目录
0. 强化学习wiki
1. 介绍
2. Exploration vs Exploitation 探索与开发
3. 各类最优化方法
3.1 Brute force猛兽蛮力法(暴力搜索)
3.2 Value function estimation(价值函数估计)
3.2.1 Monte Carlo methods 蒙特卡洛方法
3.2.2 Temporal difference methods 时差法
3.2.3 Function approximation methods 函数近似法
3.3 Direct policy search(直接策略搜索)
3.4 Model-based algoritms
4 不同RL算法对比
0. 原视频地址
1. Policy Gradient
2. Proximal Policy Optimization(PPO)
2.1 Off-Policy
2.2 Importance Sampling
2.3 具体的Policy生成方法
Q-learning
0. 强化学习wiki
大致了解当前强化学习技能树发展情况
Reinforcement learning - Wikipedia
1. 介绍
强化学习(英语:Reinforcement learning,简称RL)是机器学习中的一个领域,强调如何基于环境而行动,以取得最大化的预期利益。强化学习是除了监督学习和非监督学习之外的第三种基本的机器学习方法。与监督学习不同的是,强化学习不需要带标签的输入输出对,同时也无需对非最优解的精确地纠正。其关注点在于寻找探索(对未知领域的)和利用(对已有知识的)的平衡,强化学习中的“探索-利用”的交换,在多臂老虎机问题和有限MDP中研究得最多。在机器学习问题中,环境通常被抽象为马尔可夫决策过程(Markov decision processes,MDP)。
2. Exploration vs Exploitation 探索与开发
随机探索与选择算法认为最优项之间的平衡。
强化学习需要比较聪明的探索机制,直接随机的对动作进行采样的方法性能比较差。虽然小规模的马氏过程已经被认识的比较清楚,这些性质很难在状态空间规模比较大的时候适用,这个时候相对简单的探索机制是更加现实的。
其中的一种方法是贪婪算法,这种方法会以比较大的概率去选择现在最好的动作。如果没有选择最优动作,就在剩下的动作中随机选择一个。epsilion在这里是一个可调节的参数,更小的epsilion意味着算法会更加贪心。
3. 各类最优化方法
3.1 Brute force猛兽蛮力法(暴力搜索)
1. 对于每个可能的政策,在遵循该政策时对收益进行抽样调查
2. 选择具有最大预期收益的政策
缺陷:policies空间过大甚至无穷、返回值的方差过大需要较多采样。
可以通过价值函数估计、直接策略搜索来代替暴力搜索。
3.2 Value function estimation(价值函数估计)
价值函数方法尝试去找到一个策略,该策略能最大化奖励值,奖励值通过对一些策略的观测期望值进行估计来得到,这些被观测的策略是当前current策略(on-policy)或是最佳optimal策略(Off-Policy)。最佳策略在任意初始化的状态中总能返回最好的结果。
核心思想是从找最大状态期望V变成找最大动作期望Q。
![]()
![]()
两种base方法价值迭代value iteration和策略迭代policy iteration。这两类都是计算一系列Qk(k=0,1,2,...)来汇聚Q*,以及通过近似策略来在大的动作空间中得到期望。
策略迭代包括两步骤:策略评估、策略提升。
3.2.1 Monte Carlo methods 蒙特卡洛方法
用于策略迭代中的策略评估。
在策略评估步骤中,给出一个平稳、确定的策略π,需要去计算(或近似得到)所有状态-行为对的Qπ(s,a)得分。在有限空间中,一个s-a的得分可以用所有Q(s,a)得分的平均值来估计。
在策略提升步骤中,通过贪心算法最大化Q得分来改善策略,在实际应用中,可以通过lazy evaluation方法来推迟更新步骤。
该方法的局限性在于:
1. 在非最优/次优策略的估计中花费太多时间。
2. 对样本的使用率低。
3. 当样本分布方差高(得分的概率分布较为分散)时,收敛缓慢。
4. 只能用于episodic problems。
5. 只能用于小的有限MDPs场景(或者说是离散值场景)。
针对以上这五个问题,后续又提出了一些改进方法。
问题1:在次优策略估计中花费太多时间,可以通过允许在values settle前修改Policy来解决,不过相应的这可能会带来收敛问题。现在很多算法都这么做,它们被统称为广义上的策略迭代算法;许多actor-critic也属于此类(注:actor-critic的做法是有两个神经网络,一个是actor用于训练Policy,另一个是critic用于估计不同状态下action的reward;即同时学习Policy和value function)。
问题2:通过设置trajectories可以对路径中任意s-a对的训练做提升来解决,这同时也能缓解问题3。
3.2.2 Temporal difference methods 时差法
TD方法中的计算可以是增量incremental的(每次更新后不保留过去状态),或者是批次batch的(先收集数据然后按批次更新Policy)。
按batch的方法如最小二乘时间差分法(the least-squares temporal difference method)可以更好的利用样本samples,而按incremental的方法是在无法承担batch高计算成本与复杂度下的选择。
基于TD的方法也能解决问题4.
3.2.3 Function approximation methods 函数近似法
用于解决问题5.
3.3 Direct policy search(直接策略搜索)
直接在策略空间(的某个子集)中搜索,在这种情况下,问题变成了随机优化的情况。可用的两种方法是基于梯度的方法和无梯度的方法。
// 待补充
3.4 Model-based algoritms
最后,上述所有方法都可以与首先学习模型的算法相结合。例如,Dyna 算法从经验中构造模型,并使用模型为价值函数提供更多模型化的转换。这种方法有时可以扩展到使用非参数模型,例如就把转换存储并“重播”到算法中。
除了更新价值函数之外,还有其他使用模型的方法。例如,在模型预测控制中,模型用于直接更新行为。
4 不同RL算法对比
| Algorithm | Description | Policy | Action space | State space | Operator |
|---|---|---|---|---|---|
| Monte Carlo | Every visit to Monte Carlo | 皆可 | 离散 | 离散 | Sample-means |
| Q-learning | State–action–reward–state | Off-policy | 离散 | 离散 | Q-value |
| SARSA | State–action–reward–state–action | On-policy | 离散 | 离散 | Q-value |
| Q-learning - Lambda | 具有资格痕迹的State–action–reward–state | Off-policy | 离散 | 离散 | Q-value |
| SARSA - Lambda | 具有资格痕迹的State–action–reward–state–action | On-policy | 离散 | 离散 | Q-value |
| DQN | Deep Q Network | Off-policy | 离散 | 连续 | Q-value |
| DDPG | Deep Deterministic Policy Gradient | Off-policy | 连续 | 连续 | Q-value |
| A3C | 异步 优势Actor-Critic | On-policy | 连续 | 连续 | 平均 |
| NAF | Q-Learning with归一化优势函数 | Off-policy | 连续 | 连续 | 平均 |
| TRPO | Trust Region策略优化 | On-policy | 连续 | 连续 | 平均 |
| PPO | Proximal近端 Policy Optimization | On-policy | 连续 | 连续 | 平均 |
| TD3 | Twin Delayed双延迟 Deep Deterministic 深度确定性Policy Gradient | Off-policy | 连续 | 连续 | Q-value |
| SAC | Soft Actor-critic | Off-policy | 连续 | 连续 | 平均 |
0. 原视频地址
DRL Lecture 3: Q-learning (Basic Idea) - YouTube![]() https://www.youtube.com/watch?v=o_g9JUMw1Oc&list=PLJV_el3uVTsODxQFgzMzPLa16h6B8kWM_&index=14
https://www.youtube.com/watch?v=o_g9JUMw1Oc&list=PLJV_el3uVTsODxQFgzMzPLa16h6B8kWM_&index=14
1. Policy Gradient
env和reward是事先给定的,不能在train的时候去调整,可变参数在Actor的Policy这里。 Actor的参数常被表示为,可以计算
即为Trajectory发生的概率
这里的
是因为s2和s1也是有关系的,所以是s1和a1状况下产生s2的概率。 env不一定是neural Networks的function,它也可以是rule-based的。

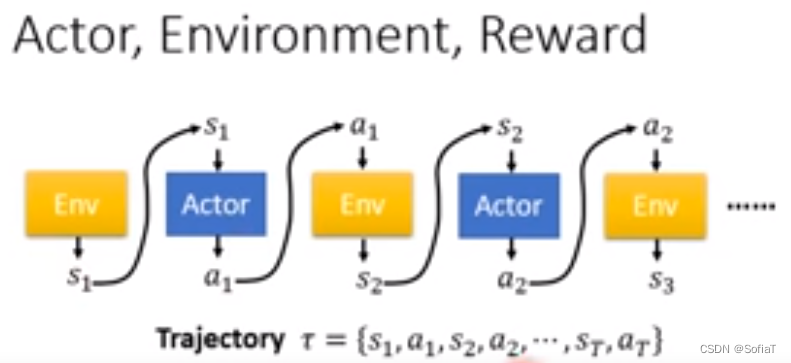
又因为这里是Score越大越好,所以是gradient ascent。update的时候正负号变了。
可以看出,这里计算梯度有一个直接的公式可以带入。所以可以这样直接算。

全部加起来就得到gradient,可以用来update参数。
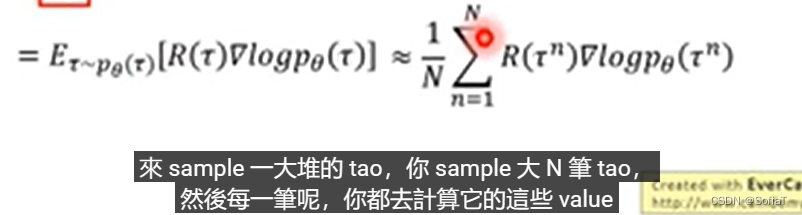
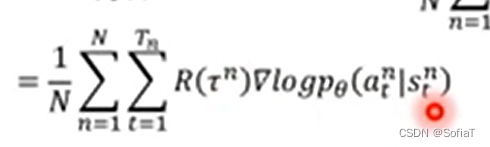
相当于,如果在状态st下做了动作at,会让分数增长,那就保留,反之就舍去。
但是有时候game的reward设置的不好,大家都是正的。所以这里要设置一个base,通过减去这个base来惩罚不好的项。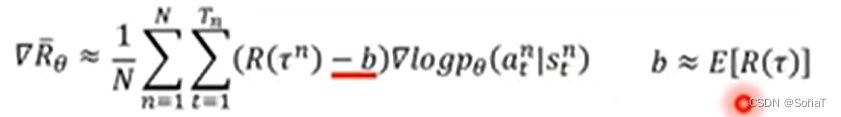
2. Proximal Policy Optimization(PPO)
2.1 Off-Policy

先介绍了一个新概念叫Off-Policy,拿去和Env做互动的Agent和learn的Agent不同了。主要是由于
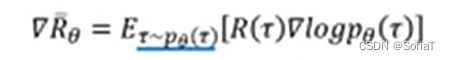 这个公式的期望,如果theta变了那之前收集到的数据就不适用了(这里对不上,不再是当前theta得到的τ的期望),所以希望用一个纯纯的工具人Agent只收集Env的τ,得到数据。可以用sample来的数据一笔train很多次。
这个公式的期望,如果theta变了那之前收集到的数据就不适用了(这里对不上,不再是当前theta得到的τ的期望),所以希望用一个纯纯的工具人Agent只收集Env的τ,得到数据。可以用sample来的数据一笔train很多次。

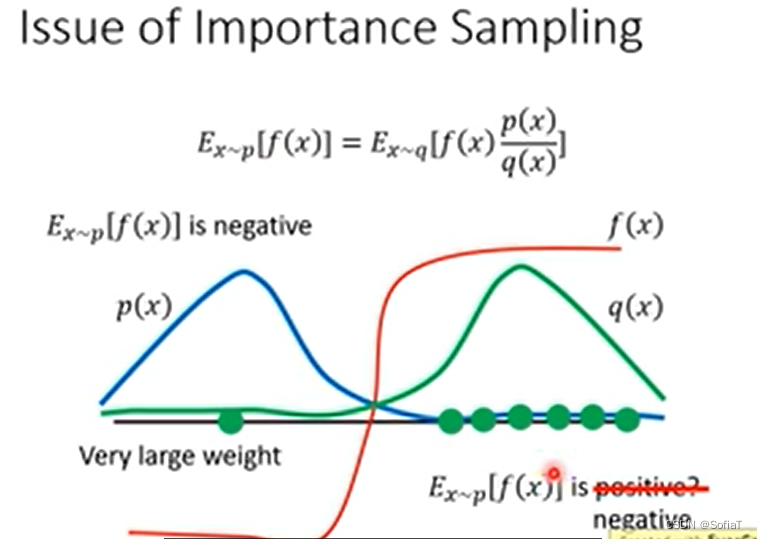
2.2 Importance Sampling
接着讲了一个期望的sample方式,不知道为什么现在没办法直接从p里面做期望值,所以我们要用q分布去采样,得到下面这样一个计算公式。

但是要注意p和q的期望值不能差太多。可以看出等式左右二者的期望一样,但是方差不一样。所以导致如果sample的次数不够多,会导致有比较大的差距。公式如下:
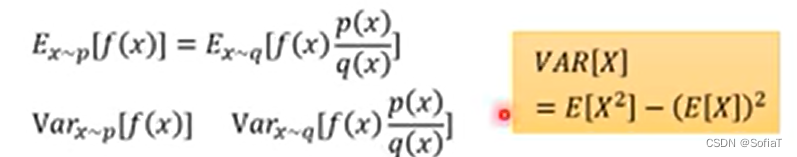
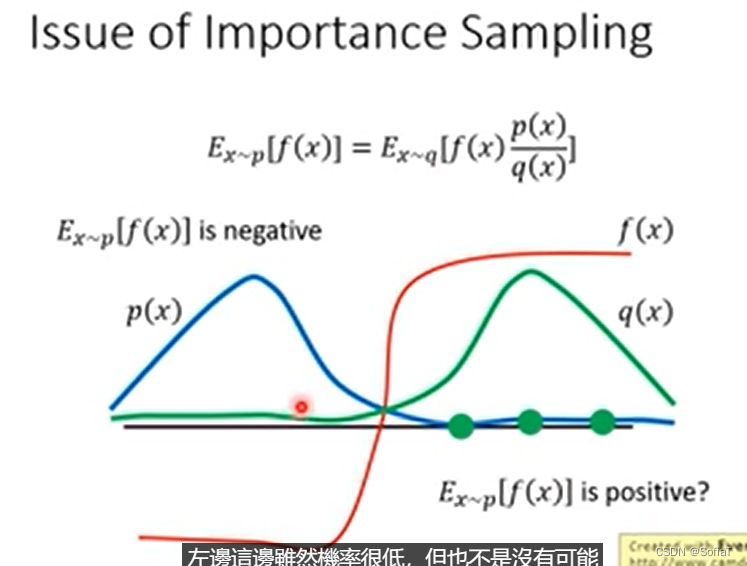
比较形象的来看:如果是单纯的p采样,那么期望应该是负的。在sample次数不够的情况下,大概率会落到f(x)是正的这边,所以期望就变成正的了,不过如果sample够多的话,就会得到一个巨大的负值(q(x)作为一个非常小的除数),然后平衡下来最后还是负的。
2.3 具体的Policy生成方法
接下来就开始讲怎么把一个actor变成两个,公式是怎么变的。

上周讲过也就是说,针对期望的计算,不是一下计算出来的,而是根据每个pair分别计算。
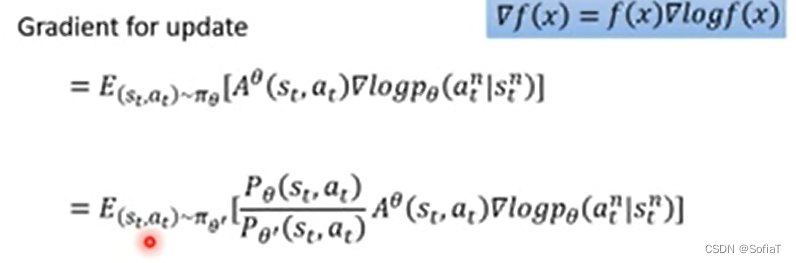
Q-learning
tbc......


![[CVE漏洞复现系列]CVE2017_0147:永恒之蓝](https://img-blog.csdnimg.cn/ce05a22ec04d4f6b82b5389b40a178c1.png#pic_center)