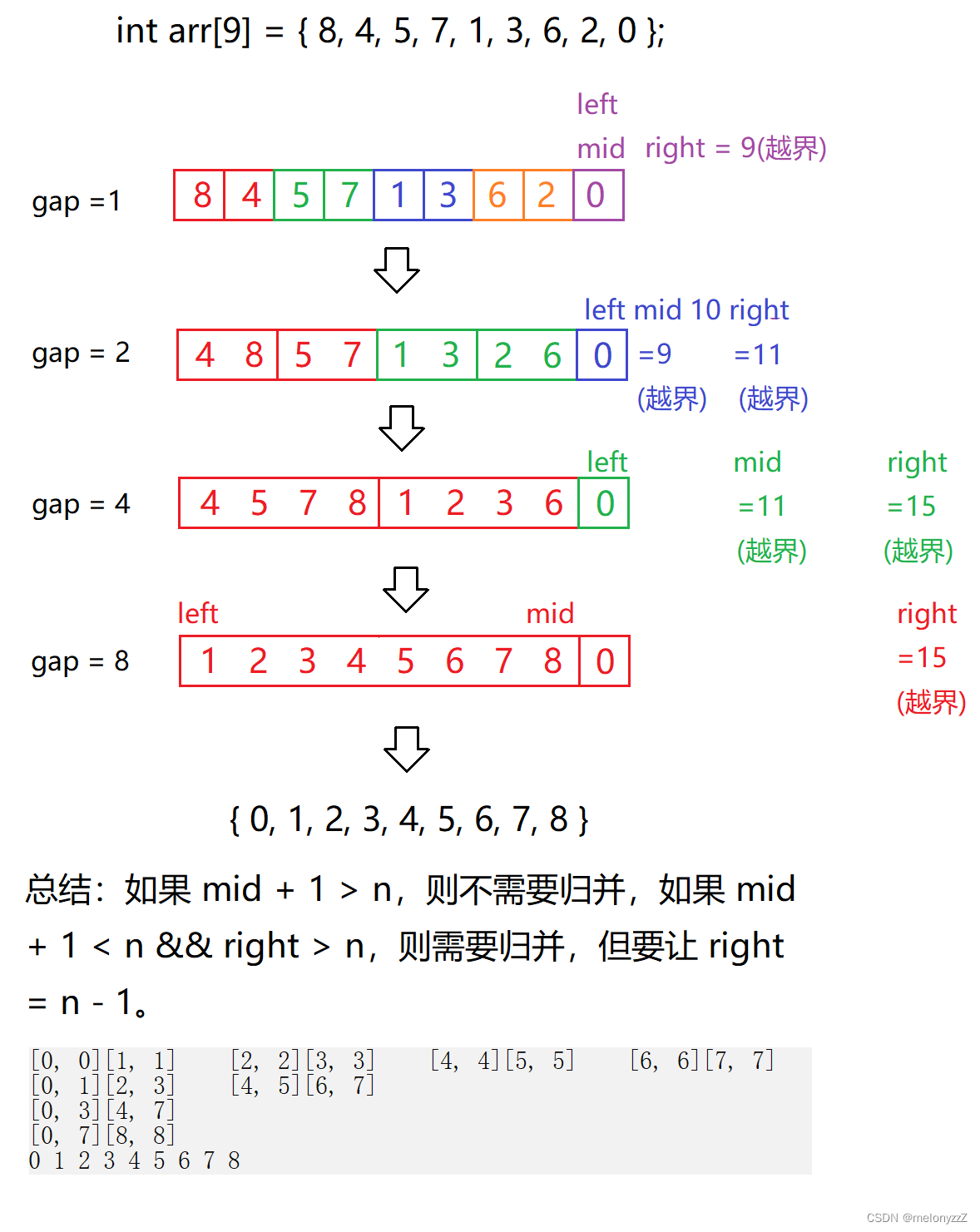
}5.2 - 迭代
void MergeSortNonRecursion(int* arr, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (NULL == tmp)
{
perror("malloc failed!");
return;
}
int gap = 1; // gap 表示间距
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
int left = i;
int right = i + 2 * gap - 1;
int mid = (left + right) / 2;
if (mid + 1 >= n)
{
break;
}
if (right >= n)
{
right = n - 1;
}
Merge(arr, tmp, left, mid, right);
}
gap *= 2;
}
free(tmp);
tmp = NULL;
}迭代过程并非模拟归并排序的递归过程。
例一:
例二:
六、排序算法复杂度及稳定性分析
| 排序方法 | 平均情况 | 最好情况 | 最坏情况 | 辅助空间 | 稳定性 |
|---|---|---|---|---|---|
| 直接插入排序 | O(n^2) | O(n) | O(n^2) | O(1) | 稳定 |
| 希尔排序 | O(nlogn) ~ O(n^2) | | O(n^2) | O(1) | 不稳定 |
| 冒泡排序 | O(n^2) | O(n) | O(n^2) | O(1) | 稳定 |
| 快速排序 | O(nlogn) | O(n^2) | O(nlogn) | O(logn) ~ O(n) | 不稳定 |
| 简单选择排序 | O(n^2) | O(n^2) | O(n^2) | O(1) | 不稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 |
性能测试:
void TestPerformace()
{
srand((unsigned int)time(NULL));
int n = 1000000;
int* arr1 = (int*)malloc(sizeof(int) * n);
int* arr2 = (int*)malloc(sizeof(int) * n);
int* arr3 = (int*)malloc(sizeof(int) * n);
int* arr4 = (int*)malloc(sizeof(int) * n);
int* arr5 = (int*)malloc(sizeof(int) * n);
int* arr6 = (int*)malloc(sizeof(int) * n);
int* arr7 = (int*)malloc(sizeof(int) * n);
if (!arr1 || !arr2 || !arr3 || !arr4 || !arr5 || !arr6 || !arr7)
{
perror("malloc failed!");
return;
}
for (int i = 0; i < n; ++i)
{
arr1[i] = rand();
arr2[i] = arr1[i];
arr3[i] = arr1[i];
arr4[i] = arr1[i];
arr5[i] = arr1[i];
arr6[i] = arr1[i];
arr7[i] = arr1[i];
}
// 开始测试
int begin1 = clock();
InsertSort(arr1, n);
int end1 = clock();
int begin2 = clock();
ShellSort(arr2, n);
int end2 = clock();
int begin3 = clock();
BubbleSort(arr3, n);
int end3 = clock();
int begin4 = clock();
QuickSort(arr4, n);
int end4 = clock();
int begin5 = clock();
SelectSort(arr5, n);
int end5 = clock();
int begin6 = clock();
HeapSort(arr6, n);
int end6 = clock();
int begin7 = clock();
MergeSort(arr7, n);
int end7 = clock();
printf("InsertSort: %d\n", end1 - begin1);
printf("ShellSort: %d\n", end2 - begin2);
printf("BubbleSort: %d\n", end3 - begin3);
printf("QuickSort: %d\n", end4 - begin4);
printf("SelectSort: %d\n", end5 - begin5);
printf("HeapSort: %d\n", end6 - begin6);
printf("MergeSort: %d\n", end7 - begin7);
free(arr1);
free(arr2);
free(arr3);
free(arr4);
free(arr5);
free(arr6);
free(arr7);
}
非比较排序(计数排序、基数排序和桶排序)会在下一篇博客中详解~
创作不易,请点点赞和关注一下博主









![py逆向-NSSCTF-[NISACTF 2022]ezpython](https://img-blog.csdnimg.cn/0670028634f0424d84e2dfc8ce24d46e.png)