在之前我们学习了如何用Pytorch去导入我们的数据和数据集,并且对数据进行预处理。接下来我们就需要学习如何利用Pytorch去构建我们的神经网络了。
目录
基本网络框架Module搭建
卷积层
从conv2d方法了解原理
从Conv2d方法了解使用
池化层
填充层
非线性层
线性层
基本网络框架Module搭建
Pytorch里面有一个工具包位于torch下面的nn,这里的nn代表的是Netural Network神经网络,这就表示这个包用于我们创建基本的神经网络。
而关于Pytorch里面的神经网络结构、方法和使用这些方法的教程都可以在Pytorch官网里面找到:
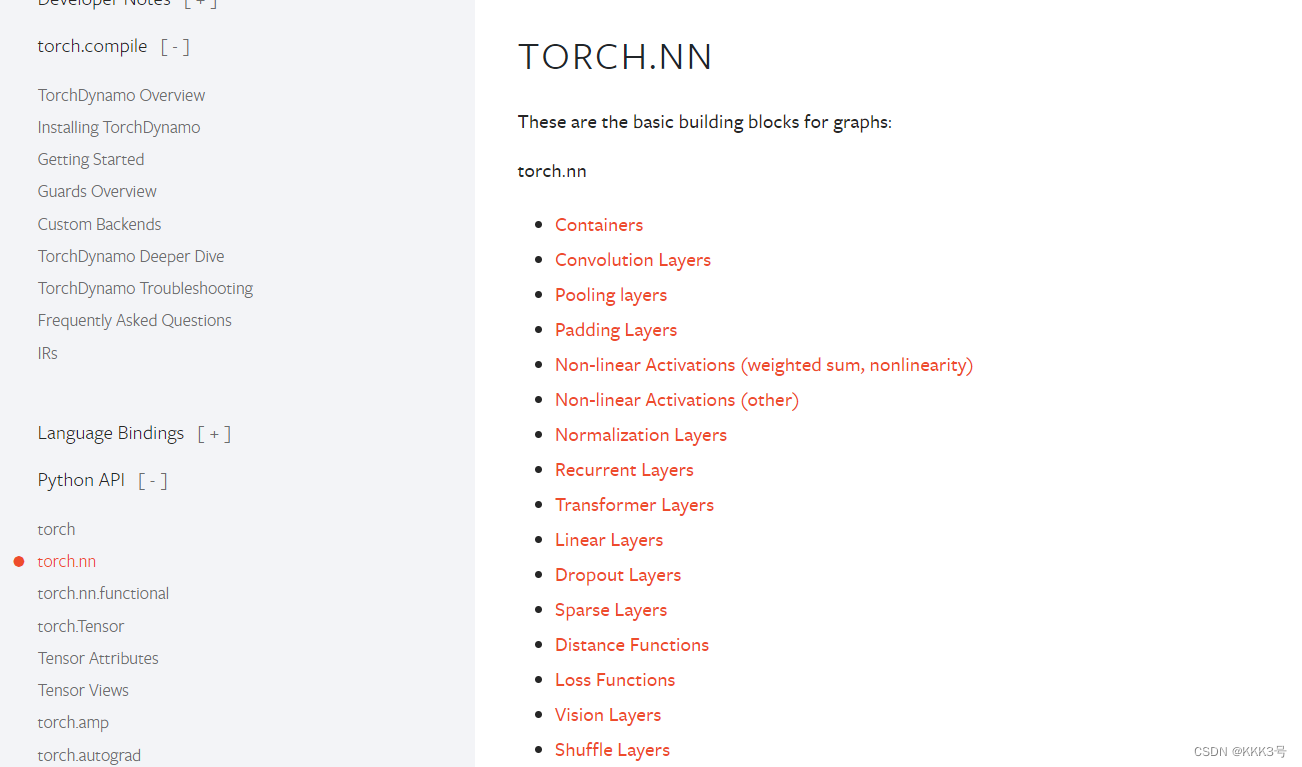
接下来我们看看如何构建一个最简单的神经网络,我要它实现的功能是将我的输入矩阵每一个元素都扩大十倍。而看了Module类的介绍文档后我们知道我们要想创建一个新的Module类型的神经网络首先需要创建一个新的类Mymodule,并且其继承自torch.nn里面的Module类。这里我们根据我们的需要,对我们新创出来的类进行方法重写:
import torch
from torch import nn
class Mymodule(nn.Module):
def __init__(self) -> None:
super().__init__()
def forward(self, x):
return x * 10
Module = Mymodule()
x = torch.tensor([[1.0, 2.0, 3.0], [1.0, 2.0, 3.0], [1.0, 2.0, 3.0]])
print('input:', x)
print('output:', Module(x))可以看到这样一个简单的神经网络就构建好了

卷积层
接下来我们来看看如何构建一个卷积层。假设现在我们有一个二维的矩阵,这个矩阵的大小是5x5,而我们卷积层的作用是利用一个卷积核(kernel)来提取这个矩阵里面的关键特征,常见的方法就是用这个卷积核去和输入的二维矩阵中对应每一项进行乘积操作,并且将其单次比较的所有乘积求和就是新的输出矩阵对应位置的数值。它表示输入矩阵在该范围(卷积核大小)内与卷积核所表示的特征的关联程度,这个位置的输出越大,表示关联程度越大。同时它也会剔除一些与我们判断无关的信息,下图是我在网上找到有关卷积层的功能的图片,左边的就是输入,中间是卷积核,而右边就是输出。

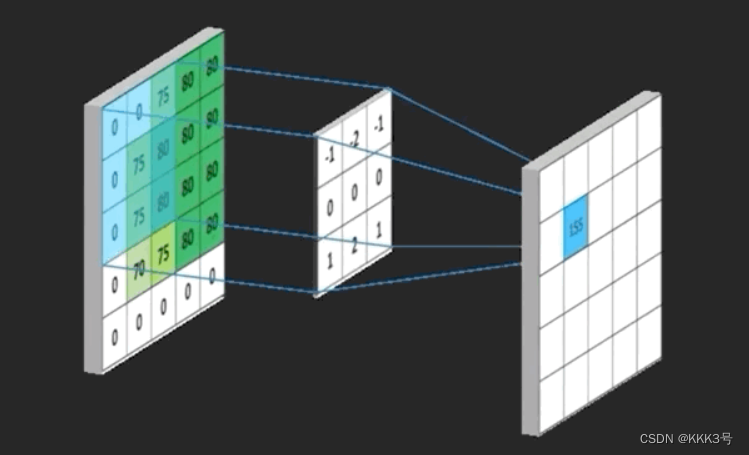
从conv2d方法了解原理
关于卷积实现的基本原理模型就是位于torch.nn.functional下面的这些conv1d、conv2d、conv3d方法, 不过我们常用的还是一维和二维的这些卷积函数。
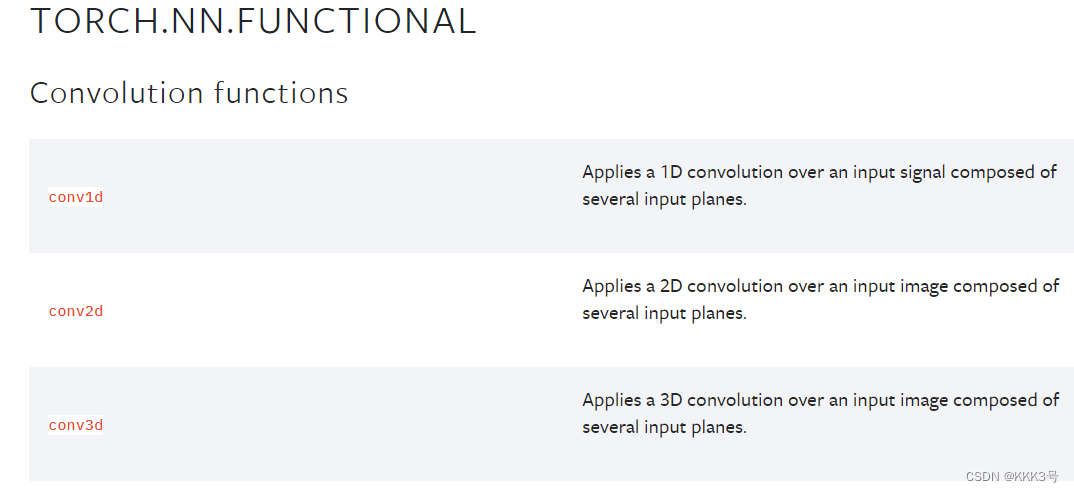
假如我们以使用一个二维的卷积方法为例,发现它需要我们输入一些参数,比如说input输入、weight权重、卷积核、bias偏置、stride步长等等这些参数。
输入
首先我们来看一下input,我们可以看到它需求的input是一个含有4种形状描述的tensor,而我们常见的二维tensor就是宽和高两个参数,那就表示如果我们要想使用卷积函数,就需要对我们的tensor进行形状转换。
![]()
其中torch为我们提供了tensor形状转换的方法,就是reshape。
那我们就把一个二维的tensor变量的形状重塑为符号题目要求的输入,不难发现我们的一个二维矩阵的前面两个参数minbatch一批最小的数量和in_channels通道数都是1,而后面的两个高和宽就分别为5和5即可。
x = torch.tensor([[1.0, 2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, 4.0, 5.0]
])
x = torch.reshape(x, (1,1,5,5))
print(x.shape)卷积核
接下来我们来看看卷积核怎么去处理,我们可以通过下面的图片知道权重需要的也是一个4参数形状的tensor,并且它的第一个参数为输出的通道数,第二个为输入的通道数除以groups组数,将整体卷积细化为分组卷积,然后后面两个为高和宽。
![]()
那么我们就可以对我们的卷积核进行处理了:
kernel = torch.tensor([[1.0, 1.0, 1.0],
[1.0, 1.0, 1.0],
[1.0, 1.0, 1.0]])
kernel = torch.reshape(kernel, (1, 1, 3, 3))步长
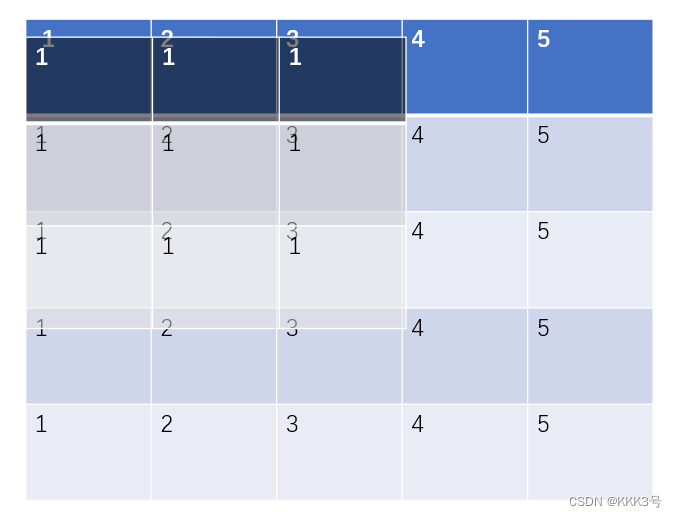
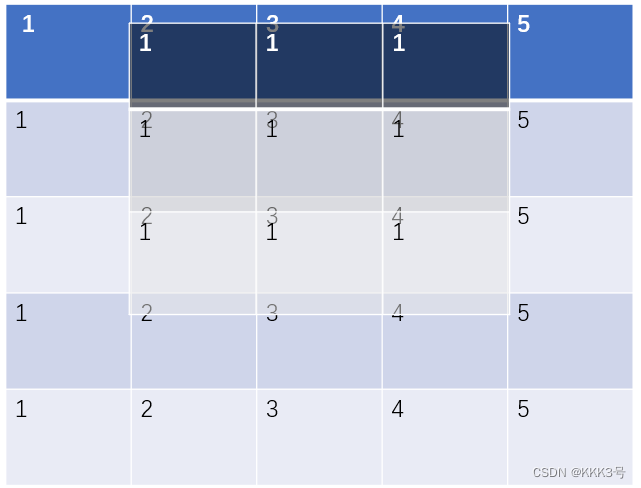
然后就是stride,这个表示kernel映射完一次后移动(向右或者向下)的步数,默认为1。它也可是同时设置宽和高方向的移动步长。
![]()
下图为步长为1和步长为2的区别:

填充
padding是决定是否需要向我们的输入矩阵进行填充,以此进行大小变换的参数,如果我们让padding等于1,那就默认让我们矩阵外周再增加一层,而且这一层填充的的默认数值就是0,如果我们想要进行修改,可以通过padding_mode这个参数进行设置。如果我们让padding等于2,那么同理它也会将我们的输入矩阵外向扩展两圈。
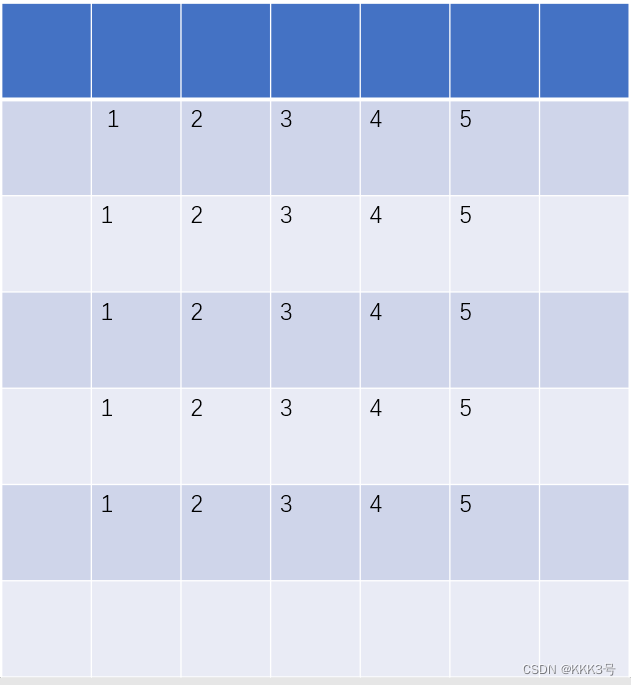
了解完几个卷积层常用到的参数之后,我们可以尝试使用一下conv2d这个函数进行卷积操作了。下面就是利用模型对卷积层进行一次封装运算:
import torch
from torch import nn
class Mymodule(nn.Module):
def __init__(self) -> None:
super().__init__()
def forward(self, x, kernel):
return torch.nn.functional.conv2d(x, kernel, stride=1)
Module = Mymodule()
x = torch.tensor([[1.0, 2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, 4.0, 5.0]
])
kernel = torch.tensor([[1.0, 1.0, 1.0],
[1.0, 1.0, 1.0],
[1.0, 1.0, 1.0]])
x = torch.reshape(x, (1, 1, 5, 5))
kernel = torch.reshape(kernel, (1, 1, 3, 3))
print(Module(x, kernel))输出结果:

从Conv2d方法了解使用
与conv2d功能类似类似,只不过conv2d是可以直接使用的工具,而Conv2d是制造工具的模板。在nn包中还另外封装好了一个我们平时更常用到的卷积层函数Conv2d,这个在nn包下面的Conv2d比起之前functional下面的conv2d方法更加普遍被我们使用,因为它的封装程度比较好。我们可以打开Pytorch官网大致了解一下它的参数:

不难看出它的参数列表和conv2d差不多,有区别的是Conv2d的第一个和第二个参数需要的是in_channels和out_channels,它们分别代表着输入的通道数和输出到通道数。我们利用不同数目的卷积核即可对应得到不同数目的输出通道,如下图就是2个out_channels的输出。
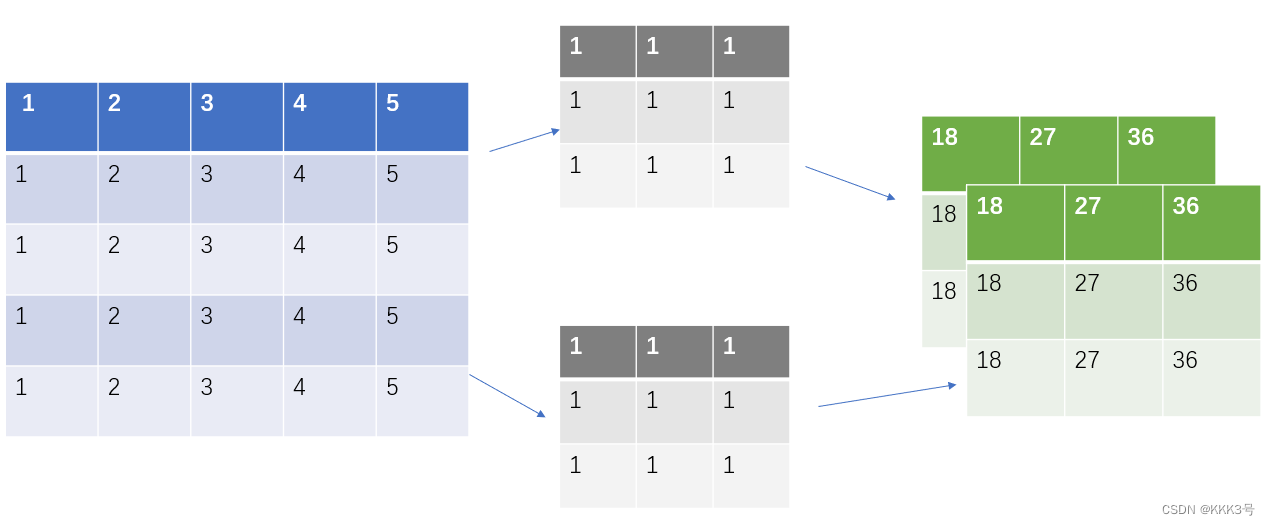
它的使用方式和前面conv2d的方法使用方式类似,下面是一个下载数据集并且使用卷积函数对里面的图片数据进行通道扩展的例子的过程:
import torch
from torch import nn
import torchvision
from torch.utils.data import DataLoader
tools = torchvision.transforms.Compose([torchvision.transforms.ToTensor()])
dataset = torchvision.datasets.MNIST('./dataset', train=True, transform=tools, download=True)
dataloader = DataLoader(dataset=dataset, batch_size=5, shuffle=True, drop_last=True)
class Module(torch.nn.Module):
def __init__(self) -> None:
super().__init__()
self.conv2d = nn.Conv2d(in_channels=1, out_channels=3, kernel_size=(3,3), stride=1, padding=0)
def forward(self, x):
x = self.conv2d(x)
return x
module = Module()
for data in dataloader:
imgs, target = data
output = module(imgs)
print(imgs.shape)
print(output.shape)我们可以很明显看到输入的每一个数据和输出的每一个数据的大小都发生了变化:从输入到单通道变成了输出到三通道,同时宽高也变小了,但是每个batch_size都保持是5没变

池化层
在学习池化层之前我们需要知道池化的作用是什么,以最池化方式为最大池化方法为例。池化的目的是从输入中的数据中提取出其中符合特征的一部分保留,以达到在减少数据量的同时保持了最能表现输入特征的数据。
之前我们学习了卷积层,卷积层是利用一个卷积核筛选出输入数据中各部分对于某个特征的符合程度,即减小了数据的大小,又能够准确描绘出各部分对于某个特征的符合程度。而卷积层输出的参数一般来说是一个tensor,这个tensor中会包含了各部分对于某个特征的符合程度(有大有小),而我们池化层一般就跟在卷积层后面,它要做的工作是从卷积层输出的tensor提取出那些符合特征的部分,而剔除掉那些不符合的部分,达到保留原先输入的特征同时又减少了数据量的目的。
查看Pytorch的官网可知,池化的参数一般有下面几个:

其中kernel_size就是我们匹配的池化核的大小,而stride就是步长,padding也是是否需要外扩,dilation是是否设置有空隙的kernel匹配核。这里比较新的是ceil_mode,这个表示我们池化数据对比过程中如果kernel的右端超出了输入tensor的右端是否保留,True则为保留,这和我们之前在卷积层时一律不保留就不同了。

当ceil_mode模式为True时,我们一律设置stride=3,结果是:
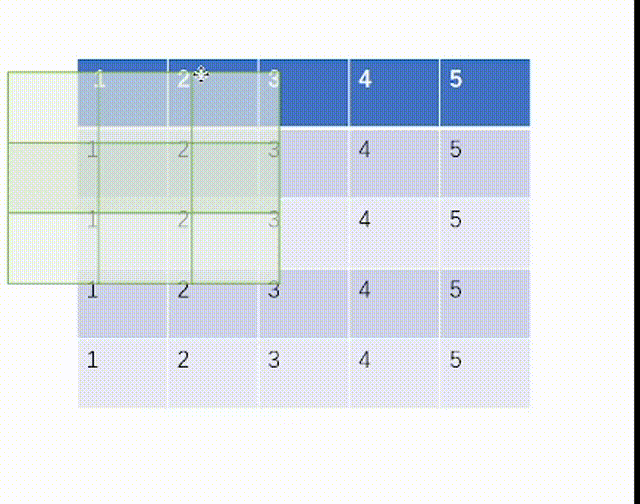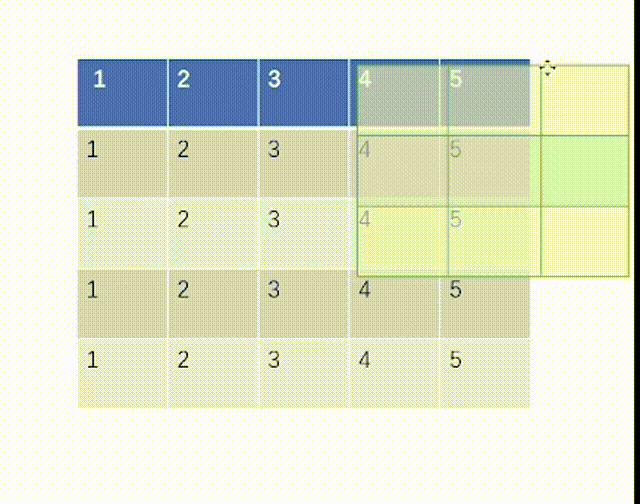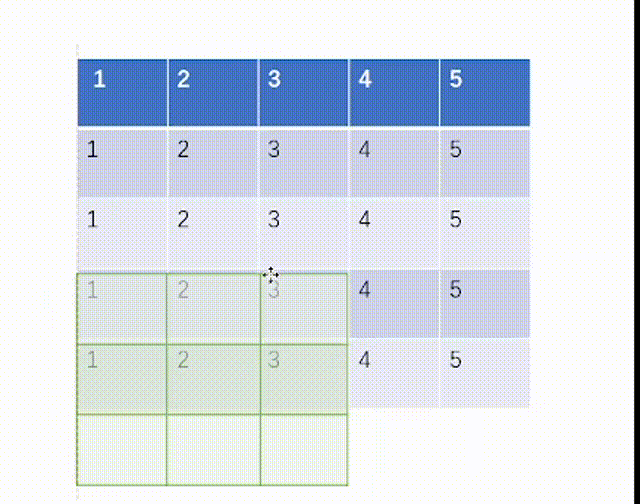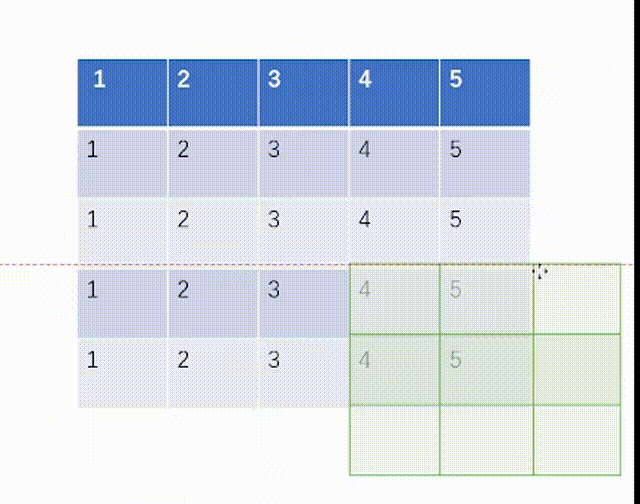
当ceil_mode模式为False时,我们一律设置stride=3,结果是:
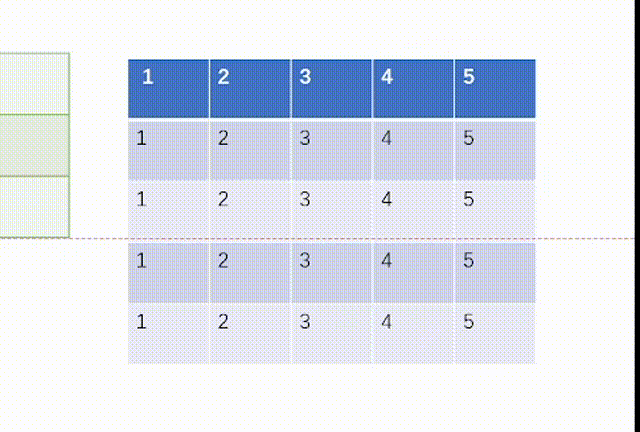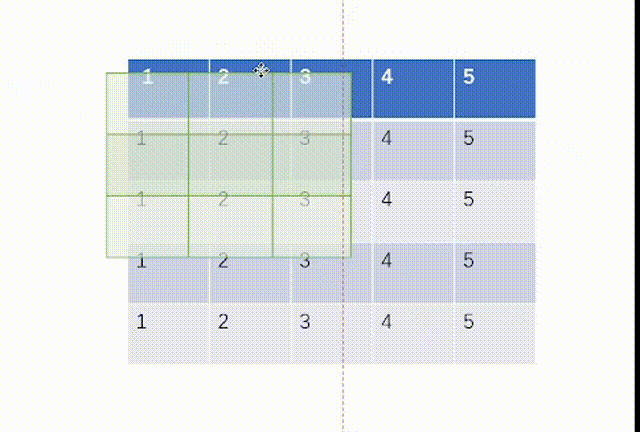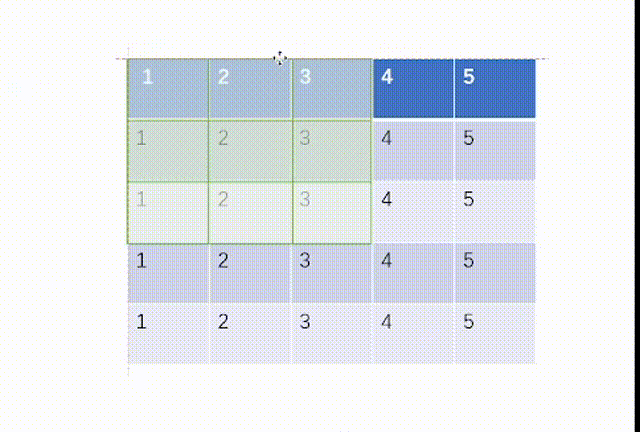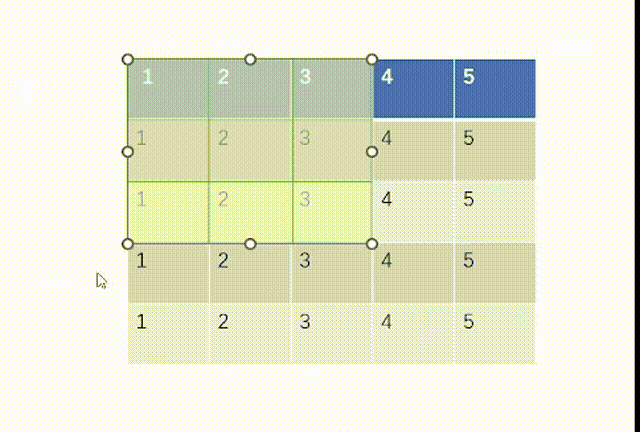
而我们用代码处理如下:不过这里要注意tensor里面要用浮点数torch.float32,并且因为MaxPool2d函数的特性,我们需要对输入x进行维度重塑,一批次1个,通道为1,高和宽均为5。但是值得注意的一点是池化后channel是不会变的,所有我们转化回3通道图片不需要reshape。

import torch
from torch.nn import Module
class Mymodule(Module):
def __init__(self) -> None:
super().__init__()
self.poolmax = torch.nn.MaxPool2d(kernel_size=(3,3), stride=3, padding=0, ceil_mode=True)
def forward(self, x):
return self.poolmax(x)
x = torch.tensor([[1.0, 2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, 4.0, 5.0]
], dtype=torch.float32)
mymodule = Mymodule()
x = torch.reshape(x, [-1, 1, 5, 5])
x = mymodule(x)
print(x)
下面是ceil_mode为True的输出:

下面是ceil_mode为False的输出:
![]()
填充层
填充层也就是padding layer,它的主要作用是对我们传入的输入tensor进行填充,其功能就类似于我们池化或者卷积层中的padding,不过它可以填充不同的常数,总之这是一个我们可能平时用得比较少的层,有需要我们可以再去官网文档那里查看👉https://pytorch.org/docs/stable/nn.html#padding-layers。
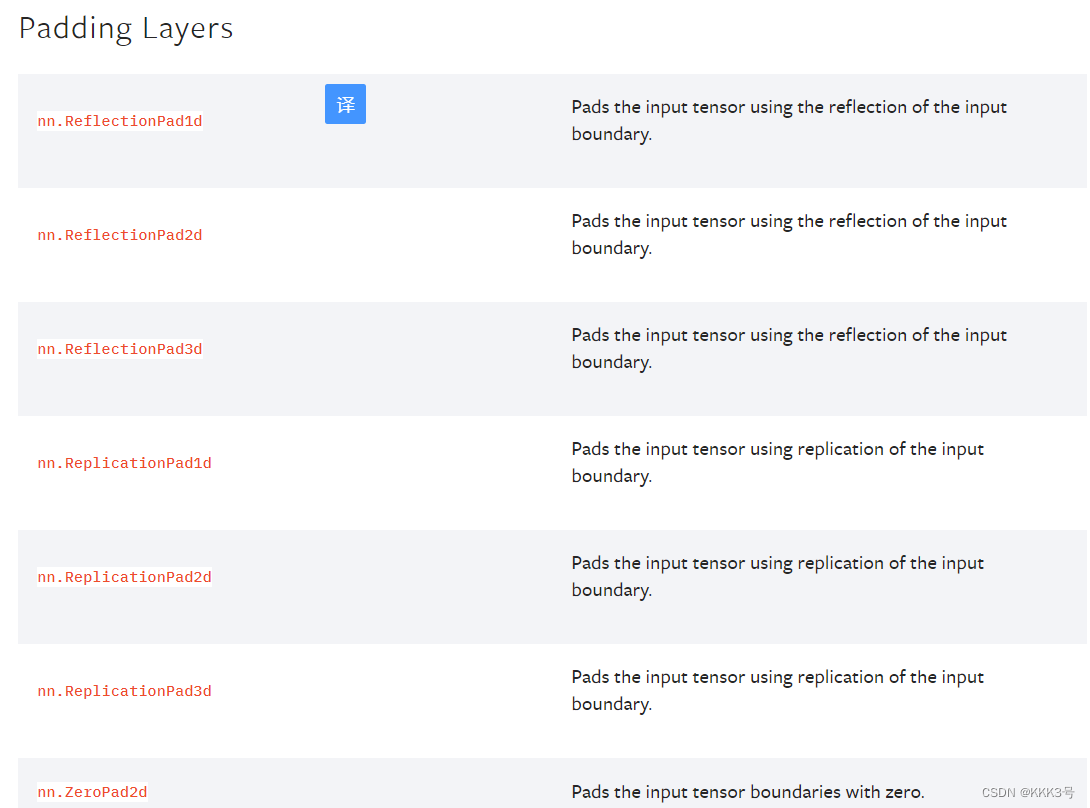
非线性层
因为线性层和线性层叠加最终还是会变成线性层,这样就会造成对一些非线性问题束手无策的问题,只能表示特征值和目标值之间的简单关系。正是因为线性层无法适用于去拟合我们日常生活中的任意非线性问题,所以引入了非线性层进行数据整合和解决这些痛点。
而我们要想进行非线性变换就需要使用到一些激活函数,利用这些激活函数可以去拟合这些非线性问题。常见的激活函数有Relu、sigmoid等。

Relu和Sigmoid的函数如下面左右图所示,通过多个这种函数我们可以大致拟合出任意一个我们需要的非线性函数。
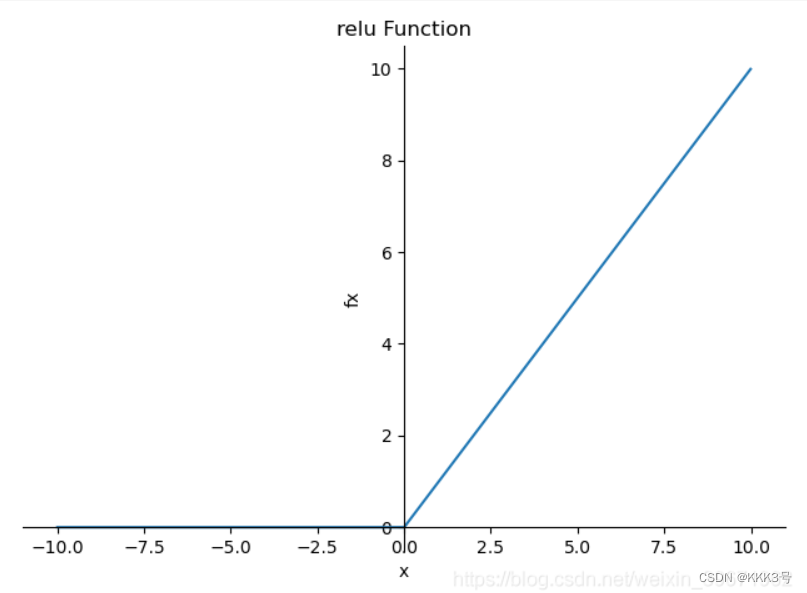

下面我们就来看看如何用代码来实现非线性层,主要还是看两个常用的激活函数:ReLU和Sigmoid。具体使用就是调用nn下面的ReLU函数和Sigmoid函数,不过值得注意的是ReLU方法有一个参数inplace,它代表的意思是在经过这个神经网络后原来的输入会不会被修改,如果会就设置为True,不会则设置为False。这个为了保持我们数据的完整性我们一般设置为False,默认情况也是为False。
import torch
from torch.nn import Module
class Mymodule(Module):
def __init__(self) -> None:
super().__init__()
self.relu = torch.nn.ReLU(inplace=False)
def forward(self, x):
return self.relu(x)
x = torch.tensor([[-1.0, 2.0, 3.0, 4.0, 5.0],
[1.0, -2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, -3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, -4.0, 5.0],
[1.0, 2.0, 3.0, 4.0, -5.0]
], dtype=torch.float32)
mymodule = Mymodule()
x = torch.reshape(x, [-1, 1, 5, 5])
y = mymodule(x)
下面就是x矩阵经过使用ReLU的非线性层后输出的矩阵:

线性层
线性层(Linear Layer)又称为全连接层,这层的特点是该层中输出的每一个节点都和上一层的所有的输入节点相连。而线性层的其中一个很大的作用就是将输入函数进行线性组合,从而获取到我们所需要的任意的非线性函数。

前面我们提到,非线性层的激活函数一个很大的作用就是可以作为构造非线性函数的部件,即如何去组合这些非线性的激活函数的任务就交给了线性层。线性层模型的参数有三个部分,前面两个是每个输入的样本的大小和每一个输出的大小,而bias就是是否添加偏置。
同时我们对于线性层的输入一般是将输入的矩阵先转化为(1,1,1,n)的矩阵,然后再输入到线性层中,经过线性层的转换获取到我们希望得到的输出(1,1,1,m)。或者我们也可以利用torch下面的flatten函数来对一个tensor进行展平。

下面是我们将一个四维(-1,1,5,5)的矩阵通过线性层转化为一个1x5的矩阵的代码:
import torch
from torch.nn import Module
class Mymodule(Module):
def __init__(self) -> None:
super().__init__()
self.Linear = torch.nn.Linear(25, 5)
def forward(self, x):
return self.Linear(x)
x = torch.tensor([[-1.0, 2.0, 3.0, 4.0, 5.0],
[1.0, -2.0, 3.0, 4.0, 5.0],
[1.0, 2.0, -3.0, 4.0, 5.0],
[1.0, 2.0, 3.0, -4.0, 5.0],
[1.0, 2.0, 3.0, 4.0, -5.0]
], dtype=torch.float32)
mymodule = Mymodule()
x = torch.reshape(x, [1, 1, 1, -1])
x = torch.flatten(x)
y = mymodule(x)
print(y.shape)经过线性层我们实现输入线性的组合:

参考资料:
https://wenku.baidu.com/view/c4ec681064ec102de2bd960590c69ec3d5bbdb84.html?_wkts_=1679107455557&bdQuery=inchannels%2Fgroups