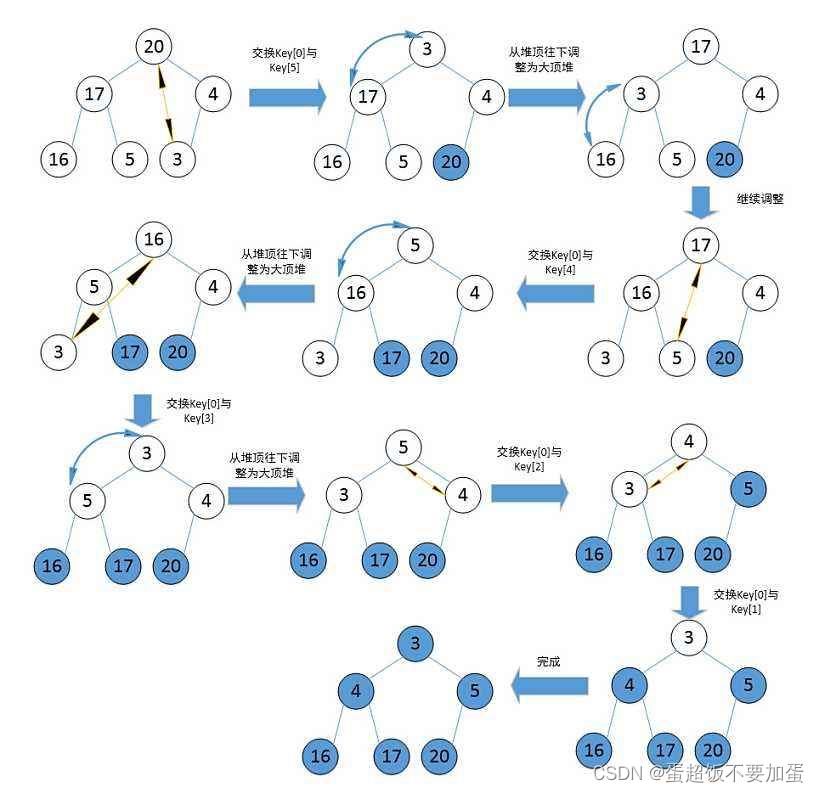
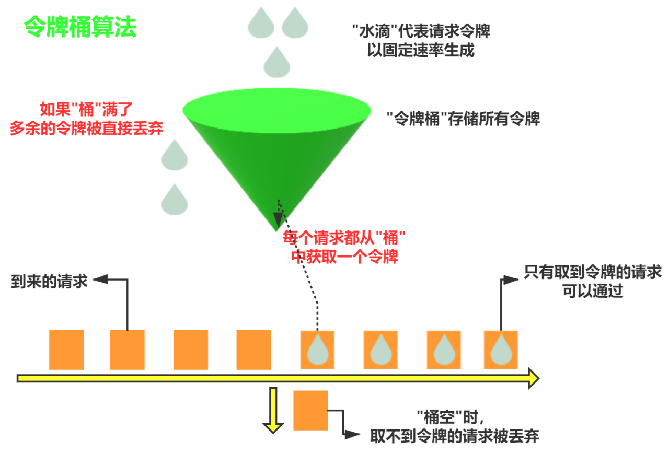
1.python文件、python控制台Terminal、jupyter代码执行比较
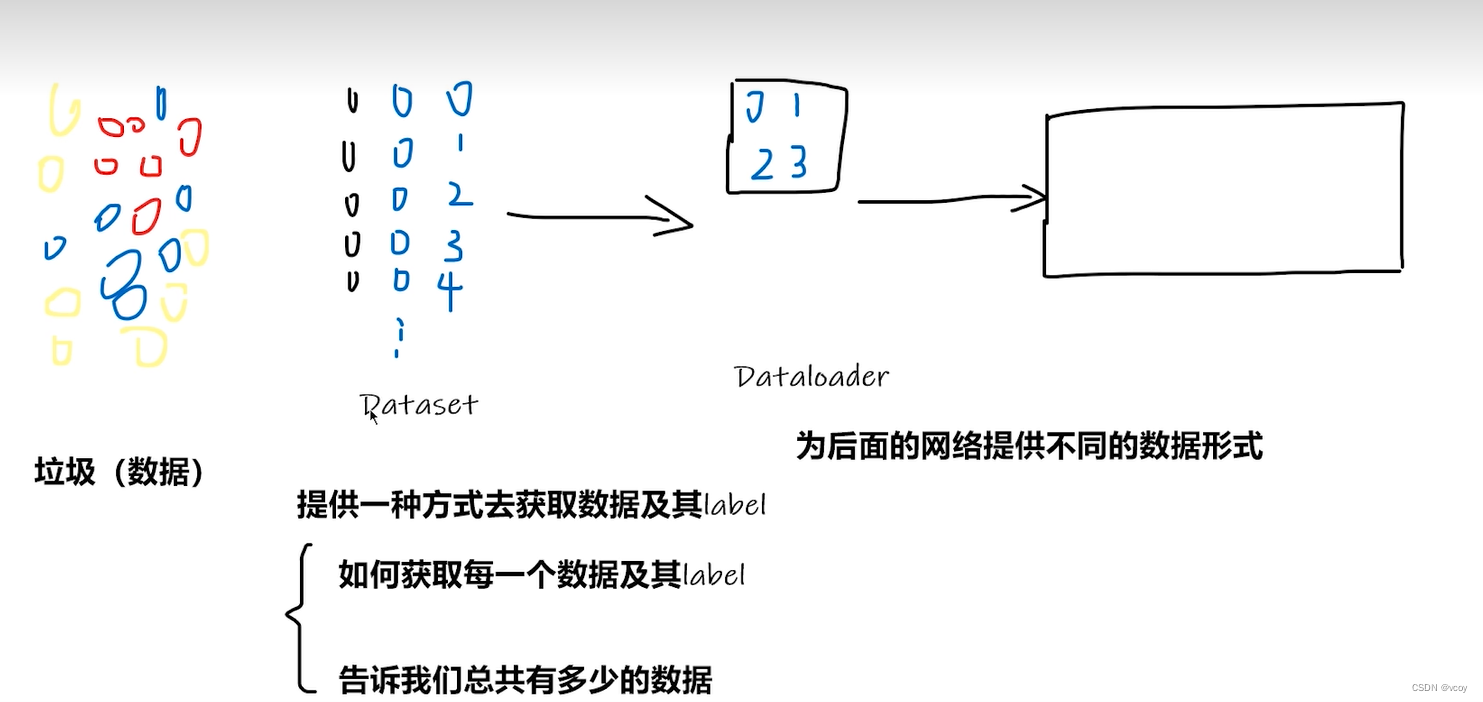
2.Dataset和Dataloader
dataset存储数据集,dataloader从数据集中批量加载数据,如
把 dataset 放入 DataLoader
loader = Data.DataLoader(
dataset=torch_dataset, # torch TensorDataset format
batch_size=BATCH_SIZE, # mini batch size 处理的数据个数
shuffle=False, # 要不要打乱数据 (打乱比较好)
num_workers=0, # 多线程来读数据
)
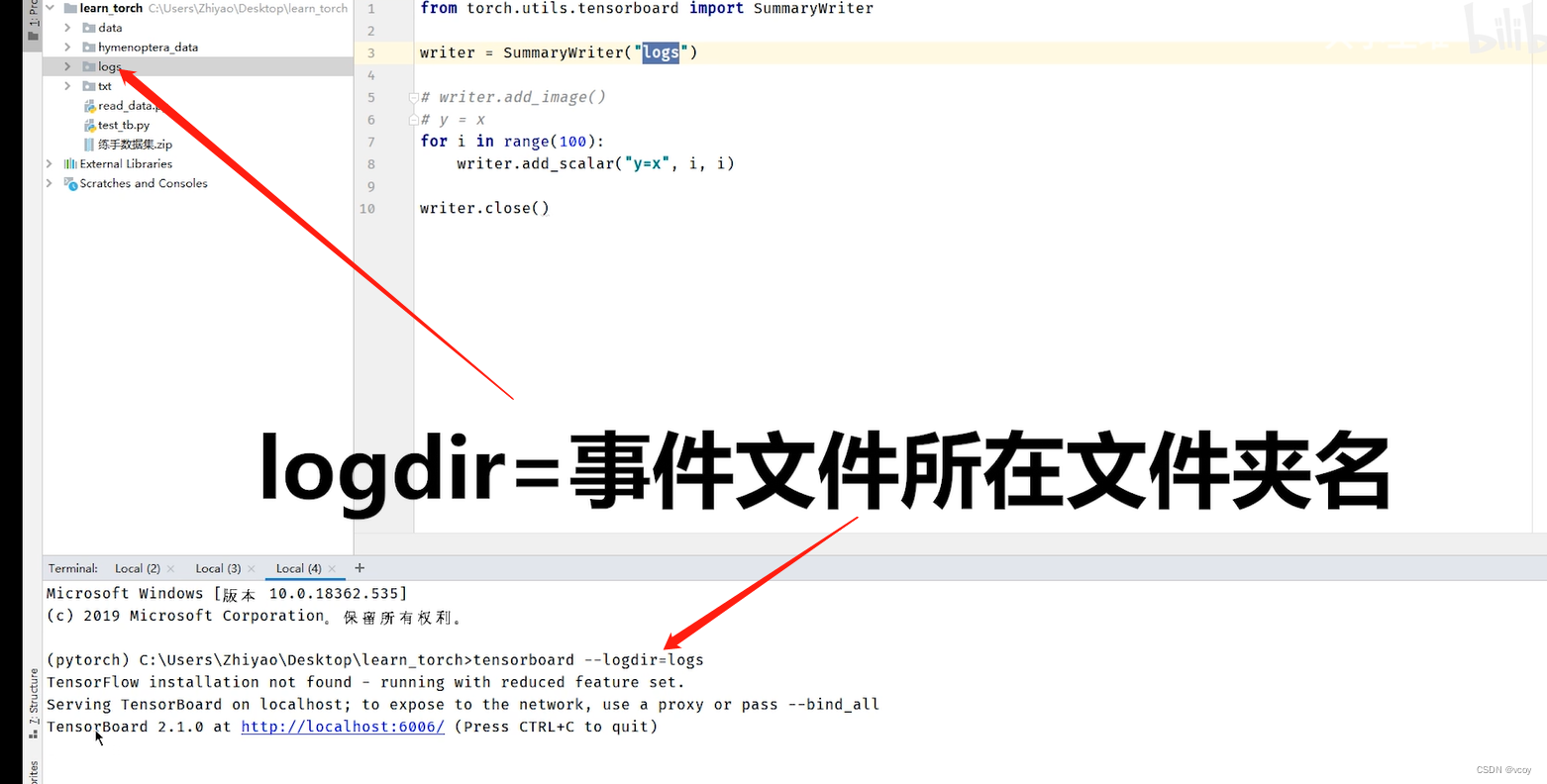
3.tensorboard
一种显示图或表格的服务器
代码示例
效果展示

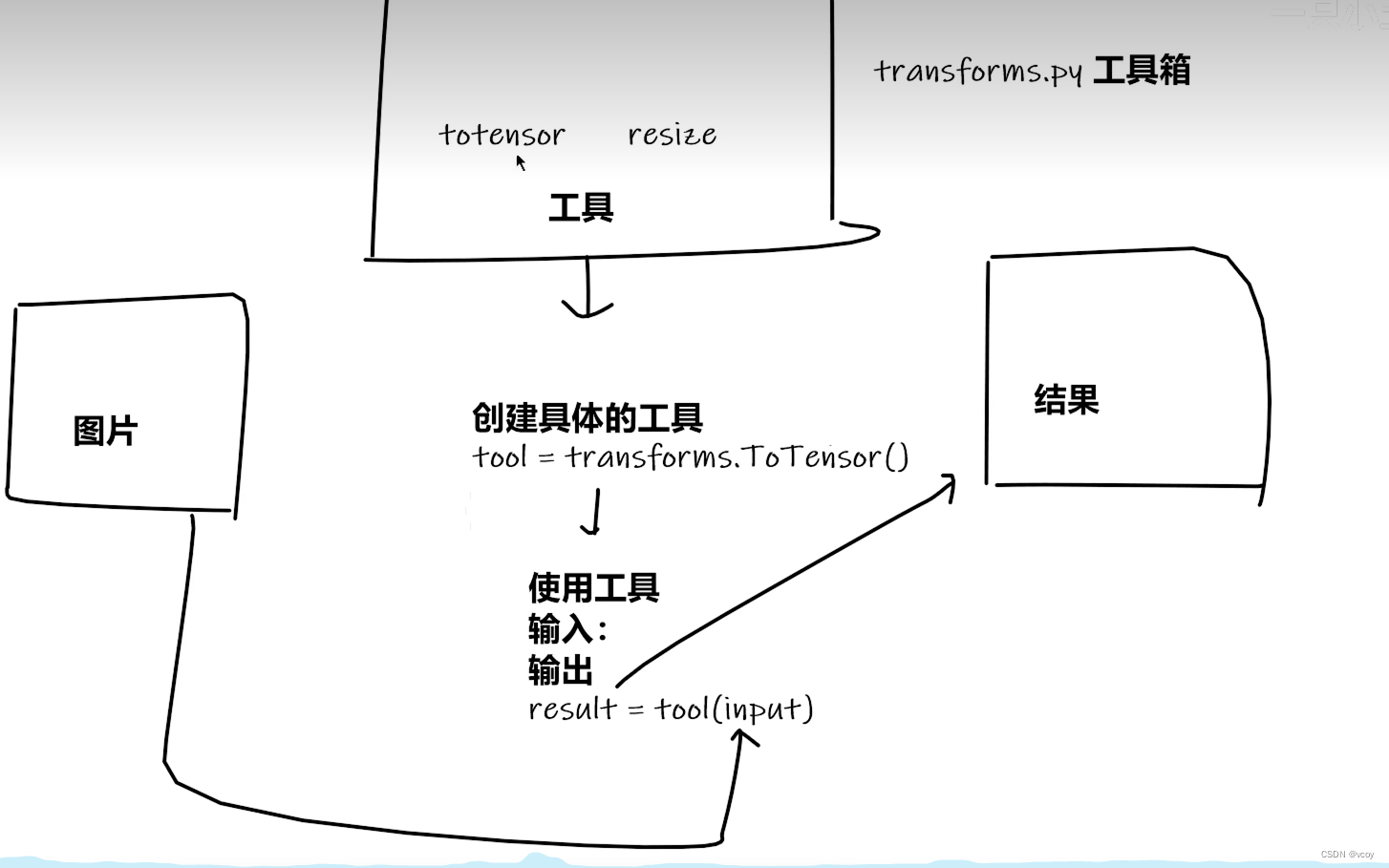
4. transform结构及用法
通常用作转换图片格式/大小的模块,如
#ToTensor方法 是transforms中的一个类, 用于将PIL或ndarray类型转化为tensor类型
# 获取PIL图片 将其转化为tensor格式
img = Image.open('xx.jpg')
# 实例化对象
trans_to_Tensor = transforms.ToTensor()
# 使用方法进行转换
img_tensor = trans_to_Tensor(img)
# Normalize:图片归一化,修改tensor图片的一些参数,对色调影响很大
# Resize改变图片尺寸
# RandomCrop:随机裁剪,按照规定尺寸随机裁剪图片的任意位置, 传入和输出都是PIL图片
# Compose:可讲totensor方法和resize方法等一并调用
transform使用totensor的问题
4.1常见的transforms案例
ToTensor: 将PIL图片转化为带神经网络参数的Tensor图片
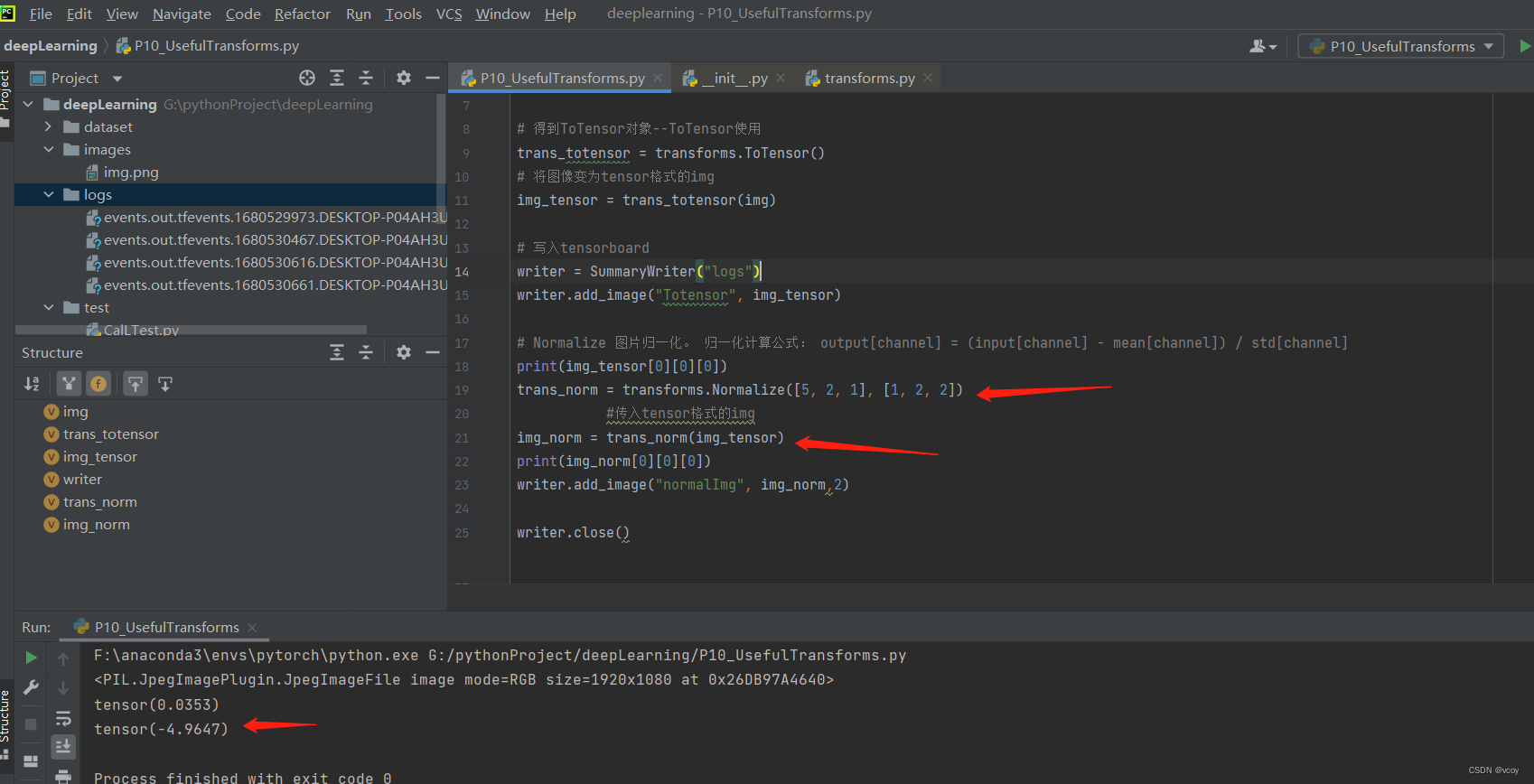
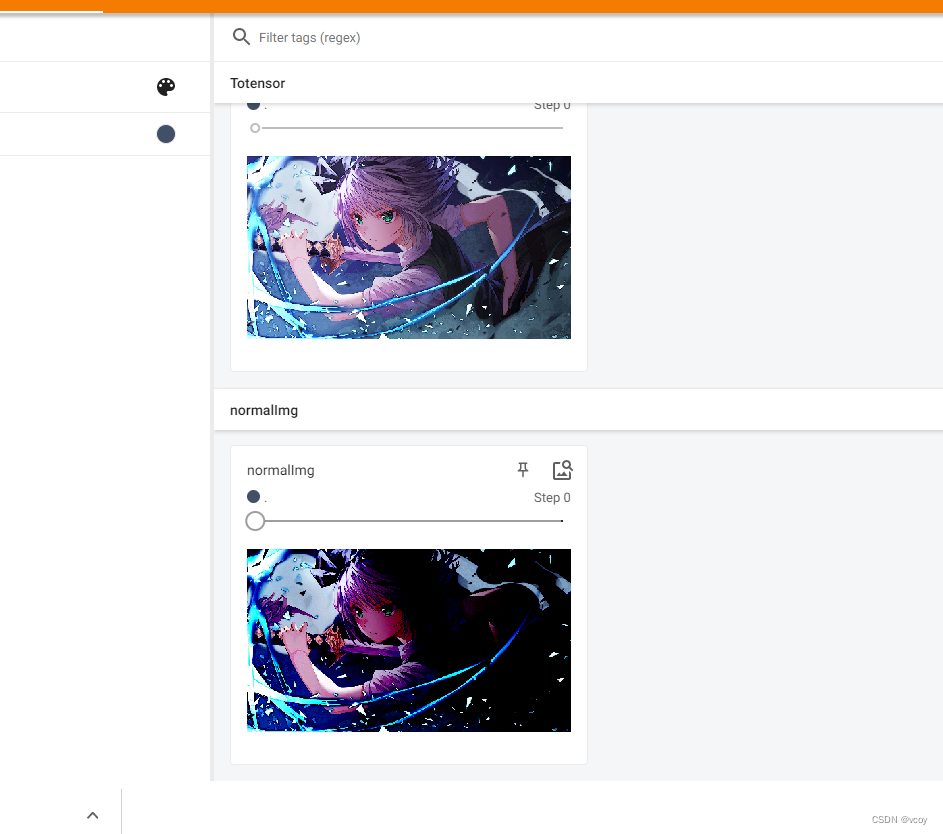
将图片归一化Normalize
归一化在tensorboard的效果

4.2 常见的Transforms
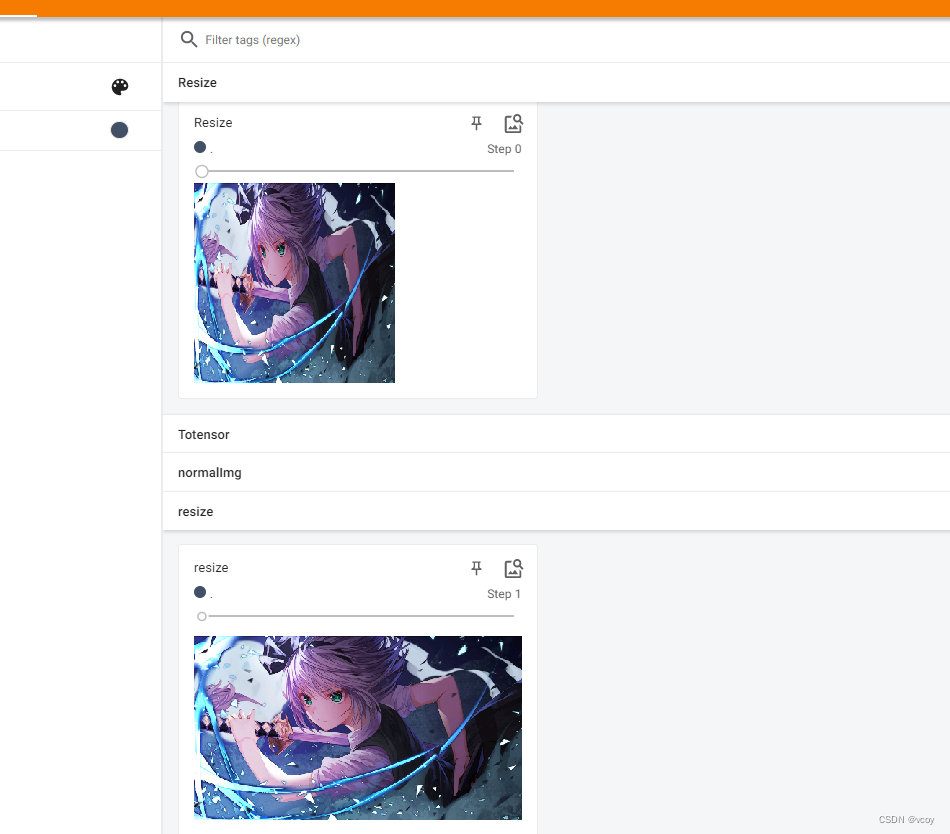
resize-图片重置长和宽
transforms.resize传入的是PIL格式img
随机裁剪 RnadomCrop-参数PIL格式图片
汇总

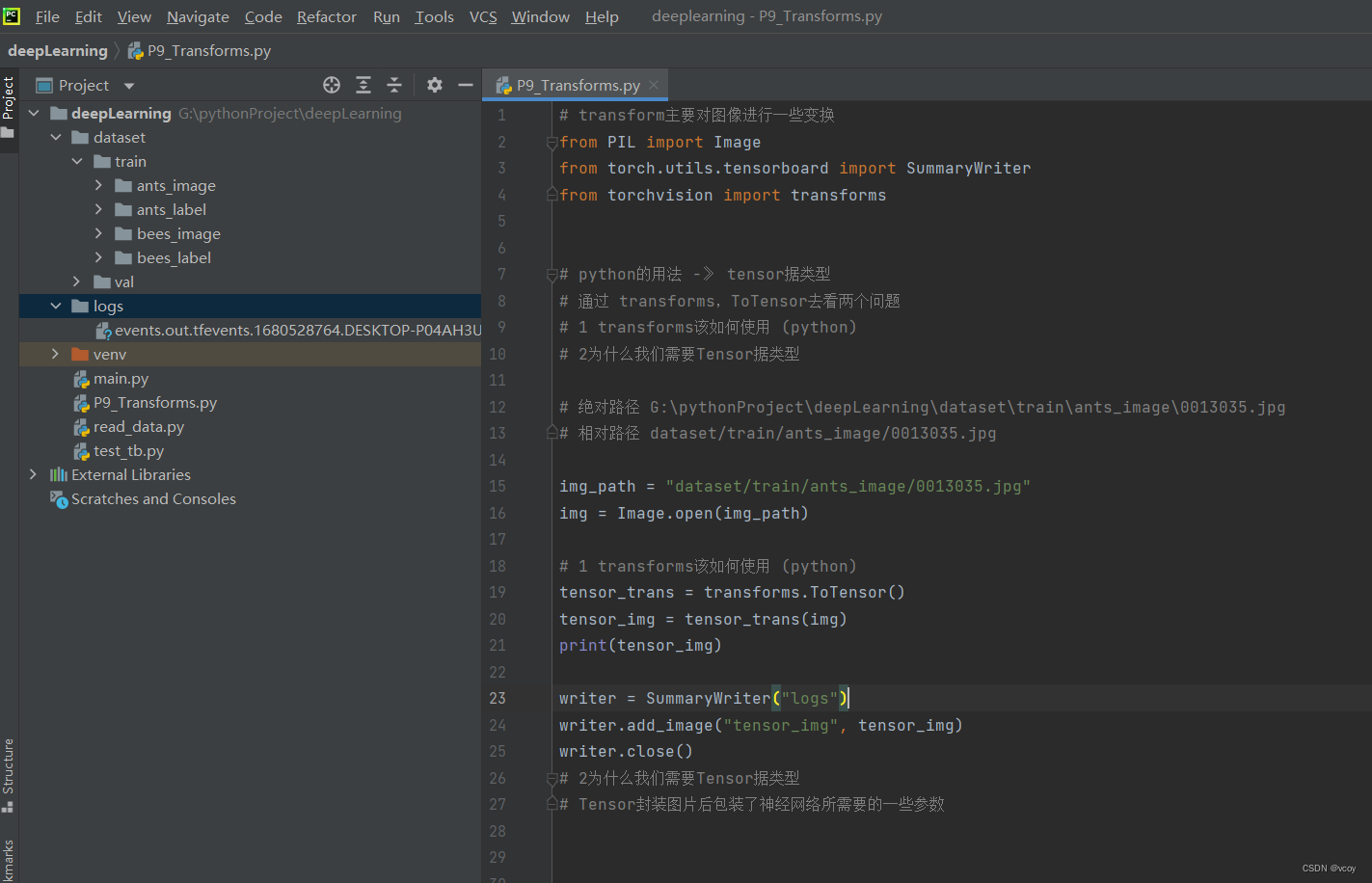
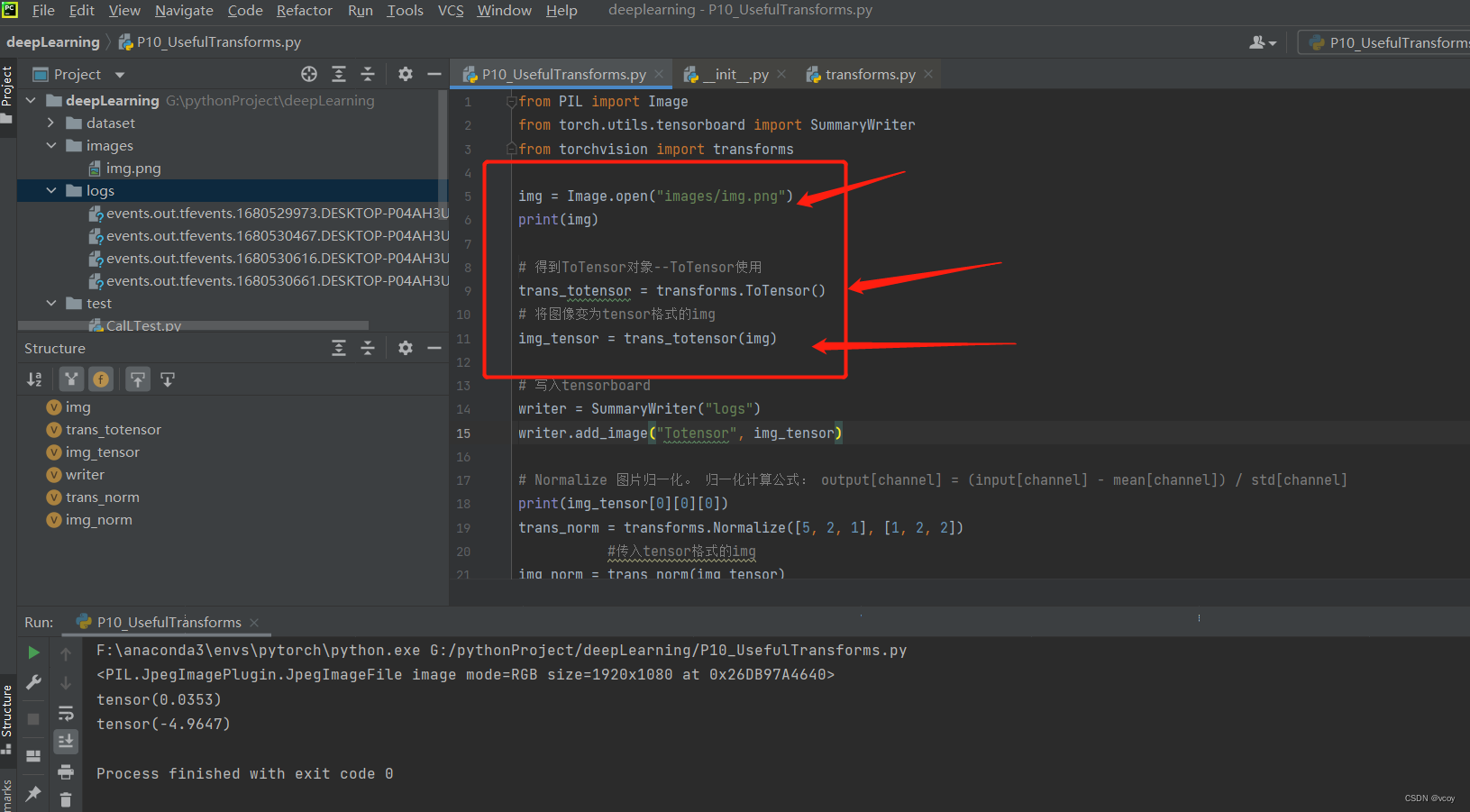
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
# transforms:Totensor--Normalize--Resize--RandomCrop
img = Image.open("images/img.png")
print(img)
# 得到ToTensor对象--ToTensor使用
trans_totensor = transforms.ToTensor()
# 将图像变为tensor格式的img
img_tensor = trans_totensor(img)
# 写入tensorboard
writer = SummaryWriter("logs")
writer.add_image("Totensor", img_tensor)
# Normalize 图片归一化。 归一化计算公式: output[channel] = (input[channel] - mean[channel]) / std[channel]
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([5, 2, 1], [1, 2, 2])
#传入tensor格式的img
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("normalImg", img_norm,2)
# resize - img PIL格式
print(img.size)
trans_size = transforms.Resize((512, 512))
# img PIL -> resize -> img_resize PIL
img_resize = trans_size(img)
# img_resize PIL -> totensor - >img_resize tensor
img_resize = trans_totensor(img_resize)
print(img_resize)
writer.add_image("Resize",img_resize,0)
# resize2 - Compose
# 得到ToTensor对象--ToTensor使用
img = Image.open("images/img.png")
trans_totensor = transforms.ToTensor()
trans_size_2 = transforms.Resize(512)
# PIL -> PIL -> tensor 后一个参数的输入 要和前一个参数的输出一致
trans_compose = transforms.Compose([trans_size_2, trans_totensor])
img_resize_2 = trans_compose(img)
writer.add_image("Resize", img_resize_2,1)
# RandomCrop 随机裁剪
img = Image.open("images/img.png")
trans_totensor = transforms.ToTensor()
trans_random = transforms.RandomCrop(512)
trans_compose_2 = transforms.Compose([trans_random, trans_totensor])
for i in range(10):
img_crop = trans_compose_2(img)
writer.add_image("RandomCrop", img_crop, i)
writer.close()
5.torchvision
torchvision是Pytorch的一个图形库,主要用来构建计算机视觉模型,torchvision由以下四个部分构成:
1 torchvision.datasets:包括一些加载数据的函数和常用的数据集接口
2 torchvision.models:包含常用的模型结构(含预训练模型),例如AlexNet、ResNet等等
3 torchvision.transforms:包含一些常见的图片变换,例如裁剪、旋转等等
4 torchvision.utils:其他用法
torchvision使用dataset拉取pytorch官网数据集到本地
将官网下载的图片用 transforms 转化为tensor类型
6.dataloader
dataset得到数据。dataloader加载器,把数据加载到神经网络,从dataset中取数据。
dataloader代码示例

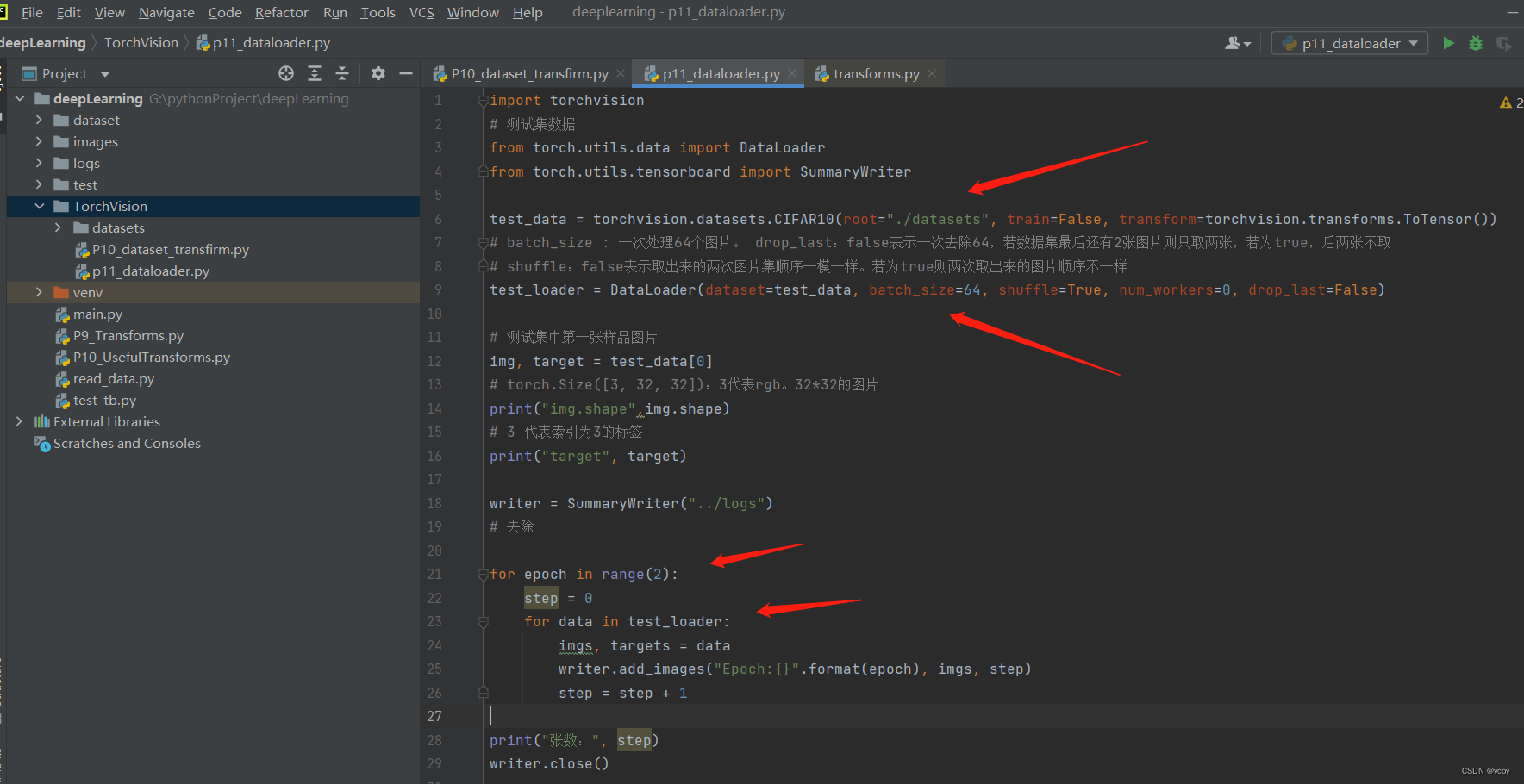
import torchvision
# 测试集数据
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
test_data = torchvision.datasets.CIFAR10(root="./datasets", train=False, transform=torchvision.transforms.ToTensor())
# batch_size : 一次处理64个图片。 drop_last:false表示一次去除64,若数据集最后还有2张图片则只取两张,若为true,后两张不取
# shuffle:false表示取出来的两次图片集顺序一模一样。若为true则两次取出来的图片顺序不一样
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
# 测试集中第一张样品图片
img, target = test_data[0]
# torch.Size([3, 32, 32]):3代表rgb。32*32的图片
print("img.shape",img.shape)
# 3 代表索引为3的标签
print("target", target)
writer = SummaryWriter("../logs")
# 去除
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("Epoch:{}".format(epoch), imgs, step)
step = step + 1
print("张数:", step)
writer.close()
7.神经网络的搭建
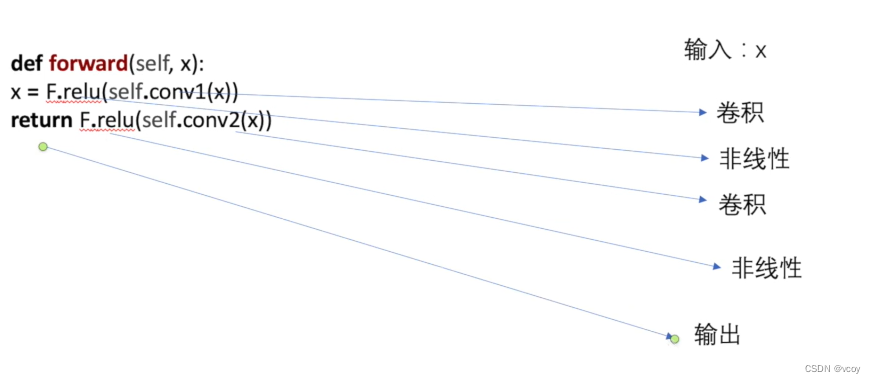
forward讲解:使用Pytorch的时候,模型训练时,不需要调用forward这个函数,只需要在实例化一个对象中传入对应的参数就可以自动调用 forward 函数。但需要在定义类中引入"nn.Module",此时如vcoy.forward(x) 就等价于 vcoy(x)
8.卷积案例
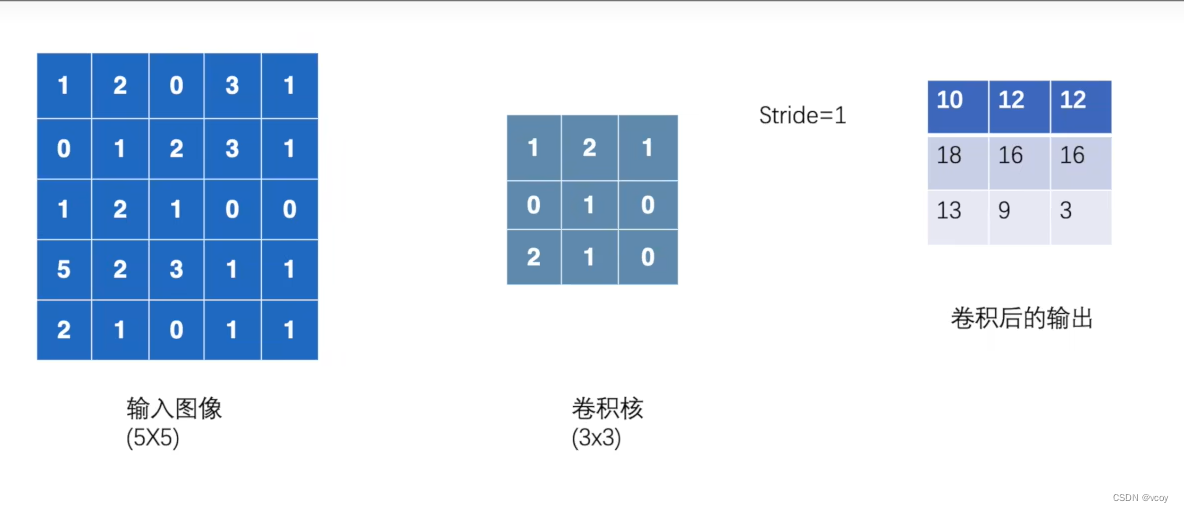
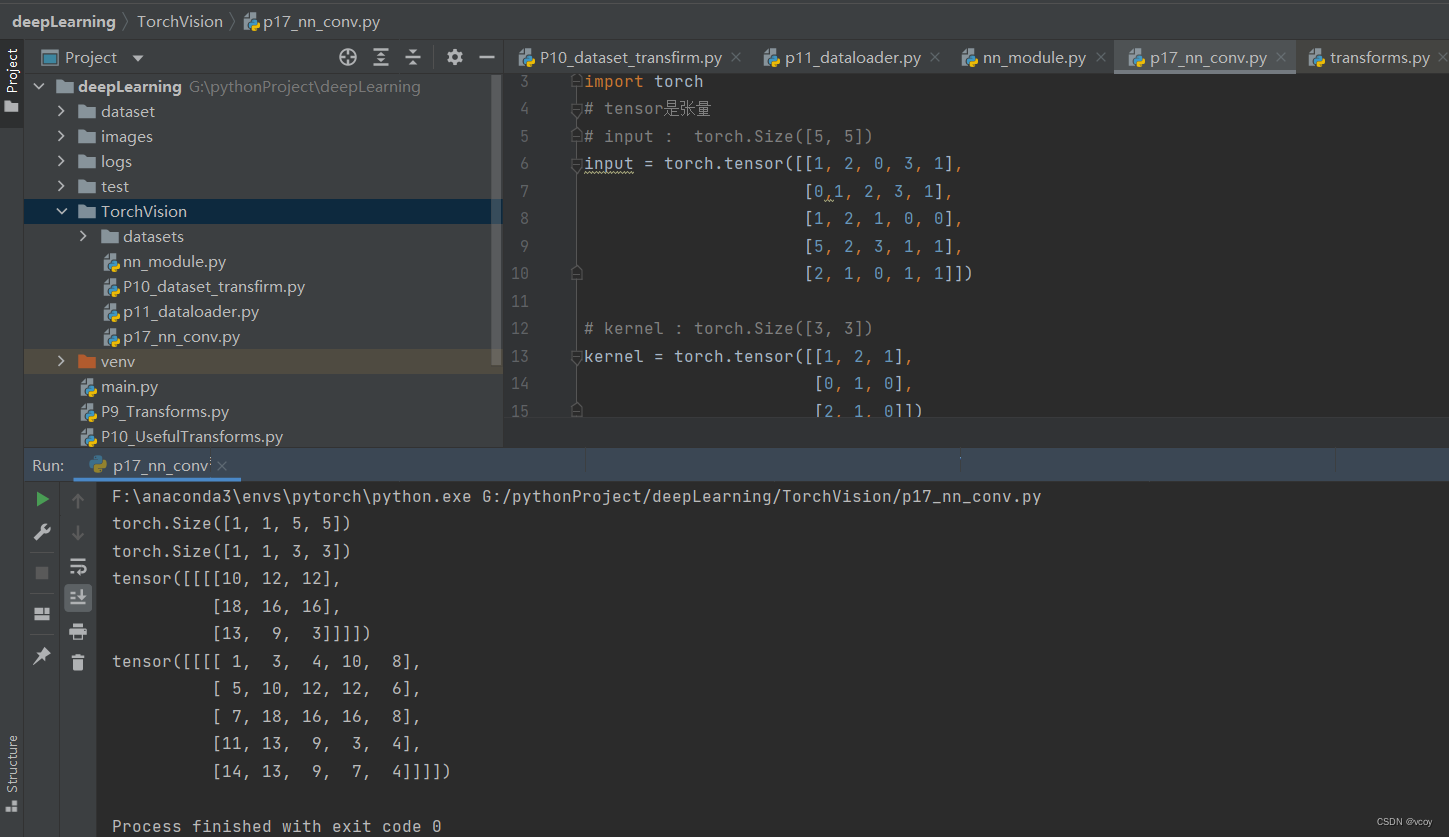
代码示例
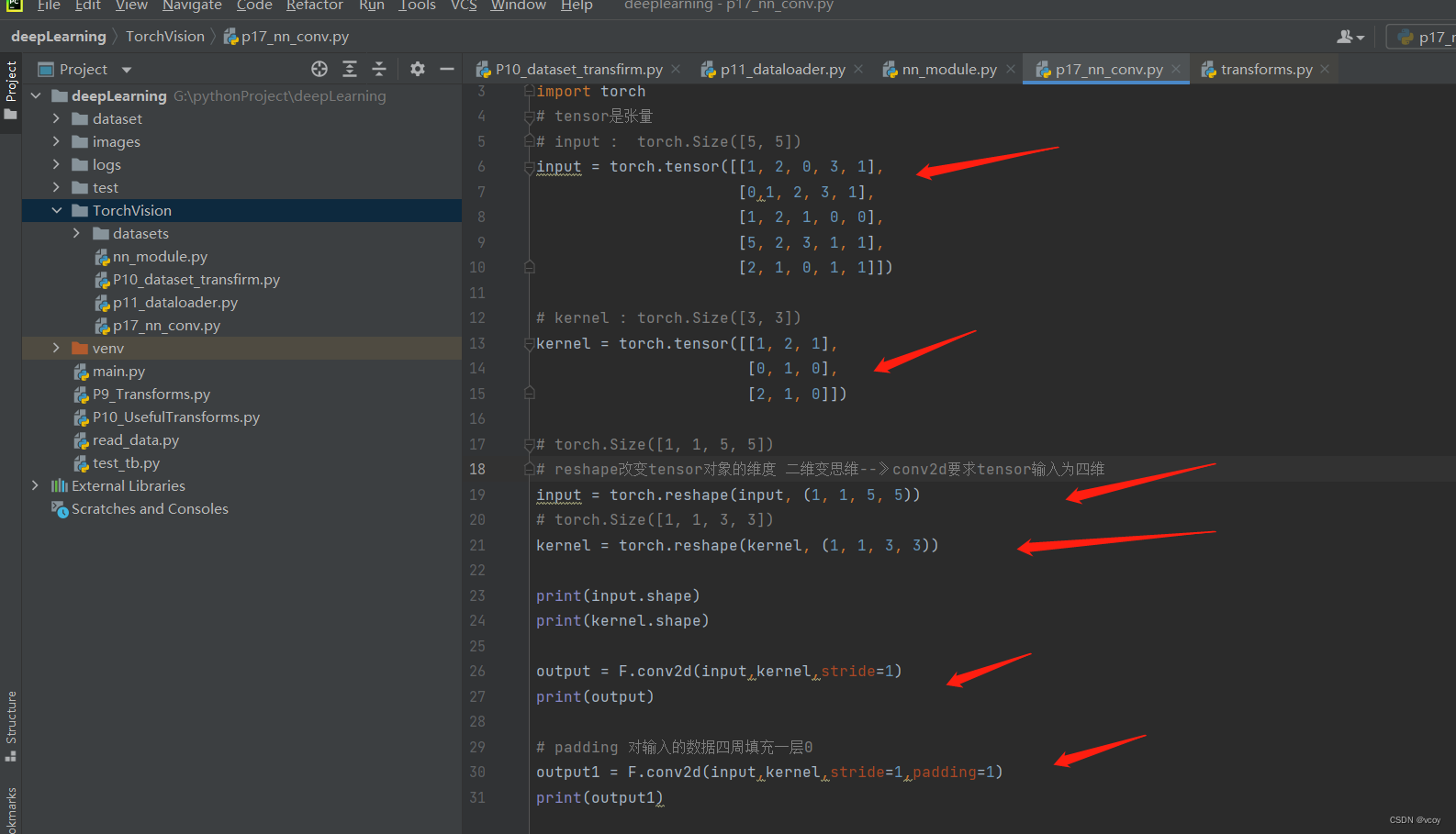
import torch.nn.functional as F
import torch
# tensor是张量
# input : torch.Size([5, 5])
input = torch.tensor([[1, 2, 0, 3, 1],
[0,1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
# kernel : torch.Size([3, 3])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
# torch.Size([1, 1, 5, 5])
# reshape改变tensor对象的维度 二维变思维--》conv2d要求tensor输入为四维
input = torch.reshape(input, (1, 1, 5, 5))
# torch.Size([1, 1, 3, 3])
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(input.shape)
print(kernel.shape)
output = F.conv2d(input,kernel,stride=1)
print(output)
# padding 对输入的数据四周填充一层0
output1 = F.conv2d(input,kernel,stride=1,padding=1)
print(output1)
9.卷积层
在定义的神经网络模型中加入卷积层,使用pytorch官网的Conv2d卷积函数。
import torchvision
import torch
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../p18_data", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=64)
class Vcoy(nn.Module):
def __init__(self):
super(Vcoy, self).__init__()
# 定义一个卷积层。in_channels:输入 图像个数。out_channels:输出的卷积结果个数。kernel_size:卷积核为3*3
self.conv1 = Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)
def forward(self, x):
self.conv1(x)
return x
vcoy = Vcoy()
writer = SummaryWriter("../logs")
step = 0
for data in dataloader:
imgs, targets = data
print(imgs.shape)
out_img = vcoy.forward(imgs)
print(out_img.shape)
# torch_Size([64,3,32,32])
writer.add_images("input",imgs,step)
# torch_Size([64,6,30,30])
writer.add_images("output",imgs,step)
step = step + 1
writer.close()
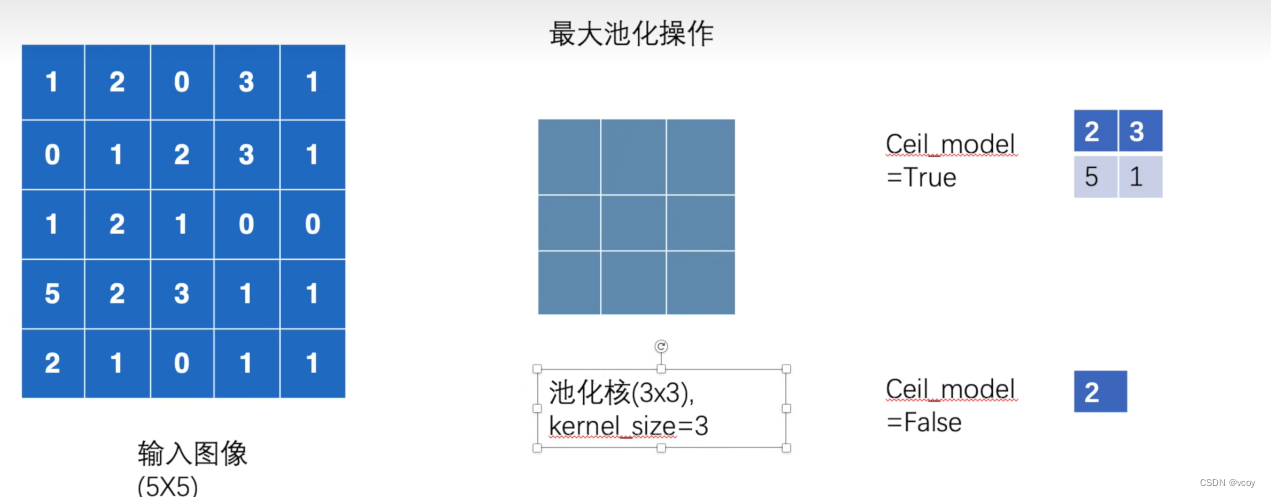
10.最大池化
上采样:插值。下采样:抽样
池化核(3*3):kernel_size=3,则步长也为3,池化层尺寸默认等于步长
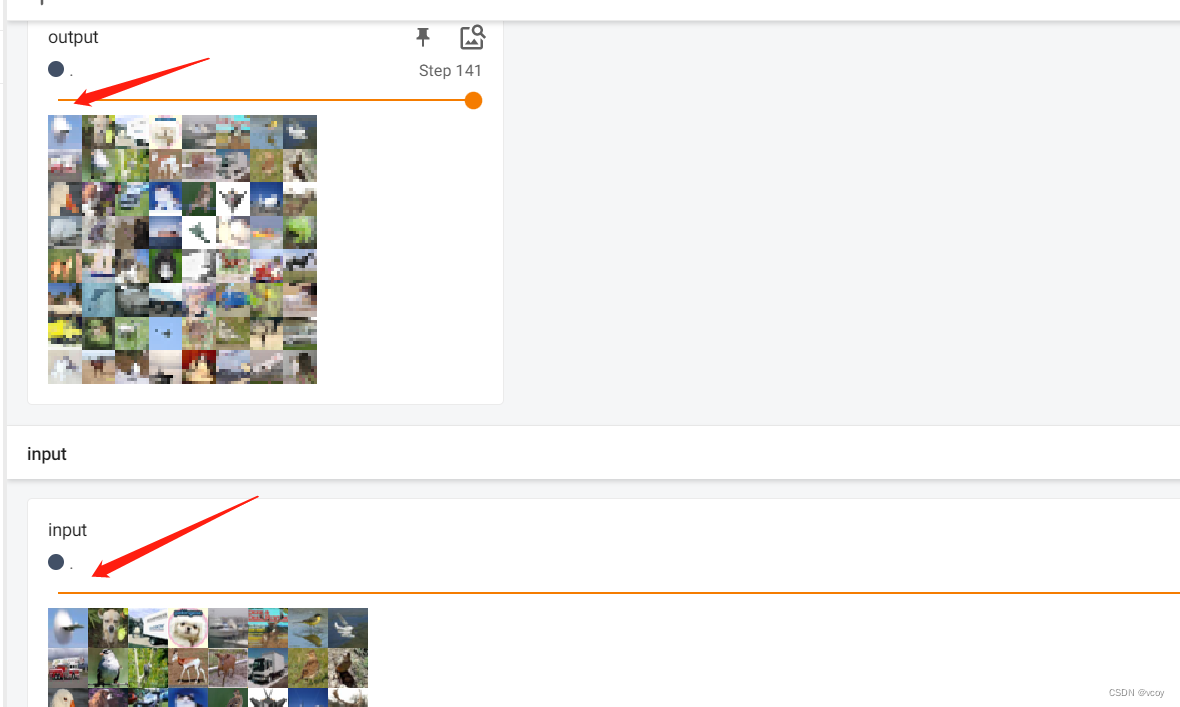
最大池化作用:最大限度的保留图片特征,同时减少数据量。加速训练速度。
reshape的作用:由于在卷积过程需要输入四维格式的图片,需要通过reshape进行转换。
神经网络中仅定义了池化,将输入矩阵经过神经网络得到最大池化的结果。
对CIFRA10数据集中的图像进行池化
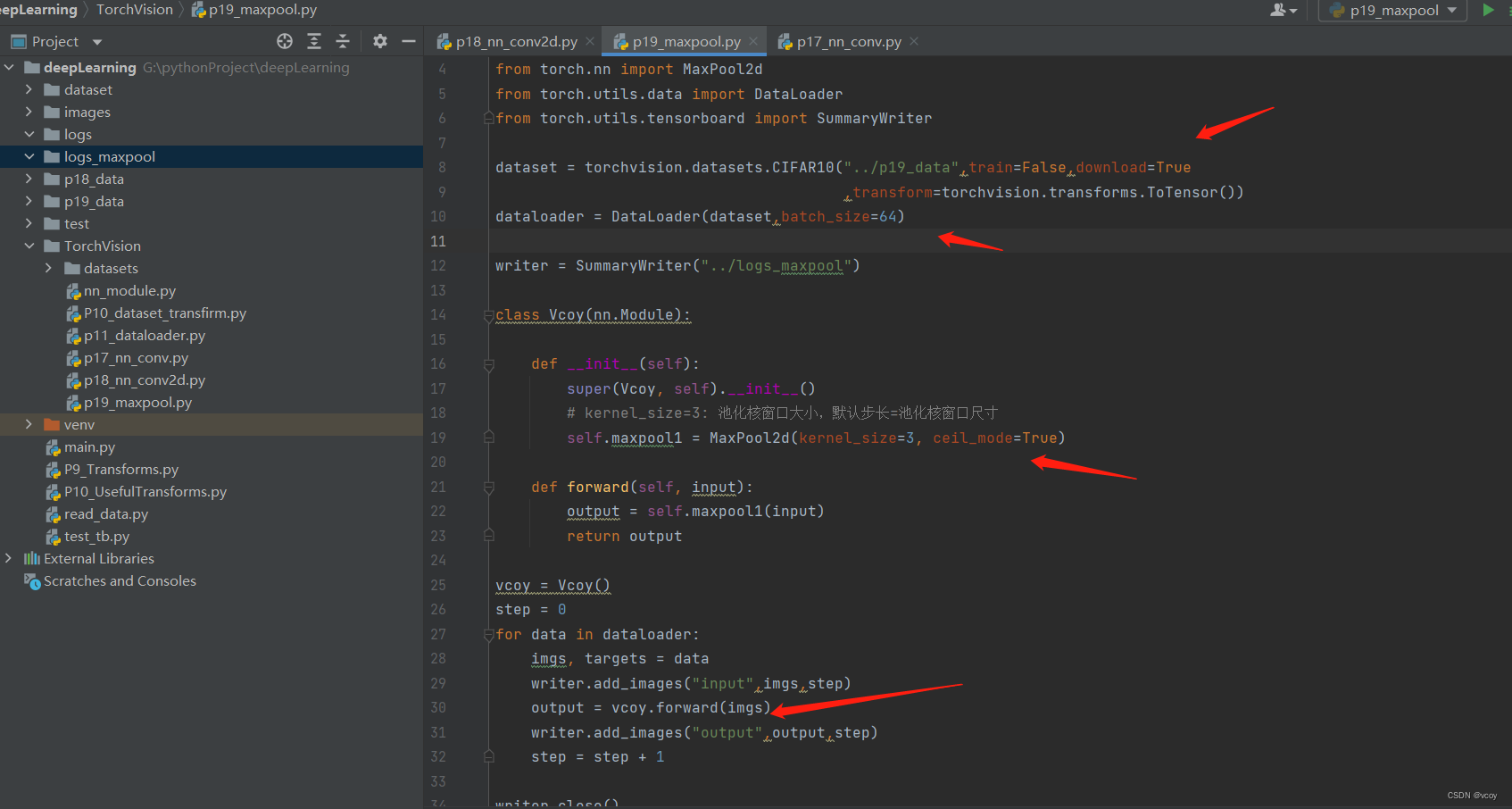
import torch
import torchvision
from torch import nn
from torch.nn import MaxPool2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset = torchvision.datasets.CIFAR10("../p19_data",train=False,download=True
,transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset,batch_size=64)
writer = SummaryWriter("../logs_maxpool")
class Vcoy(nn.Module):
def __init__(self):
super(Vcoy, self).__init__()
# kernel_size=3: 池化核窗口大小,默认步长=池化核窗口尺寸
self.maxpool1 = MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
vcoy = Vcoy()
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input",imgs,step)
output = vcoy.forward(imgs)
writer.add_images("output",output,step)
step = step + 1
writer.close()
池化效果
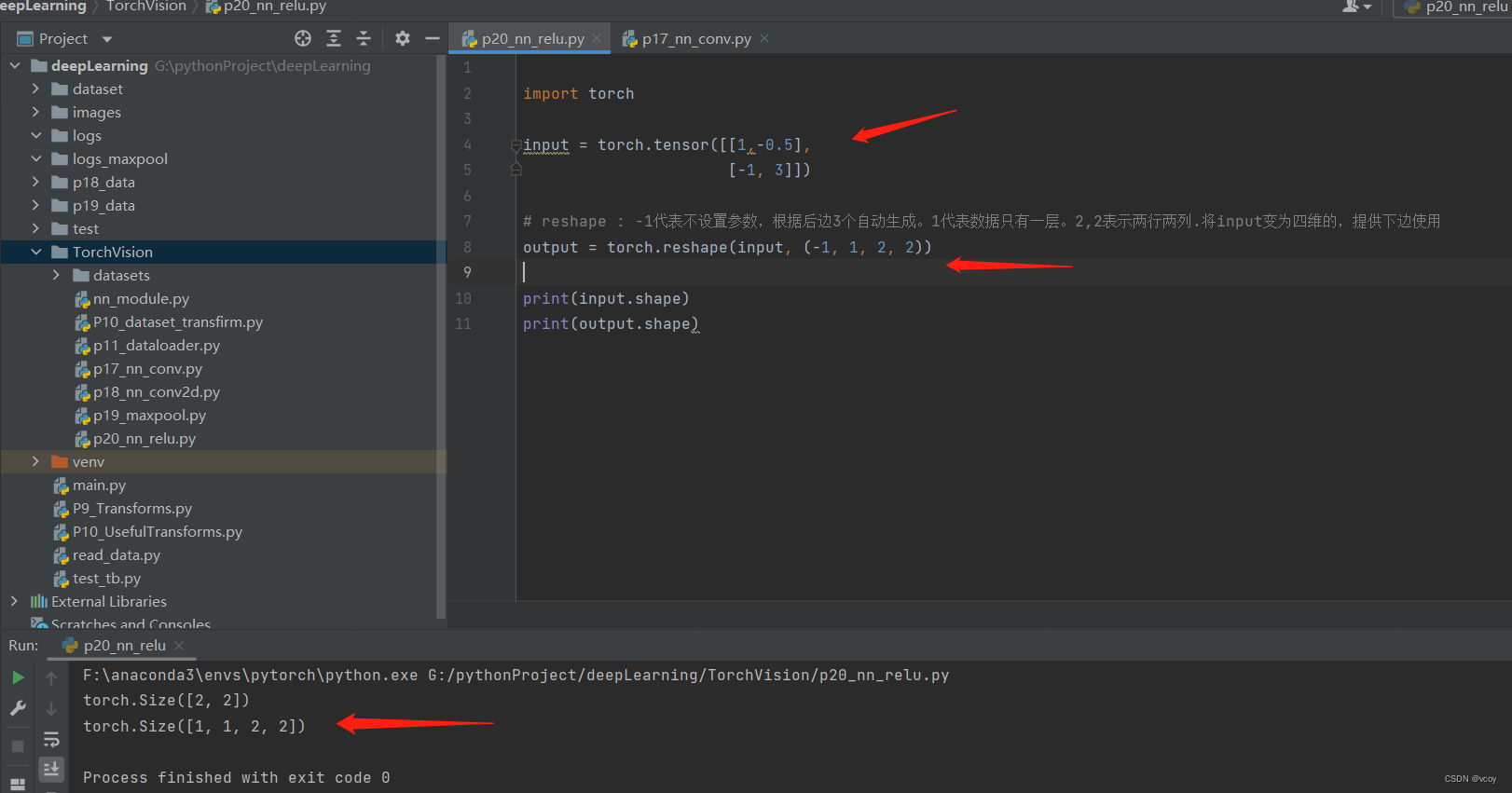
补充reshape
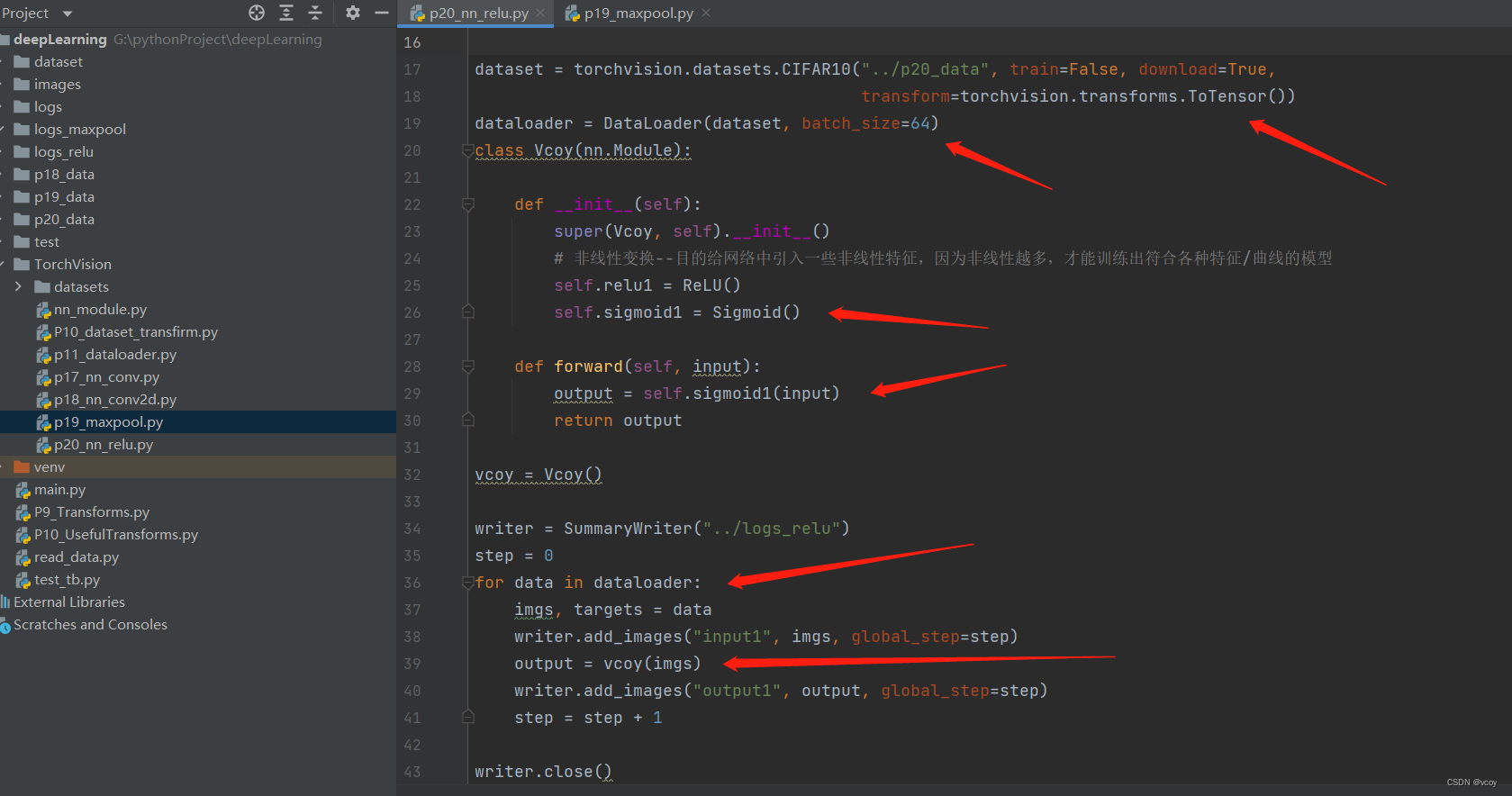
11.非线性激活
非线性激活Sigmoid(input)的使用,输入参数input为CIFAR10数据集图片。可在forward函数使用output = self.relu1(input)查看Relu函数效果
import torch
import torchvision
from torch import nn
from torch.nn import ReLU,Sigmoid
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
input = torch.tensor([[1,-0.5],
[-1, 3]])
print(input.shape)
# reshape : -1代表不设置参数,根据后边3个自动生成。1代表数据只有一层。2,2表示两行两列.将input变为四维的,提供下边使用
input = torch.reshape(input, (-1, 1, 2, 2))
print(input.shape)
dataset = torchvision.datasets.CIFAR10("../p20_data", train=False, download=True,
transform=torchvision.transforms.ToTensor())
dataloader = DataLoader(dataset, batch_size=64)
class Vcoy(nn.Module):
def __init__(self):
super(Vcoy, self).__init__()
# 非线性变换--目的给网络中引入一些非线性特征,因为非线性越多,才能训练出符合各种特征/曲线的模型
self.relu1 = ReLU()
self.sigmoid1 = Sigmoid()
def forward(self, input):
output = self.sigmoid1(input)
return output
vcoy = Vcoy()
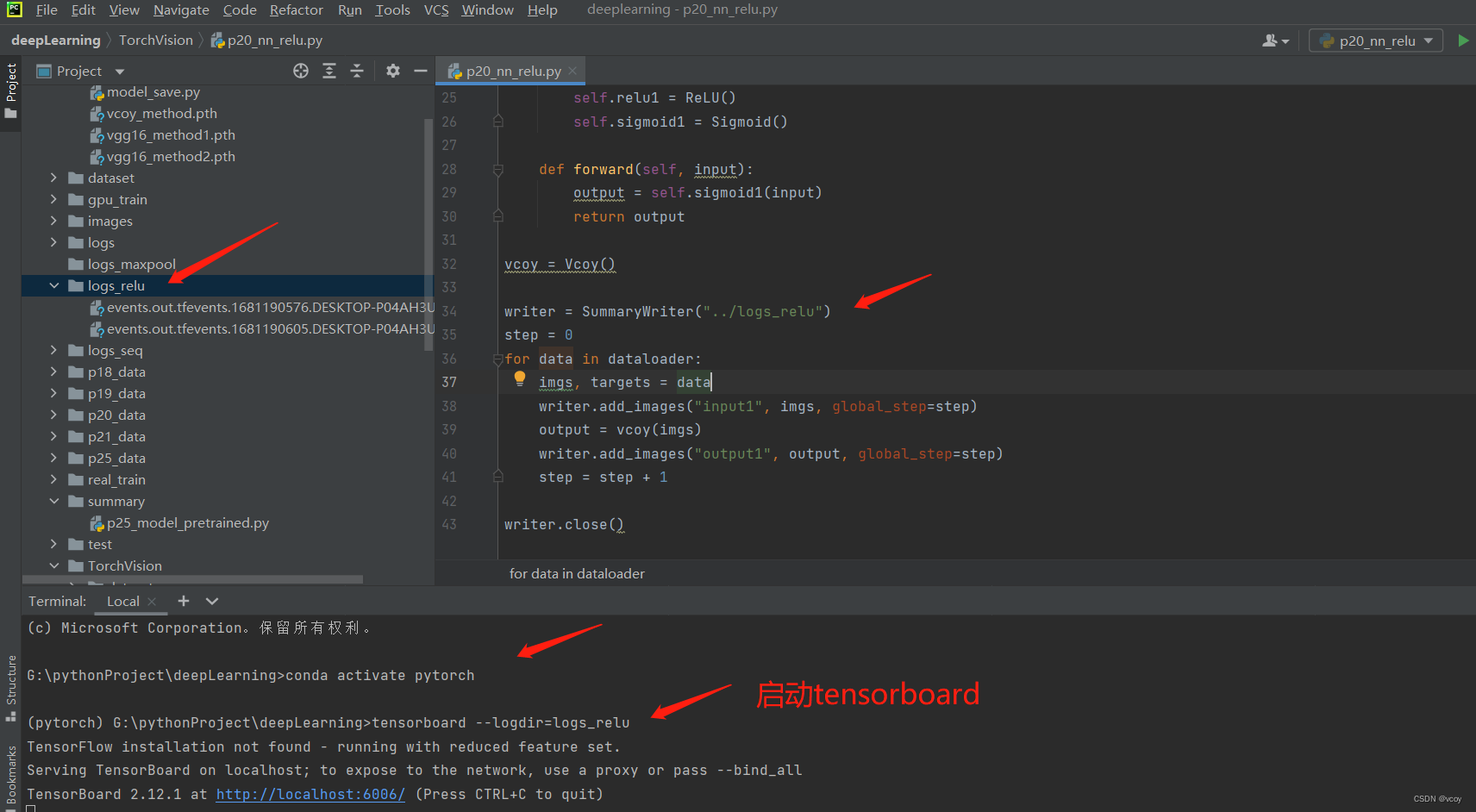
writer = SummaryWriter("../logs_relu")
step = 0
for data in dataloader:
imgs, targets = data
writer.add_images("input1", imgs, global_step=step)
output = vcoy(imgs)
writer.add_images("output1", output, global_step=step)
step = step + 1
writer.close()
在tensorboard上查看效果
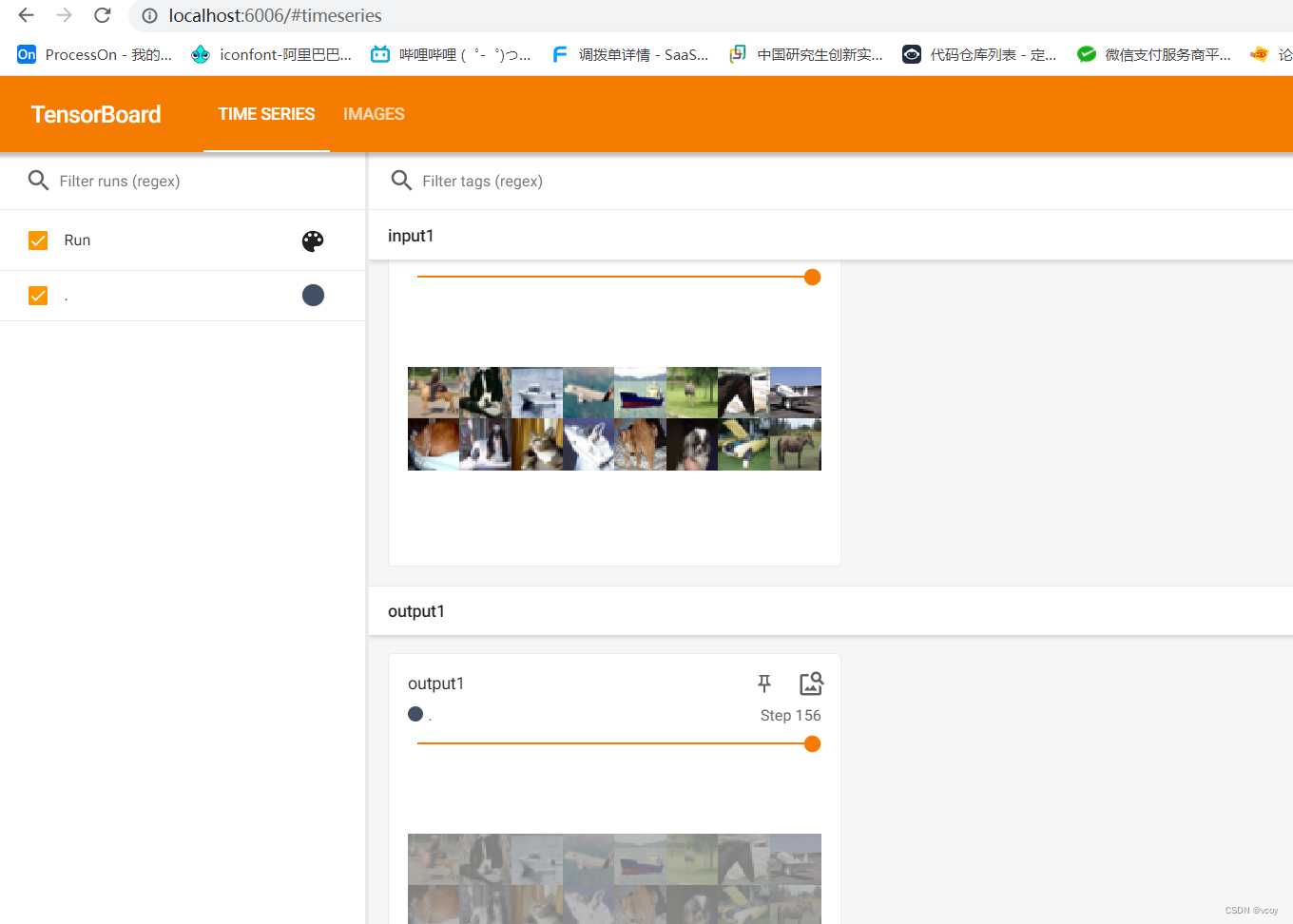
12.线性层
线性层:训练后,要评价模型的好坏,通过将最后的一层替换成线性层。线性层一般在神经网络模型的后几层,一般为全连接,转化成结果分类数。一般经过卷积(conv2d)-非线性激活(relu)-最大池化(maxpool)-平铺(flatten)-线性变化(linear)。
以CIFAR10数据集的训练过程图为例:经过线性变化输出10个值对应该数据集的10个分类的概率
线性层案例,pytorch线性函数为Linear(in_feature,out_feature)

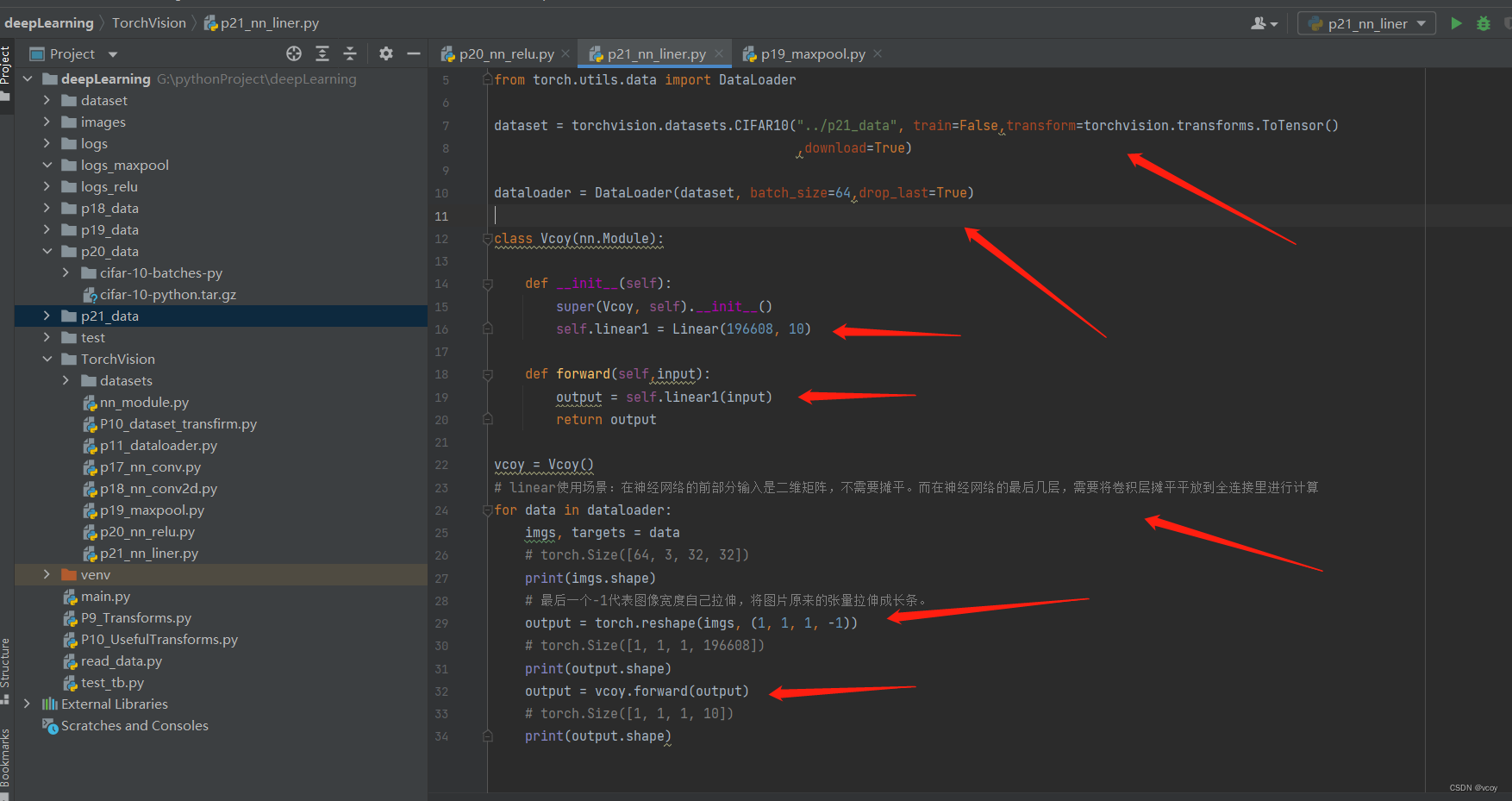
import torch
import torchvision
from torch.nn import Linear
from torch import nn
from torch.utils.data import DataLoader
dataset = torchvision.datasets.CIFAR10("../p21_data", train=False,transform=torchvision.transforms.ToTensor()
,download=True)
dataloader = DataLoader(dataset, batch_size=64,drop_last=True)
class Vcoy(nn.Module):
def __init__(self):
super(Vcoy, self).__init__()
self.linear1 = Linear(196608, 10)
def forward(self,input):
output = self.linear1(input)
return output
vcoy = Vcoy()
# linear使用场景:在神经网络的前部分输入是二维矩阵,不需要摊平。而在神经网络的最后几层,需要将卷积层摊平平放到全连接里进行计算
for data in dataloader:
imgs, targets = data
# torch.Size([64, 3, 32, 32])
print(imgs.shape)
# 最后一个-1代表图像宽度自己拉伸,将图片原来的张量拉伸成长条。
output = torch.reshape(imgs, (1, 1, 1, -1))
# torch.Size([1, 1, 1, 196608])
print(output.shape)
output = vcoy.forward(output)
# torch.Size([1, 1, 1, 10])
print(output.shape)
上图这里torch.reshape(imgs, (1, 1, 1, -1))等价于使用 flatten函数
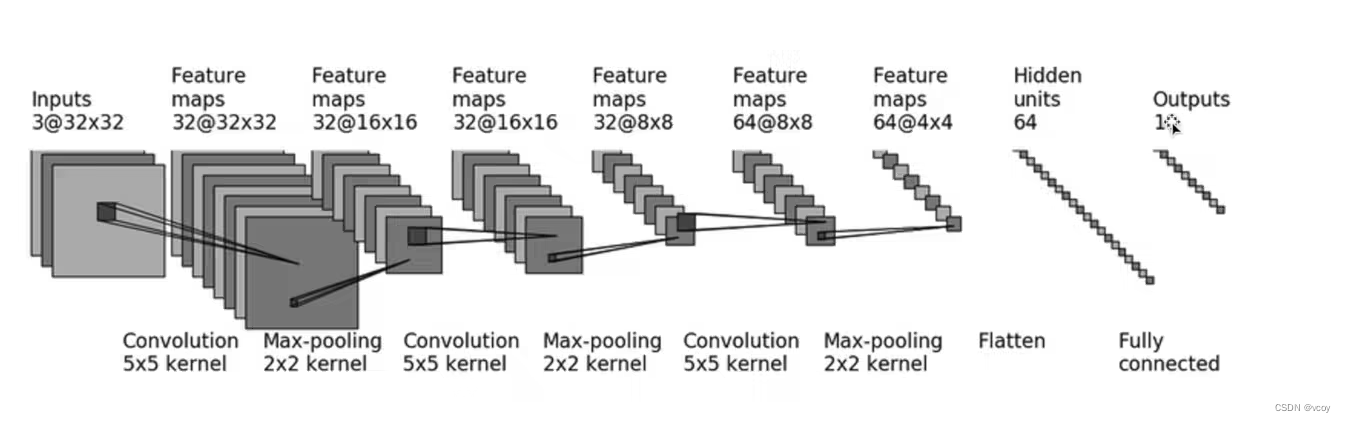
根据图片经典卷积过程套入公式反推出padding的填充值

##### 12.1简单神经网络的搭建
测试结果
简单神经网络搭建
import torch
from torch import nn
from torch.nn import Module, Conv2d, MaxPool2d, Flatten, Linear, Sequential
class Vcoy(nn.Module):
def __init__(self):
super(Vcoy, self).__init__()
# @前的是channels个数
# 3代表in_channel,若图片是彩色则代表rgb就为3,若是灰色图像就是1
# 32代表经过卷积要输出的通道channels个数,一般卷积后的通道数就是下一层的in_channel个数
# 5代表卷积核尺寸5*5 --第一次卷积
self.conv1 = Conv2d(3, 32, 5, stride=1, padding=2)
# 图中池化核尺寸为2
self.maxpool1 = MaxPool2d(2)
# 第二次卷积 和 池化
self.conv2 = Conv2d(32, 32, 5, stride=1, padding=2)
self.maxpool2 = MaxPool2d(2)
# 第三次卷积
self.conv3 = Conv2d(32, 64, 5, stride=1, padding=2)
self.maxpool3 = MaxPool2d(2)
# 数据展平--作用同 output = torch.reshape(imgs, (1, 1, 1, -1))
self.flatten = Flatten()
# 第一个线性层 64*4*4 = 1024。第一个参数1024代表输入特征个数,第二个参数64代表输出特征个数
self.linear1 = Linear(1024, 64)
# 第二个线性层 输出10个结果
self.linear2 = Linear(64, 10)
def forward(self, x):
x = self.conv1(x)
x = self.maxpool1(x)
x = self.conv2(x)
x = self.maxpool2(x)
x = self.conv3(x)
x = self.maxpool3(x)
x = self.flatten(x)
x = self.linear1(x)
x = self.linear2(x)
return x
def __str__(self):
# 打印它的全部属性
print('\n'.join(['{0}: {1}'.format(item[0], item[1]) for item in self.__dict__.items()]))
if __name__ == '__main__':
vcoy = Vcoy()
# 3和32和32 代表上边神经网络中输入的 3@32x32,即一张图片,3就是代表rgb为3个通道。 64表示batch_size=64即64张图片数据
input = torch.ones((64, 3, 32, 32))
output = vcoy.forward(input)
print(output.shape)
Sequential的引入(封装)–效果同上
Sequential的引入
import torch
from torch import nn
from torch.nn import Module, Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.tensorboard import SummaryWriter
class Vcoy(nn.Module):
def __init__(self):
super(Vcoy, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, stride=1, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, stride=1, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, stride=1, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
if __name__ == '__main__':
vcoy = Vcoy()
# 3和32和32 代表上边神经网络中输入的 3@32x32,即一张图片,3就是代表rgb为3个通道。 64表示batch_size=64即64张图片数据
input = torch.ones((64, 3, 32, 32))
output = vcoy(input)
print(output.shape)
writer = SummaryWriter("../logs_seq")
writer.add_graph(vcoy, input)
writer.close()
使用tensorboard查看搭建的神经网络结构
效果图
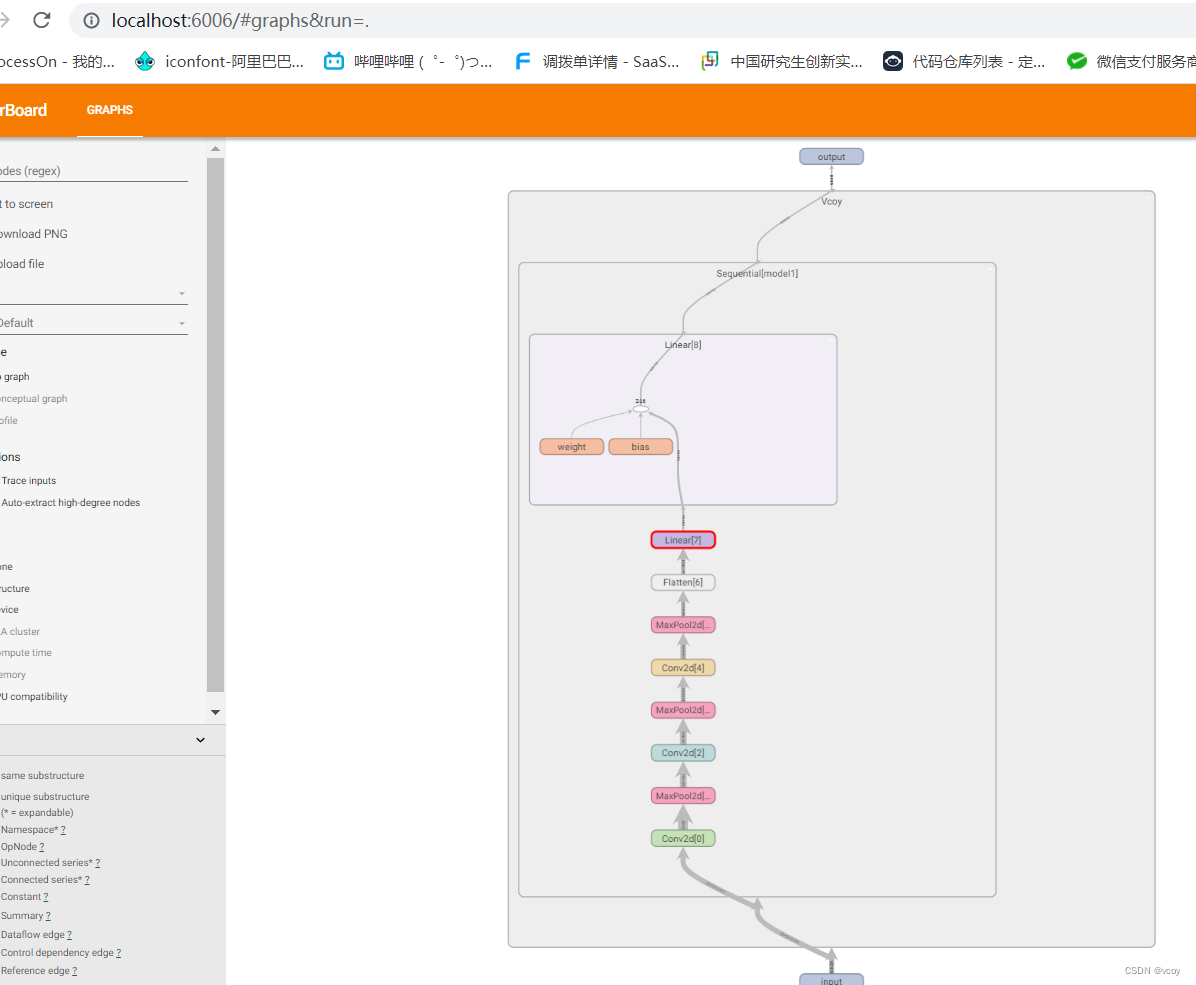
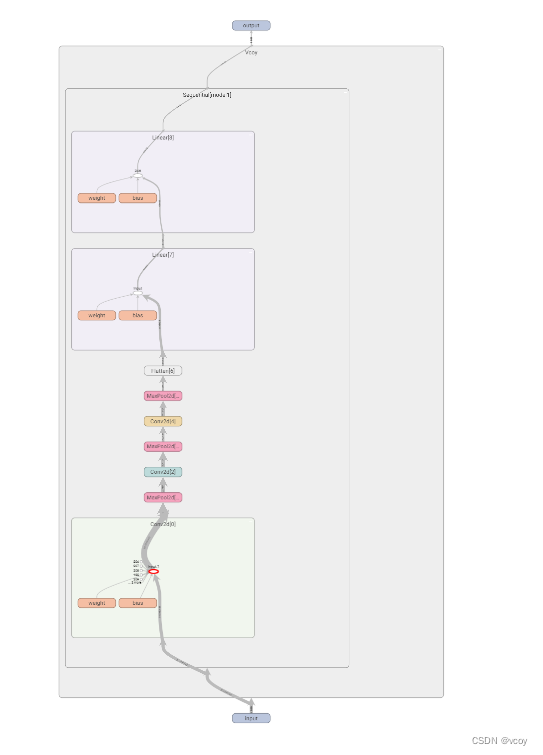
13.损失函数与反向传播
note:官方文档中参数N一般代表batch_size图片个数。
loss为实际输出和目标输出之间的差值,这个插值越小越好。3个pytorch官网求损失值的函数:

损失函数
均方误差
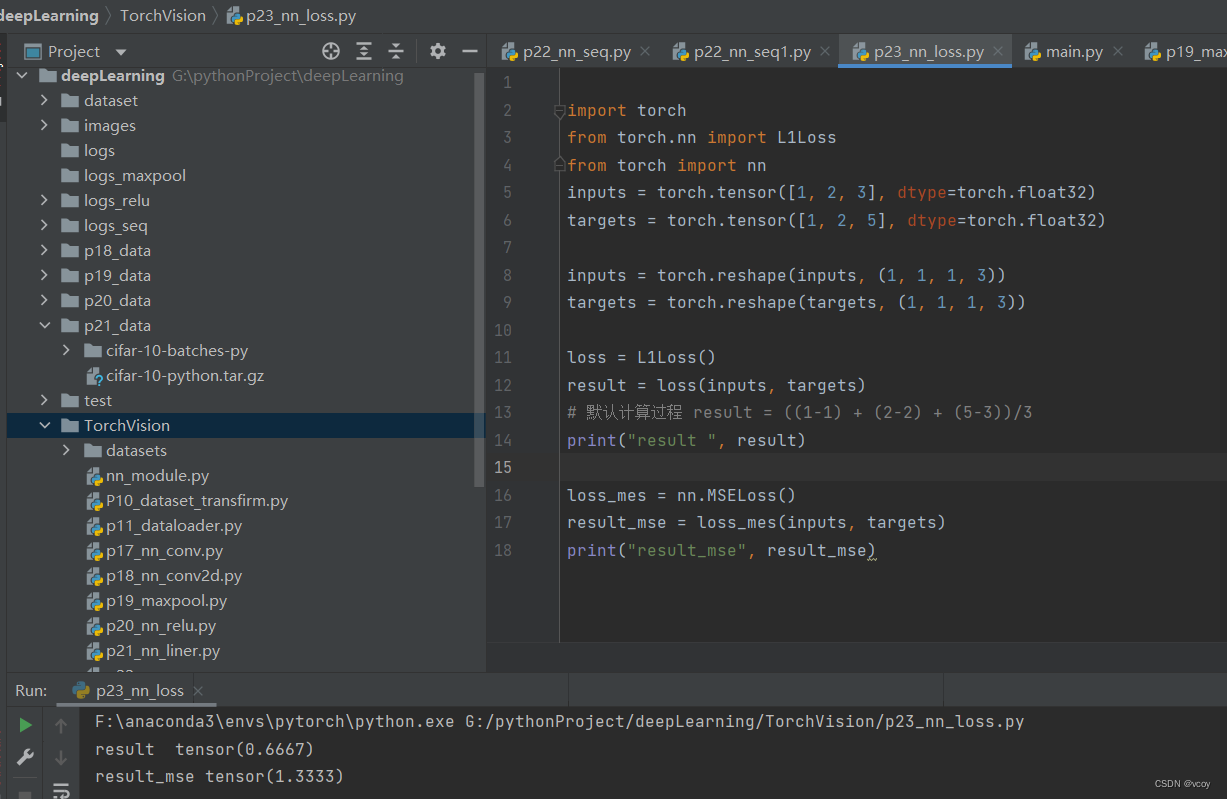
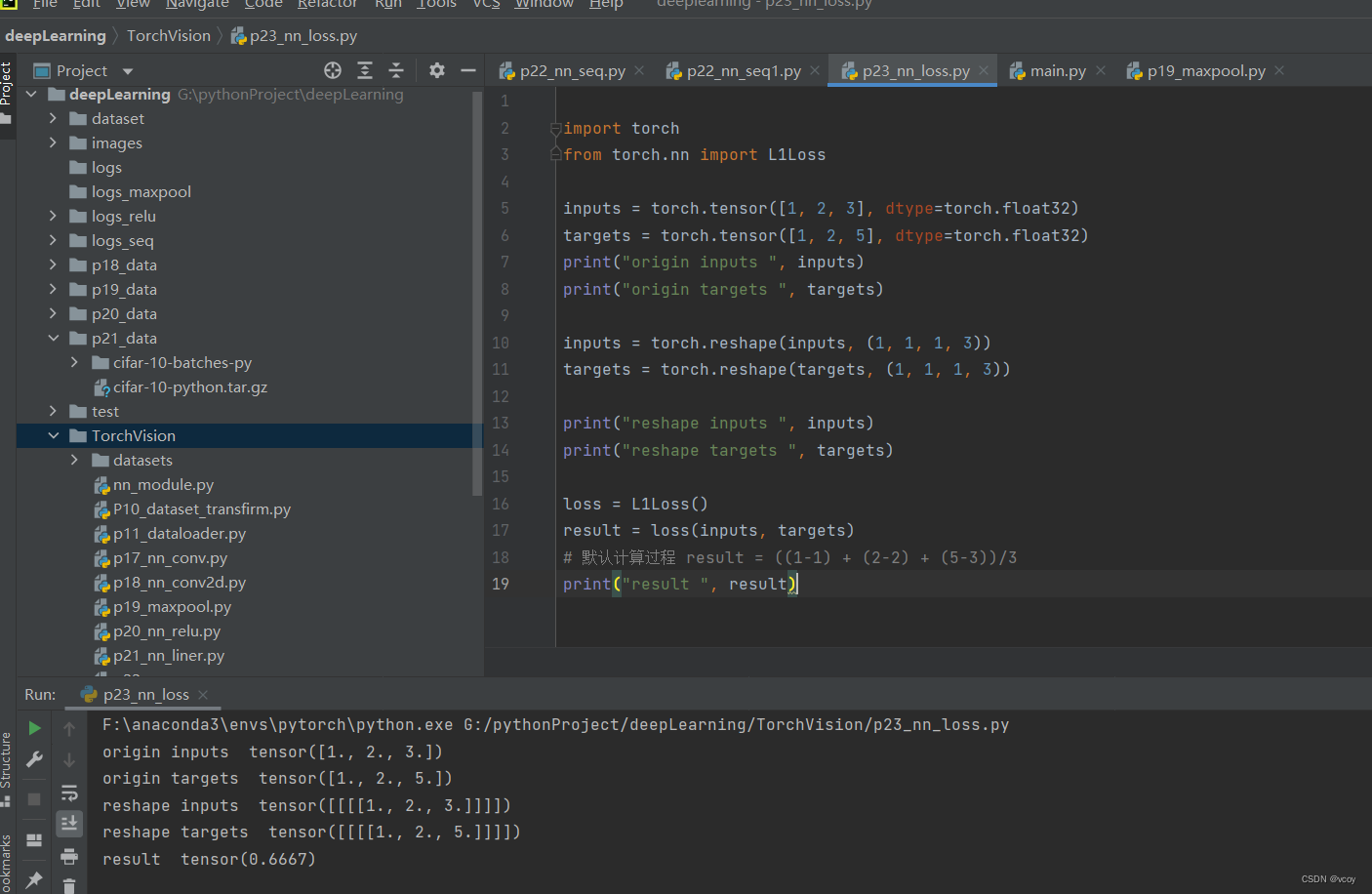
import torch
from torch.nn import L1Loss
from torch import nn
inputs = torch.tensor([1, 2, 3], dtype=torch.float32)
targets = torch.tensor([1, 2, 5], dtype=torch.float32)
inputs = torch.reshape(inputs, (1, 1, 1, 3))
targets = torch.reshape(targets, (1, 1, 1, 3))
loss = L1Loss()
result = loss(inputs, targets)
# 默认计算过程 result = ((1-1) + (2-2) + (5-3))/3
print("result ", result)
loss_mes = nn.MSELoss()
result_mse = loss_mes(inputs, targets)
print("result_mse", result_mse)
if __name__ == '__main__':
x = torch.tensor([0.1, 0.2, 0.3])
y = torch.tensor([1])
# print(x)
x = torch.reshape(x, (1, 3))
# print(x)
# 交叉熵损失函数
loss_cross = nn.CrossEntropyLoss()
result_cross = loss_cross(x, y)
print(result_cross)
交叉熵损失函数识别Person- dog- car,通过CrossEntropyLoss计算的损失值过程,参数参考官网
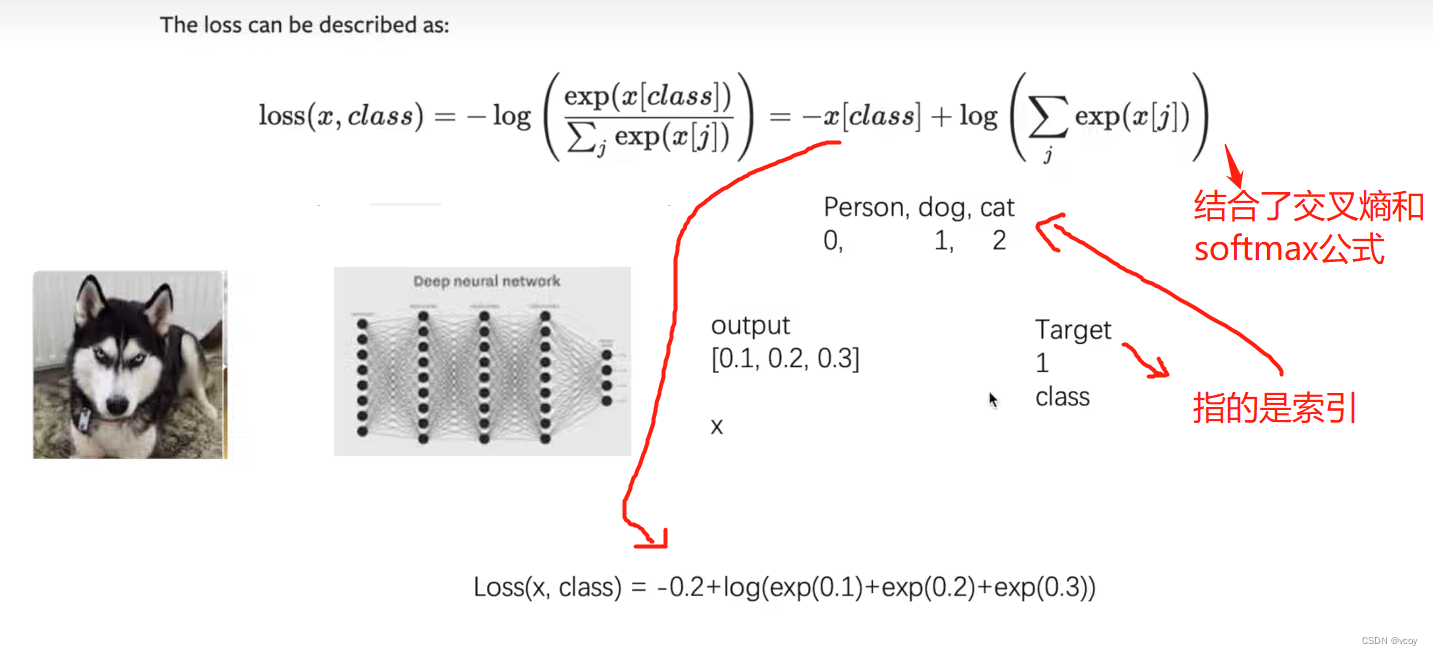
交叉熵损失函数输入为2维,reshape将数据转化为二维
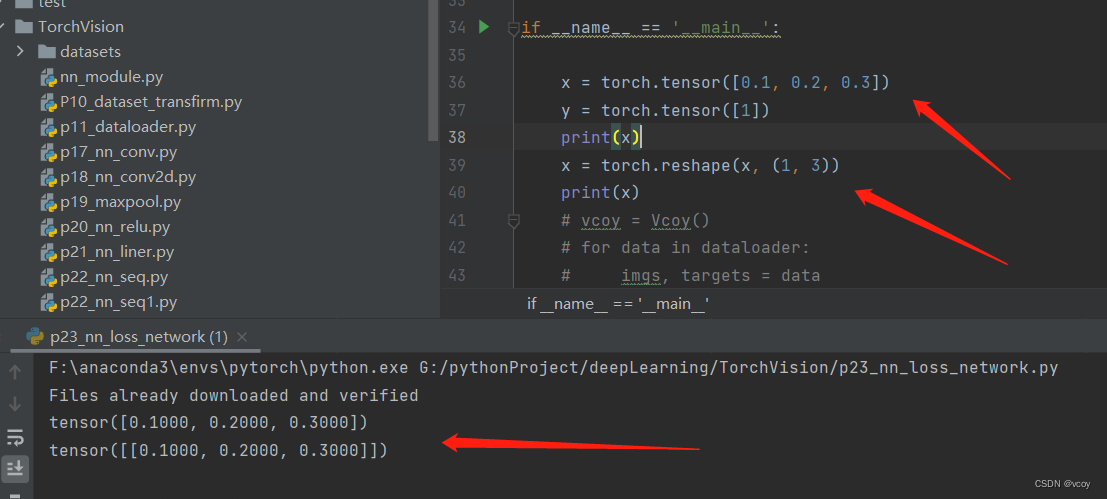
使用交叉熵计算识别 [Person- dog- car] 过程的损失函数。x为假设的网络模型输出的各个类别的概率,y为实际的类别的索引,1即是dog。通过该损失函数计算它们之间的损失值。
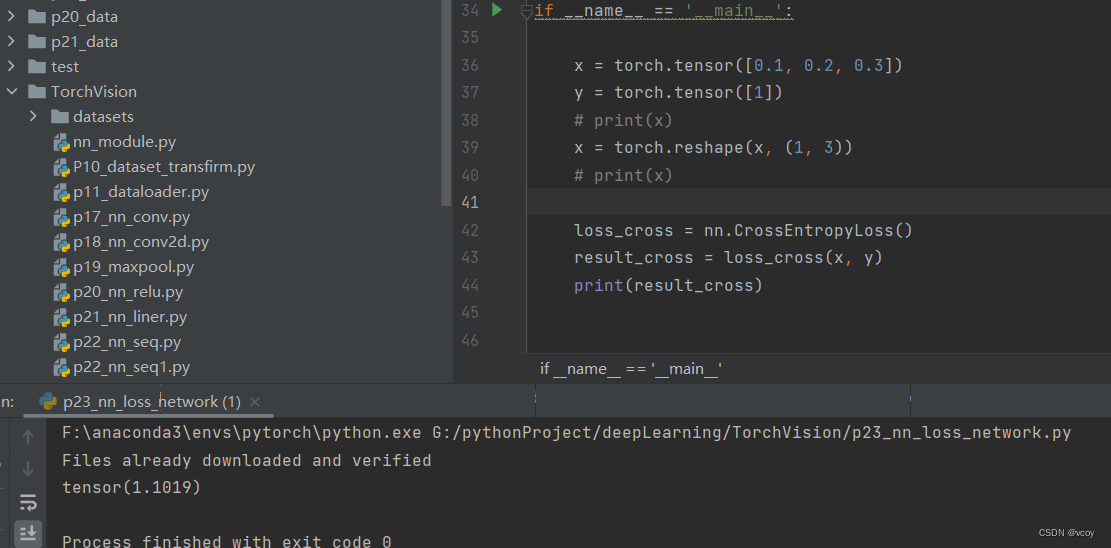
将12.1 列化后的简单神经网络序应用到CIFAR10数据集上,该数据集一共10个类别
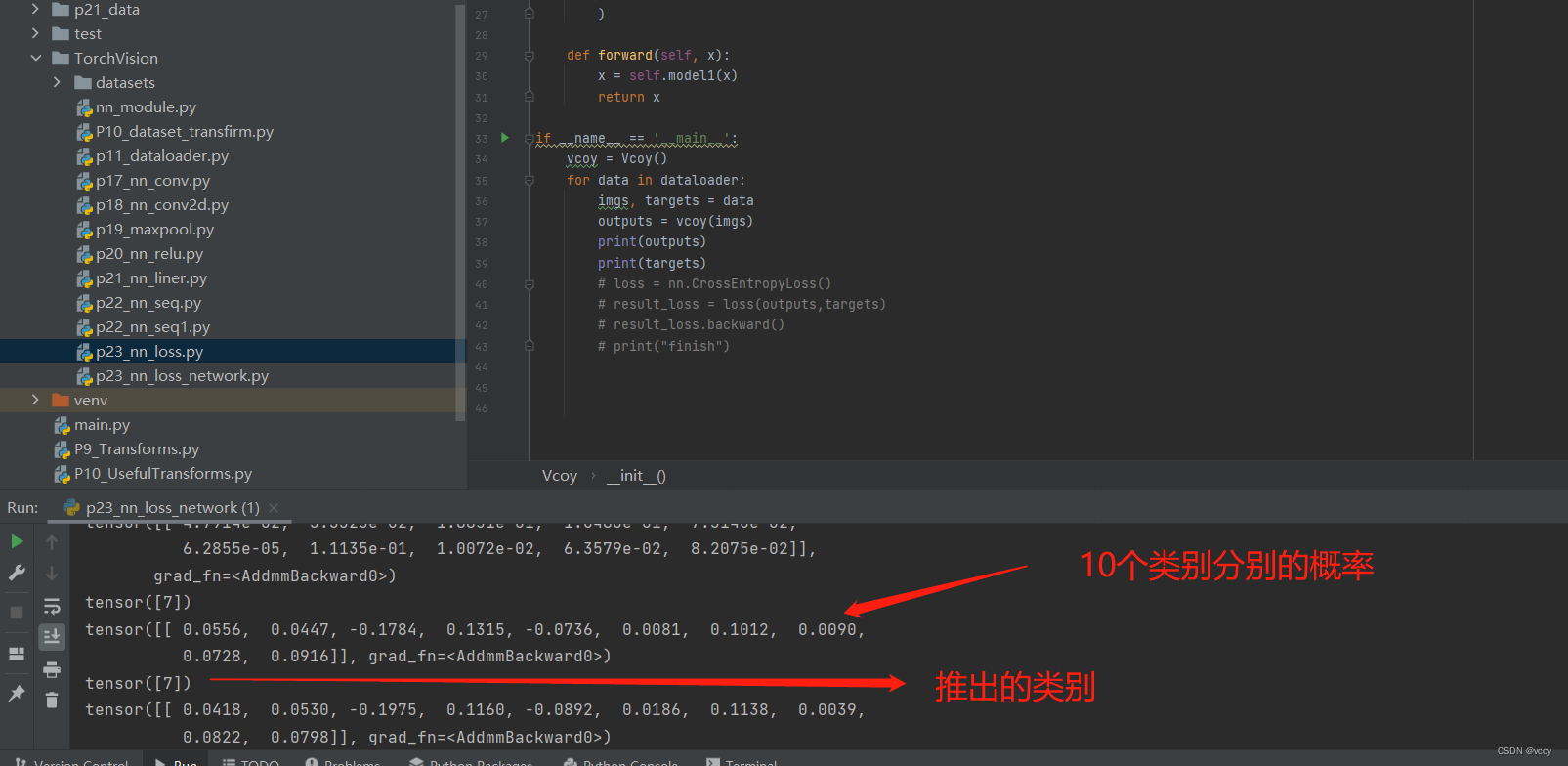
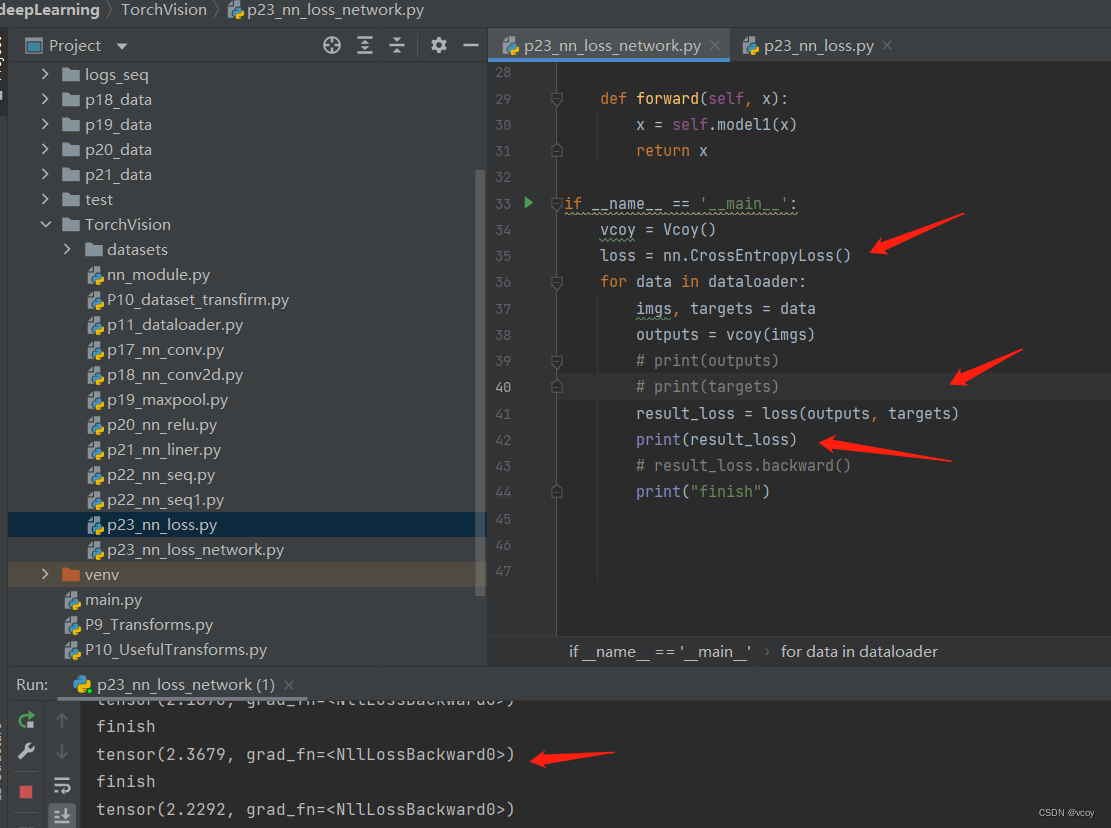
计算损失值
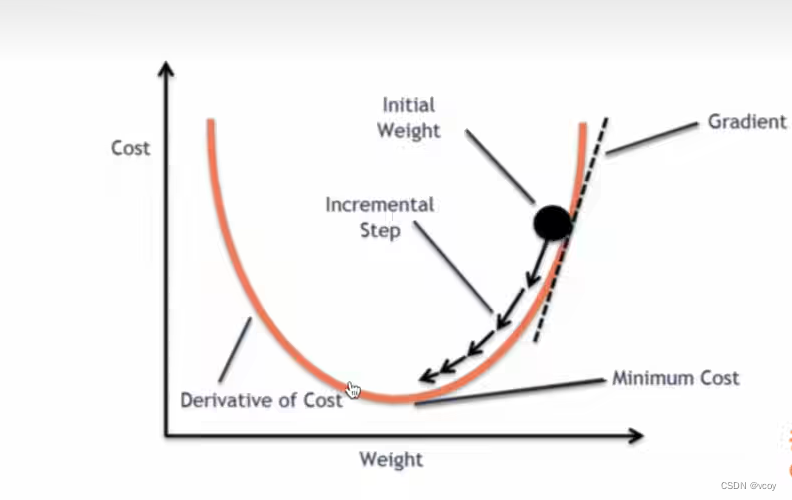
梯度下降法:通过反向传播计算某点的梯度,根据当前点进行参数变化,使得梯度下降,损失值变小
使用backward计算出每个节点的grad-梯度参数
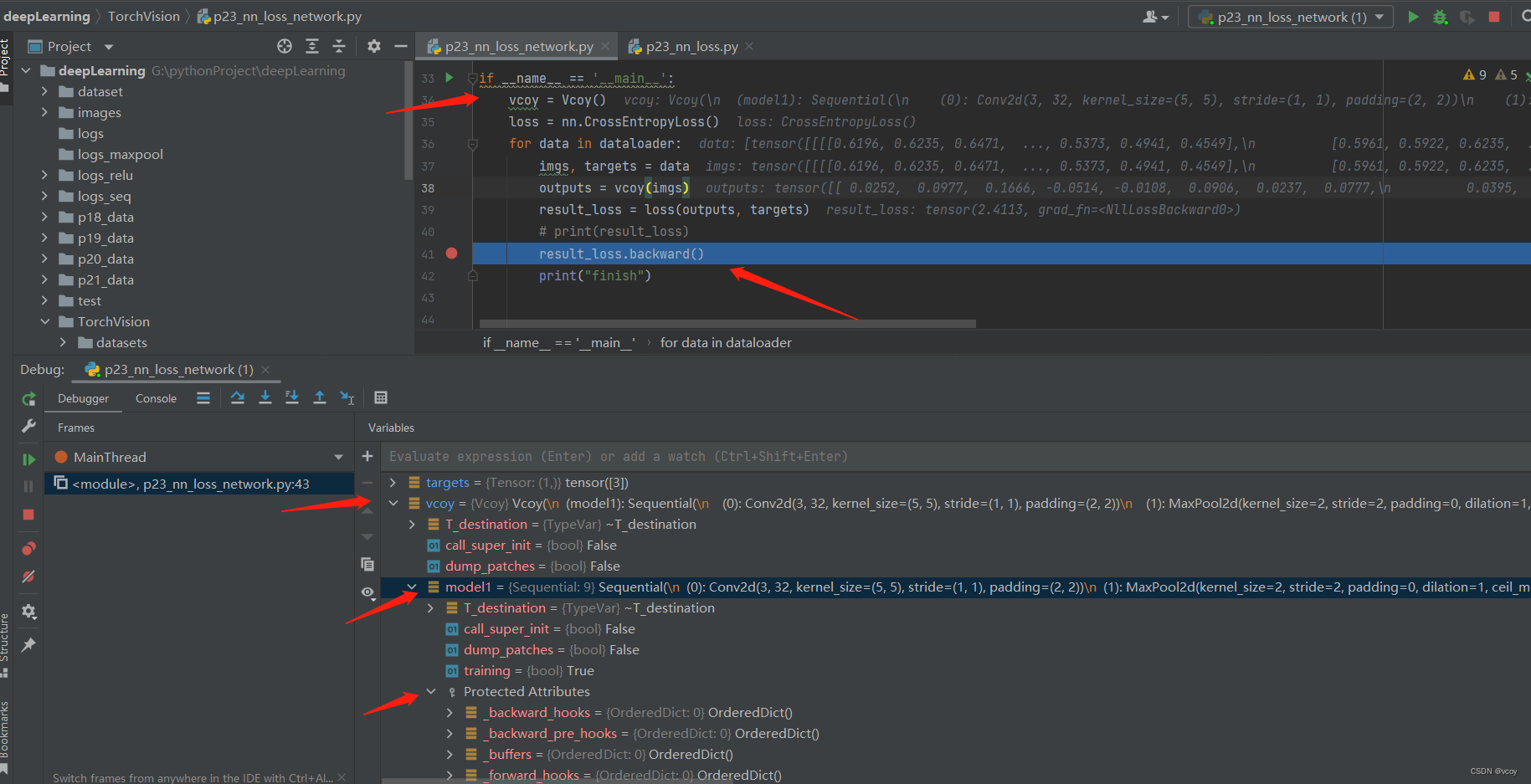
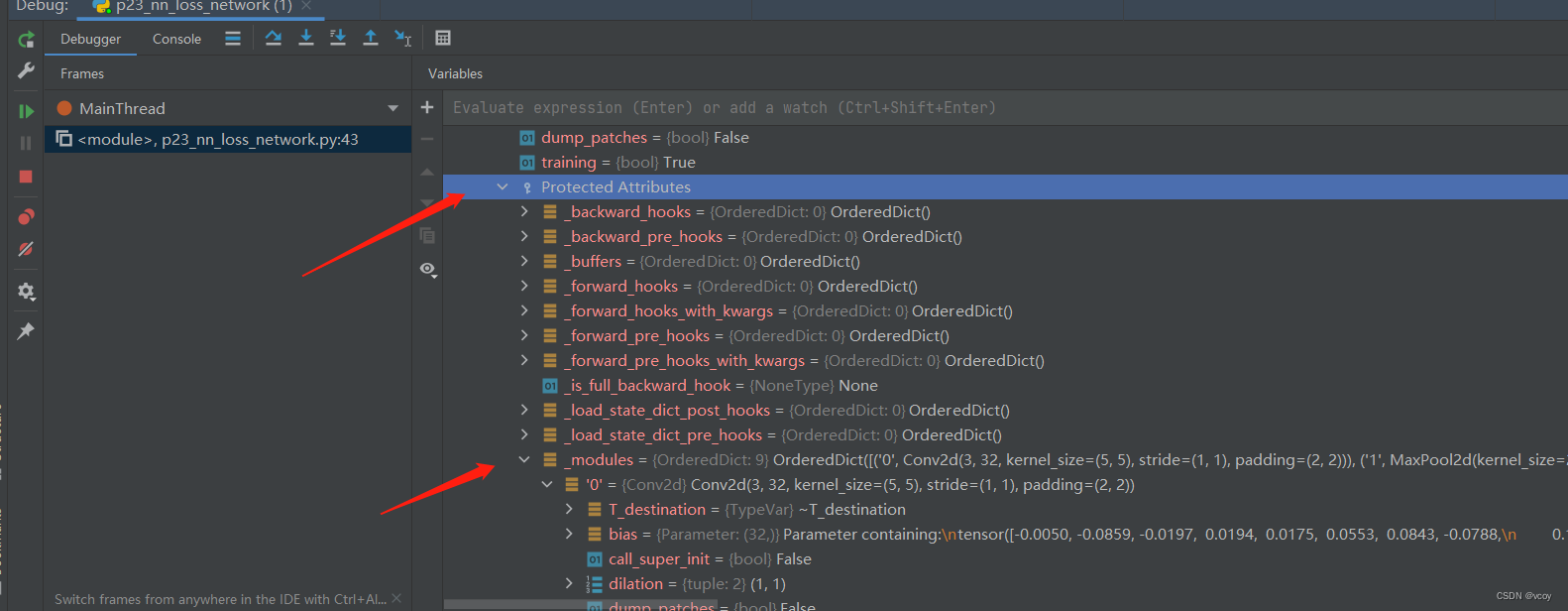
查看module-》grad(即梯度),然后通过优化器根据梯度对神经网络中的参数进行更新。
对应代码
import torch
from torch import nn
from torch.nn import Module, Conv2d, MaxPool2d, Flatten, Linear, Sequential
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
import torchvision
dataset = torchvision.datasets.CIFAR10("../p21_data", train=False, transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset, batch_size=1)
class Vcoy(nn.Module):
def __init__(self):
super(Vcoy, self).__init__()
self.model1 = Sequential(
Conv2d(3, 32, 5, stride=1, padding=2),
MaxPool2d(2),
Conv2d(32, 32, 5, stride=1, padding=2),
MaxPool2d(2),
Conv2d(32, 64, 5, stride=1, padding=2),
MaxPool2d(2),
Flatten(),
Linear(1024, 64),
Linear(64, 10)
)
def forward(self, x):
x = self.model1(x)
return x
if __name__ == '__main__':
vcoy = Vcoy()
loss = nn.CrossEntropyLoss()
for data in dataloader:
imgs, targets = data
outputs = vcoy(imgs)
result_loss = loss(outputs, targets)
# print(result_loss)
result_loss.backward()
print("finish")
官方其他损失函数
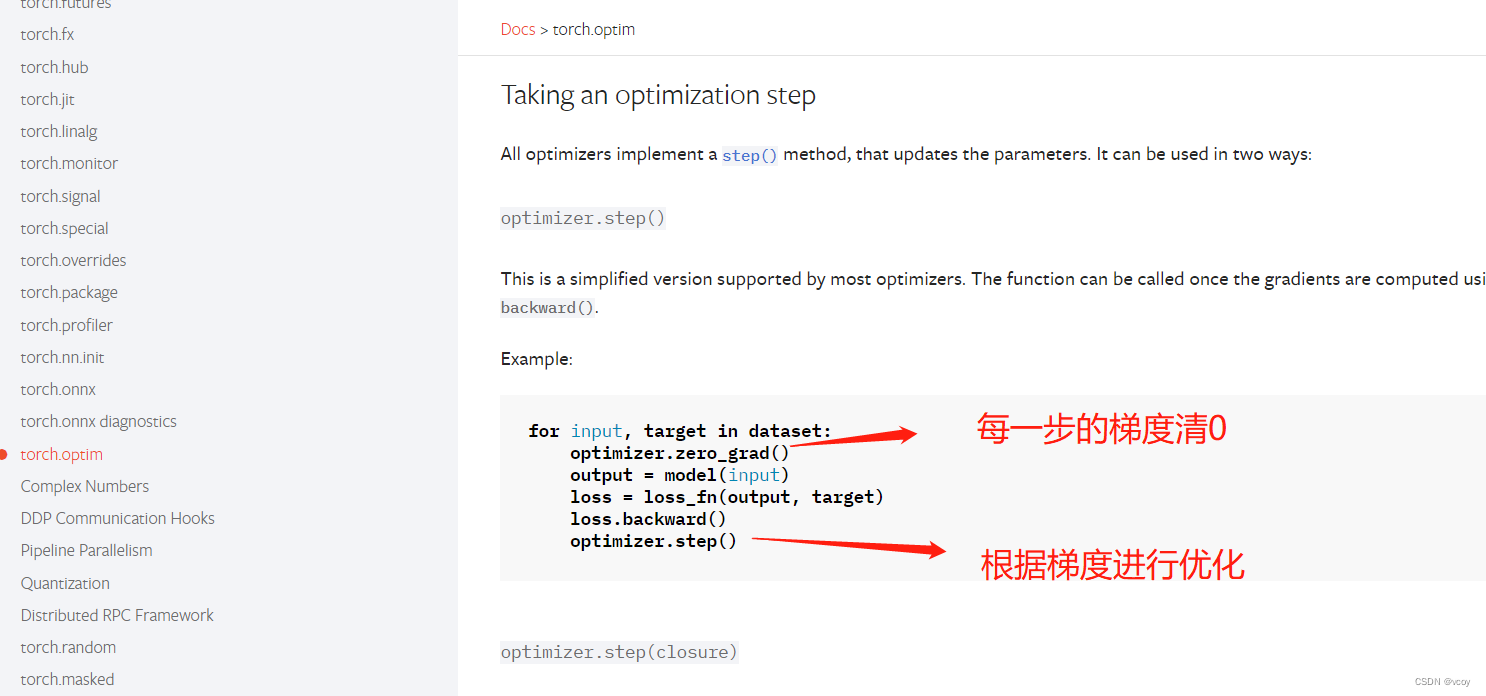
14.优化器
官方文档
优化器降低损失值的过程
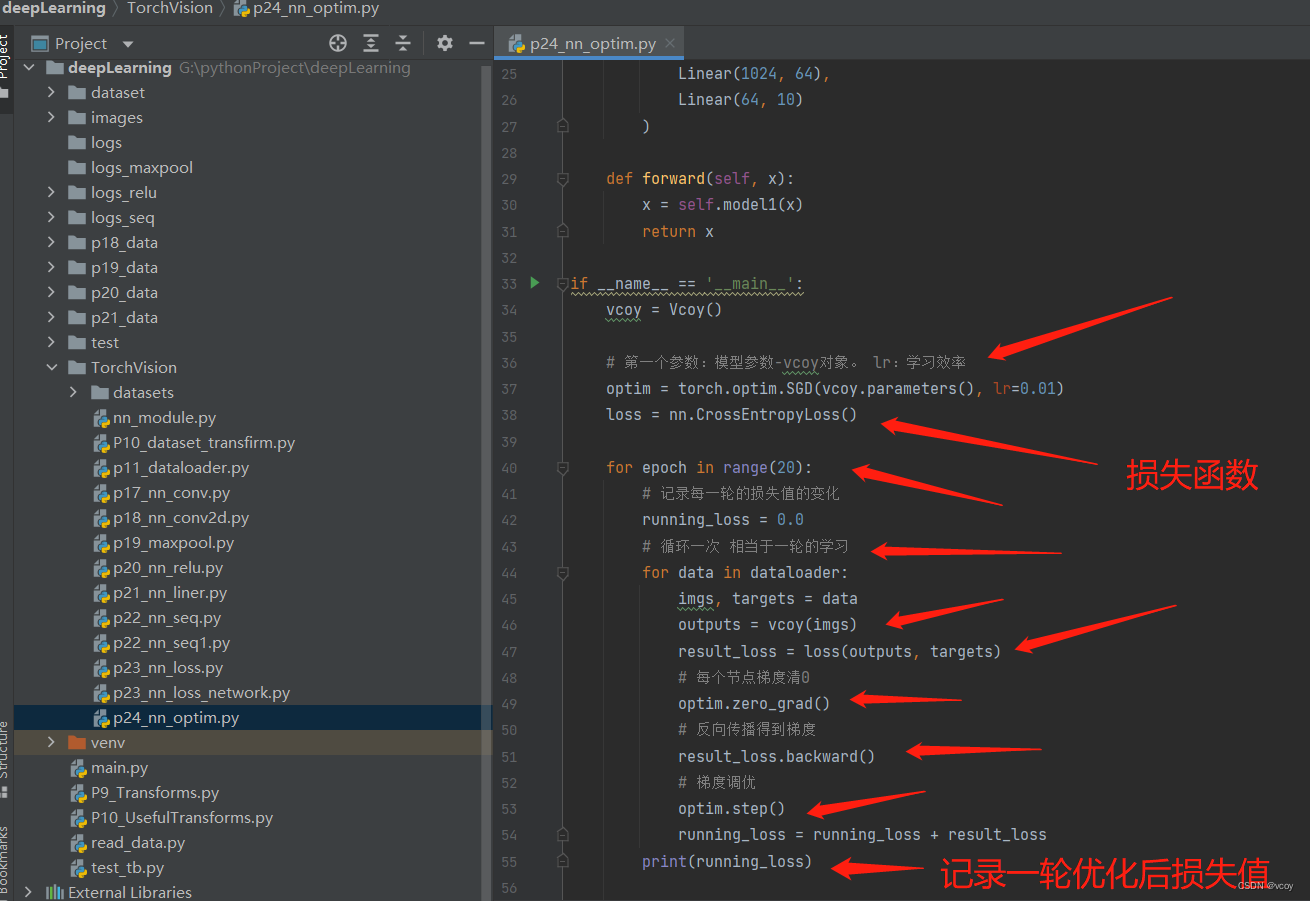
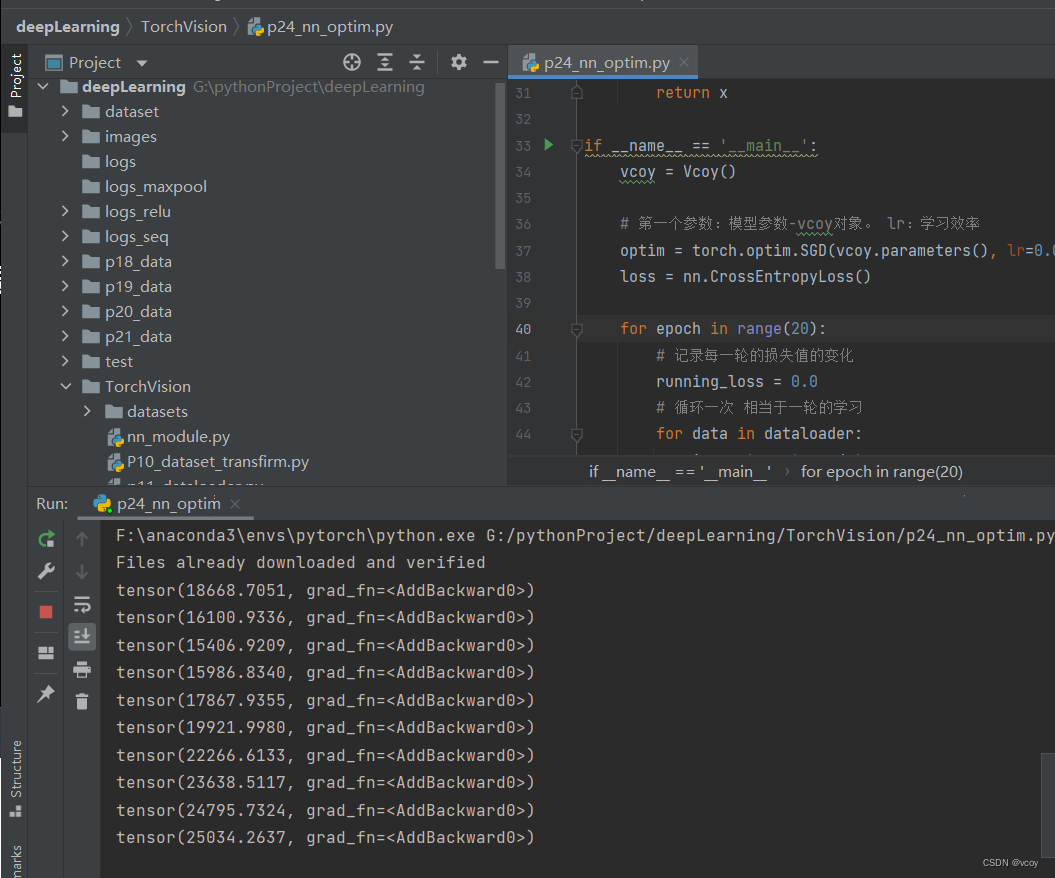
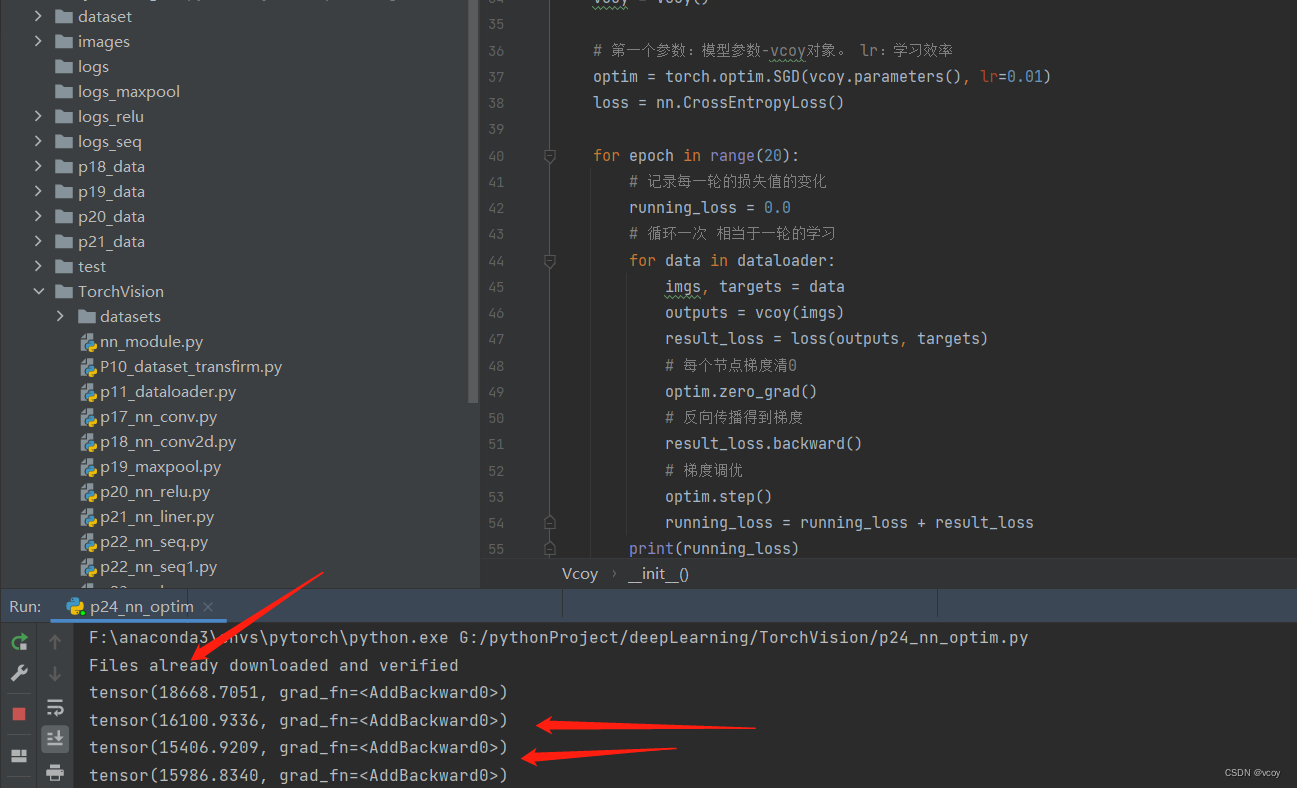 存在损失值先降低后增长的问题:在顺序寻找loss最小值,误差小,识别率高。让误差变小,但在函数中很难找到最小值,能找到极小值,需要改变幅度,再次找到最小值。可以尝试降低学习率 lr再查看损失值变化。
存在损失值先降低后增长的问题:在顺序寻找loss最小值,误差小,识别率高。让误差变小,但在函数中很难找到最小值,能找到极小值,需要改变幅度,再次找到最小值。可以尝试降低学习率 lr再查看损失值变化。
15.现有模型的使用和修改:VGG16模型
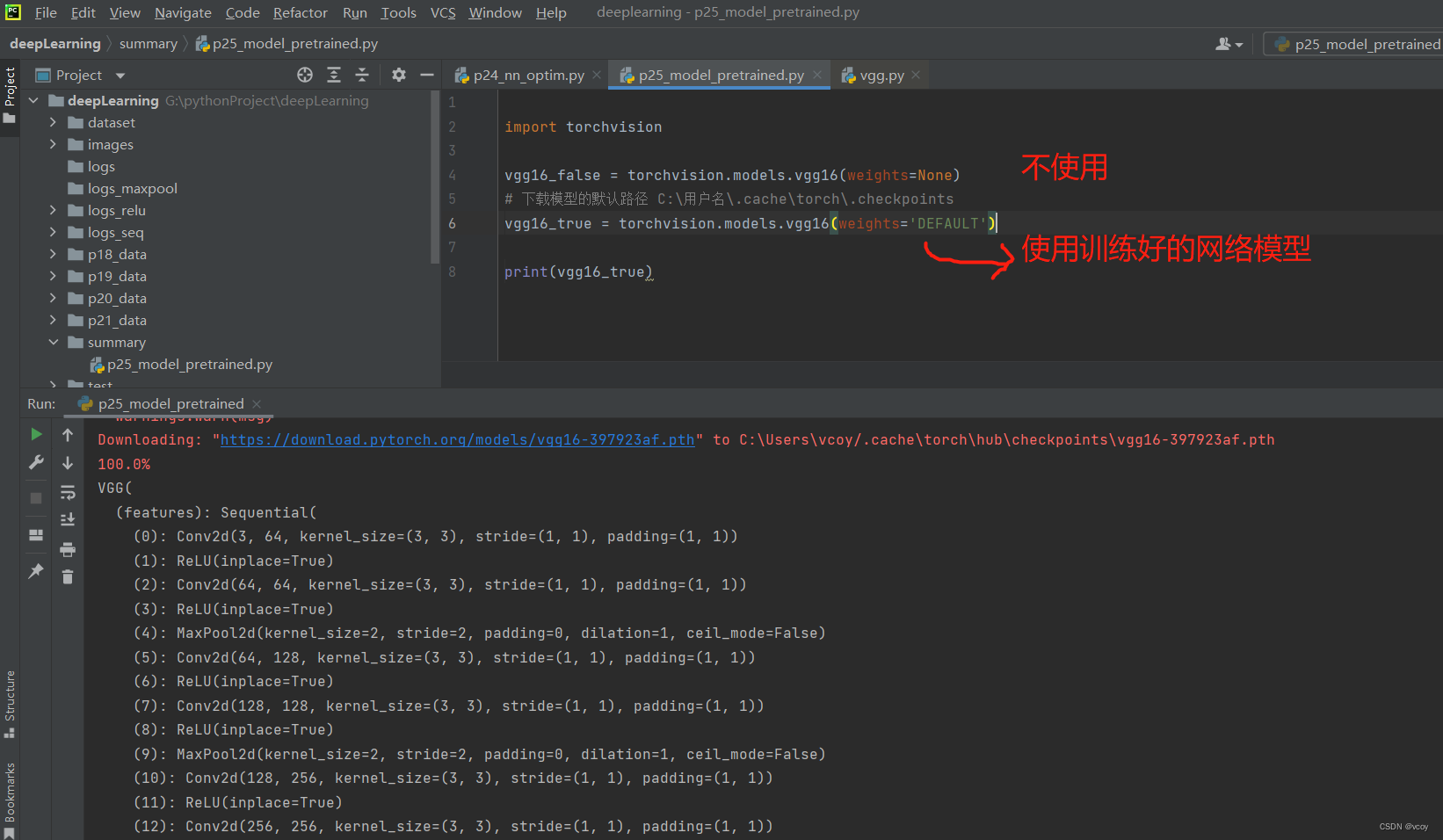
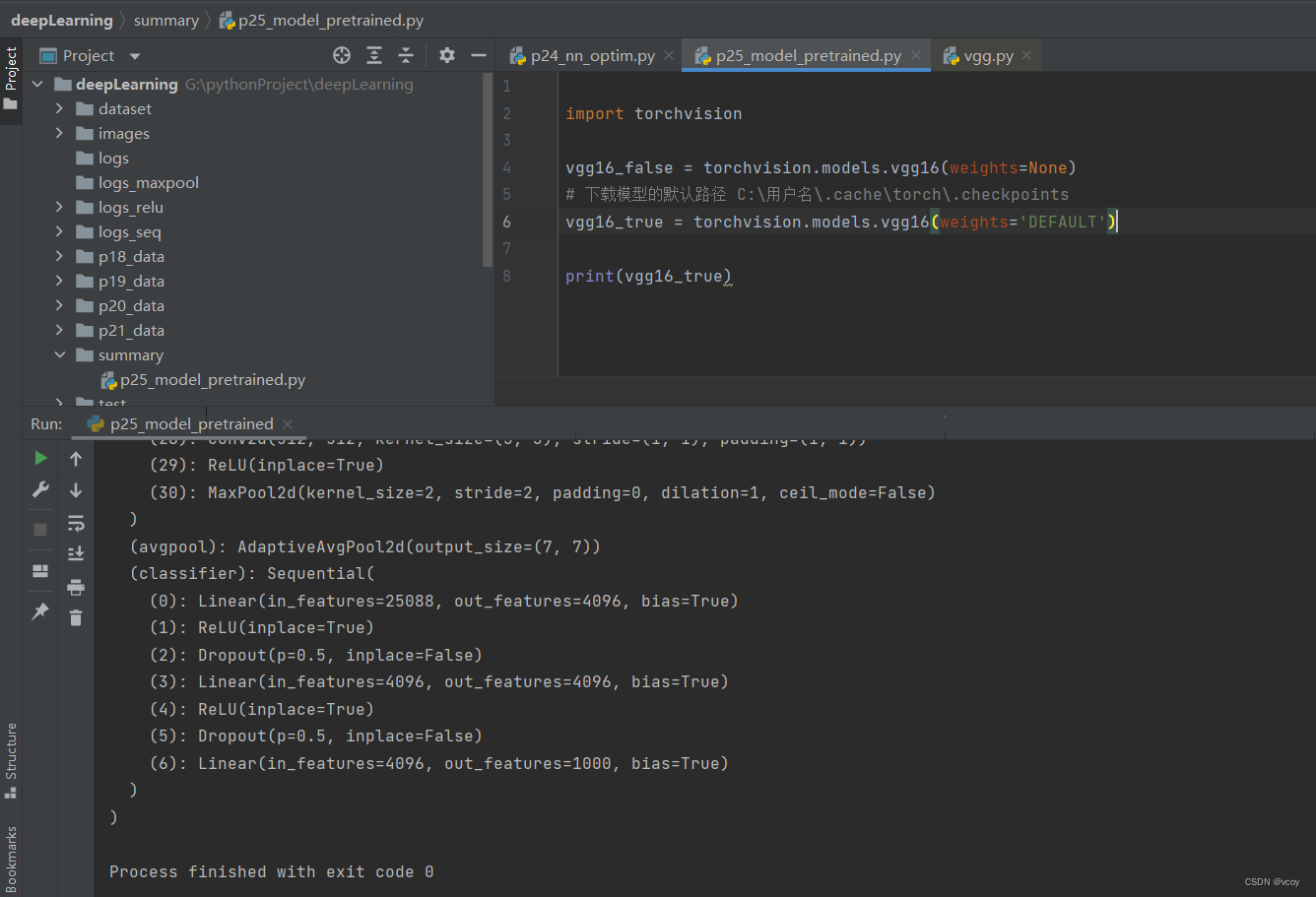
修改vgg16模型内的参数
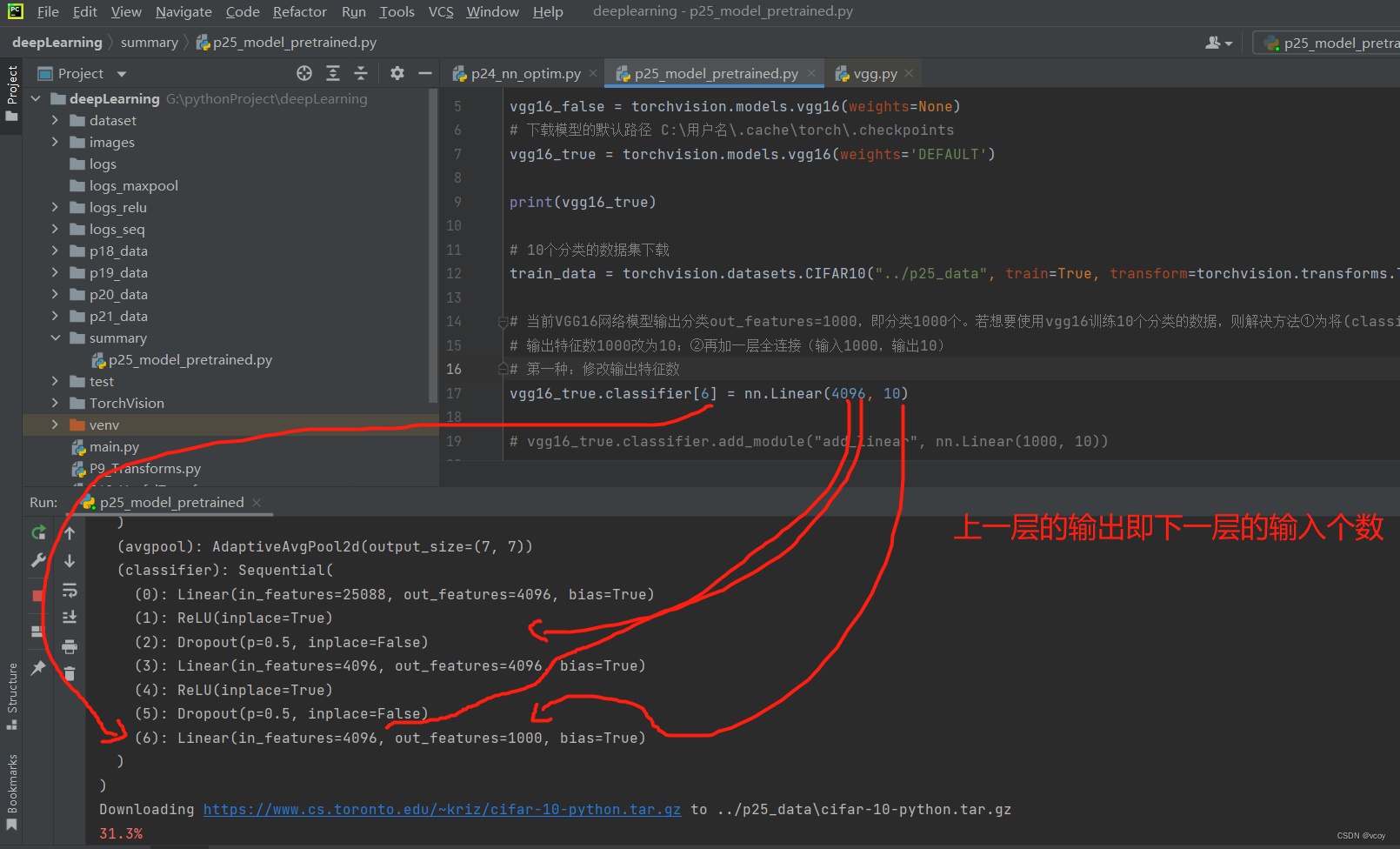
修改后
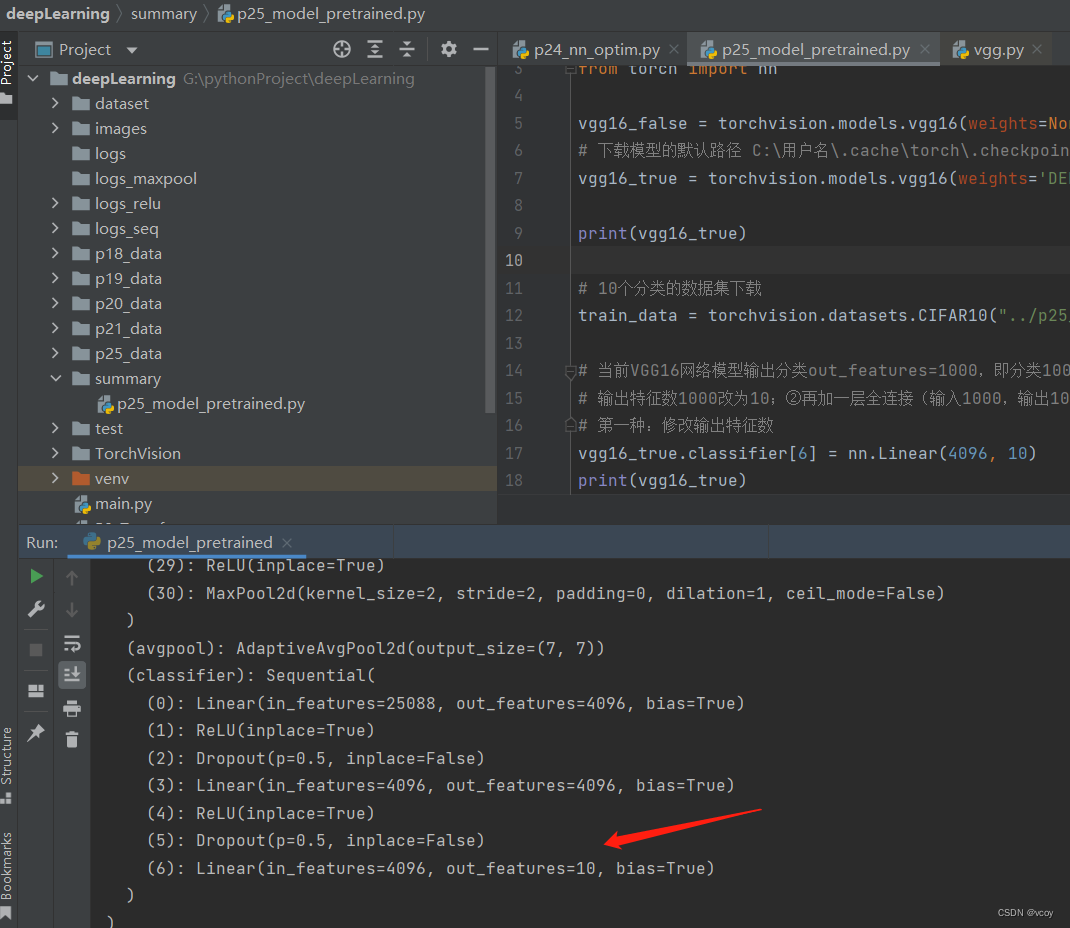
添加一步全连接层
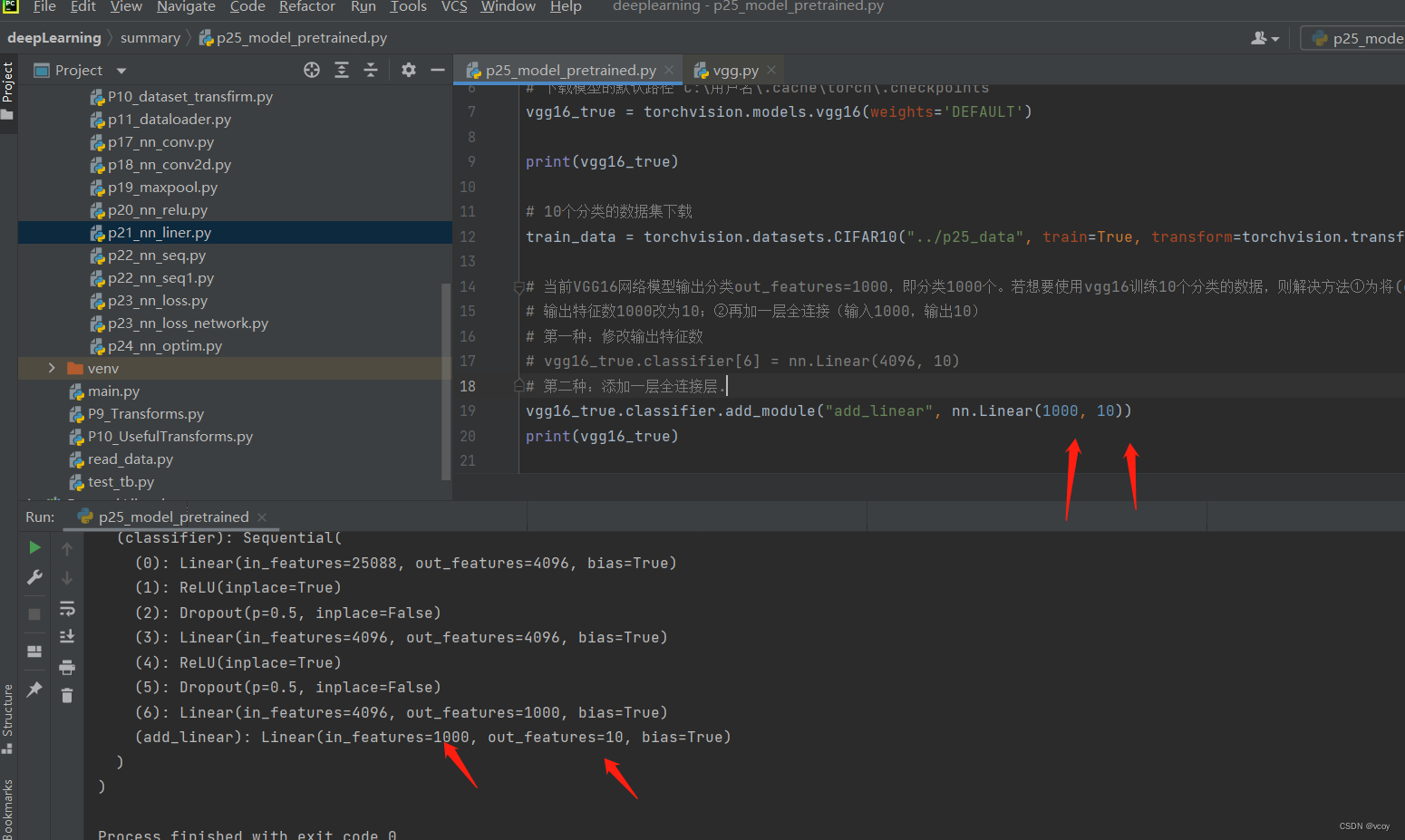
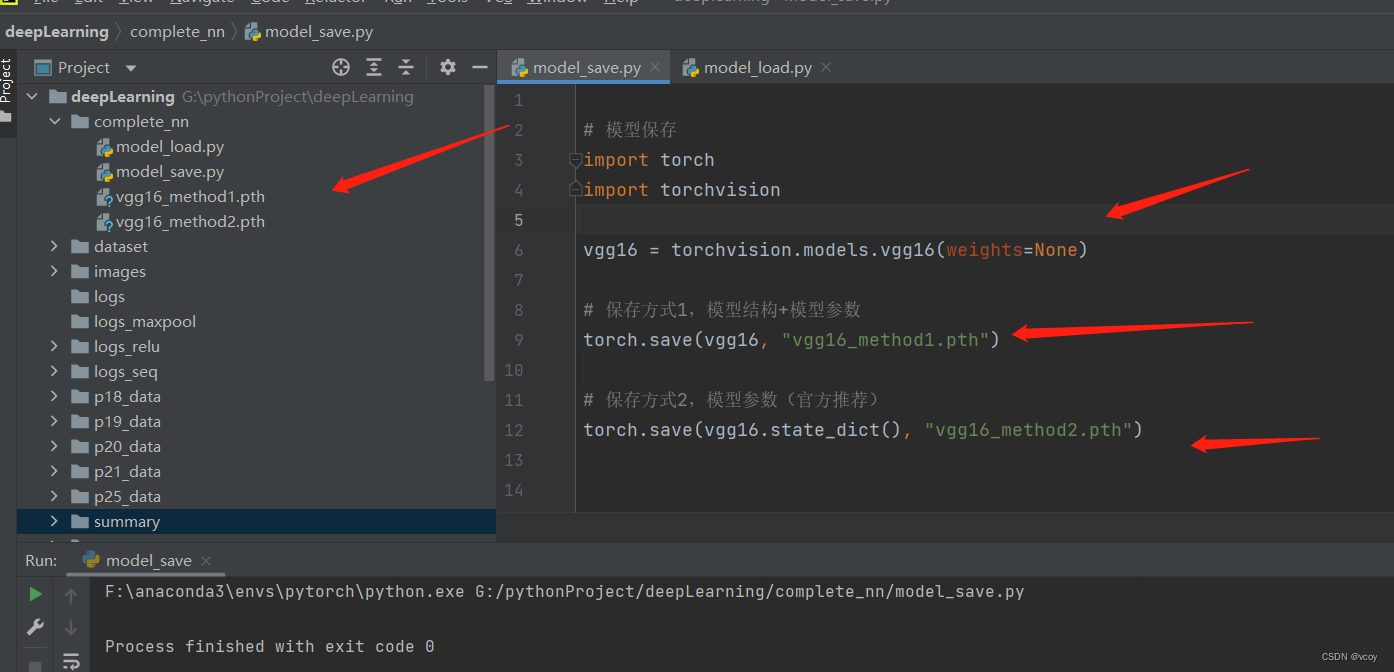
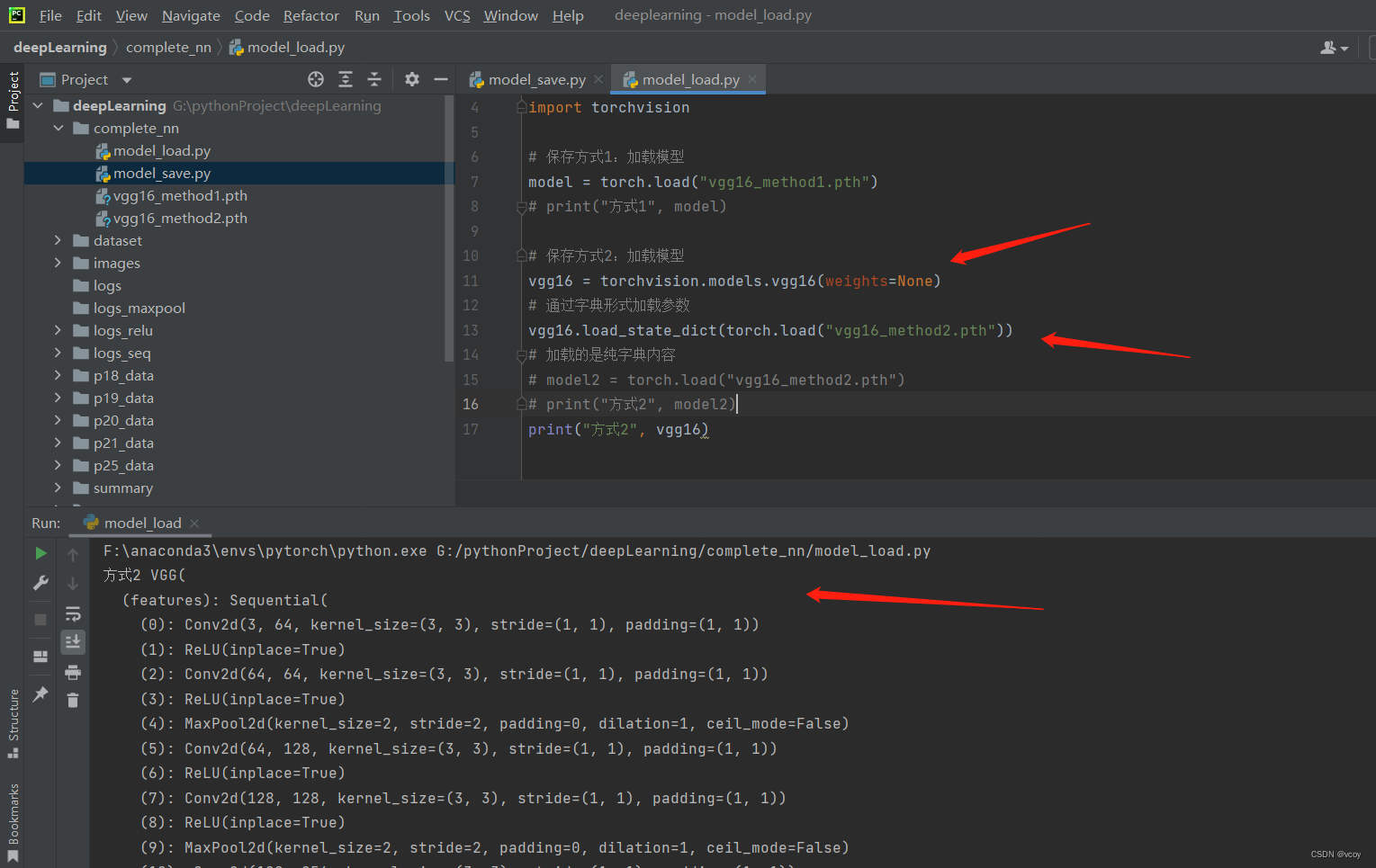
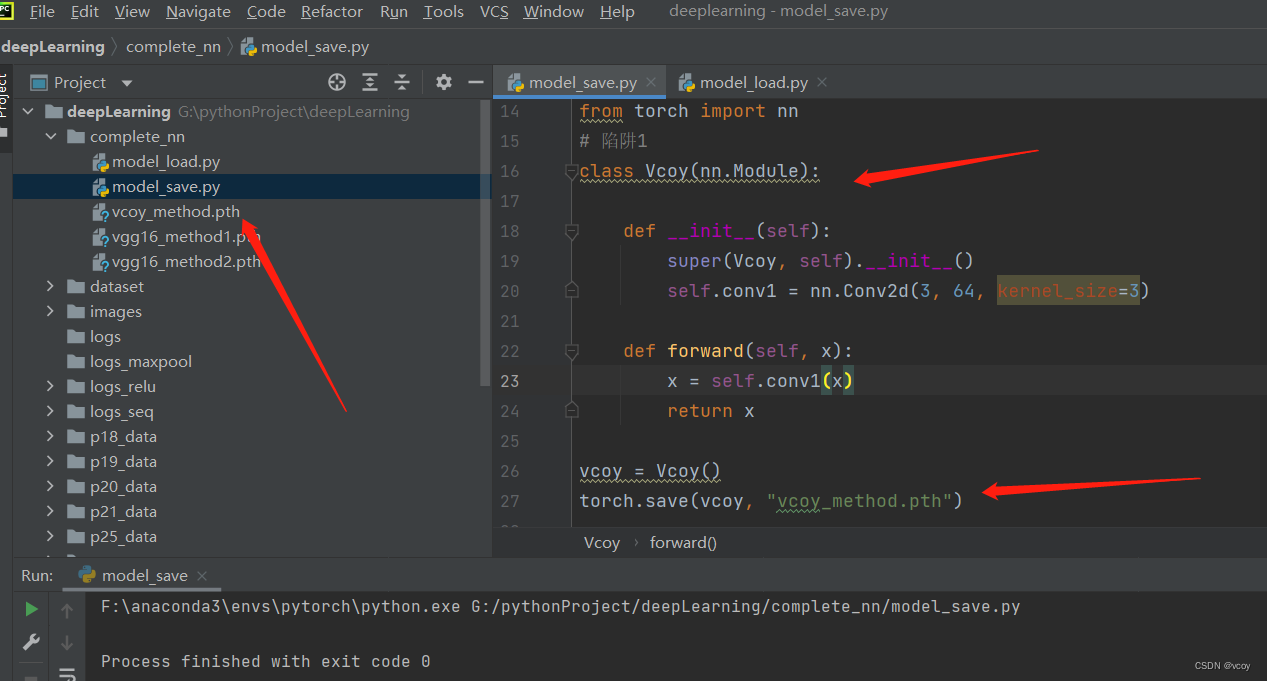
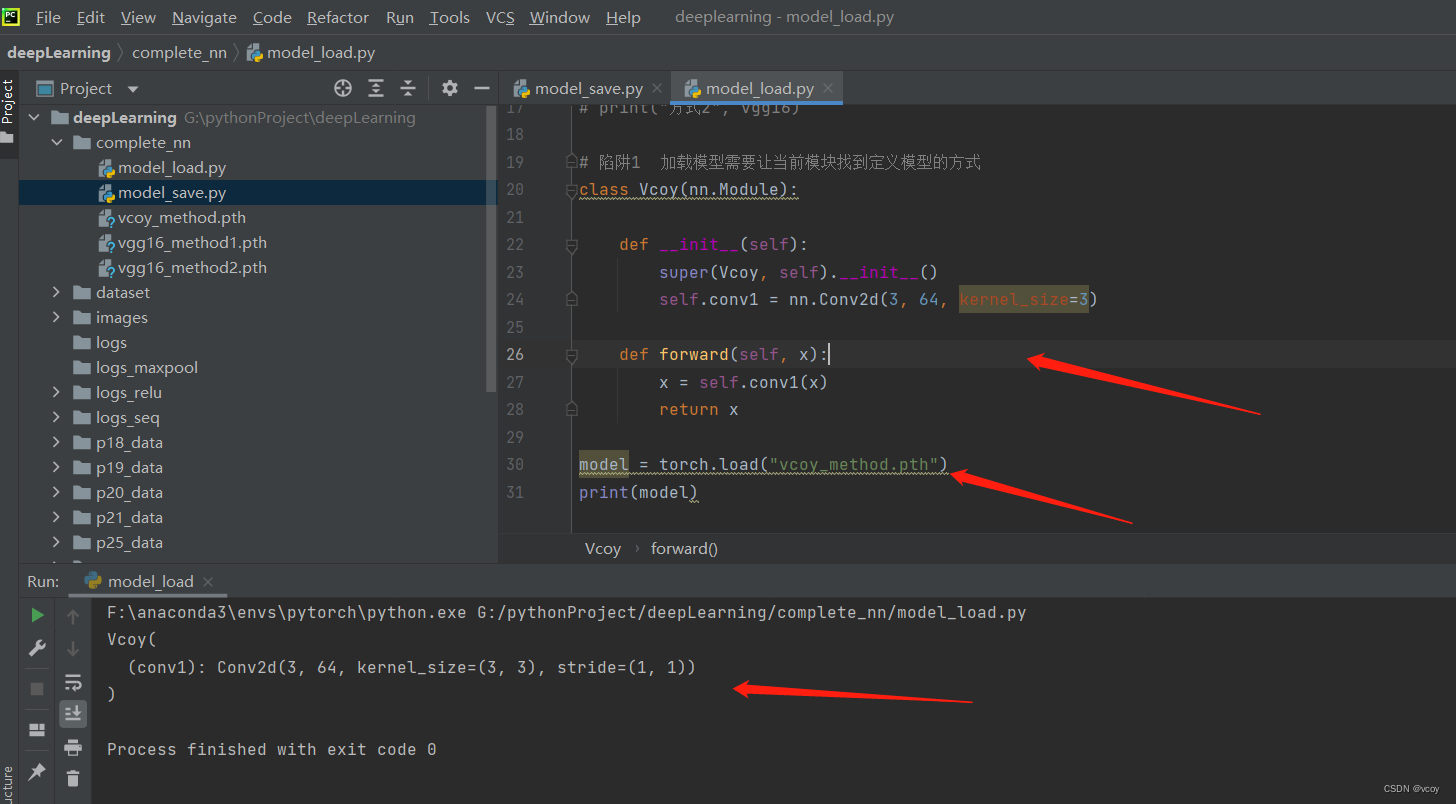
16.网络模型的保存与加载
模型保存的两种方式及加载
保存
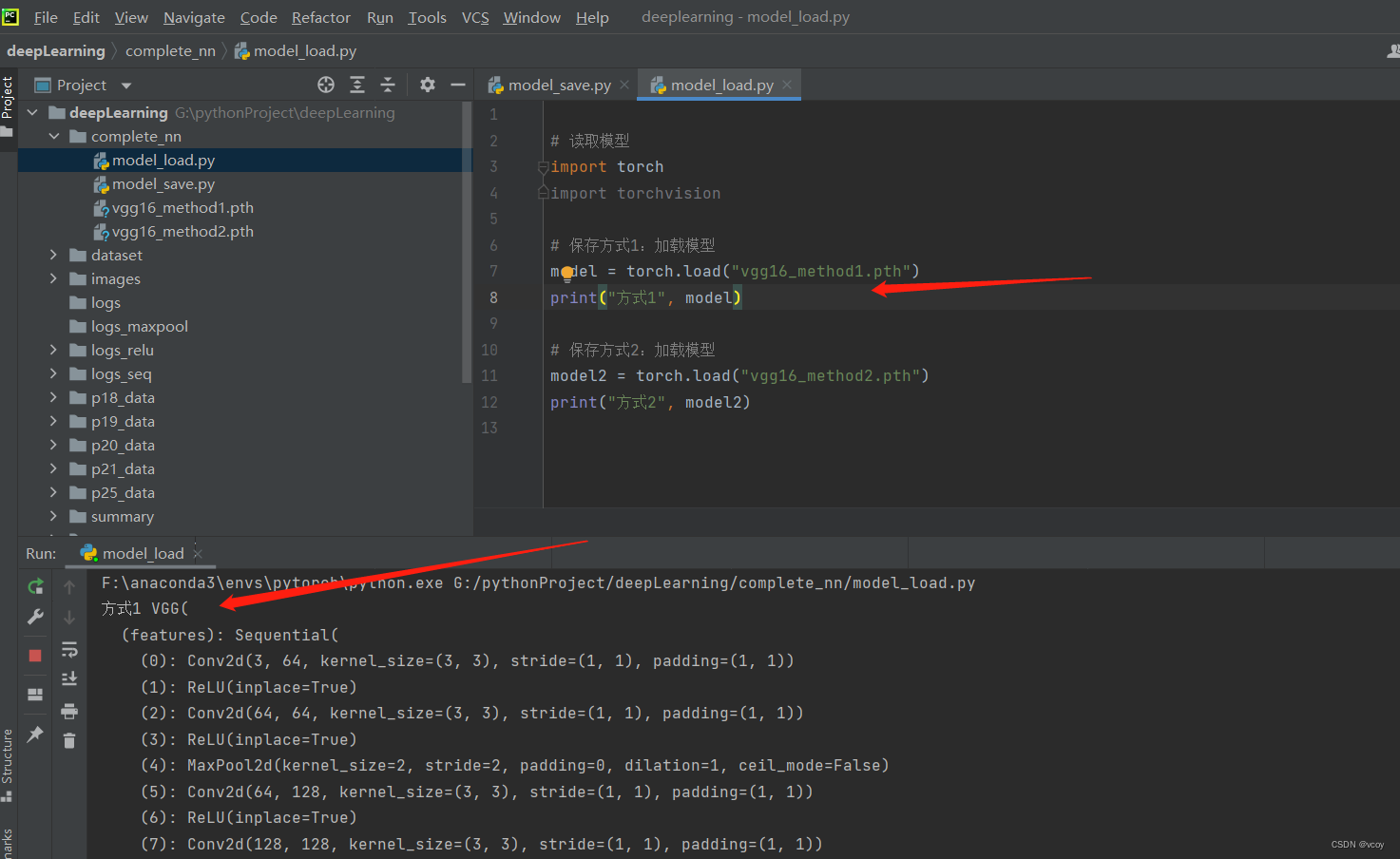
加载方式1:是正常的网络模型
加载方式2:打印的是一个个的字典形式,不再是网络模型,需要恢复成网络模型
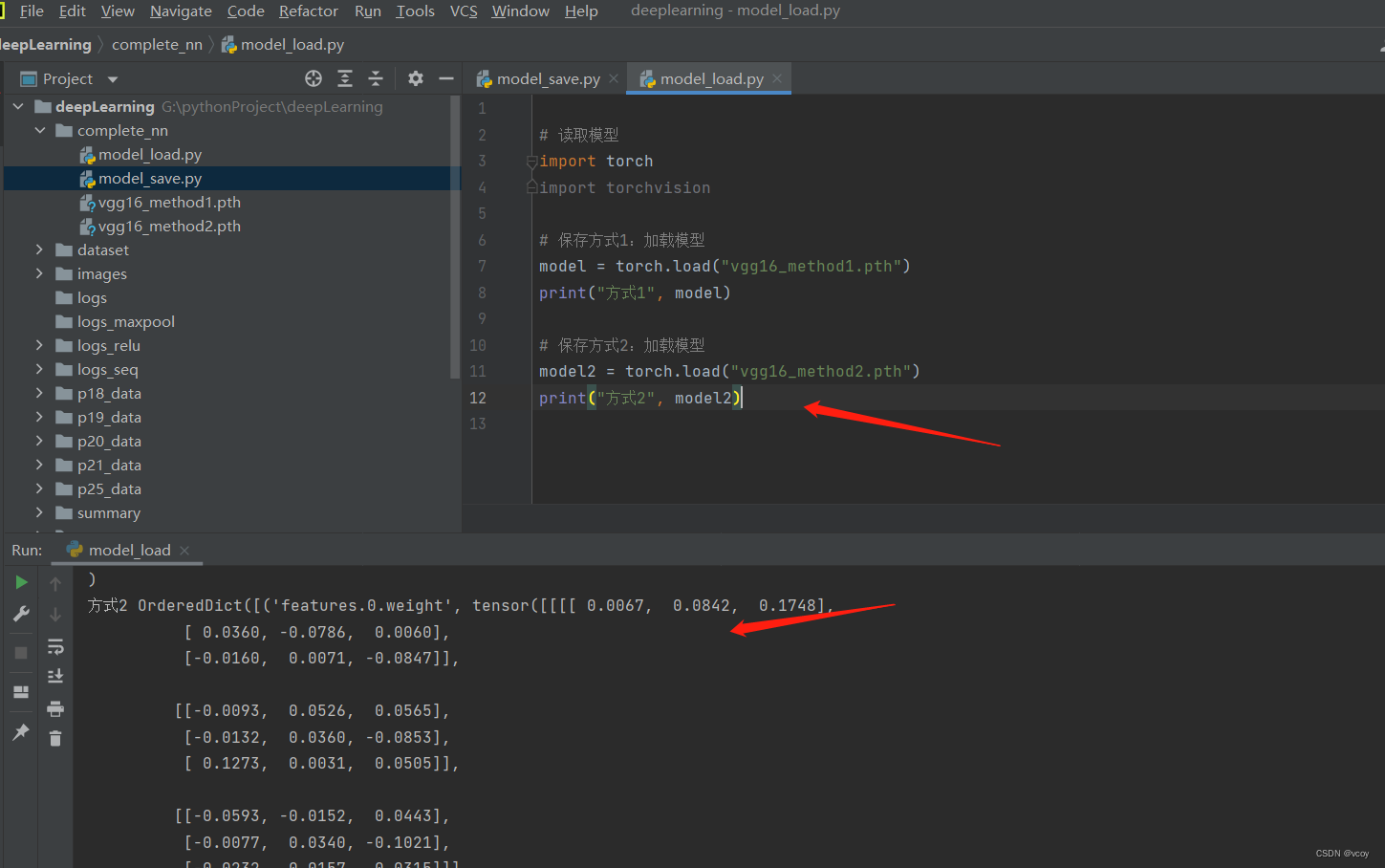
加载方式2:加载网络模型
自定义模型保存
自定义模型加载
17.完整模型训练套路(数据集CIFAR10)
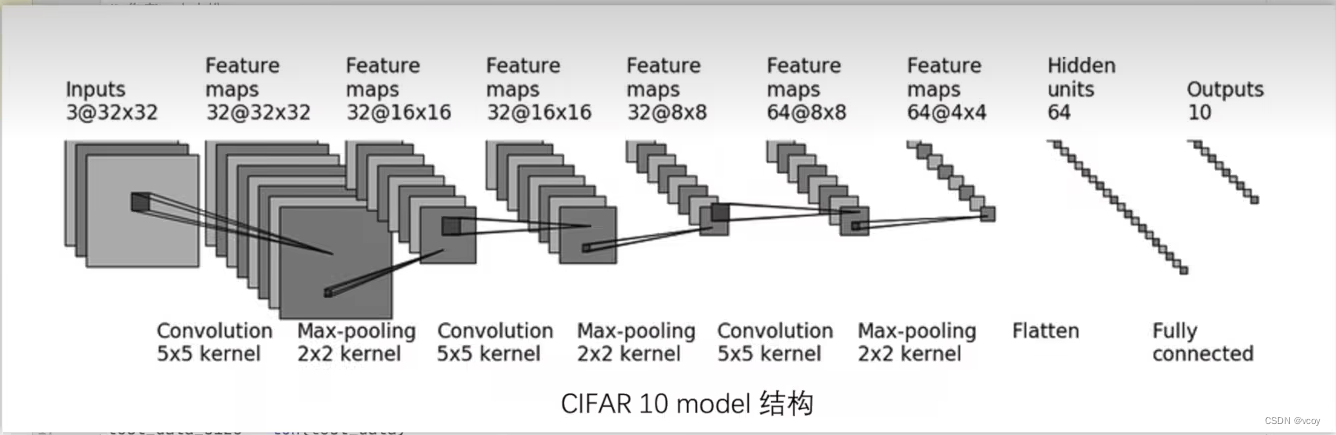
17.1搭建神经网络模型并测试
模型
测试模型输出
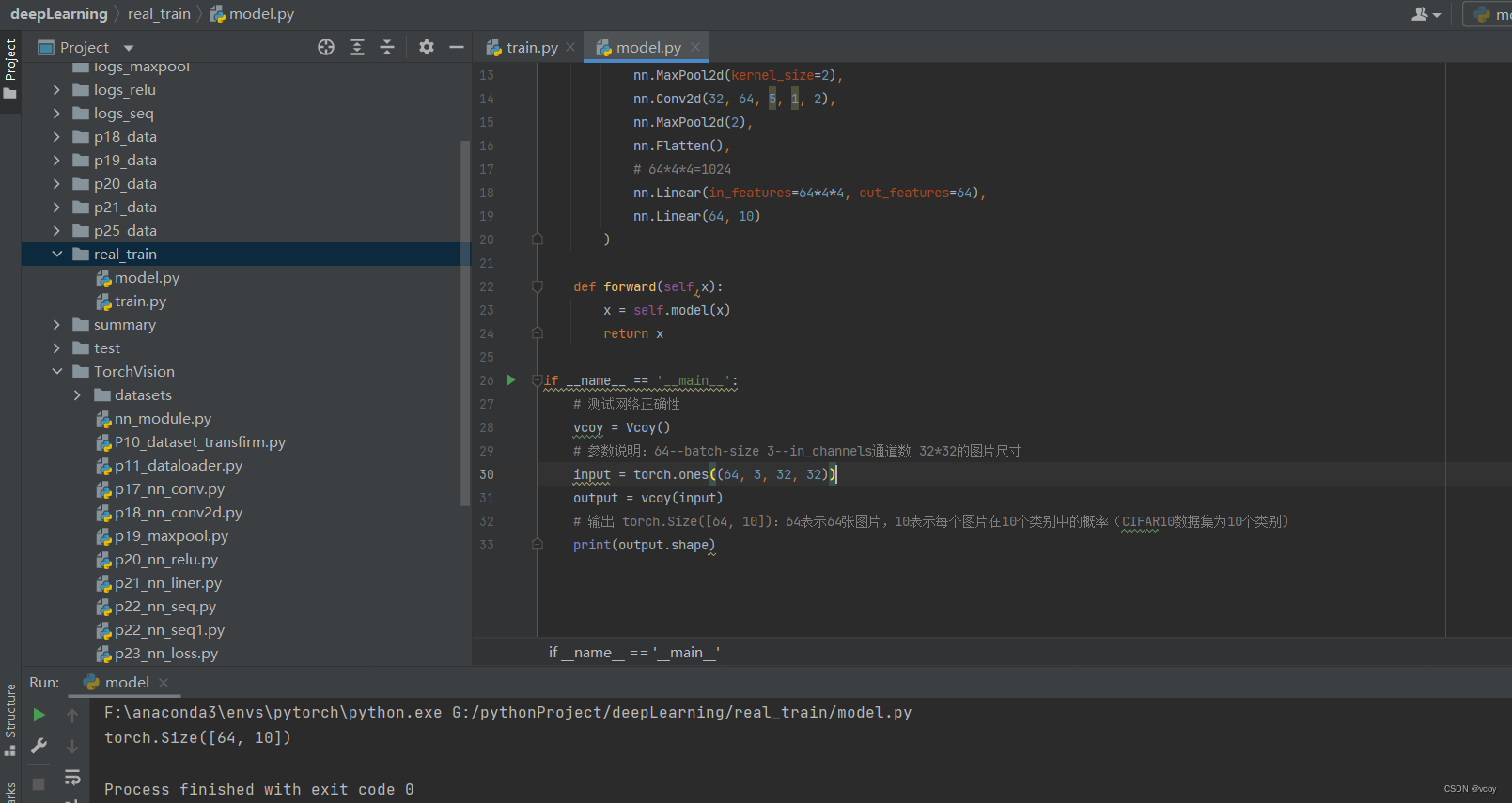
model.py
import torch
from torch import nn
# 搭建神经网络模型
class Vcoy(nn.Module):
def __init__(self):
super(Vcoy, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
# 64*4*4=1024
nn.Linear(in_features=64*4*4, out_features=64),
nn.Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
if __name__ == '__main__':
# 测试网络正确性
vcoy = Vcoy()
# 参数说明:64--batch-size 3--in_channels通道数 32*32的图片尺寸
input = torch.ones((64, 3, 32, 32))
output = vcoy(input)
# 输出 torch.Size([64, 10]):64表示64张图片,10表示每个图片在10个类别中的概率(CIFAR10数据集为10个类别)
print(output.shape)
17.2 模型进行训练、测试、保存每次训练的模型
训练
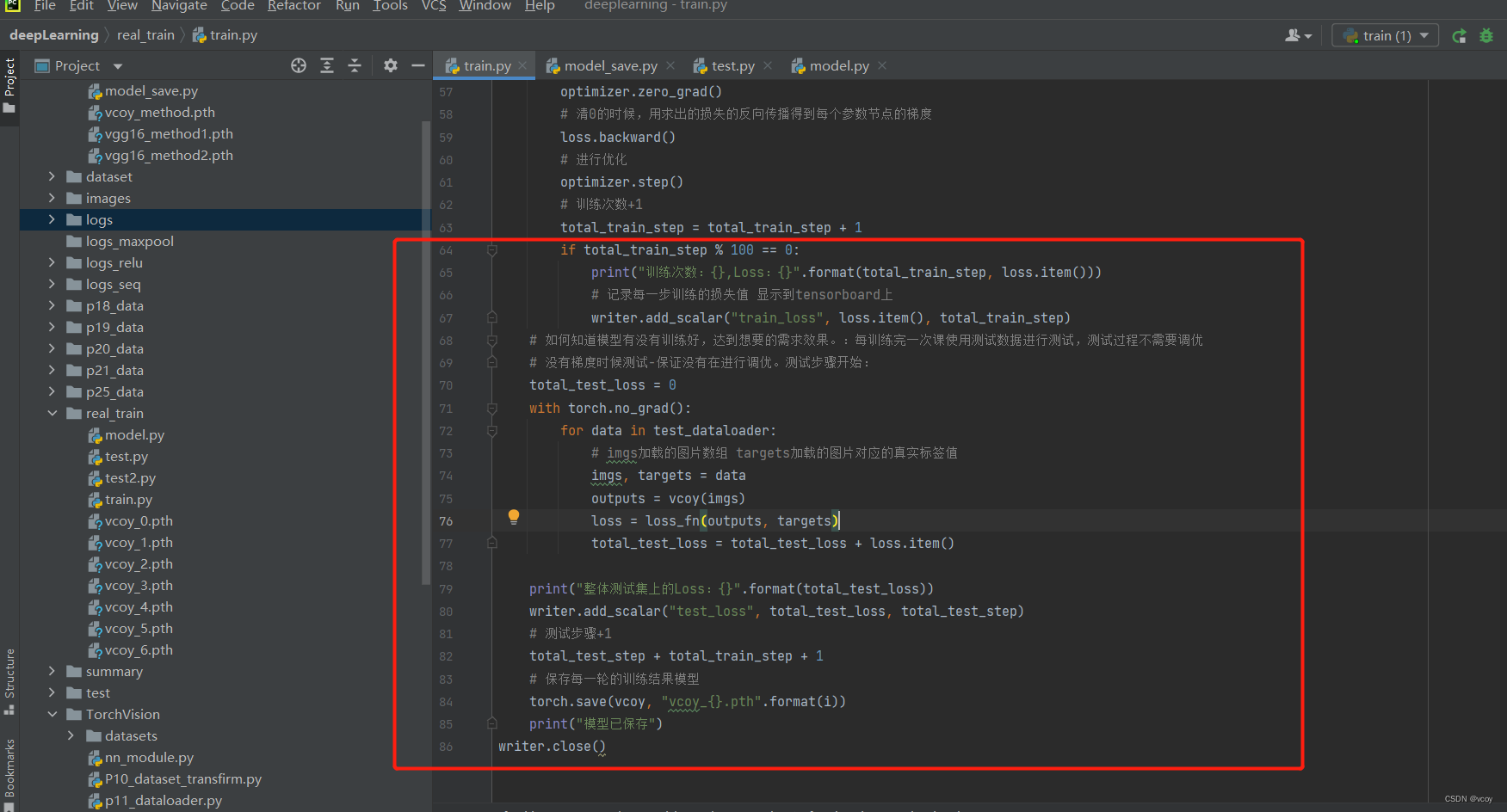
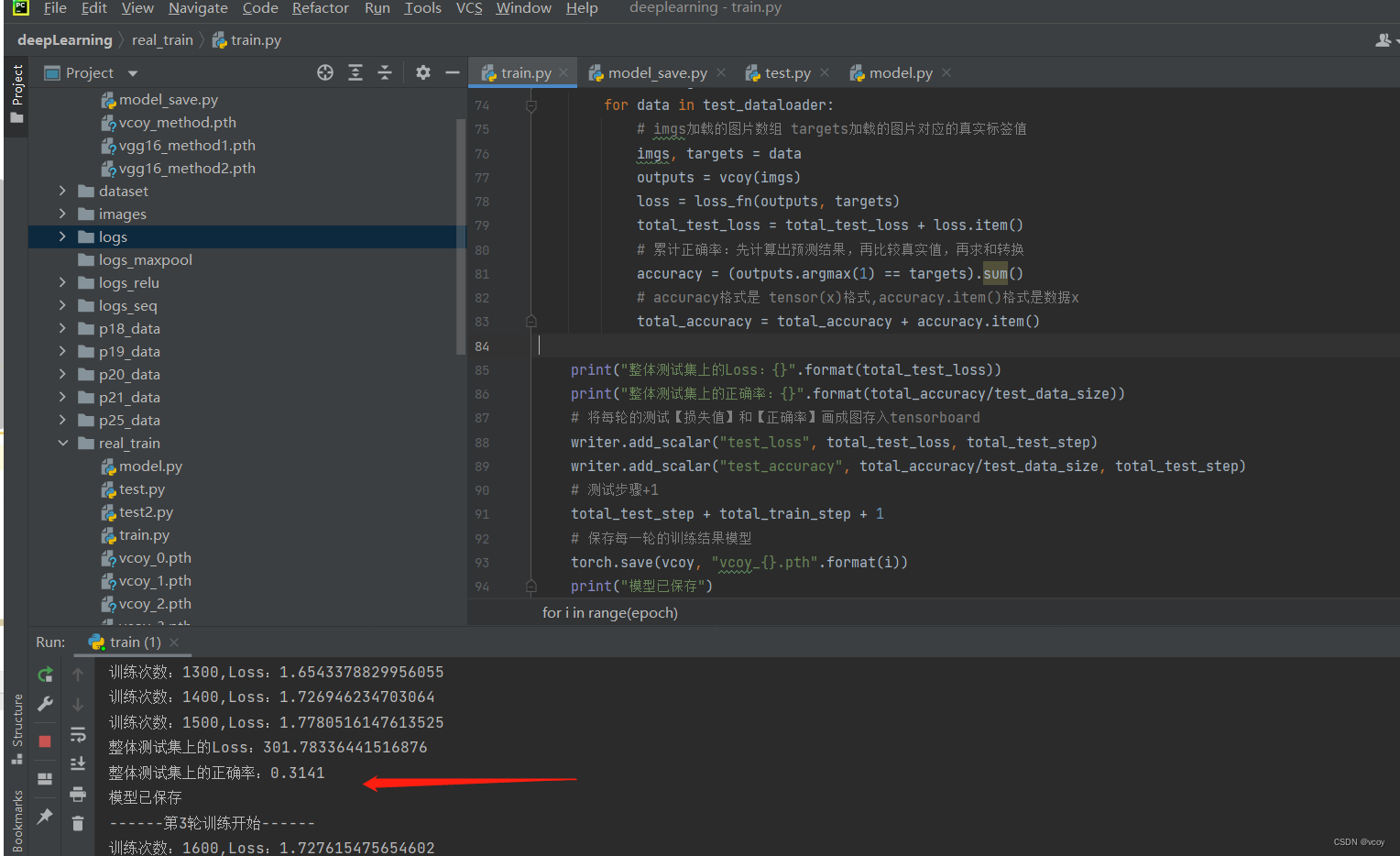
训练结果并保存每一轮训练后的模型。第76行需要变动为 total_test_loss = total_test_loss + loss.item()。 loss格式是 tensor(x)格式,loss.item()是数据x
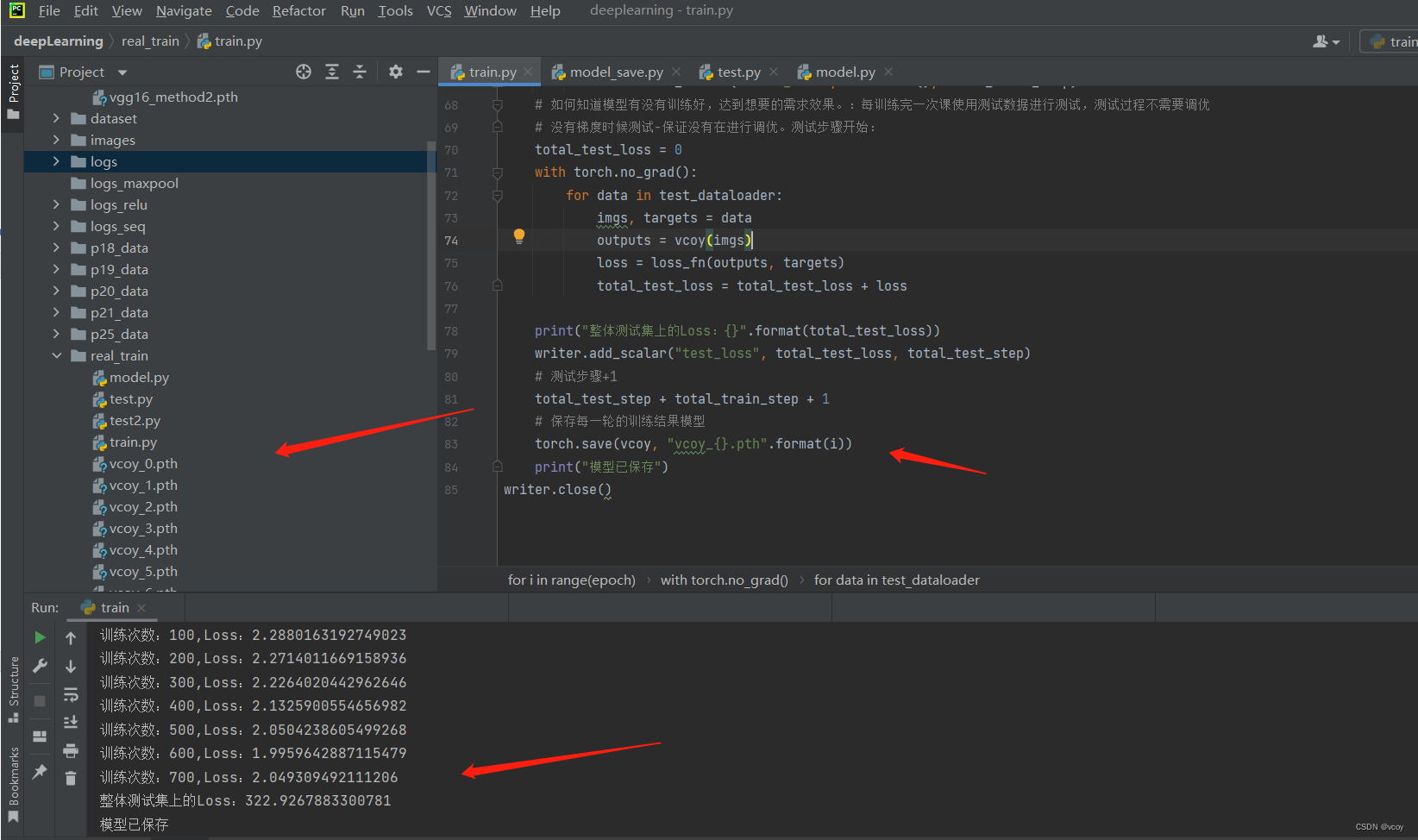
train.py
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch.utils.data import DataLoader
# 准备数据集
train_data = torchvision.datasets.CIFAR10("../train_data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("../train_data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 若train_data_size=10 则训练数据集的长度为10。 测试集长度10000 训练集50000
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
# 利用 dataLoader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
vcoy = Vcoy()
# 损失函数:分类问题可使用 交叉熵 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器: 采用随机梯度下降
# learning_rate = 1e-2 :1e-2 = 1x(10)^(-2) = 1/100 = 0.01
learning_rate = 0.01
optimizer = torch.optim.SGD(vcoy.parameters(), lr=learning_rate)
# 训练神经网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的次数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs")
for i in range(epoch):
print("------第{}轮训练开始------".format(i+1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
# 训练数据放到网络当中
output = vcoy(imgs)
# 根据训练结果得到和真实值的误差--损失值。output:通过神经网络模型后的值,targets是真实值。如猫的图片的targets=猫
loss = loss_fn(output, targets)
# 优化器优化模型
# 梯度清0
optimizer.zero_grad()
# 清0的时候,用求出的损失的反向传播得到每个参数节点的梯度
loss.backward()
# 进行优化
optimizer.step()
# 训练次数+1
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))
# 记录每一步训练的损失值 显示到tensorboard上
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 如何知道模型有没有训练好,达到想要的需求效果。:每训练完一次课使用测试数据进行测试,测试过程不需要调优
# 没有梯度时候测试-保证没有在进行调优。测试步骤开始:
total_test_loss = 0
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
outputs = vcoy(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
print("整体测试集上的Loss:{}".format(total_test_loss))
writer.add_scalar("test_loss", total_test_loss, total_test_step)
# 测试步骤+1
total_test_step + total_train_step + 1
# 保存每一轮的训练结果模型
torch.save(vcoy, "vcoy_{}.pth".format(i))
print("模型已保存")
writer.close()
训练结果
Files already downloaded and verified
Files already downloaded and verified
训练数据集的长度:50000
测试数据集的长度:10000
------第1轮训练开始------
训练次数:100,Loss:2.2880163192749023
训练次数:200,Loss:2.2714011669158936
训练次数:300,Loss:2.2264020442962646
训练次数:400,Loss:2.1325900554656982
训练次数:500,Loss:2.0504238605499268
训练次数:600,Loss:1.9959642887115479
训练次数:700,Loss:2.049309492111206
整体测试集上的Loss:322.9267883300781
模型已保存
------第2轮训练开始------
训练次数:800,Loss:1.9377368688583374
训练次数:900,Loss:1.8804967403411865
结果优化问题

argmax案例:利用argmax将上图中outputs转化到preds
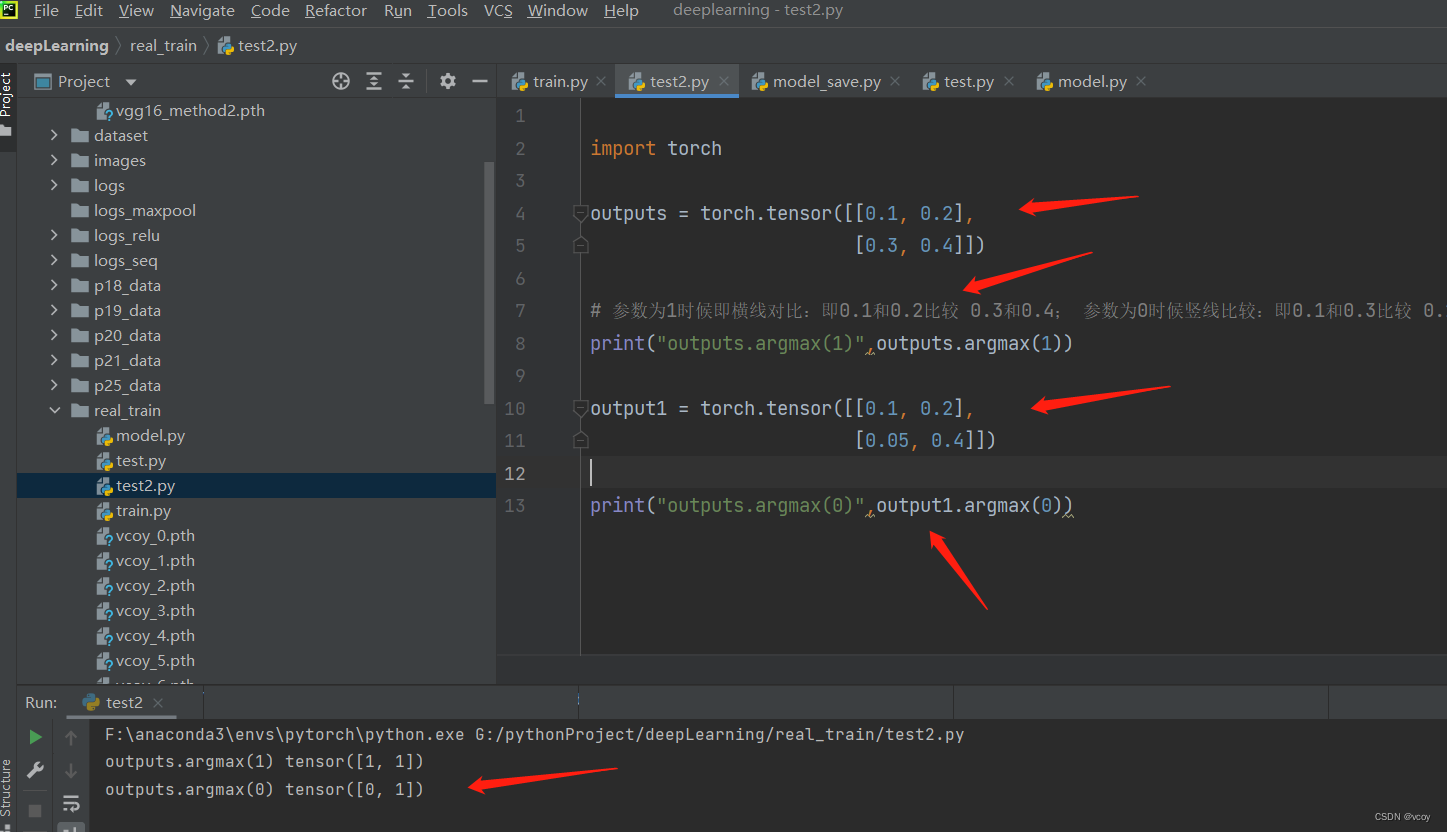
预测值和实际值比较
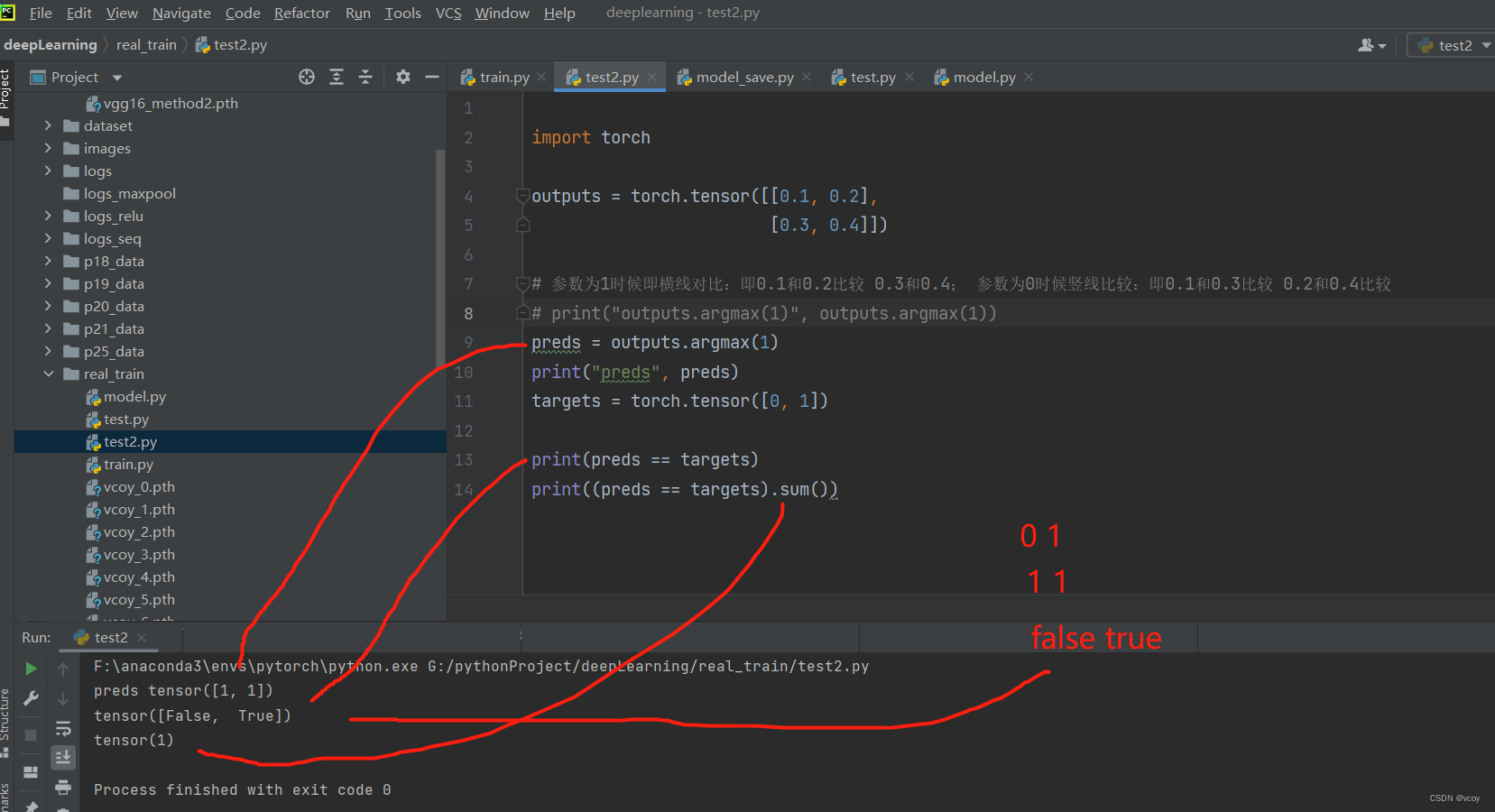
利用上述转化过程可对17.1和17.2的模型训练进一步优化,计算出整体的正确率
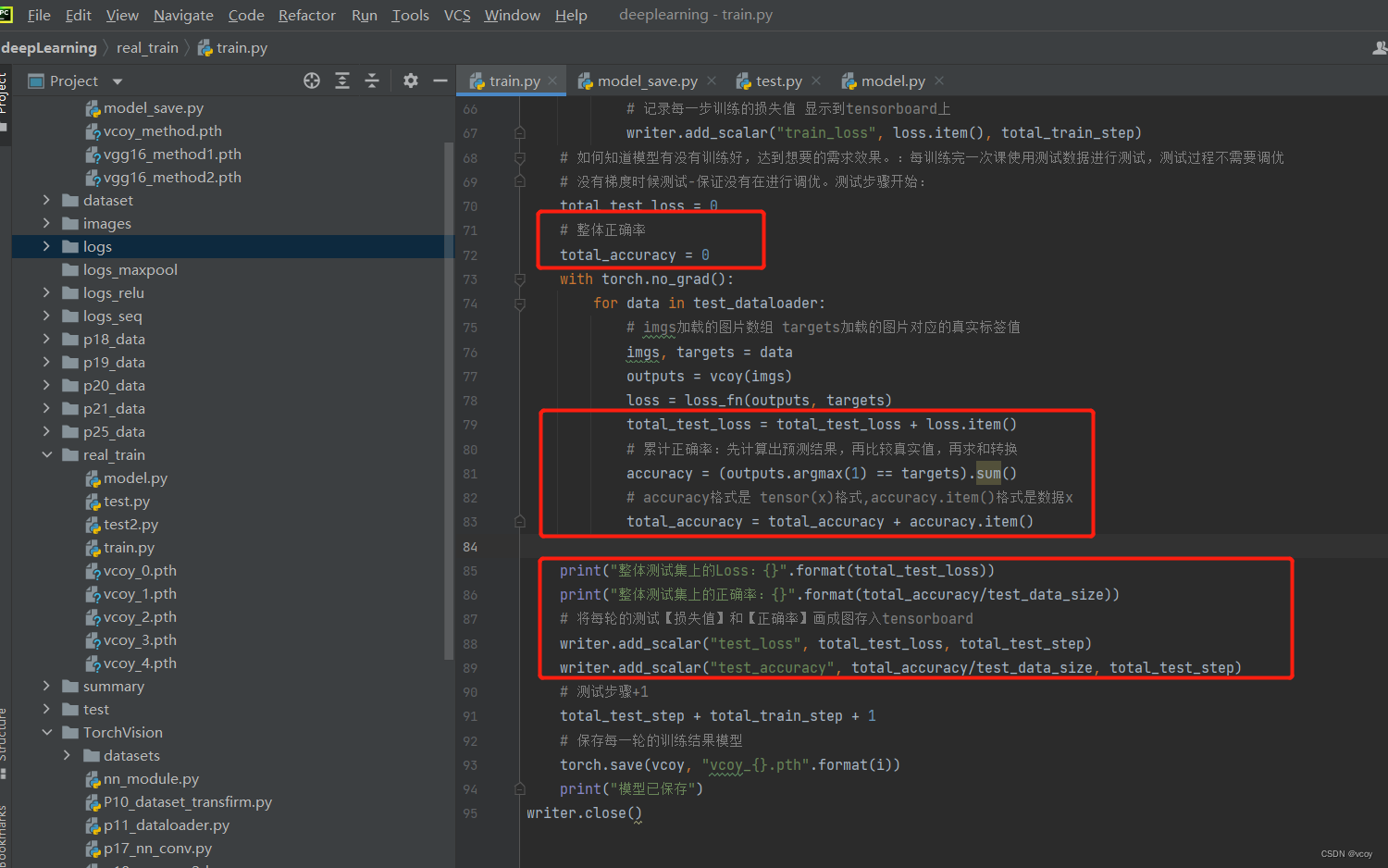
改进的train.py,model代码不变
import torch
import torchvision
from torch.utils.tensorboard import SummaryWriter
from model import *
from torch.utils.data import DataLoader
# 准备数据集
train_data = torchvision.datasets.CIFAR10("../train_data", train=True, transform=torchvision.transforms.ToTensor(),
download=True)
test_data = torchvision.datasets.CIFAR10("../train_data", train=False, transform=torchvision.transforms.ToTensor(),
download=True)
# 数据集长度
train_data_size = len(train_data)
test_data_size = len(test_data)
# 若train_data_size=10 则训练数据集的长度为10。 测试集长度10000 训练集50000
print("训练数据集的长度:{}".format(train_data_size))
print("测试数据集的长度:{}".format(test_data_size))
# 利用 dataLoader 加载数据集
train_dataloader = DataLoader(train_data, batch_size=64)
test_dataloader = DataLoader(test_data, batch_size=64)
# 创建网络模型
vcoy = Vcoy()
# 损失函数:分类问题可使用 交叉熵 损失函数
loss_fn = nn.CrossEntropyLoss()
# 优化器: 采用随机梯度下降
# learning_rate = 1e-2 :1e-2 = 1x(10)^(-2) = 1/100 = 0.01
learning_rate = 0.01
optimizer = torch.optim.SGD(vcoy.parameters(), lr=learning_rate)
# 训练神经网络的一些参数
# 记录训练的次数
total_train_step = 0
# 记录测试的次数
total_test_step = 0
# 训练的次数
epoch = 10
# 添加tensorboard
writer = SummaryWriter("../logs")
for i in range(epoch):
print("------第{}轮训练开始------".format(i+1))
# 训练步骤开始
for data in train_dataloader:
imgs, targets = data
# 训练数据放到网络当中
output = vcoy(imgs)
# 根据训练结果得到和真实值的误差--损失值。output:通过神经网络模型后的值,targets是真实值。如猫的图片的targets=猫
loss = loss_fn(output, targets)
# 优化器优化模型
# 梯度清0
optimizer.zero_grad()
# 清0的时候,用求出的损失的反向传播得到每个参数节点的梯度
loss.backward()
# 进行优化
optimizer.step()
# 训练次数+1
total_train_step = total_train_step + 1
if total_train_step % 100 == 0:
print("训练次数:{},Loss:{}".format(total_train_step, loss.item()))
# 记录每一步训练的损失值 显示到tensorboard上
writer.add_scalar("train_loss", loss.item(), total_train_step)
# 如何知道模型有没有训练好,达到想要的需求效果。:每训练完一次课使用测试数据进行测试,测试过程不需要调优
# 没有梯度时候测试-保证没有在进行调优。测试步骤开始:
total_test_loss = 0
# 整体正确率
total_accuracy = 0
with torch.no_grad():
for data in test_dataloader:
# imgs加载的图片数组 targets加载的图片对应的真实标签值
imgs, targets = data
outputs = vcoy(imgs)
loss = loss_fn(outputs, targets)
total_test_loss = total_test_loss + loss.item()
# 累计正确率:先计算出预测结果,再比较真实值,再求和转换
accuracy = (outputs.argmax(1) == targets).sum()
total_accuracy = total_accuracy + accuracy.item()
print("整体测试集上的Loss:{}".format(total_test_loss))
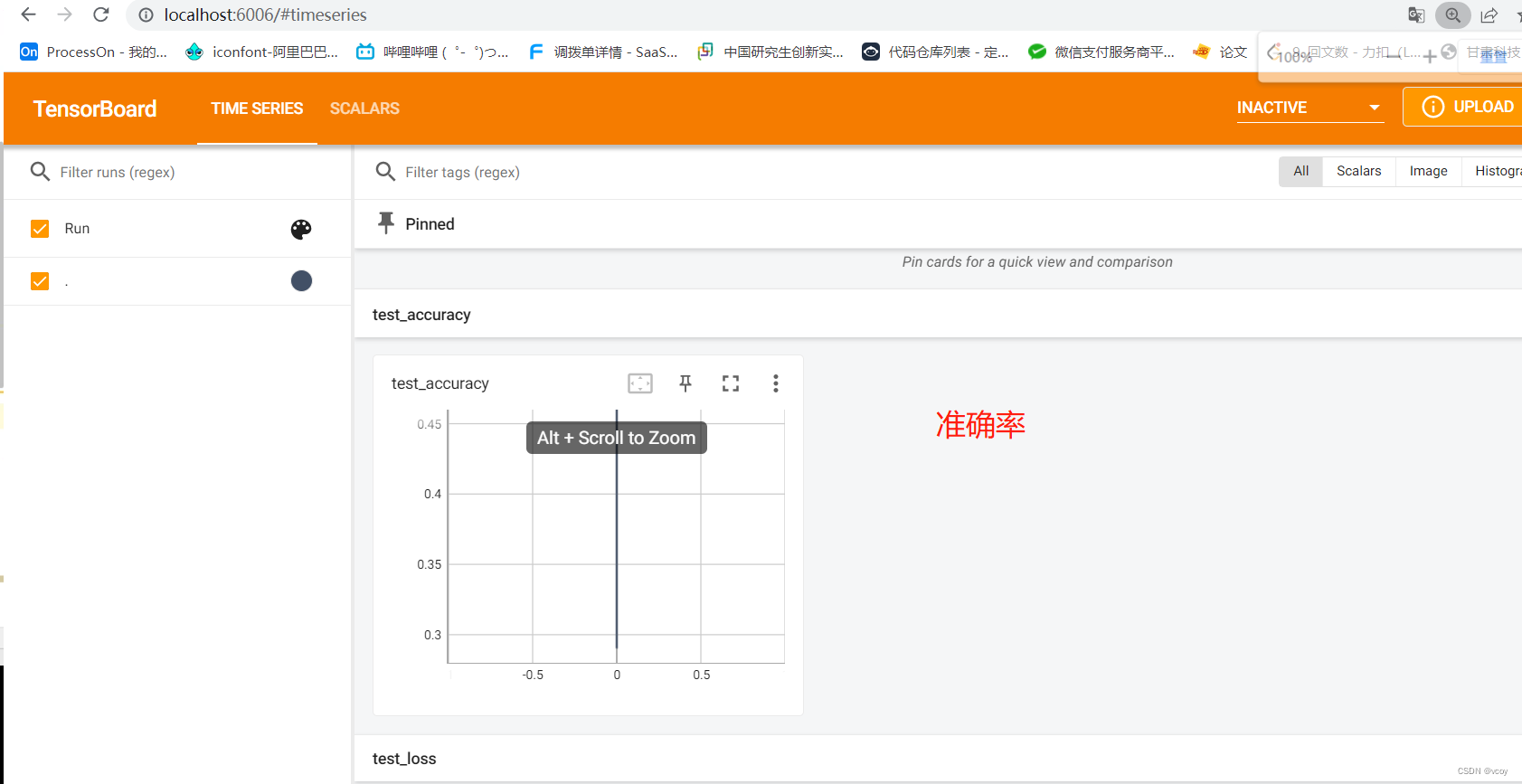
print("整体测试集上的正确率:{}".format(total_accuracy/test_data_size))
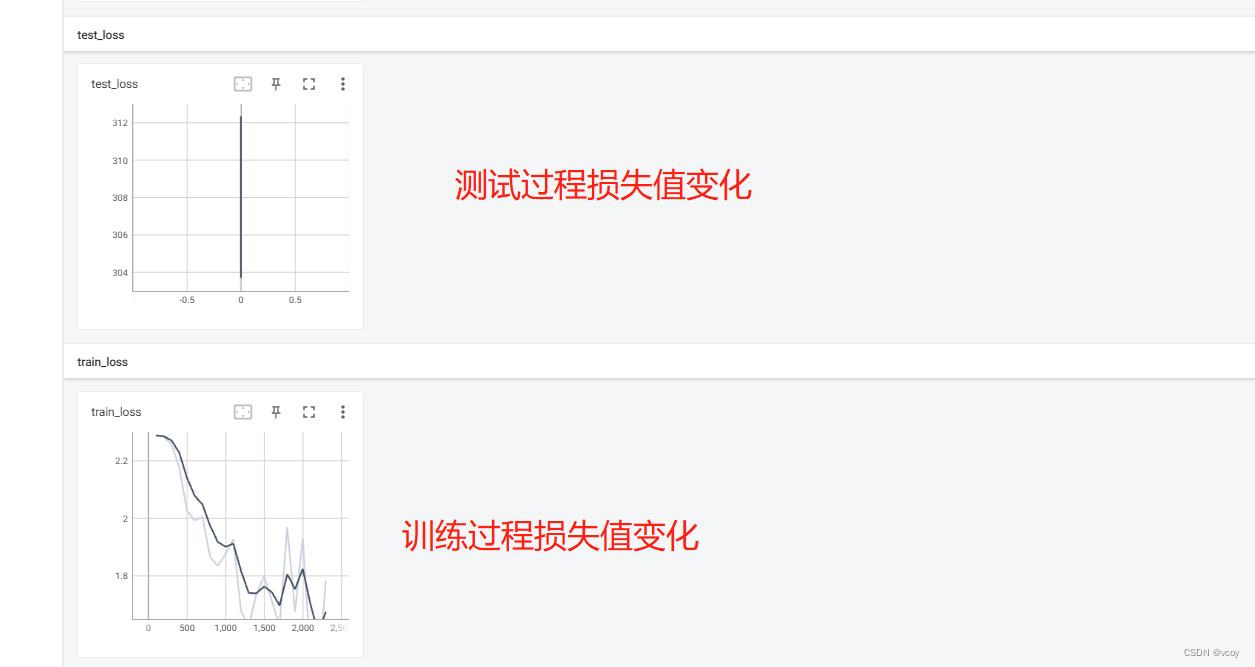
# 将每轮的测试【损失值】和【正确率】画成图存入tensorboard
writer.add_scalar("test_loss", total_test_loss, total_test_step)
writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
# 测试步骤+1
total_test_step + total_train_step + 1
# 保存每一轮的训练结果模型
torch.save(vcoy, "vcoy_{}.pth".format(i))
print("模型已保存")
writer.close()
启动tensorboard查看
准确率
进一步完善网络模型,只添加红圈内,其余不变
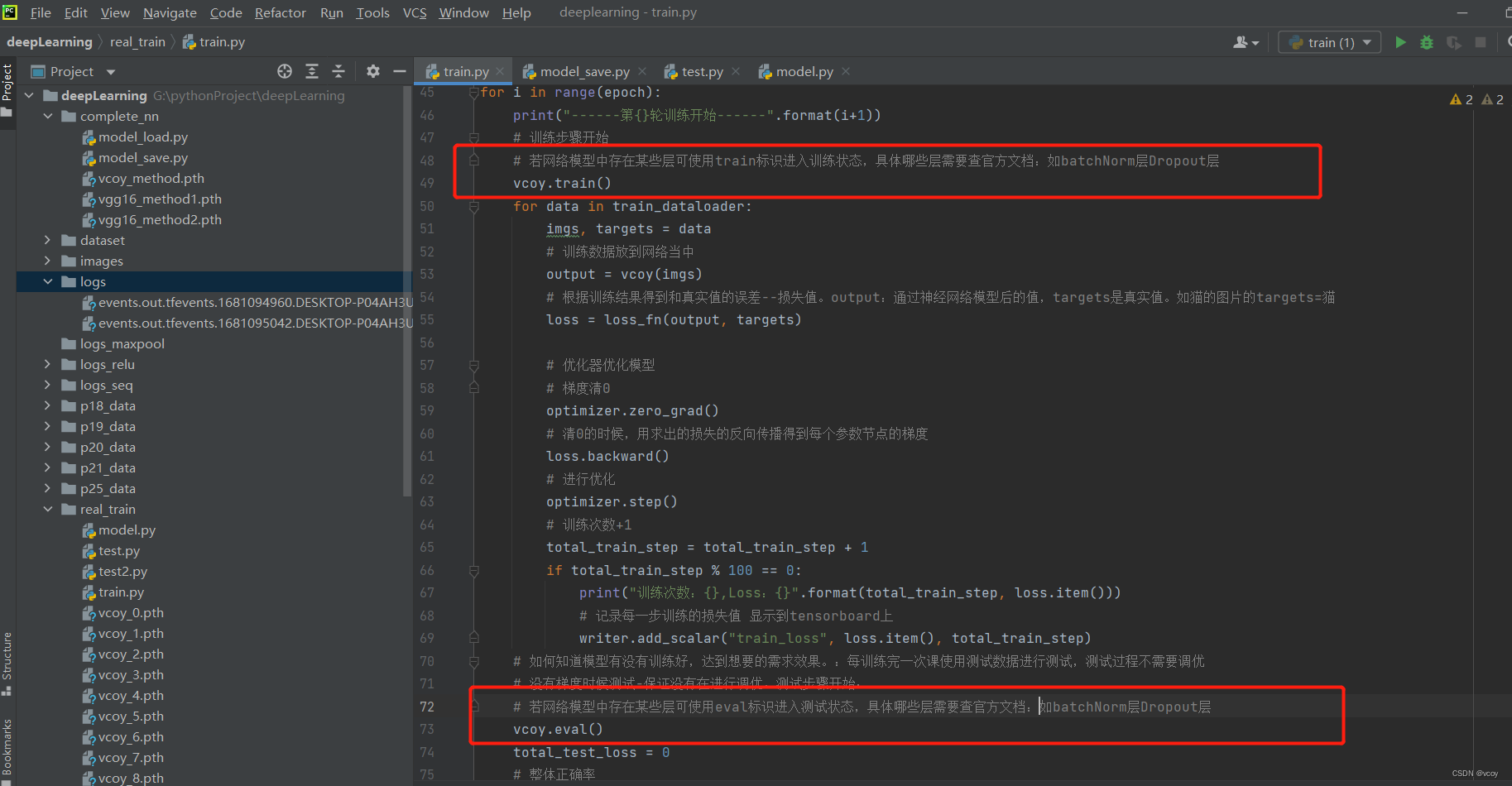
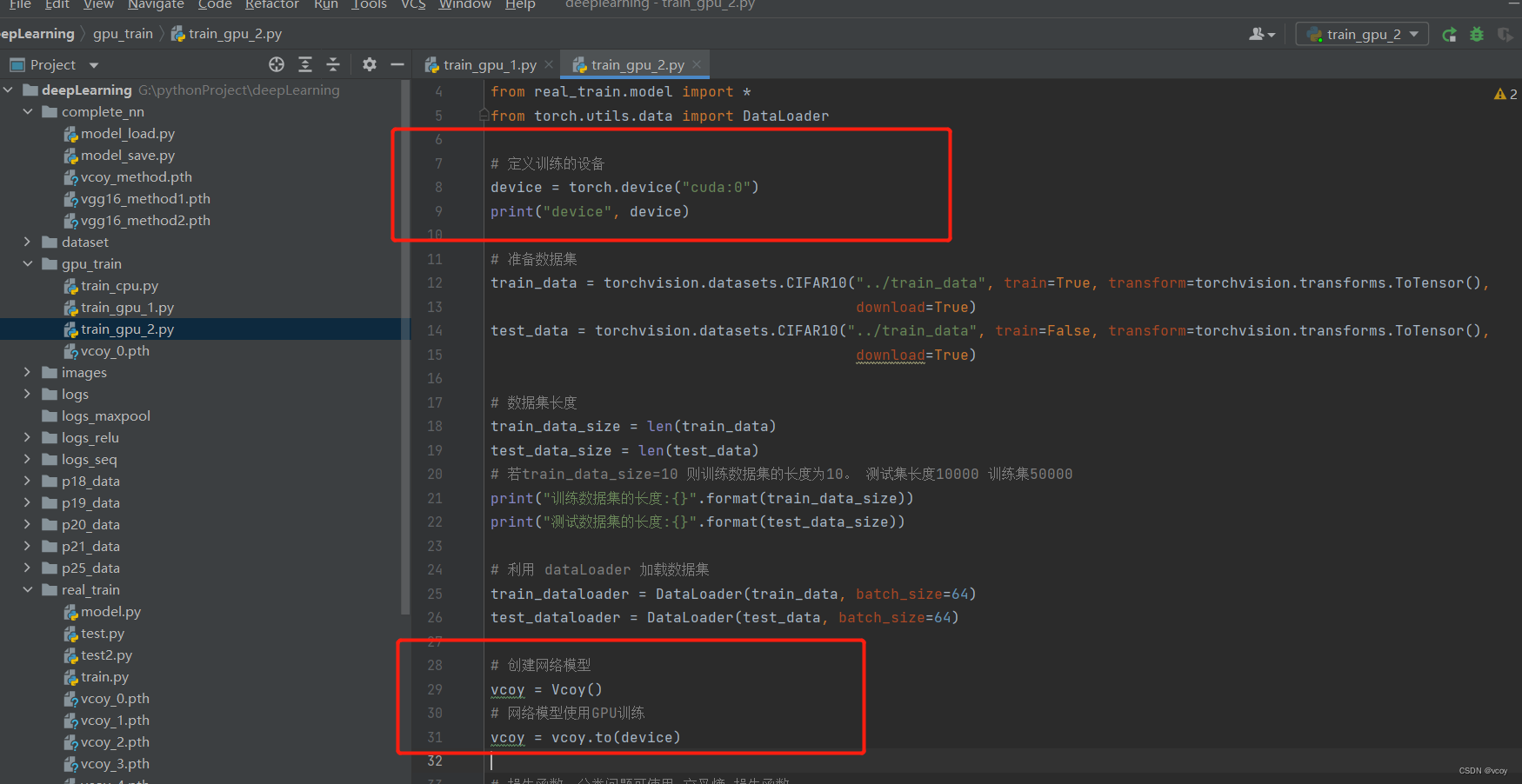
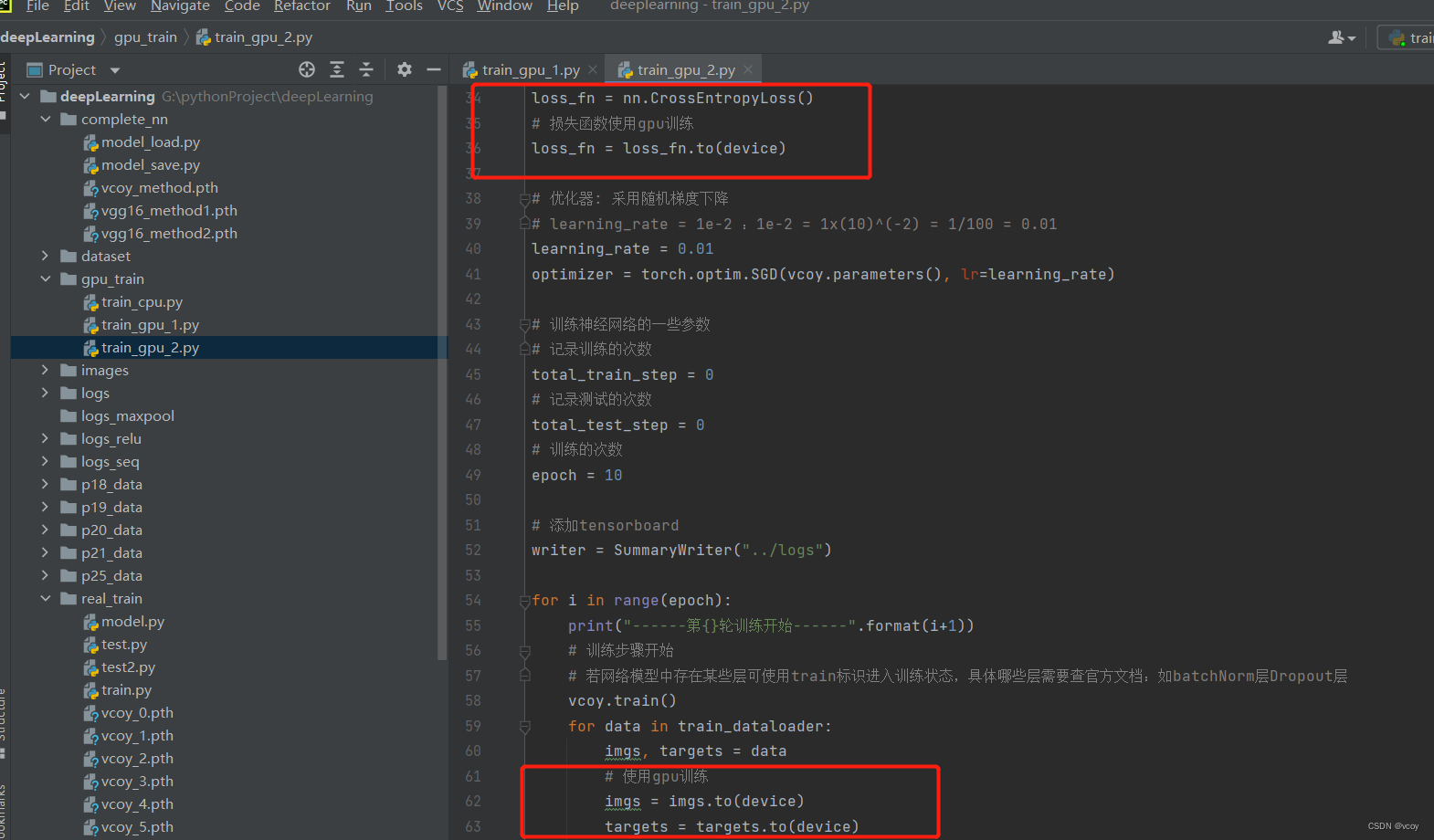
17.3 利用GPU训练
训练方式1:

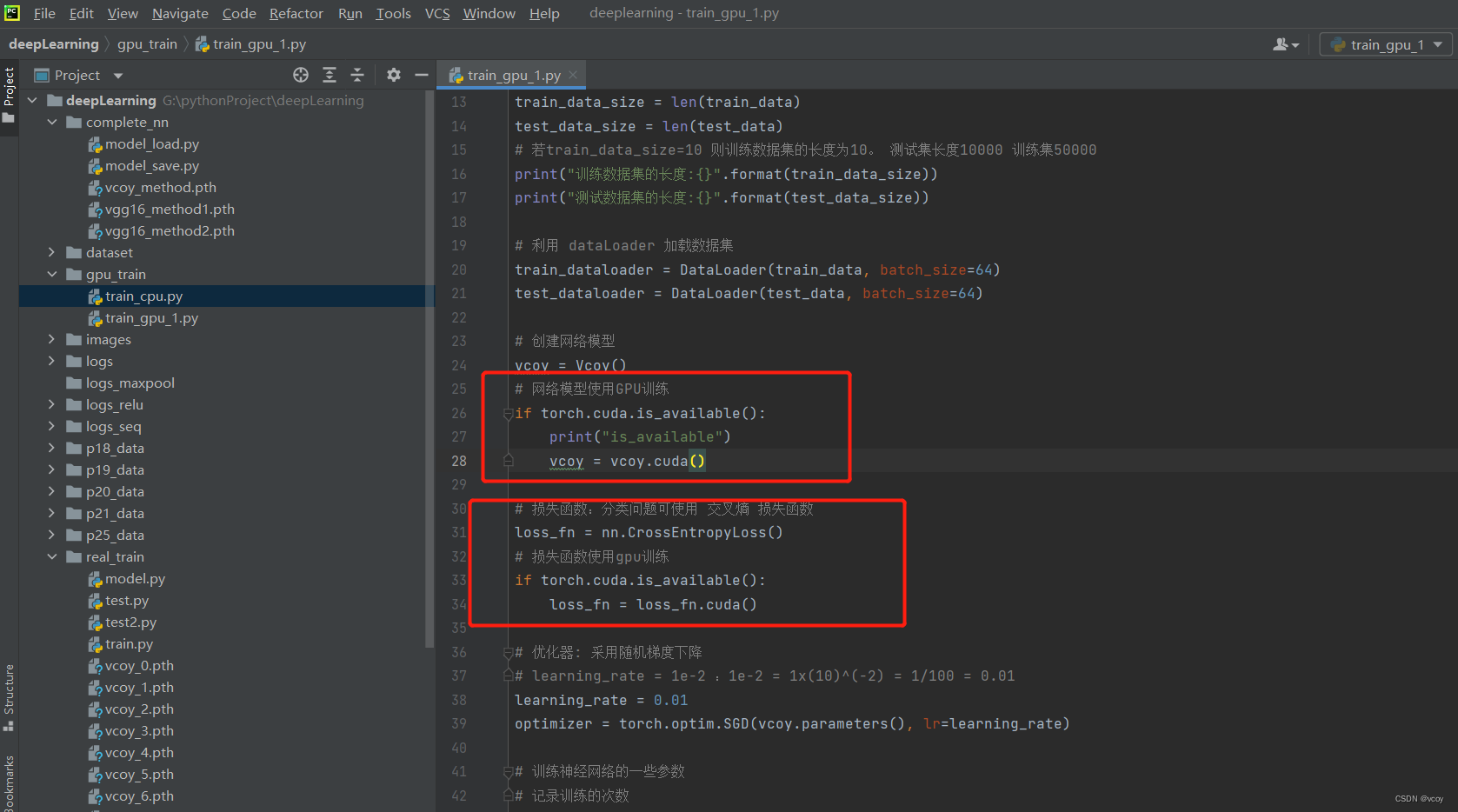
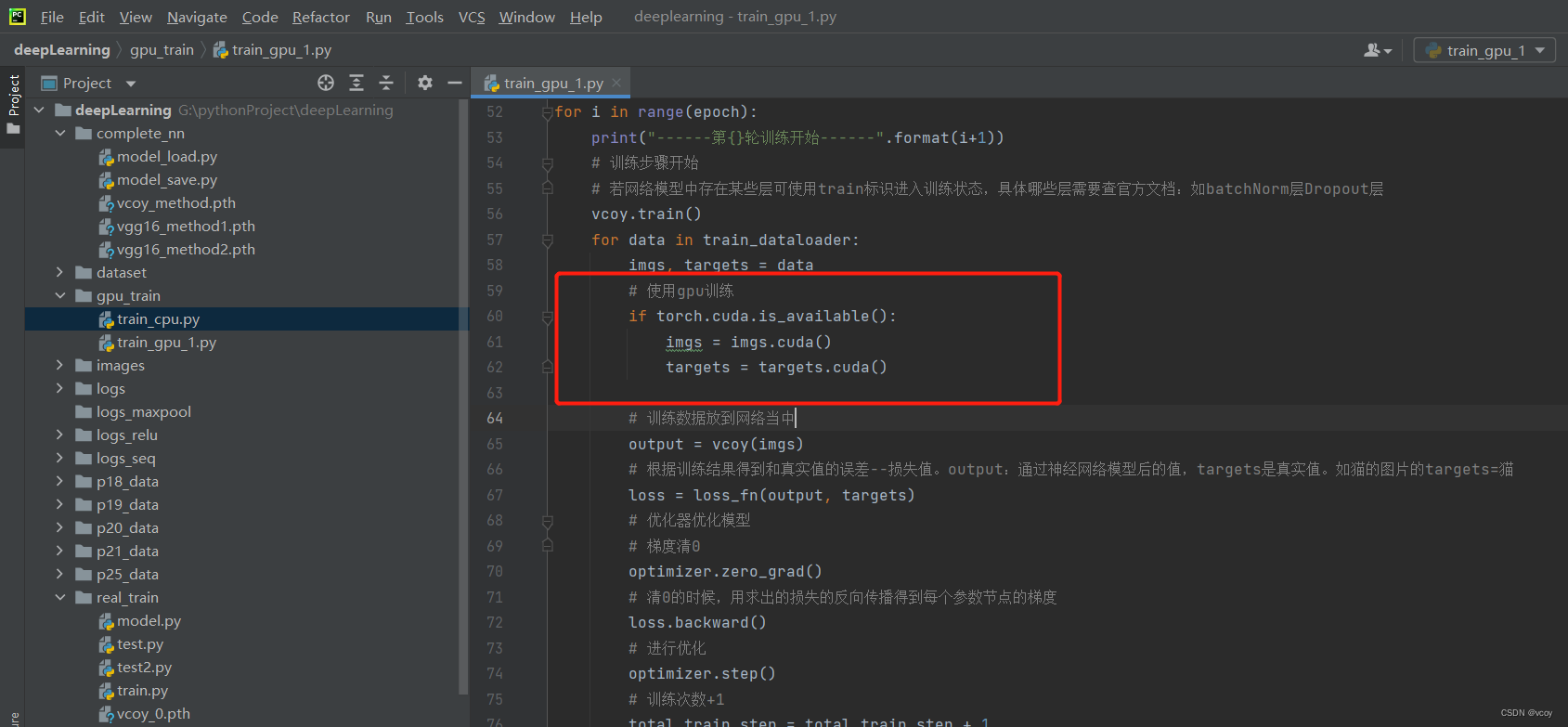
gpu训练方式2
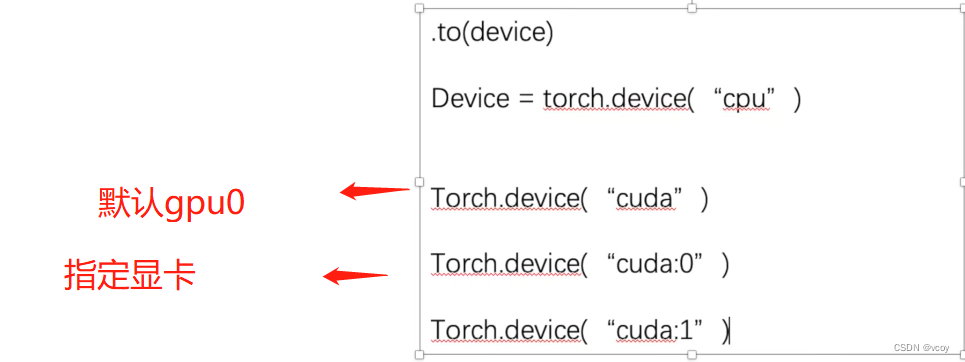
代码 实现
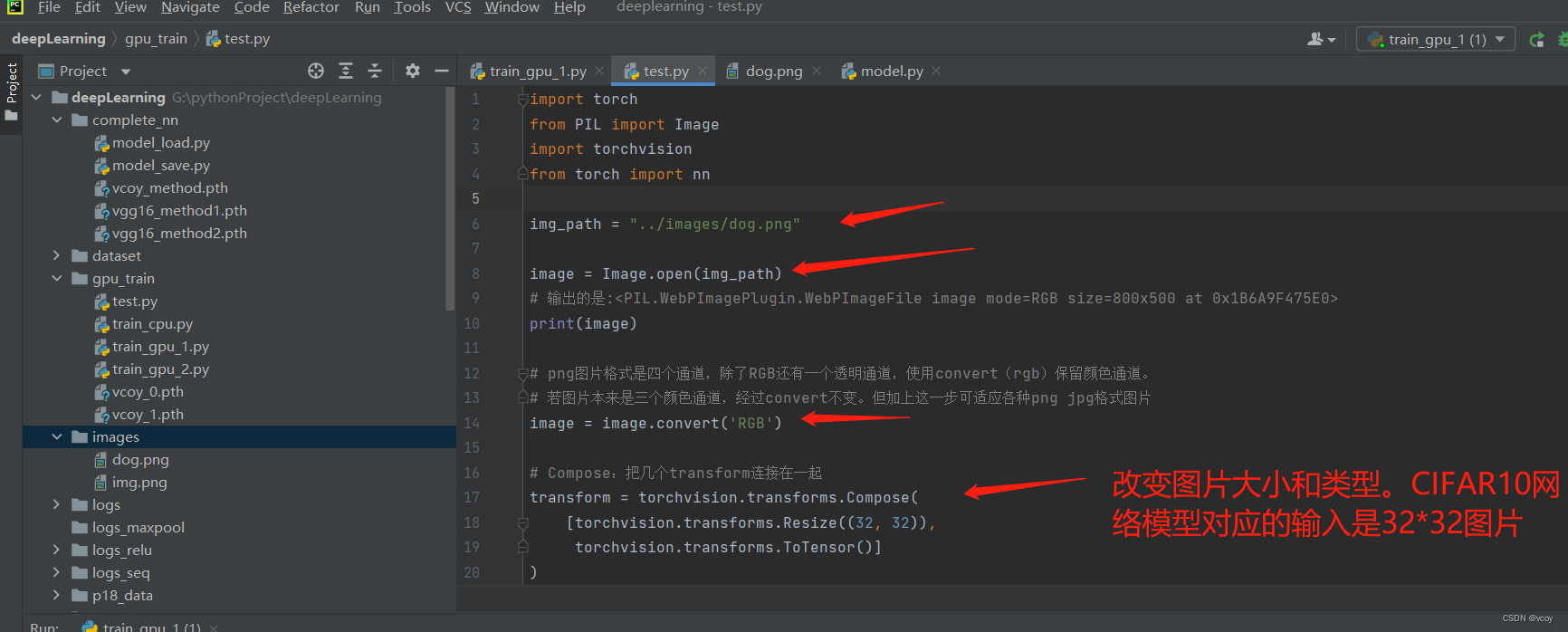
17.4 读取一张狗的图片输入模型

代码部分
第一次训练模型准确率可能不高,可切换到vcoy_8.pth模型进行测试
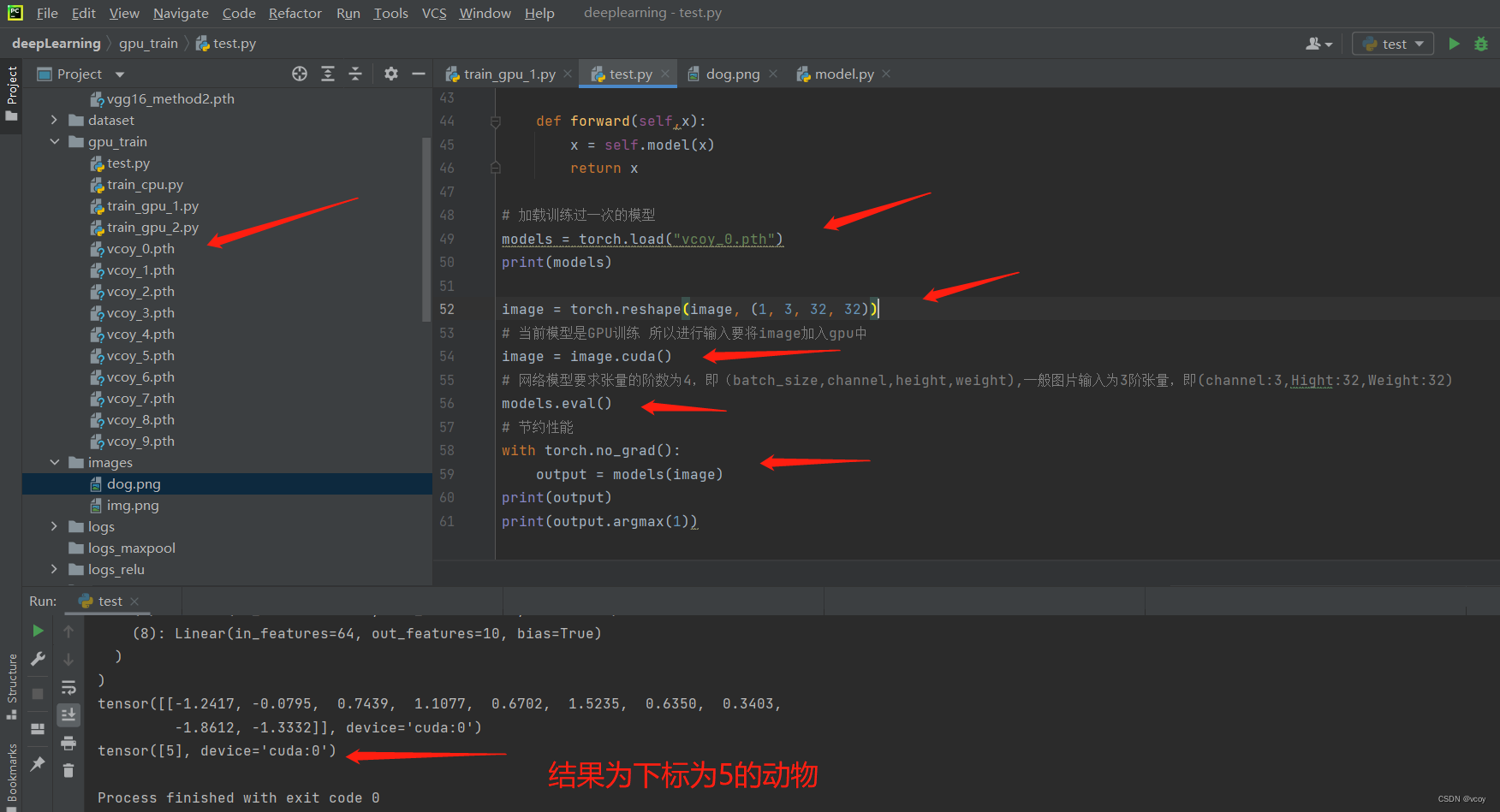
reshape目的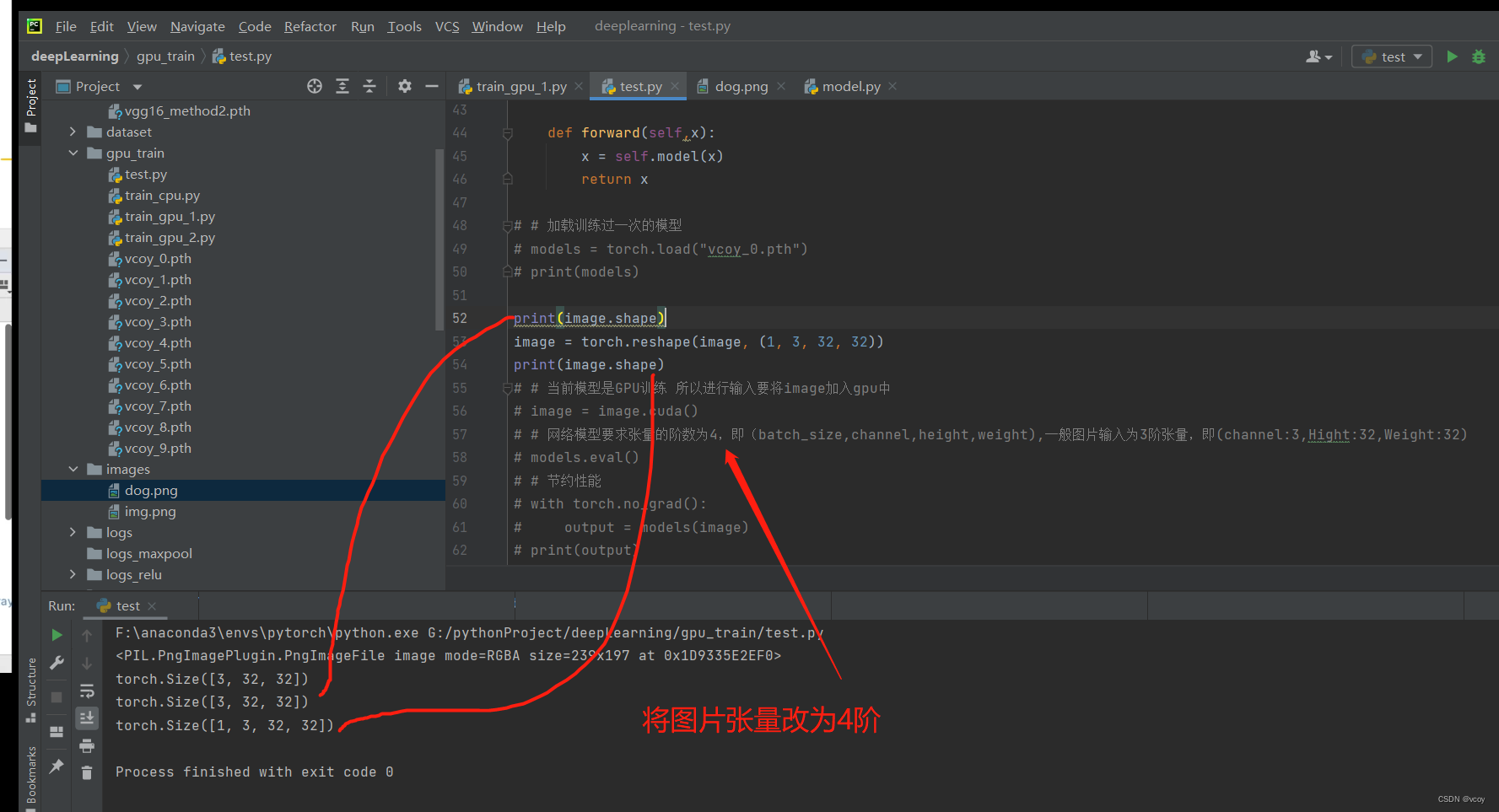
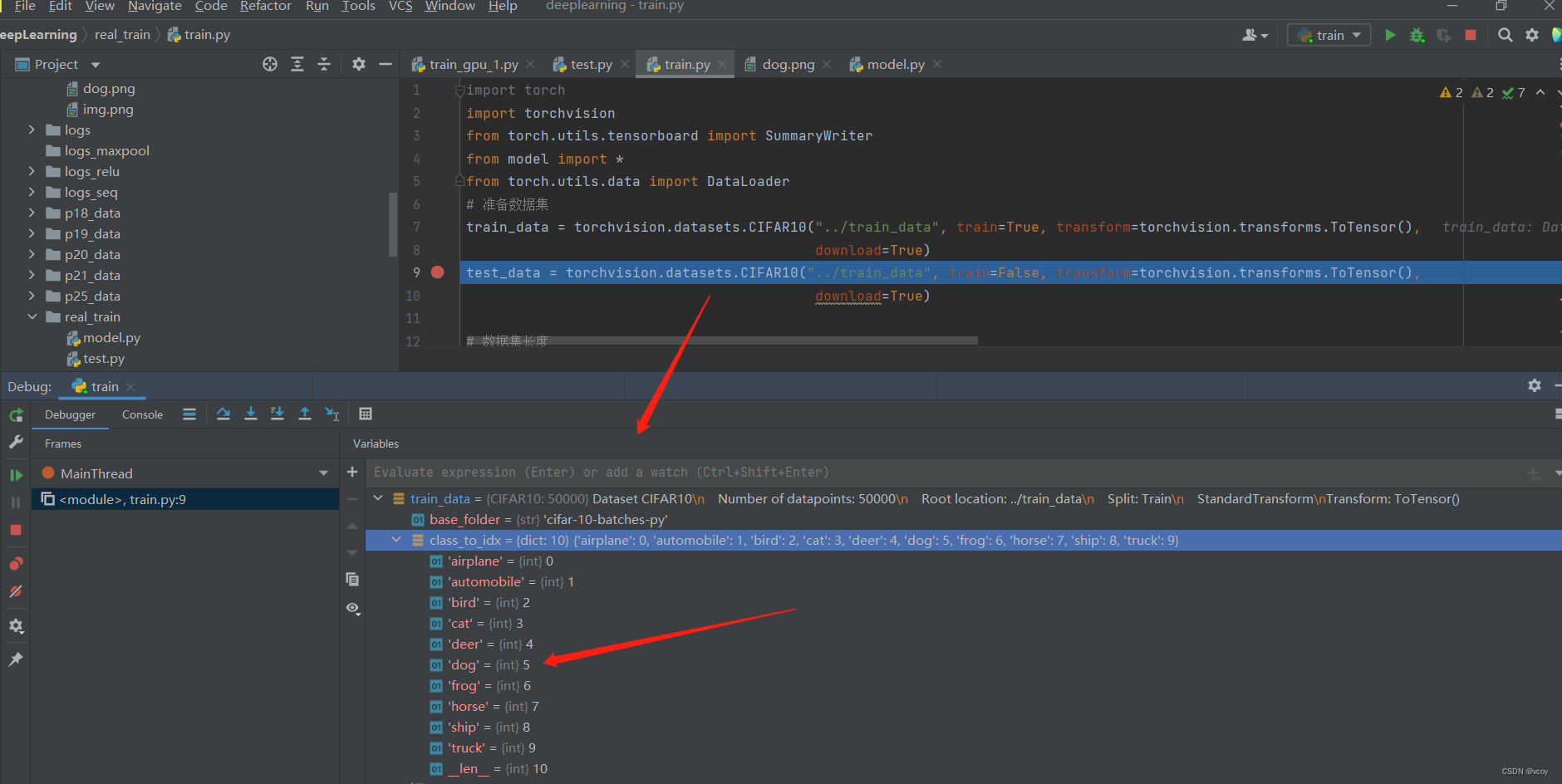
加载的数据集标签对应的索引,输出的是5对应dog的索引
识别狗的神经网络代码
import torch
from PIL import Image
import torchvision
from torch import nn
img_path = "../images/dog.png"
image = Image.open(img_path)
# 输出的是:<PIL.WebPImagePlugin.WebPImageFile image mode=RGB size=800x500 at 0x1B6A9F475E0>
print(image)
# png图片格式是四个通道,除了RGB还有一个透明通道,使用convert(rgb)保留颜色通道。
# 若图片本来是三个颜色通道,经过convert不变。但加上这一步可适应各种png jpg格式图片
image = image.convert('RGB')
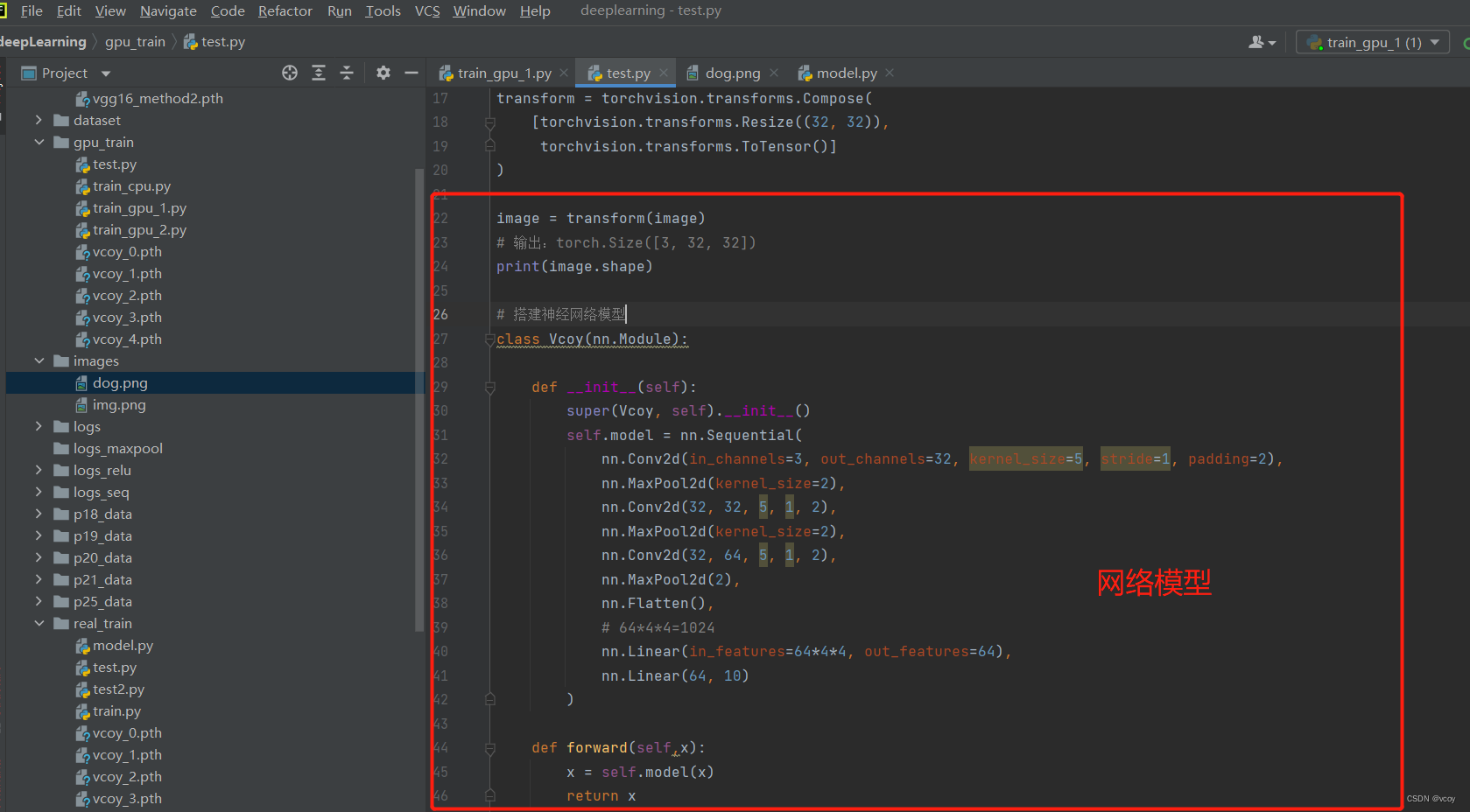
# Compose:把几个transform连接在一起
transform = torchvision.transforms.Compose(
# 转化成CIFAR10数据集中图片大小32*32,适应该网络模型输入的参数
[torchvision.transforms.Resize((32, 32)),
torchvision.transforms.ToTensor()]
)
image = transform(image)
# 输出:torch.Size([3, 32, 32])
print(image.shape)
# 搭建神经网络模型
class Vcoy(nn.Module):
def __init__(self):
super(Vcoy, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=32, kernel_size=5, stride=1, padding=2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(kernel_size=2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
# 64*4*4=1024
nn.Linear(in_features=64*4*4, out_features=64),
nn.Linear(64, 10)
)
def forward(self,x):
x = self.model(x)
return x
# 加载训练过一次的模型
models = torch.load("vcoy_0.pth")
print(models)
# 1指的是batch_size 3只rgb三通道 32是图片大小
image = torch.reshape(image, (1, 3, 32, 32))
# 当前模型是GPU训练 所以进行输入要将image加入gpu中
image = image.cuda()
# 网络模型要求张量的阶数为4,即(batch_size,channel,height,weight),一般图片输入为3阶张量,即(channel:3,Hight:32,Weight:32)
models.eval()
# 节约性能
with torch.no_grad():
output = models(image)
print(output)
print(output.argmax(1))
gpu训练的模型放到cpu运行