C++设计原则
高内聚低耦合
内聚就是一个模块内各个元素彼此结合的紧密程度,高内聚就是一个模块内各个元素彼此结合的紧密程度高。
所谓高内聚是指一个软件模块是由相关性很强的代码组成,只负责一项任务,也就是常说的单一责任原则。
耦合:一个软件结构内不同模块之间互连程度的度量(耦合性也叫块间联系。指软件系统结构中各模块间相互联系紧密程度的一种度量。模块之间联系越紧密,其耦合性就越强,模块的独立性则越差,模块间耦合的高低取决于模块间接口的复杂性,调用的方式以及传递的信息。)
常见方法:把要做的事情抽象成不同的虚类,然后分别继成实现。
比如:
Req:设计一个程序,从文件中读取数据,并处理该数据,然后打印输出到文件中。
a.没有设计的解决方案
设计一个类CDataProcessor来完成该任务:
- 获取数据
- 处理数据
- 打印结果
该方案的缺点:
1、CDataProcessor有很多职责,不能在其他程序中重用该算法,
2、高耦合,处理过程和数据提供方和输出方高耦合。
b.有设计的解决方案
为了提高内聚程度,需要为每个职责定义不同的类,需要定义三个类,如下:
· CFileProvider: 用于从一个文件获取数据
· CDataProcessing: 处理数据,这个类可以用其他的类来完成数据处理。
· CResultReporting: 将结果输出到文件
这样每个类都有它自己的职责,这样做主要的好处有:
-
各类容易理解。
-
容易维护。
-
其他程序更好复用。
c. 低耦合
如果数据不是来自一个文件而是数据库,会发生什么样的情况?上面的设计对FileProvider存在高耦合。
为了解决这个问题,需要一个接口可以从任何地方获取数据,故需要定义一个接口类IDataProvider。
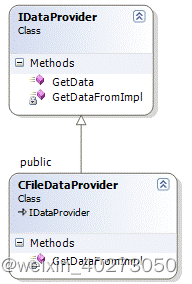
CDataProcessing 和 CReportResult两个类也可以按照上面的方法设计。
重构之后类之间的关系如下:
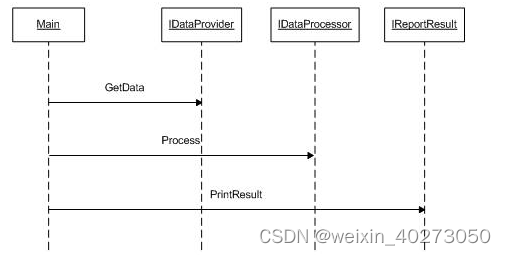
从上图可以看出,IDataProvider, IDataProcessing和IReportResult的创建都是main函数。更好的方法是把它的创建放在工厂类中,把这些类的实例化逻辑隔离开来。
控制器controller
上面各个类配合协调是在main函数实施的,更好的方法是在控制器中协调配合所有类,方便在其他应用程序中使用。
使用模板,该控制器可以这样实例化:
CController<CFileProvider,CDataProcessor,CConsoleReport>
SOLID原则
https://blog.csdn.net/qq_42672770/article/details/117650871
solid原则包括以下五个(详见上面的博客链接):
1、单一职责原则(SRP):表明一个类有且只有一个职责。一个类就像容器一样,它能添加任意数量的属性、方法等。
2、开放封闭原则(OCP):一个类应该对扩展开放,对修改关闭。这意味一旦创建了一个类并且应用程序的其他部分开始使用它,就不应该修改它。
3、里氏替换原则(LSP):派生的子类应该是可替换基类的,也就是说任何基类可以出现的地方,子类一定可以出现。值得注意的是,当通过继承实现多态行为时,如果派生类没有遵守LSP,可能会让系统引发异常。
4、接口隔离原则(ISP):表明类不应该被迫依赖他们不使用的方法,也就是说一个接口应该拥有尽可能少的行为,它是精简的,也是单一的。
5、依赖倒置原则(DIP):表明高层模块不应该依赖低层模块,相反,他们应该依赖抽象类或者接口。这意味着不应该在高层模块中使用具体的低层模块。
迪米特法则
通俗的讲就是:只和直接朋友交谈,不和陌生人说话。目的当然是降低偶合,提高独立性,修改仅影响直接相关的,降低耦合关系。
所谓的直接朋友指的是:当前对象自身、当前对象的成员对象、当前对象自己创建的对象、当前对象的方法中传入的参数等,这些对象同当前对象存在关联、聚合或组合关系,可以直接访问这些对象。
所谓的交谈指的是:可以访问这些朋友的成员。
如下代码就违背该原则, A 可以访问 b的方法,因为b是A的成员对象,但不应该访问 b的方法返回对象中的成员或者方法,带来的不好之处是 C中 value等修改,会影响到 A的修改。
class A {
public:
int GetxxValue() {
return b->GetC()->value;
};
B* b;
}
class B {
puulic:
C* GetC();
C* c;
}
class C {
public:
int value;
}
重构为 B 中提供新的方法直接返回C的value,A中调用B的这个方法, C中的实现对于A隐藏。
“Tell, Don’t ask”原则
http://blog.csdn.net/zhongweijian/article/details/7825147
命令,不要去询问(Tell, Don’t Ask)”原则。这个原则讲的是,一个对象应该命令其它对象该做什么,而不是去查询其它对象的状态来决定做什么(查询其它对象的状态来决定做什么也被称作‘功能嫉妒(Feature Envy)’)。
这篇文章里有个很生动的例子:
if (person.getAddress().getCountry() == “Australia”) {
这违反了得墨忒耳定律,因为这个调用者跟Person过于亲密。它知道Person里有一个Address,而Address里还有一个country。它实际上应该写成这样:
if (person.livesIn(“Australia”)) {
组合 / 聚合复用原则
组合/ 聚合复用原则(Composition/Aggregation Reuse Principle )经常又叫合成复用原则(Composition Reuse Principle 或 CRP )。综是在一个新的对象里使用已有的对象,使之成为新对象的一部分,新的对象通过向这些对象的委派达到复用已有功能的目的。
该原则另一个简短的表述:尽量使用组合 / 聚合,不要使用继承。
只有当以下的条件全部被满足时,才应当使用继承关系,继承关系建议不要超过3层。
(1). 子类是超类的一个特殊种类,而不是超类的一个角色,也就是区分“Has-A”和“Is-A”.只有“Is-A”关系才符合继承关系,“Has-A”关系应当使用聚合来描述。
推荐使用场景:针对子类,如果父类的所有已实现的方法均适用于子类,并且父类需要抽象出抽象方法来供子类实现,这样的关系适用于继承。
(2) .永远不会出现需要将子类换成另外一个类的子类的情况。如果不能肯定将来是否会变成另外一个子类的话,就不要使用继承。
(3) .子类具有扩展超类的责任,而不是具有置换掉或注销掉超类的责任。如果一个子类需要大量的置换掉超类的行为,那么这个类就不应该是这个超类的子类。
扩展行为推荐子类实现父类的抽象方法(虚类),这样含义明确,父类不负责抽象方法的实现,父类会保持稳定;将不稳定部分下放到子类实现,当有多个子类时,每个子类只实现自己那部分方法,这样子类之间相互不影响,子类的实现就属于高内聚,子类只关注自己的实现,子类之间没有直接的依赖关系。
基础理论
三法则和五法则
三之法则(Rule of three): 若某个类需要用户定义的析构函数、拷贝构造函或拷贝赋值操作符,则它基本同时需要这三个函数。
五之法则(Rule of five): 如果定义了析构函数、拷贝构造函数或拷贝赋值操作符,会阻止移动构造函数和移动赋值操作符的隐式定义,所以任何想要移动语义的类必须声明全部五个特殊成员函数。
零之法则(Rule of zero): 如果类不需要专门处理资源的所有权,那么就不应该有自定义的析构函数、拷贝/移动构造函数或拷贝/移动赋值操作符。
class Foo {
public:
Foo(const char* buffer, size_t size) { Init(buffer, size); }
Foo(const Foo& other) { Init(other.buf, other.size); }
Foo& operator=(const Foo& other)
{
Foo tmp(other);
Swap(tmp);
return *this;
}
Foo(Foo&& other) noexcept : buf(std::move(other.buf)), size(std::move(other.size))
{
other.buf = nullptr;
other.size = 0;
}
Foo& operator=(Foo&& other) noexcept
{
Foo tmp(std::move(other));
Swap(tmp);
return *this;
}
~Foo() { delete[] buf; }
void Swap(Foo& other) noexcept
{
using std::swap;
swap(buf, other.buf);
swap(size, other.size);
}
private:
void Init(const char* buffer, size_t size)
{
this->buf = new char[size];
memcpy(this->buf, buffer, size);
this->size = size;
}
char* buf;
size_t size;
};
让对象支持移动
- 对象应该有分开的拷贝构造和移动构造函数
- 除非你只打算支持移动,不支持拷贝----如unique_ptr
- 对象应该有 swap 成员函数,支持和另外一个对象快速交换成员;
- 对象的命名空间下应当有自由的swap函数,调用成员函数swap来实现交换;
- 实现通用的 operator=
- 对于非常追求性能的场合,可能需要单独实现拷贝赋值和移动赋值运算符
- 移动函数和swap函数不应抛异常,并应标记为 noexcept
为什么移动操作不应该抛异常?
https://blog.csdn.net/craftsman1970/article/details/104758487
抛出异常的移动操作会破坏大多数人的符合逻辑的推测。不会抛出异常的移动可以被标准库和C++语言更加高效地使用。
另外,对于自定义的移动构造和移动拷贝函数,必须要加上noexcept关键字。否则系统可能不会调用该移动函数。
C++ 中可以用左值引用或者右值引用保存数据吗?
一般不行,除非能确定被引用的对象是长期存在的。
(1) 如果是左值引用可以视具体情况而定,左值引用。
(2) 如果是右值引用,由于被引用的对象是右值,它一般都是"临时对象",更不能长期保存。
class A {
......
}
class B {
public:
A& a; // 不推荐,除非能确定别名a对应的左值生命周期大于本类的生命周期
A&& aa; // 不推荐,想不出有什么场景可以适用,经测试会导致编译不过
}
引用折叠
对于一个给定类型X:
- X& &、X& && 和 X&& & 都折叠成 X&
- 类型 X&& &&折叠成 X&&
什么情况下,T&&有可能成为左值引用?
当T是模板参数时,T&&有可能成为左值引用,这是因为当T被推导为一个非引用类型时,T&&就会被推导为一个左值引用。例如:
template<typename T>
void foo(T&& t) {
// ...
}
int main() {
int x = 0;
foo(x); // T被推导为int&,因此T&&被推导为int&
}
在这个例子中,当我们调用foo(x)时,T被推导为int&,因此T&&被推导为int& &&,即左值引用。这种情况下,我们可以使用std::forward(t)来保持参数的值类别。
上面这里例子也可以看出“T&& ”即可以接收左值类型的参数也可以接收右值类型的参数。
int& a; 和 int&& a中的a都是左值
class Obj;
Obj getObj(int n);
void foo(Obj& obj); // (1)
void foo(Obj&& obj); // (2)
int main()
{
Obj&& r = getObj(42);
foo(r);
}
标为 (1) 的 foo 将会被调用。因为右值引用的变量仍然是一个左值,会匹配重载 (1)。
函数能返回右值引用类型的参数吗?
虽然函数直接返回一个对象可以匹配相应的右值引用。但通常不应该使用 T&& 这样的返回值。返回为引用几乎永远是一种错误(这是一种未定义行为!!!)。
生命期延长规则
左值引用和右值引用会延长被引用的变量的生命周期,最终同引用变量的生命周期一致。
std::swap
std::swap是C++ STL中的一个函数模板,用于交换两个变量的值。
template< class T >
void swap( T& a, T& b );
其中,a和b是要交换的两个变量。这个函数模板可以用于任何类型的变量,包括内置类型和自定义类型。
#include <iostream>
#include <algorithm>
int main()
{
int a = 1;
int b = 2;
std::cout << "Before swap: a = " << a << ", b = " << b << std::endl;
std::swap(a, b);
std::cout << "After swap: a = " << a << ", b = " << b << std::endl;
return 0;
}
使用std::swap的优点:
- 通用性:std::swap是一个函数模板,可以用于任何类型的变量,包括内置类型和自定义类型。
- 高效性:**对于内置类型,std::swap可以直接交换它们的值,而不需要进行复制操作。**对于自定义类型,可以通过特化std::swap来提高效率。
- 可读性:使用std::swap可以使代码更加简洁易懂。
C++实战
C++17 编译
测试自己的小程序时,如果用到了C++17的语法,编译时要加上"-std=c++17", 如:
g++ main.cpp -std=c++17
boost正则匹配
参考:
基础:https://blog.csdn.net/u012198575/article/details/83624251
详尽:https://blog.csdn.net/ponew/article/details/80348352
regex_match()函数用来判断是否匹配,regex_match要求正则express与串全部匹配时才返回true,否则返回false;
regex_search()函数来搜索字符串中的匹配项,并使用smatch对象来存储匹配结果。regex_search不要求正则express与串完全匹配,但串中内容可以多不能少,即字符串中必须要有定义的正则express才会返回true。
匹配时默认是贪婪模式,可以添加’?‘选择尽可能短的匹配,如’.?';
(?:pattern):匹配pattern但不获取匹配结果;
将上面两个结合起来:(?:.?)这个表达式表示不储存(捕获)结果,并且不贪婪。
表示可以匹配0次或者多次,如果希望至少匹配1次,则不要用,例如用(.?)替换(.*?);
注意:(.)是贪婪匹配,(.?)是非贪婪匹配,比如对于字符串"aaaaa key bbbbbb key":
“(.)key" 捕获的是 "aaaaa key bbbbbb ",能要的我全要,只给你留最后一个。
"(.?)key” 捕获的是"aaaaa ",我不贪婪,只要捕获第一个能满足正则表达式的字符串我就返回。
#include <iostream>
#include <string>
#include <boost/regex.hpp>
using namespace std;
using namespace boost;
int main()
{
string str = "2023-03-28 14:37:52.891 Sessiona,adfadfadf";
regex reg("(\\d{4}-\\d{2}-\\d{2})\\s(\\d{2}:\\d{2}:\\d{2}\\.\\d{3})");
smatch m;
// 注意:只有正则表达式全部满足才会返回true,即定义的格式字符串中必须要有
if (regex_search(str, m, reg))
{
if {m[1].matched) {
cout << "日期内容:" << m[1] << endl;
}
if {m[2].matched) {
cout << "时间内容:" << m[2] << endl;
}
}
string str2 = "2023-03-28 14:37:52.891 Session \"My-Session-Name\": xxxxxxxxxx: Client host name: \"\", Client IP address: \"10.2.2.100\", Client port number: xxxx";
regex reg2("Session\\s\"(.*?)\":.*?Client IP address:\\s\"(.*?)\"");
smatch match2;
if (regex_search(str2, match2, reg2))
{
cout << "session-name:" << match2[1] << endl;
cout << "targetIP:" << match2[2] << endl;
}
return 0;
}
分析reg:
(1) ()表示捕获,要输出到外面的内容;
(2) ‘\d’即为\d,表示匹配数字;
(3) ‘\.’即为‘.’,表示匹配’.‘;(如果没有‘\’,只有单独的‘.’则表示匹配任意字符)
(4) {4}表示长度必须为4;
(5) ‘\s’即为\s,表示匹配空格;
(6) 正则表达式Session\s"(.*?)“:.Client IP address:\s"(.?)”,它匹配Session后面的任何内容,然后用‘()’捕获,再继续匹配直到找到’Client IP address’,然后继续用‘()’捕获,获取IP。
另外一个例子,如何匹配"sec_20230413_0737.log"中的日期和时间?
std::string fileName1 = "sec_20230413_0737.log";
boost::regex reg(".*?(\\d{1,8})_(\\d{1,6})\\.log");
boost::smatch m1;
regex_search(fileName1, m1, reg);
注意最前面的.*?不能改成.*,否则可能会因为贪婪只能匹配到最后一个数字(期望是能匹配1-8个数字)。
std::map—key和value分别为左值和右值时的插入性能测试
背景:为了解STL中右值版本比左值版本的插入性能对比,因为理论上左值版本插入时要多一次拷贝构造和对象析构,故性能会下降。(gcc版本为10.4.0,使用较新的C++17规则)
当map类型为std::map<std::vector<std::string>, std::string> map时,分别用左值和右值测试10000、100000、100000次添加数据,测试代码如下:
std::cout << "Test for \"std::map<std::vector<std::string>, std::string> map\" begin:" << std::endl;
std::vector<int> IterTimes = {10000, 100000, 1000000};
for (size_t t = 0; t < IterTimes.size(); t++) {
int times = IterTimes[t];
std::chrono::nanoseconds leftDura, rightDura;
{
std::map<std::vector<std::string>, std::string> mp;
auto start = std::chrono::steady_clock::now();
for (int i = 0; i < times; i++) {
auto key = std::vector<std::string>{{std::to_string(i), "testNamekey"}};
auto value = std::to_string(i) + "testValue";
mp[key] = value;
}
leftDura = std::chrono::nanoseconds(std::chrono::steady_clock::now() - start);
std::cout << "Test left copy for std::map: Duration Time = " << leftDura.count() << " ns" << std::endl;
}
{
std::map<std::vector<std::string>, std::string> mp;
auto start = std::chrono::steady_clock::now();
for (int i = 0; i < times; i++) {
mp[std::vector<std::string>{{std::to_string(i), "testNamekey"}}] = std::to_string(i) + "testValue";
}
rightDura = std::chrono::nanoseconds(std::chrono::steady_clock::now() - start);
std::cout << "Test right copy for std::map : Duration Time = " << rightDura.count() << " ns" << std::endl;
}
std::cout << "Iter Times = " << times << ", R-copy is (" << (leftDura.count() - rightDura.count()) * 1.0 / rightDura.count() << "%) faster than L-copy.\n" << std::endl;
}
执行结果:
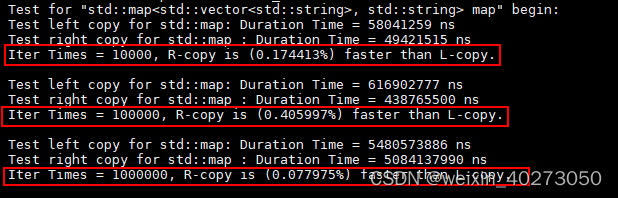
可以看出右值版本要比左值版本快7%-40%,至于为什么迭代次数到达1000000次时,反而变少了,猜测是因为std::map的红黑树构造太耗时了。
当map类型换成std::map<std::string, std::string> map时,类似的代码执行结果如下:
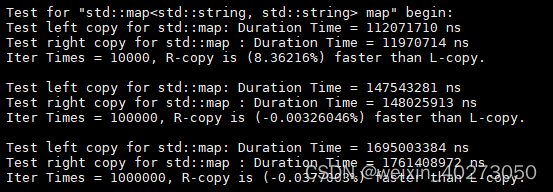
神奇地发现右值版本居然没有比左值版本快,推测是因为C++11后,对std::string类型的字符串的拷贝做了优化,性能开销几乎可以忽略不计。进而推测第一个例子中左值拷贝的开销大头是来自于key的类型std::vector<std::string>的拷贝析构。
总结std::map的使用:
(1) 当key或者value的拷贝构造较复杂时,使用右值插入会比左值插入有较大的性能提升!!!
(2) 反之,当key或者value的拷贝构造开销很低时,两者性能相当。