原文:Hands-on Deep Learning with TensorFlow
协议:CC BY-NC-SA 4.0
译者:飞龙
本文来自【ApacheCN 深度学习 译文集】,采用译后编辑(MTPE)流程来尽可能提升效率。
不要担心自己的形象,只关心如何实现目标。——《原则》,生活原则 2.3.c
一、入门
TensorFlow 是 Google 最近发布的新的机器学习和图计算库。 其 Python 接口可确保通用模型的优雅设计,而其编译后的后端可确保速度。
让我们看一下应用 TensorFlow 时要学习的技术和要构建的模型。
安装 TensorFlow
在本节中,您将学习什么是 TensorFlow,如何安装 TensorFlow 以及如何构建简单模型和进行简单计算。 此外,您将学习如何建立用于分类的逻辑回归模型,并介绍机器学习问题以帮助我们学习 TensorFlow。
我们将学习 TensorFlow 是什么类型的库,并将其安装在我们自己的 Linux 机器上;如果您无法访问 Linux 机器,则将其安装在 CoCalc 的免费实例中。
TensorFlow 主页
首先,什么是 TensorFlow? TensorFlow 是 Google 推出的新的机器学习库。 它被设计为非常易于使用且非常快。 如果您访问 TensorFlow 网站,则可以访问有关 TensorFlow 是什么以及如何使用的大量信息。 我们将经常提到这一点,特别是文档。
TensorFlow 安装页面
在我们开始使用 TensorFlow 之前,请注意,您需要先安装它,因为它可能尚未预先安装在您的操作系统上。 因此,如果转到 TensorFlow 网页上的“安装”选项卡,单击在 Ubuntu 上安装 TensorFlow,然后单击“本机 PIP”,您将学习如何安装 TensorFlow。
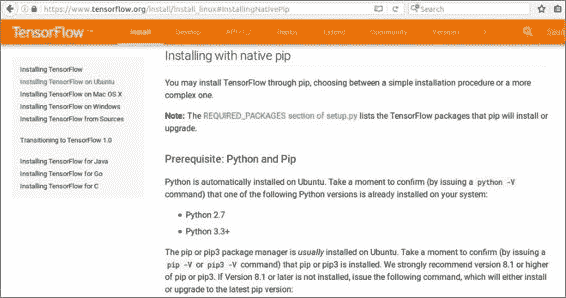
即使对于经验丰富的系统管理员来说,安装 TensorFlow 也是非常困难的。 因此,我强烈建议您使用类似pip的安装方式。 或者,如果您熟悉 Docker,请使用 Docker 安装。 您可以从源代码安装 TensorFlow,但这可能非常困难。 我们将使用称为 wheel 文件的预编译二进制文件安装 TensorFlow。 您可以使用 Python 的pip模块安装程序来安装此文件。
通过pip安装
对于pip安装,您可以选择使用 Python2 或 Python3 版本。 另外,您可以在 CPU 和 GPU 版本之间进行选择。 如果您的计算机具有功能强大的显卡,则可能适合您使用 GPU 版本。
但是,您需要检查显卡是否与 TensorFlow 兼容。 如果不是,那很好。 本系列中的所有内容都可以仅使用 CPU 版本来完成。
注意
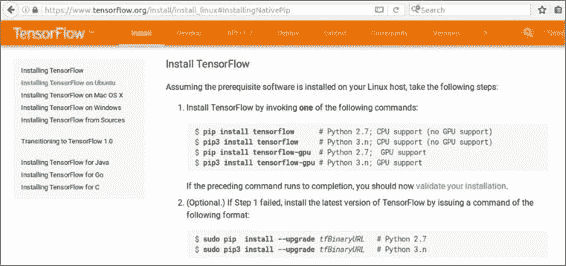
我们可以使用pip install tensorflow命令(基于您的 CPU 或 GPU 支持以及pip版本)安装 TensorFlow,如前面的屏幕截图所示。
因此,如果您为 TensorFlow 复制以下行,则也可以安装它:
# Python 3.4 installation
sudo pip3 install --upgrade \
https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.2.1-cp34-cp34m-linux_x86_64.whl
如果您没有 Python 3.4,请按照 wheel 文件的要求进行操作,那就可以了。 您可能仍然可以使用相同的 wheel 文件。 让我们看一下如何在 Python 3.5 上执行此操作。 首先,只需将以下 URL 放在浏览器中,或使用命令行程序(例如wget)直接下载 wheel 文件,就像我们在这里所做的那样:
wget https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-1.2.1-cp34-cp34m-linux_x86_64.whl
如果下载此文件,它将很快被您的计算机抓住。
现在,您需要做的就是将文件名从cp34(代表 Python 3.4)更改为您使用的任何版本的 Python3。 在这种情况下,我们将其更改为使用 Python 3.5 的版本,因此我们将4更改为5:
mv tensorflow-1.2.1-cp34-cp34m-linux_x86_64.whl tensorflow-1.2.1-cp35-cp35m-linux_x86_64.whl
现在您可以通过简单地将安装行更改为pip3 install并将新 wheel 文件的名称更改为 3.5 后,来为 Python 3.5 安装 TensorFlow:
sudo pip3 install ./tensorflow-1.2.1-cp35-cp35m-linux_x86_64.whl
我们可以看到这很好。 现在,您已经安装了 TensorFlow。
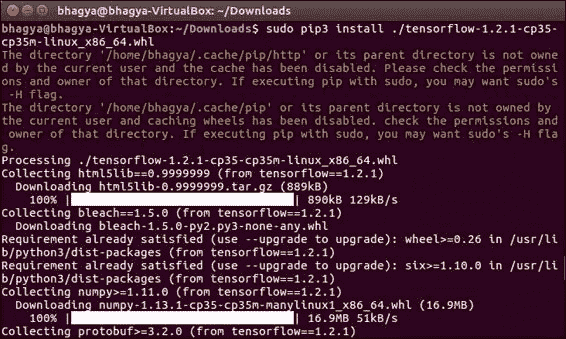
如果您的安装以后因某种原因损坏了,您可以随时跳回到该部分,以提醒自己有关安装所涉及的步骤。
通过 CoCalc 安装
如果您没有计算机的管理或安装权限,但仍然想尝试 TensorFlow,则可以尝试在 CoCalc 实例中通过 Web 运行 TensorFlow。 如果转到 cocalc.com 并创建一个新帐户,则可以创建一个新项目。 这将为您提供一种可以玩耍的虚拟机。 方便的是,TensorFlow 已经安装在 Anaconda 3 内核中。
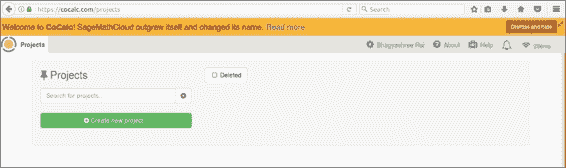
让我们创建一个名为TensorFlow的新项目。 单击+创建新项目…,为您的项目输入标题,然后单击创建项目。 现在,我们可以通过单击标题进入我们的项目。 加载将需要几秒钟。
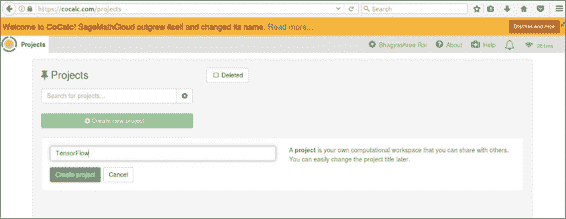
单击+新建以创建一个新文件。 在这里,我们将创建一个 Jupyter 笔记本:
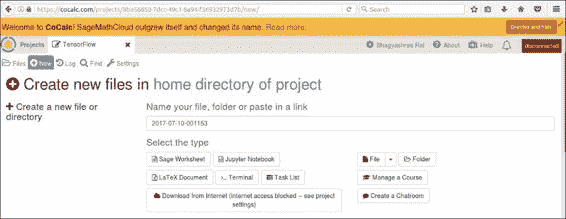
Jupyter 是与 IPython 进行交互的便捷方法,也是使用 CoCalc 进行这些计算的主要手段。 加载可能需要几秒钟。
进入下面的屏幕快照中所示的界面时,您需要做的第一件事是通过转到“内核 | 更改内核… | Python3(Anaconda)”将内核更改为 Anaconda Python3:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-yv3zYsKp-1681566150303)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00008.jpg)]
这将为您提供适当的依赖关系以使用 TensorFlow。 更改内核可能需要几秒钟。 连接到新内核后,可以在单元格中键入import tensorflow,然后转到“单元格 | 运行单元格”以检查其是否有效:
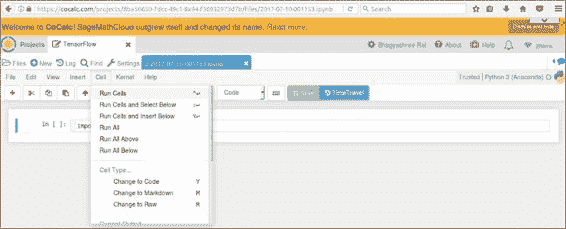
如果 Jupyter 笔记本需要很长时间才能加载,则可以使用以下屏幕截图中所示的按钮在 CoCalc 中创建终端:
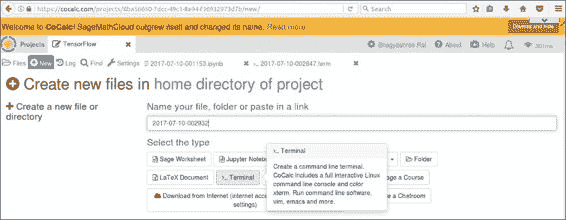
到那里后,键入anaconda3切换环境,然后键入ipython3启动交互式 Python 会话,如以下屏幕截图所示:
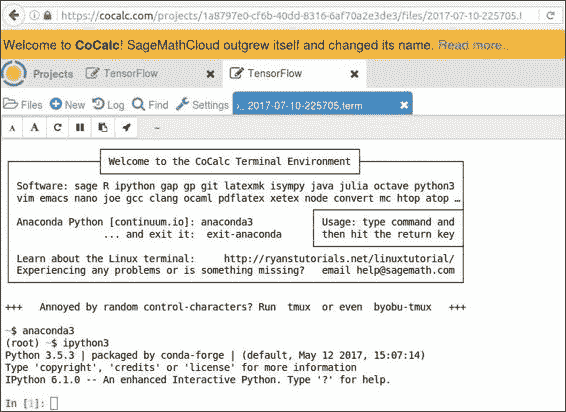
尽管您无法可视化输出,但是您可以在这里轻松地工作。 在终端中输入import tensorflow,然后离开。
到目前为止,您已经了解了 TensorFlow 是什么以及如何在本地或 Web 上的虚拟机上安装 TensorFlow。 现在我们准备在 TensorFlow 中探索简单的计算。
简单的计算
首先,我们将看一下张量对象类型。 然后,我们将理解定义计算的 TensorFlow 图。 最后,我们将使用会话运行图,显示如何替换中间值。
定义标量和张量
您需要做的第一件事是下载本书的源代码包并打开simple.py文件。 您可以使用此文件将行复制并粘贴到 TensorFlow 或 CoCalc 中,也可以直接键入它们。 首先,让我们将tensorflow导入为tf。 这是在 Python 中引用它的便捷方法。 您需要在tf.constant通话中保留常数。 例如,做a = tf.constant(1)和b = tf.constant(2):
import tensorflow as tf
# You can create constants in TF to hold specific values
a = tf.constant(1)
b = tf.constant(2)
当然,您可以将它们相加并相乘以获得其他值,即c和d:
# Of course you can add, multiply, and compute on these as you like
c = a + b
d = a * b
TensorFlow 数字以张量存储,这是多维数组的一个花哨术语。 如果您将 Python 列表传递给 TensorFlow,它将做正确的事并将其转换为适当尺寸的张量。 您可以在以下代码中看到这一点:
# TF numbers are stored in "tensors", a fancy term for multidimensional arrays. If you pass TF a Python list, it can convert it
V1 = tf.constant([1., 2.]) # Vector, 1-dimensional
V2 = tf.constant([3., 4.]) # Vector, 1-dimensional
M = tf.constant([[1., 2.]]) # Matrix, 2d
N = tf.constant([[1., 2.],[3.,4.]]) # Matrix, 2d
K = tf.constant([[[1., 2.],[3.,4.]]]) # Tensor, 3d+
V1向量(一维张量)作为[1\. , 2.]的 Python 列表传递。 这里的点只是强制 Python 将数字存储为十进制值而不是整数。 V2向量是[3\. , 4\. ]的另一个 Python 列表。 M变量是由 Python 中的列表列表构成的二维矩阵,在 TensorFlow 中创建了二维张量。 N变量也是二维矩阵。 请注意,这一行实际上有多行。 最后,K是一个真实的张量,包含三个维度。 请注意,最终维度仅包含一个条目,即一个2 x 2框。
如果该项有点混乱,请不要担心。 每当您看到一个奇怪的新变量时,都可以跳回到这一点以了解它可能是什么。
张量计算
您还可以做一些简单的事情,例如将张量相加:
V3 = V1 + V2
或者,您可以将它们逐个元素相乘,以便将每个公共位置相乘在一起:
# Operations are element-wise by default
M2 = M * M
但是,对于真正的矩阵乘法,您需要使用tf.matmul,传入两个张量作为参数:
NN = tf.matmul(N,N)
执行计算
到目前为止,所有内容都已指定 TensorFlow 图; 我们还没有计算任何东西。 为此,我们需要启动一个进行计算的会话。 以下代码创建一个新的会话:
sess = tf.Session()
打开会话后,请执行以下操作:sess.run(NN)将计算给定的表达式并返回一个数组。 通过执行以下操作,我们可以轻松地将其发送到变量:
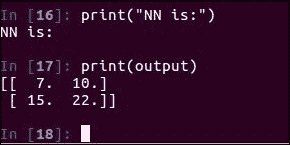
output = sess.run(NN)
print("NN is:")
print(output)
如果现在运行此单元格,则应该在屏幕上看到NN输出的正确张量数组:
使用完会话后,最好将其关闭,就像关闭文件句柄一样:
# Remember to close your session when you're done using it
sess.close()
对于交互式工作,我们可以像这样使用tf.InteractiveSession():
sess = tf.InteractiveSession()
然后,您可以轻松计算任何节点的值。 例如,输入以下代码并运行单元格将输出M2的值:
# Now we can compute any node
print("M2 is:")
print(M2.eval())
可变张量
当然,并非我们所有的数字都是恒定的。 例如,要更新神经网络中的权重,我们需要使用tf.Variable创建适当的对象:
W = tf.Variable(0, name="weight")
请注意,TensorFlow 中的变量不会自动初始化。 为此,我们需要使用一个特殊的调用,即tf.global_variables_initializer(),然后使用sess.run()运行该调用:
init_op = tf.global_variables_initializer()
sess.run(init_op)
这是在该变量中放置一个值。 在这种情况下,它将把0值填充到W变量中。 让我们验证一下W是否具有该值:
print("W is:")
print(W.eval())
您应该在单元格中看到0的W的输出值:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-evcodNgb-1681566150304)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00013.jpg)]
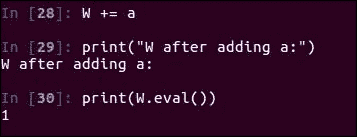
让我们看看向其中添加a会发生什么:
W += a
print("W after adding a:")
print(W.eval())
回想一下a是1,因此您在这里得到1的期望值:
让我们再次添加a,以确保我们可以递增并且它确实是一个变量:
W += a
print("W after adding a:")
print(W.eval())
现在您应该看到W持有2,因为我们已经使用a对其进行了两次递增:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RIsT1bTs-1681566150305)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00015.jpg)]
查看和替换中间值
在执行 TensorFlow 计算时,您可以返回或提供任意节点。 让我们定义一个新节点,但同时在fetch调用中返回另一个节点。 首先,让我们定义新节点E,如下所示:
E = d + b # 1*2 + 2 = 4
让我们看看E的开头是:
print("E as defined:")
print(E.eval())
如您所料,您应该看到E等于4。 现在让我们看一下如何传递E和d多个节点,以从sess.run调用中返回多个值:
# Let's see what d was at the same time
print("E and d:")
print(sess.run([E,d]))
您应该看到输出中返回了多个值,即4和2:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-pd4MYfVd-1681566150305)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00016.jpg)]
现在假设我们要使用其他中间值,例如出于调试目的。 返回值时,我们可以使用feed_dict将自定义值提供给计算中任何位置的节点。 让我们现在用d等于4而不是2来做:
# Use a custom d by specifying a dictionary
print("E with custom d=4:")
print(sess.run(E, feed_dict = {d:4.}))
请记住,E 等于 d + b,d和b的值都是2。 尽管我们为d插入了4的新值,但是您应该看到E的值现在将输出为6:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VSeI9T3C-1681566150306)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00017.jpg)]
您现在已经了解了如何使用 TensorFlow 张量进行核心计算。 现在是时候通过建立逻辑回归模型来迈出下一步。
逻辑回归模型构建
好的,让我们开始构建一个真正的机器学习模型。 首先,我们将看到提出的机器学习问题:字体分类。 然后,我们将回顾一个简单的分类算法,称为逻辑回归。 最后,我们将在 TensorFlow 中实现逻辑回归。
字体分类数据集简介
在开始之前,让我们加载所有必需的模块:
import tensorflow as tf
import numpy as np
如果要复制并粘贴到 IPython,请确保将autoindent属性设置为OFF:
%autoindent
tqdm模块是可选的; 它只是显示了不错的进度条:
try:
from tqdm import tqdm
except ImportError:
def tqdm(x, *args, **kwargs):
return x
接下来,我们将设置0的种子,以使每次运行之间的数据分割保持一致:
# Set random seed
np.random.seed(0)
在本书中,我们提供了使用五种字体的字符图像数据集。 为方便起见,这些文件存储在压缩的 NumPy 文件(data_with_labels.npz)中,该文件可在本书的下载包中找到。 您可以使用numpy.load轻松将它们加载到 Python 中:
# Load data
data = np.load('data_with_labels.npz')
train = data['arr_0']/255.
labels = data['arr_1']
这里的train变量保存从 0 到 1 缩放的实际像素值,labels保留原来的字体类型。 因此,它将是 0、1、2、3 或 4,因为总共有五种字体。 您可以打印这些值,因此可以使用以下代码查看它们:
# Look at some data
print(train[0])
print(labels[0])
但是,这不是很有启发性,因为大多数值都是零,并且仅屏幕的中央部分包含图像数据:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o78Voqoa-1681566150306)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00018.jpg)]
如果您已安装 Matplotlib,则现在是导入它的好地方。 在需要时,我们将使用plt.ion()自动调出数字:
# If you have matplotlib installed
import matplotlib.pyplot as plt
plt.ion()
这是每种字体的一些字符示例图:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wM6A6vOq-1681566150306)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00019.jpg)]
是的,他们很浮华。 在数据集中,每个图像都表示为像素暗度值的36 x 36二维矩阵。 0 值表示白色像素,而 255 表示黑色像素。 两者之间的一切都是灰色阴影。 这是在您自己的计算机上显示这些字体的代码:
# Let's look at a subplot of one of A in each font
f, plts = plt.subplots(5, sharex=True)
c = 91
for i in range(5):
plts[i].pcolor(train[c + i * 558],
cmap=plt.cm.gray_r)
如果您的图看起来确实很宽,则可以使用鼠标轻松调整窗口大小。 如果您只是以交互方式进行绘图,则在 Python 中提前调整其大小通常需要做很多工作。 鉴于我们还有许多其他标记的字体图像,我们的目标是确定图像属于哪种字体。 为了扩展数据集并避免过拟合,我们还在36 x 36区域内抖动了每个字符,为我们提供了 9 倍的数据点。
在使用较新的模型后重新回到这一点可能会有所帮助。 无论最终模型有多高级,记住原始数据都非常重要。
逻辑回归
如果您熟悉线性回归,那么您将了解逻辑回归。 基本上,我们将为图像中的每个像素分配一个权重,然后对这些像素进行加权求和(权重为beta,像素为X)。 这将为我们提供该图像是特定字体的分数。 每种字体都有自己的权重集,因为它们对像素的重视程度不同。 要将这些分数转换为适当的概率(由Y表示),我们将使用softmax函数将其总和强制在 0 到 1 之间,如下所示。 对于特定图像而言,无论最大概率是多少,我们都将其分类为关联的类别。
您可以在大多数统计建模教科书中阅读有关逻辑回归理论的更多信息。 这是它的公式:
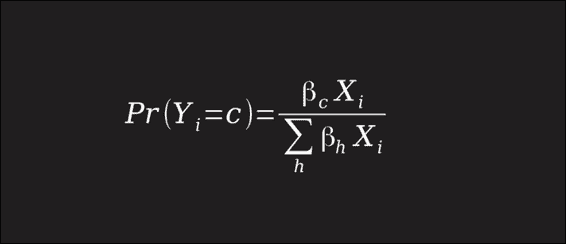
William H. Greene 的《计量经济学分析》(Pearson)于 2012 年出版,这是一本针对应用的很好的参考。
准备数据
在 TensorFlow 中实现逻辑回归非常容易,并将作为更复杂的机器学习算法的基础。 首先,我们需要将整数标签转换为单格式。 这意味着,不是将字体类标记为 2,而是将标签转换为[0, 0, 1, 0, 0]。 也就是说,我们将1放在第二个位置(注意,向上计数在计算机科学中很常见),而0则放在其他位置。 这是我们的to_onehot函数的代码:
def to_onehot(labels,nclasses = 5):
'''
Convert labels to "one-hot" format.
>>> a = [0,1,2,3]
>>> to_onehot(a,5)
array([[ 1., 0., 0., 0., 0.],
[ 0., 1., 0., 0., 0.],
[ 0., 0., 1., 0., 0.],
[ 0., 0., 0., 1., 0.]])
'''
outlabels = np.zeros((len(labels),nclasses))
for i,l in enumerate(labels):
outlabels[i,l] = 1
return outlabels
完成此操作后,我们可以继续调用该函数:
onehot = to_onehot(labels)
对于像素,在这种情况下,我们实际上并不需要矩阵,因此我们将36 x 36的数字展平为长度为 1,296 的一维向量,但这会在以后出现。 另外,回想一下,我们已经重新调整了 0-255 的像素值,使其介于 0 和 1 之间。
好的,我们的最后准备是将数据集分为训练和验证集。 这将有助于我们稍后解决过拟合问题。 训练集将帮助我们确定逻辑回归模型中的权重,而验证集将仅用于确认这些权重在新数据上是否合理:
# Split data into training and validation
indices = np.random.permutation(train.shape[0])
valid_cnt = int(train.shape[0] * 0.1)
test_idx, training_idx = indices[:valid_cnt],\
indices[valid_cnt:]
test, train = train[test_idx,:],\
train[training_idx,:]
onehot_test, onehot_train = onehot[test_idx,:],\
onehot[training_idx,:]
建立 TensorFlow 模型
好的,让我们通过创建一个交互式会话来开始 TensorFlow 代码:
sess = tf.InteractiveSession()
这样,我们就在 TensorFlow 中开始了我们的第一个模型。
我们将为x使用占位符变量,该变量代表我们的输入图像。 这只是告诉 TensorFlow 我们稍后将通过feed_dict为该节点提供值:
# These will be inputs
## Input pixels, flattened
x = tf.placeholder("float", [None, 1296])
另外,请注意,我们可以指定此张量的形状,在这里我们将None用作大小之一。 None的大小允许我们立即将任意数量的数据点发送到算法中以进行批量。 同样,我们将使用变量y_来保存我们已知的标签,以便稍后进行训练:
## Known labels
y_ = tf.placeholder("float", [None,5])
要执行逻辑回归,我们需要一组权重(W)。 实际上,五个字体类别中的每一个都需要 1,296 的权重,这将为我们提供形状。 请注意,我们还希望为每个类别添加一个额外的权重作为偏差(b)。 这与添加始终为1值的额外输入变量相同:
# Variables
W = tf.Variable(tf.zeros([1296,5]))
b = tf.Variable(tf.zeros([5]))
随着所有这些 TensorFlow 变量浮动,我们需要确保对其进行初始化。 现在给他们打电话:
# Just initialize
sess.run(tf.global_variables_initializer())
做得好! 您已经准备好一切。 现在,您可以实现softmax公式来计算概率。 由于我们非常仔细地设置权重和输入,因此 TensorFlow 只需调用tf.matmul和tf.nn.softmax就可以轻松完成此任务:
# Define model
y = tf.nn.softmax(tf.matmul(x,W) + b)
而已! 您已经在 TensorFlow 中实现了整个机器学习分类器。辛苦了。但是,我们从哪里获得权重的值? 让我们看一下使用 TensorFlow 训练模型。
逻辑回归训练
首先,您将了解我们的机器学习分类器的损失函数,并在 TensorFlow 中实现它。 然后,我们将通过求值正确的 TensorFlow 节点来快速训练模型。 最后,我们将验证我们的模型是否合理准确,权重是否合理。
定义损失函数
优化我们的模型实际上意味着最大程度地减少我们的误差。 使用我们的标签,可以很容易地将它们与模型预测的类概率进行比较。 类别cross_entropy函数是测量此函数的正式方法。 尽管确切的统计信息超出了本课程的范围,但是您可以将其视为对模型的惩罚,以期获得更不准确的预测。 为了进行计算,我们将单热的实数标签与预测概率的自然对数相乘,然后将这些值相加并取反。 为方便起见,TensorFlow 已经包含此函数为tf.nn.softmax_cross_entropy_with_logits(),我们可以这样称呼它:
# Climb on cross-entropy
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(
logits = y + 1e-50, labels = y_))
请注意,我们在此处添加了一个较小的1e-50误差值,以避免数值不稳定问题。
训练模型
TensorFlow 的便利之处在于它提供了内置的优化器,以利用我们刚刚编写的损失函数。 梯度下降是一种常见的选择,它将使我们的权重逐渐趋于更好。 这是将更新我们权重的节点:
# How we train
train_step = tf.train.GradientDescentOptimizer(
0.02).minimize(cross_entropy)
在我们实际开始训练之前,我们应该指定一些其他节点来评估模型的表现:
# Define accuracy
correct_prediction = tf.equal(tf.argmax(y,1),
tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(
correct_prediction, "float"))
如果我们的模型将最高概率分配给正确的类别,则correct_prediction节点为1,否则为0。 accuracy变量对可用数据的这些预测取平均值,从而使我们对模型的执行情况有一个整体认识。
在进行机器学习训练时,我们经常希望多次使用同一数据点,以挤出所有信息。 每次遍历整个训练数据都称为一个周期。 在这里,我们将每 10 个时间段同时保存训练和验证准确率:
# Actually train
epochs = 1000
train_acc = np.zeros(epochs//10)
test_acc = np.zeros(epochs//10)
for i in tqdm(range(epochs)):
# Record summary data, and the accuracy
if i % 10 == 0:
# Check accuracy on train set
A = accuracy.eval(feed_dict={
x: train.reshape([-1,1296]),
y_: onehot_train})
train_acc[i//10] = A
# And now the validation set
A = accuracy.eval(feed_dict={
x: test.reshape([-1,1296]),
y_: onehot_test})
test_acc[i//10] = A
train_step.run(feed_dict={
x: train.reshape([-1,1296]),
y_: onehot_train})
请注意,我们使用feed_dict传递不同类型的数据以获得不同的输出值。 最后,train_step.run每次迭代都会更新模型。 在典型的计算机上,这只需几分钟,如果使用 GPU,则要少得多,而在功率不足的计算机上则要花更多时间。
您刚刚使用 TensorFlow 训练了模型; 真棒!
评估模型准确率
在 1,000 个周期之后,让我们看一下模型。 如果您安装了 Matplotlib,则可以在绘图中查看精度; 如果没有,您仍然可以查看电话号码。 对于最终结果,请使用以下代码:
# Notice that accuracy flattens out
print(train_acc[-1])
print(test_acc[-1])
如果您确实安装了 Matplotlib,则可以使用以下代码显示图:
# Plot the accuracy curves
plt.figure(figsize=(6,6))
plt.plot(train_acc,'bo')
plt.plot(test_acc,'rx')
您应该看到类似下面的图(请注意,我们使用了一些随机初始化,因此可能并不完全相同):
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1BKlHuBV-1681566150307)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00021.jpg)]
验证精度似乎在经过约 400-500 次迭代后趋于平稳; 除此之外,我们的模型可能过拟合或没有学到更多。 同样,即使最终精度大约是 40%,看起来也很差,但请记住,对于五个类别,完全随机的猜测将仅具有 20% 的精度。 有了这个有限的数据集,简单的模型就可以做到。
查看计算出的权重通常也很有帮助。 这些可以为您提供有关模型认为重要的线索。 让我们按给定类的像素位置绘制它们:
# Look at a subplot of the weights for each font
f, plts = plt.subplots(5, sharex=True)
for i in range(5):
plts[i].pcolor(W.eval()[:,i].reshape([36,36]))
这应该给您类似于以下的结果(同样,如果图显示得很宽,则可以挤压窗口大小以使其平方):
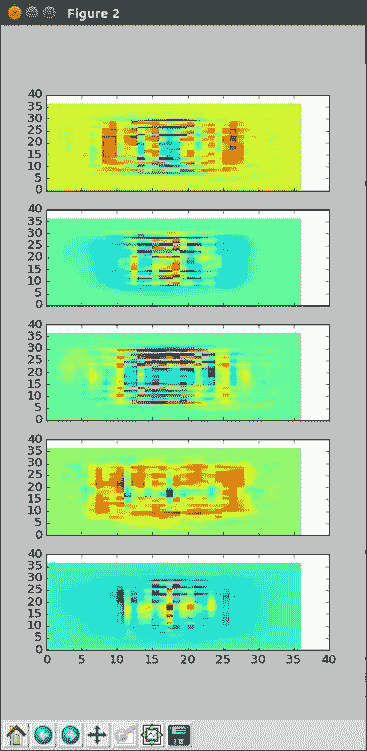
我们可以看到,在某些模型中,靠近内部的权重很重要,而外部的权重基本上为零。 这是有道理的,因为没有字体字符到达图像的角落。
同样,请注意,由于随机初始化的影响,最终结果可能看起来有些不同。 随时可以尝试并更改模型的参数; 这就是您学习新事物的方式。
总结
在本章中,我们在可以使用的机器上安装了 TensorFlow。 经过一些基本计算的小步骤,我们跳入了机器学习问题,仅通过逻辑回归和几行 TensorFlow 代码就成功构建了一个体面的模型。
在下一章中,我们将看到 TensorFlow 在深度神经网络方面的优势。
二、深度神经网络
在上一章中,我们研究了简单的 TensorFlow 操作以及如何在字体分类问题上使用逻辑回归。 在本章中,我们将深入探讨一种最流行和成功的机器学习方法-神经网络。 使用 TensorFlow,我们将构建简单和深度的神经网络,以改善字体分类问题的模型。 在这里,我们将实践神经网络的基础。 我们还将使用 TensorFlow 构建和训练我们的第一个神经网络。 然后,我们将进入具有神经元隐藏层的神经网络,并完全理解它。 完成后,您将更好地掌握以下主题:
- 基本神经网络
- 单隐藏层模型
- 单隐藏层说明
- 多隐藏层模型
- 多隐藏层的结果
在第一部分中,我们将回顾神经网络的基础。 您将学习转换输入数据的常见方法,了解神经网络如何将这些转换联系在一起,最后,如何在 TensorFlow 中实现单个神经元。
基本神经网络
我们的逻辑回归模型运作良好,但本质上是线性的。 将像素的强度加倍会使像素对得分的贡献增加一倍,但我们可能只真正关心像素是否在某个阈值之上或将较小的权重放在较小的值上。 线性可能无法捕获问题的所有细微差别。 解决此问题的一种方法是使用非线性函数转换输入。 让我们看一下 TensorFlow 中的一个简单示例。
首先,请确保加载所需的模块(tensorflow,numpy和math)并启动交互式会话:
import tensorflow as tf
import numpy as np
import math
sess = tf.InteractiveSession()
在下面的示例中,我们创建了三个五长向量的正常随机数,这些向量被截断以防止它们过于极端,中心不同:
x1 = tf.Variable(tf.truncated_normal([5],
mean=3, stddev=1./math.sqrt(5)))
x2 = tf.Variable(tf.truncated_normal([5],
mean=-1, stddev=1./math.sqrt(5)))
x3 = tf.Variable(tf.truncated_normal([5],
mean=0, stddev=1./math.sqrt(5)))
sess.run(tf.global_variables_initializer())
注意
请注意,由于这是随机的,因此您的值可能会有所不同,但这很好。
常见的转换是对输入求平方。 这样做会使更大的值变得更加极端,当然也使所有事情都变得积极起来:
sqx2 = x2 * x2
print(x2.eval())
print(sqx2.eval())
您可以在以下屏幕截图中看到结果:

对数函数
相反,如果您需要在较小的值中有更多细微差别,则可以尝试采用输入的自然对数或任何基本对数:
logx1 = tf.log(x1)
print(x1.eval())
print(logx1.eval())
请参考以下屏幕截图,请注意,较大的值往往会挤在一起,而较小的值则散布得多:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LmQujw6o-1681566150308)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00024.jpg)]
但是,对数不能处理负输入,并且您越接近零,小输入就变得越负。 因此,请注意对数。 最后,是 Sigmoid 变换。
sigmoid 函数
不必担心公式,只需知道正负两个极值分别被压缩为加一或零,而接近零的输入就接近二分之一:
sigx3 = tf.sigmoid(x3)
print(x3.eval())
print(sigx3.eval())
在这里,您将看到一个接近一半的示例。 它从四分之一开始,到现在将近一半:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KlkXSQCL-1681566150308)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00025.jpg)]
在机器学习中,我们通常将这些转换称为激活函数。 我们通常将输入的加权总和组合到其中。 当您考虑输入,权重和激活函数时,就将其称为神经元,因为它是受生物神经元启发的。
真正的神经元如何在物理大脑中工作的细节不在本书的讨论范围之内。 如果您对此感兴趣,则神经生物学文章可能包含更多内容,或者您可以参考 Gordon M. Shepherd 的《神经元学说》作为近期参考。 让我们看一下 TensorFlow 中的一个简单示例:
w1 = tf.constant(0.1)
w2 = tf.constant(0.2)
sess.run(tf.global_variables_initializer())
首先,只需创建一些常量w1和w2即可。 我们将x1乘以w1,将x2乘以w2,然后将这些中间值相加,最后将结果通过tf.sigmoid的sigmoid激活函数进行处理。 查看以下屏幕快照中显示的结果:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-C5KApowV-1681566150308)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00026.jpg)]
同样,现在不必担心确切的公式,您可以拥有各种不同的激活函数。 请注意,这是您迈向自己的神经网络的第一步。
那么,我们如何从单个神经元到整个网络? 简单! 一个神经元的输入仅成为网络下一层中另一神经元的输入。
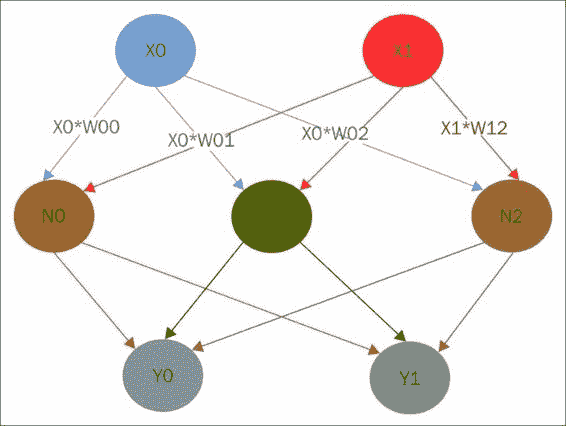
在上图中,我们有一个简单的网络,其中有两个输入X0和X1,两个输出Y0和Y1,中间有三个神经元。 X0中的值被发送到每个N神经元,但是权重不同,该权重乘以与每个相关的X0。 X1也发送到每个神经元,并具有自己的一组权重。 对于每个神经元,我们计算输入的加权总和,将其通过激活函数,然后产生中间输出。 现在,我们做同样的事情,但是将神经元的输出视为Y的输入。 注意,通过对输入加权和进行非线性激活,我们实际上只是为最终模型计算了一组新的特征。
现在您已经了解了 TensorFlow 中非线性转换的基础以及什么是神经网络。 好吧,它们可能不会让您读懂思想,它们对于深度学习至关重要。 在下一节中,我们将使用简单的神经网络来改进分类算法。
单隐藏层模型
在这里,我们将实践神经网络的基础知识。 我们将逻辑回归 TenserFlow 代码改编为神经元的单个隐藏层。 然后,您将学习反向传播背后的思想以计算权重,即训练网络。 最后,您将在 TensorFlow 中训练您的第一个真正的神经网络。
本部分的 TensorFlow 代码应该看起来很熟悉。 它只是逻辑回归代码的略微演变版本。 让我们看看如何添加神经元的隐藏层,以计算输入像素的非线性组合。
您应该从全新的 Python 会话开始,执行代码以读入,并按照逻辑模型中的步骤设置数据。 相同的代码,只是复制到新文件中:
import tensorflow as tf
import numpy as np
import math
from tqdm import tqdm
%autoindent
try:
from tqdm import tqdm
except ImportError:
def tqdm(x, *args, **kwargs):
return x
您总是可以回到前面的部分,并提醒自己该代码的作用; 直到num_hidden变量的所有内容都可以使您快速入门。
探索单隐藏层模型
现在,让我们逐步介绍单个隐藏层模型:
-
首先,让我们指定
num_hidden = 128想要多少个神经元; 最终,这实际上是将多少个非线性组合传递给逻辑对数。 -
为了适应这一点,我们还需要更新
W1和b1权重张量的形状。 他们现在正在馈送我们隐藏的神经元,因此需要匹配形状:W1 = tf.Variable(tf.truncated_normal([1296, num_hidden], stddev=1./math.sqrt(1296))) b1 = tf.Variable(tf.constant(0.1,shape=[num_hidden])) -
我们计算加权和的激活函数的方法是使用单行
h1。 这是将我们的输入像素乘以每个神经元各自的权重:h1 = tf.sigmoid(tf.matmul(x,W1) + b1)添加神经元偏差项,最后通过
sigmoid激活函数进行设置; 此时,我们有 128 个中间值: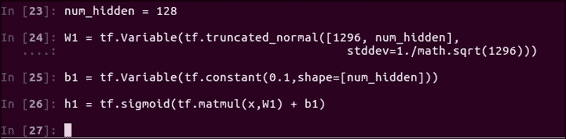
-
现在,这只是对您友好的逻辑回归; 您已经知道该怎么办。 这些新计算的 128 个特征需要它们自己的权重和偏置集来计算输出类的分数,分别为
W2和b2。 注意形状如何与神经元的形状 128 匹配,并且输出类的数量为 5:W2 = tf.Variable(tf.truncated_normal([num_hidden, 5], stddev=1./math.sqrt(5))) b2 = tf.Variable(tf.constant(0.1,shape=[5])) sess.run(tf.global_variables_initializer())在所有这些权重中,我们使用此奇怪的截断普通调用对其进行初始化。 借助神经网络,我们希望获得良好的初始值分布,以便我们的权重可以攀升至有意义的值,而不是仅仅归零。
-
截断正态具有给定标准偏差的正态分布中的随机值,该研究标准按输入数量进行缩放,但抛出的值太极端,因此被截断了。 定义好权重和神经元后,我们将像以前一样设置最终的
softmax模型,除了需要注意使用 128 个神经元作为输入h1以及相关的权重和偏差W2和b2:y = tf.nn.softmax(tf.matmul(h1,W2) + b2)
反向传播
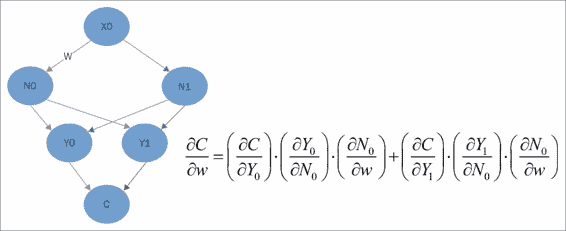
训练神经网络和许多其他机器学习模型权重的关键称为反向传播。
完整的推导超出了本书的范围,但是让我们直观地进行研究。 当您在空中训练逻辑回归之类的模型并且训练集直接来自选择不当的权重时,您可以看到应该调整哪些权重以及应该调整多少权重并相应地更改它们。
从形式上讲,TensorFlow 通过计算空气相对于权重的导数并将权重调整为该数值的一小部分来实现此目的。 反向传播实际上是同一过程的扩展。
您从最底层的输出或成本函数层开始,计算导数,然后使用它们来计算与上一层神经元相关的导数。 通过将从成本到权重的路径上的导数乘积相加,我们可以计算相对于要调整的权重的成本的适当偏导数。 上图中显示的公式仅说明了红色箭头显示的内容。 如果这看起来很复杂,请不要担心。
TensorFlow 使用优化器在后台为您处理。 由于我们使用 TensorFlow 精心指定了模型来训练模型,因此几乎与之前完全相同,因此我们将在此处使用相同的代码:
epochs = 5000
train_acc = np.zeros(epochs//10)
test_acc = np.zeros(epochs//10)
for i in tqdm(range(epochs), ascii=True):
if i % 10 == 0: # Record summary data, and the accuracy
# Check accuracy on train set
A = accuracy.eval(feed_dict={x: train.reshape([-1,1296]), y_: onehot_train})
train_acc[i//10] = A
# And now the validation set
A = accuracy.eval(feed_dict={x: test.reshape([-1,1296]), y_: onehot_test})
test_acc[i//10] = A
train_step.run(feed_dict={x: train.reshape([-1,1296]), y_: onehot_train})
需要注意的一件事是,因为我们有这些隐藏的神经元,所以有更多的权重可以拟合模型。 这意味着我们的模型将需要更长的运行时间,并且必须花费更多的迭代时间才能进行训练。 这次我们通过5000历时运行它:
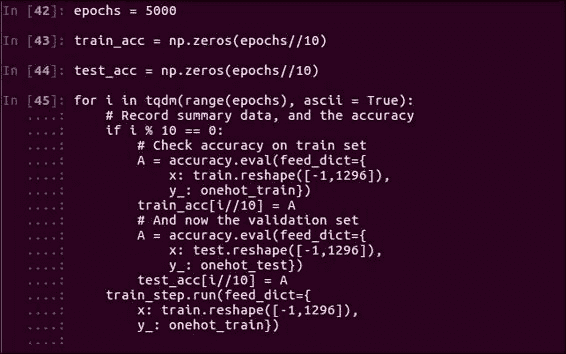
该模型可能比以前的模型花费更长的时间,可能是前一个模型的四倍。 因此,您可能需要几分钟到 10 分钟的时间,具体取决于您的计算机。 现在,通过模型训练,我们将在稍后查看验证准确率。
单隐藏层的说明
在本节中,我们将仔细研究构建的模型。 首先,我们将验证模型的整体准确率,然后查看模型出了哪些问题。 最后,我们将可视化与多个神经元相关的权重,以查看它们在寻找什么:
plt.figure(figsize=(6, 6))
plt.plot(train_acc,'bo')
plt.plot(test_acc,'rx')
确保您已经按照上一节中的步骤训练了模型,如果没有,您可能要在这里停下来并首先进行操作。 由于我们每隔 10 个训练周期就评估模型的准确率并保存结果,因此现在很容易探索模型的演变方式。
使用 Matplotlib,我们可以在同一张图上绘制训练精度(蓝色点)和测试精度(红色点):
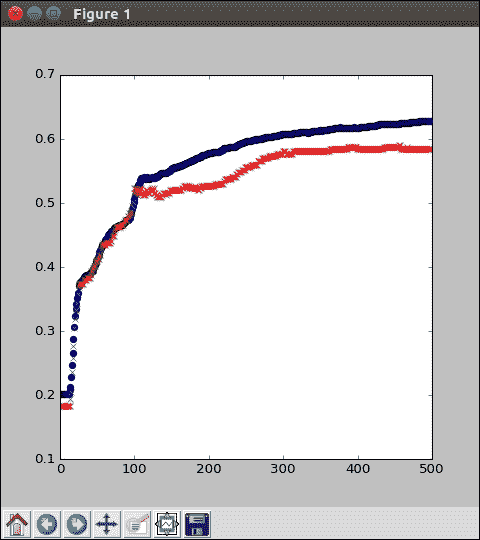
同样,如果您没有 Matplotlib,那就没关系。 您可以只查看数组值本身。 请注意,训练精度(蓝色)通常比测试精度(红色)好一点。 这并不奇怪,因为测试图像对于模型来说是全新的,并且可能包含以前看不见的特征。 另外,观察精度通常会攀升到更多的周期,然后逐渐上升,然后逐渐上升。 我们的模型在这里达到约 60% 的准确率; 并非完美,但对简单逻辑回归进行了改进。
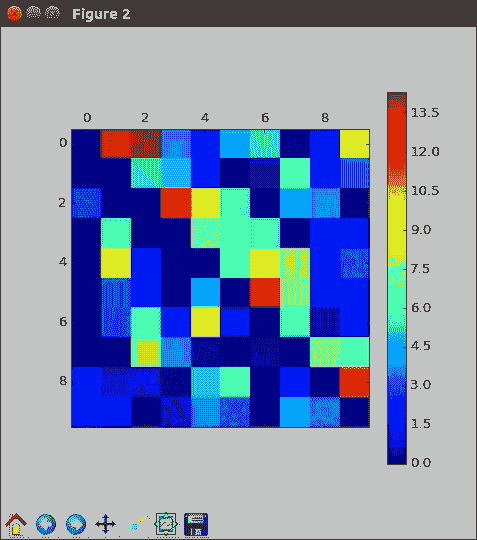
要查看我们的模型在哪里混淆,创建混淆矩阵会很有帮助。 也就是说,我们将寻找一个可以说的实际绘图类别。 该模型将其分类为什么? 形式上是5x5矩阵。 对于每个测试图像,如果图像实际上是类别i和模型预测类别j,则我们增加值和位置i j。 请注意,当模型正确时,则为i = j。
一个好的模型在对角线上将具有很大的值,而在其他地方则没有很多。 通过这种类型的分析,很容易看出两个类是否经常彼此混淆,或者模型很少选择某些类。
在以下示例中,我们通过求值y(类概率)来创建预测类:
pred = np.argmax(y.eval(feed_dict={x:
test.reshape([-1,1296]), y_: onehot_test}), axis = 1)
conf = np.zeros([5,5])
for p,t in zip(pred,np.argmax(onehot_test,axis=1)):
conf[t,p] += 1
plt.matshow(conf)
plt.colorbar()
np.argmax函数提取概率最大的位置。 同样,为了确定实际的类别,我们使用np.argmax撤消一次热编码。 创建混乱矩阵始于全零数组,然后逐步遍历所有填充的测试数据。Matplotlib 让我们看一下彩色图像,但打印与会者的效果几乎相同:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sbLo70Kb-1681566150310)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00032.jpg)]
在前面的输出中,我们看到模型通常做得不错,只是它很少预测类2。 由于初始的随机性,您的确切结果可能看起来有些不同。
了解模型的权重
正如我们查看逻辑回归模型的权重一样,我们可以监视此模型的权重:
plt.figure(figsize=(6, 6))
f, plts = plt.subplots(4,8, sharex=True)
for i in range(32):
plts[i//8, i%8].pcolormesh(W1.eval()[:,i].reshape([36,36]))
但是,现在我们有 128 个神经元,每个神经元的权重都来自输入像素,权重为36x36。 让我们看看其中的一些,以了解他们的发现。 同样,如果您没有 Matplotlib,则可以简单地打印出数组以查看相同的行为。 在这里,我们将研究 128 个神经元中的 32 个。 因此,让我们将子图的格式设置为四行八列。 现在,我们逐步求值每个神经元的权重,并将其重塑为图像大小。 双斜杠(//)使用整数除法将图像放入适当的行,而百分号(%)使用余数(实际上是模块化算术)来选择列。
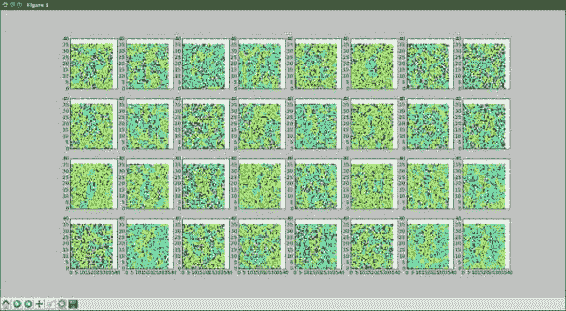
视觉上,在前面的输出中,您可以看到一些形状突出。 与它们的权重模式相比,某些神经元或多或少具有圆形形状。 其他人看起来很随意,但可能会选择我们不容易理解的特征。 我们也可以尝试可视化输出层的权重,但是这些不再直观。 我们称其为神经网络。 现在,输出逻辑回归是 128 个输入值,以及用于计算 5 个分数的权重。 不再有图像结构,因为每个像素都进入了隐藏层的每个神经元。 现在您知道了如何评估和解释神经网络结果。 做得好!
多隐藏层模型
在本节中,我们将向您展示如何使用其他隐藏层构建更复杂的模型。 我们将单层隐藏模型改编为称为深度神经网络的多层模型。 然后,我们将讨论选择要使用的神经元和层数。 最后,我们将耐心地训练模型本身,因为这可能需要一段时间才能计算出来。
还记得我们向逻辑回归模型添加神经元的隐藏层吗? 好了,我们可以再做一次,在我们的单个隐藏层模型中添加另一层。 一旦您拥有一层以上的神经元,我们就将其称为深度神经网络。 但是,您以前所学的一切都可以立即应用。 与本章前面的部分一样,您应该进行一个全新的 Python 会话并执行本部分代码文件中直到num_hidden1的代码。 然后,乐趣开始了。
探索多隐藏层模型
首先,将旧的num_hidden更改为num_hidden1,以指示第一个隐藏层上的神经元数量:
# Hidden layer 1
num_hidden1 = 128
确保更改变量,同时定义权重和偏差变量。 现在,我们将插入第二个隐藏层:
W1 = tf.Variable(tf.truncated_normal([1296,num_hidden1],
stddev=1./math.sqrt(1296)))
b1 = tf.Variable(tf.constant(0.1,shape=[num_hidden1]))
h1 = tf.sigmoid(tf.matmul(x,W1) + b1)
这次使用带有32神经元的神经元。 请注意,权重的形状必须如何解释来自上一层的 128 个中间输出中的每一个进入当前层的 32 个输入或神经元,但是我们初始化权重和偏差的方式基本上相同:
# Hidden Layer 2
num_hidden2 = 32
W2 = tf.Variable(tf.truncated_normal([num_hidden1,
num_hidden2],stddev=2./math.sqrt(num_hidden1)))
b2 = tf.Variable(tf.constant(0.2,shape=[num_hidden2]))
h2 = tf.sigmoid(tf.matmul(h1,W2) + b2)
如您在前面的代码中所见,我们像以前一样使用sigmoid函数创建h2输出,并使用矩阵乘法,加法和函数调用。
对于输出逻辑回归层,我们只需要更新变量名称:
# Output Layer
W3 = tf.Variable(tf.truncated_normal([num_hidden2, 5],
stddev=1./math.sqrt(5)))
b3 = tf.Variable(tf.constant(0.1,shape=[5]))
现在这是第三组权重,当然,此形状必须与前面的隐藏层的输出匹配,因此32 x 5:
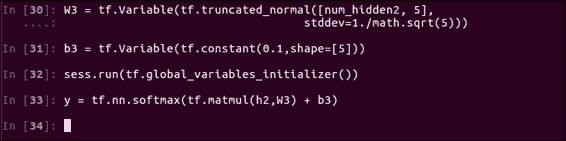
不要忘记使用h2,W3和b3变量更新y模型函数。 您不想只使用旧模型就更新所有代码。
您可能想知道我们如何决定第一层的 128 个神经元和第二层的 32 个神经元。 事实是,为网络确定合适的尺寸和形状可能是一个具有挑战性的问题。 尽管计算可能会很昂贵,但是反复试验是开发模型的一种方法。 通常,您可能会从旧模型开始并从那里开始工作。 在这里,我们从 128 个神经元的单个隐藏层开始,然后尝试在其下添加一个新层。 我们要计算一些特征以区分五类,因此在选择神经元数量时应牢记这一点。
通常,最好从小处着手,逐步发展到解释数据的最小模型。 如果在顶层具有 128 个神经元而在下一层具有 8 个神经元的模型的效果较差,则可能表明我们需要为最后一层提供更多特征,并应添加更多而不是更少的神经元。
尝试将最后一层中的神经元数量加倍,当然,最好回到较早的层并调整那里的神经元数量。 同样,您可以更改优化器的学习率,从而改变每一步调整权重的程度,甚至更改用于优化的函数。
注意
设置所有这些值称为超参数优化,这是机器学习研究中的热门话题。
请注意,我们实际上是从最简单的模型,逻辑回归开始,然后慢慢添加新的功能和结构。 如果一个简单的模型运行良好,那么甚至没有必要花时间在更高级的东西上。
现在已经指定了我们的模型,让我们实际进行训练:
# Climb on cross-entropy
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(logits= y + 1e-50, labels= y_))
# How we train
train_step = tf.train.GradientDescentOptimizer(0.01).minimize(cross_entropy)
# Define accuracy
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction, "float"))
同样,我们需要在 TensorFlow 图中重新定义我们的训练节点,但是这些与以前完全相同。 请注意,由于我们的第一个隐藏层现在挂接到神经元的另一层,因此我们需要计算更多的权重。 以下是实际的训练代码:
epochs = 25000
train_acc = np.zeros(epochs//10)
test_acc = np.zeros(epochs//10)
for i in tqdm(range(epochs)):
# Record summary data, and the accuracy
if i % 10 == 0:
# Check accuracy on train set
A = accuracy.eval(feed_dict={
x: train.reshape([-1,1296]),
y_: onehot_train})
train_acc[i//10] = A
# And now the validation set
A = accuracy.eval(feed_dict={
x: test.reshape([-1,1296]),
y_: onehot_test})
test_acc[i//10] = A
train_step.run(feed_dict={
x: train.reshape([-1,1296]),
y_: onehot_train})
以前,我们有 128 乘以 5 的权重,但是现在我们有 128 乘以 32 的权重-这是该层的六倍,这是从像素到神经元第一层的初始权重之上。 深度神经网络的一个缺点是它们可能需要一段时间才能训练。 在这里,我们将运行25000个周期,以确保权重收敛:
这可能需要一个小时或更长时间,具体取决于您的计算机和 GPU。 尽管这看起来似乎过多,但专业的机器学习研究人员通常会训练模型长达两个星期。 您可能会学得很快,但是计算机需要一些时间。
在本节中,我们使用 TensorFlow 构建并训练了一个真正的深度神经网络。 许多专业的机器学习模型没有您已经编写的复杂。
多隐藏层的结果
现在,我们将研究深度神经网络内部的情况。 首先,我们将验证模型的准确率。 然后,我们将可视化并研究像素权重。 最后,我们还将查看输出权重。
训练完您的深度神经网络后,让我们看一下模型的准确率。 我们将以与单隐藏层模型相同的方式进行操作。 这次的唯一区别是,从更多的周期开始,我们保存了更多的训练和测试准确率样本。
和往常一样,如果您没有 Matplotlib,请不要担心。 打印数组的一部分很好。
了解多隐藏层的图
执行以下代码以查看结果:
# Plot the accuracy curves
plt.figure(figsize=(6,6))
plt.plot(train_acc,'bo')
plt.plot(test_acc,'rx')
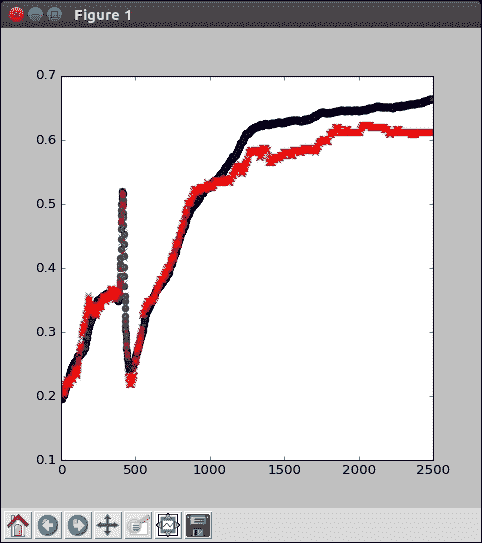
从前面的输出图中,我们可以达到约 68% 的训练精度,也许还有 63% 的验证精度。 这还不错,但是确实留出了一些改进的空间。
让我们花点时间看一下准确率在许多周期如何增长。 当然,它起步非常糟糕,并且存在一些最初的麻烦,但是权重是随机的,并且在那个时候仍在学习,并且在最初的数千个周期中它很快得到了改善。 虽然可能会暂时卡在局部最大值中,但通常会爬出并最终减慢其重音。 请注意,它仍然可以很好地进入训练阶段。 只是到了尽头,模型才可能达到其最大容量。 根据随机初始化,您的曲线可能看起来有些不同,但这没关系; 这是您的模型,非常好。
要查看我们的模型在哪里出现问题,让我们看一下混淆矩阵:
pred = np.argmax(y.eval(feed_dict={x:
test.reshape([-1,1296]), y_: onehot_test}), axis = 1)
conf = np.zeros([5,5])
for p,t in zip(pred,np.argmax(onehot_test,axis=1)):
conf[t,p] += 1
plt.matshow(conf)
plt.colorbar()
同样,这与我们用于单个隐藏层模型的过程完全相同,只是在更高级的方面:
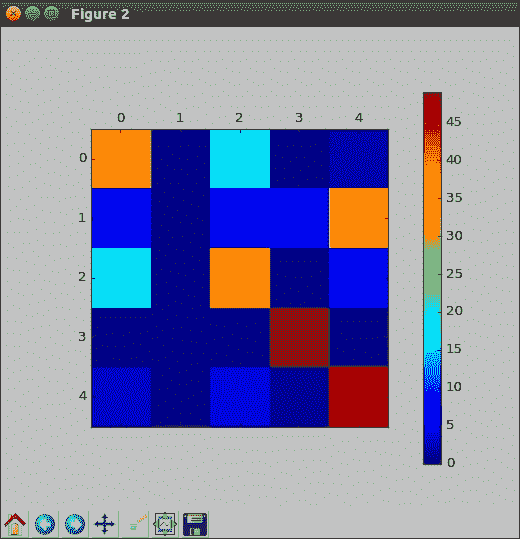
对此进行绘图,就像在前面的输出中一样,我们看到该模型总体上运行良好,但是仍然难以识别其中一个类,这次是1。 我们正在逐步取得进展。 验证准确率之后,让我们检查一下我们的第一层神经元,即 128 个人,发现了什么样的现象:
# Let's look at a subplot of some weights
f, plts = plt.subplots(4,8, sharex=True)
for i in range(32):
plts[i//8, i%8].matshow(W1.eval()[:,i].reshape([36,36]))
为了简单起见,我们仅查看前 32 个此类神经元。 使用与先前模型相同的代码,可以轻松地使用 Matplotlib 进行绘制或打印出来:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-03AQnj8j-1681566150311)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00039.jpg)]
毫不奇怪,我们看到了许多与先前模型相同的函数。 尽管在这里,由于随机初始化,即使它们看起来像是同一类型的特征,它们也会位于不同的位置。 同样,您有一些环形神经元,具有非常条纹状特征的神经元,以及具有宽条纹状特征的另一个神经元。 就我们的神经网络而言,圆形和条纹形状是确定字体类别的良好成分。
尽管我们其他隐藏层中的权重不再具有图像的结构,但查看输出的权重可能会很有帮助。 这将告诉我们每个最终神经元对每个类别的贡献。 我们可以将其绘制为热力图,或使用W3.eval任意方式打印单个数组:
# Examine the output weights
plt.matshow(W3.eval())
plt.colorbar()
因为我们仔细指定了W3,所以每一行将代表一个神经元,每一列将代表一个类:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UxmgvdbN-1681566150312)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00040.jpg)]
从前面的输出图中我们可以看到,不同的神经元对某些类别的贡献要大于其他类别,这表明神经元正在计算的某些总体非线性特征与该特定字体类别有关。 也就是说,虽然这些神经元产生的值用于计算每种字体的分数,但非常重要且权重较大的一种字体的神经元可能与另一种字体几乎无关。 例如,对于2类,N1神经元的权重非常大,而对于所有其他类别,N1神经元的权重几乎为零。 该神经元具有什么计算特征,对于2类而言非常重要,但对于其他类别而言则没有那么重要。
总结
在本章中,我们使用 TensorFlow 进行了深度学习。 尽管我们从一个神经元隐藏层的简单模型开始,但是并不需要花很长时间就可以开发和训练用于字体分类问题的深度神经网络。
您了解了单层和多层隐藏层模型,并对其进行了详细了解。 您还将了解神经网络的不同类型,并使用 TensorFlow 构建和训练了我们的第一个神经网络。
在下一章中,我们将使用卷积神经网络(一种用于图像分类的强大工具)来证明我们的模型。
三、卷积神经网络
在上一章中,我们探讨了深度神经网络,该神经网络需要更多的参数才能拟合。 本章将指导您完成深度学习中最强大的开发之一,并让我们使用有关问题空间的一些知识来改进模型。 首先,我们将解释一个神经网络中的卷积层,然后是一个 TensorFlow 示例。 然后,我们将对池化层执行相同的操作。 最后,我们将字体分类模型改编为卷积神经网络(CNN),然后看看它是如何工作的。
在本章中,我们将介绍卷积神经网络的背景。 我们还将在 TensorFlow 中实现卷积层。 我们将学习最大池化层并将其付诸实践,并以单个池化层为例。
在本章的最后,您将对以下概念有很好的控制:
- 卷积层动机
- 卷积层应用
- 池化层动机
- 池化层应用
- 深度 CNN
- 更深的 CNN
- 深层 CNN 总结
现在让我们进入卷积层。
卷积层动机
在本节中,我们将逐步使用示例图像上的卷积层。 我们将以图形方式看到卷积只是一个滑动窗口。 此外,我们将学习如何从窗口中提取多个特征以及如何接受到窗口的多层输入。
在给定神经元的神经网络的经典密集层中,每个输入特征都具有自己的权重。
如果输入特征完全独立并测量不同的事物,那么这很好,但是如果特征之间存在结构,那该怎么办。 想象发生这种情况的最简单示例是,如果您的输入特征是图像中的像素。 一些像素彼此相邻,而其他像素则相距较远。
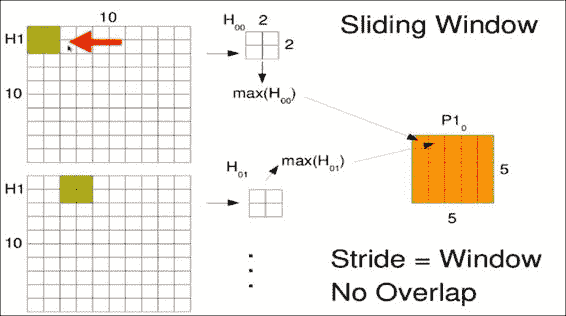
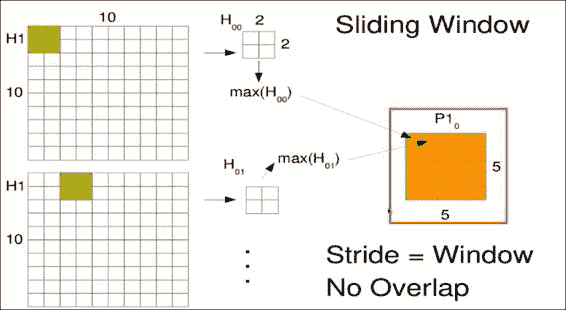
对于诸如图像分类(尤其是字体分类)之类的任务,图像中出现小比例尺特征通常并不重要。 我们可以通过在整个图像中滑动较小的窗口来在较大的图像中查找小比例尺特征,这对于使用相同的权重矩阵至关重要,无论该窗口在图像中的位置如何。 这样,我们可以随时随地寻找相同的特征。
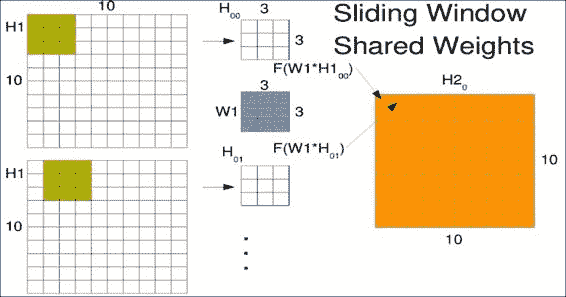
假设我们有一个10x10的图像,并且想在其中滑动3x3的窗口。 通常,机器学习工程师每次只能将此窗口滑动一个像素。 这称为跨步,因此从一个窗口到下一个窗口会有一些重叠。 然后逐个元素地将我们小的3x3权重矩阵W1乘到我们的窗口H1[00]中,对结果求和,并通过称为F的激活函数进行处理。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SsRFhE9l-1681566150312)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00042.jpg)]
第一个窗口W1进入新矩阵的第一个位置,如右图H2所示。 窗口以相同的权重滑过一个,但结果占据第二个位置。 请注意,我们实际上是使用左上像素作为存储结果的参考点。 在整个输入图像上滑动窗口以生成卷积输出。 下图中的点只是提醒您,您将在整个空间中滑动此窗口,而不仅是图中所示的两个位置:
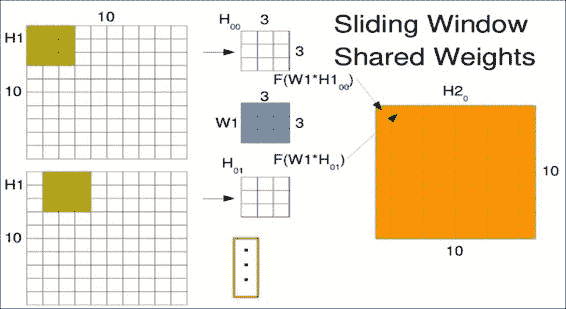
您可能想知道当窗口到达图像边缘时会发生什么。 选择实际上是在忽略超出边缘的窗口和使用占位符值填充窗口之间。 对于卷积层,通常的选择是经常用零或平均值填充它们。 由于卷积的输出形状保持不变,因此在 Tensorflow 中被称为相同的填充。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1Fww3Zea-1681566150312)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00044.jpg)]
请注意,在最后一个窗口中,这实际上只是看一个值。 但是该像素还参与了许多其他位置,因此不要觉得它被排除在外了。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9W5QdutC-1681566150313)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00045.jpg)]
提取多个特征
上一节介绍了滑动窗口的一组权重。 这实际上使您可以计算滑动特征。 但是您可能想要在同一窗口中查找多个对象,例如垂直或水平边缘。
要提取多个特征,您只需要将其他权重矩阵初始化为不同的值即可。 这些多组权重类似于其他神经元和紧密连接的层。 中心的每个权重矩阵W1(蓝色)和W2(绿色)将为您提供另一个输出矩阵,如下图所示,它们分别为H2[1](粉红色)和H2[0](橙色)。 正确的。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6lknB6Zp-1681566150313)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00046.jpg)]
正如您可以从卷积中提取多个特征一样,也可以将多个特征放入这样的网络中。 最明显的例子是具有多种颜色的图像。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WXLjSdNw-1681566150313)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00047.jpg)]
现在,观察上图中所示的矩阵。 您确实有一个红色值的矩阵,一个绿色值的矩阵和一个蓝色值的矩阵。 现在,您的权重矩阵实际上是大小为3x3x3的权重张量,并且在所有颜色上的窗口大小均相同。 当然,您可以组合所有这些方法,并且通常在计算完窗口上的 32 个特征后,尤其是在第一个卷积层之后进行; 现在,您有许多用于下一层的输入通道。
卷积层应用
现在让我们在 TensorFlow 中实现一个简单的卷积层。 首先,我们将遍历此示例中使用的显式形状,因为这通常很棘手。 然后,我们将完成实现和卷积的 TensorFlow 调用。 最后,我们将通过传递一个简单的示例图像直观地检查卷积的结果。
探索卷积层
让我们通过一个新的 IPython 会话直接进入代码。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-uXnliMUW-1681566150313)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00048.jpg)]
这只是一个小例子,可以帮助我们熟悉将 TensorFlow 用于卷积层。
导入必要的工具后,让我们制作一个假的10x10图像,但对角线的值较大:
# Make some fake data, 1 data points
image = np.random.randint(10,size=[1,10,10]) + np.eye(10)*10
请注意前面代码中指定的异常大小。 10, 10只是图像尺寸,但是1是指输入通道的数量。 在这种情况下,我们使用一个输入通道,就像一个灰度图像。 如果您有彩色图像,则这可能是代表红色,绿色和蓝色的三个通道。
尽管此处的示例和研究问题只有一个通道(灰度级),但我们将在深度 CNN 部分中看到如何从卷积层产生多个输入,从而在下一个卷积层中产生多通道输入。 因此,您仍然会感觉如何处理。
向下移动到 TensorFlow 占位符,我们还做了一些看似不寻常的事情。
x = tf.placeholder("float", [None, 10, 10])
x_im = tf.reshape(x, [-1,10,10,1])
在用10, 10和None自然地写入了占位符变量以用于可能的许多图像批量之后,我们将其称为tf.reshape。 这是为了重新排列图像的尺寸,并使它们具有 TensorFlow 期望的形状。 -1只是意味着根据需要填写尺寸以保持整体尺寸。 10,10当然是我们的图像尺寸,最后的1现在是通道数。 同样,如果您有一个带有三个通道的彩色图像,则为三个。
对于我们的卷积层示例,我们希望查看图像的三个像素高和三个像素宽的窗口。 因此,我们指定了以下代码所示的内容:
# Window size to use, 3x3 here
winx = 3
winy = 3
另外,让我们从每个窗口中提取两个特征,这就是我们的过滤器数量:
# How many features to compute on the window
num_filters = 2
您可能还会看到称为内核数量的信息。
指定权重是使事情真正有趣的地方,但是一旦您知道语法,这并不难。
W1 = tf.Variable(tf.truncated_normal(
[winx, winy,1, num_filters],
stddev=1./math.sqrt(winx*winy)))
我们正在像以前一样使用tf.truncated_normal来生成随机权重。 但是大小非常特殊。 属性winx和winy当然是我们窗口的尺寸,1这里是输入通道的数量,因此只是灰度,而最终尺寸(num_filters)是输出尺寸,过滤器的数量。
同样,这类似于密集连接层的神经元数量。 对于随机性的标准差,我们仍然可以缩放到参数数量,但是请注意,每个权重都有一个参数,因此win x*win y。
当然,每个输出神经元的偏差都需要一个变量,因此每个滤波器需要一个变量:
b1 = tf.Variable(tf.constant(
0.1,shape=[num_filters]))
tf.nn.conv2d函数实际上是此处操作的核心。 我们首先传递调整后的输入x_im,然后传递应用于每个窗口的权重,然后传递strides参数。
注意
strides参数告诉 TensorFlow 每一步移动窗口多少。
卷积层的典型用法是向右移动一个像素,完成一行后,向下移动一个像素。 因此有很多重叠之处。 如果要向右移动两个像素,向下移动两个像素; 但是,您可以输入strides=[1,2,2,1]。 最后一个数字用于在通道上移动,第一个数字用于在一批中移动单独的图像。 将这些设置为1是最常见的方法。
xw = tf.nn.conv2d(x_im, W1,
strides=[1, 1, 1, 1],
padding='SAME')
padding='SAME'与上一节完全相同。 这意味着即使部分滑动窗口超出了输入图像的范围,滑动窗口也会运行。 结合跨度为 1 的步长,这意味着卷积输出尺寸将与输入相同,当然不计算通道或滤波器的数量。
最后,我们要通过激活函数传递此卷积输出:
h1 = tf.nn.relu(xw + b1)
在这里,我们使用relu函数,它代表整流线性。 基本上,这仅意味着将任何负输入设置为零,而将正输入保持不变。 您会看到这种激活常与卷积神经网络一起使用。 因此,熟悉它是一件好事。 由于我们已经乘以W1权重,因此我们只需要在此处添加偏置项即可产生卷积层输出。
在 TensorFlow 中初始化变量:
# Remember to initialize!
sess.run(tf.global_variables_initializer())
现在,您有了一个有效的卷积。 太好了! 让我们快速看一下我们劳动成果。
首先,我们需要求值h1节点,并将示例图像作为数据传递:
# Peek inside
H = h1.eval(feed_dict = {x: image})
因此,我们知道从哪里开始,让我们使用以下代码查看示例图像:
# Let's take a look
import matplotlib.pyplot as plt
plt.ion()
# Original
plt.matshow(image[0])
plt.colorbar()
前面代码中的0只是因为奇怪的整形,实际上并没有多个数据点。 您可以看到对角线上的值大于其他值,这与纯随机的区别在于:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gbNkURWw-1681566150314)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00049.jpg)]
让我们看一下第一个输出特征,回想一下输出H的形状为1,10,10,2,因为有1数据点,10像素的宽度和高度以及2特征。 因此,要抓住第一个,我们需要所有像素和零个带过滤器。 好吧,那很有趣。
# Conv channel 1
plt.matshow(H[0,:,:,0])
plt.colorbar()
请注意清零了多少个头寸:
这是relu激活的纠正部分。 整齐。 第二个特征应该看起来相似,直到随机初始化为止。 这些权重尚未经过任何训练,因此我们不应该期望它们产生有意义的输出。 在这里,我们看到碰巧有很多零,否则,有很多小值。

您的图像看起来或多或少会有所不同,需要注意的重要一点是,我们的输出尺寸相同,但是就像我们对同一图像有两个不同的视图一样。 在本部分中,我们在 TensorFlow 中创建了我们的第一个卷积层,以掌握所需的奇数形状。
池化层动机
现在,让我们了解池化层的共同合作伙伴。 在本节中,我们将学习与卷积层相似的最大池化层,尽管它们在通用用法上有所不同。 最后,我们将展示如何组合这些层以获得最大效果。
最大池化层
假设您使用了卷积层从图像中提取特征,并假设,您有一个小的权重矩阵,可以检测图像窗口中的狗形。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Zu2KbTZf-1681566150314)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00052.jpg)]
当您围绕输出进行卷积时,可能会报告许多附近呈狗形的区域。 但这实际上只是由于重叠。 尽管可能只有小狗的形象,但彼此之间可能并没有多少只狗。 您真的只希望一次看到该特征,最好是在特征最强大的位置。 最大池化层尝试执行此操作。 像卷积层一样,池化层在图像的小滑动窗口上工作。
通常,研究人员在一个或多个卷积层之后添加一个池化层。 您最常看到的窗口大小是2x2。 您要做的只是提取四个相邻的值,此处指的是H[00],通常不会对其施加任何权重。 现在,我们希望以某种方式组合这四个值,以提取此窗口最有趣的特征。 通常,我们要提取最引人注目的特征,因此我们选择最大值(max(H[00]))的像素,然后丢弃其余像素。 但是,您也可以平均结果或做一些更奇特的事情。 同样,尽管我们的卷积窗口有很多重叠,但对于合并窗口,我们通常不希望有任何重叠,因此此步长将等于窗口大小 2。
在前面的10x10示例输出中,由于步幅的变化,我们的池化输出仅为5x5。
与卷积层的另一个主要区别是,池化层通常使用不同的填充方案,而卷积层乐于使用相同的填充并以零填充,我们最常使用具有有效填充的池化层。 这意味着,如果窗口超出图像的范围,则将其丢弃。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OTD3L4oL-1681566150315)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00055.jpg)]
这确实会丢失一些边缘信息,但要确保输出不会因填充值而产生偏差。
注意
请注意,此示例对池化层使用9x9输入,但由于有效的填充和跨度为 2,因此输出仅为4x4。 8x8输入也将具有4x4输出。
当您将卷积层和池化层组合在一起时,它们的真正优势就体现出来了。 通常,您会在模型的顶部输入端看到一个卷积层,也许带有3x3窗口。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-g5rL1tVe-1681566150315)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00056.jpg)]
这会在图像中的任何位置寻找相同的特征集。
然后立即出现一个2x2的最大池化层,仅池出最具特征的区域并缩小尺寸。 您也可以重复此过程。
合并后,您现在实际上具有较小的图像P1,但是具有像素强度,而不是像素颜色强度。 因此,您可以创建另一个卷积层以读取第一个池的输出,即底部出现的P1,然后可以对此应用另一个最大池化层。 请注意,由于池化,图像大小是如何逐渐缩小的。 直观地,您可以将其视为建立跨越图像较大区域的较大比例的特征。
早期的卷积权重经常训练以检测简单的边缘,而连续的卷积层将这些边缘组合成逐渐更复杂的形状,例如人脸,汽车甚至狗。
池化层应用
在本节中,我们将研究用于最大池化的 TensorFlow 函数,然后我们将讨论从池化层过渡到完全连接层的过程。 最后,我们将目视观察池输出以验证其减小的大小。
让我们从上一节中停下来的示例开始。 在开始本练习之前,请确保您已执行所有操作直到英镑池化层。
回想一下,我们通过3x3卷积和校正的线性激活来放置10x10图像。 现在,让我们在卷积层之后添加一个最大2x2的池化层。
p1 = tf.nn.max_pool(h1, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='VALID')
关键是tf.nn.max_pool。 第一个参数只是我们先前的卷积层h1的输出。 接下来,我们有一个奇怪的ksize。 这实际上只是定义了池的窗口大小。 在这种情况下,为2x2。 第一个1指的是一次或批量多少个数据点。 通常,我们将其保留为1。 最后的1指的是一次包含在合并中的通道数。 请注意,这里有两个通道,因为卷积产生了两个输出滤波器。 但是我们只有1在这个位置; 这是一次最多只有一个特征的唯一故障。 步幅的工作方式与卷积层相同。 此处的区别在于我们使用2x2(即合并窗口的大小),因为我们不希望有任何重叠。 1之前和之后的值与卷积层中的值完全相同。
因此,我们的输出将是每个尺寸的一半,这里是5x5。 最后,我们将padding设置为VALID。 这意味着,如果一个窗口超出了图像的边缘(实际上是卷积输出),我们将把它扔掉而不使用它。 如果我们的池化层进入另一个卷积层,则可以在以下代码行中添加它:
# We automatically determine the size
p1_size = np.product([s.value for s in p1.get_shape()[1:]])
但是,如果您已经完成了卷积层的工作,并且想要像上一节中的模型那样馈入经典的完全连接层,该怎么办? 这很容易做到; 我们只需要将具有许多输出通道的 2D 矩阵的输出展平到长的一维向量即可。
该行是自动计算展平池输出长度的一种方法。 它所做的就是乘以所有尺寸的大小。 因此,具有两个通道的5x5矩阵将产生5x5x2,即50输出。 下一行tf.reshape使用此值实际展平数组:
p1f = tf.reshape(p1, [-1, p1_size ])
前面的代码行中的-1用于一次处理许多输入图像的潜在批量。 它告诉 TensorFlow 选择第一个维度,以便参数的总数保持不变。 让我们看一下池化层的输出,以便可以看到一个具体示例:
P = p1.eval(feed_dict = {x: image})
首先,我们必须根据给定输入图像来实际求值池输出。
由于池化层取决于卷积层,因此 TensorFlow 会自动将图像首先放置在其中。 我们可以以与卷积输出完全相同的方式查看结果。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JMlULnBd-1681566150316)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00057.jpg)]
仅查看前面的第一个过滤器输出,您会注意到它是5x5。
还要注意,存在的值全部在卷积输出的某些单元中。 由于我们在池化层上的唯一激活是最大值,因此在每个2x2窗口中会丢弃三个值,并且一个值会前进到下一层。
深度 CNN
现在,在本节中,让我们着重考虑。 在本节中,我们将向我们的字体分类模型添加卷积和池化层组合。 我们将确保将其填充到一个密集层中,然后我们将看到此模型的工作方式。 在进入新的卷积模型之前,请确保开始一个新的 IPython 会话。 执行所有操作,直到num_filters = 4,您就可以准备就绪。
添加卷积和池化层组合
对于卷积层,我们将使用5x5窗口,其中提取了四个特征。 这比示例要大一些。
我们真的希望模型现在学习一些东西。 首先,我们应该使用tf.reshape将36x36的图像放入大小为36x36x1的张量中。
x_im = tf.reshape(x, [-1,36,36,1])
这仅对于保持通道数笔直很重要。 现在,我们将如上所述为过滤器和窗口的数量设置常量:
num_filters = 4
winx = 5
winy = 5
我们可以像示例问题中那样设置权重张量:
W1 = tf.Variable(tf.truncated_normal(
[winx, winy, 1 , num_filters],
stddev=1./math.sqrt(winx*winy)))
winx和winy常数只是窗口尺寸。 1值是输入通道数,仅是灰色,num_filters是我们要提取的特征数。 同样,这就像密集层中神经元的数量。 偏差的工作方式相同,但只担心过滤器的数量:
b1 = tf.Variable(tf.constant(0.1,
shape=[num_filters]))
对conv2d本身的调用也与我们的示例相同。
xw = tf.nn.conv2d(x_im, W1,
strides=[1, 1, 1, 1],
padding='SAME')
好东西,我们在那里推广了它,现在使生活变得轻松。 以下是上述代码行的描述:
x_im是要转换的输入W1属性是我们刚刚指定的权重矩阵strides告诉 TensorFlow 每一步将窗口移动一次padding='SAME'表示接受图像边缘上的窗口
现在,我们可以通过relu激活函数进行卷积,以完成卷积层。 做得好!
h1 = tf.nn.relu(xw + b1)
池化层也与上一节完全相同:
# 2x2 Max pooling, no padding on edges
p1 = tf.nn.max_pool(h1, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='VALID')
只是为了回顾一下,我们在每次跨步时将2x2窗口ksize在卷积输出上滑动两个。 当我们超出数据范围时,padding='VALID'告诉我们停止。 现在我们有了卷积池和池化层的组合,让我们附加一个典型的密集连接层:
p1_size = np.product(
[s.value for s in p1.get_shape()[1:]])
p1f = tf.reshape(p1, [-1, p1_size ])
首先,我们需要将合并输出调整为一维向量。 这正是我们在上一节中所做的。 我们自动计算池输出的尺寸,以获取用于展平的参数数量。
CNN 字体分类
现在让我们创建一个包含 32 个神经元的密集连接层:
# Dense layer
num_hidden = 32
W2 = tf.Variable(tf.truncated_normal(
[p1_size, num_hidden],
stddev=2./math.sqrt(p1_size)))
b2 = tf.Variable(tf.constant(0.2,
shape=[num_hidden]))
h2 = tf.nn.relu(tf.matmul(p1f,W2) + b2)
当然,我们需要使用p1_size该层的输入数量来初始化权重矩阵。 那只是卷积和池输出中的扁平数组。 我们需要num_hidden 32 个输出。 有偏项对一些小的非零初始值以相同的方式工作。 在这里,我们碰巧也在使用relu激活。
最后,我们像往常一样定义输出逻辑回归:
# Output Layer
W3 = tf.Variable(tf.truncated_normal(
[num_hidden, 5],
stddev=1./math.sqrt(num_hidden)))
b3 = tf.Variable(tf.constant(0.1,shape=[5]))
keep_prob = tf.placeholder("float")
h2_drop = tf.nn.dropout(h2, keep_prob)
使用旧模型工作,只需确保最终权重使用num_hidden, 5作为尺寸即可。 我们在这里有一个名为dropout的新元素。 现在不用担心。 我们将在下一部分中确切描述它的作用。 只知道它有助于过拟合。
现在,您可以初始化所有变量并实现对softmax的最终调用:
# Just initialize
sess.run(tf.global_variables_initializer())
# Define model
y = tf.nn.softmax(tf.matmul(h2_drop,W3) + b3)
请注意您的变量名正确匹配。 好的,现在完成设置,让我们对其进行训练:
# Climb on cross-entropy
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(
logits = y + 1e-50, labels = y_))
# How we train
train_step = tf.train.GradientDescentOptimizer(
0.01).minimize(cross_entropy)
# Define accuracy
correct_prediction = tf.equal(tf.argmax(y,1),
tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(
correct_prediction, "float"))
实际上,我们训练模型的方式与之前的模型完全相同。 cross_entropy节点测量我们的预测有多少误差,GradientDescentOptimizer调整矩阵的权重。 我们还应谨慎定义节点以提高准确率,以便以后进行测量。 现在让我们训练模型约 5,000 次:
# Actually train
epochs = 5000
train_acc = np.zeros(epochs//10)
test_acc = np.zeros(epochs//10)
for i in tqdm(range(epochs), ascii=True):
# Record summary data, and the accuracy
if i % 10 == 0:
# Check accuracy on train set
A = accuracy.eval(feed_dict={x: train,
y_: onehot_train, keep_prob: 1.0})
train_acc[i//10] = A
# And now the validation set
A = accuracy.eval(feed_dict={x: test,
y_: onehot_test, keep_prob: 1.0})
test_acc[i//10] = A
train_step.run(feed_dict={x: train,
y_: onehot_train, keep_prob: 0.5})
这可能需要一个小时或更长时间。 但是试想一下,如果您必须为卷积中的每个窗口训练不同的权重。 通过训练模型,让我们看一下精度曲线。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1cAHx0NC-1681566150316)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00058.jpg)]
我们可以看到,该模型优于旧的紧密连接模型,现在达到了 76% 的训练准确率和约 68% 的验证。
这可能是因为字体即使创建许多不同的字母也以相同的方式使用了许多小范围的特征。 让我们也看看混淆矩阵。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NT8nk9lI-1681566150316)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00059.jpg)]
在这里,我们看到该模型仍不完美,但正在取得进展。 第一类仍然没有得到很好的代表,但是它至少在某种程度上是正确的,这与某些以前的模型从来都不是正确的不同。 其他类大多都不错。 第三类实际上是完美的。 这不是一个容易的问题,因此任何改进都是好的。 我们还设置了一些代码来专门检查权重,但是我们将在以后的部分中保存它。 不过,请随时与他们一起玩耍。 您可以将模型权重和信息保存在检查点文件中。
# Save the weights
saver = tf.train.Saver()
saver.save(sess, "conv1.ckpt")
# Restore
saver.restore(sess, "conv1.ckpt")
这很简单。 您只需创建一个saver对象,然后将会话保存到文件名即可。 恢复同样容易。 您告诉 TensorFlow 哪个会话将已保存的文件放入和退出。 如果您更喜欢使用 NumPy 手动保存权重,则代码文件还提供以下函数:
# Or use Numpy manually
def save_all(name = 'conv1'):
np.savez_compressed(name, W1.eval(),
b1.eval(), W2.eval(), b2.eval(),
W3.eval(), b3.eval())
save_all()
def load_all(name = 'conv1.npz'):
data = np.load(name)
sess.run(W1.assign(data['arr_0']))
sess.run(b1.assign(data['arr_1']))
sess.run(W2.assign(data['arr_2']))
sess.run(b2.assign(data['arr_3']))
sess.run(W3.assign(data['arr_4']))
sess.run(b3.assign(data['arr_5']))
load_all()
因为 NumPy 格式非常可移植且相当轻巧,所以这会更方便。 如果要将值导出到另一个 Python 脚本中,从而不需要 TensorFlow,则您可能更喜欢 NumPy。 在本节中,我们建立了卷积神经网络对字体进行分类。 一个类似的模型可以解决当前的研究问题。 您处于 TensorFlow 深度学习的最前沿。
更深的 CNN
在本节中,我们将向模型添加另一个卷积层。 不用担心,我们将逐步遍历参数以使尺寸调整一致,并且我们将学习什么是丢弃训练。
将 CNN 的一层添加到另一层
与往常一样,在启动新模型时,进行一个新的 IPython 会话并执行直到num_filters1的代码。 太好了,现在您都可以开始学习了。 让我们跳入卷积模型。
我们为何不抱有雄心,将第一个卷积层设置为具有16过滤器,远远超过旧模型中的4。 但是,这次我们将使用较小的窗口大小。 只有3x3。 另请注意,我们将某些变量名称(例如num_filters更改为num_filters1)。 这是因为我们将在短时间内拥有另一个卷积层,并且我们可能希望在每个卷积层上使用不同数量的过滤器。 该层的其余部分与以前完全一样,我们可以进行卷积并进行2x2最大池化,并使用整流的线性激活单元。
现在,我们添加另一个卷积层。 一些模型先进行几次卷积,然后再进行池化,另一些模型先进行一次卷积,再进行一次池化,再进行一次卷积,依此类推。 我们在这里做后者。 假设您需要四个滤镜和一个3x3的窗口。 这很容易产生权重; 与上一层的唯一大不同是我们现在有许多输入通道,请参见num_filters1:
# Conv layer 2
num_filters2 = 4
winx2 = 3
winy2 = 3
W2 = tf.Variable(tf.truncated_normal(
[winx2, winy2, num_filters1, num_filters2],
stddev=1./math.sqrt(winx2*winy2)))
b2 = tf.Variable(tf.constant(0.1,
shape=[num_filters2]))
这是因为我们有16输入通道来自上一层。 如果我们使用num_filters1 = 8,则只有8输入通道。 将此视为我们将要建立的低级特征。 请记住,通道的数量和输入就像颜色的数量一样,因此,如果您要这样考虑,可能会有所帮助。
当我们进行实际的第二个卷积层时,请确保传入第一个池化层p1的输出。 现在,这可以进入新的relu激活函数,然后是另一个池化层。 像往常一样,我们使用有效填充进行最大2x2的池化:
# 3x3 convolution, pad with zeros on edges
p1w2 = tf.nn.conv2d(p1, W2,
strides=[1, 1, 1, 1], padding='SAME')
h1 = tf.nn.relu(p1w2 + b2)
# 2x2 Max pooling, no padding on edges
p2 = tf.nn.max_pool(h1, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='VALID')
展平卷积的池化输出也遵循与最后一个模型相同的过程。 但是,这次,我们当然致力于合并输出 2。 将其所有参数从窗口中的所有特征转换为一个大向量:
# Need to flatten convolutional output
p2_size = np.product(
[s.value for s in p2.get_shape()[1:]])
p2f = tf.reshape(p2, [-1, p2_size ])
现在,就像在前面的部分中所做的那样,将密集连接的层插入到我们的神经网络中。 只要确保更新变量名即可。
# Dense layer
num_hidden = 32
W3 = tf.Variable(tf.truncated_normal(
[p2_size, num_hidden],
stddev=2./math.sqrt(p2_size)))
b3 = tf.Variable(tf.constant(0.2,
shape=[num_hidden]))
h3 = tf.nn.relu(tf.matmul(p2f,W3) + b3)
现在,我们看到了与我们使用的相同的tf.nn.dropout,但在上一个模型中没有解释:
# Drop out training
keep_prob = tf.placeholder("float")
h3_drop = tf.nn.dropout(h3, keep_prob)
丢弃是一种从模型中暂时切断神经元的方法。 我们在训练过程中这样做是为了避免过拟合。 每批 TensorFlow 将在此连接层选择不同的神经元输出以进行删除。 面对训练期间的细微变化,这有助于模型变得健壮。 keep_prob是保持特定神经元输出的概率。 在训练过程中通常将其设置为0.5。
再一次,最终的逻辑回归层和训练节点代码与之前的相同:
# Output Layer
W4 = tf.Variable(tf.truncated_normal(
[num_hidden, 5],
stddev=1./math.sqrt(num_hidden)))
b4 = tf.Variable(tf.constant(0.1,shape=[5]))
# Just initialize
sess.run(tf.initialize_all_variables())
# Define model
y = tf.nn.softmax(tf.matmul(h3_drop,W4) + b4)
### End model specification, begin training code
# Climb on cross-entropy
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(
y + 1e-50, y_))
# How we train
train_step = tf.train.GradientDescentOptimizer(
0.01).minimize(cross_entropy)
# Define accuracy
correct_prediction = tf.equal(tf.argmax(y,1),
tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(
correct_prediction, "float"))
您现在可以执行该操作。 现在,我们可以训练我们的完整卷积神经网络,这是到目前为止建模的顶点:
# Actually train
epochs = 6000
train_acc = np.zeros(epochs//10)
test_acc = np.zeros(epochs//10)
for i in tqdm(range(epochs), ascii=True):
# Record summary data, and the accuracy
if i % 10 == 0:
# Check accuracy on train set
A = accuracy.eval(feed_dict={x: train,
y_: onehot_train, keep_prob: 1.0})
train_acc[i//10] = A
# And now the validation set
A = accuracy.eval(feed_dict={x: test,
y_: onehot_test, keep_prob: 1.0})
test_acc[i//10] = A
train_step.run(feed_dict={x: train,\
y_: onehot_train, keep_prob: 0.5})
训练该模型可能需要几个小时,因此您可能希望在下一节之前立即开始。
深度 CNN 总结
我们将通过评估模型的准确率来总结深层的 CNN。 上一次,我们建立了最终的字体识别模型。 现在,让我们看看它是如何工作的。 在本节中,我们将学习如何在训练期间处理丢弃问题。 然后,我们将看到模型达到了什么精度。 最后,我们将权重可视化以了解模型学到了什么。
确保在上一个模型中进行训练后,在 IPython 会话中接手。 回想一下,当我们训练模型时,我们使用dropout删除了一些输出。
尽管这有助于过拟合,但在测试过程中,我们要确保使用每个神经元。 这既提高了准确率,又确保我们不会忘记评估模型的一部分。 这就是为什么在以下代码行中,keep_prob为1.0以便始终保留所有神经元的原因。
# Check accuracy on train set
A = accuracy.eval(feed_dict={x: train,
y_: onehot_train, keep_prob: 1.0})
train_acc[i//10] = A
# And now the validation set
A = accuracy.eval(feed_dict={x: test,
y_: onehot_test, keep_prob: 1.0})
test_acc[i//10] = A
让我们看看最终模型是如何做的; 像往常一样看一下训练和测试的准确率:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-s6ampip1-1681566150317)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00060.jpg)]
这里的训练准确率高达 85%,并且测试准确率也相差不远。还不错。模型的效果取决于输入数据的噪声。 如果我们仅包含少量信息,无论是示例数量还是参数或像素数量,那么我们都无法期望模型表现完美。
在这种情况下,您可以应用的一种度量标准是人类将单个字母的图像分类到这些字体中的每种字体的程度。 一些字体非常有特色,而另一些则相似,尤其是某些字母。 由于这是一个新颖的数据集,因此没有直接的基准可以与之进行比较,但是您可以挑战自己以击败本课程中介绍的模型。 如果这样做,您可能希望减少训练时间。 当然,具有较少参数和更简单计算的较小网络将更快。 另外,如果您开始使用 GPU 或至少使用多核 CPU,则可以显着提高速度。 通常 10 倍更好,具体取决于硬件。
其中一部分是并行性,一部分是针对神经网络进行了微调的高效低层库。 但是,最简单的方法是从简单开始,逐步发展到更复杂的模型,就像您一直在处理此问题一样。 回到这个模型,让我们看一下混淆矩阵:
# Look at the final testing confusion matrix
pred = np.argmax(y.eval(
feed_dict={x: test, keep_prob: 1.0,
y_: onehot_test}), axis = 1)
conf = np.zeros([5,5])
for p,t in zip(pred,np.argmax(onehot_test,
axis=1)):
conf[t,p] += 1
plt.matshow(conf)
plt.colorbar()
以下是输出:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3fV2tZK4-1681566150317)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00061.jpg)]
在这里,我们可以看到该模型通常在各个类上都做得很好。 类1仍然不是完美的,但是比以前的模型要好得多。 通过将较小比例的特征分解为较大的片段,我们终于找到了一些适合这些类的指标。 您的图像可能看起来不完全相同。 根据权重的随机初始化,结果可能会有些不幸。
让我们看一下第一卷积层的 16 个特征的权重:
# Let's look at a subplot of some weights
f, plts = plt.subplots(4,4)
for i in range(16):
plts[i//4,i%4].matshow(W1.eval()[:,:,0,i],
cmap = plt.cm.gray_r)
因为窗口大小是3x3,所以每个都是3x3矩阵。 嗯! 我们可以看到,权重肯定是缩小了小范围的特征。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-my7CzNBk-1681566150317)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00062.jpg)]
您可以看到某些事物,例如检测到边缘或圆角,诸如此类。 如果我们使用更大的窗口重做模型,这可能会更加明显。 但是令人印象深刻的是,您可以在这些小补丁中发现多少特征。
我们还要看一下最终的层权重,以了解不同的字体类如何解释最终的紧密连接的神经元。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-V5IN4K4t-1681566150317)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00063.jpg)]
每行代表一类,每列代表最终的隐藏层神经元之一。 有些类别受到某些神经元的强烈影响,而另一些类别的影响则微乎其微。 您会看到,对于某些类别,给定的神经元在积极或消极方面非常重要,而对于其他类别则非常重要。
请注意,因为我们已经使卷积变平,所以我们不希望在输出中看到明显的结构。 这些列可以按任何顺序排列,但仍会产生相同的结果。 在本章的最后部分,我们检查了一个真实的,实时的,坦率的,非常好的深度卷积神经网络模型。 我们使用卷积层和池化层的做法来构筑该思想,以便提取结构化数据(例如图像)中的小规模和大规模型征。
对于许多问题,这是神经网络最强大的类型之一。
总结
在本章中,我们遍历了示例图像上的卷积层。 我们解决了理解卷积的实际问题。 它们可以令人费解,但希望不再造成混淆。 我们最终将此概念应用于 TensorFlow 中的一个简单示例。 我们探索了卷积,池化层的共同伙伴。 我们解释了常见的卷积伙伴最大池化层的工作原理。 然后,随着我们的进步,我们通过在示例中添加一个池化层将其付诸实践。 我们还练习了在 TensorFlow 中创建最大池化层。 我们开始将卷积神经网络添加到字体分类问题中。
在下一章中,我们将研究具有时间成分的模型,即循环神经网络(RNN)。
四、循环神经网络介绍
在上一章中,您了解了卷积网络。 现在,该介绍一种新型的模型和问题了-循环神经网络(RNN)。 在本章中,我们将解释 RNN 的工作原理,并在 TensorFlow 中实现一个。 我们的示例问题将是具有天气信息的简单季节预报器。 我们还将看一下skflow,它是 TensorFlow 的简化接口。 这将使我们能够快速重新实现旧的图像分类模型和新的 RNN。 在本章的最后,您将对以下概念有很好的理解:
- 探索 RNN
- TensorFlow Learn
- 密集神经网络(DNN)
探索 RNN
在本节中,我们将探索 RNN。 一些背景信息将使我们开始工作,然后我们将探讨一个激发性的天气建模问题。 我们还将在 TensorFlow 中实现和训练 RNN。
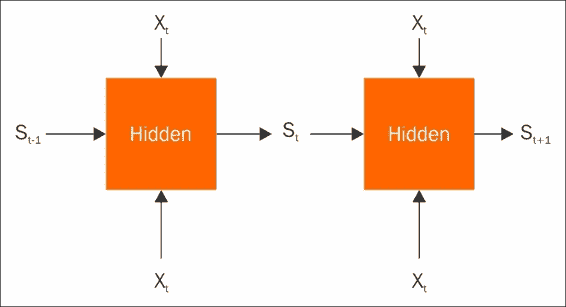
在典型模型中,您要预测一些X输入特征和一些Y输出。 我们通常将不同的训练样本视为独立的观察结果。 因此,数据点 1 的特征不应影响数据点 2 的预测。 但是,如果我们的数据点相互关联怎么办? 最常见的示例是每个数据点Xt代表在时间t收集的特征。 自然地假设时间t和时间t+1的特征对于时间t+1的预测都将很重要。 换句话说,历史很重要。
现在,在建模时,您可以只包含两倍的输入特征,将前一个时间步长添加到当前特征中,并计算两倍的输入权重。 但是,如果您正在努力构建神经网络来计算变换特征,那么可以在当前时间步网络中使用上一个时间步的中间特征就很好了。
RNN 正是这样做的。 像往常一样考虑您的输入Xt,但在某些状态下添加来自上一个时间步的St-1作为附加特征。 现在,您可以像往常一样计算权重以预测Yt,并产生一个新的内部状态St,以供下一步使用。 对于第一步,通常使用默认或零初始状态。 经典的 RNN 实际上就是这么简单,但是当今文学中有更高级的结构,例如门控循环单元和长短期存储电路。 这些不在本书的讨论范围之内,但是它们遵循相同的原理,并且通常适用于相同类型的问题。
模型权重
您可能想知道我们如何根据上一个时间步长计算所有这些相关性的权重。 计算梯度确实涉及到时间计算的递归,但不要担心,TensorFlow 处理乏味的东西,让我们进行建模:
# read in data
filename = 'weather.npz'
data = np.load(filename)
daily = data['daily']
weekly = data['weekly']
num_weeks = len(weekly)
dates = np.array([datetime.datetime.strptime(str(int(d)),
'%Y%m%d') for d in weekly[:,0]])
要使用 RNN,我们需要一个带有时间成分的数据建模问题。
字体分类问题在这里并不是很合适。 因此,让我们看一些天气数据。 weather.npz文件是几十年来来自美国一个城市的气象站数据的集合。 daily数组包含一年中每一天的测量值。 数据有六列,从日期开始。 接下来是降雨量,以英寸为单位测量当日的降雨量。 之后,出现两列降雪-第一列是当前地面上的实测雪,而第二列是当天的降雪,单位是英寸。 最后,我们有一些温度信息,以华氏度为单位的每日最高和最低每日温度。
我们将使用的weekly数组是每日信息的每周摘要。 我们将使用中间日期来表示一周,然后,我们将汇总一周中的所有降雨量。 但是,对于降雪,我们将平均降雪量,因为从一个寒冷的天气到第二天坐在地上的积雪都没有意义。 虽然降雪,但我们总共要一周,就像下雨一样。 最后,我们将平均一周的高温和低温。 现在您已经掌握了数据集,我们该如何处理? 一个有趣的基于时间的建模问题是,尝试使用天气信息和前几周的历史来预测特定一周的季节。
在美国的北半球,6 月至 8 月的气温较高,而 12 月至 2 月的气温较低,两者之间有过渡。 春季通常是多雨的,冬季通常包括雪。 尽管一周的变化很大,但一周的历史应该可以提供一定的预测能力。
了解 RNN
首先,让我们从压缩的 NumPy 数组中读取数据。 如果您想探索自己的模型,weather.npz文件也包括每日数据。 np.load将两个数组都读入字典,并将每周设置为我们感兴趣的数据; num_weeks自然就是我们拥有多少个数据点,在这里,几十年的信息的值:
num_weeks = len(weekly)
为了格式化星期,我们使用 Python datetime.datetime对象以年月日格式读取存储字符串:
dates = np.array([datetime.datetime.strptime(str(int(d)),
'%Y%m%d') for d in weekly[:,0]])
我们可以使用每周的日期来指定其季节。 对于此模型,因为我们正在查看天气数据,所以我们使用气象季节而不是普通的天文季节。 幸运的是,这很容易通过 Python 函数实现。 从datetime对象中获取月份,我们可以直接计算出该季节。 春季,零季节是 3 月至 5 月,夏季是 6 月至 8 月,秋天是 9 月至 11 月,最后是冬季 12 月至 2 月。 以下是简单的函数,它仅求值月份并实现该月份:
def assign_season(date):
''' Assign season based on meteorological season.
Spring - from Mar 1 to May 31
Summer - from Jun 1 to Aug 31
Autumn - from Sep 1 to Nov 30
Winter - from Dec 1 to Feb 28 (Feb 29 in a leap year)
'''
month = date.month
# spring = 0
if 3 <= month < 6:
season = 0
# summer = 1
elif 6 <= month < 9:
season = 1
# autumn = 2
elif 9 <= month < 12:
season = 2
# winter = 3
elif month == 12 or month < 3:
season = 3
return season
让我们注意一下,我们有四个季节和五个输入变量,例如历史状态中的 11 个值:
# There are 4 seasons
num_classes = 4
# and 5 variables
num_inputs = 5
# And a state of 11 numbers
state_size = 11
现在您可以计算标签了:
labels = np.zeros([num_weeks,num_classes])
# read and convert to one-hot
for i,d in enumerate(dates):
labels[i,assign_season(d)] = 1
通过制作全零数组并在分配季节的位置放置一个全零,我们直接以一键式格式执行此操作。
凉! 您仅用几个命令就总结了几十年的时间。
由于这些输入特征在非常不同的尺度上测量非常不同的事物,即降雨,降雪和温度,因此我们应注意将它们全部置于相同的尺度上。 在下面的代码中,我们抓住了输入特征,当然跳过了日期列,并减去平均值以将所有特征居中为零:
# extract and scale training data
train = weekly[:,1:]
train = train - np.average(train,axis=0)
train = train / train.std(axis=0)
然后,我们将每个特征除以其标准偏差来缩放。 这说明温度范围大约为 0 到 100,而降雨量仅在大约 0 到 10 之间变化。数据准备工作不错! 它并不总是很有趣,但这是机器学习和 TensorFlow 的关键部分。
现在进入 TensorFlow 模型:
# These will be inputs
x = tf.placeholder("float", [None, num_inputs])
# TF likes a funky input to RNN
x_ = tf.reshape(x, [1, num_weeks, num_inputs])
我们使用占位符变量正常输入数据,但是随后您会看到将整个数据集奇怪地重塑为一个大张量。 不用担心,这是因为从技术上讲,我们有一个漫长而连续的观测序列。 y_变量只是我们的输出:
y_ = tf.placeholder("float", [None,num_classes])
我们将计算每个季节每周的概率。
cell变量是循环神经网络的关键:
cell = tf.nn.rnn_cell.BasicRNNCell(state_size)
这告诉 TensorFlow 当前时间步长如何取决于前一个时间步长。 在这种情况下,我们将使用基本的 RNN 单元。 因此,我们一次只回首一周。 假设它具有状态大小或 11 个值。 随意尝试使用更多奇异的单元和不同的状态大小。
要使用该单元格,我们将使用tf.nn.dynamic_rnn:
outputs, states = tf.nn.dynamic_rnn(cell,x_,
dtype=tf.nn.dtypes.float32, initial_state=None)
这可以智能地处理递归,而不是简单地将所有时间步长展开成一个巨大的计算图。 因为我们在一个序列中有成千上万的观测值,所以这对于获得合理的速度至关重要。 在单元格之后,我们指定输入x_,然后指定dtype以使用 32 位将十进制数字存储在浮点数中,然后指定空的initial_state。 我们使用此输出建立一个简单的模型。 从这一点开始,该模型几乎完全符合您对任何神经网络的期望:
我们将 RNN 单元的输出,一些权重相乘,并添加一个偏差以获得该周每个类的分数:
W1 = tf.Variable(tf.truncated_normal([state_size,num_classes],
stddev=1./math.sqrt(num_inputs)))
b1 = tf.Variable(tf.constant(0.1,shape=[num_classes]))
# reshape the output for traditional usage
h1 = tf.reshape(outputs,[-1,state_size])
注意
请注意,由于我们有一个长序列,因此我们确实需要进行此重塑操作以再次获得合适的大小。
您应该非常熟悉我们的分类cross_entropy损失函数和训练优化器:
# Climb on cross-entropy
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(y + 1e-50, y_))
# How we train
train_step = tf.train.GradientDescentOptimizer(0.01
).minimize(cross_entropy)
# Define accuracy
correct_prediction = tf.equal(tf.argmax(y,1),tf.argmax(y_,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction, "float"))
搭建 TensorFlow 模型的出色工作! 为了训练这一点,我们将使用一个熟悉的循环:
# Actually train
epochs = 100
train_acc = np.zeros(epochs//10)
for i in tqdm(range(epochs), ascii=True):
if i % 10 == 0:
# Record summary data, and the accuracy
# Check accuracy on train set
A = accuracy.eval(feed_dict={x: train, y_: labels})
train_acc[i//10] = A
train_step.run(feed_dict={x: train, y_: labels})
由于这是一个虚拟的问题,因此我们不必担心模型的实际准确率。 这里的目的只是看 RNN 的工作原理。 您可以看到它像任何 TensorFlow 模型一样运行:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-r1P3J2v3-1681566150318)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00065.jpg)]
如果您确实看过准确率,您会发现它做得很好。 比 25% 的随机猜测要好得多,但仍有很多东西需要学习。
TensorFlowLearn
正如 Scikit-Learn 是传统机器学习算法的便捷接口一样,tf.contrib.learn(以前称为skflow),它是构建和训练 DNN 的简化接口。 现在,随 TensorFlow 的每次安装免费提供!
即使您不喜欢该语法,也值得将 TensorFlow Learn 作为 TensorFlow 的高级 API。 这是因为它是当前唯一受官方支持的版本。 但是,您应该知道,有许多替代的高级 API 可能具有更直观的接口。 如果有兴趣,请参阅 Keras,tf.slim(包含在 TF 中)或 TFLearn。为了了解有关 TensorFlow-Slim 的更多信息,请参阅此链接。
起步
要开始使用 TensorFlow Learn,您只需导入它即可。 我们还将导入estimators函数,这将帮助我们制作常规模型:
# TF made EZ
import tensorflow.contrib.learn as learn
from tensorflow.contrib.learn.python.learn.estimators import estimator
我们还希望导入一些用于基本操作的库 – 抓取 NumPy,math和 Matplotlib(可选)。 这里值得注意的是sklearn,这是一个通用的机器学习库,它试图简化模型的创建,训练和使用。 我们主要将其用于方便的指标,但是您会发现它具有与 Learn 类似的主接口:
# Some basics
import numpy as np
import math
import matplotlib.pyplot as plt
plt.ion()
# Learn more sklearn
# scikit-learn.org
import sklearn
from sklearn import metrics
接下来,我们将读取一些数据进行处理。 由于您熟悉字体分类问题,因此让我们继续对其建模。 为了重现性,您可以使用自己喜欢的数字为 NumPy 播种:
# Seed the data
np.random.seed(42)
# Load data
data = np.load('data_with_labels.npz')
train = data['arr_0']/255.
labels = data['arr_1']
对于本练习,将您的数据分为训练和验证集; np.random.permutation对于为您的输入数据生成随机顺序很有用,所以让我们像在以前的模块中那样使用它:
# Split data into training and validation
indices = np.random.permutation(train.shape[0])
valid_cnt = int(train.shape[0] * 0.1)
test_idx, training_idx = indices[:valid_cnt],\
indices[valid_cnt:]
test, train = train[test_idx,:],\
train[training_idx,:]
test_labels, train_labels = labels[test_idx],\
labels[training_idx]
在这里,tf.contrib.learn可以对其接收的数据类型有所变幻。 为了发挥出色,我们需要重铸数据。 图像输入将是np.float32,而不是默认的 64 位。 同样,我们的标签将是np.int32而不是np.uint8,即使这只会占用更多内存:
train = np.array(train,dtype=np.float32)
test = np.array(test,dtype=np.float32)
train_labels = np.array(train_labels,dtype=np.int32)
test_labels = np.array(test_labels,dtype=np.int32)
逻辑回归
让我们做一个简单的逻辑回归示例。 这将非常迅速,并显示learn如何使简单的模型变得异常简单。 首先,我们必须创建模型期望输入的变量列表。 您可能希望可以使用一个简单的参数来设置它,但实际上是这个不直观的learn.infer_real_valued_columns_from_input函数。 基本上,如果将输入数据提供给该函数,它将推断出您拥有多少个特征列以及其应处于的形状。在我们的线性模型中,我们希望将图像展平为一维,因此我们对其执行整形推断函数时:
# Convert features to learn style
feature_columns = learn.infer_real_valued_columns_from_input(train.reshape([-1,36*36]))
现在创建一个名为classifier的新变量,并为其分配estimator.SKCompat结构。 这是一个 Scikit-Learn 兼容性层,允许您在 TensorFlow 模型中使用某些 Scikit-Learn 模块。
无论如何,这仅仅是敷料,真正创建模型的是learn.LinearClassifier。 这样就建立了模型,但是没有训练。 因此,它只需要几个参数。 首先是那个时髦的feature_columns对象,只是让您的模型知道期望输入什么。 第二个也是最后一个必需的参数是它的反函数,模型应具有多少个输出值? 我们有五种字体,因此设置n_classes = 5。 这就是整个模型规格!
# Logistic Regression
classifier = estimator.SKCompat(learn.LinearClassifier(
feature_columns = feature_columns,
n_classes=5))
要进行训练,只需要一行。 调用classifier.fit并输入数据(当然是经过调整的形状),输出标签(请注意,这些标签不必是一字不漏的格式)以及其他一些参数。 steps参数确定模型将查看多少批次,即优化算法要采取的步骤。 batch_size参数通常是优化步骤中要使用的数据点数。 因此,您可以将步数乘以批次大小除以训练集中的数据点数来计算周期数。 这似乎有点违反直觉,但至少是一个快速的说明,您可以轻松编写帮助函数以在步骤和周期之间进行转换:
# One line training
# steps is number of total batches
# steps*batch_size/len(train) = num_epochs
classifier.fit(train.reshape([-1,36*36]),
train_labels,
steps=1024,
batch_size=32)
为了评估我们的模型,我们将照常使用sklearn的metrics。 但是,基本学习模型预测的输出现在是字典,其中包含预先计算的类标签以及概率和对数。 要提取类标签,请使用键classes:
# sklearn compatible accuracy
test_probs = classifier.predict(test.reshape([-1,36*36]))
sklearn.metrics.accuracy_score(test_labels,
test_probs['classes'])
DNN
尽管有更好的方法来实现纯线性模型,但 TensorFlow 和learn真正的亮点在于简化具有不同层数的 DNN。
我们将使用相同的输入特征,但现在我们将构建一个具有两个隐藏层的 DNN,首先是10神经元,然后是5。 创建此模型仅需一行 Python 代码; 这再简单不过了。
规格类似于我们的线性模型。 我们仍然需要SKCompat,但现在是learn.DNNClassifier。 对于参数,还有一个额外的要求:每个隐藏层上的神经元数量,以列表的形式传递。 这个简单的参数真正抓住了 DNN 模型的本质,使深度学习的力量触手可及。
也有一些可选的参数,但是我们只提及optimizer。 这样,您就可以在不同的常见优化器例程之间进行选择,例如随机梯度下降(SGD)或 Adam。 很方便!
# Dense neural net
classifier = estimator.SKCompat(learn.DNNClassifier(
feature_columns = feature_columns,
hidden_units=[10,5],
n_classes=5,
optimizer='Adam'))
训练和评估与线性模型完全一样。 仅出于演示目的,我们还可以查看此模型创建的混淆矩阵。 请注意,我们训练不多,因此该模型可能无法与使用纯 TensorFlow 的早期作品竞争:
# Same training call
classifier.fit(train.reshape([-1,36*36]),
train_labels,
steps=1024,
batch_size=32)
# simple accuracy
test_probs = classifier.predict(test.reshape([-1,36*36]))
sklearn.metrics.accuracy_score(test_labels,
test_probs['classes'])
# confusion is easy
train_probs = classifier.predict(train.reshape([-1,36*36]))
conf = metrics.confusion_matrix(train_labels,
train_probs['classes'])
print(conf)
TFLearn 中的卷积神经网络(CNN)
CNN 支持一些最成功的机器学习模型,因此我们希望learn支持它们。 实际上,该库支持使用任意 TensorFlow 代码! 您会发现这是一种祝福和诅咒。 拥有任意可用的代码意味着您可以使用learn来执行几乎可以使用纯 TensorFlow 进行的所有操作,从而提供最大的灵活性。 但是通用接口往往会使代码更难以读写。
如果您发现自己在learn中使用接口使某些复杂的模型起作用,那么可能是时候使用纯 TensorFlow 或切换到另一个 API 了。
为了证明这种通用性,我们将构建一个简单的 CNN 来解决字体分类问题。 它将具有一个带有四个过滤器的卷积层,然后将其展平为具有五个神经元的隐藏密集层,最后以密集连接的输出逻辑回归结束。
首先,让我们再进行几个导入。 我们想要访问通用的 TensorFlow,但是我们还需要layers模块以learn期望的方式调用 TensorFlow layers:
# Access general TF functions
import tensorflow as tf
import tensorflow.contrib.layers as layers
通用接口迫使我们编写为模型创建操作的函数。 您可能会发现这很乏味,但这就是灵活性的代价。
用三个参数启动一个名为conv_learn的新函数。 X将作为输入数据,y将作为输出标签(尚未进行一次热编码),mode确定您是训练还是预测。 请注意,您永远不会直接与此特征交互; 您只需将其传递给需要这些参数的构造器。 因此,如果您想改变层的数量或类型,则需要编写一个新的模型函数(或另一个会生成这种模型函数的函数):
def conv_learn(X, y, mode):
由于这是卷积模型,因此我们需要确保数据格式正确。 特别是,这意味着将输入重塑为不仅具有正确的二维形状(36x36),而且具有 1 个颜色通道(最后一个尺寸)。 这是 TensorFlow 计算图的一部分,因此我们使用tf.reshape而不是np.reshape。 同样,由于这是通用图,因此我们希望将输出进行一次热编码,tf.one_hot提供了该功能。 请注意,我们必须描述有多少类(5),应设置的值(1)和未设置的值(0):
# Ensure our images are 2d
X = tf.reshape(X, [-1, 36, 36, 1])
# We'll need these in one-hot format
y = tf.one_hot(tf.cast(y, tf.int32), 5, 1, 0)
现在,真正的乐趣开始了。 为了指定卷积层,让我们初始化一个新的作用域conv_layer。 这只会确保我们不会破坏任何变量。 layers.convolutional提供了基本的机制。 它接受我们的输入(一个 TensorFlow 张量),多个输出(实际上是内核或过滤器的数量)以及内核的大小,这里是5x5的窗口。 对于激活函数,让我们使用整流线性,可以从主 TensorFlow 模块调用它。 这给了我们基本的卷积输出h1。
实际上,最大池化的发生与常规 TensorFlow 中的发生完全相同,既不容易也不难。 具有通常的内核大小和步幅的tf.nn.max_pool函数可以正常工作。 保存到p1中:
# conv layer will compute 4 kernels for each 5x5 patch
with tf.variable_scope('conv_layer'):
# 5x5 convolution, pad with zeros on edges
h1 = layers.convolution2d(X, num_outputs=4,
kernel_size=[5, 5],
activation_fn=tf.nn.relu)
# 2x2 Max pooling, no padding on edges
p1 = tf.nn.max_pool(h1, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='VALID')
现在,要在此时展平张量,我们需要计算将要成为一维张量的元素数量。 一种方法是将所有尺寸值(batch_size除外,它占据第一个位置)相乘。 此特定操作可以在计算图之外进行,因此我们使用np.product。 一旦提供了总大小,我们就可以将其传递给tf.reshape以重新划分图中的中间张量:
# Need to flatten conv output for use in dense layer
p1_size = np.product(
[s.value for s in p1.get_shape()[1:]])
p1f = tf.reshape(p1, [-1, p1_size ])
现在是时候建立紧密连接的层了。 layers模块再次出现,这一次具有fully_connected函数(致密层的另一个名称)。 这需要上一层,神经元的数量和激活函数,它们又由通用 TensorFlow 提供。
为了演示的目的,我们也在此处添加一个dropout对象。 layers.dropout提供了接口。 不出所料,它需要上一层以及保持给定节点输出的概率。 但是它也需要我们传递给原始conv_learn函数的mode参数。 所有这些复杂的接口只不过是在训练期间丢弃节点。 如果您能解决这个问题,那么我们几乎可以遍历整个模型!
# densely connected layer with 32 neurons and dropout
h_fc1 = layers.fully_connected(p1f,
5,
activation_fn=tf.nn.relu)
drop = layers.dropout(h_fc1, keep_prob=0.5,
is_training=mode == tf.contrib.learn.ModeKeys.TRAIN)
现在有一些坏消息。 我们需要手动写出最终的线性模型,损失函数和优化参数。 这可能会因版本而异,因为在某些情况下,以前对用户来说更容易,但对后端的维护则更困难。 但是,让我们坚持下去; 确实不是很繁琐。
另一个layers.fully_connected层创建最终的逻辑回归。 请注意,此处的激活应为None,因为它是线性的。 处理方程逻辑方面的是损失函数。 值得庆幸的是,TensorFlow 提供了softmax_cross_entropy函数,因此我们无需手动将其写出。 给定输入,输出和损失函数,我们可以应用优化例程。 同样,layers.optimize_loss以及相关函数可以最大程度地减少痛苦。 将您的损失节点,优化器(作为字符串)和学习率传递给它。 此外,为其提供此get_global_step()参数,以确保优化程序正确处理衰减。
最后,我们的函数需要返回一些东西。 第一,它应该报告预测的类别。 接下来,它必须自己提供损失节点输出。 最后,训练节点必须可用于外部例程以实际执行所有操作:
logits = layers.fully_connected(drop, 5, activation_fn=None)
loss = tf.losses.softmax_cross_entropy(y, logits)
# Setup the training function manually
train_op = layers.optimize_loss(
loss,
tf.contrib.framework.get_global_step(),
optimizer='Adam',
learning_rate=0.01)
return tf.argmax(logits, 1), loss, train_op
虽然指定模型可能很麻烦,但使用它就像以前一样容易。 现在,使用最通用的例程learn.Estimator,并将模型函数传递给model_fn。 并且不要忘记SKCompat!
训练的工作原理与以前完全相同,只是请注意,我们不需要在此处重塑输入内容,因为这是在函数内部处理的。
要使用模型进行预测,您可以简单地调用classifier.predict,但是请注意,您会获得函数返回的第一个参数作为输出。 我们选择返回该类,但也可以从softmax函数中返回概率。 这就是tf.contrib.learn模型的基础!
# Use generic estimator with our function
classifier = estimator.SKCompat(
learn.Estimator(
model_fn=conv_learn))
classifier.fit(train,train_labels,
steps=1024,
batch_size=32)
# simple accuracy
metrics.accuracy_score(test_labels,classifier.predict(test))
提取权重
虽然训练和预测是模型的核心用途,但也必须研究模型的内部也很重要。 不幸的是,此 API 使得提取参数权重变得困难。 值得庆幸的是,本节提供了一些文献记载较弱的功能的简单示例,以使权重从tf.contrib.learn模型中消失。
为了拉出模型的权重,我们确实需要从基础 TensorFlow 计算图中的某些点获取值。 TensorFlow 提供了许多方法来执行此操作,但是第一个问题只是弄清楚您感兴趣的变量被称为什么。
可以使用learn图中的变量名列表,但该变量名已隐藏在_estimator隐藏属性下。 调用classifier._estimator.get_variable_names()将返回您各种名称的字符串列表。 其中许多将是无趣的,例如OptimizeLoss条目。 在我们的情况下,我们正在寻找conv_layer和fully_connected元素:
# See layer names
print(classifier._estimator.get_variable_names())
['OptimizeLoss/beta1_power',
'OptimizeLoss/beta2_power',
'OptimizeLoss/conv_layer/Conv/biases/Adam',
'OptimizeLoss/conv_layer/Conv/biases/Adam_1',
'OptimizeLoss/conv_layer/Conv/weights/Adam',
'OptimizeLoss/conv_layer/Conv/weights/Adam_1',
'OptimizeLoss/fully_connected/biases/Adam',
'OptimizeLoss/fully_connected/biases/Adam_1',
'OptimizeLoss/fully_connected/weights/Adam',
'OptimizeLoss/fully_connected/weights/Adam_1',
'OptimizeLoss/fully_connected_1/biases/Adam',
'OptimizeLoss/fully_connected_1/biases/Adam_1',
'OptimizeLoss/fully_connected_1/weights/Adam',
'OptimizeLoss/fully_connected_1/weights/Adam_1',
'OptimizeLoss/learning_rate',
'conv_layer/Conv/biases',
'conv_layer/Conv/weights',
'fully_connected/biases',
'fully_connected/weights',
'fully_connected_1/biases',
'fully_connected_1/weights',
'global_step']
找出哪个条目是您要查找的层可能是一个挑战。 在这里,conv_layer显然来自我们的卷积层。 但是,您看到两个fully_connected元素,一个是展平时的密集层,另一个是输出权重。 事实证明,它们是按指定的顺序命名的。 我们首先创建了密集的隐藏层,所以它获得了基本的fully_connected名称,而输出层位于最后,因此在其上面加上了_1。 如果不确定,可以随时查看权重数组的形状,具体取决于模型的形状。
要真正发挥作用,这是另一个不可思议的要求。 这次,classifier._estimator.get_variable_value(带有变量名字符串)提供了具有相关权重的 NumPy 数组。 试用卷积权重和偏差以及密集层:
# Convolutional Layer Weights
print(classifier._estimator.get_variable_value(
'conv_layer/Conv/weights'))
print(classifier._estimator.get_variable_value(
'conv_layer/Conv/biases'))
# Dense Layer
print(classifier._estimator.get_variable_value(
'fully_connected/weights'))
# Logistic weights
print(classifier._estimator.get_variable_value(
'fully_connected_1/weights'))
现在,掌握了如何在tf.contrib.learn神经网络内部进行交流的深奥知识,您将可以使用此高级 API 拥有更多的能力。 尽管在许多情况下很方便,但在其他情况下却很麻烦。 永远不要害怕暂停并考虑切换到另一个库; 为正确的机器学习工作使用正确的机器学习工具。
总结
从简单理解 RNN 到在新的 TensorFlow 模型中实现它们,您在本章中学到了很多东西。 我们还查看了 TensorFlow 的一个简单接口,称为 TensorFlow Learn。 我们还遍历了 DNN,并了解了 CNN 和详细提取权重。
在下一章中,我们将对 TensorFlow 进行总结,看看我们已经走了多远,以及从这里可以去哪里。
五、总结
在上一章中,我们了解了 TensorFlow 和 RNN 模型的另一个接口。 本章将对 TensorFlow 进行总结,探讨我们已经走了多远,以及从这里可以去哪里。 首先,我们将回顾字体分类问题的研究进展,然后简要介绍除深度学习之外的 TensorFlow,并查看其将来的发展方向。 在本章的最后,您将熟悉以下概念:
- 研究回顾
- 快速浏览所有模型
- TensorFlow 的未来
- 其他一些 TensorFlow 项目
现在让我们开始详细研究和评估模型。
研究回顾
在本节中,我们将比较字体分类问题中的模型。 首先,我们应该提醒自己数据是什么样的。 然后,我们将检查简单的逻辑密集神经网络和卷积神经网络模型。 使用 TensorFlow 建模已经走了很长一段路。
但是,在继续进行深度学习之前,让我们回头看看模型如何比较字体分类问题。 首先,让我们再次查看数据,这样我们就不会忽略这个问题。 实际上,让我们看一个包含每种字体的所有字母和数字的图像,只是看看我们有什么形状:
# One look at a letter/digit from each font
# Best to reshape as one large array, then plot
all_letters = np.zeros([5*36,62*36])
for font in range(5):
for letter in range(62):
all_letters[font*36:(font+1)*36,
letter*36:(letter+1)*36] = \
train[9*(font*62 + letter)]
Matplotlib 需要处理很多子图。 因此,我们将创建一个新数组,高 5 幅图像,5 种字体乘以 36 像素,宽 62 幅图像,62 个字母或数字乘以 36 像素。 分配零数组后,我们可以将训练图像堆叠到其中。 字体和字母充当索引,并且我们在大型数组中一次设置36x36的值。 注意,这里我们在train数组中有9,因为我们每个字母只采取一种抖动类型。
让我们来看一下pcolormesh的快速调用:
plt.pcolormesh(all_letters,
cmap=plt.cm.gray)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WnKqy2tx-1681566150318)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00066.jpg)]
如您所见,我们拥有整个字母,大写和小写以及数字 0 到 9。某些字体看起来与其他字体相似,而无论如何0字体在其自身的世界中,无论如何对于人眼都是如此。 每种字体都有有趣的样式属性,我们希望我们的模型能够继续使用。
快速浏览所有模型
让我们回顾一下我们构建的每个模型,以对这些字体及其优点和缺点进行建模:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-t1TAUczc-1681566150318)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00067.jpg)]
乍一看,我们缓慢地建立了更复杂的模型,并考虑了数据的结构以提高准确率。
逻辑回归模型
首先,我们从一个简单的逻辑回归模型开始:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-J5qBGGfL-1681566150319)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00068.jpg)]
它具有36x36像素外加 1 倍乘以 5 类总权重,即我们需要训练的 6,485 个参数。 经过 1,000 次训练后,此模型的验证准确率达到了 40%。 您的结果可能会有所不同。 这相对较差,但是该模型具有一些优势。
让我们回头看一下代码:
# These will be inputs
## Input pixels, flattened
x = tf.placeholder("float", [None, 1296])
## Known labels
y_ = tf.placeholder("float", [None,5])
# Variables
W = tf.Variable(tf.zeros([1296,5]))
b = tf.Variable(tf.zeros([5]))
# Just initialize
sess.run(tf.initialize_all_variables())
# Define model
y = tf.nn.softmax(tf.matmul(x,W) + b)
逻辑回归的简单性意味着我们可以直接看到并计算每个像素如何影响类概率。 这种简单性也使模型在训练中相对较快地收敛,并且当然也易于编程,因为它只需要几行 TensorFlow 代码。
单隐层神经网络模型
我们的下一个模型是具有最终 Softmax 激活层的单个隐藏层密集连接的神经网络,等效于逻辑回归:
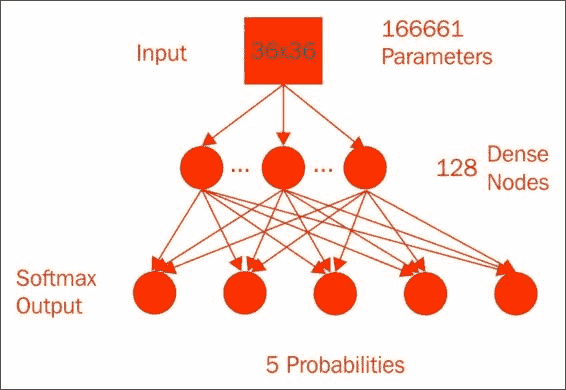
该模型具有36x36像素,外加 1 个偏移乘以 128 个节点,再加上 128 个隐藏节点加上 1 个偏移乘以 5 个类的总权重,即 166,661 个参数。 隐藏层使用sigmoid激活函数来实现非线性。 在经过 5,000 个周期后,参数的纠缠达到了约 60% 的验证准确率,这是一个很大的改进。 但是,此改进的代价是大量增加了计算复杂性中的参数数量,您可以从代码中大致了解一下:
# These will be inputs
## Input pixels, flattened
x = tf.placeholder("float", [None, 1296])
## Known labels
y_ = tf.placeholder("float", [None,5])
# Hidden layer
num_hidden = 128
W1 = tf.Variable(tf.truncated_normal([1296, num_hidden],
stddev=1./math.sqrt(1296)))
b1 = tf.Variable(tf.constant(0.1,shape=[num_hidden]))
h1 = tf.sigmoid(tf.matmul(x,W1) + b1)
# Output Layer
W2 = tf.Variable(tf.truncated_normal([num_hidden, 5],
stddev=1./math.sqrt(5)))
b2 = tf.Variable(tf.constant(0.1,shape=[5]))
# Just initialize
sess.run(tf.initialize_all_variables())
# Define model
y = tf.nn.softmax(tf.matmul(h1,W2) + b2)
我们不再具有将单个像素分类到概率的简单函数。 但这仅需要几行编码,并且表现会更好。
深度神经网络
深度神经网络更进一步,由第一层的 128 个节点组成,馈入下一层的 32 个节点,然后馈入 Softmax 以获得 170,309 个参数; 真的没有那么多:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xkbBscSP-1681566150319)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00070.jpg)]
经过 25,000 个周期后,我们的验证准确率微幅提高了 63%:
# These will be inputs
## Input pixels, flattened
x = tf.placeholder("float", [None, 1296])
## Known labels
y_ = tf.placeholder("float", [None,5])
# Hidden layer 1
num_hidden1 = 128
W1 = tf.Variable(tf.truncated_normal([1296,num_hidden1],
stddev=1./math.sqrt(1296)))
b1 = tf.Variable(tf.constant(0.1,shape=[num_hidden1]))
h1 = tf.sigmoid(tf.matmul(x,W1) + b1)
# Hidden Layer 2
num_hidden2 = 32
W2 = tf.Variable(tf.truncated_normal([num_hidden1,
num_hidden2],stddev=2./math.sqrt(num_hidden1)))
b2 = tf.Variable(tf.constant(0.2,shape=[num_hidden2]))
h2 = tf.sigmoid(tf.matmul(h1,W2) + b2)
# Output Layer
W3 = tf.Variable(tf.truncated_normal([num_hidden2, 5],
stddev=1./math.sqrt(5)))
b3 = tf.Variable(tf.constant(0.1,shape=[5]))
# Just initialize
sess.run(tf.initialize_all_variables())
# Define model
y = tf.nn.softmax(tf.matmul(h2,W3) + b3)
更深层次的静态模型可能会做得更好,但这证明了深度学习的某些优势,可以处理相当大的非线性,并且这再次花费了一些额外的编程精力。
卷积神经网络
紧密连接的神经网络工作得很好,但是字体是由它们的样式而不是特定的像素定义的:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OFG1364K-1681566150319)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00071.jpg)]
重复出现的局部特征应该是您模型的重要线索。 我们使用卷积神经网络捕获了其中一些局部特征。 我们从一个卷积层开始,一个5x5窗口,使用整流线性单元,通过四个额外的偏项计算四个特征,并提取了有趣的局部参数。 接下来,我们将2x2的最大池化层应用于每个特征,从而将中间值的数量减少到18x18x4加上 1 个偏差。 将其平整为 1,297 个数字,并放入一个密集的神经网络的 32 个节点,然后进行 Softmax 激活,从而完成了具有 41,773 个参数的模型。
尽管实现和代码比以前要花更多的精力,但是这可以很好地缩减模型的整体大小:
# Conv layer 1
num_filters = 4
winx = 5
winy = 5
W1 = tf.Variable(tf.truncated_normal(
[winx, winy, 1 , num_filters],
stddev=1./math.sqrt(winx*winy)))
b1 = tf.Variable(tf.constant(0.1,
shape=[num_filters]))
# 5x5 convolution, pad with zeros on edges
xw = tf.nn.conv2d(x_im, W1,
strides=[1, 1, 1, 1],
padding='SAME')
h1 = tf.nn.relu(xw + b1)
# 2x2 Max pooling, no padding on edges
p1 = tf.nn.max_pool(h1, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='VALID')
# Need to flatten convolutional output for use in dense layer
p1_size = np.product(
[s.value for s in p1.get_shape()[1:]])
p1f = tf.reshape(p1, [-1, p1_size ])
# Dense layer
num_hidden = 32
W2 = tf.Variable(tf.truncated_normal(
[p1_size, num_hidden],
stddev=2./math.sqrt(p1_size)))
b2 = tf.Variable(tf.constant(0.2,
shape=[num_hidden]))
h2 = tf.nn.relu(tf.matmul(p1f,W2) + b2)
# Output Layer
W3 = tf.Variable(tf.truncated_normal(
[num_hidden, 5],
stddev=1./math.sqrt(num_hidden)))
b3 = tf.Variable(tf.constant(0.1,shape=[5]))
keep_prob = tf.placeholder("float")
h2_drop = tf.nn.dropout(h2, keep_prob)
仅训练了 5000 个周期后,我们就清除了 68% 的准确率。 我们确实必须对卷积进行编码,但这并不是那么困难。 通过对问题的结构应用一些知识,我们同时减小了模型大小,但提高了准确率。 干得好!
深度卷积神经网络
结合了深度和卷积方法,我们最终创建了一个具有几个卷积层的模型:
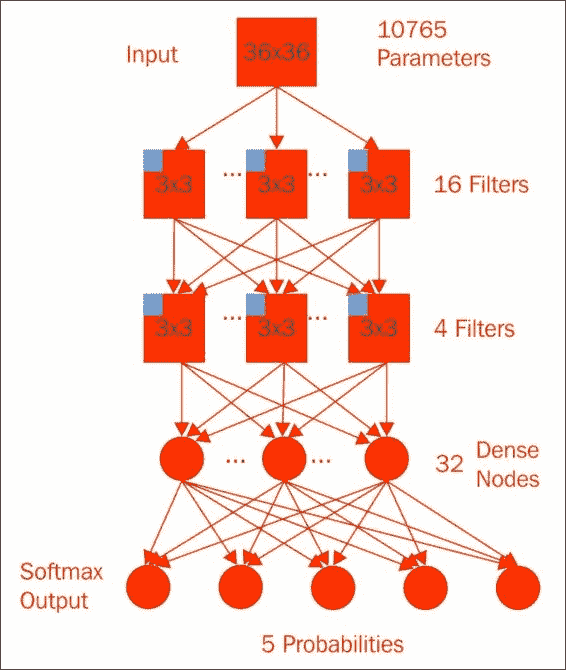
尽管我们使用了较小的3x3窗口,但我们在第一个卷积层上计算了 16 个滤镜。 在进行最大2x2的池化之后,我们再次使用另一个3x3窗口和 4 个过滤器对池化值进行了处理。 另一个合并层再次馈入 32 个紧密连接的神经元和 Softmax 输出。 因为在馈入密集神经网络之前我们在池中有更多的卷积,所以在此模型中实际上我们具有较少的参数(准确地说是 10,765 个),几乎与逻辑回归模型一样少。 但是,该模型以 6,000 个周期的速度达到了 80% 的验证准确率,证明了您的新深度学习和 TensorFlow 技能。
# Conv layer 1
num_filters1 = 16
winx1 = 3
winy1 = 3
W1 = tf.Variable(tf.truncated_normal(
[winx1, winy1, 1 , num_filters1],
stddev=1./math.sqrt(winx1*winy1)))
b1 = tf.Variable(tf.constant(0.1,
shape=[num_filters1]))
# 5x5 convolution, pad with zeros on edges
xw = tf.nn.conv2d(x_im, W1,
strides=[1, 1, 1, 1],
padding='SAME')
h1 = tf.nn.relu(xw + b1)
# 2x2 Max pooling, no padding on edges
p1 = tf.nn.max_pool(h1, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='VALID')
# Conv layer 2
num_filters2 = 4
winx2 = 3
winy2 = 3
W2 = tf.Variable(tf.truncated_normal(
[winx2, winy2, num_filters1, num_filters2],
stddev=1./math.sqrt(winx2*winy2)))
b2 = tf.Variable(tf.constant(0.1,
shape=[num_filters2]))
# 3x3 convolution, pad with zeros on edges
p1w2 = tf.nn.conv2d(p1, W2,
strides=[1, 1, 1, 1], padding='SAME')
h1 = tf.nn.relu(p1w2 + b2)
# 2x2 Max pooling, no padding on edges
p2 = tf.nn.max_pool(h1, ksize=[1, 2, 2, 1],
strides=[1, 2, 2, 1], padding='VALID')
TensorFlow 的未来
在本部分中,我们将观察 TensorFlow 的变化方式,谁开始使用 TensorFlow 以及如何产生影响。
自 2015 年底发布以来,TensorFlow 已经看到更多发布版本:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oaxgLt3O-1681566150320)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00073.jpg)]
TensorFlow 不断更新。 尽管它不是 Google 的正式产品,但它还是开源的,并托管在 GitHub 上。 在撰写本文时,TensorFlow 的版本为 1.2。 最新版本增加了分布式计算功能。 这些超出了本书的范围,但总的来说,它们允许跨多台机器上的多个 GPU 进行计算,以实现最大程度的并行化。 在繁重的开发过程中,更多功能总是指日可待。 TensorFlow 每天变得越来越流行。
几家软件公司最近发布了机器学习框架,但 TensorFlow 在采用方面表现突出。 在内部,Google 正在实践他们的讲道。 他们广受赞誉的 DeepMind 团队已改用 TensorFlow。

此外,许多拥有机器学习或数据科学程序的大学都将 TensorFlow 用于课程和研究项目。 当然,您已经在研究项目中使用过 TensorFlow,因此您处于领先地位。
其他一些 TensorFlow 项目
最后,无论大小,其他公司都在使用 TensorFlow。 现在您是 TensorFlow 的从业人员,唯一的限制就是您可能遇到的问题和您的计算资源。 以下是一些有关 TensorFlow 下一步可以解决的问题的想法:
-
图像中的叶子分类:
像字体一样,植物叶子在一个物种中具有相似的样式。 您是否可以修改在本课程中建立的模型,以仅使用图像识别物种?
-
使用行车记录仪视频的路标识别:
假设您从长途旅行中获得了许多行车记录仪镜头。 高速公路上的路标可以为您提供许多信息,例如您在哪里以及应该走多快。 您可以建立一系列 TensorFlow 模型来查找素材中的速度限制吗?
-
预测出行时间的运输研究:
此外,无论您的工作距离有多近,通勤时间都太长。 在交通和天气等当前条件下,您应该能够建立基于回归的模型来预测您的旅行时间。
-
用于查找兼容日期的匹配算法:
最后,一家初创公司正在探索使用 TensorFlow 来寻找匹配算法。 如果将来算法会给您带来一个约会,请不要感到惊讶。
基于 TensorFlow 的整洁项目太多,无法一一列举。 但是,有机会,您会发现与自己的兴趣有关的东西,如果没有,那是贡献自己的完美场所。 机器学习库很多,但是 TensorFlow 仍然存在。
尽管本书侧重于深度学习,但 TensorFlow 是一个通用的图计算库。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LlrwWFy5-1681566150320)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00075.jpg)]
深度神经网络确实是 TensorFlow 能够很好处理的一小部分数据建模。 但是,正如您在第 1 章入门中的“简单计算”部分所看到的那样,在简单计算中,可以为图规定的任何操作都可以在 TensorFlow 中进行。 一个实际的例子是在 TensorFlow 中实现 K 均值聚类。
更一般而言,可以很好地向量化并且需要某种训练的操作可能会受益于 TensorFlow 的使用。 这一切都说明您是 TensorFlow 的未来!
TensorFlow 是开源的,并且一直在变化。 因此,您可以在 GitHub 上轻松贡献新功能。 这些可能是高度复杂的新模型类型或简单的文档更新。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-peWwYSou-1681566150320)(https://gitcode.net/apachecn/apachecn-dl-zh/-/raw/master/docs/hands-on-dl-tf-zh/img/00076.jpg)]
所有更改都可以改善库。 TensorFlow 的日益普及意味着您是最早掌握它的专业人士之一。 您在机器学习事业或研究中拥有优势。 而且由于它不仅仅是深度学习,所以无论您处于哪个领域,TensorFlow 都可能适用于它的某些方面。
总结
在本章中,我们回顾了如何从谦虚的 Logistic 回归模型爬升到使用深度卷积神经网络对字体进行分类的高度。 我们还讨论了 TensorFlow 的未来。 最后,我们回顾了用于字体分类的 TensorFlow 模型,并回顾了其准确率。 我们还花了一些时间来讨论 TensorFlow 的发展方向。 恭喜! 您现在已经精通 TensorFlow。 您已将其应用于本系列中的多个研究问题和模型,并了解了其广泛应用。
下一步是在您自己的项目中部署 TensorFlow。 造型愉快!