为什么query和key相乘就能得到学生和教师的相似度呢?它的内部原理是什么?
在注意力机制中,query 和 key 相乘得到的相似度其实是通过计算两个向量之间的点积来实现的。具体而言,我们将 query 和 key 进行点积运算后【这里的点积运算可以看作是一种度量相似度的方法,它可以从数学上衡量两个向量之间的相关性。当两个向量越相似时,它们的点积结果也会越大。】,再除以一个缩小因子 self.soft(一般取值为特征维度的平方根),就可以得到对应向量之间的余弦相似度,从而得到相似度分数。
相似度计算的方法有什么?
除了点积运算,还有一种常用的度量向量相似度的方法叫做余弦相似度。
1、点积:

2、余弦相似度:

对于注意力机制来说,点积或者余弦相似度通常是在计算查询向量和键向量之间的相似度时使用的。例如,在上面的公式中,a 可以表示查询向量(即学生网络输出的特征向量),b 可以表示键向量(即教师网络输出的特征向量)。
注意:对于注意力机制来说,除了上述公式中的计算方式外,还需要在计算余弦相似度时进行归一化,以保证输出的权重矩阵符合概率分布的定义。常用的归一化方法包括 softmax 函数和 sigmoid 函数等。
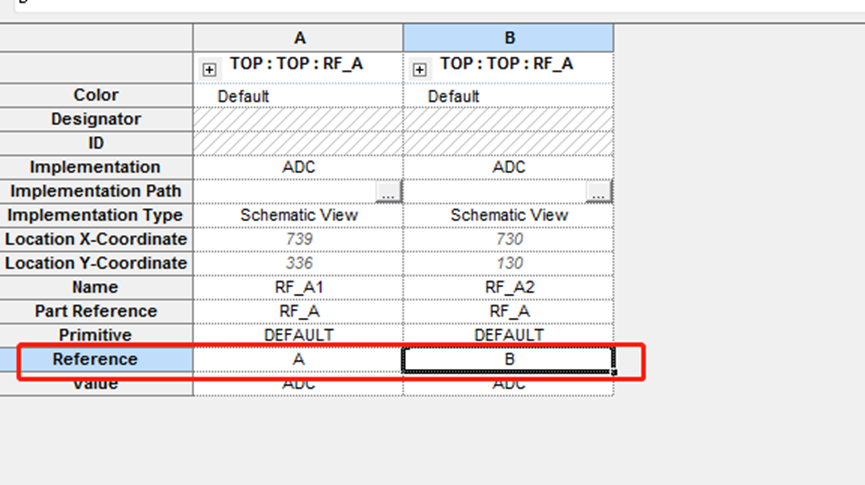
## 4、computer Q and K attention weight: batch_size X No. stu feature X No.tea feature
energy = torch.bmm(proj_query, proj_key)/self.soft
attention = F.softmax(energy, dim = -1)余弦相似度/卷积核之间的成对余弦相似性_相似度 卷积_马鹏森的博客-CSDN博客