Multi-Kernel Broad Learning systems Based on Random Features:A Novel Expansion for Nonlinear Feature Nodes
- 基于核方法的强大性能,本文提出了一种基于多核的BLS系统扩展方法。首先,将多核形式的非线性特征映射合并为广义学习系统的特征节点; 然后,通过非线性激活函数进一步增强所得到的特征。
INTRODUCTION
- 多核学习
- 多核学习(MKL)在提高不规则数据等分类性能方面具有显著优势。
- 其中支持向量机(SVM)是基于核学习算法的基础。
- 然而,单核学习方法可能行不通,因为映射的特征空间的结构完全由核函数的设计决定。
- 因此,MKL通过核函数的集合来构建学习系统,在更一般的应用中追求更好的结果。
- 多层深度模型
- 生成学习和判别学习中的深度学习算法。
- 对于生成式学习,具有代表性的学习方法是深度信念网络(DBN)和深度玻尔兹曼机(DBM)。
- 对于判别域,典型的是卷积神经网络(CNN),以及基于它的深度模型,如深度残差网络(ResNet-34)。
- 生成学习和判别学习中的深度学习算法。
- BLS
- BLS模型是判别学习中的一种范式。
- 试图通过将非线性核函数合并到特征节点中来开发一种新的结构。通过引入该技术,可以将BLS的特征节点改进为非线性多核函数。
PRELIMINARIES
在本节中,详细介绍了基于随机特征的多核广义学习系统(MKBLS)的前期工作和相关工作。
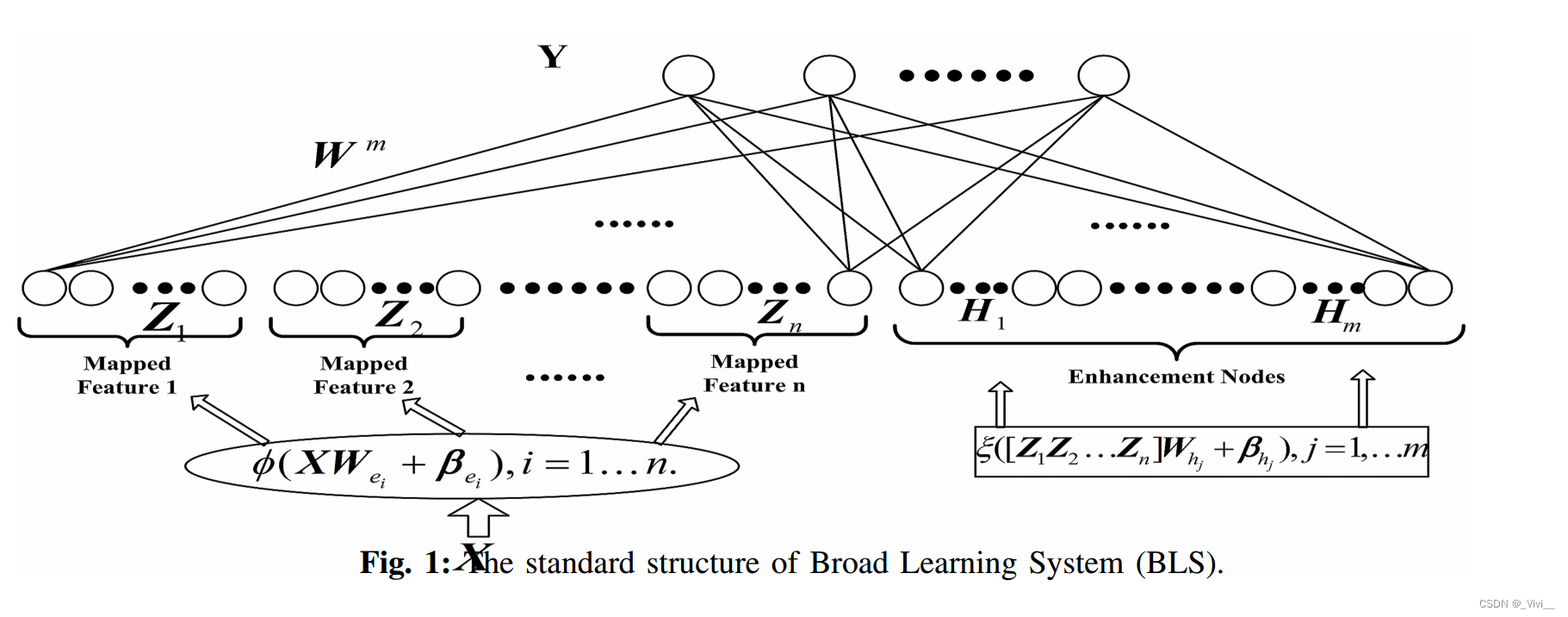
Broad Learning Systems
- 广泛学习系统(BLS)及其变体
- 大多具有其他深度神经网络在多层结构中没有丰富参数的高效和有效结构的特点。
- 判别学习算法的新范式转变不仅可以解决整个系统不需要基于梯度下降的迭代,而且避免了模型训练和再训练过程中的耗时过程。
- 在BLS框架中,输入不是直接发送到系统,而是通过一定的随机映射传递到“特征节点”。之后,通过选择激活函数等函数,将“特征节点”进一步拓宽为“增强节点”。最后,“特征节点”和“增强节点”都连接到输出层,构建整个网络。
Fourier Random Features
- Bochner’s Theorem : 如果一个移位变函数是核函数,则存在一个非负测度 p ( ω ) p(ω) p(ω),使得函数 k ( σ ) k(\sigma) k(σ)是 p ( ω ) p(ω) p(ω)的傅里叶变换。
- 经过一系列推导,具有
d
d
d维的近似可以表述为
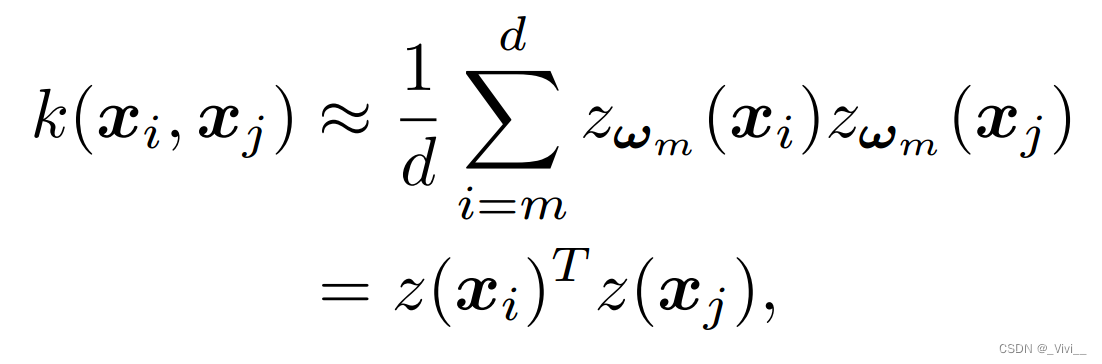
这里得到的随机特征向量为

MULTI-KERNEL BROAD LEARNING SYSTEMS BASED ON RANDOM FEATURES
- 多核BLS的过程
- 选取 M M M核作为候选核,在假设训练数据下,由给定核函数生成候选核的矩阵;
- 将傅里叶核近似方法应用于上述核,得到相关的随机特征。
- 通过随机函数传递得到的特征,形成广义学习系统的“特征节点”。
- 利用随机特征生成增强节点对神经网络进行增强,并将所有增强节点和特征节点发送到输出层。
- 对于任意训练样本
X
X
X和
Y
Y
Y, 算法的过程描述如下
- 首先给出一组候选核函数。 通常函数的选择可以是线性核、拉普拉斯核和高斯核。在本文中选取了具有不同参数的高斯核序列。
- 其次,对每个函数
k
l
k_l
kl进行傅里叶核近似,得到随机特征。为了近似核函数
k
l
k_l
kl,我们有d-dimensional的近似应该表述为:
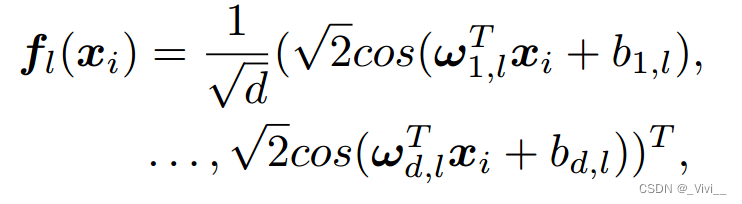
- 表示样本X的随机特征为
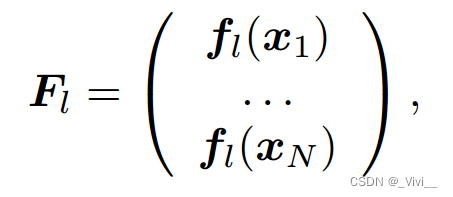
- 那么对于所有 M M M核函数,我们有 F = [ F 1 , . . . , F M ] F = [F_1,...,F_M] F=[F1,...,FM]是近似多核特征。
- 表示样本X的随机特征为
- 第三,通过给定的随机映射将多核特征
F
F
F转换为
n
n
n组特征节点。第
i
i
i组特征节点可以实现如下:
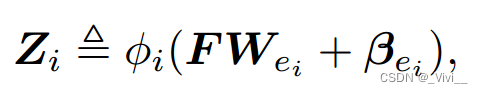
- 其中矩阵 W W W是生成特征的参数,向量 β β β是偏置,函数 ϕ ϕ ϕ是选定的映射。令 Z n ≜ [ Z 1 , . . . , Z n ] Z_{n}≜[Z_1,...,Z_n] Zn≜[Z1,...,Zn],对于 j t h jth jth增强节点,我们可以得到:
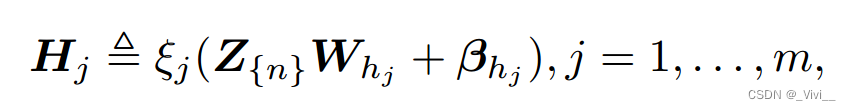
- 此处权重 W W W, β \beta β随机生成,方程为非线性映射。
- 最后,节点矩阵 Z Z Z和 H H H可以输入输出矩阵
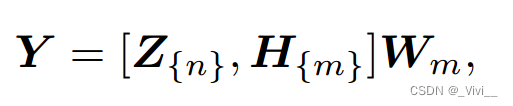
- 其中
W
W
W是原始问题的解,
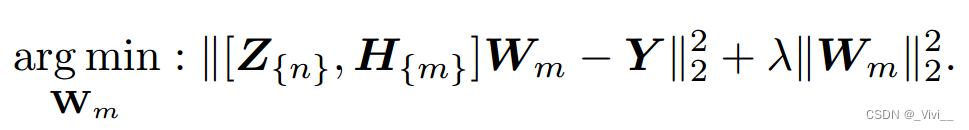
- 其中
W
W
W是原始问题的解,
PERFORMANCE EVALUATION
- 在选定的UCI机器学习存储库数据集上进行实验。
- 为了确保所提出的方法是高效和有效的,使用了几种算法来与多核BLS进行比较,包括
- Multiple Kernel Learning (MKL)
- two-stage learning (kernel Canonical Correlation Analysis (KCCA) followed by Support Vector Machine (SVM))
- single optimisation termed SVM-2K
- multiple kernel discriminant analysis with Semi-Definite Program(MKDA(SDP))
- l p l_p lp norm multiple kernel Fisher discriminant analysis with Semi-Infinite Program (SIP)
Experimental Setting
Classification performance comparison
- 发现MKBLS方法在所有选择的数据集中都能得到最好的重组结果。
- 利用核特征映射的傅里叶随机近似,可以将多个核组合在一起,提取尽可能多的数据信息,对分类结果有较大的改善。
CONCLUSIONS
本文提出了一种基于随机特征的多核BLS (MKBLS)算法。所提出的网络也可以看作是原始广义学习系统的非线性扩展,它只利用了输入数据的随机线性特征。