死锁问题
- 🏞️1. 死锁概念
- 🌁2. 为什么发生死锁
- 🌠3. 产生死锁的条件
- 🌁4. 如何避免死锁
- 📖4.1 循环等待
- 📖4.2 持有并等待
- 📖4.3 非抢占
- 📖4.4 互斥
- 🌿5. 通过调度避免死锁
- 🍁6. 检查和恢复
🏞️1. 死锁概念
死锁(deadlock)是一种在许多复杂并发系统中出现的经典问题.
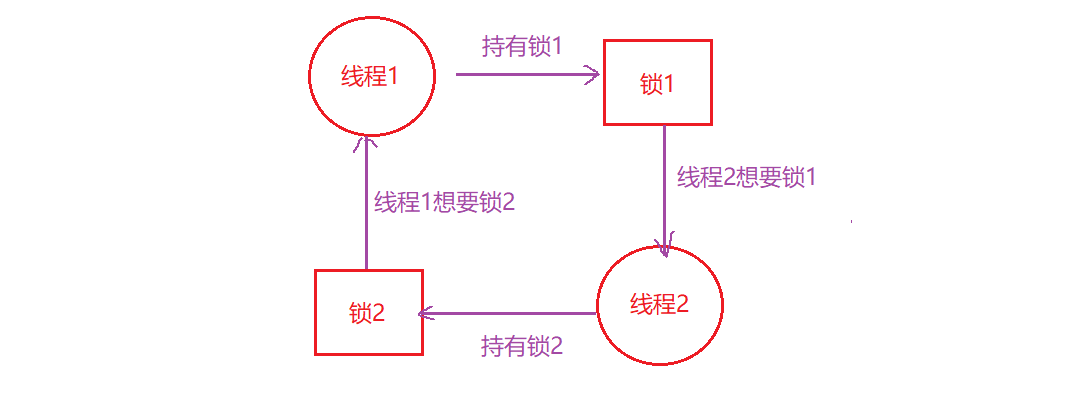
例如,当线程1持有锁L1,正在等待另外一个锁L2,而线程2持有锁L2,却在等待锁L1释放时,死锁就产生了:
Thread 1: Thread 2:
lock(L1); lock(L2);
lock(L2); lock(L1);
这段代码运行时,不是一定会出现死锁的,当线程1占有锁L1,上下文切换到线程2,线程2申请到锁L2,然后当它试图申请锁L1时,这时就产生了死锁,两个线程互相等待.
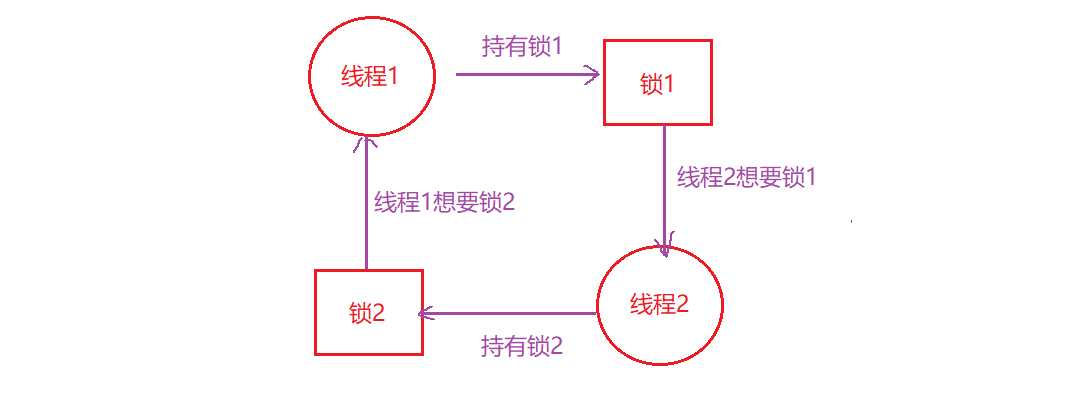
我们来看一个简单的死锁案例:
#include<iostream>
#include<semaphore.h>
#include<pthread.h>
#include<unistd.h>
using namespace std;
pthread_mutex_t mutex1 = PTHREAD_MUTEX_INITIALIZER;
pthread_mutex_t mutex2 = PTHREAD_MUTEX_INITIALIZER;
void* threadRoutinue1(void* args)
{
pthread_mutex_lock(&mutex1);
sleep(2); //此时thread1睡眠, thread2会运行并拿到mutex2, thread1无法醒来时无法拿到mutex2
pthread_mutex_lock(&mutex2);
cout << "thread1 running" << endl;
pthread_mutex_unlock(&mutex2);
pthread_mutex_unlock(&mutex1);
}
void* threadRoutinue2(void* args)
{
pthread_mutex_lock(&mutex2);
pthread_mutex_lock(&mutex1);
cout << "thread2 running" << endl;
pthread_mutex_unlock(&mutex1);
pthread_mutex_unlock(&mutex2);
}
int main()
{
pthread_t t1, t2;
pthread_create(&t1, nullptr, threadRoutinue1, nullptr);
pthread_create(&t1, nullptr, threadRoutinue2, nullptr);
cout << "main thread" << endl;
pthread_join(t1, 0);
pthread_join(t2, 0);
pthread_mutex_destroy(&mutex1);
pthread_mutex_destroy(&mutex2);
return 0;
}
🌁2. 为什么发生死锁
你可能在想,上文中提到的这个死锁的例子,很容易就可以避免,例如:只要线程1和线程2都用相同的抢锁顺序,死锁就不会发生,那么,死锁为什么还会发生?
其中一个原因是在大型的代码库中,组件之间会有复杂的依赖,以操作系统为例:虚拟内存系统需要访问文件系统才能从磁盘读到内存页;文件系统随后又要和虚拟内存交互,去申请一页内存,以便存放读到的块. 因此,在设计大型系统的锁机制时,你必须要仔细的去避免循环依赖导致的死锁.
另一个原因是封装. 软件开发者一直倾向于隐藏实现细节,以模块化的方式让软件开发更容易. 然而,模块化和锁不是很契合,某些看起来没有关系的接口可能会导致死锁.
🌠3. 产生死锁的条件
死锁的产生需要如下4个条件:
- 互斥:线程对于需要的资源进行互斥的访问
- 持有并等待:线程持有了资源(例如已经持有的锁),同时又在等待其他资源(例如,需要获得的锁)
- 非抢占:线程获得的资源(例如锁),不能被抢占
- 循环等待:线程之间存在一个环路,环路上的每个线程都额外持有一个资源,而这个资源又是另一个线程要申请的.
🌁4. 如何避免死锁
📖4.1 循环等待
经常采用的预防技术,就是让代码不会产生循环等待,最直接的方法就是获取锁时提供一个全序. 假如系统共有两个锁(L1和L2),那么我们每次都先申请L1然后申请L2,就可以避免死锁. 这样的顺序避免了循环等待,也就不会产生死锁.
更复杂的系统中不会只有两个锁,锁的全序可能很难做到,因此,偏序可能是一种有用的方法,安排锁的获取并避免死锁.
全序和偏序都需要细致的锁策略的设计和实现,另外,顺序只是一种约定,粗心的程序员很容易忽略,导致死锁,而且有序加锁需要深入理解代码库,了解各种函数的调用关系.

代码实例如下:
//.......
if(m1 > m2)
{
pthread_mutex_lock(&m1);
pthread_mutex_lock(&m2);
}
else
{
pthread_mutex_lock(&m2);
pthread_mutex_lock(&m1);
}
//.......
📖4.2 持有并等待
死锁的持有并等待条件,可以通过原子的抢锁来避免,例如通过如下代码:
lock(prevention);
lock(L1);
lock(L2);
...
unlock(prevention);
先抢到prevention这个锁后,代码保证了在抢锁的过程中,不会有不合时宜的线程切换,从而避免了死锁. 当然,这需要任何线程在任何时候抢占锁时,先抢到全局的prevention锁,这时,另一个线程就算使用不同的顺序抢锁,也不会有问题.
📖4.3 非抢占
在调用unlock之前,都认为锁是被占有的,多个抢锁操作通常会带来麻烦,因为我们等待一个锁时,持有另一个锁.
pthread_mutex_trylock()函数会尝试获得锁,没有获取到便返回-1,表示锁已经被占有,所以可以通过这一接口来实现无死锁的加锁方法:
top:
lock(L1);
if(trylock(L2) == -1)
{
unlock(L1);
goto top;
}
另一个线程可以采用相同的加锁方式,但是不同的加锁顺序,程序不会产生死锁.
但是又会带来一个新的问题:活锁. 两个线程有可能一直重复这一序列,又同时都抢锁失败,这种情况下,系统一直在运行这段代码,但是又不会有进展,因此名为活锁.
活锁的解决方法:可以在循环结束的时候,先随机等待一个时间,然后再重复整个动作,这样可以降低线程之间的重复互相干扰.
这个方案还有一个缺点:如果代码在中途获取了某些资源,必须要确保也能释放这些资源,例如,在抢到L1后,我们的代码分配了一些内存,当抢L2失败时,并且在返回开头之前,必须确保能正确释放这些资源,无形中为我们增添了负担.
📖4.4 互斥
最后的预防方法是完全避免互斥,想法很简单:通过强大的硬件指令,构造出不需要锁的数据结构.
举个简单的例子:假设我们有比较并交换指令,是由硬件提供的一种原子指令,它会做如下的事情:
int CompareAndSwap(int* address, int expected, int new)
{
if(*address == expected)
{
*address = new;
return 1; //交换成功
}
return 0; //交换失败
}
假如我们想原子的给某个值增加特定的数量,可以这样实现:
void AtomicIncrement(int* value, int amount)
{
do
{
int old = *value;
}while(CompareAndSwap(value, old, old + amount) == 0);
}
这种方式无须使用锁. 并且不会产生死锁(但这段代码有可能产生活锁).
🌿5. 通过调度避免死锁
有些场景更适合死锁避免,我们需要了解全局的信息,包括不同线程在运行中对锁的需求,从而使得后续的调度能够避免产生死锁.
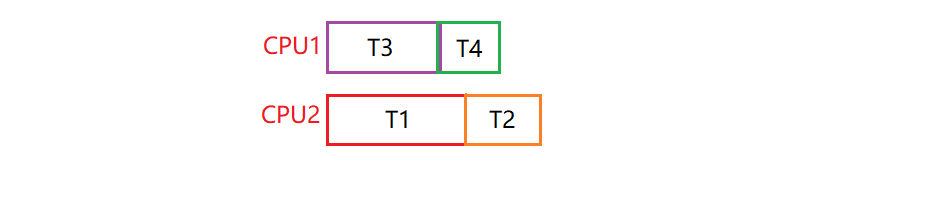
例如,我们需要在两个处理器上调度4个线程,假设我们知道线程1(T1),需要锁L1和L2,T2也需要L1和L2,T3只需要L2,T4不需要锁:

即:只要T1和T2不同时运行,就不会产生死锁:
再来看一个竞争更多的例子:

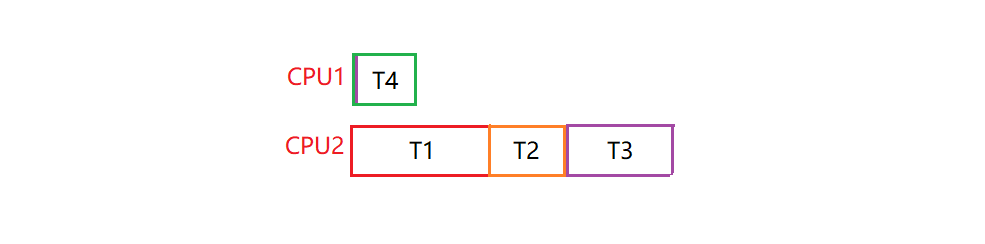
线程T1、T2、T3执行过程中,都需要锁L1和L2,所以需要让T1、T2、T3串行.
T1、T2、T3运行在同一个处理器上,这种保守的静态方案会明显增加完成任务的总时间,为了避免死锁,没有让它们并发运行,付出了性能的代价.
所以这种方法有两个缺点:
- 需要提前知道所有任务以及它们需要的锁
- 会限制并发,降低性能.
🍁6. 检查和恢复
最后一种常用的策略就是允许死锁偶尔发生,检查到死锁时再采取行动,举个例子:如果一个操作系统一年死机一次,你会重启系统,然后愉快的继续工作.
很多数据库系统使用了死锁检测和恢复技术. 死锁检测器会定期运行,通过构建资源图来检查循环. 当循环(死锁)发生时,系统需要重启. 如果还需要更复杂的数据结构相关的修复,那么需要人工参与.