目录
- 8.1 Attention 的结构
- 8.1.1 seq2seq 存在的问题
- 8.1.2 编码器的改进
- 8.1.3 解码器的改进 ①
- 8.1.4 解码器的改进 ②
- 8.1.5 解码器的改进 ③
- 8.2 带 Attention 的 seq2seq 的实现
- 8.2.1 编码器的实现
- 8.2.2 解码器的实现
- 8.2.3 seq2seq 的实现
- 8.3 Attention 的评价
- 8.3.1 日期格式转换问题
- 8.3.2 带 Attention 的 seq2seq 的学习
- 8.3.3 Attention 的可视化
- 8.4 关于 Attention 的其他话题
- 8.4.1 双向 RNN
- 8.4.2 Attention 层的使用方法
- 8.4.3 seq2seq 的深层化和 skip connection
- 8.5 Attention 的应用
- 8.5.1 GNMT
- 8.5.2 Transformer
- 8.5.3 NTM
8.1 Attention 的结构
这里将介绍进一步强化 seq2seq 的注意力机制(attention mechanism,简称 Attention)。
基于 Attention 机制,seq2seq 可以像我们人类一样,将 “注意力” 集中在必要的信息上。此外,使用 Attention 可以解决当前 seq2seq 面临的问题。
上一章我们已经对 seq2seq 进行了改进,但那些只能算是 “小改进”。下面将要说明的 Attention 技术才是解决 seq2seq 的问题的 “大改进”。
8.1.1 seq2seq 存在的问题
seq2seq 中使用编码器对时序数据进行编码,然后将编码信息传递给解码器。此时,编码器的输出是固定长度的向量。实际上,这个 “固定长度” 存在很大问题。
因为固定长度的向量意味着,无论输入语句的长度如何(无论多长),都会被转换为长度相同的向量。以上一章的翻译为例,如图 8-1 所示,不管输入的文本如何,都需要将其塞入一个固定长度的向量中。

无论多长的文本,当前的编码器都会将其转换为固定长度的向量。就像把一大堆西装塞入衣柜里一样,编码器强行把信息塞入固定长度的向量中。 但是,这样做早晚会遇到瓶颈。就像最终西服会从衣柜中掉出来一样,有用的信息也会从向量中溢出。
下面来改进 seq2seq。首先改进编码器,然后再改进解码器。
8.1.2 编码器的改进
到目前为止,我们都只将 LSTM 层的最后的隐藏状态传递给解码器,但是编码器的输出的长度应该根据输入文本的长度相应地改变。这是编码器的一个可以改进的地方。具体而言,如图 8-2 所示,使用各个时刻的 LSTM 层的隐藏状态。
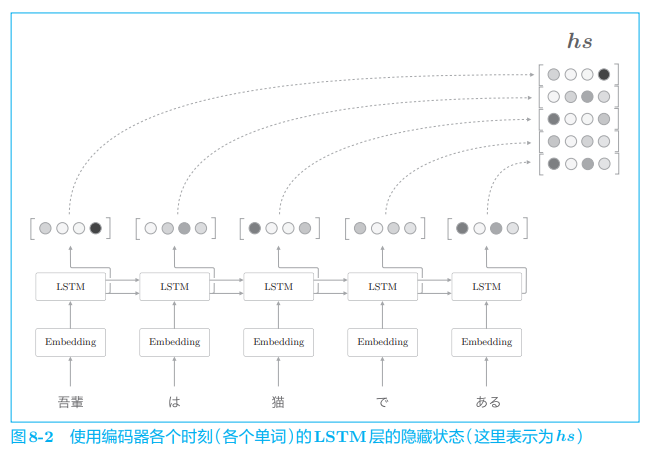
如图 8-2 所示,使用各个时刻(各个单词)的隐藏状态向量,可以获得和输入的单词数相同数量的向量。在图 8-2 的例子中,输入了 5 个单词,此时编码器输出 5 个向量。这样一来,编码器就摆脱了 “一个固定长度的向量” 的制约。
图 8-2 中我们需要关注 LSTM 层的隐藏状态的 “内容”。此时,各个时刻的 LSTM 层的隐藏状态都充满了什么信息呢?有一点可以确定的是,各个时刻的隐藏状态中包含了大量当前时刻的输入单词的信息。就图 8-2 的例子来说,输入“猫” 时的 LSTM 层的输出(隐藏状态)受此时输入的单词 “猫” 的影响最大。因此,可以认为这个隐藏状态向量蕴含许多 “猫的成分”。按照这样的理解,如图 8-3 所示,编码器输出的 h s h_s hs 矩阵就可以视为各个单词对应的向量集合。
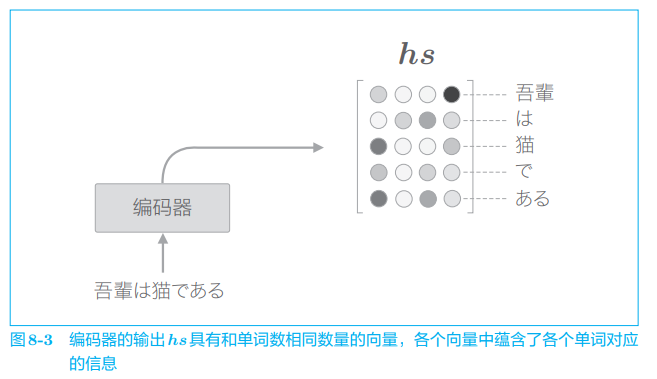
因为编码器是从左向右处理的,所以严格来说,刚才的 “猫” 向量中含有 “吾輩” “は” “猫” 这3个单词的信息。考虑整体的平衡性,最好均衡地含有单词 “猫” 周围的信息。在这种情况下,从两个方向处理时序数据的双向 RNN(或者双向 LSTM)比较有效。我们后面再介绍双向 RNN,这里先继续使用单向 LSTM。
以上就是对编码器的改进。这里我们所做的改进只是将编码器的全部时刻的隐藏状态取出来而已。通过这个小改动,编码器可以根据输入语句的长度,成比例地编码信息。那么,解码器又将如何处理这个编码器的输出呢? 接下来,我们对解码器进行改进。因为解码器的改进有许多值得讨论的地方,所以我们分 3 部分进行。
8.1.3 解码器的改进 ①
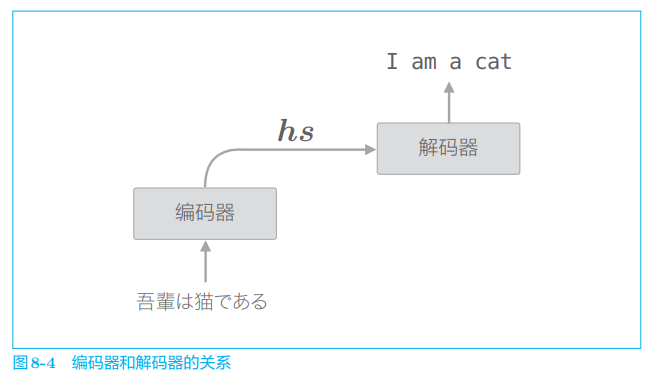
编码器整体输出各个单词对应的 LSTM 层的隐藏状态向量 h s h_s hs。然后, 这个 h s h_s hs 被传递给解码器,以进行时间序列的转换(图 8-4)。
顺便说一下,在上一章的最简单的 seq2seq 中,仅将编码器最后的隐藏状态向量传递给了解码器。严格来说,这是将编码器的 LSTM 层的 “最后” 的隐藏状态放入了解码器的 LSTM 层的 “最初” 的隐藏状态。用图来表示的话,解码器的层结构如图 8-5 所示。
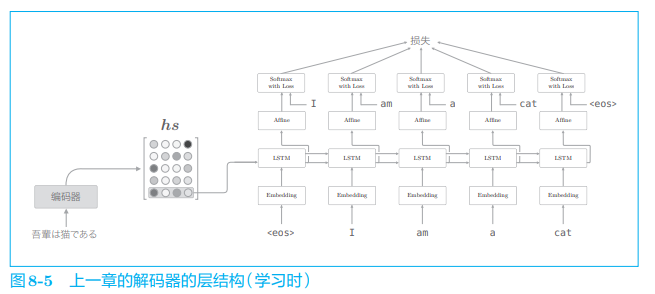
如图 8-5 所示,上一章的解码器只用了编码器的 LSTM 层的最后的隐藏状态。如果使用 h s h_s hs,则只提取最后一行,再将其传递给解码器。下面我们改进解码器,以便能够使用全部 h s h_s hs。
我们在进行翻译时,大脑做了什么呢?比如,在将 “吾輩は猫である” 这句话翻译为英文时,肯定要用到诸如 “吾輩 = I” “猫 = cat” 这样的知识。也就是说,可以认为我们是专注于某个单词(或者单词集合),随时对这个单词进行转换的。那么,我们可以在 seq2seq 中重现同样的事情吗?确切地说,我们可以让 seq2seq 学习 “输入和输出中哪些单词与哪些单词有关” 这样的对应关系吗?
在机器翻译的历史中,很多研究都利用 “猫 =cat” 这样的单词对应关系的知识。这样的表示单词(或者词组)对应关系的信息称为对齐(alignment)。到目前为止,对齐主要是手工完成的,而我们将要介绍的 Attention 技术则成功地将对齐思想自动引入到了 seq2seq 中。 这也是从 “手工操作” 到 “机械自动化” 的演变。
从现在开始,我们的目标是找出与 “翻译目标词” 有对应关系的 “翻译源词” 的信息,然后利用这个信息进行翻译。也就是说,我们的目标是仅关注必要的信息,并根据该信息进行时序转换。这个机制称为 Attention,是本章的主题。
在介绍 Attention 的细节之前,这里我们先给出它的整体框架。我们要 实现的网络的层结构如图 8-6 所示。
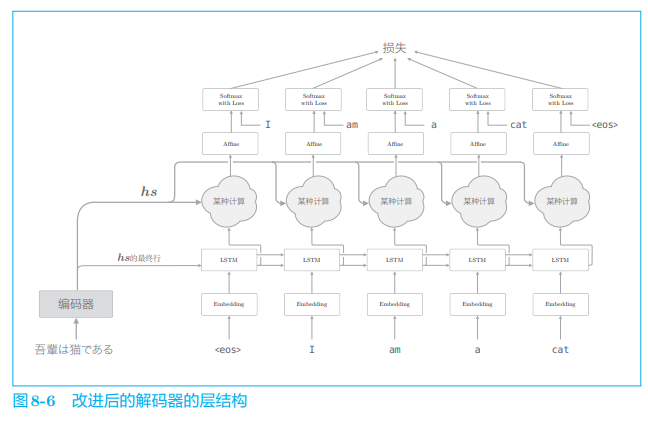
如图 8-6 所示,我们新增一个进行 “某种计算” 的层。这个 "某种计算” 接收(解码器)各个时刻的 LSTM 层的隐藏状态和编码器的 h s h_s hs。然后,从中选出必要的信息,并输出到 Affine 层。与之前一样,编码器的最后的隐藏状态向量传递给解码器最初的 LSTM 层。
图 8-6 的网络所做的工作是提取单词对齐信息。具体来说,就是从 h s h_s hs 中选出与各个时刻解码器输出的单词有对应关系的单词向量。比如,当图 8-6 的解码器输出 “I” 时,从 h s h_s hs 中选出 “吾輩” 的对应向量。也就是说,我们希望通过 “某种计算” 来实现这种选择操作。不过这里有个问题,就是选择(从多个事物中选取若干个)这一操作是无法进行微分的。
神经网络的学习一般通过误差反向传播法进行。因此,如果使用可微分的运算构造网络,就可以在误差反向传播法的框架内进行学习;而如果不使用可微分的运算,基本上也就没有办法使用误差反向传播法。
可否将 “选择” 这一操作换成可微分的运算呢?实际上,解决这个问题的思路很简单(但是,就像哥伦布蛋一样,第一个想到是很难的)。这个思路就是,与其 “单选”,不如 “全选”。如图 8-7 所示,我们另行计算表示各个单词重要度(贡献值)的权重。
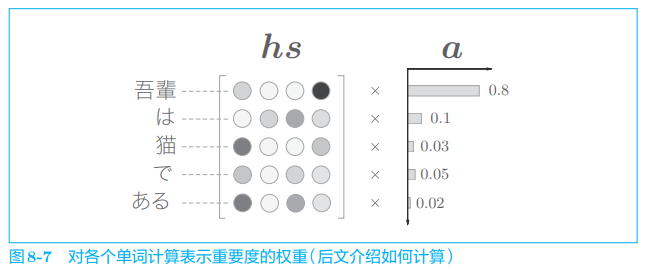
如图 8-7 所示,这里使用了表示各个单词重要度的权重(记为 a a a)。此 时, a a a 像概率分布一样,各元素是 0.0 ∼ 1.0 0.0 \sim 1.0 0.0∼1.0 的标量,总和是 1 1 1。然后,计算这个表示各个单词重要度的权重和单词向量 h s h_s hs 的加权和,可以获得目标向量。这一系列计算如图 8-8 所示。
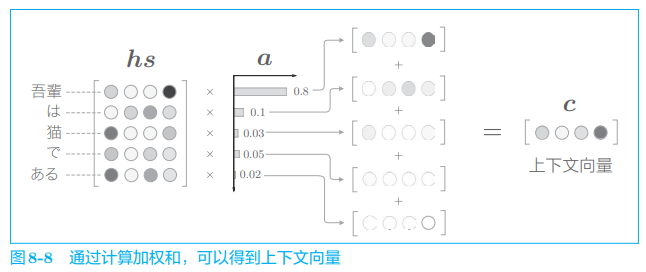
如图 8-8 所示,计算单词向量的加权和,这里将结果称为上下文向量,并用符号 c c c 表示。顺便说一下,如果我们仔细观察,就可以发现 “吾輩” 对应的权重为 0.8 0.8 0.8。这意味着上下文向量 c c c 中含有很多 “吾輩” 向量的成分,可以说这个加权和计算基本代替了 “选择” 向量的操作。假设 “吾輩” 对应的权重是 1 1 1,其他单词对应的权重是 0 0 0,那么这就相当于 “选择” 了 “吾輩” 向量。
上下文向量 c c c 中包含了当前时刻进行变换(翻译)所需的信息。更确切地说,模型要从数据中学习出这种能力。
代码实现见书
8.1.4 解码器的改进 ②
有了表示各个单词重要度的权重 a a a,就可以通过加权和获得上下文向量。那么,怎么求这个 a a a 呢?当然不需要我们手动指定,我们只需要做好让模型从数据中自动学习它的准备工作。
下面我们来看一下各个单词的权重 a a a 的求解方法。首先,从编码器的处理开始到解码器第一个 LSTM 层输出隐藏状态向量的处理为止的流程如图 8-12 所示。
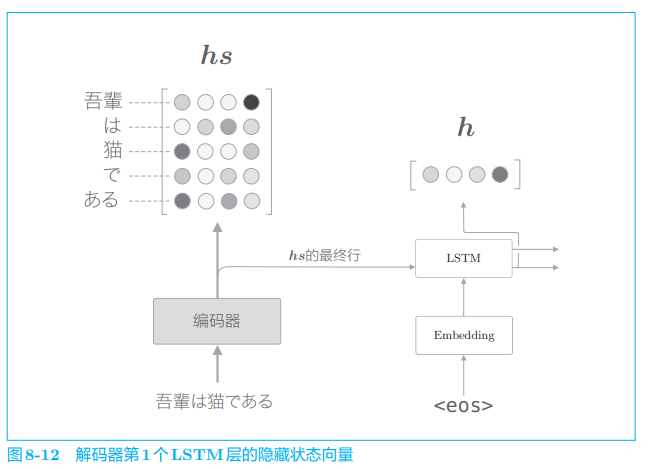
在图 8-12 中,用
h
h
h 表示解码器的 LSTM 层的隐藏状态向量。此时,我们的目标是用数值表示这个
h
h
h 在多大程度上和
h
s
h_s
hs 的各个单词向量 "相似”。 有几种方法可以做到这一点,这里我们使用最简单的向量内积。顺便说一 下,向量
a
=
(
a
1
,
a
2
,
…
,
a
n
)
a = (a_1, a_2, \dots , a_n)
a=(a1,a2,…,an) 和向量
b
=
(
b
1
,
b
2
,
…
,
b
n
)
b = (b_1, b_2, \dots , b_n)
b=(b1,b2,…,bn) 的内积为:
a
⋅
b
=
a
1
b
1
+
a
2
b
2
+
⋯
+
a
n
b
n
a \cdot b = a_1b_1 + a_2b_2 + \dots + a_n b_n
a⋅b=a1b1+a2b2+⋯+anbn
上式的含义是两个向量在多大程度上指向同一方向,因此使用内积作为两个向量的 “相似度” 是非常自然的选择。
计算向量相似度的方法有好几种。除了内积之外,还有使用小型的神经网络输出得分的做法。
下面用图表示基于内积计算向量间相似度的处理流程(图 8-13):
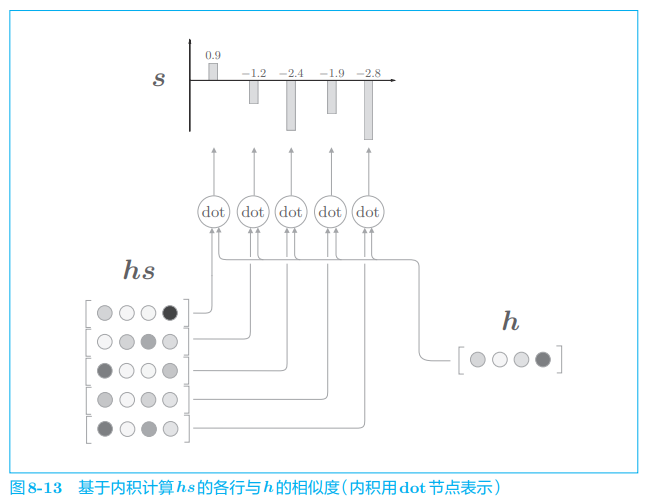
如图 8-13 所示,这里通过向量内积算出 h h h 和 h s h_s hs 的各个单词向量之间的相似度,并将其结果表示为 s s s。不过,这个 s s s 是正规化之前的值,也称为得分。接下来,使用老一套的 Softmax 函数对 s s s 进行正规化(图 8-14)。

使用 Softmax 函数之后,输出的 a a a 的各个元素的值在 0.0 ∼ 1.0 0.0 \sim 1.0 0.0∼1.0,总和 为 1 1 1,这样就求得了表示各个单词权重的 a a a。
代码实现见书
8.1.5 解码器的改进 ③
在此之前,我们分两节介绍了解码器的改进方案。8.1.3 节和 8.1.4 节分 别实现了 Weight Sum 层和 Attention Weight 层。现在,我们将这两层组合起来,结果如图 8-16 所示。
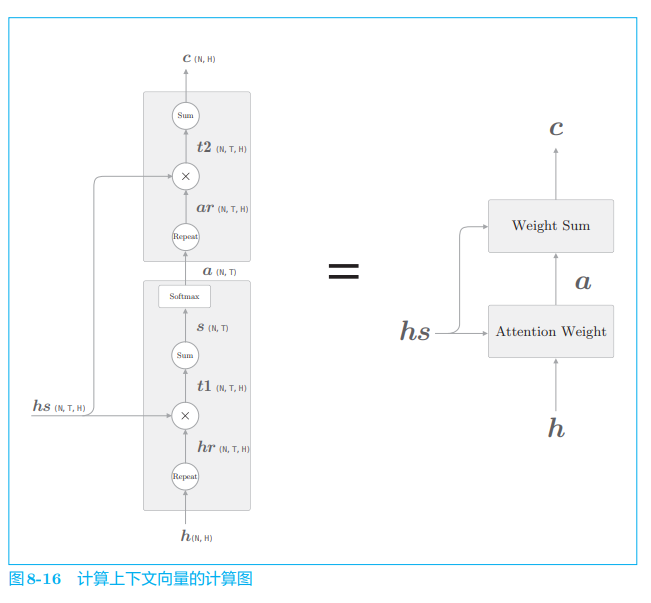
图 8-16 显示了用于获取上下文向量 c c c 的计算图的全貌。我们已经分为 Weight Sum 层和 Attention Weight 层进行了实现。重申一下,这里进行的计算是:Attention Weight 层关注编码器输出的各个单词向量 h s h_s hs,并计算各个单词的权重 a a a;然后,Weight Sum 层计算 a a a 和 h s h_s hs 的加权和,并输出上下文向量 c c c。我们将进行这一系列计算的层称为 Attention 层(图 8-17)。
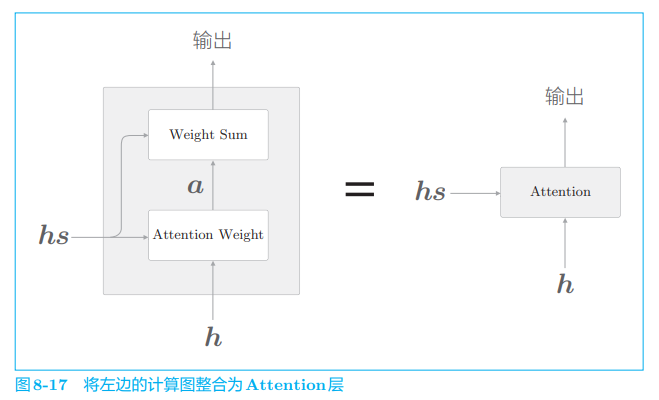
以上就是 Attention 技术的核心内容。关注编码器传递的信息 h s h_s hs 中的重要元素,基于它算出上下文向量,再传递给上一层(这里,Affine 层在上一层等待)。
代码实现见书
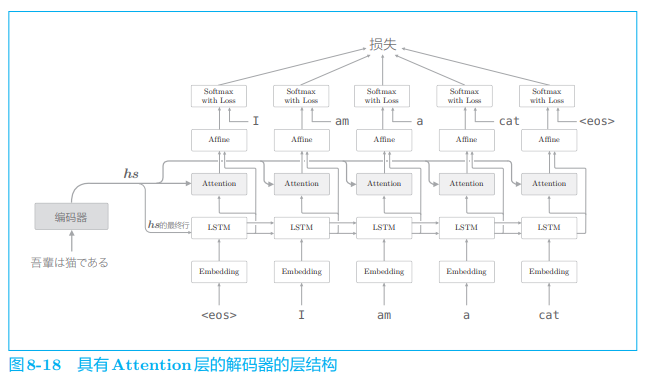
如图 8-18 所示,编码器的输出 h s h_s hs 被输入到各个时刻的 Attention 层。另外,这里将 LSTM 层的隐藏状态向量输入 Affine 层。根据上一章的解码器的改进,可以说这个扩展非常自然。如图 8-19 所示,我们将 Attention 信息 “添加” 到了上一章的解码器上。
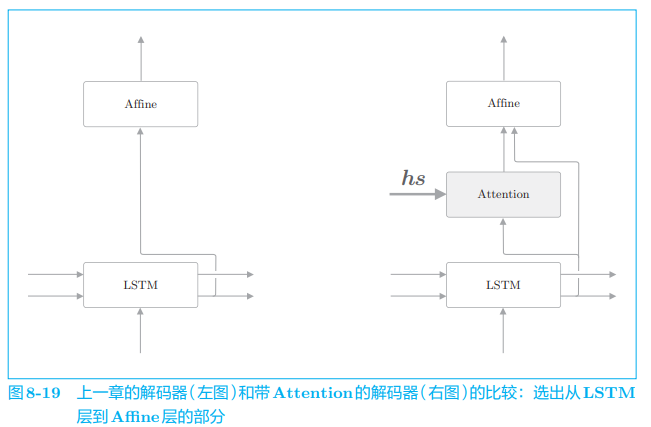
如图 8-19 所示,我们向上一章的解码器 “添加” 基于 Attention 层的上下文向量信息。因此,除了将原先的 LSTM 层的隐藏状态向量传给 Affine 层之外,追加输入 Attention 层的上下文向量。
在图 8-19 中,上下文向量和隐藏状态向量这两个向量被输入 Affine 层。如前所述,这意味着将这两个向量拼接起来,将拼接后的向量输入 Affine 层。
最后,我们将在图 8-18 的时序方向上扩展的多个 Attention 层整体实现为 Time Attention 层,如图 8-20 所示。

代码实现见书
8.2 带 Attention 的 seq2seq 的实现
8.2.1 编码器的实现
首先实现 AttentionEncoder 类。这个类和上一章实现的 Encoder 类几乎 一样,唯一的区别是,Encoder 类的 forward() 方法仅返回 LSTM 层的最后的隐藏状态向量,而AttentionEncoder类则返回所有的隐藏状态向量。因此,这里我们继承上一章的 Encoder 类进行实现。
8.2.2 解码器的实现
使用了 Attention 的解码器的层结构如图 8-21 所示

8.2.3 seq2seq 的实现
8.3 Attention 的评价
通过研究 “日期格式转换” 问题(本质上属于人为创造的问题,数据量有限),来确认带 Attention 的 seq2seq 的效果。
WMT 是一个有名的翻译数据集。这个数据集中提供了英语和法语(或者英语和德语)的平行学习数据。WMT 数据集在许多研究中都被作为基准使用,经常用于评价 seq2seq 的性能,不过它的数据量很大(超 过 20 GB),使用起来不是很方便。
8.3.1 日期格式转换问题
这里我们要处理的是日期格式转换问题。这个任务旨在将使用英语的国家和地区所使用的各种各样的日期格式转换为标准格式。例如,将人写的 “september 27, 1994” 这样的日期数据转换为 “1994-09-27” 这样的标准格 式,如图 8-22 所示。

这里采用日期格式转换问题的原因有两个。
首先,该问题并不像看上去那么简单。因为输入的日期数据存在各种各样的版本,所以转换规则也相应地复杂。如果尝试将这些转换规则全部写出来,那将非常费力。
其次,该问题的输入(问句)和输出(回答)存在明显的对应关系。具体而言,存在年月日的对应关系。因此,我们可以确认 Attention 有没有正确地关注各自的对应元素。
我们事先在 dataset/date.txt 中准备好了要处理的日期转换数据。如图 8-23 所示,这个文本文件包含 50 000 50\ 000 50 000 个日期转换用的学习数据。
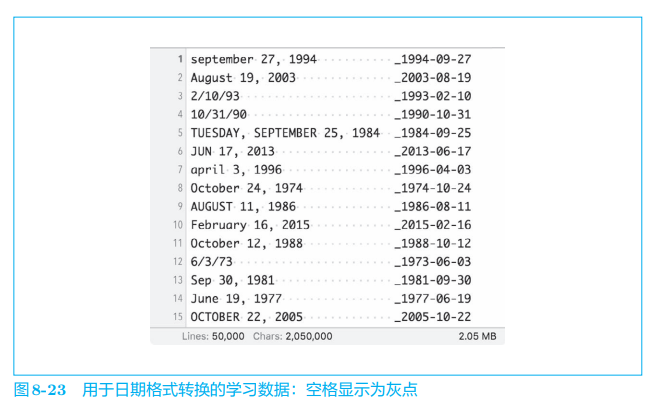
为了对齐输入语句的长度,本书提供的日期数据集填充了空格,并将 “_”(下划线)设置为输入和输出的分隔符。另外,因为这个问题输出的字符数是恒定的,所以无须使用分隔符来指示输出的结束。
8.3.2 带 Attention 的 seq2seq 的学习
8.3.3 Attention 的可视化
8.4 关于 Attention 的其他话题
8.4.1 双向 RNN
这里我们关注 seq2seq 的编码器。首先复习一下,上一节之前的编码器如图 8-29 所示。
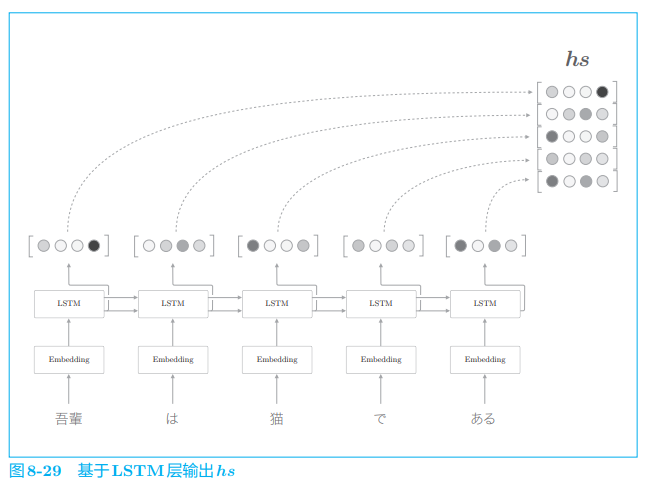
如图 8-29 所示,LSTM 中各个时刻的隐藏状态向量被整合为 h s h_s hs。这里, 编码器输出的 h s h_s hs 的各行中含有许多对应单词的成分。
需要注意的是,我们是从左向右阅读句子的。因此,在图 8-29 中,单词 “猫” 的对应向量编码了 “吾輩” “は” “猫” 这 3 个单词的信息。如果考虑整体的平衡性,我们希望向量能更均衡地包含单词 “猫” 周围的信息。
在这次的翻译问题中,我们获得了所有的时序数据(需要翻译的文本)。因此,我们既可以从左向右读取文本,也可以从右向左读取文本。
为此,可以让 LSTM 从两个方向进行处理,这就是名为双向 LSTM 的技术,如图 8-30 所示。
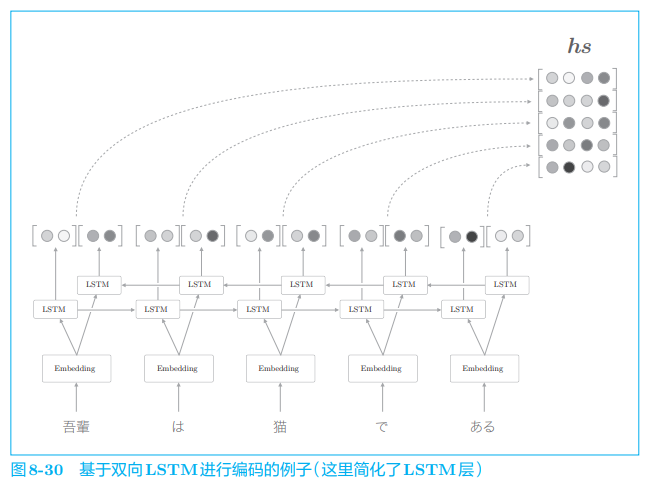
如图 8-30 所示,双向 LSTM 在之前的 LSTM 层上添加了一个反方向处理的 LSTM 层。然后,拼接各个时刻的两个 LSTM 层的隐藏状态,将其作为最后的隐藏状态向量(除了拼接之外,也可以 “求和” 或者 “取平均” 等)。
通过这样的双向处理,各个单词对应的隐藏状态向量可以从左右两个方向聚集信息。这样一来,这些向量就编码了更均衡的信息。
双向 LSTM 的实现非常简单。一种实现方式是准备两个 LSTM 层(本章中是 Time LSTM 层),并调整输入各个层的单词的排列。具体而言,其中一个层的输入语句与之前相同,这相当于从左向右处理输入语句的常规的 LSTM 层。而另一个 LSTM 层的输入语句则按照从右到左的顺序输入。如果原文是 “A B C D”,就改为 “D C B A”。通过输入改变了顺序的输入语句,另一个 LSTM 层从右向左处理输入语句。之后,只需要拼接这两个 LSTM 层的输出,就可以创建双向 LSTM 层。
为了便于理解,本章使用了单向 LSTM 作为编码器。不过,显然也可以将此处介绍的双向 LSTM 用作编码器。感兴趣的读者可以尝 试实现使用双向 LSTM 的带 Attention 的 seq2seq。
8.4.2 Attention 层的使用方法
截止到目前,我们使用的 Attention 层的层结构如图 8-31 所示。
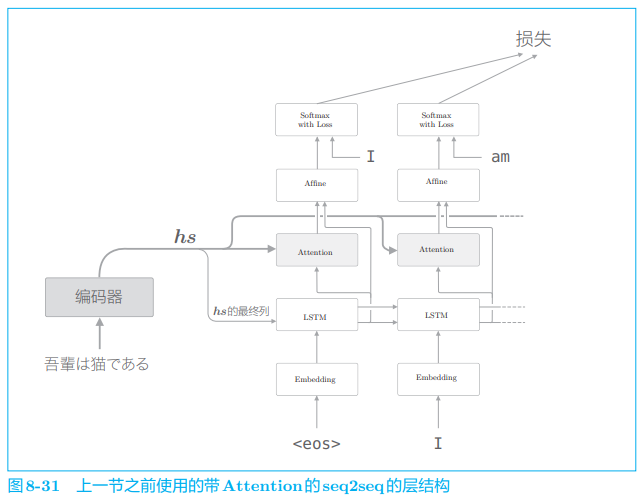
如图 8-31 所示,我们将 Attention 层插入了 LSTM 层和 Affine 层之间, 不过使用 Attention 层的方式并不一定非得像图 8-31 那样。实际上,使用 Attention 的模型还有其它好几种方式。比如,文献 [ 48 ] [48] [48] 中以图 8-32 的结构 使用了 Attention。
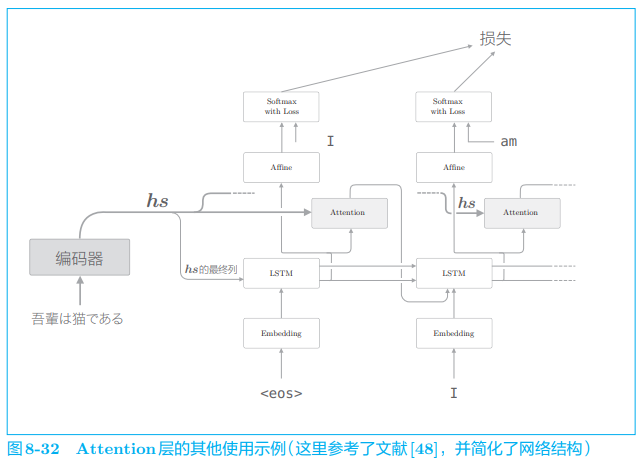
在图 8-32 中,Attention 层的输出(上下文向量)被连接到了下一时刻 的 LSTM 层的输入处。通过这种结构,LSTM 层得以使用上下文向量的信息。相对地,我们实现的模型则是 Affine 层使用了上下文向量。
那么,Attention 层的位置的不同对最终精度有何影响呢?答案要试一下才知道。实际上,这只能使用真实数据来验证。不过,在上面的两个模型中,上下文向量都得到了很好的应用。因此,在这两个模型之间,我们可能看不到太大的精度差异。
从实现的角度来看,前者的结构(在 LSTM 层和 Affine 层之间插入 Attention 层)更加简单。这是因为在前者的结构中,解码器中的数据是从下往上单向流动的,所以 Attention 层的模块化会更加简单。实际上,我们轻松地将其模块化为了 Time Attention 层。
8.4.3 seq2seq 的深层化和 skip connection
在诸如翻译这样的实际应用中,需要解决的问题更加复杂。在这种情况下,我们希望带 Attention 的 seq2seq 具有更强的表现力。此时,首先可以考虑到的是加深 RNN 层(LSTM 层)。通过加深层,可以创建表现力更强的模型,带 Attention 的 seq2seq 也是如此。那么,如果我们加深带 Attention 的 seq2seq,结果会怎样呢?图 8-33 给出了一个例子。
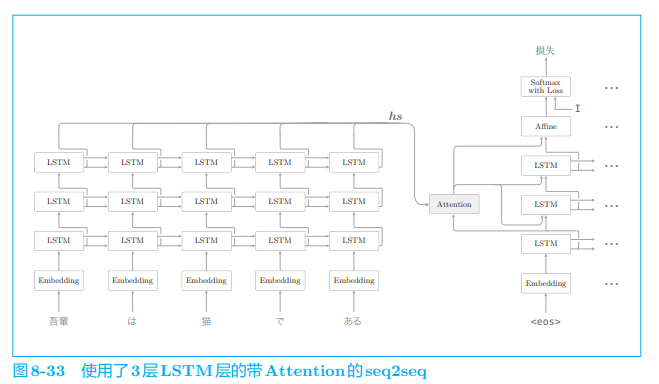
在图 8-33 的模型中,编码器和解码器使用了 3 层 LSTM 层。如本例所示,编码器和解码器中通常使用层数相同的 LSTM 层。另外,Attention 层的使用方法有许多变体。这里将解码器 LSTM 层的隐藏状态输入 Attention 层,然后将上下文向量(Attention 层的输出)传给解码器的多个层(LSTM 层和 Affine 层)。
图 8-33 的模型只是一个例子。除了这个例子之外,还有很多方式,比如使用多个 Attention 层,或者将 Attention 的输出输入给下 一个时刻的 LSTM 层等。另外,如上一章所述,在加深层时,避免泛化性能的下降非常重要。此时,Dropout、权重共享等技术 可以发挥作用。
另外,在加深层时使用到的另一个重要技巧是残差连接(skip connection,也称为 residual connection 或 shortcut)。如图 8-34 所示,这是一种 “跨层连接” 的简单技巧。

如图 8-34 所示,所谓残差连接,就是指 “跨层连接”。此时,在残差连接的连接处,有两个输出被相加。请注意这个加法(确切地说,是对应元素的加法)非常重要。因为加法在反向传播时 “按原样” 传播梯度,所以残差连接中的梯度可以不受任何影响地传播到前一个层。这样一来,即便加深了层,梯度也能正常传播,而不会发生梯度消失(或者梯度爆炸),学习可以顺利进行。
在时间方向上,RNN 层的反向传播会出现梯度消失或梯度爆炸的问题。梯度消失可以通过 LSTM、GRU 等 Gated RNN 应对,梯度爆炸可以通过梯度裁剪应对。而对于深度方向上的梯度消失,这里介绍的残差连接很有效。
8.5 Attention 的应用
到目前为止,我们仅将 Attention 应用在了 seq2seq 上,但是 Attention 这一想法本身是通用的,在应用上还有更多的可能性。实际上,在近些年的深度学习研究中,作为一种重要技巧,Attention 出现在了各种各样的场景中。
8.5.1 GNMT
回看机器翻译的历史,我们可以发现主流方法随着时代的变迁而演变。 具体来说,就是从 “基于规则的翻译” 到 “基于用例的翻译”,再到 “基于统计的翻译”。现在,神经机器翻译(Neural Machine Translation)取代了这些过往的技术,获得了广泛关注。
神经机器翻译这个术语是出于与之前的基于统计的翻译进行对比而使用的,现在已经成为使用了 seq2seq 的机器翻译的统称。
从 2016 年开始,谷歌翻译就开始将神经机器翻译用于实际的服务,其机器翻译系统称为 GNMT(Google Neural Machine Translation,谷歌神 经机器翻译系统)。关于 GNMT 的技术细节,文献 [50] 中有具体介绍。这里,我们以层结构为中心来看一下 GNMT 的架构,如图 8-35 所示。
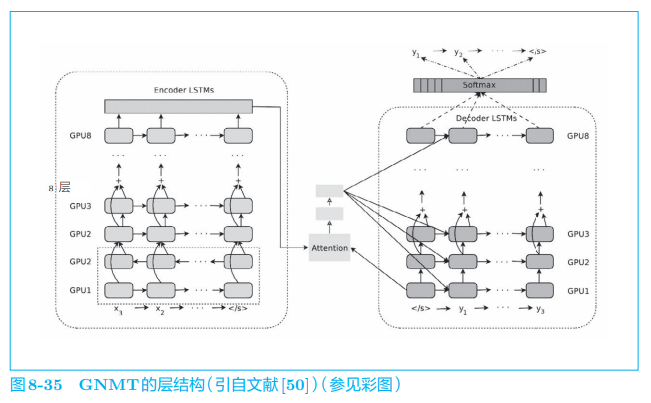
GNMT 和本章实现的带 Attention 的 seq2seq 一样,由编码器、解码器和 Attention 构成。不过,与我们的简单模型不同,这里可以看到许多为了提高翻译精度而做的改进,比如 LSTM 层的多层化、双向 LSTM(仅编码器的第 1 层)和 skip connection 等。另外,为了提高学习速度,还进行了多个 GPU 上的分布式学习。
除了上述在架构上下的功夫之外,GNMT 还进行了低频词处理、用于加速推理的量化(quantization)等工作。利用这些技巧,GNMT 获得了非常好的结果,实际报告出来的结果如图 8-36 所示。
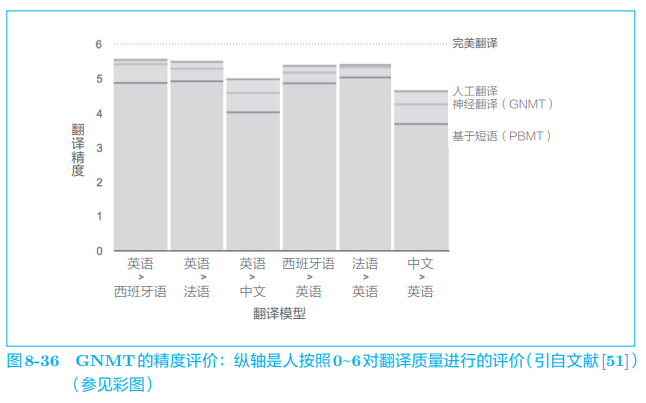
如图 8-36 所示,与基于短语的机器翻译(基于统计的机器翻译的一种)这种传统方法相比,GNMT 成功地提高了翻译精度,其精度进一步接近了人工翻译的精度。像这样,GNMT 给出了出色的结果,充分展示了神经翻译的实用性和可能性。不过,但凡用过谷歌翻译的人都知道,它仍存在许多不自然的翻译以及人绝对不会犯的错误。机器翻译的研究仍在继续。实际上,GNMT 只是一个开始,目前围绕神经翻译的研究非常活跃。
8.5.2 Transformer
到目前为止,我们在各种地方使用了 RNN(LSTM)。从语言模型到文本生成,从 seq2seq 到带 Attention 的 seq2seq 及其组成部分,RNN 都会出现。使用 RNN 可以很好地处理可变长度的时序数据,(在大多数情况下)能够获得良好的结果。但是,RNN 也有缺点,比如并行处理的问题。
RNN 需要基于上一个时刻的计算结果逐步进行计算,因此(基本)不可能在时间方向上并行计算 RNN。在使用了 GPU 的并行计算环境下进行深度学习时,这一点会成为很大的瓶颈,于是我们就有了避开 RNN 的动机。
在这样的背景下,现在关于去除 RNN 的研究(可以并行计算的 RNN 的研究)很活跃,其中一个著名的模型是 Transformer 模型。 Transformer 是在 “Attention is all you need” 这篇论文中提出来的方法。如论文标题所示,Transformer 不用 RNN,而用 Attention 进行处理。这里,我们简单地看一下这个 Transformer。
除了 Transformer 之外,还有多个研究致力于去除 RNN,比如用卷积层(Convolution 层)代替 RNN 的研究。这里我们不去探讨 该研究的细节,基本上就是用卷积层代替 RNN 来构成 seq2seq,并据此实现并行计算。
Transformer 是基于 Attention 构成的,其中使用了 Self-Attention 技巧,这一点很重要。Self-Attention 直译为 “自己对自己的 Attention”,也就是说,这是以一个时序数据为对象的 Attention,旨在观察一个时序数据中每个元素与其他元素的关系。用 Time Attention 层来说明的话,SelfAttention 如图 8-37 所示。
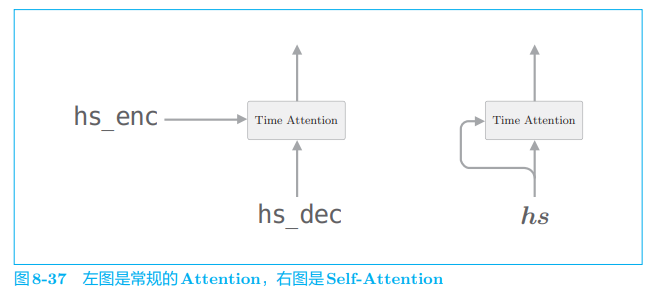
在此之前,我们用 Attention 求解了翻译这种两个时序数据之间的对应关系。如图 8-37 的左图所示,Time Attention 层的两个输入中输入的是不同的时序数据。与之相对,如图 8-37 的右图所示,Self-Attention 的两个输入中输入的是同一个时序数据。像这样,可以求得一个时序数据内各个元素之间的对应关系。
至此,对 Self-Attention 的说明就结束了,下面我们看一下 Transformer 的层结构,如图 8-38 所示。
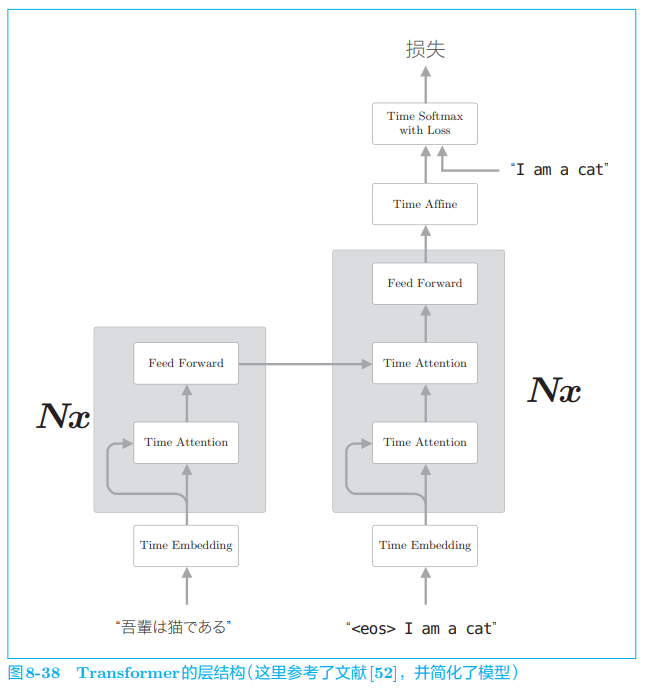
Transformer 中用 Attention 代替了 RNN。实际上,由图 8-38 可知, 编码器和解码器两者都使用了 Self-Attention。图 8-38 中的 Feed Forward 层表示前馈神经网络(在时间方向上独立的网络)。具体而言,使用具有一个隐藏层、激活函数为 ReLU 的全连接的神经网络。另外,图中的 N x Nx Nx 表示灰色背景包围的元素被堆叠了 N N N 次。
图 8-38 显示的是简化了的 Transformer。实际上,除了这个架构外,Skip Connection、Layer Normalization 等技巧也会被用到。 其他常见的技巧还有,(并行)使用多个 Attention、编码时序数据的位置信息(Positional Encoding,位置编码)等。
使用 Transformer 可以控制计算量,充分利用 GPU 并行计算带来的好处。其结果是,与 GNMT 相比,Transformer 的学习时间得以大幅减少。在翻译精度方面,如图 8-39 所示,也实现了精度提升。
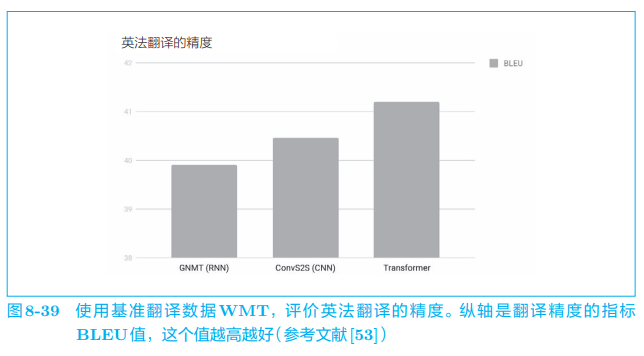
图 8-39 比较了 3 3 3 种方法。结果是,使用卷积层的 seq2seq(图中记为 ConvS2S)比 GNMT 精度高,而 Transformer 比使用卷积层的 seq2seq 还要高。如此,不仅仅是计算量,从精度的角度来看,Attention 也是很有前途的技术。
我们之前组合使用了 Attention 和 RNN, 但是由这个研究可知, Attention 其实可以用来替换 RNN。这样一来,利用 Attention 的机会可能会进一步增加。
8.5.3 NTM
我们在解决复杂问题时,经常使用纸和笔。从另一个角度来看,这可以解释为基于纸和笔这样的 “外部存储装置”,我们的能力获得了延伸。同样地,利用外部存储装置,神经网络也可以获得额外的能力。本节我们讨论的主题就是 “基于外部存储装置的扩展”。
RNN 和 LSTM 能够使用内部状态来存储时序数据,但是它们的内部状态长度固定,能塞入其中的信息量有限。因此,可以考虑在 RNN 的外部配置存储装置(内存),适当地记录必要信息。
在带 Attention 的 seq2seq 中,编码器对输入语句进行编码。然后,解码器通过 Attention 使用被编码的信息。这里需要注意的仍是 Attention 的存在。基于 Attention,编码器和解码器实现了计算机中的 “内存操作”。换句话说,这可以解释为,编码器将必要的信息写入内存,解码器从内存中读取必要的信息。
可见计算机的内存操作可以通过神经网络复现。我们可以立刻想到一 方法:在 RNN 的外部配置一个存储信息的存储装置,并使用 Attention 向这个存储装置读写必要的信息。实际上,这样的研究有好几个,NTM (Neural Turing Machine,神经图灵机) 就是其中比较有名的一个。
NTM 是 DeepMind 团队进行的一项研究,后来被改进成名为 DNC(Differentiable Neural Computers,可微分神经计算机)的方 法。关于 DNC 的论文发表在了学术期刊《自然》上。DNC 可以认为是强化了内存操作的 NTM,但它们的核心技术是一样的。
在解释 NTM 的内容之前,我们先来看一下 NTM 的整体框架。图 8-40 这张有趣的图片非常适合用于这一目的。这是 NTM 所进行的处理的概念表示,很好地总结了 NTM 的精髓(准确地说,这是发展了 NTM 的 DNC 的 一篇解说文章中用到的图)。

现在我们看一下图 8-40。这里需要注意的是图中间的一个被称为 “控制器” 的模块。这是处理信息的模块,我们假定它使用神经网络(或者 RNN)。从图中可以看出,数据 “0” 和 “1” 一个接一个地流入这个控制器,控制器对其进行处理并输出新的数据。
这里重要的是,在这个控制器的外侧有一张 “大纸”(内存)。基于这个内存,控制器获得了计算机(图灵机)的能力。具体来说,这个能力是指, 在这张 “大纸” 上写入必要的信息、擦除不必要的信息,以及读取必要信息的能力。顺便说一下,因为图 8-40 的 “大纸” 是卷式的,所以各个节点可以在需要的地方读写数据。换句话说,就是可以移动到目标地点。
像这样,NTM 在读写外部存储装置的同时处理时序数据。NTM 的有趣之处在于使用 “可微分” 的计算构建了这些内存操作。因此,它可以从数据中学习内存操作的顺序。
计算机根据人编写的程序进行动作。与此相对,NTM 从数据中学习程序。也就是说,这意味着它可以从 “算法的输入和输出” 中学 习 “算法自身”(逻辑)
NTM 像计算机一样读写外部存储装置,其层结构可以简单地绘制成 图 8-41。
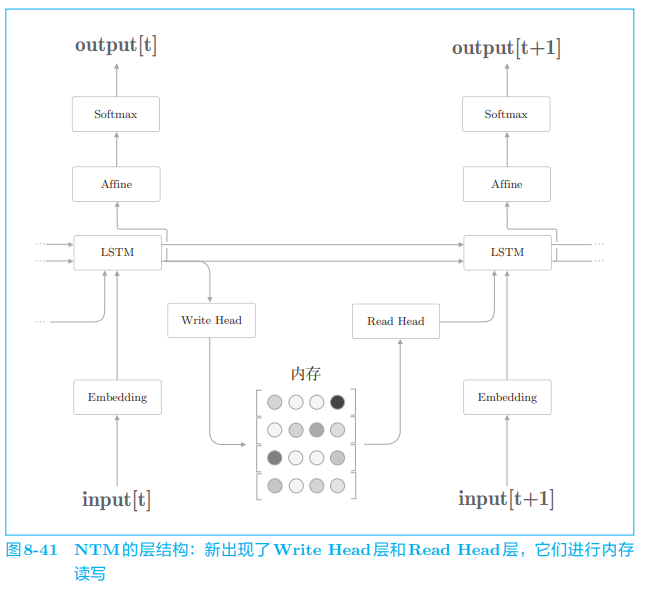
图 8-41 是简化版的 NTM 的层结构。这里 LSTM 层是控制器,执行 NTM 的主要处理。Write Head 层接收 LSTM 层各个时刻的隐藏状态,将必要的信息写入内存。Read Head 层从内存中读取重要信息,并传递给下 一个时刻的 LSTM 层。
那么,图 8-41 的 Write Head 层和 Read Head 层如何进行内存操作呢? 当然是使用 Attention。
重申一下,在读取(或者写入)内存中某个地址上的数据时,我们需要先 “选择” 数据。这个选择操作自身是不能微分的,因此先使用 Attention 选择所有地址上的数据,再利用权重表示每个数据的贡献,这样就能够利用可微分的计算替代选择这个操作。
为了模仿计算机的内存操作,NTM 的内存操作使用了两个 Attention, 分别是 “基于内容的 Attention” 和 “基于位置的 Attention”。基于内容的 Attention 和我们之前介绍的 Attention 一样,用于从内存中找到某个向量 (查询向量)的相似向量。
而基于位置的 Attention 用于从上一个时刻关注的内存地址(内存的各个位置的权重)前后移动。这里我们省略对其技术细节的探讨,具体可以通过一维卷积运算实现。基于内存位置的移动功能,可以再现 “一边前进(一 个内存地址)一边读取” 这种计算机特有的活动。
NTM 的内存操作比较复杂。除了上面说到的操作以外,还包括锐化 Attention 权重的处理、加上上一个时刻的 Attention 权重的处理等。
通过自由地使用外部存储装置,NTM 获得了强大的能力。实际上,对 于 seq2seq 无法解决的复杂问题,NTM 取得了惊人的成绩。具体而言, NTM 成功解决了长时序的记忆问题、排序问题(从大到小排列数字)等。
如此,NTM 借助外部存储装置获得了学习算法的能力,其中 Attention 作为一项重要技术而得到了应用。基于外部存储装置的扩展技术和 Attention 会越来越重要,今后将被应用在各种地方。