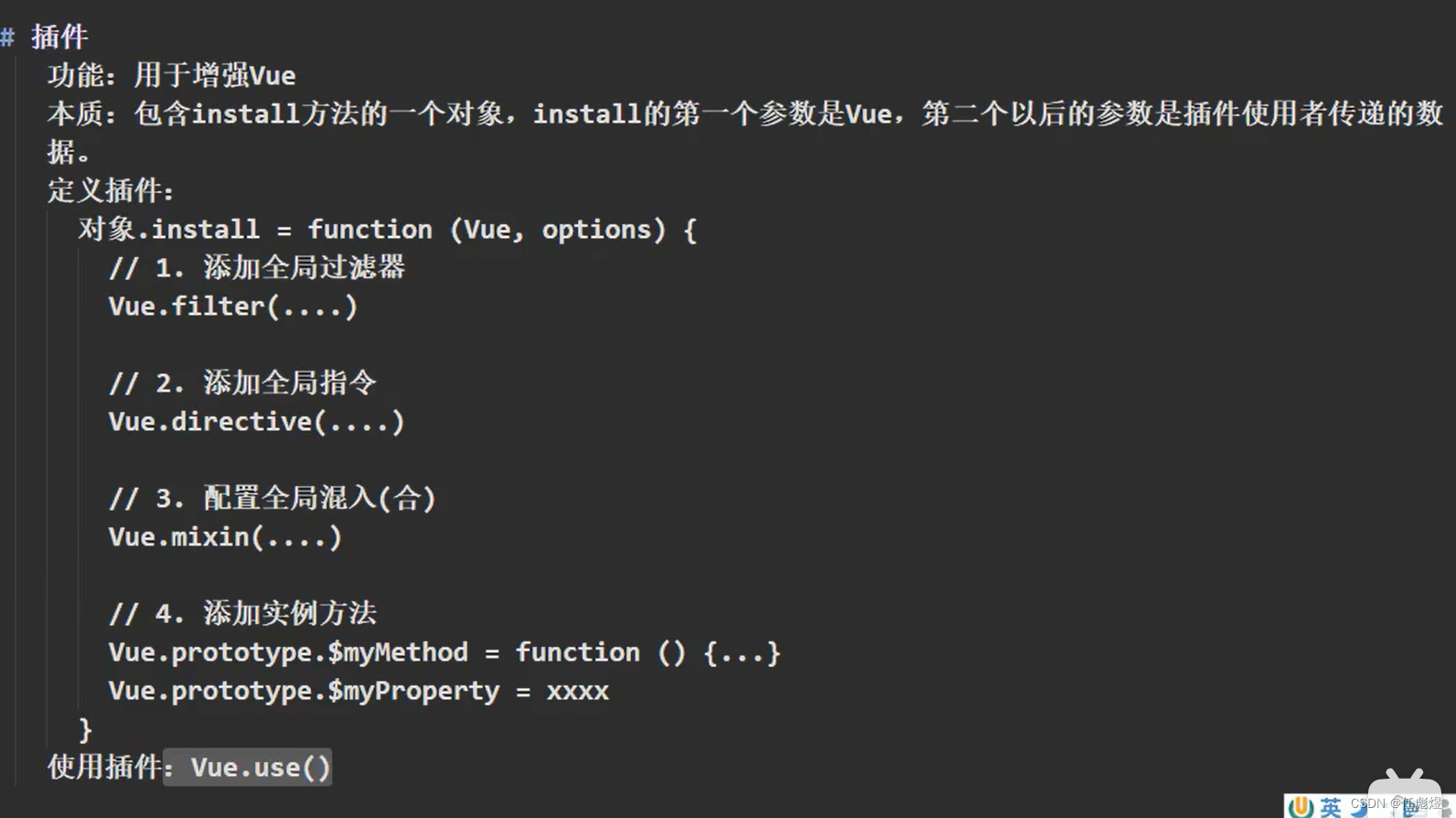
1.背景
推荐系统的两大应用场景分别是评分预测(Rating Prediction)和Top-N推荐(Item Ranking)。其中评分预测主要用于评价网站,比如用户给自己看过的电影评多少分,或者用户给自己看过的书籍评价多少分,矩阵分解技术主要应用于评分预测问题;Top-N推荐常用于购物网站或获取不到显式评分的网站,通过用户的隐式反馈为用户提供一个可能感兴趣的Item列表,此排序任务需要排序模型进行建模。本文主要介绍如何利用矩阵分解来解决评分预测问题。
2.矩阵分解概述
协同过滤技术可划分为基于内存/邻域的协同过滤(Memory-based CF)与基于模型的协同过滤技术(Model-based CF)。这里基于模型的协同过滤技术中矩阵分解(Matrix Factorization,MF)技术最为普遍和流行,因为它的可扩展性好并且易于实现。
矩阵分解是一种隐语义模型。隐语义模型是通过隐含特征(Latent Factor)联系用户兴趣和物品,基于用户行为的自动聚类。在评分预测问题中,收集到的用户行为评分数据可用一个评分矩阵表示,矩阵分解要做的是预测出评分矩阵中缺失的评分,使得预测评分能反映用户的喜欢程度,从而可以把预测评分最高的前K个电影推荐给用户。为了预测缺失的评分,矩阵分解学习 U s e r User User 矩阵和 I t e m Item Item 矩阵,使得 U s e r User User矩阵 ∗ * ∗ I t e m Item Item矩阵与评分矩阵中已知的评分差异最小,此时评分预测问题转化为了一个最优化问题,求解该最优化问题即可将评分矩阵分解成User矩阵和Item矩阵,从而可以计算出缺失的评分。
在评分预测问题中:
- 构建 user -item 评分矩阵(数据是稀疏的,矩阵分解就是填充缺失的评分)
- 学习 U s e r User User 矩阵和 I t e m Item Item 矩阵,使得评分与矩阵中已知的评分差异最小(最优化问题)
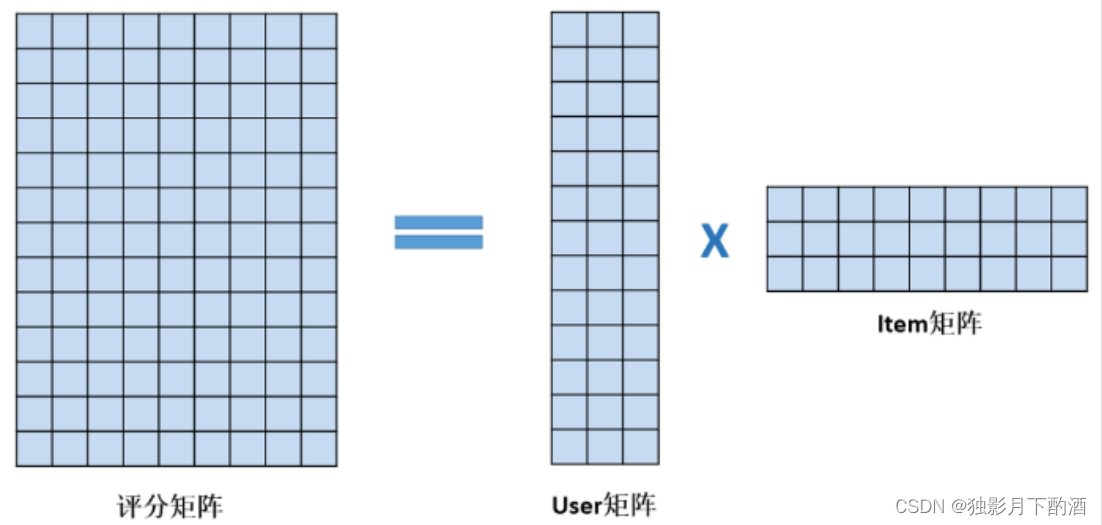
以电影评分预测为例,用评分矩阵表示收集到的用户行为数据,12个用户,9部电影。
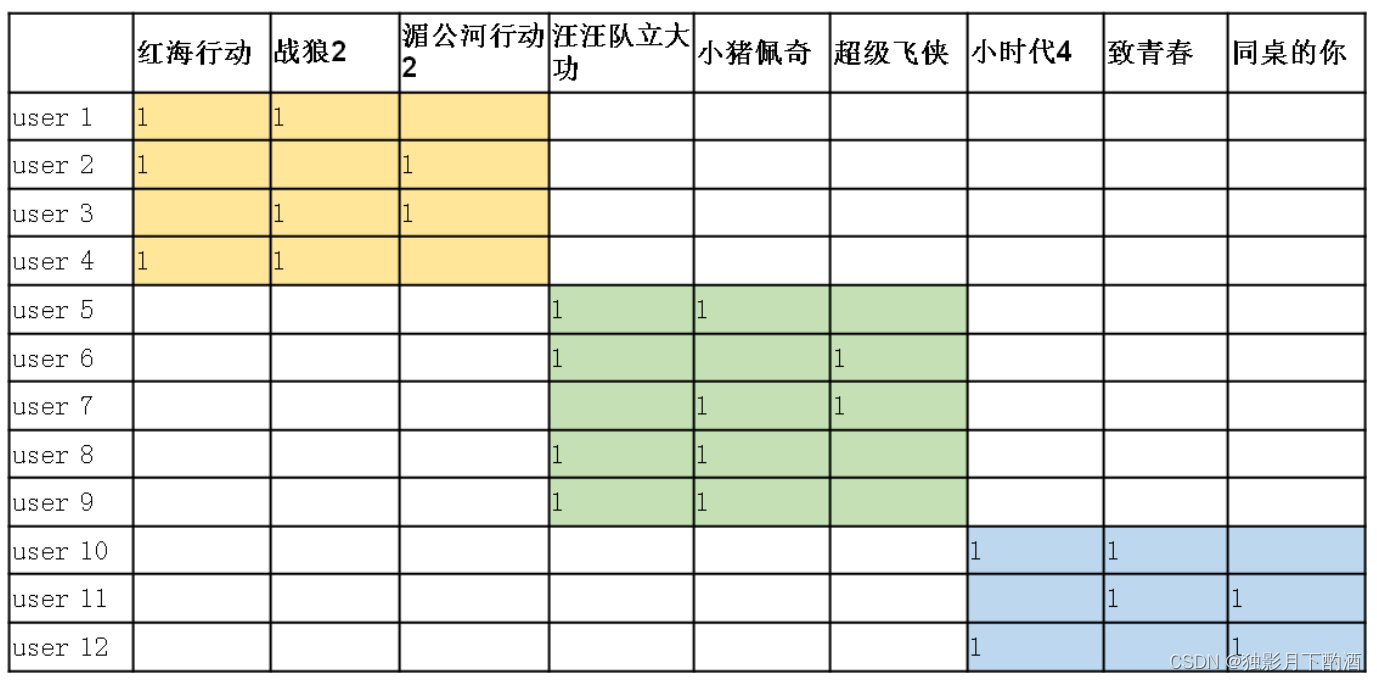
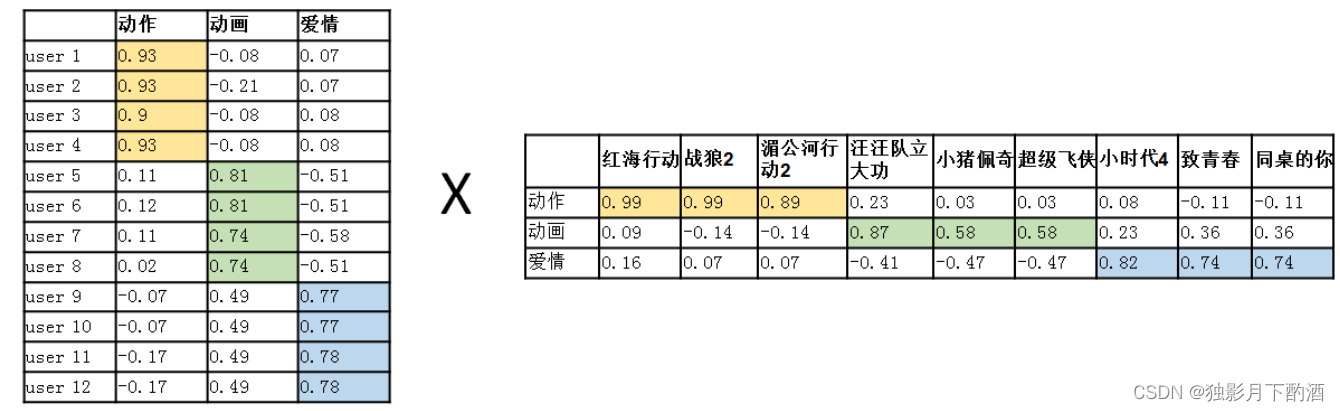
对上述用户-物品评分矩阵(12×9)进行矩阵分解,得到User(12×3)矩阵和Item(3×9)矩阵。观察下图User矩阵,可知用户的观影爱好体现在User向量上,观察Item矩阵,可知电影的风格体现在Item向量上,MF用user向量和item向量的内积去拟合评分矩阵中该user对该item的评分,内积的大小反映了user对item的喜欢程度,内积越大表明用户对该电影的喜爱程度高,反之用户对该电影的喜爱程度低。这里“动作”、“动画”、“爱情”为隐含特征,隐含特征个数k越大,隐类别分得越细,计算量越大。
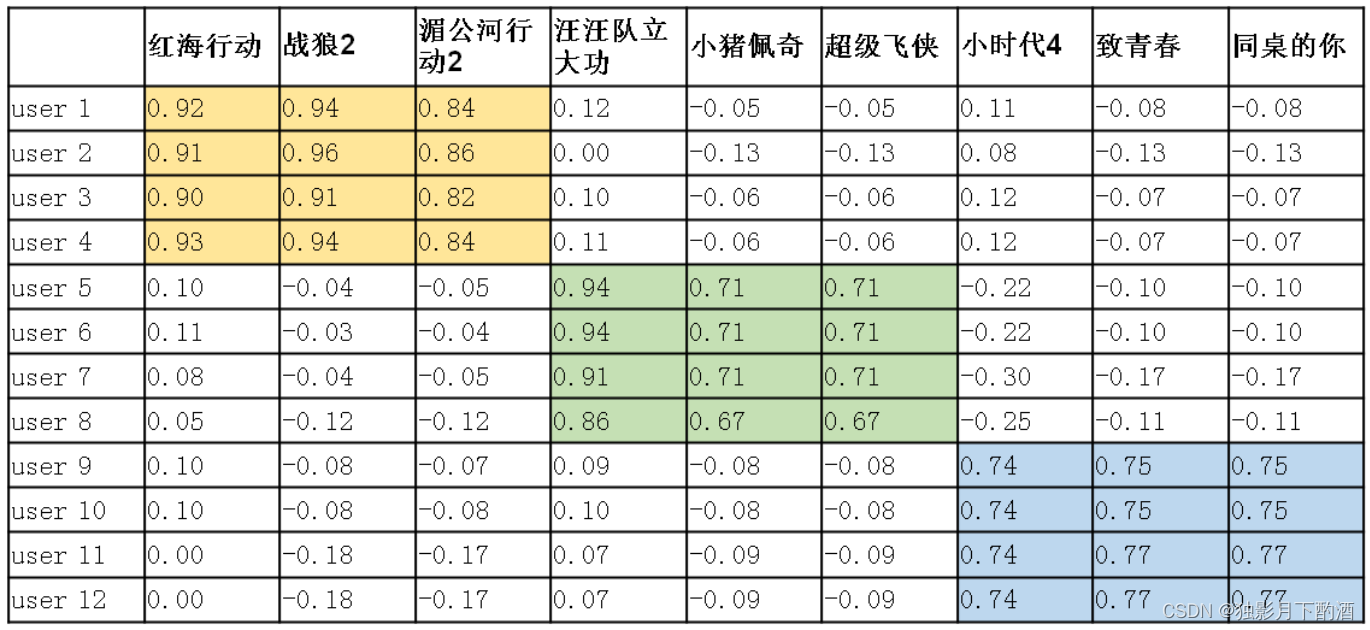
把User矩阵与Item矩阵相乘,就能预测每个用户对每部电影的预测评分了,评分值越大,表示用户喜欢该电影的可能性越大,该电影就越值得推荐给用户。
3.矩阵分解目标函数
在用户-物品评分矩阵 R \bold R R 中, r u i r_{ui} rui 表示 用户 u u u 对 Item $i$ 的评分 , 当 r u i > 0 r_{ui}\ \gt 0 rui >0 时,表示有评分,当 r u i = 0 \ r_{ui}\ = 0 rui =0,表示没有评分。
在User矩阵 X \bold X X 中( M × k M×k M×k,用户数为M), x u x_u xu 表示用户 u u u 的向量,k维列向量。 X = [ x 1 , x 2 , . . . , x M ] \bold X=[x_1,x_2,...,x_M] X=[x1,x2,...,xM]
在Item矩阵 Y \bold Y Y 中( k × N k×N k×N,物品数为N), y i y_i yi 表示用户 i t e m i item_i itemi 的向量,k维列向量。 Y = [ y 1 , y 2 , . . . , y N ] \bold Y=[y_1,y_2,...,y_{N}] Y=[y1,y2,...,yN]
用户向量与物品向量的内积,表示用户
u
u
u 对物品
i
i
i 的预测评分。矩阵分解的目标函数为:
min
X
,
Y
∑
r
u
i
≠
0
(
r
u
i
−
x
u
T
y
i
)
2
+
λ
(
∑
u
∣
∣
x
u
∣
∣
2
2
+
∑
i
∣
∣
y
i
∣
∣
2
2
)
\min \limits_{X,Y} \sum\limits_{r_{ui}\neq\ 0}\left(r_{ui}-x^T_uy_i\right)^2+\lambda\left(\sum\limits_{u}||x_u||^2_2+\sum\limits_{i}||y_i||^2_2\right)
X,Yminrui= 0∑(rui−xuTyi)2+λ(u∑∣∣xu∣∣22+i∑∣∣yi∣∣22)
上式前半部分表示的是User矩阵*Item矩阵与评分矩阵中已知的评分差异,后半部分是L2正则项,保证数值计算稳定性,防止过拟合。
4.目标函数最优化问题求解
目标函数最优化问题的工程解法一般采用交替最小二乘法( Alternating Least Squares , ALS)或随机梯度下降(SGD)。 在实际应用中,交替最小二乘更常用一些,这也是社交巨头 Facebook 在他们的推荐系统中选择的主要矩阵分解方法。
4.1 交替最小二乘法(ALS)
交替最小二乘的核心是 “交替”,接下来看看 ALS 是如何 “交替” :
矩阵分解的最终任务是找到两个矩阵
X
\bold X
X 和
Y
\bold Y
Y,让它们相乘后约等于原矩阵
R
\bold R
R:
R
m
×
n
=
X
m
×
k
×
Y
n
×
k
T
\bold R_{m×n}=\bold X_{m×k}\ ×\ \bold Y_{n×k}^T
Rm×n=Xm×k × Yn×kT
难就难在,
X
\bold X
X 和
Y
\bold Y
Y 两个都是未知的,如果知道其中一个的话,就可以按照线性代数标准解法求得,比如如果知道了
Y
\bold Y
Y,那么
X
\bold X
X 就可以这样算:
R
m
×
n
=
X
m
×
k
×
Y
n
×
k
−
1
\bold R_{m×n}=\bold X_{m×k}\ ×\ \bold Y_{n×k}^{-1}
Rm×n=Xm×k × Yn×k−1
也就是
R
\bold R
R 矩阵乘以
Y
\bold Y
Y 矩阵的逆矩阵就得到了结果,反之知道了
X
\bold X
X 再求
Y
\bold Y
Y 也是一样。
交替最小二乘通过迭代的方式解决了这个鸡生蛋蛋生鸡的难题:
- 初始化随机矩阵 Y \bold Y Y 里面的元素值;
- 把 Y \bold Y Y 矩阵当做已知的,直接用线性代数的方法求得矩阵 X \bold X X;
- 得到了矩阵 X \bold X X后,把 X \bold X X 当做已知的,故技重施,回去求解矩阵 Y \bold Y Y ;
- 上面两个过程交替进行,一直到误差满足设定条件为止。
交替最小二乘法步骤:
-
S t e p 1 \bold Step1 Step1,固定 Y \bold Y Y 优化 X \bold X X
min X ∑ r u i ≠ 0 ( r u i − x u T y i ) 2 + λ ∑ u ∣ ∣ x u ∣ ∣ 2 2 \min \limits_{X} \sum\limits_{r_{ui}\neq\ 0}\left(r_{ui}-x^T_uy_i\right)^2+\lambda\sum\limits_{u}||x_u||^2_2 Xminrui= 0∑(rui−xuTyi)2+λu∑∣∣xu∣∣22
将目标函数转化为矩阵表达形式:
J ( x u ) = ( R u − Y u T x u ) T ( R u − Y u T x u ) + λ x u T x u J(x_u)=(R_u-Y^T_ux_u)^T(R_u-Y^T_ux_u)+\lambda x^T_ux_u J(xu)=(Ru−YuTxu)T(Ru−YuTxu)+λxuTxu
其中 R u = [ r u i 1 , r u i 2 , . . . r u i n ] T R_u=[r_{ui_1},r_{ui_2},...r_{ui_n}]^T Ru=[rui1,rui2,...ruin]T 表示用户 u u u 对 n n n 个物品的评分; Y u = [ y i 1 , y i 2 , . . . y i m ] Y_u=[y_{i_1},y_{i_2},...y_{i_m}] Yu=[yi1,yi2,...yim] 为 n n n 个物品的向量。求解目标函数 J J J 关于 x u x_u xu 的梯度,并令梯度等于0,得到:
∂ J ( x u ) ∂ x u = − 2 Y u ( R u − Y u T x u ) + 2 λ x u = 0 \frac{\partial J(x_u)}{\partial x_u}=-2Y_u(R_u-Y^T_ux_u)+2\lambda x_u=0 ∂xu∂J(xu)=−2Yu(Ru−YuTxu)+2λxu=0
求解后可得:
x u = ( Y u Y u T + λ I ) − 1 Y u R u x_u = (Y_uY^T_u+\lambda I)^{-1}Y_uR_u xu=(YuYuT+λI)−1YuRu -
S t e p 2 \bold Step2 Step2,固定 X \bold X X 优化 Y \bold Y Y
min Y ∑ r u i ≠ 0 ( r u i − x u T y i ) 2 + λ ∑ i ∣ ∣ y i ∣ ∣ 2 2 \min \limits_{Y} \sum\limits_{r_{ui}\neq\ 0}\left(r_{ui}-x^T_uy_i\right)^2+\lambda\sum\limits_{i}||y_i||^2_2 Yminrui= 0∑(rui−xuTyi)2+λi∑∣∣yi∣∣22-
将目标函数转化为矩阵表达形式:
J ( y i ) = ( R i − X i T y i ) T ( R i − X i T y i ) + λ y i T y i J(y_i)=(R_i-X^T_iy_i)^T(R_i-X^T_iy_i)+\lambda y^T_iy_i J(yi)=(Ri−XiTyi)T(Ri−XiTyi)+λyiTyi
其中 R u = [ r u 1 i , r u 2 i , . . . r u m i ] T R_u=[r_{u_1{i}},r_{u_2i},...r_{u_mi}]^T Ru=[ru1i,ru2i,...rumi]T表示 m m m个用户对个物品 i i i 的评分; X i = [ x u 1 , x u 2 , . . . x u m ] X_i=[x_{u_1},x_{u_2},...x_{u_m}] Xi=[xu1,xu2,...xum] 为 m m m个用户的向量。求解目标函数 J J J关于 y i y_i yi 的梯度,并令梯度等于0,得到:
∂ J ( y i ) ∂ x i = − 2 X i ( R i − X i T y i ) + 2 λ y i = 0 \frac{\partial J(y_i)}{\partial x_i}=-2X_i(R_i-X^T_iy_i)+2\lambda y_i=0 ∂xi∂J(yi)=−2Xi(Ri−XiTyi)+2λyi=0
求解后可得:
y i = ( X i X i T + λ I ) − 1 X i R i y_i = (X_iX^T_i+\lambda I)^{-1}X_iR_i yi=(XiXiT+λI)−1XiRi
-
-
重复 S t e p 1 \bold Step1 Step1和 2 \bold 2 2,直到 X \bold X X 和 Y \bold Y Y 收敛,每次固定一个矩阵,优化另一个矩阵,都是最小二乘问题
除了针对显式评分矩阵,ALS还可以对隐式矩阵进行分解,将评分看成行为的强度,比如浏览次数,阅读时间等。 当
r
u
i
>
0
r_{ui}\ \gt 0
rui >0时, 表示用户
u
u
u对商品
i
i
i 有行为,当
r
u
i
=
0
r_{ui}\ = 0
rui =0, 表示用户
u
u
u对商品
i
i
i 没有行为。
P
u
i
=
{
1
r
u
i
>
0
0
r
u
i
=
0
P_{ui}=\begin{cases} 1 & r_{ui} \gt 0 \\ 0 & r_{ui} = 0 \end{cases}
Pui={10rui>0rui=0
上式
P
u
i
P_{ui}
Pui 称为用户偏好:当用户
u
u
u对物品
i
i
i有过行为,认为用户
u
u
u对物品
i
i
i感兴趣,
P
u
i
P_{ui}
Pui=1;当用户
u
u
u对物品
i
i
i没有过行为,认为用户
u
u
u对物品
i
i
i不感兴趣,
P
u
i
P_{ui}
Pui=0.
对隐式矩阵进行分解的步骤:
-
引入置信度( α \alpha α 为置信系数)
c u i = 1 + α r u i c_{ui}=1+\alpha r_{ui} cui=1+αrui
当 r u i > 0 \ r_{ui}\ \gt 0 rui >0时, c u i c_{ui} cui 与 r u i r_{ui} rui 线性递增,当 r u i = 0 r_{ui}\ = 0 rui =0时, c u i = 1 c_{ui}\ = 1 cui =1,即 c u i c_{ui} cui 最小值为1. -
目标函数
min X , Y ∑ u = 1 m ∑ i = 1 n c u i ( r u i − x u T y i ) 2 + λ ( ∑ u ∣ ∣ x u ∣ ∣ 2 2 + ∑ i ∣ ∣ y i ∣ ∣ 2 2 ) \min \limits_{X,Y} \sum\limits_{u=1}\limits^{m} \sum\limits_{i=1}\limits^{n}c_{ui}\left(r_{ui}-x^T_uy_i\right)^2+\lambda\left(\sum\limits_{u}||x_u||^2_2+\sum\limits_{i}||y_i||^2_2\right) X,Yminu=1∑mi=1∑ncui(rui−xuTyi)2+λ(u∑∣∣xu∣∣22+i∑∣∣yi∣∣22) -
ALS求解矩阵 X \bold X X和 Y \bold Y Y
ALS工具
- spark ml库(官方推荐)
- python代码:https://github.com/tushushu/imylu/blob/master/imylu/recommend/als.py
4.2 随机梯度下降SGD
SGD基本思路是以随机方式遍历训练集中的数据,并给出每个已知评分的预测评分。用户和物品特征向量的调整就沿着评分误差越来越小的方向迭代进行,直到误差达到要求。所以,SGD不需要遍历所有的样本即可完成特征向量的求解。
矩阵分解的目标函数为:
J
(
x
u
,
y
i
)
=
min
X
,
Y
∑
r
u
i
≠
0
(
r
u
i
−
x
u
T
y
i
)
2
+
λ
(
∑
u
∣
∣
x
u
∣
∣
2
2
+
∑
i
∣
∣
y
i
∣
∣
2
2
)
J(x_u,y_i)= \min \limits_{X,Y} \sum\limits_{r_{ui}\neq\ 0}\left(r_{ui}-x^T_uy_i\right)^2+\lambda\left(\sum\limits_{u}||x_u||^2_2+\sum\limits_{i}||y_i||^2_2\right)
J(xu,yi)=X,Yminrui= 0∑(rui−xuTyi)2+λ(u∑∣∣xu∣∣22+i∑∣∣yi∣∣22)
分别求解
J
(
x
u
,
y
i
)
J(x_u,y_i)
J(xu,yi)关于
x
u
x_u
xu 和
y
i
y_i
yi的梯度如下:
∂
J
(
x
u
,
y
i
)
∂
x
u
=
∑
u
,
r
u
i
≠
0
−
2
(
r
u
i
−
x
u
T
y
i
)
y
i
+
∑
u
2
λ
∣
∣
x
u
∣
∣
2
∂
J
(
x
u
,
y
i
)
∂
y
i
=
∑
i
,
r
u
i
≠
0
−
2
(
r
u
i
−
x
u
T
y
i
)
x
u
+
∑
i
2
λ
∣
∣
y
i
∣
∣
2
\begin{align} & \frac{\partial J(x_u,y_i)}{\partial x_u}=\sum\limits_{u,r_{ui}\neq 0}-2\left(r_{ui}-x^T_uy_i\right)y_i+\sum\limits_u 2\lambda||x_u||_2 \\[2ex] & \frac{\partial J(x_u,y_i)}{\partial y_i}=\sum\limits_{i,r_{ui}\neq 0}-2\left(r_{ui}-x^T_uy_i\right)x_u+\sum\limits_i 2\lambda||y_i||_2 \end{align}
∂xu∂J(xu,yi)=u,rui=0∑−2(rui−xuTyi)yi+u∑2λ∣∣xu∣∣2∂yi∂J(xu,yi)=i,rui=0∑−2(rui−xuTyi)xu+i∑2λ∣∣yi∣∣2
不断更新矩阵
X
\bold X
X 和
Y
\bold Y
Y
x
u
=
x
u
+
α
(
∑
u
,
r
u
i
≠
0
−
2
(
r
u
i
−
x
u
T
y
i
)
y
i
+
∑
u
2
λ
1
∣
∣
x
u
∣
∣
2
)
y
i
=
y
i
+
α
(
∑
i
,
r
u
i
≠
0
−
2
(
r
u
i
−
x
u
T
y
i
)
x
u
+
∑
i
2
λ
2
∣
∣
y
i
∣
∣
2
)
\begin{align} &x_u=x_u+\alpha(\sum\limits_{u,r_{ui}\neq 0}-2\left(r_{ui}-x^T_uy_i\right)y_i+\sum\limits_u 2\lambda_1||x_u||_2) \\[2ex] &y_i=y_i+\alpha(\sum\limits_{i,r_{ui}\neq 0}-2\left(r_{ui}-x^T_uy_i\right)x_u+\sum\limits_i 2\lambda_2||y_i||_2) \end{align}
xu=xu+α(u,rui=0∑−2(rui−xuTyi)yi+u∑2λ1∣∣xu∣∣2)yi=yi+α(i,rui=0∑−2(rui−xuTyi)xu+i∑2λ2∣∣yi∣∣2)
由于
X
\bold X
X 和
Y
\bold Y
Y 是两个不同的矩阵,通常分别采取不同的正则参数,如
λ
1
\lambda_1
λ1和
λ
2
\lambda_2
λ2
5.矩阵分解算法
MF(Matrix Factorization,矩阵分解)模型核心思想是通过两个低维小矩阵(一个代表用户embedding矩阵,一个代表物品embedding矩阵)的乘积计算,来模拟真实用户点击或评分产生的大的协同信息稀疏矩阵,本质上是编码了用户和物品协同信息的降维模型。
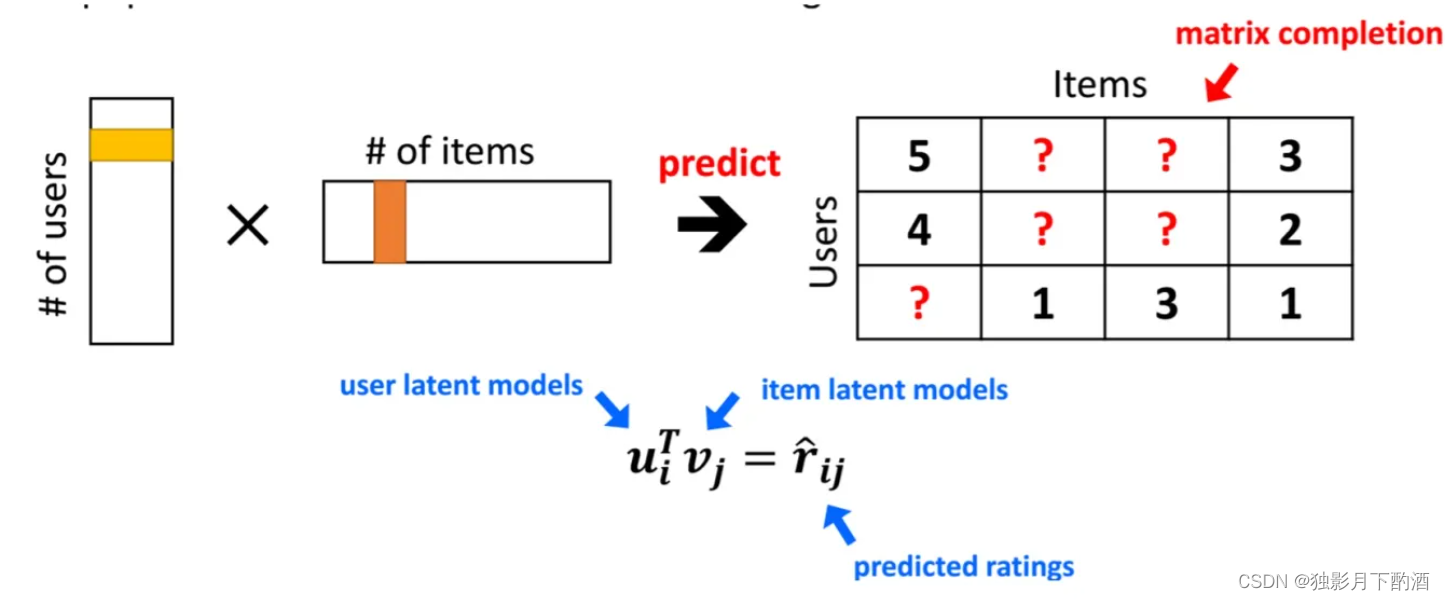
当训练完成,每个用户和物品得到对应的低维embedding表达后,如果要预测某个 U s e r i User_i Useri 对 I t e m j Item_j Itemj 的评分的时候,只要它们做个内积计算 < U s e r i , I t e m j > <User_i,Item_j> <Useri,Itemj> ,这个得分就是预测得分。
5.1 Traditional SVD
5.1.1 回顾特征值和特征向量
特征值和特征向量的定义如下:
A
x
=
λ
x
Ax=\lambda x
Ax=λx
其中
A
A
A 是一个
n
×
n
n×n
n×n 的实对称矩阵,
x
x
x 是一个
n
n
n 维向量,则我们说
λ
\lambda
λ 是矩阵
A
A
A 的一个特征值,而
x
x
x 是矩阵
A
A
A 的特征值
λ
\lambda
λ 所对应的特征向量。
求出特征值和特征向量有什么好处呢?
可以将矩阵A特征分解。
如果我们求出了矩阵
A
A
A的
n
n
n个特征值
λ
1
≤
λ
2
≤
.
.
.
≤
λ
n
λ_1≤λ_2≤...≤λ_n
λ1≤λ2≤...≤λn,以及这
n
n
n个特征值所对应的特征向量
w
1
,
w
2
,
.
.
.
w
n
{w_1,w_2,...w_n}
w1,w2,...wn,如果这
n
n
n 个特征向量线性无关,那么矩阵
A
A
A 就可以用下式的特征分解表示:
A
=
W
Σ
W
−
1
A=W\Sigma W^{-1}
A=WΣW−1
其中
W
W
W 是这
n
n
n 个特征向量所张成的
n
×
n
n×n
n×n 维矩阵,而
Σ
\Sigma
Σ 为这
n
n
n 个特征值为主对角线的
n
×
n
n×n
n×n 维矩阵。
一般我们会把
W
W
W的这
n
n
n个特征向量标准化,即满足
∣
∣
w
i
∣
∣
2
=
1
||w_i||_2=1
∣∣wi∣∣2=1, 或者说
w
i
T
w
i
=
1
w^T_iw_i=1
wiTwi=1,此时
W
W
W 的
n
n
n 个特征向量为标准正交基,满足
W
T
W
=
I
W^TW=I
WTW=I,即
W
T
=
W
−
1
W^T=W^{−1}
WT=W−1, 也就是说
W
W
W为酉矩阵。
A
=
W
Σ
W
T
A=W\Sigma W^{T}
A=WΣWT
注意到要进行特征分解,矩阵
A
A
A必须为方阵。那么如果
A
A
A不是方阵,即行和列不相同时,我们还可以对矩阵进行分解吗?答案是可以,此时我们的SVD登场了。
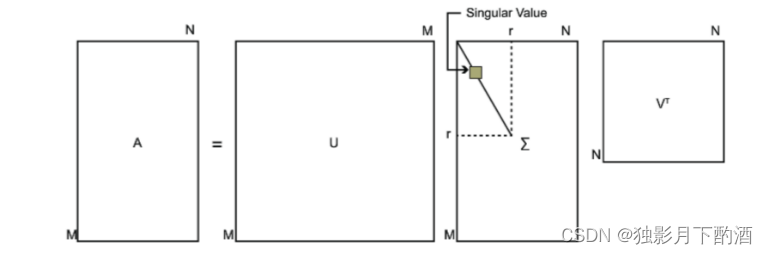
5.1.2 SVD
假设矩阵
A
A
A是一个
m
×
n
m×n
m×n的矩阵,那么我们定义矩阵
A
A
A的SVD为: :
A
=
U
Σ
V
T
A=U\Sigma V^{T}
A=UΣVT
其中
U
U
U 是一个
m
×
m
m×m
m×m 的矩阵,
Σ
\Sigma
Σ 是一个
m
×
n
m×n
m×n 的矩阵,除了主对角线上的元素以外全为
0
0
0 ,主对角线上的每个元素都称为奇异值,
V
V
V是一个
n
×
n
n×n
n×n 的矩阵。
U
U
U 和
V
V
V 都是酉矩阵,即满足
U
T
U
=
I
,
V
T
V
=
I
U^TU=I,V^TV=I
UTU=I,VTV=I。下图可以很形象的看出上面SVD的定义:
如何求出SVD分解后的 U , Σ , V U,Σ,V U,Σ,V这三个矩阵呢?
如果将
A
A
A的转置和
A
A
A做矩阵乘法,那么会得到
n
×
n
n×n
n×n的一个方阵
A
T
A
A^TA
ATA。既然
A
T
A
A^TA
ATA是方阵,那么可以进行特征分解,得到的特征值和特征向量满足下式:
(
A
T
A
)
v
i
=
λ
i
v
i
(A^TA)v_i=\lambda_i v_i
(ATA)vi=λivi
这样可以得到矩阵
A
T
A
A^TA
ATA的
n
n
n个特征值和对应的
n
n
n个特征向量
v
v
v了。将
A
T
A
A^TA
ATA的所有特征向量张成一个
n
×
n
n×n
n×n的矩阵
V
V
V,即为SVD公式里面的
V
V
V矩阵了。一般将
V
V
V中的每个特征向量叫做
A
A
A的右奇异向量。
如果我们将A和A的转置做矩阵乘法,那么会得到
m
×
m
m×m
m×m的一个方阵
A
A
T
AA^T
AAT。既然
A
A
T
AA^T
AAT是方阵,那么可以进行特征分解,得到的特征值和特征向量满足下式:
(
A
A
T
)
u
i
=
λ
i
u
i
(AA^T)u_i=\lambda_iu_i
(AAT)ui=λiui
这样可以得到矩阵
A
A
T
AA^T
AAT的
n
n
n个特征值和对应的
m
m
m个特征向量
u
u
u了。将
A
A
T
AA^T
AAT的所有特征向量张成一个
m
×
m
m×m
m×m的矩阵
U
U
U,即为SVD公式里面的
U
U
U矩阵了。一般将
U
U
U中的每个特征向量叫做
A
A
A的左奇异向量。
U
U
U和
V
V
V都求出来了,现在就剩下奇异值矩阵
Σ
\Sigma
Σ 没有求出了。由于除了对
Σ
\Sigma
Σ 角线上是奇异值其他位置都是0,那只需要求出每个奇异值
σ
\sigma
σ 就可以了。
A
=
U
Σ
V
T
⇒
A
V
=
U
Σ
V
T
V
⇒
A
V
=
U
Σ
⇒
A
v
i
=
σ
i
u
i
⇒
σ
i
=
A
v
i
/
u
i
A=U\Sigma V^T \Rightarrow AV=U\Sigma V^TV \Rightarrow AV=U\Sigma \Rightarrow Av_i = \sigma_i u_i \Rightarrow \sigma_i = Av_i / u_i
A=UΣVT⇒AV=UΣVTV⇒AV=UΣ⇒Avi=σiui⇒σi=Avi/ui
这样我们可以求出我们的每个奇异值,进而求出奇异值矩阵
Σ
\Sigma
Σ。
A
T
A
A^TA
ATA的特征向量组成的就是我们SVD中的
V
V
V矩阵,而
A
A
T
AA^{T}
AAT的特征向量组成的就是我们SVD中的
U
U
U矩阵,这有什么根据吗?这个其实很容易证明,我们以
V
V
V矩阵的证明为例。
A
=
U
Σ
V
T
⇒
A
T
=
V
Σ
T
U
T
⇒
A
T
A
=
V
Σ
T
U
T
U
Σ
V
T
=
V
Σ
2
V
T
A=U\Sigma V^T \Rightarrow A^T=V\Sigma^T U^T \Rightarrow A^TA = V\Sigma^T U^TU\Sigma V^T = V\Sigma^2V^T
A=UΣVT⇒AT=VΣTUT⇒ATA=VΣTUTUΣVT=VΣ2VT
上式证明使用了:
U
T
U
=
I
,
Σ
T
Σ
=
Σ
2
U^TU=I, \Sigma^T\Sigma=\Sigma^2
UTU=I,ΣTΣ=Σ2。 可以看出
A
T
A
A^TA
ATA的特征向量组成的的确就是我们SVD中的
V
V
V矩阵。类似的方法可以得到
A
A
T
AA^T
AAT的特征向量组成的就是我们SVD中的
U
U
U矩阵。
特征值矩阵等于奇异值矩阵的平方,也就是说特征值和奇异值满足如下关系:
σ
i
=
λ
i
\sigma_i = \sqrt{\lambda_i}
σi=λi
通过求出
A
T
A
A^{T}A
ATA的特征值取平方根来求奇异值更加方便。
5.1.3 SVD的性质
对于奇异值,它跟特征分解中的特征值类似,在奇异值矩阵中也是按照从大到小排列,而且奇异值的减少特别的快,在很多情况下,前10%甚至1%的奇异值的和就占了全部的奇异值之和的99%以上的比例。也就是说,可以用最大的
k
k
k个的奇异值和对应的左右奇异向量来近似描述矩阵。也就是说:
A
m
×
n
=
U
m
×
m
Σ
m
×
n
V
n
×
n
T
≈
U
m
×
k
Σ
k
×
k
V
k
×
n
T
A_{m \times n} = U_{m \times m}\Sigma_{m \times n} V^T_{n \times n} \approx U_{m \times k}\Sigma_{k \times k} V^T_{k \times n}
Am×n=Um×mΣm×nVn×nT≈Um×kΣk×kVk×nT
SVD可以用于PCA降维,来做数据压缩和去噪。也可以用于推荐算法,将用户和喜好对应的矩阵做特征分解,进而得到隐含的用户需求来做推荐。同时也可以用于NLP中的算法,比如潜在语义索引(LSI)。
5.1.4 SVD与PCA的关系
PCA的算法流程
求样本 x ( i ) x^{(i)} x(i)的 n ′ n' n′维的主成分其实就是求样本集的协方差矩阵 X X T XX^T XXT的前 n ′ n' n′个特征值对应特征向量矩阵 W W W,然后对于每个样本 x ( i ) x^{(i)} x(i),做如下变换 z ( i ) = W T x ( i ) z^{(i)}=W^Tx^{(i)} z(i)=WTx(i),即达到降维的PCA目的。
下面我们看看具体的算法流程。
输入: n n n维样本集 D = ( x ( 1 ) , x ( 2 ) , . . . , x ( m ) ) D=(x^{(1)}, x^{(2)},...,x^{(m)}) D=(x(1),x(2),...,x(m)),要降维到的维数 n ′ n' n′.
输出:降维后的样本集 D ′ D′ D′
-
对所有的样本进行中心化: x ( i ) = x ( i ) − 1 m ∑ j = 1 m x ( j ) x^{(i)} = x^{(i)} - \frac{1}{m}\sum\limits_{j=1}^{m} x^{(j)} x(i)=x(i)−m1j=1∑mx(j)
-
计算样本的协方差矩阵 X X T XX^{T} XXT
-
对矩阵 X X T XX^{T} XXT进行特征值分解
4)取出最大的n’个特征值对应的特征向量 ( w 1 , w 2 , . . . , w n ′ ) (w_1,w_2,...,w_n′) (w1,w2,...,wn′), 将所有的特征向量标准化后,组成特征向量矩阵 W W W。
5)对样本集中的每一个样本 x ( i ) x^{(i)} x(i),转化为新的样本 z ( i ) = W T x ( i ) z^{(i)}=W^Tx^{(i)} z(i)=WTx(i)
- 得到输出样本集 D ′ = ( z ( 1 ) , z ( 2 ) , . . . , z ( m ) ) D' =(z^{(1)}, z^{(2)},...,z^{(m)}) D′=(z(1),z(2),...,z(m))
有时候,我们不指定降维后的
n
′
n'
n′的值,而是换种方式,指定一个降维到的主成分比重阈值
t
t
t。这个阈值
t
t
t在
(
0
,
1
]
(0,1]
(0,1]之间。假如我们的n个特征值为
λ
1
≥
λ
2
≥
.
.
.
≥
λ
n
\lambda_1 \geq \lambda_2 \geq ... \geq \lambda_n
λ1≥λ2≥...≥λn,则
n
′
n'
n′可以通过下式得到:
∑
i
=
1
n
′
λ
i
∑
i
=
1
n
λ
i
≥
t
\frac{\sum\limits_{i=1}^{n'}\lambda_i}{\sum\limits_{i=1}^{n}\lambda_i} \geq t
i=1∑nλii=1∑n′λi≥t
SVD用于PCA
PCA仅仅使用了我们SVD的右奇异矩阵,没有使用左奇异矩阵,那么左奇异矩阵有什么用呢?
现有样本是
m
×
n
m×n
m×n的矩阵
X
X
X,如果我们通过SVD找到了矩阵
X
X
T
XX^{T}
XXT最大的
d
d
d个特征向量张成的
m
×
d
m×d
m×d维矩阵
U
U
U,则如果进行如下处理:
X
d
×
n
′
=
U
d
×
m
T
X
m
×
n
X'_{d \times n} = U_{d \times m}^TX_{m \times n}
Xd×n′=Ud×mTXm×n
可得一个
d
×
n
d×n
d×n的矩阵
X
'
X'
X',和原来的
m
×
n
m×n
m×n维样本矩阵
X
X
X相比,行数从
m
m
m减到了
d
d
d,可见对行数进行了压缩。也就是说,左奇异矩阵可以用于行数的压缩。相对的,右奇异矩阵可以用于列数即特征维度的压缩,也就是PCA降维。
5.2 FunkSVD(LFM)
2006年的Netflix Prize之后, Simon Funk公布了一个矩阵分解算法叫做Funk-SVD, 后来被 Netflix Prize 的冠军Koren称为Latent Factor Model(LFM)。
FunkSVD是在传统SVD面临计算效率问题时提出来的,既然将一个矩阵做SVD分解成3个矩阵很耗时,同时还面临稀疏的问题,那么能不能避开稀疏问题的同时只分解成两个矩阵呢?即现在期望我们的矩阵
M
M
M这样进行分解:
M
m
×
n
=
P
m
×
k
T
Q
k
×
n
M_{m \times n}=P_{m \times k}^TQ_{k \times n}
Mm×n=Pm×kTQk×n
目标:让用户的评分和用矩阵乘积得到的评分残差尽可能的小,也就是说,可以用均方差作为损失函数,来寻找最终的 P P P和 Q Q Q。
对于某一个用户评分
m
i
j
m_{ij}
mij,如果用FunkSVD进行矩阵分解,则对应的表示为
q
j
T
p
i
q_j^Tp_i
qjTpi,采用均方差做为损失函数,则我们期望
(
m
i
j
−
q
j
T
p
i
)
2
(m_{ij}-q_j^Tp_i)^2
(mij−qjTpi)2尽可能的小,如果考虑所有的物品和样本的组合,则我们期望最小化下式:
∑
i
,
j
(
m
i
j
−
q
j
T
p
i
)
2
\sum\limits_{i,j}(m_{ij}-q_j^Tp_i)^2
i,j∑(mij−qjTpi)2
只要能最小化上面的式子,并求出极值所对应的
p
i
,
q
j
p_i, q_j
pi,qj,则可以得到矩阵
P
P
P和
Q
Q
Q,那么对于任意矩阵
M
M
M任意一个空白评分的位置,我们可以通过
q
j
T
p
i
q_j^Tp_i
qjTpi计算预测评分。
在实际应用中,为了防止过拟合,会加入一个L2的正则化项,因此正式的FunkSVD的优化目标函数
J
(
p
,
q
)
J(p,q)
J(p,q)是这样的:
a
r
g
m
i
n
⏟
p
i
,
q
j
∑
i
,
j
(
m
i
j
−
q
j
T
p
i
)
2
+
λ
(
∣
∣
p
i
∣
∣
2
2
+
∣
∣
q
j
∣
∣
2
2
)
\underbrace{arg\;min}_{p_i,q_j}\;\sum\limits_{i,j}(m_{ij}-q_j^Tp_i)^2 + \lambda(||p_i||_2^2 + ||q_j||_2^2 )
pi,qj
argmini,j∑(mij−qjTpi)2+λ(∣∣pi∣∣22+∣∣qj∣∣22)
其中
λ
\lambda
λ 为正则化系数,需要调参。对于这个优化问题,一般通过梯度下降法来进行优化得到结果。
将上式分别对
p
i
,
q
j
p_i, q_j
pi,qj求导得:
∂
J
∂
p
i
=
−
2
(
m
i
j
−
q
j
T
p
i
)
q
j
+
2
λ
p
i
∂
J
∂
q
j
=
−
2
(
m
i
j
−
q
j
T
p
i
)
p
i
+
2
λ
q
j
\begin{align} &\frac{\partial J}{\partial p_i} = -2(m_{ij}-q_j^Tp_i)q_j + 2\lambda p_i\\[2ex] & \frac{\partial J}{\partial q_j} = -2(m_{ij}-q_j^Tp_i)p_i + 2\lambda q_j \end{align}
∂pi∂J=−2(mij−qjTpi)qj+2λpi∂qj∂J=−2(mij−qjTpi)pi+2λqj
则在梯度下降法迭代时,
p
i
,
q
j
p_i, q_j
pi,qj的迭代公式为:
p
i
=
p
i
+
α
(
(
m
i
j
−
q
j
T
p
i
)
q
j
−
λ
p
i
)
q
j
=
q
j
+
α
(
(
m
i
j
−
q
j
T
p
i
)
p
i
−
λ
q
j
)
\begin{align} & p_i = p_i + \alpha((m_{ij}-q_j^Tp_i)q_j - \lambda p_i)\\[2ex] & q_j =q_j + \alpha((m_{ij}-q_j^Tp_i)p_i - \lambda q_j) \end{align}
pi=pi+α((mij−qjTpi)qj−λpi)qj=qj+α((mij−qjTpi)pi−λqj)
通过迭代我们最终可以得到
P
P
P和
Q
Q
Q,进而用于推荐。
5.3 BiasSVD算法
BiasSVD算法是在FunkSVD算法的基础上考虑了用户和商品的偏好。用户有自己的偏好(Bias),比如乐观的用户打分偏高;商品也有自己的偏好(Bias),比如质量好的商品,打分偏高;BiasSVD算法将与个性化无关的部分,设置为偏好(Bias)部分。
假设评分系统平均分为
μ
\mu
μ,第i个用户的用户偏置项为
b
i
b_i
bi ,而第
j
j
j 个物品的物品偏置项为
b
j
b_j
bj,则加入了偏置项以后的优化目标函数
J
(
p
,
q
)
J(p,q)
J(p,q) 如下:
a
r
g
m
i
n
⏟
p
i
,
q
j
∑
i
,
j
(
m
i
j
−
μ
−
b
i
−
b
j
−
q
j
T
p
i
)
2
+
λ
(
∣
∣
p
i
∣
∣
2
2
+
∣
∣
q
j
∣
∣
2
2
+
∣
∣
b
i
∣
∣
2
2
+
∣
∣
b
j
∣
∣
2
2
)
\underbrace{arg\;min}_{p_i,q_j}\;\sum\limits_{i,j}(m_{ij}-\mu-b_i-b_j-q_j^Tp_i)^2 + \lambda(||p_i||_2^2 + ||q_j||_2^2 + ||b_i||_2^2 + ||b_j||_2^2)
pi,qj
argmini,j∑(mij−μ−bi−bj−qjTpi)2+λ(∣∣pi∣∣22+∣∣qj∣∣22+∣∣bi∣∣22+∣∣bj∣∣22)
优化目标也可以采用梯度下降法求解。
b
i
,
b
j
b_i,b_j
bi,bj一般可以初始设置为
0
0
0,然后参与迭代。
b
i
,
b
j
b_i,b_j
bi,bj迭代方法如下:
b
i
=
b
i
+
α
(
m
i
j
−
μ
−
b
i
−
b
j
−
q
j
T
p
i
−
λ
b
i
)
b
j
=
b
j
+
α
(
m
i
j
−
μ
−
b
i
−
b
j
−
q
j
T
p
i
−
λ
b
j
)
\begin{align} & b_i = b_i + \alpha(m_{ij}-\mu-b_i-b_j-q_j^Tp_i -\lambda b_i)\\[2ex] & b_j = b_j + \alpha(m_{ij}-\mu-b_i-b_j-q_j^Tp_i -\lambda b_j) \end{align}
bi=bi+α(mij−μ−bi−bj−qjTpi−λbi)bj=bj+α(mij−μ−bi−bj−qjTpi−λbj)
通过迭代我们最终可以得到
P
P
P和
Q
Q
Q,进而用于推荐。
5.4 SVD++算法
SVD++算法在BiasSVD算法上进一步做了增强,这里它增加考虑用户的隐式反馈。
对于某一个用户
i
i
i,它提供了隐式反馈的物品集合定义为
N
(
i
)
N(i)
N(i), 这个用户对某个物品
j
j
j对应的隐式反馈修正的评分值为
c
i
j
c_{ij}
cij, 那么该用户所有的评分修正值为
∑
s
∈
N
(
i
)
c
i
s
\sum\limits_{s \in N(i)}c_{is}
s∈N(i)∑cis。一般我们将它表示为用
q
s
T
y
i
q_s^Ty_i
qsTyi形式,则加入了隐式反馈项以后的优化目标函数
J
(
p
,
q
)
J(p,q)
J(p,q)如下:
a
r
g
m
i
n
⏟
p
i
,
q
j
∑
i
,
j
(
m
i
j
−
μ
−
b
i
−
b
j
−
q
j
T
p
i
−
q
j
T
∣
N
(
i
)
∣
−
1
/
2
∑
s
∈
N
(
i
)
q
s
)
2
+
λ
(
∣
∣
p
i
∣
∣
2
2
+
∣
∣
q
j
∣
∣
2
2
+
∣
∣
b
i
∣
∣
2
2
+
∣
∣
b
j
∣
∣
2
2
+
∑
s
∈
N
(
i
)
∣
∣
q
s
∣
∣
2
2
)
\underbrace{arg\;min}_{p_i,q_j}\;\sum\limits_{i,j}(m_{ij}-\mu-b_i-b_j-q_j^Tp_i - q_j^T|N(i)|^{-1/2}\sum\limits_{s \in N(i)}q_{s})^2+ \lambda(||p_i||_2^2 + ||q_j||_2^2 + ||b_i||_2^2 + ||b_j||_2^2 + \sum\limits_{s \in N(i)}||q_{s}||_2^2)
pi,qj
argmini,j∑(mij−μ−bi−bj−qjTpi−qjT∣N(i)∣−1/2s∈N(i)∑qs)2+λ(∣∣pi∣∣22+∣∣qj∣∣22+∣∣bi∣∣22+∣∣bj∣∣22+s∈N(i)∑∣∣qs∣∣22)
其中,引入
∣
N
(
i
)
∣
−
1
/
2
|N(i)|^{-1/2}
∣N(i)∣−1/2是为了消除不同
∣
N
(
i
)
∣
|N(i)|
∣N(i)∣个数引起的差异。式子够长的,不过需要考虑用户的隐式反馈时,使用SVD++还是不错的选择。
6.矩阵分解算法的优缺点
优点:
-
泛化能力强。一定程度上解决了数据稀疏的问题。
-
空间复杂度低。 仅仅存储用户和物品隐向量。空间复杂度有 n 2 n^2 n2 降低到 ( m + n ) ∗ k (m+n)*k (m+n)∗k
-
更好的扩展性和灵活性。 矩阵分解的最终产物是用户和物品隐向量, 这个深度学习的embedding思想不谋而合, 因此矩阵分解的结果非常便于与其他特征进行组合和拼接, 并可以与深度学习无缝结合。
缺点:
- 矩阵分解算法依然是只用到了评分矩阵, 没有考虑到用户特征, 物品特征和上下文特征, 这使得矩阵分解丧失了利用很多有效信息的机会。
- 在缺乏用户历史行为的时候, 无法进行有效的推荐。
本文仅仅做个人学习记录所用,不作为商业用途,谢谢理解。
参考:
1.https://www.cnblogs.com/pinard/p/6351319.html
2.https://alice1214.github.io/%E6%8E%A8%E8%8D%90%E7%AE%97%E6%B3%95/2020/07/08/%E6%8E%A8%E8%8D%90%E7%AE%97%E6%B3%95%E5%AD%A6%E4%B9%A0-%E4%BA%94-%E7%9F%A9%E9%98%B5%E5%88%86%E8%A7%A3/