数据结构(3)
一、并查集
238. 银河英雄传说
-
有 N N N 艘战舰,也依次编号为 1 , 2 , . . . , N 1,2,...,N 1,2,...,N,其中第 i i i 号战舰处于第 i i i 列。有 T T T 条指令,每条指令格式为以下两种之一:
M i j,表示让第 i i i 号战舰所在列的全部战舰保持原有顺序,接在第 j j j 号战舰所在列的尾部;C i j,表示询问第 i i i 号战舰与第 j j j 号战舰当前是否处于同一列中,如果在同一列中,它们之间间隔了多少艘战舰。 -
三种并查集的综合运用。注意unite怎么写的。以及find函数千万别设计错了,可能会出现无返回值的情况。
#include<cstdio>
#include<algorithm>
#include<cstdlib>
using namespace std;
const int maxn = 30010;
int p[maxn], d[maxn], sz[maxn];
void init(int N) {
for (int i = 1; i <= N; i++) {
p[i] = i;
sz[i] = 1;
}
}
int find(int x) {
if (p[x] != x) {
int u = find(p[x]);
d[x] += d[p[x]];
p[x] = u;
}
return p[x];
}
void unite(int a, int b) {
int pa = find(a), pb = find(b);
if (pa == pb) return;
d[pa] = sz[pb];
sz[pb] += sz[pa];
p[pa] = pb;
}
int main() {
int T;
char op[5];
scanf("%d", &T);
init(30000);
while (T--) {
int a, b;
scanf("%s%d%d", op, &a, &b);
if (op[0] == 'M') unite(a, b);
else {
int pa = find(a), pb = find(b);
if (pa != pb) printf("-1\n");
else {
if (a == b) printf("0\n");
else printf("%d\n", abs(d[a] - d[b]) - 1);
}
}
}
return 0;
}
239. 奇偶游戏
-
题意:小 A 和小 B 在玩一个游戏。首先,小 A 写了一个由 0 和 1 组成的序列 S,长度为 N。然后,小 B 向小 A 提出了 M 个问题。在每个问题中,小 B 指定两个数 l 和 r,小 A 回答 S[l∼r] 中有奇数个 1 还是偶数个 1。
-
这个题麻烦在于区间交的问题,但是通过前缀和倒是可以避免掉这个问题
-
这道题前缀和去写。[l, r] 有奇数个1,可以转化为 S r − S l − 1 S_r - S_{l-1} Sr−Sl−1是奇数,然后可知 S r S_r Sr与 S l − 1 S_{l-1} Sl−1奇偶性不同。
-
用带边权的并查集去做(其实就是类似于大雪菜讲解食物链的那道题):
#include<iostream>
#include<string>
#include<unordered_map>
#include<algorithm>
using namespace std;
const int maxn = 20010;
int p[maxn], d[maxn], N, M, num;
unordered_map<int, int> id;
int get(int x) {
if (!id.count(x)) id[x] = ++num;
return id[x];
}
void init() {
for (int i = 0; i < maxn; i++) p[i] = i;
}
int find(int x) {
if (p[x] != x) {
int u = find(p[x]);
d[x] ^= d[p[x]];
p[x] = u;
}
return p[x];
}
void unite(int a, int b, int t) {
int pa = find(a), pb = find(b);
p[pa] = pb;
d[pa] = d[a] ^ d[b] ^ t;
}
int main() {
cin >> N >> M;
int ans = 0;
init();
for(int i = 0; i < M; i++) {
int a, b;
string type;
cin >> a >> b >> type;
a = get(a - 1), b = get(b);
int t = 0;
if (type == "odd") t = 1;
if (find(a) == find(b)) {
if (d[a] ^ d[b] ^ t && !ans) {
ans = i;
}
}
else unite(a, b, t);
}
if (ans) printf("%d\n", ans);
else printf("%d\n", M);
return 0;
}
- 用邻域的方法去做(其实就是类似于白书讲解的食物链的那个方法)。但是当种类过多的时候,邻域的性能较差。
- 有几个类别就开几个邻域。1~N表示奇数,N+1 ~ 2N 表示偶数。然后就这么开始写了:
#include<iostream>
#include<string>
#include<unordered_map>
#include<algorithm>
using namespace std;
const int maxn = 40010, N = 20000;
int p[maxn], M, num;
unordered_map<int, int> id;
int get(int x) {
if (!id.count(x)) id[x] = ++num;
return id[x];
}
void init() {
for (int i = 0; i < maxn; i++) p[i] = i;
}
int find(int x) {
if (p[x] != x) return p[x] = find(p[x]);
return x;
}
void unite(int a, int b) {
if (find(a) == find(b)) return;
p[find(a)] = find(b);
}
int main() {
int len;
cin >> len >> M;
int ans = 0;
init();
bool flag = true;
for(int i = 0; i < M; i++) {
int a, b;
string type;
cin >> a >> b >> type;
if (!flag) continue;
a = get(a - 1), b = get(b);
if (type == "odd") {
if (find(a) == find(b) || find(a + N) == find(b + N)) flag = false;
else {
unite(a, b + N);
unite(a + N, b);
}
}
else {
if (find(a) == find(b + N) || find(a + N) == find(b)) flag = false;
else {
unite(a, b);
unite(a + N, b + N);
}
}
if (!flag) ans = i;
}
if (ans) printf("%d\n", ans);
else printf("%d\n", M);
return 0;
}
二、树状数组
1. 243. 一个简单的整数问题2
-
给定一个长度为 N N N 的数列 A A A,以及 M M M 条指令,每条指令可能是以下两种之一:
C l r d,表示把 A [ l ] , A [ l + 1 ] , … , A [ r ] A[l],A[l+1],…,A[r] A[l],A[l+1],…,A[r] 都加上 d d d。Q l r,表示询问数列中第 l ∼ r l \sim r l∼r 个数的和。对于每个询问,输出一个整数表示答案。 -
这道题仍可以用差分去写,但是求区间和的时候,可以转化。假设b是差分数组,p1是b的前缀和数组,p2是 i ∗ b [ i ] i*b[i] i∗b[i]的前缀和数组。那么求原数组a的前i项和,可以转会为: p 1 [ i ] ∗ ( i + 1 ) − p 2 [ i ] p_1[i]*(i + 1) - p_2[i] p1[i]∗(i+1)−p2[i]。因此我们只需要用两个树状数组维护 p 1 p_1 p1 和 p 2 p_2 p2 即可。
#include<cstdio>
#include<algorithm>
using namespace std;
const int maxn = 100010;
typedef long long ll;
ll a[maxn], tri1[maxn], tri2[maxn];
int N, M;
int lowbit(int x) {
return x & -x;
}
void add(ll tr[], int id, ll c) {
for (int i = id; i <= N; i += lowbit(i)) tr[i] += c;
}
ll sum(ll tr[], int id) {
ll res = 0;
for (int i = id; i; i -= lowbit(i)) res += tr[i];
return res;
}
ll pre(int i) {
return sum(tri1, i) * (i + 1) - sum(tri2, i);
}
int main() {
scanf("%d%d", &N, &M);
for (int i = 1; i <= N; i++) {
scanf("%lld", &a[i]);
}
for (int i = 1; i <= N; i++) {
add(tri1, i, a[i] - a[i - 1]);
add(tri2, i, i * (a[i] - a[i - 1]));
}
while (M--) {
char op[5];
int l, r;
scanf("%s%d%d", op, &l, &r);
if (op[0] == 'Q') {
printf("%lld\n", pre(r) - pre(l - 1));
}
else {
ll d;
scanf("%lld", &d);
add(tri1, l, d), add(tri1, r + 1, -d);
add(tri2, l, l * d), add(tri2, r + 1, -(r + 1) * d);
}
}
return 0;
}
2. 244. 谜一样的牛
- 有一个排列是 1 1 1 ~ n n n(但是不知道具体的排列是什么),已知逆序对,求原排列是什么.
- 原题意:有 n n n 头奶牛,已知它们的身高为 1 ∼ n 1 \sim n 1∼n 且各不相同,但不知道每头奶牛的具体身高。现在这 n n n 头奶牛站成一列,已知第 i i i 头牛前面有 A i A_i Ai 头牛比它低,求每头奶牛的身高。
- 显然最后一头牛的高度 A n + 1 A_n+1 An+1. 因此,倒数第二头牛的高度,就是在去掉 A n + 1 A_n+1 An+1 的数组中找到第 A n − 1 + 1 A_{n-1}+1 An−1+1 小的数字. 然后其实这个用树状数组或者平衡树都是可以的。树状数组就是把所有位置初始化为1,扣掉一个位置就把一个数字变成零. 然后二分找满足前多少项和是 A i + 1 A_i+1 Ai+1 的位置。
- 二分,脑子中一定要想明白求的是 lower_bound 还是 upper_bound 。求 lower_bound,结果保留 u b ub ub;求 upper_bound,结果保留 l b lb lb。不过这个也和 C 函数里面的 return 有关,这里说的是大于等于号。
#include<cstdio>
const int maxn = 100010;
int a[maxn], tr[maxn], N, ans[maxn];
int lowbit(int x) {
return x & -x;
}
void add(int id, int c) {
for (int i = id; i <= N; i += lowbit(i)) tr[i] += c;
}
int sum(int id) {
int res = 0;
for (int i = id; i; i -= lowbit(i)) res += tr[i];
return res;
}
int main() {
scanf("%d", &N);
for (int i = 2; i <= N; i++) scanf("%d", &a[i]);
//这里可以做一个小优化。add(i, 1)也可以这么写:
for (int i = 1; i <= N; i++) tr[i] = lowbit(i);
for (int i = N; i > 0; i--) {
int lb = 0, ub = N + 1;
while (ub - lb > 1) {
int mid = (lb + ub) / 2;
if (sum(mid) >= a[i] + 1) ub = mid;
else lb = mid;
}
ans[i] = ub;
add(ub, -1);
}
for (int i = 1; i <= N; i++) printf("%d\n", ans[i]);
return 0;
}
3. 二维树状数组查询小矩形最值
I. Stock Analysis
法一
应该是求 ( l , l ) (l, l) (l,l) 到 ( r , r ) (r, r) (r,r) 这个矩形的最值。但是并不能看太懂
#include<iostream>
#include<cstring>
#include<algorithm>
#include<vector>
using namespace std;
typedef long long ll;
const ll INF = 1e18;
const int maxn = 2010, maxm = 200010;
struct node {
int l, r, id;
ll val;
};
vector<node> q;
ll w[maxn], tr[maxn][maxn], ans[maxm];
int lowbit(int x) {
return x & -x;
}
bool cmp(const node& u, const node& v) {
return u.val < v.val || u.val == v.val && u.id < v.id;
}
int N, M;
void update(int x, int y, ll val) {
for (int i = x; i <= N; i += lowbit(i)) {
for (int j = y; j <= N; j += lowbit(j)) {
tr[i][j] = max(tr[i][j], val);
}
}
}
ll query(int x, int y) {
ll res = -INF;
for (int i = x; i; i -= lowbit(i)) {
for (int j = y; j; j -= lowbit(j)) {
res = max(tr[i][j], res);
}
}
return res;
}
int main() {
scanf("%d%d", &N, &M);
for (int i = 1; i <= N; i++) {
fill(tr[i], tr[i] + N + 1, -INF);
}
for (int i = 1; i <= N; i++) {
scanf("%lld", &w[i]);
w[i] += w[i - 1];
}
for (int i = 1; i <= N; i++) {
for (int j = i; j <= N; j++) {
q.push_back({ i, j, 0, w[j] - w[i - 1] });
}
}
for (int i = 1; i <= M; i++) {
int l, r;
ll x;
scanf("%d%d%lld", &l, &r, &x);
q.push_back({ l, r, i, x });
}
sort(q.begin(), q.end(), cmp);
for (auto p : q) {
int l = p.l, r = p.r, id = p.id;
ll val = p.val;
if (!id) update(N - l + 1, r, val);
else ans[id] = query(N - l + 1, r);
}
for (int i = 1; i <= M; i++) {
if (ans[i] != -INF) printf("%lld\n", ans[i]);
else printf("NONE\n");
}
return 0;
}
法二
#include<iostream>
#include<cstring>
#include<algorithm>
#include<vector>
using namespace std;
typedef long long ll;
const ll INF = 1e18;
const int maxn = 2010, maxm = 200010;
struct node {
int l, r, id;
ll val;
};
vector<node> q;
ll w[maxn], tr[maxn][maxn], ans[maxm];
int lowbit(int x) {
return x & -x;
}
bool cmp(const node& u, const node& v) {
return u.val < v.val || u.val == v.val && u.id < v.id;
}
int N, M;
void update(int x, int y, ll v) {
while (x) {
int z = y;
while (z <= N) {
tr[x][z] = max(tr[x][z], v);
z += z & -z;
}
x -= x & -x;
}
}
ll query(int x, int y) {
ll res = -INF;
while (x <= N) {
int z = y;
while (z) {
res = max(res, tr[x][z]);
z -= z & -z;
}
x += x & -x;
}
return res;
}
int main() {
scanf("%d%d", &N, &M);
for (int i = 1; i <= N; i++) {
fill(tr[i], tr[i] + N + 1, -INF);
}
for (int i = 1; i <= N; i++) {
scanf("%lld", &w[i]);
w[i] += w[i - 1];
}
for (int i = 1; i <= N; i++) {
for (int j = i; j <= N; j++) {
q.push_back({ i, j, 0, w[j] - w[i - 1] });
}
}
for (int i = 1; i <= M; i++) {
int l, r;
ll x;
scanf("%d%d%lld", &l, &r, &x);
q.push_back({ l, r, i, x });
}
sort(q.begin(), q.end(), cmp);
for (auto p : q) {
int l = p.l, r = p.r, id = p.id;
ll val = p.val;
if (!id) update(l, r, val);
else ans[id] = query(l, r);
}
for (int i = 1; i <= M; i++) {
if (ans[i] != -INF) printf("%lld\n", ans[i]);
else printf("NONE\n");
}
return 0;
}
三、线段树
1. 245. 你能回答这些问题吗
给定长度为N的数列A,以及M条指令,每条指令可能是以下两种之一:
- “1 x y”,查询区间 [x,y] 中的最大连续子段和,即 m a x x ≤ l ≤ r ≤ y ∑ i = l r A [ i ] max_{x≤l≤r≤y}{\sum\limits_{i=l}^rA[i]} maxx≤l≤r≤yi=l∑rA[i]。
- “2 x y”,把 A[x] 改成 y。
对于每个查询指令,输出一个整数表示答案。
- 线段树的节点储存:左右儿子、最大连续子段和tmax、最大前缀和lmax、最大后缀和rmax、区间和sum。
- 最大连续子段和:max{左儿子.tmax,右儿子.tmax,左儿子.rmax + 右儿子.lmax}。
- 最大前缀和lmax:max{左儿子.lmax,左儿子.sum + 右儿子.lmax}
#include<cstdio
#include<algorithm>
using namespace std;
const int maxn = 500010;
int a[maxn], N, M;
struct node {
int l, r;
int tmax, lmax, rmax, sum;
}tr[maxn * 4];
void pushup(node& u, node& l, node& r) {
u.tmax = max(max(l.tmax, r.tmax), l.rmax + r.lmax);
u.lmax = max(l.lmax, l.sum + r.lmax);
u.rmax = max(r.rmax, l.rmax + r.sum);
u.sum = l.sum + r.sum;
}
void pushup(int u) {
pushup(tr[u], tr[2 * u], tr[2 * u + 1]);
}
void build(int u, int l, int r) {
//一定注意,u对应的是线段树的下标,而l和r对应的是原数组的下标。
if (l == r) tr[u] = { l, r, a[l], a[l], a[l], a[l] };
else {
tr[u].l = l, tr[u].r = r;
int mid = (l + r) / 2;
build(2 * u, l, mid), build(2 * u + 1, mid + 1, r);
pushup(u);
}
}
node query(int u, int l, int r) {
if (l <= tr[u].l && tr[u].r <= r) return tr[u];
int mid = (tr[u].l + tr[u].r) / 2;
if (r <= mid) return query(2 * u, l, r);
else if (l > mid) return query(2 * u + 1, l, r);
else {
node left = query(2 * u, l, r);
node right = query(2 * u + 1, l, r);
node res;
//我突然意识到,这个地方的pushup,不是在修改线段树本身,而是在修改查询结果res.
pushup(res, left, right);
return res;
}
}
void modify(int u, int x, int v) {
if (tr[u].l == x && tr[u].r == x) tr[u] = { x, x, v, v, v, v };
else {
int mid = (tr[u].l + tr[u].r) / 2;
if(x <= mid) modify(2 * u, x, v);
else modify(2 * u + 1, x, v);
pushup(u);
}
}
int main() {
scanf("%d%d", &N, &M);
for (int i = 1; i <= N; i++) scanf("%d", &a[i]);
build(1, 1, N);
while (M--) {
int type, x, y;
scanf("%d%d%d", &type, &x, &y);
if (type == 1) {
if (x > y) swap(x, y);
node n = query(1, x, y);
printf("%d\n", n.tmax);
}
else modify(1, x, y);
}
return 0;
}
2. 246. 区间最大公约数
给定一个长度为N的数列A,以及M条指令,每条指令可能是以下两种之一:
1、“C l r d”,表示把 A[l],A[l+1],…,A[r] 都加上 d。
2、“Q l r”,表示询问 A[l],A[l+1],…,A[r] 的最大公约数(GCD)。
对于每个询问,输出一个整数表示答案。
- gcd(a, b, c, d) = gcd(a, b - a, c - b, d - c)。这样子,就转化成了差分数组,求区间的最大公约数也转化成了求单点的最大公约数。
- 那么,只需求一下gcd(sum(l), gcd(a[l + 1] - a[l], … g[r] - g[r - 1]))。不过,按照大雪菜的意思,如果gcd求出负数,只需要加一个绝对值就可以。
- long long让蒟蒻留下两行泪。
#include<cstdio>
#include<algorithm>
using namespace std;
const int maxn = 500010;
typedef long long ll;
int N, M;
ll a[maxn];
struct node {
int l, r;
ll sum, d; //区间和和最大公约数
}tr[maxn * 4];
ll gcd(ll a, ll b) {
if (b == 0) return a;
return gcd(b, a % b);
}
void pushup(node& u, node& l, node& r) {
u.sum = l.sum + r.sum;
u.d = gcd(l.d, r.d);
}
void pushup(int u) {
pushup(tr[u], tr[2 * u], tr[2 * u + 1]);
}
void build(int u, int l, int r) {
if (l == r) tr[u] = { l, r, a[l] - a[l - 1], a[l] - a[l - 1] };
else {
tr[u].l = l, tr[u].r = r;
int mid = (l + r) / 2;
build(2 * u, l, mid), build(2 * u + 1, mid + 1, r);
pushup(u);
}
}
node query(int u, int l, int r) {
if (l <= tr[u].l && tr[u].r <= r) return tr[u];
int mid = (tr[u].l + tr[u].r) / 2;
if (r <= mid) return query(2 * u, l, r);
else if (l > mid) return query(2 * u + 1, l, r);
else {
node left = query(2 * u, l, r);
node right = query(2 * u + 1, l, r);
node res;
pushup(res, left, right);
return res;
}
}
void modify(int u, int x, ll d) {
if (tr[u].l == x && tr[u].r == x) tr[u] = { x, x, tr[u].sum + d, tr[u].sum + d };
else {
int mid = (tr[u].l + tr[u].r) / 2;
if (x <= mid) modify(2 * u, x, d);
else modify(2 * u + 1, x, d);
pushup(u);
}
}
int main() {
scanf("%d%d", &N, &M);
for (int i = 1; i <= N; i++) scanf("%lld", &a[i]);
build(1, 1, N);
while (M--) {
char op[5];
int l, r;
scanf("%s%d%d", op, &l, &r);
if (op[0] == 'Q') {
node left = query(1, 1, l), right;
if (l + 1 <= r) right = query(1, l + 1, r);
else right = left;
ll ans = abs(gcd(left.sum, right.d));
printf("%lld\n", ans);
}
else {
ll d;
scanf("%lld", &d);
modify(1, l, d);
if (r + 1 <= N) modify(1, r + 1, -d);
}
}
return 0;
}
3. 247. 亚特兰蒂斯
- 扫描线算法
- 题意:给很多矩形(可能有些矩形相交),求矩形的并的面积。
- 操作一:将某个区间 [ l , r ] + k [l, r] + k [l,r]+k。操作二:计算整个区间长度大于0的区间总长。
- 线段树的信息:
- c n t cnt cnt:当前区间被完全覆盖的次数。
- l e n len len:不考虑祖先节点的前提下, c n t > 0 cnt > 0 cnt>0 的区间总长。
- 终于有点看懂了。这道题其实是这样的:第一步,线段树中存的是区间( y 0 y_0 y0 ~ y 1 y_1 y1, y 1 y_1 y1 ~ y 2 y_2 y2…),不过这里的 y y y 是离散化之后的。第二步,每次把 t r [ 1 ] . l e n ∗ ( x 2 − x 1 ) tr[1].len * (x_2 - x_1) tr[1].len∗(x2−x1),而 l e n len len 就是当前 x 1 x_1 x1 ~ x 2 x_2 x2 区间的矩形高度之和。
其实这里的 c n t cnt cnt 相当于懒标记。因为这里查询的区间每次都是整个数组,因此就省去了懒标记下传操作,即 p u s h d o w n pushdown pushdown
#include<cstdio>
#include<vector>
#include<algorithm>
using namespace std;
const int maxn = 100010;
struct seg {
double x, y1, y2;
int k;
bool operator < (const seg& rhs) {
return x < rhs.x;
}
}segs[maxn * 2];
struct node {
int l, r, cnt;
double len;
}tr[maxn * 8];
int N, kase;
vector<double> ys;
void pushup(int u)
{
if (tr[u].cnt) tr[u].len = (ys[tr[u].r + 1] - ys[tr[u].l]);
else if (tr[u].l != tr[u].r)
{
tr[u].len = tr[2 * u].len + tr[2 * u + 1].len;
}
else tr[u].len = 0;
}
void build(int u, int l, int r) {
tr[u] = { l, r, 0, 0 };
if (l != r)
{
int mid = (l + r) / 2;
build(2 * u, l, mid), build(2 * u + 1, mid + 1, r);
}
}
void modify(int u, int l, int r, int k) {
if (l <= tr[u].l && tr[u].r <= r) {
tr[u].cnt += k;
pushup(u);
}
else {
int mid = (tr[u].l + tr[u].r) / 2;
if (l <= mid) modify(2 * u, l, r, k);
if (r > mid) modify(2 * u + 1, l, r, k);
pushup(u);
}
}
int find(double y) {
return lower_bound(ys.begin(), ys.end(), y) - ys.begin();
}
int main() {
while (scanf("%d", &N), N) {
double x1, x2, y1, y2;
for (int i = 0, j = 0; i < N; i++) {
scanf("%lf%lf%lf%lf", &x1, &y1, &x2, &y2);
segs[j++] = { x1, y1, y2, 1 };
segs[j++] = { x2, y1, y2, -1 };
ys.push_back(y1), ys.push_back(y2);
}
sort(ys.begin(), ys.end());
ys.erase(unique(ys.begin(), ys.end()), ys.end());
sort(segs, segs + 2 * N);
build(1, 0, ys.size() - 2);
double ans = 0;
for (int i = 0; i < 2 * N; i++) {
if (i > 0) ans += tr[1].len * (segs[i].x - segs[i - 1].x);
modify(1, find(segs[i].y1), find(segs[i].y2) - 1, segs[i].k);
}
printf("Test case #%d\nTotal explored area: %.2f\n\n", ++kase, ans);
}
return 0;
}
4. 1277. 维护序列
老师交给小可可一个维护数列的任务,现在小可可希望你来帮他完成。
有长为 N N N 的数列,不妨设为 a 1 , a 2 , … , a N a_1,a_2,…,a_N a1,a2,…,aN。
有如下三种操作形式:
- 把数列中的一段数全部乘一个值;
- 把数列中的一段数全部加一个值;
- 询问数列中的一段数的和,由于答案可能很大,你只需输出这个数模 P P P 的值。
- 用了两个懒标记:add和mul。线段树维护五个值:l, r, sum, add, mul。而sum * mul + add,先乘再加,可以正确地表示这个值。
#include<cstdio>
#include<algorithm>
using namespace std;
const int maxn = 100010;
typedef long long ll;
struct node {
int l, r;
ll sum, add, mul;
}tr[maxn * 4];
int a[maxn], N, M, P;
void pushup(int u) {
tr[u].sum = (tr[2 * u].sum + tr[2 * u + 1].sum) % P;
}
void eval(node& u, ll add, ll mul) {
u.sum = (u.sum * mul % P + (u.r - u.l + 1) * add % P) % P;
u.mul = u.mul * mul % P;
u.add = (u.add * mul % P + add) % P;
}
void pushdown(int u) {
eval(tr[2 * u], tr[u].add, tr[u].mul);
eval(tr[2 * u + 1], tr[u].add, tr[u].mul);
tr[u].add = 0, tr[u].mul = 1;
}
void build(int u, int l, int r) {
if (l == r) tr[u] = { l, r, a[l], 0, 1 };
else {
tr[u] = { l, r, 0, 0, 1 };
int mid = (l + r) / 2;
build(2 * u, l, mid), build(2 * u + 1, mid + 1, r);
pushup(u);
}
}
void modify(int u, int l, int r, ll add, ll mul) {
if (l <= tr[u].l && tr[u].r <= r) eval(tr[u], add, mul);
else {
pushdown(u);
int mid = (tr[u].l + tr[u].r) / 2;
if (l <= mid) modify(2 * u, l, r, add, mul);
if (r > mid) modify(2 * u + 1, l, r, add, mul);
pushup(u);
}
}
ll query(int u, int l, int r) {
if (l <= tr[u].l && tr[u].r <= r) return tr[u].sum;
pushdown(u);
ll sum = 0;
int mid = (tr[u].l + tr[u].r) / 2;
if (l <= mid) sum = query(2 * u, l, r);
if (r > mid) sum = (sum + query(2 * u + 1, l, r)) % P;
return sum % P;
}
int main() {
scanf("%d%d", &N, &P);
for (int i = 1; i <= N; i++) scanf("%d", &a[i]);
build(1, 1, N);
scanf("%d", &M);
for (int i = 0; i < M; i++) {
int t, l, r;
scanf("%d%d%d", &t, &l, &r);
if (t == 1) {
ll c;
scanf("%lld", &c);
modify(1, l, r, 0, c);
}
else if (t == 2) {
ll c;
scanf("%lld", &c);
modify(1, l, r, c, 1);
}
else printf("%lld\n", query(1, l, r));
}
return 0;
}
四、可持久化数据结构
Easy DP Problem
-
题意:给一个数组 a,询问 ∑ i = 1 r − l + 1 i 2 \sum\limits_{i = 1}^{r - l + 1}i^2 i=1∑r−l+1i2 加上 a[l ~ r] 这个区间前 k 个大的数之和
-
这个题重点是如何求前 K 个大的数之和。用主席树修改 insert 和 query 部分的代码即可。但是要小心两个地方
- 初始化的时候要注意
- 因为可能有重复数字,因此在 query 的时候,不可以直接加上
tr[q].sum - tr[p].sum,要这样子处理(tr[q].sum - tr[p].sum) / (tr[q].cnt - tr[p].cnt) * k;
#include<iostream>
#include<algorithm>
#include<cstring>
#include<vector>
#include<functional>
using namespace std;
const int maxn = 100010;
typedef long long ll;
int N, M, a[maxn];
ll sum2[maxn];
vector<int> nums;
struct node {
int l, r;
int cnt;
ll sum;
}tr[maxn * 4 + maxn * 17];
//空间开到 4N + N * log(N)
int root[maxn], idx;
int find(int x) {
return lower_bound(nums.begin(), nums.end(), x, greater<int>()) - nums.begin();
}
int build(int l, int r) {
int p = ++idx;
tr[p] = { l, r };
if (l == r) return p;
int mid = (l + r) / 2;
tr[p].l = build(l, mid), tr[p].r = build(mid + 1, r);
return p;
}
//p 为原来的线段树的结点,q 为复制的线段是的结点
int insert(int p, int l, int r, int x) {
int q = ++idx;
tr[q] = tr[p];
if (l == r) {
tr[q].cnt++;
tr[q].sum += nums[x];
return q;
}
int mid = (l + r) / 2;
if (x <= mid) tr[q].l = insert(tr[p].l, l, mid, x);
else tr[q].r = insert(tr[p].r, mid + 1, r, x);
tr[q].cnt = tr[tr[q].l].cnt + tr[tr[q].r].cnt;
tr[q].sum = tr[tr[q].l].sum + tr[tr[q].r].sum;
return q;
}
ll query(int q, int p, int l, int r, int k) {
//这个地方要小心,因为有重复数字的话,需要这样处理,不然结果会偏大。
if (l == r) return (tr[q].sum - tr[p].sum) / (tr[q].cnt - tr[p].cnt) * k;
int cnt = tr[tr[q].l].cnt - tr[tr[p].l].cnt;
int mid = (l + r) / 2;
if (k <= cnt) return query(tr[q].l, tr[p].l, l, mid, k);
else return tr[tr[q].l].sum - tr[tr[p].l].sum + query(tr[q].r, tr[p].r, mid + 1, r, k - cnt);
}
int main() {
for (ll i = 1; i <= 100000; i++) {
sum2[i] = i * i + sum2[i - 1];
}
int T;
scanf("%d", &T);
while (T--) {
//看看如何初始化的
nums.clear();
for (int i = 0; i <= idx; i++) {
tr[i] = { 0, 0, 0, 0 };
}
fill(root, root + N + 1, 0);
idx = 0;
scanf("%d", &N);
for (int i = 1; i <= N; i++) {
scanf("%d", &a[i]);
nums.push_back(a[i]);
}
sort(nums.begin(), nums.end(), greater<int>());
nums.erase(unique(nums.begin(), nums.end()), nums.end());
root[0] = build(0, nums.size() - 1);
for (int i = 1; i <= N; i++) {
root[i] = insert(root[i - 1], 0, nums.size() - 1, find(a[i]));
}
scanf("%d", &M);
while (M--) {
int l, r, k;
scanf("%d%d%d", &l, &r, &k);
int m = r - l + 1;
printf("%lld\n", sum2[m] + query(root[r], root[l - 1], 0, nums.size() - 1, k));
}
}
return 0;
}
五、平衡树
265. 营业额统计
- 求 f i f_i fi的最大值: f i = m i n 1 ≤ j < i ∣ a i − a j ∣ f_i=min_{1≤j<i}|a_i−a_j| fi=min1≤j<i∣ai−aj∣
- 这道题转化过来,就是找到不超过 a i a_i ai的最大值和不小于 a i a_i ai的最小值。这就是平衡树嘛。但是,这个用set可以做到,不过这个题还是手写平衡树演示一下。
- 这道题不用在rank和key之间转化。所以不用维护sz,也不用pushup函数。按照题目的意思也不用维护cnt。
#include<cstdio>
#include<algorithm>
#include<cstdlib>
using namespace std;
const int maxn = 33010, INF = 1e7;
int N;
struct node {
int l, r;
int key, val;
}tr[maxn];
int root, idx;
int get_node(int key) {
tr[++idx].key = key;
tr[idx].val = rand();
return idx;
}
void zig(int& p) {
int q = tr[p].l;
tr[p].l = tr[q].r, tr[q].r = p, p = q;
}
void zag(int& p) {
int q = tr[p].r;
tr[p].r = tr[q].l, tr[q].l = p, p = q;
}
void build() {
get_node(-INF), get_node(INF);
root = 1, tr[1].r = 2;
if (tr[1].val < tr[2].val) zag(root);
}
void insert(int& p, int key) {
if (!p) p = get_node(key);
else if (tr[p].key > key) {
insert(tr[p].l, key);
if (tr[tr[p].l].val > tr[p].val) zig(p);
}
else if (tr[p].key < key) {
insert(tr[p].r, key);
if (tr[tr[p].r].val > tr[p].val) zag(p);
}
}
int get_prev(int p, int key) {
if (!p) return -INF;
//注意,这里一定要写成>,因为这个并非找的严格小于key的,而是找不大于key的.
if (tr[p].key > key) return get_prev(tr[p].l, key);
return max(tr[p].key, get_prev(tr[p].r, key));
}
int get_next(int p, int key) {
if (!p) return INF;
if (tr[p].key < key) return get_next(tr[p].r, key);
return min(tr[p].key, get_next(tr[p].l, key));
}
int main() {
build();
scanf("%d", &N);
int res = 0, x;
for (int i = 0; i < N; i++) {
scanf("%d", &x);
if (!i) res += x;
else res += min(x - get_prev(root, x), get_next(root, x) - x);
insert(root, x);
}
printf("%d\n", res);
return 0;
}
六、AC自动机
1. 1053. 修复DNA
- 题意:给定一族只由 A , G , T , C A,G,T,C A,G,T,C 组成的字符串集合 S S S,然后给一个只由 A , G , T , C A,G,T,C A,G,T,C 组成的主串,问至少需要修改主串的几个字母,才能使主串中不含有 S S S 中的任意一个字符串作为其子串.
2. 1285. 单词
- 题意:某人读论文,一篇论文是由许多单词组成的。但他发现一个单词会在论文中出现很多次,现在他想知道每个单词分别在论文中出现多少次。
- 一个单词出现的次数,就是满足这样的前缀:后缀等于该单词. 因此我们计算的是,对于每一个前缀,有多少个后缀满足要求(即后缀为一个合法单词). 比如以 i i i 结点结尾的前缀数量可以叠加到 n e [ i ] ne[i] ne[i] 上面去.
- 因此,我们可以把整个 T r i e Trie Trie 图当作一个 D A G DAG DAG,有向边就是由 i → n e [ i ] i \rightarrow ne[i] i→ne[i] 这些边组成的。由于是求满足要求的前缀的数量,其实就是求到合法终点(就是单词的最后一个字母的节点编号)的路径的数量. 那么所有起点的初始值为有多少个单词可以以它结尾,沿着拓扑序往根节点叠加即可.
- n e [ i ] ne[i] ne[i] 的值就是以下标以 i i i 结尾的后缀对应的前缀的结尾的下标。此时的这个后缀与前缀相同,且长度是最长的。
#include<bits/stdc++.h>
using namespace std;
const int maxn = 1000010;
int N;
int tr[maxn][26], f[maxn], idx;
int q[maxn], ne[maxn];
char str[maxn];
int id[210];
void insert(int x) {
int p = 0;
for (int i = 0; str[i]; i++) {
int t = str[i] - 'a';
if (!tr[p][t]) tr[p][t] = ++idx;
p = tr[p][t];
f[p]++;
}
id[x] = p;
}
void build() {
int hh = 0, tt = -1;
for (int i = 0; i < 26; i++) {
if (tr[0][i]) q[++tt] = tr[0][i];
}
while (hh <= tt) {
int t = q[hh++];
for (int i = 0; i < 26; i++) {
//这里使用引用和之前的那个题是一样的效果。
int& p = tr[t][i];
if (!p) p = tr[ne[t]][i];
else {
ne[p] = tr[ne[t]][i];
q[++tt] = p;
}
}
}
}
int main() {
scanf("%d", &N);
for (int i = 0; i < N; i++) {
scanf("%s", str);
insert(i);
}
build();
for (int i = idx - 1; i >= 0; i--) f[ne[q[i]]] += f[q[i]];
for (int i = 0; i < N; i++) printf("%d\n", f[id[i]]);
return 0;
}
七、 Splay
1. 2437. Splay
- 题意:给定一个长度为
n
n
n 的整数序列,初始时序列为
{
1
,
2
,
.
.
.
,
n
−
1
,
n
}
\{1,2,...,n-1,n\}
{1,2,...,n−1,n}。序列中的位置从左到右依次标号为
1
∼
n
1 \sim n
1∼n。我们用
[
l
,
r
]
[l,r]
[l,r] 来表示从位置
l
l
l 到位置
r
r
r 之间(包括两端点)的所有数字构成的子序列。现在要对该序列进行
m
m
m 次操作,每次操作选定一个子序列
[
l
,
r
]
[l,r]
[l,r],并将该子序列中的所有数字进行翻转。例如,对于现有序列
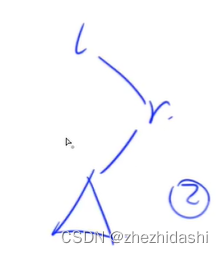
1 3 2 4 6 5 7,如果某次操作选定翻转子序列为 [ 3 , 6 ] [3,6] [3,6],那么经过这次操作后序列变为1 3 5 6 4 2 7。请你求出经过 m m m 次操作后的序列。 - 这个题就是把第 l − 1 l - 1 l−1 个点转到根节点下面,把第 r + 1 r + 1 r+1 个点转到第 l − 1 l-1 l−1 个点下面(如图),这样子的话, l l l ~ r r r 部分所形成的子树就成了第 r + 1 r+1 r+1 个点的左子树。然后把这个左子树反转即可。
#include<iostream>
#include<algorithm>
#include<cstring>
using namespace std;
const int maxn = 100010;
int N, M;
struct node {
//子结点,父结点,关键字
int s[2], p, v;
//子树大小,是否反转
int size, flag;
void init(int v_, int p_) {
v = v_, p = p_, size = 1;
}
}tr[maxn];
int root, idx;
void pushup(int x) {
tr[x].size = tr[tr[x].s[0]].size + tr[tr[x].s[1]].size + 1;
}
//将翻转子树的操作向下传递
void pushdown(int x) {
if (tr[x].flag) {
swap(tr[x].s[0], tr[x].s[1]);
tr[tr[x].s[0]].flag ^= 1;
tr[tr[x].s[1]].flag ^= 1;
tr[x].flag = 0;
}
}
//旋转分为左旋和右旋,但是经过多年的改善,已经统一成一个函数
//巧妙背诵:按照 z, y, x 的顺序从上到下,先修改 z 的儿子,再修改谁指向 z.
void rotate(int x) {
int y = tr[x].p, z = tr[y].p;
int k = (tr[y].s[1] == x); // k 是 0 的话,x 是 y 的左儿子
tr[z].s[tr[z].s[1] == y] = x, tr[x].p = z;
tr[y].s[k] = tr[x].s[k ^ 1], tr[tr[x].s[k ^ 1]].p = y;
tr[x].s[k ^ 1] = y, tr[y].p = x;
//z 的子树大小并没有变化,因此不用pushup(z)了
pushup(y), pushup(x);
}
//将 splay 下标第 x 个结点反转到第 k 个结点下面
void splay(int x, int k) {
while (tr[x].p != k) {
int y = tr[x].p, z = tr[y].p;
if (z != k) {
//判断 x, y, z 是否在一条直线上
if ((tr[y].s[1] == x) ^ (tr[z].s[1] == y)) rotate(x);
else rotate(y);
}
rotate(x);
}
if (!k) root = x;
}
void insert(int v) {
int u = root, p = 0;
while (u) p = u, u = tr[u].s[v > tr[u].v];
u = ++idx;
if (p) tr[p].s[v > tr[p].v] = u;
tr[u].init(v, p);
splay(u, 0);
}
// 找第 k 个数在 splay 中的下标
int get_k(int k) {
int u = root;
while (u) {
pushdown(u);
if (tr[tr[u].s[0]].size >= k) u = tr[u].s[0];
else if (tr[tr[u].s[0]].size + 1 == k) return u;
else {
k -= tr[tr[u].s[0]].size + 1, u = tr[u].s[1];
}
}
return -1;
}
void output(int u) {
pushdown(u);
if (tr[u].s[0]) output(tr[u].s[0]);
if (tr[u].v >= 1 && tr[u].v <= N) printf("%d ", tr[u].v);
if (tr[u].s[1]) output(tr[u].s[1]);
}
int main() {
scanf("%d%d", &N, &M);
//为了防止越界,splay会在开头和结尾加两个哨兵
//一般不是这样建splay树的,建树看下一道题
for (int i = 0; i <= N + 1; i++) insert(i);
while (M--) {
int l, r;
scanf("%d%d", &l, &r);
// 要找到第 l - 1 和第 r + 1 个点。因为加了哨兵,所以下标都往右平移一个。
l = get_k(l), r = get_k(r + 2);
splay(l, 0), splay(r, l);
//将整个左子树反转,也就是将 flag 标记一下
tr[tr[r].s[0]].flag ^= 1;
}
//将当前的整个树输出
output(root);
return 0;
}
八、树链剖分
918. 软件包管理器 - AcWing题库
- 题意:给一个
n
n
n 个点的树,一开始每个点的权值都是
0
0
0. 进行两种操作:
install x:把从 x x x 到根节点的一条路径上的的权值全部变成1;uninstall x:把以 x x x 为根节点的子树的所有结点全部置为0. 每进行一个操作,输出有多少个点的权值发生了改变。
#include<bits/stdc++.h>
using namespace std;
const int N = 100010, M = 200010;
int h[N], e[M], ne[M], idx;
int top[N], id[N], cnt;
void add(int a, int b)
{
e[idx] = b, ne[idx] = h[a], h[a] = idx++;
}
int dep[N], fa[N], sz[N], son[N];
void dfs1(int u, int father, int depth)
{
dep[u] = depth, sz[u] = 1, fa[u] = father;
for(int i = h[u]; i != -1; i = ne[i])
{
int v = e[i];
if(v == father) continue;
dfs1(v, u, depth + 1);
sz[u] += sz[v];
if(sz[son[u]] < sz[v]) son[u] = v;
}
}
void dfs2(int u, int t)
{
id[u] = ++cnt, top[u] = t;
if(!son[u]) return;
dfs2(son[u], t);
for(int i = h[u]; i != -1; i = ne[i])
{
int v = e[i];
if(v == fa[u] || son[u] == v) continue;
dfs2(v, v);
}
}
struct node
{
int l, r;
//flag = 0表示没有懒标记,flag = 1 表示整个区间都置为1,flag = 2 表示整个区间都置为0.
int flag, sum;
}tr[N * 4];
void pushup(int u)
{
tr[u].sum = tr[2 * u].sum + tr[2 * u + 1].sum;
}
void pushdown(int u)
{
auto& root = tr[u], &left = tr[2 * u], &right = tr[2 * u + 1];
if(root.flag)
{
left.flag = right.flag = root.flag;
if(root.flag == 1)
{
left.sum = left.r - left.l + 1;
right.sum = right.r - right.l + 1;
}
else left.sum = right.sum = 0;
}
root.flag = 0;
}
void build(int u, int l, int r)
{
tr[u] = {l, r};
if(l == r) return;
int mid = (l + r) / 2;
build(2 * u, l, mid), build(2 * u + 1, mid + 1, r);
}
void update(int u, int l, int r, int flag)
{
if(l <= tr[u].l && tr[u].r <= r)
{
tr[u].flag = flag;
if(flag == 1) tr[u].sum = tr[u].r - tr[u].l + 1;
else tr[u].sum = 0;
}
else{
pushdown(u);
int mid = (tr[u].l + tr[u].r) / 2;
if(l <= mid) update(2 * u, l, r, flag);
if(r > mid) update(2 * u + 1, l, r, flag);
pushup(u);
}
}
int query(int u, int l, int r)
{
if(l <= tr[u].l && tr[u].r <= r)
{
return tr[u].sum;
}
else{
pushdown(u);
int mid = (tr[u].l + tr[u].r) / 2;
int res = 0;
if(l <= mid) res += query(2 * u, l, r);
if(r > mid) res += query(2 * u + 1, l, r);
return res;
}
}
void update_path(int u, int v)
{
int res = 0; //忘记初始化res了...
while(top[u] != top[v])
{
if(dep[top[u]] < dep[top[v]]) swap(u, v);
res += (id[u] - id[top[u]] + 1) - query(1, id[top[u]], id[u]);
update(1, id[top[u]], id[u], 1);
u = fa[top[u]];
}
if(dep[u] < dep[v]) swap(u, v);
//中间的-写成+了
res += (id[u] - id[v] + 1) - query(1, id[v], id[u]);
update(1, id[v], id[u], 1);
printf("%d\n", res);
}
void update_tree(int u)
{
printf("%d\n", query(1, id[u], id[u] + sz[u] - 1));
update(1, id[u], id[u] + sz[u] - 1, 2);
}
int main()
{
int n;
scanf("%d", &n);
memset(h, -1, sizeof h);
for(int i = 2; i <= n; i++)
{
int p;
scanf("%d", &p);
add(i, p + 1), add(p + 1, i);
}
dfs1(1, -1, 1);
dfs2(1, 1);
build(1, 1, n);
int q;
scanf("%d", &q);
while(q--)
{
static char op[15];
int x;
scanf("%s%d", op, &x);
if(*op == 'i')
{
update_path(1, x + 1);
}
else
{
update_tree(x + 1);
}
}
return 0;
}
九、动态树
十、分块
- 分块是一种很灵活的思想,相较于树状数组和线段树,分块的优点是通用性更好,可以维护很多树状数组和线段树无法维护的信息。
分块数组
- 块状数组,即把一个数组分为几个块,块内信息整体保存, 若查询时遇到两边不完整的块直接暴力查询。 一般情况下,块的长度为 O ( n ) O(\sqrt n) O(n).
分块链表
莫队算法
- 莫队算法可以解决一类离线区间询问问题,适用性极为广泛。同时将其加以扩展,便能轻松处理树上路径询问以及支持修改操作。
- 离线后排序,顺序处理每个询问,暴力从上一个区间的答案转移到下一个区间答案(一步一步移动即可)。
- 对于区间 [ l , r ] [l,r] [l,r], 以 l l l 所在块的编号为第一关键字, r r r 为第二关键字从小到大排序。
- 复杂度: O ( n ∗ n ) . O(n*\sqrt n). O(n∗n).
1. D. Powerful array
- 题意:给定一个数列: a 1 , a 2 , . . . , a n a_1,a_2,...,a_n a1,a2,...,an。定义 K a K_a Ka 为区间 [ l , r ] [l,r] [l,r] 中 a a a 出现的次数。 t t t 个查询,每个查询l,r,对区间内所有 a [ i ] a[i] a[i] ,求 ∑ K 2 ∗ a [ i ] \sum{K^2*a[i]} ∑K2∗a[i]
- 用到了莫队算法:离线+分块。将n个数分成sqrt(n)块。对所有询问进行排序,排序标准:
- Q[i].left /block_size < Q[j].left / block_size (块号优先排序)
- 如果1相同,则 Q[i].right < Q[j].right (按照查询的右边界排序)
-
如果一个数已经出现了x次,那么需要累加 ( 2 ∗ x + 1 ) ∗ a [ i ] (2*x+1)*a[i] (2∗x+1)∗a[i],因为 ( x + 1 ) 2 ∗ a [ i ] = ( x 2 + 2 ∗ x + 1 ) ∗ a [ i ] (x+1)^2*a[i] = (x^2 +2*x + 1)*a[i] (x+1)2∗a[i]=(x2+2∗x+1)∗a[i], x 2 ∗ a [ i ] x^2*a[i] x2∗a[i] 是出现x次的结果, ( x + 1 ) 2 ∗ a [ i ] (x+1)^2 * a[i] (x+1)2∗a[i] 是出现 x + 1 x+1 x+1 次的结果。
-
看了代码之后,妙啊!
-
除以,看到 10^6 时,千万别用 c i n , c o u t cin, cout cin,cout,我这次差一点点超时。换成 s c a n f , p r i n t f scanf, printf scanf,printf 后就特别快。
-
似乎, GNU C++17 (64) 比 GNU C++17 快了不少。
#include<cstdio>
#include<algorithm>
#include<cmath>
using namespace std;
const int maxa = 1000010, maxn = 200010;
typedef long long ll;
struct query {
int l, r, id;
}Q[maxn];
//sum[i] 是当前查到的 i 这个数字有多少个。
ll a[maxn], sum[maxa], ans[maxn];
int N, T, block_size, L, R; //当前的左边界、右边界。
ll now; //当前的答案
bool cmp(query a, query b) {
if (a.l / block_size == b.l / block_size) return a.r < b.r;
return a.l / block_size < b.l / block_size;
}
void modify(int l, int r) {
//若当前 L 在 l 的左边
while (L < l) {
now -= (2 * sum[a[L]] - 1) * a[L];
sum[a[L]]--;
L++;
}
//若当前 L 在 l 的右边
while (L > l) {
L--;
now += (2 * sum[a[L]] + 1) * a[L];
sum[a[L]]++;
}
//若当前 R 在 r 的左边
while (R < r) {
R++;
now += (2 * sum[a[R]] + 1) * a[R];
sum[a[R]]++;
}
//若当前 R 在 r 的右边
while (R > r) {
now -= (2 * sum[a[R]] - 1) * a[R];
sum[a[R]]--;
R--;
}
}
int main() {
scanf("%d%d", &N, &T);
for (int i = 1; i <= N; i++) scanf("%I64d", &a[i]);
for (int i = 1; i <= T; i++) {
scanf("%d%d", &Q[i].l, &Q[i].r);
Q[i].id = i;
}
block_size = sqrt(N);
sort(Q + 1, Q + T + 1, cmp);
for (int i = 1; i <= T; i++) {
modify(Q[i].l, Q[i].r);
ans[Q[i].id] = now;
}
for (int i = 1; i <= T; i++) {
printf("%I64d\n", ans[i]);
}
return 0;
}