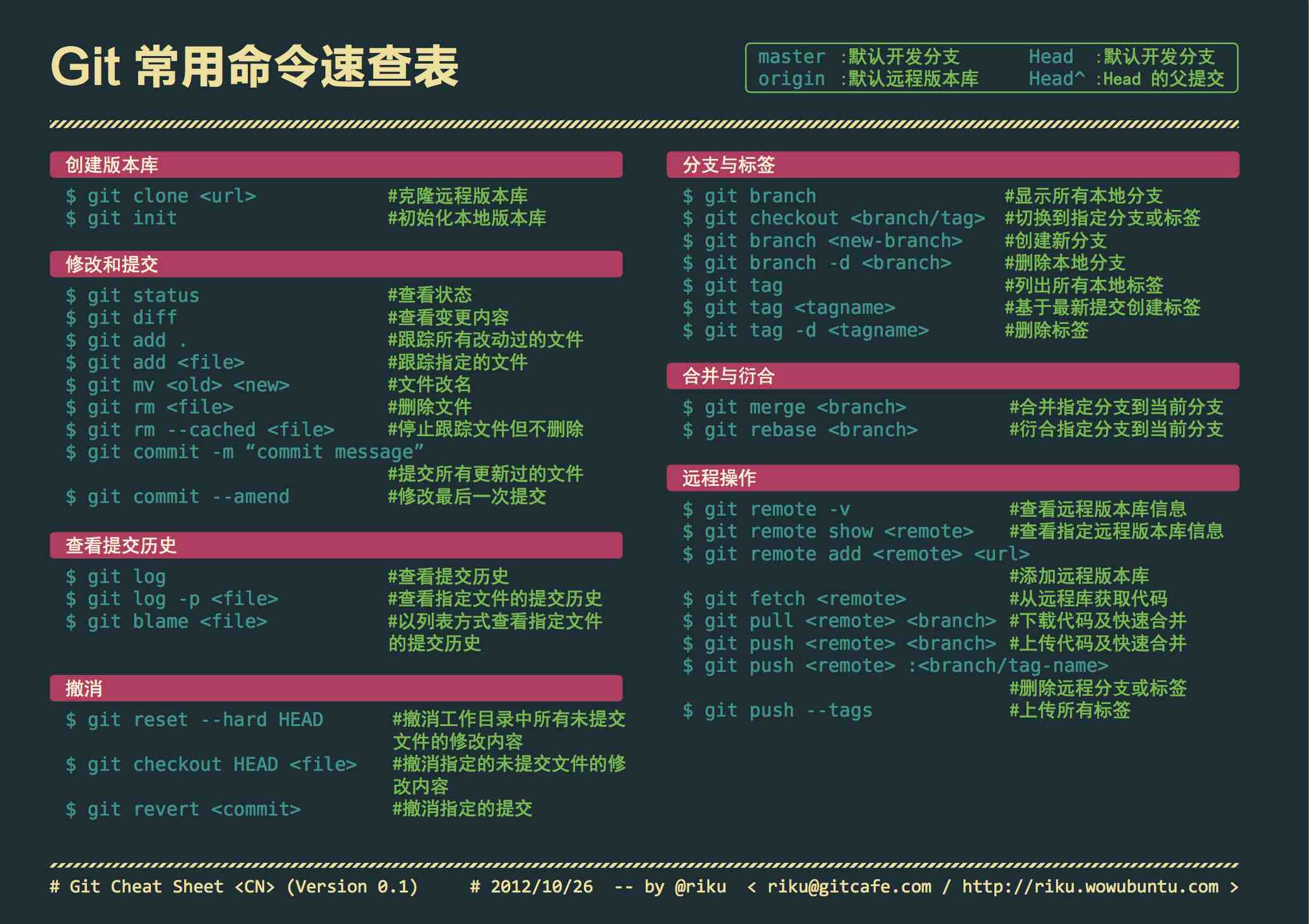
Prompt(提示)是扩散模型生成图像的内容来源,构建好的提示是每一个Stable Diffusion用户需要解决的第一步。本文总结所有关于提示的内容,这样可以让你生成更准确,更好的图像
一个好的提示
首先我们看看什么是好的提示,好的提示必须是详细和具体的。最好的办法是查看关键字类别和列表,关键字类别包括(因为提示都是英文的,所以这里我们也直接写英文的)
- Subject
- Medium
- Style
- Artist
- Website
- Resolution
- Additional details
- Color
- Lighting
你不需要所有类别的关键字,但是你需要从里面找到最需要的。
本文将使用v1.5基本模型。在本文的最后还有最新的2.0的模型结果的展示。所有图像都是用30步dpm++ 2M Karas采样器生成的,图像大小为512×704。
1、Subject
你想在图像中看到的东西。一个常见的错误是写得不够多。比如你想生成一个女巫:
A sorceress
这种词虽然简单,但是这给想象留下了太多的空间。你想让女巫长什么样?她穿什么?她在施什么魔法?她是站着,跑着,还是漂浮在空中?背景场景是什么?
一个最常见技巧是使用名人的名字。它们有很强的效果,是控制主题外观的绝佳方法。但是些名字不仅会改变脸,还会改变姿势和其他东西,所以后面我们会来解决这个问题。
作为一个演示,让我们让女巫看起来像Emma Watson,我们假设她很强大,很神秘还会使用闪电魔法。我们希望她的服装非常细致,这样她看起来会很有趣,那么提示词变为了:
Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing

名字对这个模特产生了很大的影响。我认为她在稳定扩散的用户中很受欢迎,因为她看起来体面,年轻,在各种场景中都很稳定。
2、Medium
Medium是可以理解为材料或类别。例如插图、油画、3D渲染和摄影。Medium有很强的影响力,因为一个关键字就能改变风格图像的风格。
Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting

这些图像从照片变成了digital painting。
3、Style
Style是指形象的艺术风格。例如印象派、超现实主义、波普艺术等。
Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body

风格的确是修改了,但是对于我的审美,不太喜欢这个风格
4、Artist
艺术家的名字是强修饰符。它们可以使用特定的艺术家作为参考来模仿风格。使用多个艺术家的名字来混合他也是可以的。现在让我们再加上超级英雄漫画艺术家Stanley Artgerm Lau和19世纪的肖像画家Alphonse Mucha。
Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm Lau and Alphonse Mucha

可以看到两位艺术家的风格融合在一起,效果很好。
5、Website
像Artstation和Deviant Art这样的小众网站聚集了许多不同类型的图像。在提示中使用它们可以引导图像向这些风格靠拢。
Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm Lau and Alphonse Mucha, artstation

这虽然不是一个巨大的变化,但图像确实看起来像在Artstation上找到的。
6、Resolution
分辨率表示图像的清晰度和细节。让我们添加关键字
Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm Lau and Alphonse Mucha, artstation, highly detailed, sharp focus

因为前面的图像已经非常清晰和详细了。所以可能影响不是很大,但作为补充也没什么大问题。
7、Additional details
附加细节是用来修饰图像,可以为图像添加一些氛围。
Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm Lau and Alphonse Mucha, artstation, highly detailed, sharp focus, sci-fi, stunningly beautiful, dystopian

手画的并不好,这是因为1.5的模型就这样,这是一个已知的问题。
8、Color
可以通过添加颜色关键字来控制图像的整体颜色。
Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm Lau and Alphonse Mucha, artstation, highly detailed, sharp focus, sci-fi, stunningly beautiful, dystopian, iridescent gold

就是这种黄金AK的效果😏
9、Lighting
任何摄影师都会告诉你,灯光是创造成功图像的关键因素。灯光关键字可以对图像的外观产生巨大的影响。让我们为提示符添加电影般的灯光和黑暗。
Emma Watson as a powerful mysterious sorceress, casting lightning magic, detailed clothing, digital painting, hyperrealistic, fantasy, Surrealist, full body, by Stanley Artgerm Lau and Alphonse Mucha, artstation, highly detailed, sharp focus, sci-fi, stunningly beautiful, dystopian, iridescent gold, cinematic lighting, dark

基本上一个好的提示包含的部分我们就介绍完了,在主题中添加了一些关键字的图像已经很好了。对于Stable Diffusion通常不需要有很多关键词就可以获得好的图像。但是Midjourney还是需要的。
否定提示 Negative prompt
使用否定提示是另一种很好的控制图像的方法,这里的提示内容是不想要的东西。可以是名称,可以是样式,不需要的属性,等等
使用负提示符对于v2模型是必须的。如果没有它,图像将远远不如v1。而对于我们现在介绍的v1.5,它们是可选的,但建议使用它们,因为它们就算没用,也不会有坏处。
下面是作为Negative prompt输入的词语
ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, extra limbs, disfigured, deformed, body out of frame, bad anatomy, watermark, signature, cut off, low contrast, underexposed, overexposed, bad art, beginner, amateur, distorted face, blurry, draft, grainy

看看这张,就非常的霸气。
提示的语法
如果你使用Midjourney,那么可以跳过这节,但是如果你使用稳定扩散的话,那么一定要看完。
本文以 Stable Diffusion web为例
1、关键词权重
权重语法是(keyword: factor)。Factor是一个值:小于1表示不重要,大于1表示更重要。
例如,我们可以在下面的提示中调整关键字dog的权重,这样会生成多个狗
(dog:1.5), autumn in paris, ornate, beautiful, atmosphere, vibe, mist, smoke, fire, chimney, rain, wet, pristine, puddles, melting, dripping, snow, creek, lush, ice, bridge, forest, roses, flowers, by stanley artgerm lau, greg rutkowski, thomas kindkade, alphonse mucha, loish, norman rockwell.

2、() 和 []
调整关键字强度的等效方法是使用()和[]。(keyword)将关键字强度提高1.1倍,与(keyword:1.1)相同。[keyword]将关键字强度降低为0.9倍, 与(keyword:0.9)。
也可以进行嵌套:
(keyword): 1.1
((keyword)): 1.21
(((keyword))): 1.33
都是乘法的关系:
[keyword]: 0.9
[[keyword]]: 0.81
[[[keyword]]]: 0.73
3、混合关键字
也可以混合使用两个关键字。
[keyword1 : keyword2: factor]
Factor控制keyword1切换到keyword2的步骤。它是一个0到1之间的数字。
Oil painting portrait of [Joe Biden: Donald Trump: 0.5]
如果是30步采样,那么步骤1到15中的提示为
Oil painting portrait of Joe Biden
16到30步就变为了:
Oil painting portrait of Donald Trump

可以看到中间的步骤“懂王”穿了一套白色西装,更像是拜登装。这是一个非常重要的关键字混合规则的完美示例:第一个关键字决定全局组合。早期的扩散步骤决定了整体的组成。后面的步骤细化细节。
4、脸的混合
一个常见的用例是借用演员的形象创建一个具有特定外观的新面孔,比如,[Emma Watson: Amber heard: 0.85],看看40步的结果:

如果能够仔细选择两个名称并调整因子,我们就可以精确地得到想要的外观。
以上就是一些基本的语法除此以外在Stable Diffusion web中还可以使用来指定使用的lora,这个我们在后面做演示
提示符可以有多长?
一半情况下的限制是75个令牌。这也跟据你使用的Stable Diffusion服务有所不同
这里的令牌与单词会有所不同。Stable Diffusion使用CLIP模型自动将提示转换为令牌标记,这是它所知道的单词的数字表示。如果你输入一个它以前没见过的词,它会被分解成2个或更多的子词,直到它知道它是什么,所以会被转换为更多的令牌。例如,dream是一个,beach是一个。但是如果没有空格dreambeach,因为模型不认识这个词,所以模型把这个词分解成它知道的dream和beach算作2个。
AUTOMATIC1111的Stable Diffusion web没有限制。但是如果提示符包含超过75个标记(CLIP标记器的限制),它将开始另一个75个标记的新块,新的“限制”变为150。这个过程会一直持续下去,直到你的内存耗尽。
并且每75个标记的块都是独立处理的,产生的表示在输入Stable Diffusion的U-Net之前被连接起来。
可以通过查看提示输入框右上角的小框来检查令牌的数量。
检查关键字
我们使用的关键字并不意味着它是有效的。所以需要检查关键字的有效性。例如,v1.5模型知道美国画家Henry Asencio吗?
henry asencio

看来它知道
那么wlop呢?
wlop

看来训练的时候没有这个关键词,所以我们经过测试,这个模型就别用这个关键词了。
限制想象
要想用好Stable Diffusion你需要像Stable Diffusion一样思考。它只是一个图像采样器,生成的像素值,所以你要限制他的想象,通过提示缩小它的采样空间。
看看下面的区别:
castle

castle, blue sky background

wide angle view of castle, blue sky backgroun

在提示中添加更多的描述关键字缩小了城堡的样本范围。在提示符中指定的越多,图像的变化就越少。
属性关联
有些属性是紧密相关的。稳定扩散产生最有可能产生意想不到的关联效应的图像。
a young female with blue eyes, highlights in hair, sitting outside restaurant, wearing a white outfit, side light

a young female with brown eyes, highlights in hair, sitting outside restaurant, wearing a white outfit, side light

虽然没有注明种族。但由于蓝眼睛的人主要是欧洲人,所以产生了白人。棕色眼睛在不同种族中更常见,所以你会看到更多样化的种族样本,这个看着就是亚洲人。
微调
最后就最关心的微调:使用自定义模型是最简单的方法来实现一个风格,由于大型的开源社区,数百个自定义模型是免费的。
使用DreamShaper(一种针对人像插图进行了微调的模型):

这是一种非常帅气的风格。该模型具有生成清晰而漂亮的面孔,DreamShaper是v1.5的一个很好的微调方法,但是现在已经是2.0了,我们有了更新的方法。
Stable Diffusion 2.0
我们以前介绍过Stable Diffusion 1.5的本地安装,但是现在已经更新到2.0了,借助于AUTOMATIC1111的Stable Diffusion web 我们可以很好的自定义和加载模型

上面的提示是:
<lora:koreanDollLikeness_v15:0.66>, ((Smile))),best quality, ultra high res, (photorealistic:1.4), 1girl,(green yoga pants:1), (Kpop idol), (aegyo sal:1), (Medium-sized chest), (Medium-sized breasts),(light brown short ponytail:1.2), ((puffy eyes)), looking at viewer, full body, streets, outdoors
如果你看了本文,一定只要这些内容的含义,然后需要介绍的是<lora:koreanDollLikeness_v15:0.66>我们这里使用了koreanDollLikeness_v15这个lora(新的微调模型)
否定提示是:
paintings,sketches,(worst quality:2),(lowquality:2),(normal quality:2),lowres, normalquality,((monochrome)),((grayscale)),skin spots,acnes, skin blemishes,age spot,glans
随机种子: 738359080
大图:

看着不错把,比1.5强很多了,我们在自己电脑上也可以直接使用,在明天的文章中我们将介绍:如何安装AUTOMATIC1111的Stable Diffusion web ,下载模型,找lora等操作你可以生成跟我这个一样的图片。
https://avoid.overfit.cn/post/79149f5b661c46bdaf92ae59b220d35e