原文:Hands-on unsupervised learning with Python
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
不要担心自己的形象,只关心如何实现目标。——《原则》,生活原则 2.3.c
一、无监督学习入门
在本章中,我们将介绍基本的机器学习概念,即 ,前提是您具有一些统计学习和概率论的基本知识 。 您将了解机器学习技术的使用以及逻辑过程,这些逻辑过程将增进我们对数据集的性质和属性的了解。 整个过程的目的是建立可支持业务决策的描述性和预测性模型。
无监督学习旨在为数据探索,挖掘和生成提供工具。 在本书中,您将通过具体的示例和分析来探索不同的场景,并且将学习如何应用基本且更复杂的算法来解决特定问题。
在本介绍性章节中,我们将讨论:
- 为什么我们需要机器学习?
- 描述性,诊断性,预测性和规范性分析
- 机器学习的类型
- 我们为什么要使用 Python?
技术要求
本章中提供的代码要求:
- Python3.5+(强烈建议您使用 Anaconda 发行版)
- 库:
- SciPy 0.19+
- NumPy 1.10+
- Scikit-Learn 0.19+
- Pandas 0.22+
- Matplotlib 2.0+
- Seaborn 0.9+
可以在 GitHub 存储库中找到示例。
为什么我们需要机器学习?
数据无处不在。 此刻,成千上万的系统正在收集构成特定服务历史的记录,以及日志,用户交互和许多其他上下文相关元素。 仅十年前,大多数公司甚至无法有效地管理其数据的 1%。 因此,数据库会被定期删除,并且只有重要数据才能保留在永久存储服务器中。
相反,如今,几乎每个公司都可以利用可扩展的云基础架构,以应对不断增长的传入数据量。 诸如 Apache Hadoop 或 Apache Spark 之类的工具使数据科学家和工程师都可以实现涉及大量数据的复杂管道。 在这一点上,所有的障碍都已被拆除,民主化进程已经到位。 但是,这些大型数据集的实际价值是多少? 从业务角度来看,仅当信息可以帮助做出正确的决策,减少不确定性并提供更好的上下文洞察力时,信息才有价值。 这意味着,在没有正确工具和知识的情况下,一堆数据只是对公司的一项成本,需要对其进行限制以增加利润。
机器学习是计算机科学(尤其是人工智能)的一大分支,旨在通过利用现有数据集来实现现实的描述性和预测性模型。 由于本书致力于实用的无监督解决方案,因此我们将仅关注通过查找隐藏的原因和关系来描述上下文的算法。 但是,即使仅从理论角度来看,显示机器学习问题之间的主要差异也是有帮助的。 只有对目标有完整的认识(不仅限于技术方面),才能得出对最初问题“我们为什么需要机器学习?”的合理答案。
我们可以说人类具有非凡的认知能力,这激发了许多系统,但是当元素数量显着增加时,他们就缺乏分析能力。 例如,如果您是第一次参加他/她的班级的老师,那么您可以在整个班次浏览后就能对女学生所占的百分比进行粗略估计。 通常,即使估计是由两个或更多个人进行的,估计也可能是准确的并且接近实际计数。 但是,如果我们对在院子里聚集的所有学校人口进行重复实验,性别的区别将不明显。 这是因为所有学生在班上都清晰可见; 但是,在院子里区分性别受某些因素的限制(例如,较高的人可以隐藏矮一些的人)。 摆脱类比,我们可以说大量数据通常携带大量信息。 为了提取和分类信息,有必要采取一种自动化的方法。
在进入下一部分之前,让我们讨论最初由 Gartner 定义的描述性,诊断性,预测性和规范性分析的概念。 但是,在这种情况下,我们希望专注于正在分析的系统(例如,通用上下文),以便对其行为获得越来越多的控制。
下图表示了完整的过程:
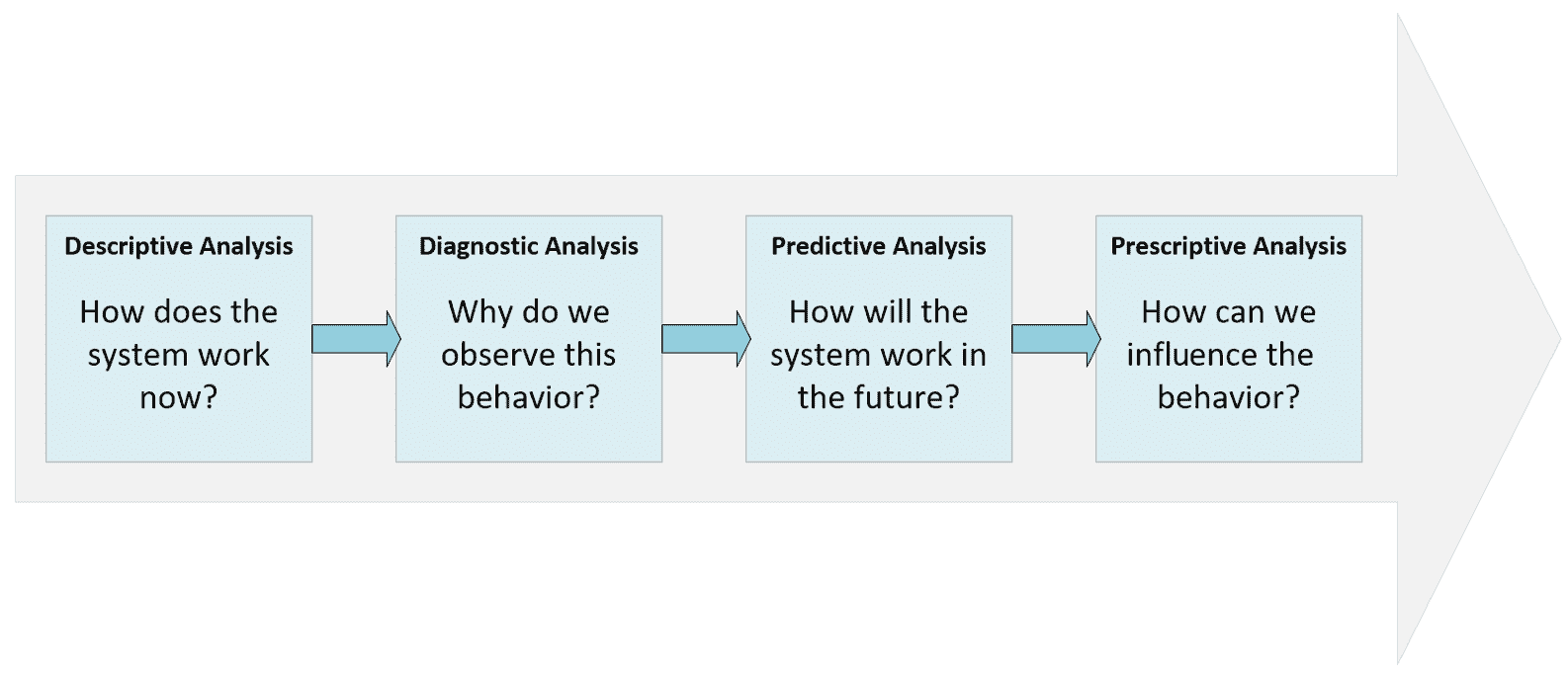
描述性,诊断性,预测性和说明性流程
描述性分析
在几乎所有数据科学场景中要解决的第一个问题都在于了解其性质。 我们需要知道系统如何工作或数据集正在描述什么。 没有这种分析,我们的知识就太局限了,无法做出任何假设或假设。 例如,我们可以观察几年中城市平均温度的图表。 如果我们无法描述发现相关性,季节性和趋势的时间序列,那么任何其他问题都将无法解决。 在我们特定的上下文中,如果我们没有发现对象组之间的相似性,则无法尝试找到一种方法来总结它们的共同特征。 数据科学家必须针对每个特定问题使用特定的工具,但是,在此阶段结束时,必须回答所有可能的(有用的)问题。
此外,由于此过程必须具有明确的业务价值,因此重要的是要让不同的利益相关者参与进来,以收集他们的知识并将其转换为通用语言。 例如,当使用医疗数据时,医生可能会谈论遗传因素,但是出于我们的目的,最好说某些样本之间存在相关性,因此我们没有完全授权将它们视为统计上独立的元素。 一般而言,描述性分析的结果是一个摘要,其中包含对环境进行限定并减少不确定性所需的所有度量评估和结论。 在温度图表的示例中,数据科学家应该能够回答自相关,峰的周期性,潜在异常值的数量以及趋势的存在。
诊断性分析
到现在为止,我们已经处理了输出数据,在特定的基础过程生成输出数据之后,才可以观察到这些数据。 描述系统后的自然问题与原因有关。 温度取决于许多气象和地理因素,可以很容易观察到或完全隐藏。 时间序列中的季节性明显受一年中的时间影响,但是离群值呢?
例如,我们在确定为冬季的区域中发现了一个高峰。 我们如何证明这一点呢? 在简单的方法中,可以将其视为可以过滤掉的嘈杂异常值。 但是,如果已观察到该措施,并且该措施背后有一个基本事实(例如,所有各方都认为这不是错误),我们应该假定存在隐藏的(或潜在)原因。
令人惊讶的是,但是大多数更复杂的场景都具有难以分析的大量潜在原因(有时称为因子)的特征。 通常,这不是一个坏条件,但是,正如我们将要讨论的,将它们包括在模型中以通过数据集了解其影响非常重要。
另一方面,决定放弃所有未知元素意味着降低模型的预测能力,并成比例地降低准确率。 因此,诊断分析的主要目标不一定是找出所有原因,而是要列出可观察和可测量的元素(称为因子)以及所有潜在的潜在因子(通常归纳为单个全局元素)。
在某种程度上,诊断分析通常类似于逆向工程过程,因为我们可以轻松地监视效果,但是要检测潜在原因和可观察效果之间的现有关系就更加困难。 因此,这种分析通常是概率性的,并有助于找到确定的特定原因带来特定影响的可能性。 这样,排除非影响元素并确定最初排除的关系也更加容易。 但是,此过程需要对统计学习方法有更深入的了解,除了一些示例(例如高斯混合算子)外,在本书中将不再讨论。
预测性分析
一旦收集了全部描述性知识,并且对潜在原因的认识令人满意,就可以创建预测模型。 这些模型的目的是根据模型本身的历史和结构来推断未来的结果。 在许多情况下,此阶段与下一个阶段一起进行分析,因为我们对系统的自由进化很少感兴趣(例如,下个月的温度将如何变化),而是影响输出的方式。
就是说,让我们仅关注预测,考虑应考虑的最重要元素。 首先要考虑的是过程的性质。 除非机器确定性过程的复杂性如此之高以至于我们不得不将它们视为黑匣子,否则我们不需要机器学习来进行确定性过程。 我们将要讨论的绝大多数例子都是关于随机过程,其中不确定性无法消除。 例如,我们知道可以将一天中的温度建模为取决于先前观测值的条件概率(例如,高斯模型)。 因此,预测表明不会将系统转变为确定性的预测(这是不可能的),而是要减小分布的方差,因此仅在较短的温度范围内概率较高。 另一方面,由于我们知道许多潜在因素在幕后发挥作用,因此我们永远都不能接受基于尖峰分布的模型(例如,基于概率为 1 的单个结果),因为这种选择会对模型的最终精度产生极大的负面影响。
如果我们的模型使用受学习过程影响的变量(例如,高斯的均值和协方差矩阵)进行参数化,则我们的目标是找出所谓的偏差-方差权衡。 由于本章只是介绍性的一章,因此我们并没有用数学公式对概念进行形式化,而是需要一个实际的定义(更多详细信息,请参见Bonaccorso G., Mastering Machine Learning Algorithms, Packt, 2018)。
定义统计预测模型的常用术语是估计器。 因此,估计器的偏差是错误假设和学习过程的可测量结果。 换句话说,如果一个过程的平均值为 5.0,而我们的估计值为 3.0,则可以说该模型存在偏差。 考虑前面的示例,如果观察值和预测之间的误差的期望值不为null,则我们正在使用有偏估计器。 重要的是要理解,我们并不是说每个估计都必须具有零误差,而是在收集足够的样本并计算均值时,其值应非常接近零(仅在无限样本中它可以为零)。 只要它大于零,就意味着我们的模型无法正确预测训练值。 显然,我们正在寻找平均能产生准确预测的无偏估计量。
另一方面,估计量的方差是存在不属于训练集的样本时鲁棒性的度量。 在本节的开头,我们说过我们的过程通常是随机的。 这意味着必须将任何数据集视为是从特定数据生成过程p_data中提取的。 如果我们有足够的代表性元素x[i] ∈ X,我们可以假设使用有限的数据集X训练分类器会导致模型能够分类可以从p_data中提取的所有潜在样本。
例如,如果我们需要建模一个人脸分类器,该人脸分类器的上下文仅限于肖像(不允许其他人脸姿势),我们可以收集许多不同个人的肖像。 我们唯一关心的是不排除现实生活中可能存在的类别。 假设我们有 10,000 张不同年龄和性别的人的图像,但是我们没有戴着帽子的肖像。 当系统投入生产时,我们收到客户的电话,说系统对许多图片进行了错误分类。 经过分析,我们发现他们始终代表戴着帽子的人。 显然,我们的模型不对错误负责,因为该模型已使用仅代表数据生成过程区域的样本进行了训练。 因此,为了解决该问题,我们收集了其他样本,并重复了训练过程。 但是,现在我们决定使用更复杂的模型,期望它会更好地工作。 不幸的是,我们观察到更差的验证准确率(例如,训练阶段未使用的子集的准确率)以及更高的训练准确率。 这里发生了什么?
当估计者学习完美地对训练集进行分类,但是其对从未见过的样本的能力很差时,我们说它是过拟合,并且对于特定任务其方差太大(相反, 欠拟合的模型具有较大的偏差,并且所有预测都非常不准确)。 凭直觉,该模型对训练数据了解得太多,并且丧失了概括能力。 为了更好地理解这个概念,让我们看一下高斯数据生成过程,如下图所示:
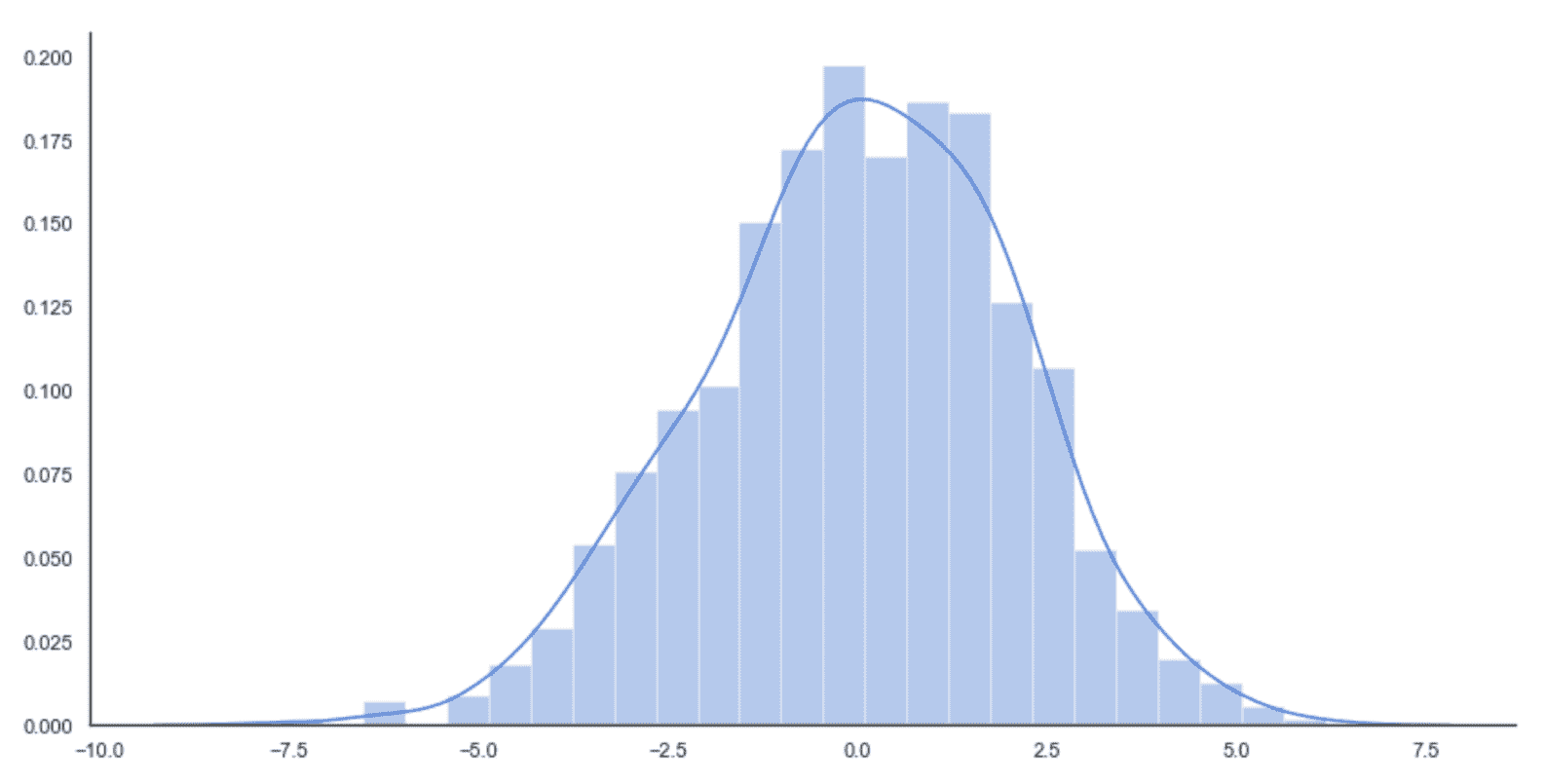
原始数据生成过程(实线)和采样数据直方图
如果没有以完全统一的方式对训练集进行采样,或者训练集部分不均衡(某些类别的样本数量少于其他类别),或者模型易于拟合,则结果可能由不正确的分布表示,如下:

习得的分布
在这种情况下,模型被迫学习训练集的细节,直到它从分布中排除了许多潜在样本。 结果不再是高斯分布,而是双峰分布,其中某些概率错误地较低。 当然,测试和验证集是从训练集未涵盖的小区域中取样的(因为训练数据和验证数据之间没有重叠),因此该模型将无法提供完全错误的结果。
换句话说,我们可以说方差太大,因为该模型已学会使用太多的细节,从而在合理的阈值上增加了不同分类的可能性范围。 例如,人像分类器可能已经知道戴蓝眼镜的人在 30 至 40 岁之间总是男性(这是不现实的情况,因为详细程度通常很低,但是,了解问题的性质非常有帮助 )。
我们可以这样概括:一个好的预测模型必须具有非常低的偏差和成比例的低方差。 不幸的是,通常不可能有效地最小化这两种措施,因此必须接受权衡。
具有良好泛化能力的系统很可能会具有较高的偏差,因为它无法捕获所有细节。 相反,高方差允许很小的偏差,但是模型的能力几乎仅限于训练集。 在本书中,我们不会讨论分类器,但您应该完全理解这些概念,以便始终了解在处理项目时可能遇到的不同行为。
规范性分析
这样做的主要目的是回答以下问题:如何影响系统的输出? 为了避免混淆,最好将此概念转换为纯机器学习语言,因此问题可能是要获得特定输出需要哪些输入值?
如前一部分所述,此阶段通常与预测分析合并在一起,因为模型通常用于两个任务。 但是,在某些特定情况下,预测仅限于空输入演变(例如在温度示例中),并且必须在说明阶段分析更复杂的模型。 主要原因在于能够控制造成特定输出的所有原因。
有时,在不必要时,仅对它们进行表面分析。 当原因不可控时(例如,气象事件),或者更简单地包括全局潜在参数集,都可能发生这种情况。 后一种选择在机器学习中非常常见,并且已经开发出许多算法来在存在潜在因素的情况下有效工作(例如 EM 或 SVD 推荐系统)。 因此,我们不关注这一特定方面(这在系统理论中非常重要),同时,我们隐式地假设我们的模型能够研究来自不同输入的许多可能的输出。
例如,在深度学习中,可以创建逆模型来生成输入空间的显着性图,从而强制使用特定的输出类。 考虑到肖像分类器的示例,我们可能会对发现哪些视觉元素会影响类的输出感兴趣。 诊断分析通常无效,因为原因非常复杂且其级别过低(例如,轮廓形状)。 因此,逆模型可以通过显示不同几何区域的影响来帮助解决说明性问题。 但是,完整的规范分析超出了本书的范围,在很多情况下,这是没有必要的,因此在接下来的章节中我们不会考虑这一步骤。 现在让我们分析不同类型的机器学习算法。
机器学习算法的类型
在这一点上,我们可以简要介绍不同类型的机器学习,重点介绍它们的主要特性和差异。 在以下各节中,我们将讨论非正式定义,然后是更正式的定义。 如果您不熟悉讨论中涉及的数学概念,则可以跳过详细信息。 但是,强烈建议您研究所有未知的理论元素,因为它们对于理解下一章中分析的概念至关重要。
监督学习算法
在有监督的情况下,模型的任务是找到样本的正确标签,假设已正确标记了训练集的存在,并且有可能将估计值与正确值进行比较。 术语受监督源自外部导师的概念,该导师在每次预测后提供准确而即时的反馈。 该模型可以使用这种反馈作为误差的度量,从而执行减少误差所需的校正。
更正式地说,如果我们假设数据生成过程,则P_data(x_bar, y)数据集的获取方式为:
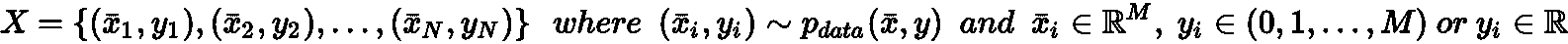
如上一节中所述,所有样本必须是独立同分布(IID)且从数据生成过程中均匀采样的值。 特别是,所有类别都必须代表实际分布(例如,如果p(y = 0) = 0.4和p(y = 1) = 0.6,则比例应为 40% 或 60%)。 但是,为了避免偏差,当类别之间的差异不是很大时,合理的选择是完全均匀的采样,并且对于y = 1, 2, ..., M具有相同的代表数。
通用分类器c(x_bar, θ_bar)可以通过两种方式建模:
- 输出预测类的参数化函数
- 参数化的概率分布,为每个输入样本输出分类概率
在第一种情况下,我们有:
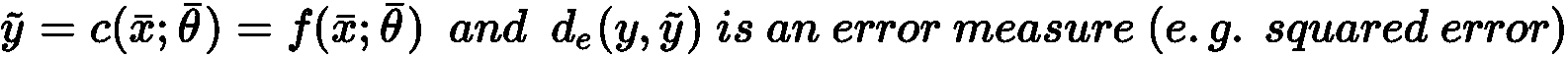
考虑整个数据集X,可以计算出全局成本函数L:
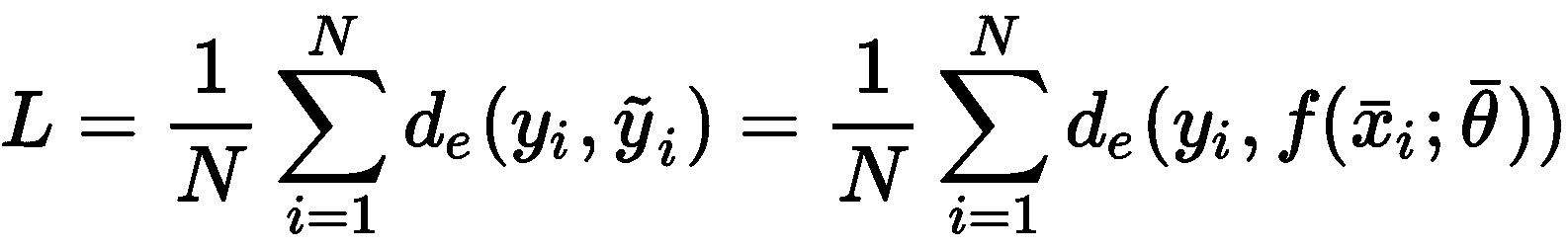
由于L仅取决于参数向量(x[i]和y[i]是常数),所以通用算法必须找到使成本函数最小的最优参数向量。 例如,在回归问题(标签是连续的)中,误差度量可以是实际值和预测值之间的平方误差:
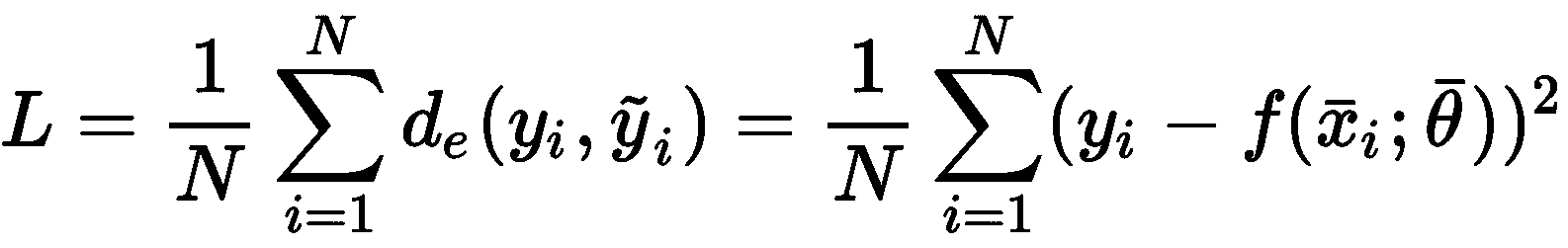
可以通过不同的方式(针对特定算法)优化这种成本函数,但是(在深度学习中最重要的)一种非常通用的策略是采用随机梯度下降(SGD)算法。 它包含以下两个步骤的迭代:
- 用一小批样本
x[i] ∈ X计算梯度∇L(相对于参数向量) - 更新权重,并沿梯度
-∇L的相反方向移动参数(请记住,梯度始终指向最大值)
相反,当分类器是概率分类器时,应将其表示为参数化的条件概率分布:
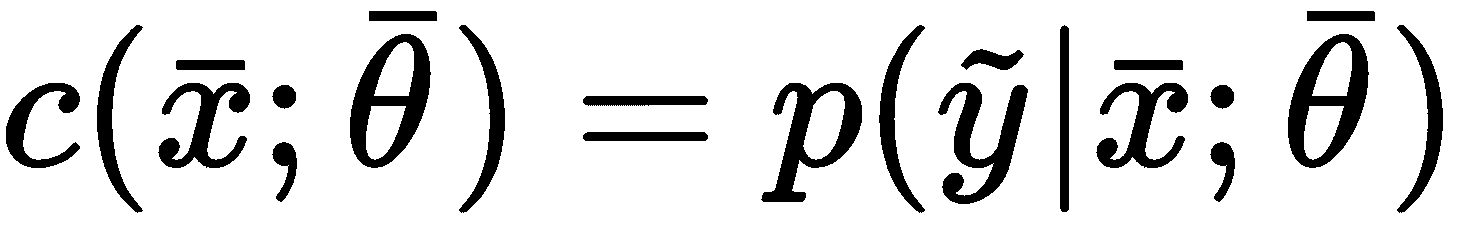
换句话说,分类器现在将在给定输入向量的情况下输出标签y的概率。 现在的目标是找到最佳参数集,它将获得:
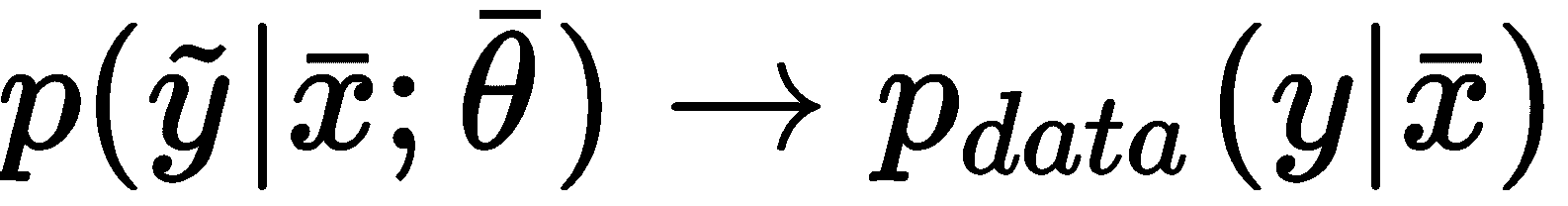
在前面的公式中,我们将p_data表示为条件分布。 可以使用概率距离度量(例如 Kullback-Leibler 散度D[KL](始终为非负D[KL] ≥ 0,仅在两个分布相同时D[KL] = 0):
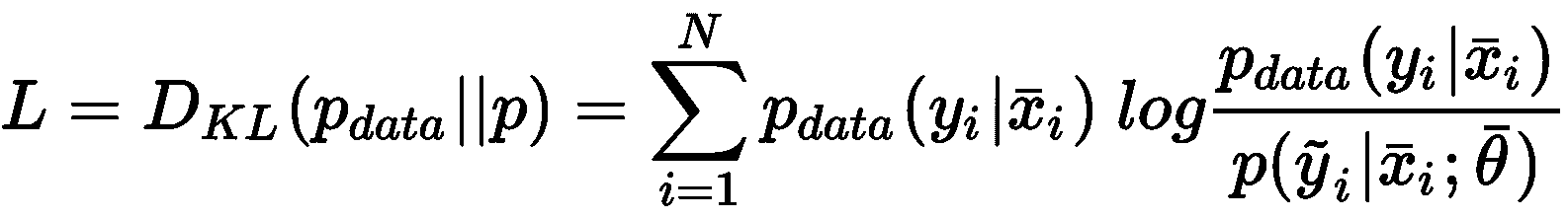
通过一些简单的操作,我们可以获得:
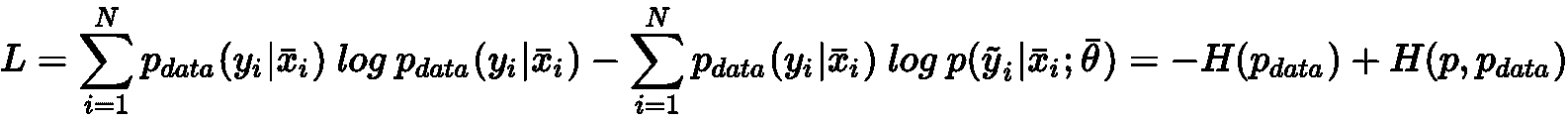
因此,所得成本函数对应于p和p_data之间的交叉熵之间的差,直到一个恒定值(数据生成过程的熵)。 因此,训练策略现在基于使用单热编码来表示标签(例如,如果有两个标签0 → (0, 1)和1 → (1, 0),因此所有元素的总和必须始终等于1),并使用内在的概率输出(例如在逻辑回归中)或 softmax 过滤器 ,将M值转换为概率分布。
在这两种情况下,很明显隐藏的教师的存在提供了对错误的一致度量,从而允许模型相应地校正参数。 特别地,第二种方法对我们的目的非常有帮助,因此,如果未知,我建议您进一步研究(所有主要定义也存在于《机器学习算法》第二版)。
现在我们可以讨论监督学习的一个非常基本的例子,它是一种线性回归模型,可以用来预测简单时间序列的演变。
监督的你好世界
在此示例中,我们想显示如何对二维数据执行简单的线性回归。 特别是,假设我们有一个包含 100 个样本的自定义数据集,如下所示:
import numpy as np
import pandas as pd
T = np.expand_dims(np.linspace(0.0, 10.0, num=100), axis=1)
X = (T * np.random.uniform(1.0, 1.5, size=(100, 1))) + np.random.normal(0.0, 3.5, size=(100, 1))
df = pd.DataFrame(np.concatenate([T, X], axis=1), columns=['t', 'x'])
我们还创建了一个 Pandas DataFrame,因为使用 seaborn 库创建图更容易。在这本书中,通常会省略绘图的代码(使用 Matplotlib 或 seaborn),但它始终存在于存储库中。
我们希望以一种综合的方式表示数据集,如下所示:
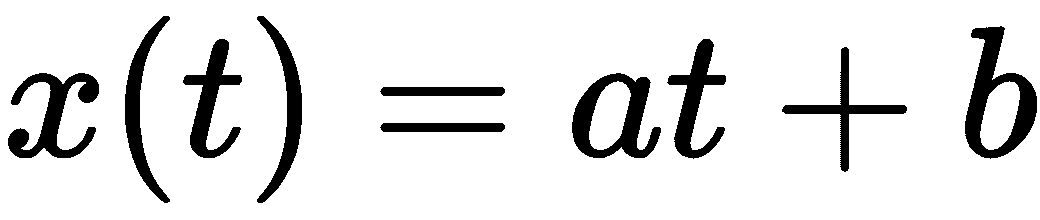
可以使用线性回归算法来执行此任务,如下:
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(T, X)
print('x(t) = {0:.3f}t + {1:.3f}'.format(lr.coef_[0][0], lr.intercept_[0]))
最后一条命令的输出如下:
x(t) = 1.169t + 0.628
我们还可以得到视觉确认,将数据集与回归线一起绘制,如下图所示:
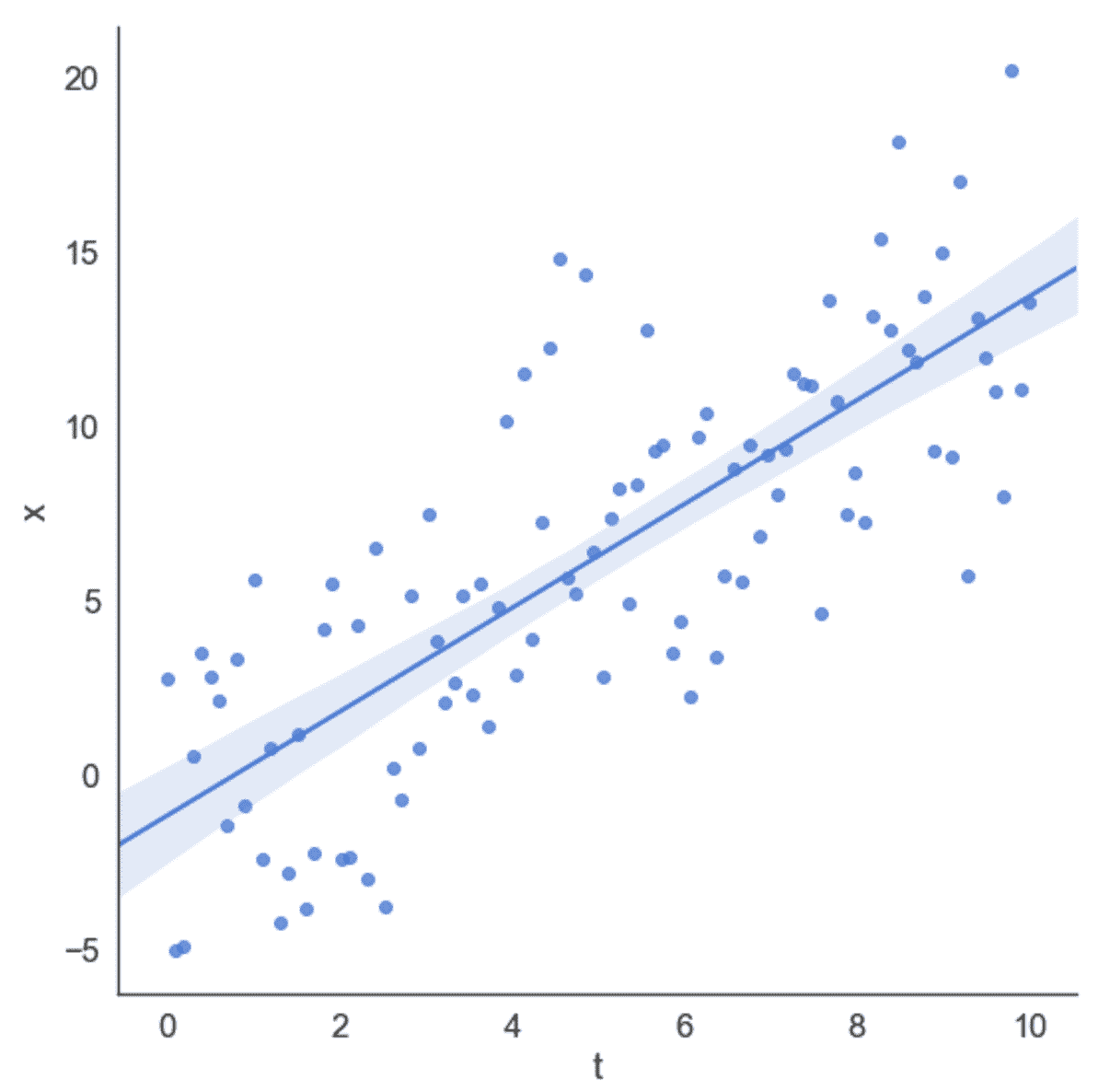
数据集和回归线
在此示例中,回归算法将平方误差成本函数最小化,试图减小预测值与实际值之间的差异。 由于对称分布,高斯噪声(均值无效)对斜率的影响最小。
无监督学习算法
可以想象,在无监督的情况下,没有隐藏的老师,因此主要目标不能与最小化关于真实性的预测误差有关。 的确,在这种情况下,相同的基本事实概念的含义稍有不同。 实际上,在使用分类器时,我们希望训练样本出现空错误(这意味着除真实类别外,其他类别也永远不会被接受为正确的类别)。
相反,在一个无监督的问题中,我们希望模型在没有任何正式指示的情况下学习一些信息。 这种情况意味着只能学习样本本身中包含的元素。 因此,无监督算法通常旨在发现样本之间的相似性和模式,或者在给定一组从中得出的向量的情况下,再现输入分布。 现在让我们分析一些无监督模型的最常见类别。
聚类分析
聚类分析(通常简称为聚类)是一项任务的示例,我们希望在其中找到大量样本之间的共同特征。 在这种情况下,我们总是假设存在数据生成过程P_data(X),并将数据集X定义为:
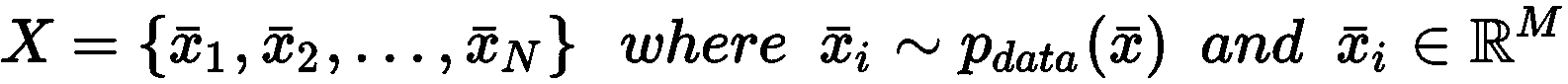
聚类算法基于隐式假设,即可以根据样本的相似性对样本进行分组。 特别地,给定两个向量,相似度函数定义为度量函数的倒数或倒数。 例如,如果我们在欧几里得空间中工作,则有:
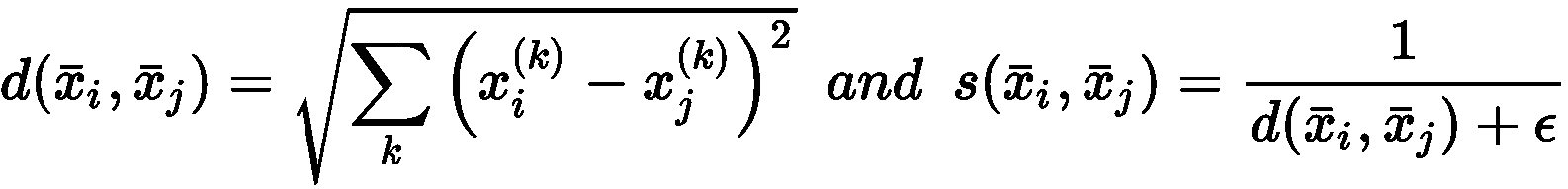
在先前的公式中,引入了常数ε以避免被零除。 显然d(a, c) < d(a, b) ⇒ s(a, c) > s(a, b)。 因此,给定每个群集的代表μ_bar[i],我们可以考虑以下规则来创建一组分配的向量:
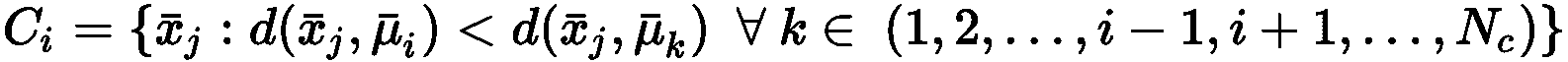
换句话说,群集包含与所有其他代表相比与代表的距离最小的所有那些元素。 这意味着聚类包含与所有代表相比与代表的相似性最大的样本。 此外,分配后,样本将获得权利,来与同一集群的其他成员共享其特征。
实际上,聚类分析最重要的应用之一就是试图提高被认为相似的样本的同质性。 例如,推荐引擎可以基于用户向量的聚类(包含有关用户兴趣和购买产品的信息)。 一旦定义了组,就将属于同一群集的所有元素视为相似,因此我们被隐式授权来共享差异。 如果用户A购买了产品P并给予正面评价,我们可以向未购买此产品的用户B推荐该产品,反之亦然 。 这个过程看似随意,但是当元素数量很大并且特征向量包含许多可区分元素(例如,等级)时,它会非常有效。
生成模型
另一种无监督的方法是基于生成模型的。 这个概念与我们已经讨论过的关于监督算法的概念没有很大不同,但是在这种情况下,数据生成过程不包含任何标签。 因此,目标是对参数化分布进行建模并优化参数,以使候选分布与数据生成过程之间的距离最小化:
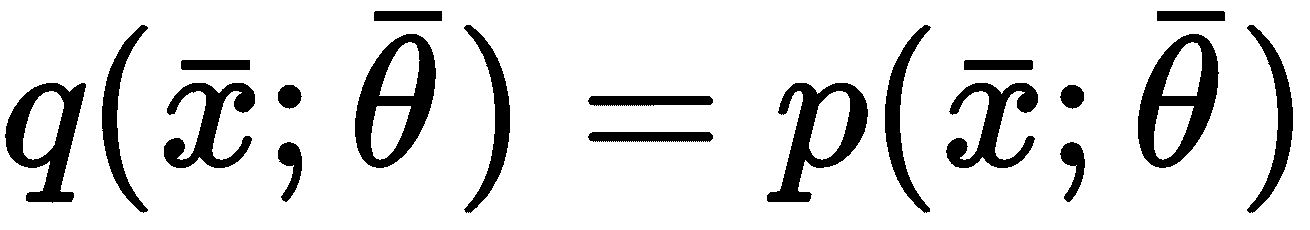
该过程通常基于 Kullback-Leibler 分歧或其他类似措施:
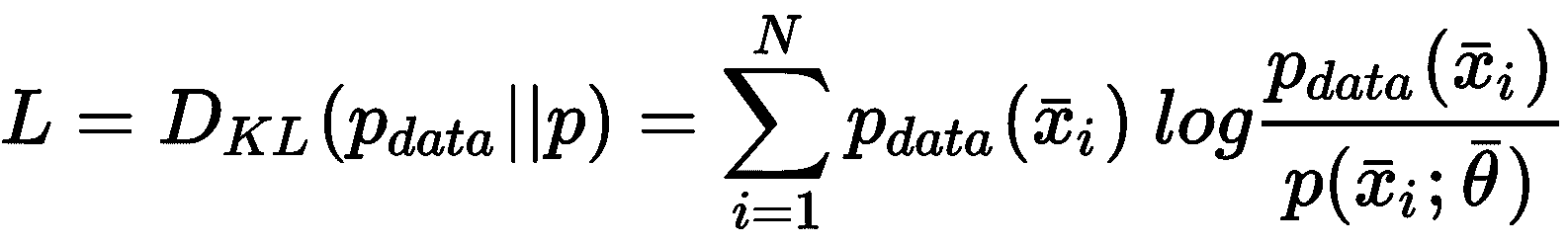
在训练阶段结束时,我们假设L → 0,所以p ≈ p_data。 通过这种方式,我们不仅将分析限于可能的样本子集,还限于整个分布。 使用生成模型,您可以绘制新样本,这些样本可能与为训练过程选择的样本有很大差异,但是它们始终属于同一分布。 因此,它们(可能)始终是可接受的。
例如,生成对抗网络(GAN)是一种特殊的深度学习模型,能够学习图像集的分布,生成几乎无法区分的新样本(来自视觉语义的观点)。 由于无监督学习是本书的主要主题,因此在本简介中,我们将不再进一步介绍 GAN。 所有这些概念将在接下来的所有章节中进行广泛讨论(并带有实际示例)。
关联规则
我们正在考虑的最后一种无监督方法是基于关联规则的发现,它在数据挖掘领域中极为重要。 常见方案是由一组商品子集组成的商业交易的集合。 目的是找出产品之间最重要的关联(例如,购买P(i)和P(j)的概率为 70%)。 特定算法可以有效地挖掘整个数据库,突出显示出于战略和物流目的可以考虑的所有关系。 例如,在线商店可以采用这种方法来促销经常与其他商品一起购买的所有那些商品。 此外,由于其他项目的销量增加,因此预测性方法可以通过建议所有极有可能售罄的产品来简化配置过程。
在这一点上,向读者介绍无监督学习的实际示例是有帮助的。 不需要特定的先决条件,但是最好具有概率论的基本知识。
无监督的你好世界
由于本书完全致力于无监督算法,因此我决定不将简单的聚类分析展示为一个“世界”! 例如,而是相当基本的生成模型。 假设我们正在每小时监控一次到达地铁站的火车的数量,因为我们需要确定车站所需的安全智能体的数量。 特别是,我们被要求每列火车至少有一名经纪人,每当火车数量减少时,我们将被罚款。
而且,在每个小时的开始发送一个组变得更容易,而不是一个个地控制智能体。 因为问题很简单,所以我们也知道泊松分布很好,它是用μ参数化的泊松分布。 从理论上,我们知道,这种分布可以在独立性的主要假设下有效地模拟固定时间范围内发生的随机事件数。 在一般情况下,生成模型基于参数化分布(例如,使用神经网络),并且没有对其族做出特定假设。 仅在某些特定情况下(例如,高斯混合),才可以选择具有特定属性的分布,并且在不失严格性的前提下,我们可以将此示例视为这样的情况。
泊松分布的概率质量函数为:
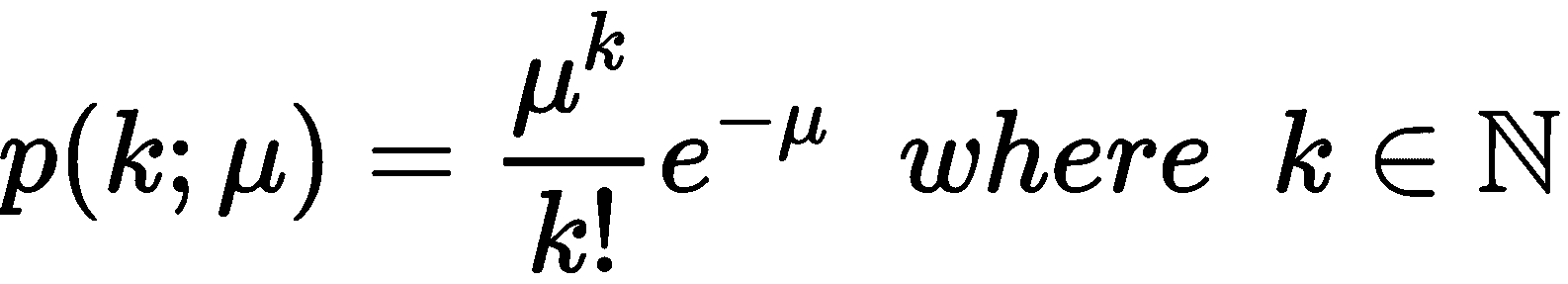
此分布描述了在预定时间间隔内观察k事件的可能性。 在我们的案例中,间隔始终为一小时,因此我们非常希望估计观察 10 列以上火车的可能性。 如何获得μ的正确数字?
最常见的策略称为最大似然估计(MLE)。 它收集了一组观测值,并找到了 μ的值,该值最大化了通过我们的分布生成所有点的概率。
假设我们收集了N个观测值(每个观测值是一个小时内的到达次数),则μ相对于所有样本的似然,就是所有样本在使用μ计算的概率分布下的联合概率(为简单起见,假设为 IID):
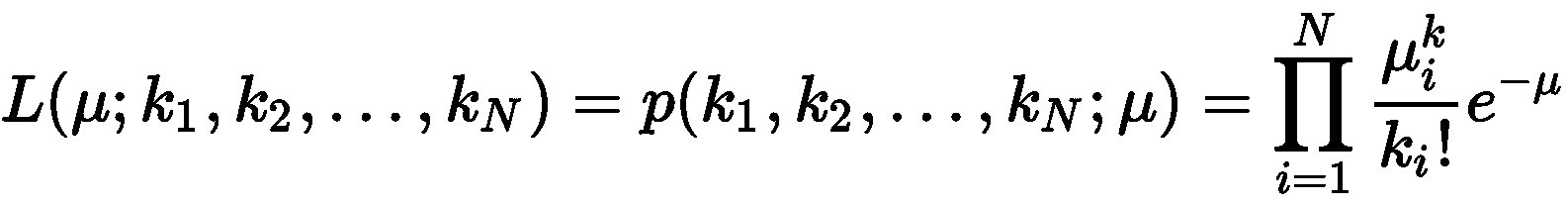
当我们使用乘积和指数运算时,计算对数似然是一条通用规则:
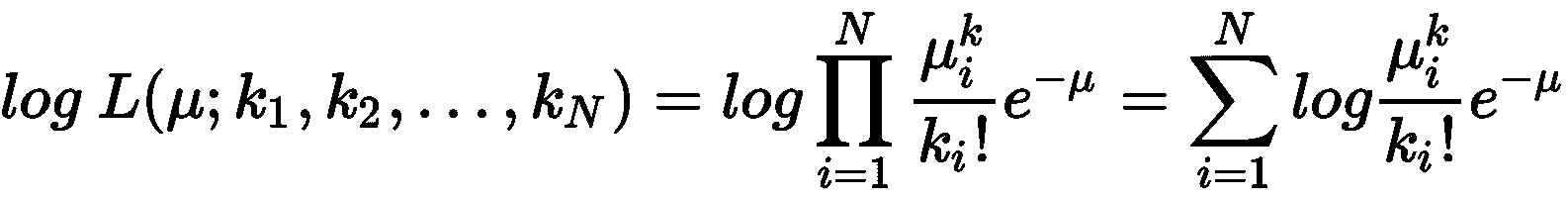
一旦计算出对数似然,就可以将μ的导数设置为 0,以找到最佳值。 在这种情况下,我们省略了证明(直接获得)并直接得出μ的 MLE 估计:
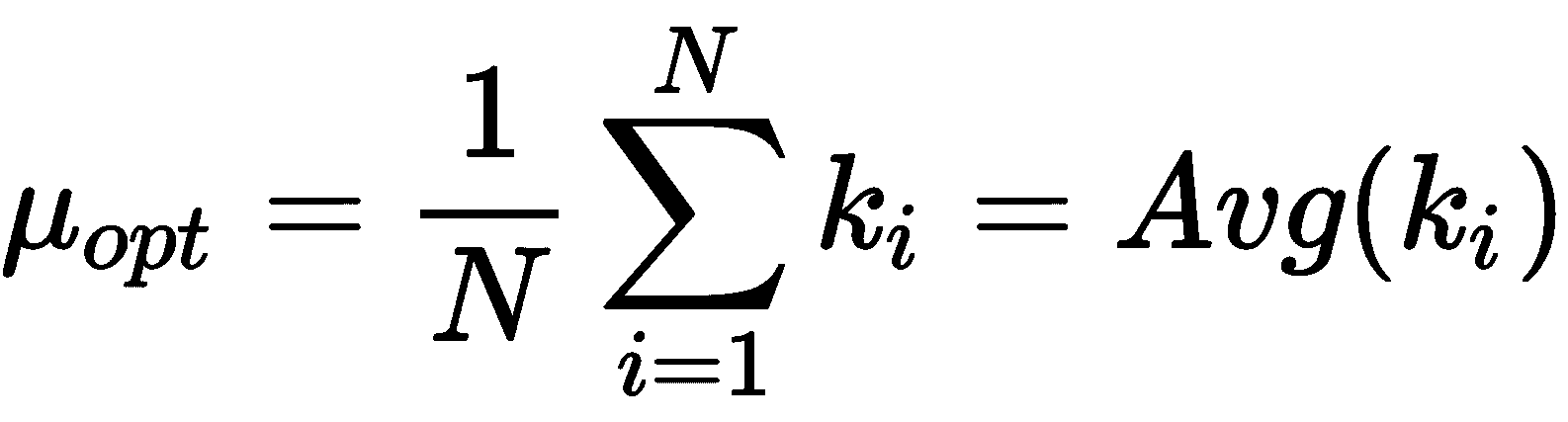
我们很幸运! MLE 估计值只是到达时间的平均值。 这意味着,如果我们观察到N值的平均值为μ,则最有可能产生它们的泊松分布为μ作为特征系数。 因此,从这种分布中提取的任何其他样本将与观察到的数据集兼容。
现在,我们可以开始第一个模拟。 假设我们在一个工作日的午后收集了 25 个观测值,如下所示:
import numpy as np
obs = np.array([7, 11, 9, 9, 8, 11, 9, 9, 8, 7, 11, 8, 9, 9, 11, 7, 10, 9, 10, 9, 7, 8, 9, 10, 13])
mu = np.mean(obs)
print('mu = {}'.format(mu))
最后一条命令的输出如下:
mu = 9.12
因此,我们的平均到达速度约为每小时 9 列火车。 直方图如下图所示:
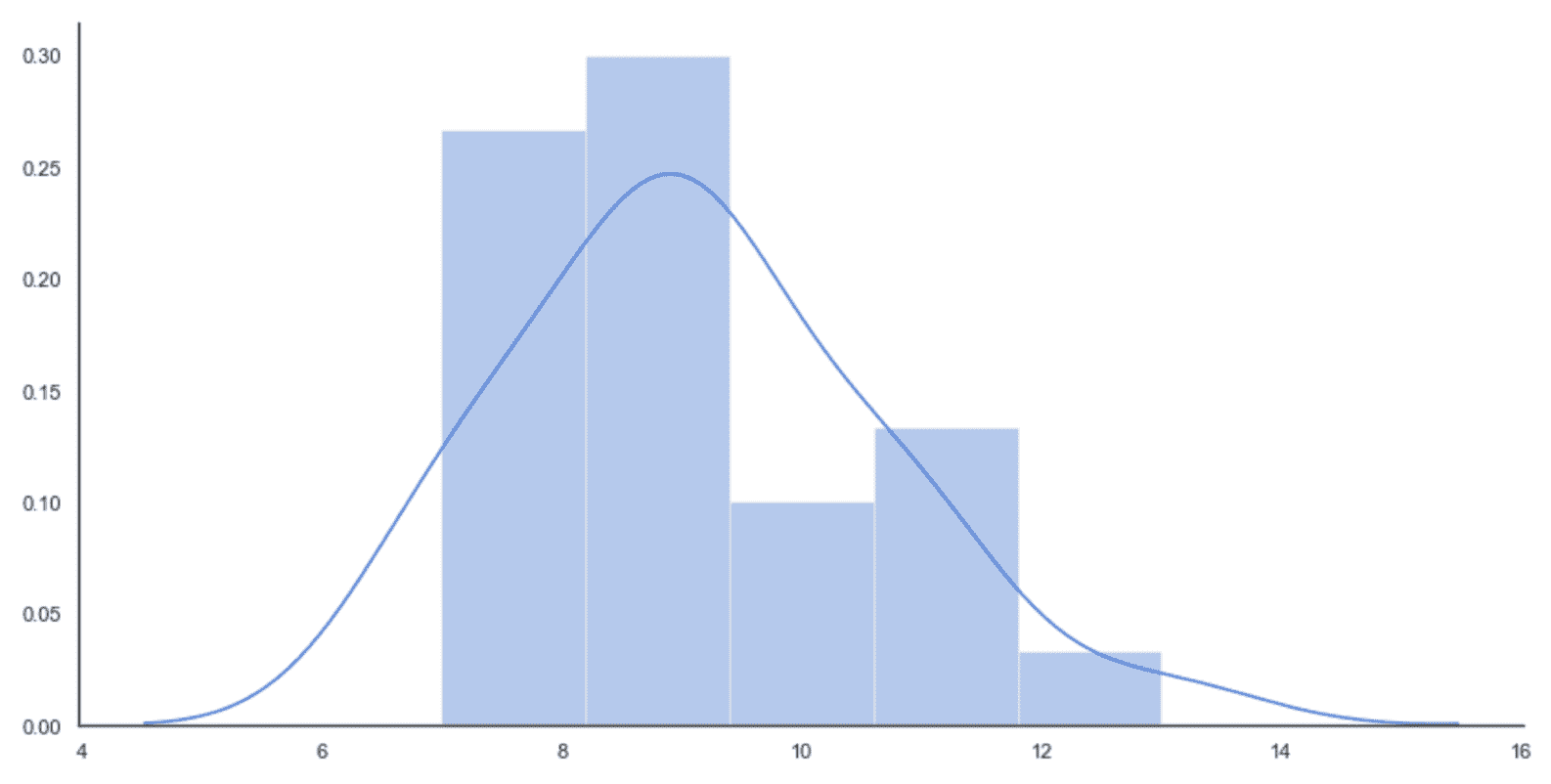
初始分布的直方图
为了计算请求的概率,我们需要使用累积分布函数(CDF),该函数在 SciPy 中实现(在scipy.stats包中)。 特别是,由于我们对观测比固定值更多的火车的可能性感兴趣,因此有必要使用生存函数(SF),它对应于1 - CDF,如下所示:
from scipy.stats import poisson
print('P(more than 8 trains) = {}'.format(poisson.sf(8, mu)))
print('P(more than 9 trains) = {}'.format(poisson.sf(9, mu)))
print('P(more than 10 trains) = {}'.format(poisson.sf(10, mu)))
print('P(more than 11 trains) = {}'.format(poisson.sf(11, mu)))
前一个代码段的输出为,如下所示:
P(more than 8 trains) = 0.5600494497386543
P(more than 9 trains) = 0.42839824517059516
P(more than 10 trains) = 0.30833234660452563
P(more than 11 trains) = 0.20878680161156604
不出所料,观察到 10 列以上火车的概率很低(30%),并且派遣 10 个特工似乎并不合理。 但是,由于我们的模型是自适应的,因此我们可以继续收集观测值(例如,在清晨),如下所示:
new_obs = np.array([13, 14, 11, 10, 11, 13, 13, 9, 11, 14, 12, 11, 12, 14, 8, 13, 10, 14, 12, 13, 10, 9, 14, 13, 11, 14, 13, 14])
obs = np.concatenate([obs, new_obs])
mu = np.mean(obs)
print('mu = {}'.format(mu))
μ的新值如下:
mu = 10.641509433962264
现在平均每小时近 11 列火车。 假设我们已经收集了足够的样本(考虑所有潜在事故),我们可以重新估计概率,如下所示:
print('P(more than 8 trains) = {}'.format(poisson.sf(8, mu)))
print('P(more than 9 trains) = {}'.format(poisson.sf(9, mu)))
print('P(more than 10 trains) = {}'.format(poisson.sf(10, mu)))
print('P(more than 11 trains) = {}'.format(poisson.sf(11, mu)))
输出为,如下所示:
P(more than 8 trains) = 0.7346243910180037
P(more than 9 trains) = 0.6193541369812121
P(more than 10 trains) = 0.49668918740243756
P(more than 11 trains) = 0.3780218948425254
使用新的数据集,观察到 9 列以上火车的概率约为 62% (这证实了我们的最初选择),但是现在观察到 10 列以上火车的概率约为 50%。 由于我们不想冒险支付罚款(高于智能体的费用),因此最好派出一组 10 名智能体。 为了进一步确认,我们决定从分布中抽取 2,000 个值,如下所示:
syn = poisson.rvs(mu, size=2000)
下图显示了相应的直方图:

从最终泊松分布中采样的 2000 个点的直方图
该图确认了在 10 点(非常接近 11)之后的一个峰值,并且从k = 13开始快速衰减,这已经使用有限的数据集发现了(比较直方图的形状以进一步确认) 。 但是,在这种情况下,我们将生成观察集中无法存在的潜在样本。 MLE 保证概率分布与数据一致,并对新样本进行相应加权。 这个例子显然非常简单,它的目标只是显示生成模型的动态。
在本书的下一章中,我们将讨论许多其他更复杂的模型和示例。 许多算法共有的一项重要技术不是选择预定义的分布(这意味着先验知识),而是使用灵活的参数模型(例如神经网络)来找出最佳分布。 仅当对基础随机过程有较高的置信度时,才有理由选择预定义的先验。 在所有其他情况下,总是最好避免任何假设,而仅依赖于数据,以便找到数据生成过程的最合适的近似值。
半监督学习算法
半监督场景可以看作是一种标准的监督场景,它利用了属于非监督学习技术的某些功能。 实际上,很容易获得大型未标记数据集,但标记成本却很高,这会引起一个非常普遍的问题。 因此,合理的做法是只标记一小部分样本,并将标记传播到与标记样本的距离低于预定义阈值的所有未标记样本。 如果数据集是从单个数据生成过程中提取的,并且标记的样本是均匀分布的,则半监督算法可以实现与监督算法相当的准确率。 在本书中,我们不会讨论这些算法。 但是,简要介绍两个非常重要的模型会有所帮助:
- 标签传播
- 半监督支持向量机
第一个称为标签传播,其目标是将一些样本的标签传播到更大的人群。 通过考虑一个图来实现此目标,其中每个顶点代表一个样本,并且使用距离函数对每个边缘进行加权。 通过迭代过程,所有标记的样本将一部分标记值发送给所有邻居,并重复该过程,直到标记停止更改为止。 该系统具有稳定点(即,不能再进化的配置),并且算法可以通过有限的迭代次数轻松达到目标。
在所有可以根据相似性度量标记样本的情况下,标记传播都非常有用。 例如,在线商店可能有大量的客户群,但是只有 10% 的顾客公开了自己的性别。 如果特征向量足够丰富,可以代表男性和女性用户的常见行为,则可以使用标签传播算法来猜测尚未公开的用户性别。 当然,重要的是要记住,所有分配均基于类似样本具有相同标签的假设。 在许多情况下这可能是正确的,但是当特征向量的复杂性增加时,也会产生误导。
半监督算法的另一个重要系列是基于将标准 SVM(Support Vector Machine 的缩写)扩展到包含未标记样本的数据集。 在这种情况下,我们不想传播现有标签,而是传播分类标准。 换句话说,我们要使用标记的数据集训练分类器,并将判别规则也扩展到未标记的样本。
与只能评估未标记样本的标准程序相反,半监督 SVM 使用它们来校正分离的超平面。 该假设始终基于相似性:如果A的标签为1,而未标签的样本B的标签为d(A, B) <ε(其中ε是预定义的阈值),可以合理地假设B的标签也是1。 这样,即使仅手动标记了一个子集,分类器也可以在整个数据集上实现高精度。 与标签传播类似,仅当数据集的结构不是非常复杂时,尤其是当相似性假设成立时,这类模型才是可靠的(不幸的是,在某些情况下,很难找到合适的距离度量,因此许多相似的样本的确不同,反之亦然)。
强化学习算法
强化学习方案可以看作是一种有监督的方案,其中隐藏的老师在模型的每个决定之后仅提供近似的反馈。 更正式地讲,强化学习的特征在于主体与环境之间的持续交互。 前者负责制定决策(行动),并最终确定其结果以增加回报,而后者则负责为每项行动提供反馈。 反馈通常被认为是一种奖励,其值可以是积极的(行动已经成功)或消极的(行动不应重复)。 当智能体分析环境(状态)的不同配置时,必须将每个奖励都视为绑定到元组(动作,状态)。 因此,最终目标是找到一个最大化预期总回报的策略(一种建议在每个州采取最佳行动的策略)。
强化学习的一个非常经典的例子是学习如何玩游戏的智能体。 在剧集期间,智能体会在所有遇到的状态下测试动作并收集奖励。 一种算法会纠正该策略,以减少非积极行为(即那些奖励为正的行为)的可能性,并增加在剧集结束时可获得的预期总奖励。
强化学习有许多有趣的应用,而不仅限于游戏。 例如,推荐系统可以根据用户提供的二进制反馈(例如,拇指向上或向下)来校正建议。 强化学习和监督学习之间的主要区别是环境提供的信息。 实际上,在有监督的情况下,校正通常与校正成比例,而在强化学习中,必须考虑一系列操作和将来的奖励来进行分析。 因此,校正通常基于预期奖励的估计,并且其效果受后续操作的值影响。 例如,一个受监督的模型没有记忆,因此它的修正是即时的,而强化学习智能体必须考虑剧集的部分推出,以便确定一个动作是否实际上是负面的。
强化学习是机器学习的一个有趣的分支。 不幸的是,该主题超出了本文的讨论范围,因此我们不对其进行详细讨论(您可以在《Python 强化学习实用指南》中找到更多详细信息)。
现在,我们可以简要地解释一下为什么选择 Python 作为这种探索无监督学习世界的主要语言。
为什么将 Python 用于数据科学和机器学习?
在继续进行更多技术讨论之前,我认为解释 Python 作为本书编程语言的选择会有所帮助。 在过去的十年中,数据科学和机器学习领域的研究呈指数增长,拥有数千篇有价值的论文和数十种完善的工具。 特别是由于 Python 的高效性,美观性和紧凑性,许多研究人员和程序员都选择使用 Python 创建一个完整的科学生态系统,该生态系统已免费发布。
如今,诸如 scikit-learn,SciPy,NumPy,Matplotlib,pandas 之类的包代表了数百种可用于生产环境的系统的骨干,并且其使用量还在不断增长。 此外,复杂的深度学习应用(例如 Theano,TensorFlow 和 PyTorch)允许每个 Python 用户创建和训练复杂模型而没有任何速度限制。 实际上,必须注意 Python 不再是脚本语言。 它支持许多特定任务(例如,Web 框架和图形),并且可以与用 C 或 C++ 编写的本机代码进行接口。
由于这些原因,Python 几乎是所有数据科学项目中的最佳选择,并且由于其功能,所有具有不同背景的程序员都可以轻松地学会在短时间内有效地使用它。 也可以使用其他免费解决方案(例如 R,Java 或 Scala),但是,在 R 的情况下,可以完全涵盖统计和数学函数,但缺少构建完整应用所必需的支持框架。 相反,Java 和 Scala 具有完整的可用于生产环境的库生态系统,但是特别是 Java 不像 Python 那样紧凑且易于使用。 而且,对本机代码的支持要复杂得多,并且大多数库都完全依赖 JVM(从而导致性能损失)。
由于 Scala 的功能特性和 Apache Spark 等框架的存在(可用于执行大数据的机器学习任务),Scala 在大数据全景图中获得了重要的地位。 但是,考虑到所有优点和缺点,Python 仍然是最佳选择,这就是为什么它被选为本书的原因。
总结
在本章中,我们讨论了证明采用机器学习模型合理的主要原因,以及如何分析数据集以描述其特征,列举特定行为的原因,预测未来行为并对其产生影响。
我们还重点研究了前两个模型,探讨了有监督,无监督,半监督和强化学习之间的差异。 我们还使用了两个简单的示例来了解监督和非监督方法。
在下一章中,我们将介绍聚类分析的基本概念,并将讨论重点放在一些非常著名的算法上,例如 K 均值和 K 最近邻(KNN) ,以及最重要的评估指标。
问题
-
当不适用监督学习时,无监督学习是最常见的选择。 这是正确的吗?
-
您公司的首席执行官要求您找出确定负面销售趋势的因素。 您需要执行哪种分析?
-
给定独立样本的数据集和候选数据生成过程(例如,高斯分布),可通过对所有样本的概率求和来获得可能性。 它是正确的?
-
在哪种假设下,可能性可以作为单个概率的乘积来计算?
-
假设我们有一个包含一些未知数字特征(例如年龄,分数等)的学生数据集。 您想将男性和女性学生分开,因此决定将数据集分为两组。 不幸的是,这两个集群大约都有 50% 的男生和 50% 的女生。 您如何解释这个结果?
-
考虑前面的示例,但重复该实验并将其分为五个组。 您希望在其中每个中找到什么? (列出一些合理的可能性。)
-
您已经将在线商店的客户聚集在一起。 给定一个新样本,您可以做出什么样的预测?
进一步阅读
Machine Learning Algorithms Second Edition, Bonaccorso G., Packt Publishing, 2018Hands-On Reinforcement Learning with Python, Ravichandiran S., Packt Publishing, 2018Hands-On Data Analysis with NumPy and pandas, Miller C., Packt Publishing, 2018
二、聚类基础
在本章中,我们将介绍聚类分析的基本概念,将注意力集中在许多算法共有的主要原理以及可用于评估方法表现的最重要技术上。
特别是,我们将讨论:
- 聚类和距离函数简介
- K 均值和 KMeans++
- 评估指标
- K 最近邻(KNN)
- 向量量化(VQ)
技术要求
本章中提供的代码要求:
- Python3.5+(强烈建议您使用 Anaconda 发行版)
- 库:
- SciPy 0.19+
- NumPy 1.10+
- Scikit-Learn 0.20+
- Pandas 0.22+
- Matplotlib 2.0+
- Seaborn 0.9+
该数据集可以通过 UCI 获得。 可以从这里下载 CSV 文件,并且不需要任何预处理来添加在加载阶段将出现的列名。
这些示例可在 GitHub 存储库上找到。
聚类介绍
如我们在第 1 章,“无监督学习入门”中所述,聚类分析的主要目标是根据相似性度量或接近性标准对数据集的元素进行分组。 在本章的第一部分中,我们将专注于前一种方法,而在第二部分和下一章中,我们将分析利用数据集其他几何特征的更多通用方法。
让我们进行一个数据生成过程p_data(x),并从中抽取N个样本:
可以假设p_data(x)的概率空间可划分为(可能无限的)配置,包含K的区域(对于K = 1, 2, ...),这样p_data(x;k)表示样本属于群集k的概率。 以这种方式,我们指出,当确定p_data(x)时,每个可能的聚类结构已经存在。 可以对聚类概率分布做出进一步的假设,以更好地近似p_data(x)(我们将在第 5 章,“软聚类和高斯混合模型”)。 但是,当我们尝试将概率空间(和相应的样本)划分为内聚组时,我们可以假设两种可能的策略:
- 硬聚类:在这种情况下,每个样本
x[p] ∈ X被分配给一个聚类K[i],对于i ≠ j,K[i] ∩ K[j] = ∅。 我们将要讨论的大多数算法都属于这一类。 在这种情况下,问题可以表示为将聚类分配给每个输入样本的参数化函数:
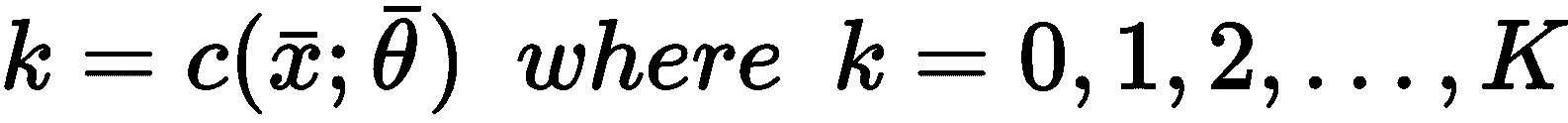
- 软聚类:通常将其细分为概率和模糊聚类,这种方法确定了每个样本的概率
p(x)属于预定群集的x[p] ∈ X。 因此,如果存在K个群集,我们就有一个概率向量p(x) = [p[1](x), p[2](x), ..., p[i](x)],其中p[i](x)表示分配给群集的概率i。 在这种情况下,聚类不是不相交的,通常,样本将属于隶属度等于概率的所有群集(此概念是模糊聚类所特有的)。
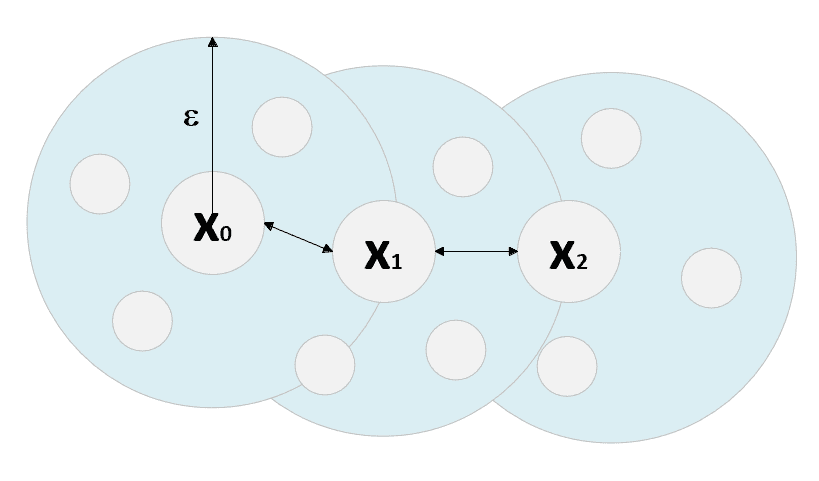
出于我们的目的,在本章中,我们仅假设数据集X来自数据生成过程,该过程的空间在给定度量函数的情况下可分为彼此分离的紧凑区域。 实际上,我们的主要目标是找到满足最大内聚和最大分离双重特征的K群集。 在讨论 K 均值算法时,这个概念会更清楚。 但是, 可能将它想象为斑点,其密度远远高于将它们隔开两个或多个的空间中可观察到的斑点,如下图所示:

遵循最大内聚和最大分离规则的二维聚类结构。 N[k]代表属于群集k的样本数,而N[out](r)是位于以每个群集中心为中心且最大半径为r的球外部的样本数。
在上图中,我们假设考虑到样本到中心的最大距离,所以大多数样本将被一个球捕获。 但是,由于我们不想对球的生长施加任何限制(也就是说,它可以包含任意数量的样本),因此最好不要考虑半径并通过对( 整个空间)并收集它们的密度。
在理想情况下,群集跨越一些子区域,其密度为D,而分隔区域的特征为密度d << D。 关于几何特性的讨论可能变得非常复杂,并且在许多情况下,这是非常理论性的。 今后,我们仅考虑属于不同聚类的最近点之间的距离。 如果此值远小于所有聚类的样本与其聚类中心之间的最大距离,则可以确保分离有效,并且很容易区分聚类和分离区域。 相反,当使用距离度量(例如,以 K 均值表示)时,,我们需要考虑的另一个重要要求是聚类的凸度。 如果∀x[1], x[2] ∈ C且连接x[1], x[2]的线段上的所有点属于C,泛集C是凸的。 在下图中,对凸和非凸(凹)群集进行了比较:
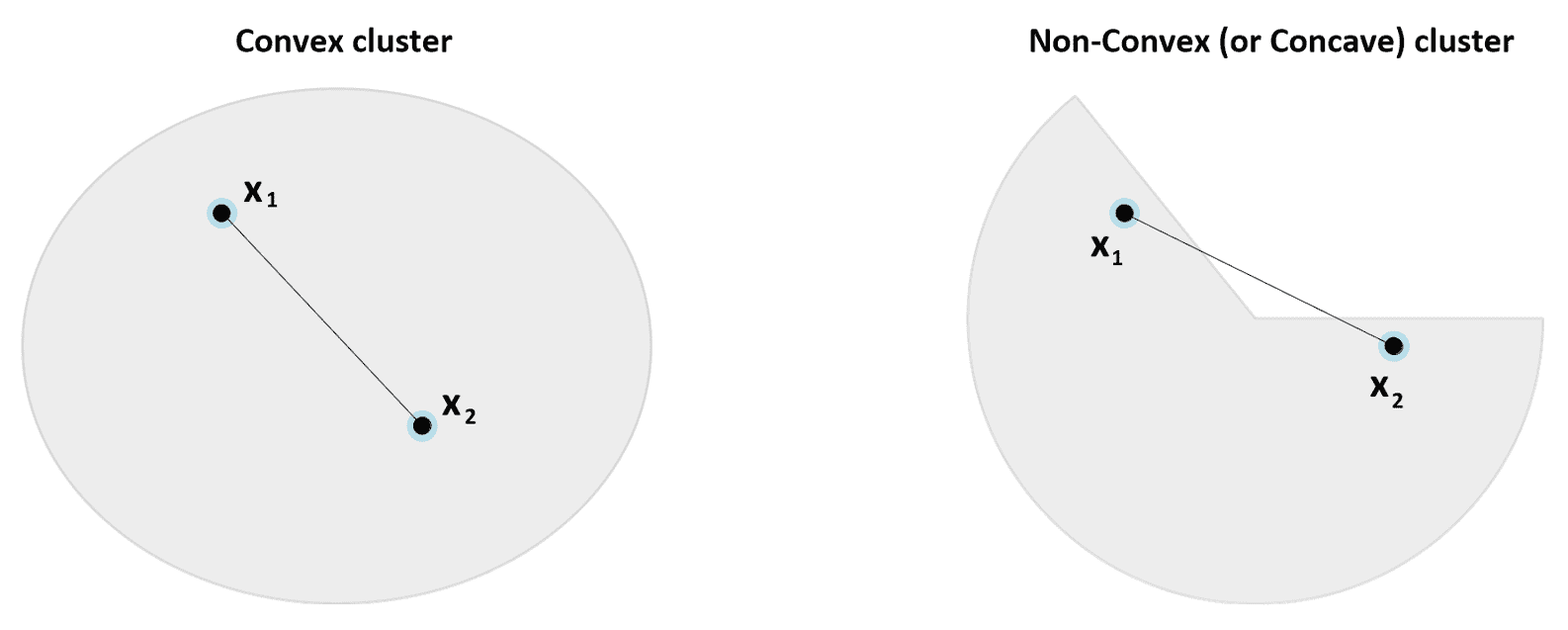
凸群集(左)和凹群集(右)的示例
不幸的是,由于距离函数的对称性,诸如 K 均值之类的算法无法管理非凸类。 在我们的探索中,我们将展示此限制以及其他方法如何克服它。
距离函数
即使聚类的一般定义通常基于相似度的概念,也很容易采用它的反函数,它由距离函数(相异性度量)表示。 最常见的选择是欧几里德距离,但是在选择它之前,必须考虑它的属性及其在高维空间中的行为。 让我们开始介绍闵可夫斯基距离作为欧几里得距离的推广。 如果样本是x[i] ∈ N,则其定义为:
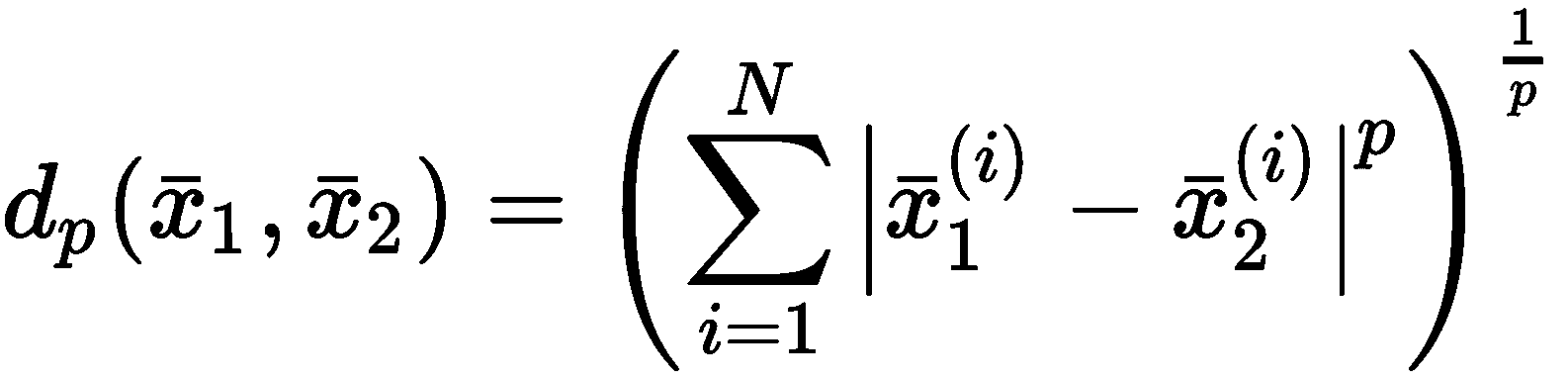
对于p = 1,我们获得曼哈顿(或城市街区)的距离,而p = 2对应于标准欧几里得距离 。 我们想了解当p → ∞时d[p]的行为。 假设我们在二维空间中工作,并且有一个群集,其中心是x[c] = (0, 0),并且采样点x = (5, 3),相对于p不同值的距离d[p](x[c], x)为:
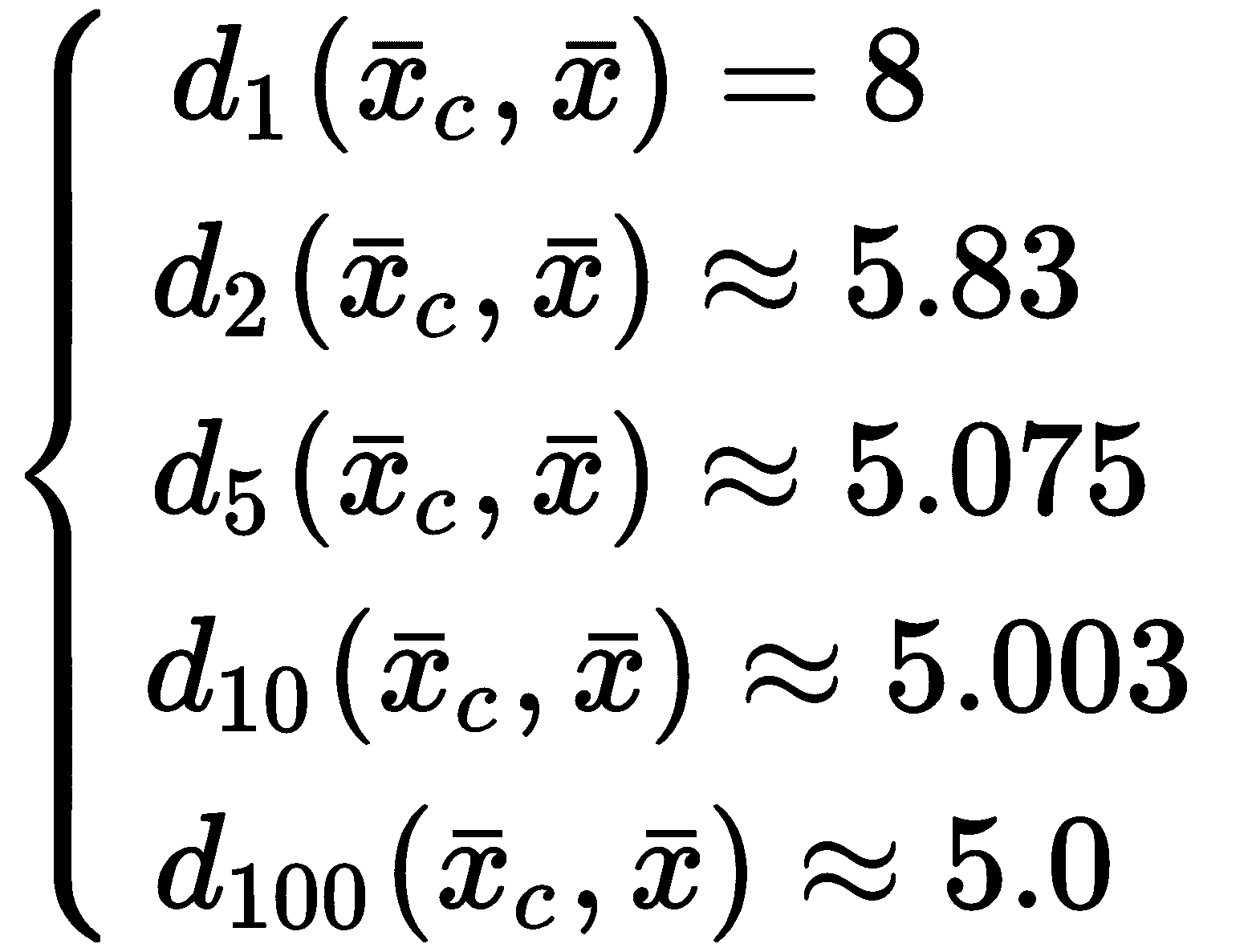
很明显(并且很容易证明),如果|x[1]^j - x[2]^j|是最大的组件绝对差,p → ∞,d[p](x[c] , x) → |x[1]^j - x[2]^j|。 这意味着,如果考虑由于所有组件的差异而导致的相似性(或相异性),则需要为p选择一个较小的值(例如p = 1或2)。 另一方面,如果必须仅根据组件之间的最大绝对差将两个样本视为不同,则p的较高值是合适的。 通常,此选择非常依赖于上下文,并且不能轻易概括。 为了我们的目的,我们通常只考虑欧几里得距离,这在大多数情况下是合理的。 另一方面,当N → ∞时,为p选择更大的值具有重要的意义。 让我们从一个例子开始。 对于不同的p和N值,我们要测量1N向量 (属于ℜ^N且所有分量均等于 1 的向量)到原点的距离 (使用对数刻度压缩y轴)。 如下:
import numpy as np
from scipy.spatial.distance import cdist
distances = np.zeros(shape=(8, 100))
for i in range(1, distances.shape[0] + 1):
for j in range(1, distances.shape[1] + 1):
distances[i - 1, j - 1] = np.log(cdist(np.zeros(shape=(1, j)), np.ones(shape=(1, j)),
metric='minkowski', p=i)[0][0])
距离如下图所示:
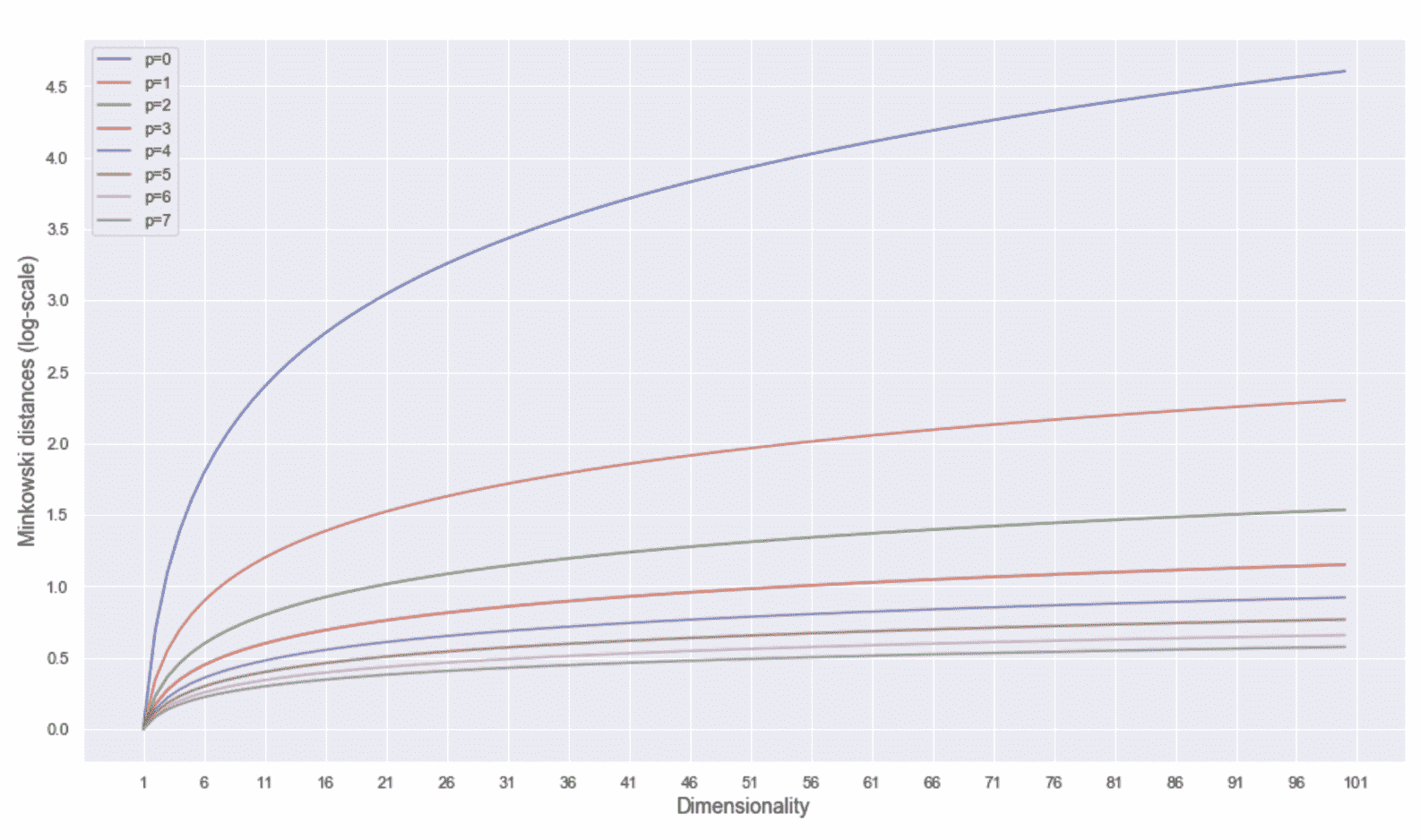
不同p和N值的 Minkowski 距离(对数刻度)
第一个结果是,如果我们选择N的值,则当p → ∞时,距离收缩并饱和。 这是 Minkowski 距离结构的正常结果,但敏锐的读者可能会注意到另一个特征。 让我们想象一下将1N向量的成分之一设置为等于0.0。 这等效于从N维超立方体的顶点移动到另一个顶点。 距离会怎样? 好吧,用一个例子很容易证明,当p → ∞时,两个距离收敛到相同的值。 特别是被 Aggarwal,Hinneburg 和 Keim(在《关于高度量空间中距离度量的惊人行为》中)证明是重要的结果。
假设我们有M个二元样本的分布p(x),x[i] ∈ (0, 1)^d。 如果采用 Minkowski 度量,则可以计算最大值(Dmax^p)和最小值(Dmin^p)从p(x)采样的两个点与原点之间的距离(通常,该距离可以通过解析来计算,但是也可以使用迭代程序持续采样,直到Dmax^p和Dmin^p停止更改)。 作者证明以下不等式成立:
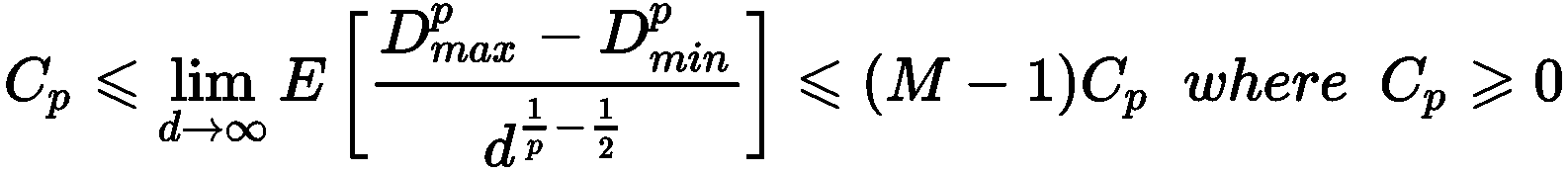
在先前的公式中,C[p]是取决于p的常数。 当p → ∞时,期望值E[D[max]^p - D[min]^p] * i在边界k[1] C[p] d^(1 / p- 1/2)和(M-1) C[p] d^(1 / p-1 / 2)。 当p > 2和d → ∞时,项d^(1 / p-1 / 2) → 0,最大和最小距离之差的期望值收敛到0。 这意味着,独立于样本,当维数足够高且p > 2时,几乎不可能使用 Minkowski 距离来区分两个样本。 当我们发现距离函数的相似性时,该定理警告我们选择d >> 1时选择p较大的值。 当d >> 1(即使p = 1是最佳选择)时,欧几里德度量标准的常用选择也相当可靠,因为它对组件的权重产生最小的效果(可以假定它们具有相同的权重),并保证在高维空间中的可区分性。 相反,高维空间中的p >> 2对于所有最大分量保持固定而所有其他分量都被修改的样本,则产生无法区分的距离(例如,如果x = (5, 0) → (5, a),其中|a| < 5),如以下示例所示 :
import numpy as np
from scipy.spatial.distance import cdist
distances = []
for i in range(1, 2500, 10):
d = cdist(np.array([[0, 0]]), np.array([[5, float(i/500)]]), metric='minkowski', p=15)[0][0]
distances.append(d)
print('Avg(distances) = {}'.format(np.mean(distances)))
print('Std(distances) = {}'.format(np.std(distances)))
输出如下:
Avg(distances) = 5.0168687736484765
Std(distances) = 0.042885311128215066
因此,对于p = 15,对于x ∈ [0.002, 5.0)的所有样本(5, x),与原点之间的距离均值约为5.0并且标准差为0.04。 当p变大时,Avg(distances) = 5.0 和Std(distances) = 0.04 。
在这一点上,我们可以开始讨论一种最常见且被广泛采用的聚类算法:K-means。
K 均值
K 均值是最大分离和最大内部凝聚力原理的最简单实现。 假设我们有一个数据集X ∈ R^(M×N)(即MN维样本),我们希望将其拆分为K群集和一组K个重心,它们对应于分配给每个群集K[j]的样本均值:
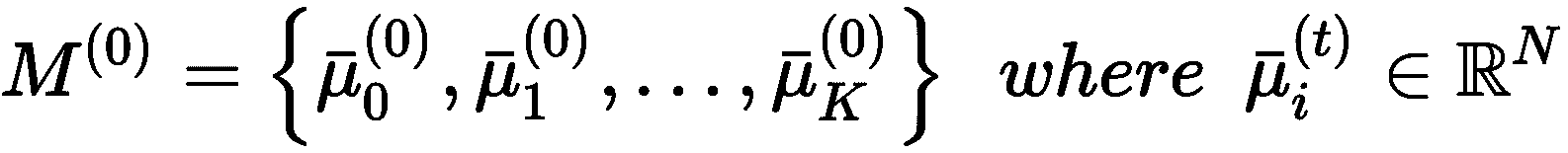
集合M和质心具有一个附加索引(作为上标),指示迭代步骤。 从初始猜测M^(0)开始,K 均值尝试最小化称为惯性的目标函数(即总平均集群内距离) 分配给群集K[j]和其质心μ[j]的样本之间):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aBQ6qpor-1681652575093)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-unsup-learn-py/img/56a960f6-4a96-4e97-883e-17277d02904c.png)]
不难理解, S(t)不能被视为绝对度量,因为其值在很大程度上受样本方差的影响。 但是,S(t + 1) < S(t)表示质心正在靠近最佳位置,在最佳位置,分配给聚类的点与相应质心的距离最小。 因此,迭代过程(也称为 Lloyd 算法)开始于使用随机值初始化M^(0)。 下一步是将每个样本x[i] ∈ X分配给群集,其质心与x[i]距离最小:
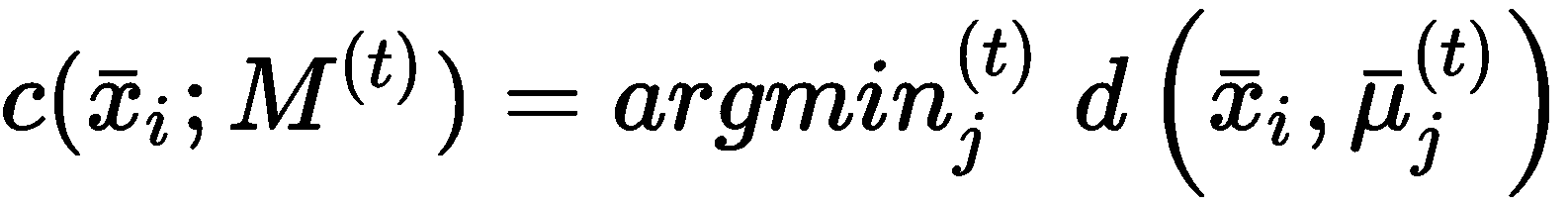
完成所有分配后,将重新计算新的质心作为算术方法:
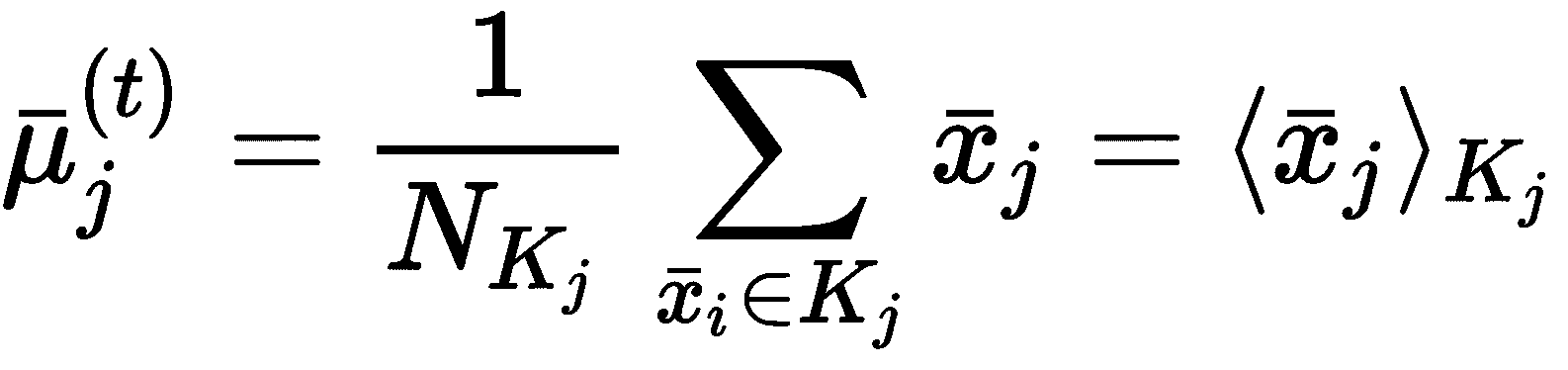
重复该过程,直到质心停止变化为止(这也意味着序列S(0) > S(1) > ... > S(t[end]))。 读者应该立即了解到,计算时间受初始猜测的影响很大。 如果M^(0)非常接近M^t[end],则可以找到一些迭代的最佳配置。 相反,当M^(0)纯粹是随机的时,无效初始选择的概率接近1(也就是说,每个初始的均匀随机选择,在计算复杂度方面几乎等价)。
KMeans++
找到最佳的初始配置等同于最小化惯性。 但是, Arthur 和 Vassilvitskii(在《KMeans++:精心播种的优势》中)提出了另一种初始化方法(称为 KMeans++),该方法可以通过选择初始质心的可能性大得多,从而提高收敛速度,而初始质心的概率接近最终质心。 完整的证明非常复杂,可以在前述论文中找到。 在这种情况下,我们直接提供最终结果和一些重要后果。
让我们考虑定义为的函数D(·):
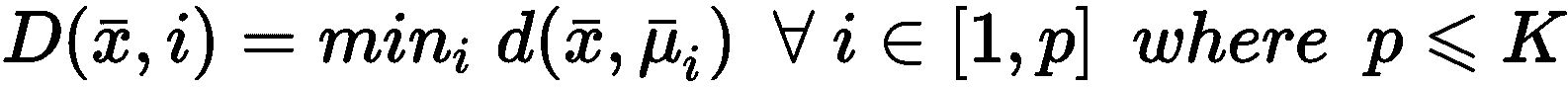
D(·)表示样本x ∈ X与已选择的质心之间的最短距离。 一旦函数被计算,就可以如下确定概率分布G(x):
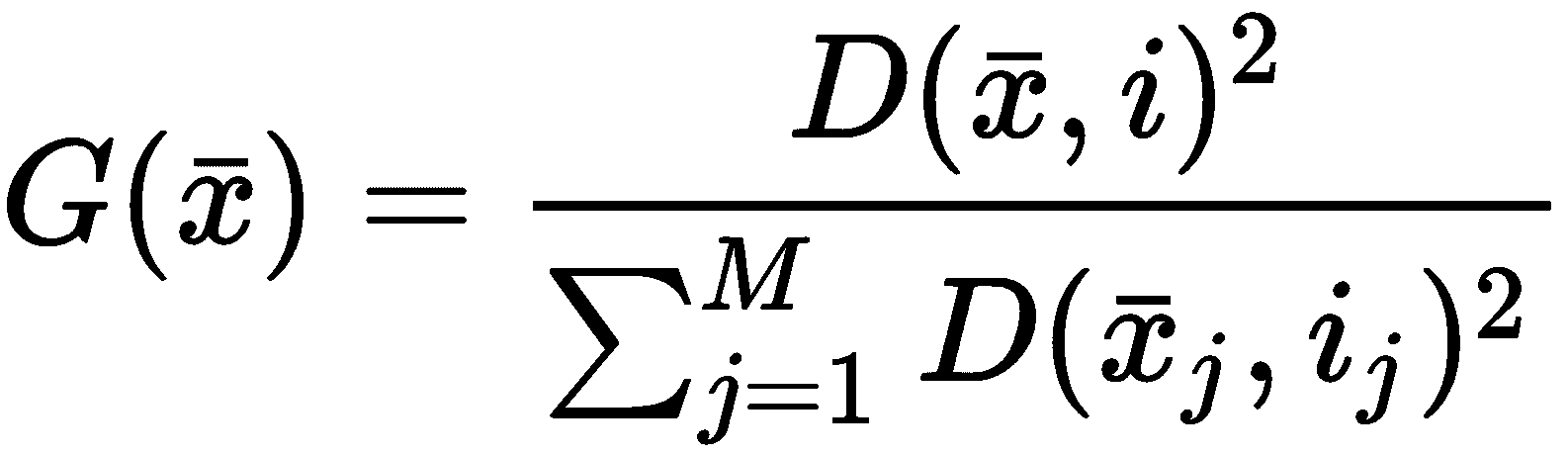
从均匀分布中采样第一个质心μ[1]。 此时,可以为所有样本x ∈ X计算D(·),因此,可以计算出分布G(x)。 直截了当,如果我们从G(x)进行采样,那么在稠密区域中选择值的概率要比在均匀区域中均匀采样或选取质心的概率大得多。 因此,我们继续从G(x)中采样μ[2]。 重复该过程,直到确定所有K重心。 当然,由于这是一种概率方法,因此我们无法保证最终配置是最佳的。 但是,使用 K-means++ 是具有竞争力的O(log K)。 实际上,如果S[opt]是S的理论最优值,则作者证明存在以下不等式:
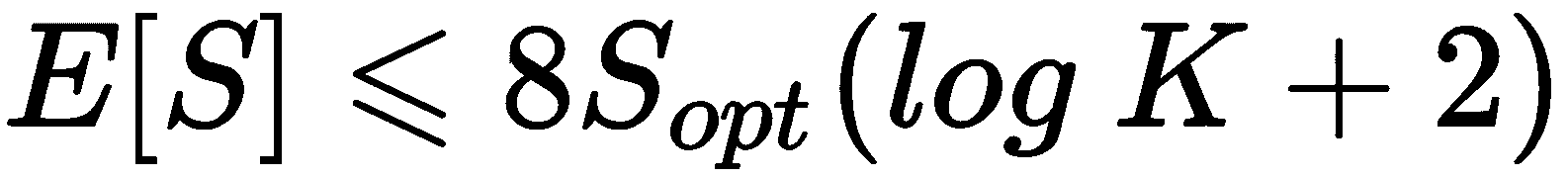
由于通过更好的选择降低了S,因此先前的公式设置了与log K大致成比例的期望值E[S]的上限。 例如,对于K = 10,E[S] <= S [opt],并且对于K = 3,E[S] <= 12.87 * S[opt]为K = 3。 该结果揭示了两个重要因素。 第一个是当K不太大时,KMeans++ 的表现会更好;第二个(可能也是最重要的)是,单个 KMeans++ 初始化不足以获取最佳配置。 因此,常见的实现(例如 scikit-learn)执行可变数量的初始化,并选择初始惯量最小的初始化。
乳腺癌威斯康星州数据集分析
在本章中,我们使用著名的乳腺癌威斯康星州数据集进行聚类分析。 最初,提出数据集是为了训练分类器。 但是,这对于非平凡的聚类分析非常有帮助。 它包含由 32 个属性(包括诊断和标识号)组成的 569 条记录。 所有属性都与肿瘤的生物学和形态学特性严格相关,但是我们的目标是考虑基本事实(良性或恶性)和数据集的统计特性来验证通用假设。 在继续之前,弄清楚一些要点很重要。 数据集是高维的,聚类是非凸的(因此我们不能期望有完美的分割)。 此外,我们的目标不是使用聚类算法来获得分类器的结果; 因此,必须仅将真实情况作为潜在分组的一般指示。 该示例的目的是演示如何执行简短的初步分析,选择最佳数量的聚类以及验证最终结果。
下载后(如技术要求部分所述),CSV 文件必须放在我们通常表示为<data_folder>的文件夹中。 第一步是加载数据集,并通过 Pandas DataFrame暴露的函数describe()进行全局统计分析,如下所示:
import numpy as np
import pandas as pd
bc_dataset_path = '<data_path>\wdbc.data'
bc_dataset_columns = ['id','diagnosis', 'radius_mean', 'texture_mean', 'perimeter_mean',
'area_mean', 'smoothness_mean', 'compactness_mean', 'concavity_mean',
'concave points_mean', 'symmetry_mean', 'fractal_dimension_mean',
'radius_se','texture_se', 'perimeter_se', 'area_se', 'smoothness_se',
'compactness_se', 'concavity_se', 'concave points_se', 'symmetry_se',
'fractal_dimension_se', 'radius_worst', 'texture_worst', 'perimeter_worst',
'area_worst', 'smoothness_worst', 'compactness_worst', 'concavity_worst',
'concave points_worst', 'symmetry_worst', 'fractal_dimension_worst']
df = pd.read_csv(bc_dataset_path, index_col=0, names=bc_dataset_columns).fillna(0.0)
print(df.describe())
我强烈建议使用 Jupyter 笔记本(在这种情况下,命令必须仅是df.describe()),所有命令都将产生内联输出。 出于实际原因,在以下屏幕截图中,显示了表格输出的第一部分(包含八个属性):
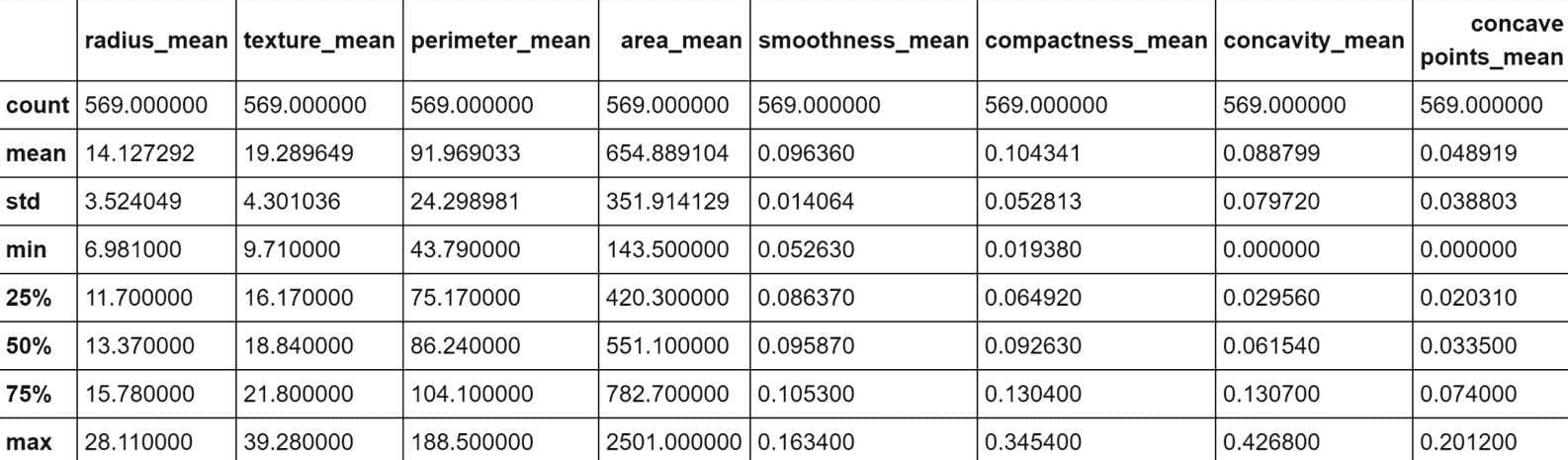
数据集前八个属性的统计报告
当然,即使我们仅将注意力集中在子集上,我也请读者检查所有属性的值。 特别是,我们需要观察前八个属性之间存在的不同尺度。 标准差的范围是 0.01 到 350,这意味着仅由于一个或两个属性,许多向量可能极其相似。 另一方面,使用方差缩放对值进行归一化将赋予所有属性相同的责任(例如143.5和2501之间的界限为area_mean,而0.05和smoothness_mean之间的界限为smoothness_mean。 强迫它们具有相同的方差会影响因素的生物学影响,并且由于我们没有任何具体的指示,因此我们没有授权做出这样的选择)。 显然,某些属性在聚类过程中将具有更高的权重,我们将它们的主要影响视为与上下文相关的条件。
让我们现在开始考虑perimeter_mean,area_mean,smoothness_mean,concavity_mean和symmetry_mean的对图的初步分析。 该图显示在以下屏幕截图中:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UpUCek57-1681652575095)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-unsup-learn-py/img/547f2d24-2fa1-442a-9fae-48d8f2101df3.png)]
周边平均值,面积平均值,平滑度平均值,凹度平均值和对称平均值的成对图
该图将每个非对角线属性绘制为其他所有属性的函数,而对角线图则表示每个属性分为两个部分的分布(在这种情况下,这就是诊断)。 因此,第二个非对角线图(左上图)是perimeter_mean作为area_mean的函数的图,依此类推。 快速分析突出了一些有趣的元素:
area_mean和perimeter_mean具有明确的相关性,并确定了清晰的间隔。 当area_mean大于约 1,000 时,显然周长也会增加,并且诊断会从良性突然转变为恶性。 因此,这两个属性是最终结果的决定因素,并且其中之一很可能是多余的。- 其他图(例如
perimeter_mean/area_mean与smoothness_mean,area_mean与symmetry_mean,concavity_mean与smoothness_mean和concavity_mean与symmetry_mean)具有水平间距( 变为垂直反转轴)。 这意味着,对于独立变量(x轴)假定的几乎所有值,都有一个阈值将另一个变量的值分成两组(良性和恶性)。 - 一些图(例如
perimeter_mean/area_mean对concavity_mean/concavity_mean对symmetry_mean)显示了略微负的斜对角线间距。 这意味着,当自变量较小时,诊断几乎对因变量的所有值均保持不变,而另一方面,当自变量变得越来越大时,诊断将按比例切换为相反的值。 例如,对于较小的perimeter_mean值,concavity_mean可以达到最大值而不影响诊断(良性),而perimeter_mean > 150总是独立于concavity_mean进行恶性诊断。
当然,我们不能轻易地从拆分分析中得出结论(因为我们需要考虑所有交互作用),但是此活动将有助于为每个群集提供语义标签。 此时,通过 T 分布随机邻居嵌入(t-SNE)变换(对于进一步的细节,请查看《使用 t-SNE 可视化数据》)。 可以按照以下步骤进行:
import pandas as pd
from sklearn.manifold import TSNE
cdf = df.drop(['diagnosis'], axis=1)
tsne = TSNE(n_components=2, perplexity=10, random_state=1000)
data_tsne = tsne.fit_transform(cdf)
df_tsne = pd.DataFrame(data_tsne, columns=['x', 'y'], index=cdf.index)
dff = pd.concat([df, df_tsne], axis=1)
生成的绘图显示在以下屏幕截图中:
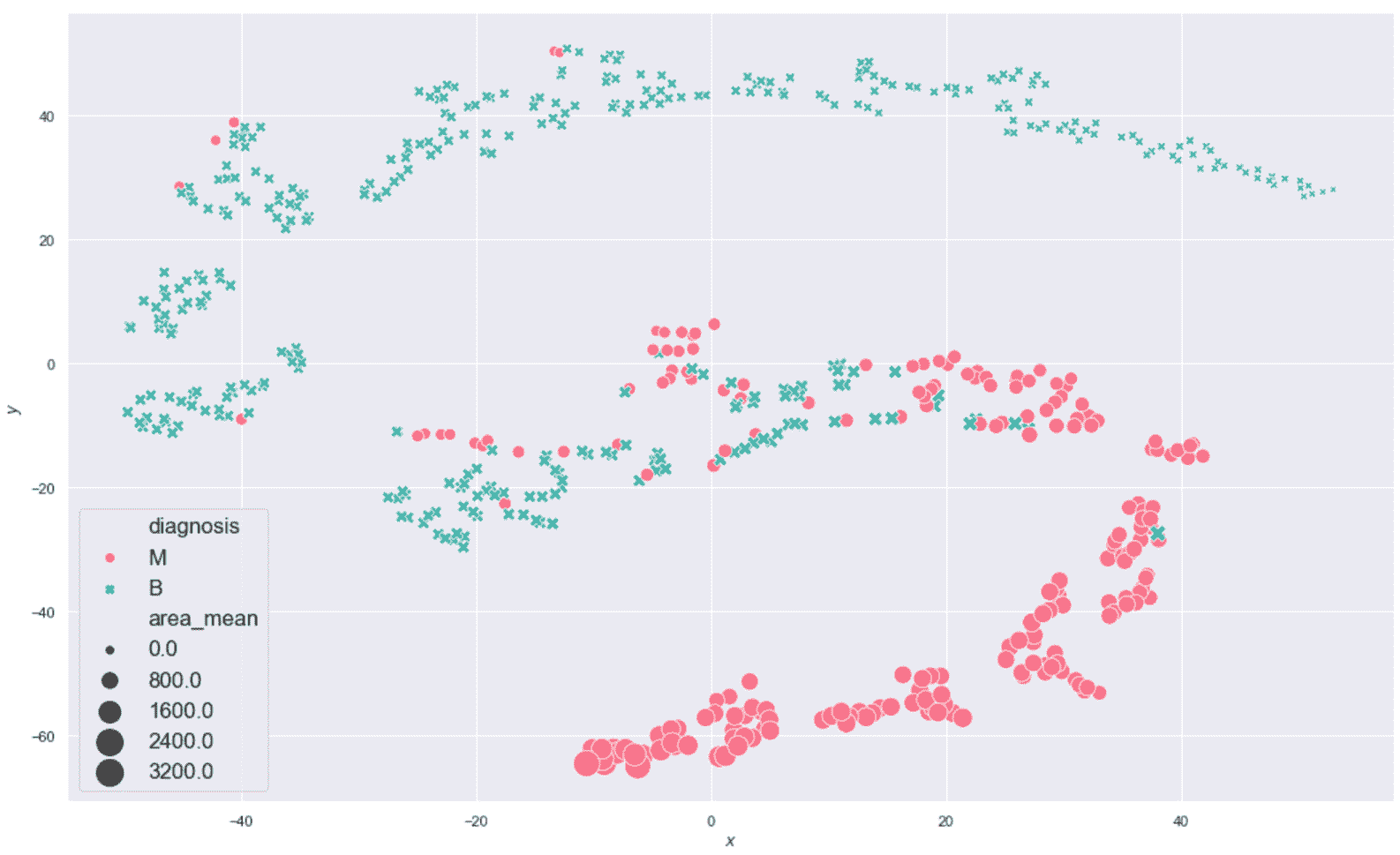
乳腺癌威斯康星州数据集的二维 t-SNE 图
该图是高度非线性的(别忘了这是从ℜ^30到ℜ^2的投影),恶性样本中的一半在半平面y < 0中。 不幸的是,在该区域中也有适度的良性样本,因此我们不期望使用K = 2进行完美分离(在这种情况下,很难理解真实的几何形状,但是 t- SNE 保证二维分布的 Kullback-Leibler 散度与原始高维散度最小。 现在,我们以K = 2进行初始聚类。 我们将使用n_clusters=2和max_iter=1000创建KMeans scikit-learn 类的实例(random_state始终设置为等于1000)。
其余参数为默认参数(使用 10 次尝试的 KMeans++ 初始化),如下所示:
import pandas as pd
from sklearn.cluster import KMeans
km = KMeans(n_clusters=2, max_iter=1000, random_state=1000)
Y_pred = km.fit_predict(cdf)
df_km = pd.DataFrame(Y_pred, columns=['prediction'], index=cdf.index)
kmdff = pd.concat([dff, df_km], axis=1)
生成的绘图显示在以下屏幕截图中:
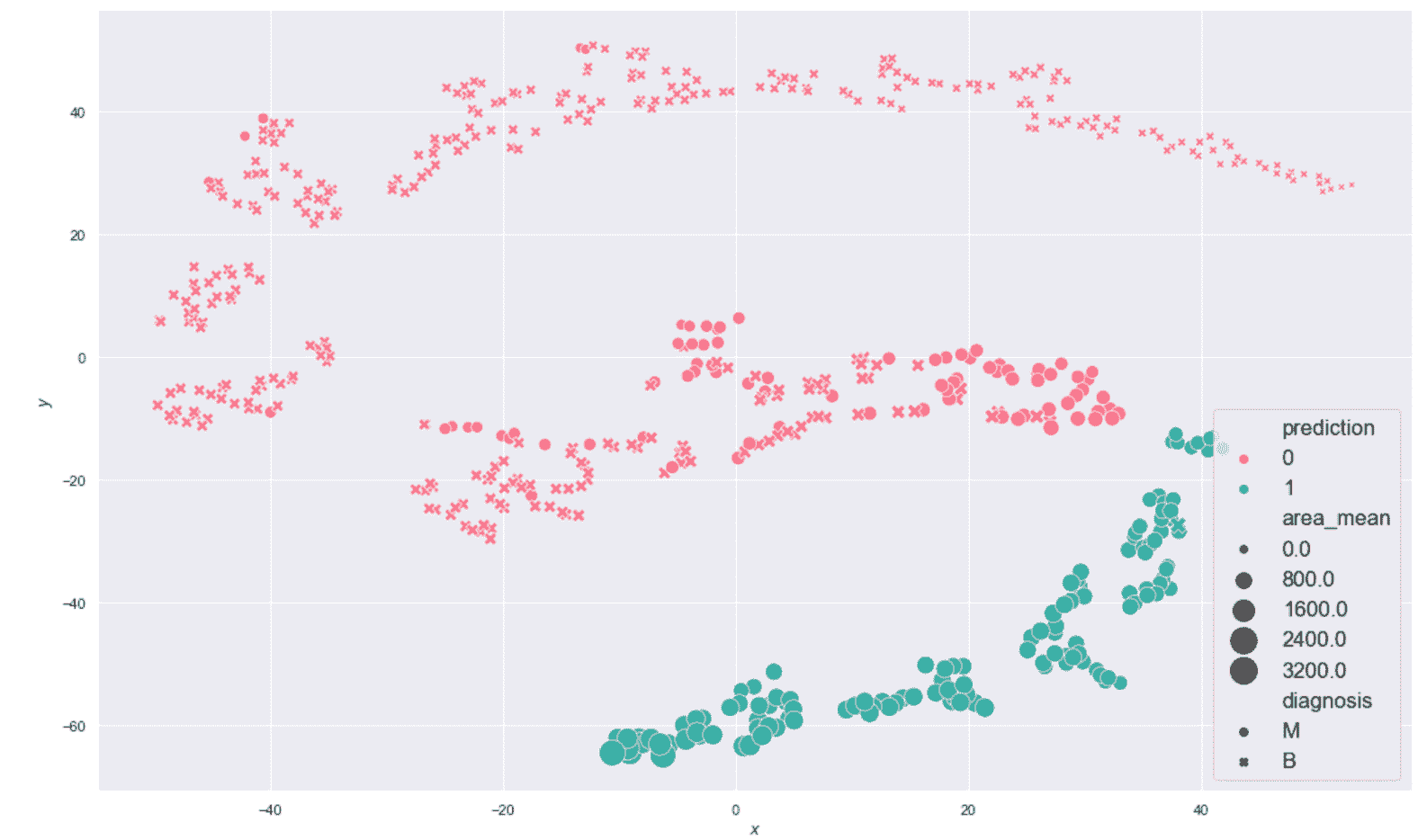
乳腺癌威斯康星州数据集的 K 均值聚类(K = 2)
毫不奇怪,该结果对于y < -20相当准确,但该算法无法同时包含边界点(y≈0)进入主要恶性集群。 这主要是由于原始集合的非凸性,并且使用 K 均值很难解决问题。 此外,在投影中,大多数y ≈ 0的恶性样本与良性样本混合在一起,因此,使用基于接近度的其他方法的错误概率也很高。 正确分离这些样本的唯一机会来自原始分布。 实际上,如果可以通过ℜ^30中的不相交球捕获属于同一类别的点,则 K 均值也可以成功。 不幸的是,在这种情况下,混合集看起来非常具有内聚性,因此我们不能指望不进行转换就可以提高性能。 但是,出于我们的目的,此结果使我们可以应用主要评估指标,然后从K > 2移到更大的值。 我们将使用K > 2分析一些聚类,并将它们的结构与配对图进行比较。
评估指标
在本节中,我们将分析一些可用于评估聚类算法表现并帮助找到最佳聚类数量的常用方法。
最小化惯性
K 均值和类似算法的最大缺点之一是对群集数的明确要求。 有时,这条信息是由外部约束施加的(例如,在乳腺癌的情况下,只有两种可能的诊断),但是在许多情况下(需要进行探索性分析时),数据科学家必须检查不同的配置并评估它们。 评估 K 均值表现并选择适当数量的聚类的最简单方法是基于不同最终惯性的比较。
让我们从下面的简单示例开始,该示例基于 scikit-learn 函数make_blobs()生成的 12 个非常紧凑的高斯 Blob:
from sklearn.datasets import make_blobs
X, Y = make_blobs(n_samples=2000, n_features=2, centers=12,
cluster_std=0.05, center_box=[-5, 5], random_state=100)
以下屏幕快照中显示了斑点。
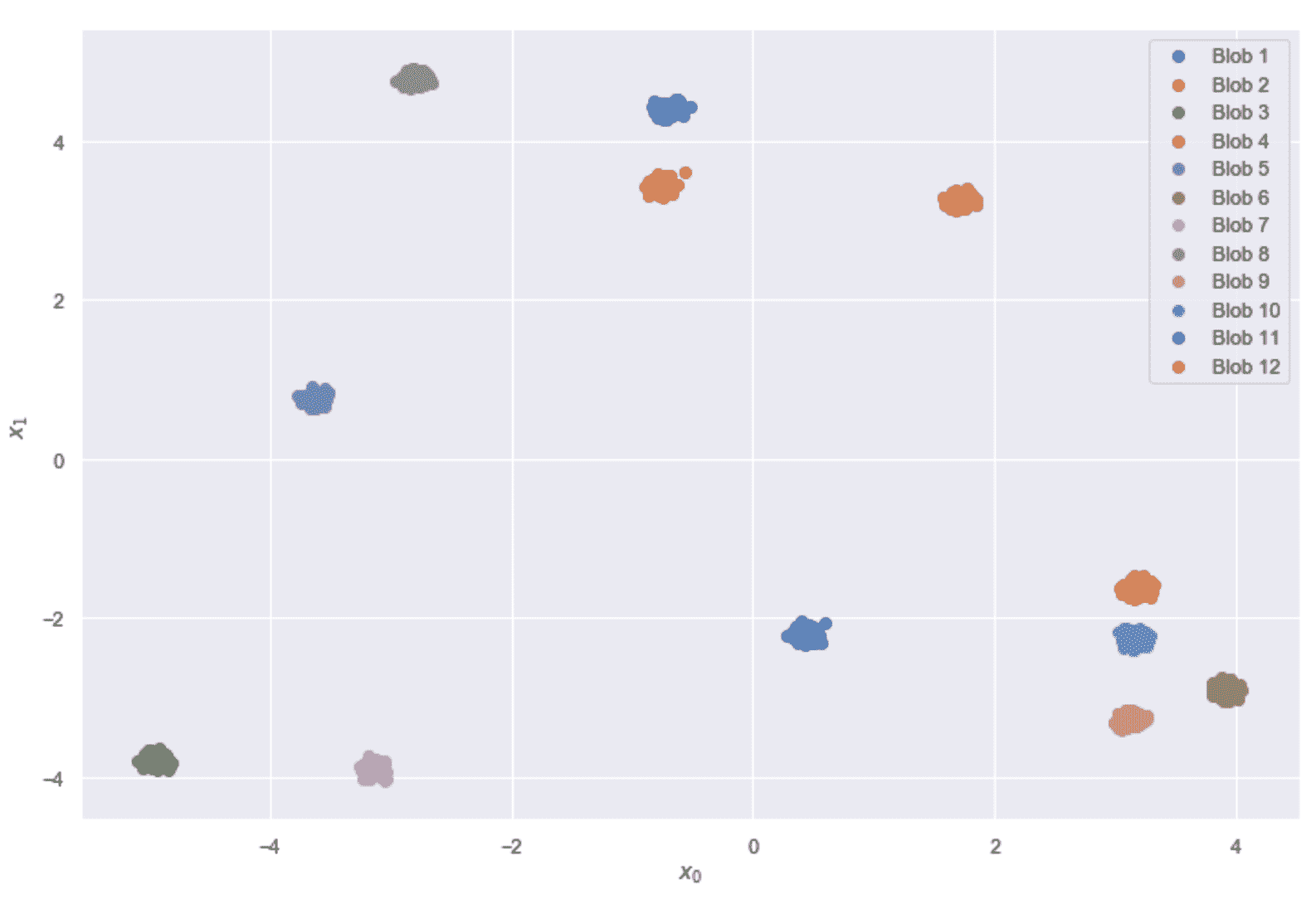
数据集由 12 个不相交的二维 Blob 组成
现在让我们计算K ∈ [2, 20]的惯性(在经过训练的KMeans模型中作为实例变量inertia_可用),如下所示:
from sklearn.cluster import KMeans
inertias = []
for i in range(2, 21):
km = KMeans(n_clusters=i, max_iter=1000, random_state=1000)
km.fit(X)
inertias.append(km.inertia_)
结果图为,如下所示 :
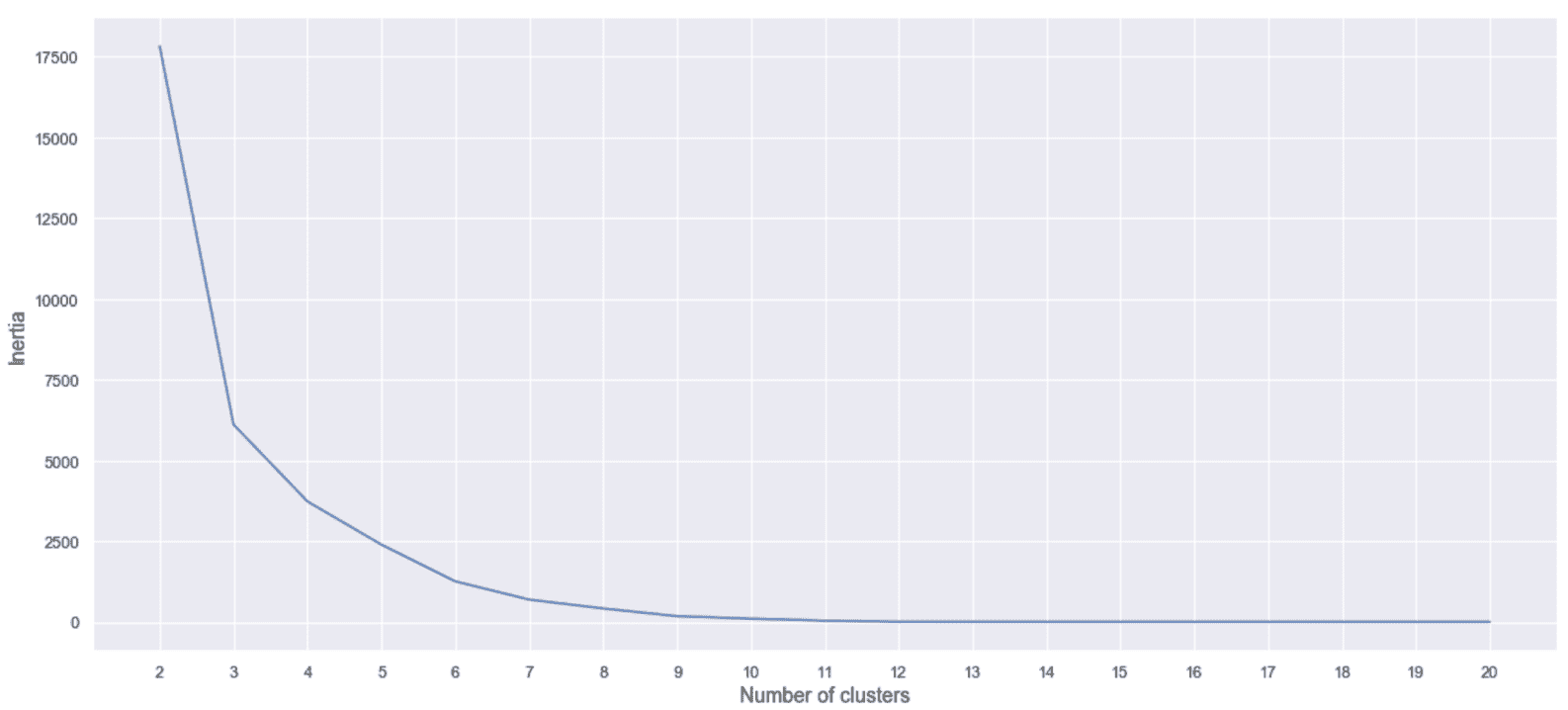
惯性与群集数的关系
上图显示了一种常见行为。 当团群集的数量非常小时,密度成比例地降低,因此内聚降低,结果,惯性也高。 群集数的增加会迫使模型创建更多的内聚组,并且惯性开始突然减小。 如果继续此过程,并且M > > K ,我们将观察到非常慢的方法,接近与K = M的配置对应的值(每个样本都是群集)。 通用启发式规则(在没有外部约束的情况下)是选择与将高变化区域与几乎平坦区域分开的点相对应的聚类数目。 这样,我们可以确保所有群集都达到了最大的凝聚力,而没有内部碎片。 当然,在这种情况下,如果我们选择K = 15,则将九个斑点分配给不同的群集,而其他三个斑点将分为两部分。 显然,当我们划分一个高密度区域时,惯性仍然很低,但是不再遵循最大分离的原理。
现在,我们可以使用K ∈ [2, 50],的乳腺癌威斯康星数据集重复该实验,如下所示:
from sklearn.cluster import KMeans
inertias = []
for i in range(2, 51):
km = KMeans(n_clusters=i, max_iter=1000, random_state=1000)
km.fit(cdf)
inertias.append(km.inertia_)
生成的绘图显示在以下屏幕截图中:
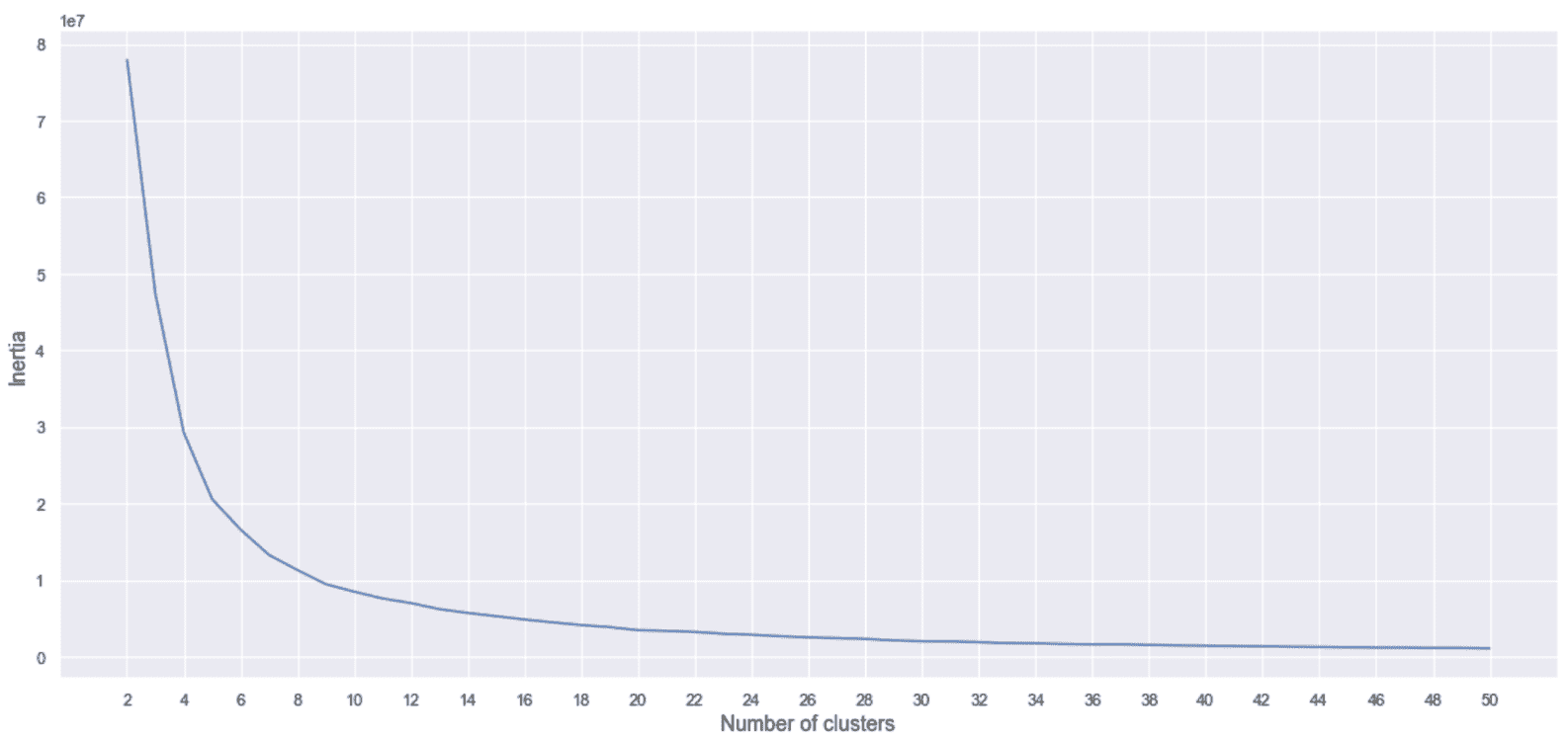
惯性,作为乳腺癌威斯康星州数据集的群集数的函数
在这种情况下,基本事实表明,我们应该根据诊断将其分为两组。 但是,该图显示了急剧下降,下降到K = 8并以较低的斜率继续,直到大约K = 40为止。 在初步分析过程中,我们已经看到二维投影由具有相同诊断的许多孤立的斑点组成。 因此,我们可以决定采用例如K = 8并分析与每个群集相对应的特征。 由于这不是分类任务,因此可以将真实情况用作主要参考,但是正确的探索性分析可以尝试理解子结构的组成,以便为技术人员(例如,医生)提供更多详细信息。
现在,我们在乳腺癌威斯康星州数据集上对八个聚类进行 K 均值聚类,以描述两个样本组, 的结构,如下所示
import pandas as pd
from sklearn.cluster import KMeans
km = KMeans(n_clusters=8, max_iter=1000, random_state=1000)
Y_pred = km.fit_predict(cdf)
df_km = pd.DataFrame(Y_pred, columns=['prediction'], index=cdf.index)
kmdff = pd.concat([dff, df_km], axis=1)
生成的绘图显示在以下屏幕截图中:
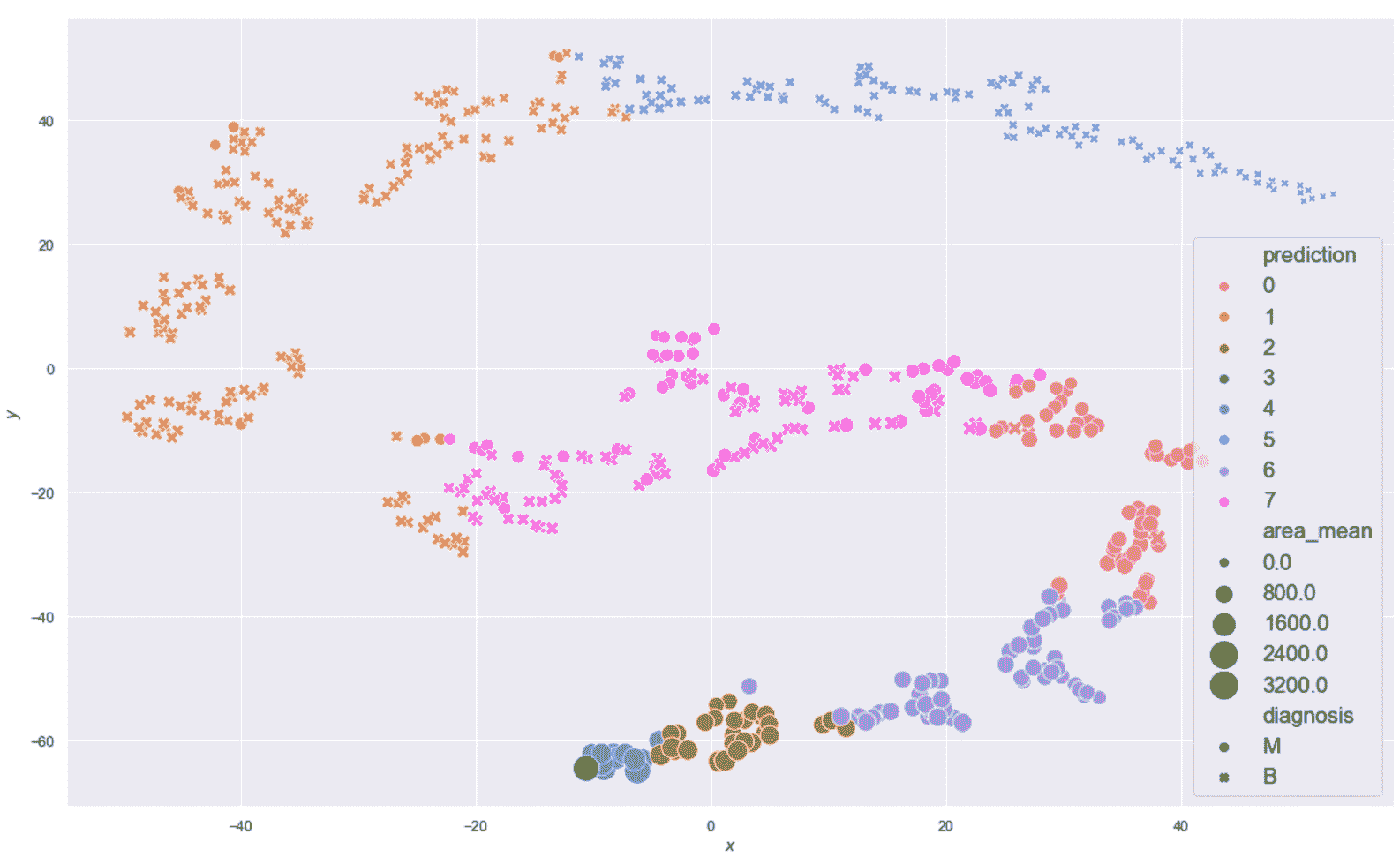
乳腺癌威斯康星州数据集的 K 均值聚类(K = 8)结果
现在,让我们考虑位于图底部的子群集(-25 < x < 30和-60 < y < -40) , 如下:
sdff = dff[(dff.x > -25.0) & (dff.x < 30.0) & (dff.y > -60.0) & (dff.y < -40.0)]
print(sdff[['perimeter_mean', 'area_mean', 'smoothness_mean',
'concavity_mean', 'symmetry_mean']].describe())
以下屏幕截图显示了统计表的打印友好版本:
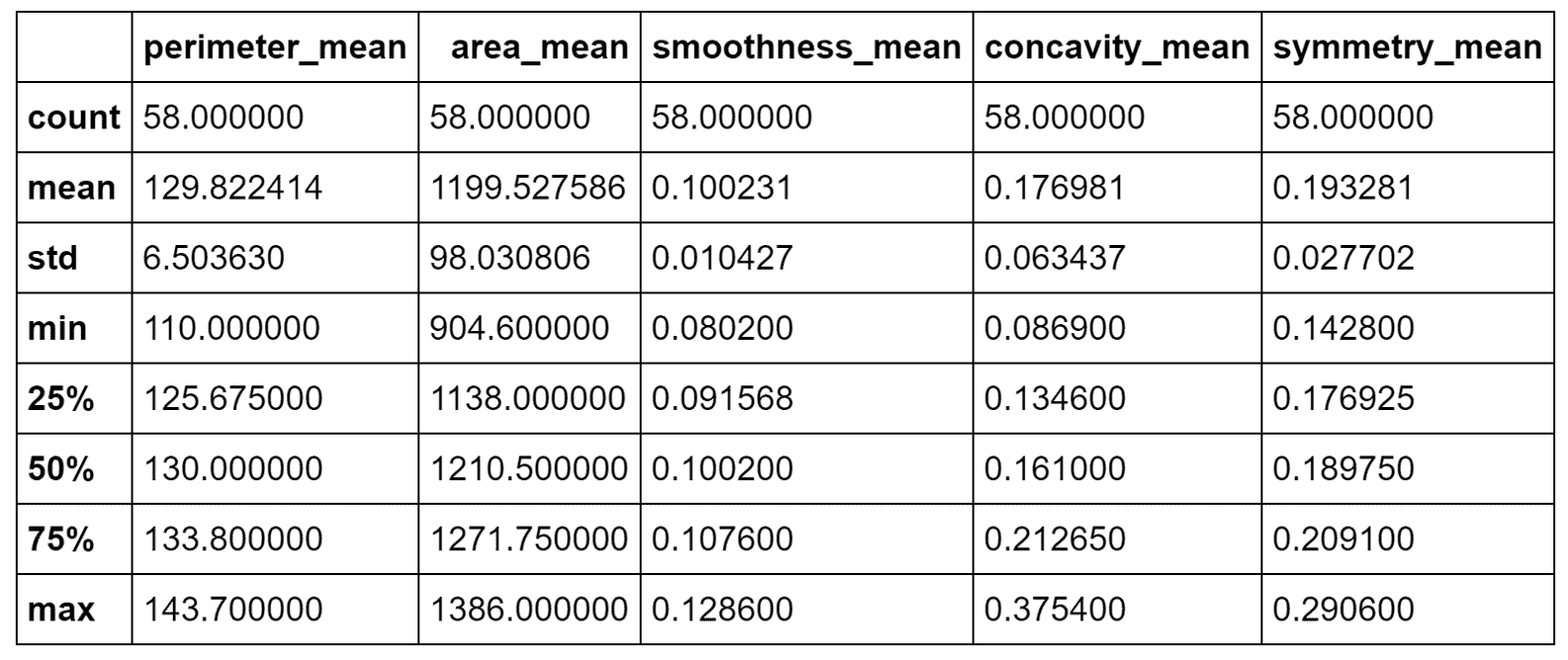
恶性群集的统计描述
根据事实,我们知道所有这些样本都是恶性的,但是我们可以尝试确定一个规则。 area_mean / perimeter_mean之比约为9.23,相对于平均值,相对标准差非常小。 这意味着这些样本在非常狭窄的范围内代表了扩展的肿瘤。 而且,concavity_mean和symmetry_mean均大于总值。 因此(在不进行科学合理分析的前提下),我们可以得出结论,分配给这些群集的样本代表了已经进入晚期的非常糟糕的肿瘤。
为了与良性样本进行比较,现在考虑由x > -10和20 < y < 50界定的区域如下:
sdff = dff[(dff.x > -10.0) & (dff.y > 20.0) & (dff.y < 50.0)]
print(sdff[['perimeter_mean', 'area_mean', 'smoothness_mean',
'concavity_mean', 'symmetry_mean']].describe())
结果显示在以下屏幕截图中:
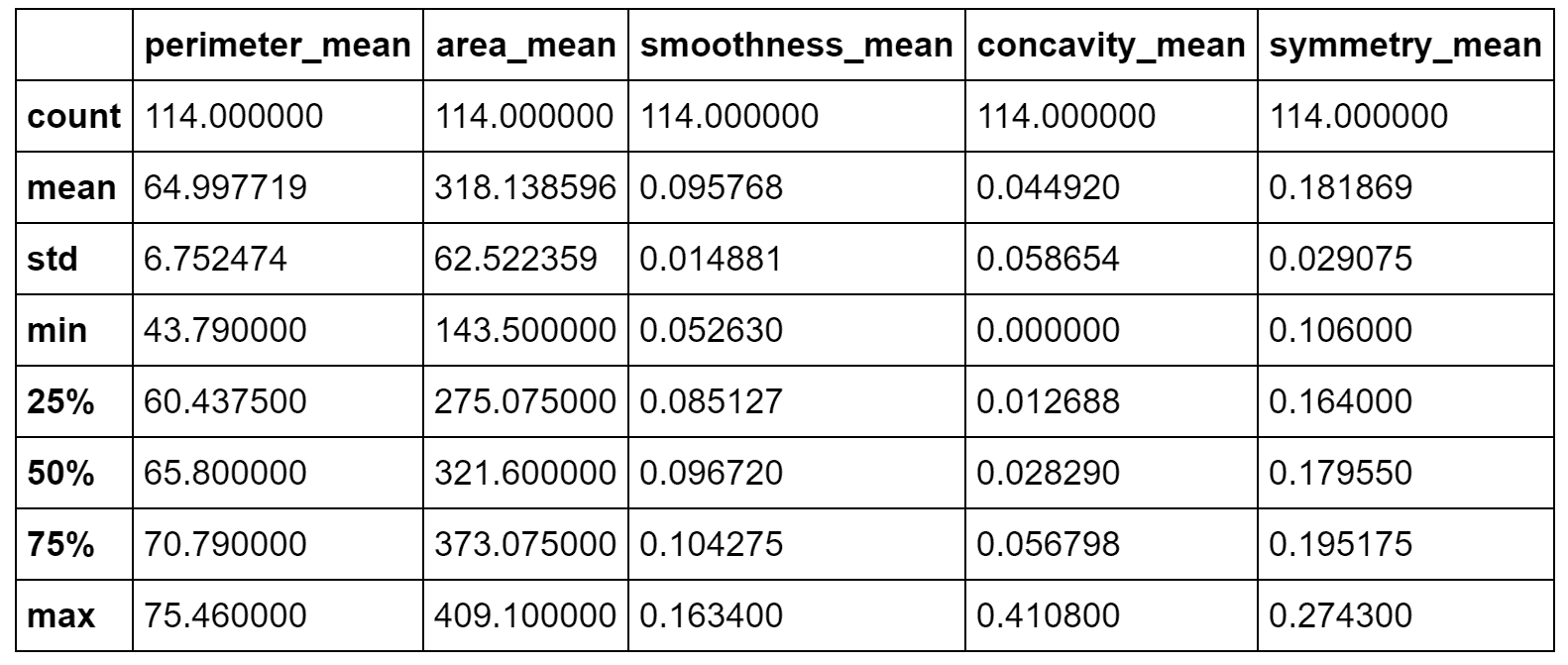
良性群集的统计描述
在这种情况下,比 area_mean / perimeter_mean 约为4.89,但是area_mean具有较大的标准差(实际上,其最大值约为410)。 concavity_mean相对于前一个非常小(即使具有近似相同的标准差),而symmetry_mean几乎相等。 从这个简短的分析中,我们可以推断出symmetry_mean不是判别特征,而concavity_mean的比值area_mean / perimeter_mean小于5.42(考虑最大值)。 小于或等于0.04应当保证良性结果。 由于concavity_mean可以达到非常大的最大值(大于与恶性样本相关的最大值),因此有必要考虑其他特征,以便确定是否应将其值视为警报。 但是,我们可以得出结论,说属于这些群集的所有样本都是良性的,错误概率可以忽略不计。 我想重复一遍,这不是真正的分析,而是更多的练习,在这种情况下,数据科学家的主要任务是收集可以支持结论的上下文信息。 即使存在基本事实,该验证过程也始终是强制性的,因为根本原因的复杂性可能导致完全错误的陈述和规则。
轮廓分数
在不了解基本事实的情况下评估聚类算法表现的最常见方法是轮廓分数。 它既提供了每个样本的索引,又提供了整体的图形表示,显示了群集的内部一致性和分离程度。 为了计算分数,我们需要引入两个辅助措施。 第一个是x[i] ∈ K[j]的平均群内距离,假设|K[j]| = n(j):
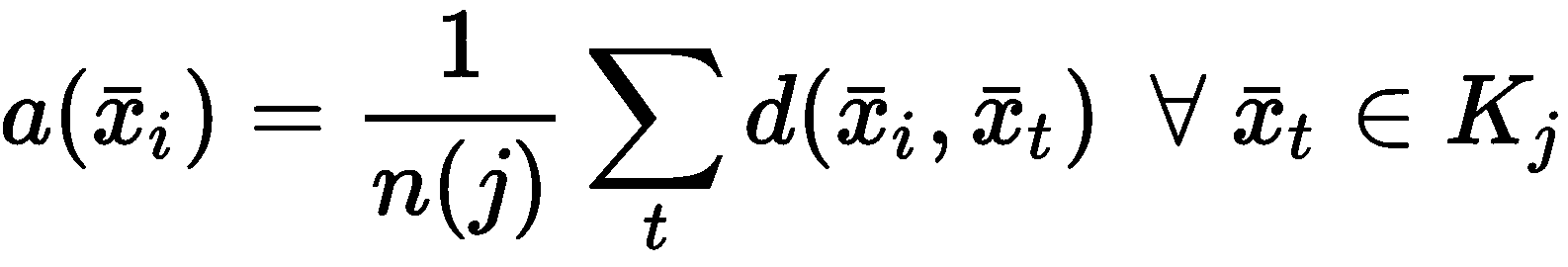
对于 K 均值,假定距离为欧几里得,但没有特定限制。 当然, d(·)必须与聚类过程中使用的距离函数相同。
给定样本x[i] ∈ K[j],让我们将最近的群集表示为K[c]。 这样,我们还可以定义最小最近集群距离(作为平均最近集群距离):
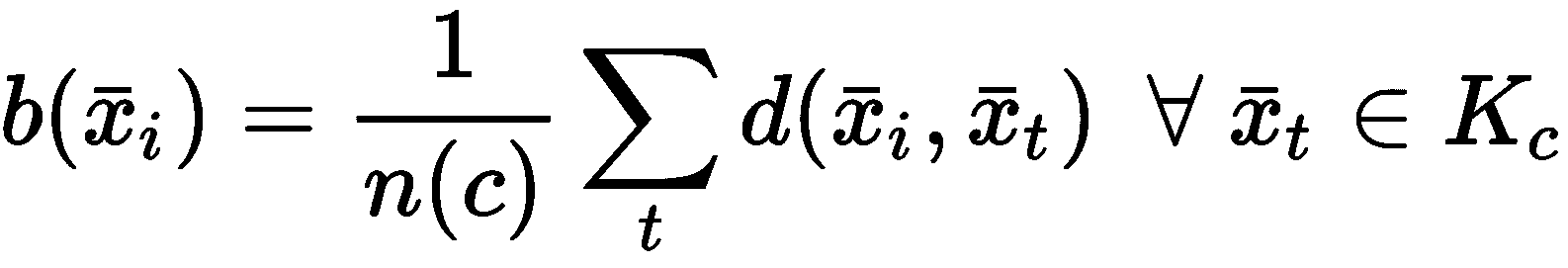
通过这两个度量,我们可以定义x[i] ∈ X的轮廓分数:
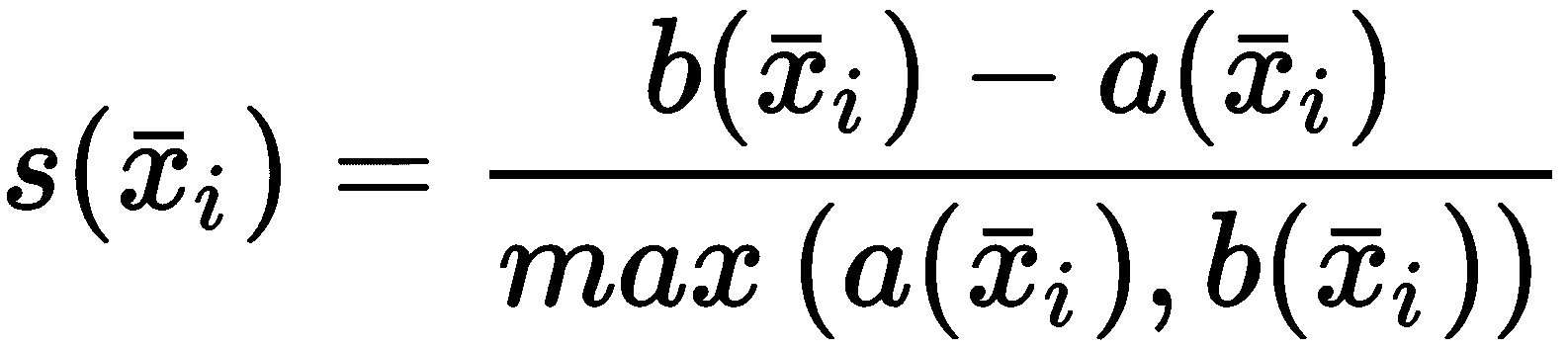
分数s(•) ∈ (-1, 1)。 当s(•) → -1时,意味着b(·) << a(·),因此样本x[i] ∈ K[j]比分配到K[j]的其他样本更接近最近的群集K[c]。 此情况表示分配错误。 相反,当s(·) → 1时,b(·) >> a(·),因此样本x[i]比分配给最近群集的任何其他点更接近其邻居(属于同一群集)。 显然,这是最佳条件,也是微调算法时要采用的参考。 但是,由于该索引不是全局索引,因此引入轮廓图很有帮助,该轮廓图显示每个样本所获得的得分,按聚类分组并以降序排序。
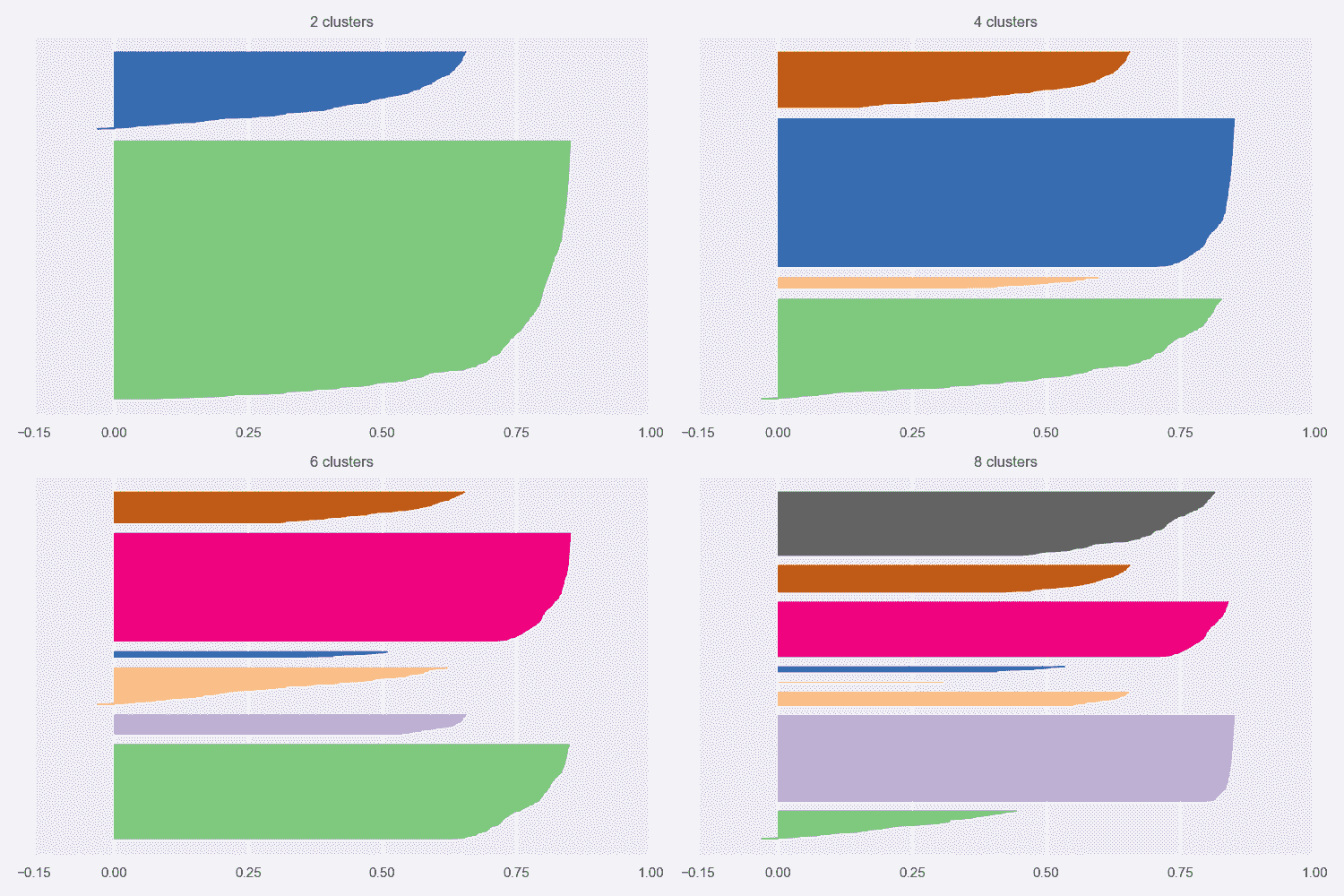
让我们考虑K = {2, 4, 6, 8}的乳腺癌威斯康星州数据集的轮廓图(完整代码包含在存储库中):
乳腺癌威斯康星州数据集的轮廓图
第一张图显示了K = 2的自然聚类。 第一个轮廓非常清晰,表明平均群集间距离具有较大的差异。 而且,一个集群比另一个集群具有更多的分配(即使它不那么尖锐)。 从数据集描述中,我们知道这两个类别是不平衡的(357 良性与 212 恶性),因此,不对称是部分合理的。 但是,一般而言,当数据集平衡时,良好的轮廓图的特征是具有均匀轮廓的均质群集,其圆形轮廓应接近 1.0。 实际上,当形状类似于长雪茄时,这意味着群集内距离非常接近其平均值(高内聚),并且相邻群集之间存在明显的分隔。 对于K = 2,我们拥有合理的分数,因为第一个群集达到 0.6,而第二个群集具有约 0.8 的峰值。 但是,尽管后者的大多数样本的特征是s(•) > 0.75,但在前一种样本中,约有一半的样本低于 0.5。 分析表明,较大的聚类更均匀,并且 K 均值更易于分配样本(即,就度量而言,x[i] ∈ K[2]的方差较小,在高维空间中,代表K[2]的球比代表K[1]的球更均匀。)。
其他图显示了类似的情况,因为已检测到非常紧密的聚类以及一些尖锐的聚类。 这意味着宽度差异非常一致。 但是,随着K的增加,由于分配的样本数趋于变得相似,因此我们获得了更加均一的群集。 具有s(·) > 0.75的非常圆形(几乎矩形)的群集的存在证实了数据集至少包含一组非常有凝聚力的样本,相对于分配给其他群集的任何其他点的距离都非常接近。 我们知道,恶性类(即使其基数更大)更为紧凑,而良性类则分布在更宽的子空间中。 因此,我们可以假设,对于所有K来说,最圆的群集是由恶性样本组成的,而其他所有群集都可以根据其清晰度进行区分。 例如,对于K = 8,第三群集很可能对应于第一图中第二群集的中心部分,而较小的群集包含属于良性子集的孤立区域的样本。
如果我们不了解基本事实,则应同时考虑K = 2和K = 8(甚至更大)。 实际上,在第一种情况下,我们可能会丢失许多细粒度的信息,但是我们正在确定一个强大的细分领域(假设由于问题的性质,一个集群的凝聚力不是很高)。 另一方面,在K > 8的情况下,群集明显更小,具有适度的内聚性,它们代表具有某些共同特征的亚组。 正如我们在上一节中讨论的那样,最终的选择取决于许多因素,这些工具只能提供一般的指示。 此外,当聚类是非凸的或它们的方差未在所有特征之间均匀分布时,K 均值将始终产生次优表现,因为所得聚类将包含较大的空白空间。 如果没有特定的方向,则群集的最佳数量与包含均匀(宽度大致相同)的圆形图的图相关联。 如果形状对于任何K值仍然保持清晰,则意味着几何形状与对称度量不完全兼容(例如,群集非常拉伸),应考虑其他方法。
完整性分数
此措施(以及从现在开始讨论的所有其他措施)是基于对基本事实的了解。 在引入索引之前,定义一些常用值会很有帮助。 如果我们用Y[true]表示包含真实分配的集合,而Y[pred]则表示预测的集合(均包含M个值和K个群集),我们可以估计以下概率:
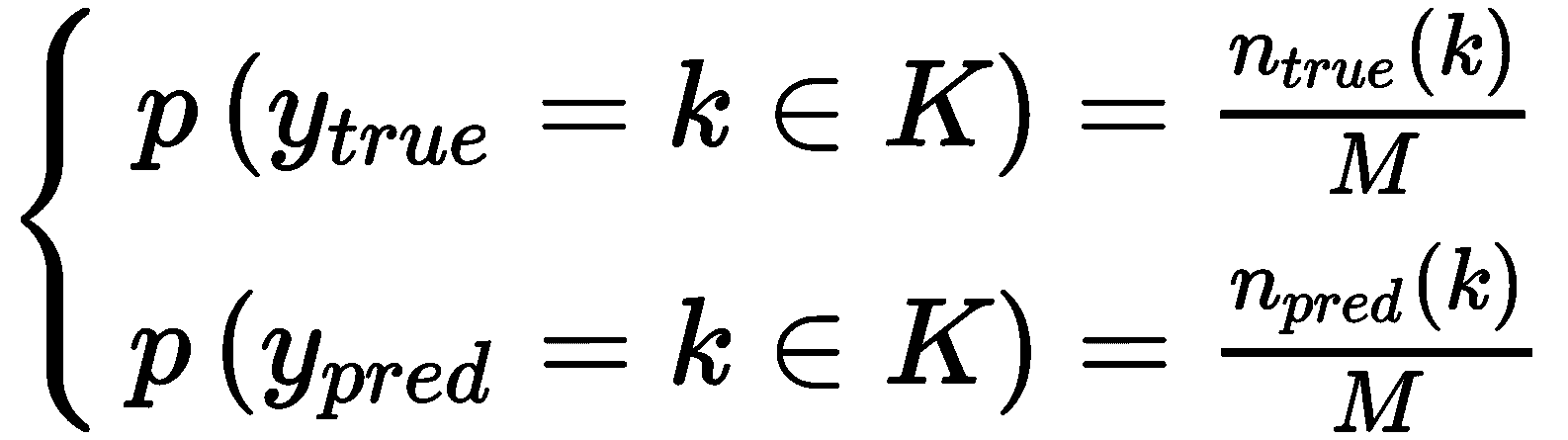
在先前的公式中,n [true/pred](k)代表属于群集k ∈ K的真实/预测样本数。 在这一点上,我们可以计算Y[true]和Y[pred]的熵:
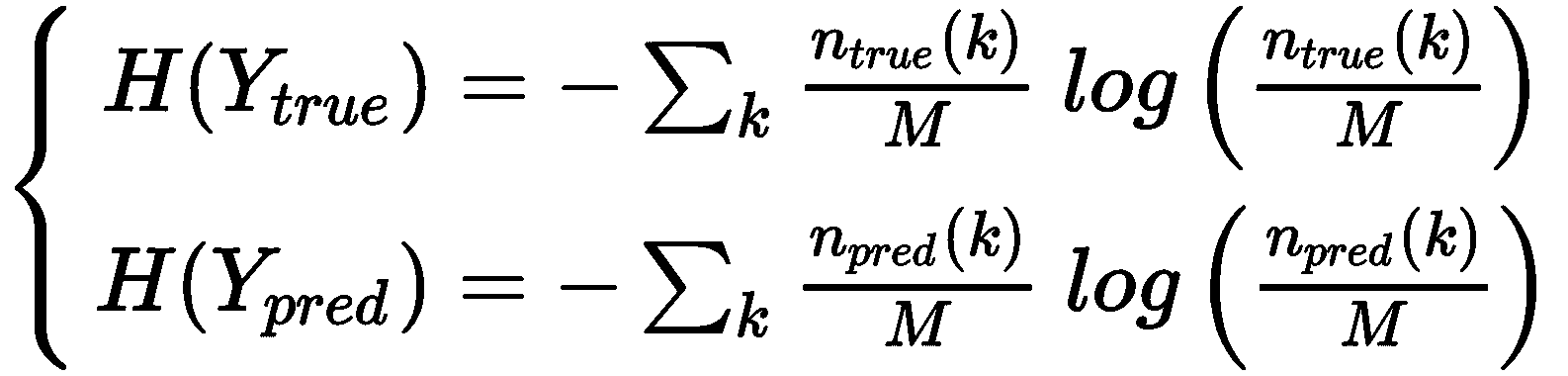
考虑到熵的定义, H(·)通过均匀分布最大化,而均匀分布又对应于每个分配的最大不确定性。 出于我们的目的,还必须引入Y[true]的条件熵(表示已知另一个变量的分布的不确定性),前提是Y以及其他方法:
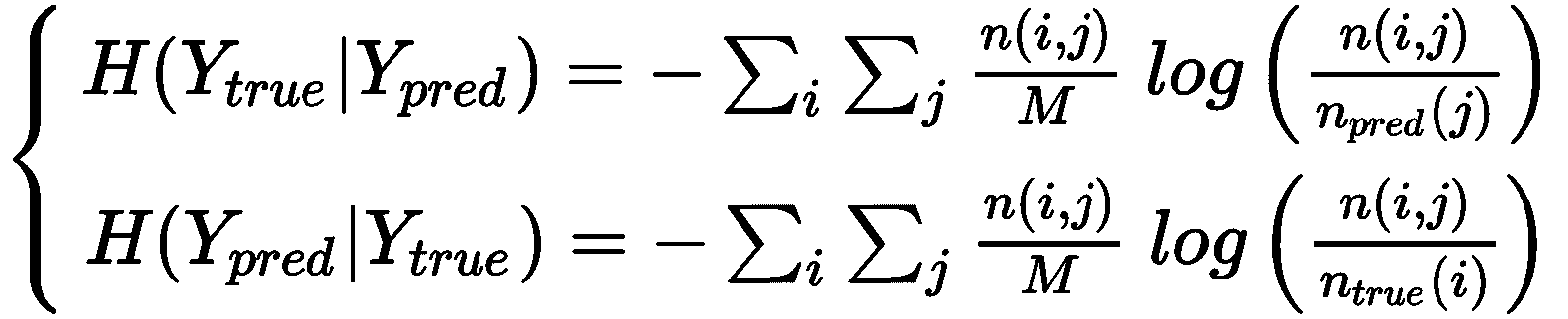
在第一种情况下,函数n(i, j)表示具有分配给K[j]的真标签i的样本数 ],在第二种情况下,将分配给K[i]的真标签j的样本数。
完整性分数定义为:
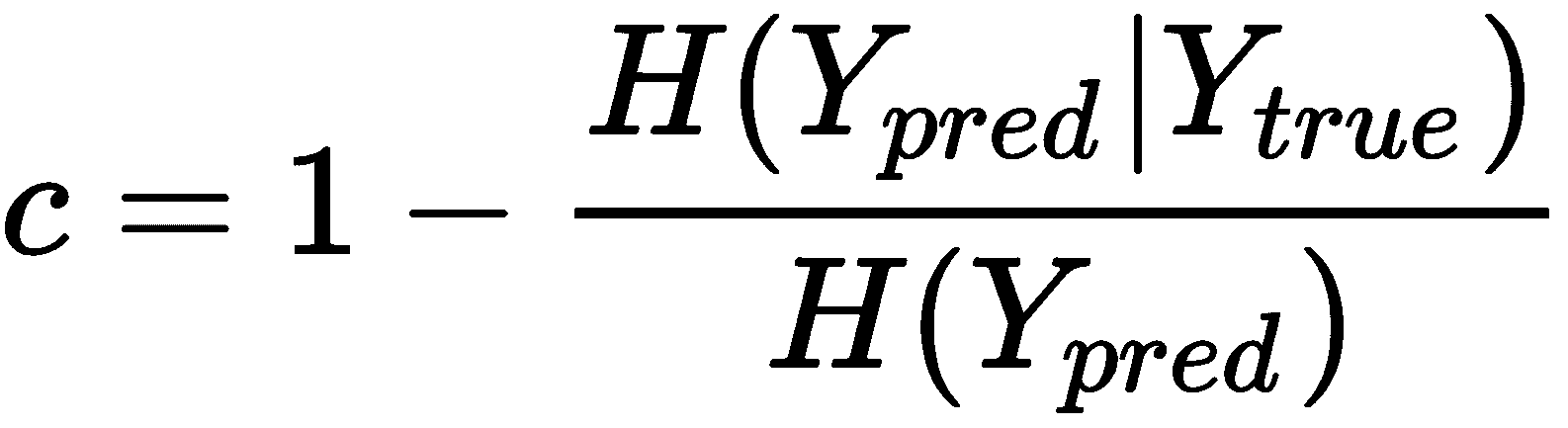
很容易理解,当H(Y[pred] | Y[true]) → 0时, Y[true]减少了预测的不确定性,因此,c → 1。 这等同于说所有具有相同真实标签的样本都分配给同一群集。 相反,当H(Y[pred] | Y[true]) → H(Y[pred]),这意味着真实情况没有提供任何信息,可以减少预测的不确定性,c → 0。
当然,良好的聚类的特征是c → 1。 对于乳腺癌威斯康星州数据集,使用 scikit-learn 函数completenss_score()(也适用于文本标签)和K = 2计算完整性评分( 与地面真相相关的唯一配置)如下:
import pandas as pd
from sklearn.cluster import KMeans
from sklearn.metrics import completeness_score
km = KMeans(n_clusters=2, max_iter=1000, random_state=1000)
Y_pred = km.fit_predict(cdf)
df_km = pd.DataFrame(Y_pred, columns=['prediction'], index=cdf.index)
kmdff = pd.concat([dff, df_km], axis=1)
print('Completeness: {}'.format(completeness_score(kmdff['diagnosis'], kmdff['prediction'])))
上一个代码段的输出如下:
Completeness: 0.5168089972809706
该结果证实,对于K = 2,K 均值不能完美地分离群集,因为如我们所见,因为某些恶性样本被错误地分配给包含大多数良性样本的群集。 但是,由于c并不是非常小,因此我们可以确保将这两个类别的大多数样本分配给了不同的群集。 邀请读者使用其他方法(在第 3 章,“高级聚类”中讨论)检查该值,并提供不同结果的简要说明。
同质性得分
同质性得分是对先前得分的补充,它基于以下假设:聚类必须仅包含具有相同真实标记的样本。 它定义为:
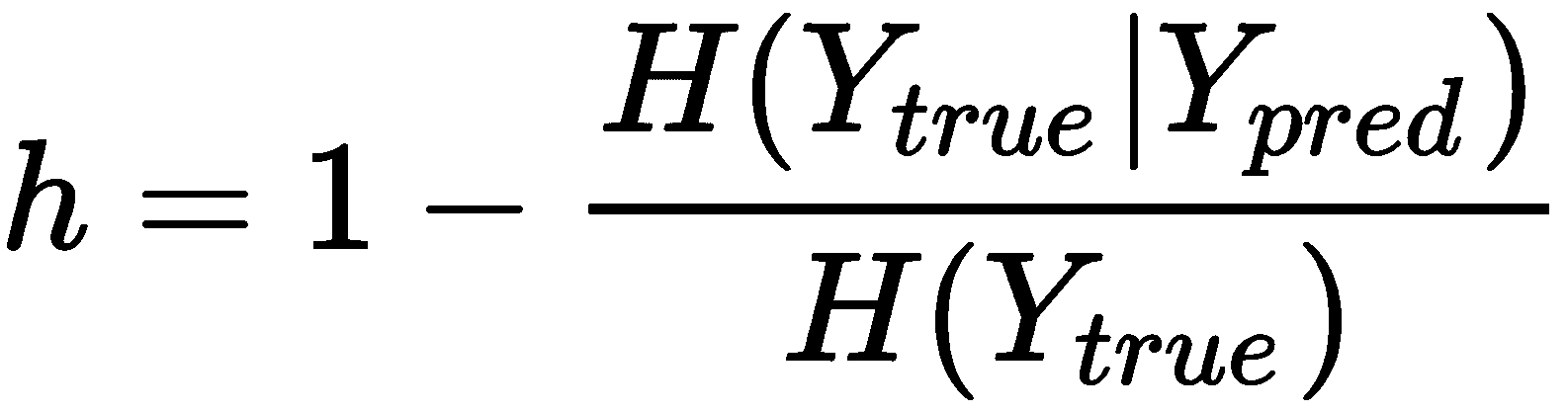
与完整性得分类似,当H(Y[true] | Y[pred]) → H(Y[true])时,表示分配对条件熵没有影响,因此在聚类(例如,每个聚类包含属于所有类别的样本)并且h → 0之后,不确定性不会降低。 相反,当H(Y[true] | Y[pred]) → 0,h → 1,因为对预测的了解减少了关于真实分配的不确定性,并且群集几乎只包含带有相同标签的样本。 重要的是要记住,仅靠这个分数是不够的,因为它不能保证一个群集包含所有带有相同真实标签的样本x[i] ∈ X。 这就是为什么同质性分数总是与完整性分数一起评估的原因。
对于乳腺癌威斯康星州数据集,K = 2,我们获得以下信息:
from sklearn.metrics import homogeneity_score print('Homogeneity: {}'.format(homogeneity_score(kmdff['diagnosis'], kmdff['prediction'])))
相应的输出如下:
Homogeneity: 0.42229071246999117
这个值(特别是K = 2)证实了我们的初步分析。 至少一个聚类(具有大多数良性样本的聚类)不是完全同质的,因为它包含属于这两个类别的样本。 但是,由于该值不是非常接近0,因此我们可以确保分配部分正确。 考虑到h和c这两个值,我们可以推断出 K 均值的效果不是很好(可能是由于非凸性),但同时正确分离所有最近群集距离在特定阈值以上的样本。 毋庸置疑,在掌握基本事实的情况下,我们不能轻易接受 K 均值,我们应该寻找另一种能够同时产生h和c → 1的算法 。
使用 V 度量在同质性和完整性之间进行权衡
熟悉监督学习的读者应该知道 F 分数(或 F 度量)的概念,它是精确度和查全率的谐调平均值。 在给出基本事实的情况下评估聚类结果时,也可以采用相同的权衡方法。
实际上,在许多情况下,有一个同时考虑同质性和完整性的度量是有帮助的。 使用 V 度量(或 V 分数)可以很容易地获得这样的结果,其定义为:
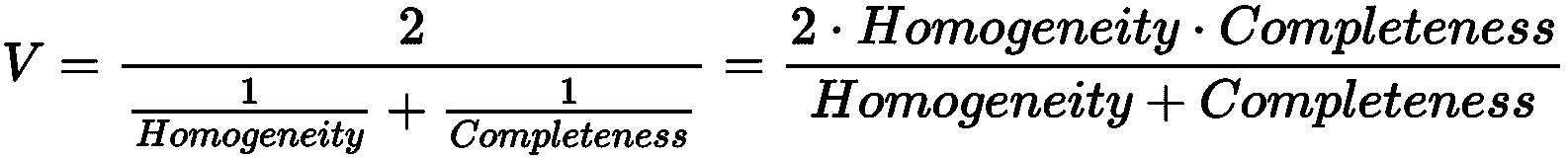
对于乳腺癌威斯康星州数据集,V 度量如下:
from sklearn.metrics import v_measure_score
print('V-Score: {}'.format(v_measure_score(kmdff['diagnosis'], kmdff['prediction'])))
上一个代码段的输出如下:
V-Score: 0.46479332792160793
不出所料,V 分数是一种平均度量,在这种情况下,它受到较低同质性的负面影响。 当然,该索引不会提供任何不同的信息,因此仅在单个值中综合完整性和同质性很有帮助。 但是,通过一些简单但乏味的数学操作,有可能证明 V 度量也是对称的(即V(Y[pred] | V[true]) = V(Y[true] | Y[pred])); 因此,给定两个独立的分配Y[1]和Y[2],V(Y[1] | Y[2]),这是衡量它们之间一致性的标准。 这种情况不是很普遍,因为其他措施可以取得更好的结果。 但是,例如,可以使用这种分数来检查两种算法(可能基于不同的策略)是否倾向于产生相同的分配,或者它们是否不一致。 在后一种情况下,即使未知的基础事实,数据科学家也可以理解,一种策略肯定不如另一种策略有效,因此可以开始探索过程以找出最佳的聚类算法。
调整后的互信息(AMI)得分
该分数的主要目标是评估Y[true]和Y[pred]之间的一致性水平 。 可以通过采用互信息(MI)的信息论概念来衡量这一目标; 在我们的例子中,它定义为:
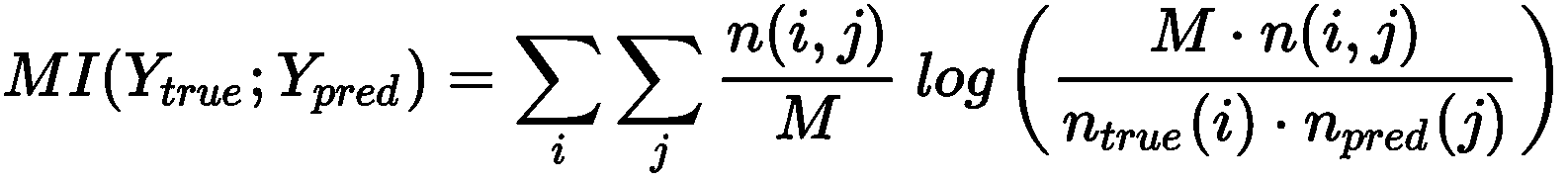
函数与先前定义的相同。 当MI → 0时, n(i, j) → n[true](i) n[pred](j),其项分别与p(i, j)和p[true](i)p[pred](j)成正比。 因此,此条件等同于说Y[true]和Y[pred]在统计上是独立的,没有共识。 另一方面,通过一些简单的操作,我们可以将 MI 重写为:
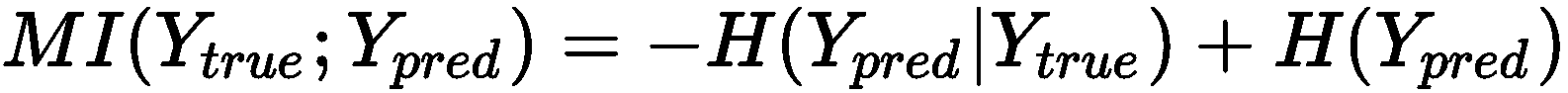
因此,当H(Y[pred] | Y[true]) ≤ H(Y[pred])时,当基础事实的知识减少了Y[pred]的不确定性时,得出H(Y[pred] | Y[true]) → 0,并且 MI 最大化。 就我们的目的而言,最好考虑同时针对偶然性进行调整的规范化版本(在0和1之间界定)(即,考虑正确分配是由于偶然的概率)。 AMI 分数的完整推导是不平凡的,并且超出了本书的范围,其定义为:
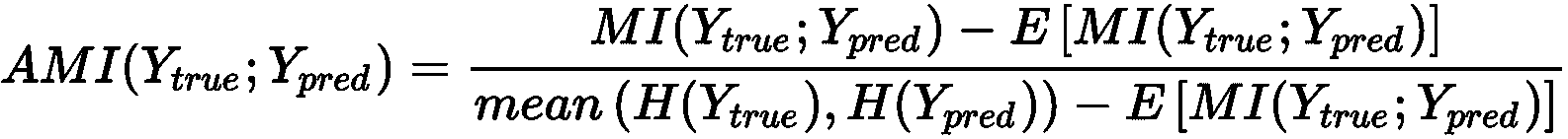
在完全不一致的情况下,此值等于0;当Y[true]时,该值等于1。 Y[pred]完全一致(也存在置换)。 对于乳腺癌威斯康星州数据集和K = 2,我们获得以下信息:
from sklearn.metrics import adjusted_mutual_info_score
print('Adj. Mutual info: {}'.format(adjusted_mutual_info_score(kmdff['diagnosis'], kmdff['prediction'])))
输出如下:
Adj. Mutual info: 0.42151741598216214
该协议是适度的,并且与其他措施兼容。 假设存在置换和机会分配的可能性,Y[true]和Y[pred]共享中等级别的信息,因为我们已经讨论过,K 均值能够正确分配重叠概率可忽略不计的所有样本,同时它倾向于考虑良性地位于两个聚类边界上的许多恶性样本(相反,良性样本的分配没有错)。 没有任何进一步的指示,该索引还建议检查其他可以管理非凸群集的聚类算法,因为缺少共享信息主要是由于无法使用标准球(尤其是在重叠区域更显著的子空间)捕获复杂的几何图形。
调整后的兰德分数
调整后的兰德评分是真实标签分布与预测标签之间差异的度量。 为了对其进行计算,必须按以下方式定义数量:
a:表示带有相同的真实标签(y[i], y[j])的样本对(x[i], x[j])的数量:y[i] = y[j]并分配给同一集群K[c]b:R代表样本对的数量(x[i], x[j]),带有不同的真实标签(y[i], y[j]):y[i] ≠ y[j]并分配给不同的集群K[c]和K[d],c ≠ d
如果存在M个值,则使用具有k = 2的二项式系数获得二进制组合的总数,因此,差异的初始度量为:
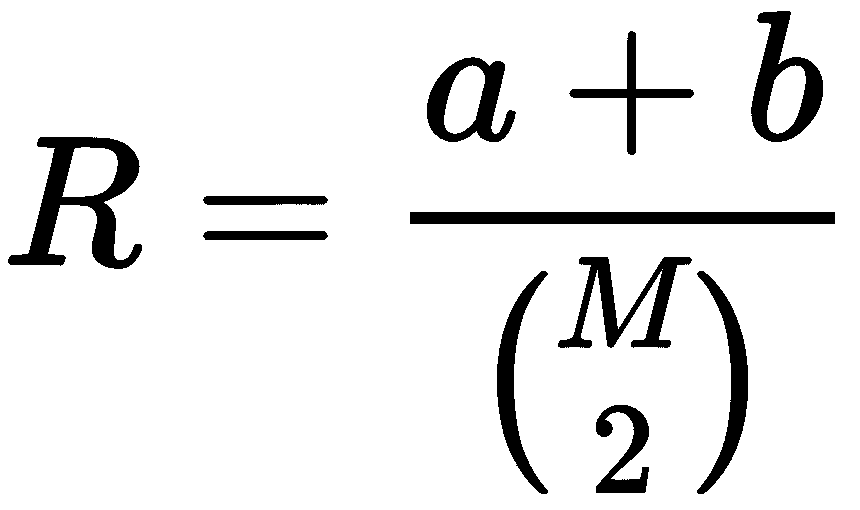
显然,该值可以由a或b主导。 在这两种情况下,较高的分数表示作业与基本事实相符。 但是,a和b都可能因机会分配而产生偏差。 这就是引入调整后的兰德分数的原因。 更新的公式为:
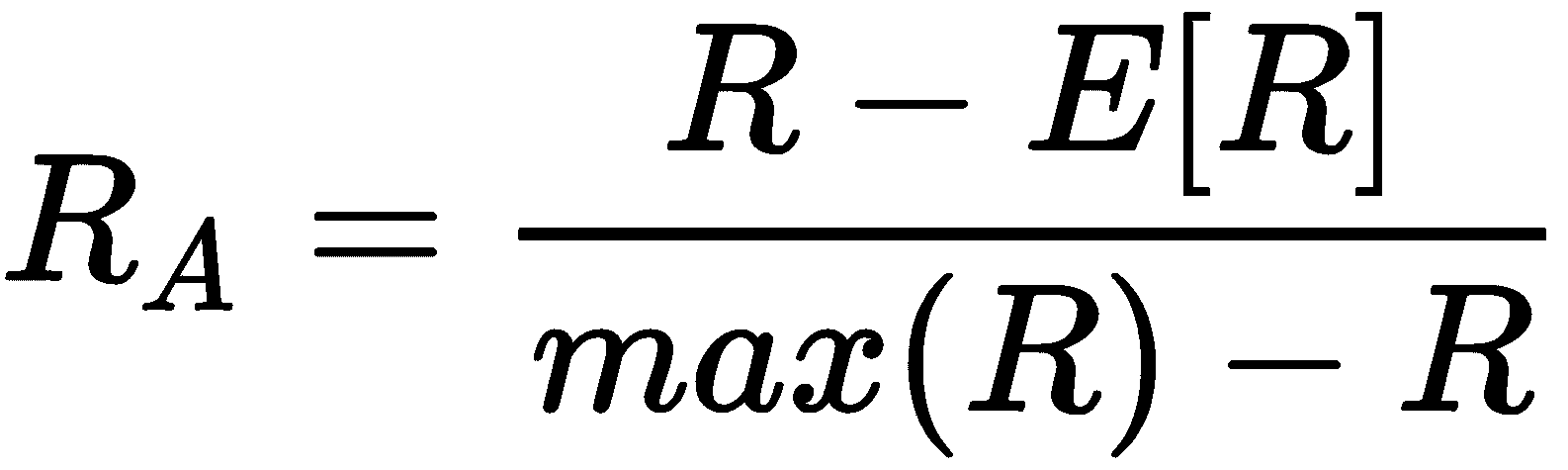
该值限制在-1和1之间。 当R[A] → -1时,a和b都非常小,并且绝大多数分配都是错误的。 另一方面,当R[A] →1时,预测分布非常接近真实情况。 对于乳腺癌威斯康星州数据集和K = 2,我们获得以下信息:
from sklearn.metrics import adjusted_rand_score
print('Adj. Rand score: {}'.format(adjusted_rand_score(kmdff['diagnosis'], kmdff['prediction'])))
上一个代码段的输出如下:
Adj. Rand index: 0.49142453622455523
由于该值大于-1(负极值),因此该结果优于其他指标。 它确认分布之间的差异不是很明显,这主要是由于样本的子集有限所致。 该分数非常可靠,也可以用作评估聚类算法表现的单个指标。 接近 0.5 的值确认 K 均值不太可能是最佳解,但与此同时,数据集的几何形状几乎可以被对称球完全捕获,除了某些重叠可能性高的非凸区域。
权变矩阵
一个非常简单而强大的工具,可以在已知真实情况时显示聚类算法的表现,它是权变矩阵C[m]。 如果存在m类,则C[m] ∈ ℜ^(m×m)和每个元素C[m](i, j)代表已分配给群集j的Y[true] = i的样本数。 因此,一个完美的权变矩阵是对角线的,而所有其他单元格中元素的存在则表明了聚类误差。
在我们的案例中,我们获得以下信息:
from sklearn.metrics.cluster import contingency_matrix
cm = contingency_matrix(kmdff['diagnosis'].apply(lambda x: 0 if x == 'B' else 1), kmdff['prediction'])
上一个代码片段的输出可以显示为热图(变量cm是2×2矩阵):
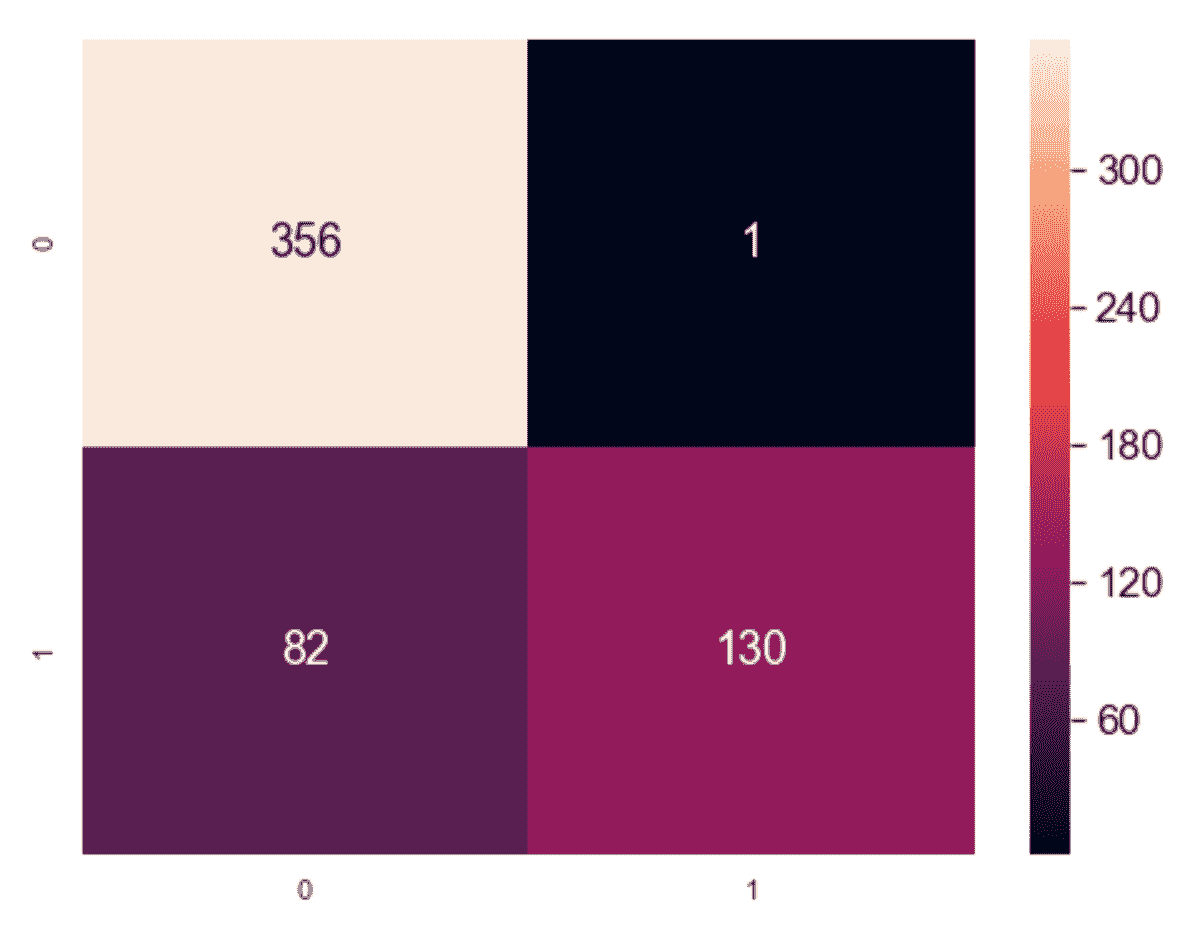
权变矩阵的图形表示
该结果表明,几乎所有良性样本均已正确聚类,而适度百分比的恶性样本已被错误地分配给第一个聚类。 我们已经使用其他度量进行了确认,但是类似于分类任务中的混淆矩阵,列联矩阵可以立即可视化最难分离的类别,从而帮助数据科学家寻找更有效的解决方案。
K 最近邻
K 最近邻(KNN)是属于称为基于实例的学习类别的方法。 在这种情况下,没有参数化模型,而是样本的重新排列以加快特定查询的速度。 在最简单的情况下(也称为暴力搜索),假设我们有一个X数据集,其中包含M个样本x[i] ∈ ℜ^N。 给定距离函数d(x[i], x[j]),则可以定义测试样本的半径邻域x[i]如下:
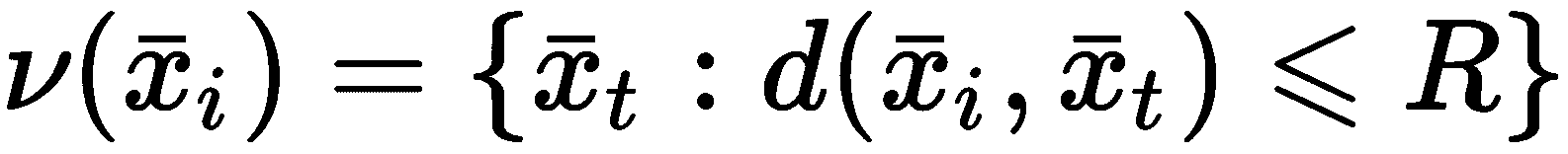
集合ν(x[i])是一个以x[i]为中心的球,包括所有距离小于或等于的样本R。 另外,也可以只计算最接近的k个邻居,即更接近x[i]的k个样本(通常, 该集合是ν(x[i])的子集,但当k非常大)。 该过程很简单,但不幸的是,从计算的角度来看太昂贵了。 实际上,对于每个查询,有必要计算M^2个N维距离(即,假设每距离N个运算) ,复杂度为O(NM^2),这是使暴力破解方法遭受维度诅咒的条件。 例如,在N = 2和M = 1,000 的情况下,复杂度为O(2 * 10^6),但是当N = 1,000和M = 10,000时,其变为O(10^11)。 例如,如果每个操作需要 1 纳秒,那么查询将需要 100 秒,这在许多实际情况下超出了可容忍的限制。 此外,对于 64 位浮点值,成对距离矩阵每次计算将需要约 764MB,再次考虑到任务的性质,这可能是一个过多的请求。
由于这些原因,仅当M非常小时并且在所有其他情况下都依赖于稍微复杂的结构时,KNN 具体实现才使用暴力搜索。 第一种替代方法基于 kd 树,这是将二叉树自然扩展到多维数据集的方法。
在下图中,表示了由3维向量组成的部分 kd 树:
具有 3 维向量的 kd 树示例
kd 树的构建非常简单。 给定一个根样本(a[1], a[2], ..., a[n]),考虑第一个特征,因此左分支包含b[1] < a[1],以此类推,和右分支c[1] > a[1],以此类推。 该过程将继续执行第二个特征,第三个特征,依此类推,直到到达叶节点为止(分配给叶的样本数量是需要调整的超参数。 该参数称为leaf_size,默认值为 30 个样本)。
当维度N不太大时,计算复杂度变为O(N log M),这比暴力搜索要好得多。 例如,在N = 1,000和M = 10,000的情况下,计算复杂度变为O(4,000) << O(10^11)。 不幸的是,当N大时,kd 树查询变为O(NM),因此,考虑前面的示例,O(10^7),它比蛮横搜索更好,但有时对于实时查询而言仍然太昂贵。
KNN 中常用的第二个数据结构是球树。 在这种情况下,根节点由R[0]球表示,精确定义为样本的邻域:
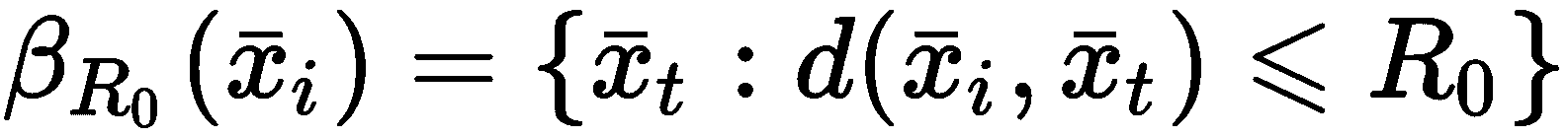
选择第一个球以便捕获所有样本。 此时,将其他较小的球嵌套到β[R0]中,以确保每个样本始终属于一个球。 在下图中,有一个简单的球树的示意图:
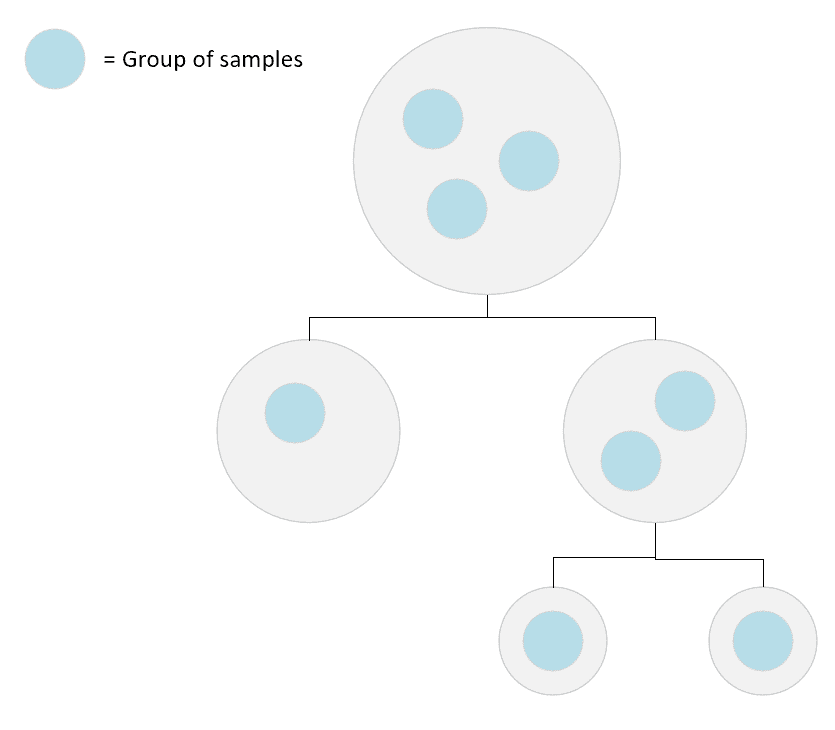
一个简单的球树的例子
由于每个球都由其中心c[j]完全确定,因此对测试样本x[i]的查询要求计算距离d(x[i], c[j])。 因此,从底部(最小的球所在的位置)开始,执行完整的扫描。 如果没有一个球包含样本,则级别会增加,直到达到根节点为止(记住一个样本可以属于一个球)。 由于球的特性,计算复杂度现在始终为O(N log M)(也就是说,给定中心和半径,可以通过一次距离计算来检查样本的隶属度) 。 确定正确的球后,样本x[i]的邻居需要计算有限数量的成对距离(该值小于叶大小,因此与数据集的维数相比通常可以忽略不计)。
当然,这些结构是在训练阶段构建的,在生产阶段不会对其进行修改。 这意味着要仔细选择最小半径或分配给叶节点的样本数。 实际上,由于查询通常需要多个邻居k,因此仅当k < |ν(x[i])|达到最佳值时,才能实现最优。* 。 换句话说,我们想在同一子结构中找到所有包含x[i]的邻居。 每当k > |ν(x[i])|,该算法还必须检查相邻结构并合并结果。 当然,当叶子大小太大(与样本总数M相比)时,这些树的优势就消失了,因为有必要计算太多的成对距离才能回答查询。 必须根据软件的生产使用情况来正确选择叶子大小。
例如,如果推荐系统需要具有 100 个邻居的初始查询和具有 10 个邻居的几个(例如 5 个)后续查询,则等于 10 的叶子大小将优化优化阶段,但在第一个查询上会产生负面影响。 相反,选择等于 100 的叶子大小将减慢所有 10 个邻居查询的速度。 权衡可能是 25,这减少了第一个查询的负担,但对细化查询的成对距离的计算产生了中等程度的负面影响。
现在,我们可以基于 Olivetti 人脸数据集(由 scikit-learn 直接提供)分析一个简短示例。 它由代表不同人物肖像的 400 张64×64灰度图像组成。 让我们从如下加载数据集开始:
from sklearn.datasets import fetch_olivetti_faces
faces = fetch_olivetti_faces()
X = faces['data']
变量X包含数据集的展开版本(400 个 4,096 维实例已经在 0 和 1 之间标准化)。 在这一点上,我们可以训练一个NearestNeighbor模型,假设使用 10 个样本(参数n_neighbors)和半径等于 20(参数radius)的默认查询。 我们保留默认的leaf_size (30),并使用p=2(欧几里得距离)明确设置 Minkowski 度量。 该算法基于一棵球树,但我邀请读者同时测试不同的指标和 kd 树。 现在,我们可以创建NearestNeighbors实例并继续训练模型:
from sklearn.neighbors import NearestNeighbors
knn = NearestNeighbors(n_neighbors=10, metric='minkowski', p=2, radius=20.0, algorithm='ball_tree')
knn.fit(X)
训练好模型后,请使用嘈杂的测试脸来查找最近的 10 个邻居,如下所示:
import numpy as np
i = 20
test_face = X[i] + np.random.normal(0.0, 0.1, size=(X[0].shape[0]))
测试面绘制在以下屏幕截图中:

嘈杂的测试面
可以使用仅提供测试样本的方法kneighbors()来执行具有默认邻居数的查询(在邻居数不同的情况下,必须调用该函数,并同时提供参数n_neighbors)。 如果参数为return_distance=True,则该函数返回包含distances, neighbors的元组,如下所示:
distances, neighbors = knn.kneighbors(test_face.reshape(1, -1))
查询结果显示在以下屏幕截图中:

测试样本的最近邻居及其相对距离
第一个样本始终是测试样本(在这种情况下,它被去噪,因此其距离不为零)。 可以看到,即使距离是一个累积函数,第二个和第四个样本是指同一个人,而其他样本共享不同的解剖元素。 当然,欧几里德距离并不是衡量图像之间差异的最合适方法,但是该示例在一定程度上证实了当图像相当相似时,全局距离也可以为我们提供用于查找相似的样本有价值的工具。
现在,使用radius_neighbors()设置radius=100的方法执行半径查询,如下所示:
import numpy as np
distances, neighbors = knn.radius_neighbors(test_face.reshape(1, -1), radius=100.0)
sd, sd_arg = np.sort(distances[0]), np.argsort(distances[0])
以下屏幕快照显示了包含前 20 个邻居的结果:

使用半径查询的前 50 个邻居
有趣的是,距离并没有很快变化(第二个样本具有d=8.91,第五个d=10.26)。 这主要是由于两个因素:第一个是样本之间的全局相似性(就几何元素和色调而言),第二个可能与欧氏距离对 4,096 维向量的影响有关。 正如在谈到聚类基本原理时所解释的那样,高维样本可能缺乏可区分性(尤其是当p >> 1时)。 在这种情况下,图片不同部分的平均效果可能会产生与分类系统完全不兼容的结果。 特别是,深度学习模型倾向于通过使用可以学会检测不同级别特定特征的卷积网络来避免此陷阱。 我建议以不同的指标重复此示例,并观察p对半径查询样本所显示的实际差异的影响。
向量量化
向量量化(VQ)是一种利用无监督学习对样本x[i] ∈ ℜ^N或整个数据集X进行有损压缩的方法。(为简单起见,我们假设多维样本被展开)。 主要思想是找到带有许多条目C << N的密码本Q,并将每个元素与条目q[i] ∈ Q相关联。 在单个样本的情况下,每个条目将代表一个或多个特征组(例如,可以是均值),因此,该过程可以描述为一种变换T,其一般表示为 :
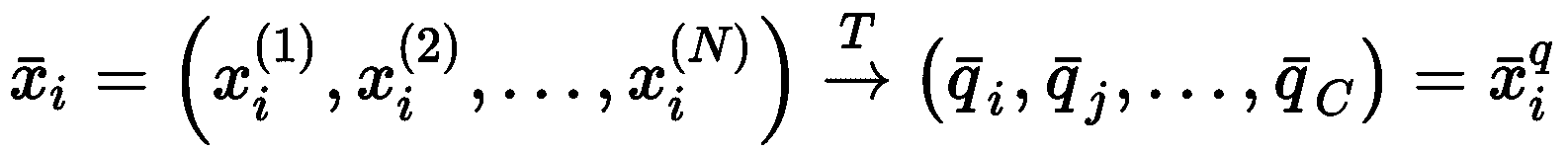
码本被定义为Q = (q[1], q[2], ..., q[C])。 因此,给定一个由一组特征集合(例如,一组两个连续元素)组成的综合数据集,VQ 将关联一个码本条目:
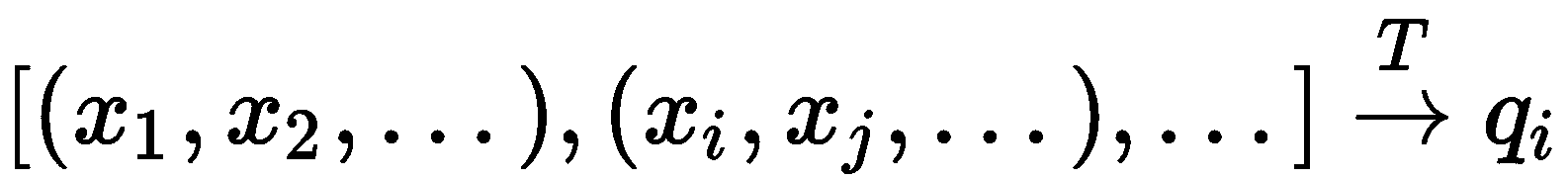
由于使用汇总整个组的固定值的组合表示输入样本,因此将过程定义为量化。 类似地,如果输入是数据集X,则转换将按样本组进行操作,就像任何标准聚类过程一样。 主要区别在于目的:使用 VQ 代表每个聚类及其质心,从而减少数据集的方差。 这个过程是不可逆的。 一旦执行了转换,就不可能重建原始聚类(唯一可行的过程是基于具有相同原始均值和协方差的分布的采样,但是重建显然是近似的)。
让我们从显示一个非常简单的高斯数据集的示例开始,如下所示:
import numpy as np
nb_samples = 1000
data = np.random.normal(0.0, 1.5, size=(nb_samples, 2))
n_vectors = 16
qv = np.random.normal(0.0, 1.5, size=(n_vectors, 2))
我们的目标是用 16 个向量表示数据集。 在以下屏幕截图中,该图显示了初始配置的示例:
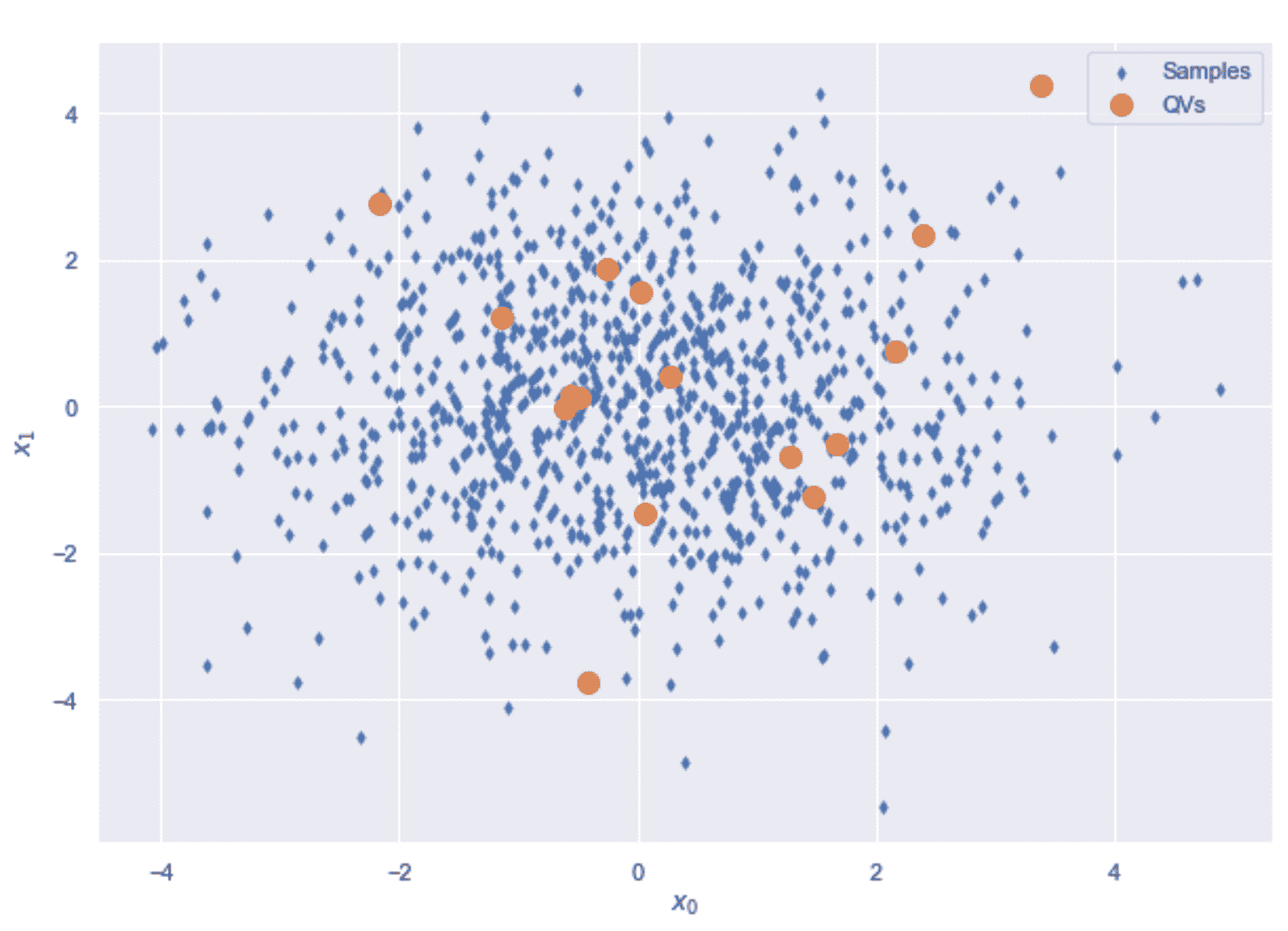
VQ 示例的向量的初始配置
当我们使用随机数时,相同代码的后续执行会产生不同的初始配置。 该过程遍历所有样本,选择最接近的量化向量,并将其距离减小固定量delta=0.05,如下所示:
import numpy as np
from scipy.spatial.distance import cdist
delta = 0.05
n_iterations = 1000
for i in range(n_iterations):
for p in data:
distances = cdist(qv, np.expand_dims(p, axis=0))
qvi = np.argmin(distances)
alpha = p - qv[qvi]
qv[qvi] += (delta * alpha)
distances = cdist(data, qv)
Y_qv = np.argmin(distances, axis=1)
除了固定的for循环外,还可以使用while循环来检查量化向量是否已达到稳态(比较t和t + 1)。 以下屏幕快照显示了该过程结束时的结果:
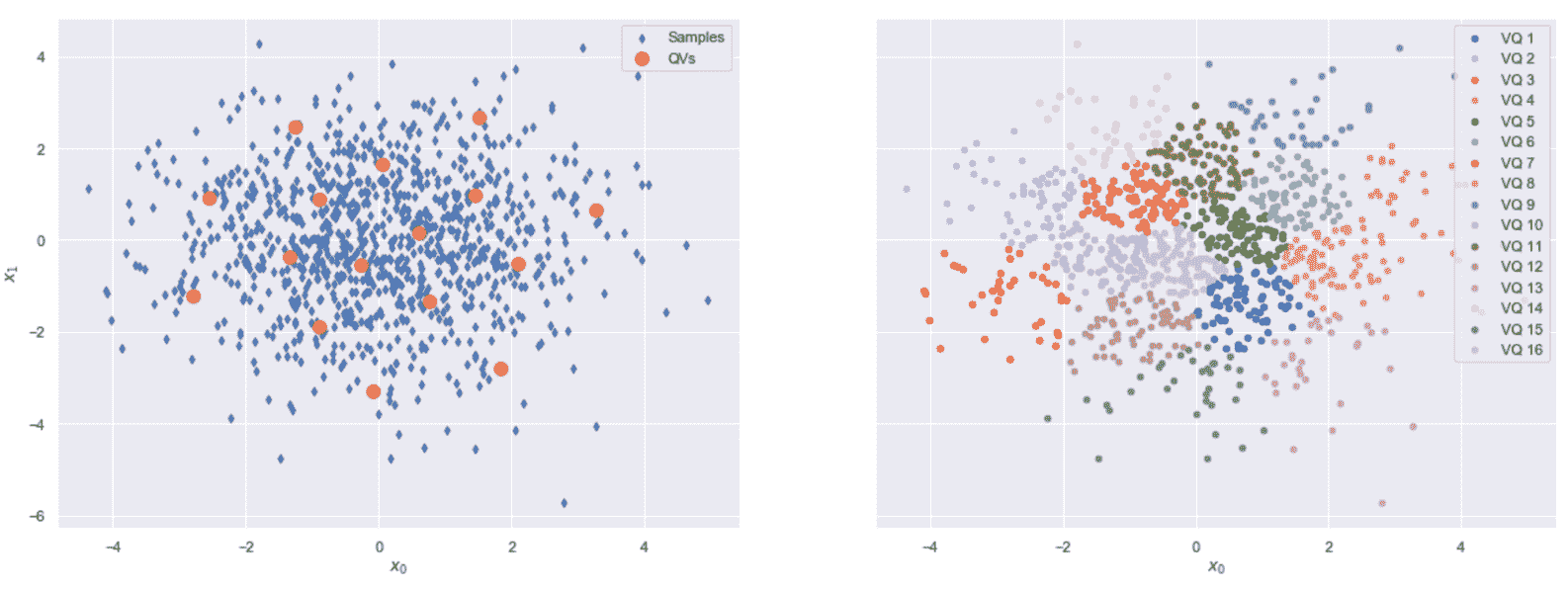
量化向量的最终配置(左)。 每个量化向量的影响范围(右)
正如预期的那样,量化向量已达到最终配置,其中每个量化向量都代表数据集的一小部分(如右图所示)。 在这一点上,给定一个点,最接近的向量将代表它。 有趣的是,全局方差并未受到影响,但是,选择任何子集后,内部方差会大大降低。 向量的相对位置反映了数据集的密度,因为区域中的更多样本吸引了更多向量。 这样,通过构建距离矩阵,可以获得粗略的密度估计(例如,当向量与向量的近邻的平均距离较高时,意味着底层区域的密度较小)。 我们将在第 6 章,“异常检测”中更详细地讨论此主题。
现在让我们考虑一个示例,该示例具有一个代表浣熊图片的单个样本。 由于过程可能很长,因此第一步是加载示例 RGB 图像(由 SciPy 提供)并将其大小调整为 192×256,如下所示:
from scipy.misc import face
from skimage.transform import resize
picture = resize(face(gray=False), output_shape=(192, 256), mode='reflect')
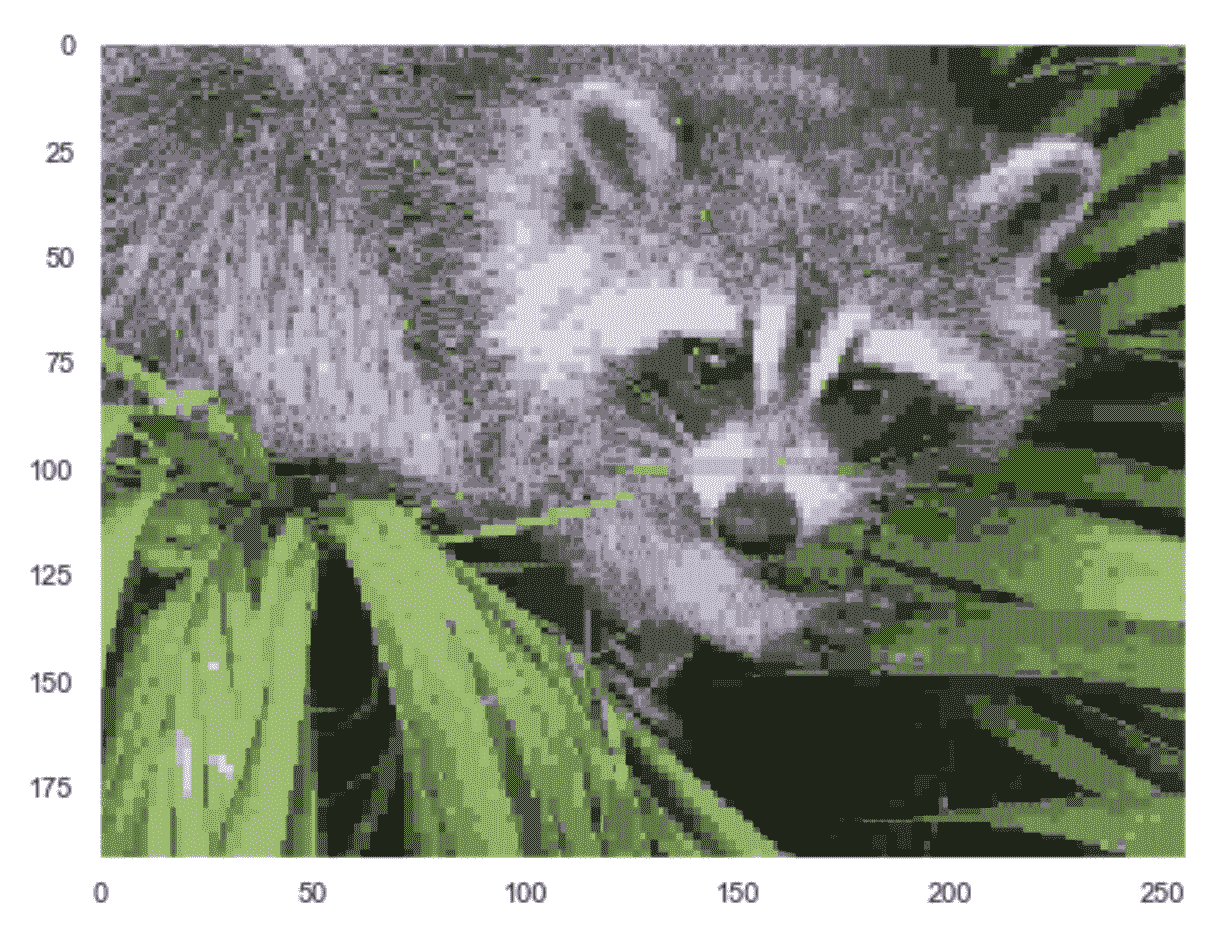
以下屏幕快照显示了原始图片(已在[0, 1]范围内标准化):

VQ 示例的 RGB 图片样本
我们想用 24 个使用2×2正方形区域计算的向量执行 VQ(由包含2×2×3特征的展开向量表示)。 但是,我们将使用 K 均值算法来查找质心,而不是从头开始执行该过程。 第一步是收集所有正方形区域,如下所示:
import numpy as np
square_fragment_size = 2
n_fragments = int(picture.shape[0] * picture.shape[1] / (square_fragment_size**2))
fragments = np.zeros(shape=(n_fragments, square_fragment_size**2 * picture.shape[2]))
idx = 0
for i in range(0, picture.shape[0], square_fragment_size):
for j in range(0, picture.shape[1], square_fragment_size):
fragments[idx] = picture[i:i + square_fragment_size,
j:j + square_fragment_size, :].flatten()
idx += 1
此时,可以使用 24 个量化向量进行 K 均值聚类,如下所示:
from sklearn.cluster import KMeans
n_qvectors = 24
km = KMeans(n_clusters=n_qvectors, random_state=1000)
km.fit(fragments)
qvs = km.predict(fragments)
在训练结束时,变量qvs将包含与每个正方形区域关联的质心的索引(可通过实例变量cluster_centers_获得)。
现在可以使用质心构建量化的图像,如下所示:
import numpy as np
qv_picture = np.zeros(shape=(192, 256, 3))
idx = 0 for i in range(0, 192, square_fragment_size):
for j in range(0, 256, square_fragment_size):
qv_picture[i:i + square_fragment_size,
j:j + square_fragment_size, :] = \
km.cluster_centers_[qvs[idx]].\
reshape((square_fragment_size, square_fragment_size, 3)) idx += 1
量化的图像显示在以下屏幕截图中:
用 24 个向量量化的图片
结果显然是原始图像的有损压缩版本。 每个组都可以用一个索引来表示(例如,在我们的示例中,它可以是 8 位整数),该索引指向码本中的条目(km.cluster_centers_)。 因此,如果最初有192×256×3 = 1,474,560个 8 位值,则在量化之后,我们有 12,288 个 8 位索引(2×2×3块的数量),再加上 24 个 12 维量化向量。 为了了解 VQ 对图像的影响,绘制原始图像和处理后图像的 RGB 直方图非常有用,如以下直方图所示:
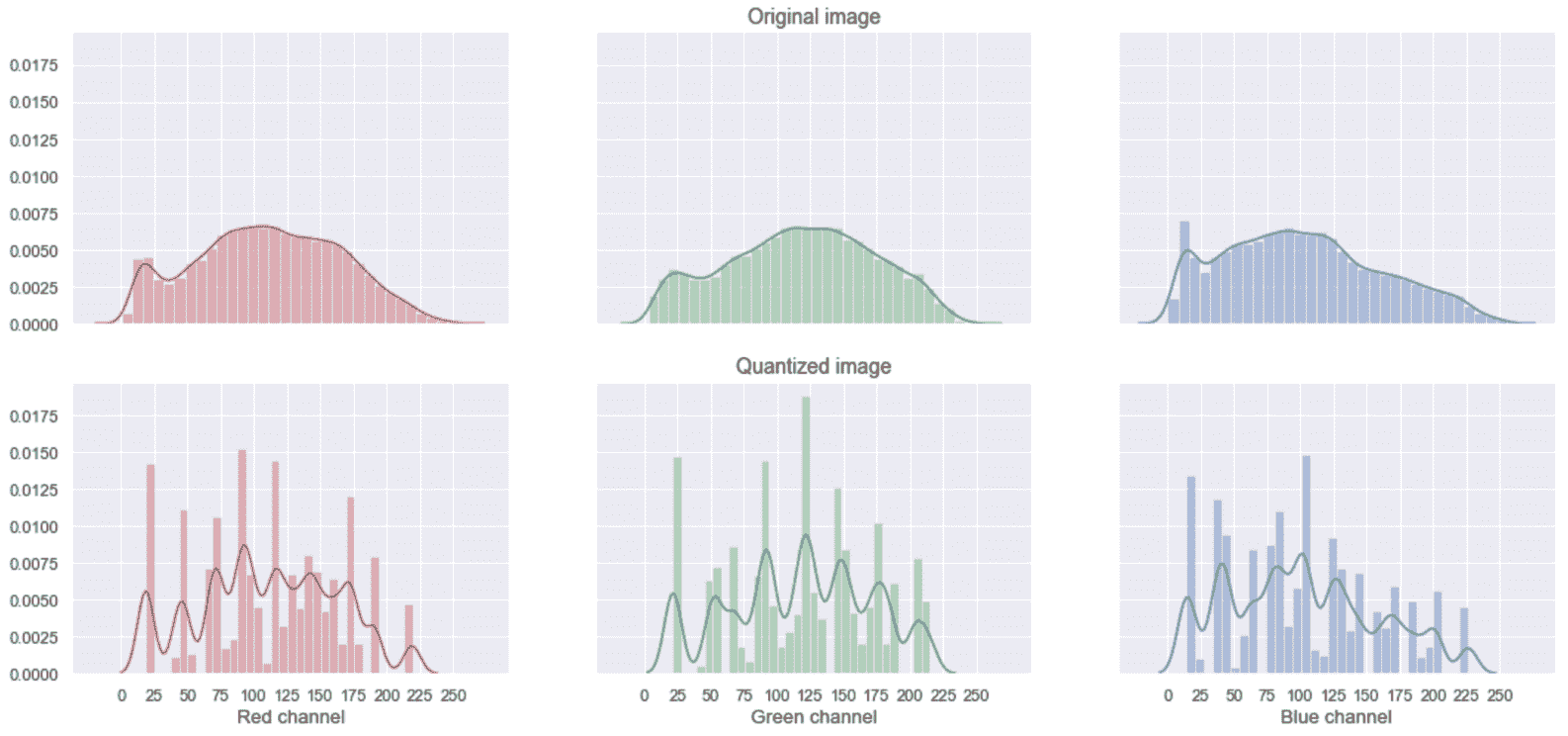
原始图像的 RGB 直方图(顶部)和量化的版本(底部)
对于不熟悉直方图的读者,我们可以简单地将其描述为具有 X 数据集和固定数量的桶。 每个单元分配一个范围(从min(X)开始,以max(X)结束),并且每个范围(a, b)与样本数量相关,从而a ≤ x < b 。 结果图与生成X的实际概率分布的近似成比例。 在我们的情况下,在 x 轴上,每个通道(8 位)的每个像素都有所有可能的值,而 y 轴表示估计的频率(Nx/像素总数)。
可以看到,量化减少了信息量,但是直方图往往会重现原始信息。 增加量化向量的数量具有减少近似值的效果,从而产生差异较小的直方图。 对该主题的完整分析超出了本书的范围。 但是,我邀请读者使用其他图像和不同数量的量化向量来测试该过程。 也可以将原始图像的(协)方差(或熵)与量化版本进行比较,并找到保留 80% 的方差的阈值。 例如,仅考虑红色通道,并使用频率计数来近似每个值(0÷255)的概率,我们可以获得以下信息:
import numpy as np
hist_original, _ = np.histogram(picture[:, :, 0].flatten() * 255.0, bins=256)
hist_q, _ = np.histogram(qv_picture[:, :, 0].flatten() * 255.0, bins=256)
p_original = hist_original / np.sum(hist_original)
H_original = -np.sum(p_original * np.log2(p_original + 1e-8))
p_q = hist_q / np.sum(hist_q)
H_q = -np.sum(p_q * np.log2(p_q + 1e-8))
print('Original entropy: {0:.3f} bits - Quantized entropy: {1:.3f} bits'.format(H_original, H_q))
上一个代码段的输出如下:
Original entropy: 7.726 bits - Quantized entropy: 5.752 bits
由于信息量与熵成正比,因此我们现在已经确认,24 个量化向量(具有2×2正方形块)能够解释红色通道原始熵的大约 74% (即使三个通道都不是)。 独立地,可以通过对三个熵求和来获得总熵的粗略近似。 该方法可以有效地用于在压缩强度和最终结果质量之间进行权衡。
总结
在本章中,我们从相似性的概念及其度量方法入手,解释了聚类分析的基本概念。 我们讨论了 K 均值算法及其优化的变体 KMeans++ ,并分析了乳腺癌威斯康星州数据集。 然后,我们讨论了最重要的评估指标(无论是否了解基本事实),并且了解了哪些因素会影响绩效。 接下来的两个主题是 KNN(一种非常著名的算法,可用于在给定查询向量的情况下查找最相似的样本),以及 VQ(一种利用聚类算法以查找样本的有损表示形式的技术)(例如, 图片)或数据集。
在下一章中,我们将介绍一些最重要的高级聚类算法,展示它们如何轻松解决非凸问题。
问题
-
如果两个样本的 Minkowski 距离(
p = 5)等于 10,那么您能说出它们的曼哈顿距离吗? -
对 K 均值的收敛速度产生负面影响的主要因素是数据集的维数。 它是否正确?
-
可以积极影响 K 均值表现的最重要因素之一是聚类的凸度。 它是否正确?
-
聚类应用的同质性得分等于 0.99。 这是什么意思?
-
调整后的兰德得分等于 -0.5 是什么意思?
-
考虑到前面的问题,不同数量的聚类能否产生更好的分数?
-
基于 KNN 的应用平均每分钟需要 100 个 5-NN 基本查询。 每分钟执行 2 个 50-NN 查询(每个查询需要 4 秒,叶子大小为 25),并在紧接其后执行 2 秒的阻塞任务。 假设没有其他延迟,则每分钟叶子大小= 50 可以执行多少个基本查询?
-
球形树结构不适合管理高维数据,因为它遭受了维数的诅咒。 它是否正确?
-
获得了一个数据集,该数据集从 3 个二维高斯分布中采样了 1,000 个样本:
N([-1.0, 0.0], diag[0.8, 0.2]),N([0.0, 5.0], diag[0.1, 0.1])和N([-0.8, 0.0], diag[0.6, 0.3])。 集群中最可能的数量是? -
可以使用 VQ 压缩文本文件吗(例如,构建具有 10,000 个单词的字典,该单词在
[0.0, 1.0]范围内均匀映射,将文本拆分为标记,然后将其转换为浮点序列)?
进一步阅读
On the Surprising Behavior of Distance Metrics in High Dimensional Space, Aggarwal C. C., Hinneburg A., Keim D. A., ICDT, 2001K-means++: The Advantages of Careful Seeding, Arthur D., Vassilvitskii S., Proceedings of the Eighteenth Annual ACM-SIAM Symposium on Discrete Algorithms, 2007Visualizing Data using t-SNE, van der Maaten L., Hinton G., Journal of Machine Learning Research 9, 2008Robust Linear Programming Discrimination of Two Linearly Inseparable Sets, Bennett K. P., Mangasarian O. L., Optimization Methods and Software 1, 1992Breast cancer diagnosis and prognosis via linear programming, Mangasarian O. L., Street W.N, Wolberg W. H., Operations Research, 43(4), pages 570-577, July-August 1995V-Measure: A conditional entropy-based external cluster evaluation measure, Rosenberg A., Hirschberg J., Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, 2007
三、高级聚类
在本章中,我们将继续探索可用于非凸任务的更复杂的聚类算法(即,例如,K 均值无法同时获得内聚和分离力。 几何形状)。 我们还将展示如何将基于密度的算法应用于复杂的数据集,以及如何正确选择超参数并根据所需结果评估表现。 这样,数据科学家就可以准备面对各种问题,排除价值较低的解决方案,而只关注最有前途的解决方案。
特别是,我们将讨论以下主题:
- 谱聚类
- 均值漂移
- 具有噪声的基于密度的应用空间聚类(DBSCAN)
- 其他评估指标:Calinski-Harabasz 指数和群集不稳定性
- K-Medoids
- 在线聚类(小批量 K 均值和使用层次结构的平衡迭代归约和聚类(BIRCH))
技术要求
本章中提供的代码要求:
- Python3.5+(强烈建议您使用 Anaconda 发行版)
- 库:
- SciPy 0.19+
- NumPy 1.10+
- Scikit-Learn 0.20+
- Pandas 0.22+
- Matplotlib 2.0+
- Seaborn 0.9+
数据集可以通过 UCI 获得。 可以从这里下载 CSV 文件,并且不需要任何预处理,除了添加将在加载阶段出现的列名。
Github 存储库中提供了示例。
谱聚类
可以管理非凸类的最常见算法家族之一是谱聚类。 主要思想是将数据集X投影到可以通过超球体捕获群集的空间(例如,使用 K-means)。 该结果可以通过不同的方式实现,但是由于该算法的目标是消除通用形状区域的凹面,因此第一步始终是X表示为图{V,E},其中顶点V ≡ X,加权边通过参数w[ij] ≥ 0表示每对样本x[i], x[j] ∈ X的邻近性。 生成的图可以是完整的(完全连接的),也可以仅在某些样本对之间具有边(即,不存在的权重的权重设置为零)。 在下图中,有一个局部图的示例:
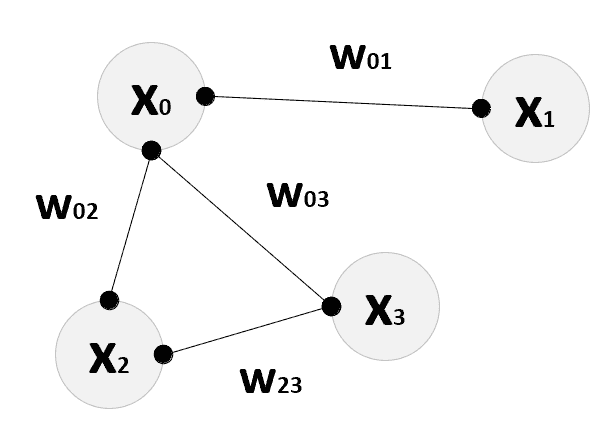
图的示例:点x[0]是连接到x[1]的唯一点
可以使用两种主要策略来确定权重w[ij]:KNN 和径向基函数(RBF)。 第一个基于上一章中讨论的相同算法。 考虑到邻居数k,数据集表示为球树或 kd 树,对于每个样本x[i],计算集合kNN(x[i])。 此时,给定另一个样本x[j],权重计算如下:
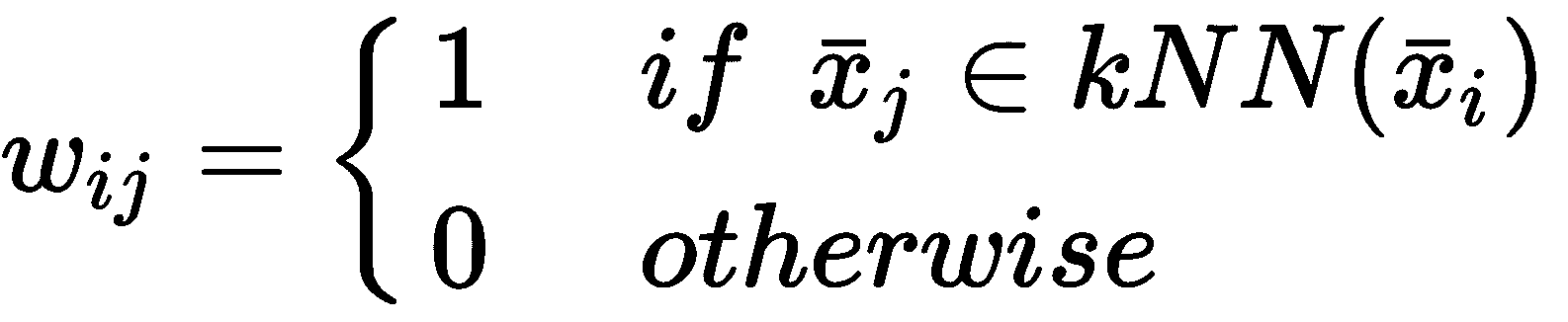
在这种情况下,该图不包含有关实际距离的任何信息,因此,考虑到 KNN 中使用的相同距离函数d(·),最好表示w[ij]如下:
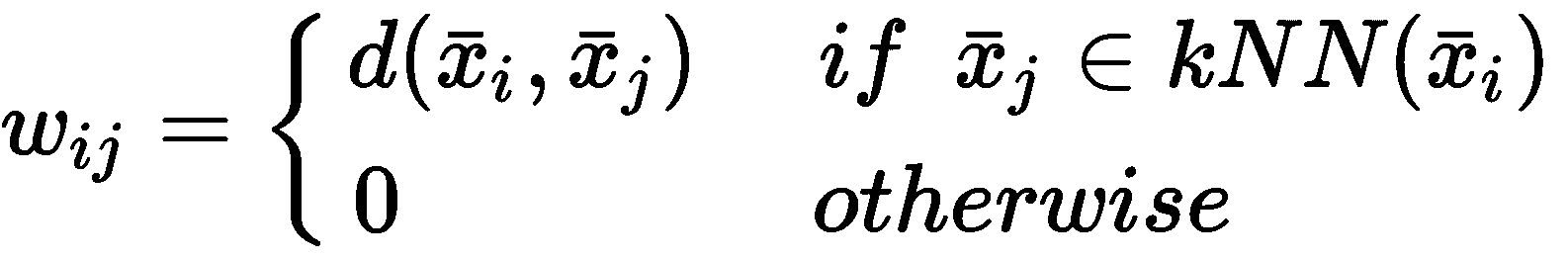
此方法简单且相当可靠,但是生成的图未完全连接。 通过采用如下定义的 RBF 可以轻松实现这种条件:
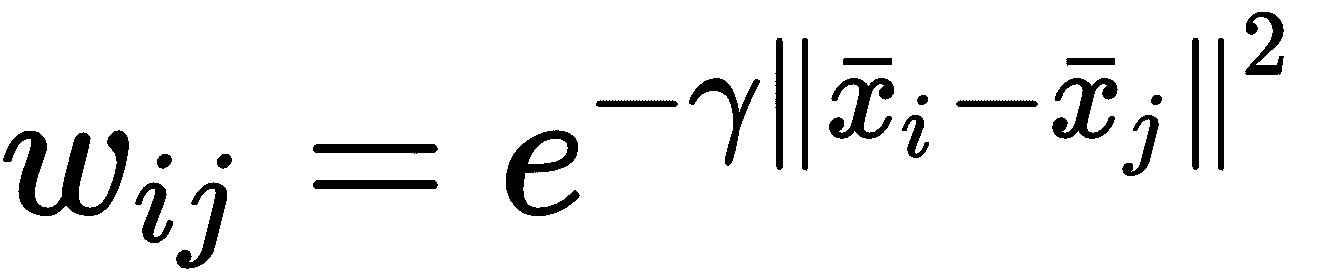
通过这种方式,将根据其距离自动对所有夫妇加权。 由于 RBF 是高斯曲线,因此当x[i] = x[j]时,它等于1,并且与平方距离成比例地减小d(x[i], x[j])(表示为差异的范数)。 参数γ确定半铃曲线的振幅(通常,默认值为γ = 1)。 当γ < 1时,振幅增加,反之亦然。 因此,γ < 1表示对距离的灵敏度较低,而γ > 1的情况下,RBF 下降得更快,如以下屏幕截图所示:
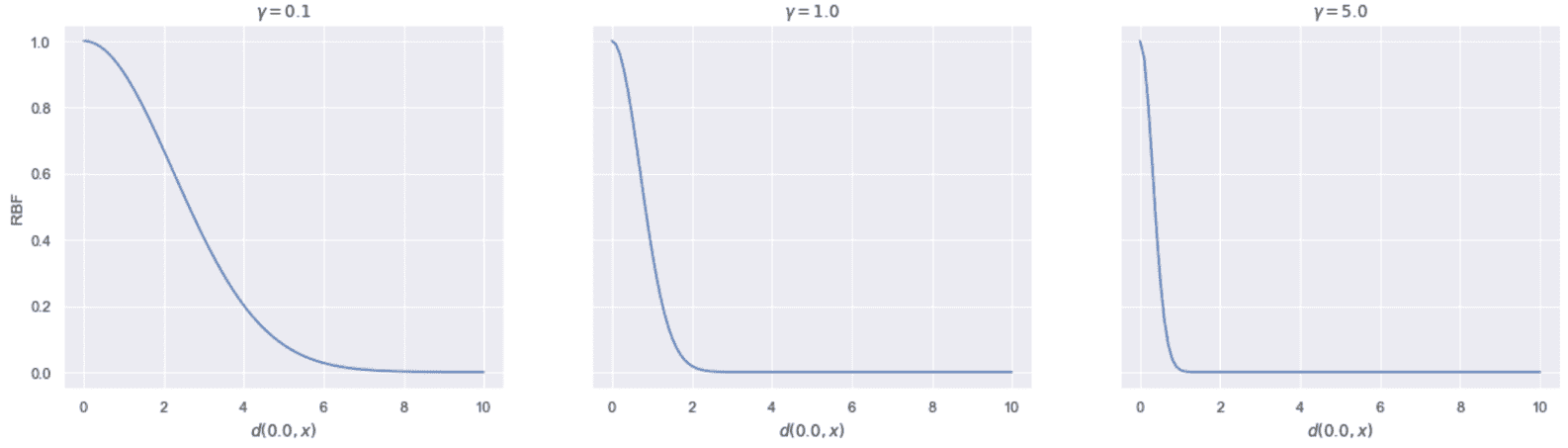
二维 RBF,作为x和 0 之间的距离的函数,γ = 0.1、1.0 和 5.0
当γ = 0.1时,x = 1(相对于 0.0)的权重约为 0.9。 对于γ = 1.0,该值约为 0.5;对于γ = 5.0,该值几乎为零。 因此,在调整频谱聚类模型时,考虑γ的不同值并选择产生最佳表现的值(例如,使用第 2 章,“聚类基础知识”)。 一旦创建了图,就可以使用对称亲和矩阵W = {w[ij]} 来表示。 对于 KNN,W通常比较稀疏,可以使用专门的库进行有效地存储和操作。 相反,对于 RBF,它始终是密集的,并且如果X ∈ R^(N×M),则它需要存储N^2个值 。
不难证明到目前为止我们分析过的程序等同于将X分割为多个内聚区域。 实际上,让我们考虑例如具有通过 KNN 获得的亲和度矩阵的图G。 连接的组件C[i]是一个子图,其中每对顶点x[a], x[b] ∈ C[i]通过属于C[i]的顶点的路径连接,并且没有连接任何顶点的边C[i]的顶点具有不属于C[i]的顶点。 换句话说,连接的组件是一个内聚子集C[i] 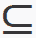
G,它代表群集选择的最佳候选者。 在下图中,有一个从图中提取的连接组件的示例:
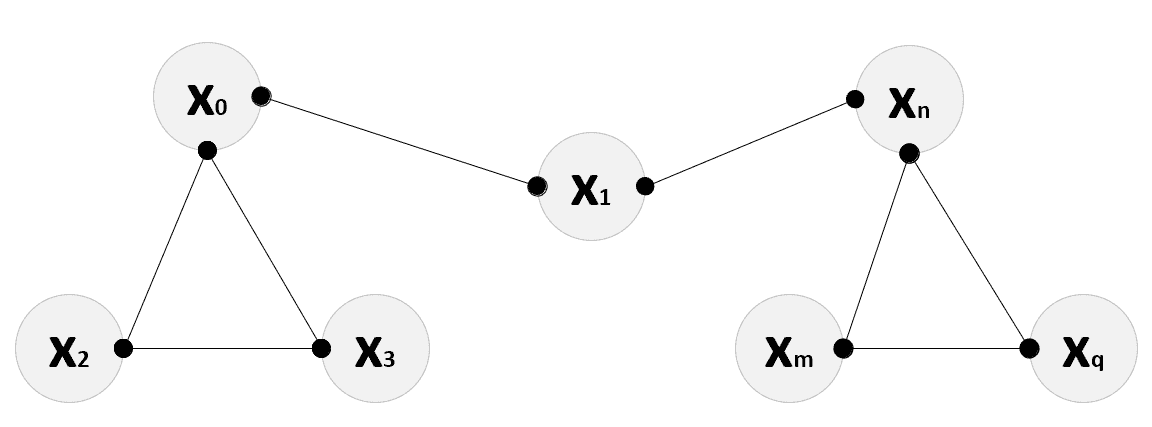
从图中提取的连通组件的示例
在原始空间中,点x[0],x[2]和x[3]通过x[1]连接到x[n],x[m]和x[q]。 这可以表示非常简单的非凸几何,例如半月形。 实际上,在这种情况下,凸度假设对于最佳分离不再是必需的,因为,正如我们将要看到的那样,这些分量被提取并投影到具有平坦几何形状的子空间中(可通过诸如此类的算法轻松管理) 以 K 均值表示)。
当使用 KNN 时,此过程更加明显,但是,通常,我们可以说,当区域间距离(例如,两个最近点之间的距离)与平均内部区域相当时,可以合并两个区域。 Shi 和 Malik(在《归一化剪切和图像分割》中)提出了解决此问题的最常用方法之一。这称为归一化剪切。 整个证明超出了本书的范围,但是我们可以讨论主要概念。 给定一个图,可以构建归一化的图拉普拉斯算子,定义为:
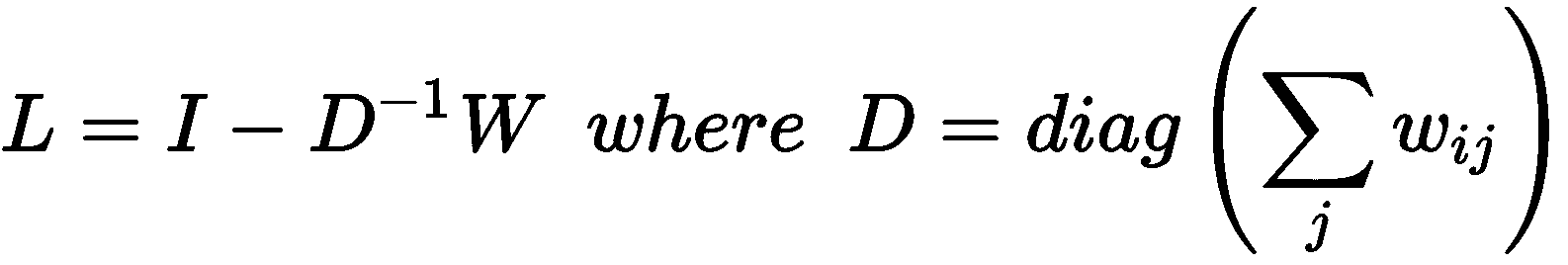
对角矩阵D被称为度矩阵,每个元素d[i][i]是相应行的权重之和,可以证明以下陈述:
- 在对
L进行特征分解之后(考虑非正规图拉普拉斯L[u] = D-W并求解方程L[u]·v =λDv,很容易计算特征值和特征向量 ),则空特征值始终以多重性出现p。 - 如果
G是无向图(因此wij] ≥ 0, ∀i, j),则连接的组件数等于p(空特征值的多重性)。 - 如果
A包含于ℜ^N和Θ是A的可数子集(即X是可计数的子集,因为样本数始终是有限的),向量v∈ℜ^N对于Θ被称为指标向量,给定θ[i] ∈ Θ,如果θ[i] ∈ A,v^(i) = 1,否则v^(i) = 0。 例如,如果我们有两个向量a = (1, 0)和b = (0, 0)(因此,Θ = {a, b}),我们认为A = {(1, n)}其中n ∈ [1, 10],向量v = (1, 0)是一个指标向量,因为a ∈ A和b ∉ A。 L的第一个p特征向量(对应于空特征值)是每个连接的分量C[1], C[2], ..., C[p]。
因此,如果数据集由M个样本x[i] ∈ ℜ^N以及图G与亲和力矩阵W^(M×M)相关联,Shi 和 Malik 建议建立矩阵B ∈ ℜ^(M×p)包含第一个p特征向量作为列,并使用诸如 K 均值的更简单方法对行进行聚类。 实际上,每一行代表样本在p维子空间上的投影,其中非凸性由可以封装在规则球中的子区域表示。
现在,我们应用频谱聚类以分离由以下代码段生成的二维正弦数据集:
import numpy as np
nb_samples = 2000
X0 = np.expand_dims(np.linspace(-2 * np.pi, 2 * np.pi, nb_samples), axis=1)
Y0 = -2.0 - np.cos(2.0 * X0) + np.random.uniform(0.0, 2.0, size=(nb_samples, 1))
X1 = np.expand_dims(np.linspace(-2 * np.pi, 2 * np.pi, nb_samples), axis=1)
Y1 = 2.0 - np.cos(2.0 * X0) + np.random.uniform(0.0, 2.0, size=(nb_samples, 1))
data_0 = np.concatenate([X0, Y0], axis=1)
data_1 = np.concatenate([X1, Y1], axis=1)
data = np.concatenate([data_0, data_1], axis=0)
数据集显示在以下屏幕截图中:
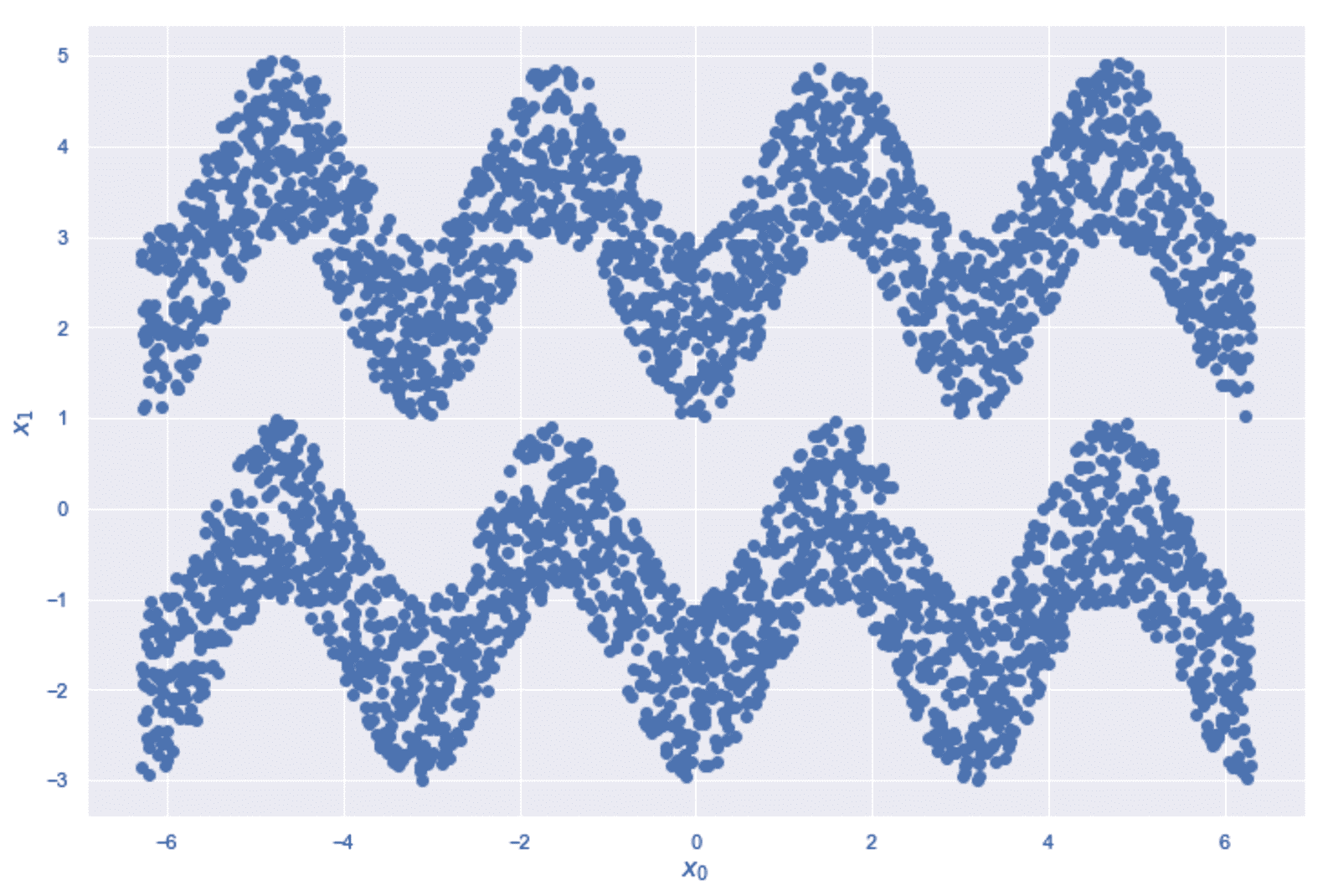
谱聚类示例的正弦数据集
我们尚未指定任何基本事实; 但是,目标是将两个正弦曲线分开(非正弦曲线)。 很容易检查捕获正弦曲线的球是否还会包含许多属于另一个正弦曲线子集的样本。 为了显示纯 K 均值和频谱聚类之间的差异(scikit-learn 实现 Shi-Malik 算法,然后进行 K 均值聚类),我们将训练两个模型,后者使用 RBF(affinity参数,其中γ = 2.0(gamma参数)。 当然,我邀请读者也测试其他值和 KNN 相似性。 以下片段显示了基于 RBF 的解决方案:
from sklearn.cluster import SpectralClustering, KMeans
km = KMeans(n_clusters=2, random_state=1000)
sc = SpectralClustering(n_clusters=2, affinity='rbf', gamma=2.0, random_state=1000)
Y_pred_km = km.fit_predict(data)
Y_pred_sc = sc.fit_predict(data)
结果显示在以下屏幕截图中:
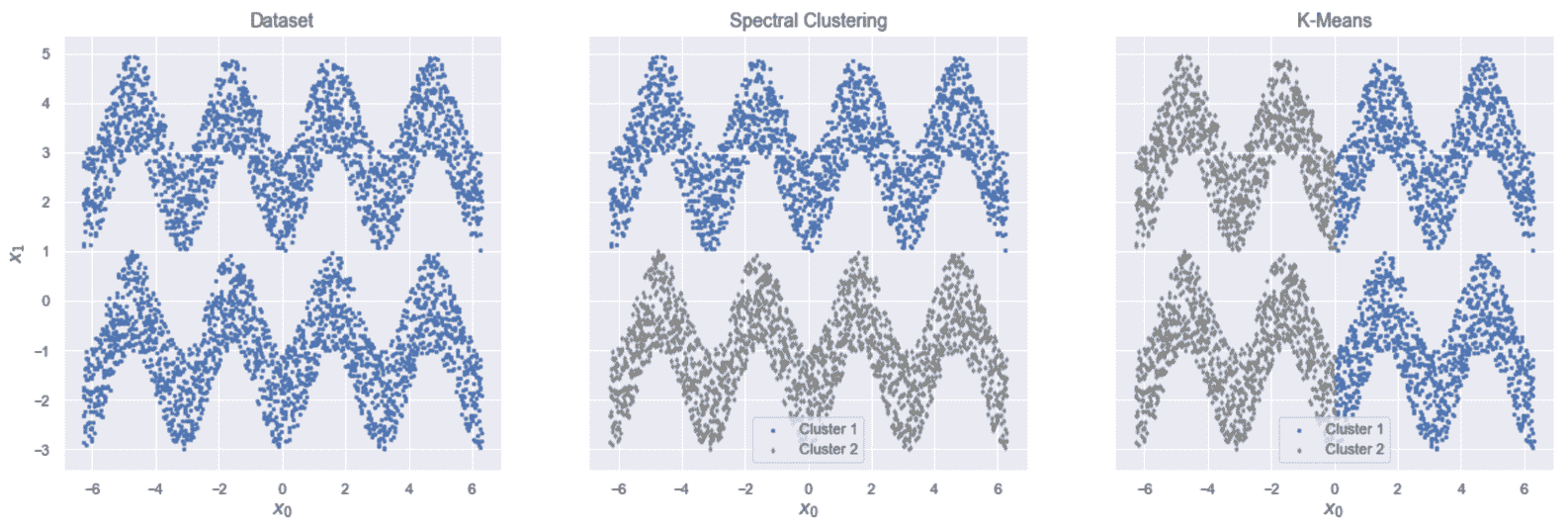
原始数据集(左)。 谱聚类结果(中心)。 K 均值结果(右)
如您所见,K 均值将数据集沿x轴划分为两个球,而谱聚类成功地正确分离了两个正弦曲线。 只要群集的数量和X的维数都不太大(在这种情况下,拉普拉斯算子的本征分解会变得非常昂贵),该算法就非常强大。 此外,由于该算法基于图切割程序,因此,当群集数为偶数时,它非常适合。
MeanShift
让我们考虑一个数据集X∈^(M×N)(MN维样本)是从多元数据生成过程p_data。 均值漂移算法应用于聚类问题的目的是找到p_data最大的区域,并将周围子区域中包含的样本关联到同一集群。 由于p_data是概率密度函数(PDF),因此将其表示为以一小部分参数(例如均值和方差)为特征的常规 PDF(例如,高斯)的总和。 以这种方式,可以认为 PDF 由样本生成的概率最高。 我们还将在第 5 章,“软聚类和高斯混合模型”,和第 6 章,“异常检测”中讨论该过程。 出于我们的目的,将问题重构为一个迭代过程,可以更新均值向量(质心)的位置,直到达到最大值为止。 当质心到达其最终位置时,将使用标准邻域函数将样本分配给每个聚类。
该算法的第一步是确定近似p_data的合适方法。 一种经典方法基于 Parzen 窗口(将在第六章,“异常检测”中进行讨论)。 就目前而言,可以说 Parzen 窗口是一个非负内核函数f(·),其特征是称为带宽的参数(有关更多详细信息,请参阅原始论文《关于概率密度函数和模式的估计》)。 顾名思义,此参数的作用是加宽或限制 Parzen 窗口接近其最大值的区域。 考虑到与高斯分布的类比,带宽具有与方差相同的作用。 因此,较小的带宽将产生在均值附近非常峰值的函数,而较大的值与较平坦的函数关联。 不难理解,在这种特定情况下,群集的数量由带宽和相反的方式隐式确定。 因此,大多数实现(例如 scikit-learn)仅采用一个参数,然后计算另一个参数。 考虑到该算法已设计为适用于概率分布,自然的选择是指定所需带宽或让实现检测最佳带宽。 这个过程看起来比施加特定数量的群集更为复杂,但是,在许多实际情况下,尤其是当至少部分地了解了基本事实时,测试不同带宽的结果会更容易。
均值平移的最常见选择是用n个扁平核的总和来近似数据生成过程(n是形心数):
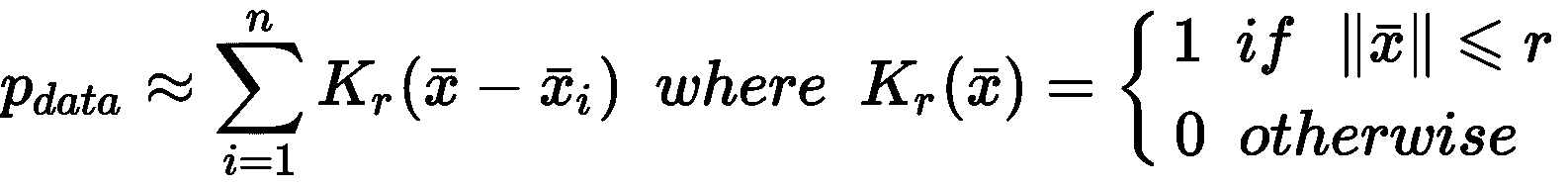
因此,收敛之后,每个样本都由最接近的质心表示。 不幸的是,这种近似导致了分段函数,该分段函数不太可能代表实际过程。 因此,最好基于相同的基础内核采用平滑的 Parzen 窗口K(·):
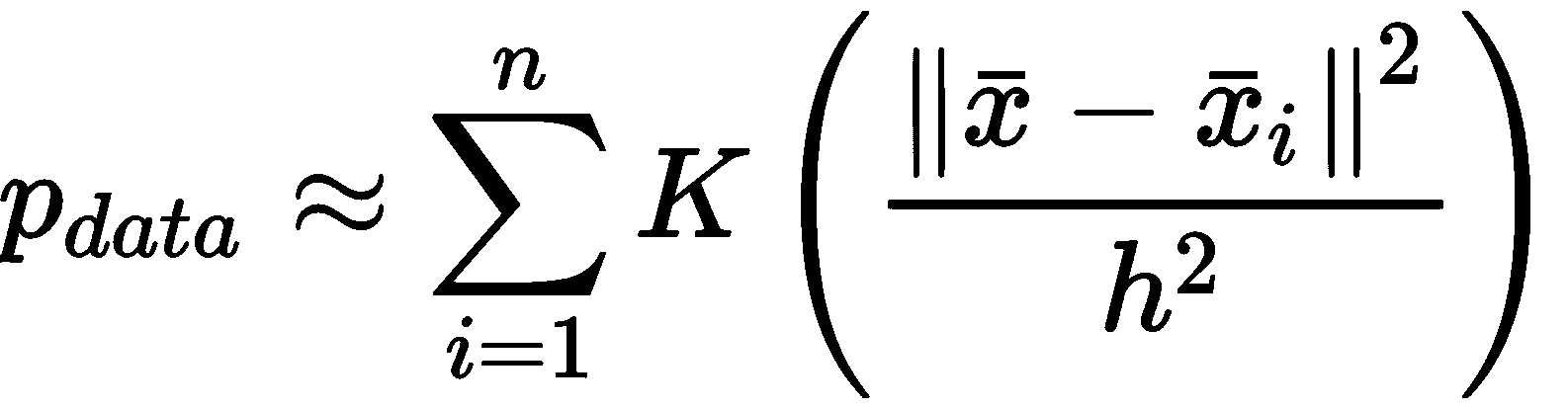
K(·)是平方距离(例如对于标准球)和带宽h的函数。 可以使用许多可能的候选函数,但是,当然最明显的是高斯核(RBF),其中h^2发挥方差的作用。 现在得到的近似值非常平滑,n峰对应于质心(即均值)。 定义函数后,就可以计算质心的最佳位置x[1], x[2], ..., x[n]。
给定质心和邻域函数(为简单起见,我们假定使用半径为h和K(x) ≠ 0, ∀x ∈ B[r]的标准球B[h]),相应的均值漂移向量定义为:
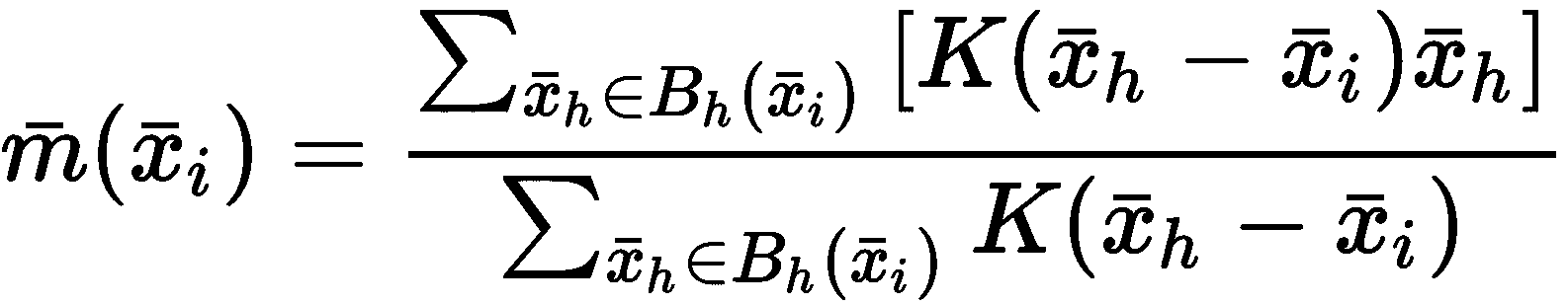
可以看到,m(·)是加权为K(·)的所有邻域样本的平均值。 显然,由于K(·)是对称的并且具有一定的距离,所以x[i]达到实际平均值。 带宽的作用是限制x[i]周围的区域。 现在应该更加清楚,较小的值会强制算法引入更多的质心,以便将所有样本分配给一个群集。 相反,较大的带宽可能导致单个群集具有最终配置。 迭代过程从初始质心猜测开始x[1]^(0), x[2]^(0), ..., x[n]^(0)等,并使用以下规则校正向量:
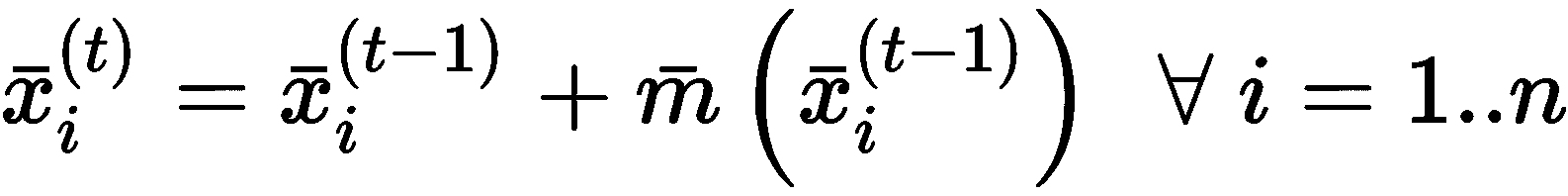
以前的公式很简单; 在每一步中,质心都会移动(移动)到m(·)附近。 这样,由于m(·)与相对于x[i]计算的邻域密度成比例。 ,当x[i]到达概率最大的位置m(·) → m[final]时,不需要更多更新 。 当然,收敛速度受样本数量的强烈影响。 对于非常大的数据集,该过程可能会变得很慢,因为每个均值漂移向量的计算都需要对邻域进行预先计算。 另一方面,当聚类标准由数据密度定义时,该算法非常有用。
作为示例,现在让我们考虑具有500二维样本的合成数据集,该样本由三个带有对角协方差矩阵的多元高斯生成,如下所示:
import numpy as np
nb_samples = 500
data_1 = np.random.multivariate_normal([-2.0, 0.0], np.diag([1.0, 0.5]), size=(nb_samples,))
data_2 = np.random.multivariate_normal([0.0, 2.0], np.diag([1.5, 1.5]), size=(nb_samples,))
data_3 = np.random.multivariate_normal([2.0, 0.0], np.diag([0.5, 1.0]), size=(nb_samples,))
data = np.concatenate([data_1, data_2, data_3], axis=0)
数据集显示在以下屏幕截图中:
MeanShift 算法示例的样本数据集
在这种情况下,我们知道基本事实,但是我们想测试不同的带宽并比较结果。 由于生成高斯粒子彼此非常接近,因此可以将某些外部区域识别为群集。 为了将研究重点放在最佳参数上,我们可以观察到平均方差(考虑不对称性)为 1,因此可以考虑值h = 0.9,1.0,1.2和 1.5。 此时,我们可以实例化 scikit-learn 类MeanShift,将h值通过参数bandwidth 传递,如下所示:
from sklearn.cluster import MeanShift
mss = []
Y_preds = []
bandwidths = [0.9, 1.0, 1.2, 1.5]
for b in bandwidths:
ms = MeanShift(bandwidth=b)
Y_preds.append(ms.fit_predict(data))
mss.append(ms)
密度分析后,训练过程会自动选择质心的数量和初始位置。 不幸的是,这个数字通常大于最后一个数字(由于局部密度差异); 因此,该算法将优化所有质心,但在完成操作之前,将执行合并过程以消除所有与其他质心太近(即重复的质心)的质心。 Scikit-learn 提供了参数bin_seeding,可以通过根据带宽对样本空间进行离散化(合并)来加快这项研究。 这样,有可能以合理的精度损失来减少候选者的数量。
下图显示了这四个训练过程结束时的结果:
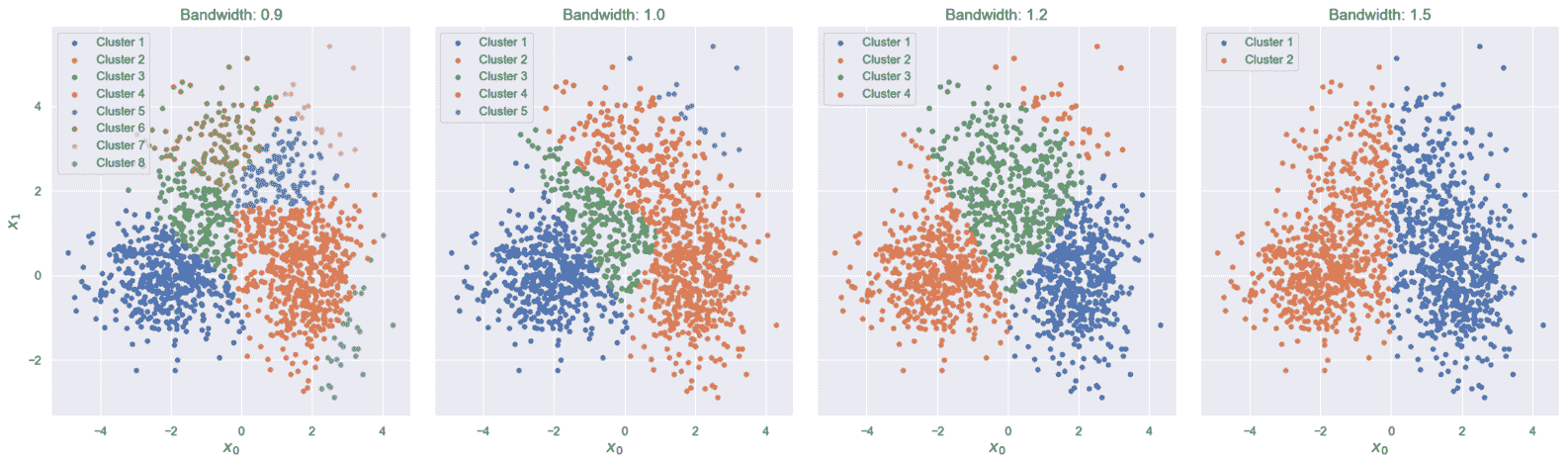
MeanShift 在不同带宽下的聚类结果
如您所见,带宽的微小差异会导致群集数量不同。 在我们的情况下,最佳值为h=1.2,它产生的结果是确定了三个不同的区域(以及一个包含潜在异常值的额外聚类)。 最大聚类的质心大致对应于实际均值,但是聚类的形状与任何高斯分布都不相似。 这是可以通过采用其他方法解决的缺陷(在第 5 章 , “软聚类和高斯混合模型”中进行了讨论)。 实际上,均值偏移适用于局部邻域,并且p_data不被认为属于特定分布。 因此,最终结果是将数据集非常准确地分割为高度密集的区域(注意不再需要最大分隔),这也可以从多个标准分布的叠加中得出。 没有任何先前的假设,我们不能期望结果非常规则,但是,将该算法与 VQ 进行比较,很容易注意到分配是基于找到每个密集 Blob 的最佳代表的想法。 因此,由高斯N(μ, Σ)产生的一些点以低概率分配给质心比μ更具代表性的另一个聚类。
DBSCAN
DBSCAN 是基于数据集密度估计的另一种聚类算法。 但是,与均值移位相反,没有直接参考数据生成过程。 在这种情况下,实际上,过程通过自下而上的分析建立了样本之间的关系,从X由高密度区域(气泡 )由低密度的分隔。 因此,DBSCAN 不仅需要最大的分隔约束,而且为了确定群集的边界,它强制执行这种条件。 而且,此算法不允许指定所需的群集数,这是X结构的结果,但是,类似于均值移位,可以控制进程的粒度。
特别是,DBSCAN 基于两个基本参数:ε,它表示球B[ε](x[i])的半径,以样本x[i]为中心,和n[min],这是B[ε](x[i])中必须包含的最小样本数,以便考虑x[i]作为核心点(即可以被视为集群的实际成员的点)。 形式上,给定一个函数N(·),该函数对集合中包含的样本数进行计数,则在以下情况下将样本x[i] ∈ X称为核心点 :
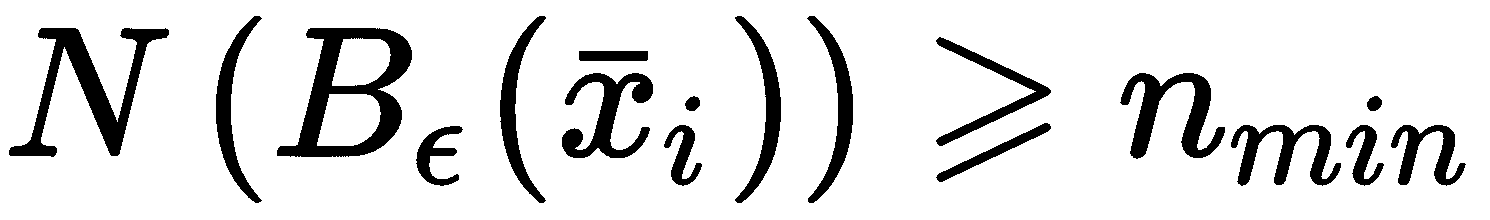
所有点x[j] ∈ B[ε](x[i])定义为从x[i]直接密度可达的。 这样的条件是点之间最强的关系,因为它们都属于以x[i]为中心的同一球。B[ε](x[i])包含的样本总数足够大,可以将邻域视为密集的子区域。 此外,如果存在x[i] → x[i + 1] → ... → x[j],其中x[i + 1]是从x[i]直接密度可达的(适用于所有顺序对),x[j]定义为x[i]中密度可达的。 该概念非常直观,可以通过考虑以下图表立即理解:
如果n[min] = 4,则点x[2]从x[0]密度可达
如果我们将样本的最小数量设置为等于 4,则x[0],x[1]和x[2]是核心点,x[1]从x[0]直接密度可达。 x[2]从x[1]直接密度可达。 因此,x[2]从x[0]密度可达。 换句话说,这意味着可以从x[0]开始并以x[2]结尾,定义一系列重叠的密集球N(·) ≥ n[min]。 通过添加更多定义,可以将此概念扩展到属于球的所有其他点:给定点x[k],点x[i]和x[j]是密度连通的,如果x[i]和x[j]从x[k]密度可达。
重要的是要了解这种情况比密度可达性弱,因为为了保证密集链,有必要考虑第三点,该点代表两个点之间的连接器 密集的次区域。 实际上,可能有两个密度连接点a和b,而a不能从b达到密度。 (反之亦然)。 只要仅在一个方向上移动就满足最小数量的样本条件(即,属于一个球的样本不是均匀分布,而是倾向于以较小的超量累积),就会发生这种情况。
因此,例如,如果N(a) >> n[min]和N(a[1]) << N(a),转换a → a[1]可以允许构建一个球B[ε](a),其中还包含a[1](以及许多其他要点)。 但是,在逆转换中a[1] →a,B[ε](a[1])的密度不足以建立直接的密度可达性条件。
因此,当在两个方向之一上移动时,较长的序列可能会被破坏,从而导密集度可达性丧失。 现在应该更清楚地知道,在x[i]和x[j]两点之间的密度连接可以使我们避免此问题,假设还有一个点可以同时达到x[i]和x[j]。
所有具有x[i]和x[j] ∈ X将分配给同一群集C[t]。 此外,如果x[k] ∈ C[t],则所有密度可达的点x[p] ∈ X * x[k]也将属于同一群集。 从任何其他点x[i] ∈ X不可达到密度的点x[n]被定义为噪声点。 因此,与其他算法相反,DBSCAN 输出n群集以及一个包含所有噪声点的附加集(不必将其视为离群值,而应视为不属于任何密集子区域的点)。 当然,由于噪声点没有标签,因此其数目应相当低; 因此,重要的是要调整参数ε和n[min],以达到双重目的:最大化内聚和分离度,避免过多的点被标记为噪点 。 没有实现此目标的标准规则,因此,我建议在做出最终决定之前测试不同的值。
最后,重要的是要记住,DBSCAN 可以处理非凸几何形状,并且与均值移位相反,它假设存在由低密度区域包围的高密度区域。 而且,它的复杂性与所采用的 KNN 方法(强力,球树或 kd 树)严格相关。 通常,当数据集不太大时,平均性能大约为O(N log N),但可能趋于O(N^2)当N非常大时。 要记住的另一个重要元素是样本的大小。 正如我们已经讨论的那样,高维度量可以减少两点的可分辨性,从而对 KNN 方法的表现产生负面影响。 因此,当维数很高时,应避免(或至少仔细分析)DBSCAN,因为生成的群集不能有效地表示实际的密集区域。
在显示具体示例之前,最好先介绍一种在未知的真实情况下可以采用的进一步评估方法。
Calinski-Harabasz 分数
假设将聚类算法应用于包含M个样本的数据集X,以便将其分割为n[c]个群集,C[i]由重心μ[i]表示,i = 1..n。 我们可以将群集内分散度(WCD)定义如下:
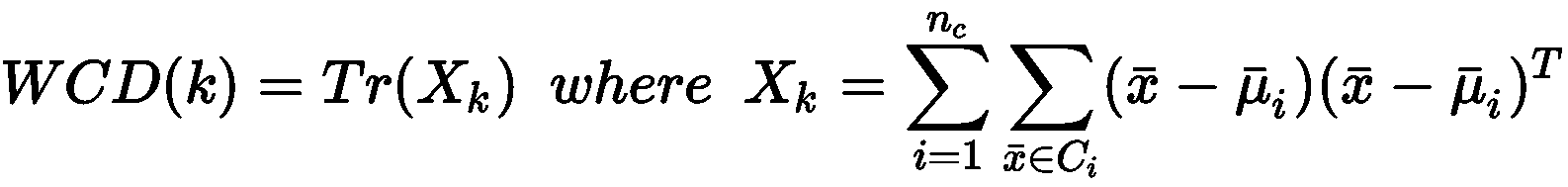
如果x[i]是N维列向量,则X[k] ∈ ℜ^(N×N)。 不难理解,WCD(k)编码有关群集的伪方差的全局信息。 如果满足最大内聚条件,我们预计质心周围的分散性有限。 另一方面,即使WCD(k)也可能受到包含异常值的单个群集的负面影响。 因此,我们的目标是在每种情况下都将WCD(k)最小化。 以类似的方式,我们可以将集群间分散度(BCD)定义为:
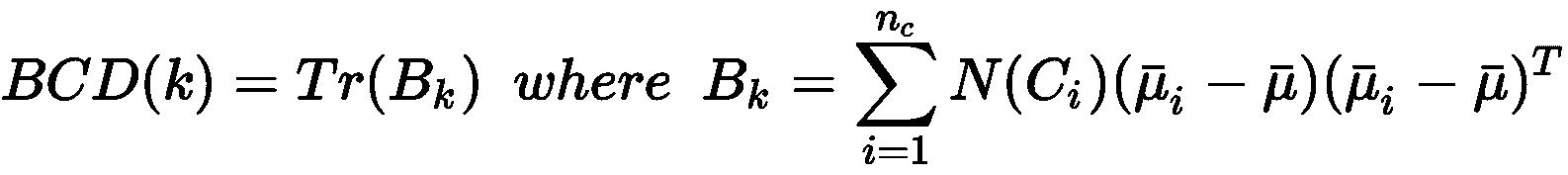
在上一个公式中, N(C[i])是分配给群集C[i]的元素数和μ是整个数据集的全局质心。 考虑到最大分离的原理,我们希望有一个远离全局质心的密集区域。 BCD(k)精确地表达了这一原理,因此我们需要对其进行最大化以实现更好的表现。
Calinski-Harabasz 分数定义为:
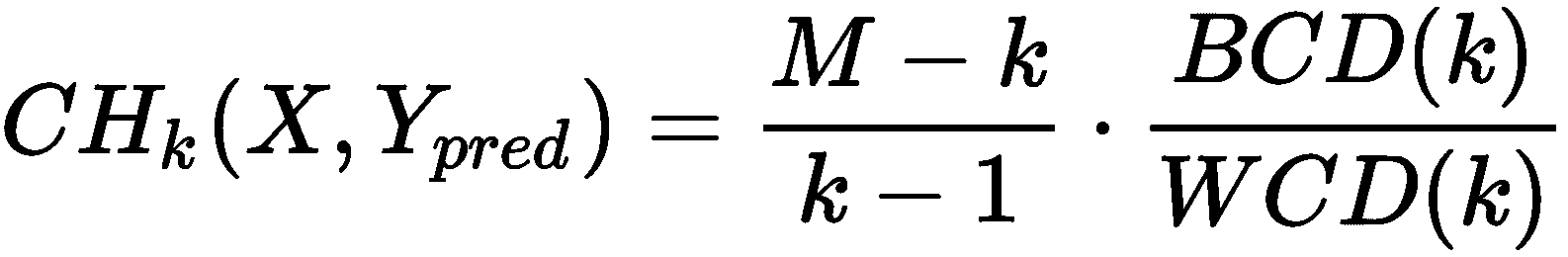
由于不考虑质心计算是聚类算法的一部分,因此引入了对预测标签的显式依赖性。 分数没有绝对含义,但是有必要比较不同的值以了解哪种解决方案更好。 显然, CH[k](·)越高,聚类表现越好,因为这种条件意味着更大的分离度和更大的内部凝聚力。
使用 DBSCAN 分析旷工数据集
旷工数据集(按照本章开头的说明进行下载)由 740 条记录组成,其中包含有关请假几天的员工的信息。 共有 20 个属性,分别代表年龄,服务时间,教育程度,习惯,疾病,纪律衰竭,交通费用,从家到办公室的距离等(这些字段的完整说明,请参见这里)。 我们的目标是预处理数据并应用 DBSCAN,以发现具有特定语义内容的密集区域。
第一步是按以下方式加载 CSV 文件(必须更改占位符<data_path>,以指向文件的实际位置):
import pandas as pd
data_path = '<data_path>\Absenteeism_at_work.csv'
df = pd.read_csv(data_path, sep=';', header=0, index_col=0).fillna(0.0)
print(df.count())
上一条命令的输出如下:
Reason for absence 740
Month of absence 740
Day of the week 740
Seasons 740
Transportation expense 740
Distance from Residence to Work 740
Service time 740
Age 740
Work load Average/day 740
Hit target 740
Disciplinary failure 740
Education 740
Son 740
Social drinker 740
Social smoker 740
Pet 740
Weight 740
Height 740
Body mass index 740
Absenteeism time in hours 740
dtype: int64
其中一些特征是分类的,并使用连续的整数进行编码(例如Reason for absence,Month of absence等)。 由于这些值可能会在没有确切语义原因的情况下影响距离(例如Month=12大于Month=10,但两个月的距离相等),因此在继续下一步之前,我们需要对所有这些特征进行单热编码 (新特征将添加到列表末尾)。 在以下代码段中,我们使用get_dummies() pandas 函数来执行编码; 然后删除原始列:
import pandas as pd
cdf = pd.get_dummies(df, columns=['Reason for absence', 'Month of absence', 'Day of the week', 'Seasons', 'Disciplinary failure', 'Education', 'Social drinker', 'Social smoker'])
cdf = cdf.drop(labels=['Reason for absence', 'Month of absence', 'Day of the week', 'Seasons', 'Disciplinary failure', 'Education', 'Social drinker', 'Social smoker']).astype(np.float64)
一键式编码的结果通常会在方法之间产生差异,因为许多特征将被限制为 0 或 1,而其他特征(例如,年龄)的范围可能会更大。 因此,最好对方法进行标准化(在不影响标准差的情况下,由于它们与现有信息内容成正比,因此保持不变是有帮助的)。 可以使用StandardScaler类设置参数with_std=False来完成此步骤,如下所示:
from sklearn.preprocessing import StandardScaler
ss = StandardScaler(with_std=False)
sdf = ss.fit_transform(cdf)
在这一点上,像往常一样,我们可以使用 t-SNE 算法来减少数据集的维数(使用n_components=2)并可视化结构。 数据框dff将包含原始数据集和 t-SNE 坐标,如下所示:
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, perplexity=15, random_state=1000)
data_tsne = tsne.fit_transform(sdf)
df_tsne = pd.DataFrame(data_tsne, columns=['x', 'y'], index=cdf.index)
dff = pd.concat([cdf, df_tsne], axis=1)
生成的绘图显示在以下屏幕截图中:
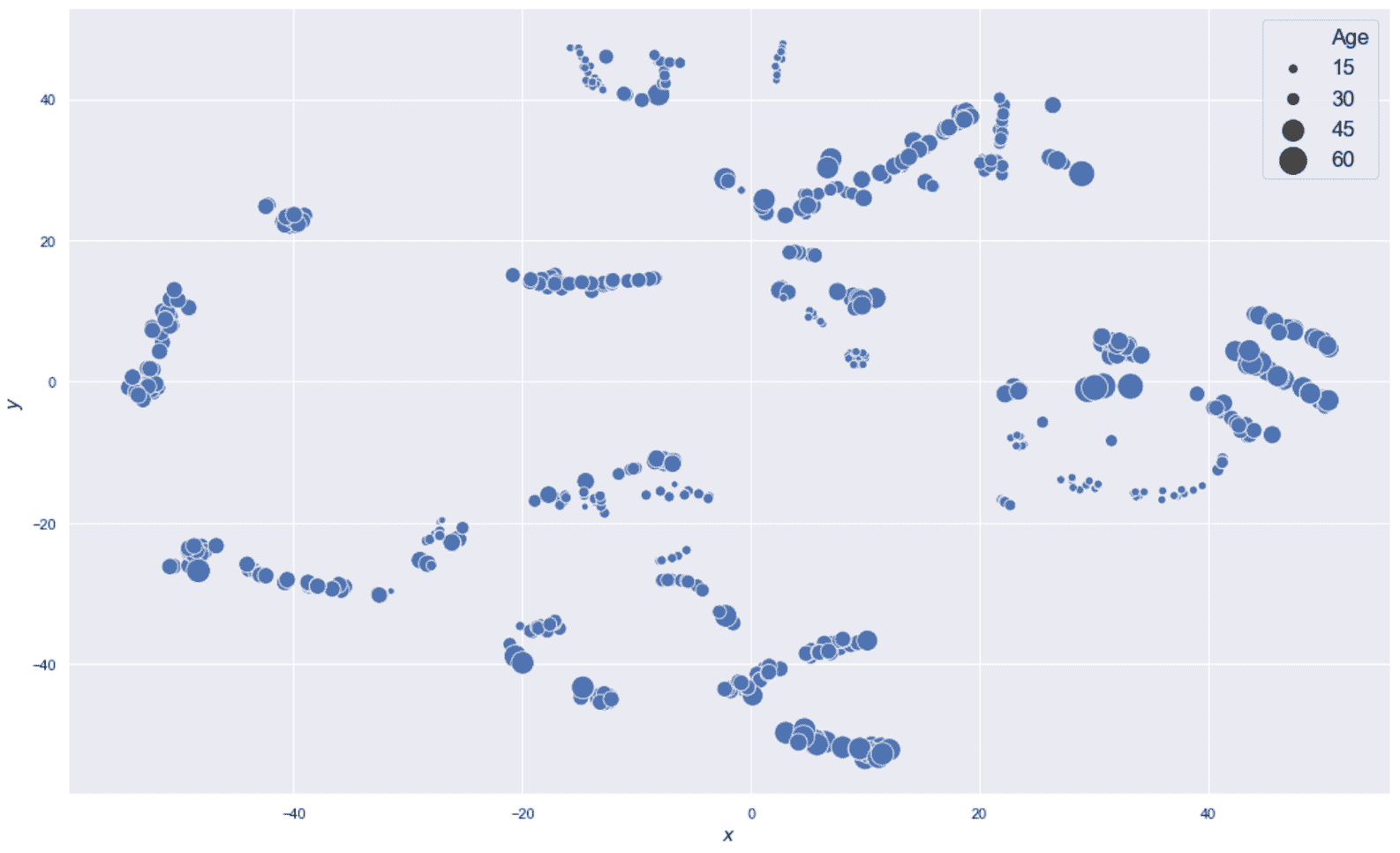
旷工数据集的 t-SNE 二维表示
在进行任何考虑之前,重复一下 t-SNE 产生最佳的低维表示很重要,但是始终必须在原始数据集上测试算法,以检查 t-SNE 标识的邻居是否对应于实际的聚集体。 特别是,考虑到 DBSCAN 的结构,考虑到 t-SNE 表示形式,ε值可能是合理的,但是当移至更高维度的空间时,这些球不再能够捕获相同的样本。 但是,先前的图显示了被空白空间包围的密集区域的存在。 不幸的是,密度极不可能是均匀的(这是 DBSCAN 的建议要求之一,因为 ε和n[min]不能改变,但是在这种情况下,我们假设所有斑点的密度都是恒定的。
为了找到适合我们目的的最佳配置,我们绘制了群集数,噪声点数,轮廓分数和 Calinski-Harabasz 分数作为ε的函数,采用了p = 2,p = 4,p = 8和p = 12,如下图所示:
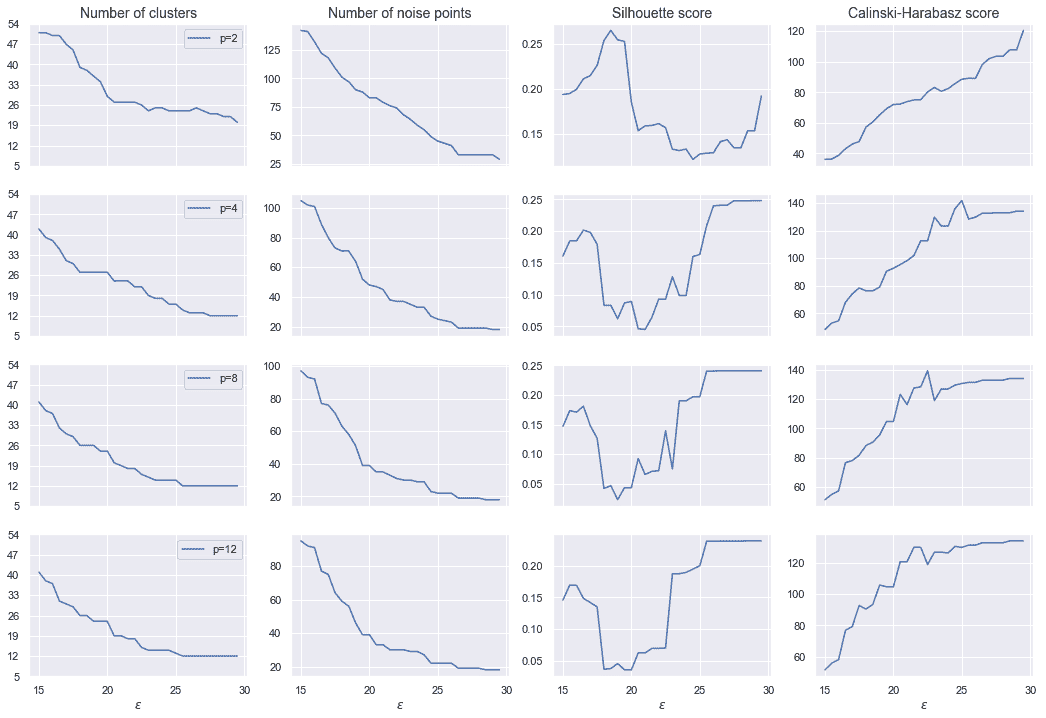
评估指标作为ε的函数
Silhouette 和 Calinski-Harabasz 均基于凸群集的假设(例如,色散显然是一种假设样本围绕质心呈放射状分布的度量),因此在非凸情况下其期望值通常较小 。 但是,我们要最大化两个分数(轮廓→ 1和 Calinski-Harabasz → ∞),同时避免大量聚类。 考虑到我们的最初目标(寻找以一组特定特征为特征的凝聚聚类),我们选择了ε = 25和 Minkowski 度量,其中p = 12, 这会产生合理数量的群集(13)和 22 个噪声点。 在第 2 章,“聚类基本原理”中,我们证明了,当p → ∞时(但效果对于p > 2已经可见),距离趋向于最大的特征差异。
因此,应该始终通过上下文分析来证明这种选择是合理的。 在这种情况下,我们可以假设每个(非)凸斑点代表一个由特定特征(具有所有其他特征的次要贡献)主导的类别,因此p = 12(导致 17 个群集) 对于中等粗粒度的分析(考虑有 20 个属性),这可能是一个很好的权衡。 此外,ε = 22.5与最高的 Calinski-Harabasz 得分之一 129.3 和轮廓得分约等于 0.2 关联。 特别是,后者的值表示总体聚类是合理正确的,但可能存在重叠。 由于基础几何很可能是非凸的,因此考虑到具有相应峰值的 Calinski-Harabasz 分数,这样的结果是可以接受的(通常在凸形场景中不是这样)。 较大的ε值会产生略高的轮廓分数(小于 0.23),但是所得的群集数和 Calinski-Harbasz 分数均不受所得构型的影响。 必须清楚这一选择尚未得到任何外部证据的证实,必须通过对结果的语义分析加以验证。 如果需要进行细粒度的分析,则可以使用具有更多群集和更多噪声点的配置(因此,读者可以玩转这些值并提供一个结果的解释)。 但是,此示例的最终目标仍然是相同的:分割数据集,以便每个群集包含特定的(可能是唯一的)属性。
现在,我们可以实例化DBSCAN模型,并使用包含规范化特征的数组sdf对其进行训练。 配置为ε = 25(参数eps)和n[min] = 3 (参数min_samples),以及 Minkowski 度量(metric='minkowski')和p=12。
现在,我们可以执行以下集群:
from sklearn.cluster import DBSCAN
from sklearn.metrics import silhouette_score, calinski_harabaz_score
ds = DBSCAN(eps=25, min_samples=3, metric='minkowski', p=12)
Y_pred = ds.fit_predict(sdf)
print('Number of clusters: {}'.format(np.max(Y_pred) + 1))
print('Number of noise points: {}'.format(np.sum(Y_pred==-1)))
print('Silhouette score: {:.3f}'.format(silhouette_score(dff, Y_pred, metric='minkowski', p=12)))
print('Calinski-Harabaz score: {:.3f}'.format(calinski_harabaz_score(dff, Y_pred)))
由于DBSCAN用标签-1标记了噪声点,因此上一个代码段的输出如下:
Number of clusters: 13
Number of noise points: 22
Silhouette score: 0.2
Calinski-Harabaz score: 129.860
生成的绘图显示在以下屏幕截图中:
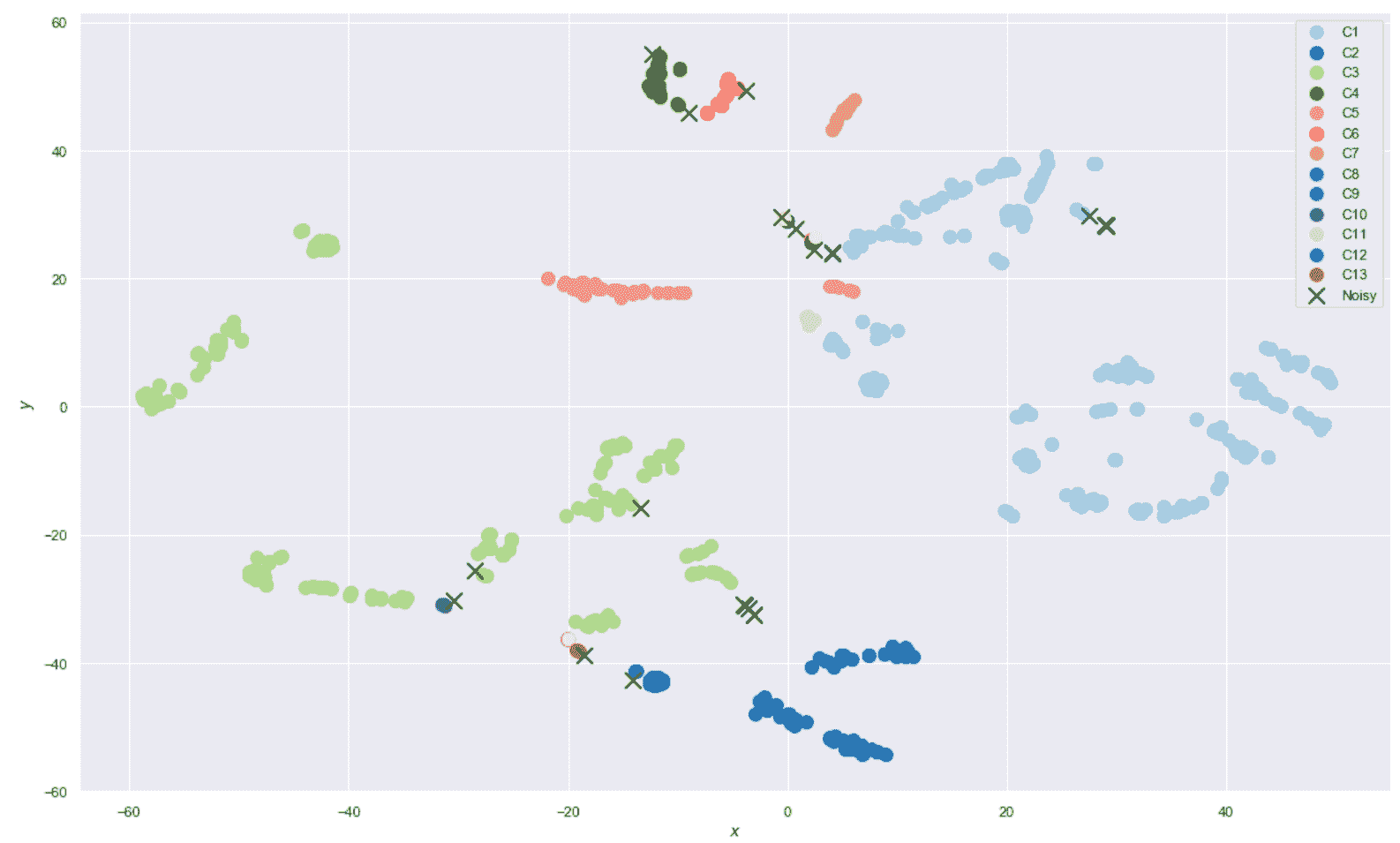
旷工数据集的聚类结果
如您所见(我建议运行代码以便获得更好的视觉确认),已成功检测出大多数孤立区域(即使在 t-SNE 图中没有内聚),并且已将样本分配给了相同群集。 我们还可以观察到两个基本结果:在 t-SNE 表示中,噪声点(带有叉号的标记)不是孤立的,并且某些群集被部分拆分。 这不是算法的失败,而是降维的直接结果。 在原始空间中,所有噪声点实际上都没有与任何其他样本紧密连接,但在 t-SNE 图中它们可能看起来重叠或接近某些斑点。 但是,我们对高密度和准粘结的非凸区域感兴趣,幸运的是,它们在二维图中也显示为连通。
现在让我们考虑两个不同的区域(为简单起见,将分析限制为单次热编码后的前 10 个属性)。 第一个是二维区域x < -45,如下所示:
sdff = dff[(dff.x < -45.0)]
print(sdff[sdff.columns[0:10]].describe())
以下屏幕截图显示了输出的打印精美版本:
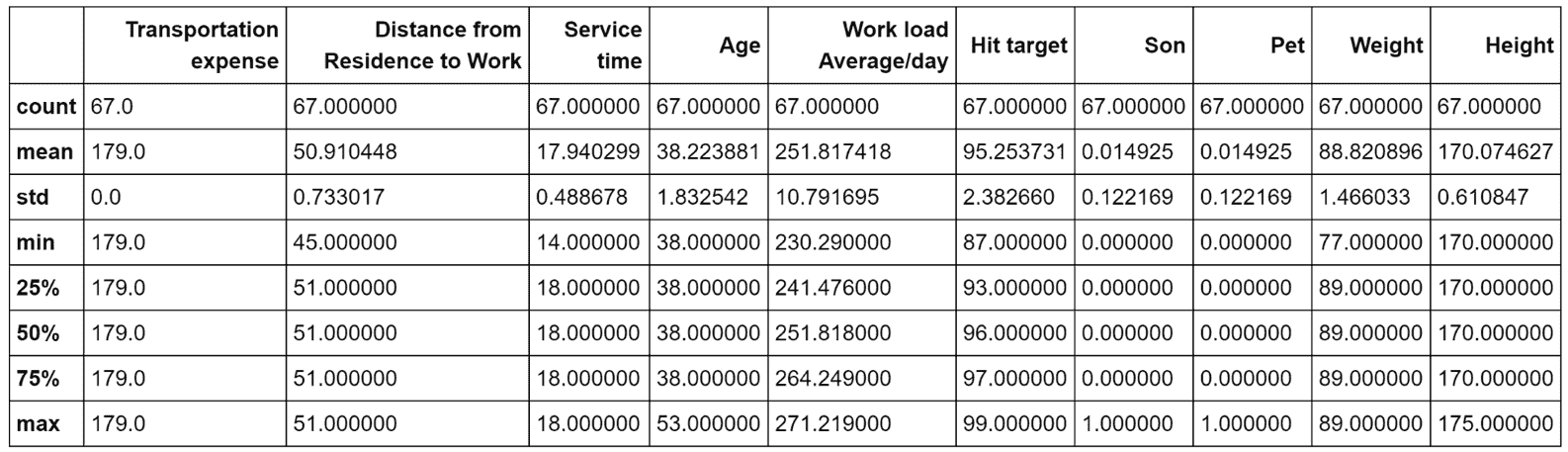
对应于子数据集x < -45的统计度量
有两个因素可以立即引起我们的注意:运输费用(这似乎标准化为 179 的值)和子孙的数量(考虑到平均值和标准差,对于大多数样本而言,其为 0)。 我们还考虑服务时间和从住所到工作的距离,这可以帮助我们找到群集的语义标签。 所有其他参数的判别力都较小,因此在此简要分析中将它们排除在外。 因此,我们可以假设这样的子集群包含大约 40 岁的没有孩子的人,服务时间较长,居住在离办公室很远的地方(我请读者检查总体统计数据以确认这一点),并且交通费用标准化( 例如一次性支出汽车)。
现在让我们将该结果与-20 < x < 20和y < 20的区域进行比较,如下:
sdff = dff[(dff.x > 20.0) & (dff.y > -20.0) & (dff.y < 20.0)]
print(sdff[sdff.columns[0:10]].describe())
相应的输出如下:
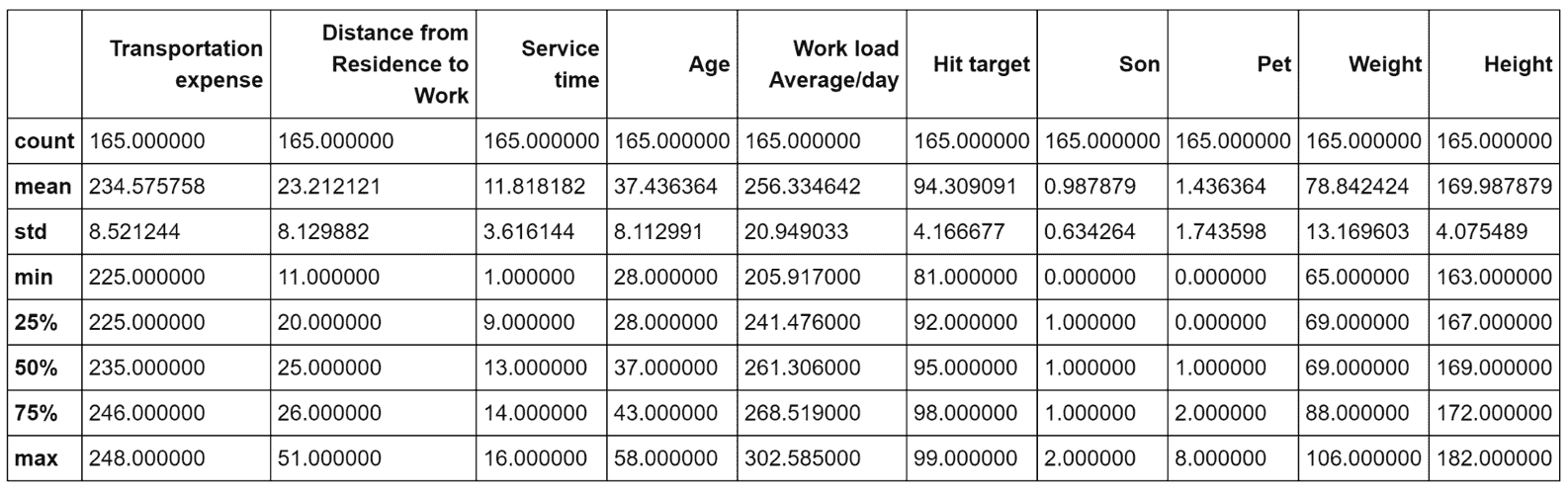
对应于子数据集-20 < x < -20和y < 20的统计度量
在这种情况下,运输费用会更大,而从住所到工作的距离大约是前一个示例的一半(还要考虑标准差)。 此外,平均儿子数为 1,雇员中有两个孩子的雇员比例适中,服务时间约为 12,标准差为 3.6。 我们可以推断出,该集群包含所有年龄在(28-58)之间有家庭的(已婚)人的所有样本,这些人有家庭,办公室相对较近,但旅行费用较高(例如,由于使用出租车服务)。 这样的员工倾向于避免加班,但是他们的平均工作量几乎与前面示例中观察到的相同。 即使没有正式的确认,我们也可以假设这样的员工通常效率更高,而第一批员工包含生产型员工,但是他们需要更多的时间来实现他们的目标(例如,由于旅行时间更长)。
这显然不是详尽的分析,也不是一组客观的陈述。 目的是展示如何通过观察样本的统计特征来找到聚类的语义内容。 在现实生活中,所有观察都必须由专家(例如,HR 经理)进行验证,以便了解分析的最后部分(特别是语义上下文的定义)是否正确或是否正确。 需要使用更多的群集,不同的指标或其他算法。 作为练习,我邀请读者分析包含单个群集的所有区域,以完成大图并测试与不同类别相对应的人工样本的预测(例如,非常小的年轻人,有三个孩子的雇员, 等等)。
作为表现指标的群集不稳定性
群集不稳定性是 Von Luxburg 提出的一种方法(在《群集稳定性:概述》中)可以用以下方法衡量算法的优缺点: 关于特定数据集。 它可以用于不同的目的(例如,调整超参数或找到最佳数目的群集),并且它相对容易计算。 该方法基于这样的想法,即满足最大内聚和分离要求的聚类结果也应该对数据集的噪声扰动具有鲁棒性。 换句话说,如果将数据集X分割为群集集C,则派生数据集X[n](基于特征的细微扰动)应映射到同一群集集。 如果不满足此条件,则通常有两种可能性:噪声扰动太强或算法对小变化过于敏感,因此不稳定。 因此,我们定义了原始数据集X的一组k扰动(或二次采样)版本:
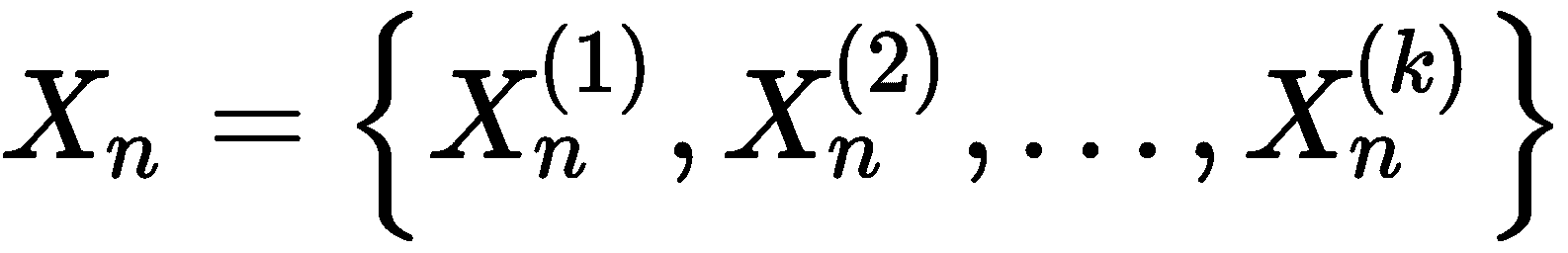
如果我们应用产生相同数目群集n[c]的算法A,我们可以定义A(X[i])和A(X[j])之间的距离度量d(·),该值测量不一致分配的数量(即A(X[i])),并且可以表示为返回对应于每个点的赋值的向量函数,因此d(·)可以简单地计算不同标签的数量,假设算法(如果需要)以相同的方式播种,并且数据集显然没有被改组,则算法的不稳定性(对于k*X的噪声变化)定义为:
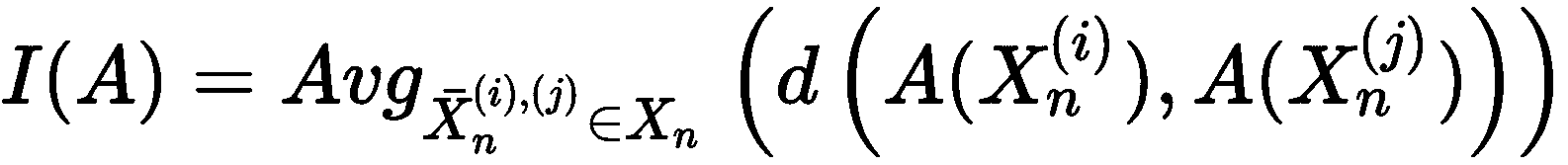
因此,不稳定性是几对噪声变化的聚类结果之间的平均距离。 当然,该值不是绝对的,因此可以得出的规则是:选择产生最小不稳定的配置。 同样重要的是,这种方法不能与之前讨论的其他方法相提并论,因为它是基于其他超参数(噪声变化的数量,噪声均值和方差,二次采样率等),因此可以产生不同的结果。 当A和X固定时。 特别是噪声的大小会极大地改变不稳定性,因此在确定高斯噪声的μ和Σ之前,有必要评估X的均值和协方差矩阵。在我们的示例中(基于“旷工”数据集中的 DBSCAN 聚类),我们从加性噪声项n[i] ~ N(E[X], Cov(X) / 4)开始创建了 20 个扰动版本。然后应用从均匀分布U(0, 1)中采样的乘法掩码。 这样,一些噪声项将被随机抵消或减少,如以下代码所示:
import numpy as np
data = sdf.copy()
n_perturbed = 20
n_data = []
data_mean = np.mean(data, axis=0)
data_cov = np.cov(data.T) / 4.0
for i in range(n_perturbed):
gaussian_noise = np.random.multivariate_normal(data_mean, data_cov, size=(data.shape[0], ))
noise = gaussian_noise * np.random.uniform(0.0, 1.0, size=(data.shape[0], data.shape[1]))
n_data.append(data.copy() + noise)
在这种情况下,我们想将不稳定性计算为ε的函数,但是可以使用任何其他算法和超参数重复该示例。 此外,我们采用归一化的汉明距离,该距离与两个聚类结果之间不一致分配的数量成正比,如下所示:
from sklearn.cluster import DBSCAN
from sklearn.metrics.pairwise import pairwise_distances
instabilities = []
for eps in np.arange(5.0, 31.0, 1.5):
Yn = []
for nd in n_data:
ds = DBSCAN(eps=eps, min_samples=3, metric='minkowski', p=12)
Yn.append(ds.fit_predict(nd))
distances = []
for i in range(len(Yn)-1):
for j in range(i, len(Yn)):
d = pairwise_distances(Yn[i].reshape(-1, 1), Yn[j].reshape(-1, 1), 'hamming')
distances.append(d[0, 0])
instability = (2.0 * np.sum(distances)) / float(n_perturbed ** 2)
instabilities.append(instability)
结果如下图所示:
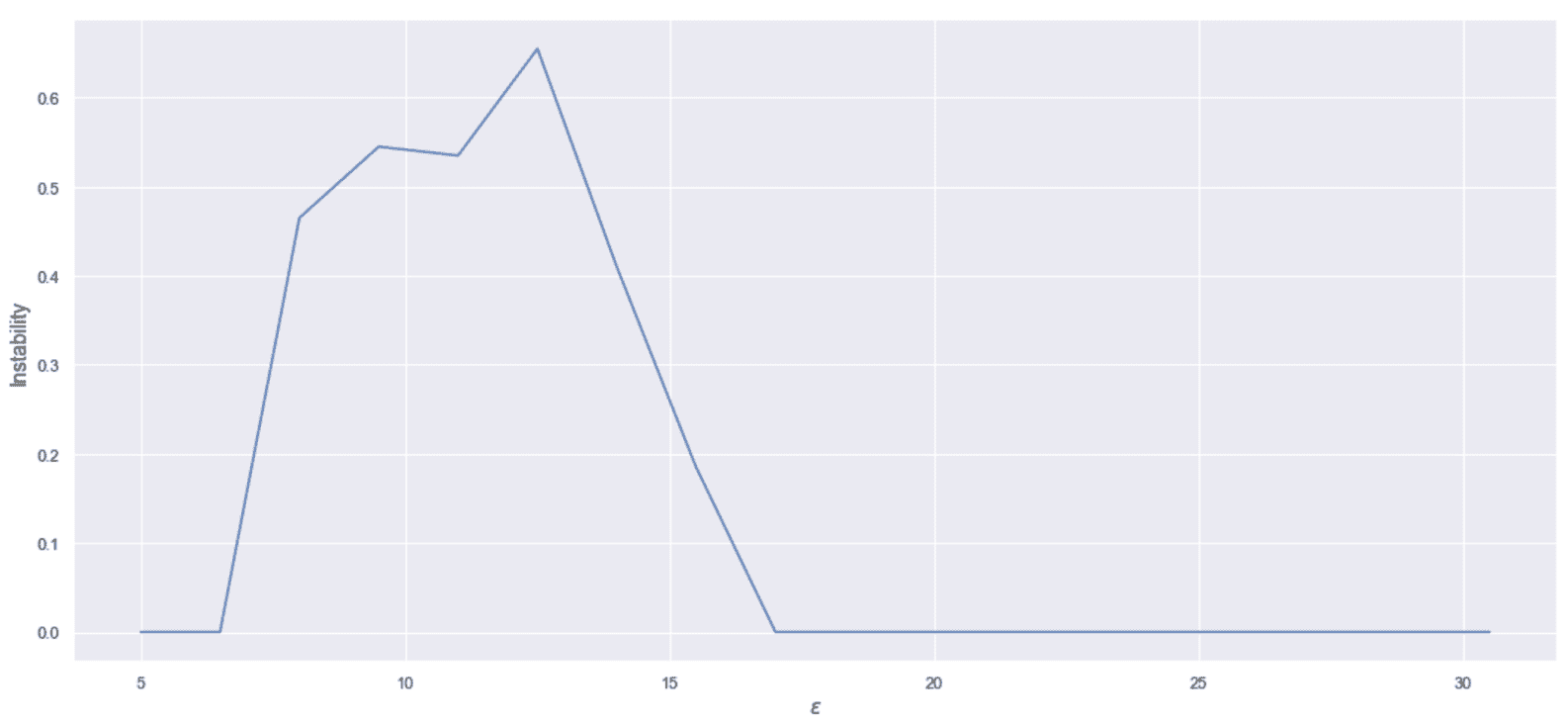
应用于旷工数据集的 DBSCAN 的集群不稳定性,作为ε的函数
对于ε < 7,该值为空。 这样的结果归因于该算法产生的大量群集和噪声样本。 由于样本分布在不同的区域,因此小的扰动不会改变分配。 对于7 < ε < 17,我们观察到一个正斜率达到最大值,大约对应于ε = 12.5,然后负斜率达到最终值 0。在这种情况下,聚类变得越来越大,并且包含了越来越多的样本。 但是,当ε仍然太小时,密度可达性链容易被小扰动破坏(也就是说,样本可以克服球的边界,因此将其排除在群集外)。 结果,在施加加性噪声之后,通常将样本分配给不同的群集。 当ε = 12.5时,此现象达到最大值,然后开始变得不太明显。
实际上,当ε足够大时,球的并集能够包裹整个群集,从而为小扰动留出足够的自由空间。 当然,在取决于数据集的阈值之后,将仅产生单个群集,并且,如果噪声不太强,则任何扰动版本将产生相同的分配。 在我们的特定情况下,ε = 25确保了高稳定性,这也可以通过 t-SNE 图得到证实。 一般而言,此方法可用于所有算法和几何形状,但建议您在决定如何创建受干扰的版本之前,先对X进行全面分析。 实际上,错误的决定会损害结果,产生较大/较小的不稳定性,并不表示表现不好/良好。 特别是,当聚类具有不同的方差时(例如,在高斯混合中),加性噪声项对某些样本的影响可以忽略不计,而它可以完全改变其余样本的结构。 在这些情况下,此方法比其他方法要弱,并且应使用方差很小(通常小于最小聚类(协)方差)的高斯噪声进行二次采样。 另一方面,使用基于密度的算法进行二次采样显然会非常危险,因为由于可达性的丧失,小型群集可能会成为一组孤立的噪声点。 我邀请读者也使用 K 均值测试此方法,以找到最佳的群集数(通常与最小不稳定性相关)。
K 中心点
在上一章中,我们显示了当群集的几何形状为凸形时,K 均值通常是一个不错的选择。 但是,该算法有两个主要局限性:度量始终为欧几里得,并且对异常值的鲁棒性不强。 第一个元素是显而易见的,而第二个元素是质心性质的直接结果。 实际上,K 均值选择质心作为不属于数据集的实际均值。 因此,当聚类具有一些离群值时,均值会受到影响并朝着它们成比例地移动。 下图显示了一个示例,其中一些异常值的存在迫使质心到达密集区域之外的位置:
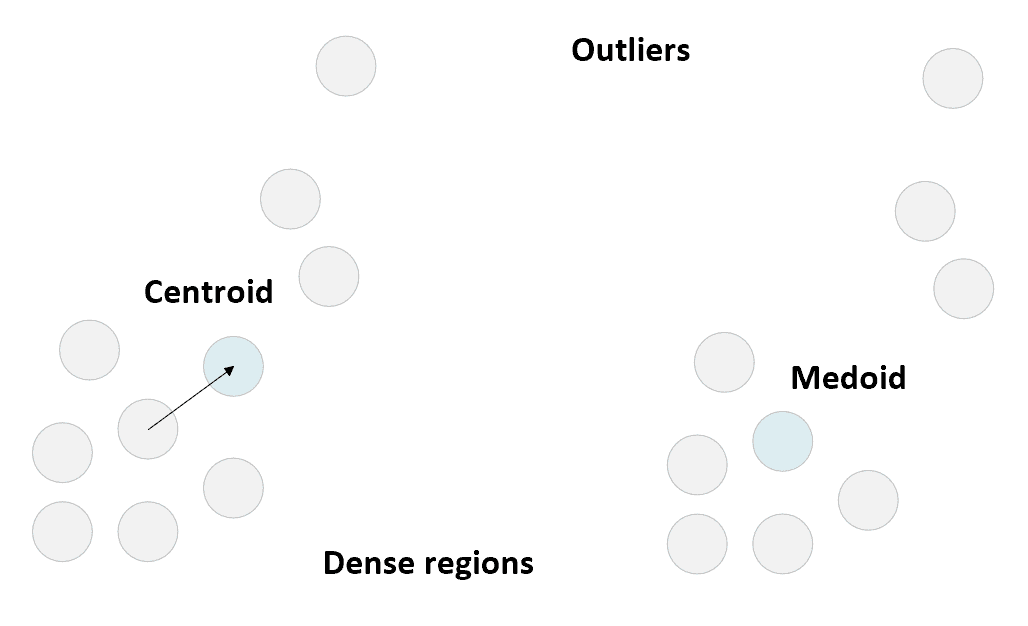
质心选择(左)和中心点选择(右)的示例
K 中心点的提出(在《基于 L1 范数和相关方法的统计数据分析》中),最初是为了缓解对异常值的缺乏鲁棒性的问题(在原始论文中,该算法仅设计用于曼哈顿度量标准),但后来设计了不同版本,以允许使用任何度量标准 (尤其是任意的闵可夫斯基指标)。 与 K 均值的主要区别在于质心的选择,在这种情况下,质心是始终属于数据集的示例性样本(称为中心点)。 该算法本身与标准 K 均值非常相似,并且替代了中心点的定义μ[i] = x[i] ∈X分配给聚类C[i]的所有其他样本的平均或总距离),然后将样本重新分配给具有最接近中心点的聚类。
容易理解的是,离群值不再具有较高的权重,因为与标准质心相反,离群值被选择为质心的可能性接近于零。 另一方面,当群集由无法归类为离群值的较远样本包围的密集斑点组成时,K 中心点表现较差。 在这种情况下,该算法会错误地分配这些样本,因为它无法生成可以捕获它们的虚拟球(请注意,半径是由质心/质心的相互位置隐式定义的)。 因此,尽管 K 均值可以将质心移动到非密集区域以捕获远点,但当密集的斑点包含许多点时,K 中心点不太可能以这种方式表现。
此外,K 中心点趋向于聚集高度重叠的斑点,斑点的密度具有两个峰值,而 K 均值通常根据手段的位置将整个区域分为两部分。 如果凸几何的假设成立,则通常会接受此行为,但是在其他情况下这可能是一个限制(我们将在示例中展示这种效果)。
最后一个基本差异是公制距离。 由于没有限制,所以 K 型药物或多或少具有攻击性。 正如我们在第 2 章,“聚类基本原理”中讨论的那样,最长的距离由曼哈顿度量标准提供(以相同的方式评估每个组件),而当p增加(以通用的闵可夫斯基度量),组件之间的最大差异成为主导。 K 均值基于最常见的权衡(欧几里德距离),但是在某些特殊情况下,较大的p可以带来更好的表现(比较p = 1与p > 1)。 例如,如果c[1] = (0, 0),c[2] = (2, 1)和x = (0.55, 1.25),曼哈顿距离d[1](x, c[1])和d[1](x, c[2])分别为 1.8 和 1.7,而欧几里得距离为 1.37 和 1.47。 因此,在p = 1的情况下,该点被分配给第二个群集,而在p = 2的情况下,该点被分配给第一个群集。
通常,预测正确的p值并不容易,但始终可以使用轮廓和调整后的 Rand 得分等方法测试几种配置,并选择产生更好分割效果的方法(即 ,最大内聚和分离度或更高的调整后的 Rand 得分)。 在我们的示例中,我们将生成一个也包含基本事实的数据集,因此我们可以使用后一个选项轻松评估表现。 因此,我们将使用函数make_blobs生成1000样本,这些样本在由[-5.0, 5.0] 界定的框中分成8个 blob,如下所示:
from sklearn.datasets import make_blobs
nb_samples = 1000
nb_clusters = 8
X, Y = make_blobs(n_samples=nb_samples, n_features=2, centers=nb_clusters,
cluster_std=1.2, center_box=[-5.0, 5.0], random_state=1000)
结果数据集呈现出一些强烈的重叠(如最终图所示),因此我们不希望使用对称方法获得高级结果,但是我们有兴趣比较 K 均值和 K 均值的赋值 。
让我们开始评估由 K 均值达到的调整后的兰德分数,如下:
from sklearn.cluster import KMeans
from sklearn.metrics import adjusted_rand_score
km = KMeans(n_clusters=nb_clusters, random_state=1000)
C_km = km.fit_predict(X)
print('Adjusted Rand score K-Means: {}'.format(adjusted_rand_score(Y, C_km)))
前一个块的输出如下:
Adjusted Rand score K-Means: 0.4589907163792297
这个值足以理解 K 均值在进行错误分配,尤其是在重叠区域中。 由于使用这种方法很难对数据集进行聚类,因此我们并不将这一结果视为真实的指标,而只是将其视为可以与 K 中心点得分进行比较的度量。 现在,我们使用带有p = 7的 Minkowski 度量来实现此算法(邀请读者更改此值并检查结果),如下所示:
import numpy as np
C = np.random.randint(0, nb_clusters, size=(X.shape[0], ), dtype=np.int32)
mu_idxs = np.zeros(shape=(nb_clusters, X.shape[1]))
metric = 'minkowski'
p = 7
tolerance = 0.001
mu_copy = np.ones_like(mu_idxs)
数组C包含分配,而mu_idxs则包含中心点。 由于存储整个中心点所需的空间量通常很小,因此我们首选此方法,而不是仅存储索引。 优化算法为,如下所示:
import numpy as np
from scipy.spatial.distance import pdist, cdist, squareform
from sklearn.metrics import adjusted_rand_score
while np.linalg.norm(mu_idxs - mu_copy) > tolerance:
for i in range(nb_clusters):
Di = squareform(pdist(X[C==i], metric=metric, p=p))
SDi = np.sum(Di, axis=1)
mu_copy[i] = mu_idxs[i].copy()
idx = np.argmin(SDi)
mu_idxs[i] = X[C==i][idx].copy()
C = np.argmin(cdist(X, mu_idxs, metric=metric, p=p), axis=1)
print('Adjusted Rand score K-Medoids: {}'.format(adjusted_rand_score(Y, C)))
行为非常简单。 在每次迭代中,我们都计算出属于一个群集的所有元素之间的成对距离(这实际上是最昂贵的部分),然后选择使总和最小的中心点。 循环后,我们通过最小化它们与类固醇的距离来分配样本。 重复该操作,直到类固醇的范数变化变得小于预定阈值为止。 调整后的 Rand 得分为,如下所示:
Adjusted Rand score K-Medoids: 0.4761670824763849
最终调整后的 Rand 分数受算法随机初始化的影响(因此,运行代码时,先前的结果可能会略有变化)。 在实际应用中,我建议根据最大迭代次数和较小的公差采用双重停止标准。
因此,即使没有解决重叠问题,其表现也比 K 均值稍好。 下面的屏幕快照显示了地面真相,K 均值和 K 质素结果:

真实情况(左),K 均值(中心)和 K 中心点(右)
如您所见,基本事实包含两个非常难以聚类的重叠区域。 在此特定示例中,我们对解决此问题不感兴趣,而是对展示两种方法的不同行为感兴趣。 如果考虑前两个 Blob(左上角),则 K 均值将整个区域分为两部分,而 K 均值将所有元素分配给同一群集。 在不知道基本事实的情况下,后一个结果可能比第一个更连贯。 实际上,观察第一张图,可能会发现密度差并不足以完全证明分裂的合理性(但是,在某些情况下这是合理的)。 由于该区域非常密集且与邻近区域分开,因此单个群集很可能是预期的结果。 此外,几乎不可能根据差异来区分样本(错误地分配了靠近分离线的大多数样本),因此,K 中心点的攻击性比 K 均值少,并且显示出更好的权衡性。 相反,两个算法几乎以相同的方式管理第二个重叠区域(右下)。 这是由于以下事实:K 均值将质心放置在非常接近某些实际样本的位置。 在这两种情况下,算法需要在 0 和 4 之间创建几乎水平的间隔,因为否则无法分割区域。 这种行为是所有基于标准球的方法所共有的,在这种特殊情况下,这是极其复杂的几何体的正常结果(许多相邻点具有不同的标签)。 因此,我们可以通过说 K 中心点对异常值更健壮,并通过避免不必要的分离而有时比 K 均值更好地表现出结论。 另一方面,在非常密集的区域中没有异常值时,这两种算法(尤其是采用相同度量时)是等效的。 作为练习,我邀请读者使用其他指标(包括余弦距离)并比较结果。
在线聚类
有时,数据集太大而无法容纳在内存中,或者样本通过通道流式传输并在不同的时间步长接收。 在这种情况下,不能使用前面讨论的算法,因为自第一步以来,它们就假定要访问整个数据集。 由于这个原因,已经提出了一些在线替代方案,并且当前它们已在许多现实生活中实现。
小批量 K 均值
该算法是标准 K 均值的扩展,但是,由于不能对所有样本都计算质心,因此有必要包括一个额外的步骤,当现有聚类不再有效时,该步骤负责重新分配样本。 特别是,小批量 K 均值代替了计算均值的方法,可以处理流平均值。 收到批量后,该算法将计算部分均值并确定质心的位置。 但是,并非所有集群都具有相同数量的分配,因此算法必须决定是等待还是重新分配样本。
通过考虑效率非常低的流处理过程,可以立即理解该概念,该过程开始发送属于半空间的所有样本,并且仅包括属于互补半空间的几个点。 由于群集的数量是固定的,因此该算法将开始优化质心,同时仅考虑一个子区域。 假设质心已放置在球的中心,该球围绕着属于互补子空间的几个样本。 如果越来越多的批量继续向密集区域添加点,则算法可以合理地决定丢弃孤立的质心并重新分配样本。 但是,如果进程开始发送属于互补半空间的点,则该算法必须准备好将它们分配给最合适的聚类(也就是说,它必须将其他质心放置在空白区域中)。
该方法通常基于称为重分配比α的参数。 当 α较小时,该算法将等待更长的时间才能重新分配样本,而较大的值会加快此过程。 当然,我们要避免两种极端情况。 换句话说,我们需要避免过于静态的算法在做出决定之前需要大量样本,同时又需要避免过于快速变化的算法来在每次批量后重新分配样本。 通常,第一种情况产生的次优解决方案具有较低的计算成本,而后一种情况可能变得非常类似于每次批量后重新应用于流数据集的标准 K 均值。 考虑到通常与实时过程有关的这种情况,我们通常对需要高计算成本的极其精确的解决方案不感兴趣,而对在收集新数据时得到改进的良好近似值不感兴趣。
但是,必须考虑每个单个上下文来评估重新分配比率的选择,包括合理地预定义流传输过程(例如,它是纯随机的吗?样本是否独立?某些样本在特定时间内是否更频繁) -帧?)。 同样,必须群集的数据量(即批量大小,这是一个非常重要的因素),当然还有可以配置的硬件。 通常,有可能证明小批 K 均值产生的结果可与标准 K 均值相媲美,并且批大小不是太小时具有较低的内存需求和较高的计算复杂性(但这通常不是可控的超参数,因为它取决于外部资源),并相应地选择重新分配比率。
相反,如果从真实数据生成过程中对批量进行均匀采样,则重新分配比率将成为次要参数,并且其影响会更低。 实际上,在这些情况下,批量大小通常是获得良好结果的主要影响因素。 如果足够大,该算法可立即确定质心的最可能位置,并且后续批量无法显着更改此配置(因此减少了对连续重新分配的需求)。 当然,在在线情况下,很难确定数据生成过程的结构,因此通常只能假设一批(如果不是太小)包含每个独特区域的足够代表。 数据科学家的主要任务是通过收集足够的样本以执行完整的 K 均值并将表现与小批量版本进行比较来验证该假设。 观察到批量量较小的最终结果(具有相同的重新分配比率)更好的方案也就不足为奇了。 通过考虑该算法不会立即重新分配样本可以理解这种现象。 因此,有时,较大的批量可能导致错误的配置,但是该配置具有更多的代表,因此重新分配的可能性较低(也就是说,算法更快但准确率更低)。 相反,在相同情况下,由于频繁的重新分配(具有更精确的最终配置),较小的批量可能会迫使算法执行更多的迭代。 由于定义通用的经验法则并不容易,因此一般建议是在做出决定之前检查不同的值。
CF 树
该算法(其名称代表使用层次结构的平衡迭代归约和聚类)具有比小批量 K 均值稍微复杂的动态特性,最后一部分采用了一种方法(层次聚类) 我们将在第 4 章,“层次结构聚类”中进行介绍。 然而,出于我们的目的,最重要的部分涉及数据准备阶段,该阶段基于称为群集特征树的特定树结构(CF 树)。 给定数据集X,树的每个节点都由三个元素的元组组成:
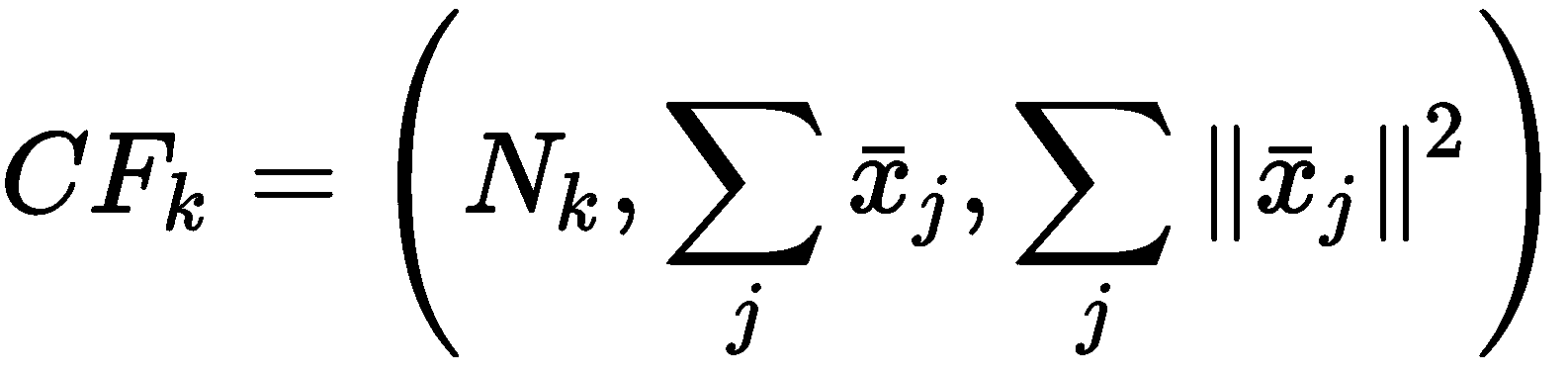
特征元素分别是属于一个节点的样本数,所有样本的总和以及平方范数的总和。 做出此选择的原因将立即清楚,但让我们现在将注意力集中在树的结构上,以及在尝试平衡高度时如何插入新元素。 在下图中,有一个 CF 树的通用表示形式,其中所有终端节点都是必须合并的实际子集群,以获得所需数量的集群:
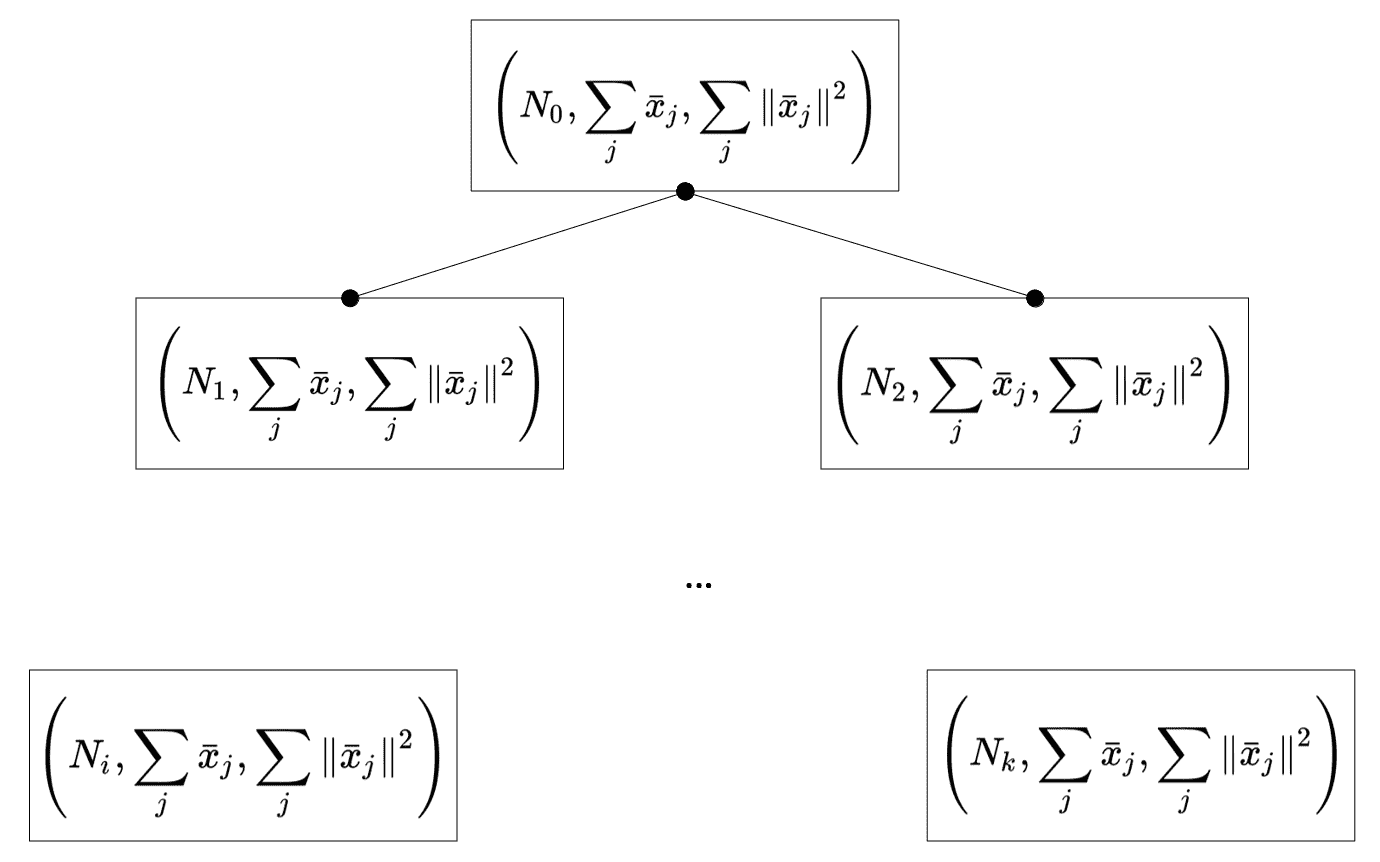
具有二元分区的简单 CF-Tree 的示例
在上图中,点代表指向子节点的指针。 因此,每个非终端节点都与指向其所有子节点的指针(CF[i], p[i])一起存储,而终端节点是纯 CF。 为了讨论插入策略,必须考虑另外两个元素。 第一个称为分支因子B,而第二个称为阈值T。 此外,每个非终端节点最多可以包含B个元组。 通过减少存储的数据量和计算数量,设计了此策略,以最大程度地提高仅依赖于主内存的流处理过程的性能。
现在考虑需要插入的新样本x[i]。 很容易理解CF[j]的质心(n[j], a[j], b[j])只是μ[j] = a[j]/n[j]; 因此,x[i]沿着树传播,因为它到达了末端 CF(子集群),在此处距离d(x[i], μ[j])是最小值。 到那时,CF 会逐步更新:
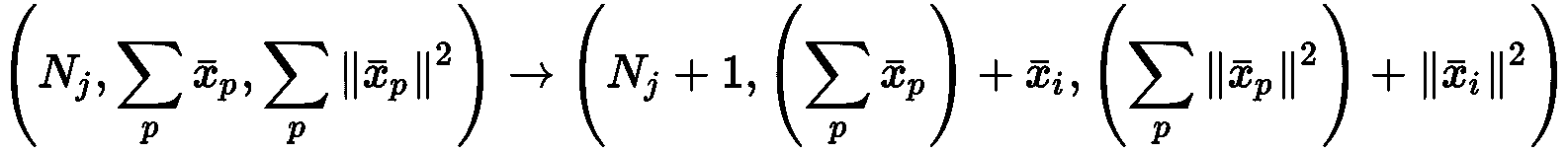
但是,如果没有控制权,则树很容易变得不平衡,从而导致表现损失。 因此,该算法执行一个附加步骤。 一旦确定了 CF,就计算更新后的半径r[j],以及是否r[j] > T并且 CF 的数量大于分支因子,分配新的块并且原始的 CF 保持不变。 由于这个新块几乎完全是空的(x[i]除外),BIRCH 会执行一个附加步骤来检查所有子集群之间的差异(此概念在第 4 章中会更清楚 , “实用的层次聚类”;但是,读者可以考虑属于两个不同子类的点之间的平均距离)。 最不相似的一对分为两部分,其中之一移到新块中。 这样的选择确保了子群集的高度紧凑性,并加快了最终步骤。 实际上,实际聚类阶段中涉及的算法需要合并子聚类,直到总数减少到所需值为止。 因此,如果先前已将总不相似性最小化,则更容易执行此操作,因为段可以立即识别为连续并合并。 在本章中将不详细讨论此阶段,但不难想象。 将所有终端 CF 依次合并到较大的块中,直到确定单个群集为止(即使当数量与所需群集数目匹配时也可以停止该过程)。 因此,与小批量 K 均值相反,此方法可以轻松管理大量群集n[c],而当n[c]很小时效果不佳。 实际上,正如我们在示例中将要看到的那样,其准确率通常比使用小批量 K 均值所能达到的精度低,并且其最佳用法要求准确选择分支因子和阈值。 由于此算法的主要目的是在在线情况下工作,因此B和T在处理了某些批量后可能会失效(而小批量 K 均值通常可以在几次迭代后纠正群集),产生次优的结果。 因此,BIRCH 的主要用例是需要非常细粒度细分的在线过程,而在所有其他情况下,通常最好选择小批量 K 均值作为初始选项。
小批量 K 均值和 BIRCH 的比较
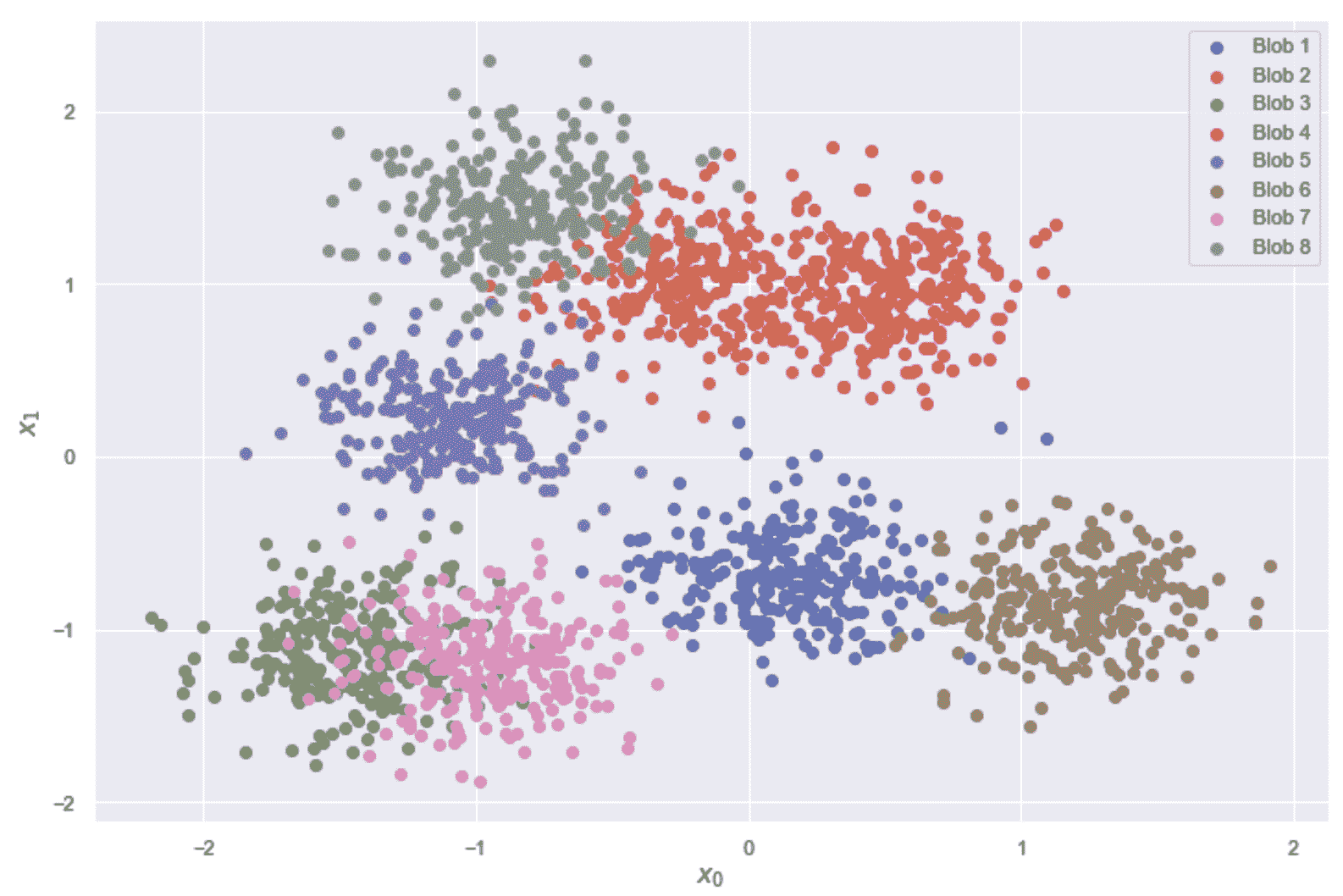
在此示例中,我们想将这两种算法的表现与包含 2,000 个样本的二维数据集进行比较,该样本分为8个 blob(出于分析目的,我们也使用了基本事实),如下所示 :
from sklearn.datasets import make_blobs
nb_clusters = 8
nb_samples = 2000
X, Y = make_blobs(n_samples=nb_samples, n_features=2, centers=nb_clusters,
cluster_std=0.25, center_box=[-1.5, 1.5], shuffle=True, random_state=100)
下面的屏幕快照显示了数据集(已被改组以除去流传输过程中的任何相互关系):
二维数据集,用于比较小批量 K 均值和 BIRCH
在执行在线聚类之前,评估标准 K 均值的调整后的兰德得分非常有用,如下所示:
from sklearn.cluster import KMeans
km = KMeans(n_clusters=nb_clusters, random_state=1000)
Y_pred_km = km.fit_predict(X)
print('Adjusted Rand score: {}'.format(adjusted_rand_score(Y, Y_pred_km)))
前一个块的输出为,如下所示:
Adjusted Rand score: 0.8232109771787882
考虑到数据集的结构(没有凹面),我们可以合理地假设此值代表在线过程的基准。 现在,我们可以实例化类MiniBatchKMeans和Birch,其参数分别等于reassignment_ratio=0.001,threshold=0.2和branching_factor=350。 这些值是经过研究后选择的,但我邀请读者重复使用不同配置的示例,比较结果。 在这两种情况下,我们都假设批量大小等于50样本,如下所示:
from sklearn.cluster import MiniBatchKMeans, Birch
batch_size = 50
mbkm = MiniBatchKMeans(n_clusters=nb_clusters, batch_size=batch_size, reassignment_ratio=0.001, random_state=1000)
birch = Birch(n_clusters=nb_clusters, threshold=0.2, branching_factor=350)
该示例的目标是现在采用方法partial_fit()逐步训练两个模型,并考虑到每个步骤之前处理的全部数据,评估调整后的兰德得分,如下所示:
from sklearn.metrics import adjusted_rand_score
scores_mbkm = []
scores_birch = []
for i in range(0, nb_samples, batch_size):
X_batch, Y_batch = X[i:i+batch_size], Y[i:i+batch_size]
mbkm.partial_fit(X_batch)
birch.partial_fit(X_batch)
scores_mbkm.append(adjusted_rand_score(Y[:i+batch_size], mbkm.predict(X[:i+batch_size])))
scores_birch.append(adjusted_rand_score(Y[:i+batch_size], birch.predict(X[:i+batch_size])))
print('Adjusted Rand score Mini-Batch K-Means: {}'.format(adjusted_rand_score(Y, Y_pred_mbkm)))
print('Adjusted Rand score BIRCH: {}'.format(adjusted_rand_score(Y, Y_pred_birch)))
前一个代码片段的输出包含整个数据集的调整后的 Rand 分数:
Adjusted Rand score Mini-Batch K-Means: 0.814244790452388
Adjusted Rand score BIRCH: 0.767304858161472
不出所料,当处理完所有样本后,小批量 K 均值几乎达到基准,而 BIRCH 表现稍差。 为了更好地理解行为,让我们考虑将增量分数作为批量函数的图表,如下图所示:
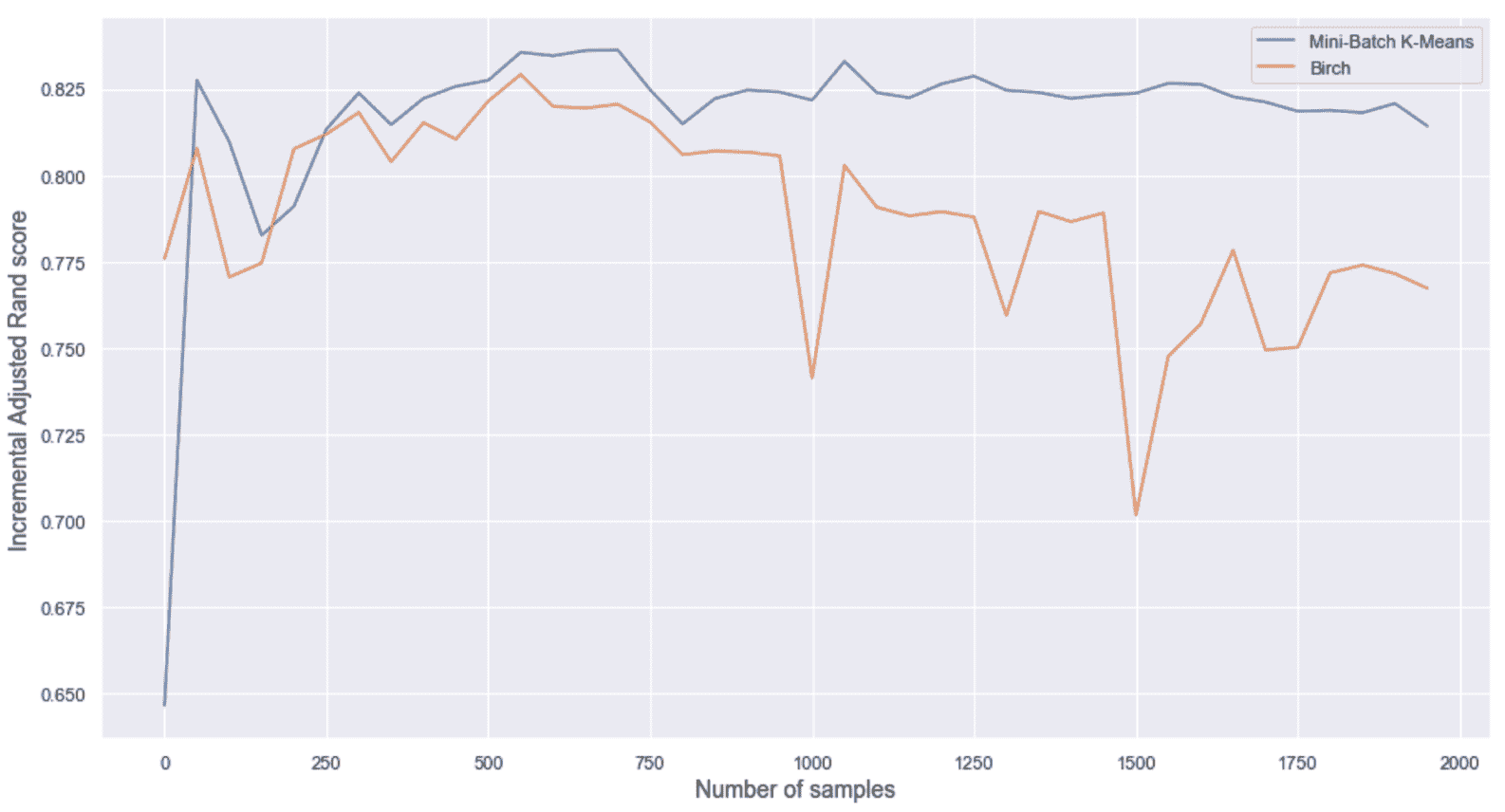
调整后的兰德评分增量作为批次(样本数量)的函数
如您所见,小批量 K 均值很快就达到最大值,所有随后的振荡都是由于重新分配。 相反,BIRCH 的表现总是较差,且呈负趋势。 出现这种差异的主要原因是由于策略不同。 实际上,小批量 K 均值可以在几次批量后纠正质心的初始猜测,并且重新分配不会显着改变配置。 另一方面,BIRCH 执行的合并数受样本数影响。
刚开始时,表现不是很相似,因为 CF 树中的子群集的数量不是很大(因此,聚合更多相干),但是经过几批之后,BIRCH 必须聚合越来越多的子群集来获得所需的最终群集数。 这种情况以及越来越多的流样本数量驱使算法重新排列树,这常常导致稳定性的损失。 此外,数据集有一些重叠,可以通过对称方法更轻松地进行管理(实际上,即使分配错误,质心在这种情况下也可以到达其最终位置),而采用分层方法(例如 BIRCH 所采用的方法更能够找到所有子区域,但是在合并具有最小间距甚至更糟的重叠的子类时,更容易出错。 但是,此示例确认,通常首选小批量 K 均值作为首选,并且仅在表现不符合预期时(应谨慎选择其参数)才应选择 BIRCH。 我邀请读者使用更多所需的群集(例如nb_clusters=20和center_box=[-10.5, 10.5])重复该示例。 可能会看到在这种情况下(保持所有其他参数不变),由小批量 K 均值执行的重新分配如何以较差的最终调整后的 Rand 分数减慢了收敛速度,而 BIRCH 立即达到了最佳值(几乎相等) 到通过标准 K 均值获得的结果),并且不再受样本数量的影响。
总结
在本章中,我们介绍了一些最重要的聚类算法,这些算法可用于解决非凸问题。 频谱聚类是一种非常流行的技术,它可以将数据集投影到一个新的空间上,在该空间上,凹形几何形状变为凸形,而标准算法(例如 K 均值)可以轻松地对数据进行分段。
相反,均值漂移和 DBSCAN 分析数据集的密度并尝试对其进行拆分,以使所有密集区域和连通区域合并在一起以构成聚类。 特别是,DBSCAN 在非常不规则的情况下非常有效,因为它基于连接的本地最近邻集,直到分离度超过预定义的阈值为止。 这样,该算法可以解决许多特定的聚类问题,唯一的缺点是,它还会产生无法自动分配给现有聚类的一组噪声点。 在基于旷工的数据集的示例中,我们展示了如何选择超参数,以便以最少的噪声点和可接受的轮廓或 Calinski-Harabasz 分数获得所需数量的聚类。
在最后一部分中,我们分析了 K 中心点作为 K 均值的替代方法,它对于异常值也更可靠。 该算法不能用于解决非凸问题,但是它有时比 K 均值更有效,因为它没有选择实际的均值作为质心,而是仅依赖于数据集,并且聚类中心(称为中心点)是示例性样本。 而且,该算法不严格地局限于欧几里得度量,因此,它可以充分利用替代距离函数的潜力。 最后一个主题涉及两种在线聚类算法(小批量 K 均值和 BIRCH),当数据集太大而无法放入内存或长时间流传输数据时,可以使用这些算法。
在下一章中,我们将分析一个非常重要的聚类算法系列,它们可以输出完整的层次结构,从而使我们能够观察到完整的聚合过程,并选择最有用和最一致的最终配置。
问题
- 半月形的数据集是凸群集吗?
- 二维数据集由两个半月组成。 第二个完全包含在第一个的凹腔中。 哪种内核可以轻松地将两个群集分离(使用谱群集)?
- 应用
ε = 1.0的 DBSCAN 算法后,我们发现噪点太多。 对于ε = 0.1,我们应该期待什么? - K 中心点基于欧几里得度量。 它是否正确?
- DBSCAN 对数据集的几何非常敏感。 它是否正确?
- 数据集包含 10,000,000 个样本,可以使用 K 均值在大型计算机上轻松进行聚类。 相反,我们可以使用更小的机器和小批量的 K 均值吗?
- 群集的标准差等于 1.0。 施加噪声
N(0, 0.005)后,80% 的原始分配被更改。 我们可以说这样的集群配置通常是稳定的吗?
进一步阅读
Normalized Cuts and Image Segmentation, J. Shi and J. Malik, IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 22, 08/2000A Tutorial on Spectral Clustering, Von Luxburg U., 2007Functions and Graphs Vol. 2, Gelfand I. M., Glagoleva E. G., Shnol E. E., The MIT Press, 1969On Estimation of a Probability Density Function and Mode, Parzen E., The Annals of Mathematical Statistics, 33, 1962Application of a neuro fuzzy network in prediction of absenteeism at work, Martiniano A., Ferreira R. P., Sassi R. J., Affonso C., in Information Systems and Technologies (CISTI), 7th Iberian Conference on (pp. 1-4). IEEE, 2012A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise, Ester M., Kriegel H. P., Sander J., Xu X., Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining, Portland, OR, AAAI Press, 1996Machine Learning Algorithms, Second Edition, Bonaccorso G., Packt Publishing, 2018Cluster stability: an overview,Von Luxburg U., arXiv 1007:1075v1, 2010Clustering by means of Medoids, Kaufman L., Rousseeuw P.J., in Statistical Data Analysis Based on the L1–Norm and Related Methods, North-Holland, 1987
四、实用的层次聚类
在本章中,我们将讨论层次聚类的概念,层次聚类是一种强大而广泛的技术,用于生成完整的聚类配置层次,从与数据集等效的单个群集(除法)开始,或者等于样本数量(凝聚法)的多个群集。 当需要立即分析整个分组过程以了解例如如何将较小的群集合并为较大的群集时,此方法特别有用。
特别是,我们将讨论以下主题:
- 层次聚类策略(分裂式和凝聚式)
- 距离度量和链接方法
- 树状图及其解释
- 凝聚聚类
- 作为一种表现指标的 Cophenetic 相关性
- 连通性约束
技术要求
本章中提供的代码要求以下内容:
- Python3.5+(强烈建议使用 Anaconda 发行版)
- 库:
- SciPy 0.19+
- NumPy 1.10+
- Scikit-Learn 0.20+
- Pandas 0.22+
- Matplotlib 2.0+
- Seaborn 0.9+
数据集可以从 UCI 机器学习存储库中获得。 可以从这里下载 CSV 文件,除了添加列名外,不需要任何预处理。 ,这将在加载阶段发生。
可以在 GitHub 存储库上找到示例。
层次聚类
在前面的章节中,我们分析了聚类算法,其中 , 输出是基于预定义数量的聚类或参数集结果和精确的基础几何结构的单个分割。 另一方面,层次聚类生成一系列聚类配置,这些聚类配置可以排列在树的结构中。 具体来说,让我们假设有一个数据集X,其中包含n个样本:
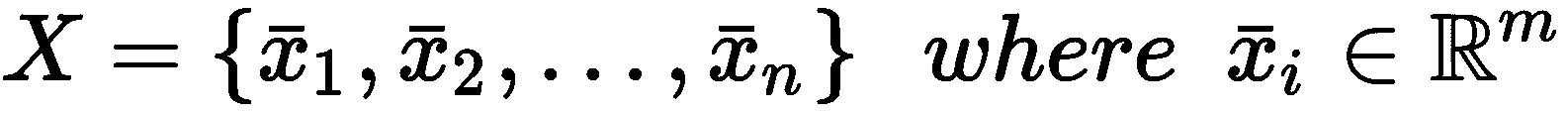
凝聚方法是通过将每个样本分配到一个集群C[i]开始的,然后通过在每个步骤合并两个集群直到单个最终集群(对应于X)已产生:
在前面的示例中,群集C[i]和C[j]合并为C[k]; 因此,我们在第二步中获得n-1个群集。 该过程继续进行,直到剩下的两个群集合并为一个包含整个数据集的单个块。 相反,分裂方法(由 Kaufman 和 Roussew 最初提出,使用 DIANA 算法)在相反的方向上操作,从X开始,最后每个群集包含单个样本:
在这两种情况下,结果都是层次结构的形式,其中每个级别都是通过在上一个级别上执行合并或拆分操作来获得的。 复杂度是这两种方法之间的主要区别,因为分裂聚类的复杂度更高。 实际上,合并/拆分决定是通过考虑所有可能的组合并通过选择最合适的组合(根据特定标准)来做出的。 例如,在比较第一步时,很明显(在团聚的情况下)找到最合适的几个样本要比考虑所有可能的组合(在X中, 分裂情形),这需要指数级的复杂性。
由于最终结果几乎相同,而除法算法的计算复杂度要高得多,因此,一般而言,没有特别的理由偏爱这种方法。 因此,在本书中,我们将仅讨论凝聚聚类(假设所有概念都可立即应用于除法算法)。 我鼓励您始终考虑整个层次结构,即使需要大多数实现(例如 scikit-learn)来指定所需的集群数量。 实际上,在实际的应用中,最好是在达到目标后停止该过程,而不是计算整个树。 但是,此步骤是分析阶段的重要组成部分(尤其是在没有很好定义群集数的情况下),我们将演示如何可视化树并针对每个特定问题做出最合理的决策。
凝聚聚类
从其他算法中可以看出,为了执行聚合,我们需要先定义一个距离度量,该度量代表样本之间的不相似性。 我们已经分析了其中许多,但在这种情况下,开始考虑通用闵可夫斯基距离(用p参数化)会有所帮助:
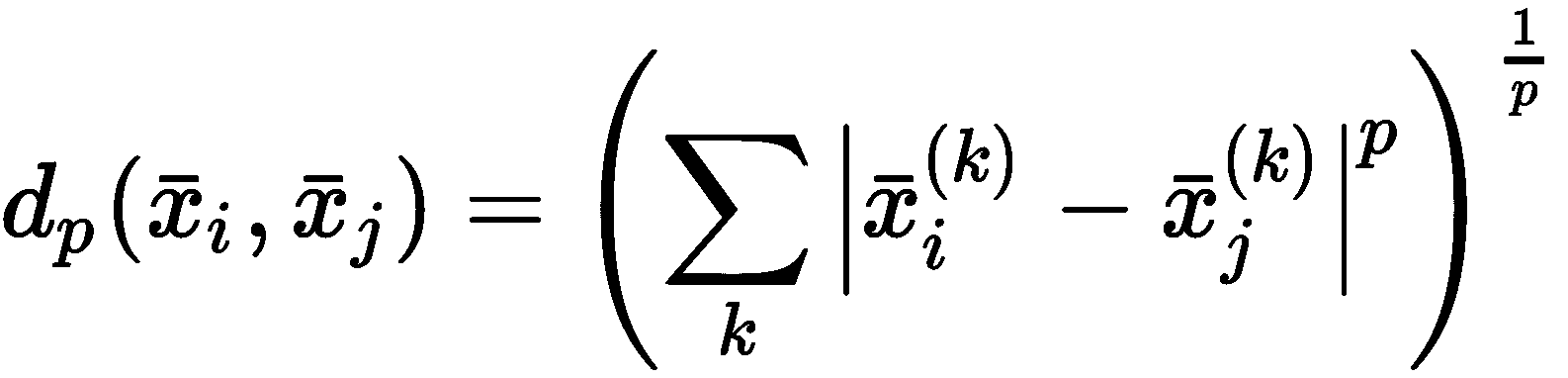
两个特定情况对应于p = 2和p = 1。 在前一种情况下,当p = 2时,我们获得标准欧几里德距离(等于L[2]范数):
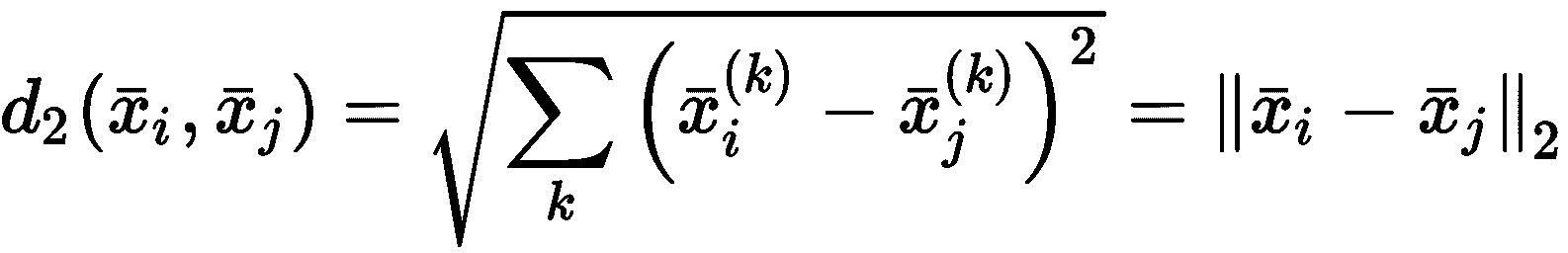
当p = 1时,我们获得曼哈顿或城市街区距离(等于L[1]范数 ):
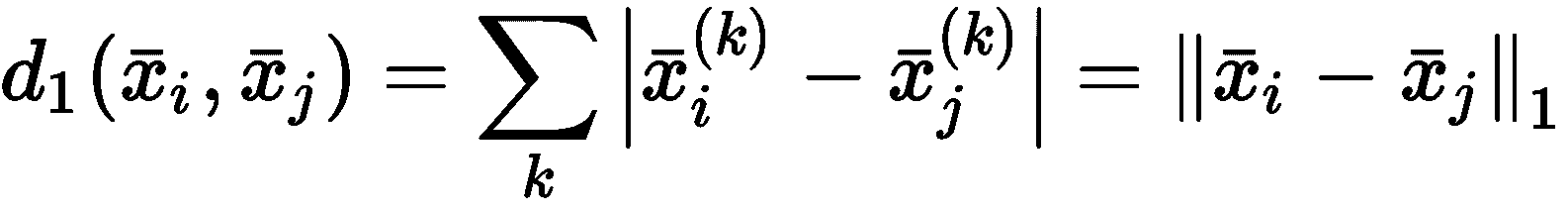
这些距离之间的主要差异在第 2 章,“聚类基础知识”中进行了讨论。 在本章中,介绍余弦距离很有用,这不是一个合适的距离度量(从数学角度来看),但是当样本之间的区分必须仅取决于他们形成的角度时,这将非常有帮助:
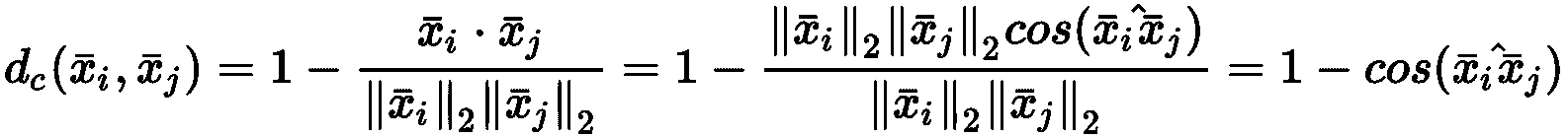
余弦距离的应用非常特殊(例如自然语言处理(NLP)),因此,这不是一个常见的选择。 但是,我建议您使用一些样本向量(例如(0, 1), (1, 0)和(0.5, 0.5),因为它可以解决许多现实生活中的问题(例如,在 word2vec 中,可以通过检查它们的余弦相似度来轻松评估两个单词的相似度)。一旦定义了距离度量,定义邻接矩阵,P:
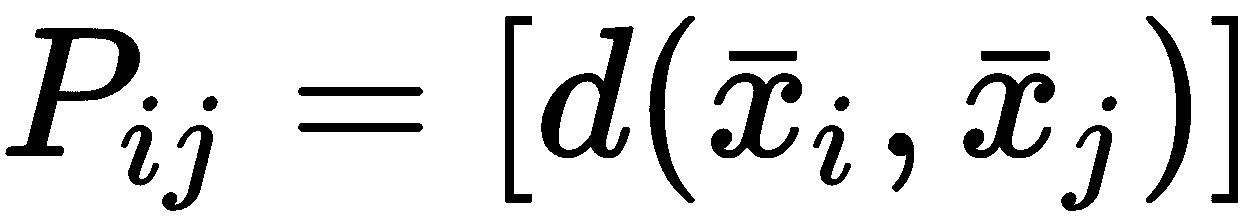
P是对称的,所有对角元素均为空。 因此,某些应用(例如 SciPy 的pdist函数)会产生一个压缩矩阵P[c],这是一个仅包含矩阵上三角部分的向量P[c]的第ij元素对应于d(x[i], x[j])。
下一步是定义合并策略,在这种情况下,该策略称为链接。 链接方法的目标是找出必须在层次结构的每个级别合并为单个群集的群集。 因此,它必须与代表群集的通用样本集一起使用。 在这种情况下,假设我们正在分析几个群集(c[a], c[b]),并且我们需要找到哪个索引a或b对应于将要合并的对。
单一和完整的联系
最简单的方法称为单个和完整链接,它们的定义如下:
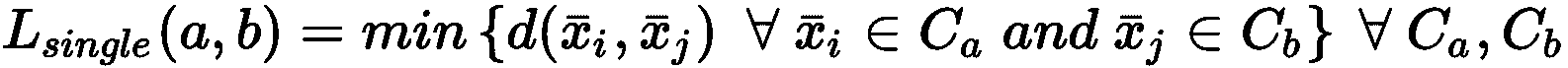
单链接方法选择包含最接近的样本对的样本对(每个样本属于不同的群集)。 下图显示了此过程,其中选择了C1和C2进行合并:
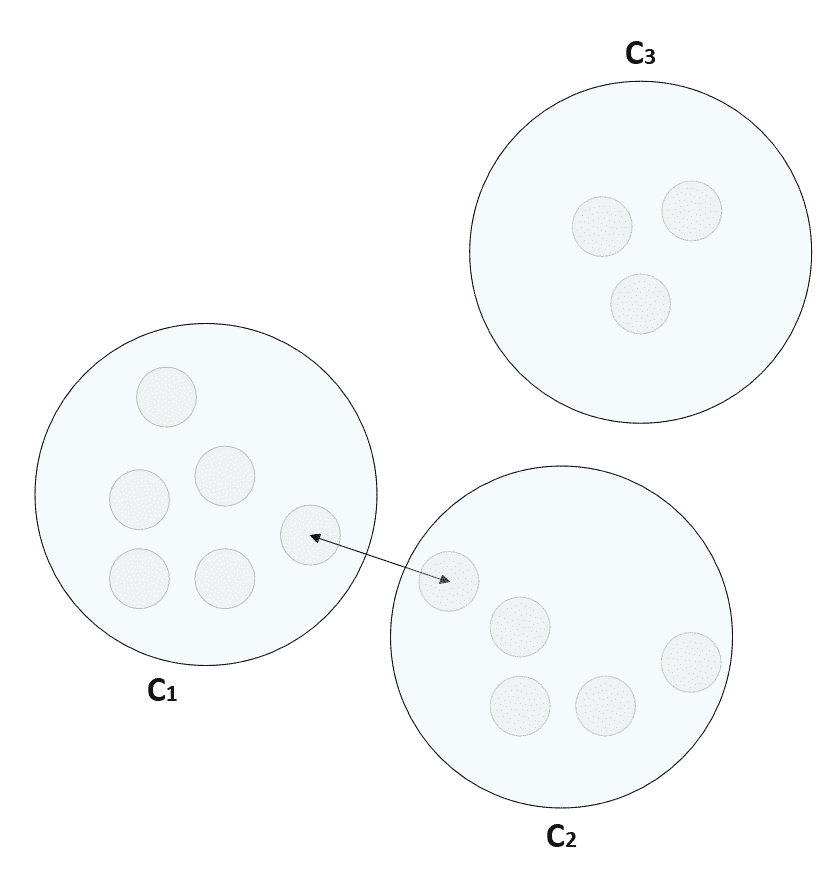
单链接的例子。 选择C[1]和C[2]来合并
这种方法的主要缺点是可能同时具有很小的群集和很大的群集。 正如我们将在下一部分中看到的那样,单个链接可以使离群值保持隔离,直到存在非常高的相异度级别为止。 为了避免或减轻该问题,可以使用平均值和沃德方法。
相反,完全链接定义为:

这种链接方法的目的是使属于合并群集的最远样本之间的距离最小。 在下图中,有一个完整链接的示例,其中已选择C[1]和C[3]:
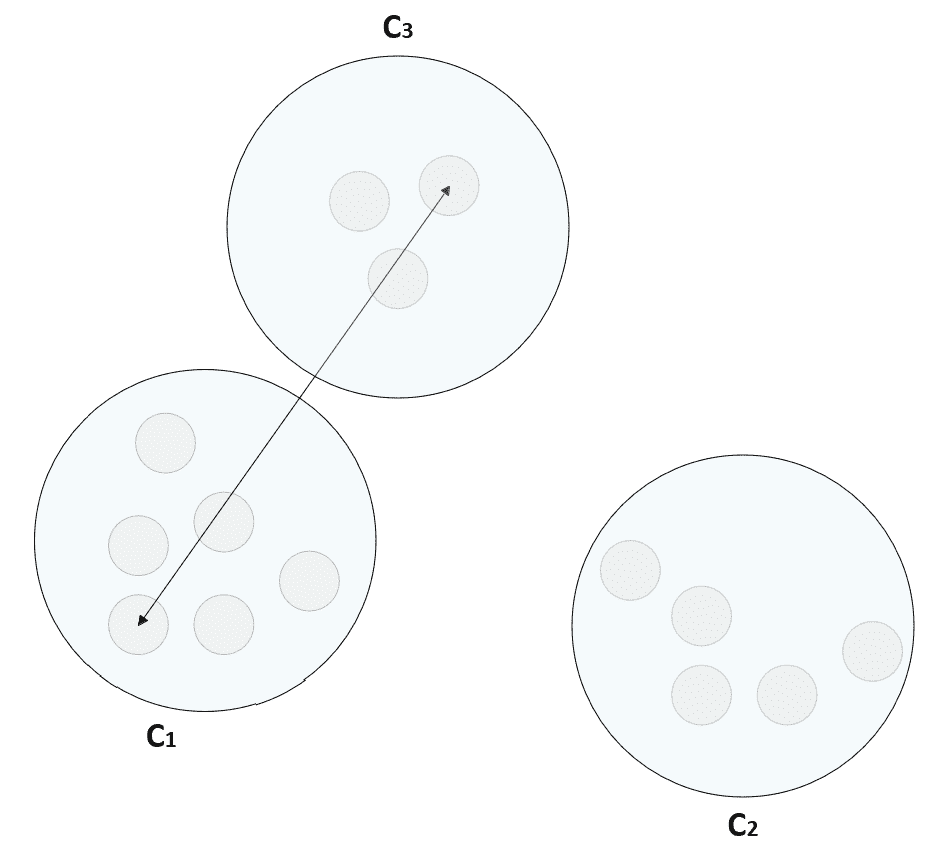
完全链接的示例。 选择C[1]和C[3]进行合并
该算法选择C[1]和C[3]为了增加内部凝聚力。 实际上,很容易理解,考虑所有可能的组合,完全链接会导致群集密度最大化。 在上图所示的示例中,如果所需的群集数为两个,则合并C[1]和C[2]或C[2]和C[3]会产生具有较小内聚的最终构型,这通常是不希望的结果。
平均链接
另一种常见的方法称为平均链接(或非加权组平均法(UPGMA))。 定义如下:
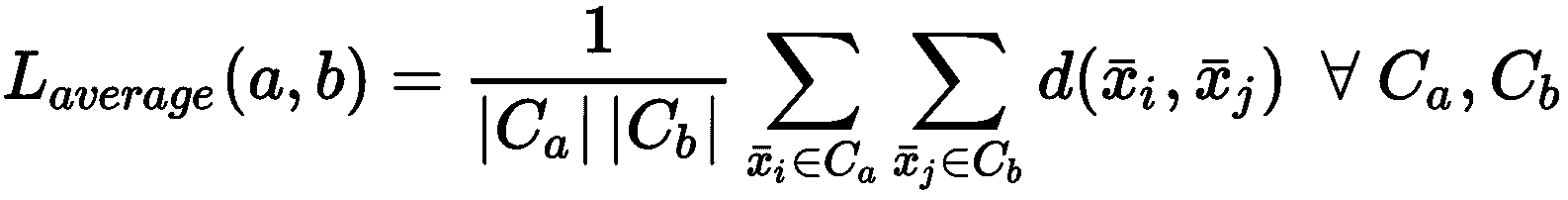
这个想法与完全链接非常相似,但是在这种情况下,考虑每个群集的平均值,并且目标是考虑所有可能的对(c[a], c[b])。 下图显示了平均链接的示例:
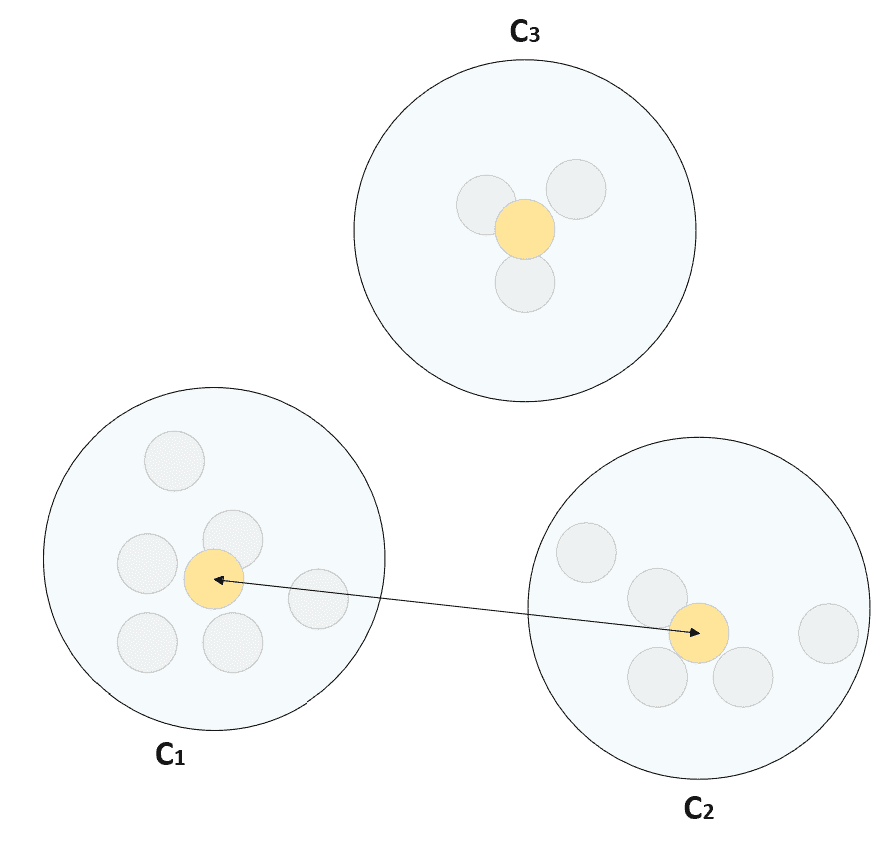
平均链接的示例。 选择C[1]和C[2]进行合并。 突出显示的点是平均值。
平均链接在生物信息学应用(定义层次聚类的主要环境)中特别有用。 对其属性的数学解释是不平凡的,我鼓励您查看原始论文(《一种评估系统关系的统计方法》),以获取更多详细信息。
Ward 链接
我们要讨论的最后一种方法称为 Ward 链接(以其作者命名,最初是在《用于优化目标函数的分层分组过程》中提出的。 它基于欧几里得距离,其正式定义如下:
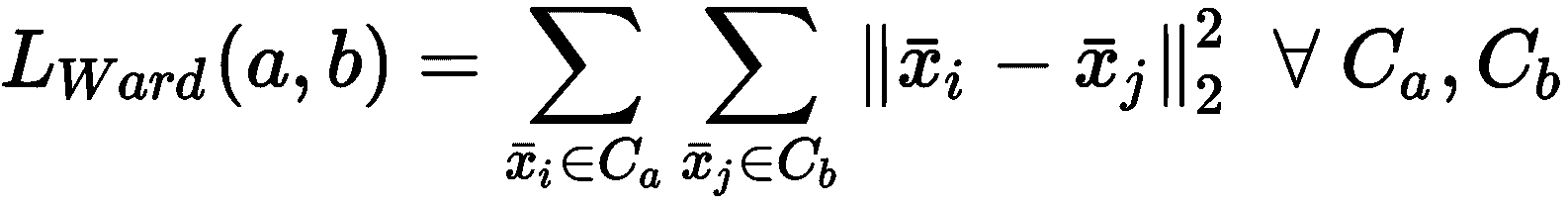
在每个级别上,都要考虑所有聚类,并选择其中两个聚类,以最小化平方距离的总和。 该过程本身与平均链接没有太大不同,并且有可能证明合并过程会导致集群方差的减少(即,增加其内部凝聚力)。 而且,沃德的联系倾向于产生包含大约相同数量样本的群集(也就是说,与单联系相比,沃德的方法避免了小群集和非常大的群集的存在,如下一节所述)。 Ward 的链接是一种流行的默认选择,但是,为了在每种特定情况下做出正确的选择,有必要引入树状图的概念。
分析树状图
树状图是一种树数据结构,它使我们能够表示由凝聚算法或分裂算法产生的整个聚类层次结构。 想法是将样本放置在x轴上,而相异度放置在y轴上。 每当两个聚类合并时,树状图就会显示与其发生的相异程度相对应的连接。 因此,在聚集情况下,树状图始终以所有被视为群集的样本开始,然后向上移动(方向完全是常规的),直到定义了一个群集。
出于教学目的,最好显示与非常小的数据集X相对应的树状图,但是我们将要讨论的所有概念都可以应用于任何情况。 但是,对于较大的数据集,通常需要应用一些截断法以更紧凑的形式可视化整个结构。
让我们考虑一个小的数据集X,它由4高斯分布生成的12二维样本组成,平均向量的范围为(01, 1) × (-1, 1):
from sklearn.datasets import make_blobs
nb_samples = 12
nb_centers = 4
X, Y = make_blobs(n_samples=nb_samples, n_features=2, center_box=[-1, 1], centers=nb_centers, random_state=1000)
数据集(带有标签)显示在以下屏幕截图中:
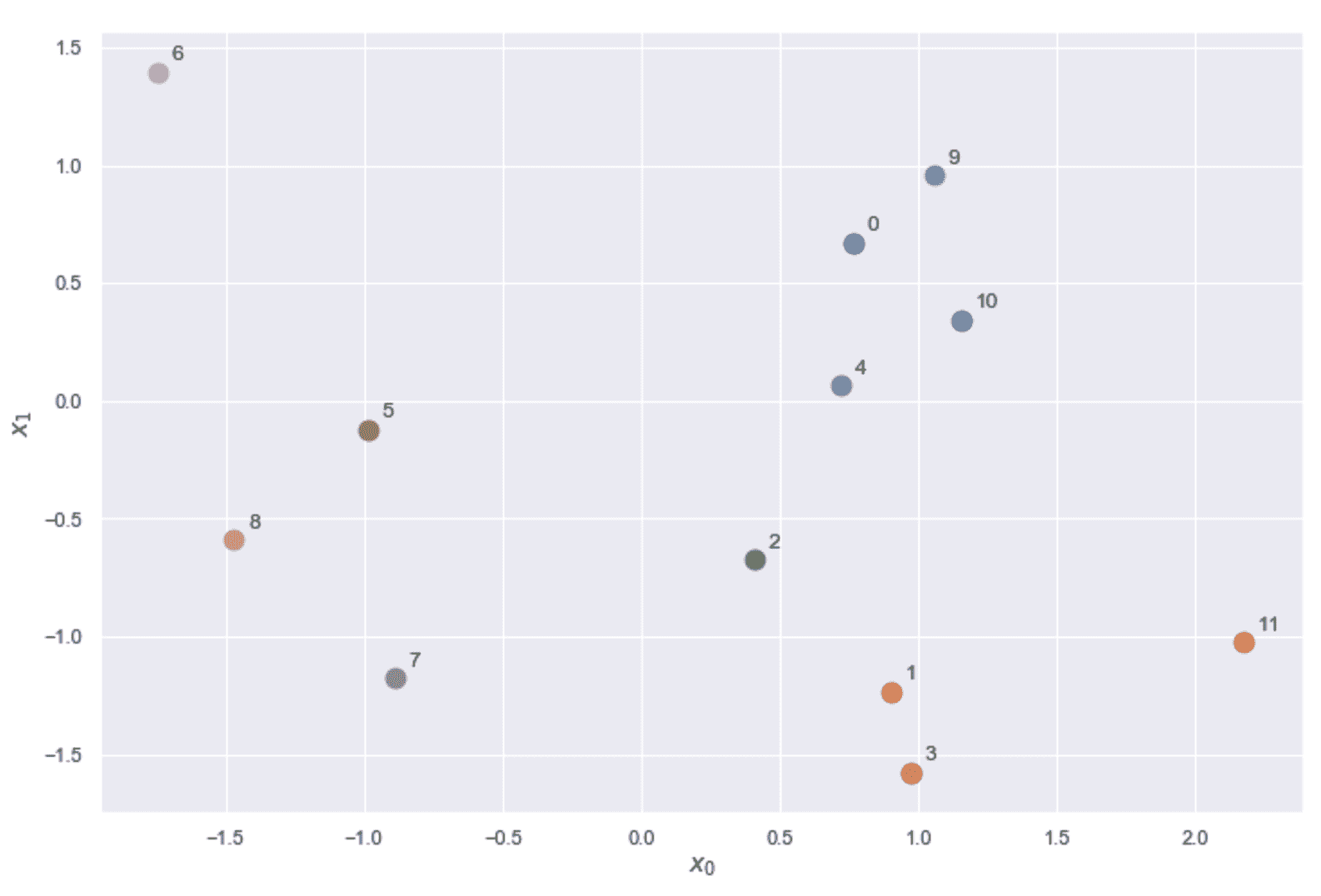
用于树状图分析的数据集
为了生成树状图(使用 SciPy),我们首先需要创建一个链接矩阵。 在这种情况下,我们选择了具有 Ward 链接的欧几里德度量标准(但是,与往常一样,我建议您使用不同的配置执行分析):
from scipy.spatial.distance import pdist
from scipy.cluster.hierarchy import linkage
dm = pdist(X, metric='euclidean')
Z = linkage(dm, method='ward')
dm数组是一个压缩的成对距离矩阵,而Z是通过沃德方法生成的链接矩阵(linkage()函数需要method参数,该参数除其他外接受single,complete,average和ward)。 此时,我们可以生成并绘制树状图(dendrogram() 函数可以使用默认或提供的 Matplotlib axis对象自动绘制图):
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram
fig, ax = plt.subplots(figsize=(12, 8))
d = dendrogram(Z, show_leaf_counts=True, leaf_font_size=14, ax=ax)
ax.set_xlabel('Samples', fontsize=14)
ax.set_yticks(np.arange(0, 6, 0.25))
plt.show()
该图显示在以下屏幕截图中:
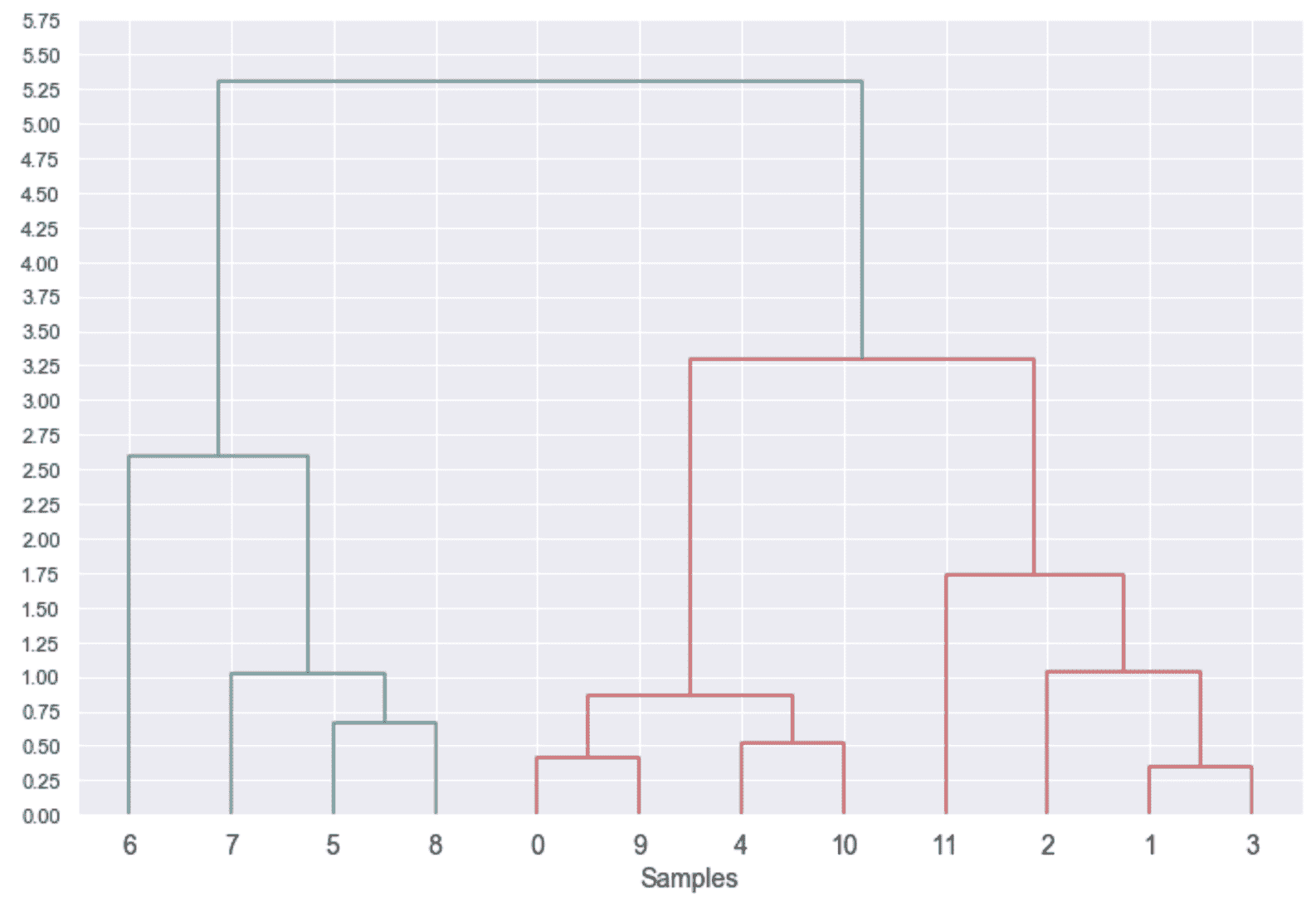
应用于数据集的对应 Ward 链接的树状图
如前面的屏幕快照中所述,x轴表示旨在最大程度降低交叉连接风险的样本,而y轴表示相异程度。 现在让我们从底部开始分析图。 初始状态对应于被视为独立聚类的所有样本(因此相异性为空)。 向上移动,我们开始观察第一次合并。 特别地,当相异度约为 0.35 时,样本 1 和 3 被合并。
当样本 0 和 9 也合并时,第二步发生的差异略小于 0.5。 创建单个群集时,该过程一直持续到相异度约为 5.25。 现在,当相差等于 1.25 时,水平剖析树状图。 查看基础连接,我们发现聚类结构为:{6}, {7, 5, 8}, {0, 9, 4, 10}, {11}, {2 , 1, 3}。
因此,我们有五个聚类,其中两个由一个样本组成。 样本 6 和 11 是最后合并的样本,这并不奇怪。 实际上,它们之间的距离比其他所有区域都远。 在以下屏幕截图中,显示了四个不同的级别(只有包含多个样本的聚类用圆圈标记):
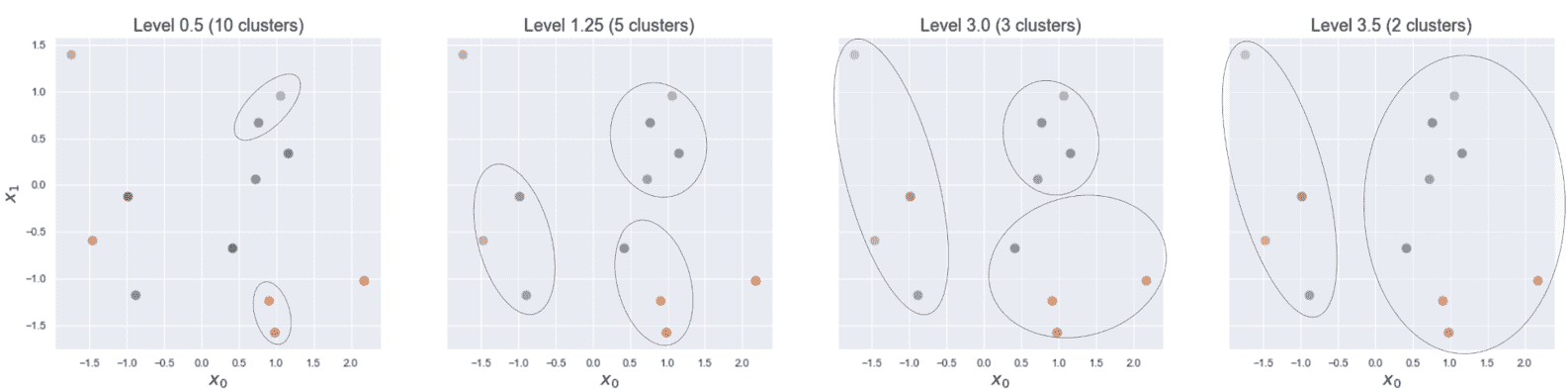
通过在不同级别切割树状图而生成的群集(沃德链接)
易于理解,聚集从选择最相似的群集/样本开始,然后通过添加最近邻,直到到达树的根为止。 在我们的情况下,在相异度等于 2.0 的情况下,已检测到三个定义明确的群集。 左一个也保留在下一个剪切中,而右两个(显然更靠近)被选择合并以生成单个群集。 该过程本身很简单,不需要特别的解释。 但是,有两个重要的考虑因素。
第一个是树状图结构本身固有的。 与其他方法相反,层次聚类允许观察整个聚类树,当需要通过增加不相似度来显示流程如何演变时,此功能非常有用。 例如,产品推荐器应用无法提供有关代表用户的所需群集数量的任何信息,但是执行管理层可能会对理解合并过程的结构和演变方式感兴趣。
实际上,观察群集是如何合并的可以深入了解底层的几何,还可以发现哪些群集可能被视为较大群集的一部分。 在我们的示例中,在级别 0.5 处,我们有一个小的群集{1, 3}。 问题是“可以通过增加不相似性将哪些样本添加到该群集中?” 可以立即用{2}回答。 当然,在这种情况下,这是一个微不足道的问题,可以通过查看数据图来解决,但是对于高维数据集,如果没有树状图的支持,它可能会变得更加困难。
树状图的第二个优点是可以比较不同链接方法的行为。 使用 Ward 的方法,第一次合并发生的相异度很低,但是五个群集和三个群集之间存在较大的差距。 这是几何形状和合并策略的结果。 例如,如果我们使用单个链接(本质上非常不同)会发生什么? 以下屏幕快照显示了相应的树状图:
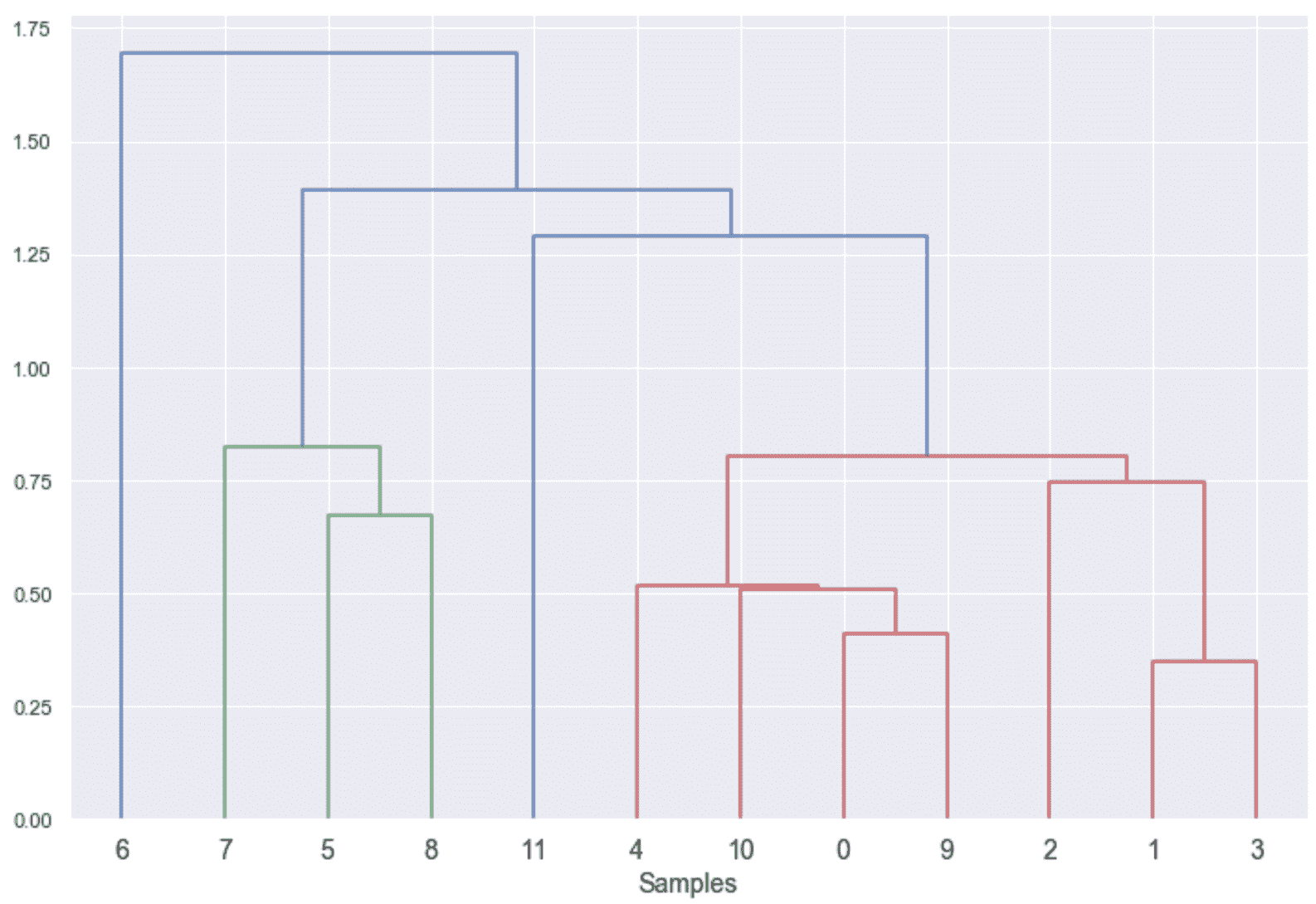
与应用于数据集的单个链接相对应的树状图
结论是,树状图是不对称的,并且群集通常与单个样本或小的附聚物合并。 从右侧开始,我们可以看到样本{11}和{6}合并得很晚。 此外,当必须生成最终的单个群集时,样本{6}(可能是异常值)被合并。 通过以下屏幕快照可以更好地理解该过程:
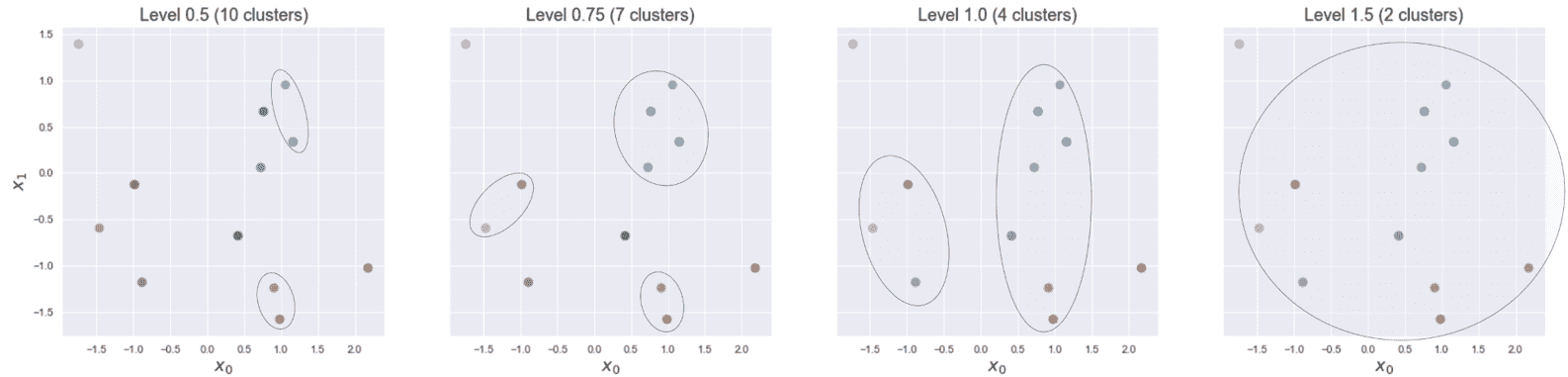
通过在不同级别切割树状图而生成的群集(单链接)
从屏幕快照中可以看到,虽然 Ward 的方法生成包含所有样本的两个聚类,但单个链接通过将潜在异常值保持在外部来聚集级别 1.0 上的最大块。 因此,树状图还允许定义聚合语义,这在心理学和社会学方面非常有用。 尽管 Ward 的链接与其他对称算法非常相似,但单个链接具有逐步显示的方式,显示了对逐步构建的聚类的潜在偏好,从而避免了相异性方面的巨大差距。
最后,有趣的是,尽管 Ward 的链接通过在级别 3.0 处切断树状图产生了潜在的最佳群集数(三个),但单个链接从未达到这样的配置(因为群集{6}仅在最后一步中合并。 该效果与最大分离和最大内聚的双重原理紧密相关。 沃德的联系往往会很快找到最具凝聚力和最独立的集群。 当相异性差距超过预定义的阈值时(当然,当达到所需的群集数时),它可以切割树状图,而其他链接则需要不同的方法,有时会产生不希望的最终配置。
考虑到问题的性质,我始终鼓励您测试所有链接方法的行为,并为某些示例场景(例如,根据教育水平,居住地, 和收入)。 这是提高认识并提高提供流程语义解释的能力的最佳方法(这是任何聚类过程的基本目标)。
作为表现指标的 Cophenetic 相关性
可以使用前面各章中介绍的任何方法来评估层次集群表现。 但是,在这种特定情况下,可以采用特定措施(不需要基本事实)。 给定一个近似矩阵P和一个链接L,几个样本x[i]和x[j] ∈ X始终分配给特定层次级别的同一群集。 当然,重要的是要记住,在团聚的情况下,我们从n个不同的群集开始,最后以一个等于X的单个群集结束。 此外,由于两个合并的群集成为一个群集,因此属于一个群集的两个样本将始终继续属于同一扩充的群集,直到该过程结束。
考虑到上一节中显示的第一个树状图,样本{1}和{3}立即合并; 然后添加样本{2},然后添加{11}。 此时,整个群集将与另一个块合并(包含样本{0}, {9}, {4}, {10})。 在最后一级,将剩余的样本合并以形成单个最终群集。 因此,命名相似度DL[0],DL[1],…和DL[k],样本{1}和{3}在DL[1]处开始属于同一群集。 例如,在DL[6]的同一群集中发现{2}和{1}。
此时,我们可以将DL[ij]定义为x[i]和x[j]首次属于同一群集,并且将以下n×n对称矩阵作为CP:

换句话说,CP[ij]元素是观察同一群集中x[i]和x[j]所需的最小差异。 可以证明CP[ij]是x[i]和x[j]之间的距离度量; 因此,CP与P类似,并且具有与邻近矩阵相同的属性(例如,所有对角元素为空)。 特别是,我们对它们的相关性感兴趣(在-1和1范围内标准化)。 这样的值(Cophenetic 系数(CPC)表示P和CP之间的一致性程度,并且可以很容易地计算出, 如以下等式所示。
由于P和CP均为n×n对称矩阵且对角元素为空,因此可以仅考虑下三角部分(不包括对角线,表示为Tril(·)),包含n (n-1) / 2值。 因此,平均值如下:
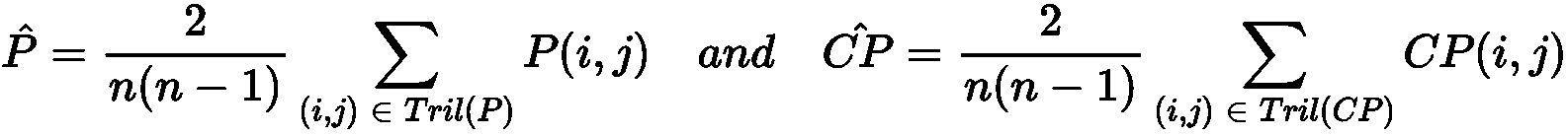
标准化平方和值如下:
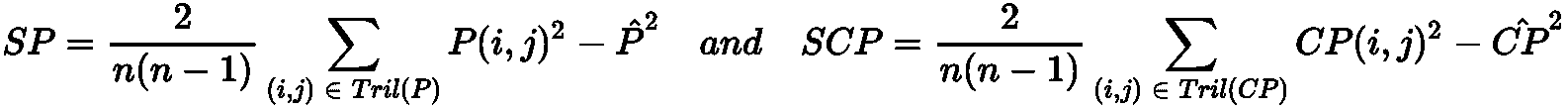
因此,归一化的同位相关仅等于以下内容:
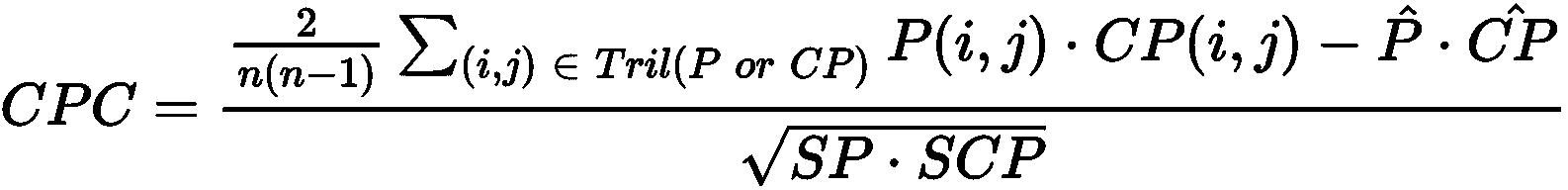
前面的方程式基于以下假设:如果x[i],x[j]和x[p]的距离,例如d(x[i], x[j]) < d(x[i], x[p]),可以合理预期x[i]和x[j]在x[i]和x[p]之前合并在同一群集中(即,对应于x[i]和x[j]的合并的差异程度低于x[i]和x[p]的合并)。 因此,CPC → 1表示链接生成了一个最佳层次结构,该层次结构反映了基础几何结构。 另一方面,CPC → -1表示完全不同意,并且潜在的聚类结果与几何形状不一致。 毋庸置疑,给定一个问题,我们的目标是找到一个最大化CPC的指标和链接。
考虑到第 3 章,“高级聚类”中描述的示例,我们可以使用 SciPy 函数cophenet计算与不同链接(假设欧几里得距离)相对应的同位矩阵和 CPC 。 此函数需要将链接矩阵作为第一个参数,将接近度矩阵作为第二个参数,并返回同义矩阵和 CPC(dm变量是先前计算出的压缩接近度矩阵):
from scipy.cluster.hierarchy import linkage, cophenet
cpc, cp = cophenet(linkage(dm, method='ward'), dm)
print('CPC Ward\'s linkage: {:.3f}'.format(cpc))
cpc, cp = cophenet(linkage(dm, method='single'), dm)
print('CPC Single linkage: {:.3f}'.format(cpc))
cpc, cp = cophenet(linkage(dm, method='complete'), dm)
print('CPC Complete linkage: {:.3f}'.format(cpc))
cpc, cp = cophenet(linkage(dm, method='average'), dm)
print('CPC Average linkage: {:.3f}'.format(cpc))
此代码段的输出如下所示:
CPC Ward's linkage: 0.775
CPC Single linkage: 0.771
CPC Complete linkage: 0.779
CPC Average linkage: 0.794
这些值非常接近,表明所有链接都产生了很好的结果(即使由于两个异常值的存在它们并不是最优的)。 但是,如果需要选择一种方法,则平均链接是最准确的方法,如果没有特殊原因,则应优先使用其他链接。
同类关系是层次聚类特有的评估指标,通常可提供可靠的结果。 但是,当几何形状更复杂时,CPC 值可能会产生误导并导致次佳配置。 因此,我总是建议也使用其他指标(例如,轮廓分数或调整后的 Rand 分数),以便仔细检查表现并做出最合适的选择。
水厂数据集上的凝聚聚类
现在,让我们考虑一个更大的数据集上的更详细的问题(在本章开头的“技术要求”部分中提供了下载说明),其中包含 527 个样本,其中有 38 个化学和物理变量描述了水处理厂的状态。 正如同一作者( Bejar,Cortes 和 Poch)所述,该域的结构较差,需要仔细分析。 同时,我们的目标是使用不可知论的方法找到最佳的聚类。 换句话说,我们将不考虑语义标记过程(需要领域专家),而仅考虑数据集的几何结构以及通过聚集算法发现的关系。
下载后,可以使用 Pandas 加载 CSV 文件(称为water-treatment.data)(当然,必须更改项目<DATA_PATH>才能指向文件的确切位置)。 第一列是与特定工厂相关的索引,而所有其他值都是数字,可以转换为float64。 缺少的值用'?' 字符表示,并且由于我们没有其他信息,因此将每个属性的均值设置为:
import pandas as pd
data_path = '<DATA_PATH>/water-treatment.data'
df = pd.read_csv(data_path, header=None, index_col=0, na_values='?').astype(np.float64)
df.fillna(df.mean(), inplace=True)
由于单个变量的大小存在很大差异(我邀请读者使用 DataFrame 上的describe函数检查此语句),因此最好在范围(-1, 1)内对其进行标准化,以保持原始差异:
from sklearn.preprocessing import StandardScaler
ss = StandardScaler(with_std=False)
sdf = ss.fit_transform(df)
在这一点上,像往常一样,我们可以使用 t-SNE 算法将数据集投影到二维空间上:
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, perplexity=10, random_state=1000)
data_tsne = tsne.fit_transform(sdf)
df_tsne = pd.DataFrame(data_tsne, columns=['x', 'y'], index=df.index)
dff = pd.concat([df, df_tsne], axis=1)
生成的绘图显示在以下屏幕截图中:
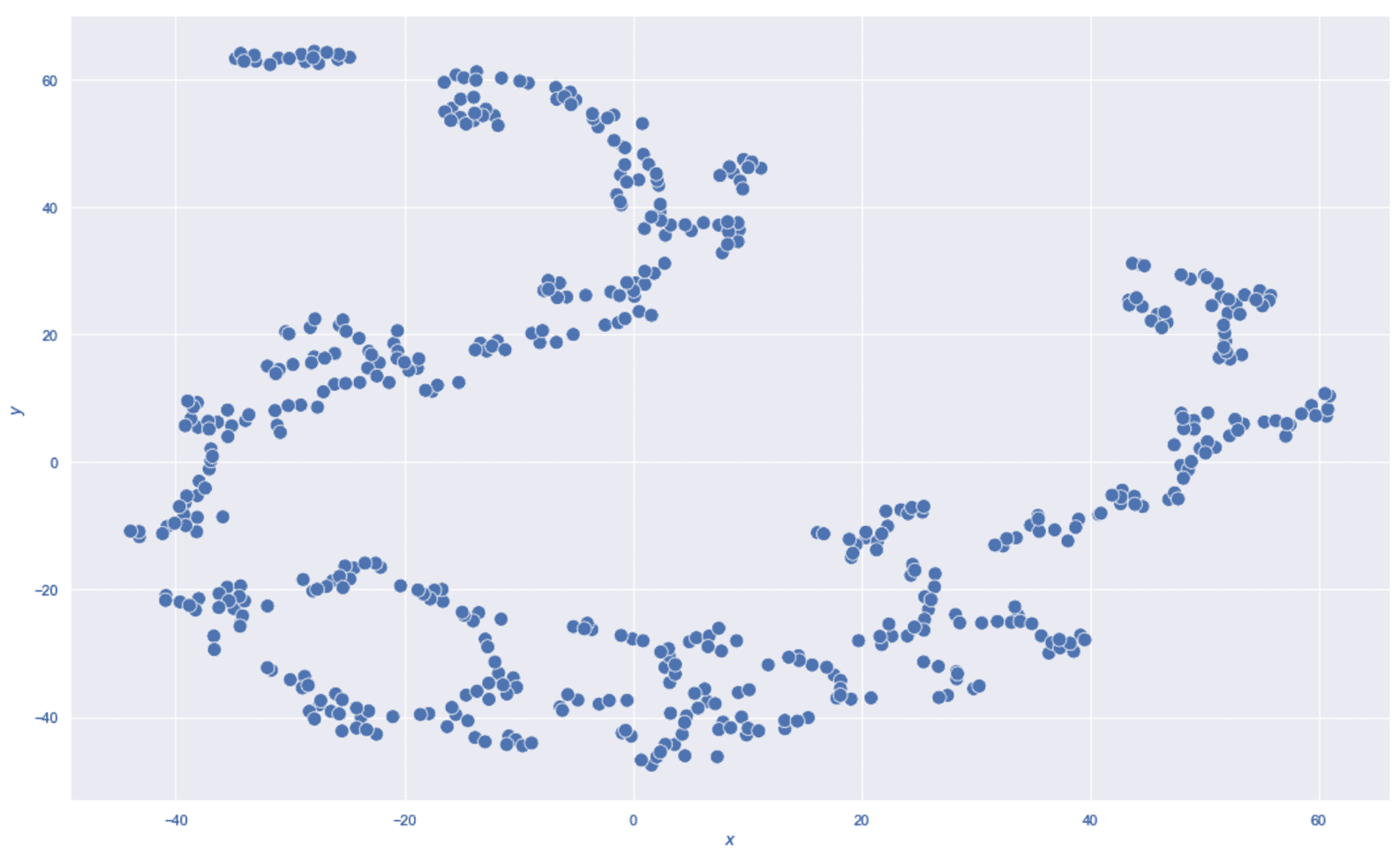
水处理厂数据集的 t-SNE 图
该图显示了潜在的非凸几何形状,其中有许多小的小岛(密集区域),这些小岛由空白空间隔开。 但是,如果没有任何域信息,则很难确定哪些斑点可以被视为同一群集的一部分。 我们可以决定施加的唯一伪约束(考虑到所有工厂都以相似的方式运行)是具有中等或较小的最终群集数。 因此,假设欧氏距离并使用 scikit-learn AgglomerativeClustering类,我们可以计算所有链接以及4,6,8和 10集群数:
import numpy as np
from sklearn.cluster import AgglomerativeClustering
from sklearn.metrics import silhouette_score
from scipy.spatial.distance import pdist
from scipy.cluster.hierarchy import linkage, cophenet
nb_clusters = [4, 6, 8, 10]
linkages = ['single', 'complete', 'ward', 'average']
cpcs = np.zeros(shape=(len(linkages), len(nb_clusters)))
silhouette_scores = np.zeros(shape=(len(linkages), len(nb_clusters)))
for i, l in enumerate(linkages):
for j, nbc in enumerate(nb_clusters):
dm = pdist(sdf, metric='minkowski', p=2)
Z = linkage(dm, method=l)
cpc, _ = cophenet(Z, dm)
cpcs[i, j] = cpc
ag = AgglomerativeClustering(n_clusters=nbc, affinity='euclidean', linkage=l)
Y_pred = ag.fit_predict(sdf)
sls = silhouette_score(sdf, Y_pred, random_state=1000)
silhouette_scores[i, j] = sls
相应的图显示在以下屏幕截图中:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-E5Hxkl3W-1681652575118)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-unsup-learn-py/img/22e87346-d2f3-4423-b75b-c700146d7550.png)]
不同数量的群集和四种链接方法的同位相关(左)和轮廓分数(右)
首先要考虑的一点是,对于完全和平均链接而言,同义相关可以合理地接受,而对于单个链接而言,它太低了。 考虑到轮廓分数,通过单联动和四个群集可实现最大值(约 0.6)。 该结果表明,即使分层算法产生了次优的配置,也可以用中等或高水平的内部凝聚力分离四个区域。
如上一节所述,同位相关有时可能会引起误解,在这种情况下,我们可以得出结论,如果潜在群集的理论数目为 4,则使用单连接是最佳选择。 但是,所有其他图均显示对应于完整链接的最大值(单个图的最小值)。 因此,第一个要回答的问题是:我们是否甚至需要集群? 在此示例中,我们假设许多工厂以非常标准的方式运行(差异由许多样本共享),但是也可能存在某些特定情况(不适当的离群值)表现出截然不同的行为。
这种假设在许多情况下都是现实的,并且可能是由于创新或实验过程,资源不足,测量过程中的内部问题等导致的。 领域专家可以确认或拒绝我们的假设,但是,由于这是一个通用示例,我们可以决定保留八个具有完全链接的聚类(轮廓分数约为 0.5)。 该值表示存在重叠,但是考虑到数据集的维数和非凸性,在许多实际情况下可以接受。
在这一点上,我们还可以分析截断为 80 片叶子的树状图(可以通过设置trucate_mode='lastp' 参数和p=80来实现),以避免间隔太小且难以区分 (但是,您可以删除此约束并提高分辨率):
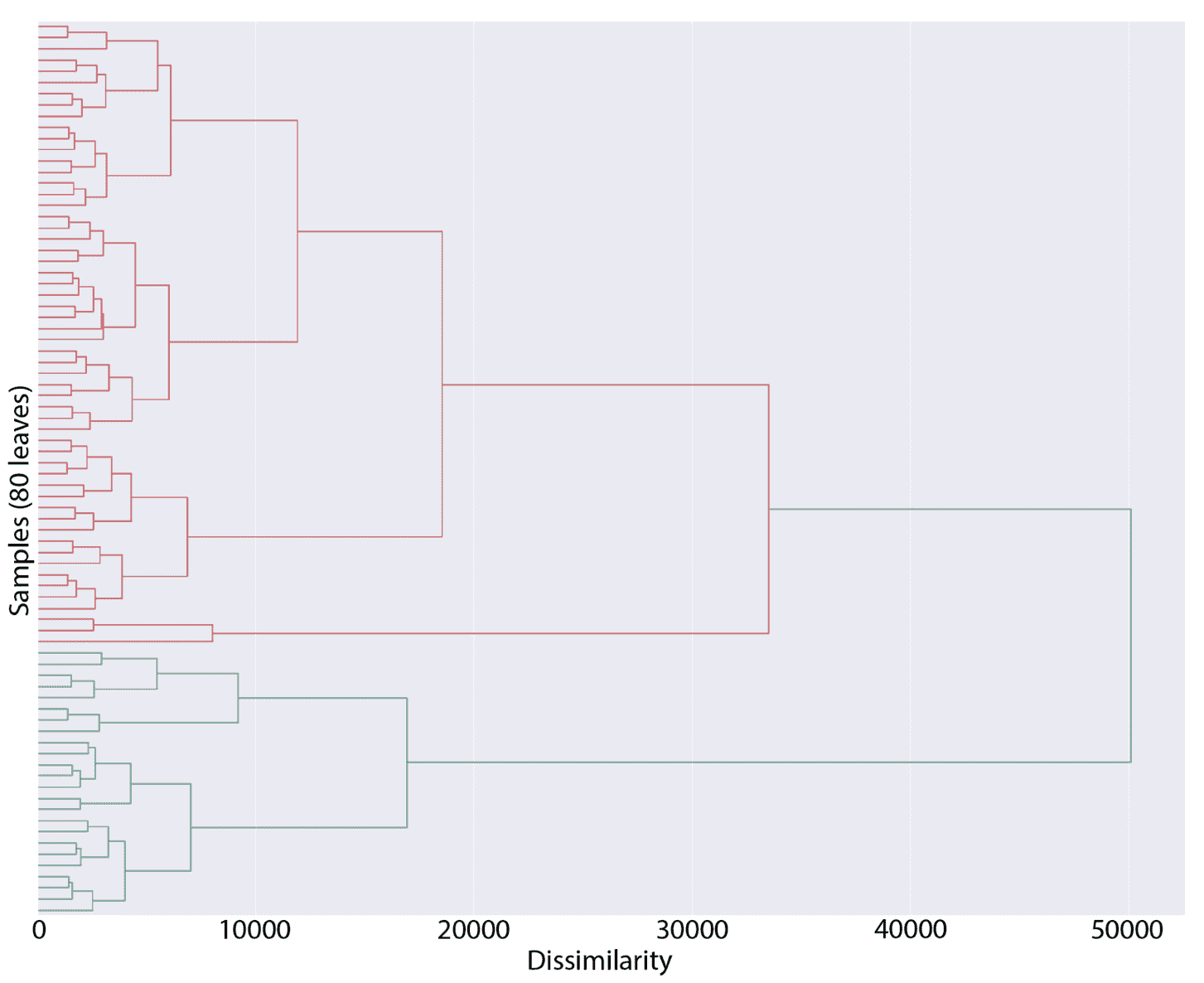
具有欧几里德度量标准和完全链接的水处理厂数据集的树状图
如我们所见,集聚过程不是均匀的。 在过程开始时,相异度的增加非常缓慢,但是在对应于大约 10,000 的值之后,跃变变大。 查看 t-SNE 图,可以理解非凸性的影响对非常大的聚类具有更强的影响,因为密度降低并且隐含地差异增大。 显而易见,很少数量的群集(例如 1、2 或 3)的特征是内部差异非常大,凝聚力非常低。
此外,树状图显示在大约 17,000 的水平上有两个主要的不均匀聚集,因此我们可以推断出粗粒度分析突出显示了主要行为的存在(从顶部观察图),以及由少量的工厂产生的次要行为。 特别是,较小的组非常稳定,因为它将以大约 50,000 的相异度级别合并到最终的单个群集中。 因此,我们应该期待伪异常值的存在,这些伪异常值被分组为更多的孤立区域(t-SNE 图也证实了这一点)。
切割级别在 4,000÷6,000(对应于大约八个群集)的范围内,较大的块比较小的块更密集。 换句话说,离群值群集将包含比其他群集少得多的样本。 这不足为奇,因为,如在专门针对树状图的“分析树状图”部分中所讨论的那样,最远的群集通常在完全链接中合并得很晚。
至此,我们终于可以执行聚类并检查结果了。 Scikit-learn 的实现不会计算整个树状图,而是会在达到所需群集数时停止该过程(除非compute_full_tree 参数不是True):
import pandas as pd
from sklearn.cluster import AgglomerativeClustering
ag = AgglomerativeClustering(n_clusters=8, affinity='euclidean', linkage='complete')
Y_pred = ag.fit_predict(sdf)
df_pred = pd.Series(Y_pred, name='Cluster', index=df.index)
pdff = pd.concat([dff, df_pred], axis=1)
最终图显示在以下屏幕截图中:
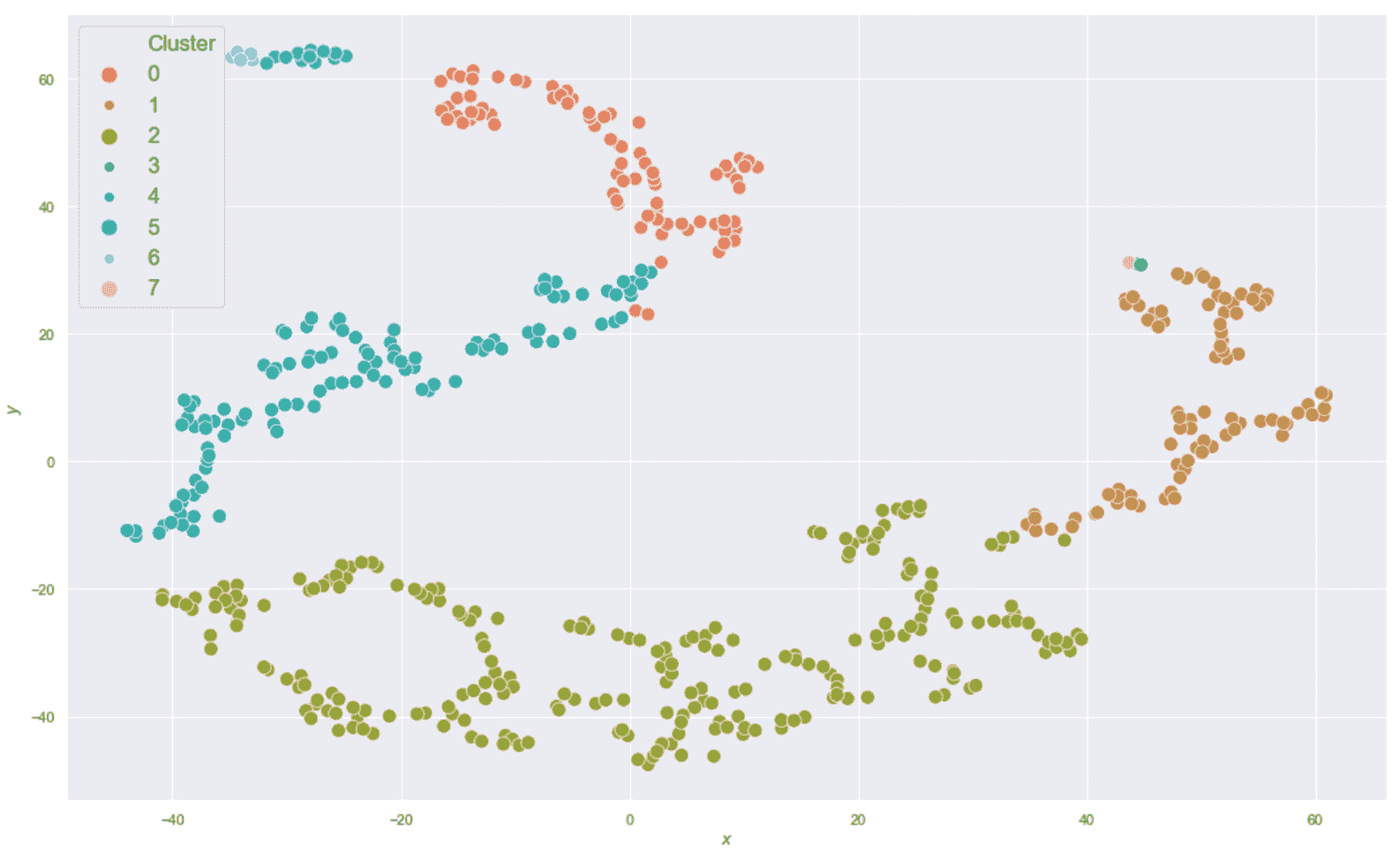
水处理厂数据集的聚类结果(八个群集)
不出所料,群集是不均匀的,但是它们与几何形状非常一致。 此外,孤立的群集(例如,在x ∈ (-40. -20)和y > 60的区域中)非常小,很可能包含真实的异常值,其行为与大多数其他样本有很大不同。 我们将不分析语义,因为问题非常具体。 但是,可以合理地认为x ∈ (-40, 40)和y ∈ (-40, -10),代表合适的基线。 相反,其他大块(在该群集的极端)对应于具有特定特性或行为的工厂,这些工厂具有足够的扩散性,可以视为标准的替代实践。 当然,如开始时所述,这是不可知的分析,应该有助于理解如何使用层次聚类。
作为最后一步,我们希望以大约 35,000(对应于两个聚类)的相似度水平切割树状图。 结果显示在以下屏幕截图中:
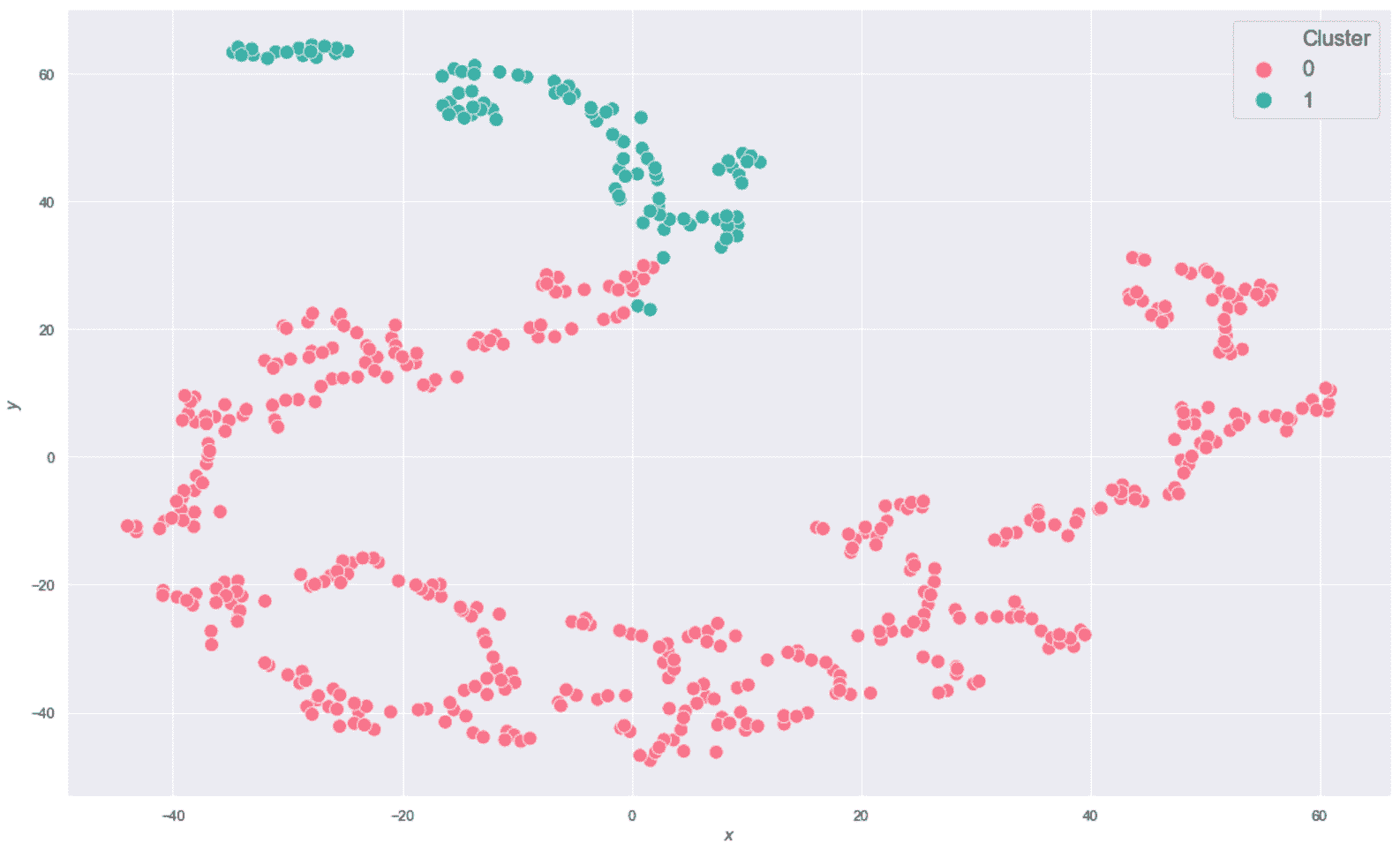
水处理厂数据集的聚类结果(两个群集)
在此级别上,树状图显示出属于群集和剩余较小块的样本数量很大。 现在我们知道,这样的次级区域对应于x ∈ (-40, 10)和y > 20。 同样,结果并不令人惊讶,因为 t-SNE 图表明,这些样本是唯一具有y > 20÷25的样本(而较大的群集,即使有很大的空白区域,也覆盖了几乎所有范围)。
因此,我们可以说这些样本代表具有极端行为的非常不同的工厂,如果将新样本分配给该群集,则可能是非标准工厂(假设一个标准工厂具有与大多数同类相似的行为)。 作为练习,我鼓励您测试其他数量的类和不同的链接(尤其是单个链接,这非常特殊),并尝试验证或拒绝某些样本,先前的假设(它们在物理上没有必要被接受) )。
连通性约束
聚集层次聚类的一个重要特征是可以包括连通性约束以强制合并特定样本。 在邻居之间有很强关系的情况下,或者当我们知道某些样本由于其固有属性而必须属于同一类时,这种先验知识非常普遍。 为了实现此目标,我们需要使用连接矩阵A ∈ {0, 1}^(n×n):
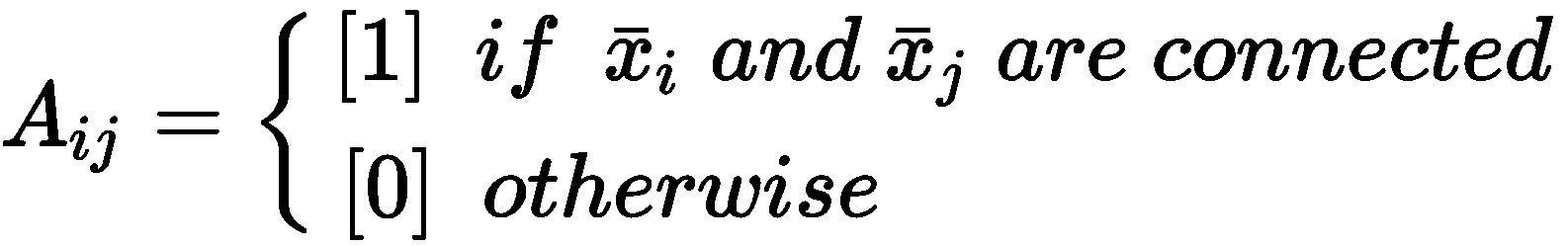
通常,A是由数据集图诱导的邻接矩阵; 但是,唯一重要的要求是没有隔离的样本(无连接),因为它们无法以任何方式合并。 连接矩阵在初始合并阶段应用,并强制算法聚合指定的样本。 由于以下聚集不会影响连接性(两个合并的样本或群集将保持合并直到过程结束),因此始终会强制执行约束。
为了理解此过程,让我们考虑一个样本数据集,其中包含从8双变量高斯分布中提取的50二维点:
from sklearn.datasets import make_blobs
nb_samples = 50
nb_centers = 8
X, Y = make_blobs(n_samples=nb_samples, n_features=2, center_box=[-1, 1], centers=nb_centers, random_state=1000)
标记的数据集显示在以下屏幕截图中:
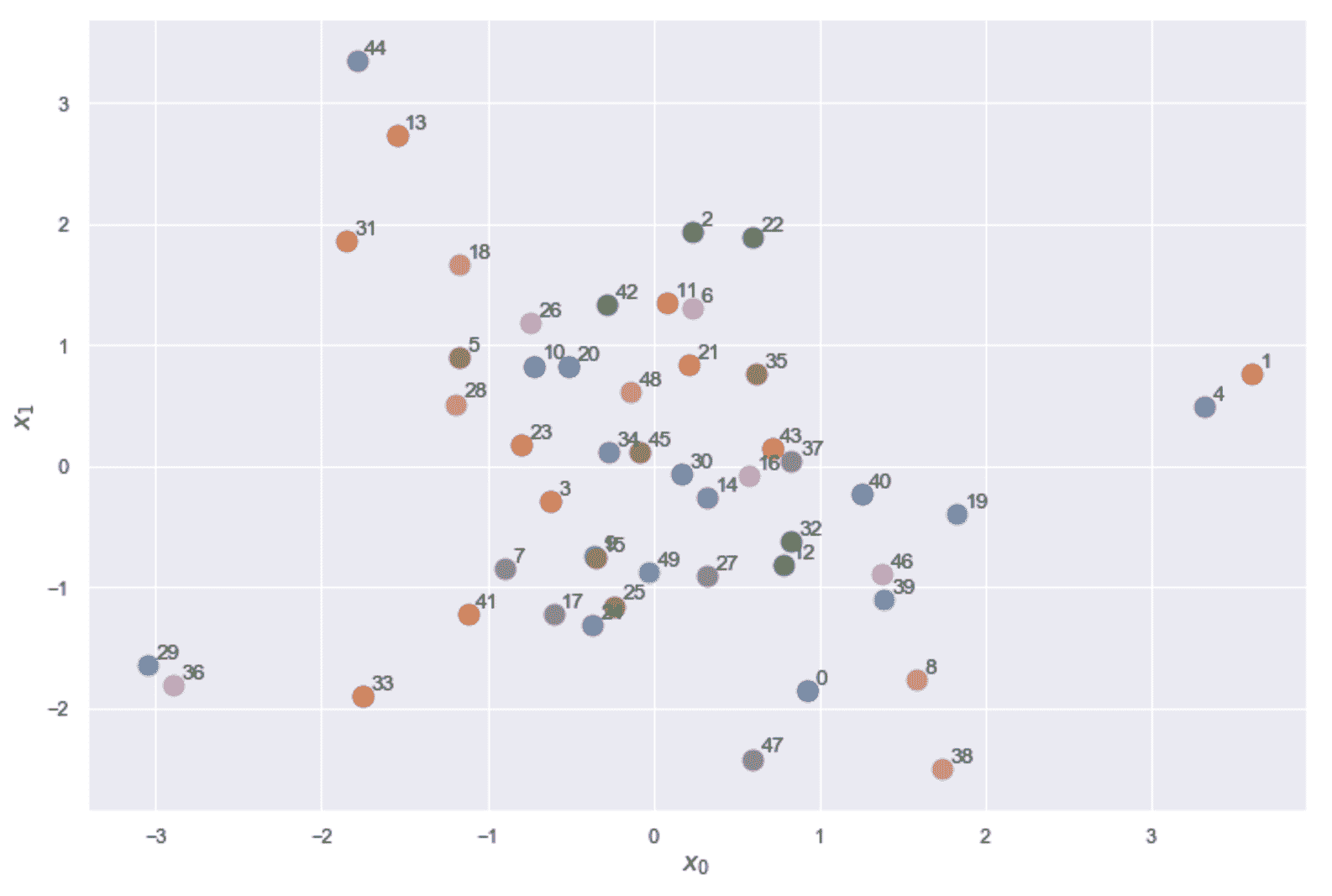
连通性约束的数据集示例
从图中可以看出,样本 18 和 31 (x[0] ∈ (-2, -1)和x[1] ∈ (1, 2)非常接近; 但是,我们不希望将它们合并,因为样本 18 在较大的中央斑点中有更多邻居,而点 31 被部分隔离,应视为一个自治群集。 我们还希望样本 33 形成单个群集。 这些要求将迫使算法合并不再考虑基础几何(根据高斯分布)的聚类,而是考虑现有知识。
为了检查聚类的工作原理,现在让我们使用欧几里德距离和平均链接计算树状图(截短为 20 片叶子):
from scipy.spatial.distance import pdist
from scipy.cluster.hierarchy import linkage, dendrogram
dm = pdist(X, metric='euclidean')
Z = linkage(dm, method='average')
fig, ax = plt.subplots(figsize=(20, 10))
d = dendrogram(Z, orientation='right', truncate_mode='lastp', p=20, ax=ax)
ax.set_xlabel('Dissimilarity', fontsize=18)
ax.set_ylabel('Samples', fontsize=18)
以下屏幕快照显示了树状图(从右到左):
具有欧氏距离和平均链接的连通性约束示例的树状图
不出所料,样本 18 和 31 立即合并,然后与另一个包含 2 个样本的群集聚合(当括号中的数字表示这是一个包含更多样本的复合块) ,可能是 44 和 13 。 样本 33 也已合并,因此不会保留在孤立的群集中。 作为确认,让我们使用n_clusters=8进行聚类:
from sklearn.cluster import AgglomerativeClustering
ag = AgglomerativeClustering(n_clusters=8, affinity='euclidean', linkage='average')
Y_pred = ag.fit_predict(X)
以下屏幕快照显示了聚类数据集的图:
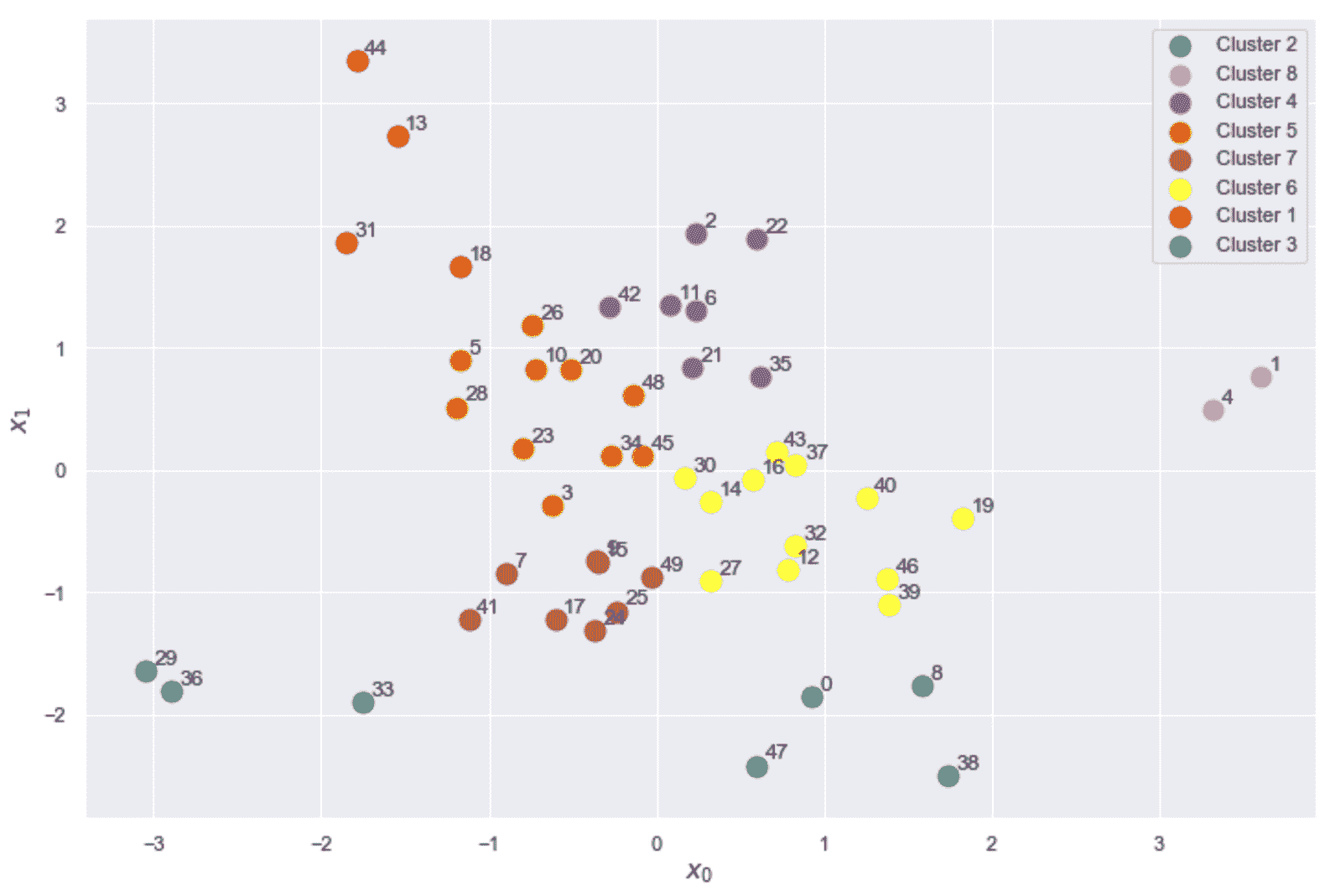
使用欧几里得距离和平均链接来聚类的数据集
结果证实了先前的分析。 在没有限制的情况下,平均链接会产生合理的分区,该分区与基本事实(八高斯分布)兼容。 为了拆分大的中心斑点并保持所需的聚类数量,即使树状图确认它们最终以最高相异度级别合并,该算法也必须合并孤立的样本。
为了施加约束,我们可以观察到,基于前两个最近邻的连通性矩阵很可能会迫使属于较密集区域的所有样本聚集(考虑到邻居更近)并最终保持孤立状态。 自治集群中的点。 出现这种假设行为的原因是基于平均链接的目标(以最大程度地减少集群间平均距离)。 因此,在施加约束之后,该算法更易于与其他邻居聚集紧密的群集(请记住,A具有空值,但在与两个最近邻相对应的位置),并且最远的点不合并,直到差异程度足够大(产生非常不均匀的群集)。
为了检查我们的假设是否正确,让我们使用 scikit-learn kneighbors_graph()函数和n_neighbors=2生成连接矩阵,并重新设置数据集,并设置connectivity约束:
from sklearn.cluster import AgglomerativeClustering
from sklearn.neighbors import kneighbors_graph
cma = kneighbors_graph(X, n_neighbors=2)
ag = AgglomerativeClustering(n_clusters=8, affinity='euclidean', linkage='average', connectivity=cma)
Y_pred = ag.fit_predict(X)
下一个屏幕截图显示了上一个片段的图形输出:
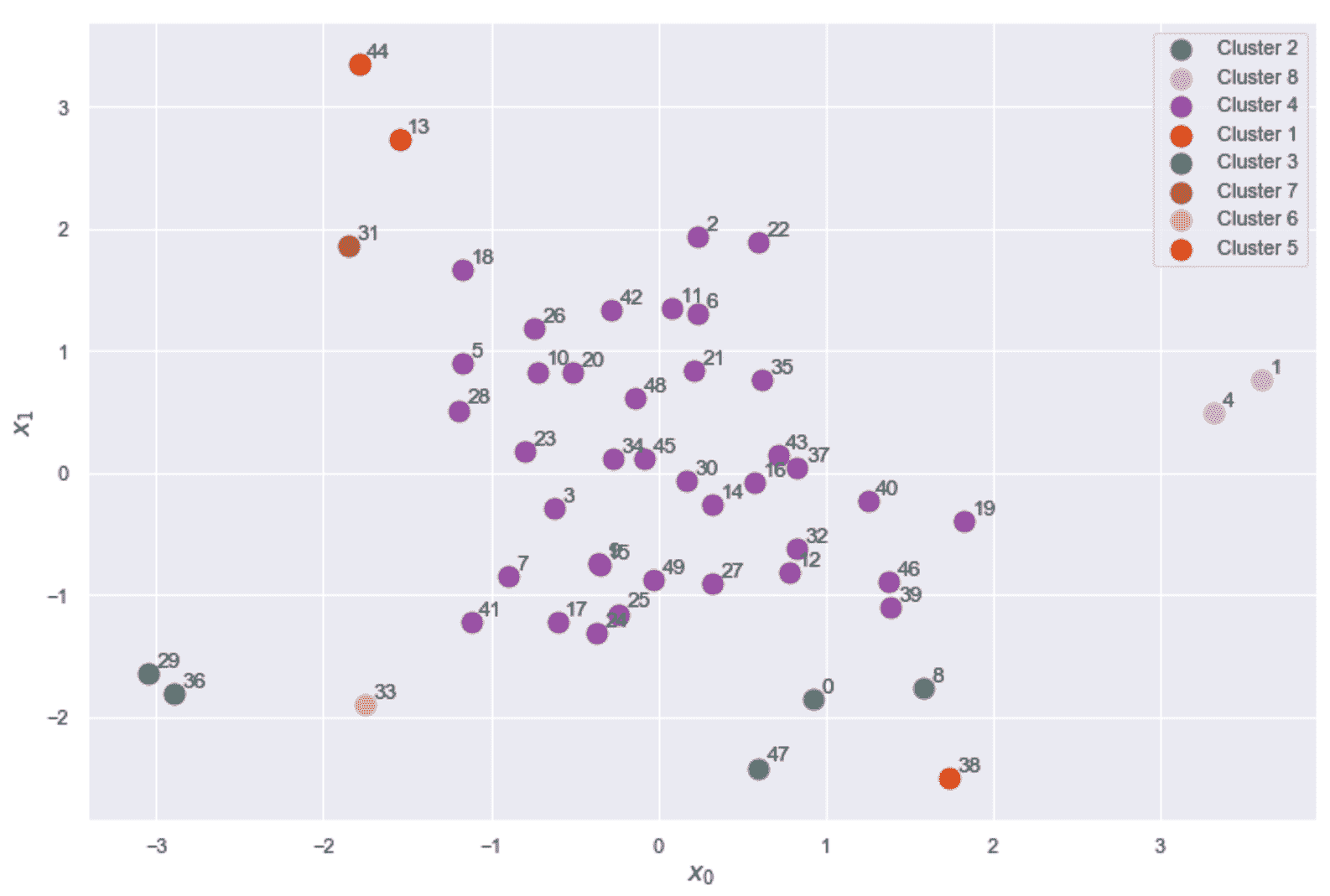
使用欧式距离和连通性约束来聚类的数据集
正如预期的那样,样本 18 已分配给大型中央群集,而点 31 和 33 现在已被隔离。 当然,由于该过程是分层的,因此施加连通性约束比分离约束更容易。 实际上,虽然可以在初始阶段轻松合并单个样本,但是使用所有链接都无法轻松保证在最终合并之前将其排除。
当需要复杂的约束条件(给定距离和链接)时,通常有必要同时调整连接矩阵和所需的群集数量。 当然,如果期望的结果是通过特定数目的聚类实现的,则也将使用较大的值来实现,直到相异性下界为止(也就是说,合并过程会减少聚类的数量;因此,如果相异性足够大,所有现有约束将仍然有效)。 例如,如果三个样本被约束为属于同一群集,则通常无法在初始合并阶段之后获得此结果。
但是,如果所有三个样本的合并都在某个不同的级别上发生(例如,对应于 30 个群集的 2.0),则它对于n < 30个群集以及具有DL > 2.0。 因此,如果我们从 5 个聚类开始,则可以轻松增加此数字,同时注意其相异度级别大于与约束所施加的最后合并对应的相异程度。 建议您与其他数据集一起测试此方法,并尝试定义可以在聚类过程之后轻松验证的先前约束。
总结
在本章中,我们介绍了层次聚类方法,重点介绍了可以采用的不同策略(分裂策略和聚集策略)。 我们还讨论了用于发现哪些群集可以合并或拆分(链接)的方法。 特别地,给定距离度量,我们分析了四种链接方法的行为:单一,完整,平均和沃德方法。
我们已经展示了如何构建树状图以及如何分析树状图,以便使用不同的链接方法来理解整个分层过程。 引入了一种称为共情相关的特定表现度量,以在不了解基本事实的情况下评估分层算法的表现。
我们分析了一个更大的数据集(水处理厂数据集),定义了一些假设并使用前面讨论的所有工具对其进行了验证。 在本章的最后,我们讨论了连通性约束的概念,该概念允许使用连通性矩阵将先验知识引入流程。
在下一章中,我们将介绍软聚类的概念,重点是模糊算法和两个非常重要的高斯混合模型。
问题
- 凝聚法和分裂法有什么区别?
- 给定两个群集
a: [(-1, -1), (0, 0)]和b: [(1, 1), (1, 0)],是否考虑欧几里得距离,什么是单一和完整链接? - 树状图表示给定数据集的不同链接结果。 它是否正确?
- 在凝聚聚类中,树状图的底部(初始部分)包含单个聚类。 它是否正确?
- 凝聚聚类中树状图的
y轴是什么意思? - 合并较小的群集时,相异性降低。 它是否正确?
- 显色矩阵的元素
C(i, j)报告相异度,其中两个对应元素x[i]和x[j]首次出现在同一群集中。 它是否正确? - 连通性约束的主要目的是什么?
进一步阅读
A Statistical Method for Evaluating Systematic Relationships, Sokal R., Michener C., University of Kansas Science Bulletin, 38, 1958Hierarchical Grouping to Optimize an Objective Function, Ward Jr J. H., Journal of the American Statistical Association. 58(301), 1963LINNEO+: A Classification Methodology for Ill-structured Domains, Bejar J., Cortes U., Poch M., Research report RT-93-10-R. Dept. Llenguatges i Sistemes Informatics, Barcelona, 1993Machine Learning Algorithms, Second Edition, Bonaccorso G., Packt Publishing, 2018
五、软聚类和高斯混合模型
在本章中,我们将讨论软聚类的概念,它允许我们针对定义的聚类配置获取数据集每个样本的隶属度。 也就是说,考虑从 0% 到 100% 的范围,我们想知道x[i]在多大程度上属于一个集群。 极限值为 0,这表示x[i]完全在集群域之外,并且为 1(100%),表示x[i]已完全分配给单个群集。 所有中间值都表示两个或多个不同群集的部分域。 因此,与硬聚类相反,在这里,我们感兴趣的不是确定固定分配,而是确定具有相同概率分布(或概率本身)属性的向量。 这种方法可以更好地控制边界样本,并帮助我们找到生成数据集的适当近似方法。
特别是,我们将讨论以下主题:
- 模糊 C 均值
- 高斯混合
- 作为表现指标的 AIC 和 BIC
- 贝叶斯高斯混合(简要介绍)
- 生成式(半监督)高斯混合
技术要求
本章将介绍的代码需要以下内容:
- Python3.5+(强烈建议使用 Anaconda 发行版)
- 以下库:
- SciPy 0.19+
- NumPy 1.10+
- Scikit-Learn 0.20+
- Scikit-fuzzy 0.2
- Pandas 0.22+
- Matplotlib 2.0+
- Seaborn 0.9+
可以在 GitHub 存储库中找到示例。
软聚类
在第 4 章,“分层活动聚类”中分析的所有算法均属于硬聚类方法家族。 这意味着给定的样本始终分配给单个群集。 另一方面,软聚类旨在将每个样本x[i]与一个向量相关联,该向量通常表示x[i]属于每个群集的概率:
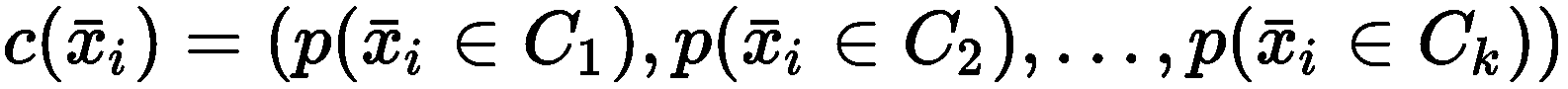
或者,可以将输出解释为隶属向量:
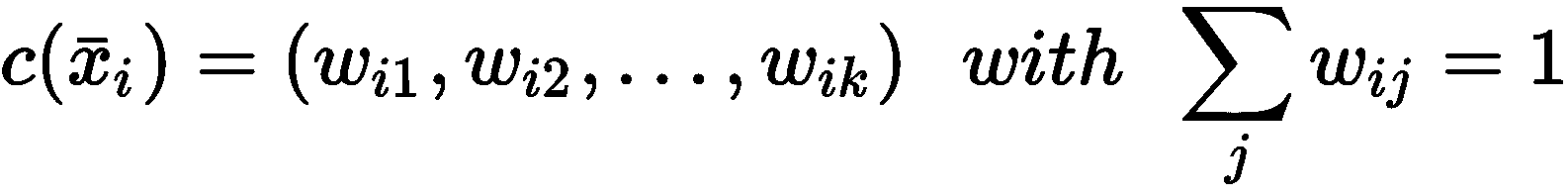
形式上,这两个版本之间没有区别,但是通常,当算法未明确基于概率分布时使用后者。 但是,出于我们的目的,我们始终将c(x[i])与概率相关联。 以此方式,激励读者考虑已经用于获取数据集的数据生成过程。 一个明显的例子是将这些向量解释为与特定贡献相关的概率,这些贡献构成了数据生成过程,p_data的近似值。 例如,采用概率混合,我们可以决定近似p_data,如下所示:
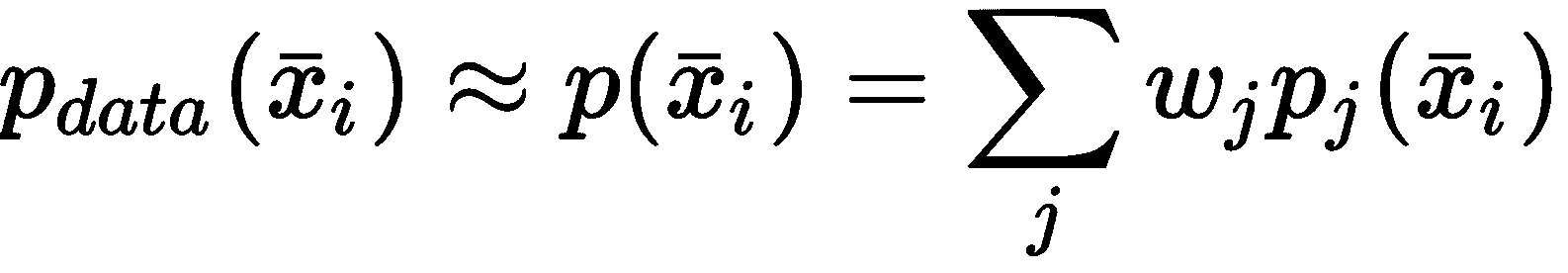
因此,将过程分为(独立)分量的加权总和,输出是每个分量的x[i]的概率。 当然,我们通常希望对每个样本都有一个主导成分,但是通过这种方法,我们对所有边界点有了很大的了解,但受到很小的扰动,这些边界点可以分配给不同的聚类。 因此,当可以将输出馈送到可以利用整个概率向量的另一个模型(例如,神经网络)时,软聚类非常有用。 例如,推荐者可以首先使用软聚类算法对用户进行细分,然后处理向量,以便基于显式反馈找到更复杂的关系。 常见的情况是通过对以下问题的答案进行更正:“此结果是否与您相关?” 或者,“您是否希望看到更多类似这些的结果?” 由于答案是由用户直接提供的,因此可以将其用于监督或强化学习模型中,这些模型的输入基于软自动细分(例如,基于购买历史记录或详细的页面浏览量)。 通过这种方式,可以通过更改原始分配的效果(由于不同集群提供的大量贡献而完全无关紧要)来轻松管理边界用户,同时为拥有强大成员资格的其他用户提供建议(例如, 接近 1)的概率可以稍加修改以提高回报率。
现在,我们可以开始对 Fuzzy c-means 的讨论,这是一种非常灵活的算法,将针对 K 均值讨论的概念扩展到了软聚类场景。
模糊 C 均值
我们将提出的第一个算法是基于软分配的 K 均值的变体。 名称模糊 C 均值源自模糊集的概念,这是经典二元集的扩展(即,在这种情况下,样本可以属于单个群集),基于代表整个集合不同区域的不同子集的叠加。 例如,一个基于某些用户年龄的集合可以将度young,adult和senior与三个不同(且部分重叠)的年龄范围相关联:18-35、28-60 和> 50。例如,一个 30 岁的用户在不同程度上既是young又是adult(并且实际上是边界用户,考虑到边界)。 有关这些类型的集合以及所有相关运算的更多详细信息,我建议这本书《概念和模糊逻辑》。我们可以想象,数据集X包含m个样本,被划分为k个重叠的群集,因此每个样本始终以隶属度w[ij]与每个群集关联(介于 0 和 1 之间的值)。 如果w[ij] = 0,则表示x[i]完全在群集C[j]之外,相反,w[ij] = 1表示对群集C[j]的硬分配。 所有中间值代表部分成员资格。 当然,出于显而易见的原因,必须将样本的所有隶属度的总和标准化为 1(如概率分布)。 这样,样本始终属于所有聚类的并集,并且将聚类分为两个或多个子聚类始终会在成员资格方面产生一致的结果。
该算法基于广义惯量S[f]的优化:

在上一个公式中,C[j]是群集C[j]的质心,而m > 1是重加权指数系数。 当m ≈ 1时,权重不受影响。 对于较大的值,例如w[ij] ∈ (0, 1),它们的重要性将按比例降低。 可以选择这样的系数以比较不同值的结果和期望的模糊程度。 实际上,在每次迭代之后(完全等同于 K 均值),权重使用以下公式更新:

如果x[i]接近质心x[i]的质心,则总和接近 0,并且权重增加(当然,为了避免数字不稳定性,在分母上添加了一个小常数,因此它永远不能等于 0)。 当m >> 1时,指数接近 0,并且所有项的总和趋向于 1。这意味着对特定群集的偏好减弱,w [ij] ≈ 1 / k对应于均匀分布。 因此,较大的m表示划分较为平坦,不同分配之间没有明显的区别(除非样本非常接近质心),而当m ≈ 1时,则是单个主要权重将几乎等于 1,其他权重将接近 0(也就是说,分配很困难)。
以类似于 K 均值的方式更新质心(换句话说,以最大化分离和内部凝聚力为目标):
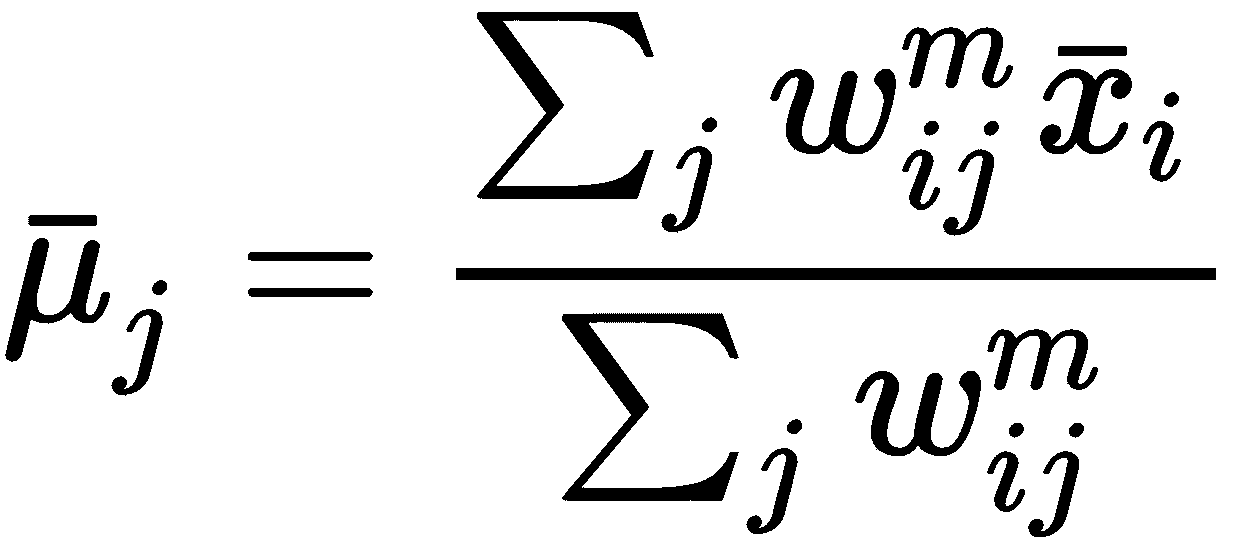
重复该过程,直到质心和权重变得稳定为止。 收敛之后,可以使用称为标准化 Dunn 分区系数的特定方法来评估结果,定义如下:
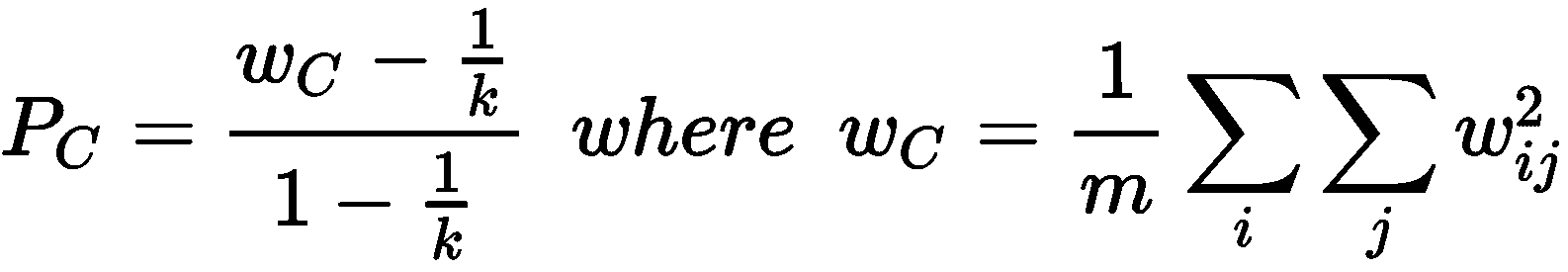
这样的系数在 0 和 1 之间。当P[C] ≈ 0时,表示w[C] ≈ 1 / k,这意味着平坦的分布和较高的模糊度。 另一方面,当P[C] ≈ 1时,则w[C] ≈ 1表示几乎是硬分配。 所有其他值都与模糊程度成正比。 因此,给定任务后,数据科学家可以根据所需结果立即评估算法的执行情况。 在某些情况下,最好使用硬分配,因此,可以将P[C]视为在切换至例如标准 K 均值之前执行的检查。 实际上,当P[C] ≈1(并且这样的结果是预期的结果)时,不再使用模糊c均值。 相反,小于 1 的值(例如P[C] = 0.5)会告诉我们,由于存在许多边界样本,因此可能会出现非常不稳定的硬分配。
现在,让我们将 scikit-learn 提供的 Fuzzy c-means 算法应用于简化的 MNIST 数据集。 该算法由 Scikit-Fuzzy 库提供,该库实现了所有最重要的模糊逻辑模型。 第一步是加载和规范化样本,如下所示:
from sklearn.datasets import load_digits
digits = load_digits()
X = digits['data'] / 255.0
Y = digits['target']
X 数组包含 1,797 个扁平化样本,x ∈ R^(64),对应于灰度8×8图像(其值在 0 和 1 之间归一化)。 我们要分析不同m系数(1.05 和 1.5 之间的 5 个均匀值)的行为,并检查样本的权重(在我们的例子中,我们将使用X[0])。 因此,我们调用 Scikit-Fuzzy cmeans函数,设置c=10(群集数)以及两个收敛参数error=1e-6和maxiter=20000。 此外,出于可重复性的原因,我们还将设置标准随机seed=1000。 输入数组应包含样本列。 因此,我们需要按如下方式转置它:
from skfuzzy.cluster import cmeans
Ws = []
pcs = []
for m in np.linspace(1.05, 1.5, 5):
fc, W, _, _, _, _, pc = cmeans(X.T, c=10, m=m, error=1e-6, maxiter=20000, seed=1000)
Ws.append(W)
pcs.append(pc)
上一个代码段执行不同类型的聚类,并将相应的权重矩阵W和分配系数pc附加到两个列表中。 在分析特定配置之前,显示测试样本(代表数字 0)的最终权重(对应于每个数字)将非常有帮助:
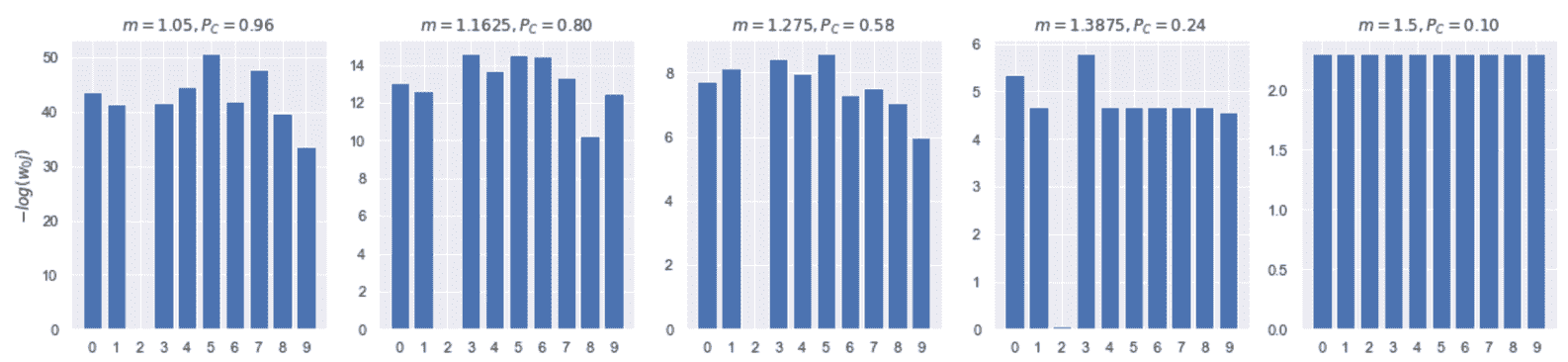
样本X[0]的权重(反对数刻度),对应于不同的m值
由于极值往往会非常不同,因此我们选择使用对数逆标(即-log(w[0][j]))而不是w[0][j])。 当m = 1.05时,P[C]约为 0.96,并且所有权重(与C[2]对应的权重除外])非常小(请记住,如果-log(w) = 30,则w = e^(-30))。 这样的配置清楚地显示了具有主要成分(C[2])的非常硬的聚类。 上图中的后续三个图继续显示优势,但是,尽管m增大(P[C]减小),但主要和次要成分之间的差异变得越来越小。 该效果证实了增加的模糊性,达到m > 1.38的最大值。 实际上,当m = 1.5时,即使P[C] ≈ 0.1,所有权重几乎相同,并且测试样本无法轻松分配给主要群集。 正如我们之前讨论的那样,我们现在知道像 K 均值这样的算法可以轻松地找到硬分区,因为平均而言,对应于不同数字的样本彼此之间非常不同,并且欧几里得距离足以将它们分配给右侧重心。 在这个例子中,我们要保持适度的模糊性。 因此,我们选择了m = 1.2(对应于P[C] = 0.73):
fc, W, _, _, _, _, pc = cmeans(X.T, c=10, m=1.2, error=1e-6, maxiter=20000, seed=1000)
Mu = fc.reshape((10, 8, 8))
Mu 数组包含质心,如下图所示:
质心对应于m = 1.2和P[C] ≈ 0.73
如您所见,所有不同的数字均已选定,并且按预期,第三个群集(由C[2]表示)对应于数字 0。现在,让我们检查一下对应于X[0]的权重(也是W的转置,因此它们存储在W[:, 0]中):
print(W[:, 0])
输出如下:
[2.68474857e-05 9.14566391e-06 9.99579876e-01 7.56684450e-06
1.52365944e-05 7.26653414e-06 3.66562441e-05 2.09198951e-05
2.52320741e-04 4.41638611e-05]
即使分配不是特别困难,集群C[2] 的优势也很明显。 第二个电位分配是C[8],对应于数字 9(比率约为 4,000)。 这样的结果与数字的形状绝对一致,并且考虑到最大权重和第二个权重之间的差异,很明显,大多数样本几乎都不会被分配(即,用 K 均值表示),即使P[C] ≈ 0.75。 为了检查硬分配的表现(使用权重矩阵上的argmax函数获得),并考虑到我们了解基本事实,可以采用adjusted_rand_score,如下所示:
from sklearn.metrics import adjusted_rand_score
Y_pred = np.argmax(W.T, axis=1)
print(adjusted_rand_score(Y, Y_pred))
上一个代码段的输出如下:
0.6574291419247339
该值确认大多数样本已成功硬分配。 作为补充练习,让我们找到权重最小的标准差的样本:
im = np.argmin(np.std(W.T, axis=1))
print(im)
print(Y[im])
print(W[:, im])
输出如下:
414
8
[0.09956437 0.05777962 0.19350572 0.01874303 0.15952518 0.04650815
0.05909216 0.12910096 0.17526108 0.06091973]
示例X[414]代表一个数字(8),如以下屏幕快照所示:

样本X[414]的图,对应于具有最小标准差的权重向量
在这种情况下,存在三个主要群集:C[8],C[4]和C[7](降序)。 不幸的是,它们都不对应于与C[5]相关的数字 8。 不难理解,这种错误主要是由于手指下部的格式不正确而导致的,其结果更类似于 9(这种错误分类也可能发生在人类身上)。 然而,低标准差和明显的主导成分的缺乏应告诉我们,这一决定不容易做出,并且样本具有属于三个主要类别的特征。 一个更复杂的监督模型可以轻松避免此错误,但考虑到我们正在执行非监督分析,并且我们仅将基本事实用于评估目的,结果并不是那么负面。 我建议您使用其他m值测试结果,并尝试找出一些可能的合成规则(即,大多数 8 位数字都被软分配给C[i]和C[j],因此我们可以假设相应的质心对部分共同特征进行编码,例如,由所有 8 位和 9 位数字共享。
现在,我们可以讨论高斯混合的概念,这是一种非常广泛使用的方法,用于建模以低密度区域包围的密集斑点为特征的数据集的分布。
高斯混合
高斯混合是最著名的软聚类方法之一,具有数十种特定应用。 它可以被认为是 K 均值之父,因为它的工作方式非常相似。 但是,与该算法相反,给定样本x[i] ∈ X和k群集(以高斯分布表示),它提供了一个概率向量, [p(x [i] ∈ C[1]), ..., p(x [i] ∈ C[k])]。
以更一般的方式,如果数据集X已从数据生成过程p_data中采样,高斯混合模型基于以下假设:
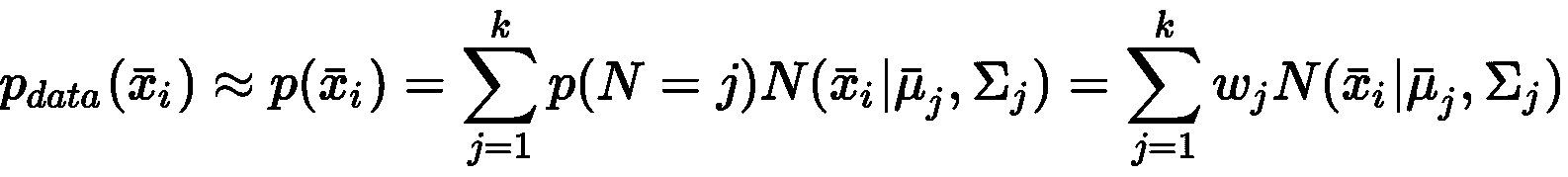
换句话说,数据生成过程通过多元高斯分布的加权和来近似。 这种分布的概率密度函数如下:

每个多元高斯变量的每个分量的影响都取决于协方差矩阵的结构。 下图显示了双变量高斯分布的三种主要可能性(结果可以轻松扩展到n维空间):
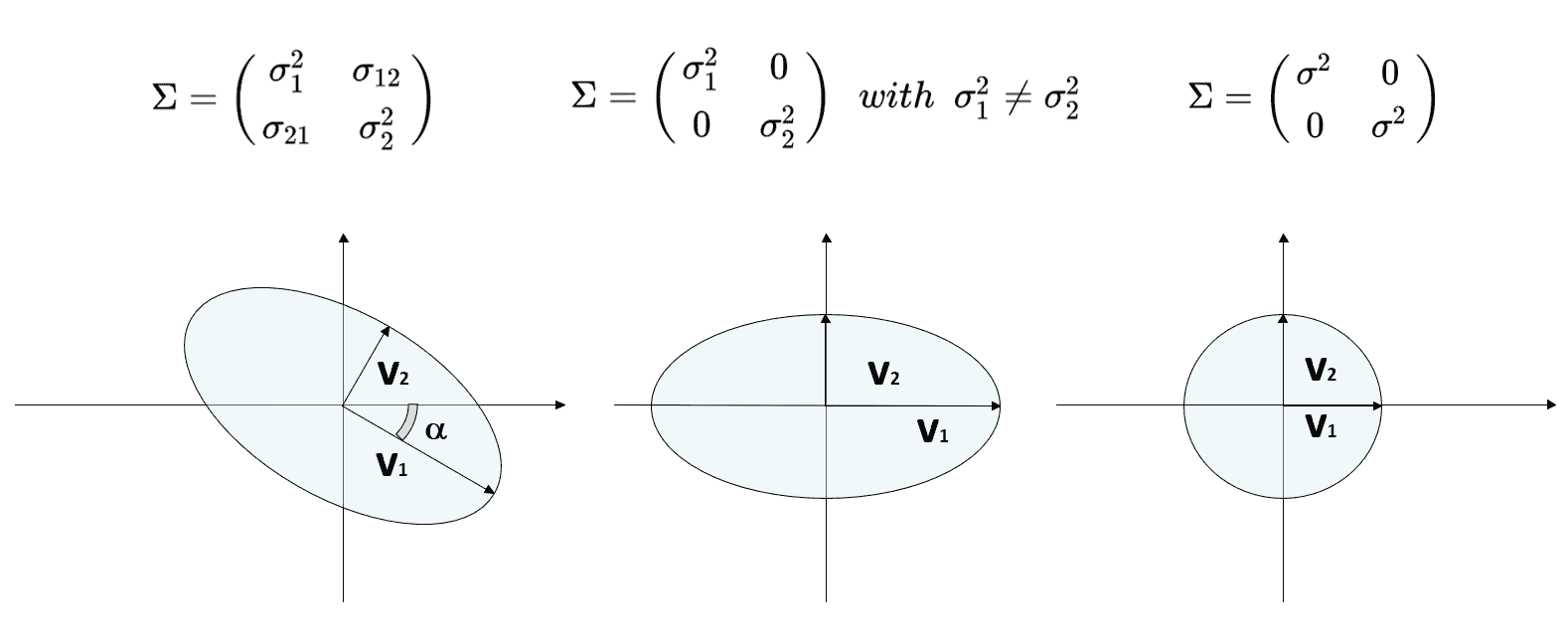
完整协方差矩阵(左); 对角协方差(中心);圆形/球形协方差(右)
从现在开始,我们将一直在考虑完全协方差矩阵的情况,该矩阵可以实现最大的表达能力。 很容易理解,当这样的分布完全对称(即协方差矩阵是圆形/球形)时,伪群集的形状与 K 均值相同(当然 ,在高斯混合中,群集没有边界,但是始终可以在固定数量的标准差后削减高斯)。 相反,当协方差矩阵不是对角线或具有不同的方差时,影响不再是对称的(例如,在双变量的情况下,一个组件可以显示出比另一个更大的方差)。 在这两种情况下,高斯混合均允许我们计算实际概率,而不是测量样本x[i]和平均向量μ[j]之间的距离(以 K 均值表示)。 下图显示了单变量混合的示例:
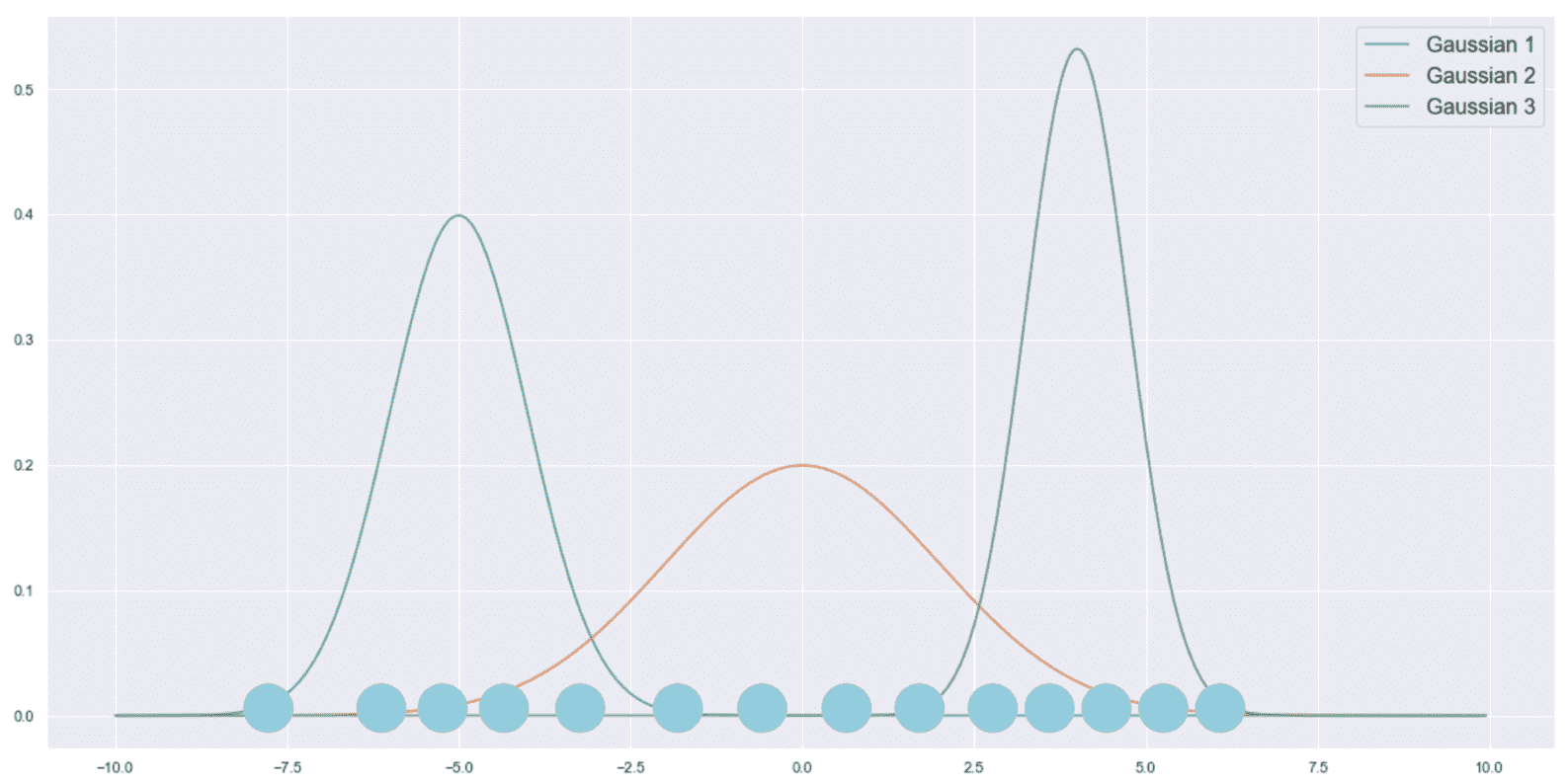
单变量高斯混合的示例
在这种情况下,每个样本在每个高斯下始终具有非零概率,其影响取决于其均值和协方差矩阵。 例如,对应于x-位置的点 2.5 既可以属于中央高斯,也可以属于右手的点(而左手的影响最小)。 如本章开头所述,通过选择影响最大的组件(argmax),可以将任何软聚类算法转换为硬聚类算法。
您将立即理解,在这种特定情况下,对于对角协方差矩阵,argmax 提供了一条附加信息(该信息已被 K 均值完全丢弃),可用于进一步的处理步骤(即, 推荐器应用可以提取所有群集的主要特征,然后根据相对概率对它们进行加权。
高斯混合的 EM 算法
完整算法(在《精通机器学习算法》中进行了全面描述)比 K 均值稍微复杂一点,并且需要更深层次的知识。 数学知识。 由于本书的范围更实际,因此我们仅讨论主要步骤,而没有提供正式证据。
让我们首先考虑一个数据集X,其中包含n个样本:
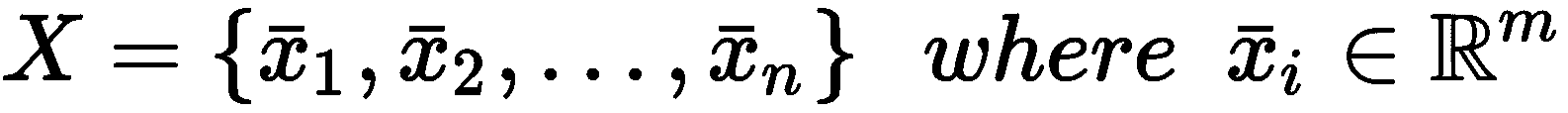
给定k分布,我们需要找到权重w[j]以及每个高斯μ[j], Σ[j],其条件如下:
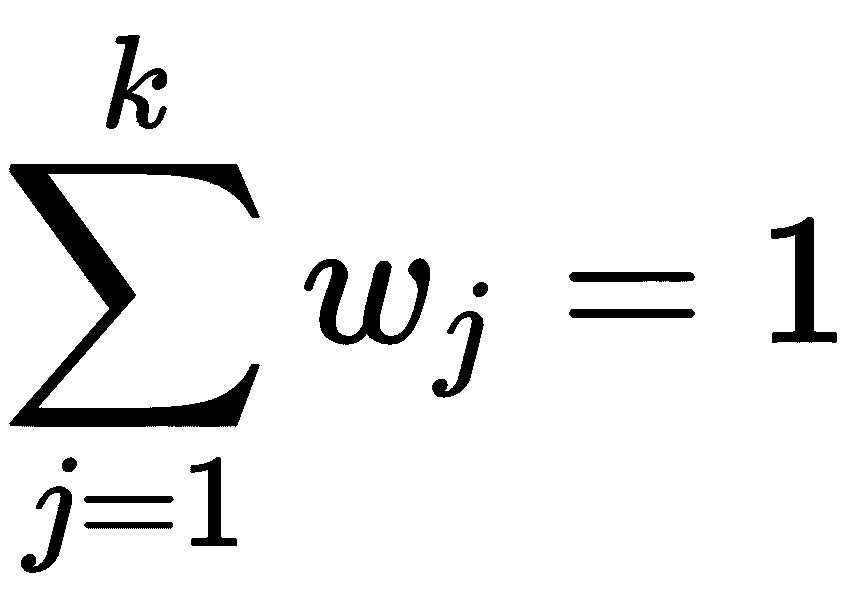
这最后一个条件对于保持与概率定律的一致性是必要的。 如果将所有参数归为一个集合,则θ[j] = (w[j], μ[j], σ[j]),我们可以定义高斯j下样本x[i]的概率,如下所示:
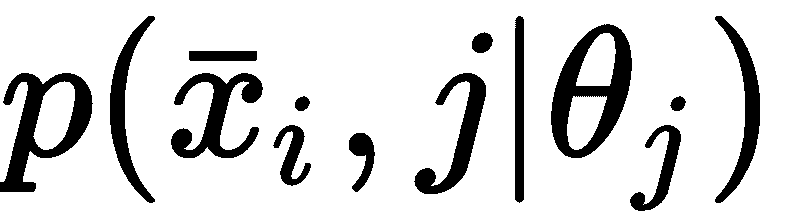
以类似的方式,我们可以引入伯努利分布,z[i][j] = p(j | x[i], θ[j]) ~ B(p),这是第j个高斯产生样本x[i]的概率。 换句话说,给定一个样本x[i],z[ij]等于 1,概率为p(j | x[i], θ[j]),否则为 0。
此时,我们可以计算整个数据集的联合对数似然,如下所示:
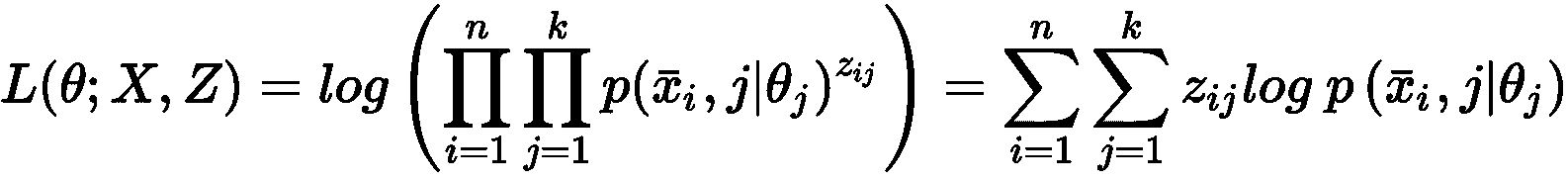
在前面的公式中,我们利用指数指示符表示法,它依赖于z[ij]只能为 0 或 1 的事实。因此,当z[ij] = 0,这意味着第j个高斯尚未生成样本x[i]乘积中的对应项变为 1(即x ^ 0 = 1)。 相反,当z[ij] = 1时,该项等于x[i]和第j个高斯。 因此,假设每个x[i] ∈ X独立同分布,则联合对数似然是模型已生成整个数据集的联合概率(IID)。 要解决的问题是最大似然估计(MLE),换句话说,就是找到最大化L(θ; X, Z)。 但是,没有观察到(或隐含)变量z[ij],因此无法直接最大化可能性,因为我们不知道它们的值。
解决此问题的最有效方法是采用 EM 算法。 完整的解释超出了本书的范围,但是我们想提供主要步骤。 首先要做的是使用概率的链式规则,以便将先前的表达式转换为条件概率的总和(可以很容易地对其进行管理):
这两个概率现在很简单。 项p(x[i] | j, θ[j])是x[i]在第j个高斯之下的概率,而p(j | θ[j])只是第j个高斯的概率,它等于权重w[j]的权重。 为了消除潜在变量,EM 算法以迭代方式进行,由两个步骤组成。 第一个(称为期望步骤或 E 步骤)是对没有潜在变量的似然性的代理计算。 如果将整个参数集表示为θ,并且在迭代t时计算出的同一参数集为x[i],则可以计算出以下函数:
Q(θ | θ[t])是相对于变量z[ij]的联合对数似然的期望值。并以数据集X和迭代时设置的参数t为条件。 此操作的作用是删除潜在变量(相加或积分后的值),并得出实际对数似然的近似值。 不难想象,第二步(称为最大化步骤或 M 步骤)的目标是最大化Q(θ | θ[t])生成一个新的参数集θ[t + 1]。 重复该过程,直到参数变得稳定为止,并且有可能证明最终的参数集与 MLE 相对应。 跳过所有中间步骤,并假设最佳参数集为$1[$2],最终结果如下:
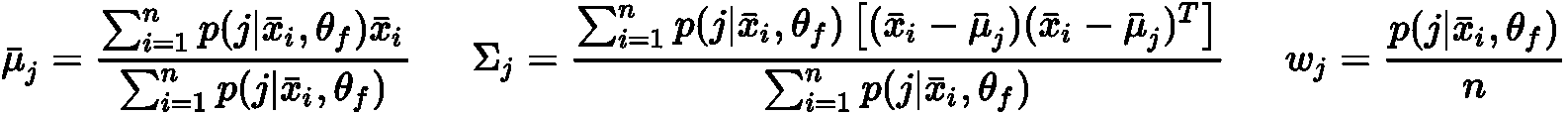
为了清楚起见,可以通过使用贝叶斯定理来计算p(j | x[i], θ[f])的概率:
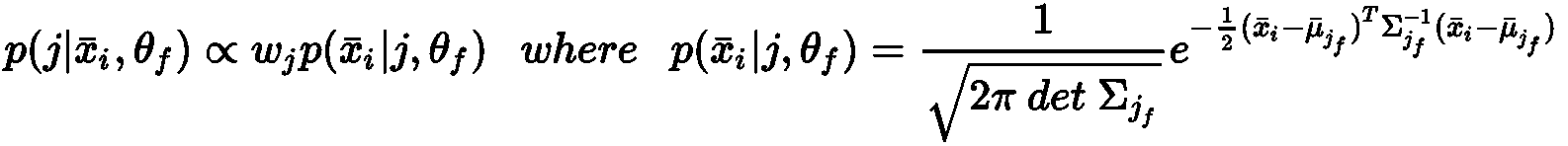
可以通过将所有项归一化以使它们的总和等于 1(满足概率分布的要求)来消除比例性。
现在,让我们考虑使用 scikit-learn 的实际示例。 由于目标纯粹是说教性的,因此我们使用了可以轻松可视化的二维数据集:
from sklearn.datasets import make_blobs
nb_samples = 300
nb_centers = 2
X, Y = make_blobs(n_samples=nb_samples, n_features=2, center_box=[-1, 1], centers=nb_centers, cluster_std=[1.0, 0.6], random_state=1000)
该数据集是通过对两个具有不同标准差(1.0 和 0.6)的高斯分布进行采样而生成的,如以下屏幕截图所示:
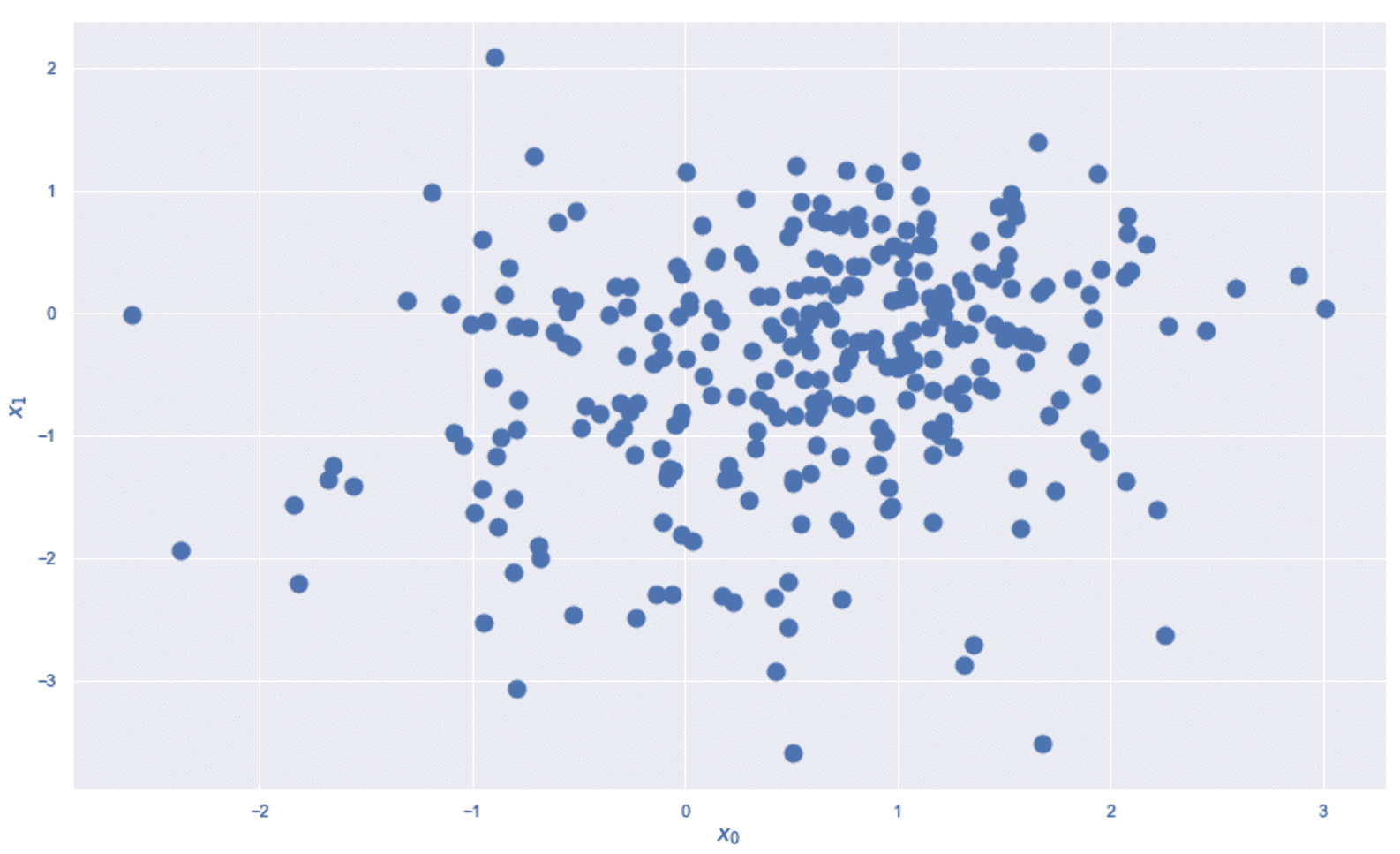
高斯混合示例的数据集
我们的目标是同时使用高斯混合模型和 K 均值,并比较最终结果。 正如我们期望的那样,有两个组成部分,数据生成过程的近似如下:
现在我们可以使用n_components=2训练GaussianMixture实例。 默认协方差类型是完整的,但可以通过设置covariance_type参数来更改此选项。 允许的值为full,diag,spherical和tied(这迫使算法对所有高斯使用共享的单个协方差矩阵):
from sklearn.mixture import GaussianMixture
gm = GaussianMixture(n_components=2, random_state=1000)
gm.fit(X)
Y_pred = gm.fit_predict(X)
print('Means: \n{}'.format(gm.means_))
print('Covariance matrices: \n{}'.format(gm.covariances_))
print('Weights: \n{}'.format(gm.weights_))
上一个代码段的输出如下:
Means:
[[-0.02171304 -1.03295837]
[ 0.97121896 -0.01679101]]
Covariance matrices:
[[[ 0.86794212 -0.18290731]
[-0.18290731 1.06858097]]
[[ 0.44075382 0.02378036]
[ 0.02378036 0.37802115]]]
Weights:
[0.39683899 0.60316101]
因此,MLE 产生两个成分,其中一个成分占主导地位(即w[2] = 0.6)。 为了知道高斯轴的方向,我们需要计算协方差矩阵的归一化特征向量(这一概念将在第 7 章,“降维和成分分析”中):
import numpy as np
c1 = gm.covariances_[0]
c2 = gm.covariances_[1]
w1, v1 = np.linalg.eigh(c1)
w2, v2 = np.linalg.eigh(c2)
nv1 = v1 / np.linalg.norm(v1)
nv2 = v2 / np.linalg.norm(v2)
print('Eigenvalues 1: \n{}'.format(w1))
print('Eigenvectors 1: \n{}'.format(nv1))
print('Eigenvalues 2: \n{}'.format(w2))
print('Eigenvectors 2: \n{}'.format(nv2))
输出如下:
Eigenvalues 1:
[0.75964929 1.17687379]
Eigenvectors 1:
[[-0.608459 -0.36024664]
[-0.36024664 0.608459 ]]
Eigenvalues 2:
[0.37002567 0.4487493 ]
Eigenvectors 2:
[[ 0.22534853 -0.6702373 ]
[-0.6702373 -0.22534853]]
在两个高斯变量中(一旦被截断并从顶部观察,都可以想象成椭圆),主要成分是第二个成分(即第二列,对应于最大的特征值)。 椭圆的偏心率由特征值之间的比率确定。 如果比率等于 1,则形状为圆形,而高斯完美对称。 否则,它们会沿轴拉伸。 主要成分与x轴之间的角度(度)如下:
import numpy as np
a1 = np.arccos(np.dot(nv1[:, 1], [1.0, 0.0]) / np.linalg.norm(nv1[:, 1])) * 180.0 / np.pi
a2 = np.arccos(np.dot(nv2[:, 1], [1.0, 0.0]) / np.linalg.norm(nv2[:, 1])) * 180.0 / np.pi
先前的公式基于主要成分v[1]与e[0] (即[1, 0]):
在显示最终结果之前,使用 K 均值对数据集进行聚类将很有帮助:
from sklearn.cluster import KMeans
km = KMeans(n_clusters=2, random_state=1000)
km.fit(X)
Y_pred_km = km.predict(X)
群集结果显示在以下屏幕截图中:
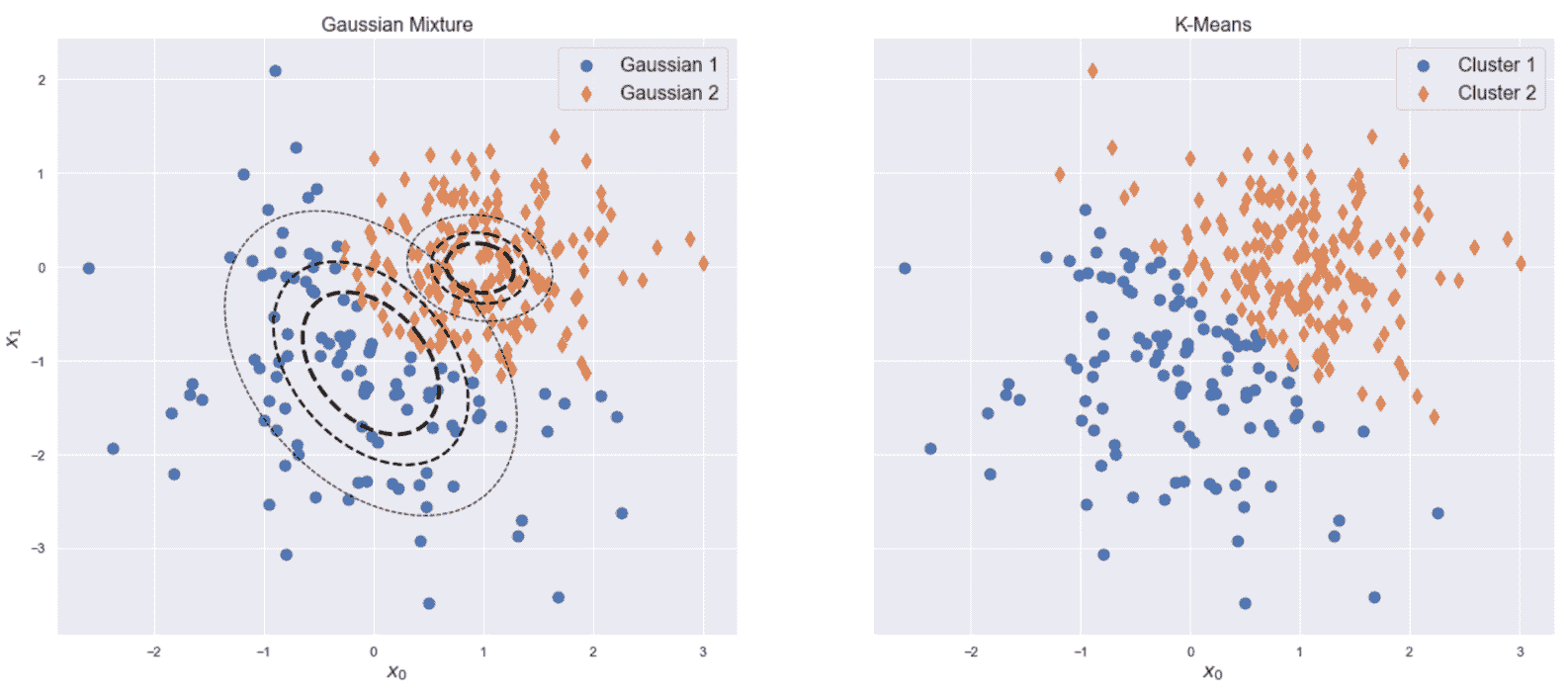
高斯混合结果(左)具有三个水平截面的形状; K 均值结果(右)
不出所料,这两种算法都产生非常相似的结果,并且主要差异是由于高斯算法的非对称性造成的。 特别地,与数据集的左下部分相对应的伪群集在两个方向上均具有较大的方差,并且对应的高斯是主要的。 为了检查混合物的行为,让我们计算三个临界样本点的概率(0, -2), (1, -1)以及(1, 0),使用predict_proba()方法:
print('P([0, -2]=G1) = {:.3f} and P([0, -2]=G2) = {:.3f}'.format(*list(gm.predict_proba([[0.0, -2.0]]).squeeze())))
print('P([1, -1]=G1) = {:.3f} and P([1, -1]=G2) = {:.3f}'.format(*list(gm.predict_proba([[1.0, -1.0]]).squeeze())))
print('P([1, 0]=G1) = {:.3f} and P([1, 0]=G2) = {:.3f}'.format(*list(gm.predict_proba([[1.0, 0.0]]).squeeze())))
前一个块的输出如下:
P([0, -2]=G1) = 0.987 and P([0, -2]=G2) = 0.013
P([1, -1]=G1) = 0.354 and P([1, -1]=G2) = 0.646
P([1, 0]=G1) = 0.068 and P([1, 0]=G2) = 0.932
我邀请读者使用其他协方差类型重复该示例,然后将所有硬分配与 K 均值进行比较。
使用 AIC 和 BIC 评估高斯混合的表现
由于高斯混合是一个概率模型,因此要找到最佳的组件数,需要的方法不同于前面章节中分析的方法。 赤池信息准则(AIC)是使用最广泛的技术之一,它基于信息论(请见《统计模型识别》)。 如果概率模型具有n[p]参数(即,必须学习的单个值)并且达到最大负对数可能性,则$1[$2],AIC 定义如下:
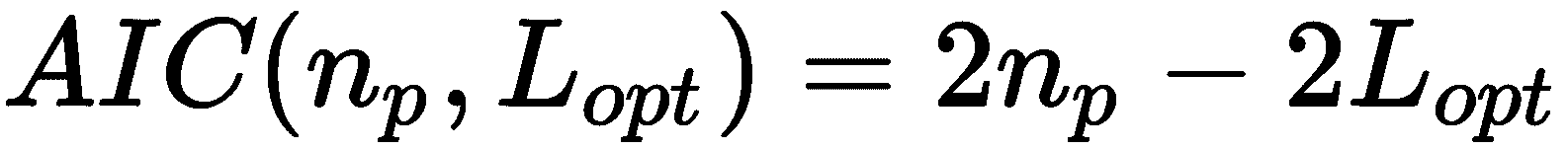
这种方法有两个重要含义。 第一个是关于值本身。 AIC 越小,得分越高。 实际上,考虑到奥卡姆(Occam)的剃刀原理,模型的目的是用最少的参数获得最佳的似然性。 第二个含义与信息理论严格相关(我们不在讨论数学上繁琐的细节),尤其是与数据生成过程和通用概率模型之间的信息丢失有关。 可以证明 AIC 的渐近最小化(即,当样本数量趋于无穷大时)等于信息丢失的最小化。 考虑基于不同成分数量的几种高斯混合(n[p]是所有权重,均值和协方差参数的总和),具有最小 AIC 的配置对应于使用最高精度再现数据生成过程的模型。 AIC 的主要局限性在于小型数据集。 在这种情况下,AIC 倾向于针对大量参数达到最小值,这与 Occam 的剃刀原理相反。 但是,在大多数现实生活中,AIC 提供了一种有用的相对措施,可以帮助数据科学家排除许多配置并仅分析最有前途的配置。
当需要强制将参数的数量保持在非常低的水平时,可以使用贝叶斯信息准则(BIC),其定义如下:
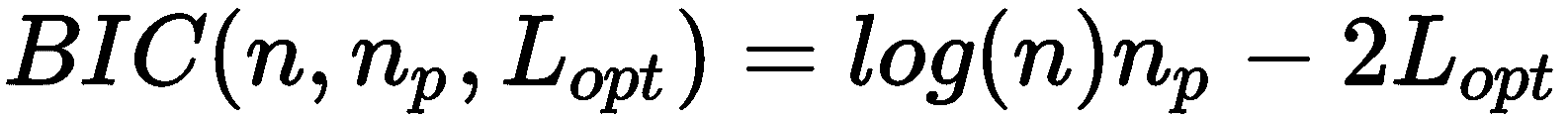
在先前的公式中,n是样本数(例如,对于n = 1000并使用自然对数,惩罚约为 6.9); 因此,BIC 几乎等同于 AIC,对参数数量的惩罚更大。 但是,即使 BIC 倾向于选择较小的模型,结果通常也不如 AIC 可靠。 BIC 的主要优势在于,当n → ∞时,数据生成过程p_data与模型之间的 Kullback-Leibler 差异,p[m](具有最小的 BIC)趋向于 0:
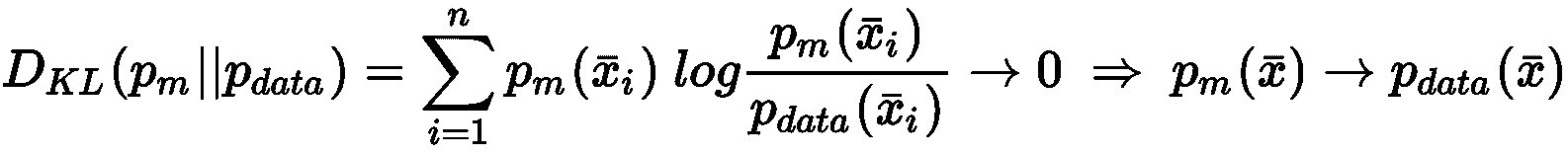
当两个分布相同时,由于 Kullback-Leibler 散度为零,因此先前的条件意味着 BIC 倾向于渐近地选择精确地再现数据生成过程的模型。
现在,让我们考虑前面的示例,检查 AIC 和 BIC 是否有不同数量的组件。 Scikit-learn 将这些度量合并为GaussianMixture类的方法(aic()和bic())。 此外,我们还想计算每个模型获得的最终对数似然率。 这可以通过将score()方法获得的值乘以(每个样本的平均对数似然率乘以样本数)来实现,如下所示:
from sklearn.mixture import GaussianMixture
n_max_components = 20
aics = []
bics = []
log_likelihoods = []
for n in range(1, n_max_components + 1):
gm = GaussianMixture(n_components=n, random_state=1000)
gm.fit(X)
aics.append(gm.aic(X))
bics.append(gm.bic(X))
log_likelihoods.append(gm.score(X) * nb_samples)
生成的图显示在以下屏幕截图中:
高斯混合物的 AIC,BIC 和对数似然(组件数量在(1, 20))
在这种情况下,我们知道数据集是由两个高斯分布生成的,但是让我们假设我们没有这条信息。 AIC 和 BIC 都具有n[c] = 2的(局部)最小值。 但是,尽管 BIC 越来越大,但 AIC 的伪全局最小值为n[c] = 18*。 因此,如果我们信任 AIC,则应该选择 18 个分量,这等效于以许多高斯对数据集进行超细分,并且方差很小。 另一方面, n[c] = 2和n[c] = 18之间的差异值不是很大,因此考虑到简单得多,我们也可以选择以前的配置。 BIC 确认了这种选择。 实际上,即使还有一个局部最小值对应于n[c] = 18,其值也比n[c] = 2。 正如我们之前所解释的,这种行为是由于 BIC 施加的样本量额外罚款。 对于n[c] = 2,每个二元高斯变量需要一个权重变量,两个均值变量和四个协方差矩阵变量,我们得到n[p] = 2 (1 + 2 + 4) = 14,对于n[c] = 18,我们得到n[p] = 18 (1 + 2 + 4) = 126。 由于有 300 个样本,BIC 会受到log(300) ≈ 5.7的惩罚,这会导致 BIC 增加约 350。随着n[c]变大(因为在极端情况下,每个点都可以被视为由具有零方差的单个高斯生成,等效于狄拉克三角洲),因此参数数量在模型选择过程中起主要作用。
没有任何额外的惩罚,很可能会选择更大的模型作为最佳选择,但是在聚类过程中,我们还需要强制执行最大分离原则。 这种情况部分与更少的组件有关,因此 BIC 应该成为最佳方法。 通常,我建议比较两个标准,以尝试找到与 AIC 和 BIC 之间的最大协议相对应的n[c]。 此外,还应考虑基本的背景知识,因为许多数据生成过程具有明确定义的行为,并且有可能通过排除所有不现实的值来限制潜在组件的范围。 我邀请读者以n[c] = 18重复前面的示例,绘制所有高斯曲线并比较某些特定点的概率。
使用贝叶斯高斯混合进行成分选择
贝叶斯高斯混合模型是基于变分框架的标准高斯混合的扩展。 该主题相当高级,需要进行全面的数学描述,这超出了本书的范围(您可以在《高斯混合模型的变分学习》找到)。 但是,在讨论主要属性之前,了解主要概念和不同之处将很有帮助。 假设我们有一个数据集X,以及一个用向量θ参数化的概率模型。 在前面的部分中,您看到了p(X | θ)的可能性是L(θ | X)的可能性, 最大化它会导致产生概率最大的X模型。 但是,我们没有对参数施加任何约束,它们的最终值仅取决于X。 如果我们引入贝叶斯定理,我们将得到以下结果:
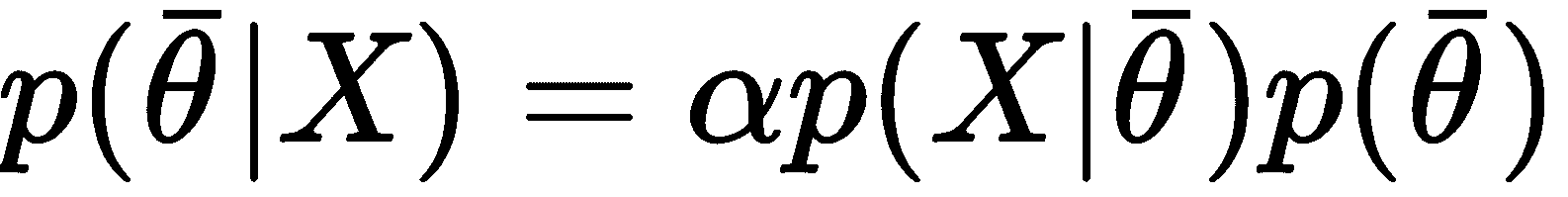
给定数据集,左侧是参数的后验概率,我们知道它与似然度乘以参数的先验概率成正比。 在标准 MLE 中,我们仅处理p(X | θ),但是,当然,我们也可以包含一部分θ的先验知识 (根据概率分布),并最大化 p(θ | X)或比例代理函数。 但是,一般来讲,p(θ | X)很难处理,而先前的p(θ)通常很难定义,因为关于高概率区域的知识不足。 因此,最好将参数建模为以η(所有特定参数的集合,例如均值,系数等)为参数的概率分布,并引入变分后验,q(θ | X; η)近似于实分布。
这种工具是称为变分贝叶斯推断(您可以在上述论文中找到更多详细信息)的技术的关键元素,它使我们能够轻松找到最佳参数而无需使用实际的p(X | θ)。 特别是,在高斯混合中,存在三组不同的参数,并且使用适当的分布对每个参数进行建模。 在这种情况下,我们不希望讨论这些选择的细节,但是理解其原理是有用的。
在贝叶斯框架中,给定可能性,p(X | θ)是属于后验的同一族的概率密度函数p(θ),p(θ | X)被称为优先于的共轭物。 在这种情况下,显然可以简化此过程,因为可能性的影响仅限于修改前一个参数。 因此,由于似然是正态的,因此为了对均值建模,我们可以采用正态分布(相对于均值的共轭先验),对于协方差矩阵,我们可以使用 Wishart 分布(即相对于协方差矩阵的逆的共轭先验)。 在此讨论中,不必熟悉所有这些分布(正态分布除外),但是记住它们是共轭先验是有帮助的,因此,在对参数进行初步猜测时,可能性的作用是调整给定数据集,以便最大程度地提高联合概率。
由于对混合物的权重进行了归一化处理,因此它们的总和必须始终等于 1,并且我们只想自动选择大量组分的子集,因此可以使用 Dirichlet 分布,该分布具有以下有用的特性: 疏。 换句话说,给定一组权重w[1], w[2], ..., w[n]的 Dirichlet 分布趋于使大多数权重的概率相当低,而较小的非空权重子集则决定了主要贡献。 Dirichlet 过程提供了一种替代方法,该过程是一种生成概率分布的特定随机过程。 在这两种情况下,目标都是调整单个参数(称为权重集中度参数),该参数增加或减少具有稀疏分布(或简单地说是 Dirichlet 分布的稀疏性)的可能性。
Scikit-learn 实现了贝叶斯高斯混合(通过BayesianGaussianMixture类),该混合可以基于 Dirichlet 过程和分布。 在此示例中,我们将保留默认值(process),并检查不同浓度值(weight_concentration_prior参数)的行为。 还可以针对逆协方差调整高斯平均值的均值和维沙特的自由度。 但是,在没有任何特定先验知识的情况下,很难设置这些值(我们假设我们不知道均值可能位于何处或协方差矩阵的结构),因此,最好保留从问题的结构中得出的值。 因此,均值(高斯)将等于X的均值(可以通过mean_precision_prior参数控制位移; < 1.0的值倾向于移动)。X平均值的单一均值,而较大的值会增加位移),并且将自由度(Wishart)的数量设置为等于特征的数量(X的维数)。 在许多情况下,这些参数会在学习过程中自动进行调整,因此无需更改其初始值。 相反,可以调整weight_concentration_prior,以增加或减少有效成分的数量(即,其权重不接近零或比其他权重低得多)。
在此示例中,我们将使用 5 个部分重叠的高斯分布(特别是其中 3 个共享非常大的重叠区域)生成 500 个二维样本:
from sklearn.datasets import make_blobs
nb_samples = 500
nb_centers = 5
X, Y = make_blobs(n_samples=nb_samples, n_features=2, center_box=[-5, 5],
centers=nb_centers, random_state=1000)
让我们从较大的重量浓度参数(1000)和最大成分数等于5开始。 在这种情况下,我们期望找到大量(可能是5)的活动组件,因为 Dirichlet 流程无法实现高度的稀疏性:
from sklearn.mixture import BayesianGaussianMixture
gm = BayesianGaussianMixture(n_components=5, weight_concentration_prior=1000,
max_iter=10000, random_state=1000)
gm.fit(X)
print('Weights: {}'.format(gm.weights_))
上一个代码段的输出如下:
Weights: [0.19483693 0.20173229 0.19828598 0.19711226 0.20803253]
正如预期的那样,所有组件的权重都大致相同。 为了得到进一步的确认,我们可以检查几乎没有(通过argmax函数)分配给每个样本的样本数量,如下所示:
Y_pred = gm.fit_predict(X)
print((Y_pred == 0).sum())
print((Y_pred == 1).sum())
print((Y_pred == 2).sum())
print((Y_pred == 3).sum())
print((Y_pred == 4).sum())
输出如下:
96
102
97
98
107
因此,平均而言,所有高斯人都产生相同数量的点。 最终配置显示在以下屏幕截图中:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zm70XfsG-1681652575127)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/handson-unsup-learn-py/img/c391f825-4d97-41f7-965e-79ccd22623fe.png)]
最终配置,具有五个活动组件
该模型通常可以接受; 但是,假设我们知道根本原因(即产生高斯分布)的数量可能是 4,而不是 5。我们可以尝试的第一件事是保持原始的最大组件数量并减少组件数量。 重量浓度参数(即 0.1)。 如果近似值可以使用较少的高斯分布成功生成X,则应该找到一个空权重:
gm = BayesianGaussianMixture(n_components=5, weight_concentration_prior=0.1,
max_iter=10000, random_state=1000)
gm.fit(X)
print('Weights: {}'.format(gm.weights_))
现在的输出如下:
Weights: [3.07496936e-01 2.02264778e-01 2.94642240e-01 1.95417680e-01 1.78366038e-04]
可以看到,第五个高斯的权重比其他高斯小得多,可以完全丢弃(我请您检查是否几乎没有分配一些样本)。 以下屏幕快照显示了具有四个活动组件的新配置:
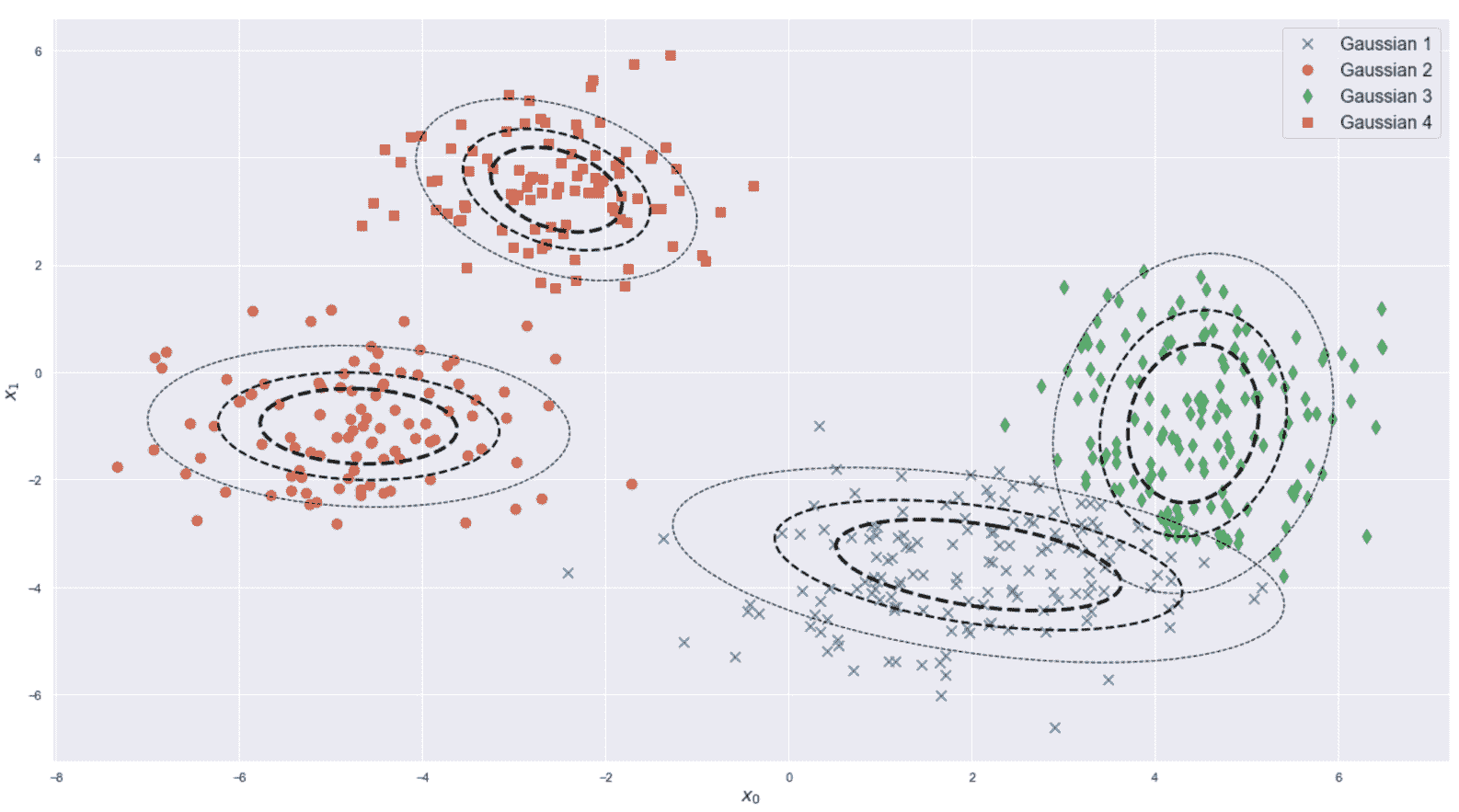
最终配置,具有四个活动组件
可以看到,该模型执行了组件数量的自动选择,并且已将较大的右 Blob 分成几乎正交的两个部分。 即使使用大量初始组件(例如 10 个)训练模型,此结果也保持不变。 作为练习,我建议使用其他值重复该示例,检查权重之间的差异。 贝叶斯高斯混合因避免过拟合的能力而非常强大。 实际上,虽然标准的高斯混合将通过减小它们的协方差来使用所有成分,但必要时(以便覆盖密集区域),这些模型利用了 Dirichlet 过程/分布的特性,以避免激活成分过多。 例如,可以通过检查模型可实现的最少组件数来深入了解潜在的数据生成过程。 在没有任何其他先验知识的情况下,这样的值是最终配置的良好候选者,因为较少数量的组件也将产生较低的最终可能性。 当然,可以将 AIC / BIC 与这种方法一起使用,以进行另一种形式的确认。 但是,与标准高斯混合的主要区别在于可以包括来自专家的先验信息(例如,均值和协方差的原因结构)。 因此,我邀请您通过更改mean_precision_prior的值来重复该示例。 例如,可以将mean_prior参数设置为与X的平均值不同的值,并调整 mean_precision_prior,以便基于某些先验知识强制模型实现不同的细分(即,区域中的所有样本应由特定组件生成)。
生成式高斯混合
高斯混合模型主要是生成模型。 这意味着训练过程的目标是优化参数,以最大程度地提高模型生成数据集的可能性。 如果假设是正确的,并且已经从特定的数据生成过程中采样了X,则最终近似值必须能够生成所有其他可能的采样。 换句话说,我们假设x[i] ∈ X是 IDD,并且x[i] ~ p_data; 因此,当找到最佳近似值p ≈ p_data时,所有样本x[j]的概率p的数据也很可能生成。
在此示例中,我们要在半监督场景中采用高斯混合模型。 这意味着我们有一个既包含标记样本又包含未标记样本的数据集,并且我们希望将标记样本用作基础事实并找出可以生成整个数据集的最佳混合。 当标记非常大的数据集非常困难且昂贵时,这种情况非常普遍。 为了克服这个问题,可以标记统一采样的子集并训练生成模型,该模型能够以最大可能的可能性生成剩余样本。
我们将采用一个简单的过程,使用主要步骤中讨论的权重,均值和协方差矩阵的更新公式,如下所示:
- 所有标记的样本均被视为事实依据。 因此,如果有 k 个类别,我们还需要定义
k个组件,并将每个类别分配给其中一个。 因此,如果x[i]是标有y[i] = {1, 2, ..., k}的通用样本, 相应的概率向量将是p(x[i]) = (0, 0, ..., 1, 1, 0, ..., 0),其中 1 对应于与y[i]类相关的高斯。 换句话说,我们信任标记的样本,并强制单个高斯生成具有相同标记的子集。 - 所有未标记的样本均以标准方式处理,概率向量是通过将权重乘以每个高斯下的概率来确定的。
让我们首先生成一个包含 500 个二维样本(标记为100,其余标记为未标记),真实标记为0和1且未标记为-1的数据集:
from sklearn.datasets import make_blobs
nb_samples = 500
nb_unlabeled = 400
X, Y = make_blobs(n_samples=nb_samples, n_features=2, centers=2, cluster_std=1.5, random_state=100)
unlabeled_idx = np.random.choice(np.arange(0, nb_samples, 1), replace=False, size=nb_unlabeled)
Y[unlabeled_idx] = -1
此时,我们可以初始化高斯参数(权重选择为相等,并且协方差矩阵必须为正半定。如果读者不熟悉此概念,则可以说对称方阵A ∈ if^(n×n)在以下情况下为正半定数:
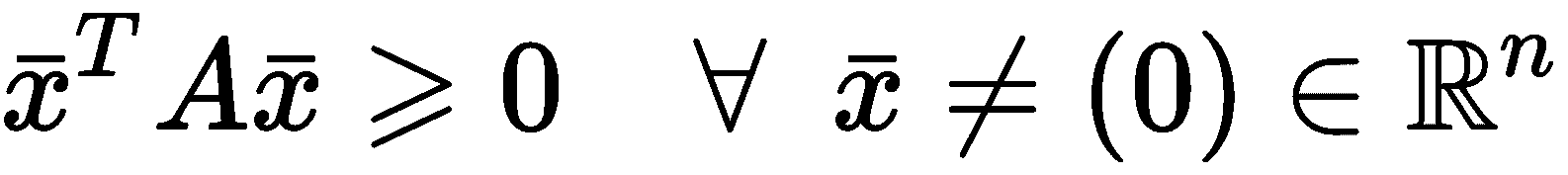
此外,所有特征值都是非负的,特征向量生成正交的基础(当在第 7 章,“降维和成分分析”中讨论 PCA 时,此概念将非常有用)。
如果协方差矩阵是随机选择的,则为了使其为正半定值,有必要将它们的每一个乘以其转置):
import numpy as np
m1 = np.array([-2.0, -2.5])
c1 = np.array([[1.0, 1.0],
[1.0, 2.0]])
q1 = 0.5
m2 = np.array([1.0, 3.0])
c2 = np.array([[2.0, -1.0],
[-1.0, 3.5]])
q2 = 0.5
下面的屏幕快照显示了数据集和初始高斯分布:
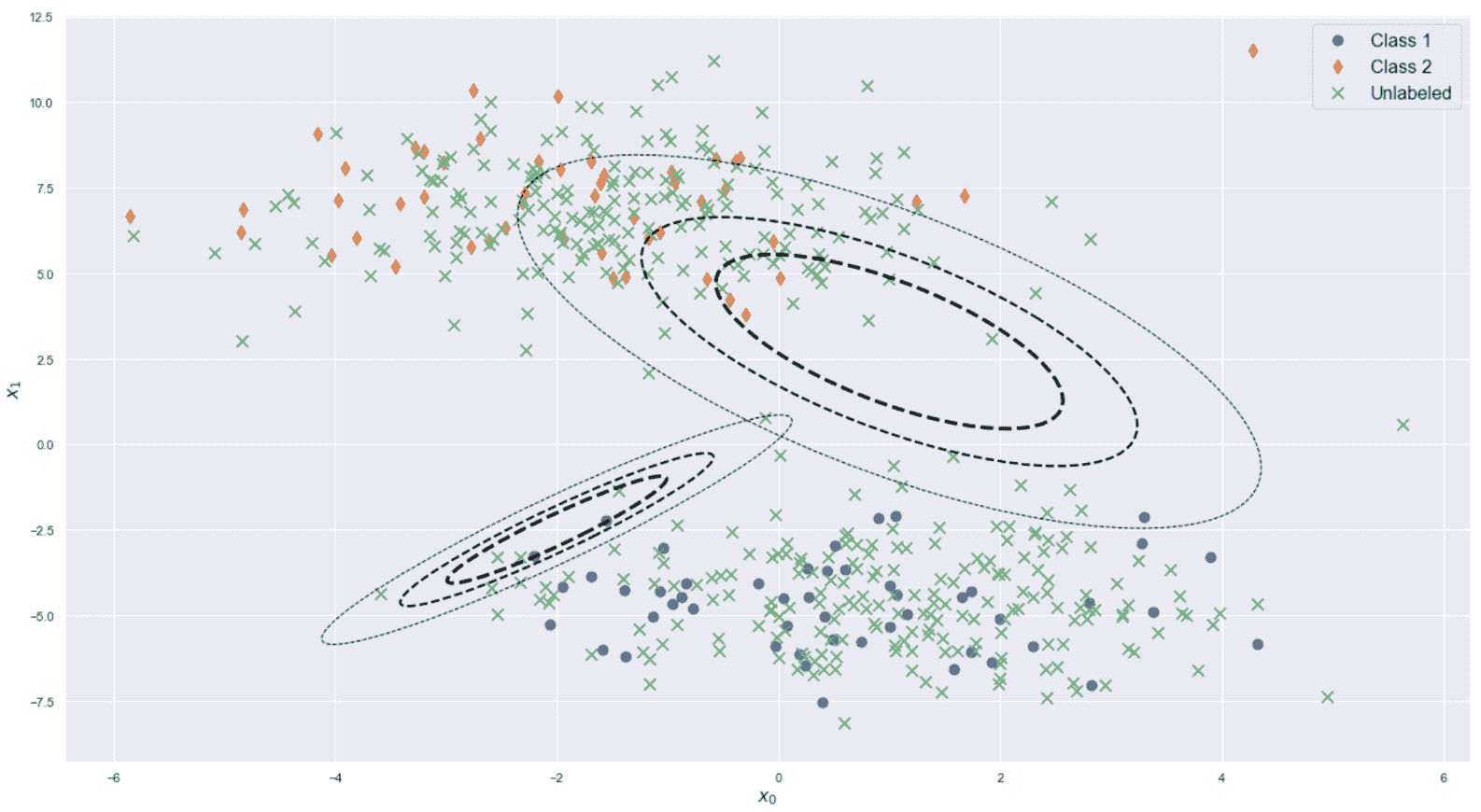
数据集(未标记的样本用x标记)和初始配置
现在,我们可以按照先前定义的规则执行几次迭代(本例中为 10 次)(当然,也可以检查参数的稳定性,以停止迭代)。 使用 SciPy multivariate_normal类计算每个高斯下的概率:
from scipy.stats import multivariate_normal
nb_iterations = 10
for i in range(nb_iterations):
Pij = np.zeros((nb_samples, 2))
for i in range(nb_samples):
if Y[i] == -1:
p1 = multivariate_normal.pdf(X[i], m1, c1, allow_singular=True) * q1
p2 = multivariate_normal.pdf(X[i], m2, c2, allow_singular=True) * q2
Pij[i] = [p1, p2] / (p1 + p2)
else:
Pij[i, :] = [1.0, 0.0] if Y[i] == 0 else [0.0, 1.0]
n = np.sum(Pij, axis=0)
m = np.sum(np.dot(Pij.T, X), axis=0)
m1 = np.dot(Pij[:, 0], X) / n[0]
m2 = np.dot(Pij[:, 1], X) / n[1]
q1 = n[0] / float(nb_samples)
q2 = n[1] / float(nb_samples)
c1 = np.zeros((2, 2))
c2 = np.zeros((2, 2))
for t in range(nb_samples):
c1 += Pij[t, 0] * np.outer(X[t] - m1, X[t] - m1)
c2 += Pij[t, 1] * np.outer(X[t] - m2, X[t] - m2)
c1 /= n[0]
c2 /= n[1]
该过程结束时的高斯混合参数如下:
print('Gaussian 1:')
print(q1)
print(m1)
print(c1)
print('\nGaussian 2:')
print(q2)
print(m2)
print(c2)
上一个代码段的输出如下:
Gaussian 1:
0.4995415573662937
[ 0.93814626 -4.4946583 ]
[[ 2.53042319 -0.10952365]
[-0.10952365 2.26275963]]
Gaussian 2:
0.5004584426337063
[-1.52501526 6.7917029 ]
[[ 2.46061144 -0.08267972]
[-0.08267972 2.54805208]]
正如预期的那样,由于数据集的对称性,权重几乎保持不变,同时均值和协方差矩阵也进行了更新,以使可能性最大化。 最终图显示在以下屏幕截图中:
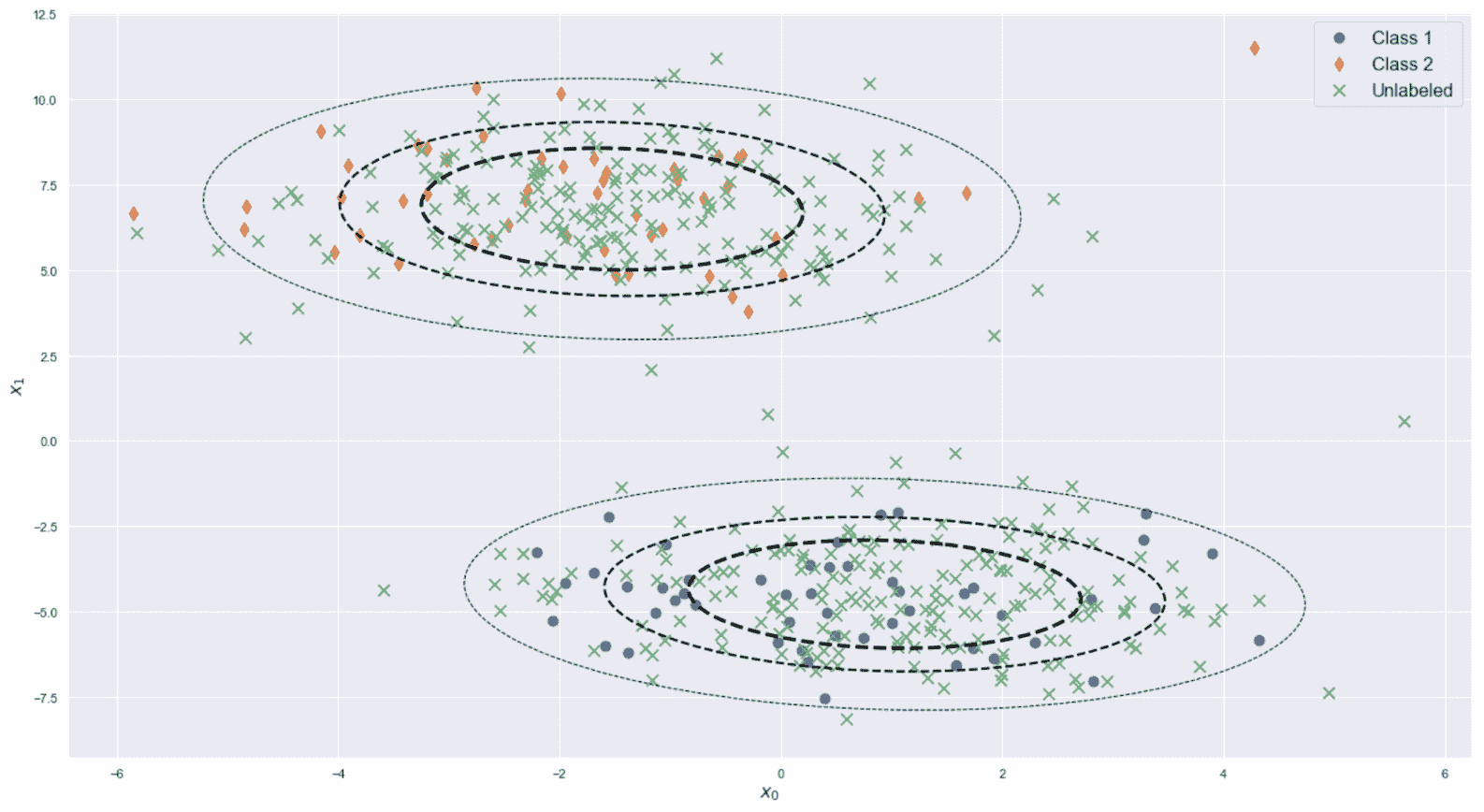
最终配置,经过 10 次迭代
可以看到,两个高斯函数均已成功优化,并且它们能够从充当受信任指南的几个标记样本开始生成整个数据集。 这种方法非常强大,因为它允许我们在不做任何修改的情况下将一些先验知识包括在模型中。 但是,由于标记的样本具有等于 1 的固定概率,因此该方法在异常值方面不是非常可靠。 如果样本尚未通过数据生成过程生成或受噪声影响,则可能导致模型放错高斯分布。 但是,通常不应该考虑这种情况,因为任何先验知识(包括在估计中)都必须进行预评估,以检查其是否可靠。 这样的步骤是必要的,以避免强迫模型仅学习原始数据生成过程的一部分的风险。 相反,当标记的样本真正代表了潜在的过程时,它们的包含减少了误差并加快了收敛速度。 我邀请读者在引入一些噪声点(例如(-20,-10))之后重复该示例,并比较一些未标记的测试样本的概率。
总结
在本章中,我们介绍了一些最常见的软聚类方法,重点介绍了它们的特性和功能。 模糊 c 均值是基于模糊集的概念对经典 K 均值算法的扩展。 群集不被视为互斥分区,而是可以与其他某些群集重叠的灵活集。 所有样本始终分配给所有聚类,但是权重向量确定每个聚类的隶属度。 连续的群集可以定义部分重叠的属性; 因此,对于两个或更多群集,给定样本的权重可能不为零。 大小决定了它属于每个段的数量。
高斯混合是一个生成过程,其基于这样的假设:可以用加权高斯分布的总和来近似实际数据生成过程。 给定预定义数量的组件,对模型进行训练,以使可能性最大化。 我们讨论了如何使用 AIC 和 BIC 作为表现指标,以找出最佳的高斯分布数量。 我们还简要介绍了贝叶斯高斯混合的概念,并研究了先验知识的包含如何帮助自动选择一小部分活性成分。 在最后一部分中,我们讨论了半监督高斯混合的概念,展示了如何使用一些带标记的样本作为指导,以优化带有大量未标记点的训练过程。
在下一章中,我们将讨论核密度估计的概念及其在异常检测领域中的应用。
问题
- 软聚类和硬聚类之间的主要区别是什么?
- 模糊 c 均值可以轻松处理非凸类。 这句话正确吗?
- 高斯混合的主要假设是什么?
- 假设两个模型达到相同的最佳对数似然性; 但是,第一个的 AIC 是第二个的 AIC 的两倍。 这是什么意思?
- 考虑到前面的问题,我们希望使用哪种模型?
- 为什么我们要采用 Dirichlet 分布作为贝叶斯高斯混合物权重的先验?
- 假设我们有一个包含 1,000 个带有标签的样本的数据集,其值已经由专家认证。 我们从相同的来源收集了 5,000 个样本,但我们不想为额外的标签付费。 为了将它们纳入我们的模型,我们该怎么做?
进一步阅读
Theoretical Neuroscience, Dayan P., Abbott L. F., The MIT Press, 2005Maximum Likelihood from Incomplete Data via the EM Algorithm, Journal of the Royal Statistical Society, Dempster A. P., Laird N. M., and Rubin D. B., Series B. 39 (1), 1977A new look at the statistical model identification, Akaike H., IEEE Transactions on Automatic Control, 19 (6)Variational Learning for Gaussian Mixture Models, Nasios N. and Bors A. G., IEEE Transactions on Systems, Man, and Cybernetics, 36/ 4, 08/2006Belohlavek R., Klir G. J. (edited by), Concepts and Fuzzy Logic, The MIT Press, 2011Chapelle O., Schölkopf B., and Zien A. (edited by), Semi-Supervised Learning, The MIT Press, 2010Mastering Machine Learning Algorithms, Bonaccorso G., Packt Publishing, 2018Machine Learning Algorithms, Second Edition, Bonaccorso G., Packt Publishing, 2018