目录
一、zookeeper
1、zookeeper简介
2、zookeeper特点
3、zookeeper工作模式及机制
4、zookeeper应用场景及选举机制
5、zookeeper集群部署
①实验环境
②安装zookeeper
二、消息队列kafka
1、为什么要有消息队列
2、使用消息队列的好处
3、kafka简介
4、kafka特点
5、kafka系统架构名词介绍
6、Kafka架构及流程
7、kafka集群部署
8、kafka报错分析
一、zookeeper
1、zookeeper简介
Zookeeper:开源分布式的服务,为分布式框架提供协调服务的apache项目
2、zookeeper特点
①、zookper是一个领导者,多个跟随着组成
②、集群中有半数以上节点存活,集群正常服务,奇数台最小3台
③、全局数据一致,每个server保存一份相同的数据副本,client无论连接到那台server,数据都一样
④、更新请求顺序执行,来自同一个client更新请求按照其发送顺序一次执行,先进先出
⑤、原子性,要么成功要么失败
3、zookeeper工作模式及机制
Zookeeper工作模式:文件系统+通知机制
工作机制:
1、每个服务端上线时需要到zookeeper集群注册信息
2、客户端从zookeeper集群获取在线服务端信息列表并监听
3、服务端上线下线时,zookeeper需要更新列表信息并通知客户端
4、客户端接收到通知重新获取zookeeper在线服务器列表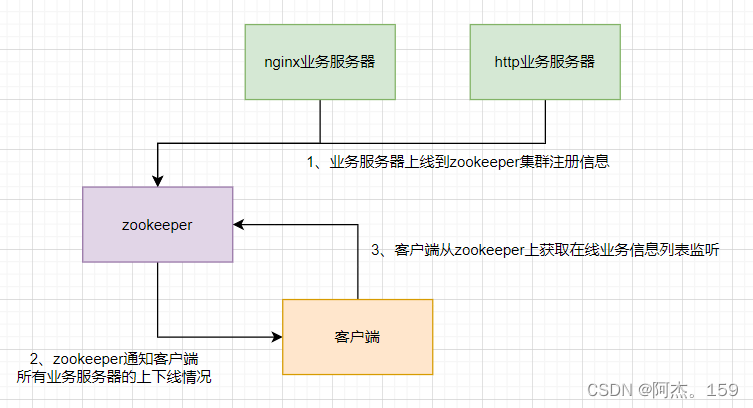
4、zookeeper应用场景及选举机制
应用场景:
统一命名服务、统一配置管理、统一集群管理、服务节点动态上下线、软负载均衡
选举机制:
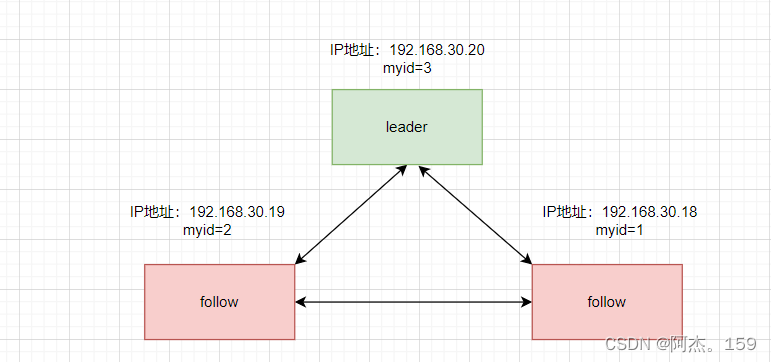
第一次启动选举机制:
服务器1启动,自己投自己一票myid(可以自己设置集群中不能重复)为1,没有明确的leader处于locking状态
服务器2启动,自己投自己一票myid为2,服务器1因为2的myid大于1则投2一票,处于locking状态
服务器3启动,自己投自己一票myid为3,服务器1和2myid小则投服务器3,服务器3成为leader
服务器4启动,已经有leader则加入leader中成为从follower。
非第一次启动选举机制:
SID:服务器id,用来表示一台zookeeper集群汇总的机器,每台机器不能重复和myid一致
ZXID:事务id,ZXID是一个事务id,用来标识服务器状态的变更。与服务器对客户端更新请求处理逻辑速度有关
Epoch:每个leader任期的代号,没有leader时同一轮投票过程中的值是一样的,每投票一次这个数据增加
①、Epoch值大的直接胜出成为leader
②、epoch值相同事务id大的胜出
③、事务id相同则服务器id大的胜出
5、zookeeper集群部署
①实验环境
②安装zookeeper
三台机器执行:
systemctl stop firewalld.service
setenforce 0
#关闭防火墙和selinux
cd /opt
tar -zxvf apache-zookeeper-3.5.7-bin.tar.gz
mv apache-zookeeper-3.5.7-bin /usr/local/zookeeper-3.5.7
#将zookeeper压缩包放入/opt目录并解压,解压后的文件移动到/usr/local下改名为zookeeper-3.5.7
cd /usr/local/zookeeper-3.5.7/conf/
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
#进入配置文件路径备份配置文件然后修改配置文件,内容如下
tickTime=2000
#通信心跳时间,Zookeeper服务器与客户端心跳时间,单位毫秒
initLimit=10
#Leader和Follower初始连接时能容忍的最多心跳数(tickTime的数量),这里表示为10*2s
syncLimit=5
#Leader和Follower之间同步通信的超时时间,这里表示如果超过5*2s,Leader认为Follwer死掉,并从服务器列表中删除Follwer
dataDir=/usr/local/zookeeper-3.5.7/data
#修改,指定保存Zookeeper中的数据的目录,目录需要单独创建
dataLogDir=/usr/local/zookeeper-3.5.7/logs
#添加,指定存放日志的目录,目录需要单独创建
clientPort=2181
#客户端连接端口
server.1=192.168.30.18:3188:3288
server.2=192.168.30.19:3188:3288
server.3=192.168.30.20:3188:3288
#添加集群信息
erver.A=B:C:D
#A是一个数字,表示这个是第几号服务器。集群模式下需要在zoo.cfg中dataDir指定的目录下创建一个文件myid,这个文件里面有一个数据就是A的值,Zookeeper启动时读取此文件,拿到里面的数据与zoo.cfg里面的配置信息比较从而判断到底是哪个server。
#B是这个服务器的地址。
#C是这个服务器Follower与集群中的Leader服务器交换信息的端口。
#D是万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
mkdir /usr/local/zookeeper-3.5.7/data
mkdir /usr/local/zookeeper-3.5.7/logs
#创建指定的数据存放位置和日志存放位置
echo 1 > /usr/local/zookeeper-3.5.7/data/myid
#192.168.30.18上执行此命令,规划时此机器的myid为1
echo 2 > /usr/local/zookeeper-3.5.7/data/myid
#192.168.30.19上执行此命令,规划时此机器的myid为2
echo 3 > /usr/local/zookeeper-3.5.7/data/myid
#192.168.30.20上执行此命令,规划时此机器的myid为3
vim /etc/init.d/zookeeper
#!/bin/bash
#chkconfig:2345 20 90
#description:Zookeeper Service Control Script
ZK_HOME='/usr/local/zookeeper-3.5.7'
case $1 in
start)
echo "---------- zookeeper 启动 ------------"
$ZK_HOME/bin/zkServer.sh start
;;
stop)
echo "---------- zookeeper 停止 ------------"
$ZK_HOME/bin/zkServer.sh stop
;;
restart)
echo "---------- zookeeper 重启 ------------"
$ZK_HOME/bin/zkServer.sh restart
;;
status)
echo "---------- zookeeper 状态 ------------"
$ZK_HOME/bin/zkServer.sh status
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
#三台机器配置开启zookeeper脚本,#脚本内容为当执行脚本位置变量1为star,stop,restart,status,*时执行对应的服务管理脚本(安装时自带管理服务的脚本)
chmod +x /etc/init.d/zookeeper
chkconfig --add zookeeper
#设置开机自启并使用service管理服务
service zookeeper start
service zookeeper status
#开启并查看服务状态二、消息队列kafka
1、为什么要有消息队列
高并发环境下,同步请求来不及处理,请求往往会发生阻塞,比如大量请求并发访问数据库,导致行锁表,最后请求线程堆积过多,引发雪崩。
雪崩:高并发情况下redis服务器无法同时处理大量请求,导致rdis崩溃直接查询数据库。
2、使用消息队列的好处
1)解耦
允许独立的扩展或修改两边的处理过程,只有确保他们遵守同样的接口约束
2)可恢复性
系统一部分组件失效不会影响整个系统,消息队列降低了过程的耦合度,即使一个处理消息的进程挂掉了,加入队列中的消息仍然可以在系统恢复后被处理。
3)缓存
有助于控制和优化数据流经过的速度,解决生成消费信息的处理速度不一致的情况
4)灵活性&峰值处理能力
能够使关键组件顶住突发的访问压力,而不会因为突发的超负荷的请求而完全崩溃
5)异步通信
允许用户把一个消息加入队列,但并不立即处理它。想向队列中放多少消息就放多少,在需要的时候去处理他们
3、消息队列的2种模式
点对点(一对一):消费者主动拉取数据,消费者将生产者生成的数据拉取完成则消费者将消息删除。
发布/订阅模式(一对多也称为观察者模式):消费者消费数据之后不会清除消息
1)、生产者发布消息到topic,同时有多个消费者
2)、观察者(实时观察消费者消费能力即处理数据能力)观察整个消息队列,根据消费者的能力配置,发送数据给消费者
3、kafka简介
kafka:是一个分布式的,支持分区的,多副本基于发布/订阅模式的消息队列(MQ message quene),主要用于日志和大数据实时处理
4、kafka特点
1)高吞吐量每秒钟可以处理几十万消息,延迟最低只是几毫秒。
2)持久性、可靠性,完善的消息存储机制存储到磁盘,保证数据的高效和持久化
3)分布式,生产者数据会存放在所有机器上,挂一台数据不会丢失。
4)容错性,允许集群中节点失败,允许副本-1个节点失败
5)高并发,支持千个客户端同时读写
5、kafka系统架构名词介绍
①broker:一台kafka服务器就是一个broker。一个集群由多个broker组成,一个broker可以容纳多个topic
②Produer:生产者。也就是写入消息的一方,将消息写入broker中
③Consumer:消费者。也就是读取消息的一方,从broker中读取消息
④Zookeeper:kafka使用zookeeper来管理集群的元数据,以及控制器的选举等操作。
⑤topic:主题。每一个消息都属于某个主题,kafka通过主题来划分消息,是一个逻辑上的分类
⑥partition:即分区
同一个主题下的消息还可以继续分成多个分区,一个分区只属于一个主题,kafka只保证partition中的数据是有序的,不保证topic中的不通partition数据是有序的,每个topic至少有一个partition,每个 partition 中的数据使用多个 segment 文件存储。
partition数据路由规则:
1.指定partition,则直接使用、 2.未指定partition但指定了key,根据key取模选择partition、3.都未指定则轮询选择partition
分区的原因:为什么在topic下有多个partition?
1.方便集群中扩展,每个partition可以通过调整以适应它所在的机器,而一个topic又可以有多个Partition组成,因此整个集群就可以适应任意大小的数据了;
2.可以提高并发,因为可以以Partition为单位读写了;
⑦Replica:副本。一个分区可以有多个副本来提高容灾性,一般是设置一个分区2个副本
⑧Offset:偏移量。消费者存在zookeeper上的记录自己访问到什么地方
⑨leader负责读写,follow只负责复制和备份
6、Kafka架构及流程
1)、生产者生产数据传给broker即kafka服务器集群
2)、kafka集群将数据存储在topic主题中,每个topic主题中有多个分片(分片做了备份在其他topic)
3)、分片中存储数据,kafka集群注册在zookeeper中,zookeeper通知消费者kafka服务器在线列表
4)、消费者收到zookeeper通知的在线列表,从broker中拉取数据
5)、消费者保存偏移量到zookeeper中,以便记录自己宕机消费到什么地方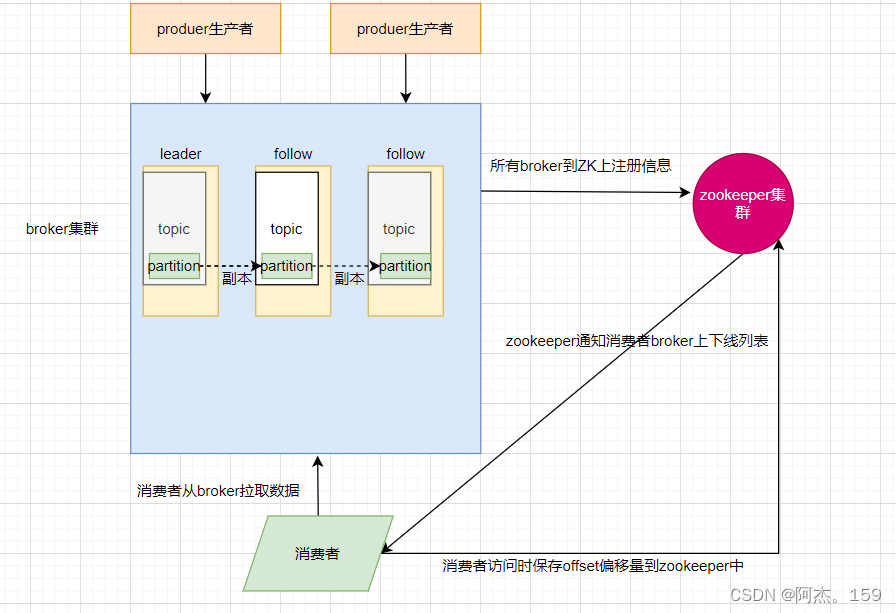
7、kafka集群部署
基于zookeeper的三台机器操作:
cd /opt/
tar zxvf kafka_2.13-2.7.1.tgz
mv kafka_2.13-2.7.1 /usr/local/kafka
#kafka安装包上传到/opt解压并移动到/usr/local中改名为kafka
#下载地址wget https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.7.1/kafka_2.13-2.7.1.tgz
cd /usr/local/kafka/config/
cp server.properties server.properties.bak
vim server.properties
#kafka主配置文件备份并编辑,内容如下
broker.id=0
#21行,broker的全局唯一编号,每个broker不能重复,因此要在其他机器上配置 broker.id=1、broker.id=2
listeners=PLAINTEXT://192.168.10.17:9092
#31行,指定监听的IP和端口,如果修改每个broker的IP需区分开来,也可保持默认配置不用修改
num.network.threads=3
#42行,broker 处理网络请求的线程数量,一般情况下不需要去修改
num.io.threads=8
#45行,用来处理磁盘IO的线程数量,数值应该大于硬盘数
socket.send.buffer.bytes=102400
#48行,发送套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#51行,接收套接字的缓冲区大小
socket.request.max.bytes=104857600
#54行,请求套接字的缓冲区大小
log.dirs=/usr/local/kafka/logs
#60行,kafka运行日志存放的路径,也是数据存放的路径
num.partitions=1
#65行,topic在当前broker上的默认分区个数,会被topic创建时的指定参数覆盖
num.recovery.threads.per.data.dir=1
#69行,用来恢复和清理data下数据的线程数量
log.retention.hours=168
#103行,segment文件(数据文件)保留的最长时间,单位为小时,默认为7天,超时将被删除
log.segment.bytes=1073741824
#110行,一个segment文件最大的大小,默认为 1G,超出将新建一个新的segment文件
zookeeper.connect=192.168.30.18:2181,192.168.30.19:2181,192.168.30.20:2181
#123行,配置连接Zookeeper集群地址,保存后退出
vim /etc/profile
#编辑全局变量文件,添加kafka全局环境变量,内容如下
export KAFKA_HOME=/usr/local/kafka
export PATH=$PATH:$KAFKA_HOME/bin
#export全局生效,修改完后保存退出
source /etc/profile
#刷新全局配置变量文件
#编写管理kafka服务的脚本
vim /etc/init.d/kafka
#!/bin/bash
#chkconfig:2345 22 88
#description:Kafka Service Control Script
KAFKA_HOME='/usr/local/kafka'
case $1 in
start)
echo "---------- Kafka 启动 ------------"
${KAFKA_HOME}/bin/kafka-server-start.sh -daemon ${KAFKA_HOME}/config/server.properties
;;
stop)
echo "---------- Kafka 停止 ------------"
${KAFKA_HOME}/bin/kafka-server-stop.sh
;;
restart)
$0 stop
$0 start
;;
status)
echo "---------- Kafka 状态 ------------"
count=$(ps -ef | grep kafka | egrep -cv "grep|$$")
if [ "$count" -eq 0 ];then
echo "kafka is not running"
else
echo "kafka is running"
fi
;;
*)
echo "Usage: $0 {start|stop|restart|status}"
esac
脚本内容为当执行脚本位置变量1为star,stop,restart,status,*时执行对应的服务管理脚本(安装时自带管理服务的脚本)
chkconfig --add kafka
#设置开机自启并使用service管理服务
service kafka start
service kafka status
#开启并查看服务状态
###随便一台机器执行:
kafka-topics.sh --create --zookeeper 192.168.30.18:2181,192.168.30.19:2181,192.168.30.20:2181 --replication-factor 2 --partitions 3 --topic test
#kafka创建topic即主题test
#--zookeeper:定义 zookeeper 集群服务器地址,如果有多个 IP 地址使用逗号分割,一般使用一个 IP 即可
#--replication-factor:定义分区副本数,1 代表单副本,建议为 2
#--partitions:定义分区数
#--topic:定义 topic 名称
kafka-topics.sh --list --zookeeper 192.168.30.18:2181,192.168.30.19:2181,192.168.30.20:2181
#查看当前服务器中的所有 topic
kafka-topics.sh --describe --zookeeper
192.168.30.18:2181,192.168.30.19:2181,192.168.30.20:2181
#查看某个 topic 的详情
kafka-console-producer.sh --broker-list 192.168.30.18:9092,192.168.30.19:9092,192.168.30.20:9092 --topic test
#进入test的topic主机发布消息,输入完命令后输入123456
kafka-console-consumer.sh --bootstrap-server 192.168.30.18:9092,192.168.30.19:9092,192.168.30.20:9092 --topic test --from-beginning
#在另外一台主机输入消费信息的命令,查看是否可以收到发布的消息
#--from-beginning:会把主题中以往所有的数据都读取出来,即从最开始读取
kafka-topics.sh --zookeeper 192.168.30.18:2181,192.168.30.19:2181,192.168.30.20:2181 --alter --topic test --partitions 6
#修改名为test的topic主题的分区数
kafka-topics.sh --delete --zookeeper 192.168.30.18:2181,192.168.30.19:2181,192.168.30.20:2181 --topic test
#删除名为test的topic
8、kafka报错分析
[2023-04-10 20:01:57,373] WARN [Producer clientId=console-producer] Bootstrap broker 192.168.30.18:2181 (id: -1 rack: null) disconnected (org.apache.kafka.clients.NetworkClient)
[2023-04-10 20:01:57,475] WARN [Producer clientId=console-producer] Bootstrap broker 192.168.30.19:2181 (id: -2 rack: null) disconnected (org.apache.kafka.clients.NetworkClient)
[2023-04-10 20:01:57,577] WARN [Producer clientId=console-producer] Bootstrap broker 192.168.30.20:2181 (id: -3 rack: null) disconnected (org.apache.kafka.clients.NetworkClient)
[2023-04-10 20:01:57,679] WARN [Producer clientId=console-producer] Bootstrap broker 192.168.30.18:2181 (id: -1 rack: null) disconnected (org.apache.kafka.clients.NetworkClient)
[2023-04-10 20:01:57,782] WARN [Producer clientId=console-producer] Bootstrap broker 192.168.30.19:2181 (id: -2 rack: null) disconnected (org.apache.kafka.clients.NetworkClient)
###报错信息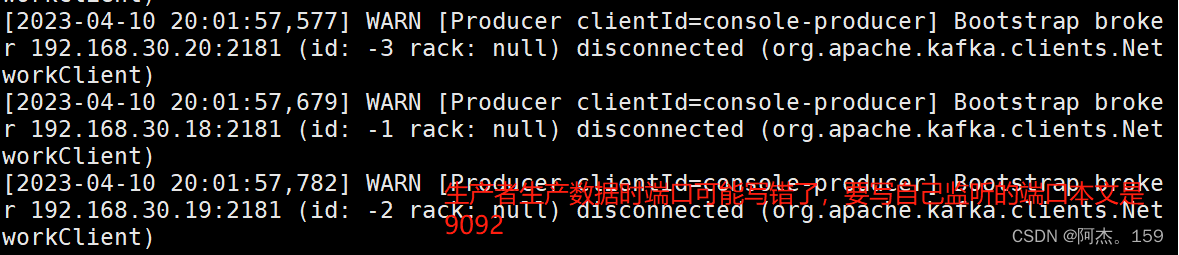
ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: Replication factor: 2 larger than available brokers: 1(kafka.admin.TopicCommand$)
##三台kafka只起来一台,查看是否配置文件中的broker.id相同了,或者其他俩台防火墙启动错误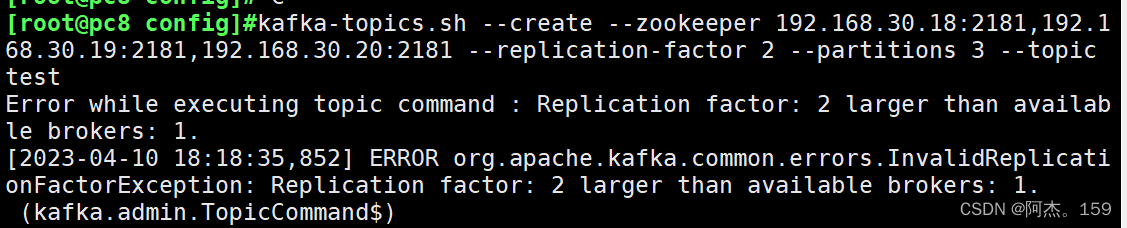
安装zookeeper和kafka后启动报错,查看日志显示有no route host 没有路由等信息,则表示是三台中有防火墙未关闭