文章目录
- HBase高手之路3—HBase的shell操作
- 一、hbase的shell命令汇总
- 二、需求
- 三、表的操作
- 1.进入shell命令行
- 2.创建表
- 3.查看表的定义
- 4.列出所有的表
- 5.删除表
- 1)禁用表
- 2)启用表
- 3)删除表
- 四、数据的操作
- 1.添加数据
- 2.获取(查看)数据
- 1)获取一行数据
- 2)获取单个数据
- 3.更新(修改)数据
- 4.删除数据
- 1)删除指定列的数据
- 2)删除整行数据
- 3)清空表
- 五、导入数据
- 1.数据文件的准备
- 2.把数据文件上次到服务器
- 3.创建表,根据数据文件的定义
- 4.执行命令导入命令数据文件
- 5.查看数据
- 六、计数操作
- 1.计数命令
- 2.MR程序计数
- 七、扫描操作
- 1.全表扫描
- 2.限定记录数
- 3.限定列
- 4.限定rowkey
- 八、HBase的过滤器
- 1.简介
- 2.过滤器
- 3.过滤器的用法
- 1)比较运算符
- 2)比较器
- 3)比较器表达式
- 4.案例一:查询指定订单id的数据
- 1)需求
- 2)分析
- 3)实现
- 5.案例二:查询状态为已付款的订单
- 1)需求
- 2)分析
- 6.案例三:组合多条件过滤1
- 1)需求
- 2)分析
- 7. 案例四:组合多条件过滤2
- 1)需求
- 2)分析
- 8.作业
- 九、INCR
- 1. 需求
- 2. incr操作
- 3.基本使用
- 4.导入准备好的数据
- 5.获取计数器值的命令
- 6.使用incr进行累加操作,修改计数器的值
- 十、Shell管理操作
- 1.status
- 2.whoami
- 3.list
- 4.count
- 5.describe
- 6.exists
- 7.is_enabled、is_disabled
- 8.alter
- 参考文章

HBase高手之路3—HBase的shell操作
一、hbase的shell命令汇总
| 命令 | 功能 |
|---|---|
| create | 创建表 |
| put | 插入或者更新数据 |
| get | 获取限定行或者列的数据 |
| scan | 全表扫描或扫描表并返回表的数据 |
| describe | 查看表的结构 |
| count | 统计行数 |
| delete | 删除指定的行或列的数据 |
| deleteall | 删除整个行或者列的数据 |
| truncate | 删除表的数据,结构还在 |
| drop | 删除整个表(包括数据) |
二、需求
有以下的订单数据,需要将其保存在HBase中
| 订单id | 订单状态 | 支付金额 | 支付方式 | 用户id | 操作时间 | 商品分类 |
|---|---|---|---|---|---|---|
| 001 | 已付款 | 189.5 | 1 | 100001 | 2023-3-6 9:10:24 | 手机 |
三、表的操作
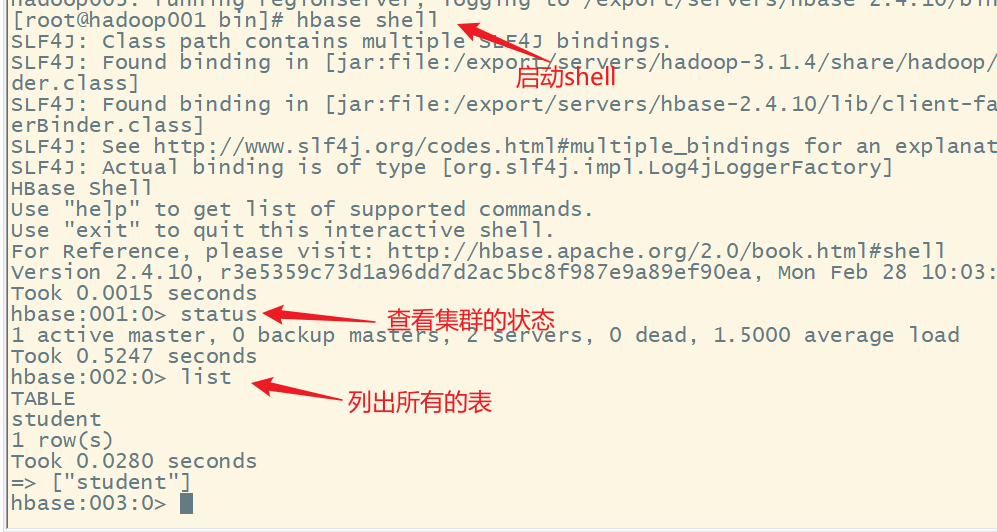
1.进入shell命令行
注意:需要提前启动 ZooKeeper、hdfs、hbase集群
2.创建表
命令格式:
create '表名','列簇名1'[,'列簇名2',...]
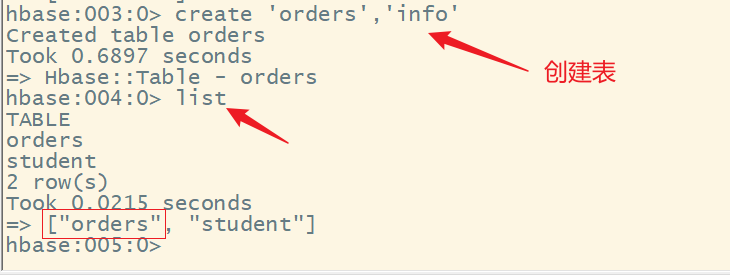
注意:create要小写,一个表可以有多个列簇
3.查看表的定义
命令格式:
describe '表名'

4.列出所有的表
命令格式:
list
5.删除表
1)禁用表
命令格式:
disable '表名'

2)启用表
命令格式:
enable '表名'

3)删除表
命令格式:
drop '表名'
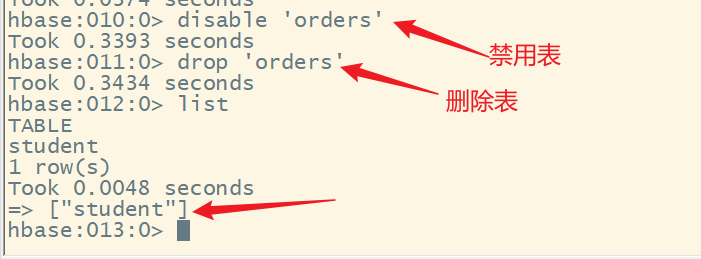
注意:表处于启用状态时是无法删除的,若要删除表需要先禁用表,在进行删除。
四、数据的操作
1.添加数据
命令格式:
put '表名','rowkey行键','列簇名:列名',值

依次添加其他的数据

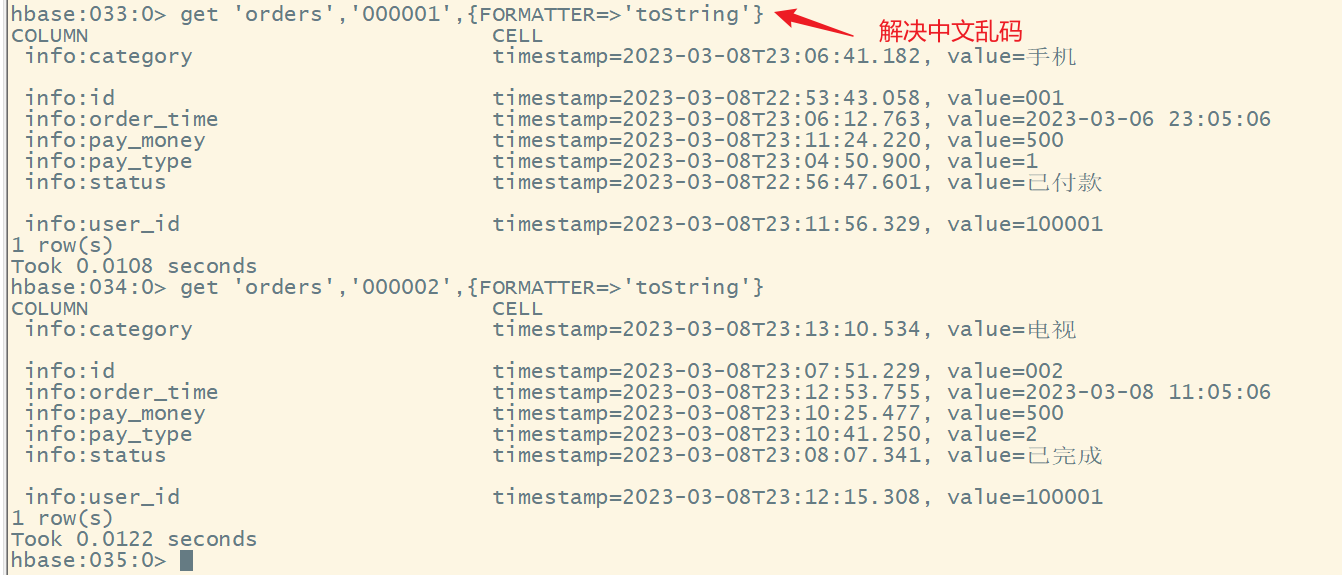
注意:如果显示中文乱码,是因为hbase的shell中显示的是中文的十六进制编码,要解决中文乱码,需要添加选项,jrubby语法格式:
{属性名=>属性值}如果有多个属性,中间用逗号格式

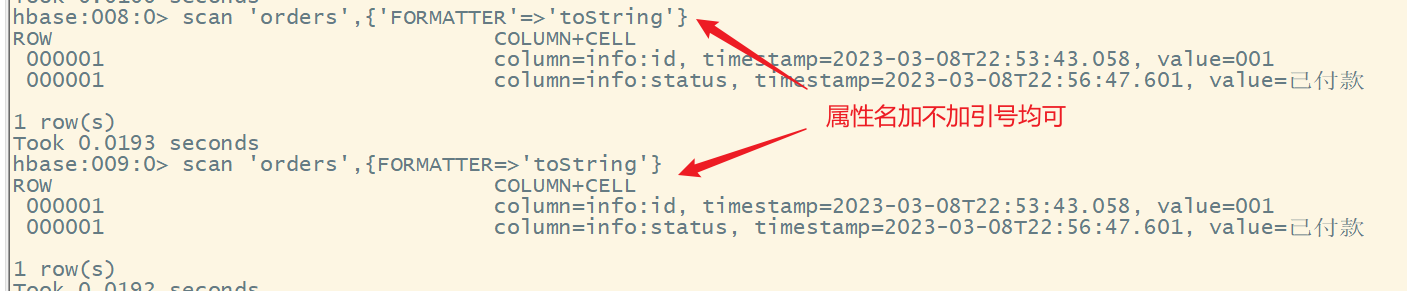

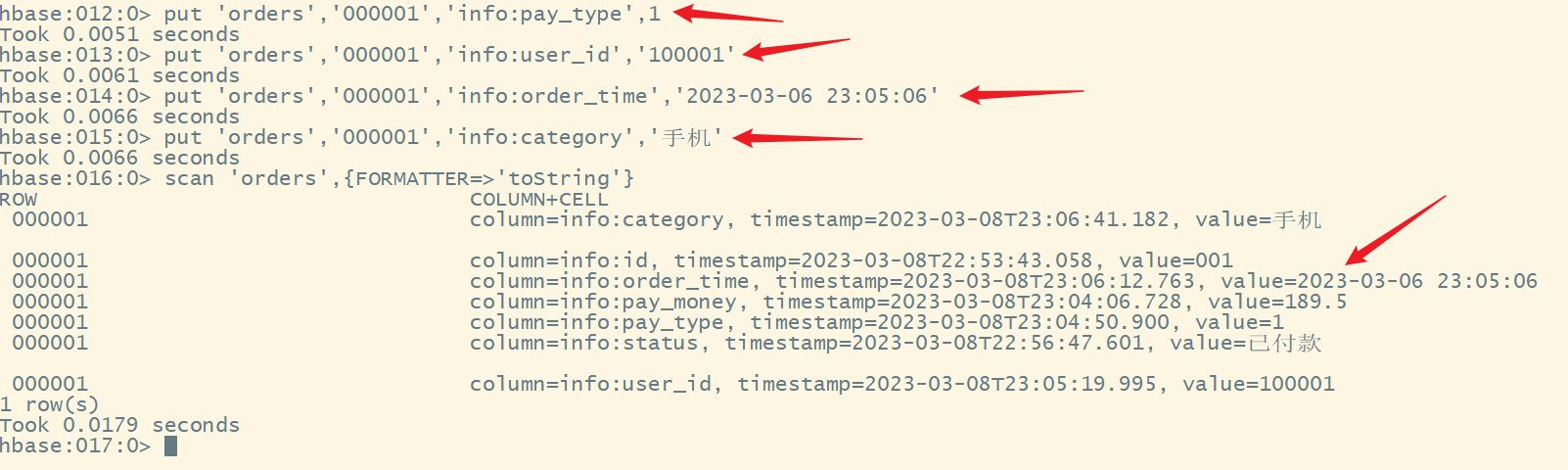
再次添加另一个rowkey的数据

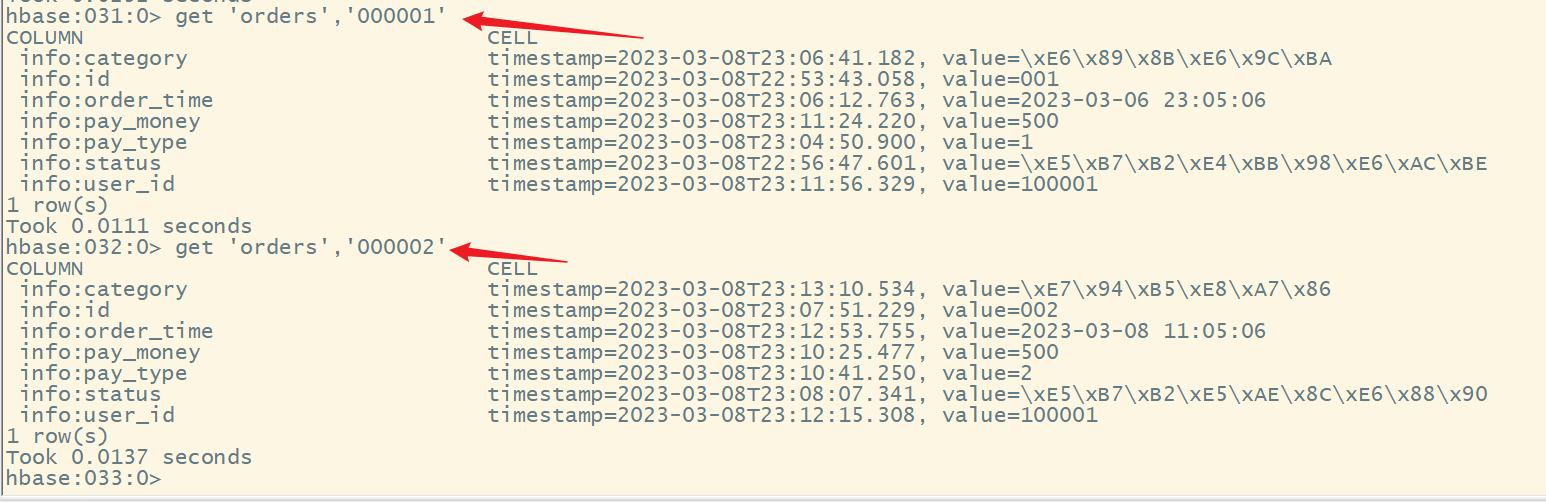
2.获取(查看)数据
1)获取一行数据
命令格式:
get '表名','rowkey'
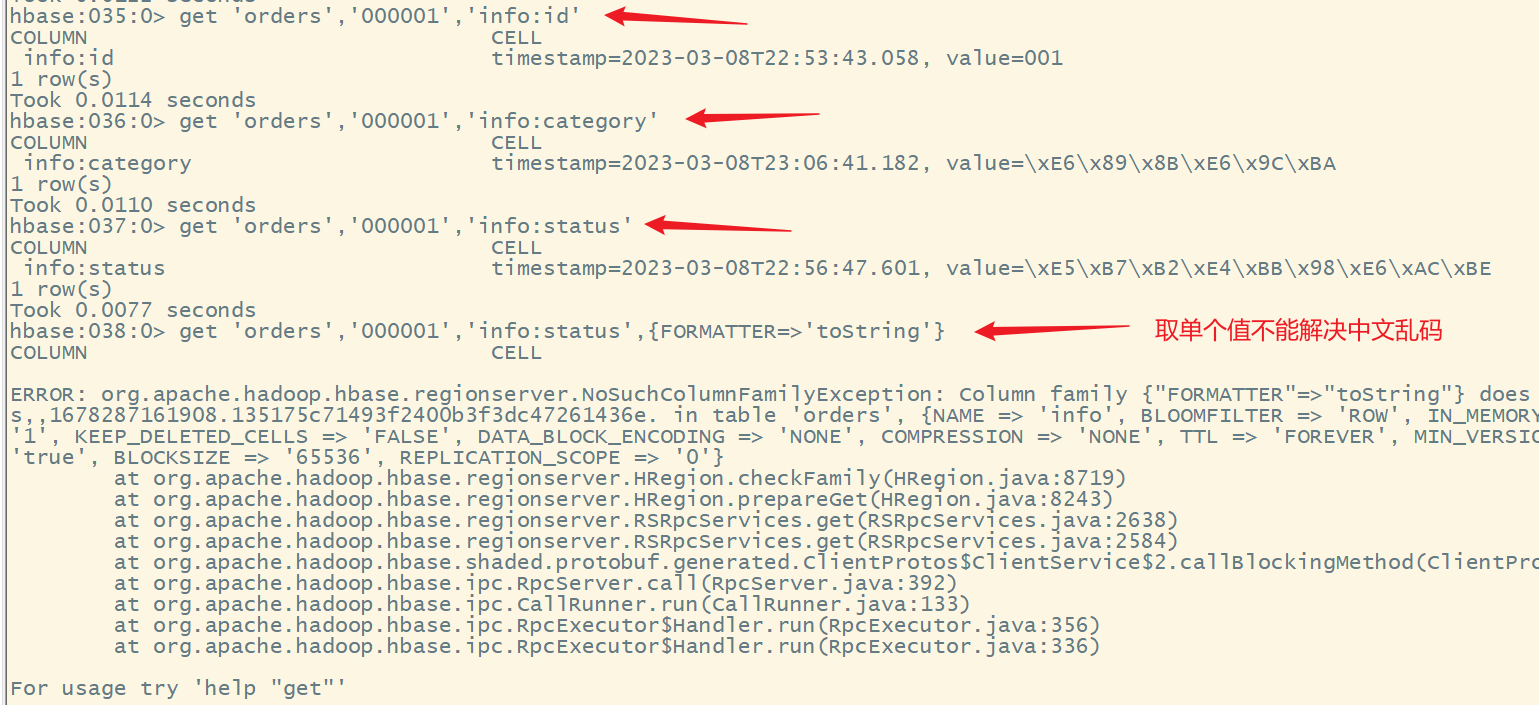
2)获取单个数据
命令格式:
get '表名','rowkey','列簇名:列名'
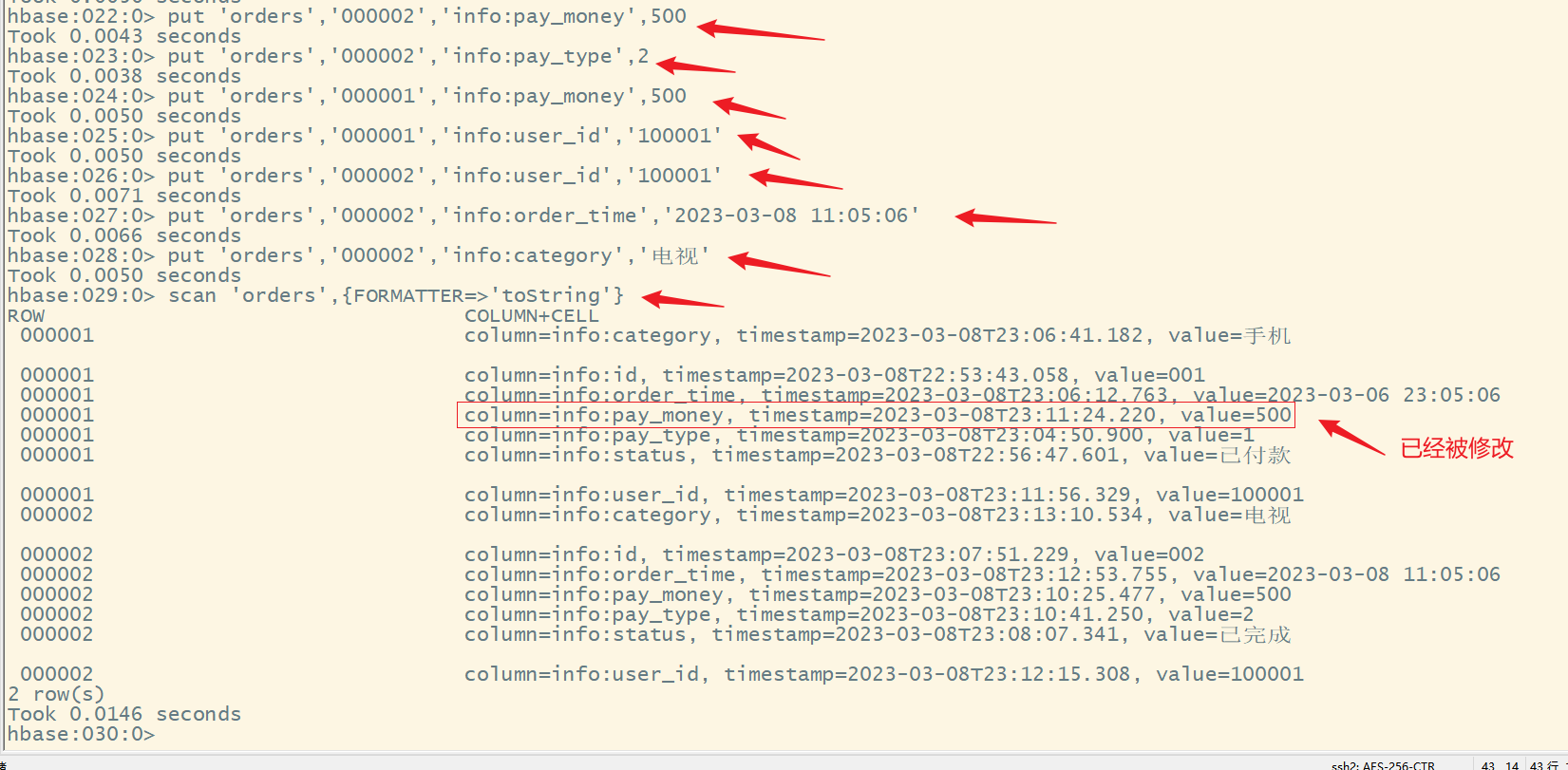
3.更新(修改)数据
命令格式:
put '表名','rowkey行键','列簇名:列名',新值

说明:
- put命令如果键值存在则修改,如果不存在则添加
- 在HBase中会自动维护表中数据的版本,即时间戳
- 每执行一次put操作,都会生产一个新的时间戳
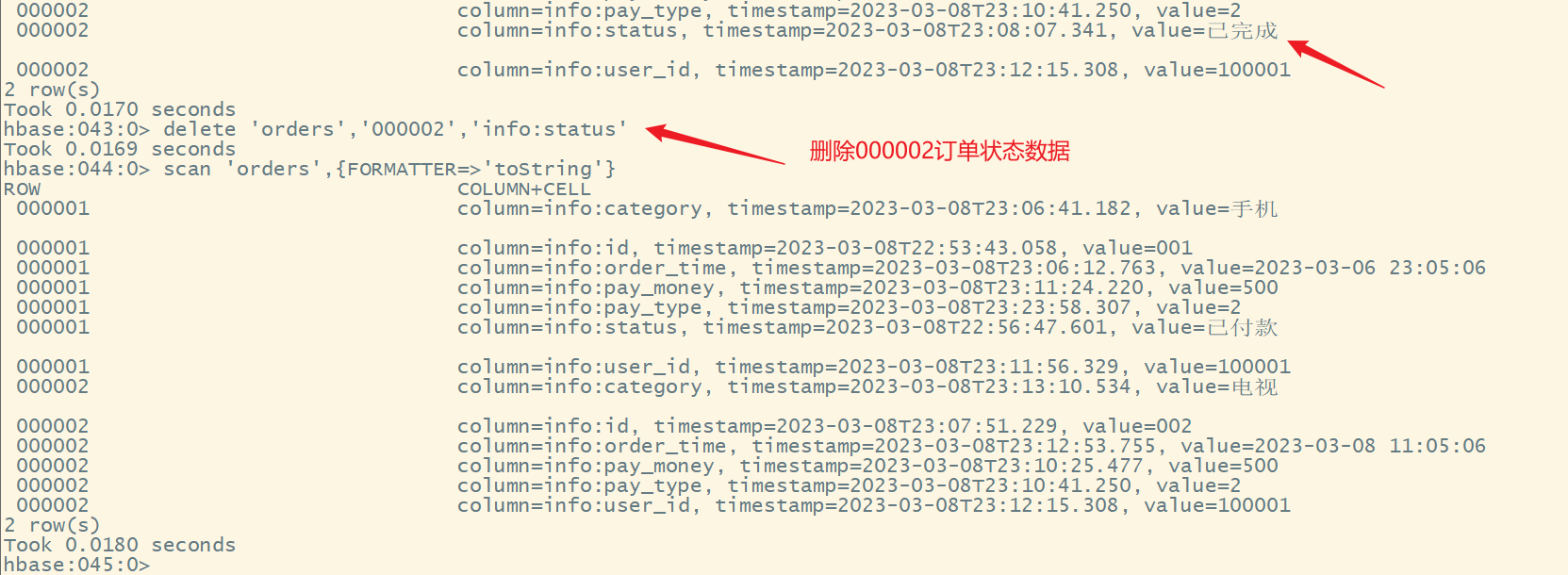
4.删除数据
1)删除指定列的数据
命令格式:
delete '表名','行键','列簇名:列名'
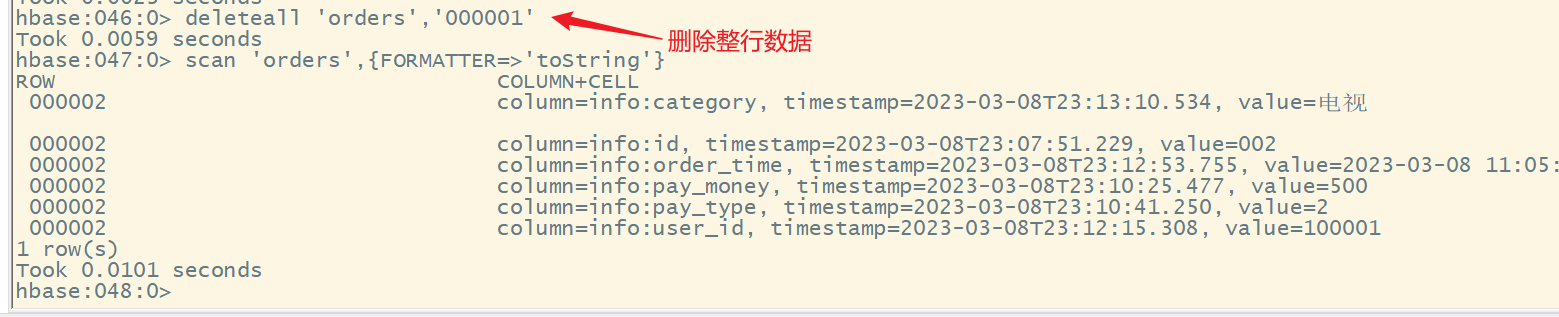
2)删除整行数据

命令格式:
deleteall '表名','行键'
3)清空表
命令格式:
truncate '表名'

五、导入数据
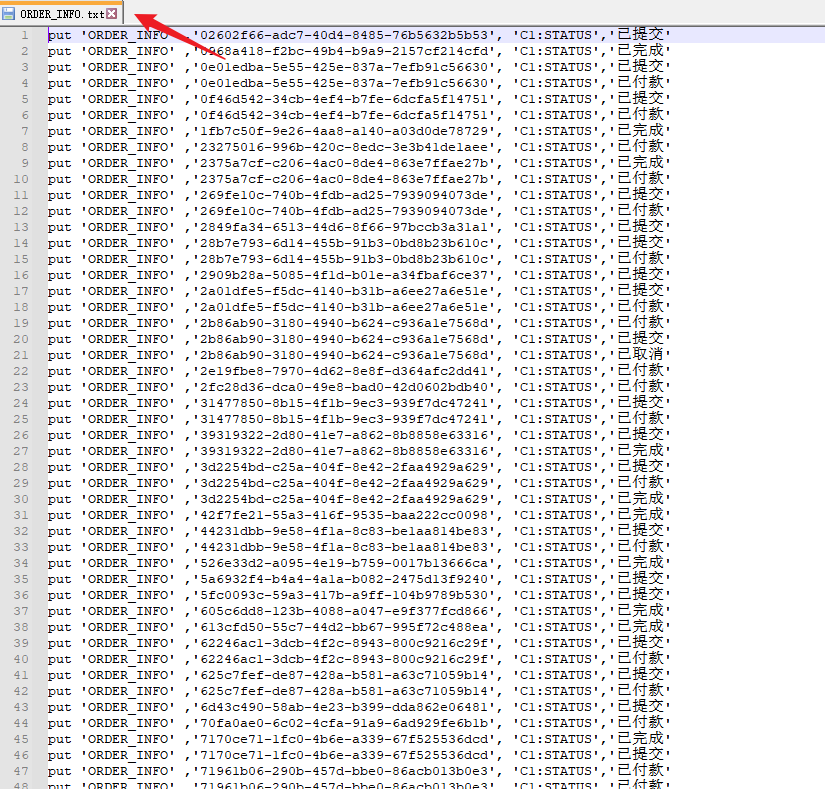
1.数据文件的准备
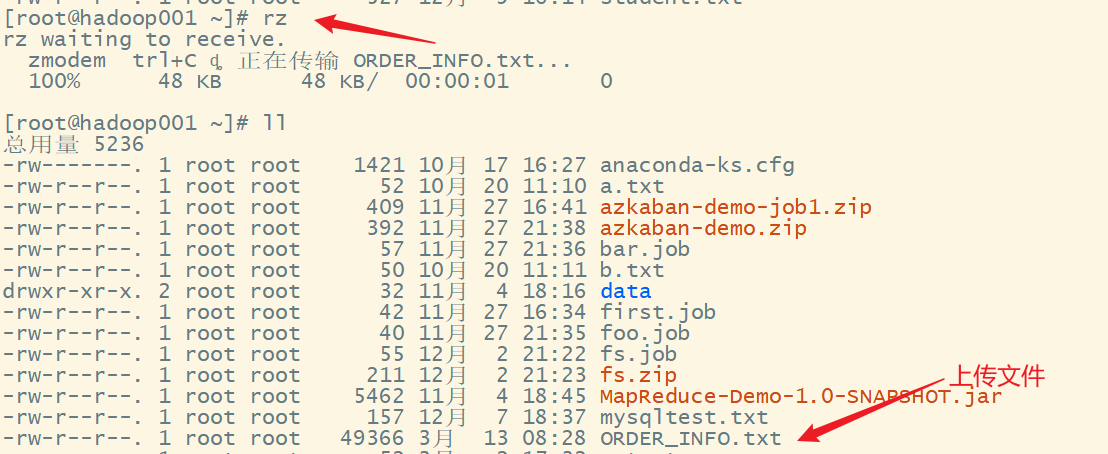
2.把数据文件上次到服务器
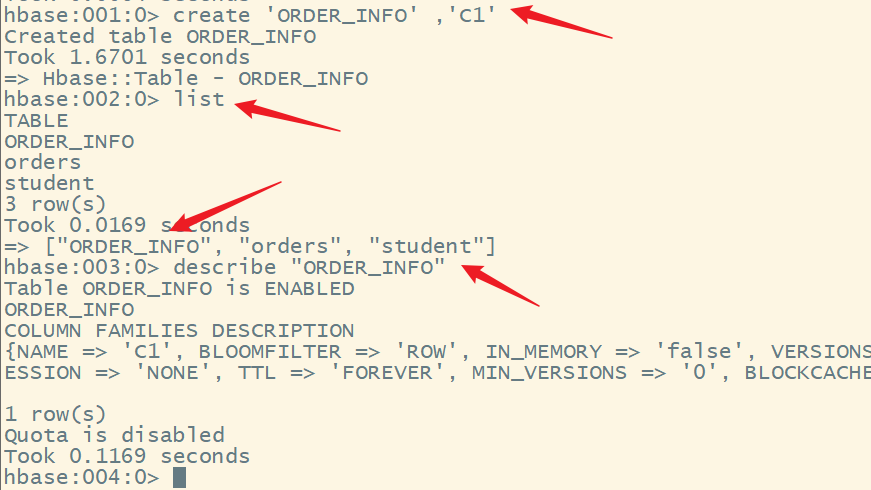
3.创建表,根据数据文件的定义
注意:集群启动
- 启动ZooKeeper
- 启动hdfs
- 启动HBASE
- 进入shell命令行
create 'ORDER_INFO' ,'C1'
4.执行命令导入命令数据文件

5.查看数据

此时,HBase的数据在HDFS上是的存储查看
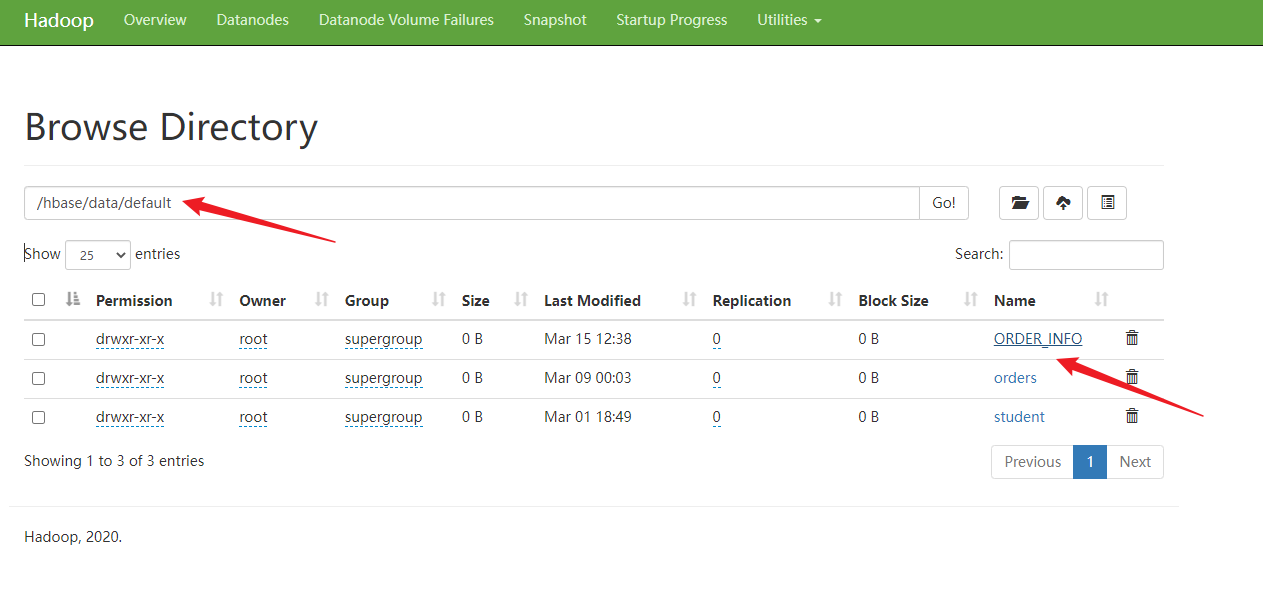
六、计数操作
统计表中有多少条数据
1.计数命令
语法:
count '表名'
功能:统计rowkey不同的行数
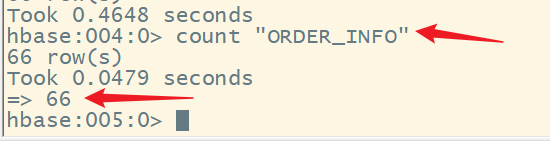
注意:当数据量很大的时候,这个操作是比较耗时的
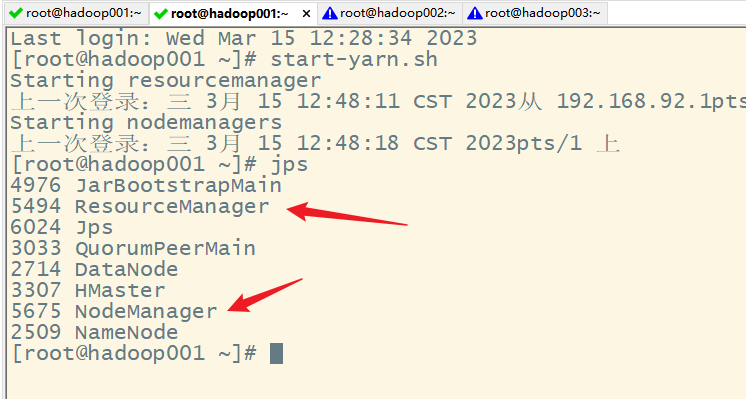
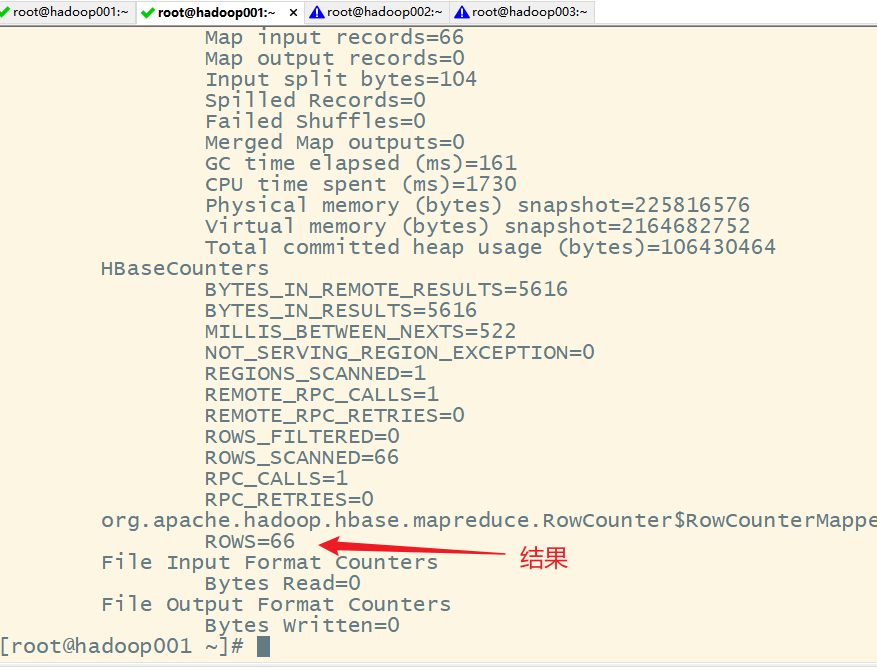
2.MR程序计数
当数据量很大很大的时候,可以通过HBase提供的MR程序进行计数,这个mr程序是
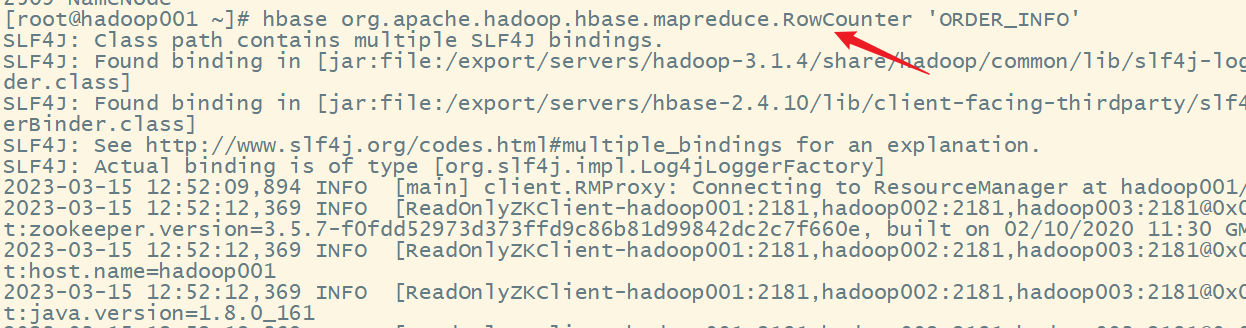
org.apache.hadoop.hbase.mapreduce.RowCounter,语法格式:
hbase org.apache.hadoop.hbase.mapreduce.RowCounter '表名'
此时需启动yarn
启动计数命令
hbase org.apache.hadoop.hbase.mapreduce.RowCounter 'ORDER_INFO'
七、扫描操作
1.全表扫描
语法:
scan ‘表名’,{FORMATTER=>‘toString’}

注意:尽量避免全表扫描一张很大很大的表
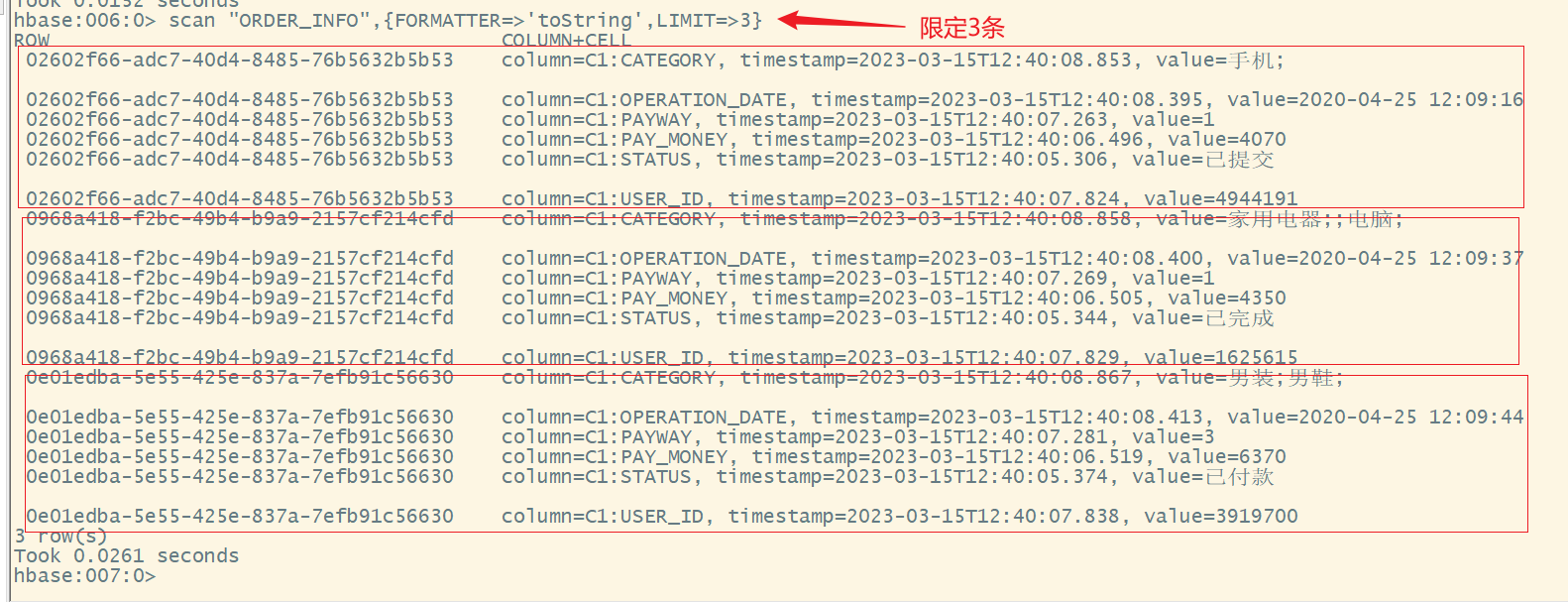
2.限定记录数
语法:
scan ‘表名’,{FORMATTER=>'toString',LIMIT=>数字}
3.限定列
Rubby语法:
scan ‘表名’,{FORMATTER=>'toString',COLUMNS=>[‘列簇名1:列名1’,’列簇名1:列名2’,...]}
scan "ORDER_INFO",{FORMATTER=>'toString',LIMIT=>3,COLUMNS=>['C1:CATEGORY','C1:PAY_MONEY']}
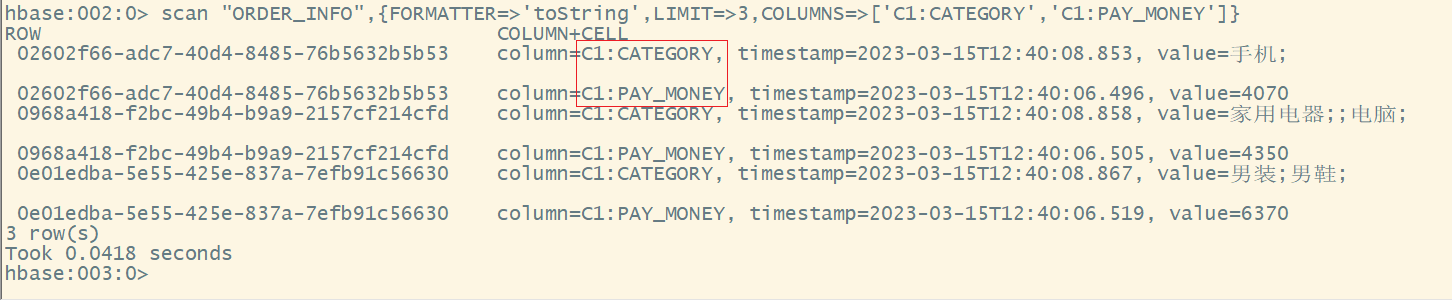
4.限定rowkey
语法:
scan ‘表名’,{FORMATTER=>'toString',ROWPREFIXFILTER=>’rowkey一部分’}
scan "ORDER_INFO",{FORMATTER=>'toString',COLUMNS=>['C1:CATEGORY','C1:PAY_MONEY'],ROWPREFIXFILTER=>'e'}
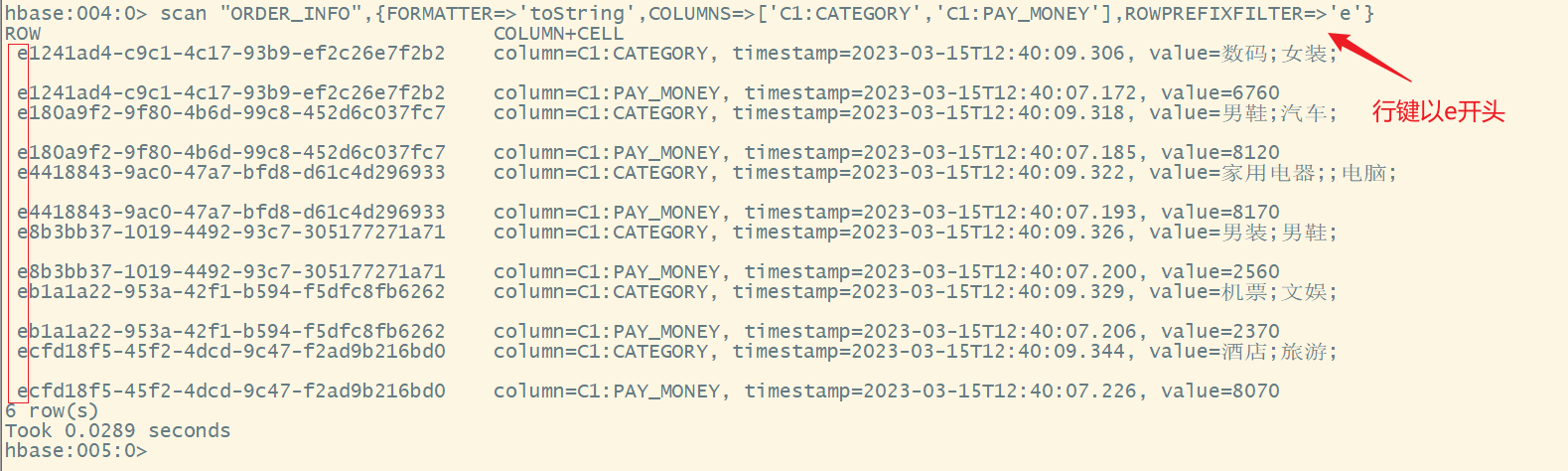
八、HBase的过滤器
1.简介
在HBase中,如果要对海量的数据进行扫描查询,尤其是全表扫描效率很低,可以使用过滤器Filter来提高查询的效率。过滤器Filter可以根据主键、列簇、列、版本号(时间戳)等条件对数据进行查询过滤。
在HBase中,使用过滤器有两种方式,一种就是使用命令行基于jRubby语法的选项实现交互式查询,另一种是基于HBase的JAVA API的方式进行编程开发。
官网文档:https://hbase.apache.org/devapidocs/index.html
2.过滤器
可以通过show_filters命令,查看hbase内置的过滤器
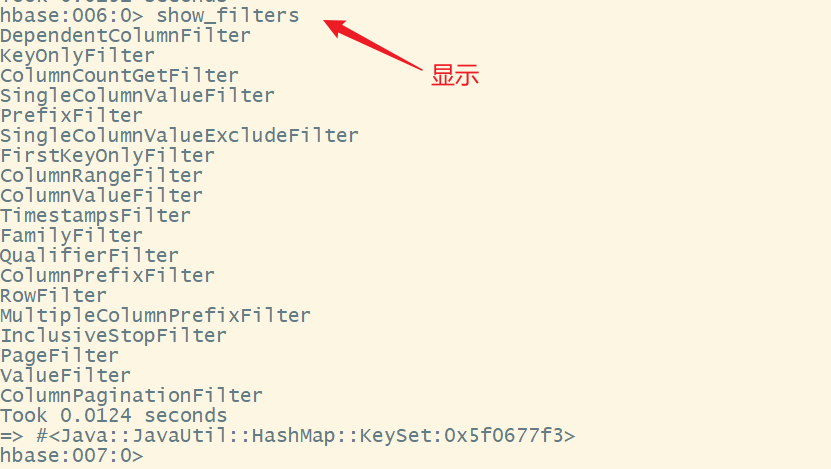
我们来解释一下这些过滤器的用法:
| 类型 | 过滤器 | 功能 |
|---|---|---|
| rowkey过滤器 | RowFilter | 实现行键字符串的比较和过滤 |
| PrefixFilter | rowkey的前缀过滤器 | |
| KeyOnlyFilter | 只对单元格的键过滤不显示值 | |
| FirstKeyOnlyFilter | 只扫描显示相同键的第一个单元格,其对应的键值会显示出来 | |
| 列过滤器 | FamilyFilter | 列簇过滤器 |
| QualifierFilter | 列限定符过滤器,只显示对应列簇列名的数据 | |
| ColumnPrefixFilter | 对列名的前缀进行限定 | |
| MultipleColumnPrefixFilter | 对多个列名的前缀进行限定 | |
| ColumnRangeFilter | 列名称范围的过滤器 | |
| 值过滤器 | ValueFilter | 值过滤器,查询符合条件的键值对 |
| SingleColumnValueFilter | 对单个值进行过滤 | |
| ColumnValueFilter | 列值的过滤器 | |
| SingleColumnValueExcludeFilter | 排除匹配成功的值 | |
| 其他过滤器 | ColumnPaginationFilter | 列分页过滤器,返回offset、limit的列 |
| PageFilter | 分页过滤器,分页显示 | |
| TimestampsFilter | 时间戳过滤器 | |
| ColumnCountGetFilter | 限制每个逻辑行返回值对的个数 | |
| DependentColumnFilter | 依赖列过滤器 | |
3.过滤器的用法
过滤器一般结合scan来使用
scan "ORDER_INFO",{FORMATTER=>'toString',FILTER=>"RowFilter(=,'binary:02602f66-adc7-40d4-8485-76b5632b5b53')"}

一般语法:
scan ‘表名’,{FILTER=>”过滤器的名称(参数列表(如比较运算符,比较器))”}
1)比较运算符
比较运算符是我们比较常见的。
| 运算符 | 功能 |
|---|---|
| = | 等于 |
| > | 大于 |
| < | 小于 |
| >= | 大于等于 |
| <= | 小于等于 |
| != | 不等于 |
2)比较器
| 比较器 | 功能 |
|---|---|
| BinaryComparator | 匹配完整的字节数组 |
| BinaryPrefixComparator | 匹配字节数组的前缀 |
| BitComparator | 匹配比特位 |
| NullComparator | 匹配空值 |
| RegexStringComparator | 匹配正则表达式 |
| SubstringComparator | 匹配子字符串 |
3)比较器表达式
| 比较器 | 表达式缩写 |
|---|---|
| BinaryComparator | binary:值 |
| BinaryPrefixComparator | binaryprefix:值 |
| BitComparator | bit:值 |
| NullComparator | null |
| RegexStringComparator | regexstring:正则表达式 |
| SubstringComparator | substring:值 |
4.案例一:查询指定订单id的数据
1)需求
查询指定订单的数据,订单号为“e8b3bb37-1019-4492-93c7-305177271a71”,订单状态及支付方式
2)分析
- 因为订单id就说表的rowkey,所以应该使用rowkey过滤器RowFilter
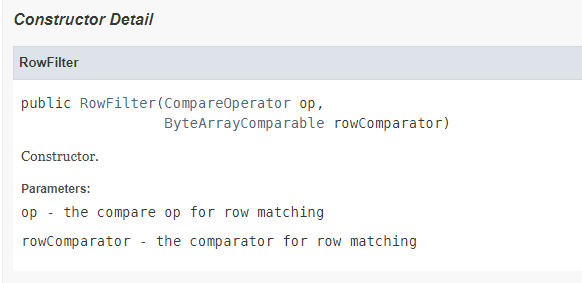
只需要两个参数
- 比较运算符:=
- 比较器表达式:binary:订单号
3)实现
scan 'ORDER_INFO',{FORMATTER=>'toString',COLUMNS=>['C1:STATUS','C1:PAYWAY'],FILTER=>"RowFilter(=,'binary:e8b3bb37-1019-4492-93c7-305177271a71')"}

5.案例二:查询状态为已付款的订单
1)需求
查询状态为已付款的订单
2)分析
- 因为查询状态为已付款要查询指定值,所以应该使用值过滤器SingleColumnValueFilter
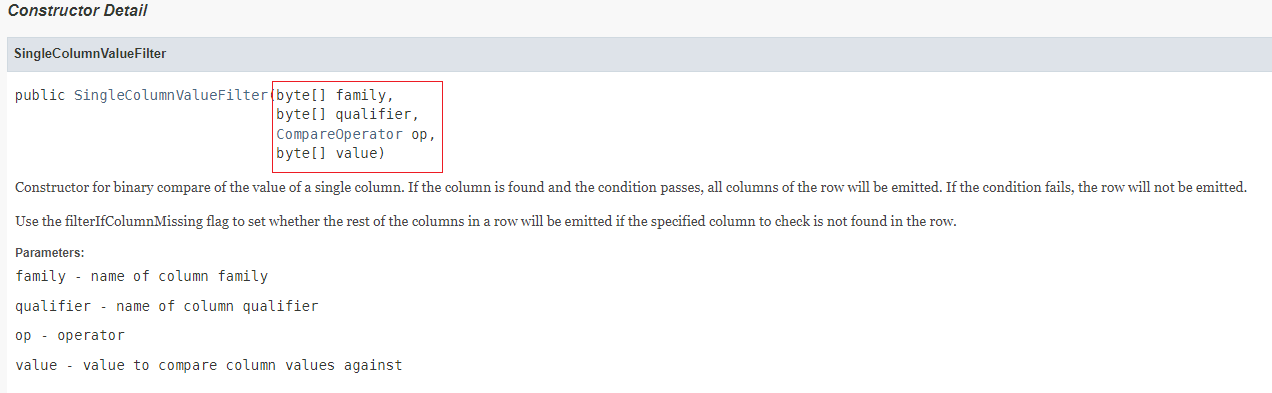
需要传入四个参数
- 列簇
- 列名
- 比较运算符
- 比较器表达式
scan 'ORDER_INFO',{FORMATTER=>'toString',FILTER=>"SingleColumnValueFilter('c1','STATUS',=,'binary:已付款')"}
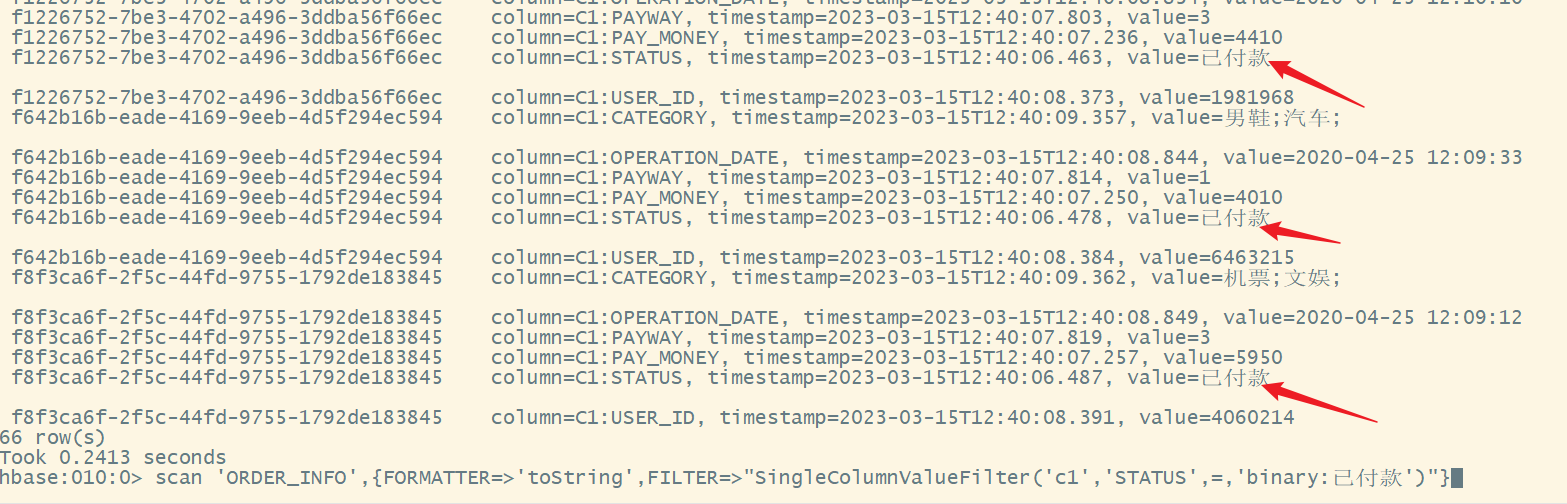
注意:
- 列簇名和列名大小写一定要写对
- 如果列簇名和列名大小写写错并不能过滤数据,但是HBase不会报错,而是显示全部的数据,因为HBase是无模式的
6.案例三:组合多条件过滤1
1)需求
查询支付方式为1,且支付金额大于8000的订单
2)分析
- 此处需要使用多个过滤器共同来实现查询,多个过滤器,可以使用AND(并且)或者OR(或者)来组合多个过滤器完成查询
- 使用SingleColumnValueFilter实现对应列的查询
- 支付方式为1的过滤器
SingleColumnValueFilter('C1', 'PAYWAY', = , 'binary:1')
- 支付金额大于8000的过滤器
SingleColumnValueFilter('C1', 'PAY_MONEY', > , 'binary:8000')
- 完整的命令
scan 'ORDER_INFO', {FORMATTER => 'toString',FILTER => "SingleColumnValueFilter('C1', 'PAYWAY', = , 'binary:1') AND SingleColumnValueFilter('C1', 'PAY_MONEY', > , 'binary:8000')"}

注意:
- HBase shell中比较默认都是字符串比较,所以如果是比较数值类型的,会出现不准确的情况
- 例如:在字符串比较中4000是比100000大的
- 外层必须使用双引号,内层使用单引号
我们还可以加上限定列:
scan 'ORDER_INFO', {FORMATTER => 'toString',FILTER => "SingleColumnValueFilter('C1', 'PAYWAY', = , 'binary:1') AND SingleColumnValueFilter('C1', 'PAY_MONEY', > , 'binary:8000')",COLUMNS=>['C1:PAYWAY','C1:PAY_MONEY']}

7. 案例四:组合多条件过滤2
1)需求
查询类别为“维修;手机;”或者“数码;女装;”,并且状态为“已付款”的订单,只显示类别和状态
2)分析
- 此处需要使用多个过滤器组合使用,多个过滤器可以使用AND(并且)、OR(或者)来进行组合
- 使用值过滤器中的SingleColumnValueFilter实现对应列值的查询
完整的命令
scan 'ORDER_INFO', {FORMATTER => 'toString',FILTER => "(SingleColumnValueFilter('C1', 'CATEGORY', = , 'binary:维修;手机;') OR SingleColumnValueFilter('C1', 'CATEGORY', = , 'binary:数码;女装;')) AND SingleColumnValueFilter('C1', 'STATUS', =, 'binary:已付款')",COLUMNS=>['C1:CATEGORY','C1:STATUS']}
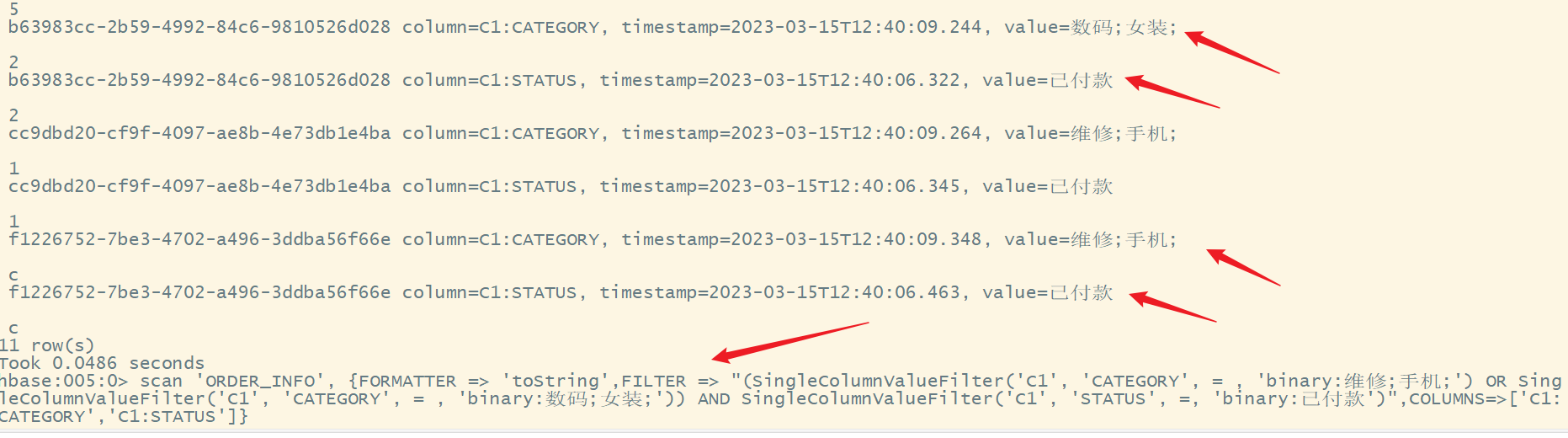
8.作业
选择操作时间在2020-04-25,12点8分到9分之间的已完成的订单,只显示操作时间和状态
scan 'ORDER_INFO', {FORMATTER => 'toString',FILTER => "SingleColumnValueFilter('C1', 'OPERATION_DATE', > , 'binary:2020-04-25 12:08:00') AND SingleColumnValueFilter('C1', 'OPERATION_DATE', = , 'binary:2020-04-25 12:09:00')",COLUMNS=>['C1:OPERATION_DATE','C1:STATUS']}

九、INCR
incr(increament)命令可以实现某个单元格的值进行原子性计数累加,默认累加1
1. 需求
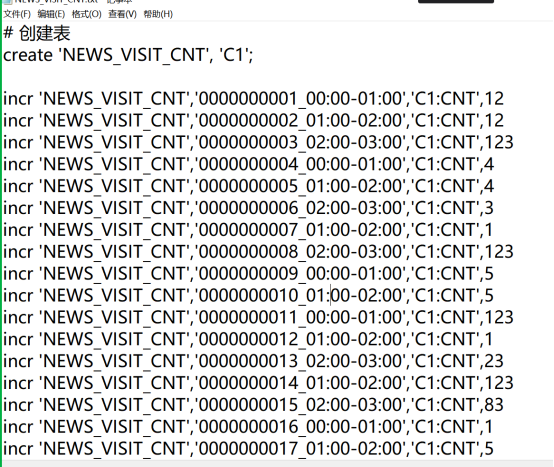
某新闻app应用为了统计每个新闻的每隔一段时间的访问次数,将新闻数据保存在HBase中,该表格的数据如下所示,要求原子性的增加新闻的访问次数
| 新闻ID | 访问次数 | 时间段 | rowkey |
|---|---|---|---|
| 0000000001 | 12 | 00:00-01:00 | 0000000001_00:00-01:00 |
| 0000000002 | 20 | 01:00-02:00 | 0000000002_01:00-02:00 |
2. incr操作
语法:
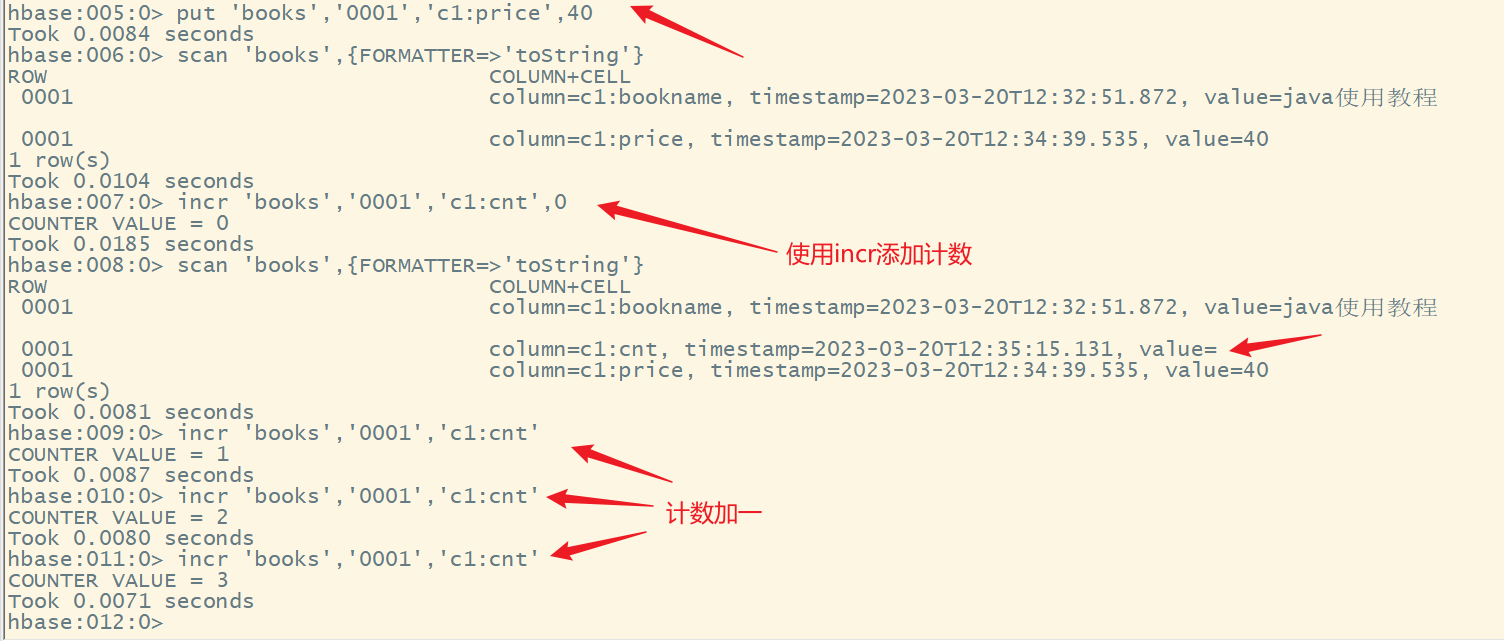
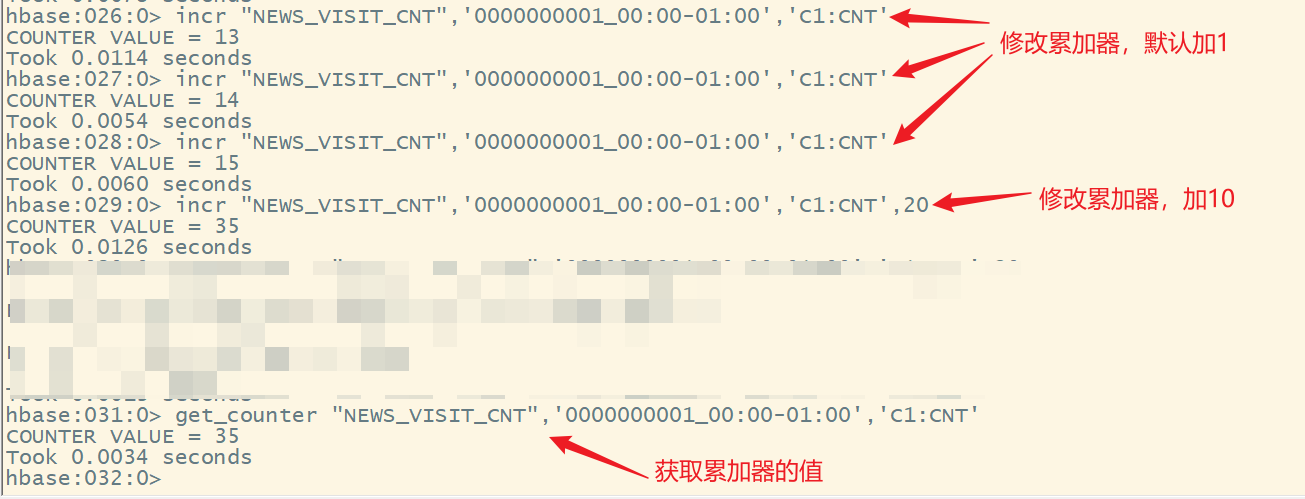
incr ‘表名’,‘rowkey’,‘列簇名:列名’,[累加值]
说明:
- 如果某一列要实现计数功能,必须要使用incr来创建对应的列
- 使用put创建的额列是不能实现累加的
- 默认累加1
3.基本使用


4.导入准备好的数据
上传服务器
导入HBase
显示前5条数据
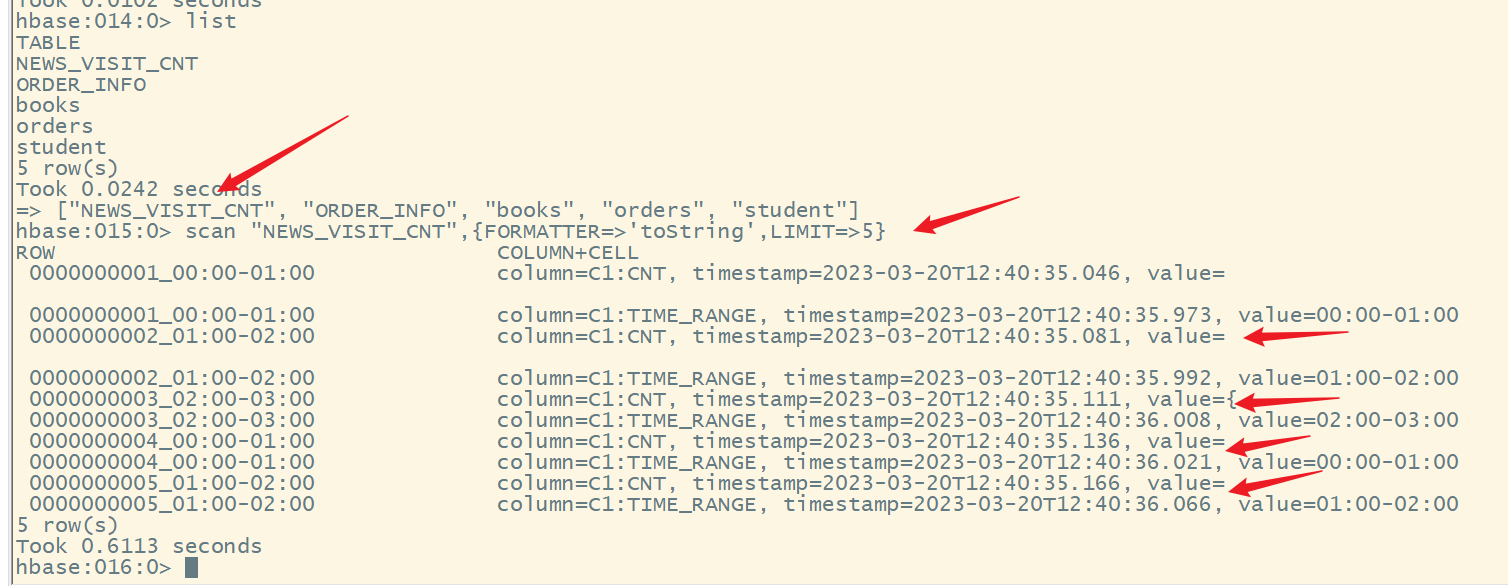
5.获取计数器值的命令
不能使用get来获取计数器的值
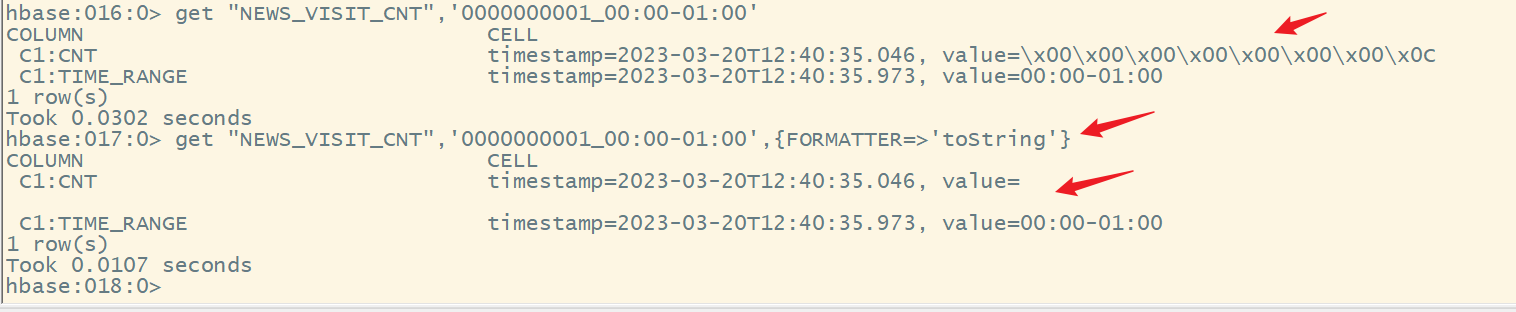
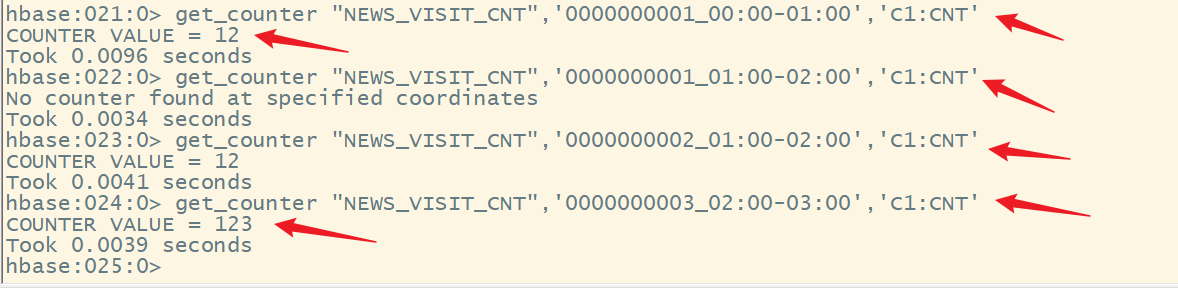
语法:
get_counter ‘表名’,‘rowkey’,‘列簇名:列名’

6.使用incr进行累加操作,修改计数器的值

十、Shell管理操作
1.status
查看服务器的状态

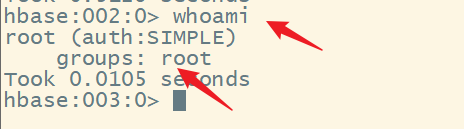
2.whoami
显示当前用户
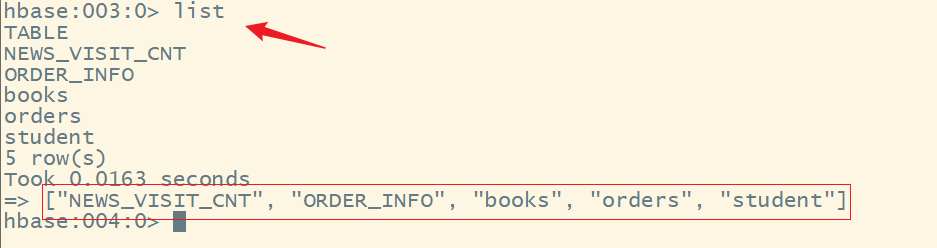
3.list
显示当前的所有的表
4.count
统计表的记录数

5.describe
显示表的结构信息

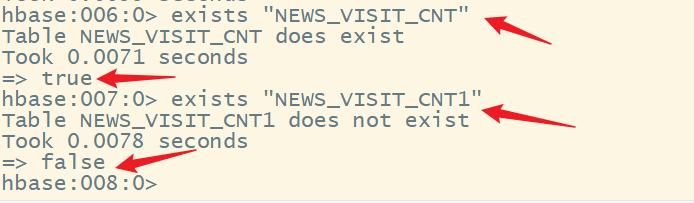
6.exists
判断某个表是否存在
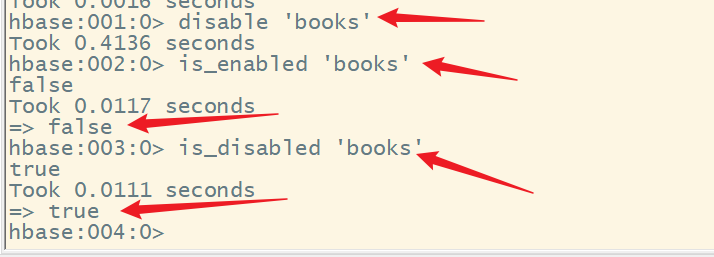
7.is_enabled、is_disabled
判断某个表是否被启用或者禁用
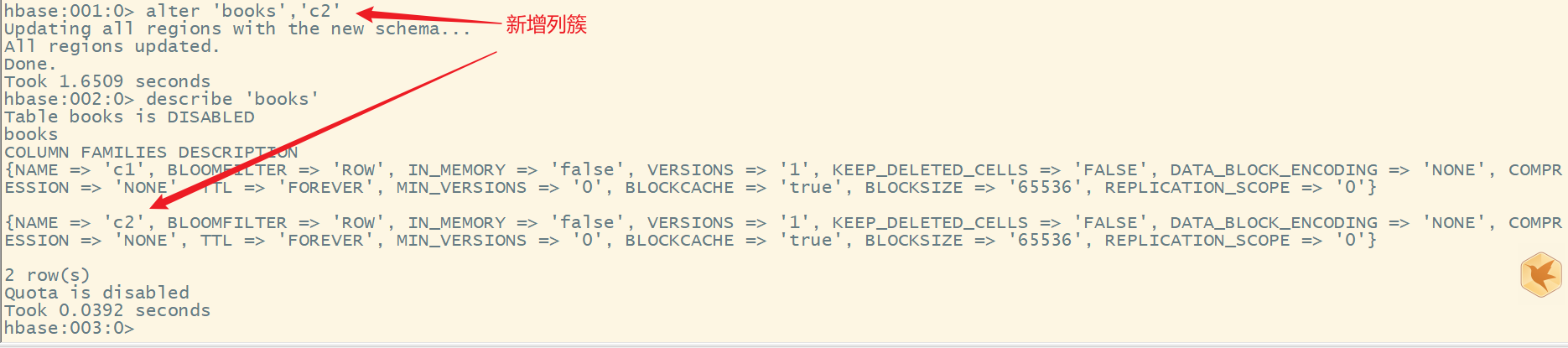
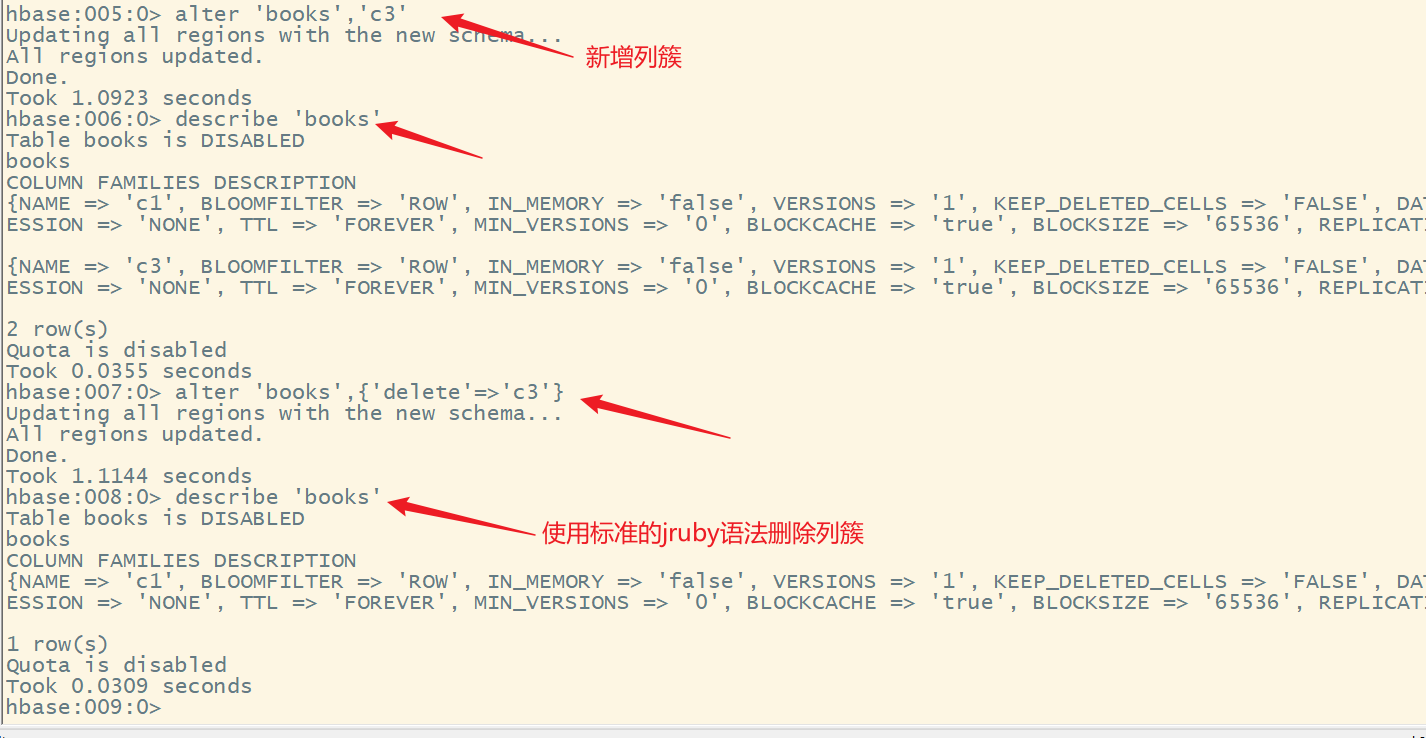
8.alter
改变表和列簇的模式
- 新增列簇
- 删除列簇

参考文章
HBASE官网文档