导读
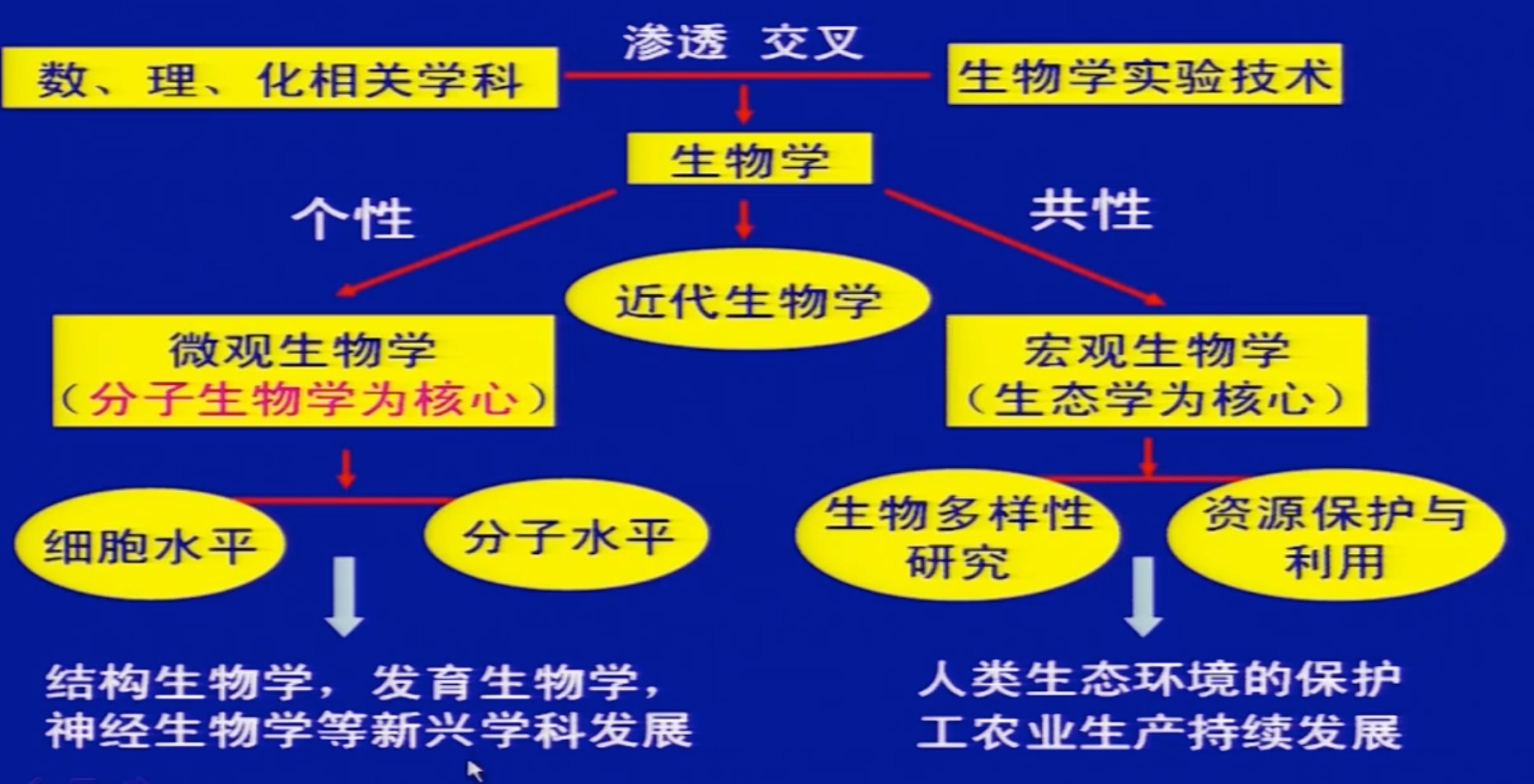
为了发挥清华大学多学科优势,搭建跨学科交叉融合平台,创新跨学科交叉培养模式,培养具有大数据思维和应用创新的“π”型人才,由清华大学研究生院、清华大学大数据研究中心及相关院系共同设计组织的“清华大学大数据能力提升项目”开始实施并深受校内师生的认可。项目通过整合建设课程模块,形成了大数据思维与技能、跨界学习、实操应用相结合的大数据课程体系和线上线下混合式教学模式,显著提升了学生大数据分析能力和创新应用能力。
回首2022年,清华大学大数据能力提升项目取得了丰硕的成果,同学们将课程中学到的数据思维和技能成功地应用在本专业的学习和科研中,在看到数据科学魅力的同时,也将自己打造成为了交叉复合型的创新型人才。下面让我们通过来自8个院系的10位同学代表一起领略他们的风采吧!
基于小波分析的时间序列事件检测方法
随着信息技术的快速发展,人们发现问题、描述问题、解决问题的思路较以往有了很大区别,基于信息化、智能化的方法逐渐取代传统的基于经验和人工的方法,成为人们对现实系统进行观测、分析和优化的主要手段。工业互联网背景下,传感器和传感技术得到了广泛的应用,可以说已经成为连通现实世界和赛博世界的桥梁。在过程挖掘领域,过程模型是通过事件挖掘而来的,而传统的事件日志依赖于人工标注,无法适应于工业场景规模大、来源广、时间长、维度高、系统复杂的特点。因此,需要从时间序列数据出发,通过事件检测的方法,结合过程挖掘的知识,将过程挖掘的基础从人工标注的事件日志扩展为时间序列数据,从而对系统的状态和运行情况进行建模和优化,进而发现和解决系统中存在的问题。
时间序列(timeseries)是指按时间顺序获得的一系列有序观测值,是对物理世界的待观测系统进行描述和分析的重要手段和表现形式,在物联网、计量经济学、生物医学分析、气象研究及恶劣天气预测等领域都有着广泛的应用。随着物联网(IoT)技术的发展和传感器监控系统的应用,日志的规模和数据的维度都在不断增长,因此使用事件的概念对时间序列进行挖掘和抽象具有重要意义。事件(event)是过程挖掘中的一个重要概念,记录了一个活动的基本属性及其发生的时间戳。对事件日志的分析挖掘可以对一个业务过程进行发现,也可以将事件日志与已知的过程模型进行比较来检验其合规性,或者是利用实际业务过程中产生的事件日志来扩展或改进现有的过程模型。
从时间序列中检测事件的方法有很多,本工作基于现有相关成果,使用两次抽象的方法,完成时间序列数据事件发现的工作。第一阶段抽象过程称为状态划分。按照一定的规则将时间序列划分为不同的区间,相同标签区间内的数据具有一种简单且相似的模式。将这种模式称为数据的一个状态(state),将只包含数据的一种状态的时间区间称为状态区间。第二阶段抽象过程称为事件检测。划分状态区间后,将状态区间按照一定模式组装起来,获得一个更复杂的数据的模式,这种模式称为时间模式,频繁的时间模式被认为是一个可能的事件。
首先,在状态划分阶段,预先使用平滑技术对原始数据进行噪声的消除,然后再根据平滑后的数据提取出形状特征。例如,计算平滑信号的一阶导数和零点,可以将数据划分为递增和递减集合。进一步计算函数的二阶导数,结合一阶和二阶导数零点,可以将数据划分为凸增加、凸减少、凹增加、凹减少四个集合。根据上述方法,能够计算一个序列的标签,进而将原始的时间序列数据划分为不同的状态区间,并为其赋予不同的标签,由此就完成了对时间序列的第一级抽象。下面给出其形式化定义:
定义1(状态区间序列):给定一个非空区间序列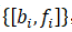 ,每个区间包含一个标签
,每个区间包含一个标签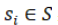 ,三元组
,三元组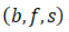 称为状态区间。如果满足
称为状态区间。如果满足 ,有
,有 ,则称
,则称 是上的一个状态区间序列。
是上的一个状态区间序列。
之后,进入事件检测阶段。定义状态区间序列后,进一步考虑区间之间的关系,将两个区间之间的时间关系划分为13种,如表所示:
区间A与B位置关系及其符号表示

给定任意的n个状态区间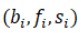 ,其中
,其中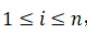 ,这n个区间的相对位置关系可以由一个
,这n个区间的相对位置关系可以由一个 的矩阵R来描述。矩阵R的第i行第j列的值
的矩阵R来描述。矩阵R的第i行第j列的值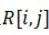 描述第i个区间和第j个区间的位置关系,取值为上述的13种之一。
描述第i个区间和第j个区间的位置关系,取值为上述的13种之一。
令 表示状态区间的集合。
表示状态区间的集合。 表示
表示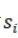 在区间
在区间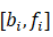 中成立,则该三元组描述了一个变量在一段时间内的状态,这个状态被视为对应区间的标签。由此,给出时间模式的定义:
中成立,则该三元组描述了一个变量在一段时间内的状态,这个状态被视为对应区间的标签。由此,给出时间模式的定义:
定义2(时间模式):称二元组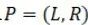 为一个
为一个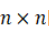 的时间模式(temporalpattern),其中
的时间模式(temporalpattern),其中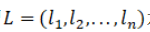 是一个标签序列,
是一个标签序列,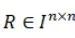 是n个区间之间相对位置关系的描述矩阵。
是n个区间之间相对位置关系的描述矩阵。
根据上述定义,时间模式可以是任意几个状态区间的位置组合。对于一个大小为n的状态集S,可能存在的时间模式种类为n的指数级别。只需考虑那些出现频率更高的时间模式。所以,需要检测给定的时间模式在状态区间序列中的出现频率。

算法1给出了子关系检测的方法。对于两个模式P和Q,该算法可以检测出P是否是Q的子模式。其中,子模式的定义为,若对于模式Q,通过删除Q中的一些状态s及其位置关系,可以得到模式P,则P是Q的子模式。
通过此算法,可以使用一个滑动窗口,检测待测模式P是否位于该窗口中。沿着时间轴滑动此窗口,即可计算出模式P在全区间序列中出现的次数,从而获得最频繁出现的模式。
对于任意的k
 频繁模式,其包含的(k-1)阶子模式也应该是频繁的。因此,从k=0开始计算,每次只保留频繁的模式,向上即可递推出k
频繁模式,其包含的(k-1)阶子模式也应该是频繁的。因此,从k=0开始计算,每次只保留频繁的模式,向上即可递推出k 阶频繁模式。改进后的算法如算法2所示。
阶频繁模式。改进后的算法如算法2所示。
基础的演绎导出方法存在一些问题:平滑不仅会消除噪声,也会在一定程度上消除时间序列的原始特征。另一方面,即使不考虑随着噪声被消除的高频信号特征,低频信号的极值点位置也会随着平滑过程发生一定的偏移。
一个典型的时间序列往往受到各种来源的信号的分量的影响,每段信号都有可能是一些在时域和频域上有着不同的行为特征的组合。在这种复杂情况下,一般的平滑方法很难选择一个合适的核函数和带宽参数,也无法将组合在一起的不同频率的信号分量拆分开来。对于这种情况,本工作应用了基于小波分析的多尺度分析方法,以分别在不同的尺度中对信号进行分析,将存在于不同频域中的信号区分开来。
小波分析(waveletanalysis)是一种信号分析的技术,往往被用于描述信号中的局部现象。多尺度分析方法使用一列近似函数的极限来逼近原函数。每个近似函数都是原函数的一个平滑逼近,且越来越接近原函数。这些函数是原函数在不同尺度上的近似,也就反应了不同尺度上的特征。
此外,频繁时间模式发现方法的复杂度可以通过剪枝策略进一步降低。对于两个k-1维子模式P和Q,其状态按照在模式中出现的先后顺序排列后,前k-2维的状态完全相同,第k-1维状态不同,这两个子模式中的k个状态组成了一个k候选模式。算法3给出了上述过程的伪代码描述。
为了评估算法效果,使用Savitzky-Golay平滑方法作为基线算法进行对照,使用了模拟数据集、UCR数据集中的“ECG200”数据、以及变电站在2020年6月至2020年12月时间段站内机组各传感器记录的时间序列数据进行实验。结果显示,本工作提出的方法在识别准确率、覆盖率上均明显提升。在“ECG200”数据上的状态划分结果如图所示:

状态划分结果(左图和右图分别使用:基线方法、多尺度分析方法)
时间序列数据的事件识别是过程挖掘的重要环节之一。从时间序列出发,在已有工作基础上,通过数据预处理、状态划分和事件识别等环节,能够从多维时间序列中提取出有效的事件信息,为工业互联网背景下的过程挖掘工作提供支持。本文在已有的事件提取算法基础上,主要从两个方面进行了优化和改进:第一,引入小波分析的方法,对原始信号在不同频域上进行分解,在多个尺度上划分状态,消除噪声信号的同时尽可能多的保留了原始的信号,得到了优于函数近似和平滑算法的结果。第二,在频繁模式发现阶段,通过数据结构的优化和剪枝策略,在不损失精度的同时提升了事件识别的效率。最后,通过模拟数据实验和真实数据集的实验,验证了算法的有效性和执行效率。
上述成果已整理成论文《基于小波分析的时间序列事件检测方法》,被第十一届中国业务过程管理大会(CBPM2021)录用,并推荐发表于核心期刊《计算机集成制造系统》。
编辑:文婧
校对:林亦霖